44 如何搭建一个 MySQL 监控平台?
你好,我是俊达。
整个专栏到这儿,差不多也快结束了。这一讲中,我们来聊一聊,MySQL的监控怎么做。把监控放到专栏的最后,其实也有一定的原因。当你对整个MySQL的体系结构和运行环境有了全面的了解后,就能更好地理解MySQL需要监控什么。
监控什么?
我们期望一个监控系统,能给我们提供哪些价值呢?
首先是可用性监控。如果数据库无法连接上,或者无法正常执行基本的SQL语句,或者执行SQL的速度很慢,或者有大量业务SQL积压,要能及时通知到运维人员,以便于运维人员快速响应并恢复服务,减少对业务的影响。
其次,监控系统要将数据库运行环境和内部的一些关键运行信息采集下来。这里的运行信息,包括MySQL运行环境(操作系统)的监控数据,也包括MySQL Server层和InnoDB存储引擎的一些状态变量、数据库的会话信息、事务和锁的信息、数据库中执行过的SQL语句等。当应用程序访问数据库出现异常后,我们要分析出问题背后的根本原因。对于一些偶发的问题,如果缺少详细的监控数据,有时会很难分析出问题的真正原因。
最后,从监控数据也能分析出业务的一些运行趋势,我们可以对业务的增长做出一些评估,规划数据库系统的容量。
我们先来看一下上面提到的这些监控数据,具体怎么采集。
可用性监控
对于可用性监控,我们一般会使用一个普通的账号定时连接数据库,还可以到数据库执行一个简单的SQL语句,更新一个心跳表。如果连接不上数据库,或者执行SQL超时了,都可能说明数据库有异常了。这里最好把报错信息也记录下来,这可以用来区分是由于监控账号问题导致的报错,还是数据库真的有异常了。
状态变量
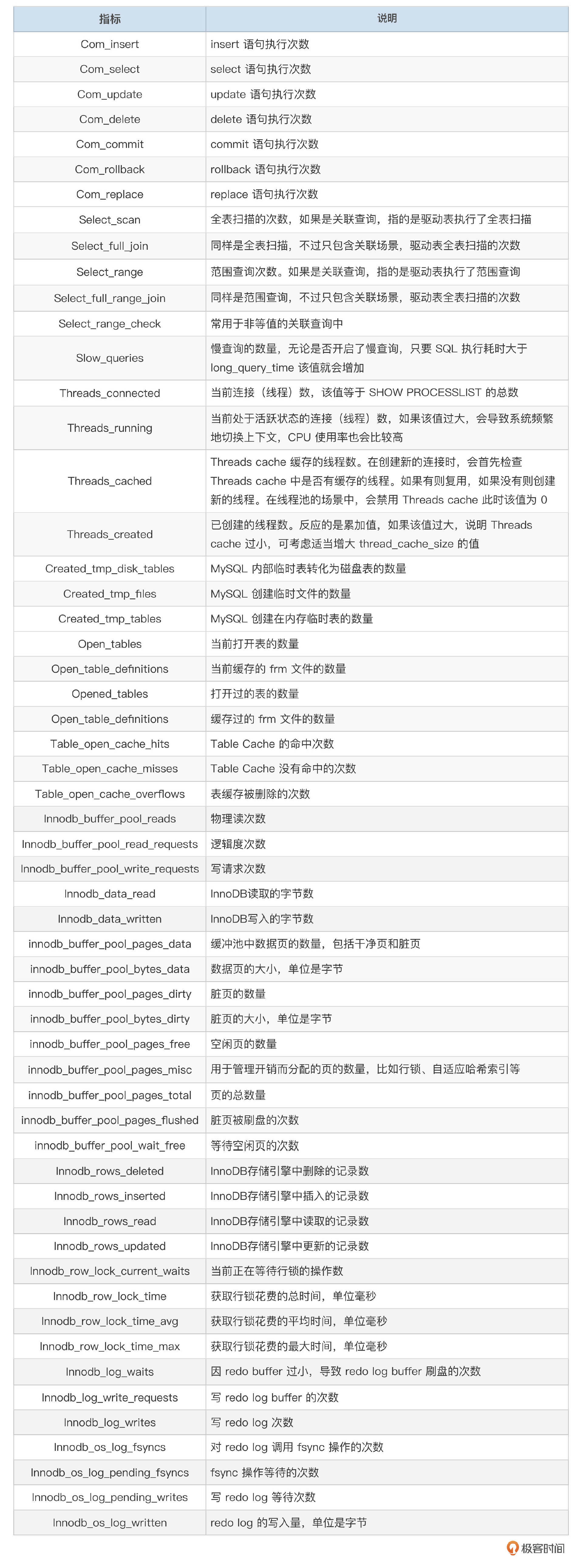
MySQL的内部运行信息,可以通过状态变量、一些系统命令和系统表查看。可以用show global status命令采集状态变量。有的状态变量是累加值,有的状态变量是当前值,采集或使用时需要注意。如果用时序数据库来存储指标数据,一般都会提供一些函数(如rate)来计算指标的差值。如果用传统的数据库存储指标数据,一般会在采集的时候就计算好指标的差值。
下面这个表格里,整理了一些常用的监控指标。实际上,你还可以采集更多的指标,这对分析问题有帮助。
对于InnoDB,有一些重要的信息没有在状态变量中输出,可以从show engine innodb status的输出中解析出一些重要的信息。比如Undo History链表长度、Redo日志的几个序列号、InnoDB存储引擎内的查询数量、Read View的数量。
Purge done for trx's n:o < 117495 undo n:o < 0 state: running but idle
History list length 0
Ibuf: size 1, free list len 0, seg size 2, 0 merges
Log sequence number 3090029475
Log buffer assigned up to 3090029475
Log buffer completed up to 3090029475
Log written up to 3090029475
Log flushed up to 3090029475
Added dirty pages up to 3090029475
Pages flushed up to 3090029475
Last checkpoint at 3090029475
...
0 queries inside InnoDB, 0 queries in queue
0 read views open inside InnoDB
备库状态和复制延迟
异步复制状态一般通过show slave status或show replica status命令采集,主要关注IO线程和SQL线程是否都在运行中,以及Seconds_Behind_Source。36讲中还提到过,使用Seconds_Behind_Source来监控备库延迟有时候并不精确,可以引入Percona的pt-heartbeat工具。
如果使用了MGR,还要监控集群成员的状态,以及事务接收和应用延迟。从replication_group_members表获取节点的状态、角色。
mysql> select member_host,member_port, member_state, member_role
from replication_group_members;
+----------------+-------------+--------------+-------------+
| member_host | member_port | member_state | member_role |
+----------------+-------------+--------------+-------------+
| 172-16-121-237 | 3307 | ONLINE | PRIMARY |
| 172-16-121-234 | 3307 | ONLINE | SECONDARY |
| 172-16-121-236 | 3307 | ONLINE | SECONDARY |
+----------------+-------------+--------------+-------------+
从replication_group_member_stats表获取组复制的一些指标。
mysql> select * from replication_group_member_stats\G
*************************** 1. row ***************************
CHANNEL_NAME: group_replication_applier
VIEW_ID: 17308812763445921:11
MEMBER_ID: 5adc0339-8cfd-11ef-a49e-facd3cef0300
COUNT_TRANSACTIONS_IN_QUEUE: 0
COUNT_TRANSACTIONS_CHECKED: 11
COUNT_CONFLICTS_DETECTED: 0
COUNT_TRANSACTIONS_ROWS_VALIDATING: 0
TRANSACTIONS_COMMITTED_ALL_MEMBERS: 21c128a6-9b57-11ef-9dc0-fab81f64ee00:1-37,
b094c003-8cfa-11ef-bf79-fab81f64ee00:1-2302,
d1204af7-8cfb-11ef-857e-fa8338b09400:1
LAST_CONFLICT_FREE_TRANSACTION: 21c128a6-9b57-11ef-9dc0-fab81f64ee00:34
COUNT_TRANSACTIONS_REMOTE_IN_APPLIER_QUEUE: 0
COUNT_TRANSACTIONS_REMOTE_APPLIED: 14
COUNT_TRANSACTIONS_LOCAL_PROPOSED: 0
COUNT_TRANSACTIONS_LOCAL_ROLLBACK: 0
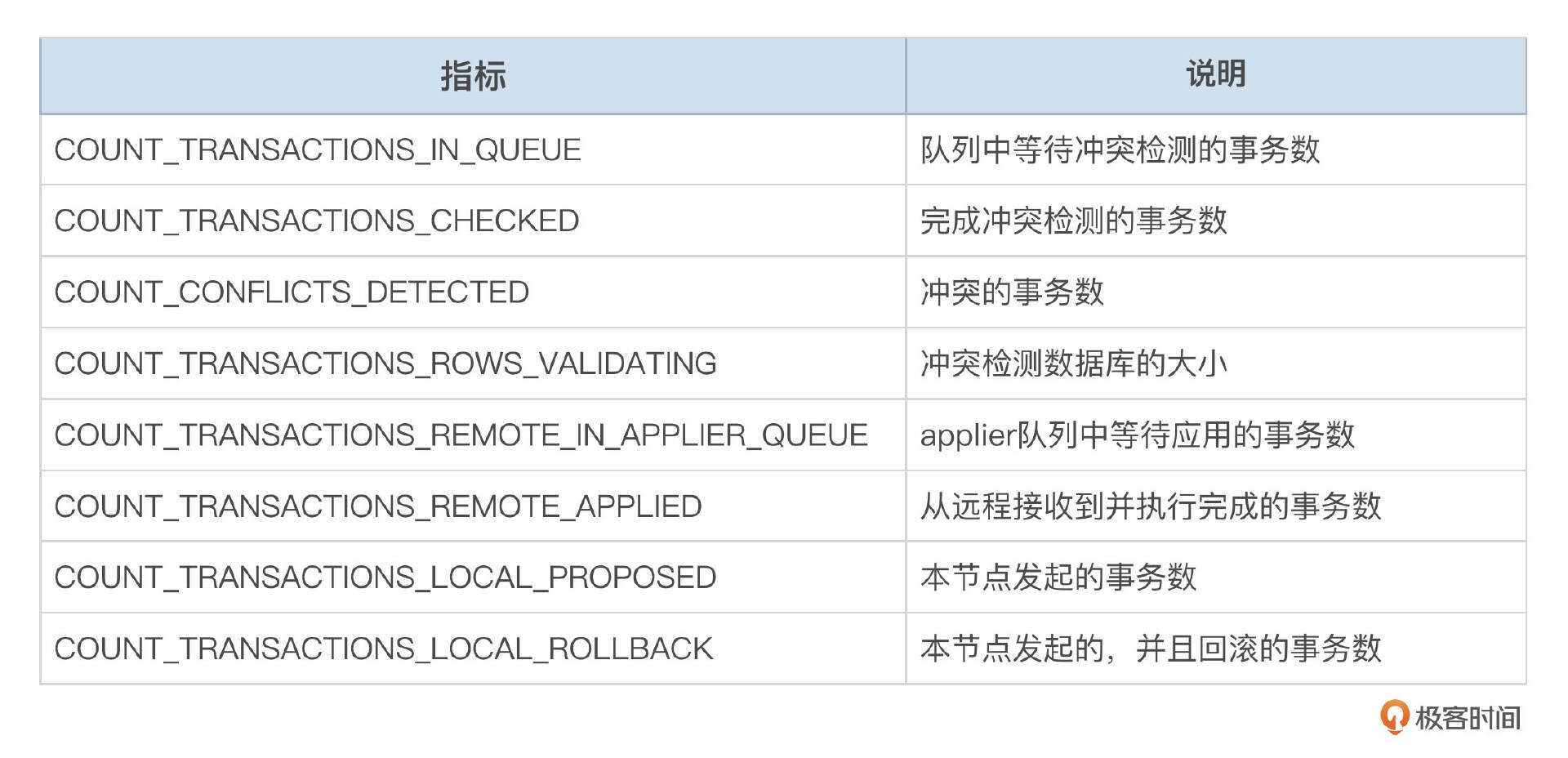
下面这个表格,对这些指标做了简单的说明。如果冲突检测队列或Applier队列中的事务数超过一定限制,会触发MGR流控,需要重点关注。
从replication_applier_status_by_coordinator和replication_applier_status_by_worker表中,还能获取到正在处理的Binlog事件的一些信息。GTID事件中,增加了original_committed_timestamp和immediate_commit_timestamp信息,分别表示事务在源节点上和中间节点上的提交时间。
# at 1722630
#241031 15:01:15 server id 234 end_log_pos 1722716 CRC32 0xb2d35e04 GTID
last_committed=23
sequence_number=24
rbr_only=yes
original_committed_timestamp=1730358075343041
immediate_commit_timestamp=1730358075365889
transaction_length=333
使用下面这两个SQL,分别获取协调线程处理事件的延迟,以及Worker线程应用事务的延迟。
select CHANNEL_NAME, service_state,
LAST_PROCESSED_TRANSACTION_END_BUFFER_TIMESTAMP - LAST_PROCESSED_TRANSACTION_ORIGINAL_COMMIT_TIMESTAMP as last_process_delay,
PROCESSING_TRANSACTION_START_BUFFER_TIMESTAMP - PROCESSING_TRANSACTION_ORIGINAL_COMMIT_TIMESTAMP as current_process_delay
from replication_applier_status_by_coordinator;
select
CHANNEL_NAME, service_state,
worker_id,
LAST_APPLIED_TRANSACTION_END_APPLY_TIMESTAMP - LAST_APPLIED_TRANSACTION_ORIGINAL_COMMIT_TIMESTAMP as last_apply_delay,
APPLYING_TRANSACTION_START_APPLY_TIMESTAMP - APPLYING_TRANSACTION_ORIGINAL_COMMIT_TIMESTAMP as current_apply_delay
from replication_applier_status_by_worker;
会话和事务信息
MySQL的会话信息在排查一些问题的时候有比较重要的作用。我们可以把ProcessList中运行时间超过一定阈值的会话采集下来。MySQL中的长事务和大事务有时也会对性能有负面影响,可以到innodb_trx表把长事务也采集下来。
select trx_id,
trx_mysql_thread_id,
trx_started,
trx_tables_in_use,
trx_tables_locked,
trx_lock_structs,
trx_lock_memory_bytes,
trx_rows_locked,
trx_rows_modified
from innodb_trx
SQL采集
对数据库来说,SQL语句的监控有着不可替代的作用。SQL 语句通常是实现业务逻辑的关键部分。通过监控 SQL 语句的运行,可以深入了解业务流程在数据库层面的执行情况。而且SQL也是引起数据库性能问题的一个主要的原因,通过监控 SQL 语句的运行,可以确定哪些 SQL 语句消耗了大量的系统资源。
一个繁忙的数据库,执行的SQL量可能会非常多,怎么采集SQL语句呢?MySQL中,通常有几种选择。
一种是采集慢SQL日志。我们可以把参数long_query_time设置成毫秒级别。当然这样会生成更多的慢SQL日志,需要注意清理和归档日志文件。通过参数log_output,可以将慢SQL输出到CSV引擎的表中(mysql.slow_log),或者输出到文件中。存储到CSV存储引擎时,日志更容易解析。输出到文件时,需要解析慢SQL日志中的一些关键信息。不同的MySQL发行版本、不同的参数设置下,慢日志的格式可能会有一些区别,但是有一些基本的信息要解析出来。
下面的表格中,整理了慢SQL的关键字段。
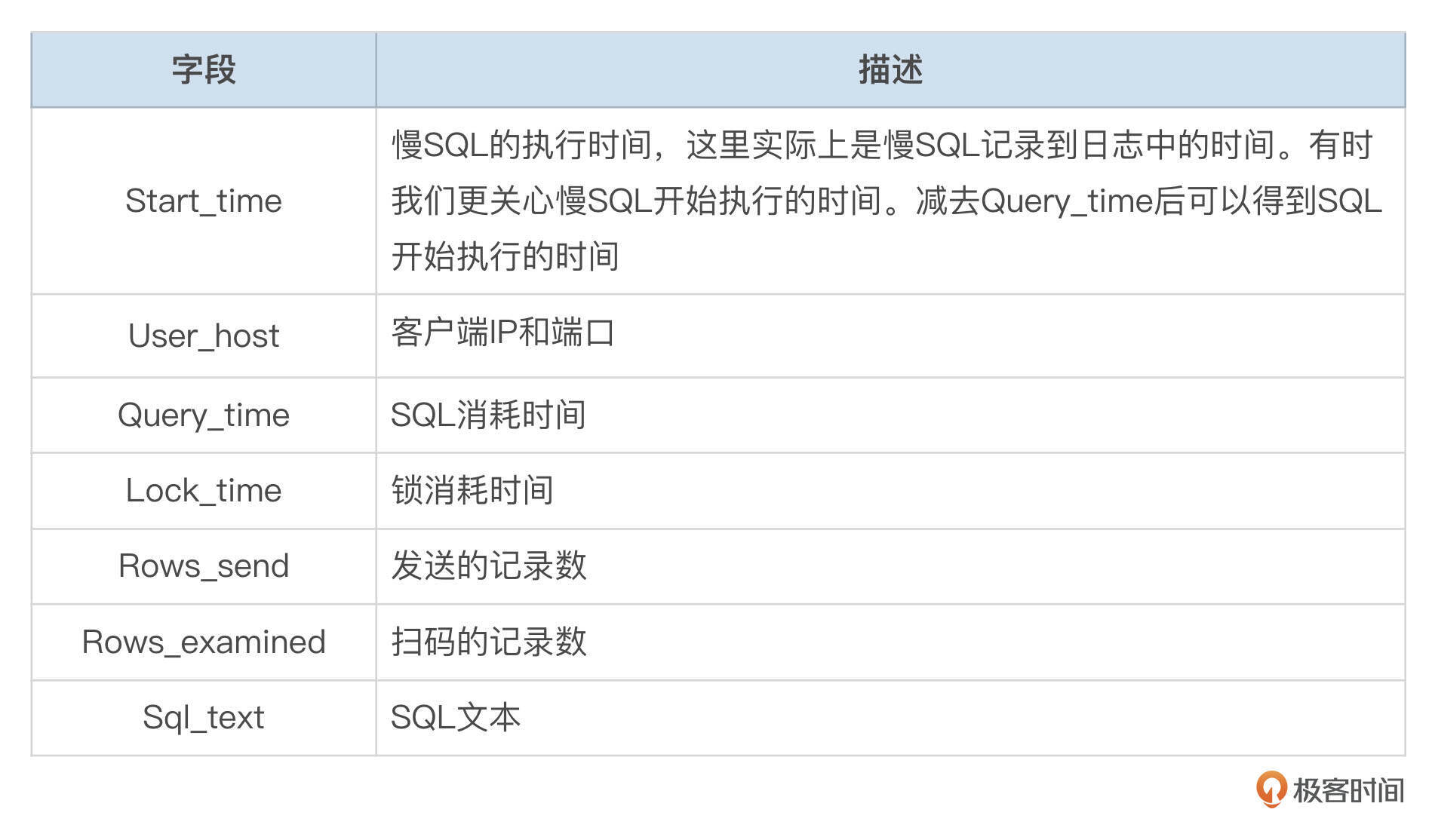
使用慢SQL,一般无法统计到数据库里执行的全部SQL。有的SQL,单次执行时间可能没有超过long_query_time,但是执行的频率特别高。
MySQL 8.0默认开启了performance_schema,从events_statements_summary_by_digest表中,也能获取到SQL语句的一些汇总信息。这个表按SCHEMA_NAME和参数化之后的SQL文本的Hash值为Key,统计同一类SQL的一些累计指标。
下面的表格,对这个表的一些字段做了说明。
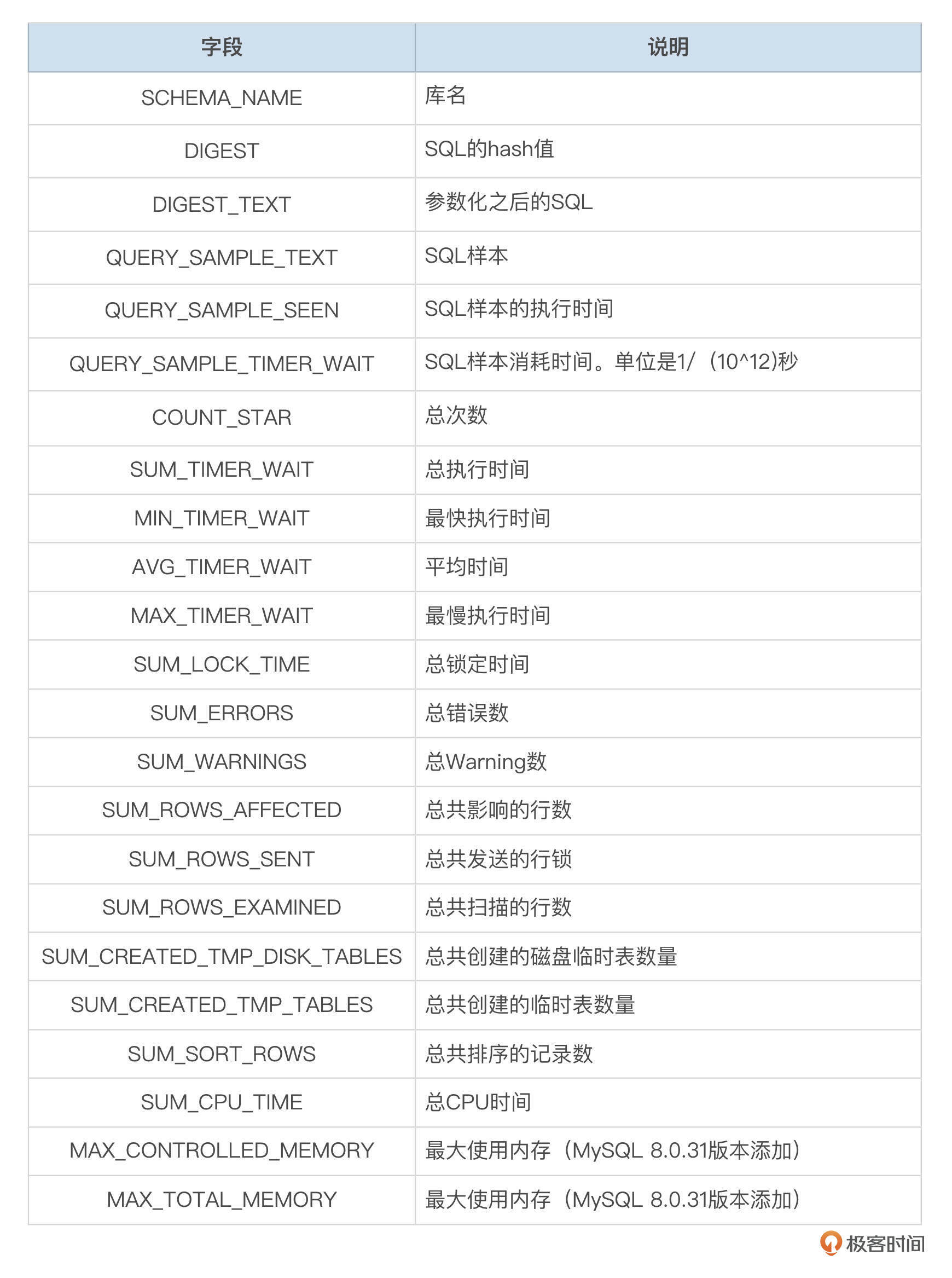
可以看到,这个表提供了比较丰富的SQL运行信息。由于这个表很多字段记录的都是累积值,采集程序要做一定的处理,可以得到某一个时间段内的SQL运行情况。
表和空间信息
使用了自增长字段的表,当字段中保存的值达到了数据类型允许的最大值后,再写入数据就会报错,可以使用下面这个SQL采集自增长列。
SELECT c.table_schema, c.table_name, column_name, auto_increment,
pow(2, case data_type
when 'tinyint' then 7
when 'smallint' then 15
when 'mediumint' then 23
when 'int' then 31
when 'bigint' then 63
end+(column_type like '% unsigned'))-1 as max_int
FROM information_schema.columns c
STRAIGHT_JOIN information_schema.tables t ON ( c.table_schema=t.table_schema AND c.table_name=t.table_name)
WHERE c.extra = 'auto_increment' AND t.auto_increment IS NOT NULL
and c.table_schema not in ('mysql')
+--------------+------------+-------------+----------------+------------+
| TABLE_SCHEMA | TABLE_NAME | COLUMN_NAME | AUTO_INCREMENT | max_int |
+--------------+------------+-------------+----------------+------------+
| db01 | t02 | id | 32767 | 32767 |
| db01 | t01 | id | 2147483647 | 2147483647 |
+--------------+------------+-------------+----------------+------------+
表占用的空间,特别是大表的空间,也可以监控起来。
SELECT
TABLE_SCHEMA,
TABLE_NAME,
TABLE_TYPE,
ifnull(ENGINE, 'NONE') as ENGINE,
ifnull(TABLE_ROWS, '0') as TABLE_ROWS,
ifnull(DATA_LENGTH, '0') as DATA_LENGTH,
ifnull(INDEX_LENGTH, '0') as INDEX_LENGTH,
ifnull(DATA_FREE, '0') as DATA_FREE
FROM information_schema.tables
WHERE TABLE_SCHEMA not in ('mysql', 'information_schema', 'performance_schema', 'sys')
+--------------+------------+------------+--------+------------+-------------+--------------+-----------+
| TABLE_SCHEMA | TABLE_NAME | TABLE_TYPE | ENGINE | TABLE_ROWS | DATA_LENGTH | INDEX_LENGTH | DATA_FREE |
+--------------+------------+------------+--------+------------+-------------+--------------+-----------+
| db01 | ta | BASE TABLE | InnoDB | 2 | 16384 | 0 | 5242880 |
| db01 | t01 | BASE TABLE | InnoDB | 1 | 16384 | 0 | 0 |
开源的MySQL监控方案
关于MySQL应该监控什么,前面已经做了比较多的介绍了。那么具体怎么来监控呢?有很多可选的方案。接下来我介绍两种基于Prometheus和Grafana的监控方案。
基于Prometheus和Grafana的MySQL监控系统
使用Prometheus官方提供的mysqld_exporter,可以采集到上面提到过的很多指标。使用起来也比较容易上手,大致分为几个步骤。
1. 安装Exporter
mysqld_exporter需要连接到MySQL数据库中采集监控指标,先到待监控的MySQL中创建监控账号并授权。
CREATE USER 'mon'@'172.16.%' IDENTIFIED BY 'somepass' WITH MAX_USER_CONNECTIONS 10;
GRANT SELECT, PROCESS, REPLICATION CLIENT, RELOAD, BACKUP_ADMIN ON *.* TO 'mon'@'172.16.%';
CREATE USER 'mon'@'127.0.0.1' IDENTIFIED BY 'somepass' WITH MAX_USER_CONNECTIONS 10;
GRANT SELECT, PROCESS, REPLICATION CLIENT, RELOAD, BACKUP_ADMIN ON *.* TO 'mon'@'127.0.0.1';
到官网下载对应操作系统版本的二进制包,这里我们使用了Linux版本。解压后就是一个二进制程序。
你可以把连接数据库的账号密码存到.my.cnf文件中,然后启动mysqld_exporter。
mysqld_exporter默认端口是9104,访问这个端口,确认exporter是否正常。
# curl http://172.16.121.234:9104/metrics
# HELP go_gc_duration_seconds A summary of the wall-time pause (stop-the-world) duration in garbage collection cycles.
# TYPE go_gc_duration_seconds summary
go_gc_duration_seconds{quantile="0"} 3.4301e-05
go_gc_duration_seconds{quantile="0.25"} 7.3643e-05
go_gc_duration_seconds{quantile="0.5"} 0.000115865
...
一个mysqld_exporter可以采集多个数据库的指标,访问probe路径,target参数指向目标mysql的地址。
# curl http://172.16.121.234:9104/probe?target=127.0.0.1:3307
...
# HELP mysql_global_status_buffer_pool_pages Innodb buffer pool pages by state.
# TYPE mysql_global_status_buffer_pool_pages gauge
mysql_global_status_buffer_pool_pages{state="data"} 2486
mysql_global_status_buffer_pool_pages{state="free"} 5689
mysql_global_status_buffer_pool_pages{state="misc"} 17
mysqld_exporter支持采集的指标很多,默认很多指标是不采集的,你可以添加命令行参数。使用–help选项查看支持的指标。
2. 安装和配置Prometheus
Prometheus也有很多不同的运行方式,下面的演示案例中使用了二进制安装。到官网下载对应的版本。
我们到配置文件prometheus.yml中添加采集配置。
global:
scrape_interval: 15s
evaluation_interval: 15s
.......
scrape_configs:
- job_name: "prometheus"
static_configs:
- targets: ["localhost:9090"]
- job_name: "linux"
static_configs:
- targets: ["172.16.121.234:9100", "172.16.121.236:9100", "172.16.121.237:9100"]
- job_name: "mysql"
params:
static_configs:
- targets: ["172.16.121.234:3306", "172.16.121.234:3307", "172.16.121.234:3308","172.16.121.236:3307", "172.16.121.236:3308","172.16.121.237:3307", "172.16.121.237:3308"]
labels:
host: "172.16.121.234"
relabel_configs:
- source_labels: [__address__]
target_label: __param_target
- source_labels: [__param_target]
target_label: instance
- target_label: __address__
replacement: 172.16.121.234:9104
启动prometheus后,检查监控指标是否都采集到了。使用浏览器访问prometheus所在服务器的9090端口。
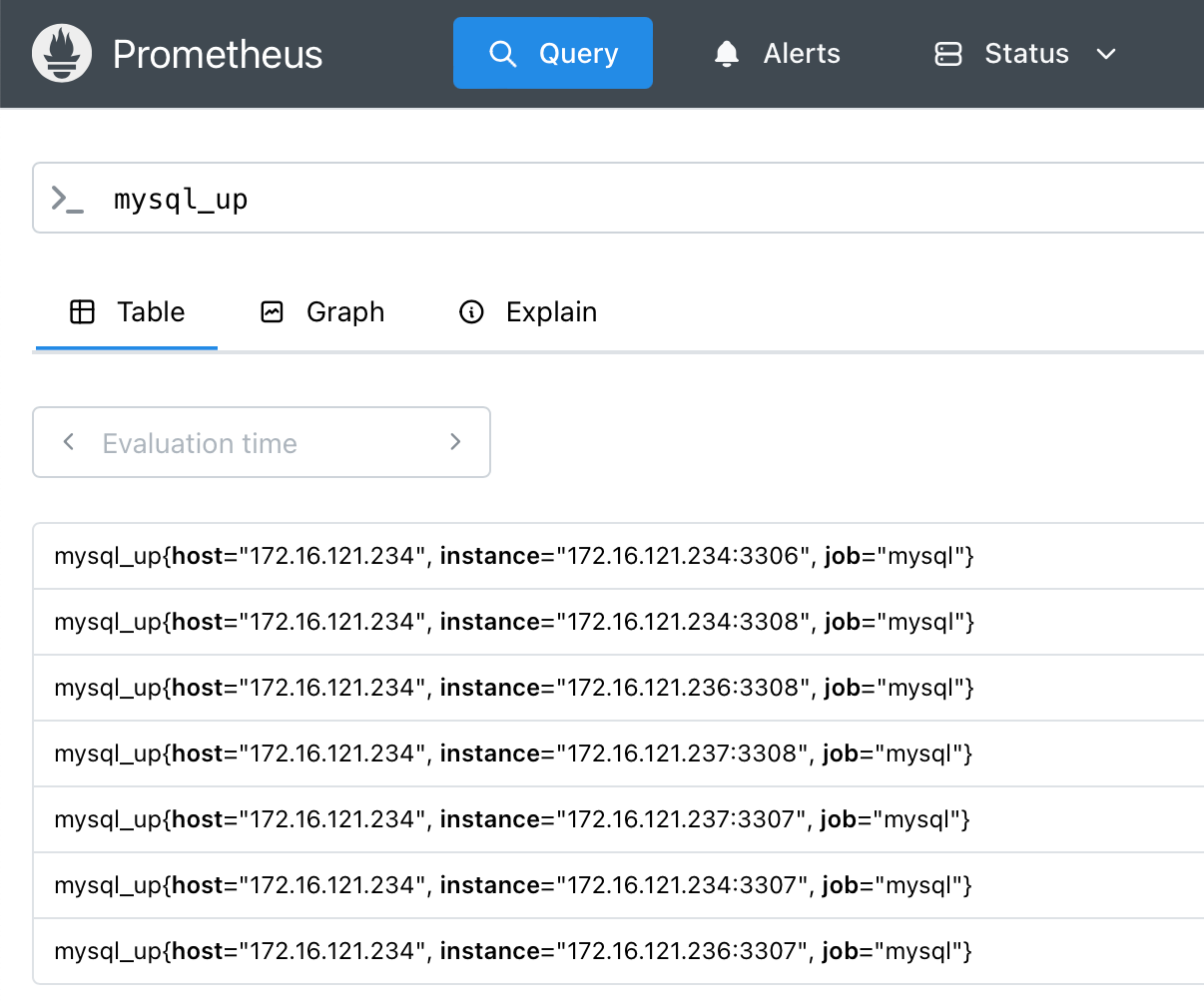
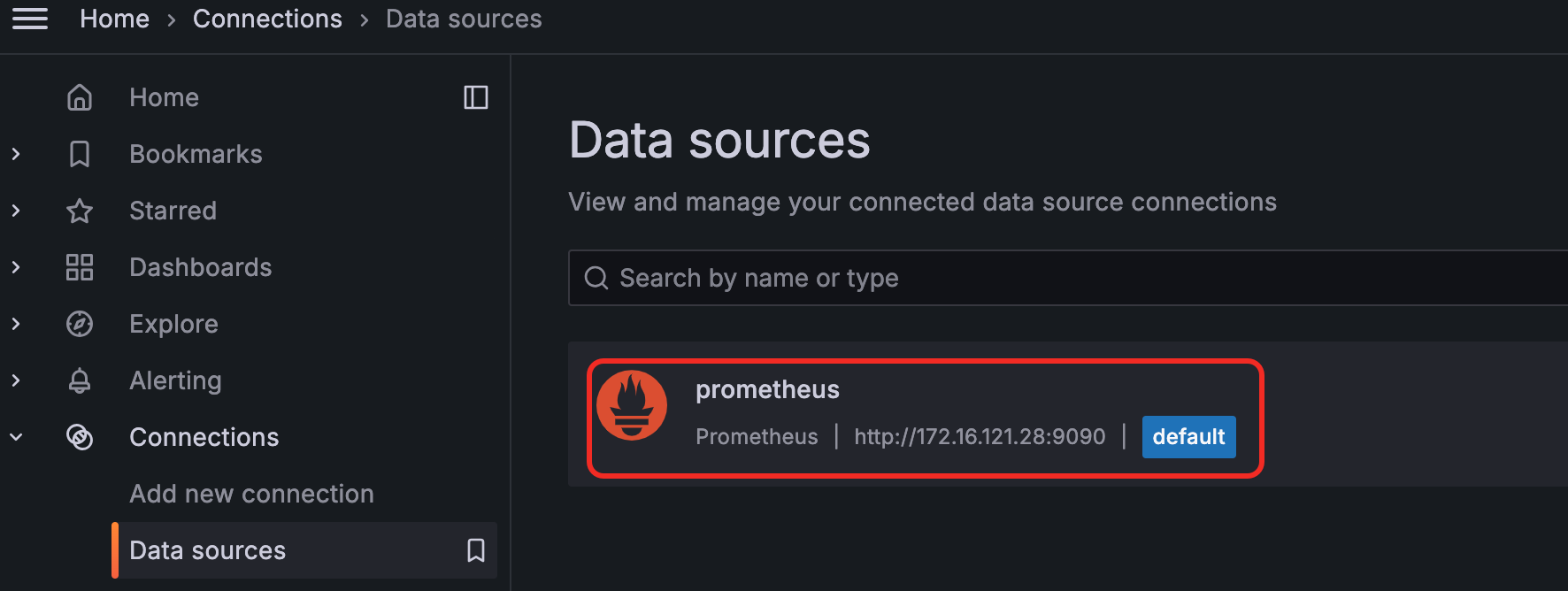
3. 使用Grafana展示数据
在Grafana中添加Prometheus的数据源。
Grafana的网站上,有很多监控模板可以参考。你可能需要根据自己的偏好,配置一些适合自己使用习惯的监控大屏。
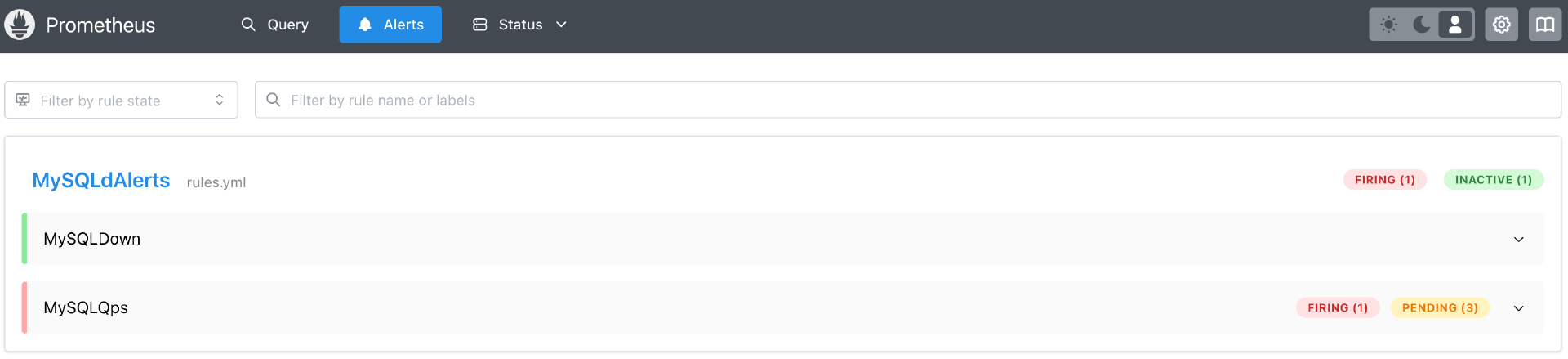
4. 告警规则和告警消息推送
Prometheus配套的alertmanager用来发送告警。先配置告警规则,可以把告警规则保存到rules.yml中。
### rules.yml
groups:
- name: MySQLdAlerts
rules:
- alert: MySQLDown
expr: mysql_up != 1
for: 5m
labels:
severity: critical
annotations:
description: 'MySQL {{$labels.job}} on {{$labels.instance}} is not up.'
summary: MySQL not up.
- alert: MySQLQps
expr: sum by (instance) ( round(irate(mysql_global_status_questions[3m]))) > 5
for: 3m
labels:
severity: warning
annotations:
description: 'MySQL {{$labels.job}} on {{$labels.instance}} QPS high, Current Value {{ .Value | humanize }}'
summary: MySQL QPS High
然后在prometheus.yml中配置规则文件和altermanager的地址。
rule_files:
- "rules.yml"
### prometheus.yml
alerting:
alertmanagers:
- static_configs:
- targets:
- 127.0.0.1:9093
Prometheus会按evaluation_interval指定的时间运行告警规则。Prometheus Web页面上的Alerts模块可以看到每个告警规则是否触发。
告警触发后,Prometheus将告警消息推给alertmananger进行处理。alertmanager是一个单独的程序,在alertmanager.yml中配置告警消息的推送规则。下面这个例子中,告警消息通过webhook发送到钉钉群。
### alertmanager.yml
route:
group_by: ['alertname']
group_wait: 30s
group_interval: 1m
repeat_interval: 3m
receiver: 'web.hook'
receivers:
- name: 'web.hook'
webhook_configs:
- url: 'http://127.0.0.1:8060/dingtalk/webhook1/send'
inhibit_rules:
- source_match:
severity: 'critical'
target_match:
severity: 'warning'
equal: ['alertname', 'dev', 'instance']
altermanager也提供了一个简易的web,可以用来查看告警和屏蔽告警。
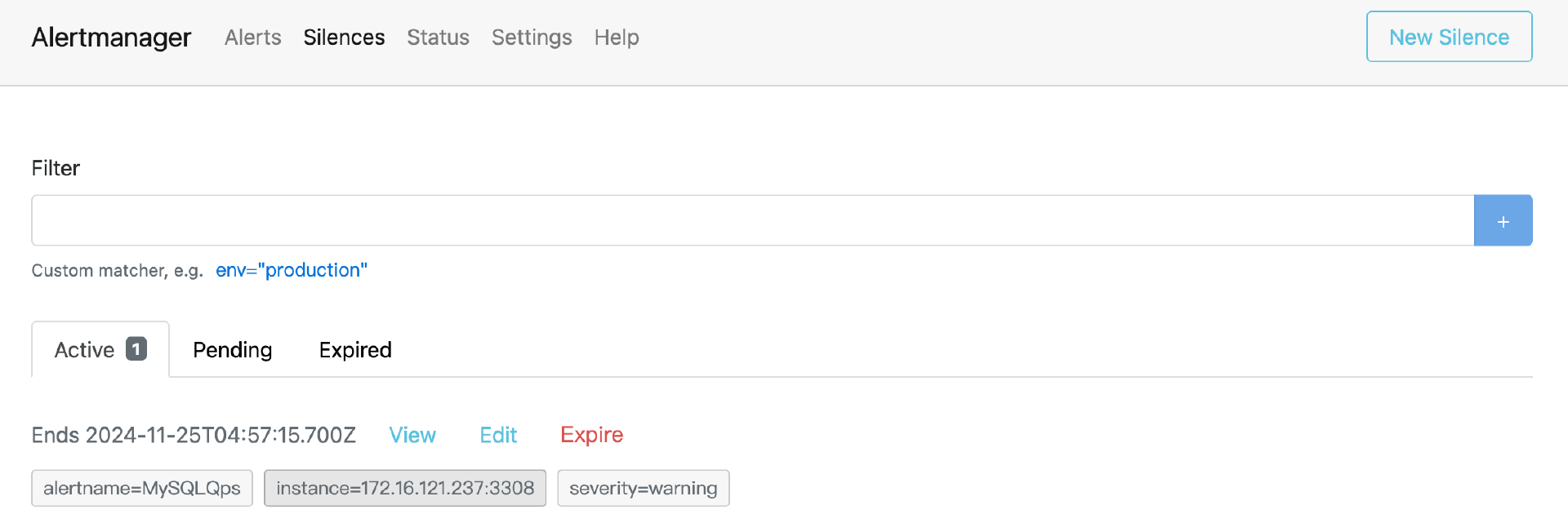
这个例子中,使用了prometheus-webhook-dingtalk,将消息推送到钉钉群,下面的配置文件中,url是钉钉群自定义机器人的Webhook地址。
这样,使用Promehteus和Grafana,就基本上实现了MySQL数据库的监控数据采集、监控数据可视化、告警规则检测和告警消息推送。
使用Percona PMM监控MySQL
使用mysqld_exporter和其他一些exporter,再加上prometheus、grafana,已经可以搭建一个基本的MySQL监控系统了。不过对于数据库监控,这里少了SQL监控的能力。Percona的PMM,整合了mysqld_exporter、grafana等技术,还提供了SQL采集和分析的功能。你可以使用PMM来监控MySQL。或者如果你要开发一个数据库的监控平台,PMM也是一个很好的参考。
接下来我简单介绍下PMM的使用。PMM由Server和Client组成。
1. 安装PMM Server
官方提供了Server的docker镜像和一键安装脚本。
如果下载镜像超时,可能是需要配置docker代理。配置好代理后,重启docker服务,然后再安装PMM Server。
# cat /etc/docker/daemon.json
{ "registry-mirrors": [ "https://dockerproxy.net" ] }
# service docker reload
# service docker restart
如果安装好之后PMM Server容器的状态不健康(unhealth),可能是权限的原因。
# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
70540cffcdc4 percona/pmm-server:2 "/opt/entrypoint.sh" 16 hours ago Up 16 hours (unhealthy) 80/tcp, 0.0.0.0:443->443/tcp pmm-server
删除容器,docker run增加–privileged参数再启动容器。
docker run \
--privileged \
--detach \
--restart \
always \
--publish 443:443 \
-v pmm-data:/srv \
--name pmm-server \
percona/pmm-server:2
访问网站地址(https://server-ip),如果出现登录界面,就说明安装成功了。
2. 安装PMM Client
可以用docker的方式运行client,也可以使用操作系统的包管理器安装client。下面的例子使用yum安装pmm client。
yum install -y https://repo.percona.com/yum/percona-release-latest.noarch.rpm
yum install -y pmm2-client
3. 添加采集配置
server和client都安装好之后,在client的机器上配置采集任务。
先使用pmm-admin config命令,配置server端的信息。下面的例子中,使用了默认的admin账号。
再通过pmm-admin命令,添加需要监控的MySQL信息。下面命令中的用户密码,就是之前创建的mysql监控账号的信息。query-source指定SQL采集的方式,可以使用perfschema或slowlog。
pmm-admin add mysql \
--query-source=perfschema \
--username=mon \
--password=somepass \
--service-name=172.16.121.236:3307 \
--host=127.0.0.1 \
--port=3307
4. 查看图表
添加采集配置后,如果一切正常,就可以在PMM的web界面查看监控图表了。从界面风格上可以看出,PMM的监控图表也使用了grafana。
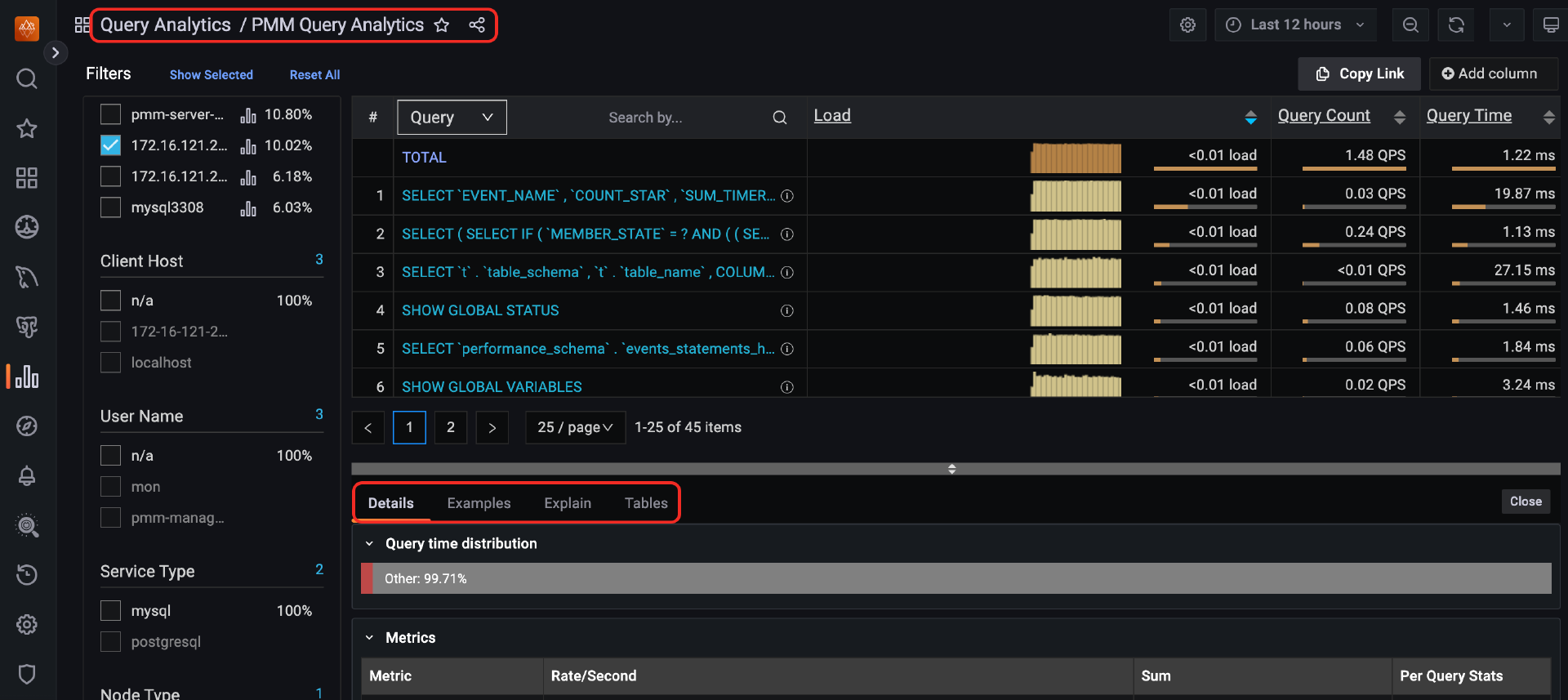
在查询分析模块(Query Analytics),可以分析数据库中运行的SQL,这里还能看到SQL的执行计划、表结构,使用起来比较方便。
总结
监控是运维很重要的一部分工作。这一讲里我们介绍了MySQL中需要监控的一些关键指标。这一讲还介绍了几种监控MySQL的开源工具。
真实环境中,要保证监控系统自身的可用性。而且采集的监控指标越多,监控的服务数量越多,监控系统的压力就越大。监控数据怎么存储、怎么处理,也是建设一个监控系统时需要重点考虑的。比如PMM,用VictoriaMetrics存储指标数据,用Clickhouse存储SQL信息。
思考题
系统出了问题,我们希望监控系统能及时告警出来,但是如果监控系统自身出问题了,我们有哪些方法能及时发现问题呢?
期待你的思考,欢迎在留言区中与我交流。如果今天的课程让你有所收获,也欢迎转发给有需要的朋友。我们下节课再见。
- 小猪猪猪蛋 👍(0) 💬(2)
老师 怎么用一个exporter采集多台mysql 实例呢,因为现在用的云RDS
2024-12-02