39 数据误操作了如何快速恢复?
你好,我是俊达。
上一讲中,我们知道了如何使用Xtrabackup来备份数据库和恢复数据库。不管是全量备份,还是增量备份,实际上都只能将数据库恢复到一个固定的时间点,这个时间点就是Xtrabackup备份完成的那个时刻。
但是在现实中,数据恢复的要求往往会更高。假设我们每天凌晨都会备份数据库。某一天下午,由于误操作,某一个重要的业务表的数据被清空了。使用凌晨的备份文件,只能恢复一部分数据。从凌晨到误操作发生的那一刻,这个表上进行了很多DML操作,这部分数据如何恢复呢?
这一讲我们就来解决这个问题。根据误操作的不同情况,我们可以选择不同方法来恢复数据。
Binlog备份
为了将数据库恢复到任意一个时间点,我们需要将Binlog也备份起来。如果Binlog没有备份,同时你又把Binlog删除了,那么就可能无法将数据恢复到这些Binlog覆盖的时间点。
备份Binlog实际上比较简单,一个Binlog,一旦完成切换,里面的内容就不会发生变化。你可以使用操作系统的命令,比如cp,将除了最后一个binlog之外其他Binlog,拷贝到备份空间。使用这种方式,无法实时备份最新的那个Binlog文件。极端情况下,如果这个时候数据库所在的服务器崩溃了,而且无法启动,那么你可能会丢失最后一个Binlog中的数据。
命令行工具mysqlbinlog提供了一个功能,可以实时接收远程数据库上生成的Binlog事件。
mysqlbinlog \
--read-from-remote-server \
--host=172.16.121.234 \
--port=3307 \
--user=backup \
--password=somepass \
--protocol=tcp \
--stop-never \
--raw \
--result-file=/path/to/binlog-backup/ \
mysql-binlog.00000N
mysqlbinlog的命令行参数中,加上read-from-remote-server后,可以模拟IO线程,连接到数据库,执行BINLOG_DUMP命令,接收Binlog。加上参数stop-never,读取完当前所有的Binlog后,也不会退出,而是继续等待主库生成新的Binlog事件。
使用mysqlbinlog备份远程的Binlog时,一般要加上raw参数。你可以将参数result-file设置为一个目录,这样Binlog会写到这个目录中,如果不加这个参数,默认会将Binlog文件保存到当前目录下。
最后一个参数(mysql-binlog.00000N)是开始读取的第一个Binlog的文件名。如果发生一些异常,如网络超时,或Dump线程被Kill了,mysqlbinlog命令会异常退出。如果mysqlbinlog命令异常退出了,你可以先看一下最后备份的那个Binlog文件,然后再重新从这个文件开始,备份Binlog。
恢复到指定时间点
只要有全量备份,以及全量备份后的所有binlog,就能将数据库恢复到全量备份之后的任意时间点。
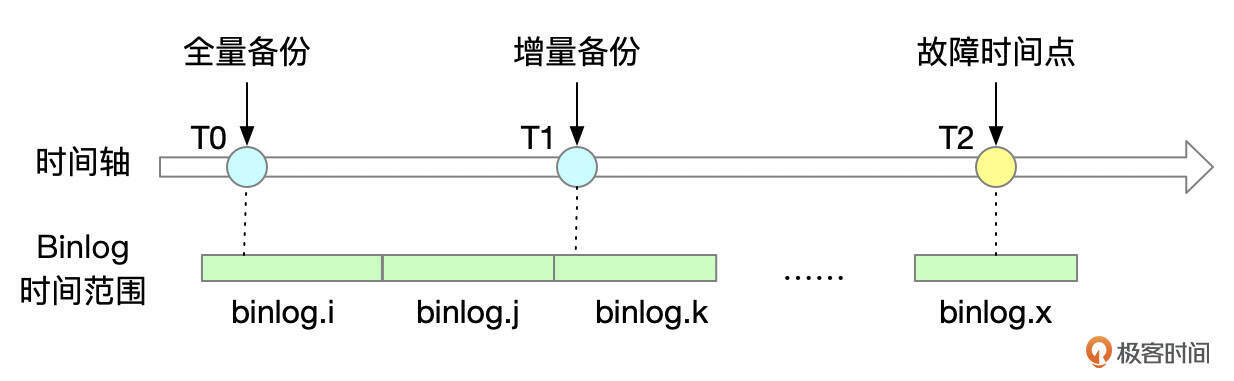
看上面这个图,如果在T2时间点发生了数据丢失故障,就可以找一个在T2时间之前完成的全量备份。假设在时间点T0有一个全量备份,T1有一个增量备份,就可以先恢复全量备份和增量备份,然后再应用T1到T2之间的Binlog。如果没有增量备份,也可以恢复全量备份后,应用T0到T2之间的Binlog。这样都能将数据恢复到发生故障前的那个时间点。
找到时间点对应的binlog
时间点恢复具体怎么操作呢?首先要定位该时间点对应的binlog位点(binlog文件和文件内的偏移量)。每个binlog头部都记录了binlog产生的时间,我们可以使用mysqlbinlog工具解析binlog,查看binlog的第一个event的时间。
# mysqlbinlog -v binlog.000021 | head
/*!50530 SET @@SESSION.PSEUDO_SLAVE_MODE=1*/;
/*!50003 SET @OLD_COMPLETION_TYPE=@@COMPLETION_TYPE,COMPLETION_TYPE=0*/;
DELIMITER /*!*/;
# at 4
#230625 16:44:06 server id 23480 end_log_pos 126 CRC32 0x245d7ed7 Start: binlog v 4, server v 8.0.32 created 230625 16:44:06
如果我们需要恢复到某个时间点T,那么我们需要找的binlog开始时间不大于T,并且该binlog的下一个binlog的开始时间大于T。
这里提供一个python的脚本,可以批量查看binlog时间。
import sys
import struct
if len(sys.argv) >= 2:
pattern = sys.argv[1]
else:
pattern = 'mysql-bin.[0-9]*'
print ('binlog pattern: %s' % pattern)
def parse_binlog_header(filename):
with open(filename, 'rb') as f:
data = f.read(8)
return struct.unpack('i', data[4:])[0]
def main():
import glob
from datetime import datetime
for f in sorted(glob.glob(pattern), key=lambda x: int(x.split('.')[-1])):
ts = parse_binlog_header(f)
print f, ts, datetime.fromtimestamp(ts)
if __name__ == '__main__':
main()
使用脚本,传入binlog匹配模式,显示binlog时间:
# python parse_binlog_time.py 'binlog/binlog.[0-9]*'
binlog pattern: binlog/binlog.[0-9]*
binlog/binlog.000001 1686640790 2023-06-13 15:19:50
binlog/binlog.000002 1686647377 2023-06-13 17:09:37
binlog/binlog.000003 1686647391 2023-06-13 17:09:51
......
binlog/binlog.000020 1687682137 2023-06-25 16:35:37
binlog/binlog.000021 1687682646 2023-06-25 16:44:06
binlog/binlog.000022 1687683127 2023-06-25 16:52:07
我们的全量备份binlog位点是binlog.000020。
# cat xtrabackup_binlog_info
binlog.000020 610 58224b02-09b7-11ee-90bd-fab81f64ee00:1-13191,7caa9a48-b325-11ed-8541-fab81f64ee00:1-27
假设我们希望将数据库恢复到2023-06-25 16:45:00,那么根据各个binlog的时间信息,我们需要恢复到binlog.000021,从这个binlog中找到16:45:00对应的位点。
# mysqlbinlog --stop-datetime="2023-06-25 16:45:01" binlog/binlog.000021 | grep -A 1 "^# at" | tail -2
# at 340009
#230625 16:45:00 server id 23480 end_log_pos 340040 CRC32 0xa1841663 Xid = 88279
我们需要应用binlog.000021偏移量340040之前的binlog。
接下来要解决怎么应用Binlog的问题。MySQL提供了命令行工具mysqlbinlog,可以解析Binlog,解析出来后,可以直接发送给MySQL执行。这可能也是平时比较常用的一个方法。更好的方法,是利用MySQL的复制模块来应用Binlog。我们来看一下这两种方法分别是怎么操作的。
方法一:使用mysqlbinlog解析binlog并执行
从前面的步骤,我们得到了需要执行的binlog。
- binlog开始位点:binlog.000020,偏移量610。
- binlog结束位点:binlog.000021,偏移量340040。
依次使用mysqlbinlog解析binlog,并发送给mysql执行。执行第一个binlog时指定参数start-position,执行最后一个binlog时,指定参数stop-position。
使用下面的命令执行第一个binlog。
执行中间的binlog,如果binlog数量比较多,你可能需要写一个脚本来处理。当然,这个测试案例中只有2个binlog。
使用下面的命令执行最后一个binlog。
binlog执行完成后,校验一下数据。这里我们查看最后一个应用的binlog事件。
mysqlbinlog -v --stop-position=340040 binlog.000021 | tail -30
# at 339746
#230625 16:45:00 server id 23480 end_log_pos 339817 CRC32 0x89660c48 Query thread_id=29218 exec_time=0 error_code=0
SET TIMESTAMP=1687682700/*!*/;
BEGIN
/*!*/;
# at 339817
#230625 16:45:00 server id 23480 end_log_pos 339880 CRC32 0xd5fb3c23 Table_map: `demo`.`last_gtid` mapped to number 209
# has_generated_invisible_primary_key=0
# at 339880
#230625 16:45:00 server id 23480 end_log_pos 340009 CRC32 0x8153feb1 Write_rows: table id 209 flags: STMT_END_F
BINLOG '
jP6XZBO4WwAAPwAAAKgvBQAAANEAAAAAAAEABGRlbW8ACWxhc3RfZ3RpZAACAw8CoA8CAQEAAgP8
/wAjPPvV
jP6XZB64WwAAgQAAACkwBQAAANEAAAAAAAEAAgAC/wBsaAAAVwA1ODIyNGIwMi0wOWI3LTExZWUt
OTBiZC1mYWI4MWY2NGVlMDA6MS0yOTExMCwKN2NhYTlhNDgtYjMyNS0xMWVkLTg1NDEtZmFiODFm
NjRlZTAwOjEtMjex/lOB
'/*!*/;
### INSERT INTO `demo`.`last_gtid`
### SET
### @1=26732
### @2='58224b02-09b7-11ee-90bd-fab81f64ee00:1-29110,\n7caa9a48-b325-11ed-8541-fab81f64ee00:1-27'
查看数据,验证数据是否恢复到了正确的时间点。
mysql> select * from demo.last_gtid order by id desc limit 1;
+-------+-----------------------------------------------------------------------------------------+
| id | gtid |
+-------+-----------------------------------------------------------------------------------------+
| 26732 | 58224b02-09b7-11ee-90bd-fab81f64ee00:1-29110,
7caa9a48-b325-11ed-8541-fab81f64ee00:1-27 |
+-------+-----------------------------------------------------------------------------------------+
1 row in set (0.00 sec)
方法二:使用MySQL原生复制功能实现时间点恢复
虽然使用mysqlbinlog解析并执行binlog,是实现mysql时间点恢复的一种常用的方法,但是这么做其实有一些缺点。
- 先解析Binlog,再发送给MySQL执行,性能不够好,事务只能单线程应用。
- 如果中间某个Binlog执行时出错了,脚本中还要做好错误处理。
在正式环境中,我更建议使用下面这种方法,利用MySQL的数据复制功能来实现时间点恢复。
操作方法其实很简单。
- 启动一个空的mysql实例,将需要恢复的binlog注册到这个实例中。
- 将需要恢复数据的那个实例,作为备库,从步骤1创建的binlog实例中复制数据。
启动binlog实例
先初始化一个空白实例。
## 创建相关目录
mkdir -p /data/servebinlog/{data,log,binlog,relaylog,tmp,run}
## 准备my.cnf
## 初始化数据库
/opt/mysql/bin/mysqld --defaults-file=/data/servebinlog/my.cnf --initialize
tail -1 /data/servebinlog/log/alert.log
2023-06-26T08:54:33.758630Z 6 [Note] [MY-010454] [Server] A temporary password is generated for root@localhost: ar2sWPCf4.++
## 修改文件owner,并启动实例
chown -R mysql:mysql /data/servebinlog/
mysqld_safe --defaults-file=/data/servebinlog/my.cnf &
## 修改默认密码,创建复制账号
mysql -uroot -par2sWPCf4.++ -h127.0.0.1 -P16380
mysql> alter user 'root'@'localhost' identified by 'abc123';
Query OK, 0 rows affected (0.01 sec)
mysql> create user 'rep'@'%' identified by 'rep123';
Query OK, 0 rows affected (0.02 sec)
mysql> grant replication slave on *.* to 'rep'@'%';
Query OK, 0 rows affected (0.01 sec)
注册binlog。将需要的binlog复制到binlog实例的目录中,并编辑binlog.index文件,重启binlog实例。
## 停实例
mysqladmin -h127.0.0.1 -P16380 -uroot -pabc123 shutdown
## 清空原有binlog,将需要的binlog复制到指定目录
rm /data/servebinlog/binlog/binlog.00000*
cp /data/mysql8.0/binlog/binlog.0000{20,21,22} /data/servebinlog/binlog/
## 编辑binlog.index,最终内容如下
# cat /data/servebinlog/binlog/binlog.index
/data/servebinlog/binlog/binlog.000020
/data/servebinlog/binlog/binlog.000021
/data/servebinlog/binlog/binlog.000022
## 启动实例
chown -R mysql:mysql /data/servebinlog/
mysqld_safe --defaults-file=/data/servebinlog/my.cnf &
到这一步,binlog实例就准备完成了。
mysql> show binary logs;
+---------------+-----------+-----------+
| Log_name | File_size | Encrypted |
+---------------+-----------+-----------+
| binlog.000020 | 5598638 | No |
| binlog.000021 | 4751928 | No |
| binlog.000022 | 3944712 | No |
| binlog.000023 | 237 | No |
+---------------+-----------+-----------+
mysql> select @@gtid_purged\G
*************************** 1. row ***************************
@@gtid_purged: 0b06b27c-13ff-11ee-8d21-fab81f64ee00:1-3,
58224b02-09b7-11ee-90bd-fab81f64ee00:1-13191,
7caa9a48-b325-11ed-8541-fab81f64ee00:27
1 row in set (0.00 sec)
mysql> select @@gtid_executed\G
*************************** 1. row ***************************
@@gtid_executed: 0b06b27c-13ff-11ee-8d21-fab81f64ee00:1-3,
58224b02-09b7-11ee-90bd-fab81f64ee00:1-51514,
7caa9a48-b325-11ed-8541-fab81f64ee00:27
1 row in set (0.00 sec)
从binlog实例复制数据
先查看全备的binlog位点。
# cat xtrabackup_binlog_info
binlog.000020 610 58224b02-09b7-11ee-90bd-fab81f64ee00:1-13191,7caa9a48-b325-11ed-8541-fab81f64ee00:1-27
到需要进行时间点恢复的实例上执行下面这些命令,建立数据复制通道,使用start slave until命令将数据恢复到指定的Binlog位点。
mysql> reset slave all;
Query OK, 0 rows affected, 1 warning (0.03 sec)
mysql> change master to master_host='172.16.121.234', master_port=16380, master_user='rep', master_password='rep123', get_master_public_key=1, master_log_file='binlog.000020', master_log_pos=610;
Query OK, 0 rows affected, 9 warnings (0.13 sec)
mysql> start slave until master_log_file='binlog.000021', master_log_pos=340009;
Query OK, 0 rows affected, 3 warnings (0.03 sec)
等待SQL线程执行完成,执行完成的标志是Slave_SQL_Running=No,并且Relay_Master_Log_File和Exec_Master_Log_Pos和start slave until命令中指定的位点一样。
mysql> show slave status\G
*************************** 1. row ***************************
Slave_IO_State: Waiting for source to send event
Master_Host: 172.16.121.234
Master_User: rep
Master_Port: 16380
Connect_Retry: 60
Master_Log_File: binlog.000023
Read_Master_Log_Pos: 237
Relay_Log_File: relaylog.000004
Relay_Log_Pos: 340210
Relay_Master_Log_File: binlog.000021
Slave_IO_Running: Yes
Slave_SQL_Running: No
......
Exec_Master_Log_Pos: 340040
和直接使用mysqlbinlog解析binlog并执行的方法对比,用binlog实例进行时间点恢复需要创建一个临时空白实例,看起来更加复杂,但是有下面这些优点。
- 更加可靠。使用了mysql原生的复制代码来执行binlog,比使用mysqlbinlog解析binlog并执行更可靠。
- 效率更高。如果开启了多线程复制,应用binlog的效率会更高。
- 更容易处理异常。如果应用binlog的过程中遇到各种错误,可以像处理一个普通的备库遇到的问题那样来处理。
时间点恢复注意事项
使用备库产生的binlog恢复数据时,需要注意备库是否有延迟。如果备库本身存在延迟,那么备库上生成的binlog的时间戳和真实的业务时间可能存在偏差,依据这个时间来进行恢复,就可能达不到业务上的恢复目标。所以进行时间点恢复时,优先选择使用主库的binlog来进行恢复。当然在实际业务场景中,主备库之间可能会存在角色切换,需要想办法确定待恢复的时间点上,哪一个实例是主库。
我们也需要监控好主备库的复制状态,如果存在复制中断、复制延迟、甚至是主备库数据不一致的情况,需要及时处理。不然,在对备库进行的备份可能实际上是无效的。
前面讲的时间点恢复方案,优点是适应性广,理论上能恢复所有类型的数据误操作。但是如果数据库特别大,恢复的时间可能会比较久。恢复数据消耗的时间越长,业务受到的损失就可能越大。在一些特定的场景下,还可以采用其他一些恢复方法,提升恢复的速度,作为整个数据恢复方案的补充。
基于Binlog回滚的数据恢复
如果使用了ROW格式的Binlog,并且参数binlog_row_image为FULL,那么在执行DML语句时,会在Binlog中记录修改的记录的所有字段。如果是执行UPDATE或DELETE语句导致的数据问题,你可以在Binlog中找到修改前的数据,进行数据恢复。当然,如果是因为执行了tuncate table或drop table导致的数据丢失,binlog中没有记录具体的数据,就不能使用这种方式来恢复了。
怎么解析Binlog中的数据呢?有一些开源的工具,比如binlog2sql。其实你也可以使用mysqlbinlog来解析。
对于ROW格式的Binlog,mysqlbinlog加上-v选项,可以输出文本格式的数据。比如我在数据库上执行了这几个SQL。
使用mysqlbinlog -v,可以解析出这样的数据。
### UPDATE `employees`.`salaries`
### WHERE
### @1=10001
### @2=60117
### @3='1986:06:26'
### @4='1987:06:26'
### SET
### @1=10001
### @2=999999
### @3='1986:06:26'
### @4='1987:06:26'
### UPDATE `employees`.`salaries`
### WHERE
### @1=10001
### @2=62102
### @3='1987:06:26'
### @4='1988:06:25'
### SET
### @1=10001
### @2=999999
### @3='1987:06:26'
### @4='1988:06:25'
### DELETE FROM `employees`.`employees`
### WHERE
### @1=20
### @2='2013:10:10'
### @3='AAAA'
### @4='BBBB'
### @5=1
### @6='2024:08:03'
### DELETE FROM `employees`.`employees`
### WHERE
### @1=10001
### @2='1953:09:02'
### @3='Georgi'
### @4='Facello'
### @5=1
### @6='2024:08:03'
如果是Update更新错了,可以把Update的Binlog中,Where部分的字段提取出来,这些是更新前的数据。如果是Delete错了,把Where部分的字段提取出来,也可以恢复数据。
这里的格式比较简单,你可以写一些脚本来提取这些数据。这里我提供一段python代码作为参考。
import re
import sys
"""
mysqlbinlog --no-defaults -v binlog_file | python parse_binlog.py
or
mysqlbinlog --no-defaults -v binlog_file > decoded_binlog
python parse_binlog.py decoded_binlog
"""
if len(sys.argv) == 1:
file = sys.stdin
else:
file = open(sys.argv[1])
STATE_UPDATE = 10
STATE_DELETE = 20
STATE_INIT = 0
m_update = re.compile('### UPDATE `(.*)`[.]`(.*)`')
m_delete = re.compile('### DELETE FROM `(.*)`[.]`(.*)`')
m_set = re.compile('### @[0-9]+=(.*)$')
def get_lines(file):
while True:
line = file.readline()
if line:
yield line
else:
return
def parse_binlog():
state = STATE_INIT
db = ''
table = ''
columns = []
for line in get_lines(file):
line = line.strip()
if state == STATE_INIT:
m = m_update.match(line)
if m:
state = STATE_UPDATE
db, table = m.groups()
columns = []
continue
m = m_delete.match(line)
if m:
state = STATE_DELETE
db, table = m.groups()
columns = []
continue
elif state == STATE_UPDATE:
if line == '### WHERE':
continue
elif line == '### SET':
state = STATE_INIT
print_sql(db, table, columns, 'update')
columns = []
else:
m = m_set.match(line)
if m:
val = m.groups()[0]
columns.append(val)
elif state == STATE_DELETE:
if line == '### WHERE':
continue
else:
m = m_set.match(line)
if m:
val = m.groups()[0]
columns.append(val)
else:
print_sql(db, table, columns, 'delete')
columns = []
m = m_delete.match(line)
if m:
state = STATE_DELETE
db, table = m.groups()
else:
state = STATE_INIT
def print_sql(db, table, columns, dml_type):
print "-- dml_type: {}, db: {}, table: {}, columns: {}".format(dml_type, db, table, len(columns))
print "replace into {}.{} values({})".format(db, table, ", ".join(columns))
if __name__ == '__main__':
parse_binlog()
这样,你就可以找回误更新或误删除的数据了。
# mysqlbinlog -v mysql-binlog.000014 | python parse_binlog.py
-- dml_type: update, db: employees, table: salaries, columns: 4
replace into employees.salaries values(10001, 60117, '1986:06:26', '1987:06:26')
-- dml_type: update, db: employees, table: salaries, columns: 4
replace into employees.salaries values(10001, 62102, '1987:06:26', '1988:06:25')
...
-- dml_type: delete, db: employees, table: employees, columns: 6
replace into employees.employees values(10028, '1963:11:26', 'Domenick', 'Tempesti', 1, '1991:10:22')
-- dml_type: delete, db: employees, table: employees, columns: 6
replace into employees.employees values(10029, '1956:12:13', 'Otmar', 'Herbst', 1, '1985:11:20')
这里的方法虽然看起来比较简陋,但是在一些特定的场景下,可以帮你快速恢复数据。当然,如果在正式环境使用这类工具,我的建议是先把从Binlog中找回的数据写到一个临时表里,对数据进行验证后,再更新到正式的业务表里。
Xtrabackup单表恢复
如果表被DROP或Truncate了,你还可以考虑使用xtrabackup的单表恢复功能。当然,能使用单表恢复的前提,是使用了独立表空间(innodb_per_table=1)。
接下来我给你演示一下单表恢复的操作步骤。
1. Prepare备份文件
prepare时带上参数–export,xtrabackup会生成import tablespace需要的文件。
查看日志,确认prepare成功。
查看目标数据库下的文件,这里我们希望恢复demo.last_gtid表。
# ls -l demo/last_gtid.*
-rw-r--r-- 1 root root 715 6月 27 11:03 demo/last_gtid.cfg
-rw-r----- 1 root root 9437184 6月 26 16:08 demo/last_gtid.ibd
2. 目标数据库上创建希望恢复的表
表结构要和备份时的表结构一致。
mysql> show create table last_gtid\G
*************************** 1. row ***************************
Table: last_gtid
Create Table: CREATE TABLE `last_gtid` (
`id` int NOT NULL AUTO_INCREMENT,
`gtid` varchar(1000) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=26733 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci
1 row in set (0.00 sec)
我们先将表drop掉,模拟数据丢失的场景。
创建结构,并执行discard tablespace命令。
mysql> CREATE TABLE `last_gtid` (
`id` int NOT NULL AUTO_INCREMENT,
`gtid` varchar(1000) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB;
Query OK, 0 rows affected (0.06 sec)
mysql> alter table last_gtid discard tablespace;
Query OK, 0 rows affected (0.01 sec)
3. 将备份的文件copy到目标实例的数据库目录下
我们将表的cfg和ibd文件copy到目标实例数据库对应目录下,并修改文件owner。如果文件owner没有正确设置,下一步import表空间时可能会出错。
# cp last_gtid.* /data/full_restore/data/demo/
# ls -l /data/full_restore/data/demo/
-rw-r--r-- 1 root root 715 6月 27 11:06 last_gtid.cfg
-rw-r----- 1 root root 9437184 6月 27 11:06 last_gtid.ibd
# chown -R mysql:mysql /data/full_restore/data/demo/
4. import表空间
执行import tablespace命令恢复数据。确认数据已经恢复。
mysql> alter table demo.last_gtid import tablespace;
Query OK, 0 rows affected (0.29 sec)
mysql> select count(*) from demo.last_gtid;
+----------+
| count(*) |
+----------+
| 10813 |
+----------+
1 row in set (0.00 sec)
如果不知道表的表结构,可以使用ibd2sdi工具,从ibd文件中提取表结构信息。
# ibd2sdi last_gtid.ibd | more
["ibd2sdi"
,
{
"type": 1,
"id": 371,
"object":
{
"mysqld_version_id": 80032,
"dd_version": 80023,
"sdi_version": 80019,
"dd_object_type": "Table",
"dd_object": {
"name": "last_gtid",
"mysql_version_id": 80032,
"created": 20230621022444,
"last_altered": 20230621022444,
"hidden": 1,
"options": "avg_row_length=0;encrypt_type=N;key_block_size=0;keys_disabled=0;pack_record=1;stats_a
uto_recalc=0;stats_sample_pages=0;",
"columns": [
{
"name": "id",
"type": 4,
"is_nullable": false,
"is_zerofill": false,
"is_unsigned": false,
"is_auto_increment": true,
"is_virtual": false,
......
"column_key": 2,
"column_type_utf8": "int",
"elements": [],
"collation_id": 255,
"is_explicit_collation": false
},
{
"name": "gtid",
"type": 16,
"is_nullable": true,
"is_zerofill": false,
"is_unsigned": false,
"is_auto_increment": false,
"is_virtual": false,
"hidden": 1,
"ordinal_position": 2,
"char_length": 4000,
.....
"column_key": 1,
"column_type_utf8": "varchar(1000)",
"elements": [],
"collation_id": 255,
"is_explicit_collation": false
},
总结
在备份系统的设计中,要把Binlog备份也考虑进去,有了完整的Binlog,你可以将数据库恢复到任意一个时间点。在有些场景下,使用Binlog回滚的方案,能加快数据恢复的速度,减少业务的故障时长。
针对可能存在的数据丢失故障,你可以有计划地进行恢复演练,这不仅能验证备份和数据恢复方案的有效性,还能给恢复时长建立一个基线。这样,当需要紧急恢复数据时,你可以比较精确地估算出恢复需要多少时间。
思考题
如果数据库中有几个表被错误地Truncate了,如何在最短的时间内,将这几个表的数据恢复到执行truncate命令前的时间点?
期待你的思考,欢迎在留言区中与我交流。如果今天的课程让你有所收获,也欢迎转发给有需要的朋友。我们下节课再见。
- 一本书 👍(1) 💬(1)
“如果备库本身存在延迟,那么备库上生成的 binlog 的时间戳和真实的业务时间可能存在偏差”,老师,针对这句话我有一些疑问,备库的 binlog 时间戳是binlog在备库中应用的时间点还是与主库保持一致?如果是跟主库保持一致,那就和真实的业务时间应该是一样的吧?gpt说备库的 binlog 时间戳通常与主库保持一致。 如果选择主备之前存在1分钟延迟,要备份12点的数据,而11:59到12点的数据没应用到备库上,备库的binlog也就没有这部分数据,从而用备库恢复会丢失这部分数据,所以达不到业务上的恢复目标,我猜测是老师想说的是这个意思?
2024-11-21 - 牧野静风 👍(0) 💬(1)
有个问题,在使用binlog恢复过程中,这个库只能作为从库了吧,主库要切走之后才好操作,如果是主库,应用连着在写入,这块怎么处理,并且后续正常写入呢
2024-11-20