27 InnoDB Buffer Pool 如何提高数据库性能?(上)
你好,我是俊达。
从前两讲中,我们知道了InnoDB表和索引的物理存储格式。执行Select语句的时候,最终会从ibd文件中获取数据,执行Insert/Update/Delete语句的时候,最终会将数据写入到ibd文件。读取或修改ibd文件中的数据时,都需要先将数据页缓存到InnoDB Buffer Pool中。这主要是因为访问内存的响应时间比访问磁盘要低几个数量级,将数据页缓存在Buffer Pool中再操作,可以减少磁盘的访问次数,提升性能。
那么数据页是怎么加载到Buffer Pool中,又是怎么写回到ibd文件中的,缓存页在Buffer Pool中是怎么组织的?这就是这一讲中我们要学习的内容。
另外,Buffer Pool中还有一些用来提升性能和保证数据一致性的结构,包括Change Buffer、自适应Hash索引、Double Write Buffer,对这些结构我们也会做一些介绍。
InnoDB Buffer Pool
InnoDB将数据存储在表空间中,读取或写入数据时,需要先将数据从文件加载到内存中。InnoDB分配了专门的内存来缓存表空间中的数据(包括表、索引以及回滚段等),这一块内存称为Buffer Pool。
缓存的单位是页面(Page),即使你只访问一条记录的一个字段,也要将记录所在的整个页加载到Buffer Pool。读取数据时,InnoDB会将记录所在的页面加载到缓冲池,然后解析缓存页面中的记录数据,将结果返回给客户端。
修改数据时,会先在缓存页面中修改。修改后的页面称为脏页,脏页不会立刻写回到文件。InnoDB会在执行Checkpoint时,或者寻找空闲的替换页面时,将脏页写回文件。
下面是一个数据块缓存到Buffer Pool中的简单示意图。
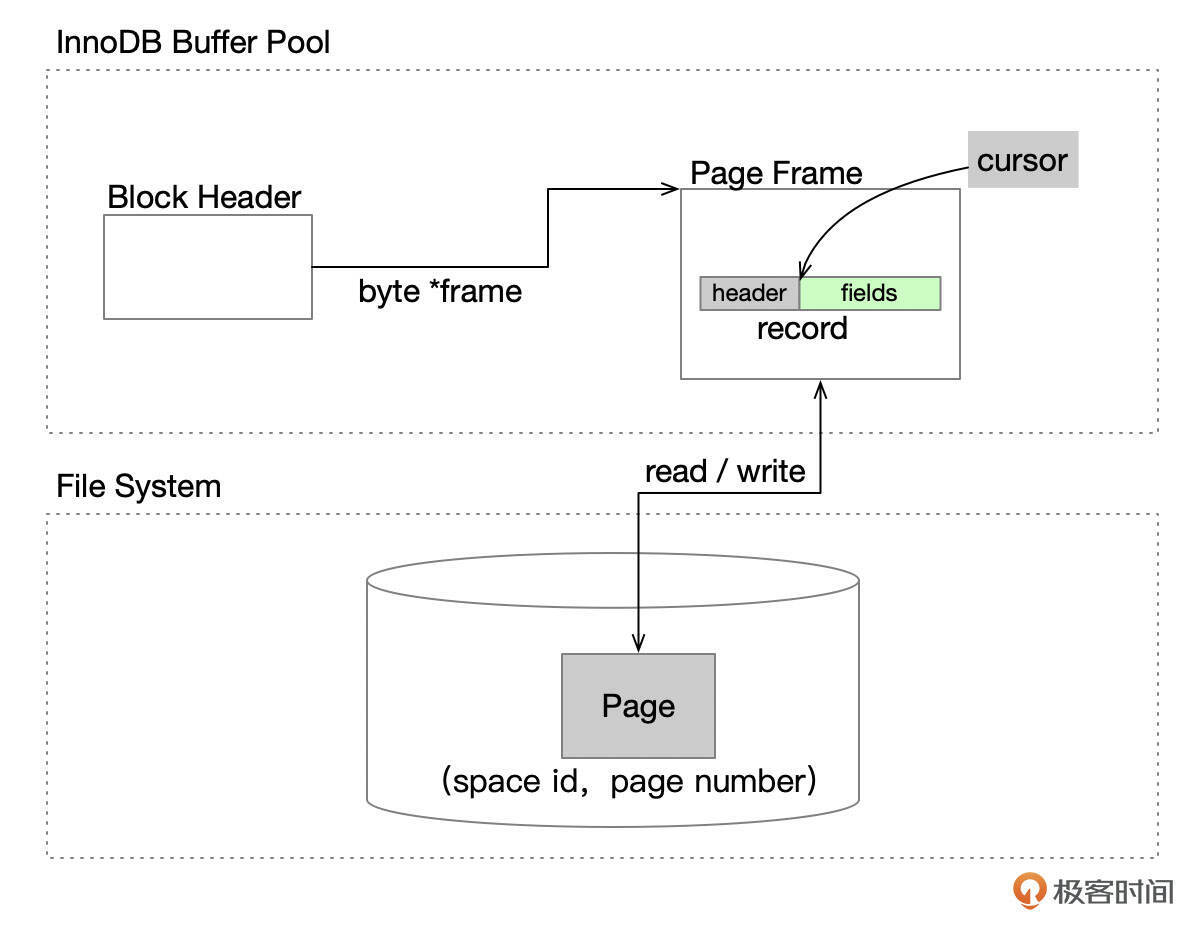
- 数据文件中使用(space id,page number)来定位一个数据页。
- Buffer Pool中的缓存页(page frame)和数据页的大小一致,比如都是16K。(注:业界有时也将page frame称为页框、页帧,这个课程里我称为缓存页)。
- 每一个缓存页都有一个对应的控制块(Bock Header结构),控制块中记录缓存页的相关信息。后面我们会看到控制块的具体结构。
- InnoDB 内部有一个命名为cursor的对象,cursor实际上是一个指针,指向缓存页中的某行记录。这和客户端驱动(如JDBC)中的cursor不是一个概念。
InnoDB使用缓冲池,主要有几方面的原因。
- 提升数据库性能。当前普遍使用的PC服务器中,访问内存中的数据耗时大约是几十纳秒,访问高性能SSD的耗时大约在几十到几百微秒,而读取机械磁盘中的一个数据块的耗时在毫秒级别。将数据缓存到Buffer Pool中,可以提升数据库的读写性能。
- 合并写入操作。Buffer Pool中的数据被修改后,不会实时写回到文件系统中。一个数据页被多次修改后,只需要将页面写回一次,就能将所有的操作都持久化。
当然,由于数据先在内存中修改,为了保证事务的ACID属性,InnoDB使用REDO和UNDO等机制,后续几讲我们会详细分析。
Buffer Pool结构
InnoDB Buffer Pool由1个或多个实例组成。Buffer Pool实例数量由参数innodb_buffer_pool_instances控制。只有Buffer Pool的大小超过1G时,才可以配置多个Buffer Pool实例。
引入多个Buffer Pool实例,主要是为了减轻使用大内存Buffer Pool时存在的资源争用。Buffer Pool中存在多个链表结构,查询和修改这些链表结构时都需要先获取相关的锁,以保证多个线程并发访问这些链表时数据的一致性。Linux系统下,如果innodb_buffer_pool_size超过1G,默认innodb_buffer_pool_instances设置为8。
对于大内存Buffer Pool,适当增加innodb_buffer_pool_instances可以提高数据库的整体性能。当然,这个参数并不是越大越好,因为维护多个Buffer Pool实例会有一些额外的开销。InnoDB参数的设置,你可以参考第 4 讲。
下面是一个Buffer Pool 实例的示意图。
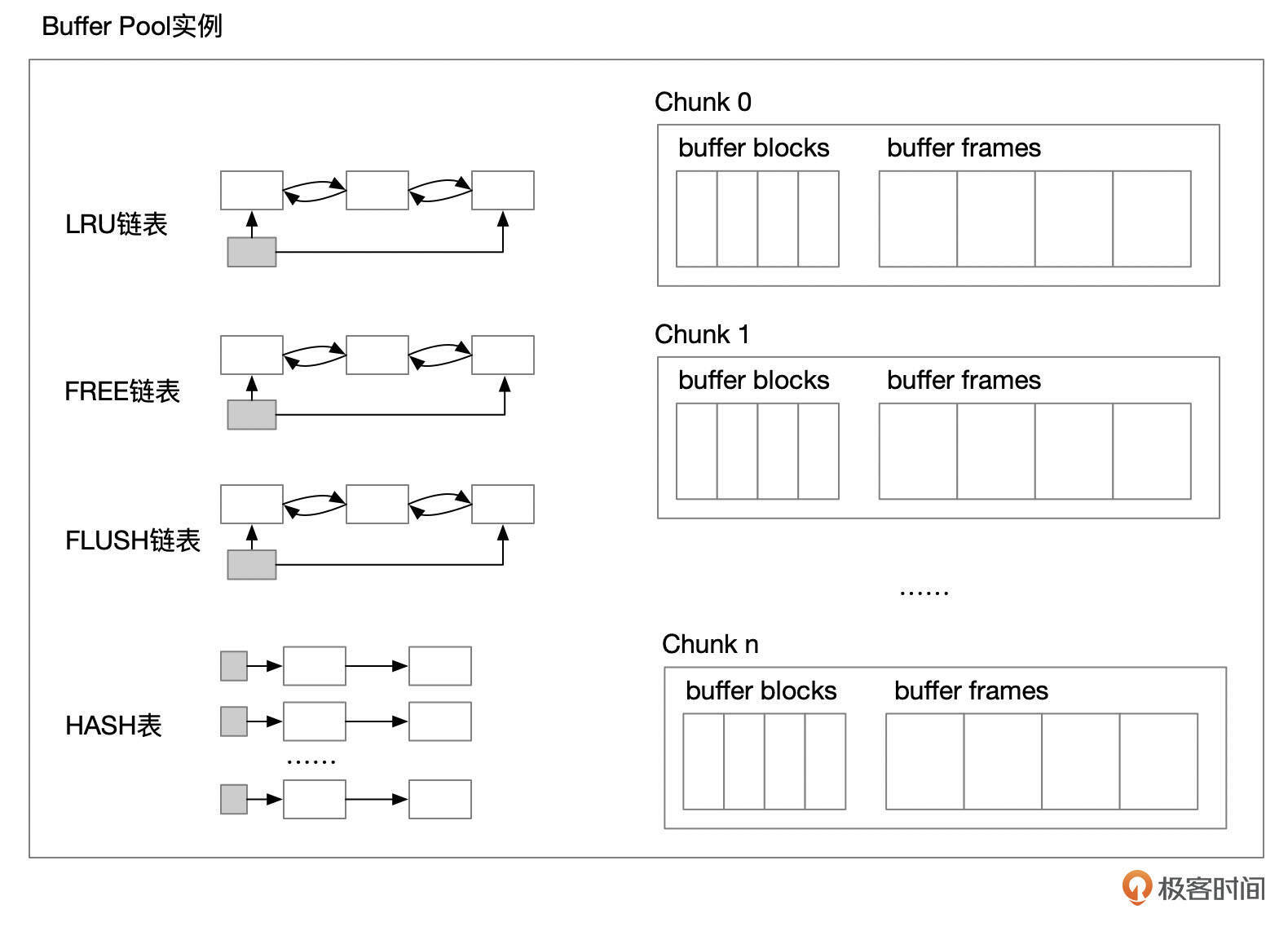
- 每个buffer pool实例中都有几个链表,包括lru链表、free链表、flush链表、hash表。
- buffer pool实例中,内存会分割成多个块(Chunk)。
一个Chunk是一块连续的内存空间,通过参数innodb_buffer_pool_chunk_size来设置每个Chunk的大小。Chunk中的内存主要分为控制块(buf block)和缓存页(page frame)。缓存页的大小和InnoDB物理文件页的大小一致(由参数innodb_page_size指定),用来缓存InnoDB数据文件页的数据。
对应于每一个缓存页,有一个控制块(Buffer Block),记录了缓存页相关的信息,包括缓存页的页面编号(Page No)、缓存页的访问情况、页面是否被修改。每个控制块大约占用几百字节的内存,对于16K的页面,控制块占用的内存大约是页面大小的4%-5%。
参数innodb_buffer_pool_chunk_size指定的是缓存页占用的空间,所以实际上Buffer Pool分配的内存要比参数指定的大4%-5%。每一个Chunk中分配的连续的内存中,开始的一部分内存用来存放控制块,剩余的内存给缓存页使用。每个控制块都记录了对应的缓存页的地址。每个缓存页的地址按页面大小对齐。
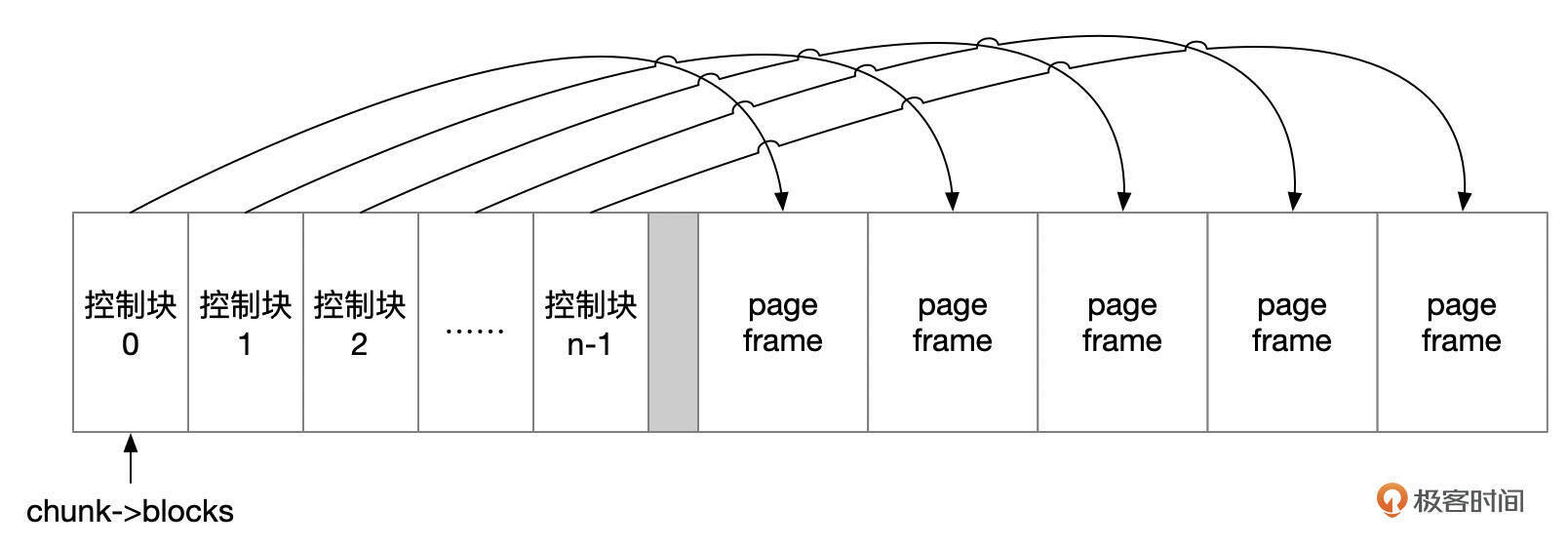
控制块在MySQL的源码中是一个结构体,结构体的成员可以参考下面这两个表格。
控制块(结构体buf_block_t)

结构体buf_page_t

为了使Buffer Pool的机制能高效地运作,至少需要做到几点:
- 可以根据数据文件页面编号快速定位到对应的缓存页。
- 如果数据页还没有被缓存,能快速找到空闲的缓存页,缓存数据。
- 将经常访问的数据尽可能久地缓存到内存中。
- 控制好脏页刷新的策略,既要避免大量数据刷新影响实例性能,也要避免大量脏页没有回写导致实例崩溃恢复的时间太久。
InnoDB使用了一些数据结构来实现这些需求。
Buffer Pool中的链表结构
每个InnoDB Buffer实例中都存在一些双向链表结构。
- FREE链表:当需要新的缓存页来加载文件数据时,先到FREE链表中查找。如果FREE链表为空,则需要从LRU链表中淘汰一个页面,将淘汰的页面加入到FREE链表中。
- LRU链表:Buffer Pool中的页面大致按访问的先后顺序加入到LRU链表中。最近访问过的页面放到链表的头部,访问较少的页面则会位于链表的尾部。淘汰页面时,从链表的尾部开始查找。
- unzip_LRU链表:unzip_LRU链表的缓存页内都是压缩表中页面解压后的内容。
- FLUSH链表:缓存页的数据被修改后,需要加入到FLUSH链表。FLUSH链表中的页面大致按页面最先被修改的时间排列,最新修改的页面加入到FLUSH链表头部。执行Checkpoint时,依次将FLUSH链表尾部的页面刷新到文件。
- zip_free链表:zip_free链表用来管理压缩页面的空闲空间。压缩表可以使用不同的页面大小,因此zip_free实际上是多个列表,每个列表对应不同大小的压缩页。
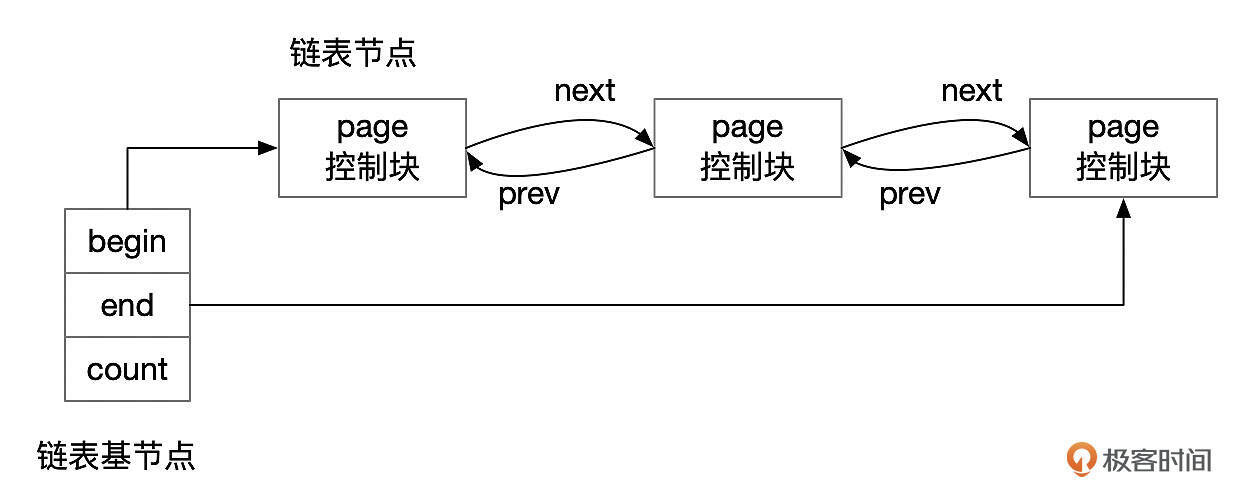
这些链表在结构上都是一样的,由链表基节点和链表节点组成。链表基节点记录了链表的头部和尾部,因此访问链表开始和结尾处的节点很快。每个链表节点通过prev和next指针分别指向前后相邻的节点,通过这些指针可以双向遍历整个链表。当然,访问这些链表时,都需要先获取相关的互斥锁。
Buffer Pool中的Hash表
查询数据时,先从数据字典中得到索引的根页面号,然后再根据索引条目,找到下一层页面的编号。InnoDB怎么判断某个页面是否已经缓存呢?这是通过Hash表来实现的。每个页面都会根据hash算法映射到某一个Hash链表中。
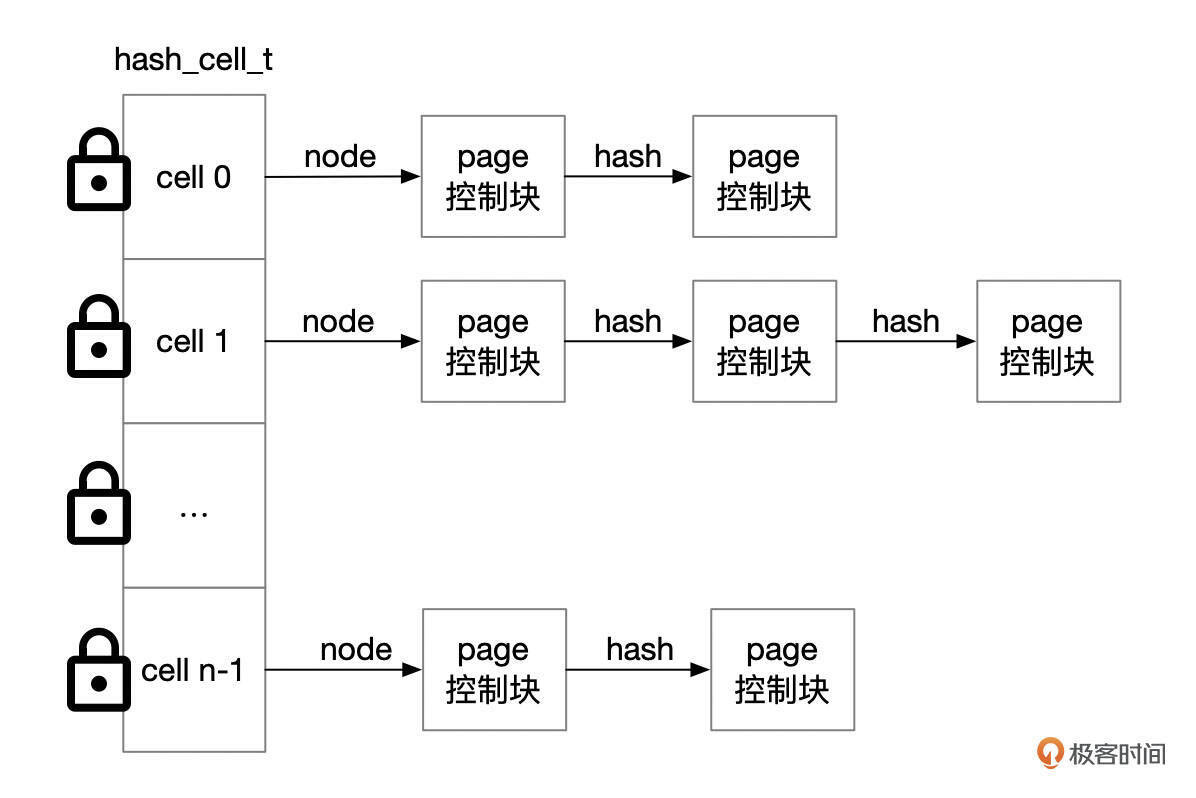
在Hash表中查找缓存页主要有下面这几个步骤。
- 根据页面号(Space no,Page No)计算得到Buffer Pool实例编号。同一个区(extent)的页面分配给同一个Buffer Pool实例。
- 使用hash函数,将页面号(Space no,Page No)转换成hash桶的编号。多个页面可能会映射到同一个hash桶,这些页面组成一个单向链表。
- 到Hash桶的单向链表中查找页面。通常这个单向链表很短,因此查找速度一般很快。
Hash桶的数量根据Buffer Pool的大小来确定,会取一个比Buffer Pool中页面数稍大的质数。Hash函数的设计会尽量保证将不同的页面分配到不同的Hash桶,因此每一个Hash桶内链表节点数都比较少。
访问hash桶里面的节点时,需要先获取对应的读写锁。InnoDB并不会给每一个hash桶都创建一个读写锁,而是在每个Buffer Pool实例中,默认创建16个读写锁。Debug版本的MySQL中,有一个参数innodb_page_hash_locks,用来设置hash锁的数量。
LRU链表
初次访问一个数据页时,要分配一个空闲的缓存页。InnoDB空闲页都链接到free链表中。随着数据库持续运行,当所有的页面都已经被使用后,这时再缓存新的数据页,就要淘汰一个现有的缓存页。应该淘汰哪个页面呢?
InnoDB会从LRU链表的尾部淘汰页面。InnoDB使用了改良的LRU算法,将LRU链表分为new和old这两个区域。OLD区域的占比由参数innodb_old_blocks_pct控制,该参数默认为37,也就是LRU链表中,尾部大约3/8的页面被划入OLD区。
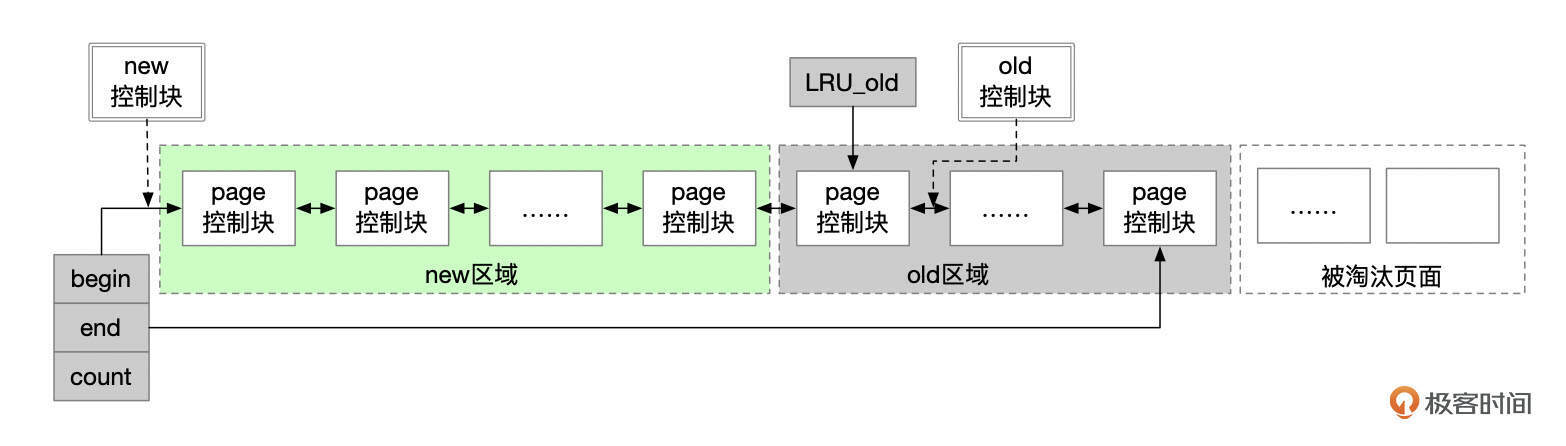
改良的LRU算法运行过程大致如下:
- 新的页面首次加入到LRU链表中时,会插入到OLD区。LRU_old指向old区域的第一个控制块。新加入的控制块插入到LRU_old所指的控制块后面。页面首次加入LRU链表后,还会设置页面的访问时间(access_time)。
- OLD区域的页面后续再次被访问时,判断当前时间和首次访问时间的间隔是否足够长,如果访问的时间间隔超过了参数innodb_old_blocks_time设置的值,就将页面移到LRU链表的头部。innodb_old_blocks_time默认为1000毫秒。也就是加入到old区的页面,1秒之后再次被访问时,会移到LRU链表的头部。
- 实例运行过程中,有的页面被加入到OLD区,有的页面被淘汰,有的页面被移到LRU链表头部,这些操作会导致new区域和old区域内的页面数量偏离预定的设置,InnoDB会移动指针LRU_old,使2个区域的页面数保持在预定的设置内。
- new区域内的页面,并不会在每次访问时都移动到LRU链表的头部,因为在LRU链表中移动一个页面需要获取互斥锁,大量的页面移动操作会带来额外的性能开销。InnoDB为每个Buffer Pool实例维护了freed_page_clock变量,每次淘汰一个页面时该变量加1。一个页面加入到LRU链表头部时,在控制块中记录实例当前的freed_page_clock。new区域内的页面再次被访问时,如果在该页面首次加入new区域之后,Buffer Pool中被淘汰的页面数超过了new区域总页面数的1/4,则InnoDB认为该页面被淘汰的风险较高,会将该页面移动到LRU链表头部。
改进的LRU算法可以在一定程度上避免大表单次全表扫描时将Buffer Pool中经常访问的页面淘汰掉。在大表单次全表扫描的场景下,页面加载到Buffer Pool中,首次访问之后不会再次访问,将这些页面限制在OLD区域,可以减少对new区域内缓存页的影响。
文件IO
首次访问数据页时,需要发起IO操作,从文件读取数据,缓存到Buffer Pool中。
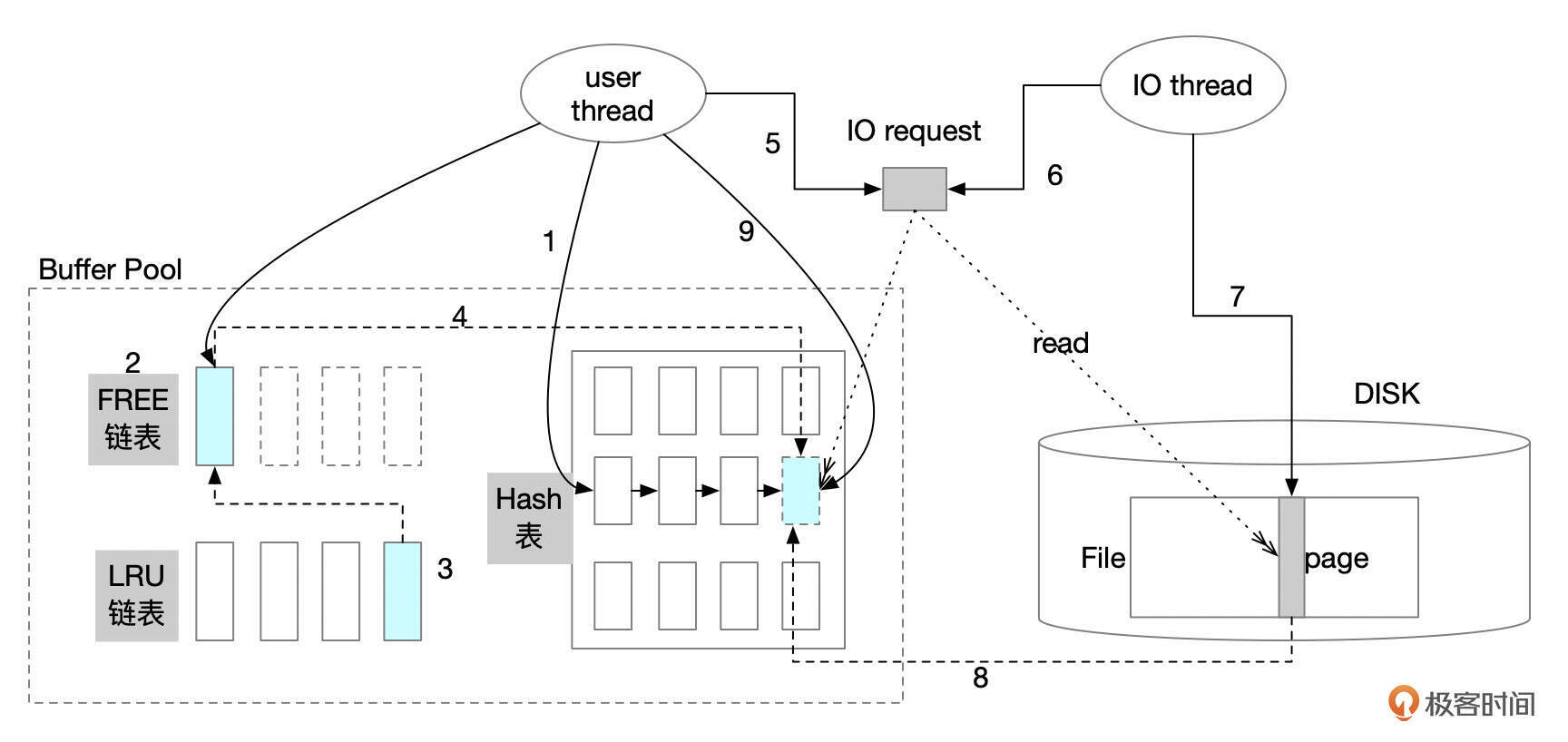
InnoDB使用了异步IO读取数据,大致上可以分为几个步骤。
- 用户执行SQL,根据页面编号(space id,page number)到Buffer Pool中查找该页面是否已经被缓存。先计算得到页面对应的Buffer Pool实例,然后到Buffer Pool实例的Hash表中查找。
- 如果页面已经被缓存,就不需要进行文件IO。否则,需要到FREE链表中找一个空闲的缓存页,用来缓存数据。
- 如果FREE链表中没有空闲页面,需要到LRU链表尾部淘汰掉一个页面。淘汰的页面先加入到FREE链表,然后再分配给用户线程使用。
- 获取到空闲的缓存页后,将页面加入到对应的Hash链中。
- 用户线程发起IO请求,将文件页读取到缓存中。IO请求分为同步IO和异步IO。有些页面的读取使用同步IO,用户线程直接调用read系统调用,将数据读取到内存。使用异步IO时,用户线程先发起IO请求,然后等待其他线程完成IO,然后才可以继续执行。
- 异步IO可分为内核原生异步IO和模拟异步IO。Linux系统下,如果操作系统内核支持异步IO,MySQL会自动使用这种方式,通过参数innodb_use_native_aio可以观察是否使用了内核原生异步IO。如果采用了内核原生异步IO,用户线程会通过系统调用(如io_submit)将IO请求分派给操作系统内核。
- 如果使用了内核原生的异步IO,MySQL的IO线程会轮询IO操作是否完成。如果使用了模拟的异步IO,用户线程只是将IO请求放到IO队列中,由IO线程执行具体的IO操作。IO线程的数量由参数innodb_read_io_threads和innodb_write_io_threads控制。
- IO操作完成后,数据就缓存到了Buffer Pool中。
- 数据页缓存后,用户线程可以继续执行,读取或写入记录。
我们知道,Linux中文件系统本身也提供了缓存机制,而InnoDB数据文件也存储在文件系统中,那么数据是否会被多次缓存呢?这和参数innodb_flush_method的设置有关,一般建议设置为O_DIRECT,这样就不会在文件系统中缓存文件的数据。
Buffer FLUSH
执行DML修改数据时,会先修改Buffer Pool中的缓存页。事务提交时,不需要等待脏页刷新。脏页会异步刷新到磁盘。那么脏页是什么时候刷新到磁盘的呢?
我们来考虑一个问题,如果脏页一直不刷新,会发生什么情况?
- 如果脏页一直不刷新,Buffer Pool中所有的页面最终都会变脏,那么就没有空闲页面可用了。
- 如果数据库或服务器崩溃了,大量脏页没有刷新到磁盘。虽然有REDO日志,数据不会丢失,但是下次数据库启动时,应用REDO日志的时间可能会很长。
- REDO日志有空间限制,不能无限增长。InnoDB会循环使用REDO日志文件,新产生的REDO日志会覆盖之前的日志。如果脏页一直不刷新,就无法覆盖老的REDO日志文件。
上面这几种情况,实际上也是会触发脏页刷新的几个场景。
- 如果LRU链表中扫描了一些页面(数量由参数innodb_lru_scan_depth控制)后找不到干净的替换页,就需要将一些脏页写回到文件。
- InnoDB会定期将flush链表尾部的页面刷新回磁盘。刷新行为受参数innodb_adaptive_flushing控制。开启innodb_adaptive_flushing后,InnoDB会根据REDO日志产生的速率来决定刷新频率。
- 重用REDO日志文件时,需要保证被重用的REDO文件的LSN号小于数据库的Checkpoint LSN号,否则要发起Checkpoint操作,官方文档将这种情况称为sharp checkpoint,此时数据库的写入操作都会被暂停,会严重影响性能。
- 参数innodb_max_dirty_pages_pct_lwm和innodb_max_dirty_pages_pct也会影响脏页刷新。当脏页的比例超过innodb_max_dirty_pages_pct_lwm时,InnoDB会开始刷新一些脏页。当脏页比例接近innodb_max_dirty_pages_pct时,InnoDB会开始大量刷新脏页。
总结
这一讲中我们对InnoDB Buffer的结构做了一些介绍。在实践中,要正确地设置相关的参数。对性能影响最大的参数应该是innodb_buffer_pool_size和innodb_buffer_pool_instances,你可以参考第4讲中的相关内容。为了保证数据库的事务ACID属性,修改Buffer Pool中的数据时,要生成REDO和UNDO日志,修改记录时还需要先获取行锁,这是接下来几节课要介绍的内容。
思考题
读写InnoDB表时,会先把数据页缓存到Buffer Pool中,那么删除表和索引时,表和索引中已经缓存在Buffer Pool中的页面要怎么处理?是不是需要释放这些缓存页?如果有脏页,需要先刷新脏页吗?如果不对这些页面做任何处理,会有什么问题吗?
期待你的思考,欢迎在留言区中与我交流。如果今天的课程让你有所收获,也欢迎转发给有需要的朋友。我们下节课再见!
- binzhang 👍(0) 💬(1)
思考题: 对于drop的表和索引没有必要同步刷脏页和清理非脏页。mysql 可以在内存里或者文件头记录该space ID是否被drop了。可以采用异步的方式 刷脏页线程遇见drop table/index的脏页直接抛弃。新创建一个线程专门异步处理lru中的非脏页。 这样drop 超级大的表也可以很快结束。
2024-10-23