12 表太大了,修改表结构太慢怎么解决?(下)
你好,我是俊达。
在上一讲中,我们介绍了几种执行很快的DDL操作,这些DDL操作只需要修改元数据,因此即使表很大,也不影响执行速度。但是还有很多DDL操作,在执行的过程中需要读取全表的数据,或者是重建整个表,因此表的大小会直接影响执行的速度。这一讲中,我们就来看看这些DDL的执行策略。
InnoDB在线DDL
添加字段、删除字段可以使用Instant DDL,但是还有其他很多DDL并不能仅仅修改元数据。比如创建索引时,需要读取全表的数据,对索引字段进行排序,生成新的索引。优化表(optimize table)时,需要重建整个表的数据。MySQL从5.6开始支持在线DDL。在线DDL的主要含义,是指在DDL执行的期间,应用程序可以正常地读写表中的数据。对于只需要修改元数据的DDL,前面已经做了比较多的介绍了,这里我们只讨论创建索引和需要重建表的在线DDL。
创建二级索引
创建二级索引可以使用INPLACE的方式执行。这里只讨论普通的B+树索引,不讨论全文索引、空间索引。下面的这个例子中,我们使用ALTER TABLE命令新建了一个索引。
mysql> alter table employees
add key idx_firstname_lastname(first_name, last_name),
algorithm=inplace,
lock=none;
Query OK, 0 rows affected (0.73 sec)
Records: 0 Duplicates: 0 Warnings: 0
创建二级索引主要分为几个步骤。
1. 扫描整个表,读取新建索引需要的字段。
InnoDB可以使用多个线程并发读取聚簇索引,参数innodb_parallel_read_threads用来设置并发读取的线程数,默认值是4。如果表比较大,服务器的配置比较好,可以将这个参数设置得大一些,来提升读取的速度。读取到的数据会先写到一块临时的内存中,参数innodb_ddl_buffer_size用来控制这块临时内存的大小,最终临时内存中的数据会写到临时排序文件中。如果你的表比较大,临时文件也可能占用比较大的空间。
2. 合并排序步骤1生成的多个临时文件中的数据。
如果步骤1使用了多个线程,那么每个线程都会生成临时排序文件。步骤2需要将所有临时文件中的数据合并到一起。合并排序时,InnoDB也使用了多个线程,线程的数量由参数innodb_ddl_threads控制。
3. 将步骤2得到的数据加载到新建的索引中。
步骤2得到的数据已经按索引字段排序好了,这里需要将这些数据插入到新的索引中。
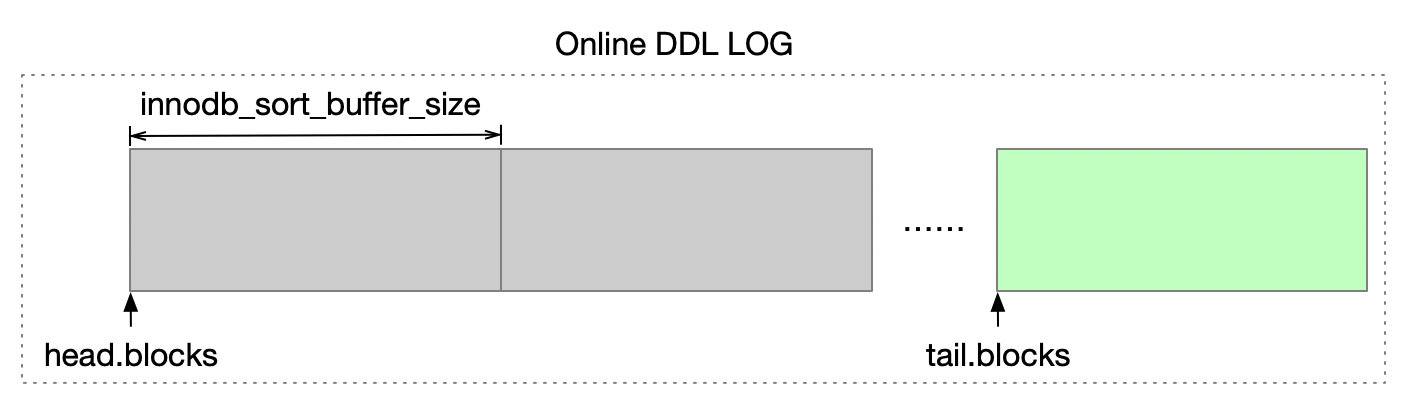
前面这3个步骤在执行的过程中,其他会话还可以正常读取和修改表里面的数据。InnoDB需要将这期间修改过的数据记录下来,数据会先写入到一块临时的内存中,这块临时内存的大小由参数innodb_sort_buffer_size控制。最终这些数据会写到一个临时文件中,我们把这个临时文件称为在线变更日志。如果在创建索引的过程中,表中的数据变更特别频繁,那么在线变更日志中就要记录很多数据,参数innodb_online_alter_log_max_size限制了在线变更日志的大小,如果期间产生的变更日志超过了这个限制,DDL最终会失败。
4. 将在线变更日志中的数据更新到索引中。
为了保障索引数据和表中数据的一致性,步骤3执行完成后,InnoDB需要将在线变更日志中的数据更新到索引结构中。这个过程中,需要锁定新创建的这个索引,因此,其他会话插入新的数据,或者更新这个新创建的索引中包含的字段时,都会被阻塞。
处理在线变更日志中的数据时,可能会遇到几个问题。
如果创建索引的过程中发生变化的数据太多,超过了innodb_online_alter_log_max_size的限制,那么DDL最后会报DB_ONLINE_LOG_TOO_BIG的错误。如果新创建的是唯一索引,那么如果在线变更日志中如果有数据违反了唯一性约束,DDL也会失败。
下面我通过一个例子来说明这种情况。
我们在会话1中创建一个唯一索引。此时表中这几个字段的数据是唯一的。
在索引创建的过程中,我们在另外一个会话中执行下面这几个SQL。因为新的唯一索引还没有创建好,所以这些INSERT语句可以正常执行。
mysql> insert into employees values
(10, '2013-10-10', 'AAAA', 'BBBB', 'M', '2020-10-01');
Query OK, 1 row affected (5.05 sec)
mysql> insert into employees values
(20, '2013-10-10', 'AAAA', 'BBBB', 'M', '2020-10-01');
Query OK, 1 row affected (5.45 sec)
mysql> insert into employees values
(30, '2013-10-10', 'AAAA', 'BBBB', 'M', '2020-10-01');
Query OK, 1 row affected (2.10 sec)
mysql> delete from employees where emp_no in (10,30);
Query OK, 2 rows affected (0.90 sec)
当会话1完成新索引的创建,在处理在线变更日志中的数据时,发生了数据冲突,因此DDL最终失败了。
mysql> alter table employees add unique key uk_x(first_name, last_name, birth_date, hire_date);
ERROR 1062 (23000): Duplicate entry 'AAAA-BBBB-2013-10-10-2020-10-01' for key 'employees.uk_x'
需要重建表的在线DDL
还有一些DDL操作,虽然能以INPLACE的方式执行,但是在执行过程中需要重建表,因此开销也是比较大的。
创建主键、修改主键这几个操作都需要重建表。这一点很容易理解,因为InnoDB表以聚簇索引的方式组织数据,主键变了,数据的物理格式就会发生变化。下面是一个修改主键的例子。
mysql> alter table employees_bak
drop primary key,
add primary key(emp_no, last_name, first_name),
algorithm=inplace;
Query OK, 0 rows affected (46.97 sec)
Records: 0 Duplicates: 0 Warnings: 0
修改字段的顺序和NOT NULL属性也需要重建表。这几个操作会改变行的存储格式,因此也需要重建表。下面这个例子中,将字段first_name移到了第1列。当然,我们一般应该不太会特意去修改表的字段顺序。
mysql> desc employees_bak;
+------------+---------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+------------+---------------+------+-----+---------+-------+
| first_name | varchar(14) | NO | PRI | NULL | |
| emp_no | int | NO | PRI | NULL | |
| birth_date | date | NO | | NULL | |
| last_name | varchar(16) | NO | PRI | NULL | |
| gender | enum('M','F') | NO | | NULL | |
| hire_date | date | YES | | NULL | |
+------------+---------------+------+-----+---------+-------+
mysql> alter table employees_bak
modify first_name varchar(14) not null first,
algorithm=inplace;
Query OK, 0 rows affected (41.22 sec)
Records: 0 Duplicates: 0 Warnings: 0
另外,优化表、修改表的行格式或key_block_size属性也都需要重建表。
使用optimize table命令优化表。
mysql> optimize table employees_bak;
+-------------------------+----------+----------+-------------------------------------------------------------------+
| Table | Op | Msg_type | Msg_text |
+-------------------------+----------+----------+-------------------------------------------------------------------+
| employees.employees_bak | optimize | note | Table does not support optimize, doing recreate + analyze instead |
| employees.employees_bak | optimize | status | OK |
+-------------------------+----------+----------+-------------------------------------------------------------------+
2 rows in set (42.58 sec)
optimize table命令的语法中,不支持algorithm关键字,但是实际上优化表是做了一次在线的表重建。和下面这个命令的效果类似。
mysql> alter table employees_bak engine=innodb, algorithm=inplace, lock=none;
Query OK, 0 rows affected (45.60 sec)
Records: 0 Duplicates: 0 Warnings: 0
InnoDB重建表的时候,需要将整个表的数据写到一个临时的ibd文件中,这个临时文件和表的ibd文件放在同一个目录下,文件名以 “#sql-ib” 开头,在重建表的过程中,你可以在数据目录中看到这个文件。
# ls -lrt /data/mysql01/data/employees
......
-rw-r----- 1 mysql mysql 37748736 8月 3 16:08 employees.ibd
-rw-r----- 1 mysql mysql 7340032 8月 3 16:28 #sql-ib1396-1337919602.ibd
表中的二级索引,也需要加载到新生成的这个ibd文件中。
和在线创建二级索引类似,重建表的过程中,其他会话可以正常读写表中的数据。这个过程中,如果表中的记录被修改了,需要将修改的数据记录到在线变更日志中。
当聚簇索引和二级索引的数据全部都写到新的ibd文件中后,需要将在线变更日志中的数据更新到新的ibd文件中,这个过程中,会先锁定老的聚簇索引。因此,在应用在线变更日志时,应用程序无法读写表的数据,注意,这个过程中连查询都会被阻塞。
如果在重建表的过程中,修改的数据超过了innodb_online_alter_log_max_size的限制,DDL最终会失败。你可以增加innodb_online_alter_log_max_size,但是,这同时也可能会导致应用在线变更日志的时间变长,因此会增加锁表的时间。
在线变更日志应用完成之后,InnoDB删除老的ibd文件,修改新创建的ibd文件,并在元数据中记录这些操作。
在线DDL小结
在线DDL是MySQL为了增加数据库可维护性引入的一个很有用的特性。你可以适当地调大innodb_parallel_read_threads、innodb_ddl_threads、innodb_ddl_buffer_size、innodb_sort_buffer_size等参数,以加快DDL的执行效率,当然前提是服务器的性能要跟得上。
在线DDL的执行过程中,需要占用一些额外的空间,包括临时排序文件,在线变更日志文件,以及临时的ibd文件。临时排序文件默认存放在tmpdir下,如果tmpdir空间紧张,你也可以设置参数innodb_tmpdir,将这些文件放到一个空间足够大的目录下。你可以根据表ibd文件当前的大小来估算临时排序文件和临时ibd文件需要的空间。
虽然在线DDL极大地减少了锁表的时间,但是在应用在线变更日志时,还是会将表或二级索引锁住,因此应用程序还是会有影响的,锁的时间取决于表的大小以及和DDL期间发生变化的数据量有关。
InnoDB在线变更日志按innodb_sort_buffer_size的设置,分为多个块。在应用在线变更日志时,如果是在应用最后一个日志块中的记录,需要获取主键或索引的锁。
如果你的表特别大,并且表中数据的修改非常频繁,InnoDB原生的在线DDL并不一定能满足你的需求。
不支持在线执行的DDL
虽然MySQL增加了在线DDL的能力,但还是存在一些情况无法使用在线DDL,执行这些DDL时,需要使用MySQL最原始的COPY方式,先创建一个临时表,再锁住源表,将源表的记录插入到临时表,最后,当数据复制完成后,将临时表改为正式表。
下面这些操作都不支持在线DDL。
- 删除表的主键。
mysql> alter table salaries drop primary key, algorithm=inplace;
ERROR 1846 (0A000): ALGORITHM=INPLACE is not supported. Reason: Dropping a primary key is not allowed without also adding a new primary key. Try ALGORITHM=COPY.
- 修改字符集。
注意,使用alter table table_name convert to character set才会修改表中已有数据的编码。alter table table_name character set只是修改了表的默认字符集,不会修改现有数据的编码方式。
mysql> alter table employees_bak CONVERT TO CHARACTER SET GBK, algorithm=inplace;
ERROR 1846 (0A000): ALGORITHM=INPLACE is not supported. Reason: Cannot change column type INPLACE. Try ALGORITHM=COPY.
- 修改字段的数据类型。
mysql> desc salaries;
+-----------+------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-----------+------+------+-----+---------+-------+
| emp_no | int | NO | PRI | NULL | |
| salary | int | NO | | NULL | |
| from_date | date | NO | PRI | NULL | |
| to_date | date | YES | | NULL | |
+-----------+------+------+-----+---------+-------+
4 rows in set (0.01 sec)
mysql> alter table salaries modify salary bigint, algorithm=inplace;
ERROR 1846 (0A000): ALGORITHM=INPLACE is not supported. Reason: Cannot change column type INPLACE. Try ALGORITHM=COPY.
- 缩减VARCHAR字段的长度,或者将VARCHAR字段的长度从不到255字节修改为超过255字节。这一点对CHAR类型其实也一样。
mysql> desc departments;
+-----------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-----------+-------------+------+-----+---------+-------+
| dept_no | char(4) | NO | PRI | NULL | |
| dept_name | varchar(40) | NO | UNI | NULL | |
+-----------+-------------+------+-----+---------+-------+
2 rows in set (0.01 sec)
mysql> alter table departments modify dept_name varchar(30), algorithm=inplace;
ERROR 1846 (0A000): ALGORITHM=INPLACE is not supported. Reason: Cannot change column type INPLACE. Try ALGORITHM=COPY.
mysql> alter table departments modify dept_name varchar(64), algorithm=inplace;
ERROR 1846 (0A000): ALGORITHM=INPLACE is not supported. Reason: Cannot change column type INPLACE. Try ALGORITHM=COPY.
mysql> alter table departments modify dept_no char(64), algorithm=inplace;
ERROR 1846 (0A000): ALGORITHM=INPLACE is not supported. Reason: Cannot change column type INPLACE. Try ALGORITHM=COPY.
mysql> alter table departments modify dept_no char(2), algorithm=inplace;
ERROR 1846 (0A000): ALGORITHM=INPLACE is not supported. Reason: Cannot change column type INPLACE. Try ALGORITHM=COPY.
虽然有些INPLACE操作也需要重建表,需要复制整个表的数据,但是和COPY方式相比,还是存在比较大的区别的。首先,以COPY的方式执行DDL时,整个过程中都会锁表。其次COPY是在MySQL的Server层执行的,需要先从存储引擎获取一行数据,再调用存储引擎的接口写入一行数据,直到处理完所有的记录。而INPLACE DDL是在InnoDB存储引擎的内部复制数据,这个过程中不需要记录UNDO日志和REDO日志,而且二级索引的条目会预先排好序,因此理论上写入的速度会更快。
第三方在线DDL工具
如果你要执行的DDL不支持以INSTANT和INPLACE的方式执行,或者你的表非常大,数据变更也很频繁,使用MySQL原生的在线DDL也无法满足业务的可用性要求,那么你可以考虑使用一些第三方的在线DDL工具,业界比较知名的有percona出品的pt-online-schema-change工具,以及Github出品的gh-ost工具。当然,可能还存在其他类似的第三方工具,实际上你自己也可以写一个类似的工具。
接下来我们来一起探讨下,怎么实现一个在线DDL工具。假设我们要对一个表SRC_TAB执行一个开销很大的DDL,我们可以将DDL拆分成几个步骤。
- 创建一个表结构一样的空表。
- 在新建的临时表上执行DDL。由于新表中没有任何数据,因此DDL很快就能执行完。
- 分批读取源表的数据,插入到新建的临时表中。
当然,在复制数据的过程中,源表的数据会不断地发生变化,因此我们需要想办法同步这些发生了变化的数据,否则两个表的数据就不一致了。
- 我们可以给源表建几个触发器,将源表发生过变化的记录都捕捉下来。
实际上,要在复制数据前,先把触发器建好,因此这一步要在步骤3之前执行。触发器的实现上,有几种不同的策略可以选择。一种是在触发器中,将整条记录直接写到目标临时表中。
还有一种方式是先将发生过变化的数据写到一个日志表中,日志表中只保存主键字段和数据的变更类型。
日志表的结构类似于下面建的__SRC_TAB_DML_LOG表。PK字段是源表的主键字段,当然数据类型要和源表保持一致,用来标识发生过变化的记录的主键。DML_TYPE字段用了标识发生的DML类型。DML类型分为INSERT、UPDATE、DELETE。如果是更新了主键,那么需要记录两条日志,一条是删除操作,一条是插入操作。
create table __SRC_TAB_DML_LOG(
id bigint not null auto_increment,
pk bigint not null,
dml_type tinyint not null comment '0: insert, 1: update, 2: delete',
ts timestamp,
applied tinyint not null comment '0: not applied, 1: applied',
primary key(id)
) engine=innodb;
- 按顺序处理增量日志表中的数据。
根据增量日志表中记录的主键ID,依次将数据从源表复制到目标表。
如果是DELETE操作,则需要到目标表中删除对应的记录。
处理增量日志表中的数据时,你可以想办法做并行处理。还可以将主键相同的多条变更记录合并到一起执行。比如源表中有一行记录被更新了100次,你只要将该记录最新的数据同步到目标表就可以了。
- 锁定源表,处理增量日志表中剩余的数据。
当增量日志表中的数据基本处理完之后,锁定源表。源表锁定后,就不会再发生数据变化了,然后你再将增量日志表中所剩不多的数据处理完。
- 交换源表和目标表。
此时源表和目标表的数据已经完全同步了,执行rename操作,交换两个表的表名。
这样,你就完成了SRC_TAB表的DDL操作。当然,在实现上,还有很多细节问题需要处理。比如,如果源表使用了联合主键,你应该如何分批复制数据。如果有其他表对源表有外键依赖,这样做也会有问题。更重要的是,如何保证源表和目标表的数据是完全一致的。
总结
这一讲中,我们讨论MySQL中执行DDL的几种不同的方式。
DDL,特别是对大表进行DDL,最好是安排在业务访问的低峰期进行。如果你的数据库非常繁忙,即使是DROP TABLE这样看似简单的操作,都有可能对业务造成明显的影响。
还有,即使你执行的DDL只需要修改元数据,在DDL执行开始和执行结束的时候,也是需要短暂地获取元数据锁的,如果数据库中有别的长事务提前获取了元数据锁,那么DDL就会被阻塞,而DDL被阻塞后,后续其他会话访问同一个表时,也会被阻塞。因此在DDL执行的过程中,需要注意观察数据库的整体状况,特别是要注意有没有会话在等待元数据锁。
MySQL的在线DDL并不是完全无锁的。还有一些DDL并不支持在线执行。你可以考虑使用第三方的在线DDL工具,但是在使用前一定要在你自己的环境中做好充分的测试,这些工具可能会有一些额外的限制。你需要重点验证下这些工具是否能保证数据的一致性。
思考题
gh-ost是比较知名的一款在线DDL工具,在实现上也非常有特色。gt-ost在执行DDL变更时,不需要给源表建触发器,而是通过BINLOG来捕捉DDL变更期间发生过变化的数据。我尝试在测试环境做了一个实验。
gh-ost -alter "alter table employees_bak modify hire_date date" \
-user user_01 \
-host 127.0.0.1 \
-password somepass \
-database employees \
--allow-on-master \
--execute \
-heartbeat-interval-millis 1000
在执行gh-ost前,我先开启了general_log,最终在general log中发现有以下这几类SQL。
- create table like
- alter table
- select
select /* gh-ost `employees`.`employees_bak` iteration:0 */
`emp_no`
from `employees`.`employees_bak`
where ((`emp_no` > _binary'10001') or ((`emp_no` = _binary'10001')))
and ((`emp_no` < _binary'20000') or ((`emp_no` = _binary'20000')))
order by `emp_no` asc
limit 1
offset 999
- insert ignore into
insert /* gh-ost `employees`.`employees_bak` */
ignore into `employees`.`_employees_bak_gho`
(`emp_no`, `birth_date`, `first_name`, `last_name`, `gender`, `hire_date`)
(
select `emp_no`, `birth_date`, `first_name`, `last_name`, `gender`, `hire_date`
from `employees`.`employees_bak` force index (`PRIMARY`)
where (((`emp_no` > _binary'10001') or ((`emp_no` = _binary'10001')))
and ((`emp_no` < _binary'11000') or ((`emp_no` = _binary'11000'))))
lock in share mode
)
- replace into
replace /* gh-ost `employees`.`_employees_bak_gho` */ into
`employees`.`_employees_bak_gho`(`emp_no`, `birth_date`, `first_name`, `last_name`, `gender`, `hire_date`)
values (20001, '1962-05-16', _binary'Atreye', _binary'Eppinger', ELT(1, 'M','F'), '1990-04-18')
- rename table
rename /* gh-ost */ table `employees`.`employees_bak` to `employees`.`_employees_bak_del`, `employees`.`_employees_bak_gho` to `employees`.`employees_bak`
上面的这几类SQL,分别起到了什么作用?insert ignore into和replace into的执行顺序,对最终数据的一致性有影响吗?执行insert ignore into … select from … 的时候,为什么要加上lock in share mode?
期待你的思考,欢迎在留言区中与我交流。如果今天的课程让你有所收获,也欢迎转发给有需要的朋友。我们下节课再见!
- 叶明 👍(1) 💬(1)
insert ignore into用来同步全量数据,replace into是从binlog中解析出来的insert和update事件。binlog中的delete事件应该会解析成delete语句。我测试的结果是 update 语句并没有转为 replace into,仍旧是 update。全量日志如下 2024-09-20T03:59:21.024359Z 1451 Query update employees_bak set first_name = '2024-09-20' where emp_no = 10001 2024-09-20T03:59:21.044251Z 1467 Query START TRANSACTION 2024-09-20T03:59:21.044461Z 1467 Query SET SESSION time_zone = '+00:00', sql_mode = CONCAT(@@session.sql_mode, ',NO_AUTO_VALUE_ON_ZERO,STRICT_ALL_TABLES') 2024-09-20T03:59:21.044739Z 1467 Query update /* gh-ost `employees`.`_employees_bak_gho` */ `employees`.`_employees_bak_gho` set `emp_no`=10001, `birth_date`='1953-09-02', `first_name`=_binary'2024-09-20', `last_name`=_binary'Facello', `gender`=ELT(1, 'M','F'), `hire_date`='1986-06-26' where ((`emp_no` = 10001)) 2024-09-20T03:59:21.051821Z 1467 Query COMMIT 我理解的转化规则,不知道对否 1、insert -> replace into 2、update -> update,如果记录已经拷贝到影子表中,那么直接 update 影子表,影子表中记录达到最新;如果记录尚未拷贝到影子表,直接更新影子表,但此时影子表中没有这条记录,因此更新 0 行,待后面 insert ignore into 插入新的记录,影子表中对应的行仍旧为最新的记录 3、delete -> delete Binlog可见和事务可见之间存在一个时间差,这是两阶段提交导致的吧,innodb prepare -> binlog write -> innodb commit,binlog 比 innodb commit 提前完成,所以说 binlog 比事务可见早一点。
2024-09-23 - Shelly 👍(1) 💬(1)
思考题: gh-ost做DDL变更期间,有三种操作:(1). 对原表的copy到影子表 (2). 应用binlog到影子表 (3). 业务对原表的DML操作 由于copy原表操作和应用binlog到影子表是交替进行的,所以: 1. insert ingore into ...操作,如果业务先对原表进行了一些插入操作(注意此时对应的行还没有被copy到影子表),然后应用binlog到影子表,这时copy对应的行到影子表,如果不加ingore就会导致主键冲突错误 2. replace into 操作,如果业务对表进行了一些插入操作,对原表相应记录copy到影子表(此时对应的binlog还未被应用),后续在应用binlog时影子表已经有了相应记录,所以要加inplace into 覆盖掉copy操作的相应记录,否则会导致主键冲突错误 3. insert ingore into ...操作和replace into 操作的顺序不会对最终的数据一致性有影响 4. 个人理解查询时加lock in shared mode原因:假设一个场景主从半同步(after_sync),有个用户在主库对表进行了几行删除操作,此时从库由于某些原因没有回复ack,如果binlog已经被捕获,应用binlog到影子表时操作会被忽略(此时相应的记录还没有被copy到影子表),然后再copy相应原表记录到影子表(由于主库没有收到从库的ack,所以主库是可以查询到这些被删除的表),于是实际上已经被删除的数据却被拷贝到了影子表,导致原表和影子表的数据不一致。 如果在copy数据时,查询加上lock in shard mode共享锁,就会等待删除的事务提交后才能获取数据相应行的数据,防止了DDL变更前后数据不一致的情况发生。
2024-09-14 - 123 👍(1) 💬(7)
思考题: 1 - create table like:创建临时表,复制表结构; 2 - alter table:根据命令更改表表结构; 3 - select:并发读取数据(看到了偏移量,应该是多线程)写入临时文件,使用_binary应该是可以忽略字符集,直接比较二进制文本,减少开销提升性能; 4 - insert ignore into:将数据插入到临时表中,忽略唯一键报错; 5 - replace into:将增量数据更新至临时表中; 6 - rename table:将临时表变更为生产表; insert into 应该是原表的数据,replace into 的是增量的数据,改变执行顺序,会导致数据不一致,特别是涉及删除操作的内容,如果仅仅是数据的插入和更新,更新本身就带有全量数据,插入后就代表了该行的最新数据,后续的insert into ignore也会忽略,觉得仅仅是replace into 和 insert into的替换感觉也不会出问题,望老师指正 执行insert时需要lock in share mode加上共享锁,应该是防止进行数据更新,仅供查询。
2024-09-14 - 木几丶 👍(0) 💬(2)
老师,请问下修改字段数据类型这些操作不能用OnlineDDL?
2024-12-19 - 陈星宇(2.11) 👍(0) 💬(1)
老师,这些都是8.0才有的吧?innodb_online_alter_log_max_size
2024-09-25 - binzhang 👍(0) 💬(1)
为啥有些inplace的ddl也显示rows affected是0? 只有copy模式会显示非0 的rows affected吗?
2024-09-13