29 数据都在内存里修改,服务器或数据库宕机会丢数据吗?
你好,我是俊达。
InnoDB使用REDO和UNDO来实现事务的ACID属性,保障数据不丢。事务修改缓存页里的数据时,会生成UNDO和REDO日志,事务提交时,虽然缓存页没有实时刷新,但是会确保REDO日志已经完成持久化。
下面是REDO和UNDO机制的一个简单的示意图。
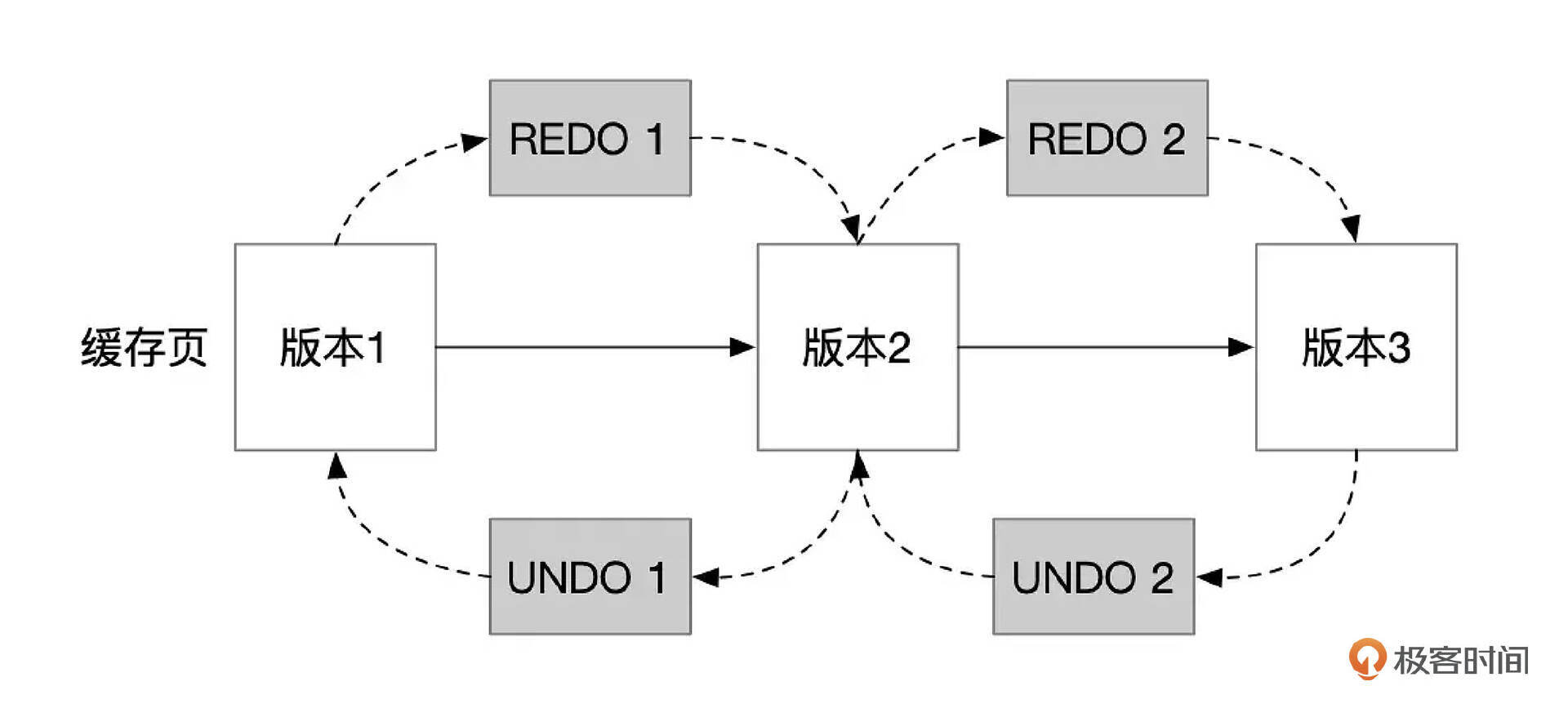
缓存页被修改后,最新的数据为版本3,文件中保存的还是版本1的数据。如果此时数据库崩溃了,下次启动时,应用REDO日志,可以将文件中版本1的数据重新更新到版本3。如果数据库崩溃时事务还没有提交,会应用UNDO日志,将数据回滚到已经提交的版本。
这一讲中,我们先通过几个具体的例子,来了解基本的DML操作是怎么修改数据页的,然后再来分析这些操作,在REDO日志中是怎么记录的。
页面内的变更
表刚刚创建时,表中还没有数据,B+树只有空的根页面。随着不断往表中插入数据、更新数据,一个页面的空间无法容纳新的数据,需要对页面进行分裂,往B+树中添加新的页面。
插入记录(insert)
执行Insert语句插入记录时,需根据新记录的主键值,在聚簇索引上定位这行记录的位置,定位完成后,游标(cursor)会指向待插入数据的上一行记录。我们先考虑最简单的情况,当前页面有足够的空闲空间来容纳新的记录。在第25讲中,我们已经知道,页面内的空闲空间主要由两部分组成。
- 未使用的空间。页面头部top字段指向未使用空间的起始地址。
- 已经删除的记录释放出来的碎片空间。页面头部free字段指向碎片空间的起始地址。
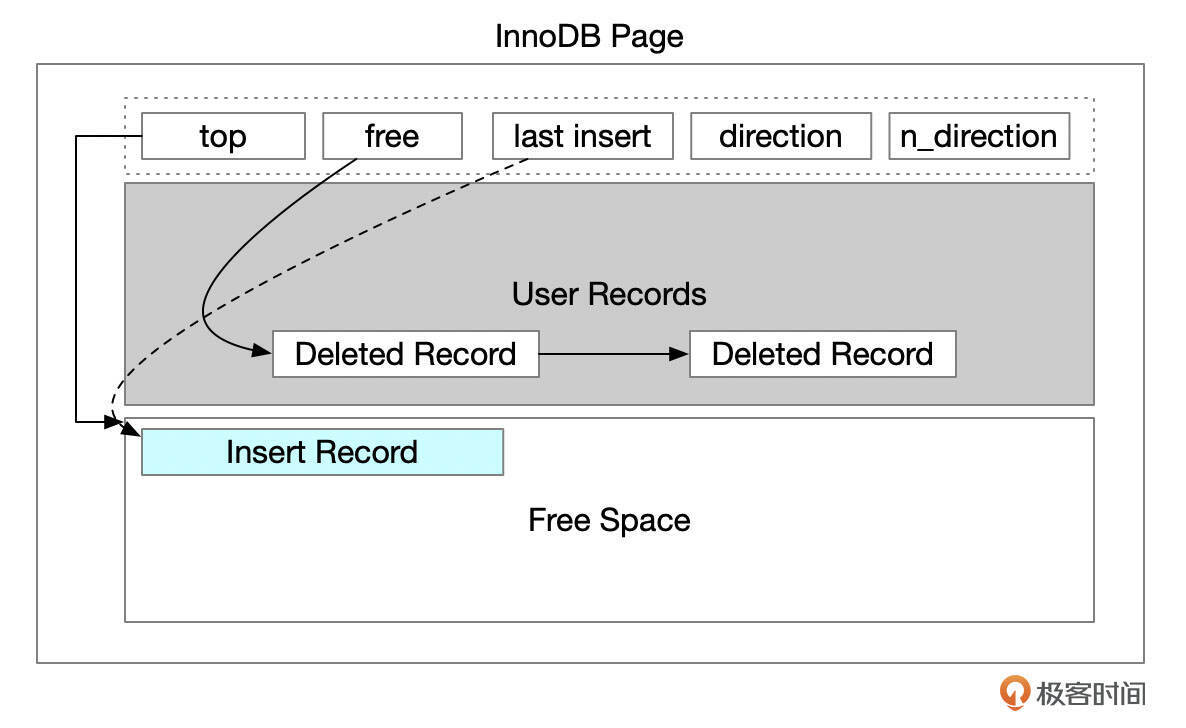
一行记录在页面中会占用一段连续的空间。如果页面内空间够用,记录会重用已删除记录占用的空间,或者在未使用空间中分配一段连续的空间。记录插入后,还需要维护页面头部的相关字段。比如上面这个示意图中,插入记录后,top需要指向新插入记录的结尾处,也就是新的未使用空间的起始位置。
新插入的记录,还要添加到单向链表中。比如页面内原先有记录x、z,新插入了记录y。cursor会先定位到记录x,记录y插入到页面后,记录x的next record offset设置为y,记录y的next record offset设置为z。
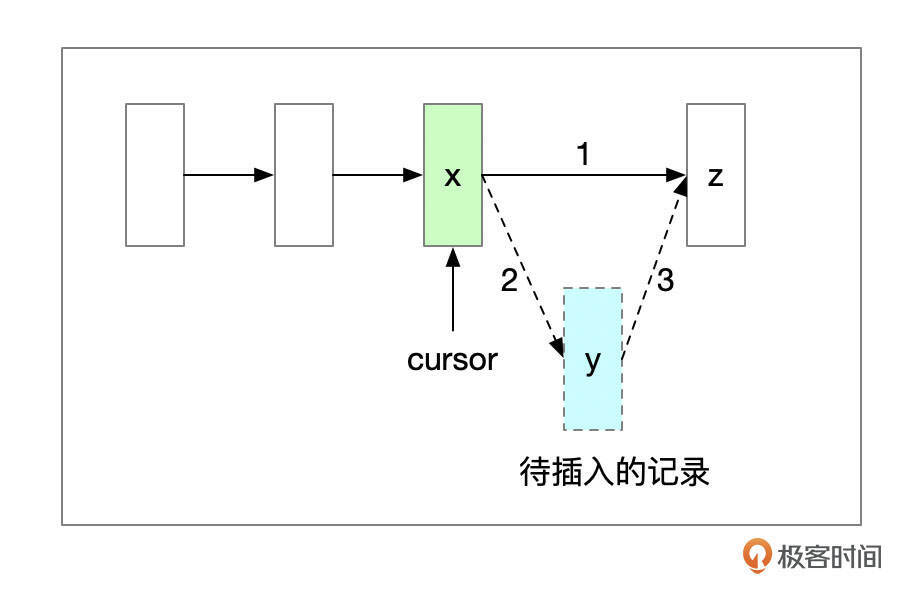
此外,新插入记录后,还需要修改记录组的n_owned属性,还可能要添加新的页目录项。
删除记录(delete)
InnoDB中删除记录分为2种情况,一种称为删除标记(delete mark),仅在记录头部中设置DELETED_FLAG标记,记录链中依然保留该记录。另一种是真正删除,将记录从记录链中移除,记录占用的空间可被重用。
执行delete语句时,会先给记录打上删除标记,此时还不能直接删除记录,因为其他会话可能还需要读取这行记录未删除的版本。
下面这张图中,记录Record 2被标记为删除。
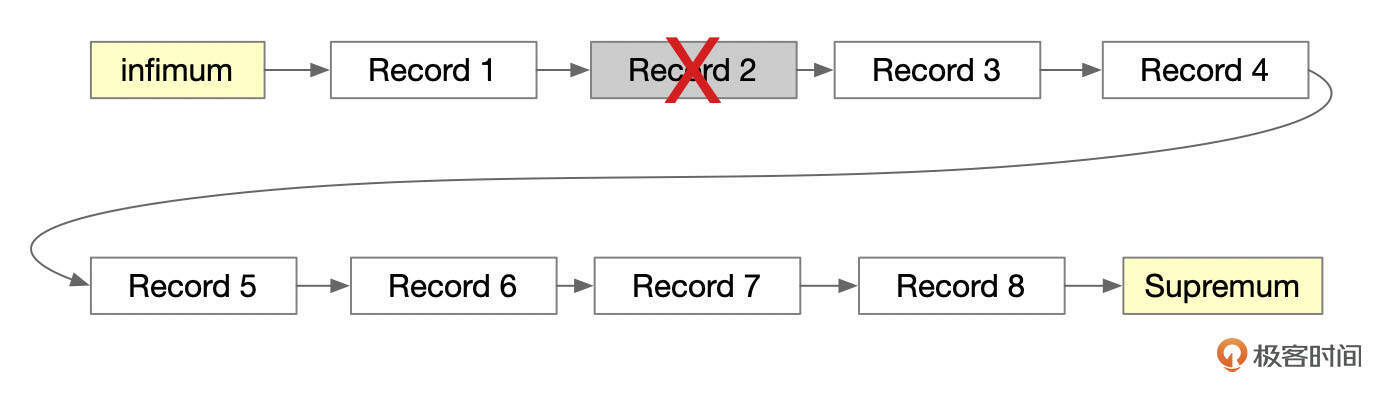
什么时候才能真正删除记录呢?当系统中所有的会话都不再需要记录删除前的版本时,Purge线程会把记录物理删除掉。下面这张图中,删除了记录Record 2,页面头部的Free指向该记录。
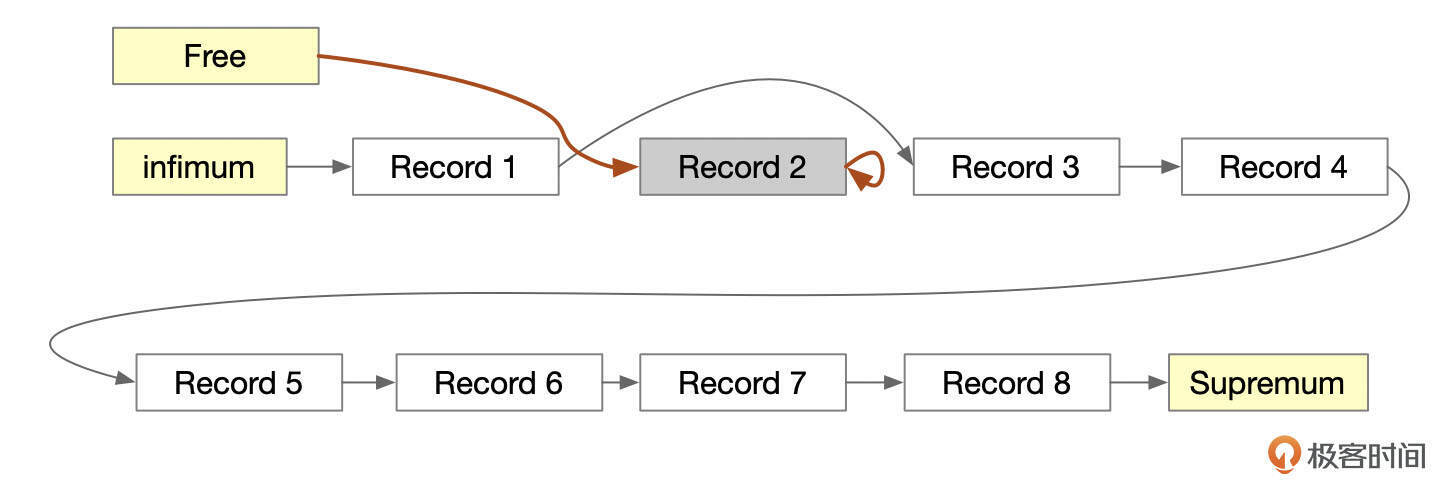
页面内所有删除的记录也组成了一个单向链表,页面头部的free字段指向这个单向链表。
下面这个示意图中,记录Record 7也被删除了。
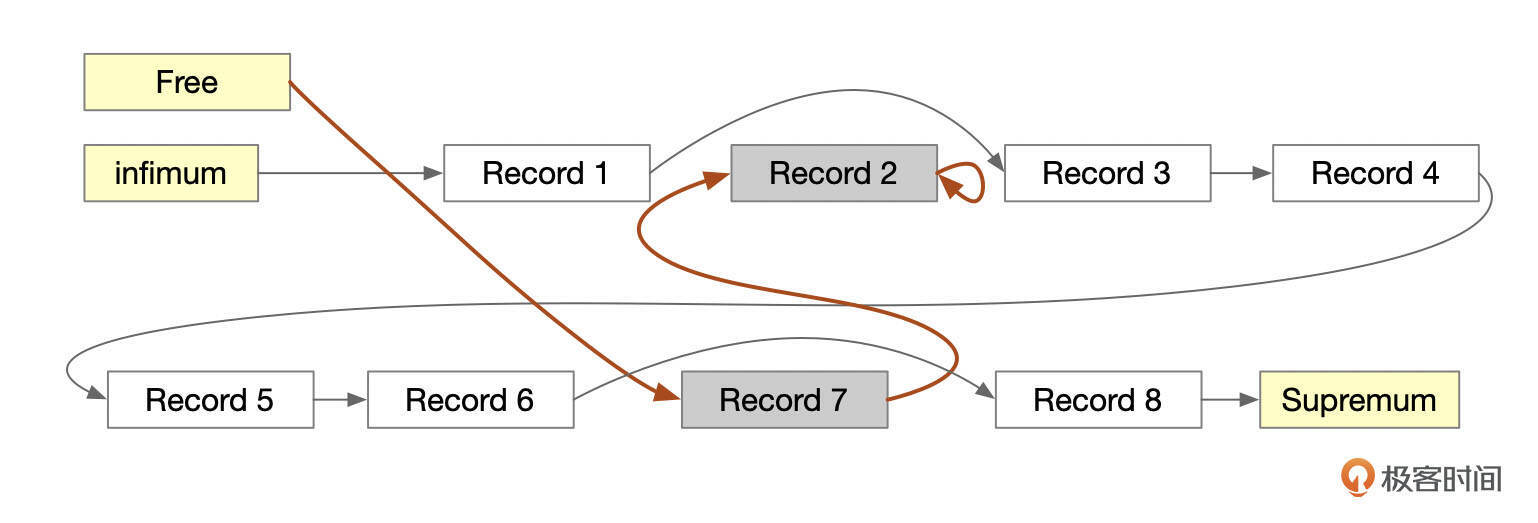
从图中也可以看到,页面内记录删除后,释放出来的空间很可能是不连续的,我们可以称之为碎片空间。
更新记录(update)
执行update语句更新记录时,要分成几种情况。如果更新后所有字段的长度都没有发生变化,也没有更新行外存储的字段,那么更新可以在原地进行(in place update)。如果更新后字段长度发生变化(变长或变短),就无法进行原地更新,需要先将记录删除(此时的删除是直接真正删除记录,不是给记录加DELETED_FLAG标记)后,再重新插入。当然,这里假设了没有更新主键字段。
如果更新了主键字段,那么相当于执行了一个DELETE操作,再加一个Insert操作。对于二级索引而言,所有的更新操作都会被转换为delete和insert。
页面碎片整理
如果页面内的未使用空间不足,无法容纳新插入的数据,但是碎片空间中有足够的空间,可以先对页面进行碎片回收后,再插入新的数据。碎片回收大致上会执行这几个步骤。
- 内存中分配一个空闲页面。
- 将碎片页面内的记录依次插入到新的页面。
- 释放原先的碎片页。
页面分裂
如果插入记录时,页面内的空间无法容纳新的记录(即使进行碎片整理后也无法容纳新的记录),就需要将页面分裂成2个新的页面。页面分裂大致上分为几个步骤。
- 找到分裂点。一般情况下,会以页面中的中间记录作为分裂点。假设页面中原先有n条记录,则页面分裂后,2个页面各占n/2条记录。这里有几种特殊情况,后面我们会具体介绍。
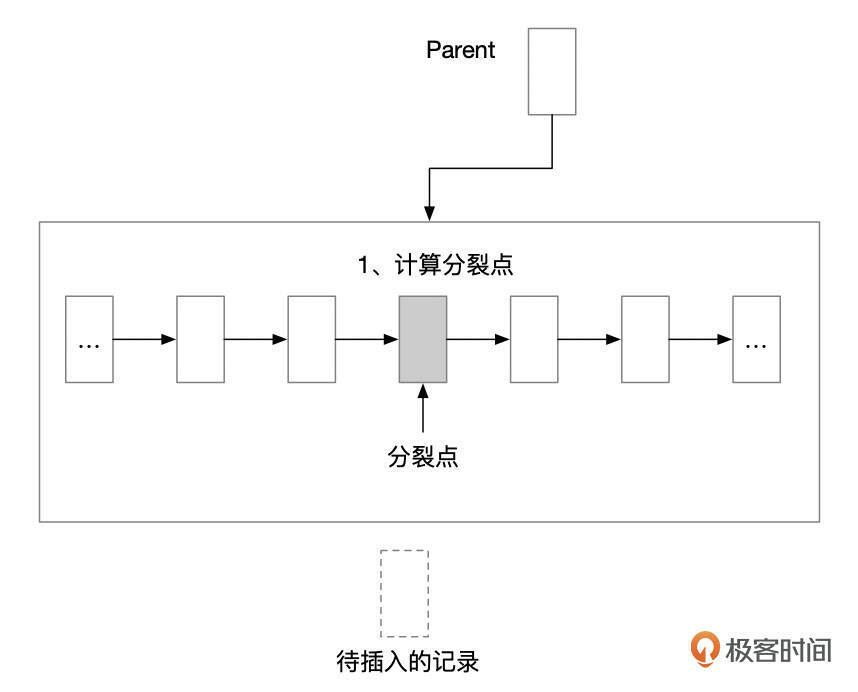
- 分裂页面
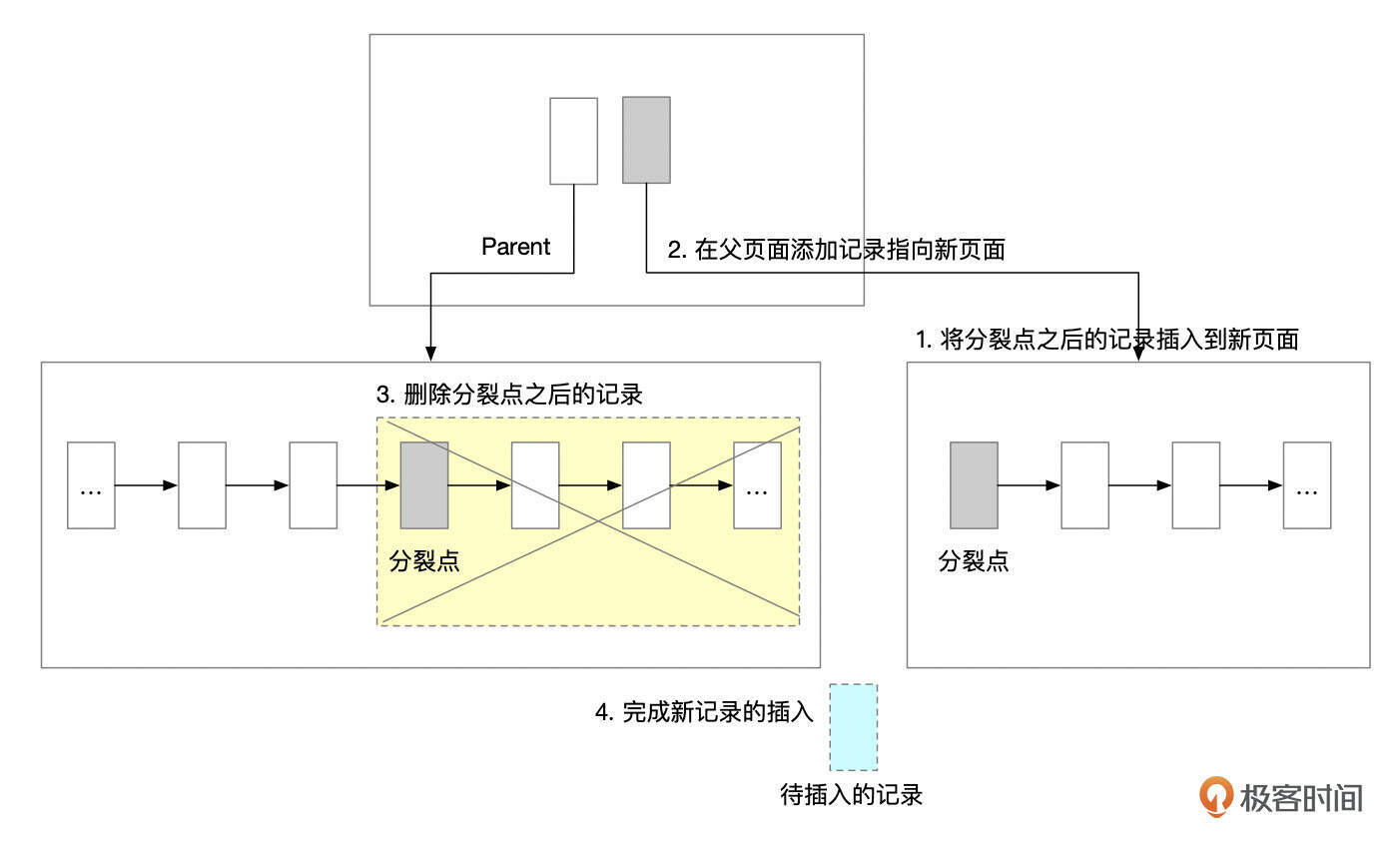
- 新分配一个页面。将原先页面中分裂点以及之后的记录插入到新页面。
- 在父页面中添加指向新页面的记录。如果父页面中空间无法容纳新记录,则需要递归地分裂父页面。
- 在原先页面中,删除分裂点以及之后的记录。
- 比较待插入记录和分裂点记录,判断新记录应该插入到哪个页面,并执行插入操作。
 页面分裂有几种特殊情况,分别是ROOT页面分裂,向右分裂,向左分裂。
页面分裂有几种特殊情况,分别是ROOT页面分裂,向右分裂,向左分裂。
ROOT页面分裂
ROOT页面的分裂有几个特殊的地方。
- ROOT页面的页面编号(Page Number)在分裂时需要保持不变。因为B+树的搜索都是从ROOT页面开始,InnoDB元数据中记录了ROOT页面的编号。如果ROOT页面编号发生变化,则还需要同时更新元数据中的信息,增加了复杂度。
- ROOT页面分裂后,B+树的高度会增加1层。其他页面的分裂都不会改变B+树的高度。ROOT页面分裂后,B+树的高度会增加1层。
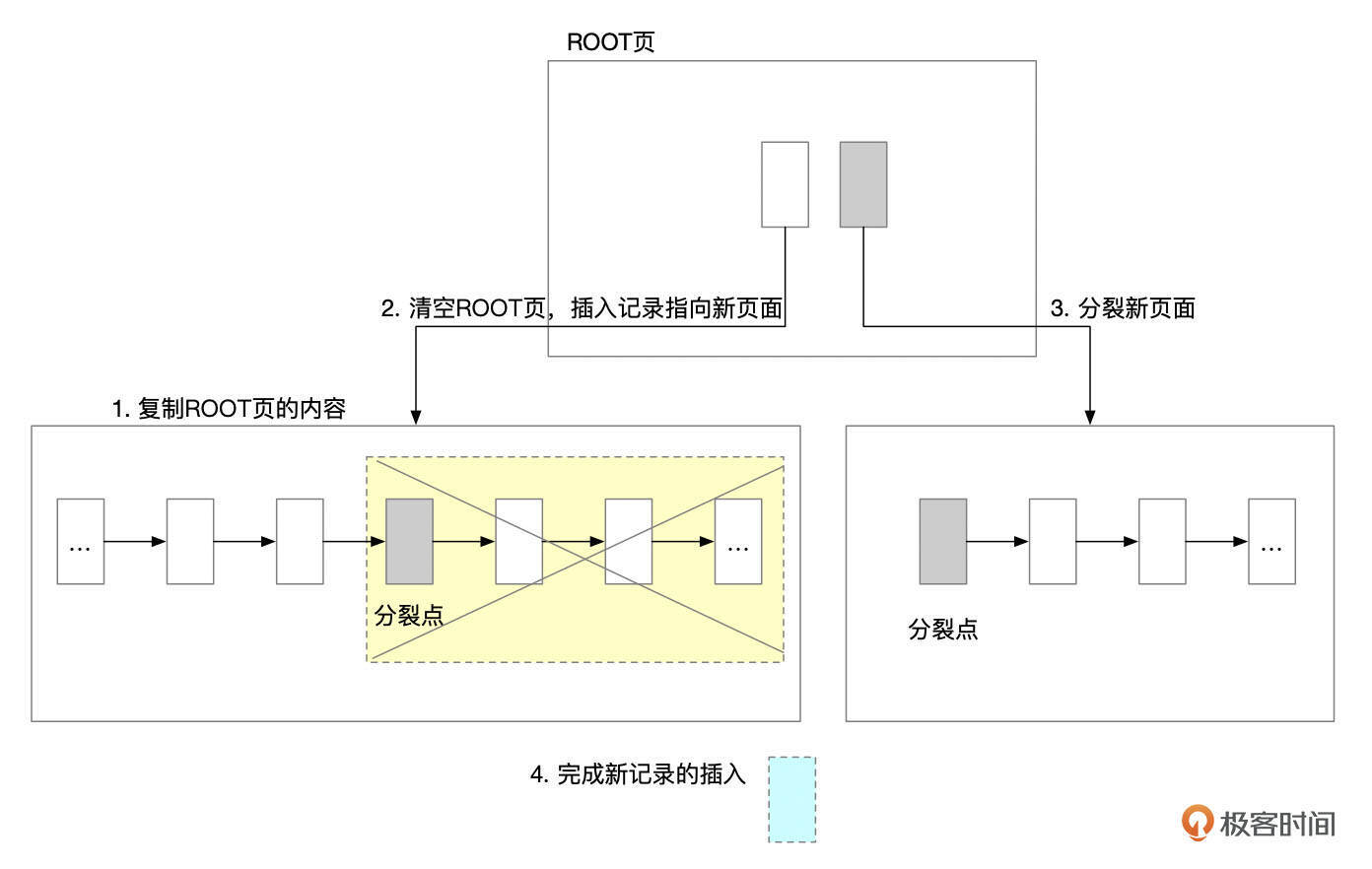 ROOT页面分裂大致需要执行这几个步骤。
ROOT页面分裂大致需要执行这几个步骤。
- 分配一个新的页面。将ROOT页面的内容复制到新页面。
- 清空ROOT页面中的内容。并在ROOT页面中插入记录,指向新复制出来的页面。
- 在新页面上执行分裂操作。
- 插入记录。
向右分裂/向右插入
往表中插入数据时,如果按Key值从小到大的顺序(如自增主键)插入,InnoDB会采用向右分裂的方式来分裂页面。因为在这种情况下,如果还是采用平均分裂页面的方法,则左边的页面只用了一半的空间,但是后续并不会再往这个页面中插入数据,造成空间浪费。而右边的页面复制了原先页面一半的记录,更容易写满。
InnoDB插入记录时,在页面头部维护了Last Insert字段,里面保存了上一次插入的记录的位置。如果新插入的记录位于上次位置之后,就会使用向右分裂。
向右分裂分为几种情况。
- 情况1:插入的记录是原先页面中最大的记录。这种情况下,以新插入的记录作为分裂点。
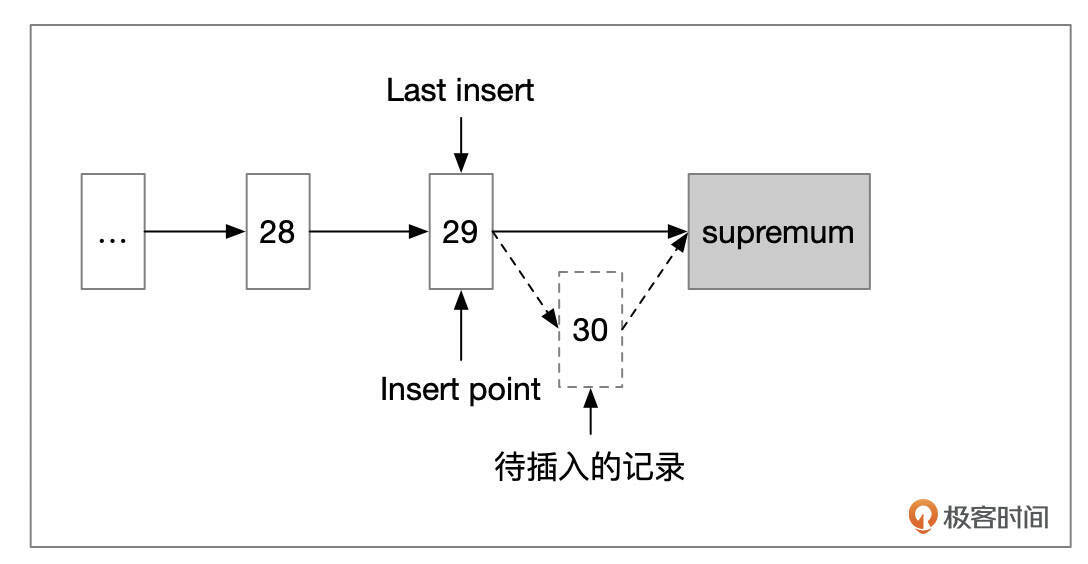
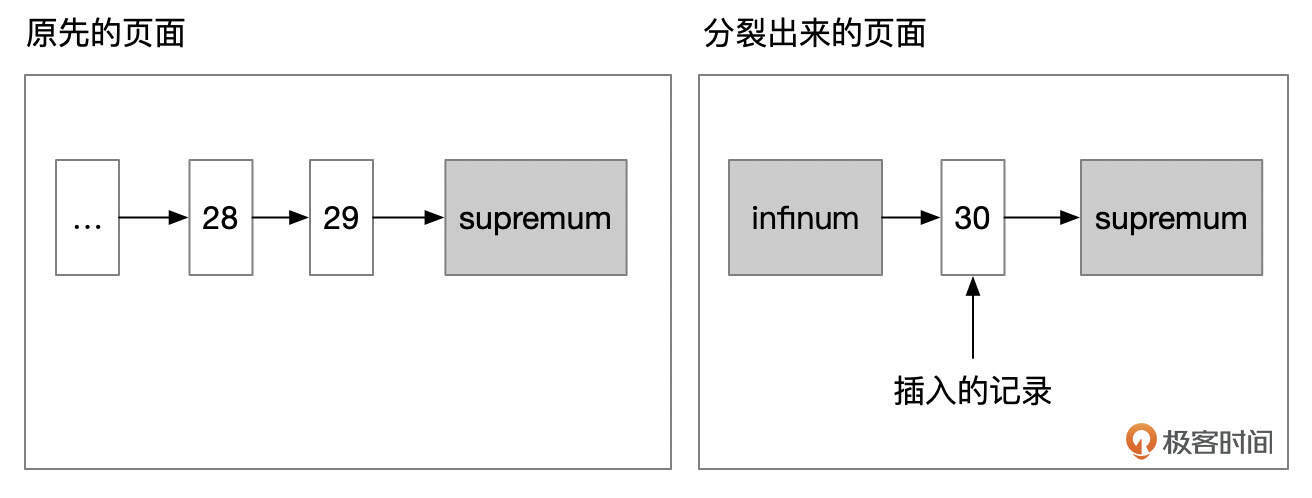
- 情况2:插入的记录后面,只有1条更大的记录。这种情况下,也是以新插入的记录作为分裂点。
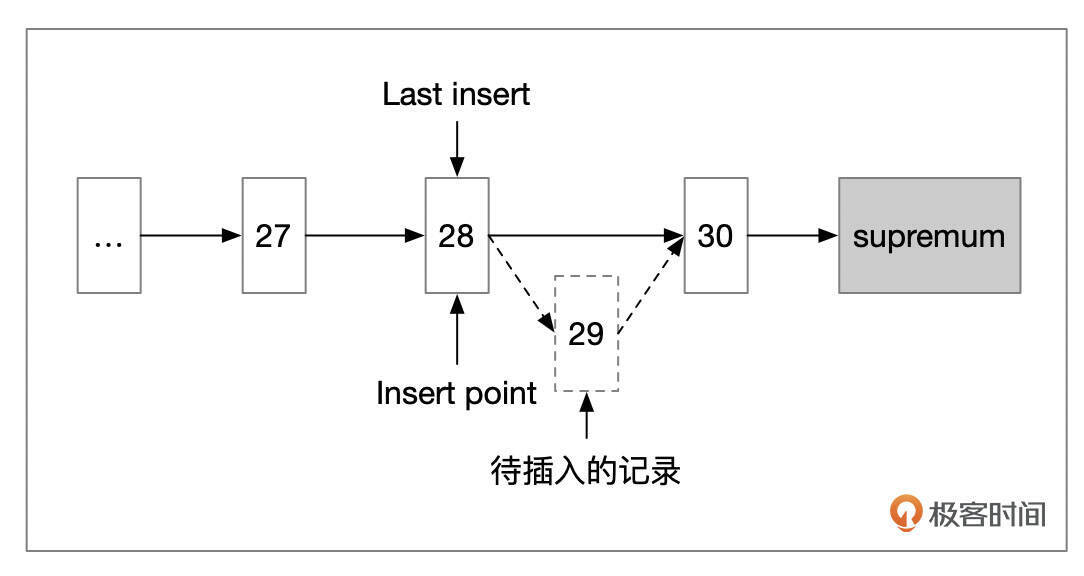
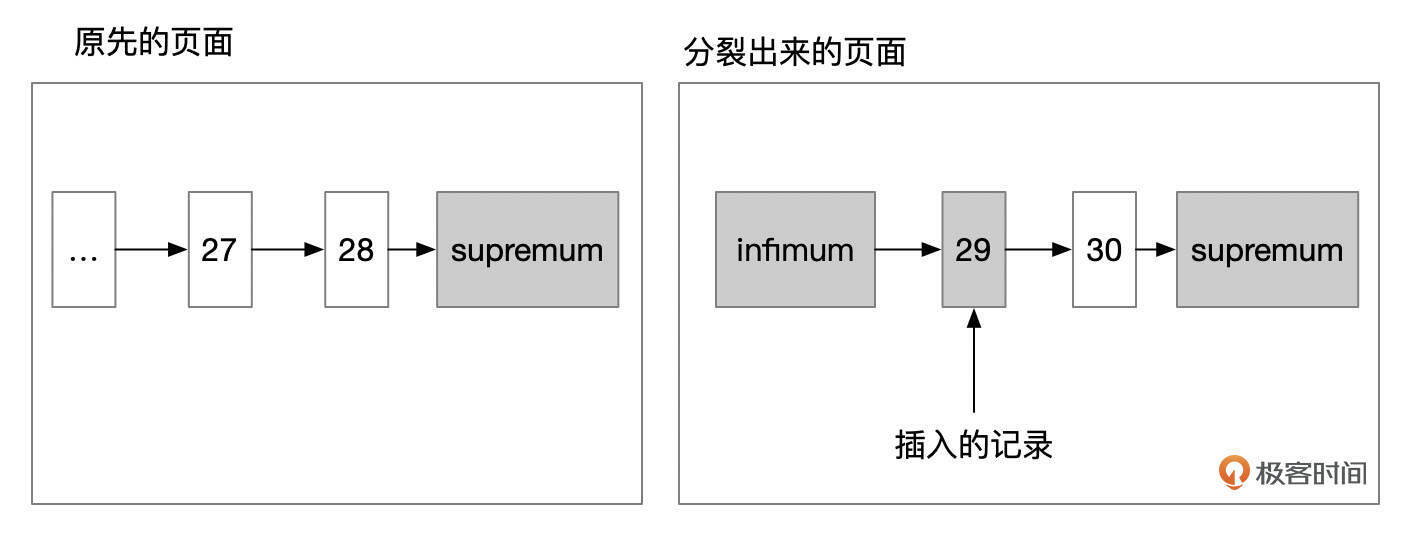
- 情况3:插入的记录后面,有2条或更多的记录。这种情况下,以待插入记录的后面第2条记录作为分裂点。
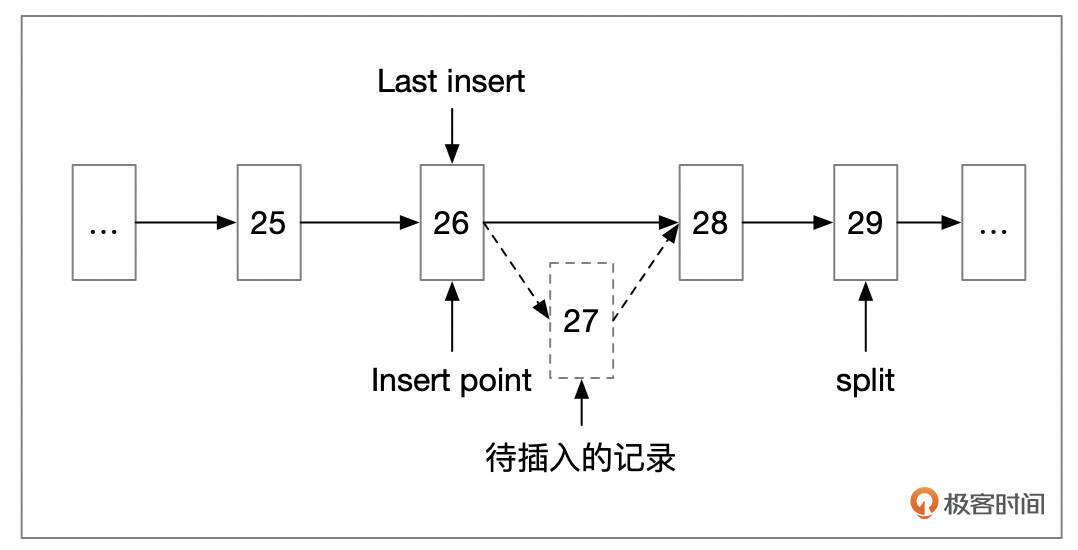
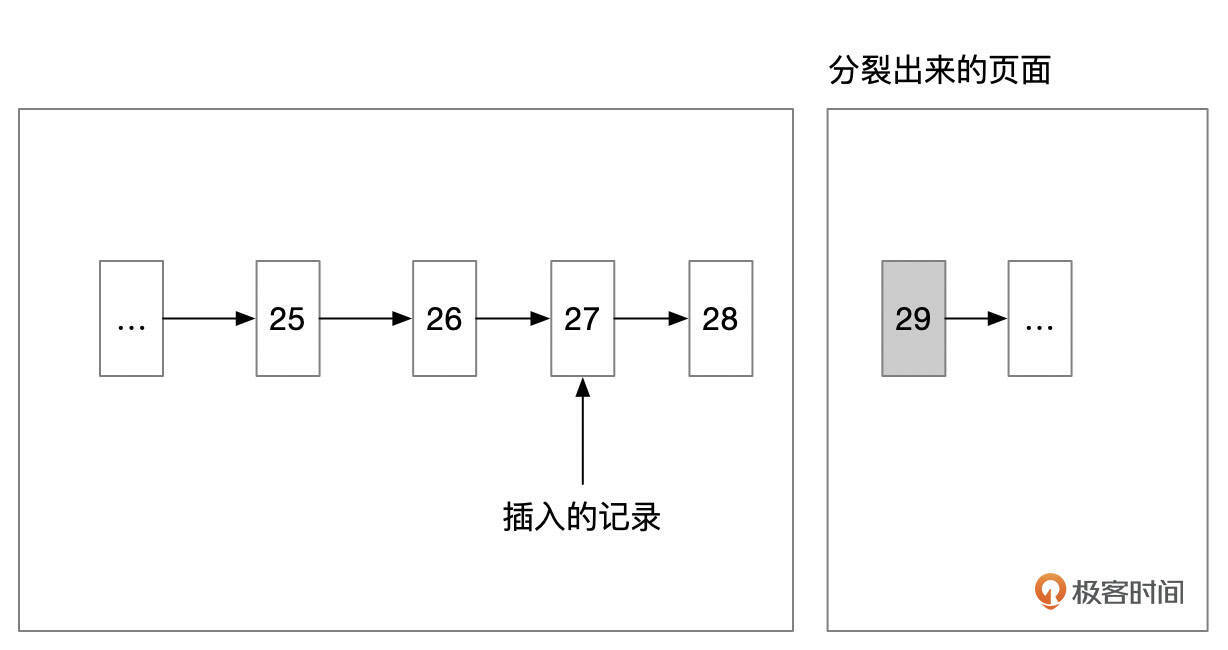
和向右分裂类似的,如果插入的记录,按Key值从大到小的顺序插入,则会采用向左分裂。
REDO记录格式
通过前面这些内容,我们对页面数据修改已经有一些了解了。实际上,页面数据修改还有其他很多不同的情况,比如执行DML语句时,还需要生成UNDO日志,UNDO日志会写到UNDO表空间中。比如分配空间时,需要维护空间管理相关的一些数据,包括我们在25讲中介绍过的那些结构。
InnoDB使用REDO记录,来描述所有这些对数据页的修改操作。下面这张图描述了REDO记录的基本格式。

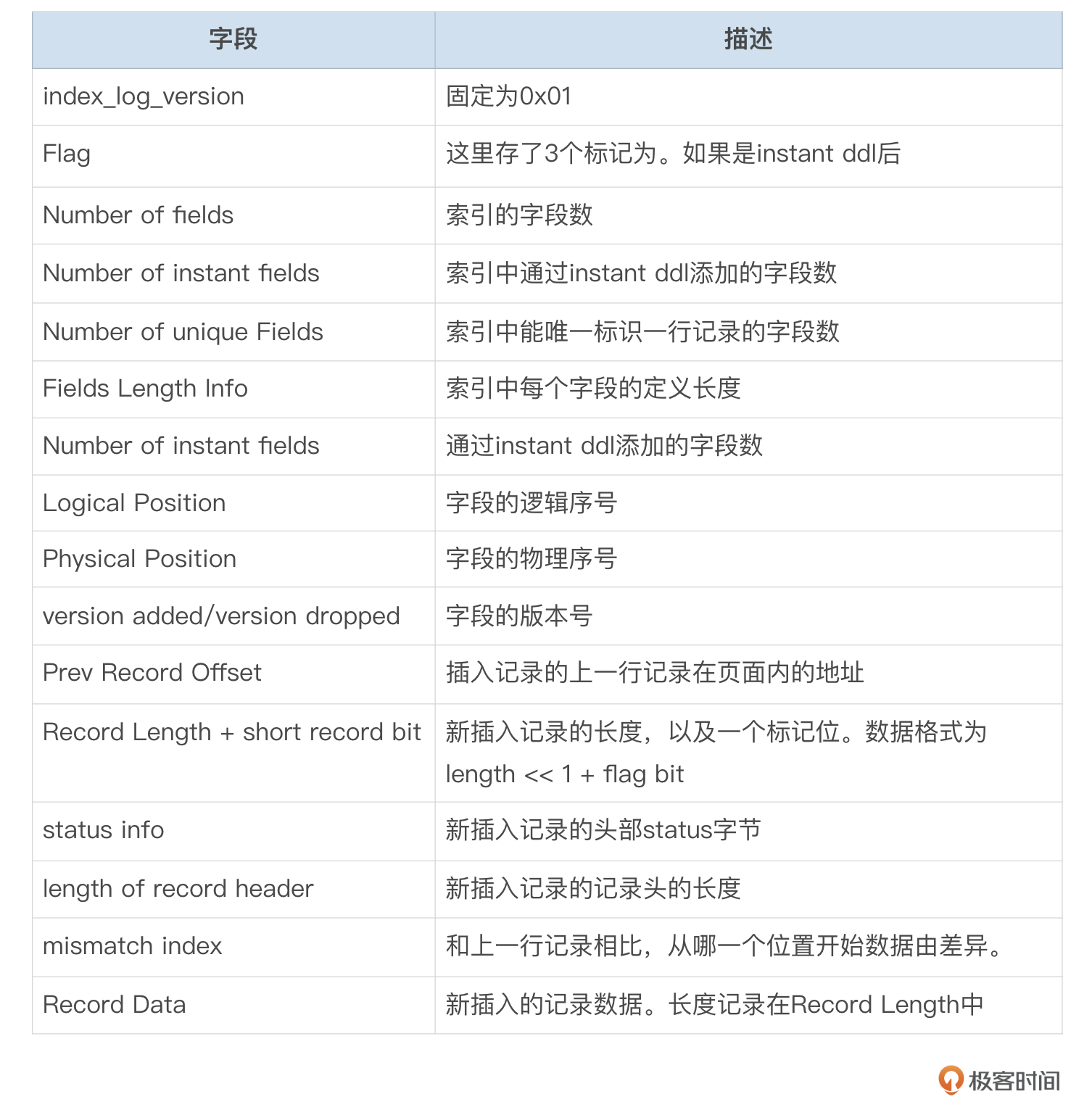
每条REDO记录都包含了这些基本字段,字段的含义我整理到了下面这个表格中。
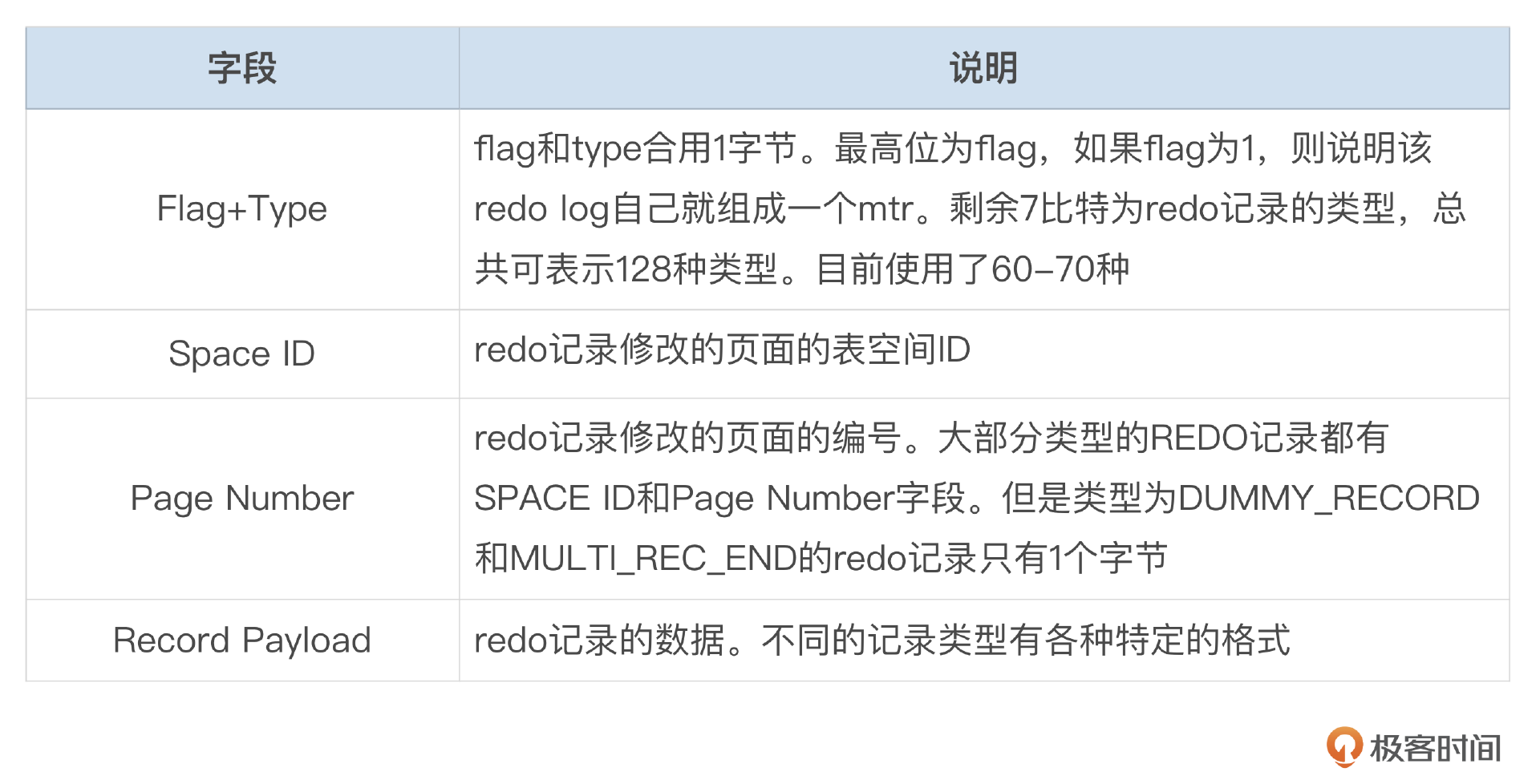
InnoDB使用1个字节中的7个比特来表示REDO类型。7比特总共可以表示128种类型,8.0.32版中,最大的Redo type为76。Redo日志描述了对某个物理页面的数据修改,Space id和Page number表示修改的页面。不同的redo类型有不一样的数据格式。我们来看一下其中部分Redo类型的记录格式。
MLOG_nBYTE
MLOG_nBYTE,往数据页中写入n字节数据,这里的n为1、2、4,或者8。

Offset是写入的数据在页面内的偏移地址。Data是实际写入的数据,长度由类型中的n指定。
MLOG_WRITE_STRING
MLOG_WRITE_STRING表示在数据页中写入一串数据。

Offset是写入的数据在页面内的偏移地址,Len是写入数据的长度,String是实际写入的数据。
MLOG_REC_INSERT
前面我们已经看到了,插入一行数据要在页面内修改好几地方。而且根据插入记录的长度、页面内剩余的空间,还可能需要整理页面内的碎片空间或者分裂页面。Redo记录怎么描述所有的这些变更呢?
对于在当前页面中插入一行数据,REDO的类型为MLOG_REC_INSERT,REDO记录中的内容比较多,可以参考下面这张图片。
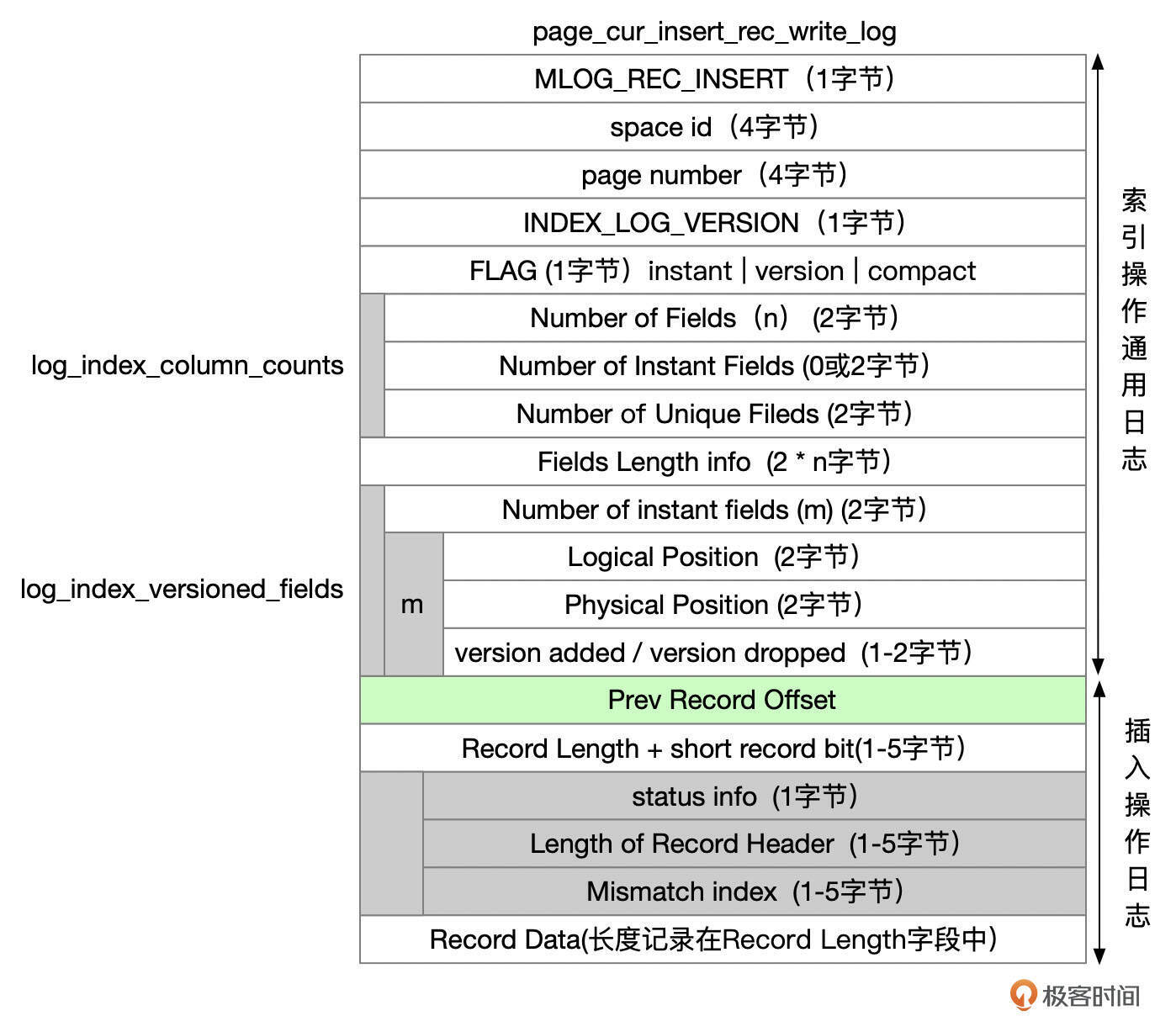
图里面这些字段的含义,我整理到了下面这个表格中。
InnoDB在生成插入记录的redo日志时,做了一个优化,会对比新插入的记录和上一条记录,如果两条记录有一些内容是相同的,就可以在Redo中少记录一些信息。参考下面这张图,mismatch index左边,两行记录的内容是一样的。
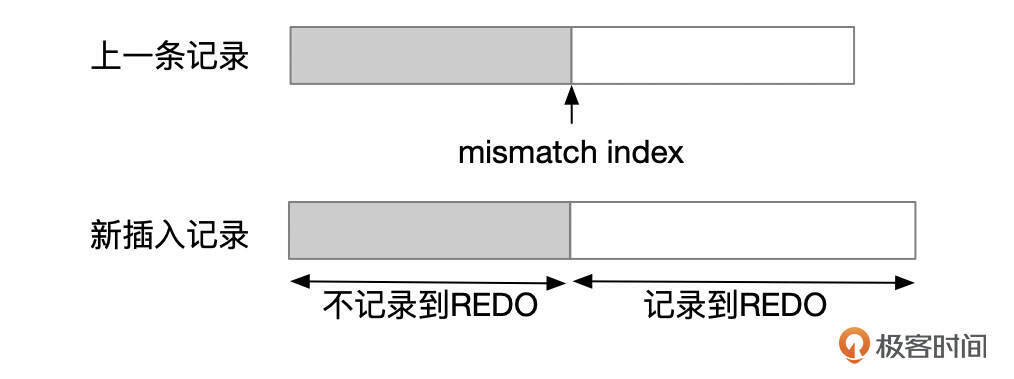
上面对MLOG_REC_INSERT类型REDO格式的描述,主要是基于page_cur_insert_rec_write_log这个函数整理出来的,如果你有兴趣的话,可以到源码中看一下这个函数的实现。
MLOG_REC_UPDATE_IN_PLACE
更新记录时,如果所有字段的长度都没有发生变化,也没有更新行外存储的字段,那么可以在页面内原地更新记录,否则就需要先将原来的记录删除掉,然后再插入新的记录。原地更新时,REDO类型为MLOG_REC_UPDATE_IN_PLACE,格式参考下面这张图。
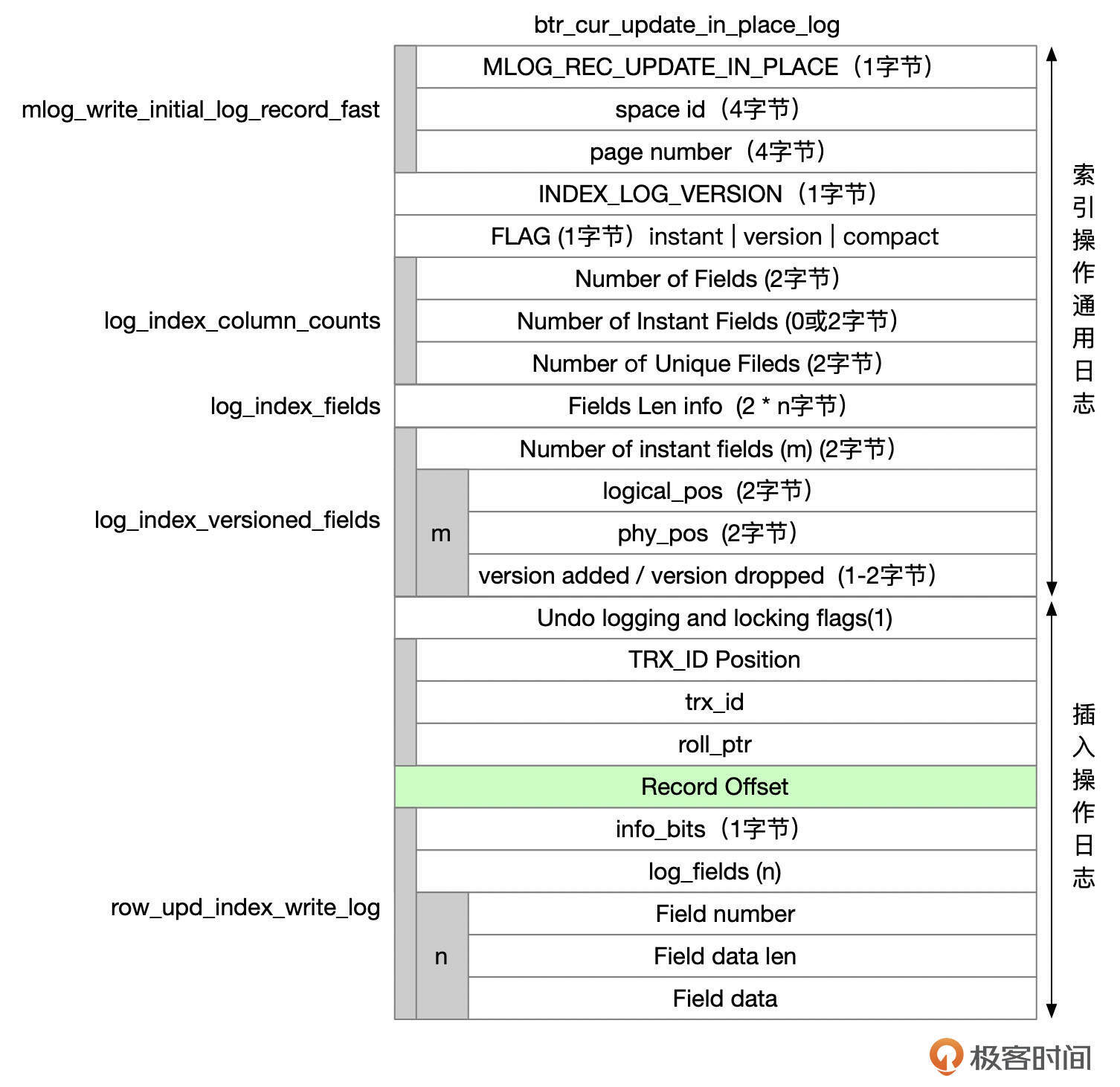
可以看到,原地更新操作的REDO格式,和INSERT的REDO格式很多内容是一样的。这些内容主要是从源码中的btr_cur_update_in_place_log函数中整理出来的。
MLOG_REC_DELETE
删除一行记录时,Redo类型为MLOG_REC_DELETE,格式参考下面这张图。
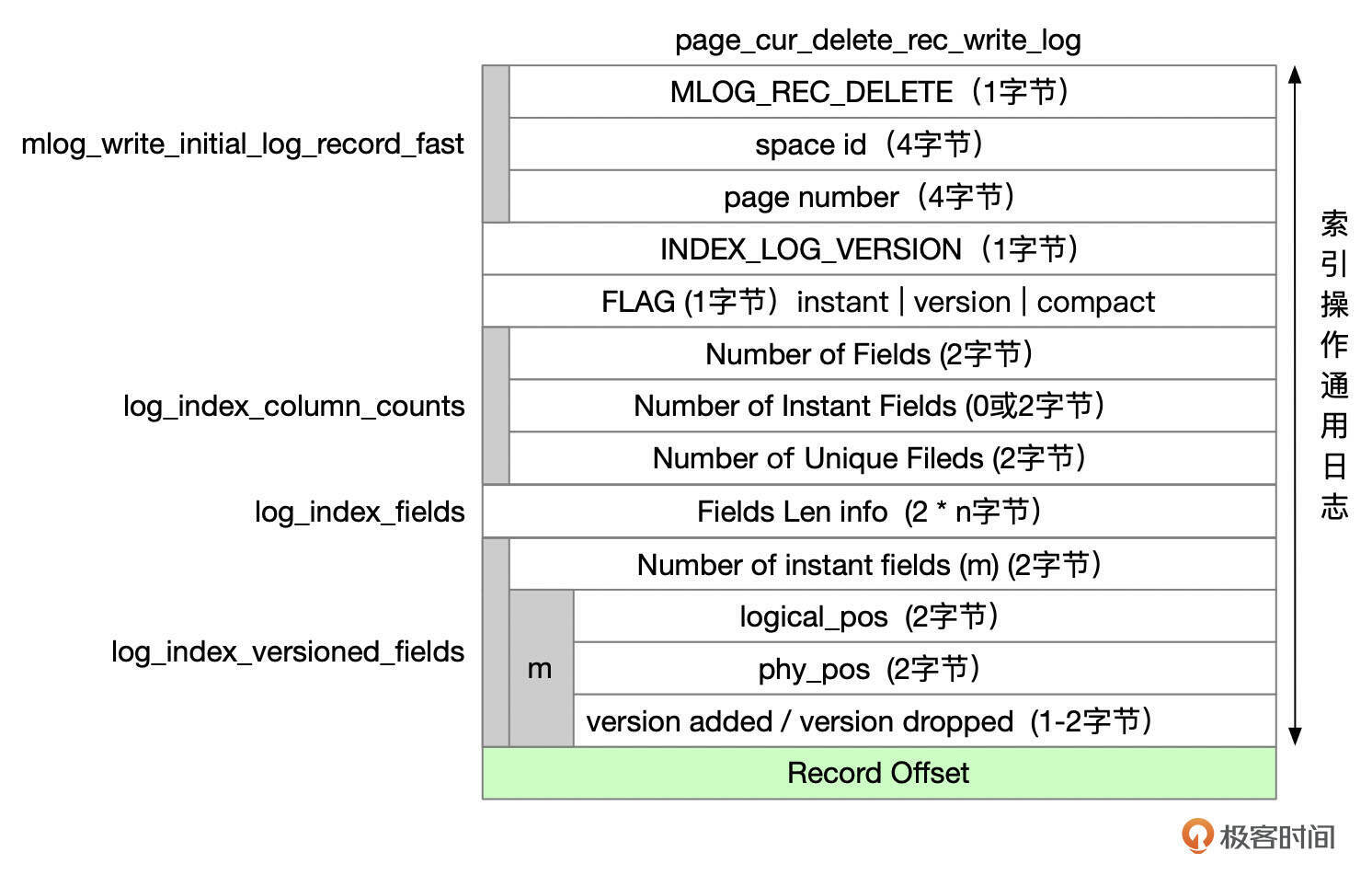
MLOG_REC_CLUST_DELETE_MARK
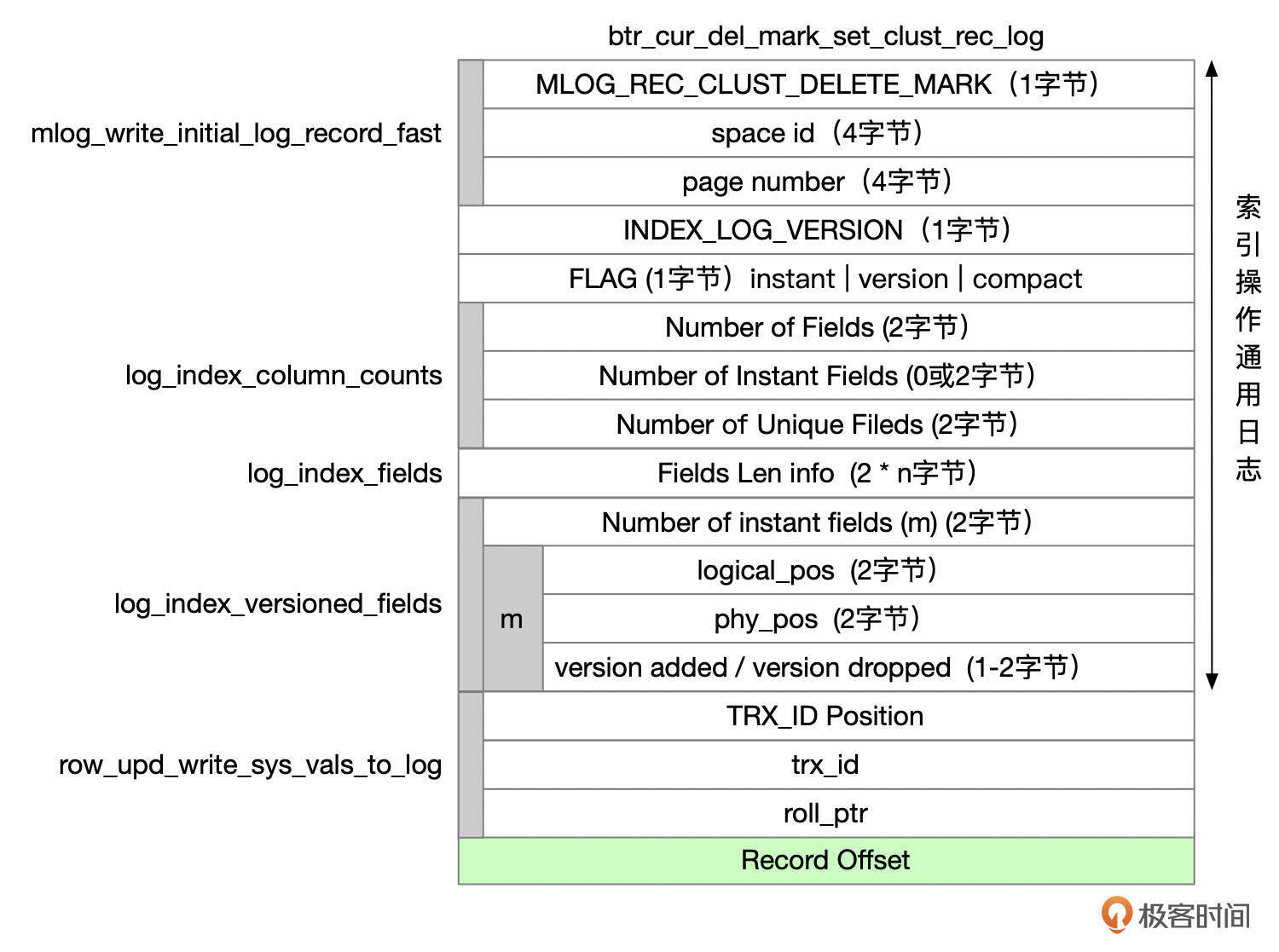
给记录打上删除标记时,redo类型为MLOG_REC_CLUST_DELETE_MARK,格式参考下面这张图。
还有几十种Redo类型,这里就不详细分析每一种类型了,有兴趣的话,你可以到源码中搜索这些REDO类型,看看这些REDO类型是什么情况下使用的,日志的格式是怎样的。
MLOG_INIT_FILE_PAGE2
MLOG_COMP_PAGE_CREATE
MLOG_LIST_END_COPY_CREATED
MLOG_LIST_END_DELETE
MLOG_UNDO_INSERT
MLOG_UNDO_ERASE_END
MLOG_UNDO_INIT
MLOG_UNDO_HDR_REUSE
MLOG_UNDO_HDR_CREATE
MLOG_LIST_END_COPY_CREATED
MLOG_PAGE_REORGANIZE
MLOG_LIST_END_DELETE
MLOG_LIST_START_DELETE
REDO如何保护数据?
我们已经大致了解了REDO记录的格式,那么REDO是怎么保护数据不丢的呢?
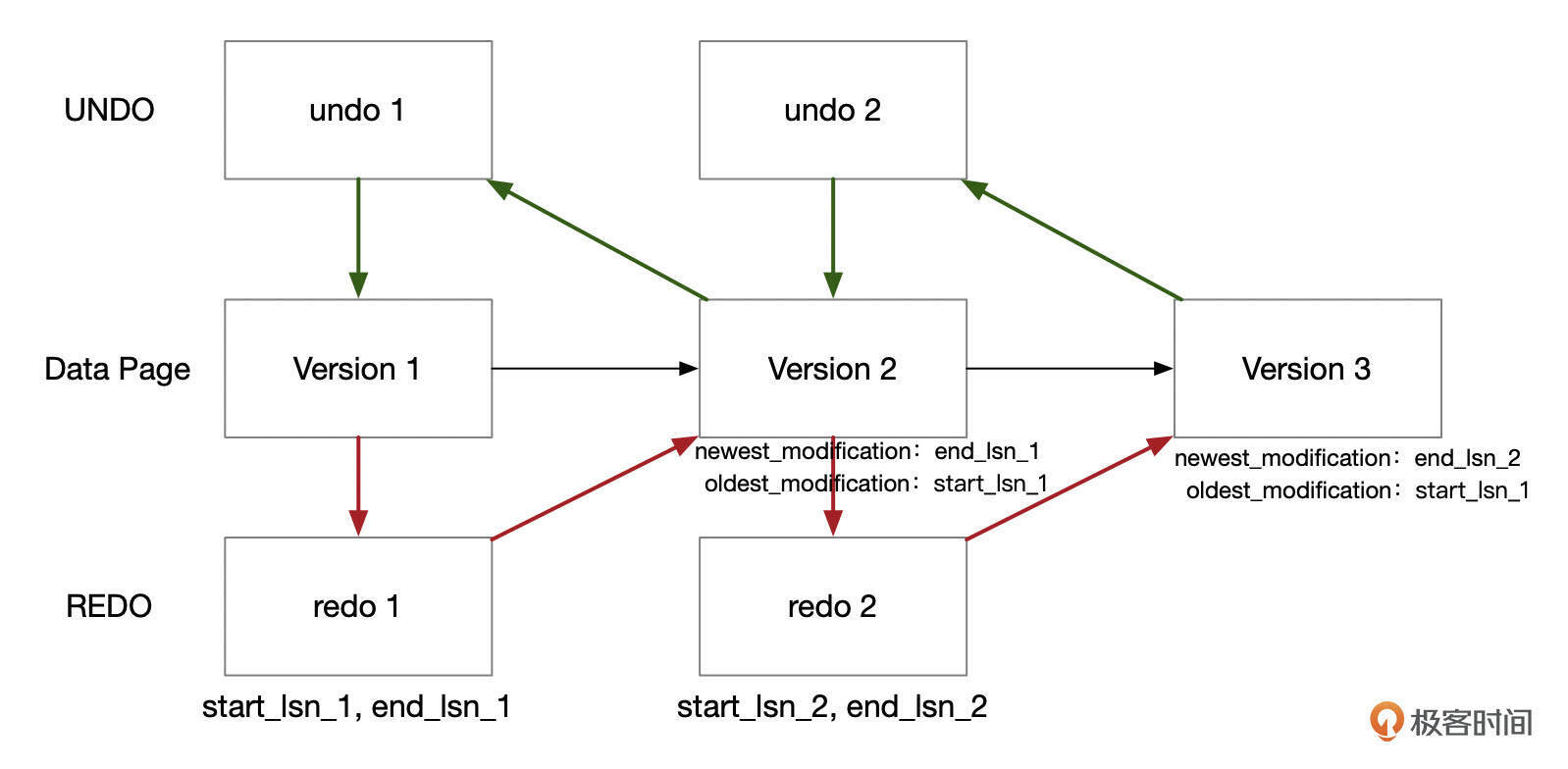
- 事务执行过程中,修改缓存页的时候,会生成REDO日志和UNDO日志。
- 事务提交时,不需要同步刷新缓存页,但是会将REDO日志刷新到磁盘中(这里假设innodb_flush_log_at_trx_commit设置为1)。
- 如果事务提交后,数据库崩溃了,ibd文件中,数据页还是版本Version 1,但是redo都已经持久化了,数据库启动时,解析redo文件,发现有数据页相关的redo日志,对比lsn号后,重新执行redo日志,将数据页更新到最新的版本。
- 如果在事务提交前数据库就崩溃了,如果数据页的新版本version 3已经写到了ibd文件中,数据库启动时,应用完redo日志后,扫描Undo表空间,发现有事务还没有提交,就开始回滚事务,undo日志中记录了回滚事务需要的信息。回滚完成后,数据也不会有问题。
一个事务里面,可能会包含多条DML语句,每条语句执行时,可能会修改多个数据页,比如要给事务分配UNDO段,记录UNDO信息,修改B+树的页面数据,InnoDB将这些修改组织成一个一个的mini transaction。
修改数据会按一定的步骤进行。
- 开启mini transaction,获取待修改页面的锁。
- 修改缓存页内的数据,生成UNDO日志和REDO日志。REDO日志会先记录到用户线程的私有内存中。
- 完成修改后,提交mini transaction,此时会给redo日志分配LSN号,更新控制块中的newest_modification。如果缓存页是首次修改,还要记录oldest_modification,将修改的页面加入到Flush列表中。并将REDO日志复制到REDO buffer中。
InnoDB的后台线程会异步将脏页写回到磁盘。写脏页时,需要确保脏页对应的REDO日志都已经持久化到磁盘中,这也称为日志先行(WAL)。
mini transaction执行过程中,会获取页面锁,所以mini transaction提交前,页面内的数据不会被回写到磁盘。mini transaction提交时,会更新页面控制块中的newest_modification。只有当页面的newest_modification不超过已经刷新到磁盘的redo日志的LSN号时,才能将缓存页刷新到磁盘。
MTR的结构
REDO记录按MTR分组。数据库崩溃恢复时,一个MTR中的REDO日志,要么全部应用,要么全部丢弃。如果mtr中包含了多条redo记录,那么在mtr提交时,会写入一条类型为MULTI_REC_END的记录, 标识mtr的结束。

如果一个mtr中只包含1条redo记录,则会给这条redo记录打上一个MLOG_SINGLE_REC_FLAG标记位。
MTR提交过程
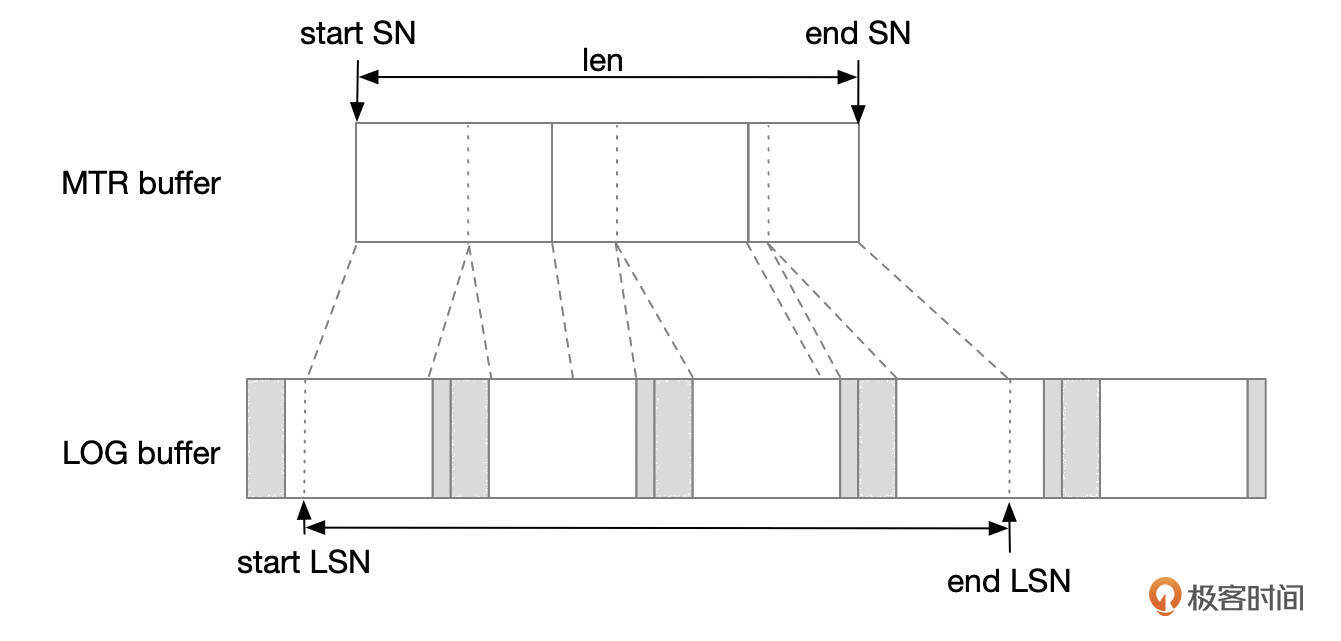
- 事务执行过程中,REDO记录会先写入到mtr buffer中。每个线程会分配独立的mtr buffer。mtr buffer中,以512字节为单位分配内存块。
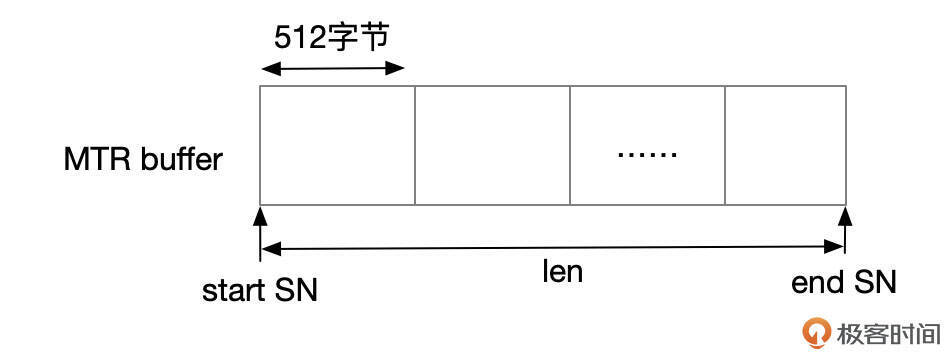
- mtr提交时,分配一段连续的SN号。start SN从变量log.sn中获取,end SN号为start SN号加上MTR内容长度。根据SN计算得到LSN号。
为什么需要将SN号转化成LSN号呢?因为InnoDB将REDO日志文件划分为一系列512字节的日志块。每个日志块头部和尾部分别占用12字节和4字节,剩下496字节用来存储REDO记录数据。SN转换成LSN号时,需要留出日志块头部和尾部占用的空间。
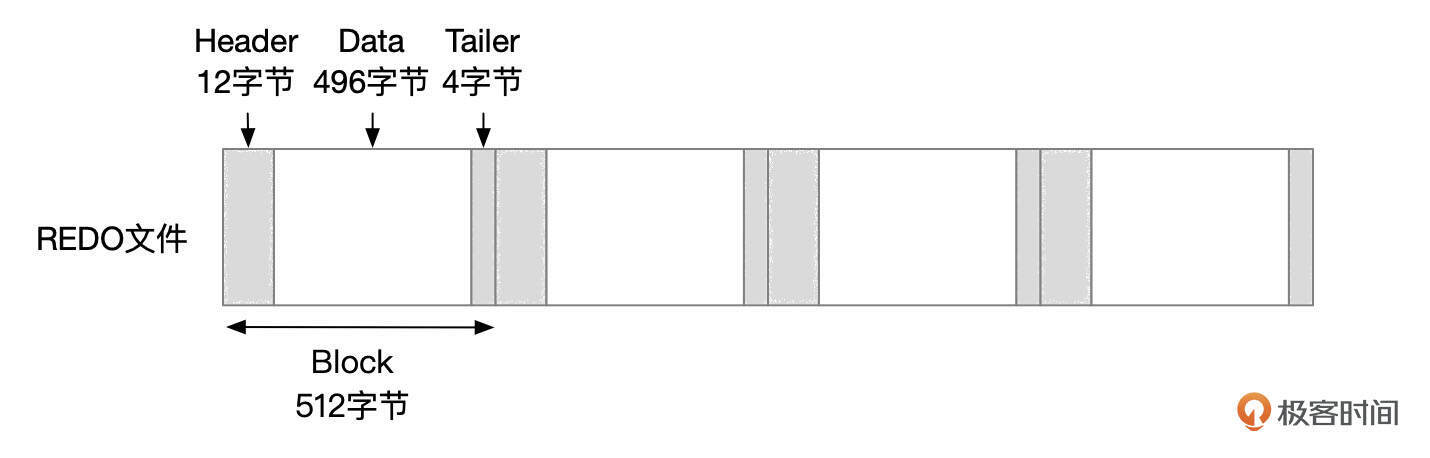
- 将redo记录从mtr buffer复制到redo log buffer中。在log buffer中,数据按LOG Block的方式组织,往log buffer中复制数据时,需要将日志块头部和尾部占用的空间预留出来。
在数据从log buffer写入到REDO日志文件前,会先填充日志块头部和尾部信息。
- 将mtr中修改过的缓存页加入到flush链表中。页面的newest_modification设置为mtr的end LSN。
- 释放mtr执行过程中获取的缓存页的锁。
LOG Buffer
MTR提交时,redo记录会复制到redo buffer中。多个线程并发往log buffer中写入redo记录时,并不保证写入的顺序。相当于log buffer中存在一些空洞。在下面这张图中,用户线程2已经完成了redo记录写入,但是用户线程1的redo记录,虽然lsn号更低,但是还没有完成写入。
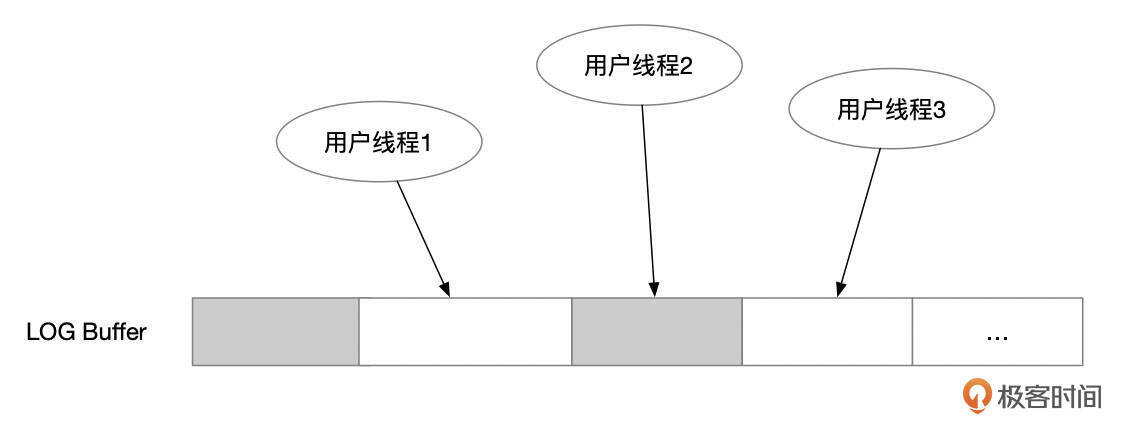
Log writer线程负责将Log Buffer中的REDO记录写到REDO文件中。Log Writer会将Log Buffer中没有空洞的那一部分redo日志写到REDO文件中,并释放Log Buffer空间。
REDO相关的线程和LSN号
REDO日志从产生,到最终持久化到磁盘设备,中间经过多个环节,涉及到多个线程的协作。
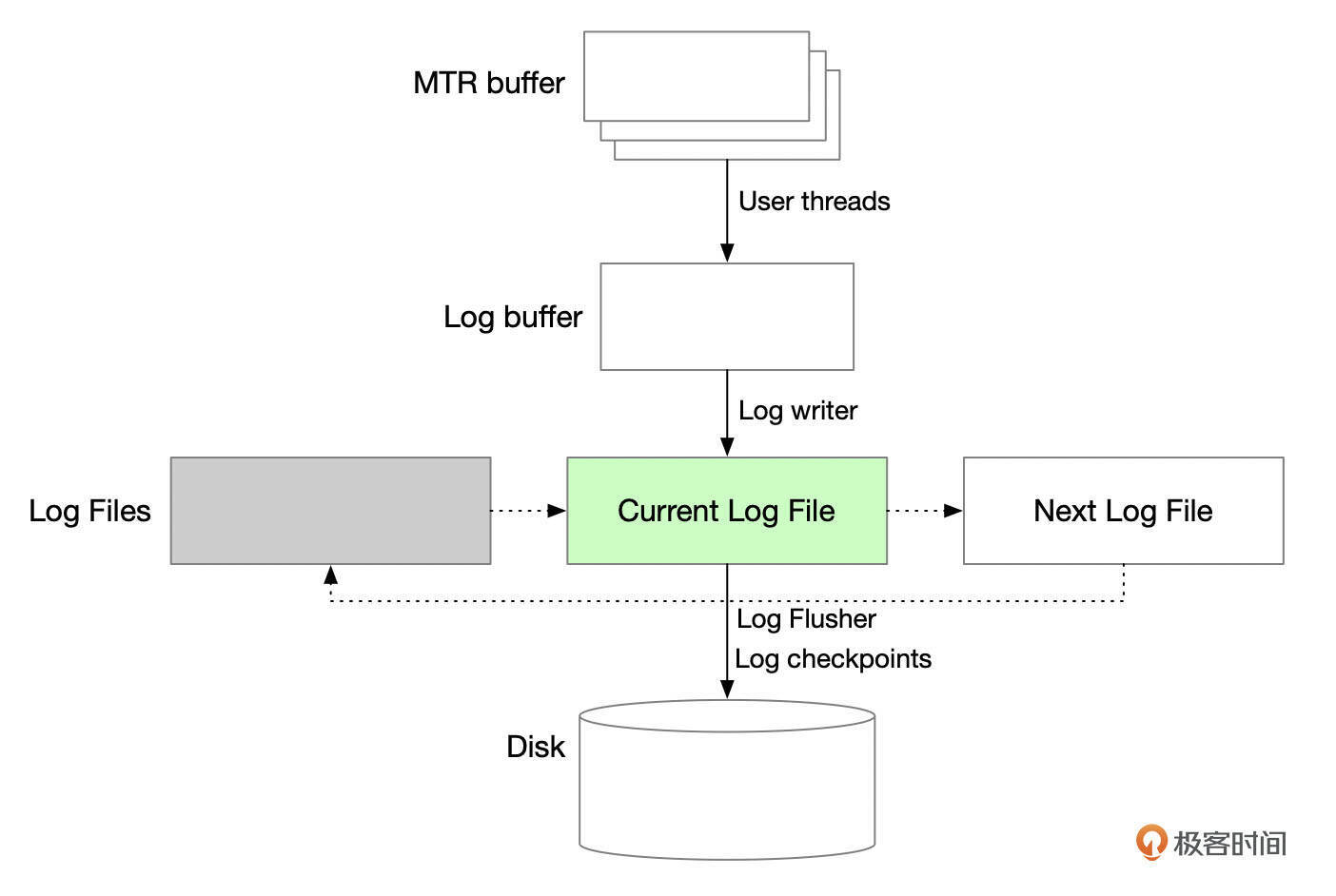
日志系统的线程通过一系列LSN号来协调。
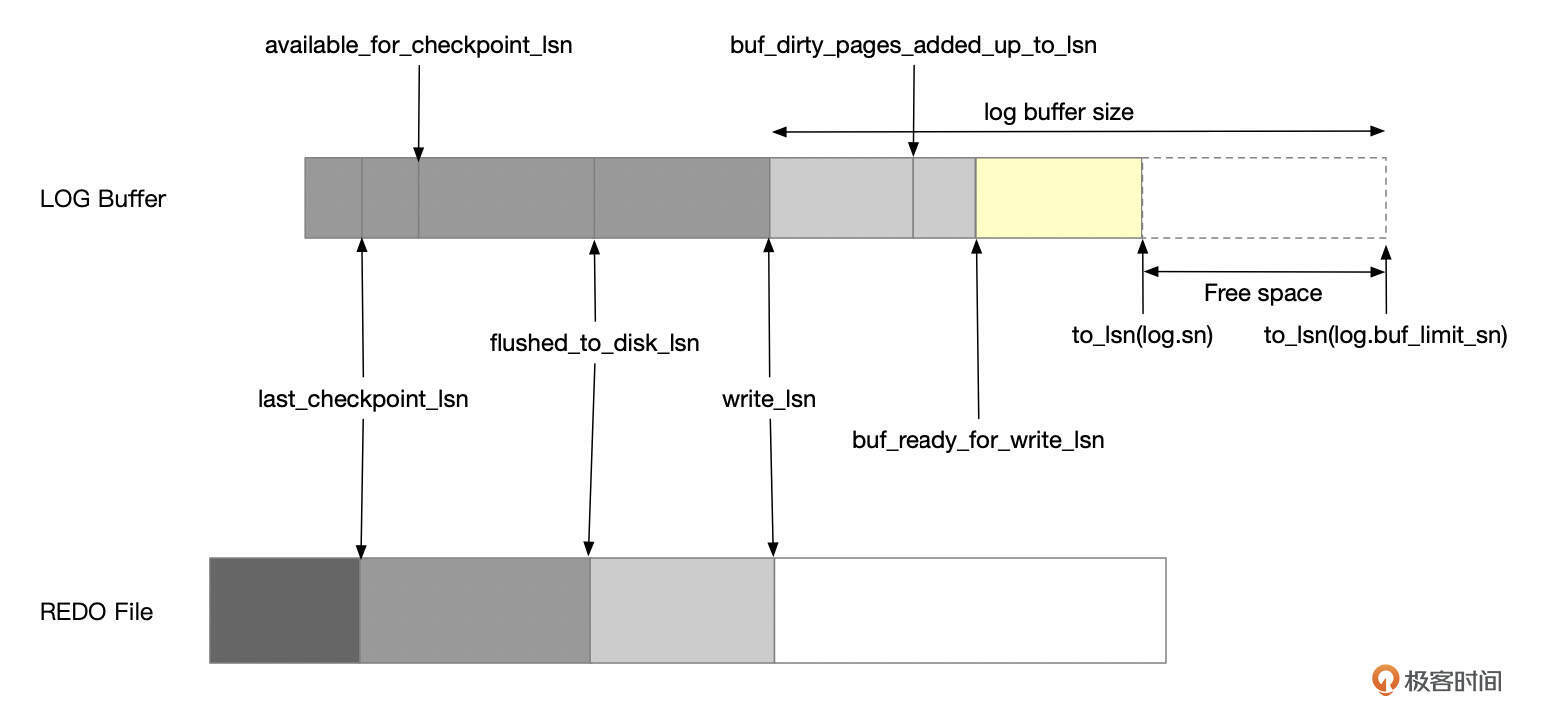
InnoDB维护了日志系统的各个LSN号。
- write_lsn:小于该LSN号的redo日志都已经写入到REDO文件中。log writer线程会定期将redo日志从log buffer中写入到redo日志文件中,推进write_lsn号。
- flushed_to_disk_lsn:小于该LSN号的redo日志都已经刷新到REDO文件中。log flusher线程负责刷新日志文件(调用fsync)。
- last_checkpoint_lsn:小于该LSN号的redo日志对应的修改,已经从buffer pool刷新到数据文件中,并且lsn号已经保存到checkpoint记录中。数据库崩溃恢复从该lsn号开始。
-
available_for_checkpoint_lsn:该LSN号之前的脏页都已经刷新回数据文件中。该LSN号取以下值中的较小值。
-
所有buffer pool实例中 flush链表中最后一个page的lsn号,减去一个固定值。
- buf_dirty_pages_added_up_to_lsn。
- buf_ready_for_write_lsn:LSN号位于write_lsn和buf_ready_for_write_lsn之间的redo日志,已经全部写入到log buffer中。log writer线程定期将这些redo日志写入到redo文件。
- log.sn:将log.sn转换得到的LSN号,就是已经分配的最大的LSN号。LSN号位于buf_ready_for_write_lsn和to_lsn(log.sn)之间的REDO日志,有一些还没有完全从mtr buffer中复制到log buffer中。
- buf_dirty_pages_added_up_to_lsn:小于该LSN号的脏页,都已经加入到flush链表中。
show innodb status命令的输出中,就包含了一些LOG LSN信息。
---
LOG
---
Log sequence number 108382356
Log buffer assigned up to 108382356
Log buffer completed up to 108382356
Log written up to 108382356
Log flushed up to 108382356
Added dirty pages up to 108382356
Pages flushed up to 96774021
Last checkpoint at 96773372
Log minimum file id is 29
Log maximum file id is 33
11673 log i/o's done, 368.45 log i/o's/second
REDO日志文件
REDO记录持久化到REDO文件中后,才真正保证了数据不丢。早期版本中,REDO日志文件大小和数量由参数innodb_log_file_size和innodb_log_files_in_group配置。8.0.30版本开始,废弃了这2个参数,而改用参数innodb_redo_log_capacity。如果配置了innodb_redo_log_capacity,则会忽略参数innodb_log_file_size和innodb_log_files_in_group。innodb_redo_log_capacity最大可设置为128G。
REDO日志文件默认位于DATADIR下的#innodb_redo目录中(可通过参数innodb_log_group_home_dir配置REDO文件的存储路径)。InnoDB总共分配了32个REDO日志文件,每个文件的大小为innodb_redo_log_capacity/32。
[root@172-16-121-234 #innodb_redo]# ls -l /data/mysql01/data/#innodb_redo
总用量 102400
-rw-r----- 1 mysql mysql 3276800 1月 8 11:54 #ib_redo55
-rw-r----- 1 mysql mysql 3276800 1月 17 18:04 #ib_redo56
-rw-r----- 1 mysql mysql 3276800 1月 4 11:01 #ib_redo57_tmp
-rw-r----- 1 mysql mysql 3276800 1月 4 11:01 #ib_redo58_tmp
-rw-r----- 1 mysql mysql 3276800 1月 4 11:01 #ib_redo59_tmp
-rw-r----- 1 mysql mysql 3276800 1月 4 11:01 #ib_redo60_tmp
-rw-r----- 1 mysql mysql 3276800 1月 4 11:01 #ib_redo61_tmp
-rw-r----- 1 mysql mysql 3276800 1月 4 11:01 #ib_redo62_tmp
.......
以tmp结尾的日志文件暂时还没有使用,其他每个REDO日志文件中都存储了LSN在一定范围内的REDO记录。可通过performance_schema中的表查看每个REDO文件里存储的日志的LSN范围。
mysql> SELECT FILE_NAME, START_LSN, END_LSN FROM performance_schema.innodb_redo_log_files;
+--------------------------------------------+-----------+-----------+
| FILE_NAME | START_LSN | END_LSN |
+--------------------------------------------+-----------+-----------+
| /data/mysql01/data/#innodb_redo/#ib_redo55 | 200243712 | 203518464 |
| /data/mysql01/data/#innodb_redo/#ib_redo56 | 203518464 | 206793216 |
+--------------------------------------------+-----------+-----------+
执行Checkpoint时,InnoDB将Checkpoint记录写入到包含当前checkpoint LSN的REDO文件中。
日志文件格式
REDO日志文件块大小为512字节。每个日志文件头部的4个数据块有特殊用处。
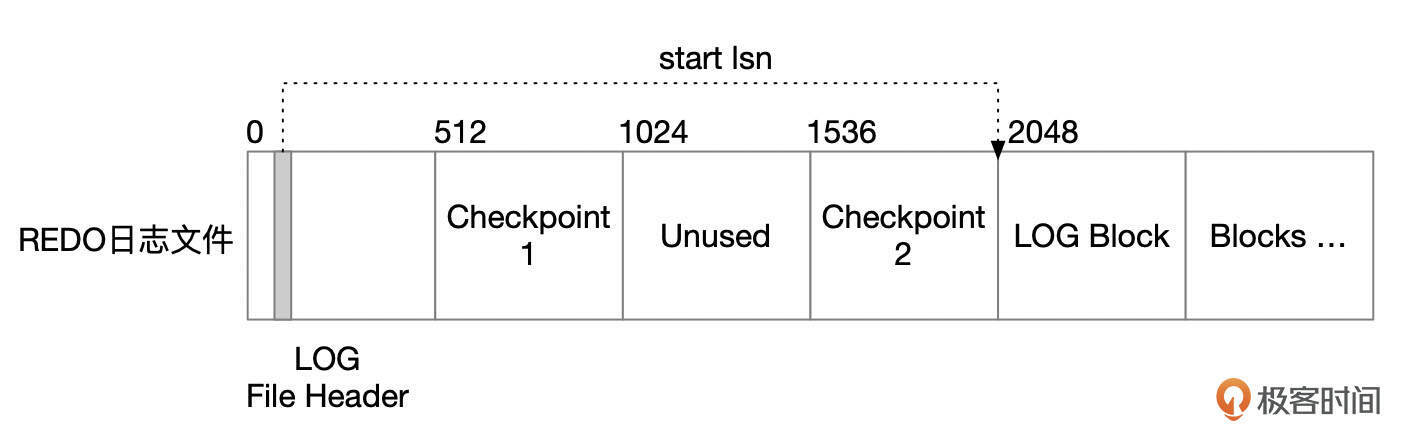 LOG文件头格式参考下面这张图,其中start lsn记录了这个redo文件中,第一条redo日志的起始lsn号。
LOG文件头格式参考下面这张图,其中start lsn记录了这个redo文件中,第一条redo日志的起始lsn号。

Log Checkpointer线程会定期将checkpoint LSN持久化到Redo日志文件头部的Checkpoint记录中。Checkpoint记录的格式参考下面这张图。

崩溃恢复(Crash recovery)
MySQL启动时,会先进行崩溃恢复,大致分为几个步骤。
- 读取redo文件中的checkpoint记录。checkpoint是恢复的起点。lsn号在checkpoint lsn之后的redo日志,才是崩溃恢复时需要的日志。
- 解析redo文件中的日志。解析时,如果某个MTR的结束标记没有读取到,就说明之后的redo日志都是不完整的,退出redo解析。解析出来的redo日志,按(space_id, page_no)加入到一个hash表中。
- 执行redo。每个页面的redo记录,按产生的时间,依次执行。执行时先对比数据页的LSN号和Redo记录的lsn号,如果页面的LSN号比REDO记录的LSN大,就跳过这条redo记录。
- redo执行完成后,开始执行undo,回滚数据库中还没有提交的事务。关于事务回滚的具体实现,我们下一讲再讨论。
总结
这一讲中我们对InnoDB的REDO机制做了一些基本的介绍,其中有几个参数需要注意。
- innodb_flush_log_at_trx_commit:设置为1的时候,才能保证数据不丢。
- innodb_log_buffer_size:Log Buffer一般设置几十M到几百M。
- innodb_redo_log_capacity(或innodb_log_file_size,innodb_log_files_in_group):如果数据库写入量特别大,buffer pool也比较大,可以考虑适当增加innodb_redo_log_capacity。
思考题
这节课我们介绍了一些REDO日志的格式,比如insert、update、delete的REDO格式。那么事务提交时(commit),REDO的格式是怎样的?数据库启动时,怎么知道一个事务已经提交了?
期待你的思考,欢迎在留言区中与我交流。如果今天的课程让你有所收获,也欢迎转发给有需要的朋友。我们下节课再见!
- 笙 鸢 👍(0) 💬(1)
老师,MTR buffer—log buffer—current log file—disk;其中cuurent log file就算是redo log 文件了吧,那为什么还有个disk文件?没看懂这块逻辑还有log flusher这个线程的功能
2024-12-14 - binzhang 👍(0) 💬(1)
看到日志类型有mlog_undo_***, 写undo page的时候也会产生redo的吧?
2024-10-28