45 MySQL源码分析和GDB调试器的应用
你好,我是俊达。
之前在评论区有同学留言问是否能加一讲源代码调试的内容。考虑到这个专栏中有相当多的篇幅是讲MySQL和InnoDB的内部实现机制,而我自己在整理这些内部原理时,也参考了大量的MySQL源码,有时也会用GDB来调试跟踪代码的执行,因此在这一讲中,我们就来聊聊MySQL源码分析和GDB在源码分析中的一些使用场景。
这里我们只讨论MySQL的源码分析,不涉及到怎么修改MySQL源码来实现一些定制化的功能。
MySQL源码介绍
这一讲中,我们就以当前8.0系列中最新的Release版本8.0.40为例,下载代码并解压。我们先简单看一下MySQL源码文件的组织(只是为了看结构,下面的输出中,把很多内容删减掉了)。
# tree -d -L 2
...
├── include
├── mysys
├── plugin
│ ├── auth
│ ├── clone
...
│ ├── group_replication
...
│ ├── semisync
│ └── x
......
├── sql
│ ├── auth
│ ├── binlog
│ ├── changestreams
│ ├── conn_handler
│ ├── containers
│ ├── daemon_proxy_keyring
│ ├── dd
│ ├── examples
│ ├── gis
│ ├── histograms
│ ├── iterators
│ ├── join_optimizer
│ ├── locks
│ ├── memory
│ ├── partitioning
│ ├── protobuf
│ ├── raii
│ ├── range_optimizer
│ ├── server_component
│ └── xa
├── sql-common
│ └── oci
├── storage
......
│ ├── innobase
│ └── temptable
└── vio
我们先对源码中的一部分目录做一个简单的介绍。
plugin
plugin目录下是插件的源码,比如专栏中介绍过的clone插件、semisync插件、group_replication插件,每个plugin的代码在对应的目录下。
sql
MySQL Server核心模块的大量源代码都在sql目录下。8.0.40版本中,这个目录下有接近100万行源码。
# find sql -regextype posix-egrep -regex '(.*\.cc)|(.*\.h)' | \
xargs wc -l | \
tail -1
940750 total
- sql/sql_yacc.yy是比较特殊的一个文件,这里定义了MySQL中SQL的语法。
- sql/mysqld.cc里定义了mysqld_main,这是MySQL数据库启动时调用的入口函数。
- sql/iterators目录下是SQL执行引擎的代码,包括表扫描、索引扫描、表连接的执行。
- sql/sql_optimizer.cc里的JOIN::optimize是优化器的一个入口函数。
- sql/sql_parse.cc中的do_command函数,读取客户端发送过来的请求(命令或SQL),并根据请求的类型进行分发(dispatch_command)。
- sql/conn_handler目录中是MySQL处理新建连接请求的代码。默认使用connection_handler_per_thread.cc,也就是给每个客户端分配一个独立的线程,处理客户端的请求。
- sql/dd目录下是数据字典的实现代码。数据字典表的定义,初始化数据库(mysqld --initialize)时怎么创建数据字典表,数据库启动时怎么加载数据字典表,很多代码都在这个目录下。
- sql/log_event.cc里,定义了不同类型Binlog事件的格式。
- sql/handler.cc里实现了handler类。读取或修改表里的数据,都会通过handler接口来实现。存储引擎继承handler类(比如innodb的ha_innobase),实现数据的读写功能。
storage/innobase
storage目录中是MySQL支持的各个存储引擎的实现代码。InnoDB的代码在innobase目录中,代码量接近50万行。
# find storage/innobase -regextype posix-egrep -regex '(.*\.cc)|(.*\.h)|(.*\.ic)' | \
xargs wc -l | \
tail -1
460953 total
InnoDB的代码,按功能模块,分为多个目录。
# tree -d -L 1
.
|-- api
|-- arch
|-- btr
|-- buf
|-- clone
|-- data
|-- ddl
|-- dict
|-- eval
|-- fil
|-- fsp
|-- fts
|-- fut
|-- gis
|-- ha
|-- handler
|-- ibuf
|-- include
|-- lob
|-- lock
|-- log
|-- mach
|-- mem
|-- mtr
|-- os
|-- page
|-- pars
|-- que
|-- read
|-- rem
|-- row
|-- srv
|-- sync
|-- trx
|-- usr
`-- ut
这里先做一个简单的介绍。
include目录
include目录里是InnoDB代码使用的一些头文件。
fil0types.h中定义了InnoDB页面的基本格式,这里定义了页面头部和尾部中各个字段在页面内的偏移地址。
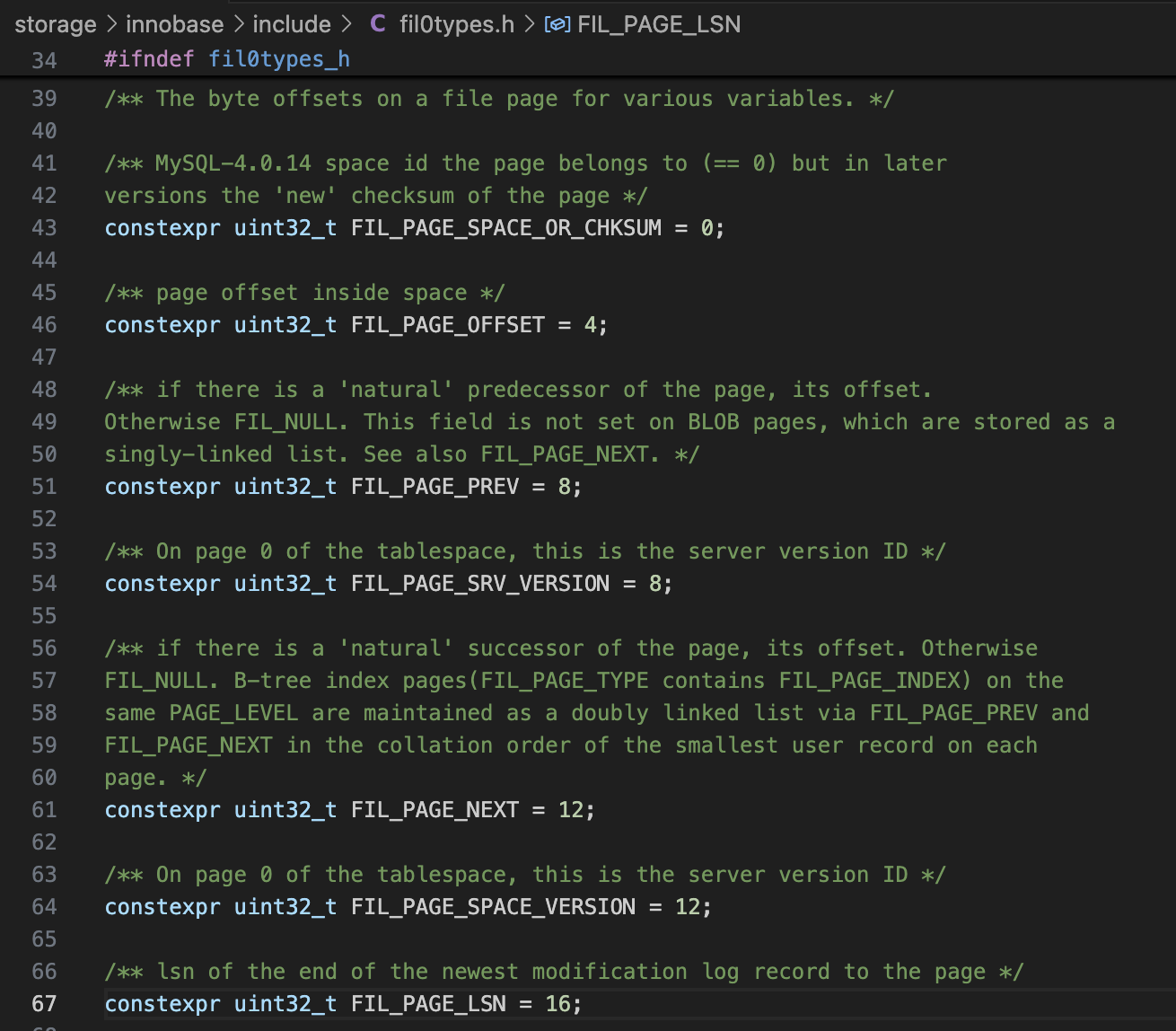
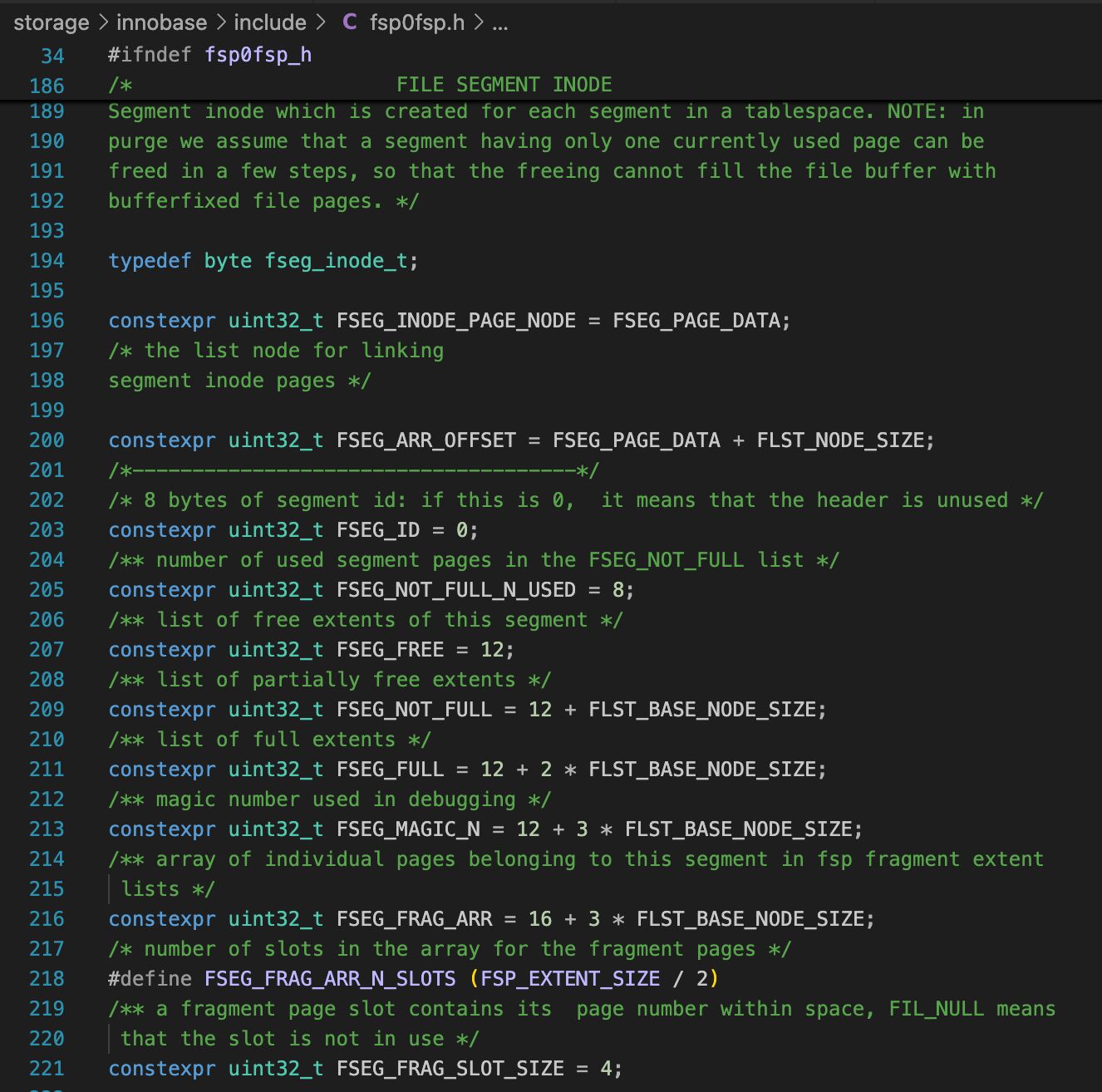
fsp0fsp.h中定义了文件头(Space Header)的格式,还定义了Inode、区描述符(XDES)等这些用来管理文件空间的数据结构的存储格式。
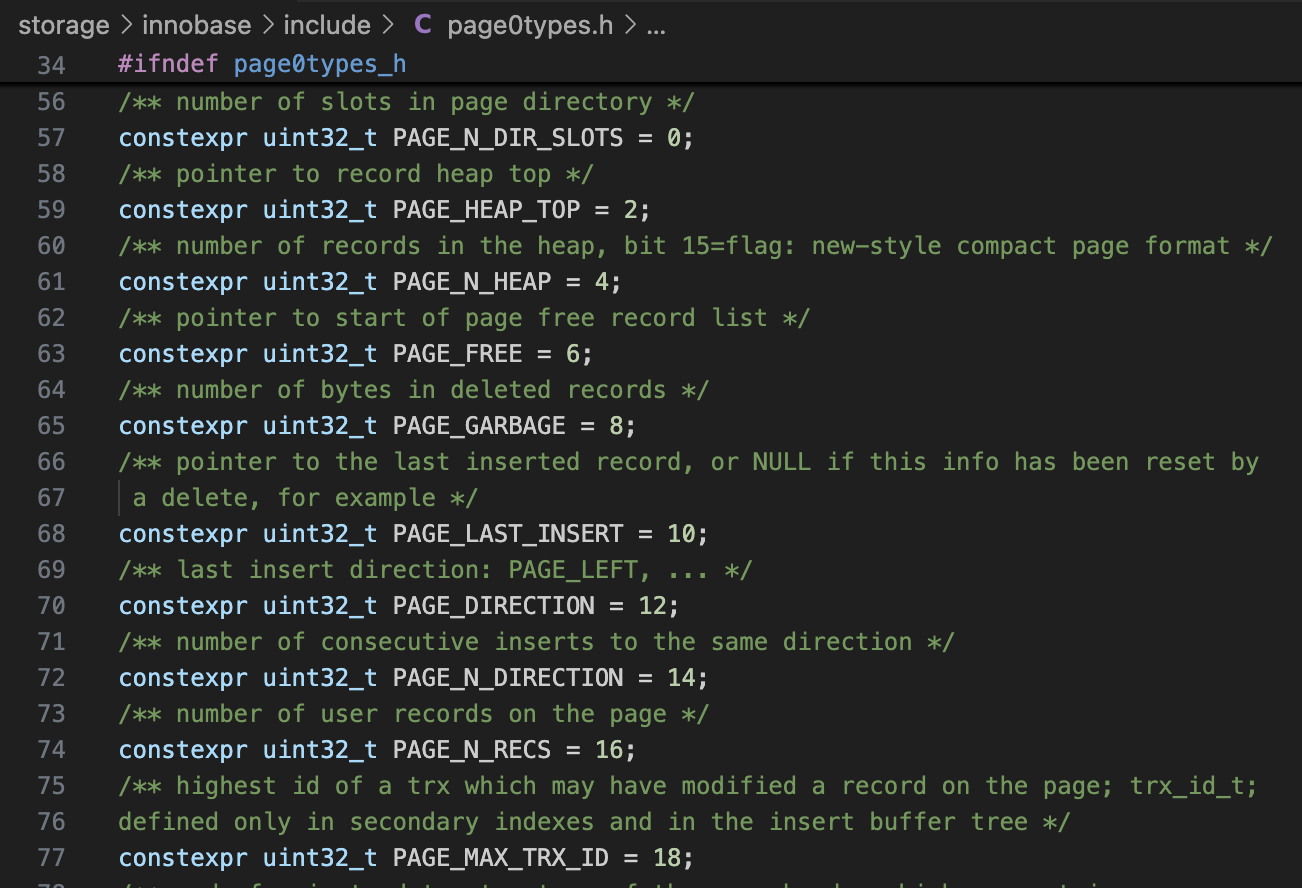
page0types.h中定义了B+树页面头的格式。
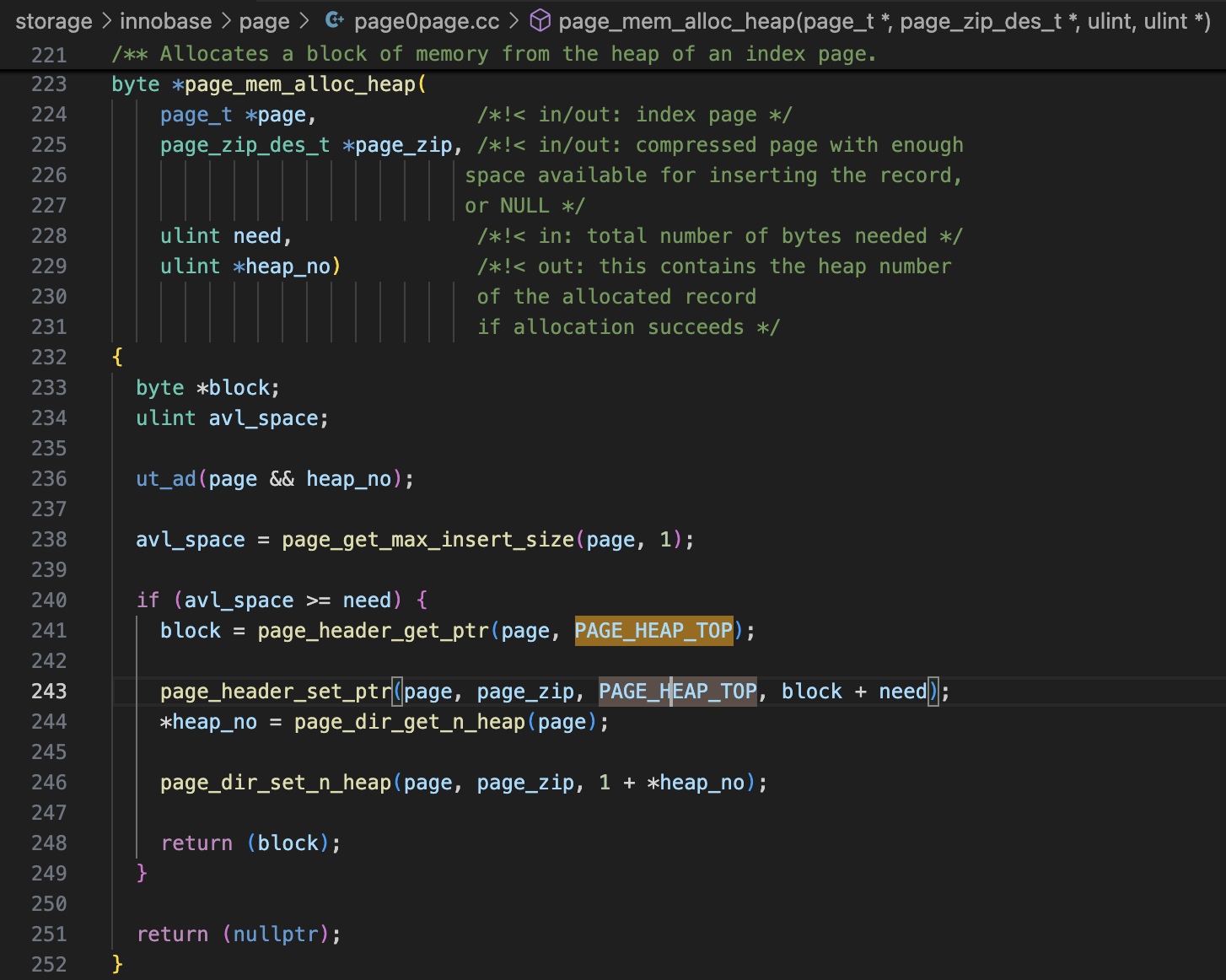
在代码里搜索这里定义的常量,能很快找到使用这些常量的代码,就能理解这些字段的作用。比如搜索PAGE_HEAP_TOP,看到函数page_mem_alloc_heap中会写入这个字段(page0page.cc 243行)。
再搜索page_mem_alloc_heap,发现这个函数在insert时被调用(page0cur.cc page_cur_insert_rec_low),然后就可以看到insert的记录是怎么写到数据块中了(参考page_cur_insert_rec_low中标了编号的几行代码注释)。
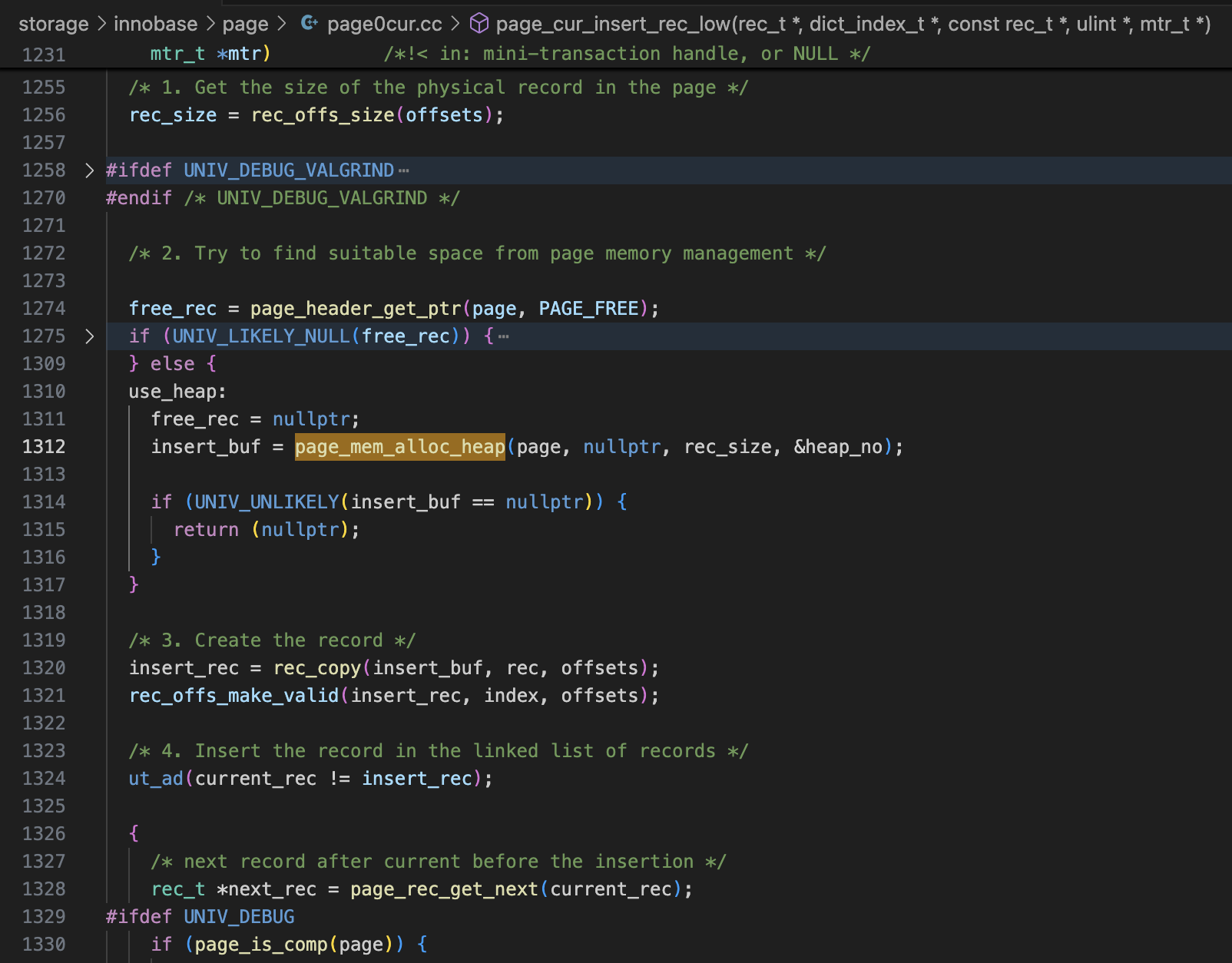
根据这几个头文件,再到代码中搜索和分析使用了这些常量的一些代码,就能整理出25、26这两讲中的页面物理格式了。
rem
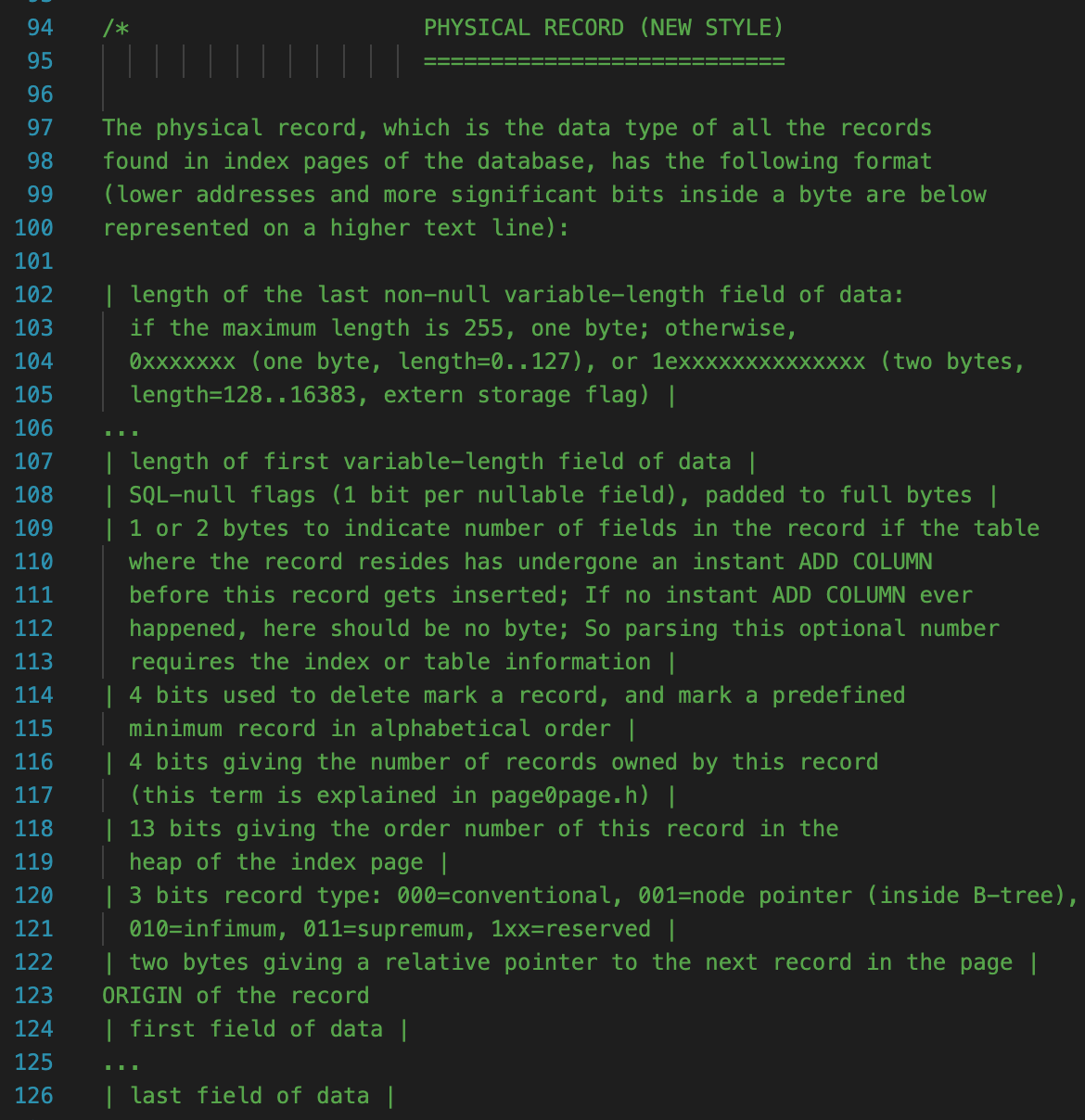
rem目录下是定义和操作行记录格式的代码。rem0rec.cc里定义了InnoDB支持的两大类行格式,一类是REDUNDANT格式,也就是注释中的“OLD STYLE”,另一类是Compact类型,包括compact、dynamic、compressed,也就是注释中的“NEW STYLE”。
page
page目录下主要是操作B+树页面内容的代码,包括创建B+树页面、往页面中插入记录、删除页面中的记录等代码,还有维护页目录项的代码。
btr
btr目录下主要B+树相关的代码。B+树是InnoDB中最核心的一个数据结构。这里包括在B+树中查找记录(btr_cur_search_to_nth_level)、插入记录(btr_cur_optimistic_insert,btr_cur_pessimistic_insert)、更新记录(btr_cur_update_in_place、btr_cur_optimistic_update、btr_cur_pessimistic_update)、删除记录(btr_cur_optimistic_delete、btr_cur_pessimistic_delete)的代码,也包括了维护自适应Hash索引的代码。
row
row目录下包括了操作行的相关代码,比如插入行(row_insert_for_mysql)、更新或删除行(row_update_for_mysql)、清理行(row_purge)。
row_search_mvcc是这里比较重要的一个函数,从InnoDB中查询数据,包括执行Select语句,或者执行Delete和Update语句时,都会通过这个函数来查询数据。函数row_vers_build_for_consistent_read用来构建记录的历史版本。
MySQL Server层和InnoDB层使用了不同的行和字段存储格式,这里提供了格式转换函数,row_mysql_convert_row_to_innobase将MySQL行格式转换成InnoDB行格式,row_sel_store_mysql_rec将InnoDB行格式转换成MySQL行格式。
这里还包括了回滚行操作的代码(row_undo,row_undo_ins,row_undo_mod)。
当表上有Online DDL在执行时,对表的DML操作需要记录到在线变更日志中。在线创建索引时,DML操作通过row_log_online_op记录,DDL执行结束前,通过row_log_apply函数应用在线变更日志。在线Rebuild表时,表上的DML操作通过row_log_table函数来记录,DDL执行完成前,使用row_log_table_apply应用在线变更日志。
trx
trx目录中是事务处理的相关代码,包括事务提交(trx_commit,trx_commit_in_memory, trx_release_impl_and_expl_locks)、事务回滚(trx_rollback_for_mysql)。
Undo日志,通过函数trx_undo_report_row_operation记录。如果想了解事务执行过程中记录了哪些Undo日志以及Undo日志的具体格式,可以分析这个函数。数据库启动时,要执行崩溃恢复,函数trx_recover_for_mysql用来查找处于Prepared状态的事务。这里还包括了回滚段和Undo段处理的相关代码。
buf
buf目录中是InnoDB Buffer Pool的实现代码,包括Buffer Pool的结构,Buffer Pool中的各个链表和Hash表。
fsp
fsp目录中是InnoDB表空间管理的相关代码,包括分配页面、释放页面空间等。
handler
hander目录下是MySQL 存储引擎Handler接口的实现代码。MySQL Server层调用InnoDB Handler代码,读取或写入数据,提交或回滚事务。类ha_innobase中实现了访问InnoDB数据的函数。
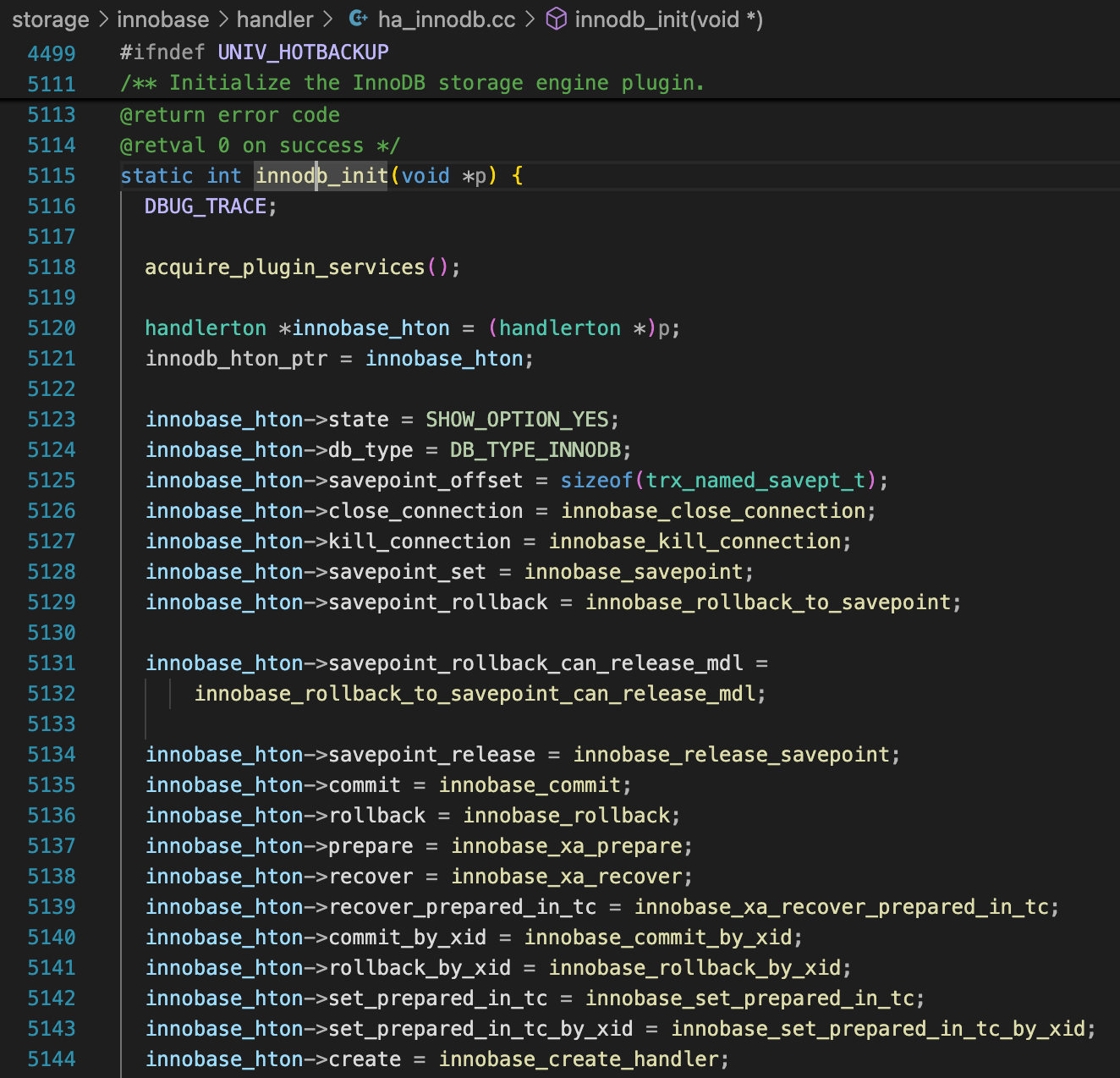
函数innodb_init中设置了一系列给server层调用的函数。加载InnoDB插件时调用这个函数。
log
log目录下是Redo的相关代码,包括管理Log Buffer空间,分配Log序列号,将Redo日志写入Log Buffer。
log_writer、log_flusher、log_checkpointer这几个是Redo系统的几个关键线程的主函数,负责Redo日志的持久化。数据库启动时,调用log_start_background_threads函数,启动这些线程,以及其他一些线程。
数据库启动时,调用函数recv_recovery_from_checkpoint_start,扫描和解析checkpoint之后的所有Redo日志。
函数recv_scan_log_recs解析Redo日志,并将解析出来的日志先加到Hash表中。函数recv_apply_hashed_log_recs应用hash表中的Redo日志。
mtr
mtr目录中是Mini Transaction相关代码。mlog_write开头的一系列函数(mlog_open_and_write_index,mlog_write_string,mlog_write_ulint,mlog_write_ull,mlog_write_initial_dict_log_record等)生成Redo日志,写到mtr buffer中。在这些函数上设置断点,就能看到事务执行过程中会生成哪些Redo日志,以及日志的格式。
mlog_parse开头的一系列函数(mlog_parse_initial_log_record,mlog_parse_nbytes,mlog_parse_string,mlog_parse_index等)从Redo文件中解析日志。mtr_t是一个比较重要的数据结构,m_impl.m_memo记录了mtr执行过程中修改的数据块、获取的锁对象和锁模式,m_impl.m_log中记录了Redo日志。mtr提交时(mtr_t::commit),m_log中的Redo日志复制到Redo Log Buffer,修改过的脏页添加到Flush链表,mtr执行过程中获取的锁,也会在提交时解锁(memo_slot_release)。
srv
srv目录下,包括了InnoDB一些服务线程的代码,如srv_master_thread、srv_worker_thread、srv_purge_coordinator_thread、srv_monitor_thread、srv_error_monitor_thread。数据库启动时调用srv_start启动InnoDB。
使用代码分析工具
前面对MySQL的代码做了一个非常简单的介绍,还提供了一些比较关键的函数,这些函数可以作为了解MySQL源码的一个起点。但是MySQL的源码,代码文件数多,代码量大,代码风格不统一,函数调用层次比较深。利用一些工具,能帮我们更好地理解这些代码。
有一些代码分析工具,比如SourceInsight,能分析函数、方法、全局变量、结构、类等符号信息。能显示参考树、类继承图和调用树等,直观地展示函数的调用关系、类的继承层次等。还能迅速搜索整个项目,找到符号的定义位置、被调用位置等所有引用,方便追踪代码的执行路径和数据流向。
这里,我介绍一款轻量,但功能强大的源代码编辑器,VSCode。安装上C/C++扩展后,使用VSCode可以方便地分析MySQL源码。VSCode还可以整合编译、调试工具,不过这里我只用了代码分析功能。如果你有兴趣,也可以尝试在VSCode中整合调试工具。
使用VSCode分析代码
接下来就使用VSCode,来分析下数据库崩溃恢复时,怎么处理Prepared状态的事务。35 讲中的“二阶段提交”这一小节中,提到过Prepared状态的事务,在数据库启动时是提交还是回滚,取决于Binlog中是否存在对应的XID事件。
函数trx_recover_for_mysql
innobase/trx/trx0trx.cc中有一个函数trx_recover_for_mysql,看起来和崩溃恢复有关,我们就从这个函数开始分析。
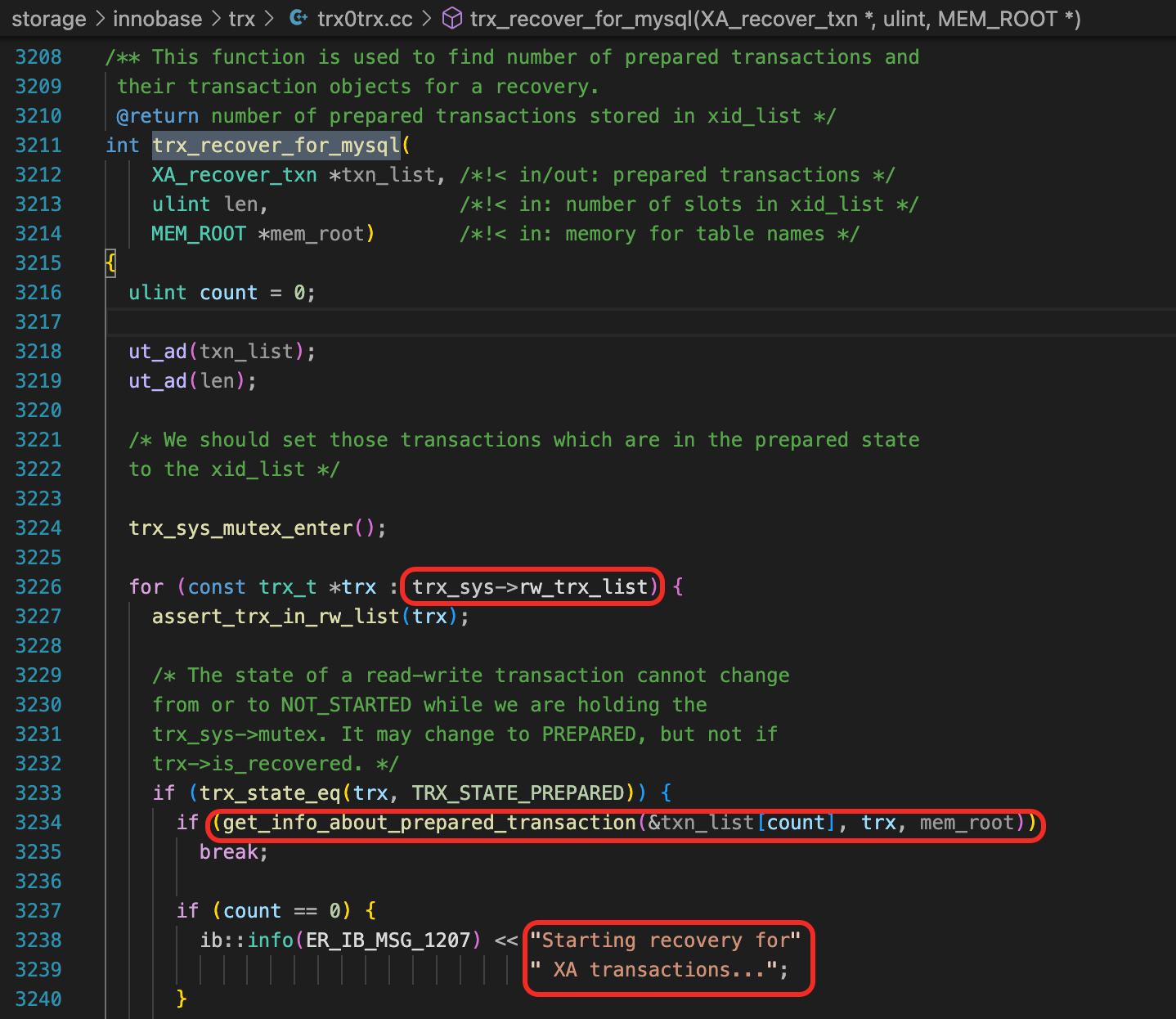
这个函数的逻辑比较简单,就是统计trx_sys->rw_trx_list中状态为TRX_STATE_PREPARED的事务,函数的返回值就是Prepared状态的事务数。
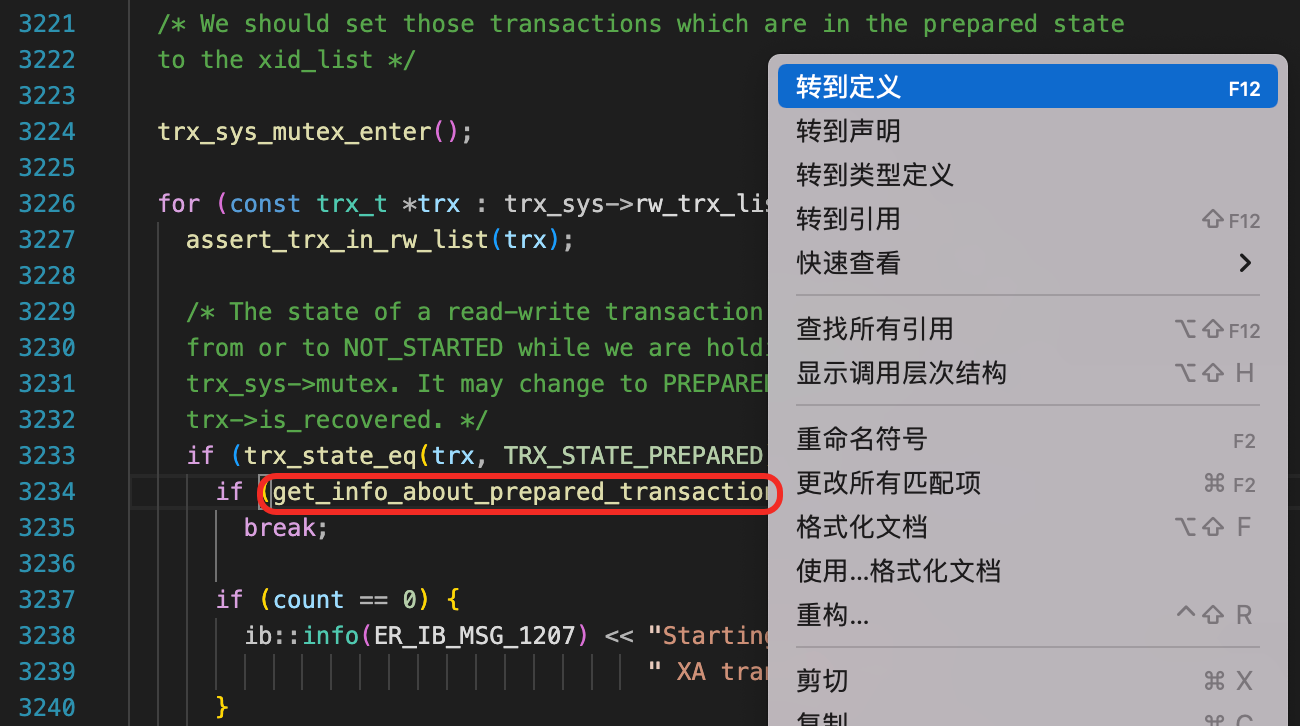
这里还调用了一个函数get_info_about_prepared_transaction,可以直接跳转到函数的定义中。这里还有一点值得注意,函数get_info_about_prepared_transaction的第一个参数,传入了一个指针,指向trx_list的第N个元素,调用这个函数后,就把第N个Prepared状态的事务加到了trx_list中。
链表trx_sys->rw_trx_list的数据从哪里来?
那么数据库启动时,rw_trx_list里的数据是从哪里来的呢?使用查找功能(CMD + SHIFT + F)进行搜索,发现trx0trx.cc中有一处代码会往这个列表中插入数据(UT_LIST_ADD_FIRST)。
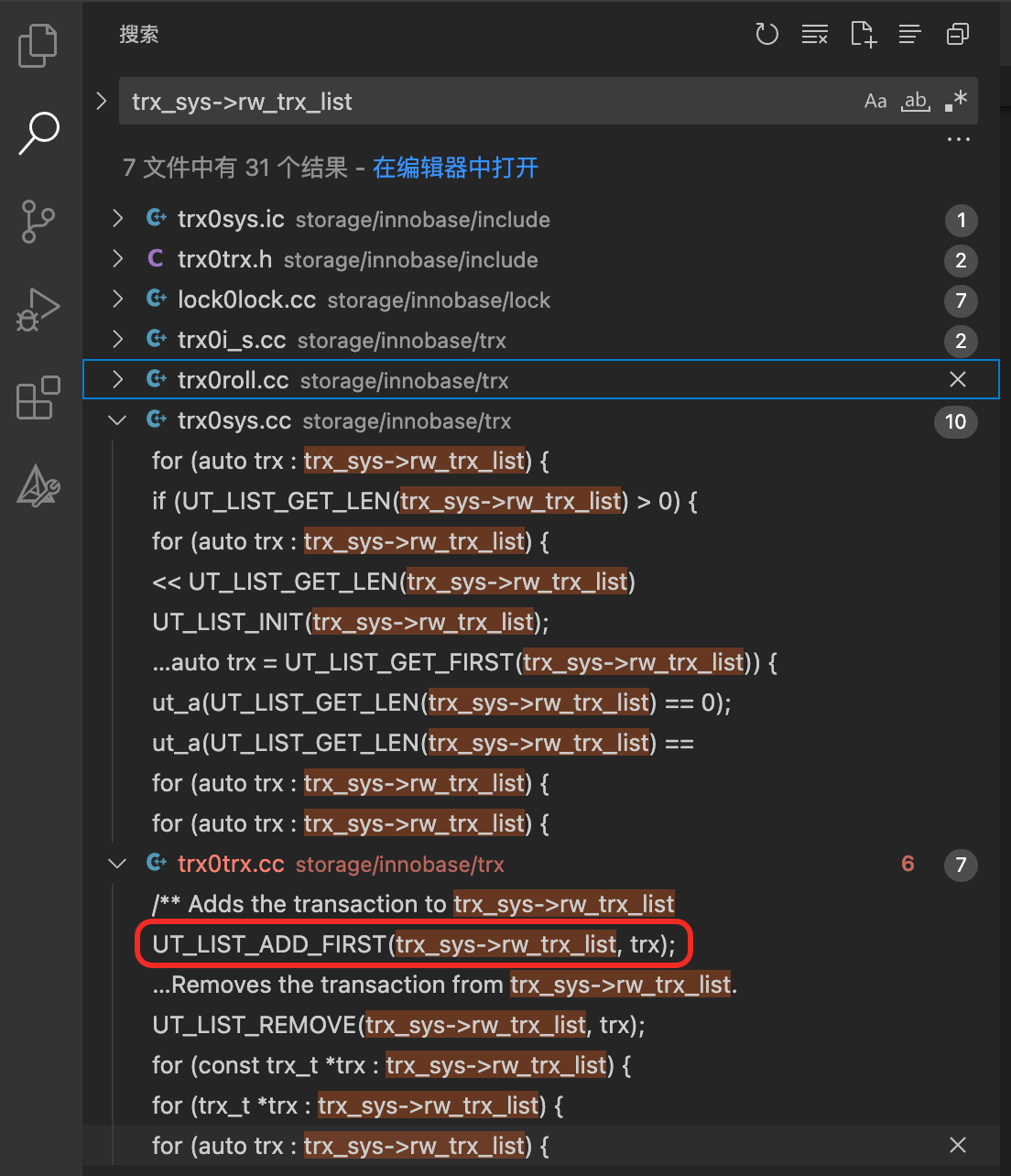
查看代码,这里只是封装了一个函数trx_add_to_rw_trx_list。
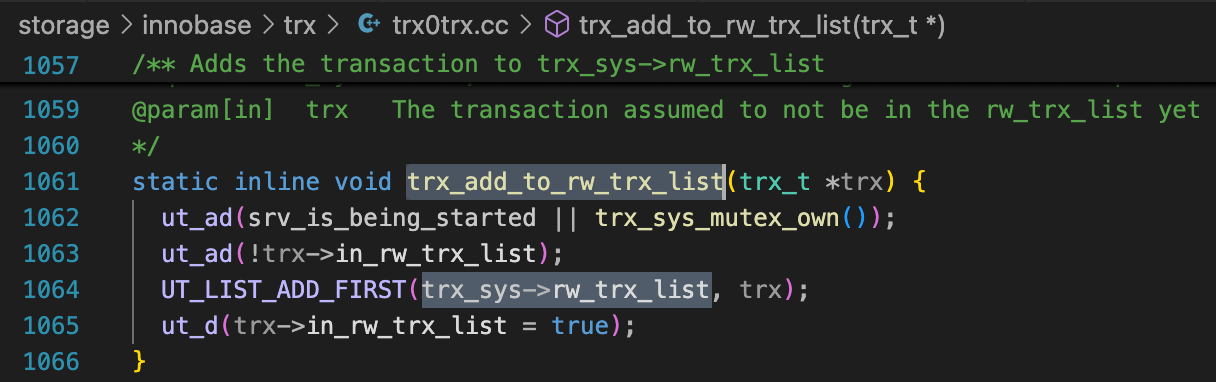
接下来要看哪些地方调用了这个函数。这里可以使用全局搜索,也可以使用“查找所有引用”(快捷键ALT + SHIFT + F12)。
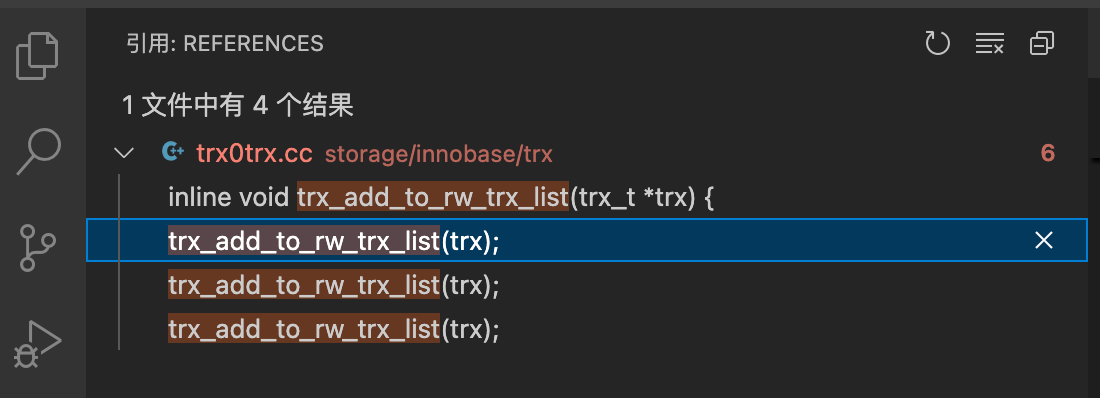
调用这个函数的地方不多,分别查看后,trx_sys_init_at_db_start应该是我们想找的函数。
函数trx_sys_init_at_db_start
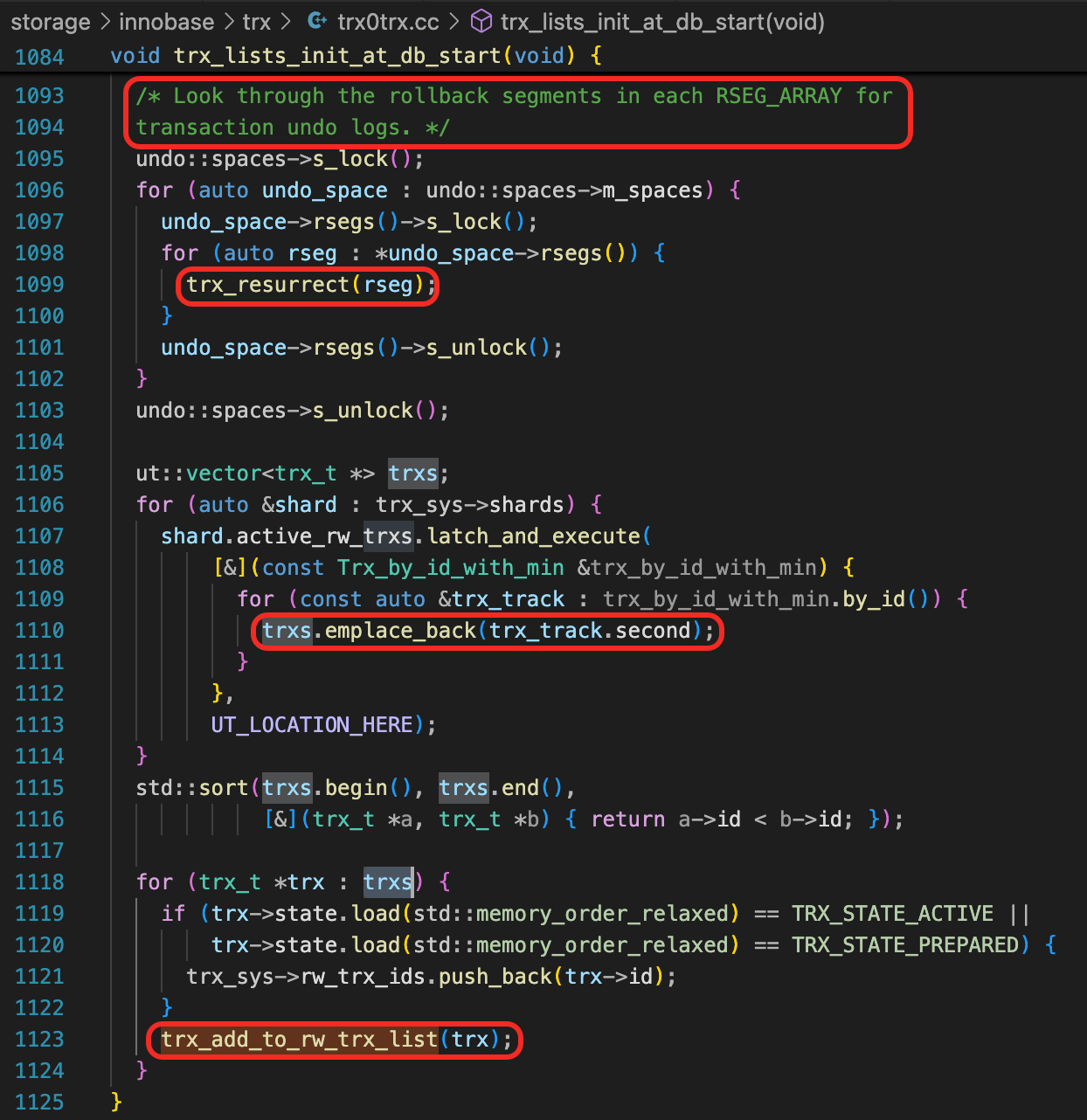
这个函数中主要做了几件事情。
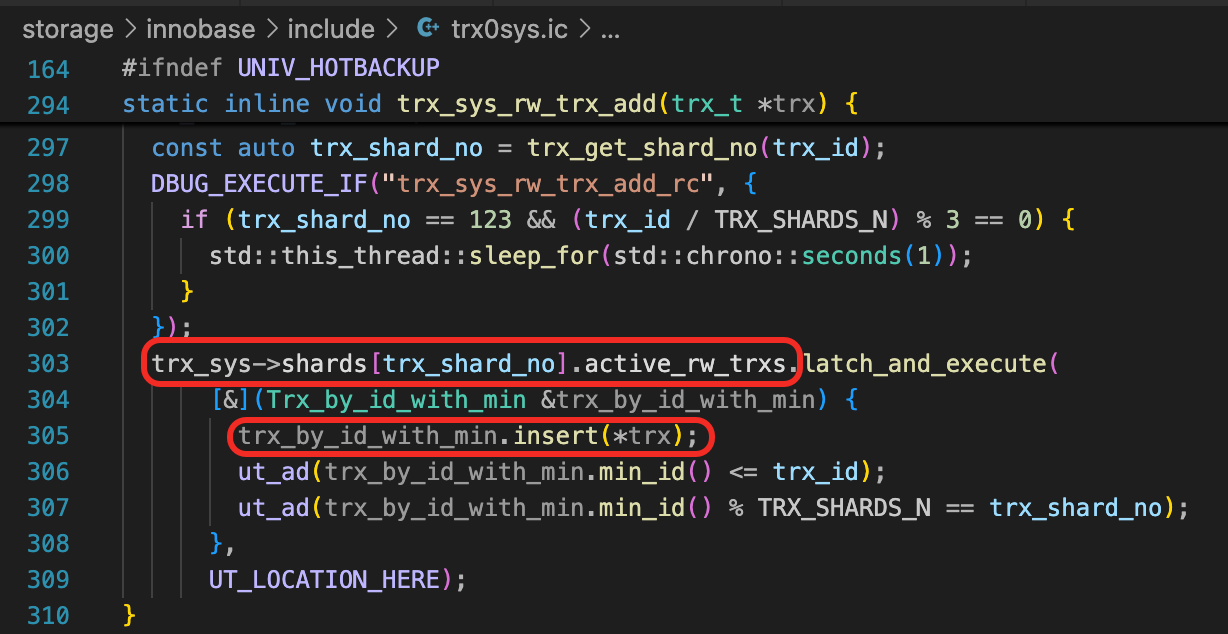
- 扫描每一个Undo表空间中的每一个回滚段,调用trx_resurrect函数,读取回滚段中所有的Undo段,把未完成的事务识别出来。trx_resurrect函数中最终会调用trx_sys_rw_trx_add,把事务加到trx_sys->shars中。
- 事务加到trxs,按事务ID排序后,加到trx_sys->rw_trx_list中。
当然,你还可以继续分析回滚段、Undo段中的数据怎么读取。
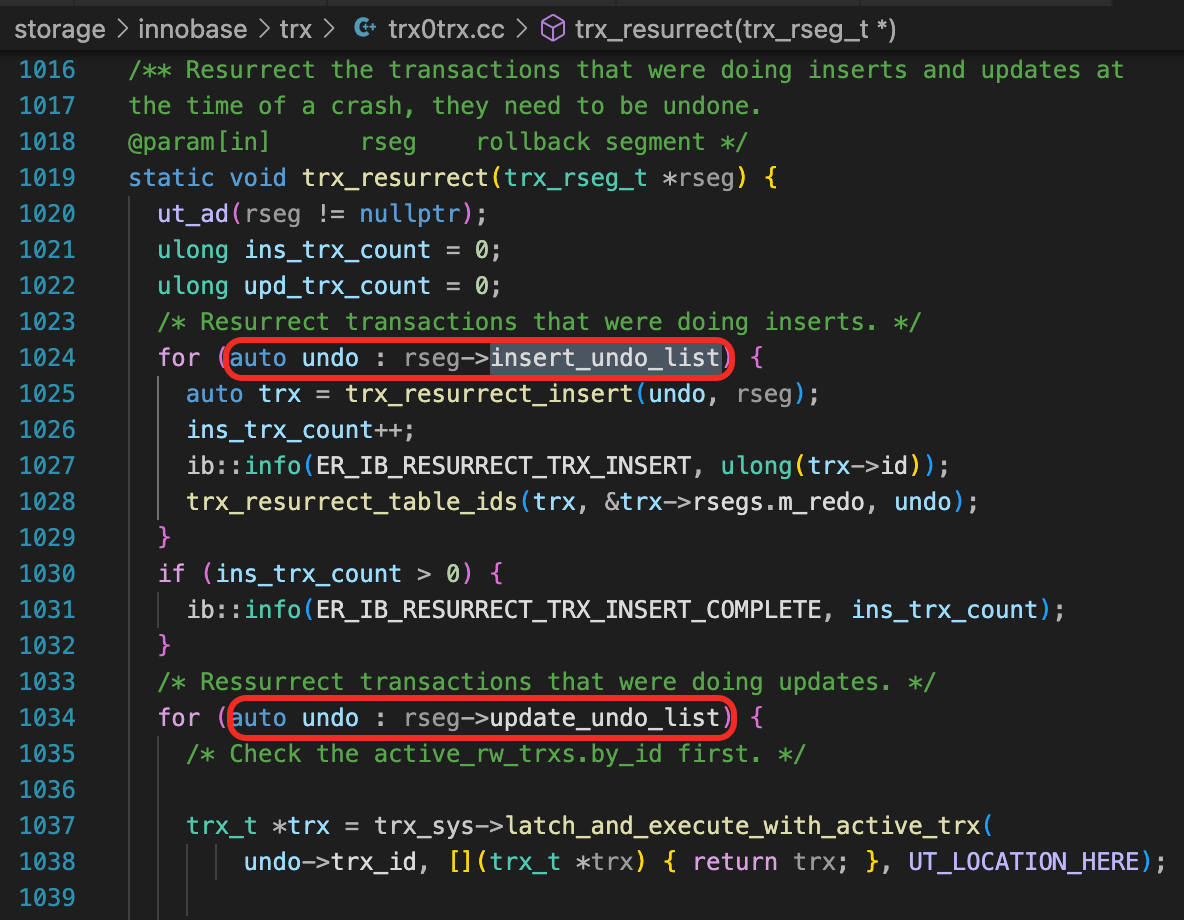
函数trx_resurrect中用到了rseg->insert_undo_list,rseg->update_undo_list,分析这几个列表的数据怎么添加,最终可能会发现下面这个调用链路。这里我就不具体展开了。
你还可以分析trx_sys_init_at_db_start是什么时候调用的。最终你可能会发现大致的调用链路是这样的。
mysqld_main -> process_bootstrap -> dd::init -> Dictionary_impl::init
-> bootstrap::initialize -> DDSE_dict_init -> innobase_ddse_dict_init
-> innobase_init_files -> srv_start -> trx_sys_init_at_db_start
当然你也可以在调试器中设置断点,代码运行到trx_sys_init_at_db_start时,查看调用栈,这样更方便,也更准确。不过直接阅读源码进行分析也是一个很好的练习。
事务是怎么恢复的
上面我们只是分析了怎么从Undo表空间中把未完结的事务扫描出来。但是这些事务具体是怎么恢复的呢?
回到trx_recover_for_mysql这个函数,谁调用了这个函数呢?很快就找到了innobase_xa_recover。
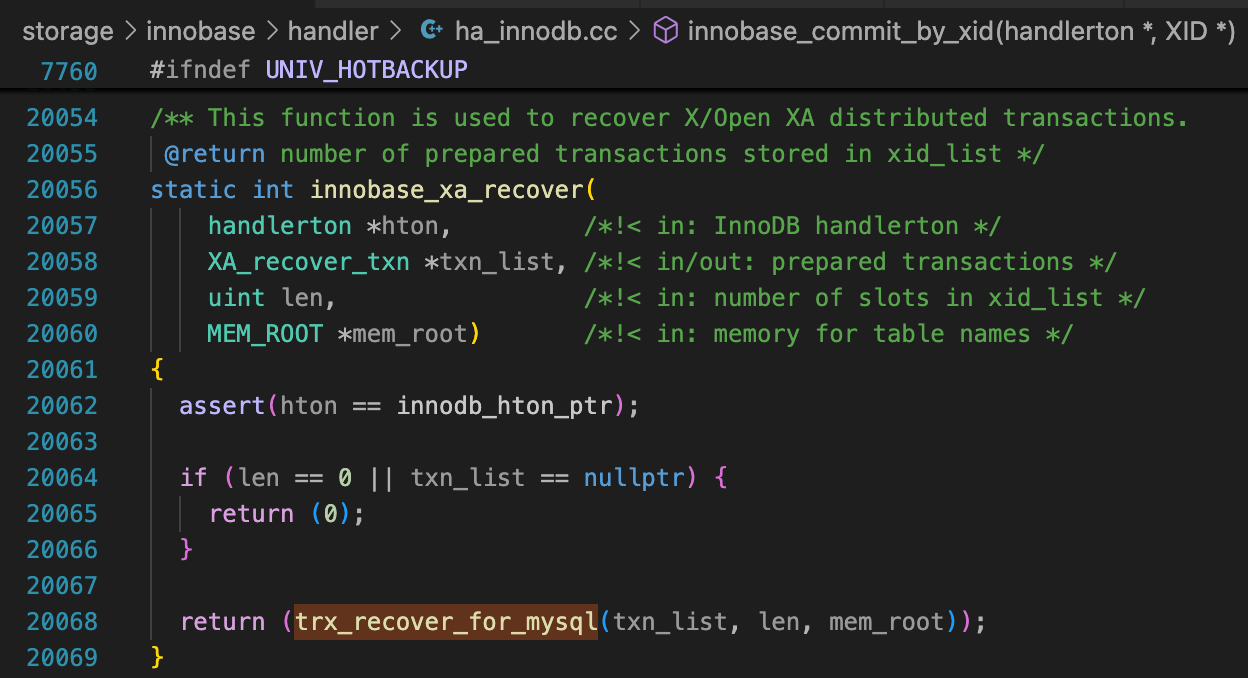
谁调用了innobase_xa_recover呢?你会发现代码中并没有直接调用这个函数。但是innodb_init中,这个函数赋值给了innobase_hton->recover这个函数指针。执行innobase_hton->recover时,实际上就是在执行innobase_xa_recover。
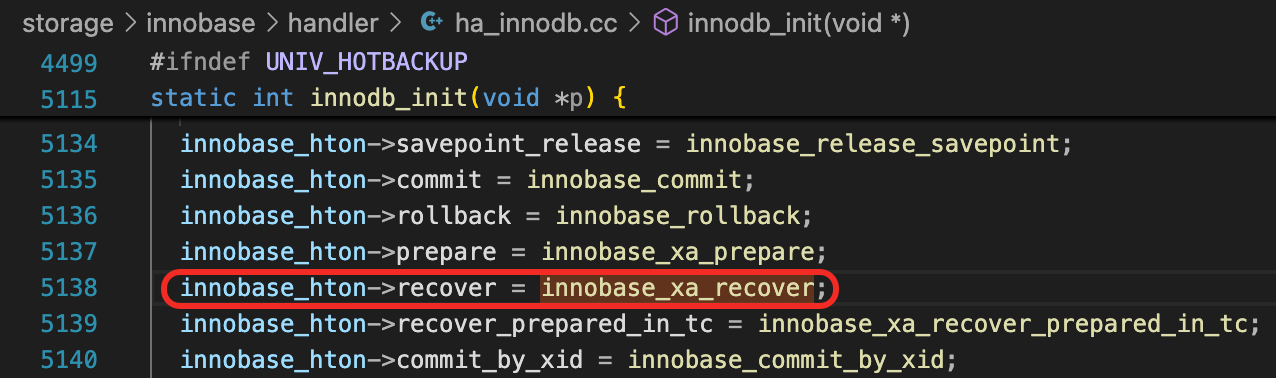
你可以试着查一下hton->recover在哪里调用。直接搜索innobase_hton->recover或hton->recover找不到调用的地方,因为在调用的地方,变量名不是innobase_hton或hton。改成搜索“->recover(”,可以找到调用的地方。
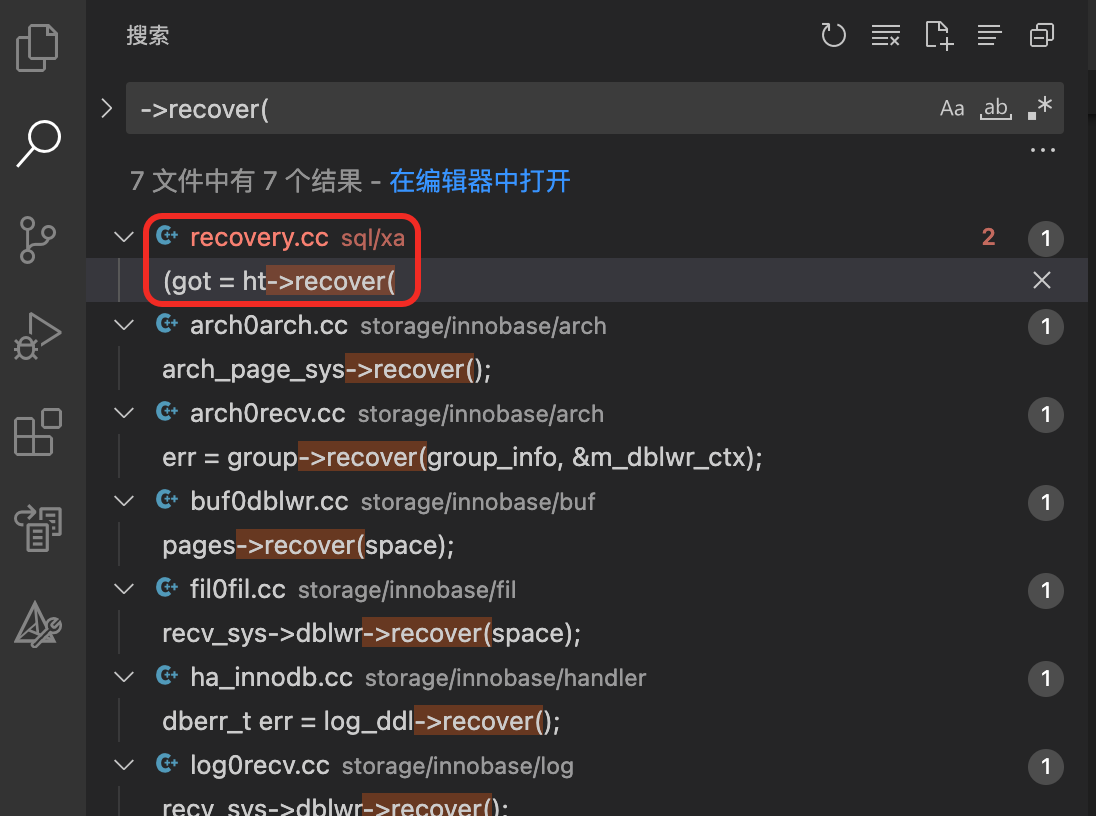
recover_one_ht
recover_one_ht中调用了ht->recover。我们已经知道,调用recover时,会把Prepared状态的事务加到trx链表中,也就是这里的info->list中。
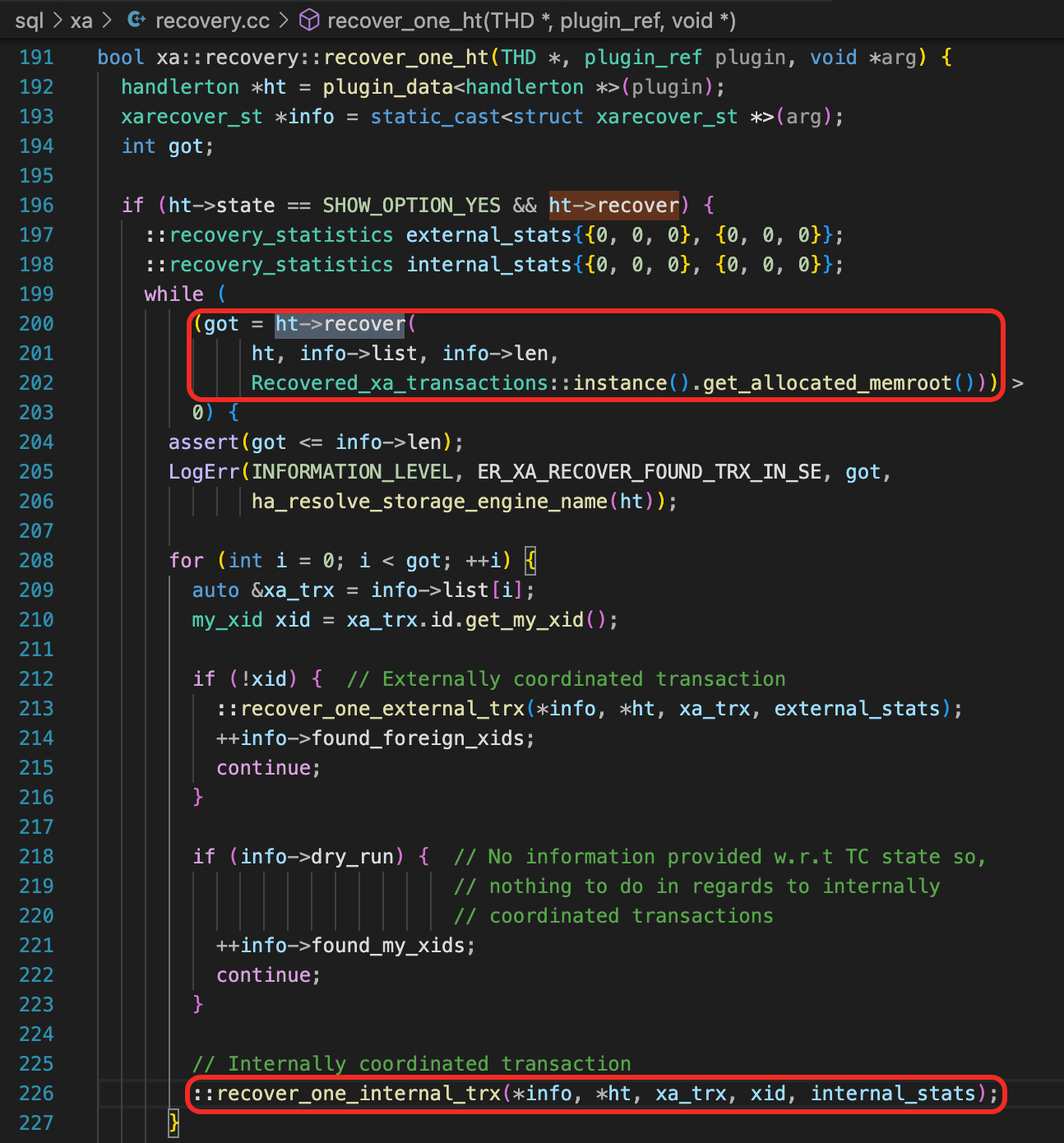
208行的循环中,依次处理每一个事务,调用函数recover_one_external_trx或recover_one_internal_trx恢复事务。这个专栏中,没有涉及到XA事务,这里只分析recover_one_internal_trx。
recover_one_internal_trx
函数recover_one_internal_trx中,会判断info.commit_list中是否有当前处理的事务的XID,如果有,就执行ht.commit_by_xid提交事务,如果没有,就执行ht.rollback_by_xid回滚事务。
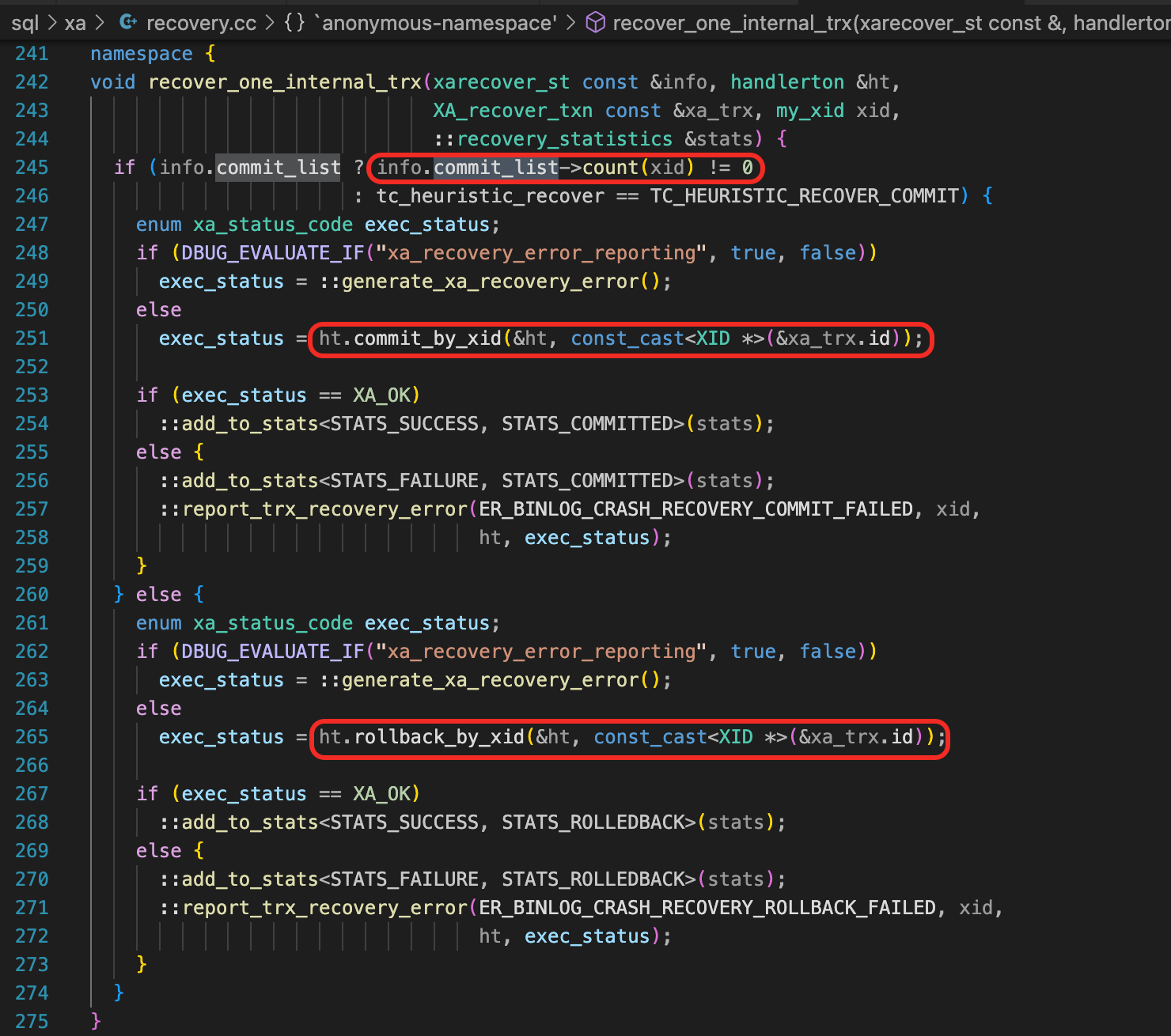
commit_list
接下来我们要分析commit_list。commit_list作为参数传给ha_recover函数。
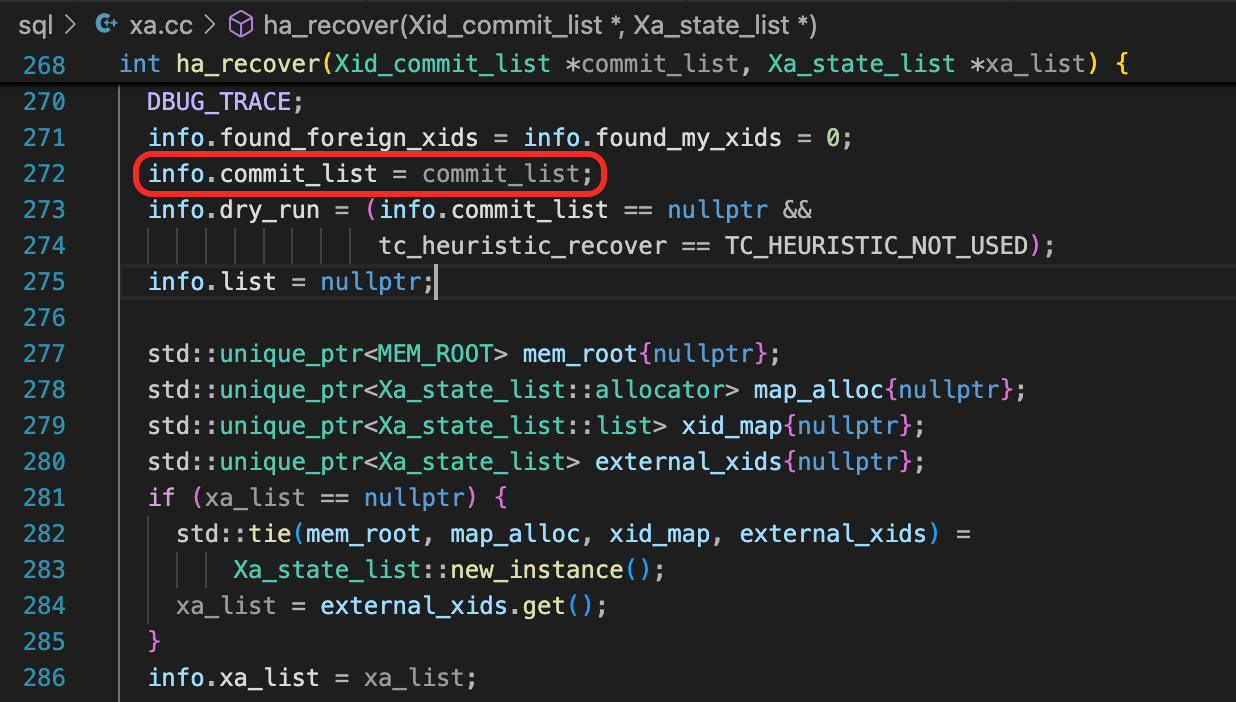
Binlog_recovery::recover
ha_recover由函数Binlog_recovery::recover调用,传入的参数是this->m_internal_xids。这里的this,就是Binlog_recovery对象。
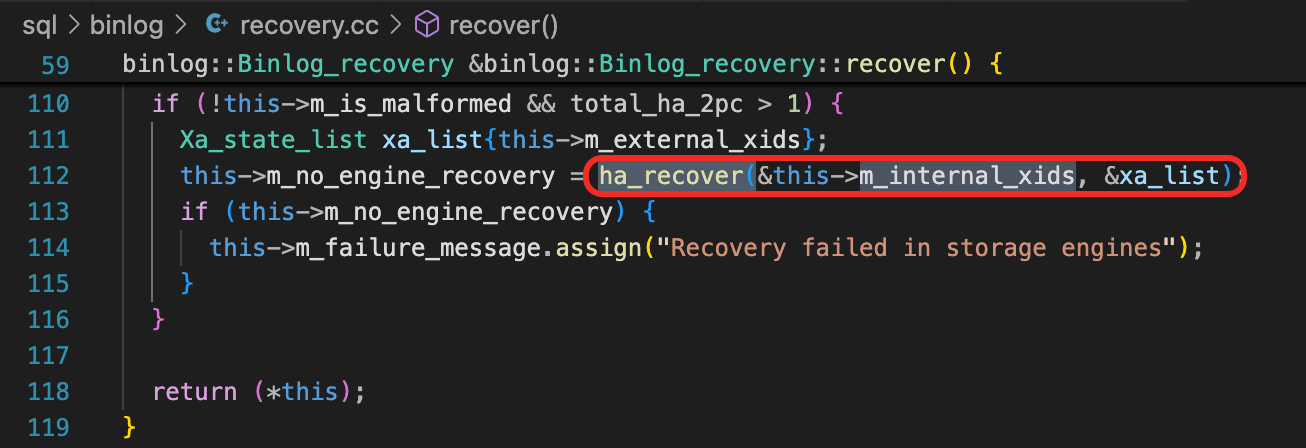
m_interal_xids
再搜索m_internal_xids,可以找到Binlog_recovery::process_xid_event函数中会把XID加进来。
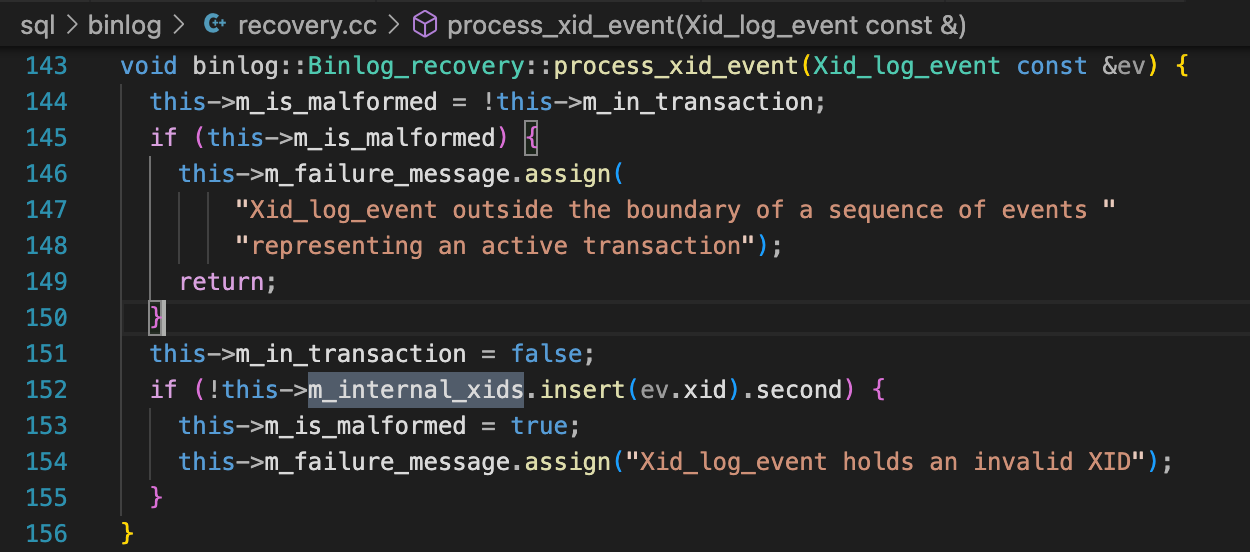
Binlog_recovery::recover
Binlog_recovery::recover函数中会调用process_xid_event。64行的循环中,读取Binlog文件中的每一事件,如果读取到一个XID事件,就把XID加到m_interal_xids中。
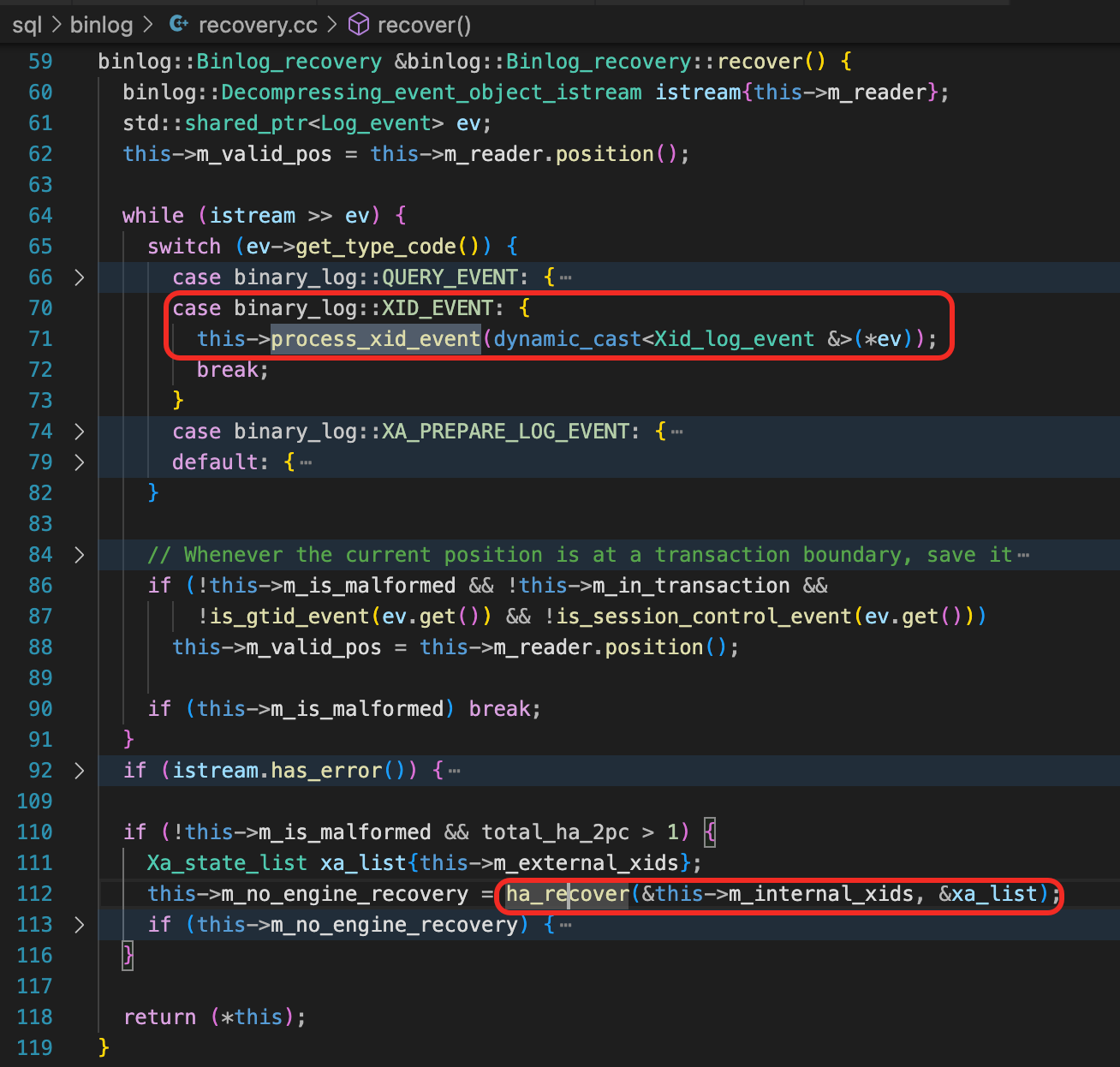
open_binlog
Binlog_recovery::recover在函数open_binlog中调用。open_binlog判断当前的Binlog是不是数据库崩溃时在使用的,这实际上是根据Binlog头部的FORMAT_DESCRIPTION_EVENT事件中,是否有LOG_EVENT_BINLOG_IN_USE_F标记来判断的。如果有这个标记,就执行Binlog_recovery::recover,读取Binlog中的所有XID,调用ha_recover处理Prepared状态的事务。
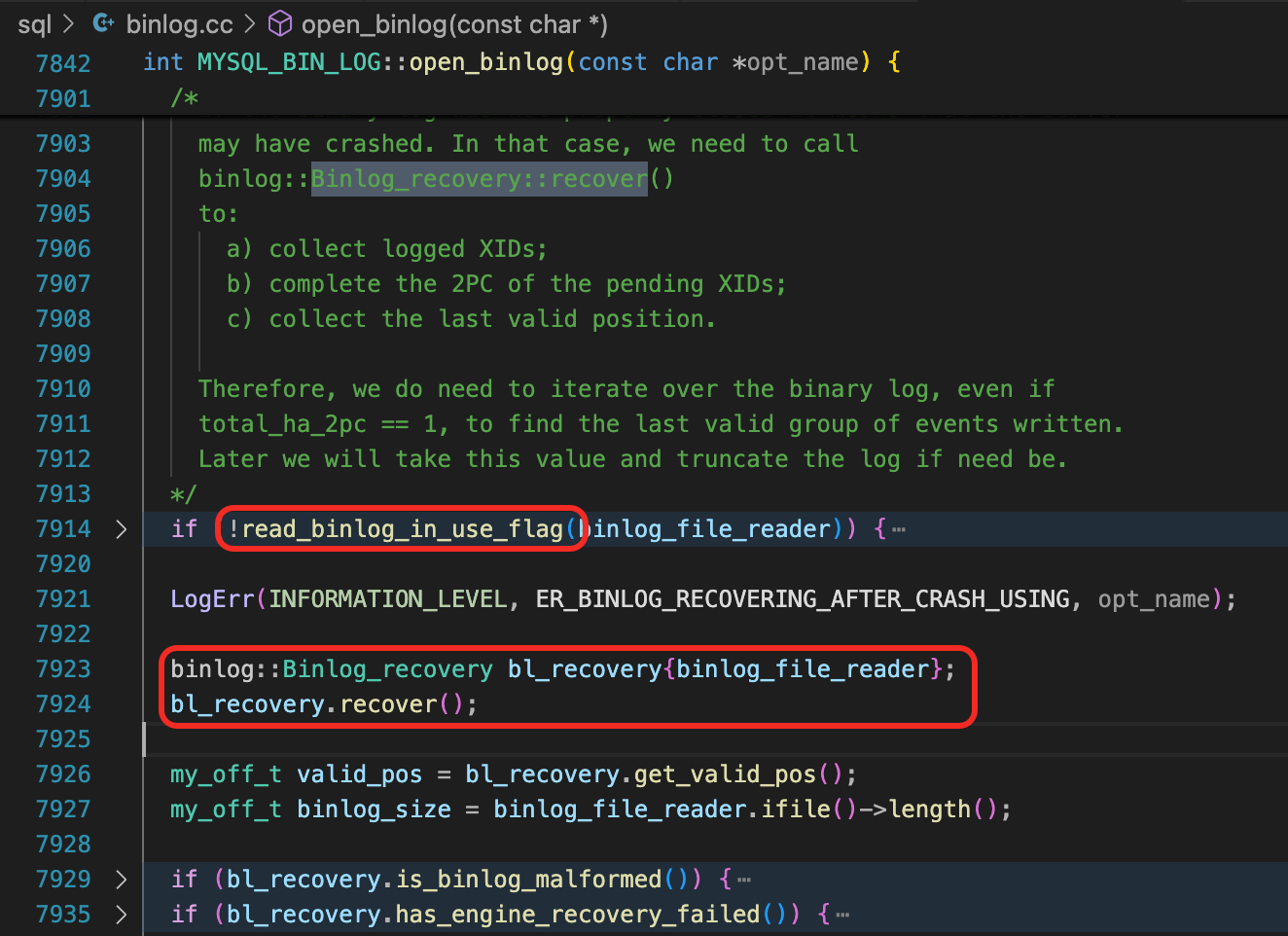
继续分析,能找到下面这个调用链路。
上面分析了Prepared状态的事务,在恢复时的处理逻辑。
继续搜索trx_sys->rw_trx_list,还能找到活动的事务的处理过程。
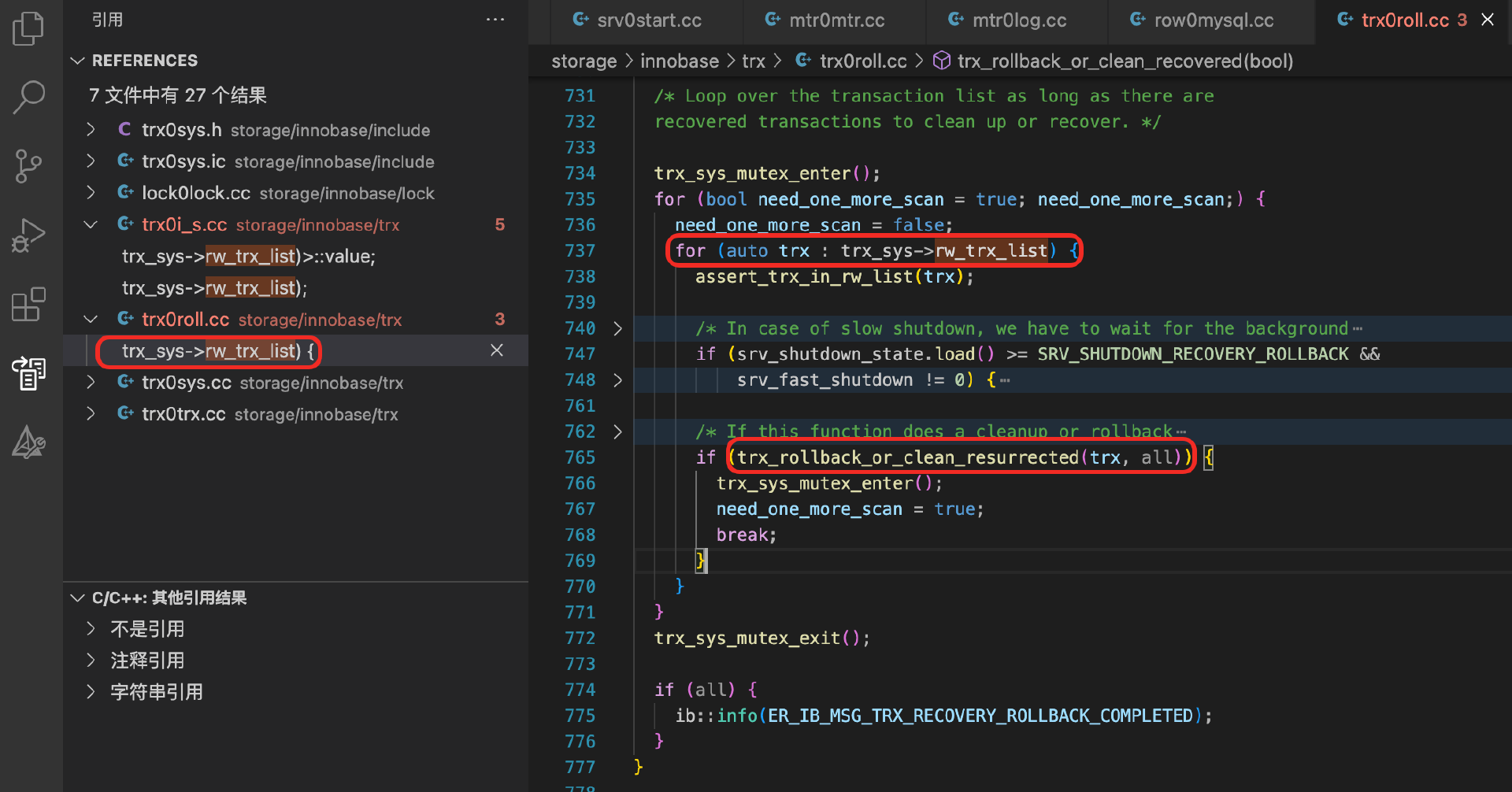
从代码中,还能找到下面这个调用链路。
trx_recovery_rollback_thread -> trx_recovery_rollback
-> trx_rollback_or_clean_recovered -> trx_rollback_or_clean_resurrected
trx_recovery_rollback_thread是回滚线程的主函数,这个线程在srv_start_threads_after_ddl_recovery中创建。
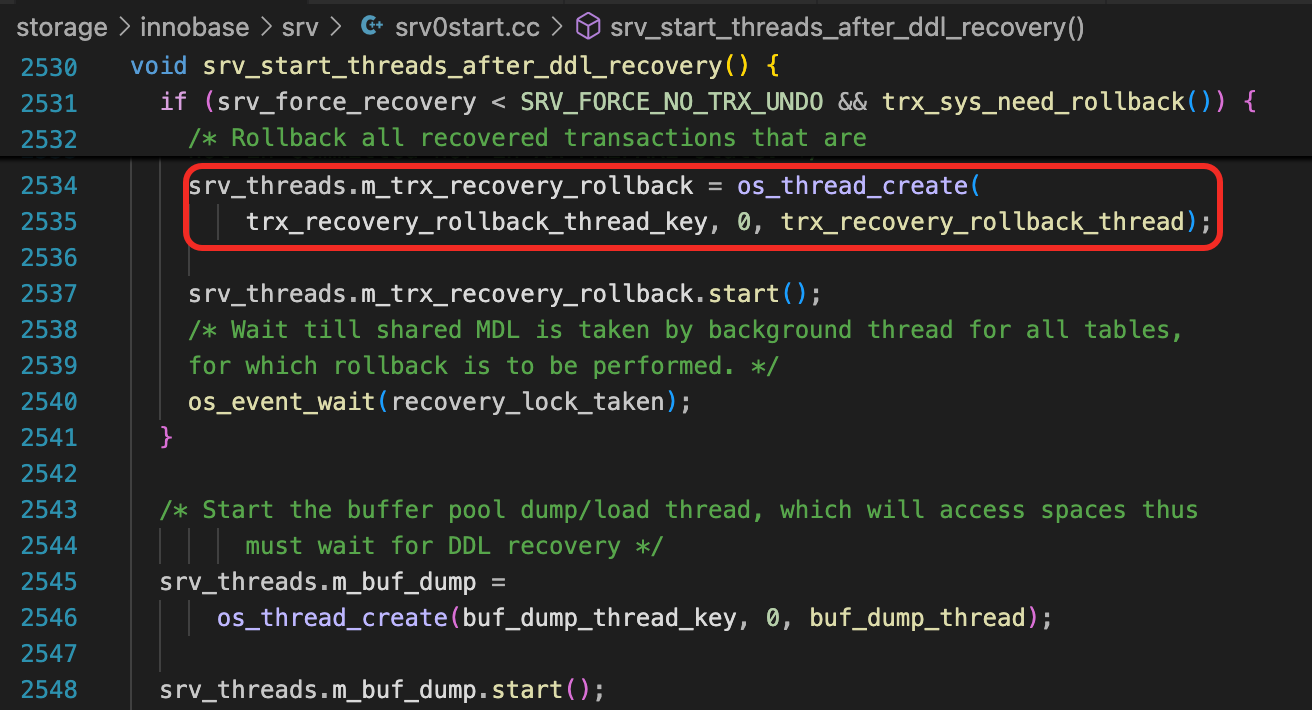
调用链路大概这这样的。
mysqld_main -> init_server_components -> ha_post_recover
-> post_recover_handlerton -> post_recover
-> innobase_post_recover -> srv_start_threads_after_ddl_recovery
使用GDB调试MySQL源码
现在我们对MySQL的源码结构已经有了一定的了解,并且可以借助一些工具来分析源码。但是,MySQL是不是一定按我们理解的方式在运行呢?毕竟MySQL有上百万行代码,看代码时,有时候很容易忽略掉一些细节。而且有些情况下,代码比较复杂,并不一定能完全理解代码的含义。
- 传给函数的参数取什么值是怎么确定的?比如函数row_search_mvcc的参数中,参数mode、prebuilt、match_mode是怎么确定的,和执行的SQL有什么关系?
- 函数执行时,会走到哪个分支?
- 事务提交过程中,执行到哪一行代码后,修改的数据对其他会话可见?
使用调试器,就能观察程序在运行时的状态,查看参数和变量具体的值,分析函数的调用栈。还能使用调试器来构建一些边界条件。比如要调试Prepared事务在恢复时的处理逻辑,就得先生成一些Prepared状态的事务,然后重启数据库。使用调试器,就能让事务停留在Prepared状态。
接下来,我会通过一些调试场景,来初步介绍GDB的一些用法。
先准备一个调试环境,Build一个Debug版本的MySQL,创建一个数据库。具体的步骤在第1讲介绍过,这里就不重复了。
如果遇到下面这样的报错,很可能是gdb的版本太低,可以安装一个高版本的试试。
Reading symbols from /usr/local/mysql/bin/mysqld...
Dwarf Error: wrong version in compilation unit header (is 5, should be 2, 3, or 4) [in module /usr/local/mysql/bin/mysqld]
(no debugging symbols found)...
done.
我的测试环境是CentOS 7.9的系统,用了devtoolset-11。
SQL如何执行?
第 8 讲中介绍过“SELECT语句是怎么执行的”,到gdb中验证一下。先运行gdb,attach到mysqld进程。先给do_command函数设置一个断点(break do_command),执行continue命令。
# gdb /opt/mysql8.0/bin/mysqld 12312
GNU gdb (GDB) Red Hat Enterprise Linux 10.2-6.el7
(gdb) break do_command
Breakpoint 1 at 0x330a841: file /root/buildenv/mysql-8.0.40/sql/sql_parse.cc, line 1311.
(gdb) c
Continuing.
连接到MySQL,执行一个简单的SQL语句。
执行next命令,单步跟踪。执行完dispatch_command后,你会发现SQL执行完成了。
Thread 44 "connection" hit Breakpoint 1, do_command (thd=0x7fa5d8017480)
at /root/buildenv/mysql-8.0.40/sql/sql_parse.cc:1311
1311 NET *net = nullptr;
(gdb) n
1312 enum enum_server_command command = COM_SLEEP;
(gdb)
1314 DBUG_TRACE;
(gdb)
1315 assert(thd->is_classic_protocol());
(gdb)
1321 thd->lex->set_current_query_block(nullptr);
(gdb)
1329 thd->clear_error(); // Clear error message
......
1438 DEBUG_SYNC(thd, "before_command_dispatch");
(gdb)
1440 return_value = dispatch_command(thd, &com_data, command);
(gdb)
所以需要跟踪到dispatch_command函数里面去。可以在这里设置一个断点,或者使用step命令。
这里我们在sql_parse.cc的1440行设置一个断点,运行到这里后,执行step命令进到函数dispatch_command里。执行backtrace命令查看调用堆。
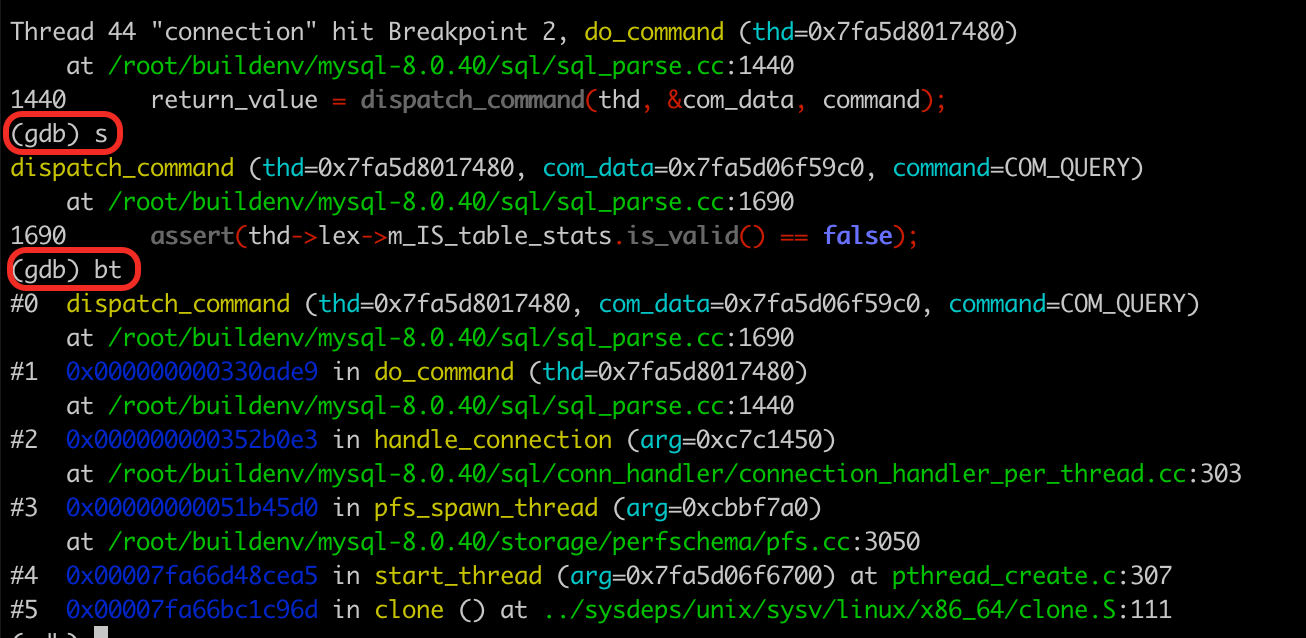
类似这样,你可以继续单步跟踪执行。因为我们知道查询数据时,会调用row_search_mvcc获取记录,因此就给函数row_search_mvcc设置一个断点。
(gdb) break row_search_mvcc
Breakpoint 3 at 0x4c85040: file /root/buildenv/mysql-8.0.40/storage/innobase/row/row0sel.cc, line 4423.
(gdb) continue
Continuing.
Thread 44 "connection" hit Breakpoint 3, row_search_mvcc (buf=0x7fa5d8008420 "\375\351\a",
mode=PAGE_CUR_G, prebuilt=0x7fa5d8b3c9a8, match_mode=0, direction=0)
at /root/buildenv/mysql-8.0.40/storage/innobase/row/row0sel.cc:4423
4423 DBUG_TRACE;
查看调用堆,可以看到很多函数调用。
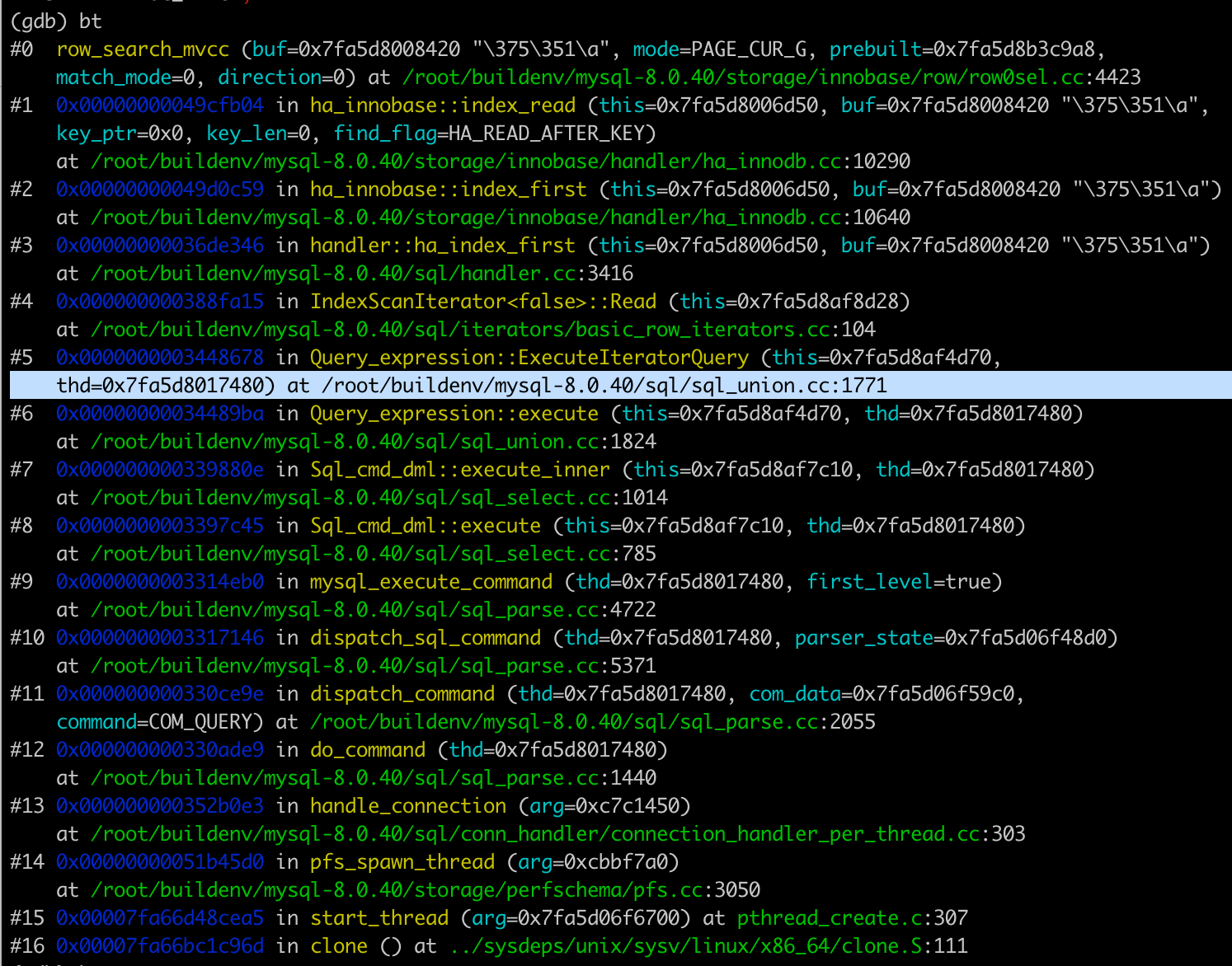
经过一些分析,发现sql_union.cc的1771行可能有我们感兴趣的代码。
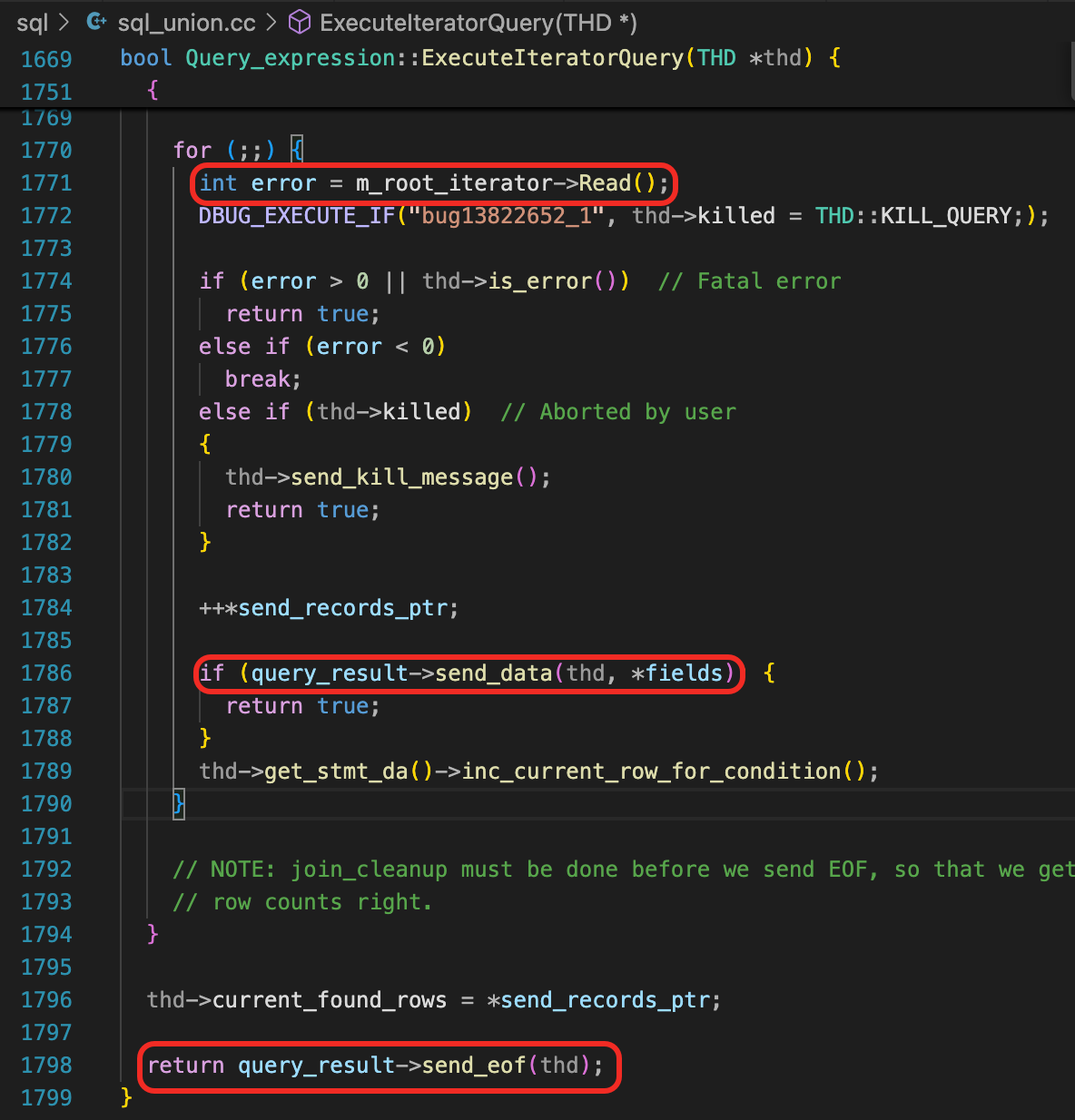
在函数ExecuteIteratorQuery中,可以看到SQL引擎的一个基本执行过程。
- 1771行,调用存储引擎接口,获取数据。
- 1774行,判断存储引擎的返回码,如果数据取完了,就退出for循环。如果有异常,直接返回。
- 1786行,调用send_data,将数据发送给客户端。
- 1798行,数据取完了,发送一个结束标记给客户端。
但是,再仔细观察一下,你可能会有一个疑惑,存储引擎中获取的记录,是怎么传递给send_data函数的呢?从函数的返回值、参数中都看不出来。
回到前面这个调用栈,可以发现一些线索。
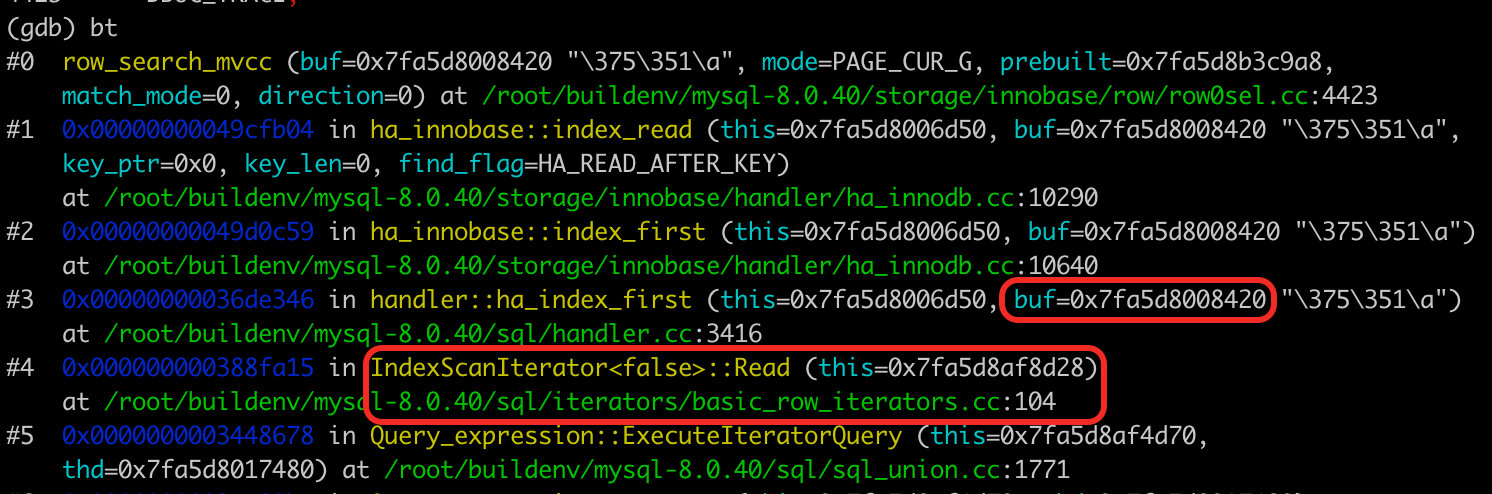
handler::ha_index_first有一个buf参数,分析代码(row_search_mvcc)后可以知道,InnoDB是将查到的记录写到了这个buf中。
这个参数是IndexScanIterator::Read中传入的。
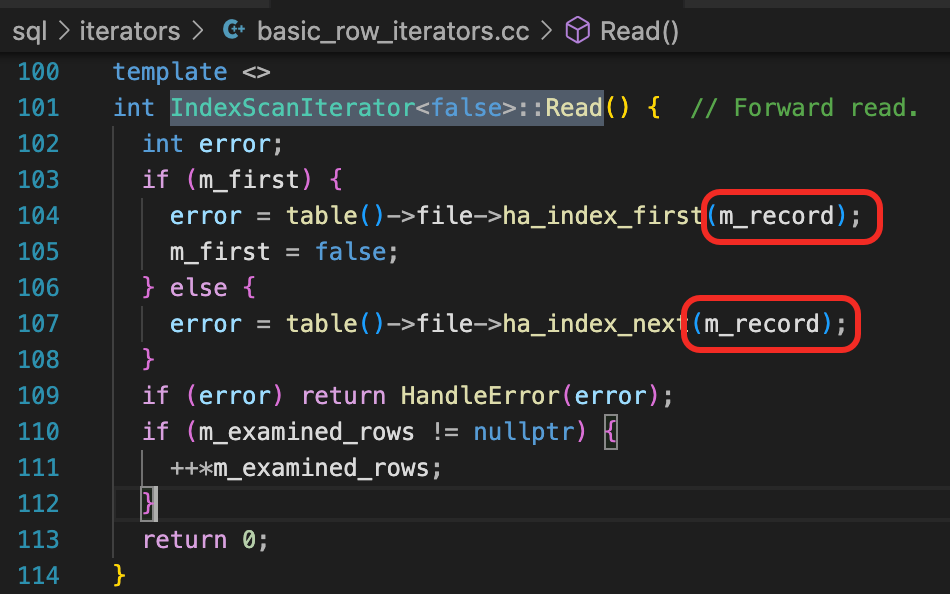
这个m_record又是从哪里来的呢?这是IndexScanIterator类的一个成员,在构造函数中初始化成table->record[0]。
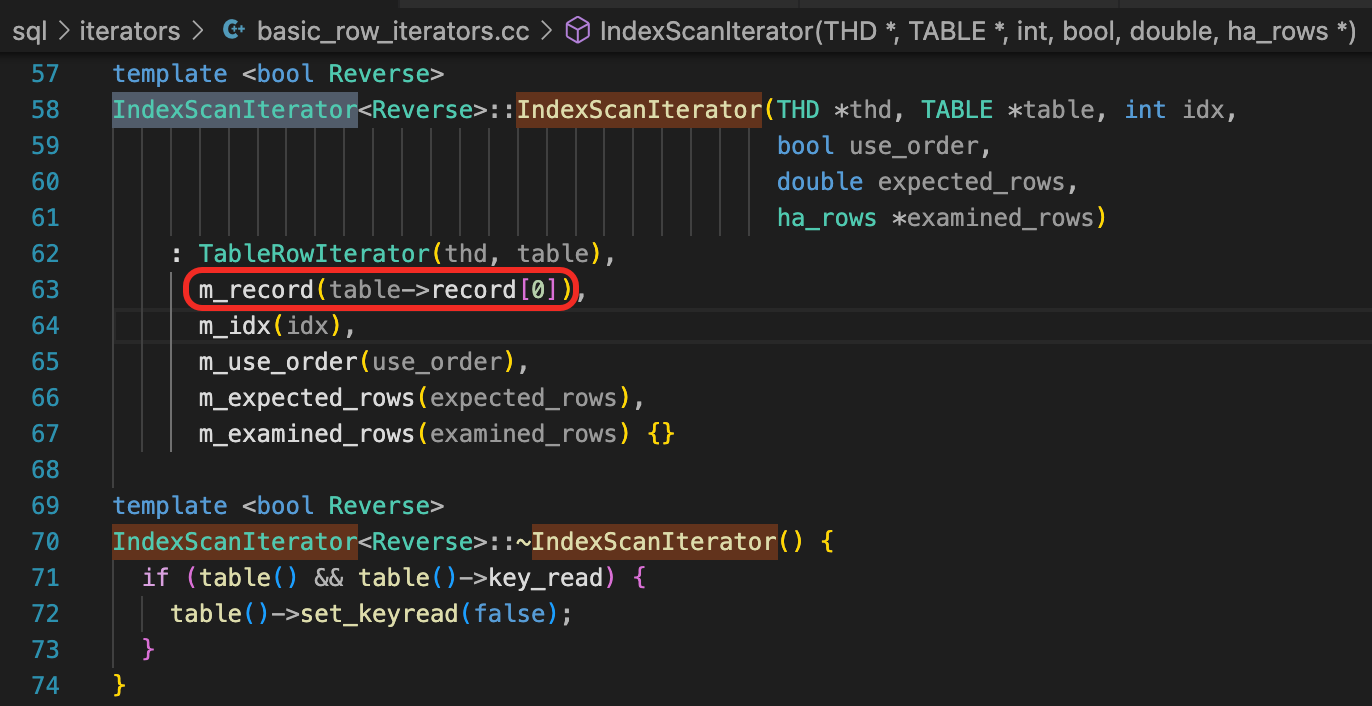
我们可以在IndexScanIterator的构造函数上加一个断点。
(gdb) break IndexScanIterator<true>::IndexScanIterator
Breakpoint 4 at 0x389096e: file /root/buildenv/mysql-8.0.40/sql/iterators/basic_row_iterators.cc, line 67.
(gdb) break IndexScanIterator<false>::IndexScanIterator
Breakpoint 5 at 0x3890bd8: file /root/buildenv/mysql-8.0.40/sql/iterators/basic_row_iterators.cc, line 67.
(gdb) c
Continuing.
Thread 44 "connection" hit Breakpoint 5, IndexScanIterator<false>::IndexScanIterator (this=0x7fa5d8af8d28, thd=0x7fa5d8017480, table=0x7fa5d80063a0, idx=0, use_order=false, expected_rows=4,
examined_rows=0x7fa5d8af7ea0) at /root/buildenv/mysql-8.0.40/sql/iterators/basic_row_iterators.cc:67
67 m_examined_rows(examined_rows) {}
就可以看到这样的调用栈,看起来是在优化SQL的时候传进来的table变量。
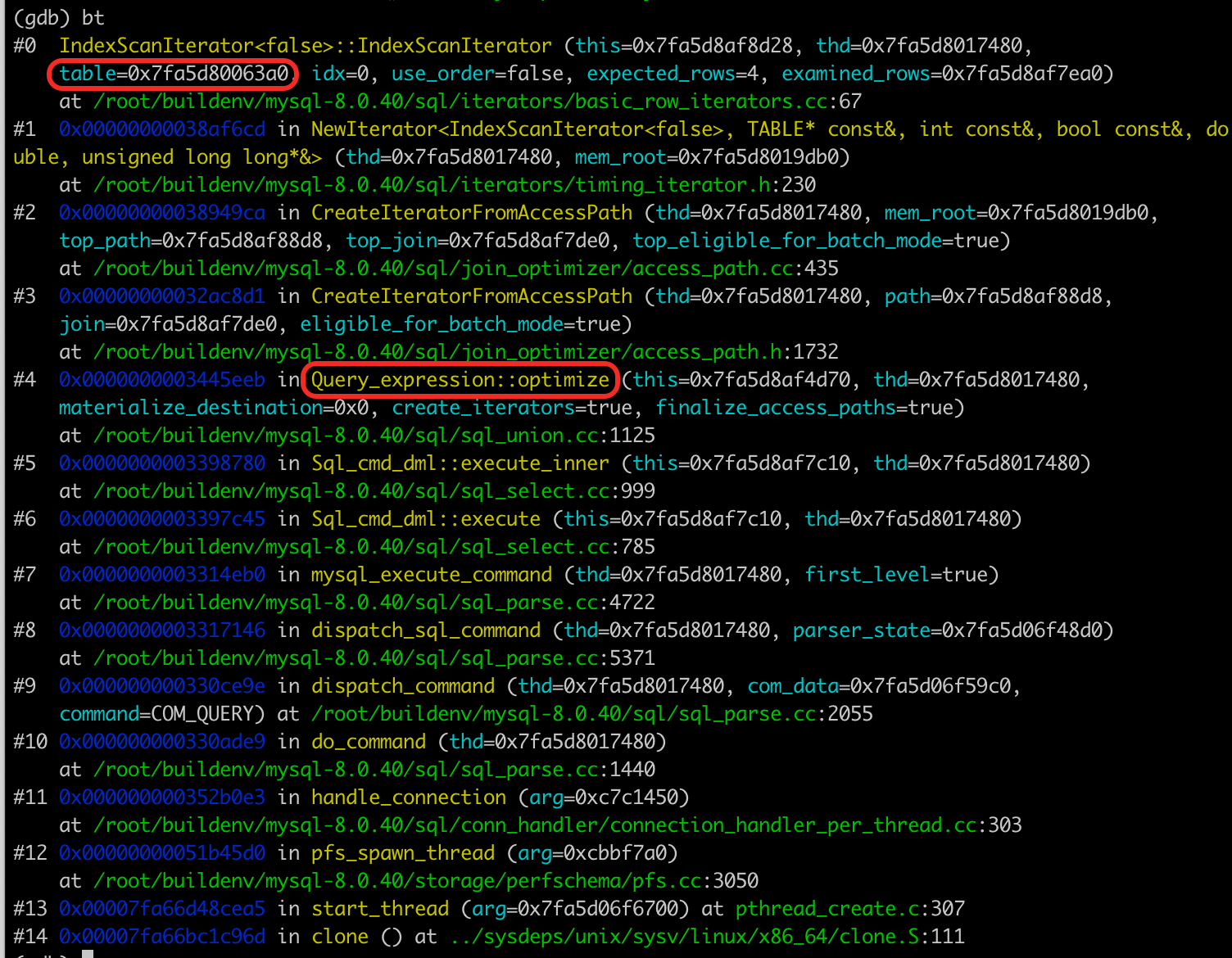
这里的table是一个重要的结构,我们说的Open table cache里缓存的,是不是就是这个table结构呢?
可以用print命令查看变量table的值。
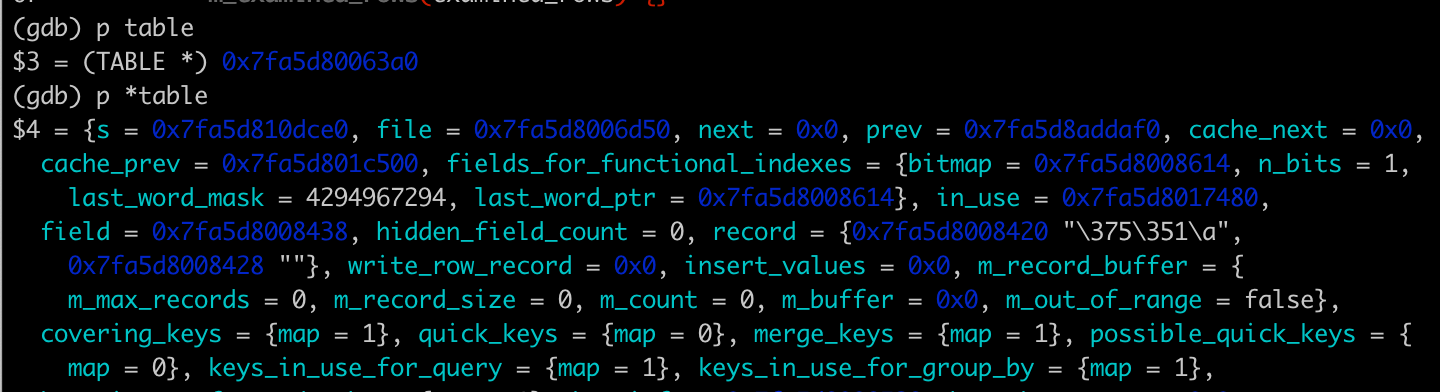
好了,这个调试案例就先到这儿。借助GDB,我们分析了一个简单的SELECT语句执行的基本步骤,我们还知道了MySQL Server层和InnoDB存储引擎之间,是通过TABLE结构体的record buffer来传递数据的。
数据库启动流程分析
上一个案例中,我们使用gdb attach到一个运行中的mysqld进程上进行调试。如果要调试MySQL的启动过程,就要在gdb中启动MySQL。
我们先看一下当前mysqld进程的运行参数。
# ps -elf | grep mysqld
... /opt/mysql8.0/bin/mysqld --defaults-file=/data/mysql8.0/my.cnf --basedir=/opt/mysql8.0 --datadir=/data/mysql8.0/data --plugin-dir=/opt/mysql8.0/lib/plugin --user=mysql --log-error=/data/mysql8.0/log/alert.log --open-files-limit=1024 --pid-file=/data/mysql8.0/run/mysqld.pid --socket=/data/mysql8.0/run/mysql.sock --port=3380
启动gdb,加载mysqld。
设置断点,比如在崩溃恢复的一些函数上设置断点。
(gdb) break trx_sys_init_at_db_start
Breakpoint 1 at 0x4d3627f: file /root/buildenv/mysql-8.0.40/storage/innobase/trx/trx0sys.cc, line 440.
(gdb) break open_binlog
Breakpoint 2 at 0x44e2953: open_binlog. (2 locations)
(gdb) break recv_recovery_from_checkpoint_start
Breakpoint 3 at 0x4b5afee: file /root/buildenv/mysql-8.0.40/storage/innobase/log/log0recv.cc, line 3770.
(gdb) break do_command
然后用run命令,启动MySQL。
(gdb) run --defaults-file=/data/mysql8.0/my.cnf --basedir=/opt/mysql8.0 --datadir=/data/mysql8.0/data --plugin-dir=/opt/mysql8.0/lib/plugin --user=mysql --log-error=/data/mysql8.0/log/alert.log --open-files-limit=1024 --pid-file=/data/mysql8.0/run/mysqld.pid --socket=/data/mysql8.0/run/mysql.sock --port=3380
会先运行Redo恢复。
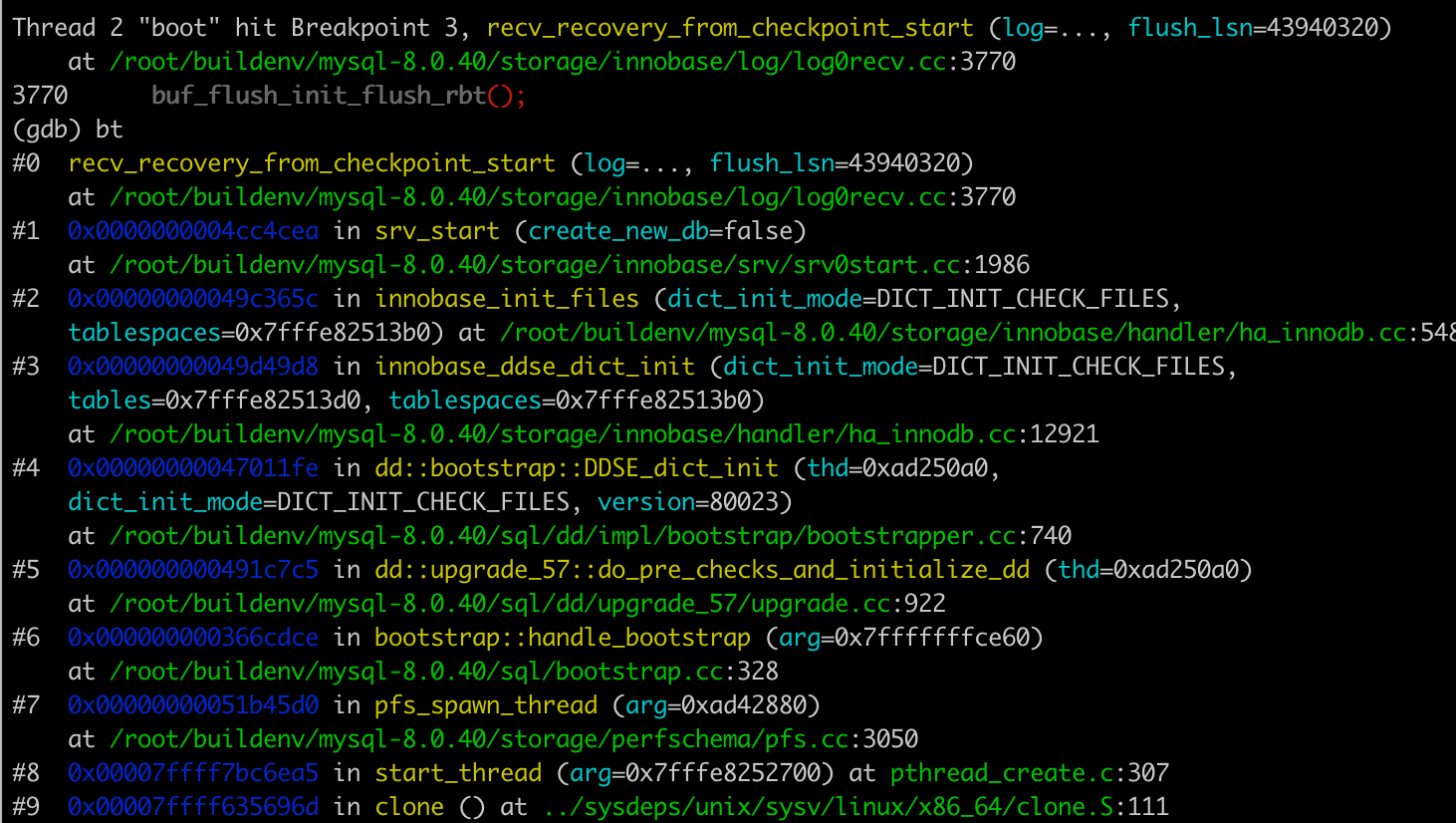
运行fininish命令,执行完recv_recovery_from_checkpoint_start后,可以接着调试。
(gdb) fin
Run till exit from #0 recv_recovery_from_checkpoint_start (log=..., flush_lsn=43940320)
at /root/buildenv/mysql-8.0.40/storage/innobase/log/log0recv.cc:3770
0x0000000004cc4cea in srv_start (create_new_db=false)
at /root/buildenv/mysql-8.0.40/storage/innobase/srv/srv0start.cc:1986
1986 err = recv_recovery_from_checkpoint_start(*log_sys, flushed_lsn);
Value returned is $1 = DB_SUCCESS
你会发现接下来先运行到trx_sys_init_at_db_start处的断点,然后再运行到open_binlog。在一些关键的代码点上设置断点,可以观察到一些代码的运行顺序。比如数据库启动时,先执行Redo,再执行Undo。
GDB命令参考
gdb的功能很强大,我把一些基本的命令整理到了下面这个表格中。可以使用命令的简称,比如执行c就是执行continue命令。

总结
MySQL使用C/C++编写,因此理论上,你只要熟悉C/C++,就能看懂MySQL的实现。当然,由于MySQL的代码量比较多,分析这些代码需要花比较多的时间。这一讲中提到的一些方法,可以供你参考,更重要的其实是花大量的时间去尝试。
思考题
MySQL是一个多线程的服务器,代码运行到一个断点时,所有线程都会暂停运行。有些情况下,我们可能只想调试其中一个线程,调试过程中,其他线程要保持运行状态。使用GDB,怎么实现这一点呢?
期待你的思考,欢迎在留言区中与我交流。如果今天的课程让你有所收获,也欢迎转发给有需要的朋友。我们下节课再见。
- 小猪猪猪蛋 👍(1) 💬(1)
讲的非常详细,一步一步跟下来 受益匪浅! 谢谢老师
2024-12-16 - hDEC2突变 👍(0) 💬(1)
进入某个线程用thread n ,info threads显示当前的所有线程,正在运行的前面有*号 老师,有个问题,就是p thread_id和info threads里面的线程id都不对应,我想知道某个函数运行的时候调用的哪个线程,如何确定?
2025-01-27