35 MySQL半同步能提高主备数据的一致性吗?
你好,我是俊达。
上一讲中,我留了一个问题,就是在默认的情况下,MySQL的数据复制是异步的,当主库意外崩溃后,备库是否有可能比主库多执行一些事务?
回答这个问题,需要对主库事务提交的过程,以及数据复制的细节有更深入的了解。这一讲我们就来看一看事务的提交过程,分析Binlog是什么时候发送给备库的,还有Semi-Sync插件在中间起到的作用。这里我假定只使用了InnoDB存储引擎,开启了GTID,并且使用了ROW格式Binlog,这也是推荐的使用方式。
MySQL数据复制回顾
下面这张数据复制的架构图,你应该在上一讲中就看到过了。
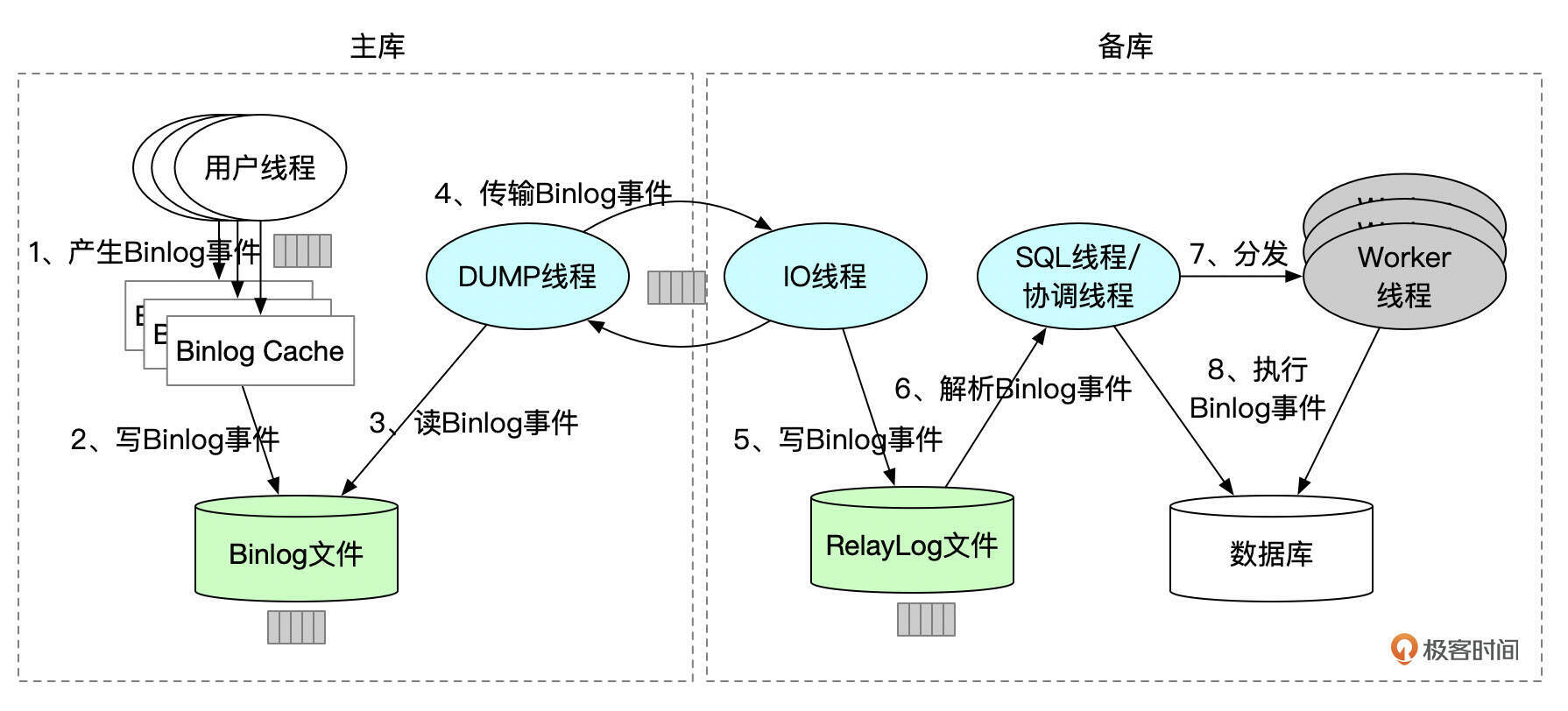
我们回顾一下。
- 用户线程在执行事务的过程中不断产生Binlog事件。Binlog事件的内容和事务中执行的语句相关,同时也受参数binlog_format影响。产生的Binlog事件会先缓存到Binlog Cache中。每一个用户线程都有各自独立的Binlog Cache。
- 提交事务时,用户线程将Binlog Cache中的数据写入到Binlog文件。一个事务会产生多个Binlog事件,这些事件在Binlog文件中是连续存放的。一个线程在往Binlog文件中写入数据时,其他线程要等待之前的线程写完数据,才能写入Binlog文件。
- 用户线程将Binlog事件写入到文件或将Binlog文件同步到磁盘后,通知Dump线程有新的binlog事件产生,通知的具体时机跟参数sync_binlog的设置有关系。
- 对每一个备库上的IO线程,主库上都会创建一个Dump线程。Dump线程负责将已提交事务的Binlog事件发送给IO线程。
- IO线程接收到Binlog事件后,将事件写入RelayLog文件。
- SQL线程从RelayLog文件中解析出Binlog事件,并进行应用。启用了多线程复制时,SQL线程也称为协调线程。备库上参数replica_parallel_workers设置为大于1的值,就能开启多线程复制。参数replica_parallel_type用来控制并行复制的方式,建议设置为LOGICAL_CLOCK。
- 如果启用了多线程复制,SQL线程会将Binlog事件分发给各个Worker线程。
- SQL线程或Worker线程执行Binlog事件。
如果主库完成了事务提交,但是Dump线程由于各种原因没有及时将Binlog发送出去(可能是主备之间的网络有抖动),这个时候如果主库崩溃了,切换到了备库,备库就比主库少执行了一些事务。
如果主库提交事务时,Binlog在完成持久化之前(可能是IO hang),Dump线程已经将Binlog发送给了备库,这个时候如果主库崩溃了,切换到了备库,备库就会比主库多执行一些事务。
这两种情况是不是有可能发生呢?我们先来看一下主库上事务提交的过程。
主库事务提交过程
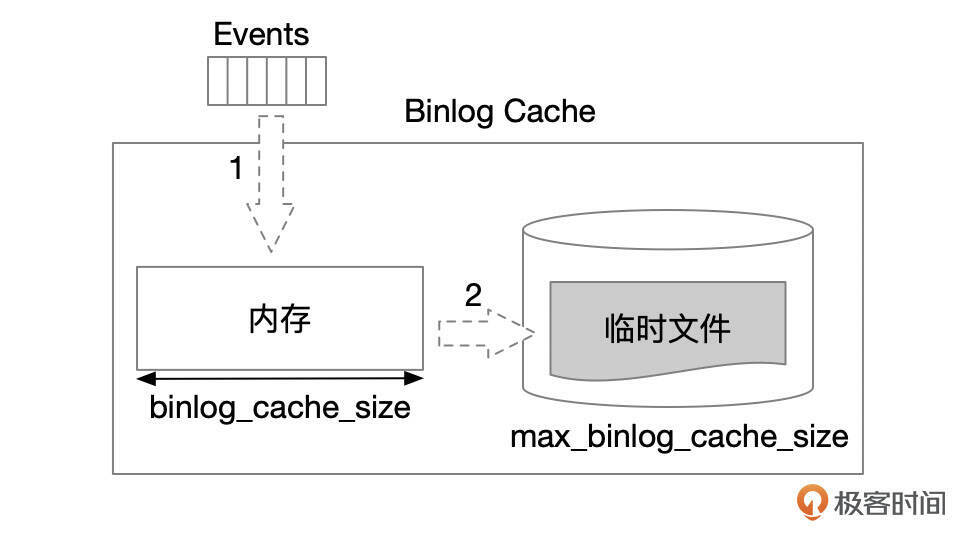
Binlog Cache
用户线程执行过程中生成的Binlog事件会先缓存到Binlog Cache。Binlog Cache内部分配了一块内存空间,大小由参数binlog_cache_size控制。Binlog事件先写入到内存空间中,如果事务生成的Binlog超过了binlog_cache_size,就会将数据写到临时文件中。临时文件的大小由参数max_binlog_cache_size控制。如果事务生成的Binlog超过了参数max_binlog_cache_size的限制,事务会失败。
二阶段提交
如果使用InnoDB存储引擎,并且开启了Binlog,为了保障InnoDB和Binlog中数据的一致性,MySQL会使用两阶段提交协议来提交事务。
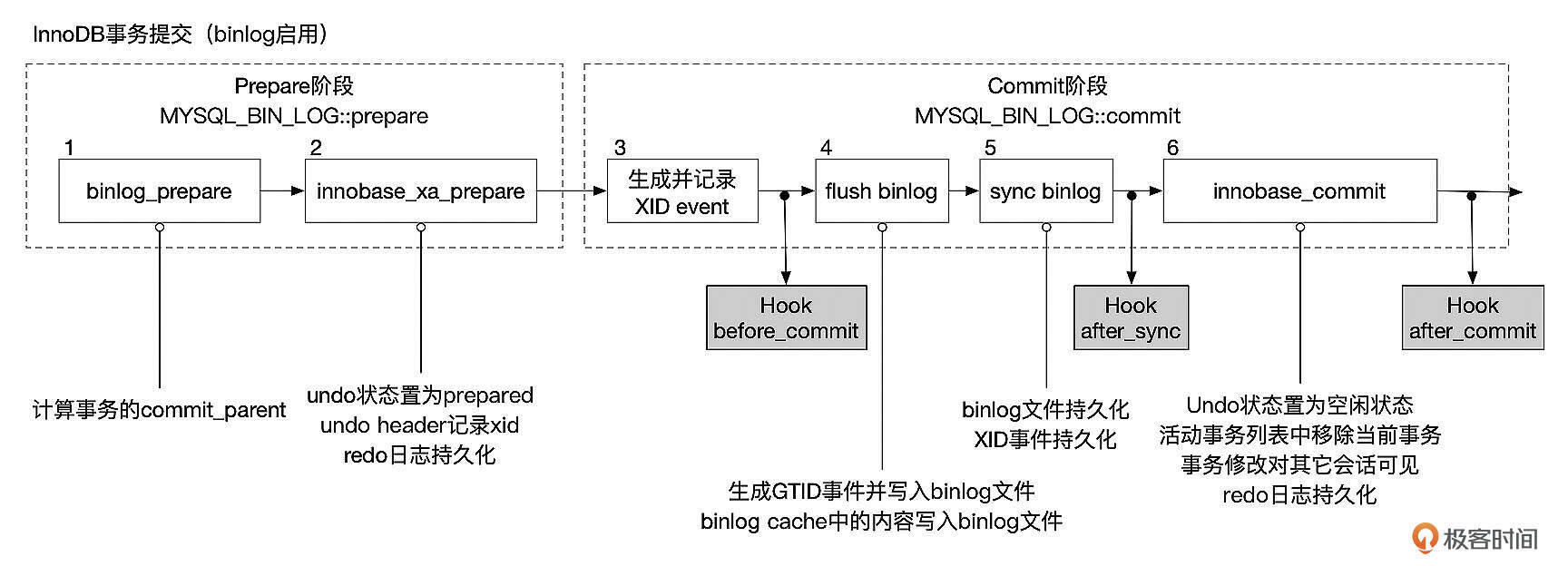
如上图所示,MySQL事务的提交分为Prepare和Commit两个阶段。在Prepare阶段,依次进行Binlog Prepare和InnoDB Prepare,只有当Binlog和InnoDB都Prepare成功后,事务才能进行后续的提交步骤。
- Binlog Prepare:Binlog Prepare时会计算事务的commit_parent。使用多线程复制时,会根据事务的commit_parent来判断该事务是否可以并行执行。
- InnoDB Prepare:31讲中说过,InnoDB会给每个事务分配Undo段。InnoDB Prepare时,需要将Undo段的状态设置为TRX_UNDO_PREPARED,并且在Undo段中记录事务的XID。MySQL中每个事务都有各自的XID,在一个实例的生命周期中(也就是实例没有重启),XID是唯一的。
InnoDB Prepare完成后,需要刷新REDO日志,这样才能保证TRX_UNDO_PREPARED状态不会丢失。如果数据库在事务完成Prepare后崩溃了,那么在下次启动时,会读取到状态为TRX_UNDO_PREPARED的事务,但是由于事务的Binlog还没来得及持久化,因此也无法在Binlog中找到这些事务的XID事件,MySQL会回滚这些事务。
Prepare成功后,进入到Commit阶段。在Commit阶段依次执行下面这几个步骤。
- 生成XID事件,并将XID写入到Binlog Cache中。
- Flush Binlog:将Binlog Cache中的数据写入到Binlog文件中。如果开启了GTID,这时会先生成GTID事件,并将GTID事件先写入到Binlog文件。如果参数sync_binlog没有设置为1,执行完Binlog Flush后,通知Dump线程读取Binlog。
- 持久化Binlog。这一步是否真正进行Binlog持久化还依赖参数sync_binlog的设置。如果sync_binlog设置为1,则在这一步将binlog持久化到磁盘中,并通知Dump线程读取Binlog。Binlog持久化之后,事务事实上就已经完成提交了,只不过这时其他会话暂时还无法读取到当前事务所做的修改。如果这一步完成后MySQL服务器崩溃了,在实例重启时,会在Undo段中读取到状态为TRX_UNDO_PREPARED的事务。因为Binlog已经完成了持久化,所以会在Binlog中读取到事务的XID事件,因此会将事务状态设置为已经提交。
- InnoDB Commit:在InnoDB存储引擎层执行Commit操作,包括释放Undo段,将事务从活动事务列表中移除,持久化Redo日志等。这一步完成后,实例中的其他会话就能读取到当前事务所做的修改了。
所以,如果参数sync_binlog没有设置为1时,理论上存在备库比主库执行更多事务的可能性。
组提交
接下来我们来看一下组提交。MySQL使用了组提交(Group Commit)技术来提交事务。并发提交事务的会话会先进入到一个队列,最先进入队列的线程称为Leader,负责提交操作,其它线程等待Leader线程完成提交操作。提交的过程分为Flush Binlog、Sync Binlog、Commit三个阶段,每个阶段都有相应的队列。
Binlog Flush阶段
线程完成Prepare后,调用MYSQL_BIN_LOG::commit函数,开始进行提交阶段的工作。
下面图中,框框里是MySQL源码中的函数名,你可以到源码中查看具体的代码实现。
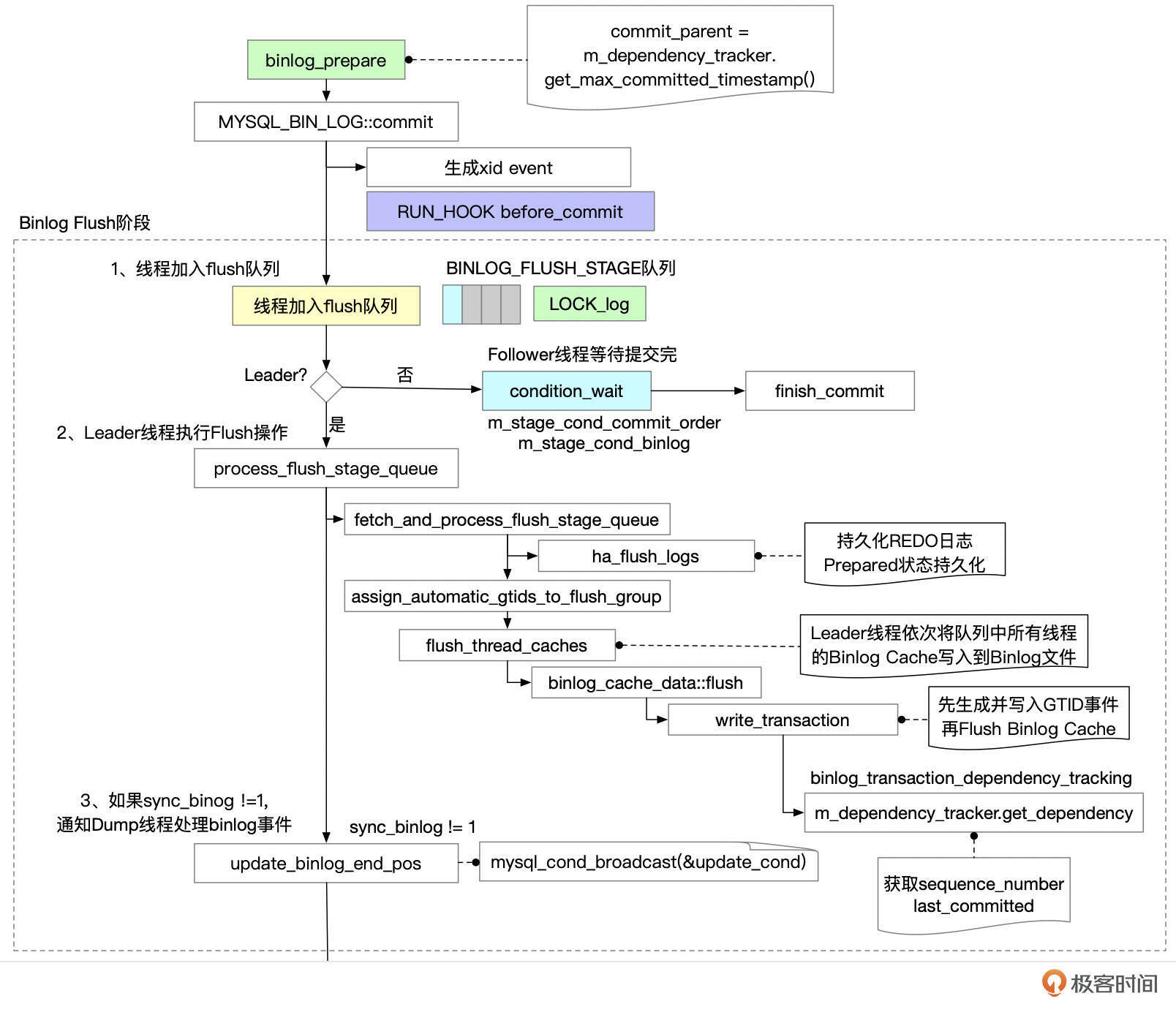
Binlog Flush的执行过程大致如下:
- 提交事务的线程进入Flush队列。第一个进入队列的线程成为Leader往下执行。其他线程成为follower,等待Leader提交完成后再进行后续处理。
- Leader线程执行Flush操作,主要包括下面这些操作。
- 将队列中的线程提取出来,同时清空队列,以便后续提交事务的线程可以加入队列。
- 持久化REDO日志。REDO日志持久化之后,即使实例发生崩溃重启,事务的Prepared状态也不会丢失。Leader线程持久化REDO日志时,其他线程的REDO日志也自动完成了持久化。
-
依次将队列中所有线程的Binlog Cache都刷到Binlog文件中。
-
如果开启了GTID_MODE,则给事务分配一个GTID。
- 给事务分配last_committed、sequence_number,生成GTID事件,并将GTID事件写入到binlog文件中。注意这里GTID事件需要直接写入Binlog文件,而不是加入Binlog Cache,因为GTID事件要放在事务的其他事件之前。last_committed值的计算方式跟参数binlog_transaction_dependency_tracking的设置相关。
- 将binlog cache中的事件写入到binlog文件中。这里只是将事件写到Binlog文件,还没有进行fsync操作。
- 如果sync_binlog != 1,唤醒Dump线程发送binlog。
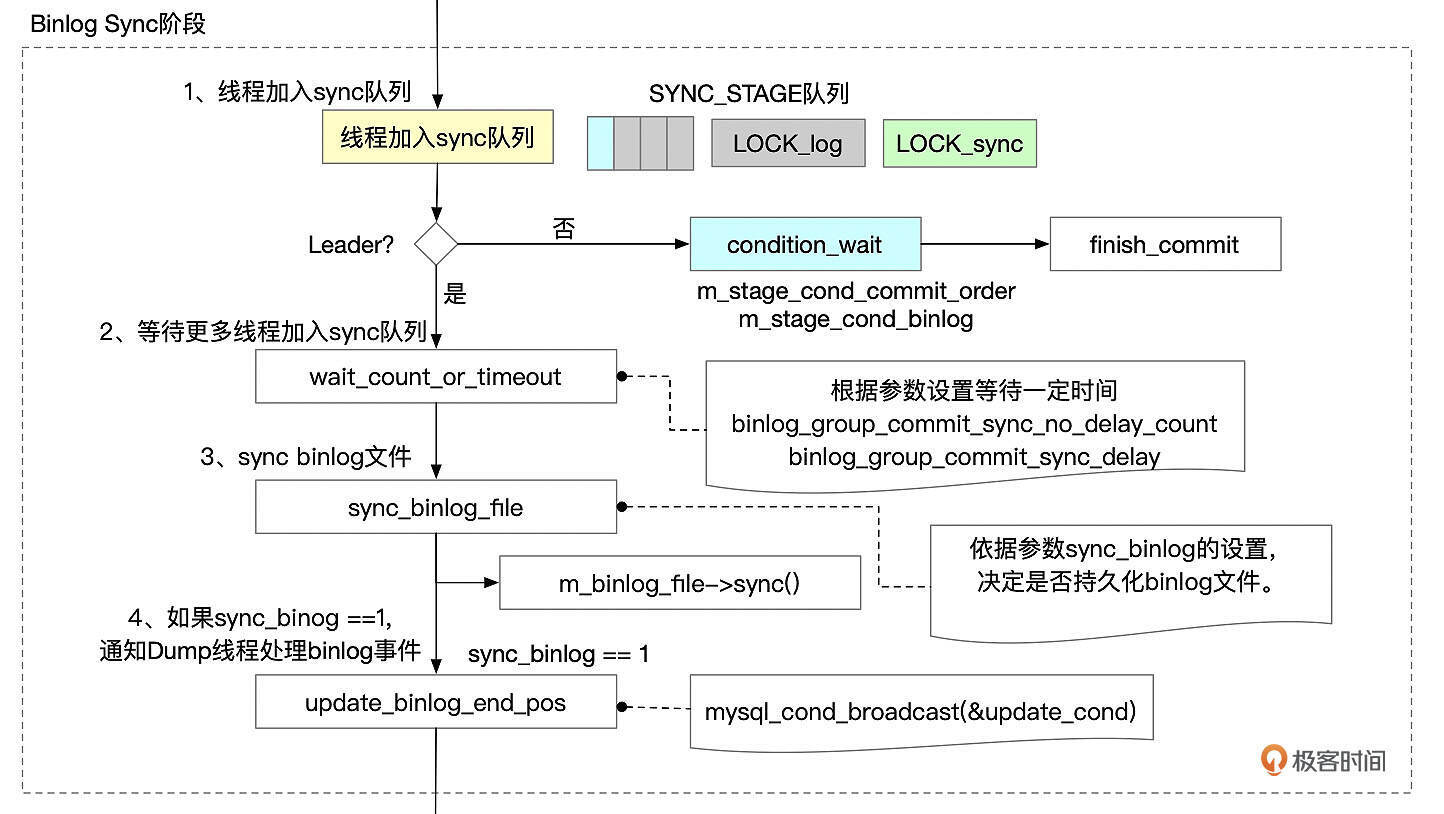
Binlog Sync 阶段
Binlog Flush阶段的Leader线程完成Binlog Flush后,进入到Binlog Sync阶段。
 Binlog Sync阶段依次执行下面这些步骤。
Binlog Sync阶段依次执行下面这些步骤。
- 线程先加入sync队列。第一个加入队列的成为leader,执行sync操作。其他线程成为follower,等待leader线程完成提交操作后再执行。
- 如果设置了参数binlog_group_commit_sync_delay和binlog_group_commit_sync_no_delay_count,等待一定的时间,让更多的线程加入到group中。
- 根据sync_binlog设置来决定是否将binlog刷新到磁盘。如果sync_binlog设置为1,则每次提交时都需要将binlog文件刷新(fsync)到磁盘。如果sync_binlog为0,就不刷新binlog文件。如果sync_binlog的设置值N大于1,那么就每N次执行一次刷新。Binlog文件刷新到磁盘后,事务实际上就已经完成了持久化,但是事务的修改对其它会话暂时还不可见。如果此时数据库发生崩溃重启,从UNDO段中可以获取到处于Prepared状态的事务。因为事务的XID事件已经持久化到了Binlog文件中,MySQL会将事务状态设置为已经提交。
- 如果sync_binlog为1,唤醒dump线程发送binlog
Commit阶段
Binlog Sync阶段的Leader线程完成相关处理后,进入到Commit阶段。
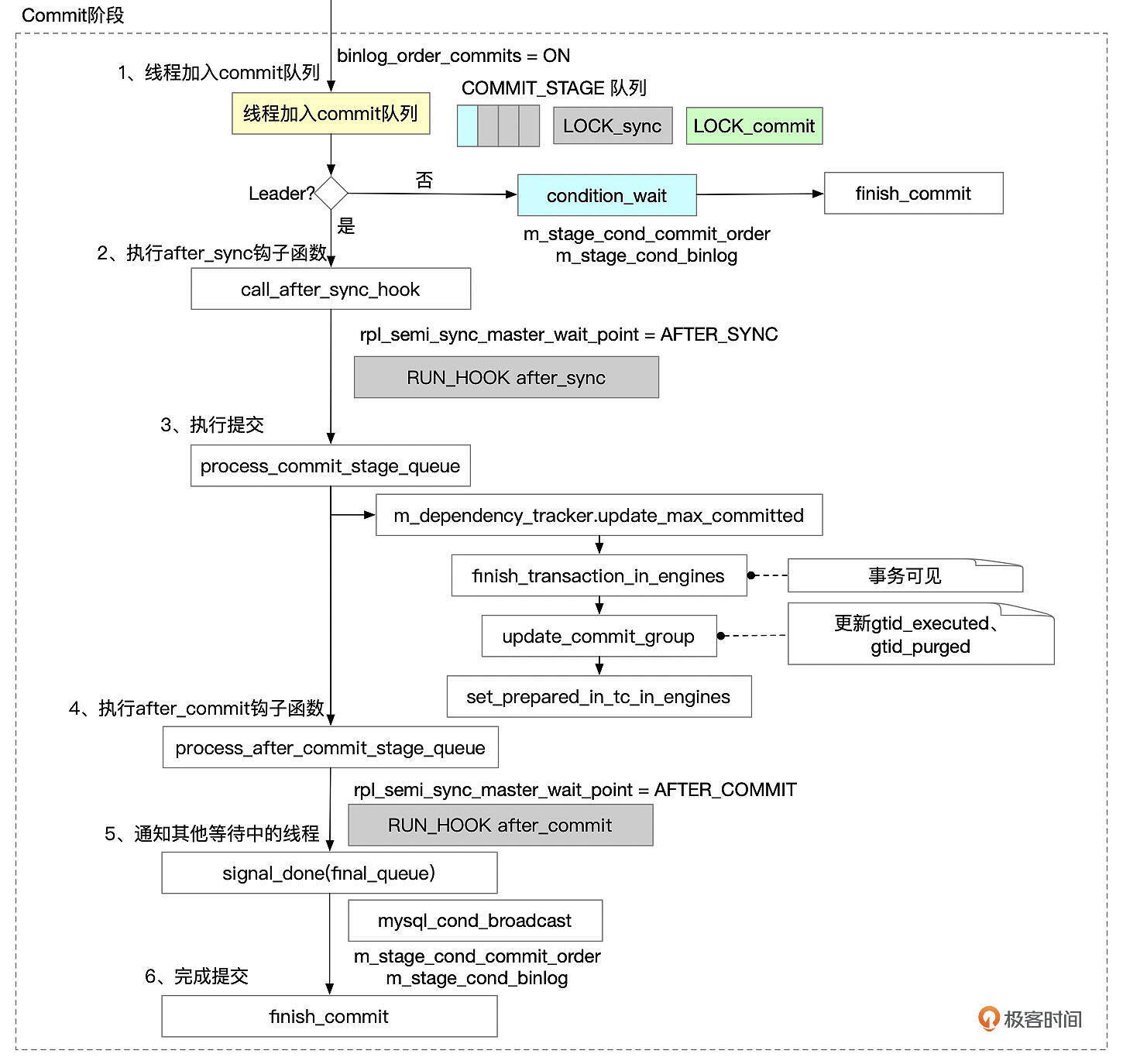
- 如果参数binlog_order_commits设置为ON,则sync阶段的leader线程加入commit队列。第一个加入队列的线程成为leader,进行后续的提交操作。其他线程作为follower,等待leader完成提交后再继续处理。如果binlog_order_commits设置为OFF,则线程不需要进入commit队列,在调用after_sync钩子函数后,然后直接进入到第5步唤醒其它等待提交的事务,由各个事务各自完成提交动作。
- 如果启用了semi-sync,并且rpl_semi_sync_master_wait_point设置为after_sync,则在这里等待binlog同步到备库。
- 依次执行以下几个步骤。
- 更新max_committed变量。下一个group进行提交的时候,会根据变量max_committed的值来设置last_committed值。
-
在InnoDB存储引擎内提交事务。InnoDB引擎内部的提交需要进行一系列操作。包括:
-
设置事务回滚段的状态。
- 如果开启了GTID_MODE,在回滚段中记录事务的GTID。
- 将事务从活动事务列表中移除。这一步完成之后,其它会话就能看到这个事务修改的数据了。
- 更新gtid相关变量:gtid_executed、gtid_purged,更新gtid_executed表。
- 如果启用了semi-sync,并且rpl_semi_sync_master_wait_point设置为after_commit,则在这里等待binlog同步到备库。
- 唤醒其他等待提交的线程(signal_done)。
- 执行finish_commit,完成commit。
Binlog同步
最后,我们来看一下Binlog是怎么从主库同步到备库的。同步操作由主库的Dump线程和备库的IO线程一起配合完成。
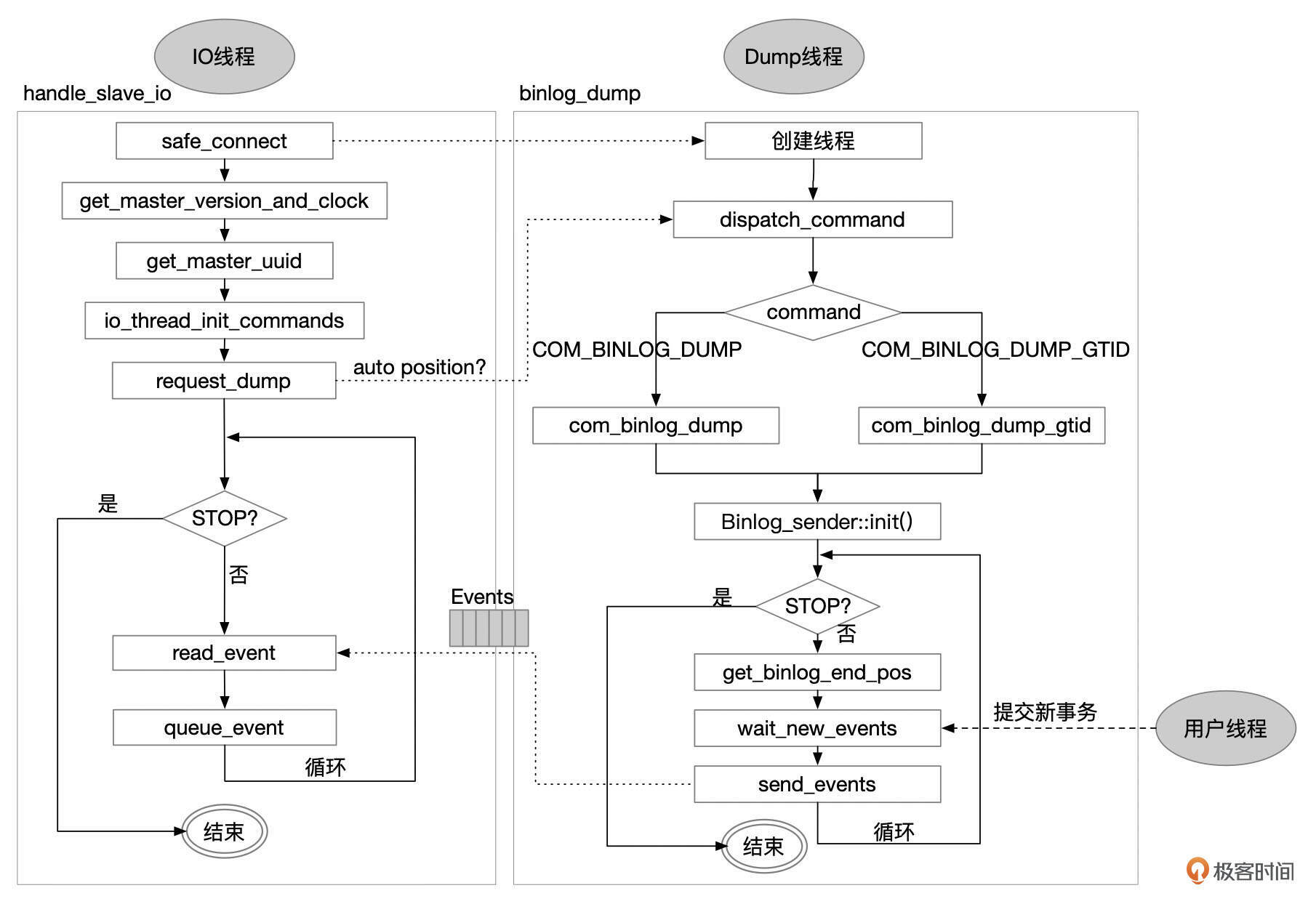
IO 线程
备库上使用START SLAVE或START REPLICA命令启动复制。当参数skip_slave_start、skip_replica_start为OFF时,实例启动时也会自动启动复制。
- IO线程基于master_info中的信息,和主库建立连接。如果建立连接失败,还会进行重连。master_info以文件或表的形式存储。我建议你把参数master_info_repository设置为TABLE,将master_info存储在表中。
- 和主库建立连接后,获取主库的一些基础信息,包括下面这些信息。
- 主库的UUID;
- 主库的server id、GTID_MODE;
- 获取主库的当前时间,计算主库和备库之间的时间差clock_diff_with_master,在计算备库延迟时需要用到这个信息。
- 发送Dump Binlog命令。
- 如果启用了GTID并且使用了GTID AUTO Position,就发送COM_BINLOG_DUMP_GTID命令,命令的参数中包括备库的GTID_EXECUTED。
- 如果没有使用AUTO Position,就发送COM_BINLOG_DUMP命令,命令参数中包括需要读取的Binlog文件名和位点。
- 接收主库Dump线程发送过来的Binlog事件。
- 将Binlog事件保存到RelayLog文件中,并更新相关binlog位点信息,根据参数设置持久化relaylog文件和master info。
- 更新备库读取Binlog的位点信息(Show slave status输出中的Master_Log_File和Read_Master_Log_Pos)。如果开启GTID,还要更新Retrieved_Gtid_Set。
- 根据参数sync_relay_log的设置决定是否持久化Relay Log文件。
- 根据参数sync_master_info的设置决定是否持久化master info。
DUMP线程
IO线程启动时,会跟主库建立连接,主库上会启动一个Dump线程。Dump线程主要执行下面这几个步骤。
- 处理备库上IO线程发送过来的读取Binlog的命令。如果备库启用了AUTO_POSITION,则命令中还包括了备库的GTID_EXECUTED信息。如果没有使用AUTO_POSITION,则命令中包括了Binlog的起始文件名和位点。
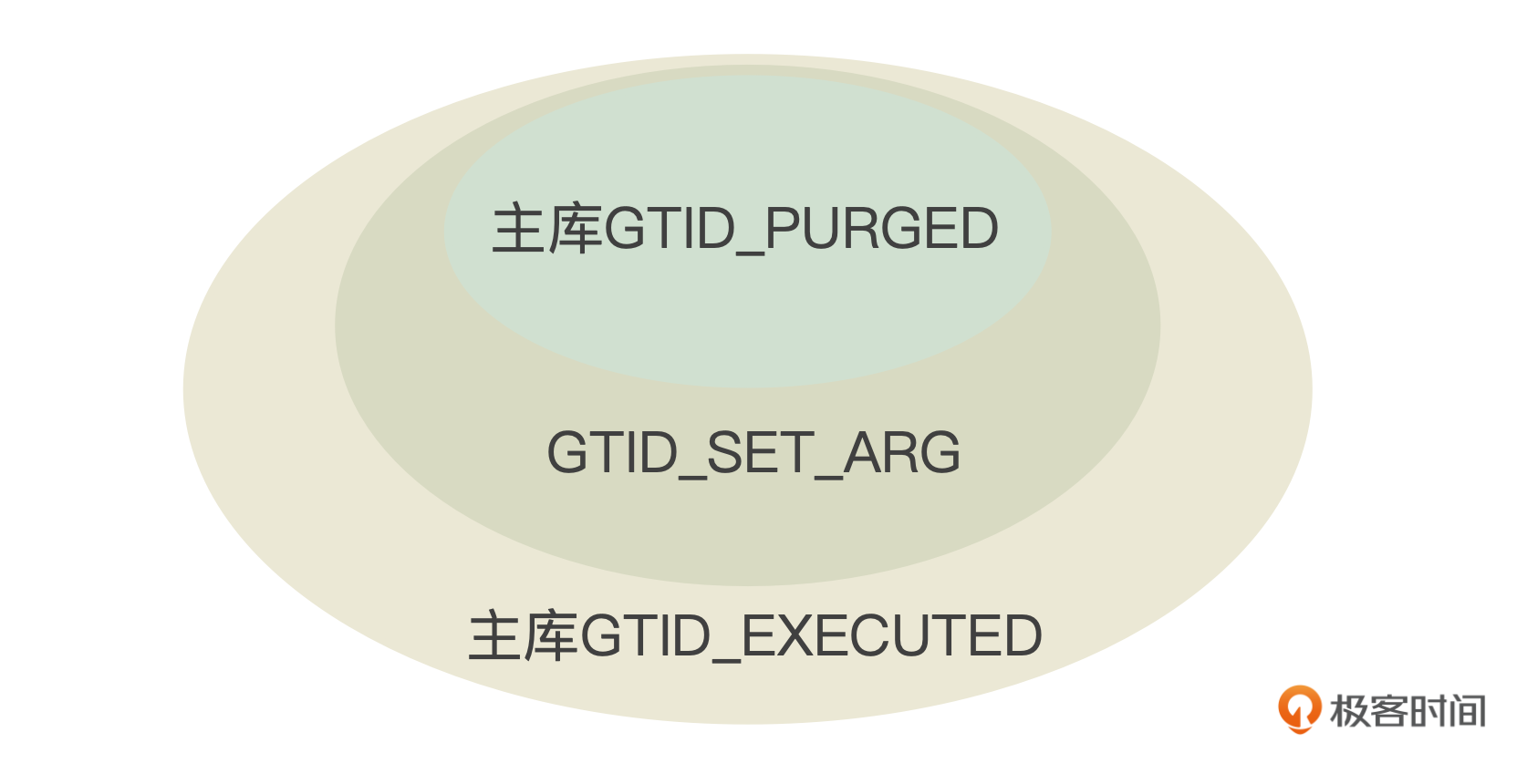
- 初始化Binlog读取工作。如果备库使用了AUTO_POSITION,则Dump线程需要根据发送过来的GTID_SET_ARG信息来计算Binlog的起始文件名和位点。这里可能会遇到几种情况。
- 如果主库没有开启GTID,就直接返回错误消息:The replication sender thread cannot start in AUTO_POSITION mode。
- 如果备库发送过来的GTID_SET_ARG中包含主库上不存在的GTID(相对于主库的UUID),就返回错误消息:Got fatal error 1236 from master when reading data from binary log: 'Slave has more GTIDs than the master has, using the master’s SERVER_UUID.
- 如果主库的GTID_PURGED不是备库发送过来的GTID_SET_ARG的子集,就说明备库上需要的一些事务已经被清理了,报错:Got fatal error 1236 from master when reading data from binary log: 'Cannot replicate because the master purged required binary logs. Replicate the missing transactions from elsewhere, or provision a new slave from backup.
一般在正常情况下,备库发送过来的GTID_SET_ARG应该是主库GTID_EXECUTED的子集,而主库的GTID_PURGED应该是GTID_SET_ARG的子集。
如果满足了上面这几个条件,Dump线程开始扫描Binlog,定位从哪个BINLOG开始复制数据。
- 根据Binlog Index文件中的binlog列表逆序扫描。
- 打开Binlog文件,读取Binlog头部的Previous GTIDs事件。如果Previous GTIDs是GTID_SEG_ARG的子集,就从当前Binlog开始复制数据。否则,继续读取上一个Binlog文件。
- 发送Binlog。如果没有使用AUTO_POSITION,那么Dump Binlog命令的参数中就包含了起始Binlog的文件和位点。如果使用AUTO_POSITION,那么前面的步骤已经定位到了起始Binlog,这时从Binlog文件的头部开始读取数据。Dump线程依次读取Binlog文件中的事件,发送给备库。如果使用了AUTO_POSITION,会在发送前先检查事件的GTID是不是包含在GTID_SET_ARG中,如果GTID_SET_ARG中已经有这个GTID了,就跳过这个事件。
当所有Binlog内容都已经发送给备库后,Dump线程开始等待新的Binlog事件生成。用户线程提交新的事务时,会通知Dump线程进行处理。
半同步(Semi Sync)
默认情况下,MySQL主备库之间的数据是异步进行的。主库提交事务时,并不需要等待Binlog复制到备库。这样做的好处是减少了备库对主库性能的影响,坏处是主库如果异常崩溃,可能最新的Binlog还没有同步到备库,如果业务切换到备库,就有可能出现数据丢失。半同步插件(semi-sync)能在一定程度上减少这种情况的出现。
开启半同步
开启半同步需要在主库和备库安装插件,并设置相关参数。
主库上安装rpl_semi_sync_source插件。
备库上安装rpl_semi_sync_replica插件。
主库上设置参数。
备库上设置参数。
开启半同步后,主库上事务提交时,会等待Binog发送完成。如果由于各种原因,备库没有接收到Binlog,主库会一直等待,状态是“Waiting for semi-sync ACK from replica”,直到超时。超时时间通过参数rpl_semi_sync_source_timeout设置。
mysql> show processlist \G
*************************** 2. row ***************************
Id: 11
User: root
Host: localhost:54932
db: db01
Command: Query
Time: 10
State: Waiting for semi-sync ACK from replica
Info: insert into ta values(1100)
超时后,半同步会退化成异步复制。可以查看参数Rpl_semi_sync_source_status,判断半同步有没有生效。
mysql> show global status like '%semi%status%';
+-----------------------------+-------+
| Variable_name | Value |
+-----------------------------+-------+
| Rpl_semi_sync_source_status | ON |
+-----------------------------+-------+
如果你使用了半同步,建议把Rpl_semi_sync_source_status和半同步的等待耗时监控起来。错误日志中也有半同步状态变化的信息,也可以监控起来。
[Warning] [MY-011153] [Repl] Timeout waiting for reply of binlog (file: mysql-binlog.000010, pos: 2654), semi-sync up to file mysql-binlog.000010, position 2381.
[Note] [MY-011155] [Repl] Semi-sync replication switched OFF.
[Note] [MY-011156] [Repl] Semi-sync replication switched ON at (mysql-binlog.000010, 2927).
AFTER_SYNC和AFTER_COMMIT
半同步是在事务提交的哪个阶段等待Binlog发送呢?这和参数rpl_semi_sync_master_wait_point的设置有关。
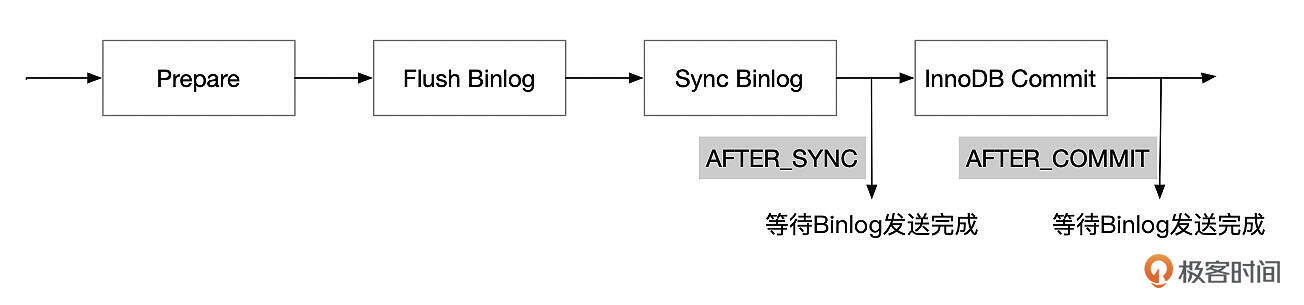 rpl_semi_sync_master_wait_point可以设置为AFTER_SYNC或AFTER_COMMIT。
rpl_semi_sync_master_wait_point可以设置为AFTER_SYNC或AFTER_COMMIT。
- AFTER_SYNC
在AFTER_SYNC的设置下,事务的Binlog Sync到磁盘之后,等待Binlog发送给备库。Binlog Sync之后,事务对其他线程还不可见。如果这个时候主库异常崩溃了,业务切换到备库。由于Binlog还没有同步到备库,所以备库上也看不到事务所做的修改。从业务的角度看,主备库数据是一致的。
但是原来的主库重新启动时,由于事务的Binlog已经完成了持久化,MySQL会将事务设置为已提交状态。因此相比于备库,主库多执行了一些事务。因此主库启动后,需要将这些事务的修改撤销后才能和新主库保持数据一致。
- AFTER_COMMIT
在AFTER_COMMIT的设置下,主库在完成InnoDB Commit之后,等待Binlog同步到备库。此时,主库上其他会话已经能看到事务所做的修改了。如果这个时候主库发生异常崩溃,业务切换到备库。由于Binlog还没有同步到备库,因此备库上看不到事务所做的修改。从业务上看,备库比主库少执行了一些事务。
半同步不能保证主备数据之间完全同步,因为半同步可能会退化成异步复制。半同步在没有退化的状态下,可以提升主备数据的一致性。如果使用半同步,一般会给主库添加多个备库,只要有一个备库接收到Binlog,主库事务就可以完成提交,减少由于单个备库的问题导致主库性能下降。
总结
好了,这一讲中,我们分析了MySQL事务的二阶段提交。使用默认的异步复制,在极端情况下,主备数据可能会出现不一致。sync_binlog设置为1时,可以保障主库的数据一致性。
半同步可以部分提升主备之间的数据一致性,开启半同步会有一些性能开销,使用半同步需要做好监控。
思考题
主备库数据的一致性非常重要。如果数据不一致了,会带来很多问题,备库的复制可能会中断,业务切换到备库后,会取到错误的数据,影响业务。而且一般我们会在备库上备份,避免备份时影响主库性能,但如果备库的数据有问题,那么我们的备份也都是有问题的。
那么怎么检查主备库之间的数据是不是一致的呢?
期待你的思考,欢迎在留言区中与我交流。如果今天的课程让你有所收获,也欢迎转发给有需要的朋友。我们下节课再见。
- 叶明 👍(3) 💬(1)
可以用 pt-table-checksum 工具来校验主备数据的一致性。主要原理是让主备处于理论上数据一致的视图里,利用事务的可重复读以及函数 WAIT_FOR_EXECUTED_GTID_SET(gtid_set[, timeout]) / MASTER_POS_WAIT(log_name,log_pos[,timeout][,channel]) 来拿到主备理论上的一致性视图, 然后分别计算主备上表分批的 checksum,不同就代表这段范围的数据不一致,再到行级别比对数据。
2024-11-12 - binzhang 👍(2) 💬(1)
Question: in chapter "事务怎么回滚(上)", you mention in undo segment header save TrxID, XA XID, GTID. what's difference between TrxID and XA XID and this chapter's XID? looks like innodb also write GTID to undo header during two-phase commit?
2024-11-21