26 数据库无法启动,如何读取InnoDB文件中的数据?(下)
你好,我是俊达
这一讲中,我们接着上一讲的内容,介绍InnoDB中B+树的物理结构,以及InnoDB管理数据文件的一些数据结构。
先创建一个测试表,写入一些数据。
CREATE TABLE t_btree (
id varchar(100) NOT NULL,
a varchar(100),
padding varchar(1024),
PRIMARY KEY (id),
KEY idx_a (a)
) ENGINE=InnoDB;
insert into t_btree(id, a, padding)
select concat('PK', rpad('', 93, '-'), 10000 + n),
concat('KEY', rpad('', 92, '-'), 10000 + n),
rpad('', 512, 'DATA')
from numbers
order by n;
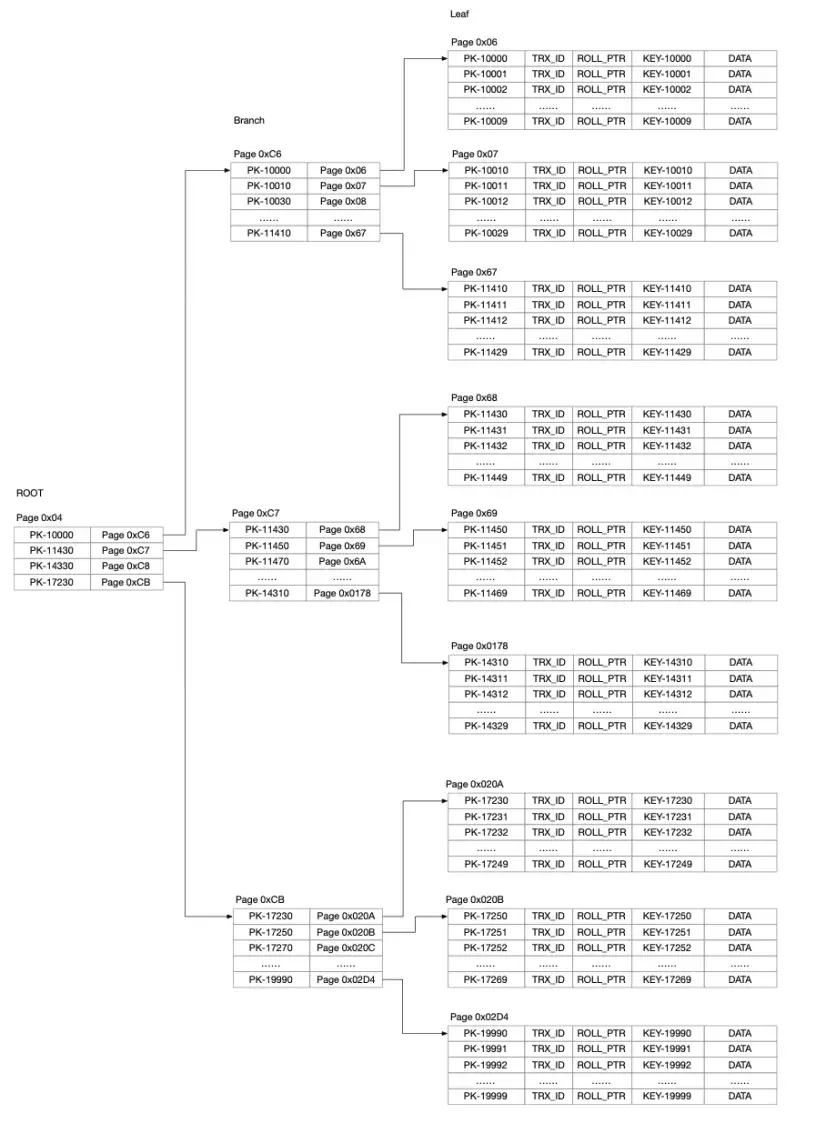
InnoDB中的B+树
之前我们提到过,InnoDB中表和索引都是B+树的结构,下面就是B+树的一个简单示意图。
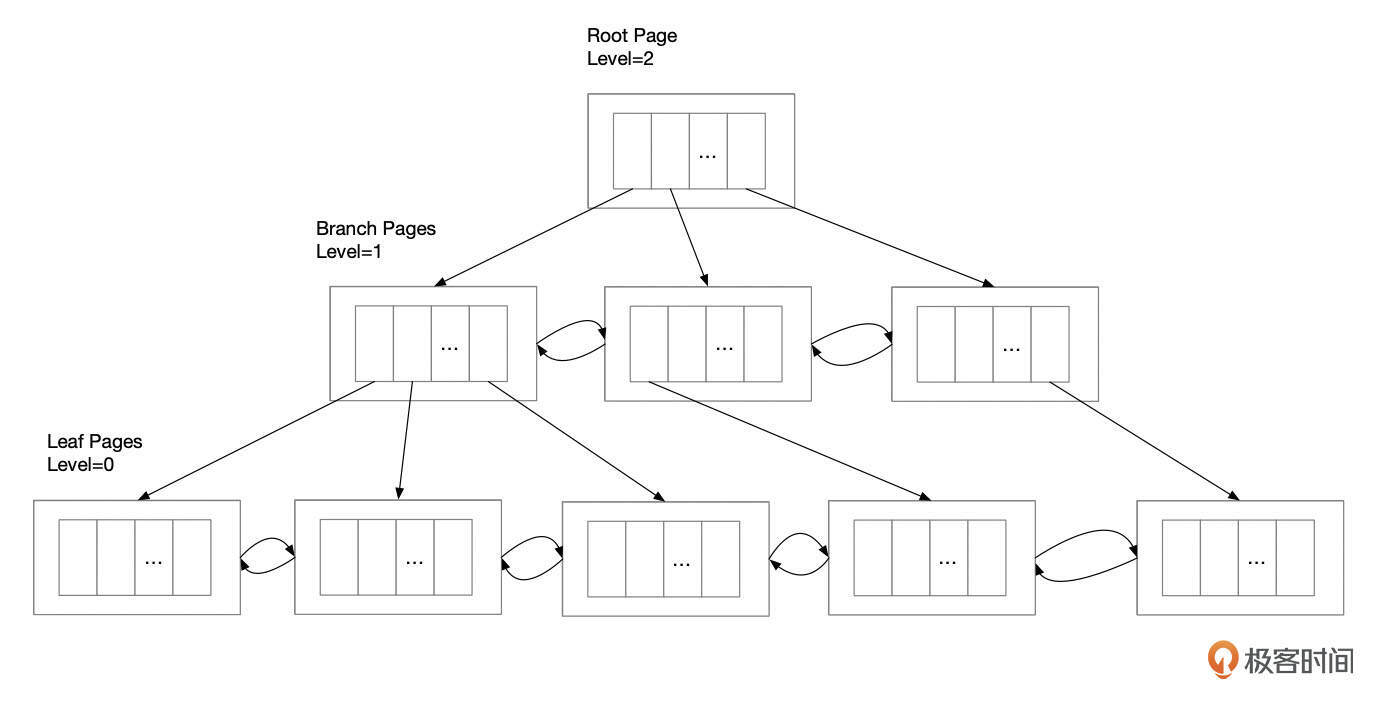 B+树由根节点(root page)、分支节点(branch page)和叶子节点(leaf page)组成。每个页面由头部信息和页面记录组成。分支页面的记录中,有指向下一个层级的页面编号。页面头部还记录了同一层级中相邻页面的编号,这些页面组成一个双向链表。页面记录包含Key和Value两个部分。对于主键,Key就是组成Primary Key的字段,分支页面中的Value值是页面编号(Page Number),叶子页面中,Value值包括隐藏字段DB_TRX_ID,DB_ROLL_PTR,以及表结构中Primary Key之外的字段。
B+树由根节点(root page)、分支节点(branch page)和叶子节点(leaf page)组成。每个页面由头部信息和页面记录组成。分支页面的记录中,有指向下一个层级的页面编号。页面头部还记录了同一层级中相邻页面的编号,这些页面组成一个双向链表。页面记录包含Key和Value两个部分。对于主键,Key就是组成Primary Key的字段,分支页面中的Value值是页面编号(Page Number),叶子页面中,Value值包括隐藏字段DB_TRX_ID,DB_ROLL_PTR,以及表结构中Primary Key之外的字段。
二级索引中,分支页面中的记录由索引定义中的字段、主键字段和页面编号组成,而叶子页面中的记录由索引字段和主键字段组成。
这个结构,在物理文件中是怎么体现的呢?我们来看一下测试表t_btree中的索引结构。先查看索引的元数据,聚簇索引的根页面是page 4,idx_a的根页面是page 5,表空间ID是411(0x019B)。
mysql> SET SESSION debug='+d,skip_dd_table_access_check';
mysql> select t2.name, t2.se_private_data
from mysql.tables t1, mysql.indexes t2
where t1.id = t2.table_id
and t1.name = 't_btree';
+---------+---------------------------------------------------------+
| name | se_private_data |
+---------+---------------------------------------------------------+
| idx_a | id=779;root=5;space_id=411;table_id=1477;trx_id=122435; |
| PRIMARY | id=778;root=4;space_id=411;table_id=1477;trx_id=122435; |
+---------+---------------------------------------------------------+
然后再查看索引字段,聚簇索引里包含了表中所有的字段,还有2个隐藏字段db_trx_id、db_roll_ptr。二级索引的字段包含了主键字段。
mysql> use mysql;
mysql> select t2.name, t4.ordinal_position as pos, t4.hidden, t3.name,
t3.hidden, t3.column_type_utf8
from tables t1, indexes t2, columns t3, index_column_usage t4
where t1.id = t2.table_id
and t1.id = t3.table_id
and t2.id = t4.index_id
and t3.id = t4.column_id
and t1.name = 't_btree'
order by t2.name, t4.ordinal_position
+---------+-----+--------+-------------+---------+------------------+
| name | pos | hidden | name | hidden | column_type_utf8 |
+---------+-----+--------+-------------+---------+------------------+
| idx_a | 1 | 0 | a | Visible | varchar(100) |
| idx_a | 2 | 1 | id | Visible | varchar(100) |
| PRIMARY | 1 | 0 | id | Visible | varchar(100) |
| PRIMARY | 2 | 1 | DB_TRX_ID | SE | |
| PRIMARY | 3 | 1 | DB_ROLL_PTR | SE | |
| PRIMARY | 4 | 1 | a | Visible | varchar(100) |
| PRIMARY | 5 | 1 | padding | Visible | varchar(1024) |
+---------+-----+--------+-------------+---------+------------------+
聚簇索引结构
ROOT
聚簇索引的根页面编号是0x04,Page 4的内容见下面这个图,图上标注了一些关键信息。
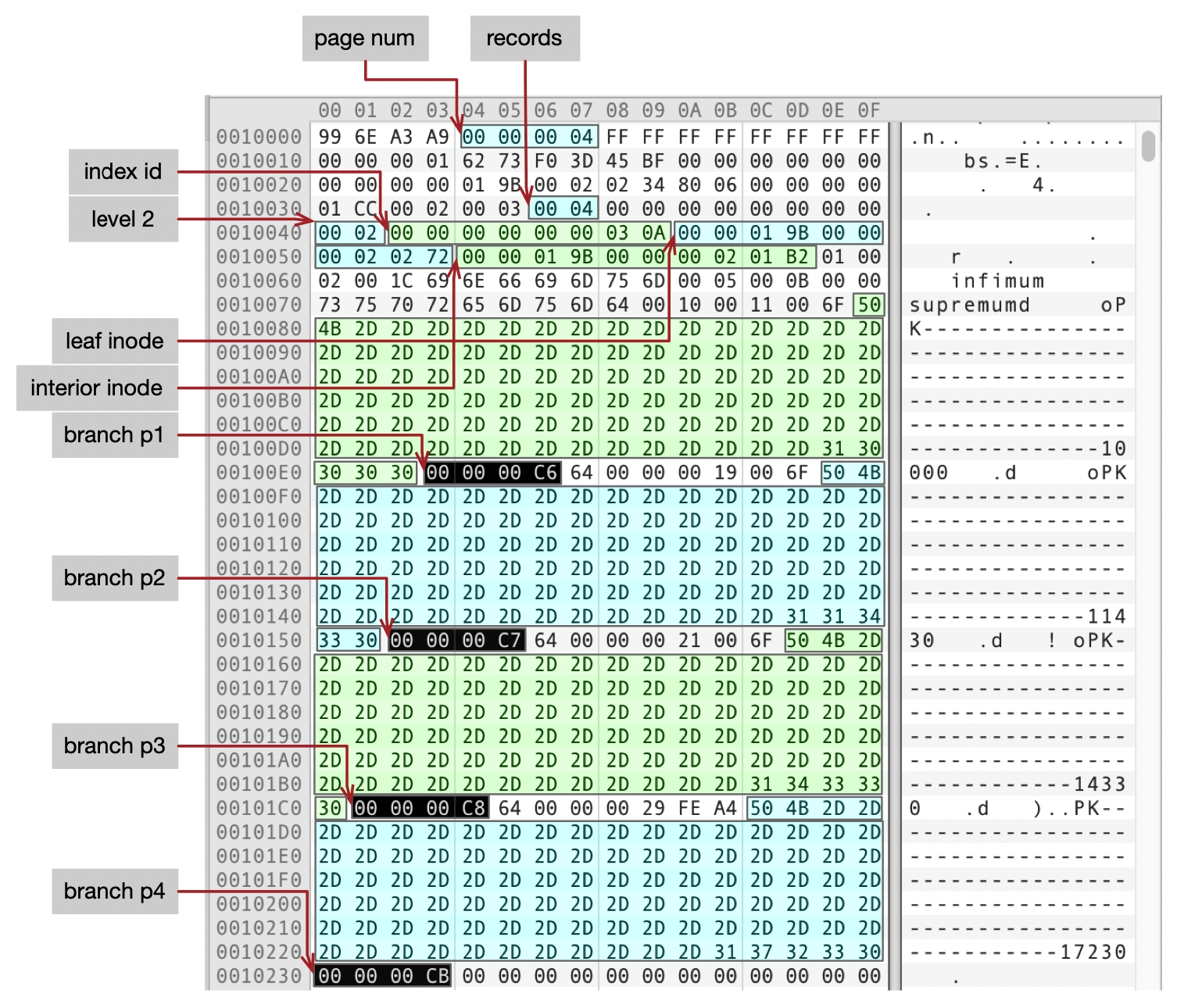
- index id为0x030A,也就是778,和元数据中查到的一样。
- level为2,这棵B+树的高度为3层。
- leaf inode和interior inode分别记录了叶子页面和分支页面所在段(Segment)的段描述符(inode)的地址。inode的作用稍后再介绍。
- 根页面中有4条索引记录,分别是(PK-10000,Page C6)、(PK-11430,Page C7)、(PK-14330,Page C8)、(PK-17230,Page CB)。
Branch
从根页面,我们得到了分支页面的编号,我们来看一下其中一个分支页面Page C6的内容。
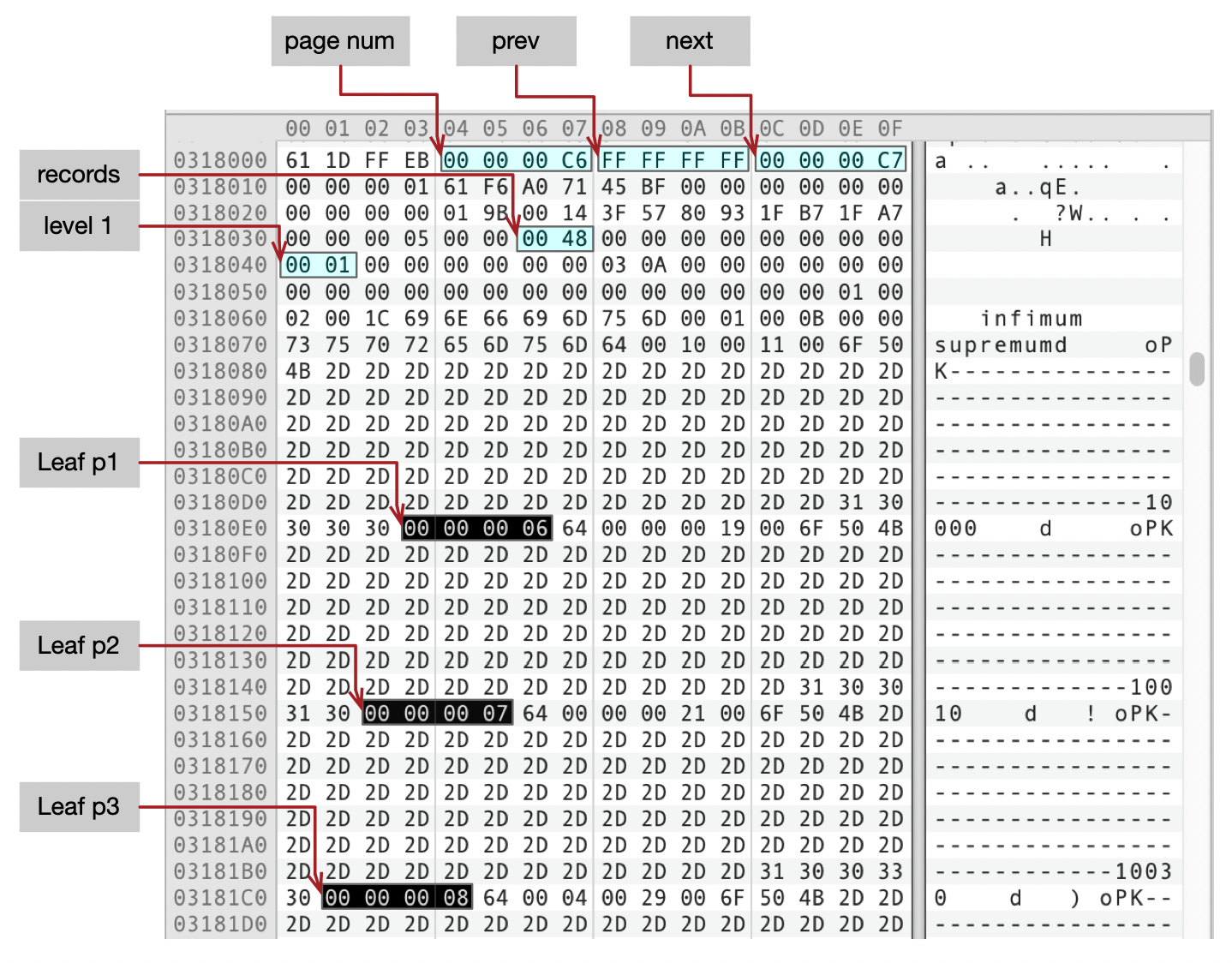
- Level为1。
- Prev为null,说明这是Level 1中的第一个页面。Next为Page C7。
- records为0x48,说明页面中有72条索引记录。
- 图中展示了部分索引条目,分别是(PK-10000,Page 06),(PK-10010,Page 07),(PK-10030,Page 08)。
Leaf
从分支页面中,我们知道了叶子页面的编号,我们来看一下页面07的内容。
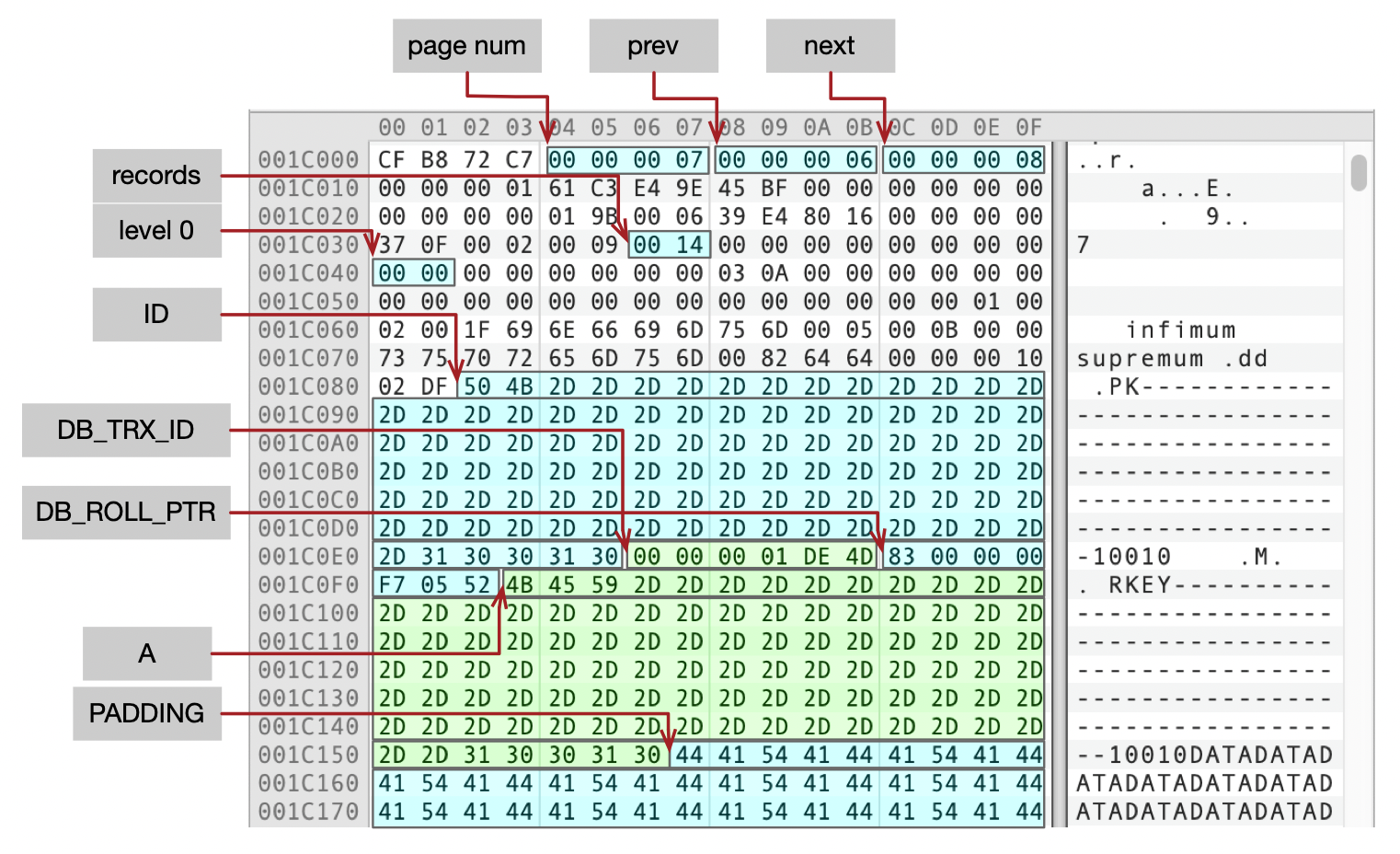
- Level为0,说明这是一个叶子页面。
- records为0x14,说明页面内有20条记录。因为每行记录比较长,页面内只存了20条记录。
- Prev为Page 06,Next为Page 08,分别指向当前页面的前后相邻的页面。
- 每行数据的字段依次为(ID,DB_TRX_ID,DB_ROLL_PTR,A,PADDING),和我们从数据字典中查到的一样。
如果把整个聚簇索引画出来,大概就是下面这个图。
二级索引结构
我们再来看一下二级索引的物理结构。先从根页面开始。
ROOT
我们已经从数据字典中查到,索引idx_a的根页面为Page 05。下图就是Page 05的内容。
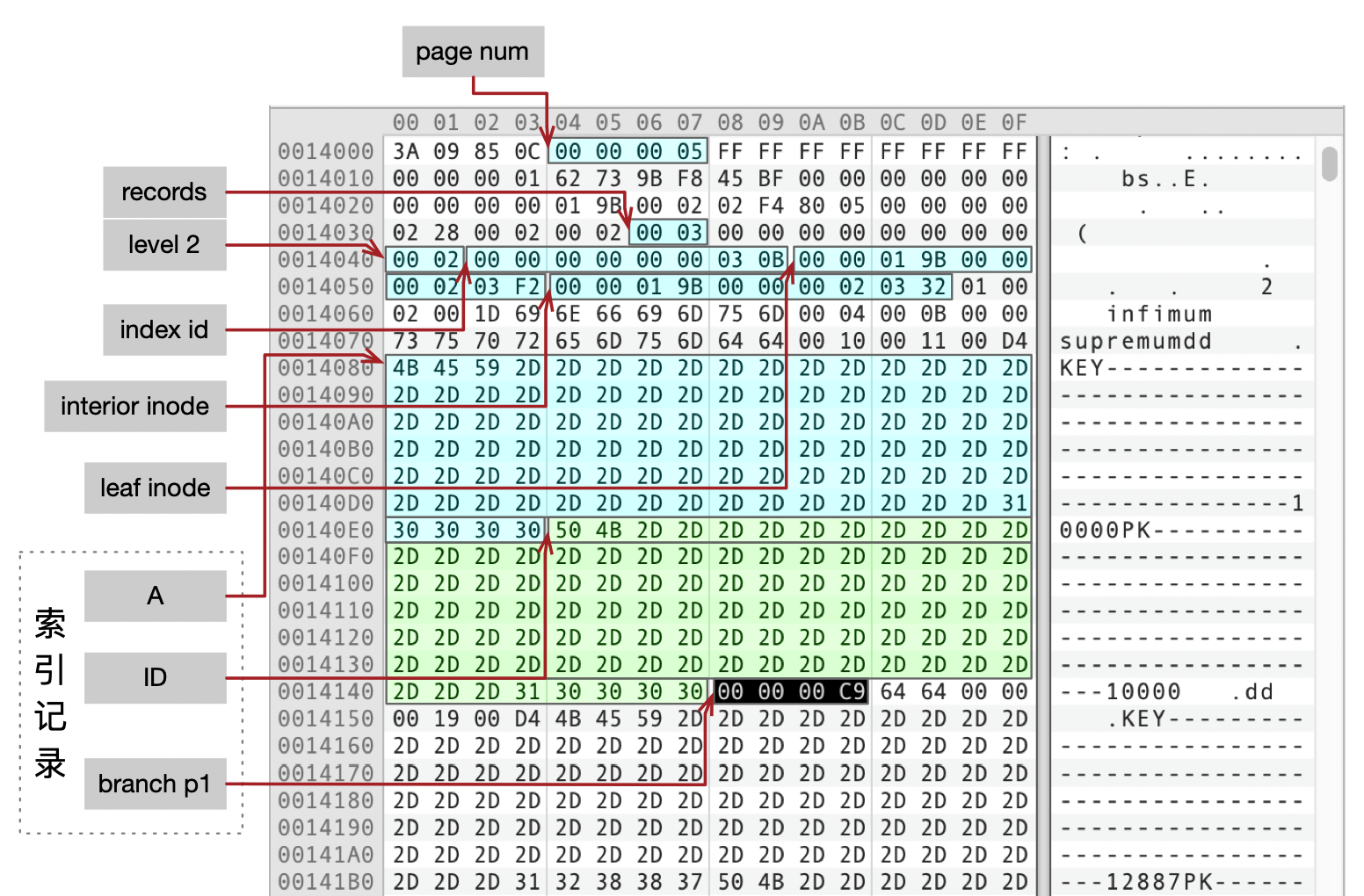
Branch
下图展示了第一个分支页面Page C9的内容。
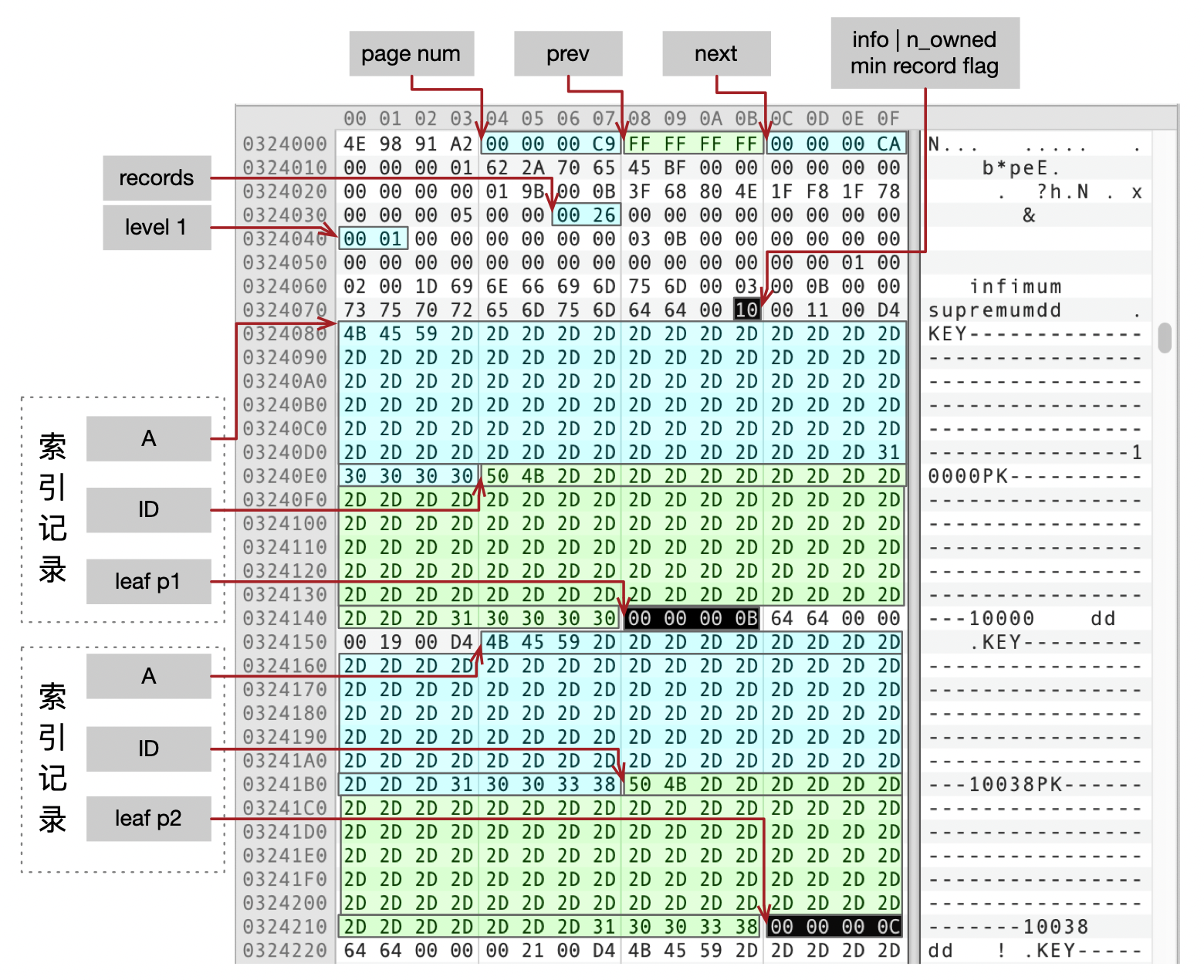
- prev为空,next指向Page CA。
- records为0x26,说明页面内有38条记录。
- level为1。
- 索引记录由字段A、ID和指向叶子页面的编号组成。图中显示了两条索引记录,分别是(KEY-10000,PK-10000,Page 0B)和(KEY-10038,PK-10038,Page 0C)。
Leaf
叶子页面Page 0B的内容展示在下面这个图中。
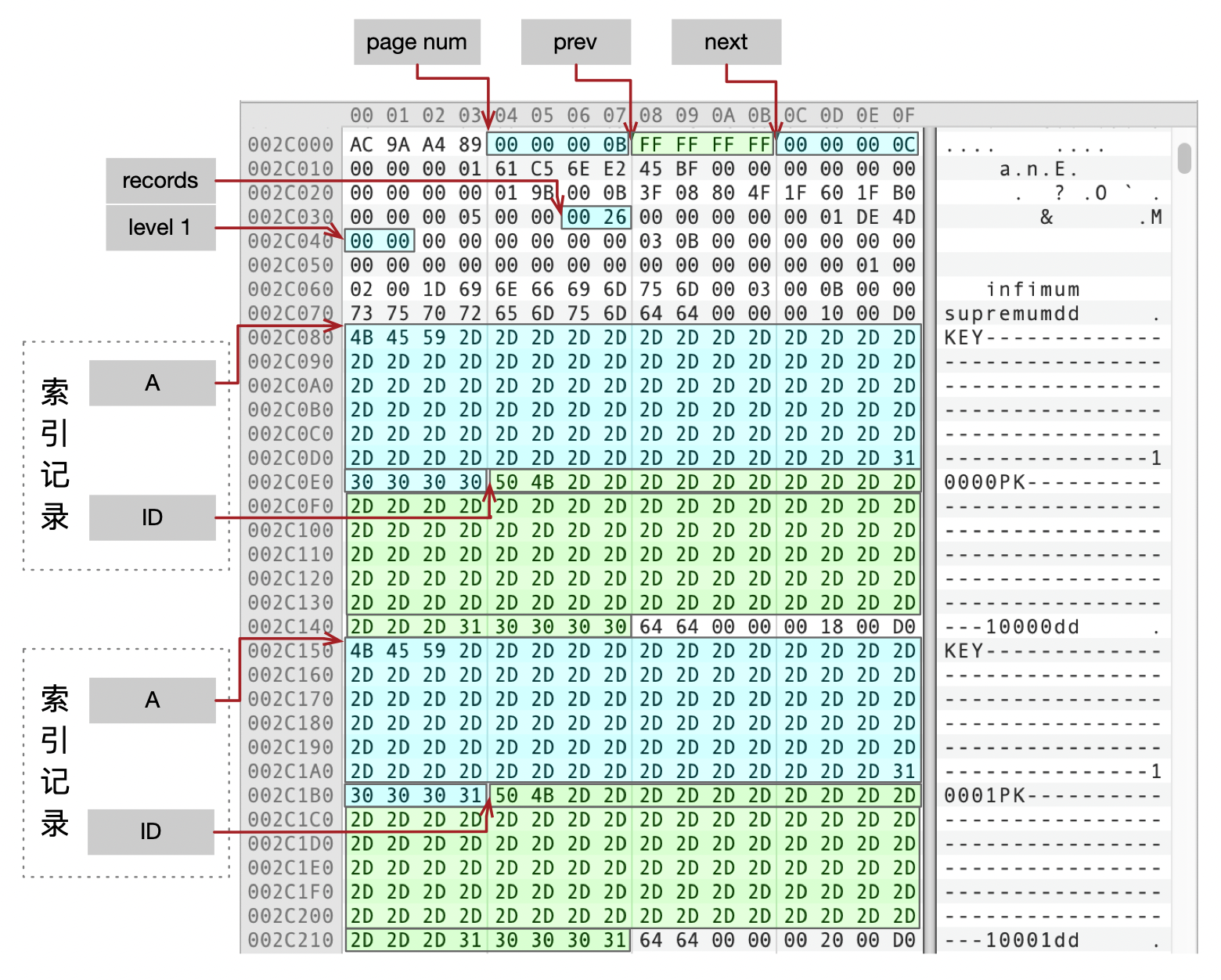
- Prev为null,next指向页面Page 0C。
- records为0x26,页面内有38条记录。
- level为0,说明是叶子页面。
- 图中有两条索引记录,分别是(KEY-10000,PK-10000)和(KEY-10001,PK-10001)。
段空间管理
InnoDB每个索引都由2个段(Segment)组成,在索引的根页面中,记录了这2个段的段描述符的地址。测试表t_btree的两个索引的段描述符地址我整理到了下面这个表格中。
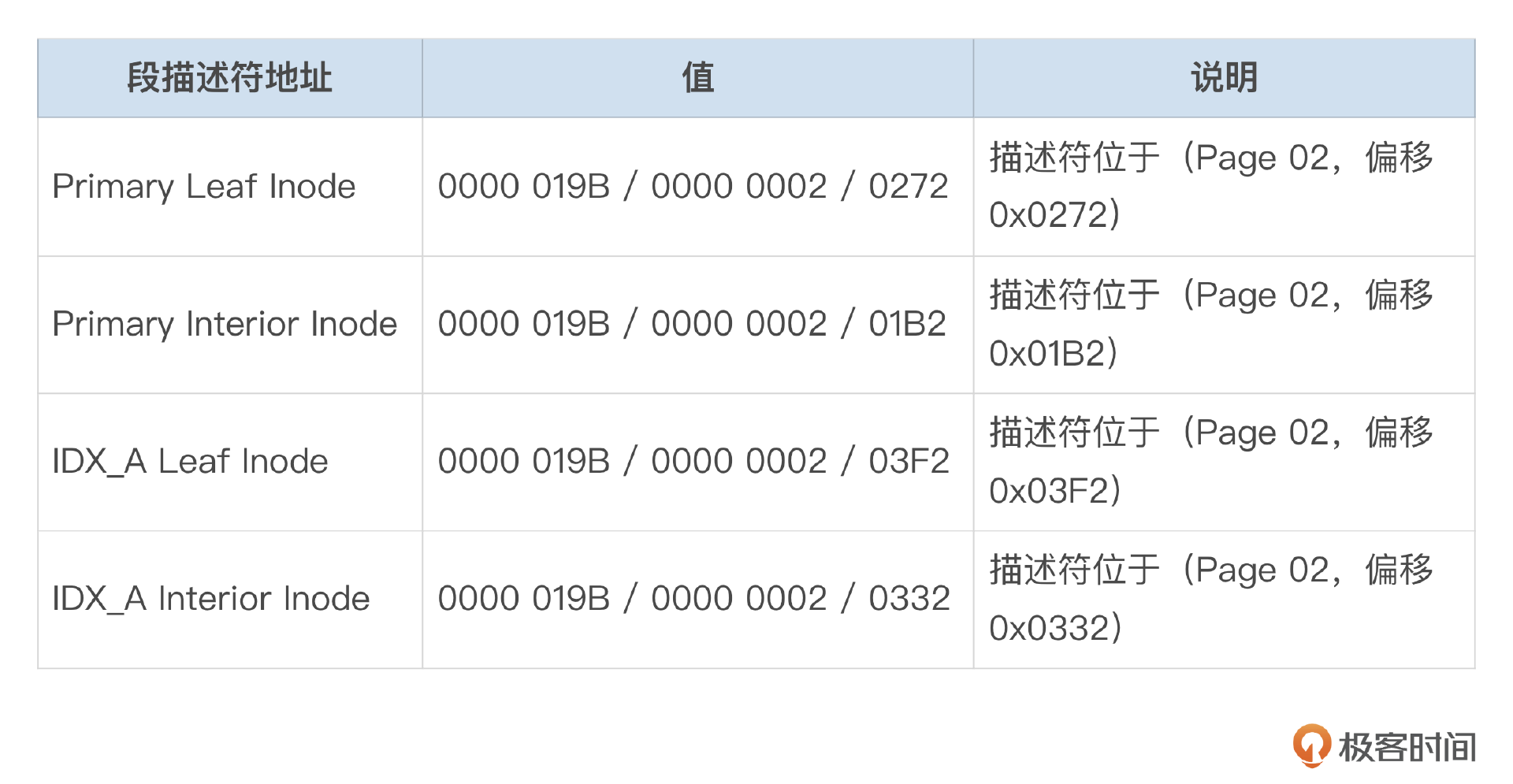
段描述符(INODE)
InnoDB使用段来管理空间,段描述符(inode)记录了段的相关信息,inode中的信息我整理到了下面这个表格中。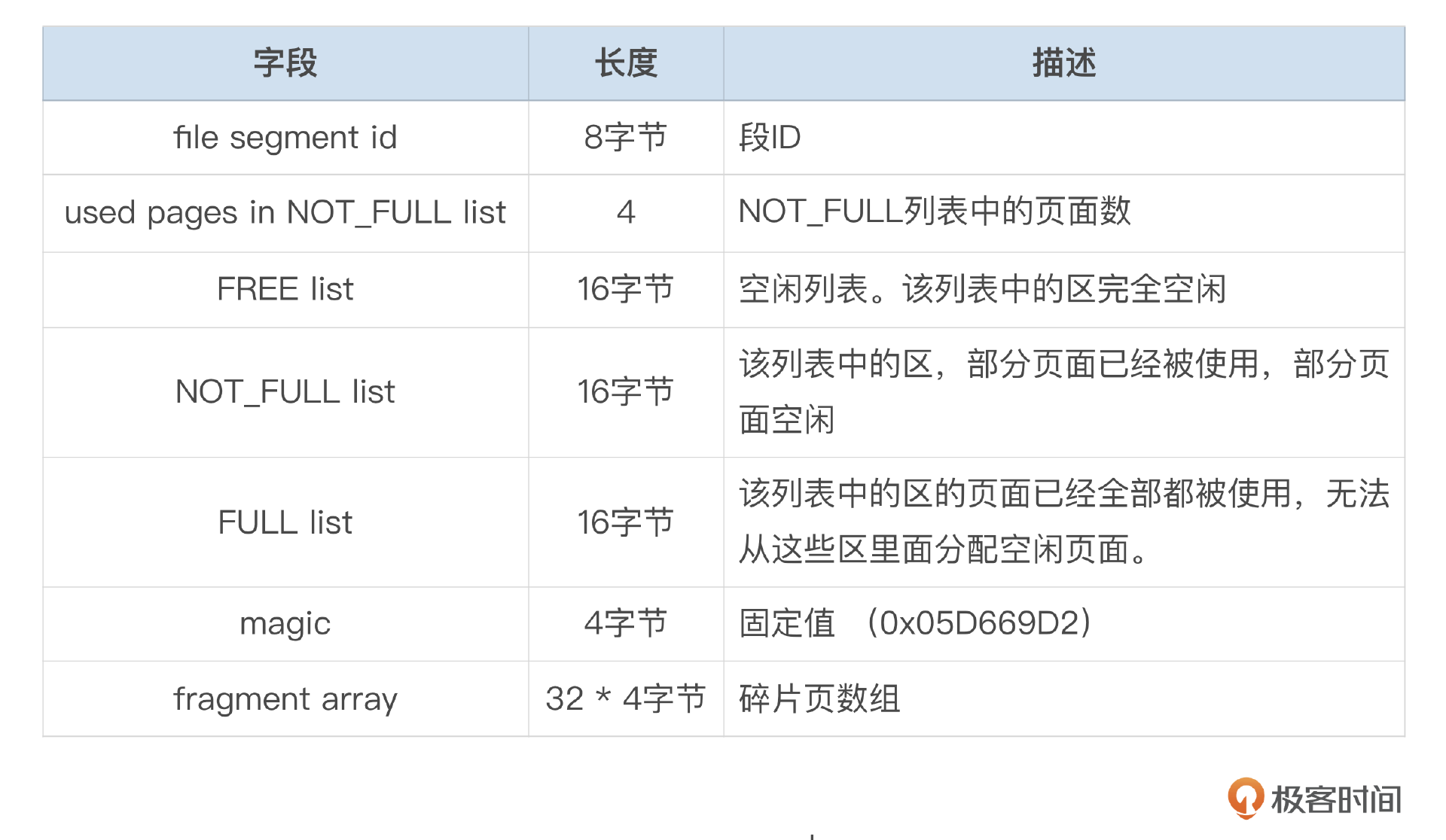
下面这个图里面,展示了聚簇索引的2个段的描述符。
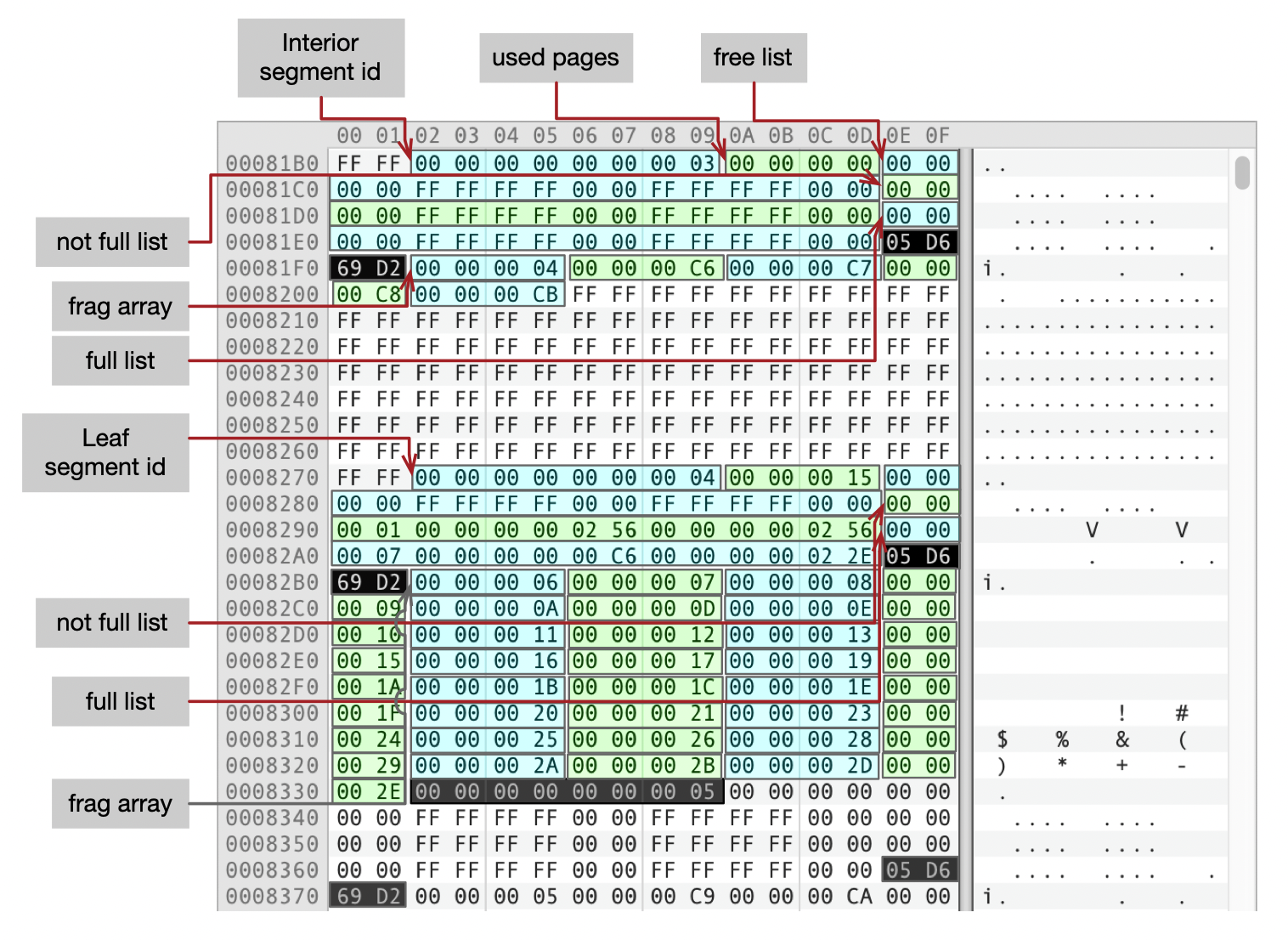
- 聚簇索引跳转页面段的ID为3,段内总共有5个页面(包括根页面),编号分别是04、C6、C7、C8、CB。 这和我们在聚簇索引根页面中看到的一致。
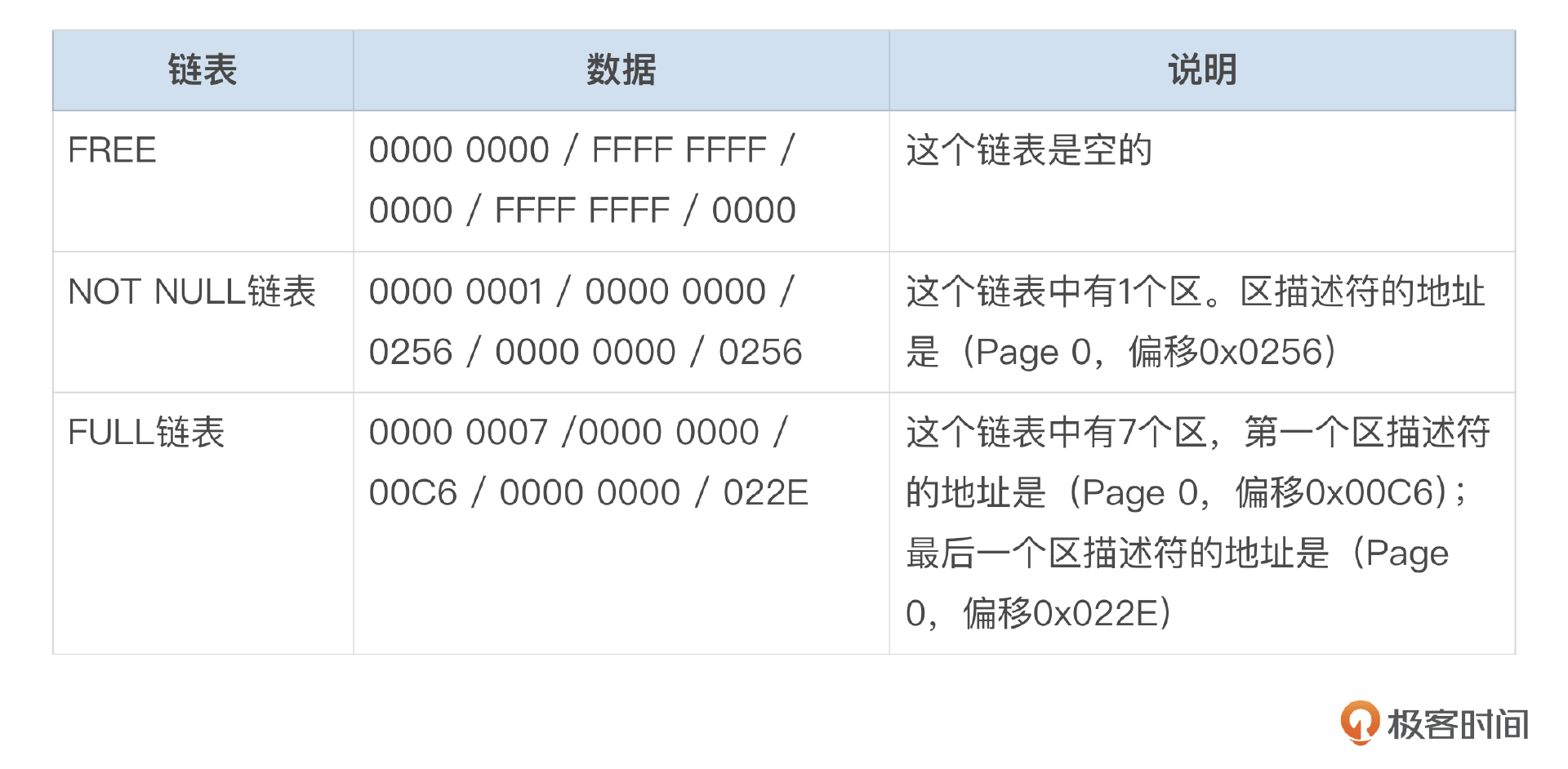
- 聚簇索引叶子页面段ID为4。Not Full链表中有一个区(Extent),使用了15个页面。Full链表中有7个区(Extent)。
数据文件中的区(Extent)可分为两种类型,一种是常规的区,常规的区最多只能分配给1个段使用。还有一种称为碎片区,碎片区的页面可以分配给不同的段使用。
为什么要这么设计呢?因为对于小表,记录数很少,如果给这些表分配一个完整的区(1M),就会浪费空间。另外,对于一些特殊类型的段,比如回滚段,对于小事务而言,每个回滚段需要的空间很小,如果分配一个完整的区,会浪费大量空间。
给段分配空间时,先会从碎片区中分配页面,这些页称为碎片页,页面编号会记录到INODE的碎片页数组中。只有分配给一个段的碎片页数量达到32之后,才会分配完整的区。
每个段里面,所有的区组成了3个链表。
- Free链表:这个链表中的区是完全空闲的。
- Not Full链表:这个链表中的区,部分页面已经分配,其他页面是空闲的。
- Full链表:这个链表中的区,所有的页面都已经分配。
数据文件中的链表结构
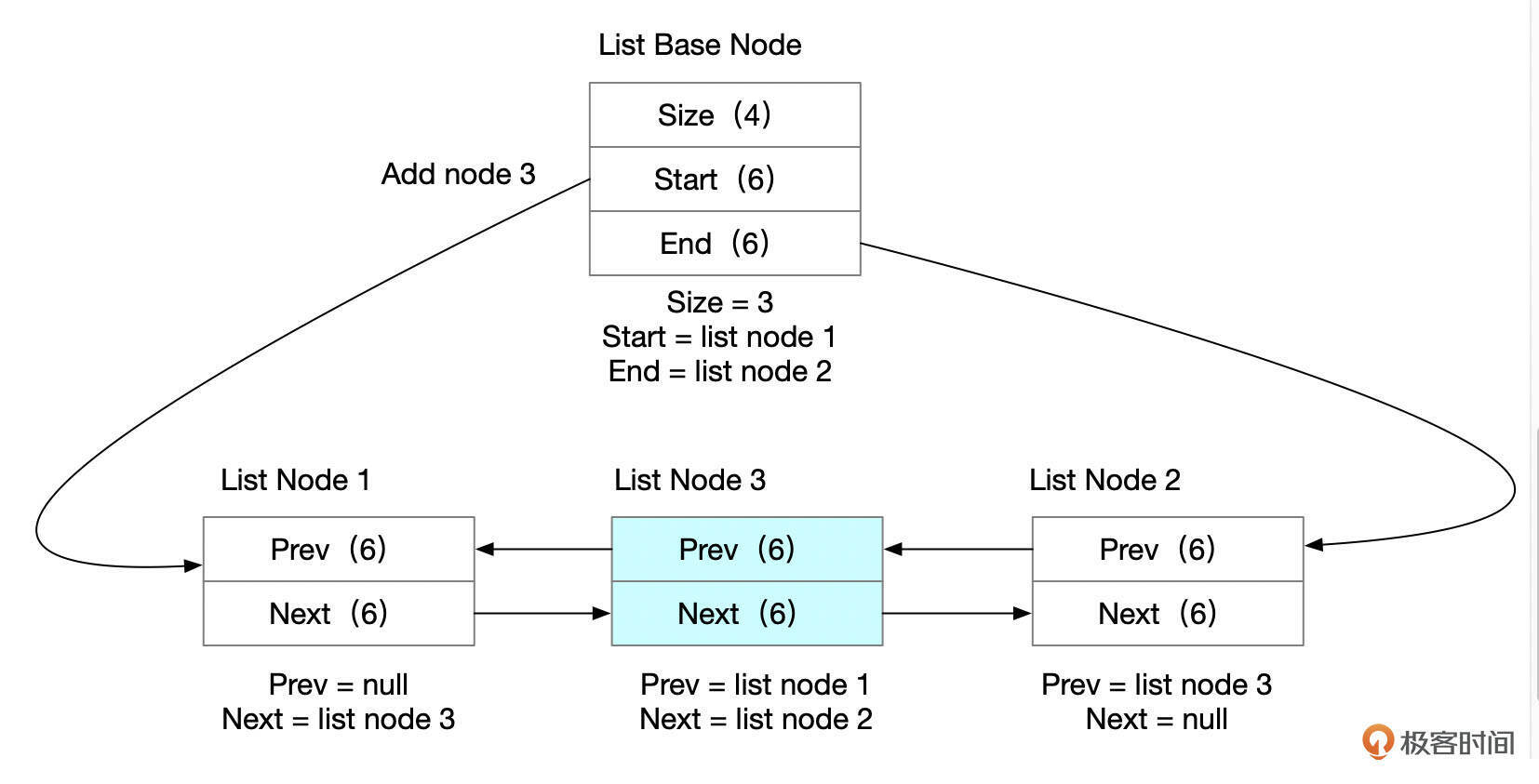
InnoDB的数据文件中存在大量双向链表结构,这些链表结构上是一样的,都由链表基节点和链表节点组成。链表基节占用16字节,由下面这3个字段组成。

链表节点占用12个字节,由下面这2个字段组成。
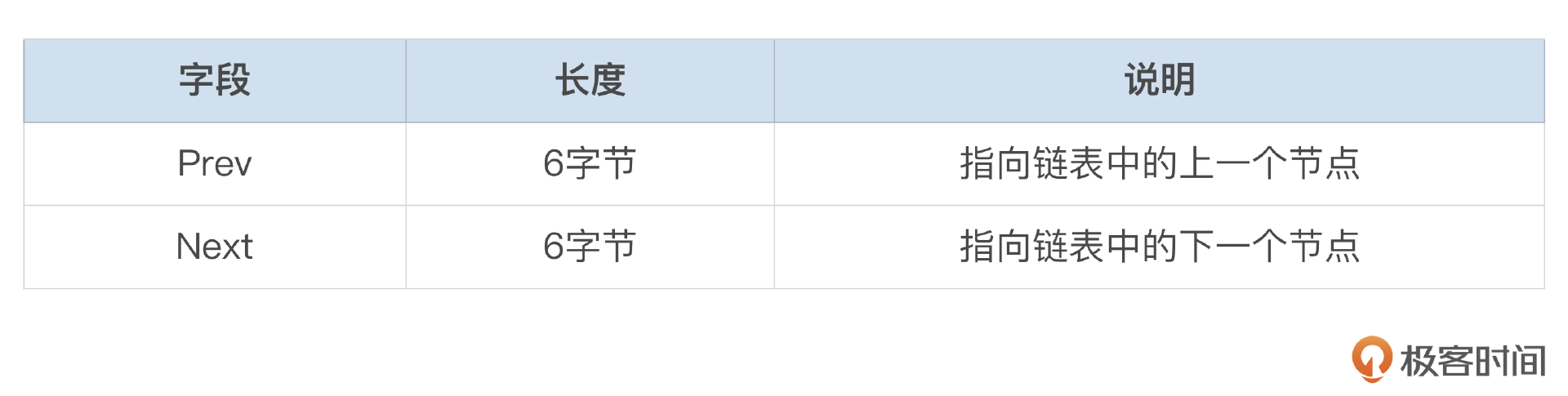 下图是InnoDB物理文件中双向链表的一个示意图,基节点中记录了链表头部节点和尾部节点,所有节点通过prev和next指针连接在一起。
下图是InnoDB物理文件中双向链表的一个示意图,基节点中记录了链表头部节点和尾部节点,所有节点通过prev和next指针连接在一起。
我们来看一下测试表t_btree聚簇索引Leaf段中的几个链表。
我们来看一下FULL链表在物理文件中的存储方式,下面这个图中,标注了Full链表中的区描述符。
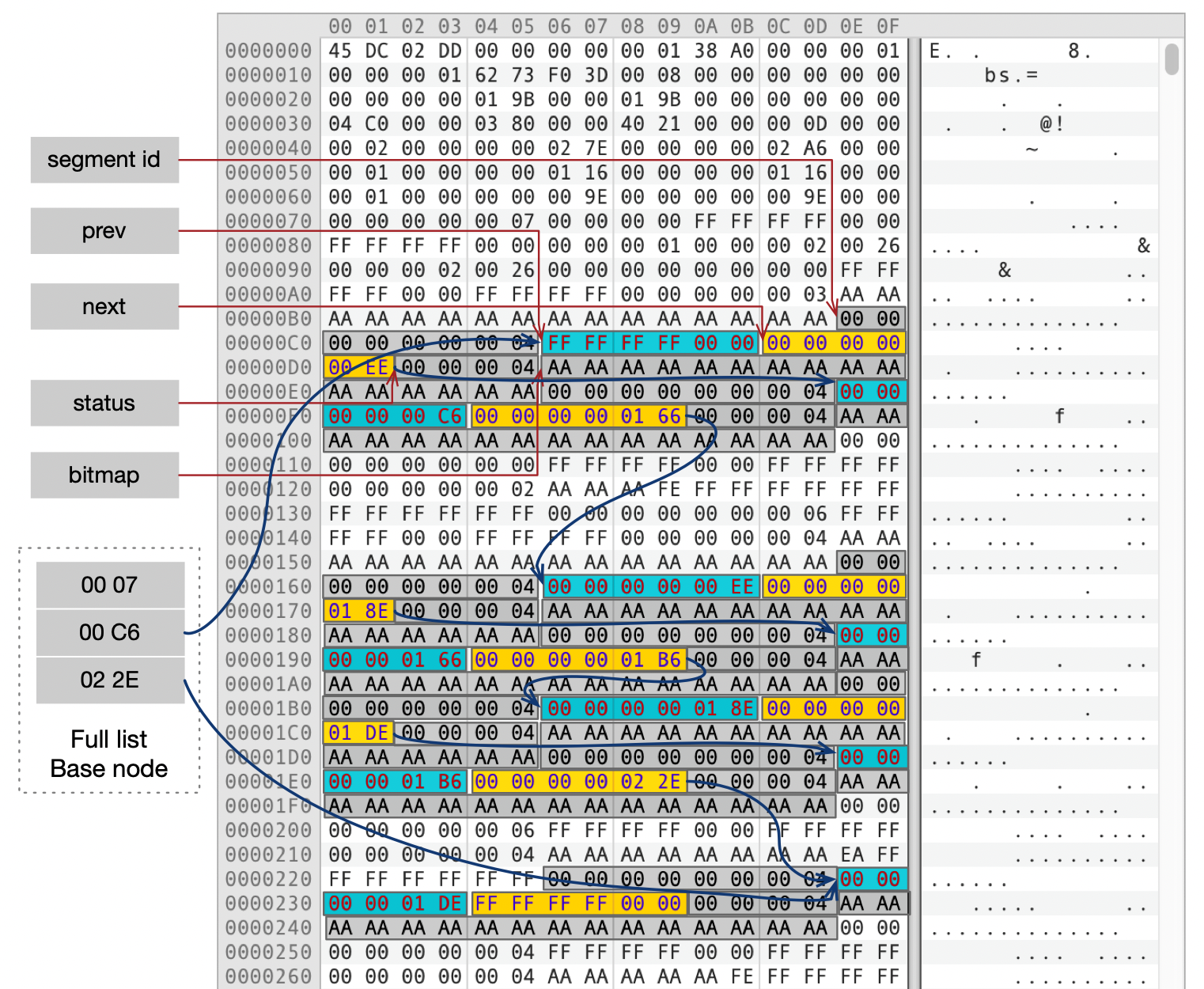
- segment id为4。
- prev和next指向链表中相邻的区。
- status是区的状态。
- bitmap中记录了区中每一个页面的状态,一个区有64个页面。
关于区描述符的更多信息,后面我还会详细介绍。
将Full链表中的所有区都整理出来,可以得到下面这个图。
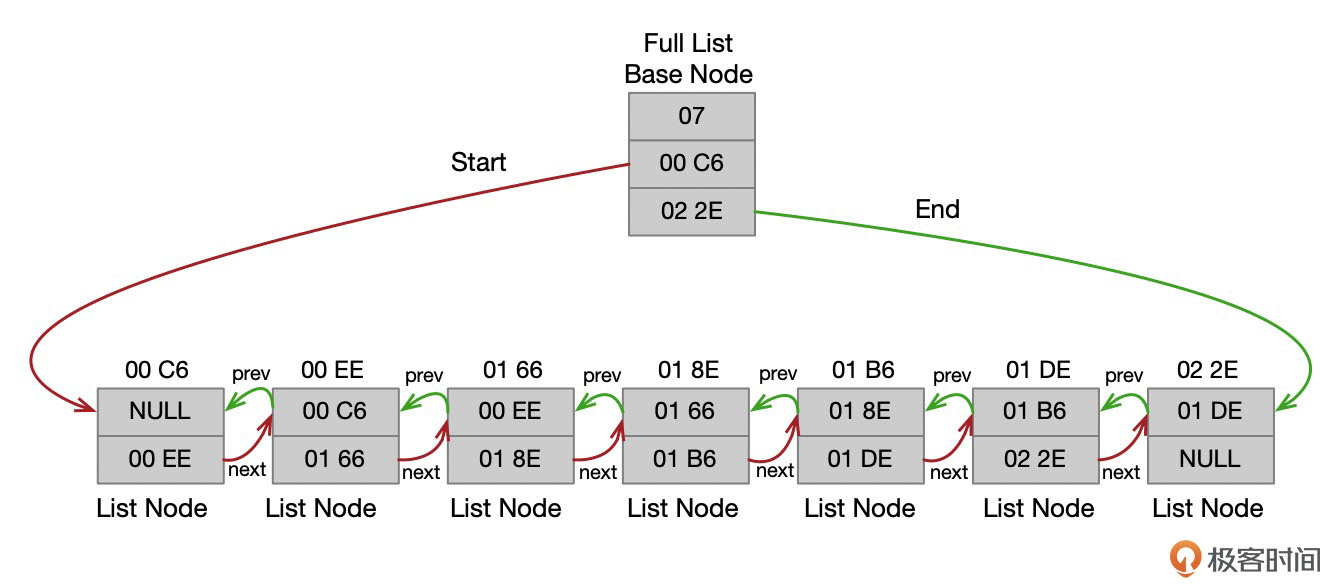
表空间管理
最后,我们来看一下InnoDB是怎么管理空间的。InnoDB中,表和索引数据都存储在表空间中。从系统表information_schema.innodb_tablespaces可以查看当前数据库中的所有表空间。
mysql> select space, name, row_format, space_type
from information_schema.innodb_tablespaces
order by space;
+------------+---------------------+----------------------+------------+
| space | name | row_format | space_type |
+------------+---------------------+----------------------+------------+
| 1 | sys/sys_config | Dynamic | Single |
| 3 | hello/test | Dynamic | Single |
| 4294967277 | undo_x001 | Undo | Undo |
| 4294967278 | innodb_undo_002 | Undo | Undo |
| 4294967279 | innodb_undo_001 | Undo | Undo |
| 4294967293 | innodb_temporary | Compact or Redundant | System |
| 4294967294 | mysql | Any | General |
+------------+---------------------+----------------------+------------+
表空间分为几种不同的类型,我整理成了下面这个表格。

InnoDB数据文件格式
InnoDB中,除了系统表空间,其它每个表空间都是由1个数据文件组成。
数据文件有固定的格式,每个数据文件被分割为固定大小的页(Page),相邻的页组成区(Extent)。表和索引的数据通过段(Segment)来组织,每个段由一些页和区组成。
Page
InnoDB以Page为最小单位来分配空间,每个Page的大小由参数innodb_page_size指定。该参数只能在数据库初始化之前配置,数据库初始化完成后,不能再修改。InnoDB Page大小可设置为4K、8K、16K、32K或64K,默认为16K。后续我们以16K的Page大小来分析。
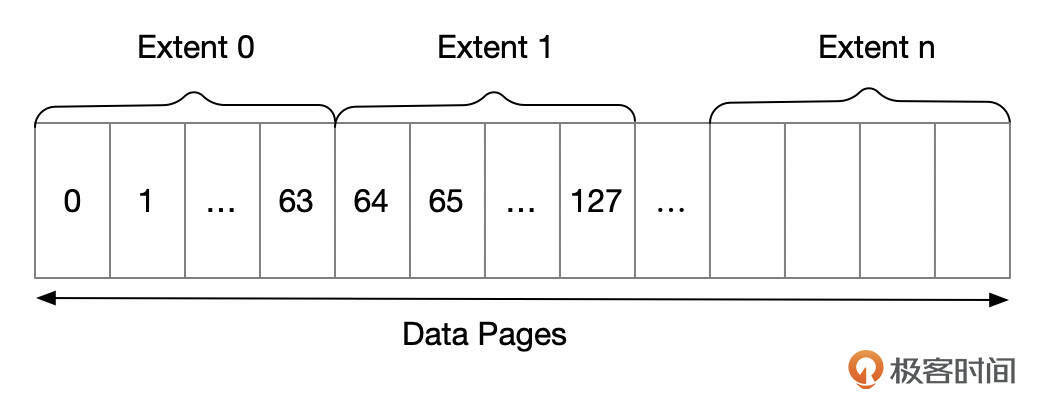
Extent
InnoDB将相邻的页面组成一个区(Extent),每个区的大小固定,具体大小和页的大小有关。对于16K的页面大小,一个区由64个页面组成,大小为1M。
Segment
InnoDB中每一个索引(包括聚簇索引)都由2个段(Segment)组成。索引中所有的叶子页面组成一个段,其他页面组成一个段。每个段由页面(Page)和区(Extent)组成。
数据文件的第一个页面称为文件头(FSP Header),里面存储了整个表空间的相关信息。文件头的具体存储格式,可以参考下面这个图和表格。
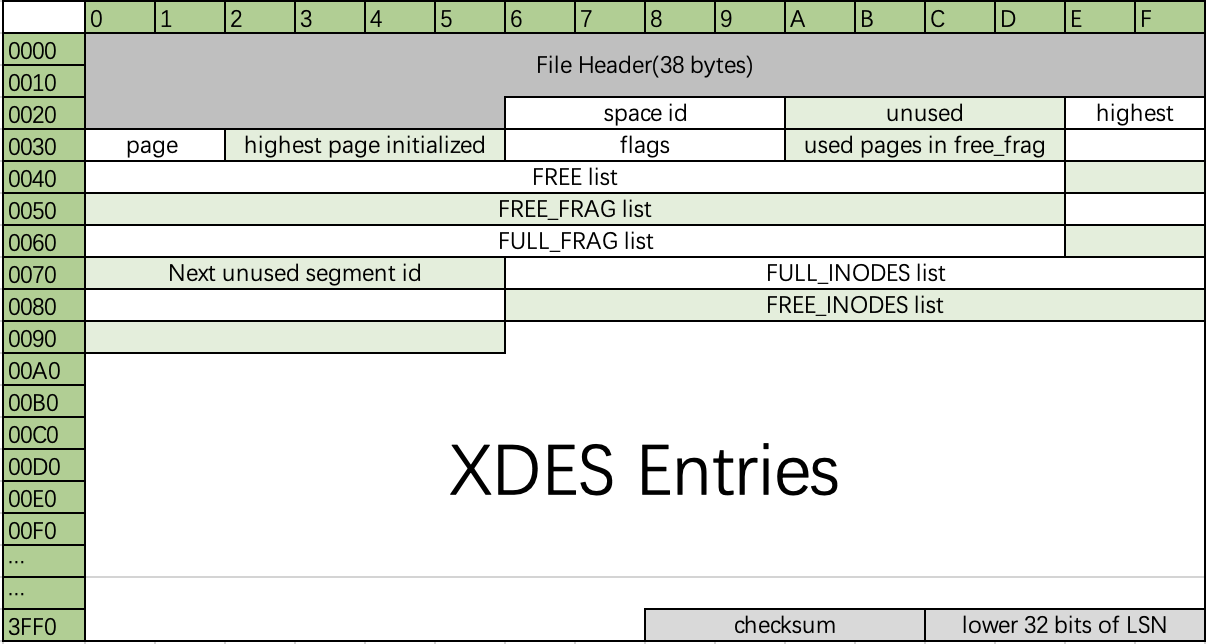
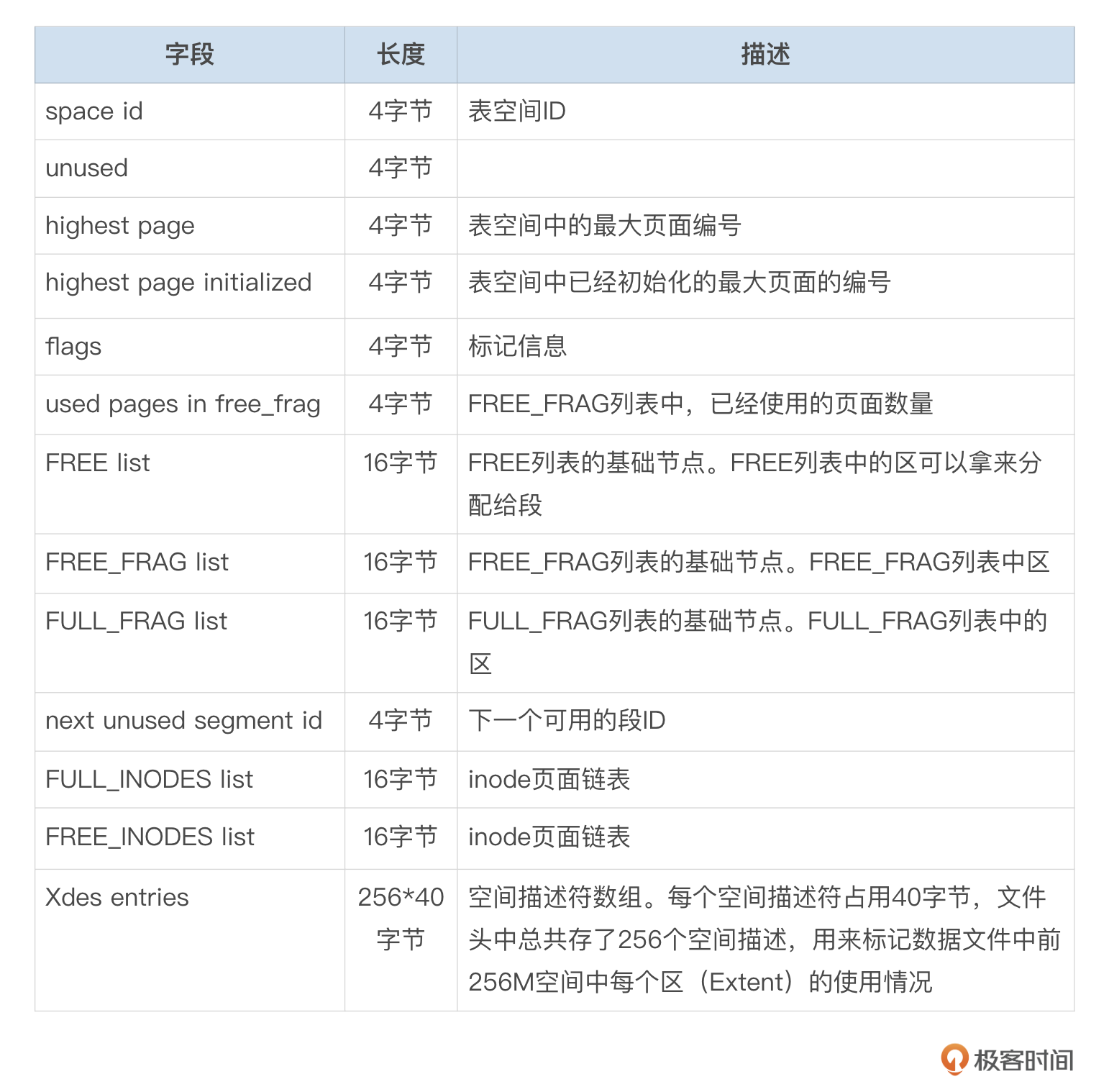
表空间文件分为3个区域,FSP Header中的highest page initialized和highest page字段分别记录已初始化空间和未初始化空间的最大页面编号。
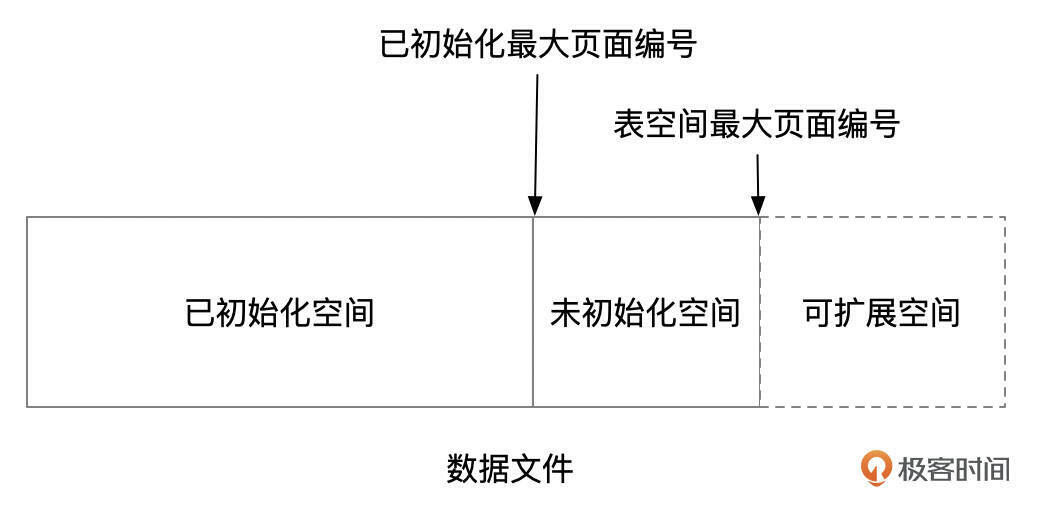 已初始化空间区域内的区(Extent),要么加入到FSP Header头部的3个链表中,要么已经分配给某个段(Segment)。未初始化空间区域内的区还没有被格式化,也就是这些区还没有加入到任何链表中。当需要分配空间时,可以将这个区域内的区加入到FSP Header中的空闲列表中,然后再分配给某个表或索引。如果数据文件内的区都已经被使用,分配空间时就需要先扩充文件的长度。
已初始化空间区域内的区(Extent),要么加入到FSP Header头部的3个链表中,要么已经分配给某个段(Segment)。未初始化空间区域内的区还没有被格式化,也就是这些区还没有加入到任何链表中。当需要分配空间时,可以将这个区域内的区加入到FSP Header中的空闲列表中,然后再分配给某个表或索引。如果数据文件内的区都已经被使用,分配空间时就需要先扩充文件的长度。
FSP Header维护了几个重要的链表。
- FREE链表
位于FREE链表中的区完全空闲。当需要分配一个完整的区时,从FREE链表中获取。如果FREE链表中没有可分配的区,则需要将未初始化空间中的区加入进来,或者扩展文件后再将区加入进来。
- FREE_FRAG链表
InnoDB将区(Extent)分成两种不同的类型:普通的区和碎片区。普通的区是指分配时分配空间时,将整个区分配给某个段。而碎片区会以页为单位,每次只将1个页分配给某个段。这么设计的原因,前面已经讲过了,主要是为了节省空间。
分配碎片页时,先从FREE_FRAG列表中获取一个碎片区,然后在碎片区中获取一个空闲的页面进行分配。如果碎片区中的所有页都已经分配完,则会将该碎片区移到FULL_FRAG链表中。如果FREE_FRAG链表中没有碎片区可用,则需要从FREE链表中获取一个空闲的区加入进来。
- FULL_FRAG链表
FREE_FRAG链表中的碎片区,当页面都已经分配后,就会移到FULL_FRAG链表中。FULL_FRAG链表中的区,如果有页被释放,则会移到FREE_FRAG链表中。
- FREE_INODES链表
INODE用来跟踪段的空间使用情况。每一个段都有一个对应的INODE结构。InnoDB使用专门的页面来存储INODE信息,而FREE_INODES链表将还有空闲INODE的页面链接在一起。InnoDB创建段的时候,需要从FREE_INODES列表中找到一个Inode页面,然后从页面中找到一个未被使用的INODE。
如果FREE_INODES列表中没有可用的页面,则需要重新分配一个空闲的页面,将页面格式化后加入到链表中。如果一个Inode页面中的Inode都已经被分配,则需要将该Inode页面移到FULL_INODES链表中。
- FULL_INODES链表
FULL_INODES链表用来跟踪已经完全被使用的INODE页面。
区描述符(Extent Descriptor,XDES)
区描述符记录了区的使用情况。数据文件中每一个区都有一个对应的区描述符(XDES)。每一个区描述符占用40字节,具体信息可以参考下面这个表格。
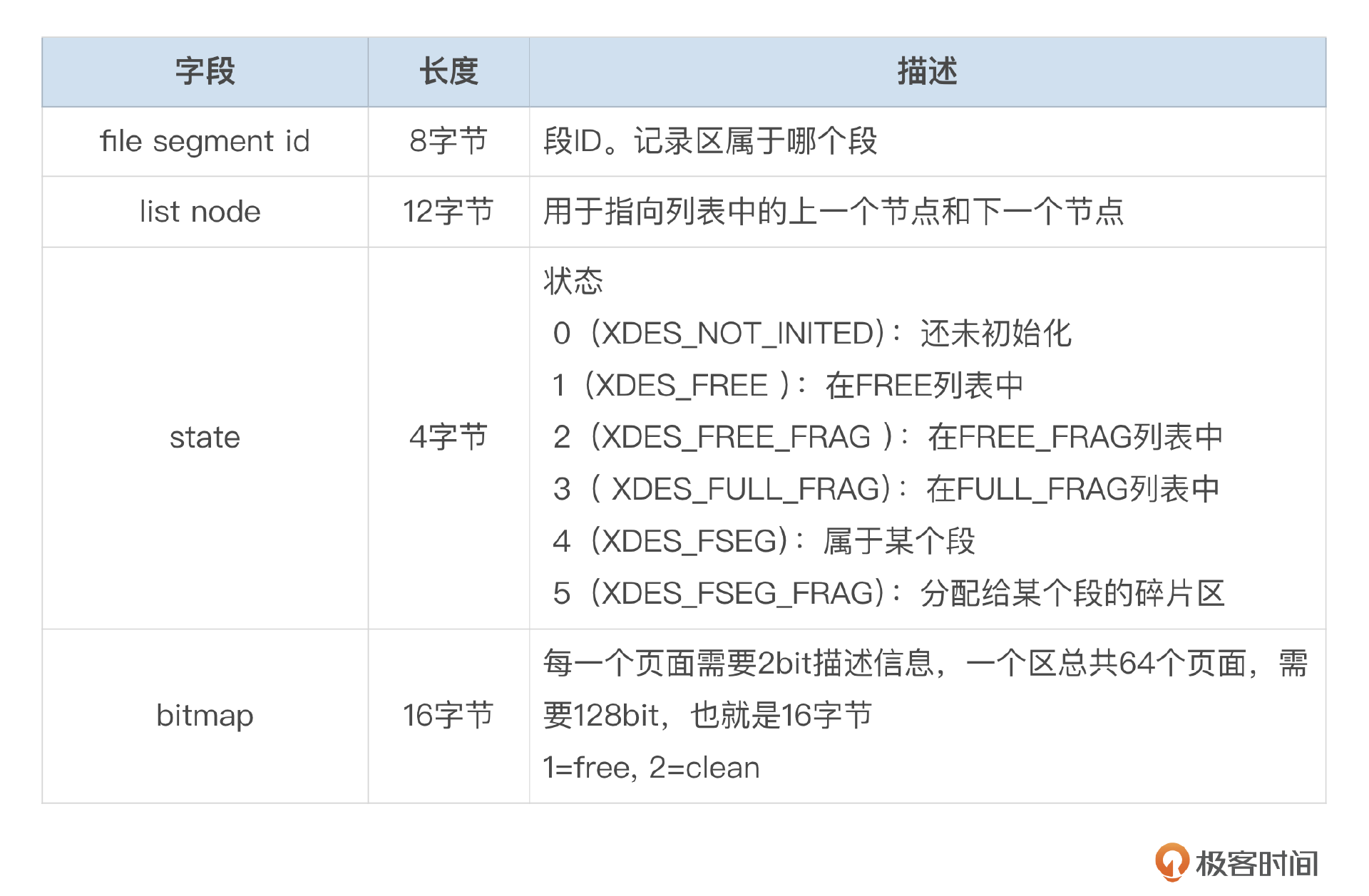
FSP HEADER中,存储了256个区描述符,可以管理256M空间。如果数据文件超过256M,则每256M的第一个页面都会用来存储区描述符。
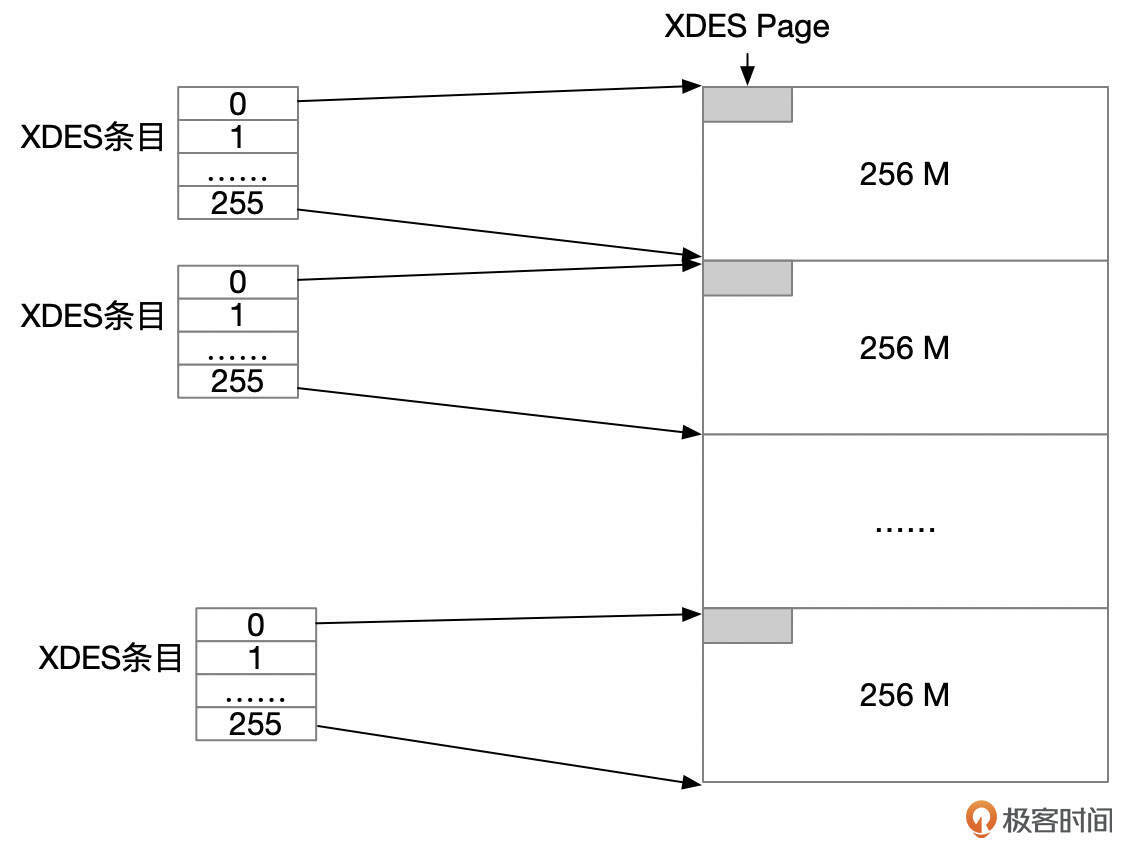 数据文件中,每256M空间开头的第一个区有点特殊,因为这些区的第一个页面总是用来存放区描述符,第二个页面总是用来存放ibuf位图信息,因此这些区都是碎片区。
数据文件中,每256M空间开头的第一个区有点特殊,因为这些区的第一个页面总是用来存放区描述符,第二个页面总是用来存放ibuf位图信息,因此这些区都是碎片区。
我把测试表的第一个页面放在了下面这个图中,对一些重要的字段做了标注。
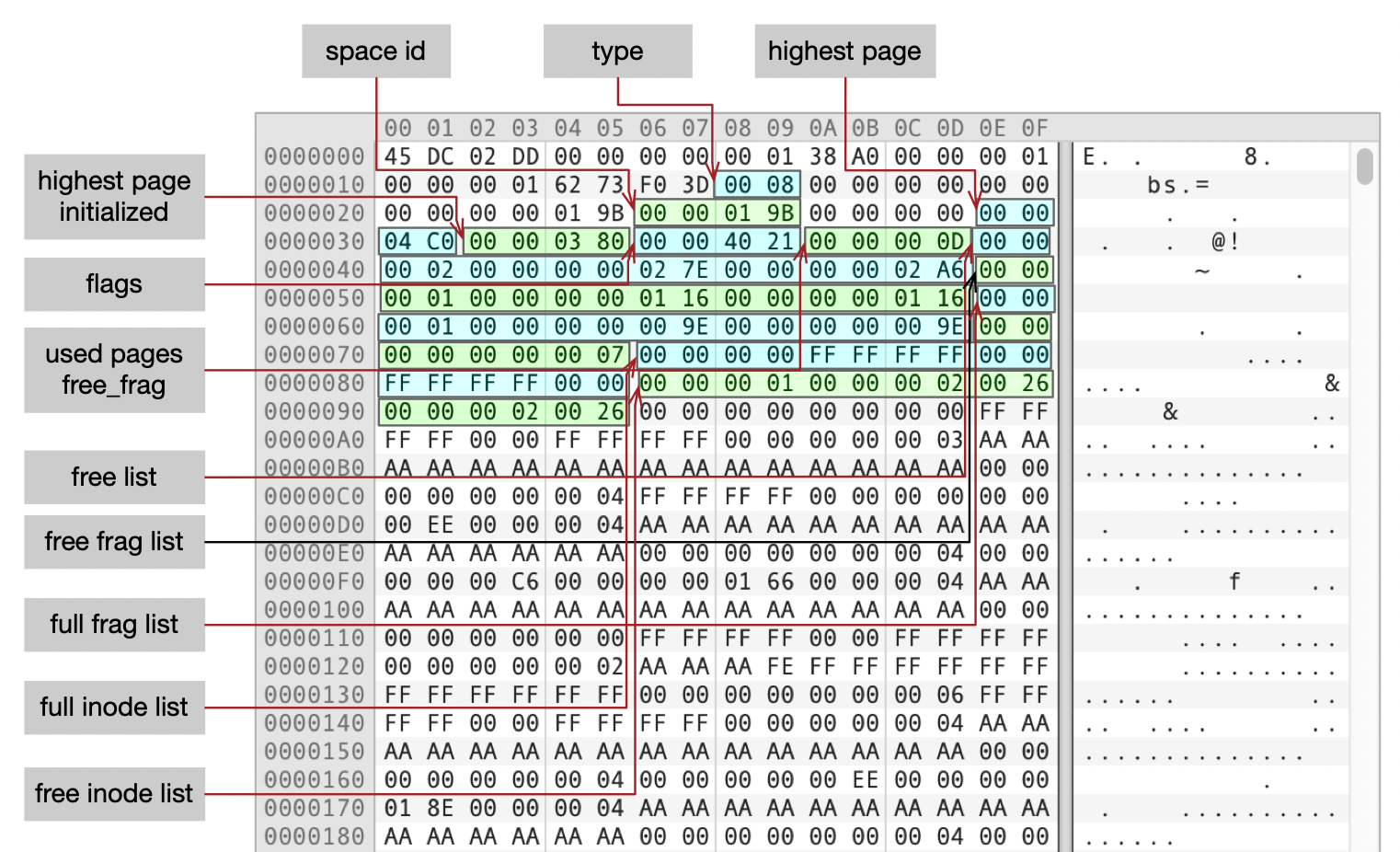
- type为8,也就是FIL_PAGE_TYPE_FSP_HDR。
- highest page为0x04C0,转换字节数是0x4C0 * 16K = 19M,刚好是ibd文件的大小。
- highest page initialized为0x0380。
- free list、free frag list、full frag list分别是三个链表。
- full inode list是空的。
- free inode list中有一个节点,指向(页面Page 2,偏移0x0026)。
Page 2是一个Inode页面,页面内容参考下面这个图。

- type为3,也就是FIL_PAGE_INODE
- prev和next分别指向相邻的Inode页面,这里只有一个inode页面,所以prev和next都为空。
- 图片中还展示了3个段描述符,segment 1中只有一个页面,segment 2也是一个特殊的段,segment 3属于聚簇索引。
总结
这一讲中,我们通过一个具体的例子,解析了InnoDB聚簇索引和二级索引的存储格式,你可以看到,我们之前关于InnoDB表和索引结构的描述,都是有依据的。
我们还看到了InnoDB管理段和空间的一些数据结构,包括段描述符、区描述符、Inode页面。InnoDB数据文件中,藏着很多链表结构,有单向链表,还有双向链表,后续的课程中,还有更多的链表结构等我们去发现。
思考题
我们知道,在B+树中检索数据时,要先从根页面开始,数据字典表mysql.indexes记录了每个索引的根页面。
但是indexes本身也是一个InnoDB表,因此从indexes表检索数据时,需要先知道这个表的根页面编号,那么MySQL怎么知道indexes表的根页面编号是什么呢?
期待你的思考,欢迎在留言区中与我交流。如果今天的课程让你有所收获,也欢迎转发给有需要的朋友。我们下节课再见!
- binzhang 👍(1) 💬(1)
为啥在二级索引的root和branch page上要存储主键列的值? 感觉没必要啊
2024-10-21 - 叶明 👍(0) 💬(1)
我觉得和系统表空间 ibdata1 有关系,系统表 mysql.indexes 在实例初始化时生成,其元数据信息(如根页面编号)可能被存储在系统表空间里,Innodb 在启动时可以直接访问这些位置,而不需要依赖数据字典。
2024-10-21