37 备库服务器异常重启,备库损坏了该如何修复?
你好,我是俊达。
上一讲中,我留了几个问题,就是备库异常崩溃后,复制位点信息是否会丢失?备库重新启动后,复制能不能正常运行?位点信息如果有延迟,对备库有什么影响?这些问题实际上和一些复制参数的设置有关,也和是否使用了GTID Auto Position、是否开启了多线程复制有关。
复制位点信息的存储
我们先来看一下复制过程中会涉及到哪些位点,以及这些位点是怎么更新的。
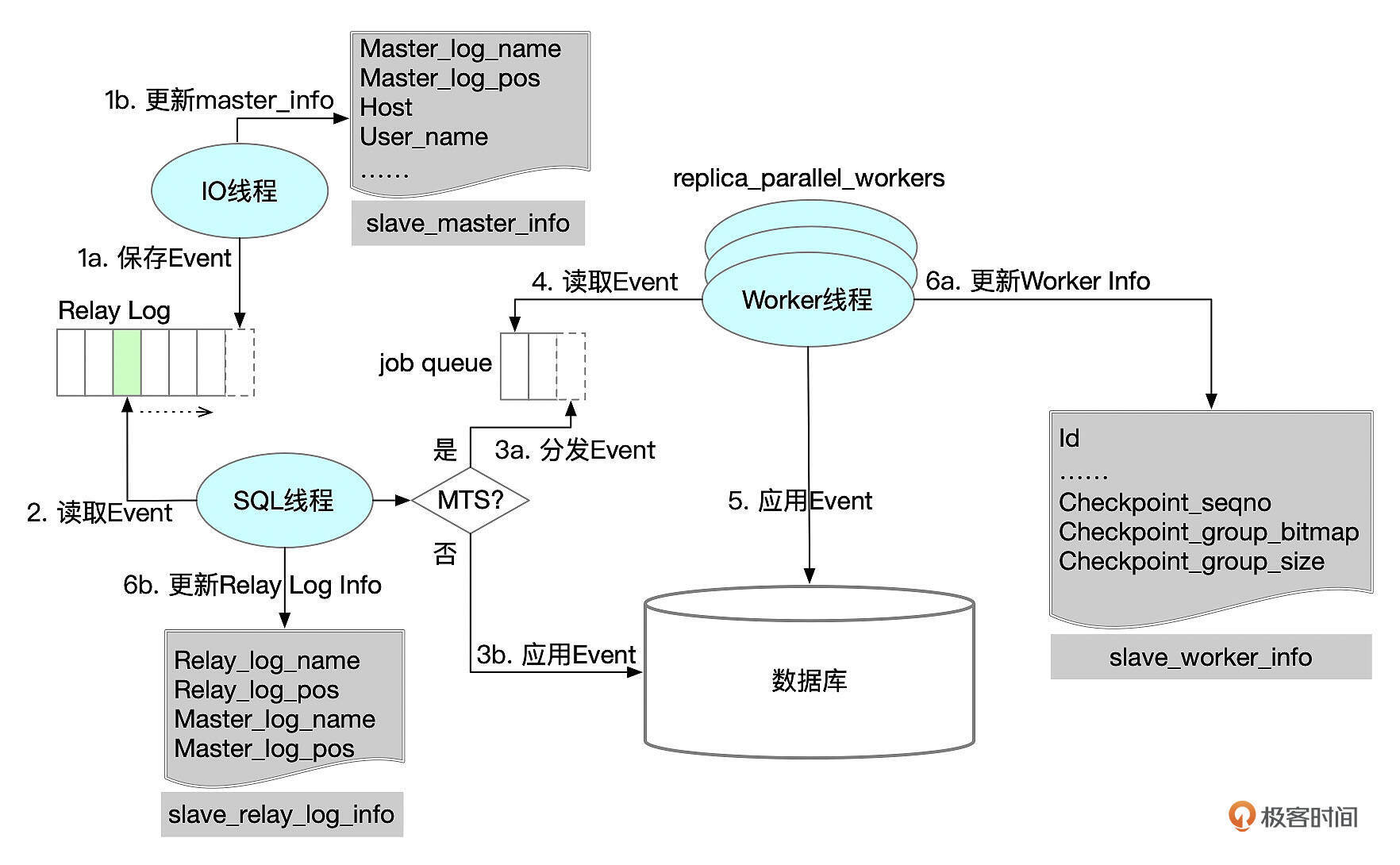
备库复制的大致流程:
- IO线程从主库接收Binlog,写到RelayLog,在Master Info中记录读取主库的Binlog位点(master_log_name,master_log_pos)。参数sync_source_info用来控制master info的刷新频率。
- SQL线程从Relay Log中解析Binlog事件。读取的位点信息记录在Relay Log Info中。事务提交后,SQL线程会更新Relay Log Info。如果是单线程复制,事务提交时,会同步修改Relay Log Info。如果使用了多线程复制,SQL线程会在执行GAQ Checkpoint时更新Relay Log Info。(Relay_log_name,Relay_log_pos)指向下一个待执行的事务,如果使用了多线程复制,那么这个位点有可能会比备库上已经提交的事务的位点更老。
- a–如果开启了多线程复制,SQL线程将Binlog分发给Worker线程,由Worker线程来执行。同一个事务的Binlog事件会分发给同一个worker线程。b–如果没有启用多线程复制,SQL线程会直接执行Binlog事件。
- 每个Worker线程都有各自的事件队列,Worker线程从各自的队列中获取Binlog事件。
- worker线程依次执行Binlog事件。
- Worker线程提交事务时,同步更新slave worker Info。worker Info中以位图的形式记录了各个worker线程提交的事务。
数据复制可能会由于各种原因中断,如主库异常、备库异常崩溃、Binlog应用异常、日常维护,当引起中断的原因解除后,我们需要重新启动复制。备库上使用Master Info、RelayLog Info和Worker Info来记录复制的进展,重新启动复制时,需要根据这些信息来确定从哪里开始复制数据。
复制位点信息
备库上位点信息以文件或表的形式存储,建议将参数master_info_repository和relay_log_info_repository都设置为table,把位点存储到innodb表中。如果位点信息存储到文件,无法保证位点和执行的事务的一致性,极端情况下,可能会存在事务提交了,但是位点信息没有更新的情况。
- Master Info
Master Info记录了备库IO线程用户连接主库的相关信息,以及读取主库Binlog的位点。存储在slave_master_info表中。这个表的一些字段可以参考下面这个表格。
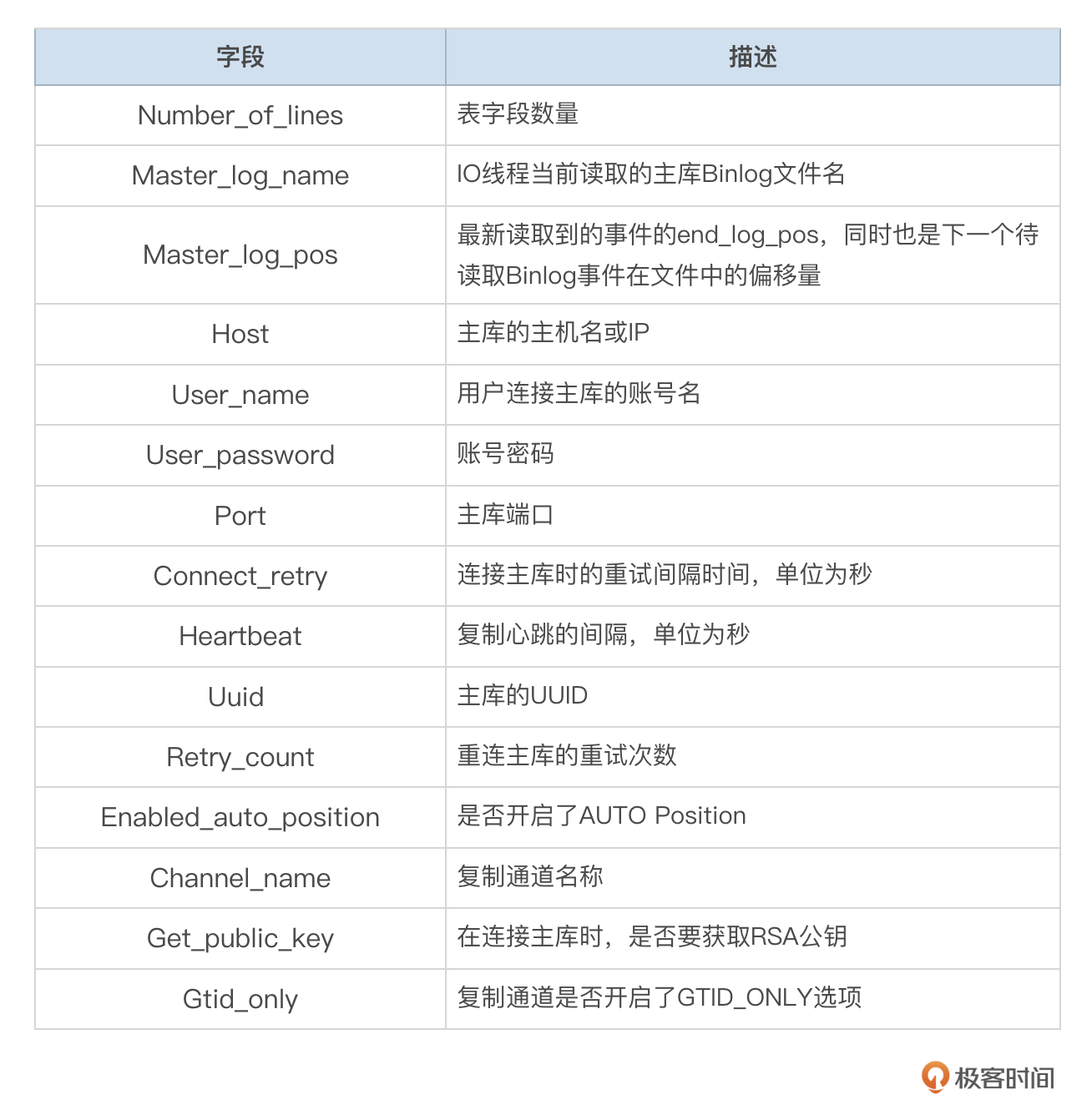
参数sync_master_info设置读取多少个Binlog事件后,更新一次Mater Info信息,默认为10000,也就是从主库每读取到10000个事件后,就将最新的位点信息更新到Master Info。如果复制通道开启了GTID_ONLY选项,就不需要更新Master Info信息。
如果没有使用GTID AUTO Position,那么在master info中记录精确的位点信息就比较重要。在备库异常崩溃重启的情况下,如果master info中记录的位点比IO线程实际已经读取过的Binlog位点更老,那么重新开始复制时,有一部分Binlog事件会重复读取,备库再重复执行这些事件时,就有可能发生数据冲突,导致备库中断。
如果使用了GTID AUTO Position,那么master info中的位点信息就没那么重要了。复制重新启动时,会根据GTID信息重新计算正确的位点。如果事务的GTID在备库已经存在了,那么主库的Dump线程会忽略这些Binlog,不会重复发送。
- Relay Log Info
Relay Log Info记录了备库SQL线程执行Relay Log的位点。slave_relay_log_info表的字段参考下面这个表格。
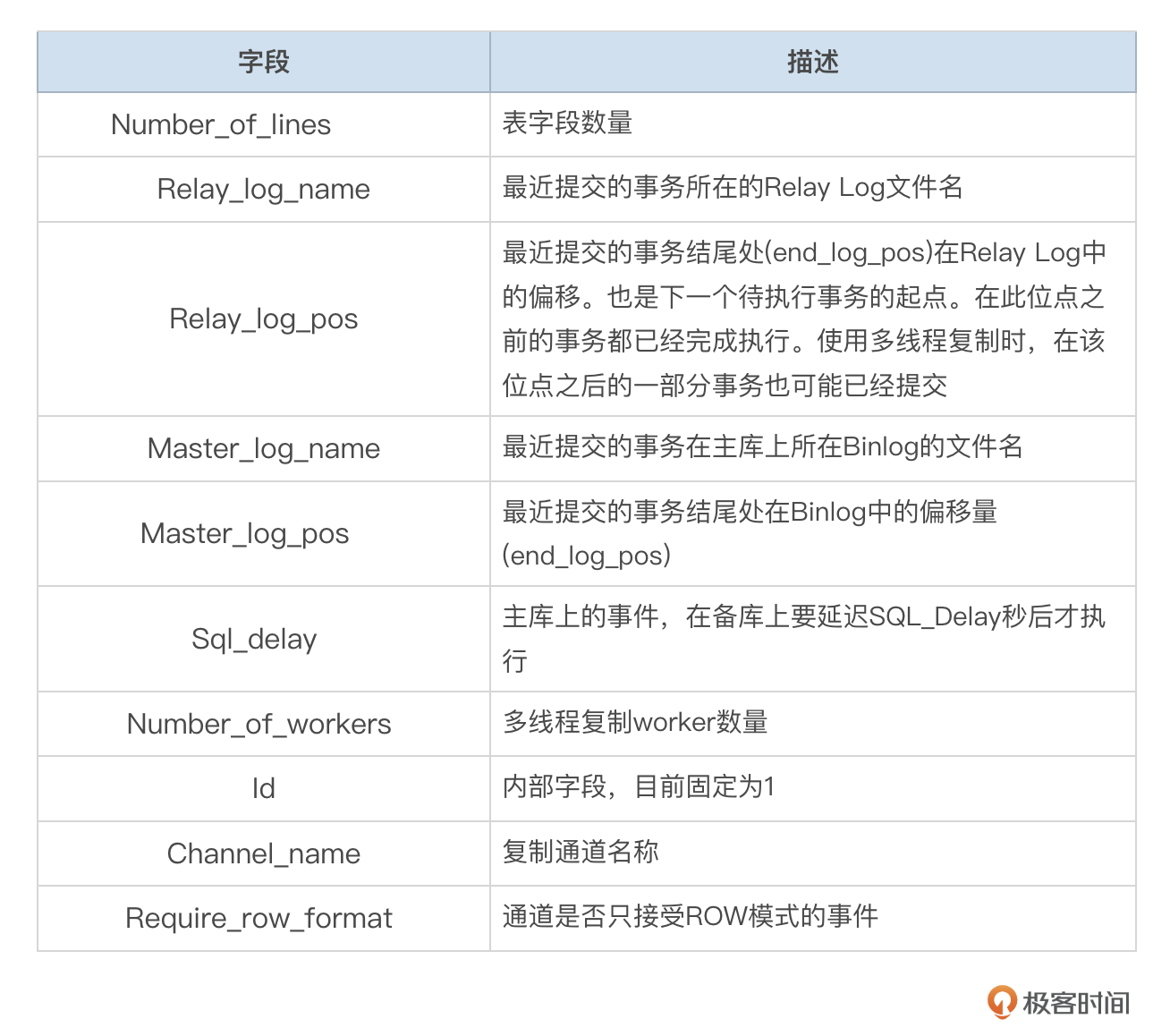
如果没有使用多线程复制,那么SQL线程在提交事务时,会先更新slave_relay_log_info表,Relay Log Info中的位点和已提交的事务保持一致。使用TABLE模式存储Relay Log Info时,参数sync_relay_log_info实际上没有用。
如果使用了多线程复制,那么slave_relay_log_info表中存储的位点信息跟备库实际上已经提交的事务的位点相比有延后。Worker线程提交事务时,会更新slave_worker_info表的位图信息,标记当前事务已经提交,但是并不会立刻更新slave_relay_log_info表。slave_relay_log_info表的信息由SQL线程在执行GAQ队列Checkpoint操作时更新。
在备库异常崩溃,重新启动复制时,不能直接从Relay Log Info中记录的位点开始执行事务,因为这里有一部分事务可能已经执行过了。在没有开启GTID_AUTOPOSITION的情况下,重复执行有可能引起数据冲突,因此需要先执行MTS恢复操作。
- Worker Info
Worker Info中记录Worker的事务提交信息。每个Worker线程在slave_worker_info表中有一行记录,这个表的字段信息可以参考下面这个表格。
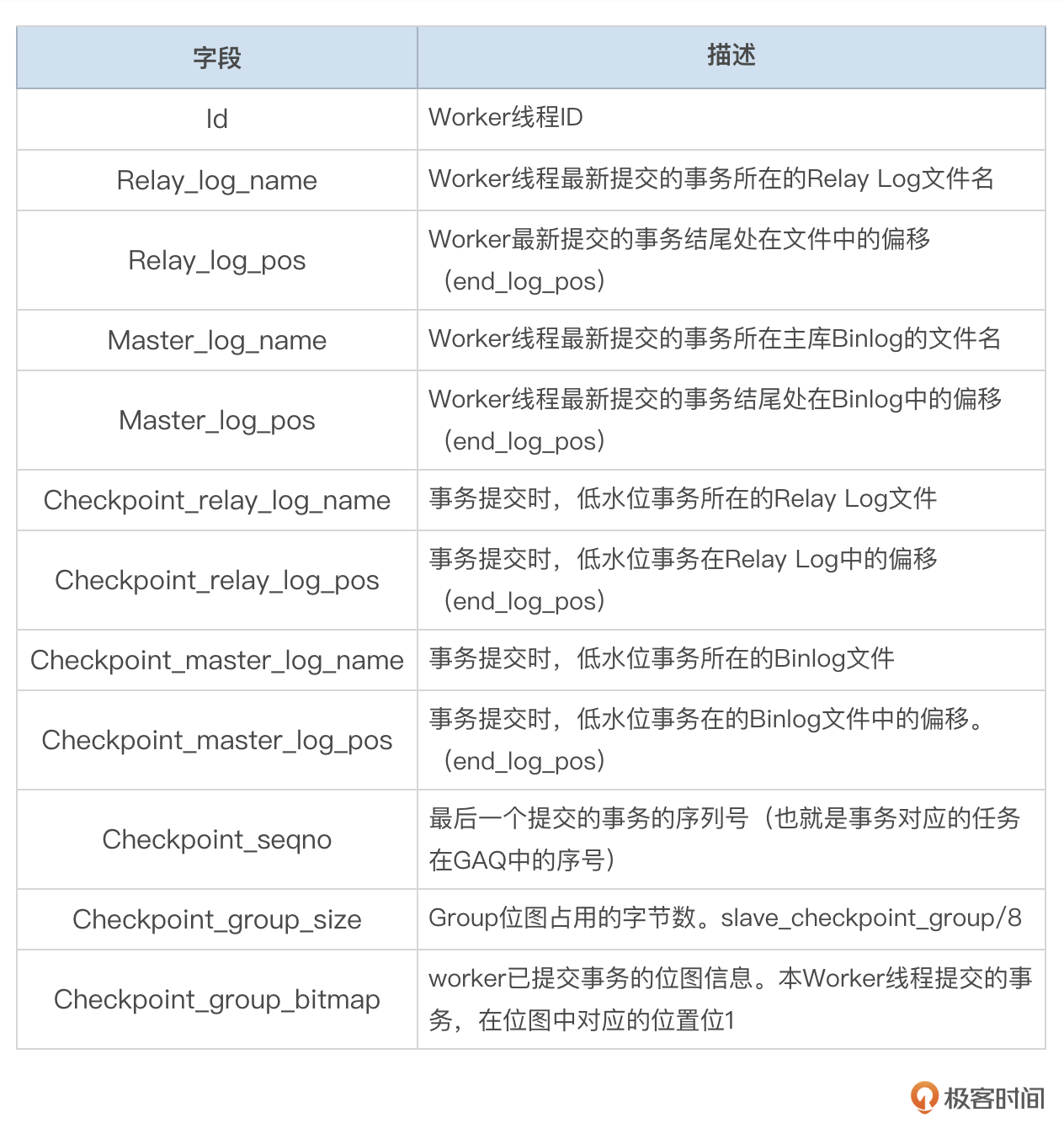
worker线程提交事务时,会更新slave_worker_info表中对应的那行记录,更新的信息会和事务一起提交,因此woker info中的信息和已经提交的事务总是一致的。
单线程复制的恢复
使用单线程复制时,如果没有开启GTID,那么Master Info中Binlog读取位点的准确性就非常关键,如果这个位点有延迟,就会重复读取一部分Binlog,导致事务重复执行。怎么保证Master Info位点准确呢?可以将参数sync_master_info设置为1。
如果使用了GTID Auto Position,那么Master Info中的Binlog位点有延迟也没有关系,主库会根据备库的GTID集合自动定位复制位点。
如果sync_relay_log没有设置为1,那么备库服务器异常崩溃后,Relay Log可能会损坏。这种情况下,备库复制无法正常启动,一种解决方法是使用reset replica命令重置备库,然后再根据slave_relay_log_info中的(Master_log_name,Master_log_pos)位点,重新指向主库,进行数据复制。
解决Relay Log损坏的另外一种方法是将参数relay_log_recovery设置为ON,这样备库重启时,会忽略Master Info中的位点,清空现有的Relay Log,然后根据slave_relay_log_info中的位点重新指向主库,开始复制。
总结一下,使用单线程复制时,relay_log_recovery设置为ON,备库重启时可以找到正确位点复制数据。使用relay_log_recovery有一个潜在的风险,就是如果备库上积压了大量的Relay Log,重启时清空了这些Relay Log,而主库上对应的Binlog如果也已经被清理了,那么复制无法建立,需要重搭备库。
你可以考虑使用GTID Auto Position。如果备库异常重启后,Relay Log有损坏,可以手动执行reset replica、change replication source命令,进行修复。
多线程复制的恢复
启用多线程复制的情况下,备库的恢复会更加复杂一些。首先,slave_relay_log_info中记录的位点(Master_log_name,Master_log_pos),可能比已经提交的事务的位点更老。有的worker线程,可能已经提交了一些在这个位点之后的事务。
怎么确定哪些事务已经提交了呢?如果开启了GTID,就比较简单了,根据备库的gtid_executed变量,就可以判断哪些事务已经提交了。那么gtid_executed变量一定是准确的吗?这个问题稍后再看。我们先看一下,如果没有开启GTID,备库怎么恢复。
slave_worker_info的checkpoint_group_bitmap字段中,记录了每个worker提交的事务,如果一个worker线程提交了事务序号为n的事务,那么checkpoint_group_bitmap中第n个比特就设置为1。事务的序号是怎么确定的?这和上一讲中说过的GAQ有关。
GAQ是一个环形队列,事务分发给worker线程前,会加入GAQ队列,事务的序号实际上就是它在GAQ队列中的位置,序号从0开始。
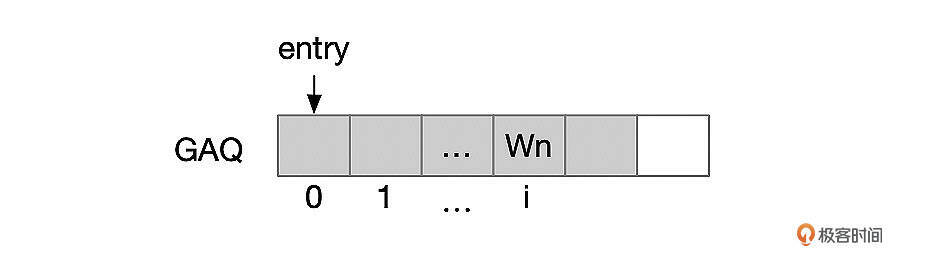
Worker线程提交事务时,在slave_worker_info保存事务的相关信息,包括下面这些信息:
- (Master_log_name,Master_log_pos)事务的Binlog位点。一般是XID事件的位点。
- Checkpoint_seqno,事务在GAQ队列中的序号。
- checkpoint_group_bitmap中第Checkpoint_seqno个比特值为1。
GAQ的空间不能无限增加,他的大小由参数replica_checkpoint_group控制。随着事务不断地加入GAQ,队列很快就会占满。SQL线程定期执行checkpoint操作,将队列头部已经提交的事务移出队列,释放空间。执行checkpoint后,在slave_relay_log_info记录低水位事务(下面图中lwm指向的事务)的位点信息。
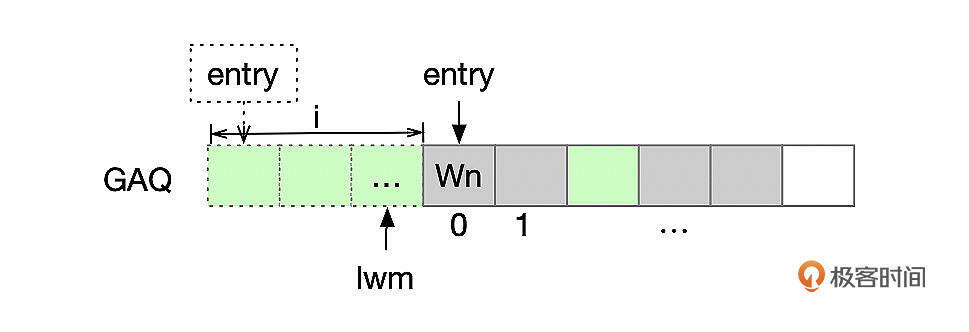
执行checkpoint后,事务在GAQ中的序号发生了变化,SQL线程还要通知各个worker线程,调整bitmap,GAQ队列中移出了多少个事务,bitmap就要相应地左移多少位。worker线程在下一次提交事务时调整bitmap。
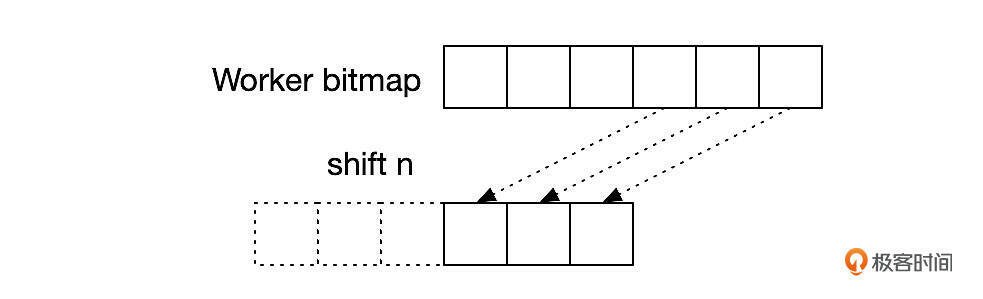
MTS恢复逻辑
备库重启时,进行MTS恢复,主要包括这几个步骤。
- 从slave_relay_log_info读取位低水位事务的位点信息(master_log_file,master_log_pos)。
- 从slave_worker_info读取每一个worker线程最新提交的事务的位点信息(master_log_file,master_log_pos)。
- 统计步骤1和步骤2得到的两个位点之间的事务数,这些事务就是需要进行MTS恢复的事务。
事务数怎么统计呢?先在relaylog中定位到步骤1取到的位点,然后解析Relaylog,统计事务的数量,直到读取到步骤2中的位点所指的事件。
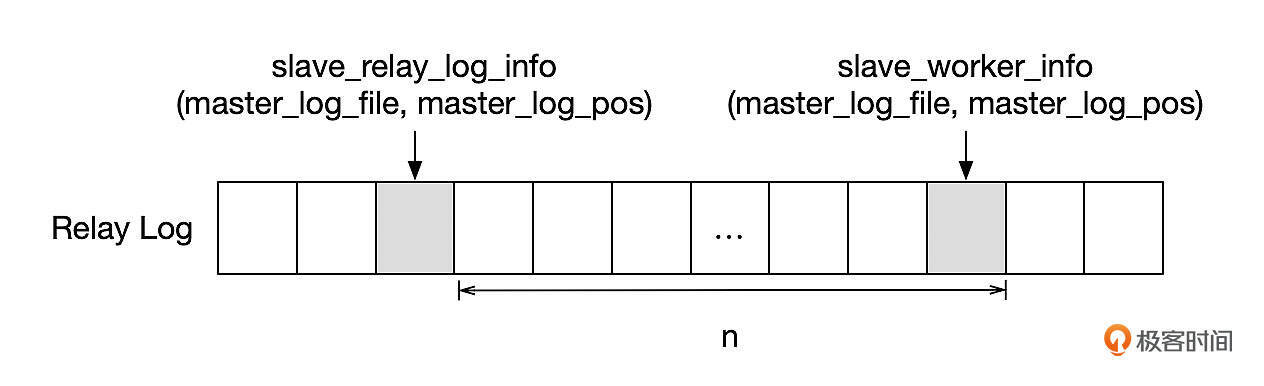
- 到worker线程的位图中检查步骤3中每个事务是否已经提交,如果已经提交,则在位图recovery_groups中设置对应的标记。
根据每一个worker线程的信息,执行完上面这几个步骤后,就得到了从低水位事务到最新提交的事务之间所有事务的提交情况。有了这些信息后,备库上重新执行事务时,就可以根据位图recovery_groups里的情况,跳过已经提交的事务,避免重复执行事务。
怎么解决Relay Log损坏的问题?
MTS恢复逻辑依赖备库上relay log的完整性。如果备库异常崩溃时,relay log也损坏了,那么MTS恢复逻辑可能就无法正常进行。备库启动时,如果读取到损坏的relay log,可能会报类似下面这样的错误。
[ERROR] [MY-013121] [Repl] Slave SQL for channel '': Relay log read failure: Could not parse relay log event entry. The possible reasons are: the master's binary log is corrupted (you can check this by running 'mysqlbinlog' on the binary log), the slave's relay log is corrupted (you can check this by running 'mysqlbinlog' on the relay log), a network problem, the server was unable to fetch a keyring key required to open an encrypted relay log file, or a bug in the master's or slave's MySQL code. If you want to check the master's binary log or slave's relay log, you will be able to know their names by issuing 'SHOW SLAVE STATUS' on this slave. Error_code: MY-013121
怎么保证relay log不损坏呢?一个办法是把参数sync_relay_log设置为1,每写入一个事件,就刷新relay log。但是这样设置会严重影响备库的性能,一般不太建议这么设置。
为了避免Relay log损坏影响备库恢复,可以开启GTID Auto Position,这样,备库启动时就不需要进行MTS恢复了。如果relay log损坏了,你可以清空relay log,重建复制关系。因为已经开启了GTID Auto Position,所以事务不会重复执行。
和单线程复制一样,使用多线程复制时,也可以设置relay_log_recovery=ON,这样实例启动时就会直接新创建一个的Relay Log,并将slave_relay_log_info指向新的relay log文件的开始位置。
- 如果使用了GTID AUTO Position,那么IO线程会直接使用备库的GTID_EXECUTED向主库发起Binlog Dump命令,重新拉取Binlog。
- 如果没有使用GTID AUTO POSITION,那么SQL线程要先进行MTS恢复,使用START REPLICA UNTIL SQL_AFTER_MTS_GAPS命令解决掉GAP后,再从主库拉取Binlog。在Relay log损坏的情况下,可能无法正常处理备库事务的GAP,因此建议只使用GTID AUTO POSITION。
这里简单总结一下,如果使用了GTID Auto Position,即使备库Relay Log损坏了,也问题不大,只要使用change replication source命令重新指向主库,或者设置参数relay_log_recovery,都能恢复。
GTID怎么持久化
使用GTID Auto Position,可以保障备库故障后,能正常恢复数据复制。这里依赖一点,就是数据库重启后,事务的GTID不会丢失。MySQL是怎么做到这一点的呢?事务提交后,GTID会加入到内存变量gtid_executed中,数据库重启后,怎么初始化gtid_executed变量呢?
MySQL会在Binlog中记录GTID,但是在备库上,即使不开启Binlog,GTID也不会丢失。实际上事务提交后,gtid会持久化到mysql.gtid_executed表中。
mysql> select * from mysql.gtid_executed;
+--------------------------------------+----------------+--------------+
| source_uuid | interval_start | interval_end |
+--------------------------------------+----------------+--------------+
| b094c003-8cfa-11ef-bf79-fab81f64ee00 | 1 | 2283 |
| b094c003-8cfa-11ef-bf79-fab81f64ee00 | 2284 | 2284 |
| d1204af7-8cfb-11ef-857e-fa8338b09400 | 1 | 1 |
+--------------------------------------+----------------+--------------+
事务提交时,会将gtid写到Undo段中,还会将gtid添加到内存中的一个队列中。
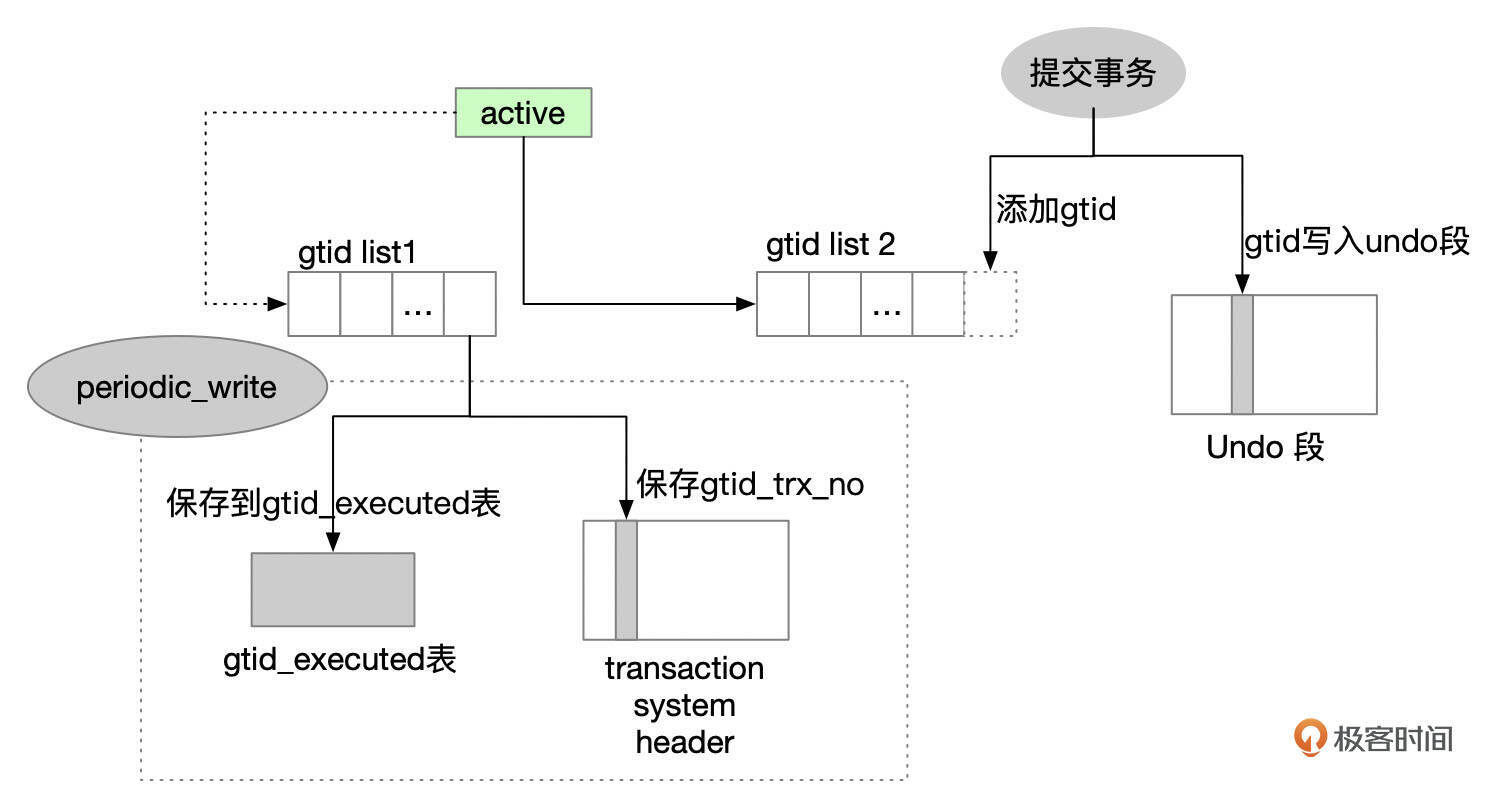
有一个后台线程会定期将队列中的gtid写到数据库中,还会在系统表空间中保存已经完成GTID持久化的事务的trx_no。这里MySQL维护了2个GTID的队列,主要是为了提高并发性能。
数据库启动时,从系统表空间读取已经完成GTID持久化的事务号(trx_no),然后扫描回滚段,根据Undo段中事务的序列号,判断GTID是否已经完成持久化,如果GTID还没有持久化,就将GTID解析出来,写入到gtid_executed表。数据库启动完成后,内存中的gtid_executed变量就包含了所有提交了的事务的gtid。
我们知道Undo受Redo的保护,只要Undo数据不丢,GTID就不会丢失。另外,Undo Purge线程在清理Undo段时,也只清理gtid已经保存到gtid_executed表里的Undo段。
总结
数据库和服务器有时难免会出现异常,如果备库异常重启了,怎么保证数据复制还能正常进行下去呢?建议的做法是使用GTID Auto Position,这样,即使slave_master_info表里的位点信息没及时更新也没有影响,relay log损坏了也没有关系。
否则,你需要将参数sync_source_info设置为1,确保读取主库Binlog的位点是准确的。使用多线程复制时,还要将参数sync_relay_log设置为1,保证Relay log及时刷新,这对性能会有比较大的影响。当然,参数master_info_repository和relay_log_info_repository都要设置成Table。
思考题
MySQL 8.0默认就开启了GTID,5.7版本中,默认还没有开启GTID。如果没有开启GTID,但是又使用了多线程复制,存在的风险是什么?怎么解决?
期待你的思考,欢迎在留言区中与我交流。如果今天的课程让你有所收获,也欢迎转发给有需要的朋友。我们下节课再见。