24 10+ SQL执行性能不佳的真实案例(下)
你好,我是俊达。这节课我们继续看剩下的几个案例。
案例七:优化or查询的另一个例子
下面是另一个在where中使用了or的例子,这个SQL的性能非常差,需要将3个表的数据全部关联起来。
SELECT t_msg.msg_id,t_msg.content , ......
FROM t_msg
LEFT JOIN t_user ON t_msg.user_id = t_user.user_id
LEFT JOIN t_group ON t_msg.group_id = t_group.group_id
WHERE t_msg.gmt_modified >= date_sub('2018-05-20 09:31:45', INTERVAL 30 SECOND)
OR t_user.gmt_modified >= date_sub('2018-05-20 09:31:45', INTERVAL 30 SECOND)
OR t_group.gmt_modified >= date_sub('2018-05-20 09:31:45', INTERVAL 30 SECOND)
业务的需求,是查询最近半分钟内发生过变化的数据。这个SQL的where条件中,用到了3个表的gmt_modified字段来过滤数据,而且这些条件使用or相连。看一下下面的示意图,业务关心的是新数据,每个表中,最近修改过的数据都只占了整个表数据的一小部分。而且t_user、t_group表的数据很少更新。但由于SQL的写法,每次都需要连接全量的数据,然后再过滤出一小部分数据,因此SQL的效率很低。
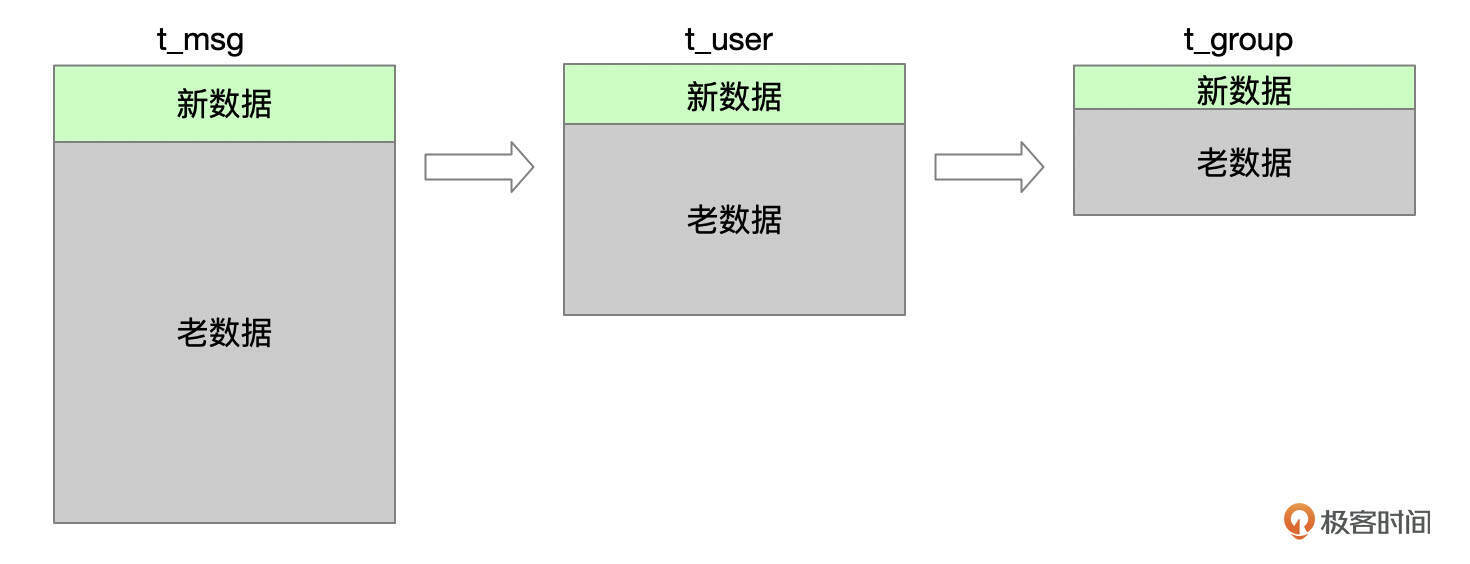
我们将SQL拆分成3个部分。
- SQL片段1
SELECT t_msg.msg_id,t_msg.content , ......
FROM t_msg
LEFT JOIN t_user ON t_msg.user_id = t_user.user_id
LEFT JOIN t_group ON t_msg.group_id = t_group.group_id
WHERE t_msg.gmt_modified >= date_sub('2018-05-20 09:31:45', INTERVAL 30 SECOND)
SQL片段1以t_msg表作为驱动表,先过滤出表中gmt_modified在半分钟之内的数据,然后再去连接t_user和t_group表,大大减少了连接的数据。
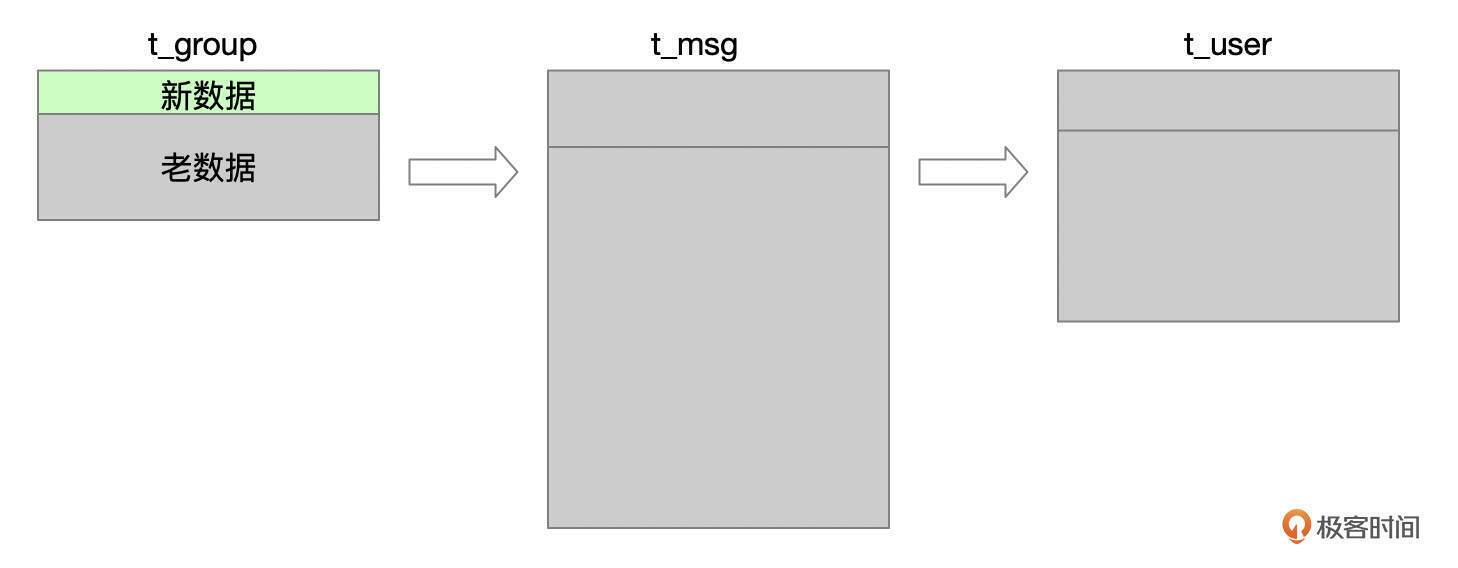
- SQL片段2
SELECT t_msg.msg_id,t_msg.content , ......
FROM t_msg
LEFT JOIN t_user ON t_msg.user_id = t_user.user_id
LEFT JOIN t_group ON t_msg.group_id = t_group.group_id
WHERE t_user.gmt_modified >= date_sub('2018-04-29 09:31:44', INTERVAL 30 SECOND)
SQL片段2中,对t_user表的left join等价于普通join。以t_user表为驱动表,先过滤t_user表最近修改过的数据,再去连接t_msg和t_group表。
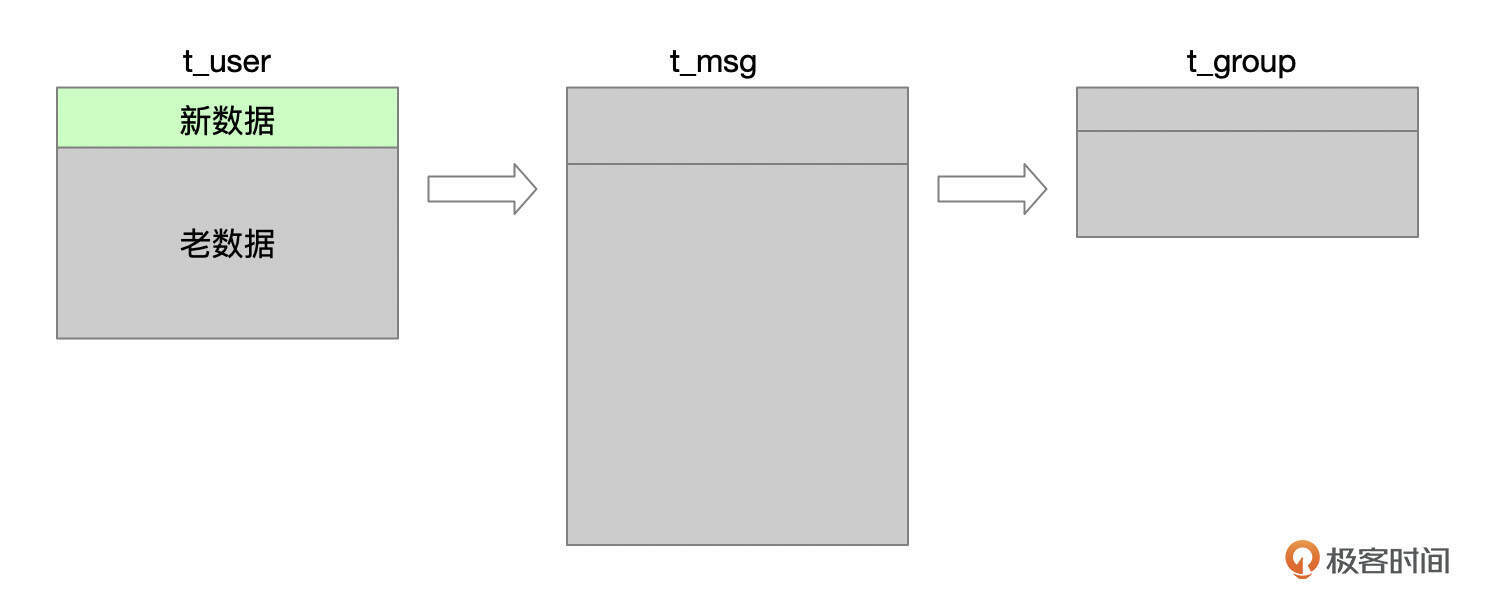
- SQL片段3
SELECT t_msg.msg_id,t_msg.content , ......
FROM t_msg
LEFT JOIN t_user ON t_msg.user_id = t_user.user_id
LEFT JOIN t_group ON t_msg.group_id = t_group.group_id
WHERE t_group.gmt_modified >= date_sub('2018-04-29 09:31:44', INTERVAL 30 SECOND)
SQL片段3中,对t_group表的left join等价于普通join。以t_group表为驱动表,先过滤t_group表最近修改过的数据,再去连接t_msg和t_user表。
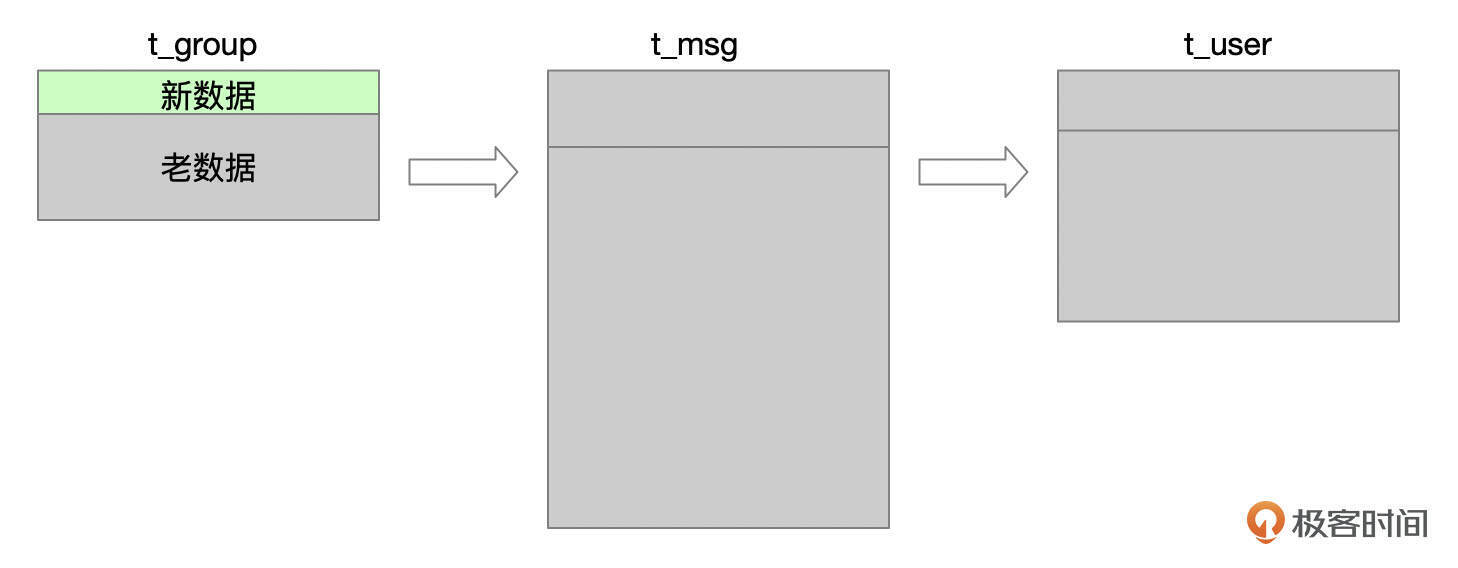
将SQL拆分成3个部分后,优化器可以对这3个SQL片段分别优化,选取不同的表关联顺序。在这个业务场景下,由于t_user和t_group表的数据很少有变化,因此SQL片段2和SQL片段3大部分时间没有数据返回。
SQL的写法灵活,但是在有些场景下,我们需要拆分SQL,使优化器可以选择到更好的执行计划。
案例八:exists子查询优化一例
下面是一个带了exists子查询的SQL,当时这个SQL执行需要120秒。
SELECT u.id userId, u.mobile, u.created_date createdDate
FROM `user` u
LEFT JOIN user_cash_detail ucd ON u.id= ucd.user_id
WHERE 1=1
AND EXISTS(
SELECT 1
FROM borrow b
WHERE b.user_id= u.id
AND b.borrow_no LIKE '202001011212XXX%')
ORDER BY u.id limit 13;
我们来看一下执行计划,要扫描的记录数好像(rows 13)很少,连接的几个表也都有索引,索引的过滤性也都很好(rows=1)。这个SQL性能应该是比较好的,为什么执行需要120s 的时间呢?

我们来分析一下这个SQL的执行过程:先执行主查询,从user表获取一行记录,再执行exists里的子查询,检查是否有匹配的记录。如果匹配了,检查已经获取到的记录数是否已经达到limit的要求。如果没匹配,那么从user表获取下一行记录,继续这个过程。如果主表的记录数比较大,而且在执行exists子查询时一直没有匹配到记录,那么整个查询的执行时间就会比较长。
上一讲中,我们提到了,从5.6开始,MySQL会自动将子查询转换为半连接。但是为什么这个SQL没有被转化为半连接呢?
原因是8.0之前的版本,MySQL还不支持转换exists子查询。在上面这个例子中,exists子查询中有一个b.borrow_no的条件,看起来过滤性比较高,因此我们手动改写了SQL。原始SQL中的LEFT JOIN user_cash_detail实际上是多余的,SQL改写为这个样子。
SELECT distinct u.id userId, u.mobile, u.created_date createdDate
FROM borrow b
join `user` u on b.user_id= u.id
where b.borrow_no LIKE '202001011212XXX%'
order by u.id limit 13
改写后,SQL的执行时间从120秒降到了3毫秒。

将exists子查询改写为常规的表关联,有几个地方要注意。
- 原始SQL中并没有使用到user_cash_detail表,可以将left join去掉。
- Exists 改成join后,由于borrow表user_id不唯一,可能会有重复数据出现,需要添加distinct去重。
我们在SQL优化的时候,一个基本思想是尽早过滤掉尽可能多的数据。这个例子中,先执行exists中的子查询可以提前过滤掉大量数据。
对于这个案例中的SQL,如果使用了8.0,就不再需要手动改写了。我们来构造一些测试数据验证一下。先创建SQL中的测试表,写入一些数据。
create table user (
id int not null auto_increment,
mobile varchar(20),
created_date datetime,
padding varchar(2000),
primary key(id)
) engine=innodb;
create table user_cash_detail(
id int not null auto_increment,
user_id int not null,
padding varchar(2000),
primary key(id),
key idx_userid(user_id)
) engine=innodb;
create table borrow(
id int not null auto_increment,
user_id int not null,
borrow_no varchar(30),
padding varchar(2000),
primary key(id),
key idx_user_id(user_id),
key idx_borrowno(borrow_no)
) engine=innodb;
insert into user(id, mobile, created_date, padding)
select 1000000 + n, 13500000000 + n, date_add('2024-01-01 00:00:00', interval n hour), rpad('', 1000, 'abcd ')
from numbers;
insert into user_cash_detail(user_id, padding)
select 1000000 + n, rpad('', 1000, 'abcd ')
from numbers;
insert into borrow(user_id, borrow_no, padding)
select 1000000 + n - n % 2, date_format(date_add('2019-06-01 00:00:00', interval n hour), '%Y%m%d%H%i%s'), rpad('', 1000, 'abcd ')
from numbers;
在8.0中,这个SQL自动转换成了半连接。
explain> SELECT u.id userId, u.mobile, u.created_date createdDate
FROM user u
LEFT JOIN user_cash_detail ucd ON u.id= ucd.user_id
WHERE 1= 1
AND EXISTS(
SELECT 1
FROM borrow b
WHERE b.user_id= u.id
AND b.borrow_no LIKE '202007201%')
ORDER BY u.id limit 13;
+----+--------------+-------------+--------+--------------------------+--------------+---------+---------------------+------+----------+---------------------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+--------------+-------------+--------+--------------------------+--------------+---------+---------------------+------+----------+---------------------------------+
| 1 | SIMPLE | <subquery2> | ALL | NULL | NULL | NULL | NULL | NULL | 100.00 | Using temporary; Using filesort |
| 1 | SIMPLE | u | eq_ref | PRIMARY | PRIMARY | 4 | <subquery2>.user_id | 1 | 100.00 | NULL |
| 1 | SIMPLE | ucd | ref | idx_userid | idx_userid | 4 | <subquery2>.user_id | 1 | 100.00 | Using where; Using index |
| 2 | MATERIALIZED | b | range | idx_user_id,idx_borrowno | idx_borrowno | 123 | NULL | 10 | 100.00 | Using index condition |
+----+--------------+-------------+--------+--------------------------+--------------+---------+---------------------+------+----------+---------------------------------+
案例九:range和ref
优化器在计算REF和Range的访问成本时,使用了不同的公式。在有些情况下,使用同一个索引,虽然range使用了更多的索引字段,但是成本比REF高,有时Range的成本比全表扫描还要高,此时优化器会使用REF访问路径,而不是效率更高的Range。
下面的这个例子就是这种情况。这是在5.6版本中遇到的问题。先创建一个表,写入一些模拟数据。
mysql> create table mysql_stat(
id int not null auto_increment,
tenant_id int not null,
instance_name varchar(30) not null,
check_time datetime not null,
padding varchar(200),
primary key(id),
key idx_tenantid_instname_checktime(tenant_id, instance_name, check_time)
) engine=innodb;
mysql> insert into mysql_stat(tenant_id, instance_name, check_time, padding)
select 1, 'dtstack-dev1:3306',
date_add('2024-01-01 00:00:00', interval n * 10 second) as check_time,
rpad('x', 100, 'abcd ')
from numbers_1m
mysql> select min(check_time), max(check_time) from mysql_stat;
+---------------------+---------------------+
| min(check_time) | max(check_time) |
+---------------------+---------------------+
| 2024-01-01 00:00:00 | 2024-04-25 17:46:30 |
+---------------------+---------------------+
我们来看一下这个SQL的执行计划,type为ref,只用到了tenant_id和instance_name的索引条件。
mysql> explain SELECT *
FROM mysql_stat
WHERE tenant_id = 1
and instance_name='dtstack-dev1:3306'
and check_time >='2024-02-01' and check_time <= '2024-03-01'
ORDER BY check_time desc limit 1\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: mysql_stat
type: ref
possible_keys: idx_tenantid_instname_checktime
key: idx_tenantid_instname_checktime
key_len: 36
ref: const,const
rows: 468284
Extra: Using where
check_time字段上的条件,本来也可以用来过滤数据,但是优化器却没有使用。在我的测试环境中,这个SQL耗时1秒多。从慢日志中,可以观察到SQL扫描了48万行数据。
# Query_time: 1.245558 Lock_time: 0.000281 Rows_sent: 1 Rows_examined: 481600
SET timestamp=1725604597;
SELECT *
FROM mysql_stat
WHERE tenant_id = 1
and instance_name='dtstack-dev1:3306'
and check_time >='2024-02-01' and check_time <= '2024-03-01'
ORDER BY check_time desc limit 1;
我们给这个SQL加上一个force index提示。
mysql> explain SELECT *
FROM mysql_stat force index(idx_tenantid_instname_checktime)
WHERE tenant_id = 1
and instance_name='dtstack-dev1:3306'
and check_time >='2024-02-01' and check_time <= '2024-03-01'
ORDER BY check_time desc limit 1\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: mysql_stat
type: range
possible_keys: idx_tenantid_instname_checktime
key: idx_tenantid_instname_checktime
key_len: 41
ref: NULL
rows: 468284
Extra: Using index condition
加上force index之后,执行计划type变成了range。观察慢日志,SQL只扫描了1行数据,执行时间不到1毫秒。
# Query_time: 0.000468 Lock_time: 0.000162 Rows_sent: 1 Rows_examined: 1
SET timestamp=1725604885;
SELECT *
FROM mysql_stat force index(idx_tenantid_instname_checktime)
WHERE tenant_id = 1
and instance_name='dtstack-dev1:3306'
and check_time >='2024-02-01' and check_time <= '2024-03-01'
ORDER BY check_time desc limit 1;
从optimizer trace中可以看到,加了force index后,ref的成本还是比range低。
"considered_execution_plans": [
{
"plan_prefix": [
],
"table": "`mysql_stat` FORCE INDEX (`idx_tenantid_instname_checktime`)",
"best_access_path": {
"considered_access_paths": [
{
"access_type": "ref",
"index": "idx_tenantid_instname_checktime",
"rows": 468284,
"cost": 123354,
"chosen": true
},
{
"access_type": "range",
"rows": 351213,
"cost": 655599,
"chosen": false
}
]
},
"cost_for_plan": 123354,
"rows_for_plan": 468284,
"chosen": true
}
]
但是优化器最终还是选择了range,因为range能用到更多的索引字段。
"attached_conditions_computation": [
{
"access_type_changed": {
"table": "`mysql_stat` FORCE INDEX (`idx_tenantid_instname_checktime`)",
"index": "idx_tenantid_instname_checktime",
"old_type": "ref",
"new_type": "range",
"cause": "uses_more_keyparts"
}
}
]
上面的这个SQL,在5.7和8.0的环境中,不需要加force index,也会使用效率更高的range访问路径。有兴趣的话,你可以自己测试一下,使用优化器跟踪对比一下区别。
案例十:in参数列表过长导致的全表扫描
这是一个在MySQL 5.6中遇到的性能问题。我们来看这个单表查询的SQL。表里有几千万行数据。
SELECT *
FROM t_exp t
WHERE t.link_id in (x,x,x, ......)
and t.com_id = xx
and t.expense in (x,x,x)
and t.link_type= 1
and ledger_status= 1
AND status = 1
表上有一个唯一索引。where条件中,link_id、com_id、expense, link_type这几个字段是索引的前缀。
理论上这个SQL是可以用上这个索引的,但是SQL却使用了全表扫描。而且即使加上force index提示,还是全表扫描。
SQL中link_id传入了几万个,我尝试着减少link_id的个数,当数量少于某个临界值时,就可以用上索引了,查询的性能也没有问题。但是为什么当IN列表中的参数多一点时,就使用全表扫描了呢?
我们来对比下这两种情况下的优化器跟踪信息。
- 使用全表扫描时的跟踪信息
当IN传入的参数超过一定的个数后,优化器只考虑了全表扫描。从considered_execution_plans中可以看出这一点。

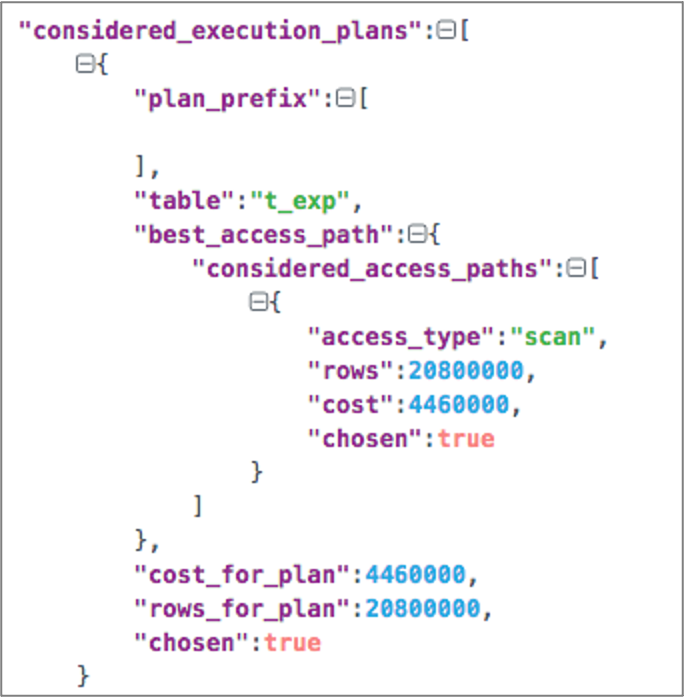
- 使用索引时的跟踪信息
将IN的参数减少到某个临界值之后,优化器考虑了range访问路径,并且基于成本,选择了range执行计划。
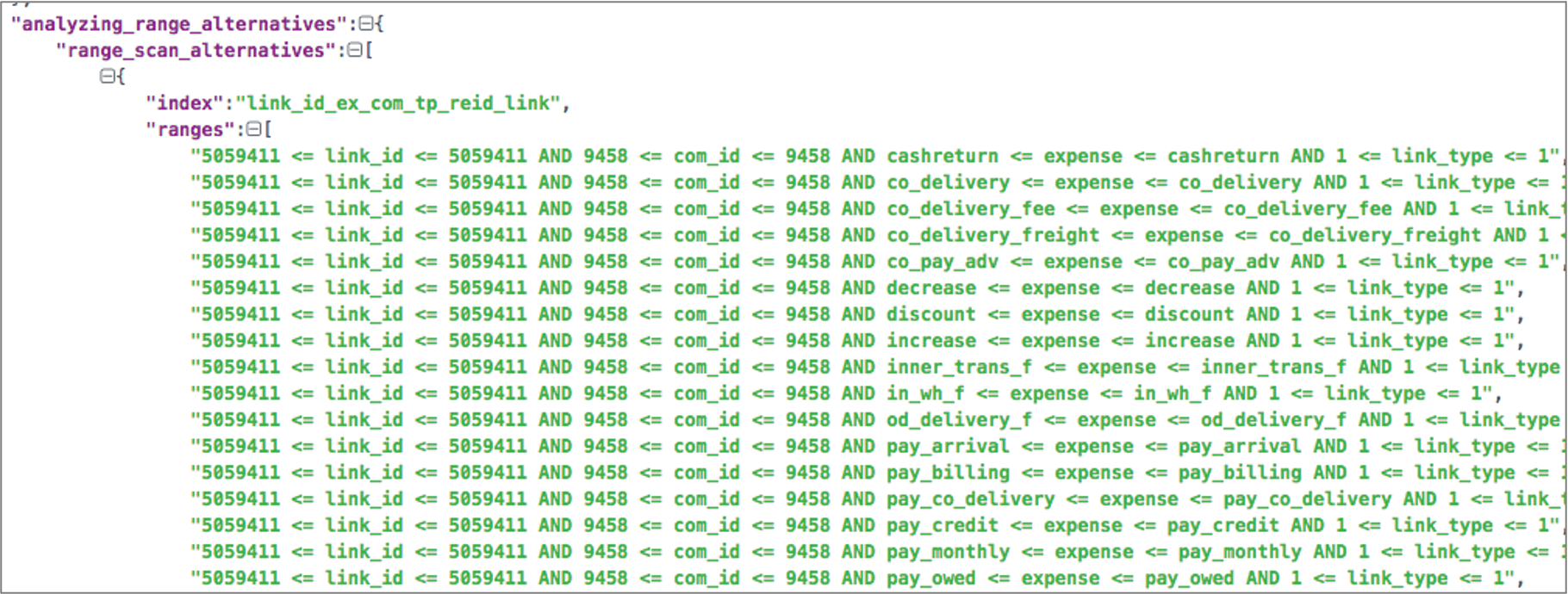
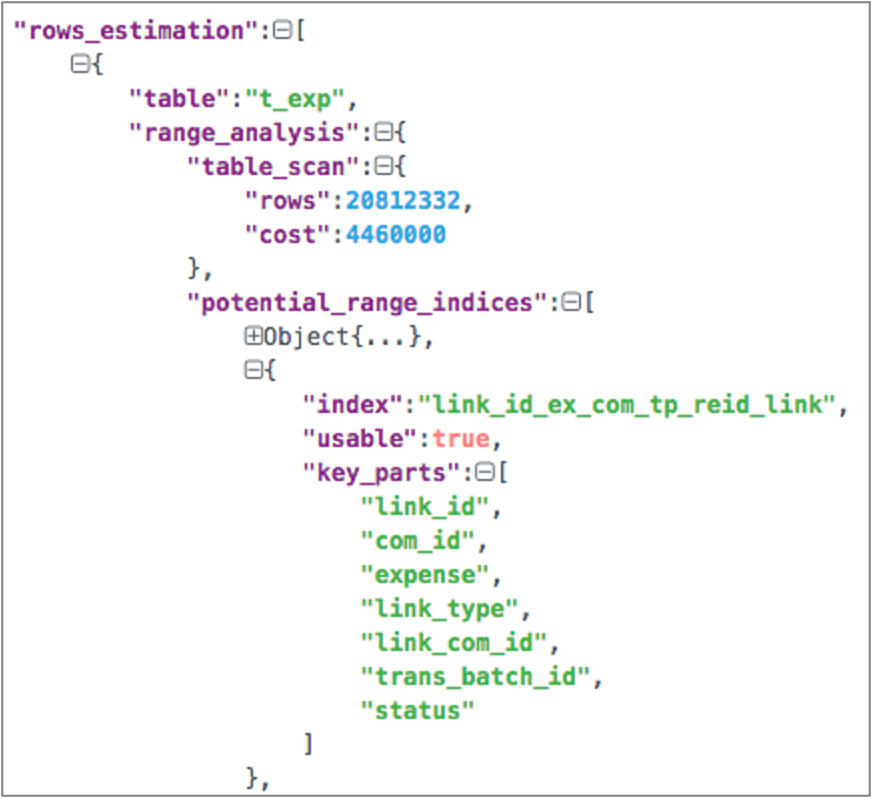

当in条件中的值超过一定数量时,优化器会放弃使用range执行计划。原因是MySQL限制了生成range执行计划时使用的内存,当IN参数列表太长时,消耗的内存太多,超出了限制,因此放弃使用range执行计划,最终使用了全表扫描。MySQL 5.6中,range优化内存的上限是固定的。MySQL 5.7引入了参数range_optimizer_max_mem_size,我们可以调整这个参数来解决in参数列表过长无法使用索引的问题。实际上,在5.7版本中,如果in参数列表过长导致无法使用range优化,会有这样的warning信息。
Warning 3170 Memory capacity of N bytes for
'range_optimizer_max_mem_size' exceeded. Range
optimization was not done for this query.
根据官方文档的描述,每个OR条件使用230字节,每个AND条件使用125字节,单个字段上的IN条件,会转换成OR。多个字段使用IN,会以组合形式展开,比如 c1 in (a,b) and c2 in (x,y,z)会转换成 (c1 = a and c2 = x) or (c1 = a and c2=y) or ( c1=a and c2=z) or (c1 = b and c2 = x) or (c1 = b and c2=y) or ( c1=b and c2=z) 。
我们案例中的SQL,有2个in条件会在range优化时展开。
SELECT *
FROM t_exp t
WHERE t.link_id in (x,x,x,…)
and t.com_id = xx
and t.expense in (x,x,x)
and t.link_type= 1
and ledger_status= 1
AND status = 1
怎么解决这个问题呢?一个方法是减少IN里面传入的参数个数,但这需要修改代码。所以当时我采用另外一种方法,调整索引字段顺序,将expense字段调整到了link_com_id之后。因为SQL缺少link_com_id的条件,调整索引字段顺序后,只需要展开link_id,而不是link_id和expense的组合,这样SQL就用上了索引。
案例十一:数据倾斜引起的性能问题
下面这个SQL是在一个系统压测时发现的。
select *
FROM trans_001 a LEFT JOIN purchase_001 b
ON a.serial_no = b.order_no
AND a.dist_name = b.inst_id
AND a.alino = b.alino
WHERE b.order_no IS NULL
AND a.serial_no >= '201809200000057858291ALI'
AND a.serial_no <= '201809216100342526601ALI'
AND a.business_code = 'xx'
AND a.trans_date = '20180921';
这是一个两表连接的SQL,当时这个SQL执行了两百多秒,从慢日志中看到扫描行数有1.1亿。下面是当时诊断报告的输出。

这个系统使用了分库分表,这两个表大概有几十万行数据。SQL的执行计划并没有问题,连接条件中的字段上也建立了正确的联合索引。但是为什么扫描行数会这么高呢?你是不是会怀疑慢SQL的输出有问题?
有经验的同学可能已经想到原因了,这其实是数据倾斜引起的问题。分别查看2个表中连接条件上的数据分布就能发现问题。
select serial_no, dist_name, alino, count(*)
from trans_001
group by serial_no, dist_name, alino
order by count(*) desc limit 10;
select order_no, inst_id, alino, count(*)
from purchase_001
group by order_no, inst_id, alino
order by count(*) desc limit 10;
只要某个组合条件下的记录数超过1万,连接时扫描的记录数就会超过1亿。找到问题后,需要业务方来分析为什么会有这样的数据,并进行相应的处理。
案例十二:Range checked for each record
MySQL优化器在评估一个索引的访问效率时,要么使用Index Dive,要么使用索引统计信息。在表连接时,如果连接条件是一个范围,那么对于驱动表中的每一行记录,都需要进行一次Index Dive,来评估被驱动表里满足条件的记录数。这种情况下,执行计划的Extra 列中会显示“Range checked for each record”,很多时候,这也是一个查询性能不好的信号。
我们来看下面这个例子。
SELECT t1.ppd , (
SELECT sum(amount) AS total_amount
FROM `order`
WHERE pay_date <= t1.ppd
AND pay_date >= date_sub(t1.ppd, INTERVAL 7 DAY)
) AS total_amount
FROM (
select distinct pay_date as ppd
from `order`
where pay_date is not null
) t1

这样的SQL还有优化的空间吗?我们来尝试一下。先准备一点测试数据。
create table t_order(
id int not null auto_increment,
pay_date date not null,
amount int not null,
padding varchar(2000),
primary key(id),
key idx_paydate(pay_date)
) engine=innodb;
insert into t_order(pay_date, amount, padding)
select date_add('2023-01-01', interval n % 365 day),
2000 + n % 1000,
rpad('', 1000, 'abcd ')
from numbers;
在我的测试环境中,原始SQL耗时35秒。
# Query_time: 35.923849
# Lock_time: 0.000086
# Rows_sent: 365
# Rows_examined: 3650365
SELECT t1.ppd , (SELECT sum(amount) AS total_amount
FROM t_order
WHERE pay_date <= t1.ppd
AND pay_date >= date_sub(t1.ppd, INTERVAL 7 DAY) ) AS total_amount
FROM (
select distinct pay_date as ppd
from t_order
where pay_date is not null
) t1;
我尝试把SQL改写成表连接,执行时间减少了一些。
# Query_time: 7.566888
# Lock_time: 0.000050
# Rows_sent: 365
# Rows_examined: 365
SELECT t1.ppd, sum(amount) AS leiji_amount
FROM (select distinct pay_date as ppd
from t_order
where pay_date is not null) t1
, t_order t2
WHERE t1.ppd >= t2. pay_date
AND t2.pay_date >= date_sub(t1.ppd, INTERVAL 7 DAY)
GROUP BY t1.ppd;
就这个SQL的逻辑,我们还可以使用MySQL 8.0的窗口函数,这样SQL执行又更快了一些。
# Query_time: 0.776545
# Lock_time: 0.000046
# Rows_sent: 365
# Rows_examined: 730
select pay_date, sum(total_amount) over(
order by pay_date
range BETWEEN INTERVAL 7 DAY PRECEDING AND CURRENT ROW)
from (
select pay_date, sum(amount) as total_amount
from t_order
where pay_date is not null
group by pay_date
) t;
考虑到SQL中只用到了2个字段,我们给这个SQL建立一个联合索引。
这样执行的速度又提升了一些。
# Query_time: 0.090399
# Lock_time: 0.000026
# Rows_sent: 365
# Rows_examined: 730
select pay_date, sum(total_amount) over(
order by pay_date
range BETWEEN INTERVAL 7 DAY PRECEDING AND CURRENT ROW)
from (
select pay_date, sum(amount) as total_amount
from t_order
where pay_date is not null
group by pay_date
) t;
我们的测试表里,只写入了10000行数据,如果你有兴趣,可以尝试写入10万行或100万行数据,对比下这几种情况下几个SQL的耗时。
总结
SQL优化是一项基本的技能。你需要掌握索引的特点,了解不同表连接算法的特点和适用场景,还需要了解优化器的一些工作原理。有的时候你可能需要改写SQL,或者使用SQL提示,来获得更好的性能。
这两讲的十几个例子,都是从真实的业务场景中挑选出来的,当时使用的版本包括5.5、5.6、5.7。可以看到,在8.0中,有一些SQL实际上优化器已经能自动优化得更好了。这也是我们要使用新版本的一个重要的原因。
思考题
下面这类SQL按多个表的字段来排序,请分析下这么排序,对SQL性能的影响是什么?如果只使用一个表的字段来排序,性能上会有什么区别吗?
期待你的思考,欢迎在留言区中与我交流。如果今天的课程让你有所收获,也欢迎转发给有需要的朋友。我们下节课再见!
- 叶明 👍(1) 💬(1)
1、对 SQL 性能的影响,t1.s1 和 t2.s2 这两个字段来源不同表,并且没有关联关系,驱动表只有一个,当其中一个字段有序时,无法保证另一个字段也有序,因此必须使用到临时表和文件排序,另外如果数据量较大,则还会使用到更慢的磁盘临时表来处理。 2、如果只使用一个表的字段来排序,性能上会有什么区别吗?如果表上这一个用来排序的字段上有索引,那么以这个表作为驱动表,一来不用建立临时表和排序,只需要有序遍历这个索引的前 100条记录就可以返回了,二来只用返回 100 条数据,大大减少了扫描行数
2024-10-16