36 备库有延迟怎么办?
你好,我是俊达。
在MySQL高可用架构中,备库延迟一直很重要。备库延迟会带来各种问题。在读写分离架构下,如果备库有延迟,读备库时就可能会读到陈旧的数据,影响业务。当主库发生故障,需要切换到备库时,如果备库有延迟,就需要先等备库执行完积压的Binlog,这会影响业务的可用性。
MySQL中Binlog复制和Binlog应用是分开的。使用半同步,或者使用MGR架构,也只是保证主库事务提交时,Binlog同步到了备库。备库上,SQL线程应用Binlog事件后,数据才真正能被访问到。
很多不同的原因会引起备库延迟,这一讲我们就来聊一聊备库延迟的一些原因,以及一些解决方法。
认识备库延迟
怎么查看备库延迟?
怎么判断备库有延迟,最简单的方法就是看show replica status中的Seconds_Behind_Source。如果Seconds_Behind_Source大于0,说明有延迟。但有时候,Seconds_Behind_Source并不一定可靠。
- 如果IO线程或SQL线程中断了,Seconds_Behind_Source显示为NULL。
- 级联复制架构下,一级备库上可能复制有延迟或中断了,但是二级备库上,Seconds_Behind_Source可能还是正常的。
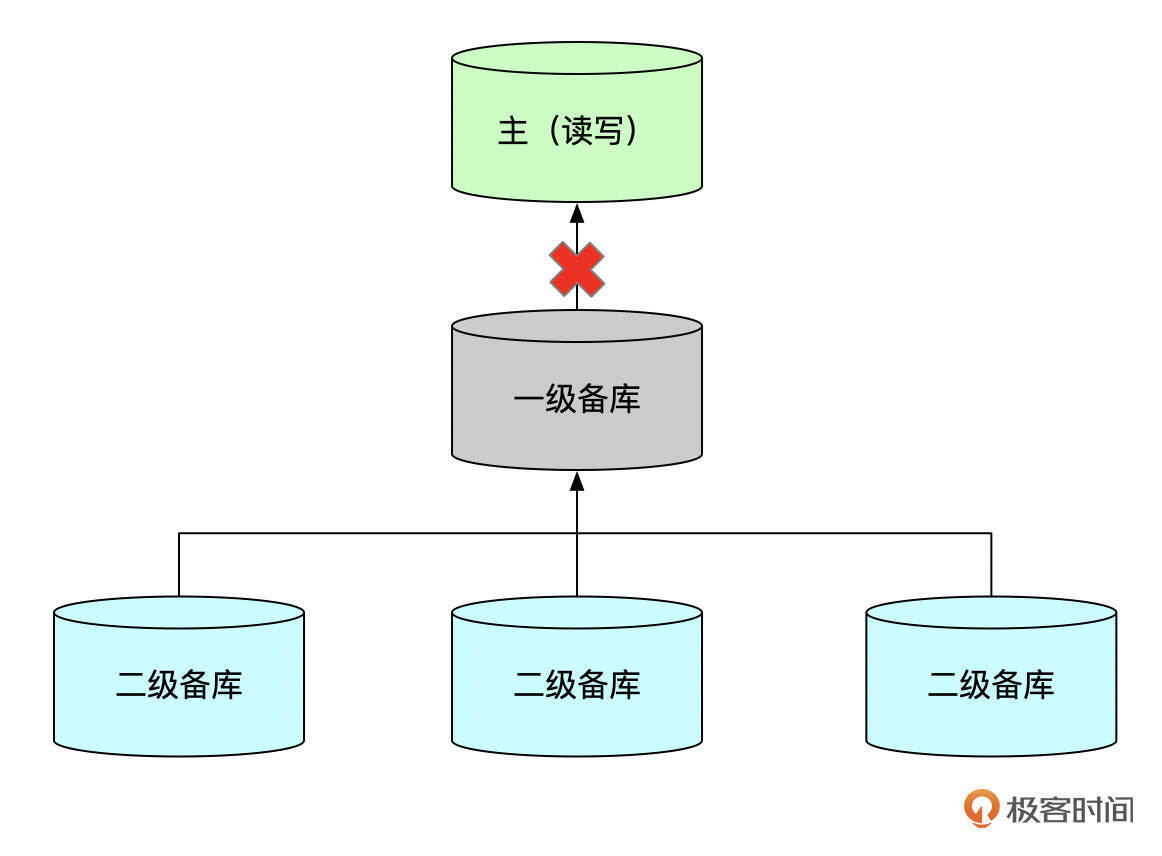
- 有时复制代码可能存在Bug,或者有二级备库的server_id和主库相同,数据实际没有复制到备库,但Seconds_Behind_Source显示为0。
- 如果主备库之间的网络有瓶颈,Binlog没有及时同步到备库,此时Seconds_Behind_Source可能为0,但是主备之间存在延迟。
虽然Seconds_Behind_Source存在一些局限性,毕竟这是MySQL自带的一个指标,我们有必要了解下它是怎么得到的。
Seconds_Behind_Source在执行show replica status命令时计算,下面是核心的计算公式。
- time()取备库的当前时间。
- clock_diff_with_master是备库和主库的时间差,在备库启动复制时计算。
- last_master_timestamp是备库当前处理的Binlog事件中的信息,通过下面这个公式计算得到。
- tv_sec:主库上事件生成的时间。
- exec_time:主库上执行的时间。不过对于ROW格式的Binlog,这里exec_time通常是0,不能反映事务实际的执行时间。
先来看一个DDL语句的Binlog,SQL执行了3分12秒多,exec_time是193。
#241022 11:29:02 server id 119 end_log_pos 919 CRC32 0x94a7dbc0 Query thread_id=96 exec_time=193 error_code=0 Xid = 414340
SET TIMESTAMP=1729567742/*!*/;
/*!80013 SET @@session.sql_require_primary_key=0*//*!*/;
alter table employees add xx int, algorithm=copy
/*!*/;
备库上执行这个事件时,last_master_timestamp设置为tv_sec + exec_time。备库执行这个DDL的过程中,如果查看延迟,会看到延迟从0增长的exec_time(假设备库执行速度和主库一样),然后变为0。如果有二级备库,那么二级备库的延迟从exec_time开始,一直增长到2倍的exec_time,然后变成0。
你可以参考下面这张图。
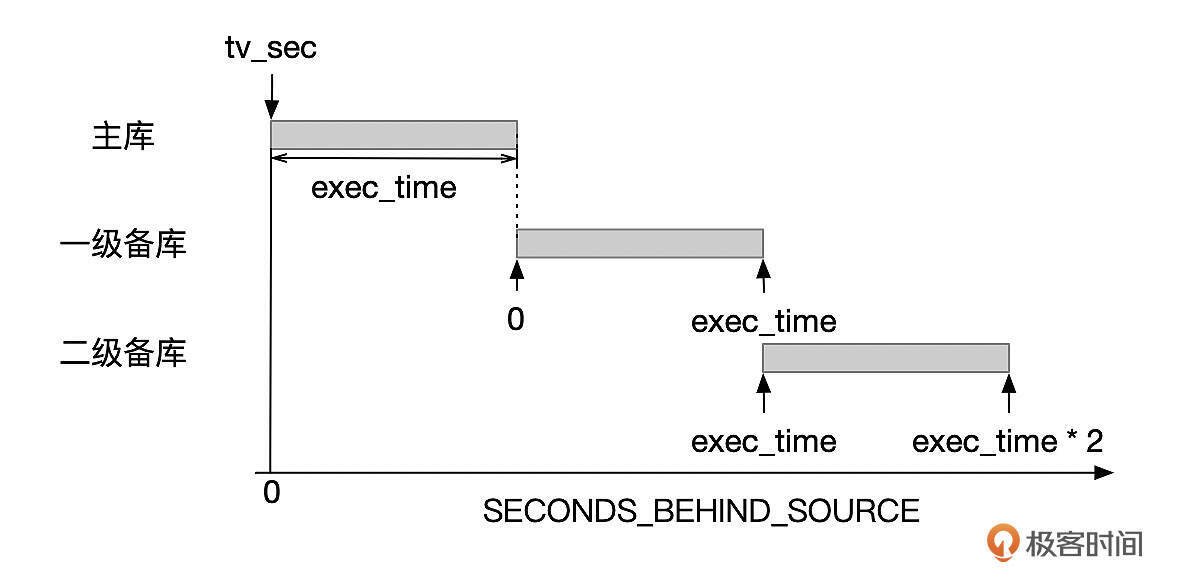
对于ROW模式的DML语句,情况就不一样了。我们来看一个Binlog,事务从11:17:39开始,11:23:10提交,中间经过了5分多钟。但是exec_time为0。因此备库上刚开始执行这个Binlog时,延迟就是5分多钟。
#241022 11:17:39 server id 234 end_log_pos 12641940 CRC32 0x463fb265 Query thread_id=33 exec_time=0 error_code=0
SET TIMESTAMP=1729567059/*!*/;
BEGIN
#241022 11:17:39 server id 234 end_log_pos 12642034 CRC32 0xced9fe46 Update_rows: table id 94 flags: STMT_END_F
#241022 11:23:07 server id 234 end_log_pos 12642128 CRC32 0x6a5c159f Update_rows: table id 94 flags: STMT_END_F
#241022 11:23:10 server id 234 end_log_pos 12642159 CRC32 0x61a7e401 Xid = 88074
COMMIT/*!*/;
前面讨论的备库延迟的计算方式,实际上只是单线程复制时采用的逻辑。对于多线程复制,计算方式又有点不一样了。你可以试一下,启用多线程复制时,执行一个耗时比较长的DDL语句,应该能发现,备库刚开始执行DDL时,延迟就是exec_time,然后一直增长到2倍的exec_time,然后再变成0。
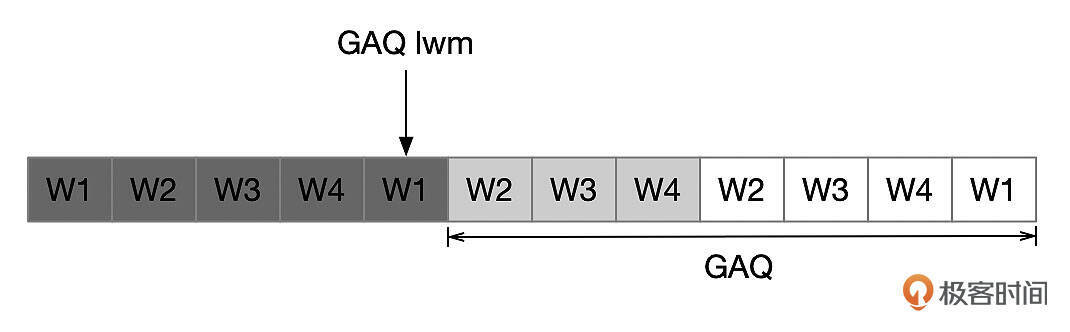
使用多线程复制时,协调线程(SQL线程)使用GAQ队列来管理Binlog事件的分发,跟踪事务执行进度。last_master_timestamp计算也跟GAP队列有关。下面这张图中,每一个框对应一个事务,灰色框中的事务已经提交,白色框中的事务还在执行中。GAQ lwm指向一个已经提交的事务。MySQL会定期执行mta checkpoint,将GAQ中已经完成的任务移出队列,更新last_master_timestamp的值。
怎么判断备库已经执行完所有binlog?
使用Seconds_Behind_Source指标来判断备库延迟,有时并不是非常可靠。如果要做一个主备切换,怎么判断备库已经把从主库同步过来的Binlog都执行完了呢?一个更可靠的方法,是先查看主库Binlog的位点,然后检查备库上的Relay_Source_Log_File,Exec_Source_Log_Pos是否到达主库的位点。如果开启了GTID,就检查主备库上的GTID集合是否一致。
MySQL提供了几个函数,用来判断备库执行进度。函数SOURCE_POS_WAIT用来等待备库执行到主库的某个位点。函数WAIT_FOR_EXECUTED_GTID_SET用来等待给定的gtid集合中的事务都执行完成。
先查看主库的位点。
mysql> show master status\G
*************************** 1. row ***************************
File: mysql-binlog.000001
Position: 703
Binlog_Do_DB:
Binlog_Ignore_DB:
Executed_Gtid_Set: b094c003-8cfa-11ef-bf79-fab81f64ee00:1-2
备库上调用函数SOURCE_POS_WAIT,等待binlog事件应用完成,返回值大于等于0说明事件应用完成,返回值-1说明等待超时了。
mysql> select SOURCE_POS_WAIT('mysql-binlog.000001', 703);
+---------------------------------------------+
| SOURCE_POS_WAIT('mysql-binlog.000001', 703) |
+---------------------------------------------+
| 0 |
+---------------------------------------------+
如果开启了GTID,可以使用WAIT_FOR_EXECUTED_GTID_SET等待事务应用完成。返回值为0说明事务都已经执行。返回值为1说明等待超时了。
mysql> select WAIT_FOR_EXECUTED_GTID_SET('b094c003-8cfa-11ef-bf79-fab81f64ee00:1-5');
+------------------------------------------------------------------------+
| WAIT_FOR_EXECUTED_GTID_SET('b094c003-8cfa-11ef-bf79-fab81f64ee00:1-5') |
+------------------------------------------------------------------------+
| 0 |
+------------------------------------------------------------------------+
1 row in set (23.47 sec)
这两个函数还可以加上一个超时的参数,控制等待的时间。
mysql> select SOURCE_POS_WAIT('mysql-binlog.000001', 1600, 5);
+-------------------------------------------------+
| SOURCE_POS_WAIT('mysql-binlog.000001', 1600, 5) |
+-------------------------------------------------+
| -1 |
+-------------------------------------------------+
1 row in set (5.00 sec)
mysql> select WAIT_FOR_EXECUTED_GTID_SET('b094c003-8cfa-11ef-bf79-fab81f64ee00:1-100', 8);
+-----------------------------------------------------------------------------+
| WAIT_FOR_EXECUTED_GTID_SET('b094c003-8cfa-11ef-bf79-fab81f64ee00:1-100', 8) |
+-----------------------------------------------------------------------------+
| 1 |
+-----------------------------------------------------------------------------+
数据复制怎么监控?
平时怎么监控数据复制是否运行正常、是否有延迟呢?首先要监控IO线程、SQL线程是否都在正常运行。
mysql> show replica status\G
*************************** 1. row ***************************
Replica_IO_State: Waiting for source to send event
......
Relay_Source_Log_File: mysql-binlog.000001
Replica_IO_Running: Yes
Replica_SQL_Running: Yes
......
Seconds_Behind_Source: 0
......
Relay_Log_Space: 99246711
备库的空间也要关注,有时候复制延迟可能会积压大量的Relay Log,如果备库空间满了,复制也会出问题。
对于备库延迟,只依赖Seconds_Behind_Source有时候可能不够可靠,你可以使用类似pt-heartbeat的工具,在主库上定期更新一行心跳记录的时间戳,然后到备库上计算当前时间和心跳记录时间戳之间的差距。
这里我们演示下pt-heartbeat的基本用法。先把工具下载下来。
创建一个数据库用来存放心跳表。创建一个监控账号,需要DML权限和查看复制信息的权限。
create user 'monitor'@'%' identified by 'somepass';
create database monitor;
grant select,create,insert,update,delete on monitor.* to 'monitor'@'%';
grant replication client on *.* to 'monitor'@'%';
主库上使用pt-heartbeat定期更新心跳表,使用–update参数。
$ pt-heartbeat u=monitor,p=somepass,h=127.0.0.1,P=3307,D=monitor --database monitor --create-table --update
备库上使用pt-heartbeat检查延迟,使用–monitor参数。master-server-id参数指定主库的server-id。如果有延迟,可以在输出中看到。
pt-heartbeat u=monitor,p=somepass,h=127.0.0.1,P=3307,D=monitor --database monitor --monitor --master-server-id 234
0.00s [ 0.00s, 0.00s, 0.00s ]
0.00s [ 0.00s, 0.00s, 0.00s ]
1.00s [ 0.02s, 0.00s, 0.00s ]
2.00s [ 0.05s, 0.01s, 0.00s ]
3.00s [ 0.10s, 0.02s, 0.01s ]
4.00s [ 0.17s, 0.03s, 0.01s ]
备库延迟的一些原因
如果备库有延迟,怎么分析延迟的原因,并进行解决呢?这里我总结了一下比较常见的情况。
- 主库执行了大事务或运行时间比较长的DDL。
主库上,事务提交后,才会传到备库上。假设事务在主库上执行了N秒,那么备库刚接收到Binlog,开始执行时,延迟就是N秒了,如果备库上执行速度和主库一样,那么备库上延迟最高会达到2N秒。对于DDL,如果使用单线程复制,备库上的延迟时间会从0秒开始,最高N秒。如果使用了多线程复制,那么备库开始执行DDL时,延迟可能就已经是N秒了,最高会达到2N秒。
为了避免这类延迟问题,首先我们要尽量不用大事务。如果是DDL引起的延迟,可能要改变DDL的执行方式,比如使用一些第三方的在线DDL工具来做表结构变更。
- 表缺少主键和索引。
使用ROW格式的Binlog时,如果表上没有主键和唯一索引,并且表的数据量比较大,那么备库上执行Binlog时,需要进行全表扫描,就很容易引起延迟。虽然在参数slave_rows_search_algorithms中增加HASH_SCAN能在一些情况下提升性能,但最根本的解决方法,还是给表添加主键。
如果是缺少主键引起的延迟,在监控系统或在show engine innodb status的输出中,经常能观察到一些现象。下面这个例子中的inserts/s、updates/s、deletes/s 和 reads/s 指标,每秒读取的记录数很高,修改的记录数却很低。你可以看一下。
mysql> show engine innodb status\G
--------------
ROW OPERATIONS
--------------
0 queries inside InnoDB, 0 queries in queue
0 read views open inside InnoDB
Process ID=1240, Main thread ID=139629400499968 , state=sleeping
Number of rows inserted 34184665, updated 72258, deleted 0, read 51112044
0.00 inserts/s, 145.62 updates/s, 0.00 deletes/s, 1074316.89 reads/s
Number of system rows inserted 8662, updated 60525, deleted 8182, read 76426
0.00 inserts/s, 0.00 updates/s, 0.00 deletes/s, 0.00 reads/s
- 备库上数据库或表被锁定了。
备库中其他会话获取了表或记录锁,或者获取了全局锁,也会导致复制延迟。如果是锁引起的延迟,就需要找到锁的源头,并进行相应的处理。我们可以到processlist中,查看SQL线程或worker线程的状态。下面这个例子中,状态分别是等待全局锁和元数据锁。在备库上执行备份的时候,可能会获取全局锁。
*************************** 7. row ***************************
Id: 239
User: system user
Host:
db: NULL
Command: Connect
Time: 26
State: Waiting for global read lock
Info: NULL
*************************** 6. row ***************************
Id: 239
User: system user
Host:
db: NULL
Command: Query
Time: 4
State: Waiting for table metadata lock
Info: NULL
下面这个例子中,从状态中看不出问题。
*************************** 7. row ***************************
Id: 239
User: system user
Host:
db: db01
Command: Query
Time: 150
State: Applying batch of row changes (write)
Info: NULL
但是从innodb status中,可以看到事务在等待行锁。
---TRANSACTION 129890, ACTIVE 48 sec inserting
mysql tables in use 1, locked 1
LOCK WAIT 2 lock struct(s), heap size 1128, 1 row lock(s)
MySQL thread id 239, OS thread handle 139629391050496, query id 111062 Applying batch of row changes (write)
------- TRX HAS BEEN WAITING 48 SEC FOR THIS LOCK TO BE GRANTED:
RECORD LOCKS space id 2 page no 4 n bits 104 index PRIMARY of table `db01`.`ta` trx id 129890 lock_mode X locks gap before rec insert intention waiting
Record lock, heap no 33 PHYSICAL RECORD: n_fields 3; compact format; info bits 0
0: len 4; hex 8000c583; asc ;;
1: len 6; hex 00000001ccec; asc ;;
2: len 7; hex 82000000fc0110; asc ;;
如果SQL线程或worker线程应用binlog时,锁超时了,错误日志中会有一些信息,也可以监控起来。
2024-10-23T08:34:44.198466Z 239 [Warning] [MY-010584] [Repl] Replica SQL for channel '': Worker 1 failed executing transaction 'b094c003-8cfa-11ef-bf79-fab81f64ee00:2255' at source log mysql-binlog.000001, end_log_pos 8578161; Could not execute Write_rows event on table db01.ta; Lock wait timeout exceeded; try restarting transaction, Error_code: 1205; handler error HA_ERR_LOCK_WAIT_TIMEOUT; the event's source log mysql-binlog.000001, end_log_pos 8578161, Error_code: MY-001205
- 主库写入并发高,备库跟不上主库。
还有一种情况,是主库上写入的并发太高了,备库跟不上主库的执行速度。原先使用单线程复制时,这个问题尤其突出。使用多线程复制后,备库的延迟能得到很大程度的缓解。除了使用多线程复制,有时也会采取一些临时措施来提升备库的性能,比如备库上innodb_flush_log_at_trx_commit和sync_binlog不设置为双1。如果使用了半同步,那么备库上不要开启rpl_semi_sync_source_enabled。
使用多线程复制(MTA)
如果是由于主库并发写入高引起的延迟,我们可以尝试使用多线程复制。实际上,8.0中默认就开启了多线程复制。
多线程复制配置
在备库上将参数replica_parallel_workers设置为大于1的值,就可以开启多线程复制。参数replica_parallel_type指定多线程复制的方式,这个参数可以设置为LOGICAL_CLOCK或DATABASE。
- LOGICAL_CLOCK:按事务在主库上的提交顺序进行并发执行。主库上同一个Group Commit组里提交的事务,在备库上可以并行执行。在主库上将参数binlog_transaction_dependency_tracking设置为WRITESET,可以提高备库执行的并行度。
- DATABASE:主库上不同库里执行的事务可以在备库上并行执行。
LOGICAL_CLOCK并行复制适用性更广,所以我们后续不讨论DATABASE的并行复制方式。
设置这些参数后,会在重新启动复制后生效。参数replica_preserve_commit_order设置为ON时,备库事务的提交顺序会和主库保持一致。
备库如何并行执行BINLOG?
Binlog中的事务,一个挨着一个,顺序传输到备库、记录到RelayLog中。协调线程,以相同的顺序从RelayLog中解析出Binlog,这些Binlog是怎么并行应用的呢?Binlog中的多个事务,什么情况下才并行应用呢?
这主要是根据Binlog中GTID事件中的last_committed和sequence_number来确定。
mysqlbinlog -v mysql-binlog.000002 | grep -i gtid | egrep -v 'Prev|SET' | awk '{print $1, $2, $11, $12, $13}'
#241024 10:08:13 last_committed=2261 sequence_number=2262 rbr_only=yes
#241024 10:08:35 last_committed=2262 sequence_number=2263 rbr_only=yes
#241024 10:09:10 last_committed=2263 sequence_number=2264 rbr_only=yes
#241024 14:14:51 last_committed=2264 sequence_number=2265 rbr_only=no
#241024 14:14:58 last_committed=2265 sequence_number=2266 rbr_only=yes
#241024 14:15:00 last_committed=2265 sequence_number=2267 rbr_only=yes
#241024 14:15:02 last_committed=2265 sequence_number=2268 rbr_only=yes
# mysqlbinlog -v mysql-binlog.000002 | grep -i gtid | egrep -v 'Prev|SET' | awk '{print $1, $2, $11, $12, $13}'
#241024 14:17:46 last_committed=0 sequence_number=1 rbr_only=yes
#241024 14:17:48 last_committed=1 sequence_number=2 rbr_only=yes
#241024 14:17:50 last_committed=1 sequence_number=3 rbr_only=yes
#241024 14:17:57 last_committed=1 sequence_number=4 rbr_only=yes
sequence_number按事务写入binlog的顺序依次分配,可以看作是事务的编号。last_committed按一定的规则生成,代表了一个已经提交的事务的编号。备库能并行执行事务的主要依据,就是系统中已经提交的事务编号,不小于GTID事件中的last_committed属性。比如上面mysql-binlog.000002中的事务,sequence_number=1的事务提交后,sequence_number为2、3、4的这3个事务可以并行执行。
last_committed是怎么生成的?
last_committed的生成,和主库上参数binlog_transaction_dependency_tracking的设置有关。这个参数可以设置成COMMIT_ORDER、WRITESET、WRITESET_SESSION。
上一讲中,我们说过,MySQL使用了组提交技术。一组事务提交时,last_committed默认设置为上一组已经提交的事务的最大的序列号binlog_transaction_dependency_tracking设置为WRITESET后,MySQL还会检查事务修改的数据,是否和之前提交的事务有冲突,如果数据没有冲突,last_committed可以设置为更早的事务的序列号。
在MySQL8.4中,已经去掉了binlog_transaction_dependency_tracking,默认就使用WRITESET的方式。
多线程复制运行细节
最后我们来看一下多线程复制的一些运行细节。
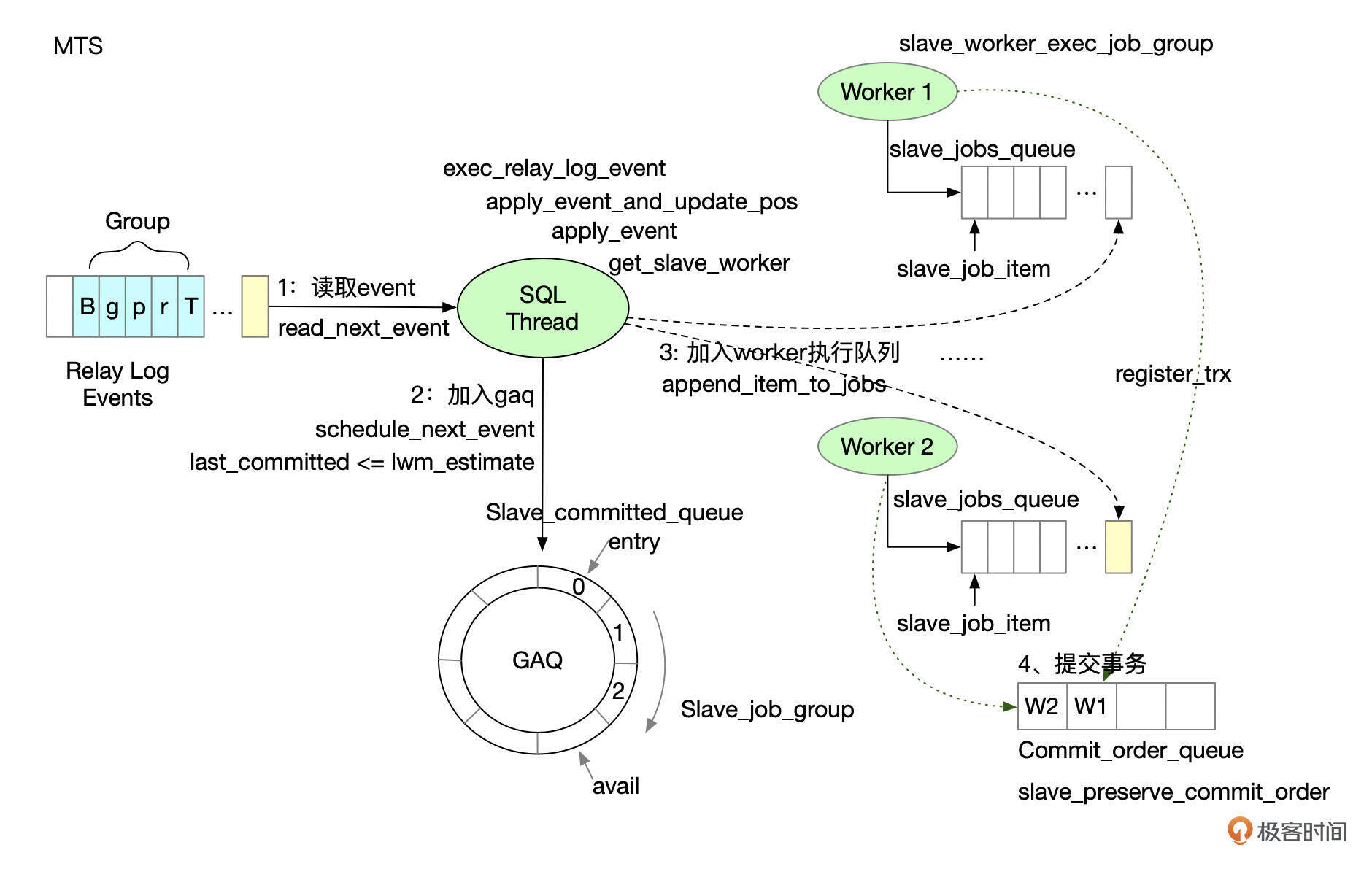
事件分发
协调线程(SQL Thread)负责解析relay log,将事件分发给worker线程执行。分发时,同一个事务的binlog要全部分发给同一个worker线程。
一个完整的事务由几种不同类型的Binlog事件组成,这些事件也称为一个组。事务中Binlog类型可分为几大类。
- 事务开始,一般为GTID事件、Begin事件。在图中标记为B。
- 分区事件,如Table_map事件、Query_log_event事件,包含数据库名。如果并行类型为DATABASE,需要根据库名来决定将事件分发给哪个工作线程。在图中的标记为g。
- 内部事件,如设置用户会话变量的事件、RAND事件等。在图中的标记为p。
- 常规事件,包括ROW模式下的Delete、Update、Write rows事件。在图中的标记为r。
- 事务结束,包括XID事件。在图中的标记为T。
SQL线程依次解析Relay Log中的Binlog事件,根据事件的类型分别处理。
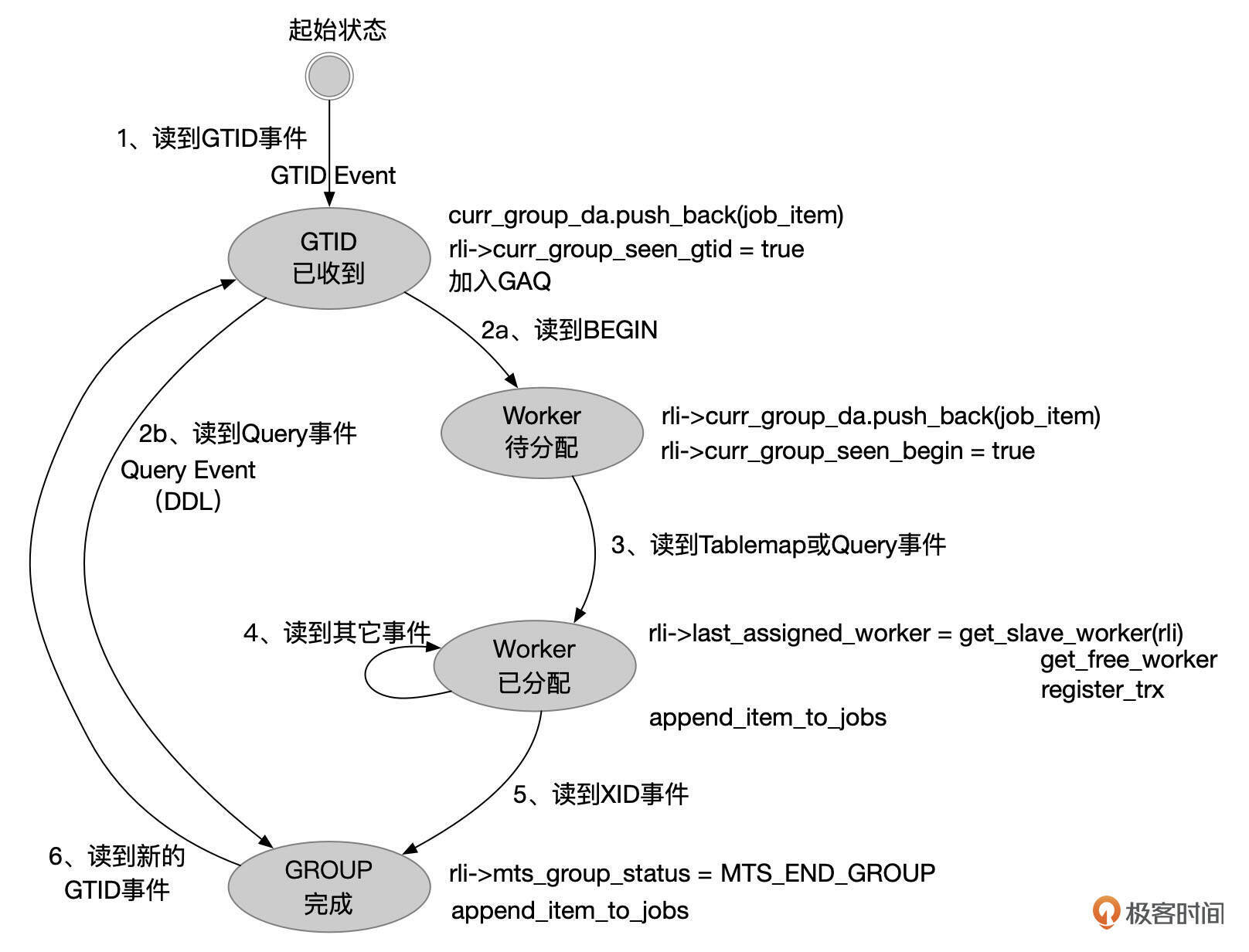
- GTID事件
如果读取到GTID或匿名的GTID事件,就说明有一个新的事务要处理。根据事件中的last_comitted信息判断当前是否可以开始执行这个事务。如果事件的last_comitted值不超过备库中已提交事务的低水位序列号(last_comitted <= lwm_estimate),说明可以执行这个事务。否则需要等待依赖的事务完成提交,此时可以从Processlist中看到SQL线程的状态为Waiting for dependent transaction to commit。
如果当前事务已经可以执行,SQL线程将当前事务加入到GAQ(Group Assigned Queue)队列中。读取到GTID事件后,worker线程还没有分配。GTID事件会先放在一个临时的队列中(rli->curr_group_da)。
2a. BEGIN事件
一般在事务开始时,都会有一个BEGIN事件(事件类型为QUERY_EVENT,内容为BEGIN)。读取到BEGIN事件后,也不分配worker线程。BEGIN事件会先放在临时队列rli->curr_group_da中。
2b. DDL事件
如果紧接着GTID事件后的第一个事件不是BEGIN事件,而是一个普通的QUERY_EVENT,就说明这个事件单独组成一个事务。DDL语句就是这样的情况。读取到DDL事件后,分配一个worker线程,并将DDL事件加入到worker线程的队列中。当然在将DDL事件加入队列前,需要先将存放在临时队列(rli->curr_group_da)中的GTID事件加入worker线程的队列。
- Table_Map或Query_EVENT
一般的事务,BEGIN事件之后是Table_MAP事件(binlog_format为ROW)或Query_Event(binlog_format为STATEMENT)。读取到这些事件后,分配worker线程,并将事件加入到Worker线程的队列中。当然,需要先将临时队列(rli->curr_group_da)中的GTID事件和BEGIN事件加入worker线程的队列。
- 其它事件
一个事务中可能包含多个Insert、Update、Delete事件或Query事件。SQL线程依次读取这些事件,并将事件加入到worker线程的队列中。每个worker线程的队列容量有限制,如过队列中的事件总大小超过了slave_pending_jobs_size_max的设置,或者加入的事件是大事件,那么SQL线程需要等待Worker线程执行掉队列中的一些事件。此时可以从Processlist中看到SQL线程的状态为Waiting for Replica Workers to free pending events。
如果worker队列中任务的数量超过了限制(worker队列长度限制为16384),也需要进行等待,此时SQL线程的状态为Waiting for Replica Worker queue。
- XID事件
XID事件是事务的最后一个事件,读取到XID事件后,说明当前事务的事件已经全部都读取完了。将XID事件加入worker线程的队列中,设置标志(rli->mts_group_status = MTS_END_GROUP),准备处理下一个事务。
GAQ队列
GAQ队列是一个环形的队列,队列中的每一项都和Binlog中的一个事务相对应。GAQ队列的最大长度由参数slave_checkpoint_group指定。
GAQ队列中的任务可能存在几种状态:
- Worker线程未分配。任务刚加入GAQ时,还没有分配worker线程。
- 未完成。任务处于未提交状态,worker线程还在执行对应的事务。
- 已完成。worker线程提交事务后,将GAQ中对应任务的状态设置为已经完成。
GAQ队列头部已经完成的任务,由SQL线程定期执行的GAQ Checkpoint回收。
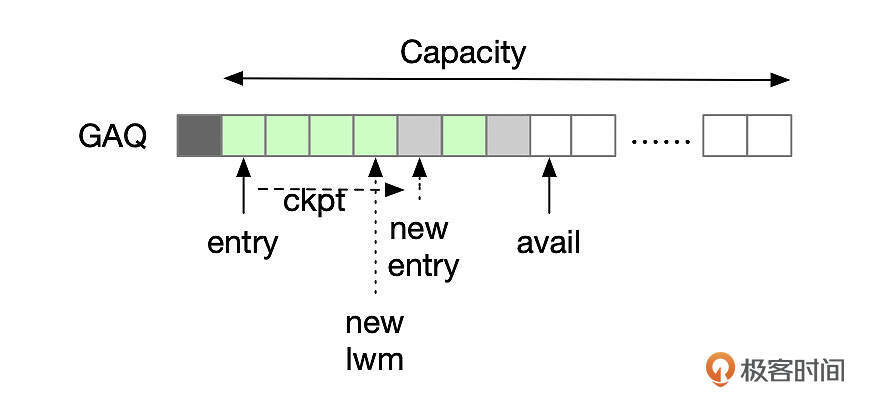
上面这张图中,entry指向GAQ的起始处,avail指向GAQ的尾部,新的任务会加入到avail所指的位置。GAQ中可以容纳的任务数由参数slave_checkpoint_group控制。当GAQ队列头部的任务完成后,GAQ Checkpoint操作会将这些任务占用的位置释放出来。checkpoint操作由SQL线程定期执行,执行频率跟参数slave_checkpoint_period和slave_checkpoint_group的设置有关。
当离上一次checkpoint的时间超过了slave_checkpoint_period,或者离上一次checkpoint后,新处理的事务数超过了slave_checkpoint_group的设置,就要进行checkpoint操作。
分配worker线程
首次给事务分配worker线程时,先判断当前是否有空闲的线程。空闲线程是指worker线程的队列是空的,当前没有执行事务。如果有空闲线程,则直接分配。如果所有worker线程都繁忙,则SQL线程需要等待worker线程执行完队列中的事件。此时SQL线程的状态为Waiting for replica workers to process their queues。
如果参数slave_preserve_commit_order设置为ON,还要将分配的worker线程加入到一个队列中。这是为了保证备库上事务提交的顺序和主库保持一致。
事务分配到worker线程后,同一个事务中后续的事件会分发给同一个worker线程执行。
worker线程
worker线程从队列中依次读取事件,根据事件的类型分别处理,处理完一个事件后,将事件从队列中移走。当队列中没有事件时,worker线程处于等待状态,processlist中线程状态为Waiting for an event from Coordinator。
执行XID事件时,要更新slave_worker_info表,将worker info位图中当前事务对应的bit置为1,然后再提交事务。更新slave_worker_info表的事务和主事务实际上是同一个事务,因此事务提交后,slave_worker_info表的更新也同时生效。XID事件执行完成后,worker线程将GAQ队列中对应的任务状态设置为已完成。
关于参数slave_preserve_commit_order
启用多线程复制时,多个worker线程并行执行Binlog中的事务,这些事务的提交顺序,可能和主库的提交顺序不一致。比如Binlog中有事务T1、T2,在主库上T1比T2先完成提交,但是在备库上,事务T2有可能比T1先完成提交。对于业务来说,主备库提交顺序不一致有可能会有一些影响。备库上将参slave_preserve_commit_order设置为ON后,可以保证事务在备库的提交顺序和主库保持一致。
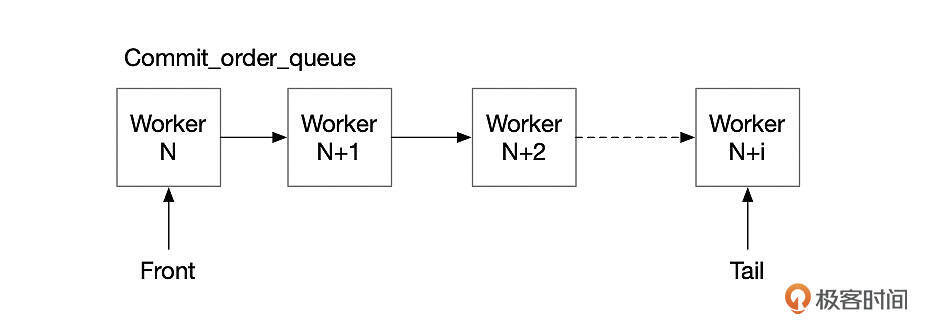
开启slave_preserve_commit_order后,SQL线程在给事务分配worker线程时,会将worker线程加入到Commit_order_queue队列中。因为SQL线程按Binlog中事件的顺序依次进行处理,因此worker线程加入Commit_order_queue的顺序和主库事务提交的顺序一致。worker线程提交事务时,只有排在队列最前面时才能提交事务,否则就要等排在前面的事务先提交。第一个线程完成提交后,退出队列,通知下一个线程进行提交操作。
总结
使用MySQL的数据复制功能时,要监控好备库的状态和延迟情况。很多原因都会导致备库延迟,这一讲中提供了一些基本的方法。有一些延迟问题是可以避免的。如果是因为主库写入并发高引起的延迟,使用多线程复制能在一定程度上降低延迟。主库上参数binlog_transaction_dependency_tracking设置为WRITESET,能提升事务在备库的可并行度。如果你使用了级联复制架构,中间层的实例上,也要将 binlog_transaction_dependency_tracking设置为WRITESET。
思考题
备库在运行过程中,会实时更新一些位点信息,包括主库Binlog的读取位点、SQL线程解析Relaylog的位点,以及worker线程执行事务的情况。如果备库异常崩溃,下次启动时,还能恢复这些位点信息吗?有没有可能出现位点信息没有及时更新的情况?如果这些位点有一些延迟,对备库复制会有影响吗?
期待你的思考,欢迎在留言区中与我交流。如果今天的课程让你有所收获,也欢迎转发给有需要的朋友。我们下节课再见!
- 一本书 👍(0) 💬(1)
假设事务在主库上执行了 N 秒,那么备库刚接收到 Binlog,开始执行时,延迟就是 N 秒了,如果备库上执行速度和主库一样,那么备库上延迟最高会达到 2N 秒。对于 DDL,如果使用单线程复制,备库上的延迟时间会从 0 秒开始,最高 N 秒。如果使用了多线程复制,那么备库开始执行 DDL 时,延迟可能就已经是 N 秒了,最高会达到 2N 秒。 老师,我对以上这个流程不是很理解,这里单线程复制与多线程复制的差异在哪里啊,前面说开始执行时,延迟就是 N 秒,那么延迟最低是N秒吧,但是为什么单线程复制时,延迟从 0 秒开始,最高是 N 秒呢?
2024-12-12