15 非典型数据库故障解析:数据库故障一定是数据库的锅吗?
你好,我是俊达。
在前两讲中,我分别介绍了MySQL和Linux操作系统问题排查的基本思路,提供了一些判断数据库和操作系统是否有问题的方法。这一讲我们就以一个生产环境中发生的故障为例,来看看怎么运用前面讲到的基本方法,来分析和定位真实环境下的问题。
背景介绍
这是我们公司服务的一家客户在线业务系统中发生的故障。这家客户提供在线支付业务,大量的消费者日常都会使用到这项服务。比如我们中午或傍晚到店里扫码点餐付款时,或者在商场里扫码付款时,都可能会用到这项服务。当时,我们给这家公司提供了数据库运维保障的服务。客户的核心业务数据库采用了国内头部的一家云厂商提供的RDS for MySQL产品。
有一天下午,快接近6点钟的时候,短促的告警声打破了办公室的平静,客户的告警通知群里面,出现了大量的实例CPU和活跃会话数的告警消息。通过监控大屏,我们发现问题都出在一个核心数据库上,数据库实例的CPU资源,几乎在瞬间达到了100%。同时客户也反馈,业务端有大量的付款失败了。
怎么分析数据库CPU使用率高的问题?
对于数据库CPU使用率打满的问题,一般我们都会先从实例中运行的SQL入手。有两种情况都可能会导致CPU打满,一种情况是实例中运行了执行效率特别低的SQL,如大表全表扫描、大表连接并且缺少合适的连接条件或连接索引。另外一种情况是SQL的执行频率太高了。更差的情况是,SQL效率很低,同时执行的并发量还很高。
一般我们会先到PROCESSLIST和慢SQL日志中找可疑的SQL。但是PROCESSLIST只是实例所有会话的一个快照,如果SQL执行的时间比较长,那么在PROCESSLIST中看到这个SQL的概率就比较高,但是对于执行时间没那么长的SQL,你很可能就看不到。
而慢查询日志,只有查询的执行时间超过long_query_time后,才会记录下来。有时候我们需要分析全量SQL,才能精确定位问题。各大云厂商提供的RDS产品,通常会提供SQL审计功能,将实例中执行的每一条SQL都记录下来,我们可以充分利用全量SQL审计日志,来分析某一个时间数据库中运行的SQL。
此外,对于CPU使用率突变的情况,我们还要找到是什么原因导致了SQL的执行情况发生突变。一般我们可以先从以下几个方面来考虑。
- 业务上有没有做推广引流,是不是有什么活动?
- 是不是触发了平时不怎么执行的一些SQL,比如后台人员在对账,或者大数据系统在大规模抽取数据,或者是有大商户操作了管理后台,执行了一些开销很大的SQL,或者研发人员执行数据订正。
- 应用程序是不是发布了新的版本,修改了SQL代码,导致SQL性能变化?
- 是不是有SQL的执行计划发生了变化,导致原先效率还可以的SQL,性能急剧下降?
- 有没有可能数据库底层的操作系统和硬件环境的异常导致性能抖动,从而引起SQL积压?
在客户的这次故障中,我们排除了上面所有的可能性。由于使用了RDS,我们没有底层操作系统的权限,但是云厂商的工程师也参与到了故障分析中,他们确认了底层操作系统和硬件并没有问题。而且分析之后,我们也没有发现特别明显的问题SQL,ProcessList中看到的都是平时也一直在运行的正常的业务SQL。
优先恢复业务
故障期间数据库还发生了几次自动切换,但是业务依然没有恢复正常。初步分析业务SQL,也没有找到明确的问题。此时故障还在持续,每一分钟的故障时间,都会给业务造成直接的资金损失。既然数据切换之后也没有恢复,当时我们就把应用程序进行了重启。应用重启之后,业务就立刻恢复了正常。
这也是我们处理故障的一个原则,遇到故障时,快速收集故障现场必要的信息之后,即使无法迅速定位到故障的根本原因,也要在第一时间恢复业务的正常运行。
全量SQL分析
当然,在故障恢复之后,我们需要找到引起故障的真正原因,因为只有定位到了根本原因,你才能避免下一次出现同样的故障。针对这次故障中的实例,已经启用了RDS产品提供的SQL洞察和审计功能,我们使用这个功能对故障期间执行的SQL做了分析。我们分析了故障发生前,数据库中扫描行数、返回行数看起来比较高的一些SQL,并对这些SQL进行了一些优化。
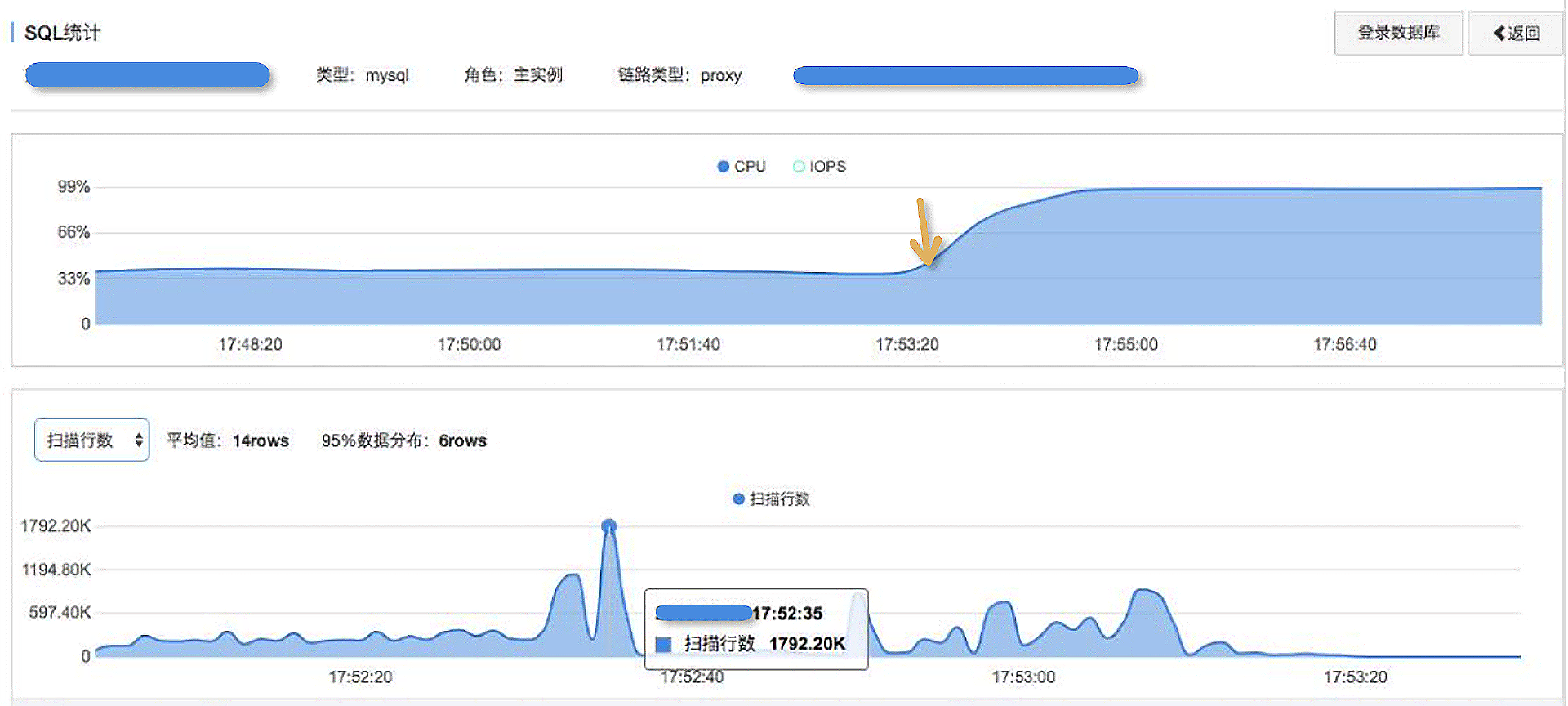
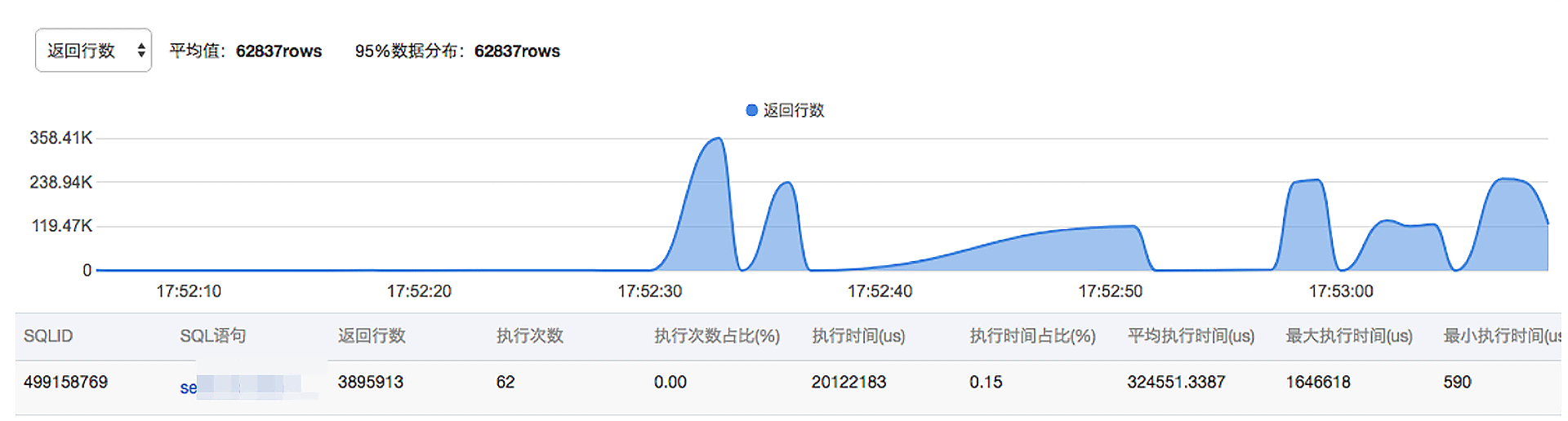
故障再次发生
虽然我们找到了一些SQL,做了相应的优化,但实际上,这并不是引起故障的真正原因。在接下来几天的时间里,我们严密监控数据库的运行情况,这期间数据库运行得很平稳。然后,差不多离上次故障近1周的一个下午,也是在下午5点多的业务高峰期,又发生了类似的故障。有了上次的经验,客户先重启了应用系统,恢复了业务。
但是故障的根本原因是什么?这次必须找出来。我和几位DBA同事一起赶到客户现场,在一间会议室里,跟客户侧的技术负责人、架构师、运维和研发人员,一起分析问题。上次使用常规的分析方法并没有定位到故障的根本原因。我们遗漏了哪些关键信息呢?
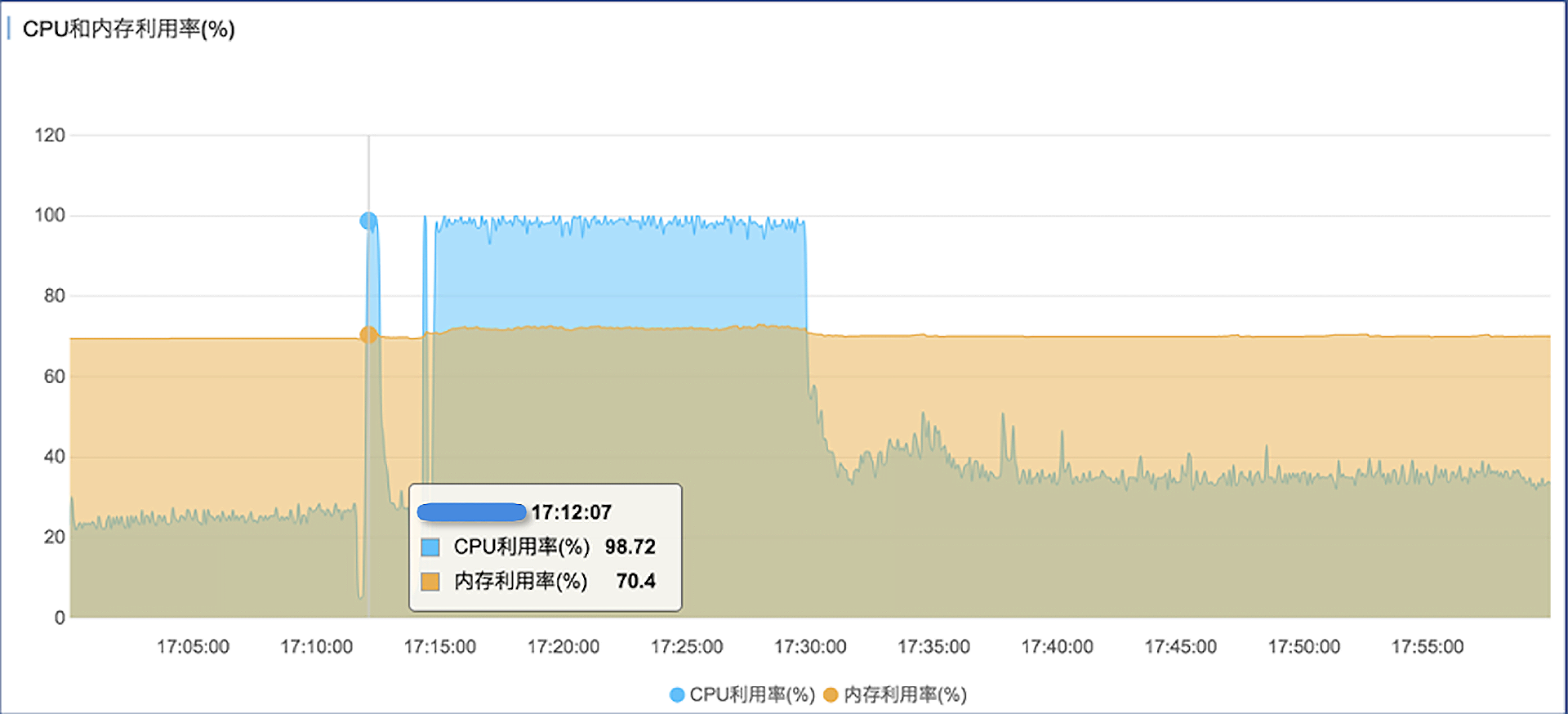
针对这次故障,我重新梳理了一下思路。从RDS的监控指标中可以确认几点。
- 数据库的CPU确实在极短的时间里,冲到了100%。之后有短暂的回落,但是后面CPU使用率又上升到了100%,并且一直持续高位运行,直到最后重启了应用系统后才恢复正常。
- CPU上涨的同时,数据库SQL执行量也差不多翻了一倍,时间上很吻合。
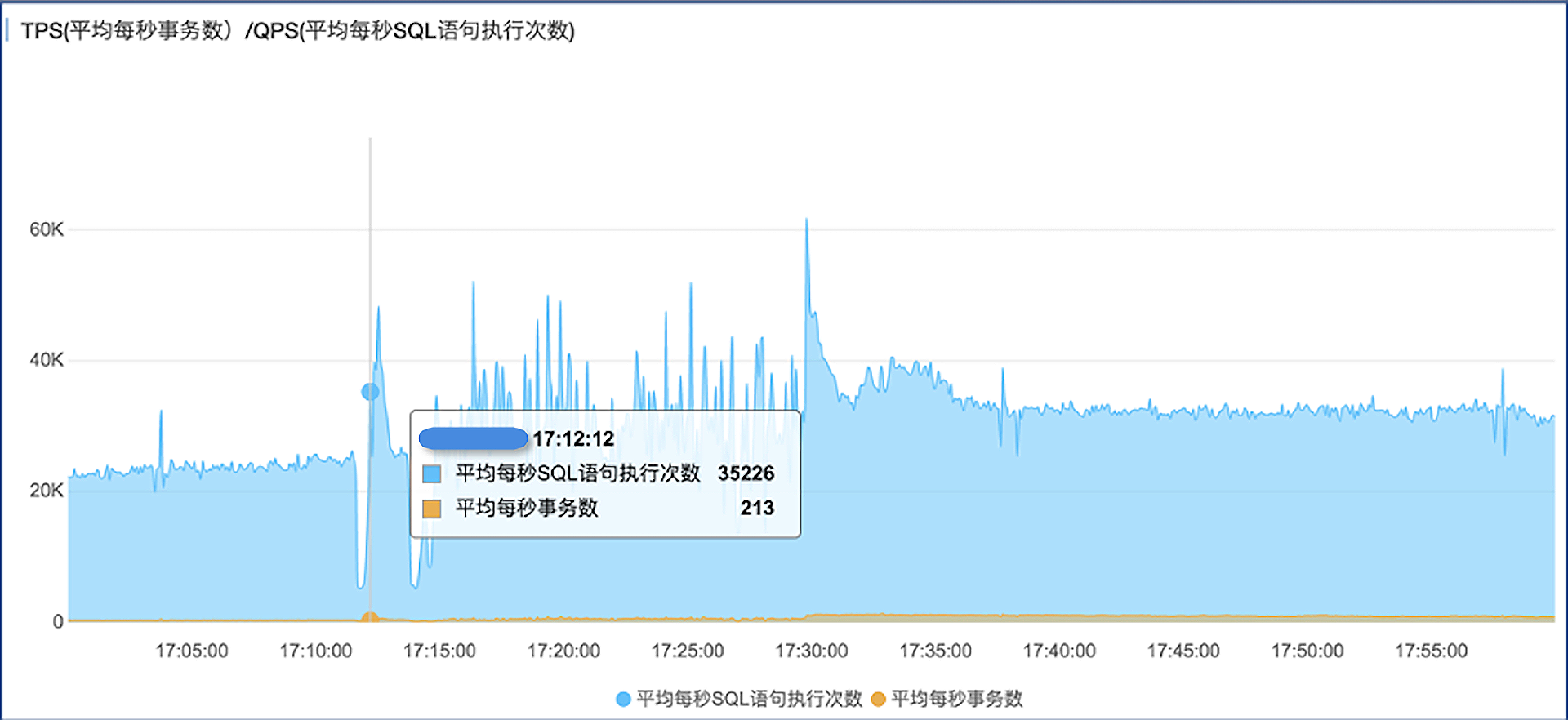
- 在CPU使用率上升的同时,数据库连接数上涨了好几倍。因此我们认为,由于某种原因,应用程序在瞬间创建了大量连接并执行SQL,超过了MySQL的承受能力,引起性能恶化。
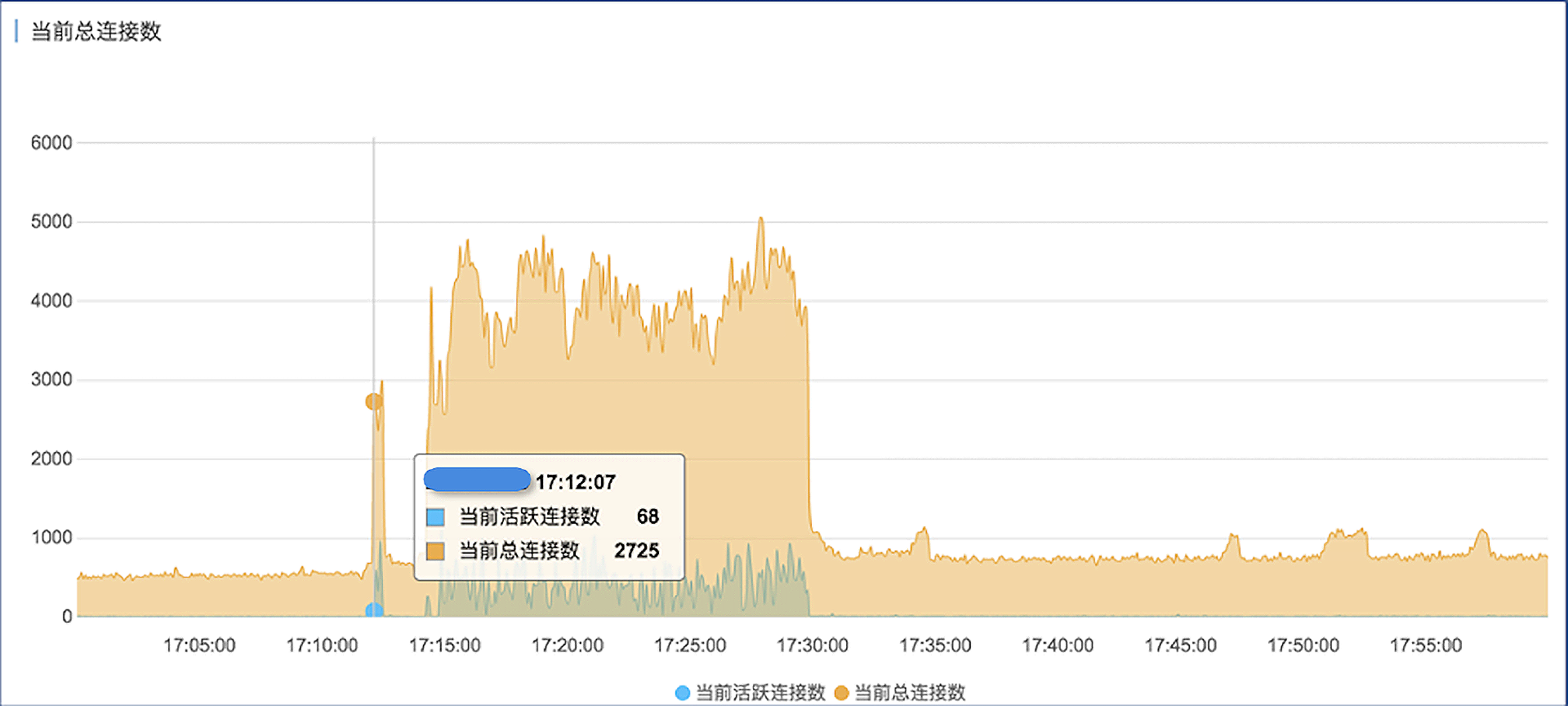
但是我们跟客户确认过,当时并没有做任何推广活动,应用系统也没有任何发布、变更。虽然当时是一天内业务的一个高峰期,但正常的业务流量是逐渐上涨的,也不会说一下子就涨好几倍。
- 我们再来看数据库的网络流量趋势图,和CPU使用率、QPS等指标的变化趋势是完全一致的。
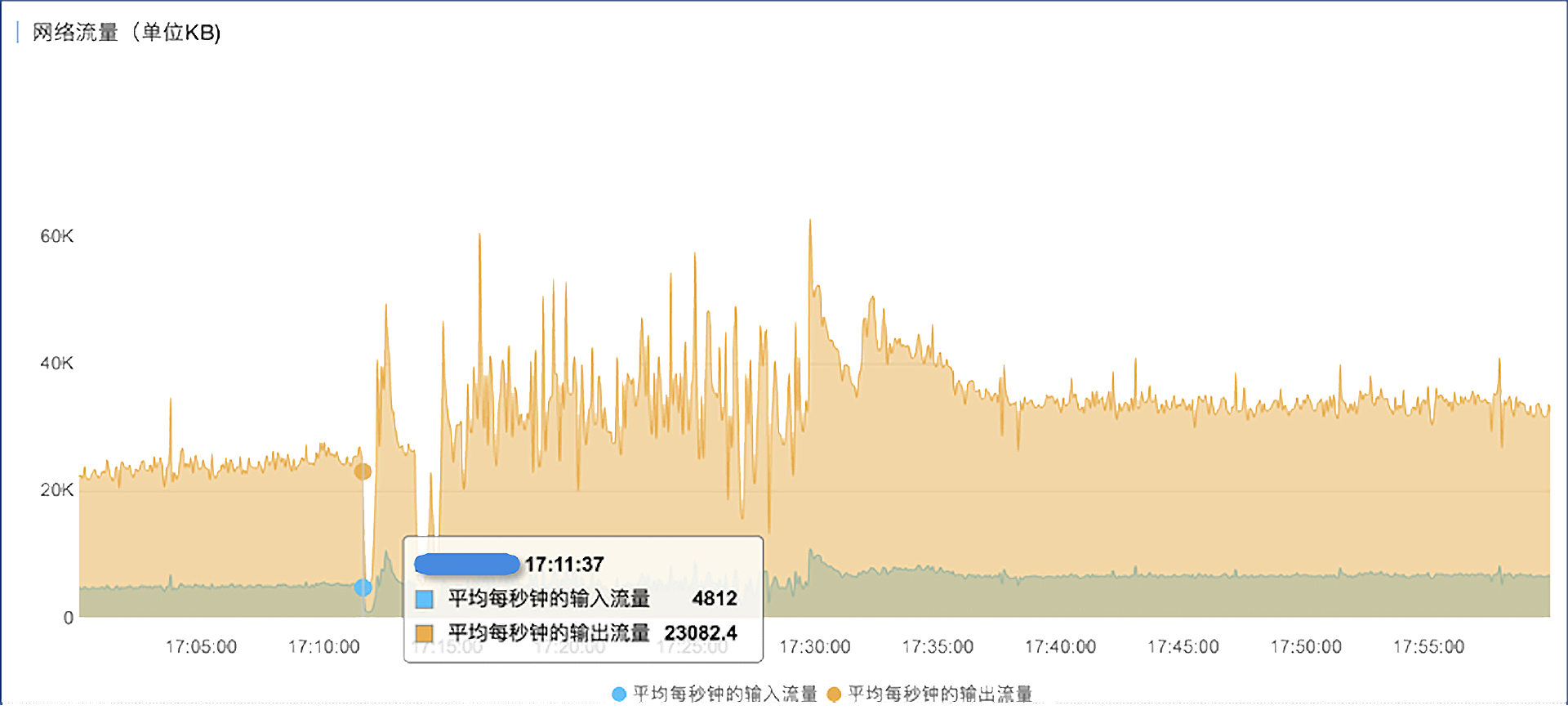
仔细观察上面这几个性能趋势图,可以发现有一个共同点,就是在指标暴涨之前,先有一个短暂的下跌的过程,这个过程很短,大概也就10-20秒的时间。实际上在上一次的故障中,我们也观察到了同样的现象。当时也对可能的原因做了一些思考,是不是数据库底层环境有性能抖动?但是云厂商的运维人员做了细致地排查后,排除了这种可能性。是不是应用程序的某些特定的逻辑引起的?我们和客户侧的技术人员进行了一些探讨,但也没找到确切的原因。是不是最终用户在那个时间点都不用这个系统了?我们想想也觉得可能性不大。
从业务链路上来看问题
我们跟客户侧的架构师一起,梳理了业务系统的部署结构和调用链路。下面这个架构图中,位于最上层的是负载均衡设备,会把来自用户的请求分发到nginx,nginx再把请求转到后端应用,后端应用还会通过Web Service调用一些服务接口,位于架构最底层的是RDS和Redis。这也是比较典型的一种Web应用部署架构。
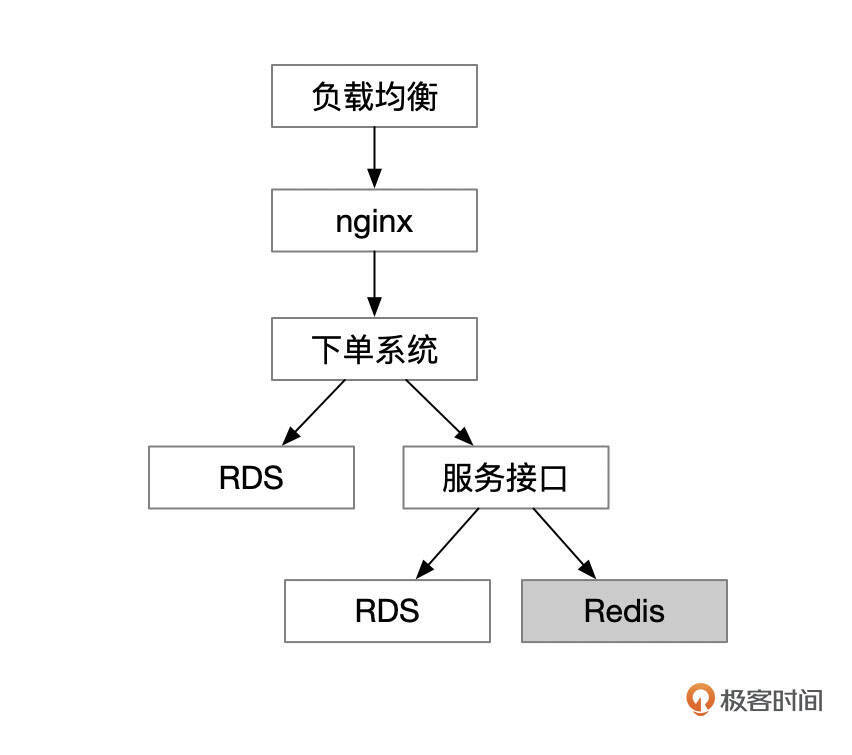
要判断来自用户的请求量是否有大的变化,实际上可以看入口处负载均衡的调用量,也可以通过分析nginx的访问日志得到。通过这些日志,我们得到了第一个结论,就是来自用户的请求在故障发生的时间点前后,并没有发生明显的变化。
是不是链路上的某个应用内部发生了什么变化?
我询问了客户侧的参会人员,当天下午发生故障前,有没有对应用系统做过任何操作?当天肯定没有做应用发布。后来一位工程师反馈,当时他做了一个数据订正,订正的内容是删除了Redis中的几个Key。正常来说,删除缓存中的几个Key,也不至于造成这么大的影响。我又详细询问了这位工程师,当时操作执行了哪些具体命令。工程师反馈说,他先通过keys pattern命令查找需要删除的Key,然后再把这几个Key删除掉。
到这里,你可能已经知道问题出在哪里了。Redis中执行 keys * 命令是非常危险的一个操作,如果key的数量比较多,keys * 命令可能需要执行很长的时间,更严重的是,执行期间会导致其他请求被阻塞。
这个客户的Redis没有在我们的服务范围内,因此我们也根本没有想过这方面的问题。听到工程师的反馈后,我们立刻查看了Redis的监控。在数据库流量下跌的同一个时间,Redis的CPU使用率有大幅度的上涨,最高达到了100%。
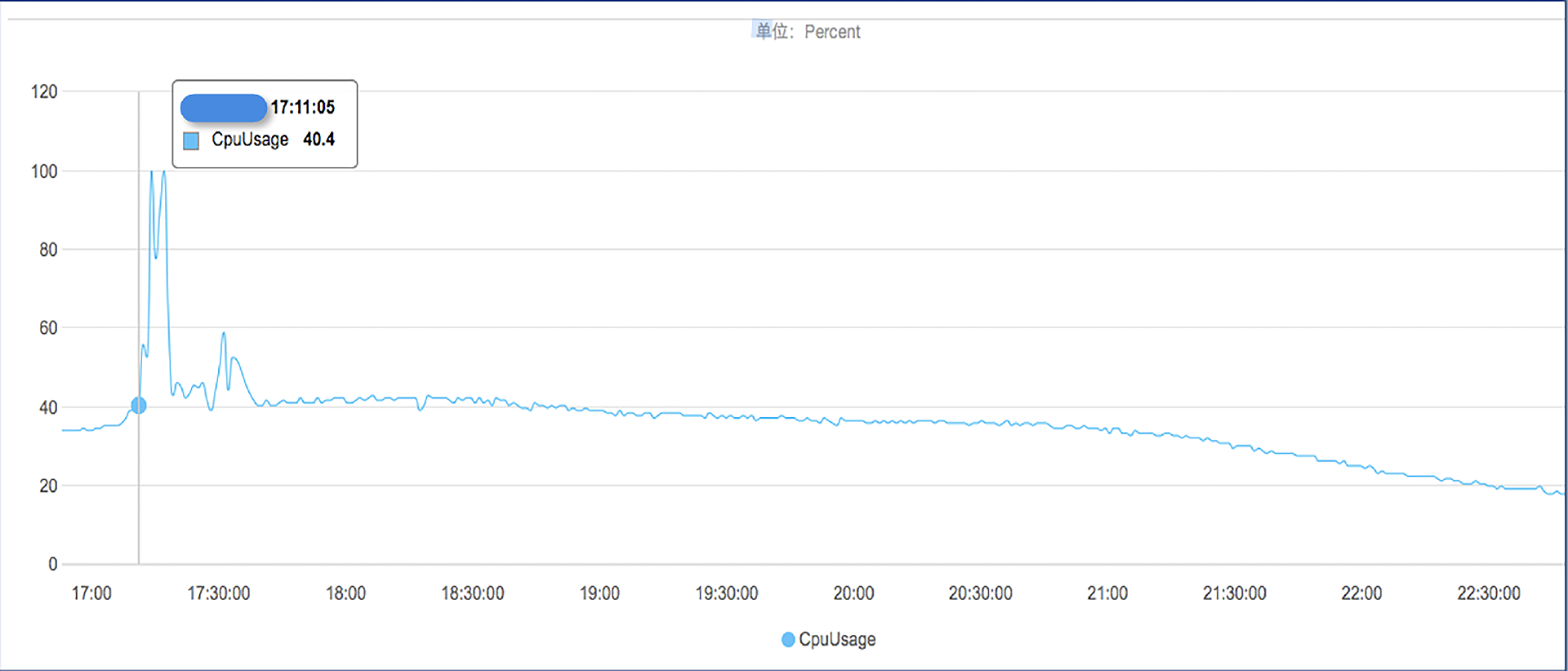
看来对Redis的操作才是引起故障的真正原因。为了更好地理解这个问题,我画了一个程序访问的时序图。用户扫码付款时,应用程序请求某个API,读取Redis中的一个Key,但由于当时Redis在执行 keys * 命令,读取Key的请求就被阻塞了。
keys * 命令执行了十几秒,因此这十几秒里,调用这个接口的用户线程都需要等待。最终,keys * 命令执行完成,等待的用户线程都完成了接口调用,然后再调用其他接口,到MySQL中执行SQL。积压了十几秒的用户线程,几乎在同一个时间点连接数据库,执行SQL,最终超出了数据库的承受能力,发生了故障。这和我们从前面几个监控图表中观察到的现象完全一致。
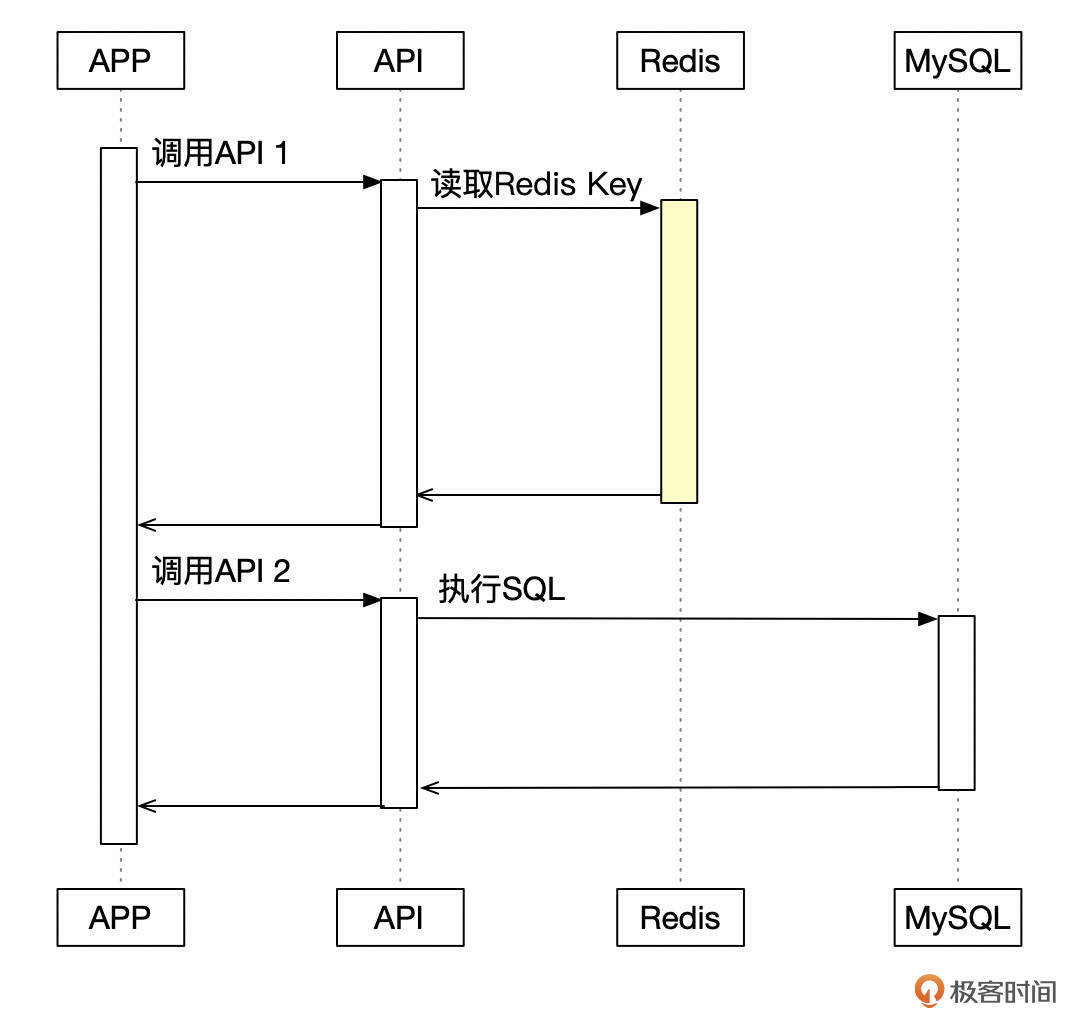
下面这个图可以更好地解释这个现象。应用程序发起的请求,先在Redis中积压了十几秒,然后又几乎在同一个时间点从Redis请求中返回,一瞬间,这些请求同时涌向了MySQL,MySQL不堪重负,发生了故障。
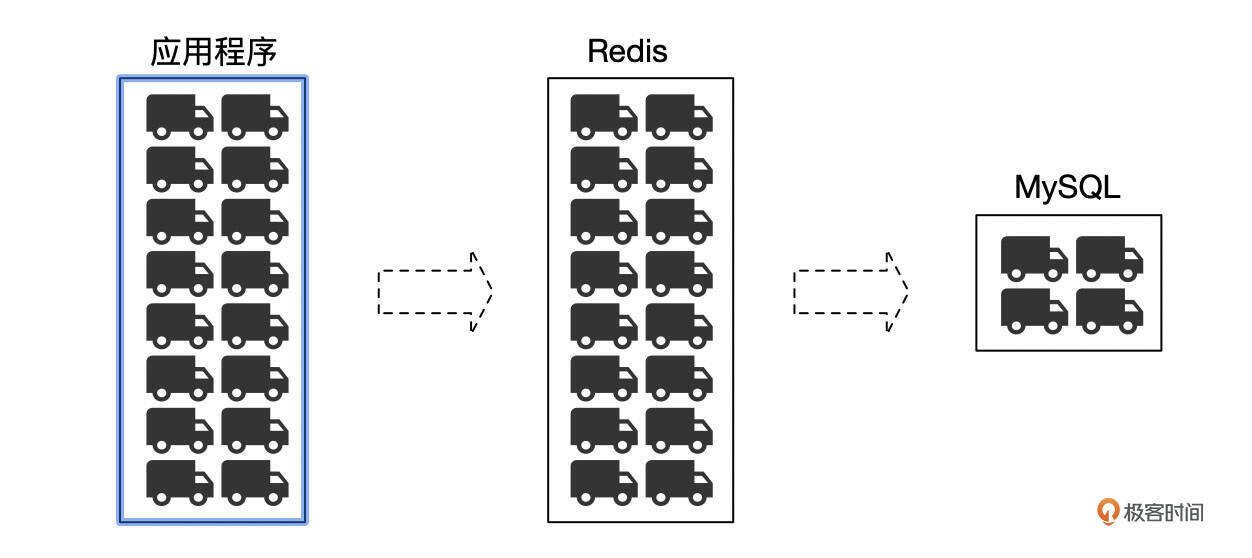
定位到最终问题后,我们和客户悬着的心终于放了下来。接下来,客户在内部进行了强调,禁止在线上执行危险的操作。对于keys *操作,也可以在Redis层面禁用掉。之后,就再也没有发生过这样的故障了。
总结
在这个故障案例中,MySQL的故障,由看起来毫不相关的一个Redis操作引起。这也警示了我们,在分析问题时,要从系统全局出发,不能局限在数据库内部。同时也要注意,在给一个问题下结论的时候,要多问问自己,这个问题真的是这个原因引起的吗?是不是能解释问题中的所有现象?
思考题
MySQL中存在这么一个现象,平时执行得好好的SQL,在数据库很繁忙的时候,执行效率也会变得很差,当然,这可以理解。你从Processlist或慢SQL日志中看到执行耗时比较长的SQL,其中有些是引起数据库性能问题的罪魁祸首,有些则是受害者。你应该怎么区分这两种情况,找到真正需要优化的那些SQL呢?
期待你的思考,欢迎在留言区中与我交流。如果今天的课程让你有所收获,也欢迎转发给有需要的朋友。我们下节课再见!
- 叶明 👍(1) 💬(1)
老师你的这个案例是因为 keys 查询阻塞了 redis,导致请求积压,等 redis 恢复正常后,积压的请求 reids 能处理过来,但 mysql 处理不过来,从而被打满。不知道我理解的对不对。我去做 redis key 删除时,都是用 scan 不断遍历来模糊匹配,避免 keys 这种重操作。 另外,开发一般都有接口超时时间的吧,通常 redis 查询非常快,高于某个阈值不返回,就应该中断请求。 比较喜欢用阿里云的全量 SQL 功能,当告警时,无法确定是慢 SQL 日志中哪个 SQL 造成的时候,我就开启全量 SQL,让它跑着,再次出现问题时,去分析报警这个时间段内哪些 SQL 的 CPU 和 IO 占用较高,很多时候,从慢 SQL 日志中并不能确定引起告警的查询,即使慢日志中的 SQL 是真的慢,而且看起来真的有问题。 思考题 1、从扫描行和返回行以及执行时间来区分,如果扫描行数很多,返回行数无论是多还是少(可能是聚合查询),都说明不了什么问题,但扫描和返回行数都少的情况下,执行时间却很长的语句,更大的可能是被别的线程所影响 2、我们公司用的是阿里云的 RDS MySQL 和 Polardb MySQL,通过阿里云提供的接口,定期将云上的慢 SQL 采集到自己的平台,这样在自己的平台就可以查看一个 sql 在一段时间范围内的耗时时间,如果耗时突然增高,那么一般认为是被影响的 3、实在确定不了,我还是用阿里云的全量 SQL,就分析告警前后那段时间范围内的 CPU 占用和 IO 占用,它还有会话快照,可以用来做参考,目前用起来很爽,查找问题也很方便。
2024-09-20 - 范特西 👍(0) 💬(1)
最后的问题我也喜欢看扫描行数,这里分享一个之前遇到了一次有趣的场景,就是问题 SQL 执行计划使用了 index merge ,慢日志中的扫描行数,只包含了取交集时的扫描行数,结果就是慢日志中显示扫描 9w 行,查询执行了 100 多秒,当时第一眼看的时候很奇怪,使用了 trace 才分析明白😊
2024-10-17 - TheOne 👍(0) 💬(1)
好有指导意义的一篇文章🤙🤙🤙
2024-09-23 - 123 👍(0) 💬(1)
思考题: 1、首先分析当前数据库繁忙的原因是什么,是因为业务量增大,用户增多,发布一些重要活动,还是在没有外部客观原因的情况下导致的数据库繁忙,例如老师文中的例子; 2、分析数据库内部的原因,首先拿到processlist列表,观察那些time时间较长的回话,查看当前的state,分析原因;通过工具查看慢sql,分析慢SQL的数量、时间、执行次数的排序、执行时间等,同时需要检查是否有锁等待情况,业务繁忙的情况下,除了大量执行业务核心sql以外,关注非核心功能,可能存在并发问题的“sql组合”; 3、检查下原sql的执行计划是否发生了改变,例如发生了索引的更改等; 4、查看系统资源监控,是否可能是底层硬件存在瓶颈,cpu、内存、磁盘IO、网络情况,拉取资源监控分析图表,查看点位的变化的情况,是否有异常; 5、检查这个业务链路,是否是业务链路的某个环节,特别是redis缓存,如果缓存失效,并发量大,也会有大量sql请求一起到达数据库;
2024-09-20