28 InnoDB Buffer Pool如何提高数据库性能?(下)
你好,我是俊达。
上一讲的思考题中,我留了一个问题,就是删除表或索引时,表或索引已经缓存在Buffer Pool中的数据要怎么处理。实际上处理的方式跟表的类型(是普通表还是临时表,是否使用per-table)以及操作类型有关,还跟MySQL的版本有关,这一讲我会对这些情况做一些分析。
InnoDB还使用了自适应Hash索引(Adaptive Hash Index,AHI)、Change Buffer、Double Write Buffer,来提升性能或数据的可靠性,这一讲中我也会分别进行介绍。
DDL和Buffer Pool
删除表(DROP Table/Truncate Table)
我们先来看一下DROP一个使用独立表空间(innodb_file_per_table=ON)的普通表时,InnoDB内部需要做哪些处理。
首先要将AHI中,跟这个表相关的索引条目清理掉。上一讲中我们提到过,每一个页面的控制块中,有一个AHI结构。如果一个索引页面缓存在AHI中,那么控制块的ahi.index中会指向这个索引。索引在内存中还维护了一个search_info结构,里面记录了索引中有多少个页面缓存到了AHI中。如果被删除的表,确实有页面缓存在AHI中,那么就要扫描每个Buffer实例的LRU链表,检查每个页面是不是存在和正在删除的这个表相关的AHI条目。如果有,先将页面添加到一个临时数组中,临时数组中的页面达到一定数量时,再批量清理这些页面相关的AHI条目。
其次,DROP表时,还需要删除对应的表空间。8.0.23版本对这一步操作做了优化。之前的版本中,删除表空间时,要扫描Flush链表,将这个表的脏页移出Flush链表。新版本中,删除表空间时,只需要增加表空间的版本号,不再扫描Flush链表。后台线程在刷新脏页时,如果遇到了已经删除的表空间的脏页,会发现页面控制块中记录的表空间的版本号低于表空间最新的版本号,就不需要执行真正的IO操作了。
最后,需要删除ibd文件。
8.0中,使用truncate table命令清空一个表的数据时,执行的操作类似于先执行drop table,再create table,对Buffer Pool的操作和执行Drop table命令时基本一样。
删除索引(DROP Index)
和删除表类似,删除索引时,要先将这个索引相关的AHI条目清理掉。清理的步骤和删除表时清理AHI的步骤基本是一样的。
删除索引时,还需要回收索引占用的空间。我们在24、25讲中说过,一个索引由两个段组成,索引根页面中记录了两个段描述符的地址。分配给一个段的所有区块和页面,可以通过段描述符中的三个链表和碎片页数组找到。回收空间时,从三个链表和碎片页数组中找到分配给索引的区块和页面,依次回收。回收页面时,要再次检查AHI是否还有条目指向这个页面,有的话,需要先清理掉AHI中的相关条目。
如果删除索引时,Buffer Pool中还有这个索引的脏页,需要做处理吗?这应该是不用做特殊处理的,因为删除索引后,表空间还在,有脏页的话,后台线程会自动刷新脏页。
回收临时表
如果会话使用create temporary table命令创建临时表,或者执行一些SQL(如select count(*) from information_schema.processlist)时用到了临时表,那么在退出连接的时候,要清理会话用到的临时表。在8.0.23版本之前,这个清理的开销比较大,需要扫描两次LRU链表,清理AHI中的索引条目,并将临时表缓存在Buffer Pool中的页面从LRU链表和FLUSH链表中移走。
Buffer Pool越大,扫描LRU链表和FLUSH链表需要的时间越长,而且操作这些链表结构时,都会获取相关的mutex,这会导致其他会话被阻塞,对性能有很大的影响。8.0.23版本做了优化,回收临时表时,不再需要将临时表的页面从LRU和Flush链表中移走。
第一章中我们讲DDL时,提到过DROP Table、删除索引这些操作通常是很快的。现在我们知道了,执行这些操作时,会涉及到Buffer Pool中的一些修改,在高并发的环境下,执行这些操作可能对业务系统造成明显的影响,因此建议DDL尽量放在业务的低峰期执行。
自适应Hash索引(Adaptive hash index)
自适应Hash索引是InnoDB用来提升查询性能的一个方法。在B+树索引中查找时,需要先到根页面中查找,再依次在索引树的每一层中查找,最终定位到叶子页面,树的层级越多,搜索的页面就越多。而使用Hash查找时,先计算出一个Hash值,然后直接到Hash表中查找。
自适应Hash索引由MySQL自动维护。MySQL会基于查询的访问模式,自动识别热点块,为热点块建立hash索引。hash索引完全存在于内存中。为了提高并发性,AHI分为多个分区,默认分为8个分区,可通过参数innodb_adaptive_hash_index调整分区数量。
你可以通过参数innodb_adaptive_hash_index来控制是否开启AHI,8.0时,AHI默认开启,但是到了8.4,默认关闭了AHI。
下面是AHI的一个示意图,AHI中,Key是索引记录或索引记录的前缀,Value指向索引叶子页面中的索引条目。
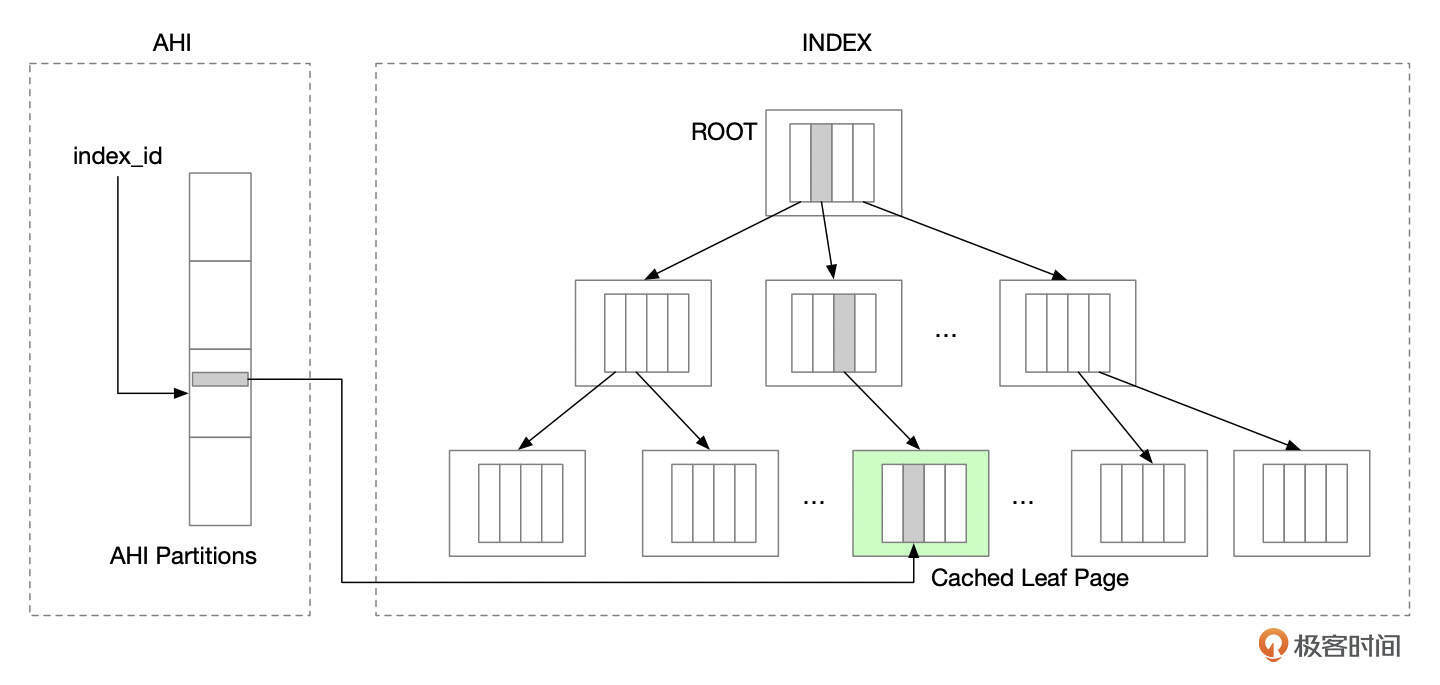
在为某个索引页面建立Hash索引时,InnoDB会给这个索引页面中的所有记录都创建Hash索引。
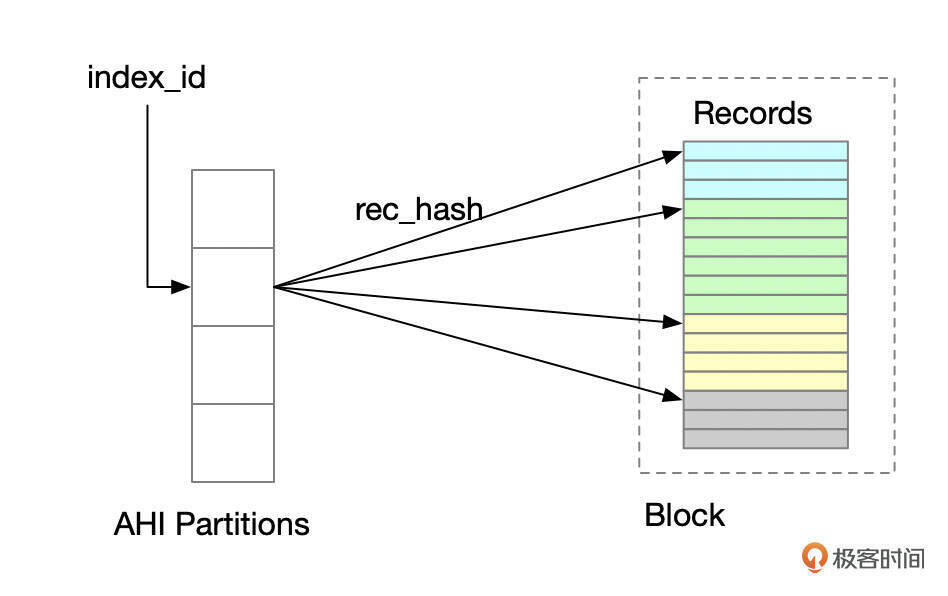
开启AHI后,InnoDB需要维护AHI,这带来一定的开销。查询如果能使用到hash索引,可以提升查询的性能。在具体的应用场景下,AHI是否能提升数据库的整体性能,需要通过实际的测试才能确定。
你也可以观察show engine innodb status命令的输出中,ADAPTIVE HASH INDEX相关的信息,对比hash查找和非hash查找的次数。
-------------------------------------
INSERT BUFFER AND ADAPTIVE HASH INDEX
-------------------------------------
Ibuf: size 1, free list len 0, seg size 2, 0 merges
merged operations:
insert 0, delete mark 0, delete 0
discarded operations:
insert 0, delete mark 0, delete 0
Hash table size 17393, used cells 0, node heap has 1 buffer(s)
Hash table size 17393, used cells 0, node heap has 1 buffer(s)
Hash table size 17393, used cells 408, node heap has 3 buffer(s)
Hash table size 17393, used cells 0, node heap has 1 buffer(s)
Hash table size 17393, used cells 375, node heap has 2 buffer(s)
Hash table size 17393, used cells 0, node heap has 1 buffer(s)
Hash table size 17393, used cells 0, node heap has 0 buffer(s)
Hash table size 17393, used cells 0, node heap has 1 buffer(s)
Hash table size 17393, used cells 0, node heap has 1 buffer(s)
Hash table size 17393, used cells 41, node heap has 1 buffer(s)
Hash table size 17393, used cells 1, node heap has 1 buffer(s)
Hash table size 17393, used cells 0, node heap has 1 buffer(s)
Hash table size 17393, used cells 151, node heap has 2 buffer(s)
Hash table size 17393, used cells 6, node heap has 1 buffer(s)
Hash table size 17393, used cells 186, node heap has 2 buffer(s)
Hash table size 17393, used cells 64, node heap has 1 buffer(s)
34.17 hash searches/s, 274.16 non-hash searches/s
自适应hash索引的建立
InnoDB怎么判断要给某个叶子页面创建Hash索引呢?
- 在索引中查找数据,访问叶子页面时,更新索引访问模式的相关信息,包括索引访问信息(search_info.n_hash_potential,search_info.prefix_info)和索引页面的访问信息(block->n_hash_helps,block->ahi.recommended_prefix_info)。
-
如果多次访问一个索引时,访问模式一致(prefix_info一致),并且对索引页的访问次数超过一定的阈值,就给当前的页面建立hash索引。这个阈值是由下面这几点决定。
-
访问次数超过block中的记录数/BTR_SEARCH_PAGE_BUILD_LIMIT
- 访问索引的次数超过BTR_SEARCH_BUILD_LIMIT
- 如果检测到索引访问模式发生变化,则会重建block的hash索引。
Change Buffer
数据写入到非唯一的二级索引时,如果对应的索引页面还没有缓存在Buffer Pool中,正常情况下需要发起IO操作,将索引页面加载到buffer pool中,而IO操作通常比内存操作慢几个数量级。为了优化数据写入的性能,InnoDB使用了change buffer。在执行DML时,如果二级索引的页面还没有缓存,InnoDB会尝试先将写入操作缓存到change buffer中。在合适的时机(比如其他查询语句将页面加载到buffer pool时),innodb再将该页面缓存在change buffer中的操作合并到页面中,以此来减少数据库随机IO的数量。
下面是官方文档中,Change Buffer的一个示意图。
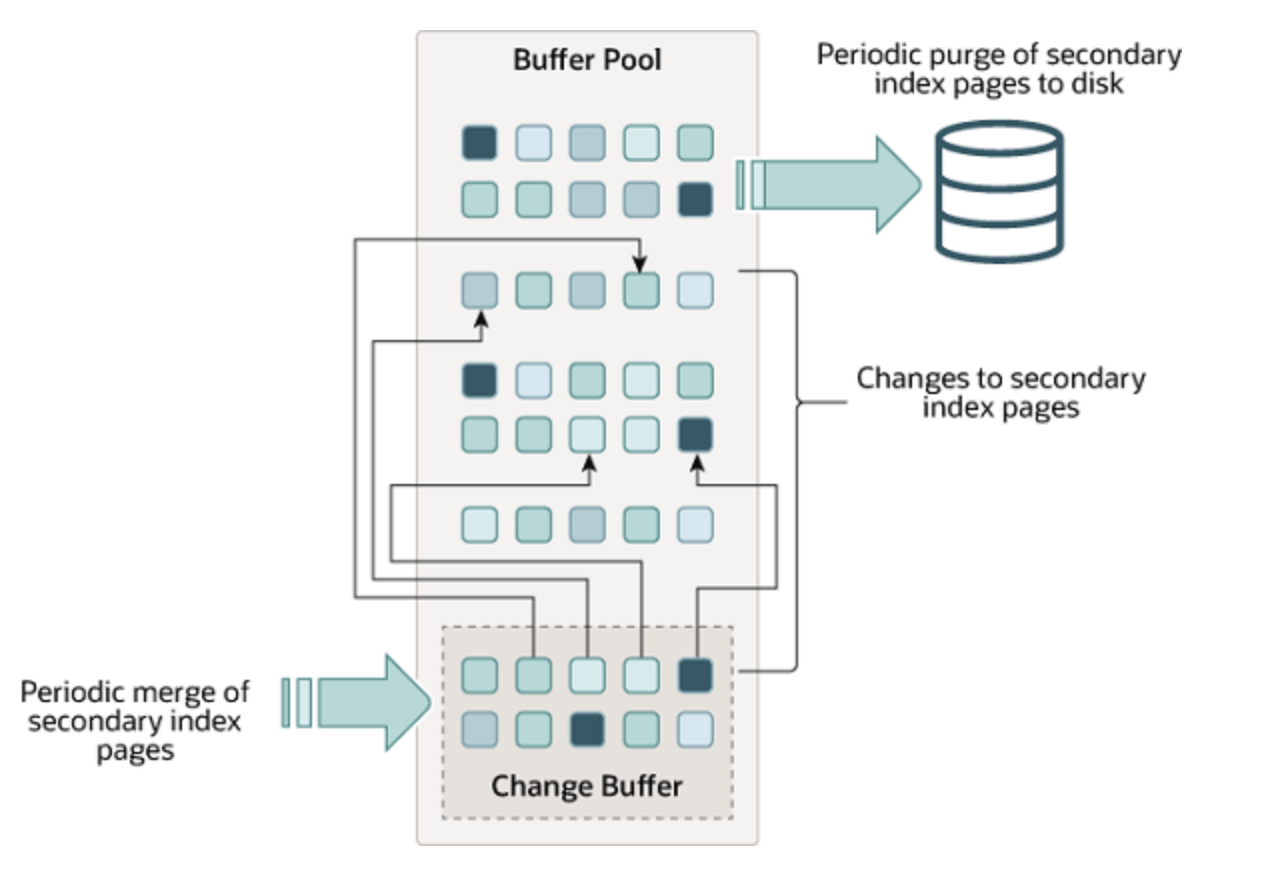
change buffer只对非唯一索引生效。对于唯一索引,写入数据时需要判断新数据是否和老数据有冲突,所以需要将索引页加载到内存中进行判断,因此没有必要将写入操作缓存到change buffer中。
参数innodb_change_buffer_max_size控制change buffer允许使用的最大内存,默认为innodb buffer pool大小的25%。参数innodb_change_buffering用于控制将哪些操作缓存到change buffer中,参数可设置的值请参考下面这个表格。
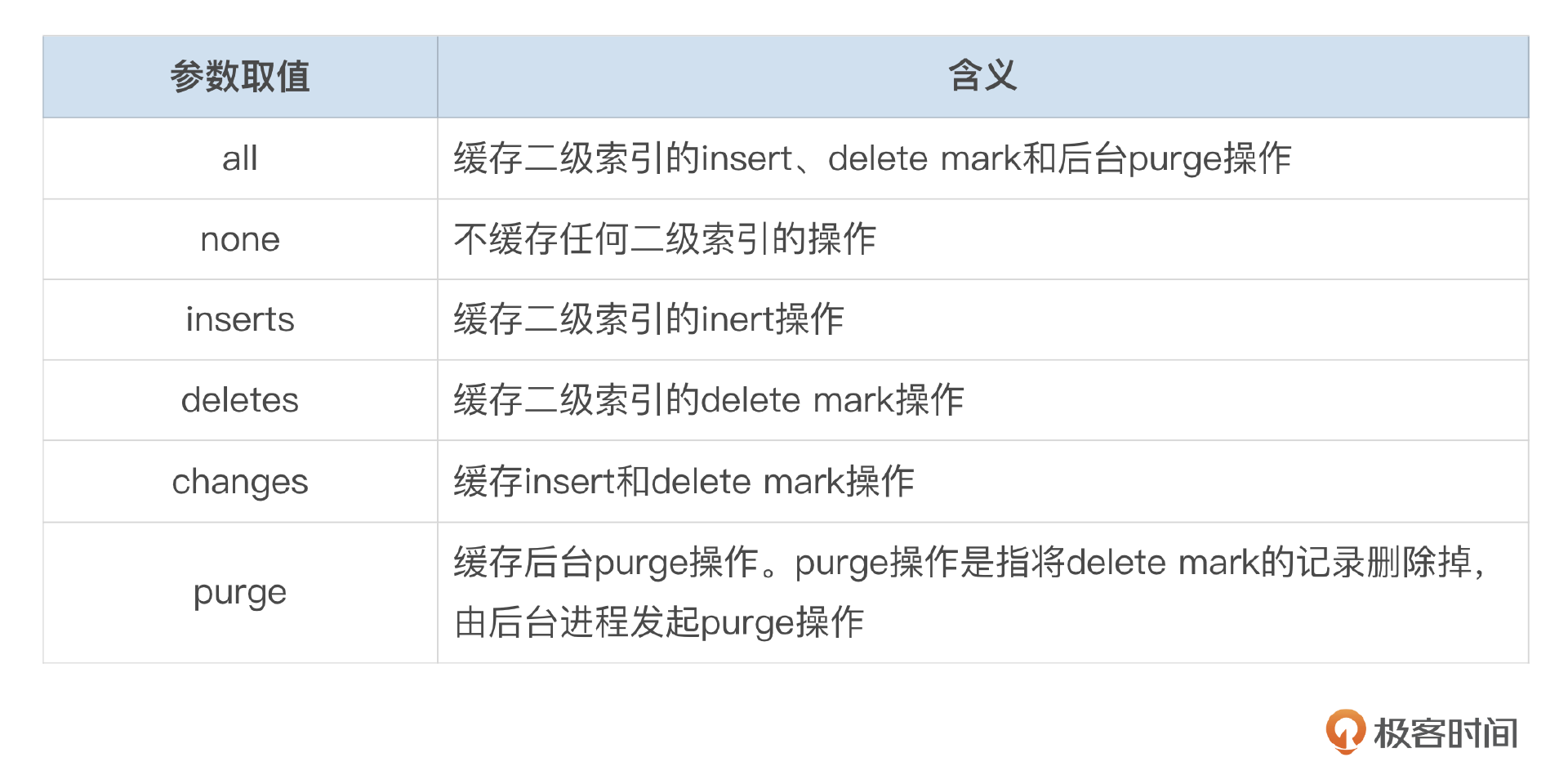
8.0中innodb_change_buffering默认设置为all,不过在8.4版本中,默认值改成了none,这可能是由于SSD磁盘的大量使用,减少了Change Buffer的重要性。如果要关闭change buffer,建议先进行性能测试,评估对应用的影响。
Change Buffer本身是一个B+树,存储在系统表空间中。Change Buffer中记录的格式我整理到了下面这个表格中。
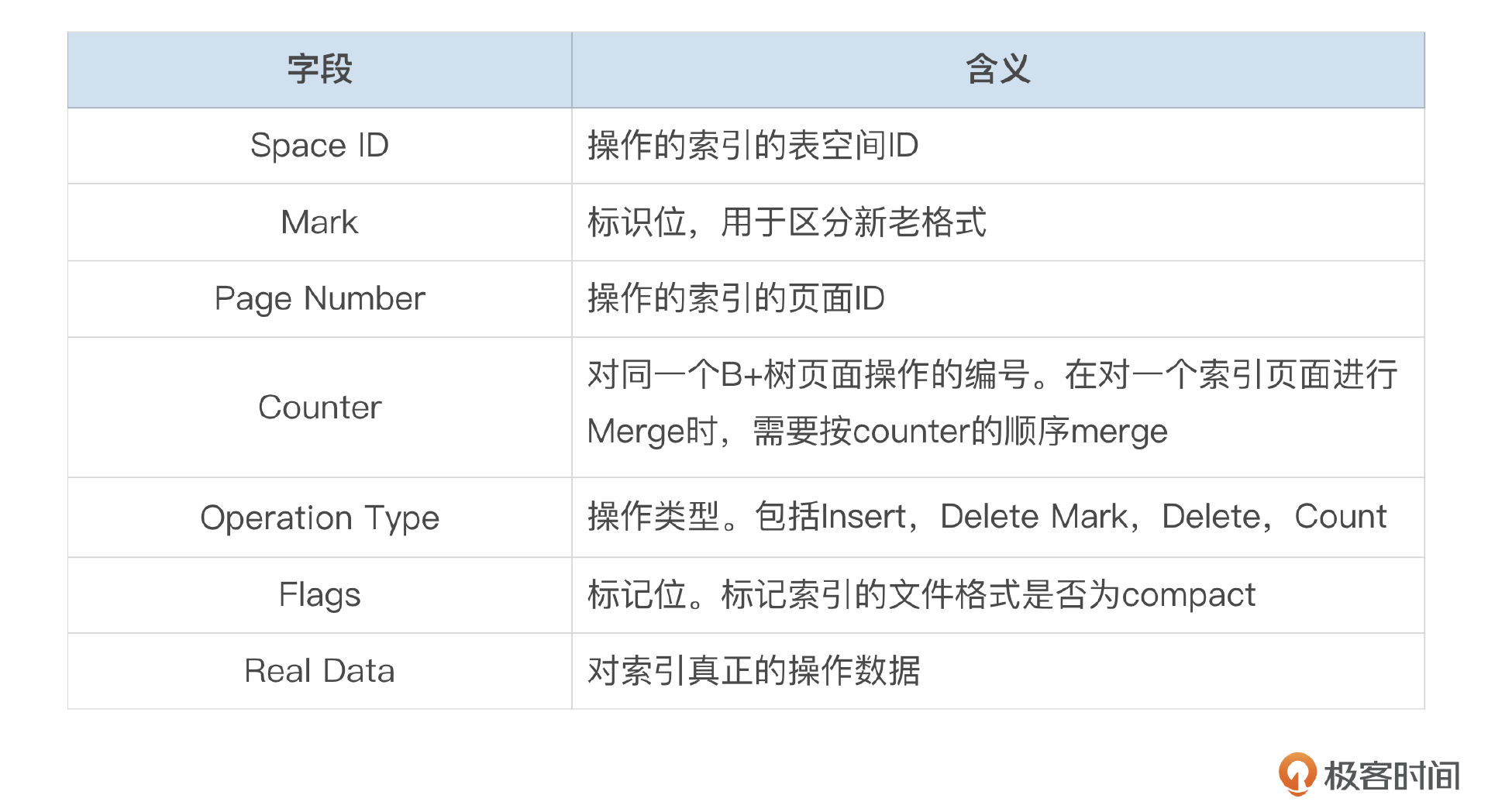
change buffer记录以space id和page number为前缀,所以对同一个二级索引页面的操作,在change buffer中存储在相邻的位置。
change buffer bitmap
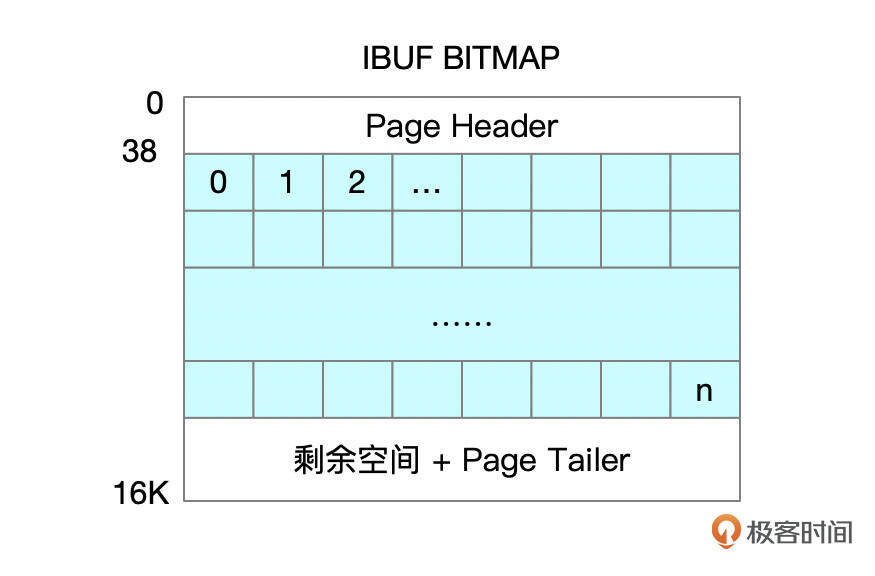
Change Buffer位图信息中,记录了每个索引页面的剩余空间信息。位图页和数据页存储在相同的表空间中。数据文件中,每256M连续空间中的第二个页面用来存储位图信息。

每个索引页面使用4bit来描述页面状态,这些信息的含义参考下面这个表格。
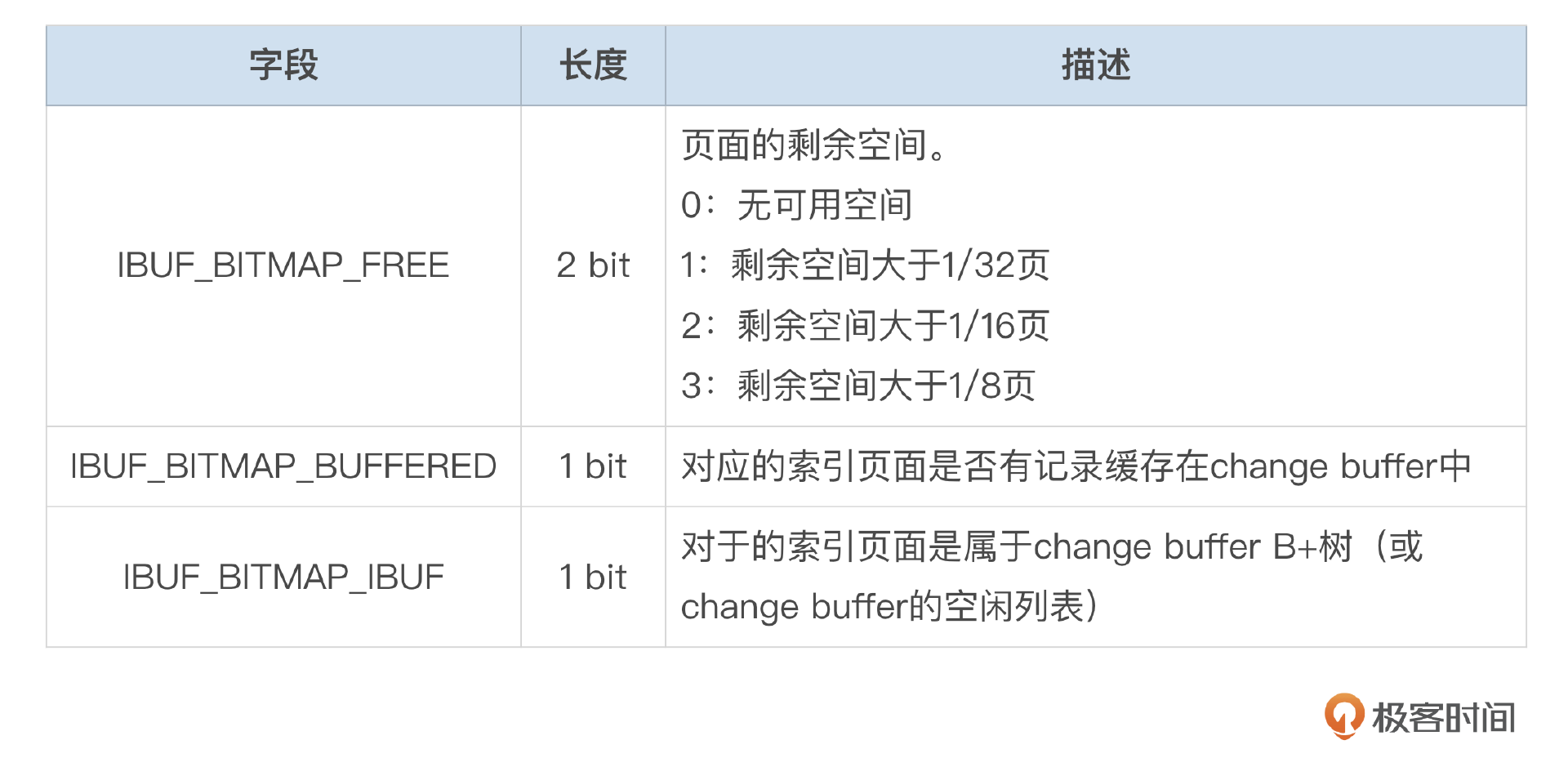
每个Page需要4bit的位图信息,那么存放16384个页面的位图信息需要8192字节,1个16K的IBUF位图页面足够存放这些信息。根据页面编号可直接获取对应的位图信息。
change buffer合并
change buffer中的内容,会在一些情况下合并回索引页面。
- 将索引页面从磁盘加载到InnoDB Buffer Pool时。比如执行select操作时。
- master线程每秒合并部分ibuf,每次合并的页面数和innodb io capacity有关。每次会随机选择一些页面进行合并。
- 写入到ibuf前,会计算二级索引页面已经缓存在ibuf中的大小。如果已经缓存的内容加上本次插入的内容超过了页面的空闲空间,则需要进行merge。如何在不读取页面的情况下,获取页面的空闲空间呢?这需要从ibuf bitmap中获取。
- ibuf本身占用空间超过最大值。
- 实例进行崩溃恢复时,会合并ibuf。
- 关闭实例时,若没有开启快速关闭(innodb_fast_shutdown设置为OFF),也会进行ibuf合并。
Double write buffer
Double write buffer是用来保障数据可靠性的一种机制。有些系统中,InnoDB缓存页写到磁盘设备时,不是一个原子操作。一个缓冲页对应了多个磁盘扇区,可能会存在部分扇区写成功,部分扇区写失败的情况,这样数据页的数据就不一致了。
为了避免出现这种情况,InnoDB使用了Double Write Buffer。脏页刷新时,先写到Double Write Buffer,然后再将Double Write Buffer中的页面批量刷新到Double Write文件中,如果这个过程失败了,那么数据文件中的页面还是好的。如果写Double Write文件成功了,但是后续在写数据文件时失败了,那么就可以用Double Write文件中的内容来恢复数据。
下图是脏页刷新写Double Write文件的一个示意图。
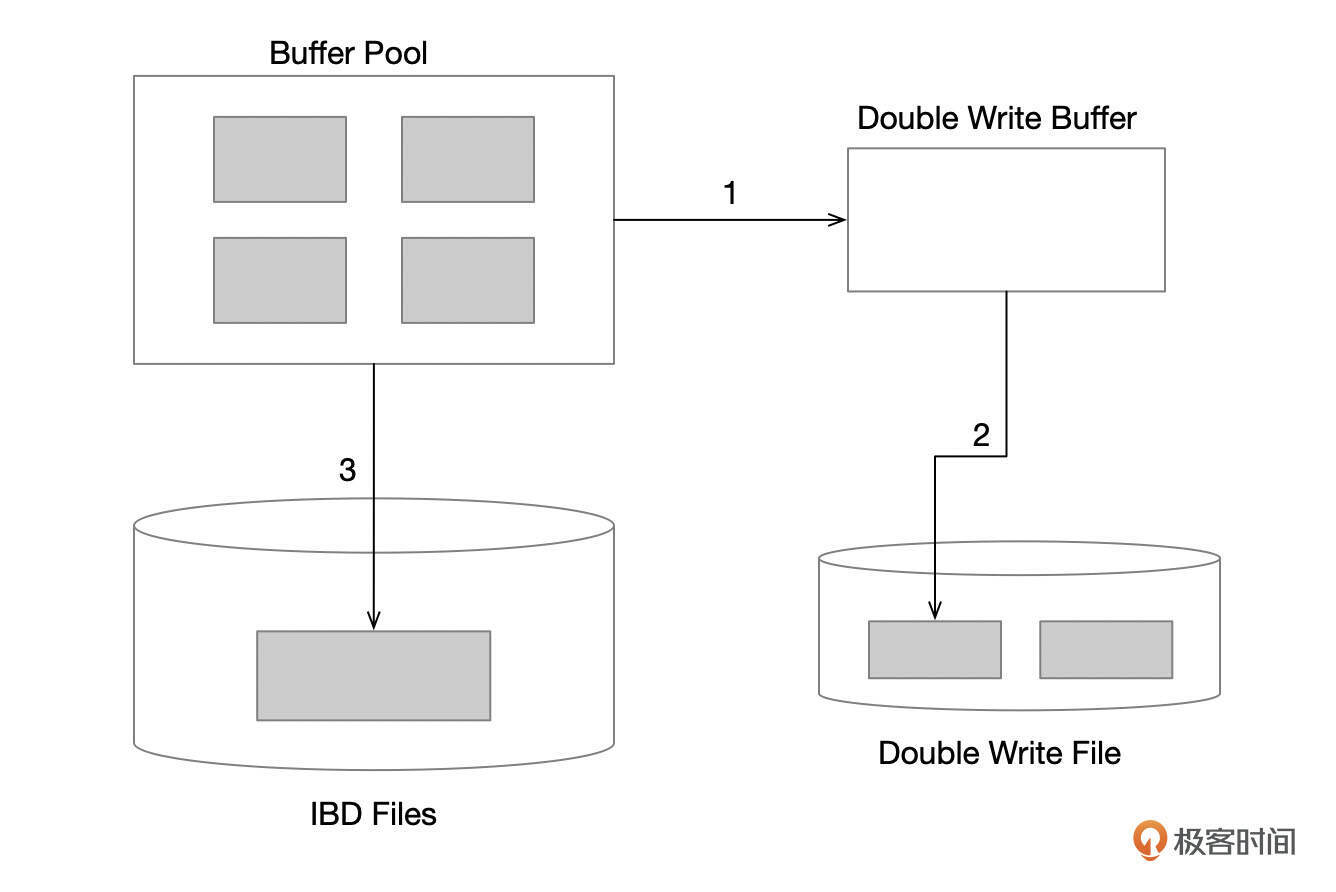
- 先在Double Write Buffer积攒一批脏页。
- 脏页写入Double Write文件中。
- 脏页写入到ibd文件中。
MySQL 8.0将Double Buffer从系统表空间拆分到了单独的文件。
总结
这一讲中,我们介绍了执行DROP TABLE、TRUNCATE TABLE、DROP INDEX等DDL操作时,InnoDB内部进行的一些处理,包括清理AHI、删除表空间、回收索引段的空间。如果你使用的版本小于8.0.23,那么执行这些DDL时对性能可能会有比较大的影响,特别是把Buffer Pool设置得比较大的实例。
InnoDB还使用了自适应hash索引、Change Buffer来提升性能,我们也做了一些介绍。
Double Write Buffer是用来保证数据一致性的,有一定的性能开销。如果你的磁盘设备支持原子写入,可以关闭Double Write Buffer。
思考题
MySQL 8.4中,默认关闭了Change Buffer和自适应Hash索引,具体可以参考官方文档。MySQL这么做可能的原因是什么?关闭Change Buffer和自适应Hash索引对性能会产生哪些影响?
期待你的思考,欢迎在留言区中与我交流。如果今天的课程让你有所收获,也欢迎转发给有需要的朋友。我们下节课再见!
- 笙 鸢 👍(0) 💬(1)
老师,change buffer和double write buffer的内存地址是都在buffer pool的内存里面,还是自己单独的内存空间啊
2024-12-14 - 叶明 👍(0) 💬(1)
相比于以前机械硬盘的几百 IOPS,现在的固态硬盘硬盘动不动上万的 IOPS,IO 能力提升了好几个数量级。 关闭的原因有几个 首先,如果你是固态硬盘,那么开启 change buffer 和 ahi 带来的性能提升很小,但维护 change buffer 代码的代价却不小,现在很多新的功能已经不兼容 change buffer 了,比如倒序索引,https://github.com/mysql/mysql-server/blob/trunk/storage/innobase/rem/rem0cmp.cc#L676-L682 其次,关闭掉 change buffer 和 ahi,buffer pool 能缓存的数据页更多,加上固态磁盘随机 IO 能力的增强,即使多几次 IO 影响也不大。
2024-10-25