10 MySQL如何快速导入导出数据?(下)
你好,我是俊达。
上一讲我介绍了mysqldump和MySQL Shell的Dump工具。使用mysqldump导出的,实际上是一个SQL文件,将这个文件直接拿到数据库中执行,就可以完成数据导入。MySQL Shell Dump工具将建表语句、表中的数据导出到了不同的文件中,而且数据以文本文件的形式存储,需要使用MySQL Shell配套的Load工具,或者使用Load Data命令导入数据。
这一讲我们来学习MySQL Shell Load工具的使用方法,以及导出和导入单个表数据的一些其他方法。
MySQL Shell Load工具
使用load_dump导入
MySQL Shell Dump导出的数据,可以用MySQL Shell Load工具导入。load_dump有两个参数,第一个参数是Dump文件的路径。第二个参数是一个字典,用来指定导入的各个选项。
load_dump默认会导入Dump路径下的所有文件。你可以使用includeSchemas、includeTables来指定需要导入的库和表,用excludeSchemas、excludeTables忽略指一些库和表。这里includeTables和excludeTables中表名的格式为"db_name.table_name"。
将loadDdl设置为True,loadData设置为False,你可以只导入表结构,不导入数据。
util.load_dump("employees_dump", {
"includeTables":["employees.salaries"],
"loadDdl":True,
"loadData":False
})
如果你只导出了一个库,还可以通过schema选项,数据导入到另外一个库中。如果指定的库不存在,load_dump会自动创建这个数据库。
如果Dump文件中包含了多个库,那么使用schema选项时,会报出下面这样的错误信息。
注意事项
- load_dump工具使用LOAD DATA LOCAL INFILE命令导入数据,因此需要在目标库上将local_infile设置为ON,否则会报错“ERROR: The ‘local_infile’ global system variable must be set to ON in the target server, after the server is verified to be trusted.”。
- 使用load_dump导入时,如果目标库中已经有同名的表,导入操作会报错。
ERROR: Schema `employees` already contains a table named employees
ERROR: One or more objects in the dump already exist in the destination database. You must either DROP these objects or exclude them from the load.
你可以设置excludeTables,不导入这些表。或者设置ignoreExistingObjects,忽略已经存在的表。注意,设置ignoreExistingObjects只是不重新创建表,数据还是会重新导入的,表中已经存在数据,会被Dump文件中的数据覆盖。
- load_dump将导入的进度记录在progressFile文件中。如果导入过程异常中断,下次继续导入时,会根据progressFile文件中的内容跳过已经完成的步骤。如果你想重新导入数据,可以将resetProgress设置为True。
util.load_dump("/data/backup/backup_employees", {
"schema":"employees_restore",
"resetProgress": True,
})
Load选项
下面的表格整理了Load工具支持的一部分参数,供你参考。完整的选项请参考官方文档。

MySQL Shell Dump导出的文件,实际上还可以直接使用LOAD DATA命令导入,或者使用MySQL Shell的import_table导入,接下来我会依次介绍。
单表数据导出
MySQL Shell Dump导出的数据,实际上使用了比较常用的一种数据格式。在MySQL中,还有其他几个方法也能将数据导出成一样的格式,包括使用SELECT INTO OUTFILE和使用MySQL Shell的export_table功能。
使用SELECT INTO OUTFILE
使用SELECT INTO OUTFILE可以将数据导出到文本文件。不过使用这个功能时,需要先设置数据库参数secure_file_priv。修改secure_file_priv需要重启数据库,我们将参数加到配置文件中,重启数据库。
OUTFILE不能指向已经存在的文件,否则会报错。
mysql> select * from employees.employees limit 10 into outfile '/tmp/emp.txt';
Query OK, 10 rows affected (0.19 sec)
SELECT INTO不加额外参数时,使用Tab分割字段,使用换行符分割记录。
# head -5 /tmp/emp.txt
10001 1953-09-02 Georgi Facello M 1986-06-26
10002 1964-06-02 Bezalel Simmel F 1985-11-21
10003 1959-12-03 Parto Bamford M 1986-08-28
10004 1954-05-01 Chirstian Koblick M 1986-12-01
10005 1955-01-21 Kyoichi Maliniak M 1989-09-12
你可以分别指定列分割符、行分割符、转义符。下面这个例子中,列分割符是逗号 ",",行分割符是换行符 "\n",字段的数据用引号引用起来。
mysql> select * from employees limit 10
into outfile '/tmp/emp1.txt'
character set utf8mb4
fields terminated by ','
optionally enclosed by '"'
escaped by '\\'
lines terminated by '\n';
Query OK, 10 rows affected (0.01 sec)
这样导出的文件,就是非常常见的CSV格式。
# cat /tmp/emp1.txt
10001,"1953-09-02","Georgi","Facello","M","1986-06-26"
10002,"1964-06-02","Bezalel","Simmel","F","1985-11-21"
10003,"1959-12-03","Parto","Bamford","M","1986-08-28"
10004,"1954-05-01","Chirstian","Koblick","M","1986-12-01"
10005,"1955-01-21","Kyoichi","Maliniak","M","1989-09-12"
实际场景中,字段中存储的数据中很可能也包含了列分割符、行分割符、引号、转义符,这会引起文件格式错乱吗?我们用一个例子来测试下。
mysql> create table emp2(
emp_no int,
emp_name varchar(60),
emp_intro varchar(100),
primary key (emp_no)
) engine=InnoDB;
mysql> insert into emp2 values
(10001, '张三', '一生二,二生三,三生万物。'),
(10002, '李某', '引用一句名言:"天行健\n君子以自强不息"'),
(10003, '陈某', 'D:\\Pictures\\myself.png');
mysql> select * from emp2;
+--------+----------+------------------------------------------------------+
| emp_no | emp_name | emp_intro |
+--------+----------+------------------------------------------------------+
| 10001 | 张三 | 一生二,二生三,三生万物。 |
| 10002 | 李某 | 引用一句名言:"天行健
君子以自强不息" |
| 10003 | 陈某 | D:\Pictures\myself.png |
+--------+----------+------------------------------------------------------+
3 rows in set (0.00 sec)
上面这个表的几行数据中,有逗号、双引号、换行符、反斜杠这些特殊的字符。将数据导出后,可以看到这些特殊字符都进行了转义处理。因此导入这些数据时,只要指定相同的参数,就不会有任何问题。
mysql> select * from emp2 limit 10
into outfile '/tmp/emp2.txt'
character set utf8mb4
fields terminated by ','
optionally enclosed by '"'
escaped by '\\'
lines terminated by '\n';
Query OK, 3 rows affected (0.00 sec)
# cat /tmp/emp2.txt
10001,"张三","一生二,二生三,三生万物。"
10002,"李某","引用一句名言:\"天行健\
君子以自强不息\""
10003,"陈某","D:\\Pictures\\myself.png"
SELECT INTO OUTFILE只能将数据导出在数据库服务器的目录中,使用起来并不是很方便。因为你可能并没有数据库服务器的权限,比如你可能使用了云数据库,无法访问底层操作系统。
使用MySQL Shell export_table导出数据
MySQL Shell提供了export_table功能,可以将表的数据导出到本地文件中。下面这个例子使用export_table导出emp2表。
mysqlsh -u user_01 -h172.16.121.234 -psomepass --py --mysql
MySQL Py > util.export_table("employees.emp2", "/data/backup/emp2.csv", {
"linesTerminatedBy": "\n",
"fieldsTerminatedBy": ",",
"fieldsEnclosedBy": "\"",
"fieldsOptionallyEnclosed": True,
"fieldsEscapedBy": "\\"
})
Initializing - done
Gathering information - done
Running data dump using 1 thread.
NOTE: Progress information uses estimated values and may not be accurate.
Starting data dump
100% (3 rows / ~3 rows), 0.00 rows/s, 0.00 B/s
Dump duration: 00:00:00s
Total duration: 00:00:00s
Data size: 170 bytes
Rows written: 3
Bytes written: 170 bytes
Average throughput: 170.00 B/s
The dump can be loaded using:
util.import_table("/data/backup/emp2.csv", {
"characterSet": "utf8mb4",
"fieldsEnclosedBy": "\"",
"fieldsEscapedBy": "\\",
"fieldsOptionallyEnclosed": true,
"fieldsTerminatedBy": ",",
"linesTerminatedBy": "\n",
"schema": "employees",
"table": "emp2"
})
指定相同的参数后,使用export_table生成的文件和SELECT INTO OUTFILE基本一致。
# cat ./employees_dump/emp2.csv
10001,"张三","一生二\,二生三\,三生万物。"
10002,"李某","引用一句名言:\"天行健\n君子以自强不息\""
10003,"陈某","D:\\Pictures\\myself.png"
单表数据导入
前面讲到,load_dump底层实际上使用了LOAD DATA LOCAL INFILE命令来导入数据。我们也可以在MySQL客户端中直接使用LOAD DATA命令。
使用Load Data导入数据
LOAD DATA命令的基本格式如下:
LOAD DATA
[LOCAL]
INFILE 'file_name'
[REPLACE | IGNORE]
INTO TABLE tbl_name
[CHARACTER SET charset_name]
[FIELDS
[TERMINATED BY 'string']
[[OPTIONALLY] ENCLOSED BY 'char']
[ESCAPED BY 'char']
]
[LINES
[STARTING BY 'string']
[TERMINATED BY 'string']
]
[IGNORE number {LINES | ROWS}]
[(col_name_or_user_var
[, col_name_or_user_var] ...)]
[SET col_name={expr | DEFAULT}
[, col_name={expr | DEFAULT}] ...]
INFILE指定文件路径,如果不加LOCAL,那么文件需要存放在数据库服务器的指定路径下,并且登录用户需要有FILE权限。如果加上了LOCAL,那么文件需要在客户端所在的机器上。如果导入的数据和表里原有的数据有冲突,默认会报错,可以加上REPLACE,覆盖表中的数据,或者加上IGNORE,跳过冲突的数据。
你可以使用IGNORE忽略文件开头的几行内容。如果你的文件前几行是标题,使用IGNORE就很方便。
下面的例子中,我们使用LOAD DATA命令来导入之前生成的CSV文件。注意mysql命令行需要加上参数–local-infile。
mysql -vvv -uuser_01 -h172.16.121.234 -pabc123 -psomepass --local-infile employees <<EOF
load data local infile '/data/backup/emp2.csv'
replace into table emp3
character set utf8mb4
fields terminated by ','
optionally enclosed by '"'
escaped by '\\\\'
lines terminated by '\n';
EOF
导入后要检查命令的输出信息,如果有Warning,需要检查下产生warning的具体原因。
我们来检查下导入的数据,没有发现什么问题。
mysql> select * from emp3;
+--------+----------+------------------------------------------------------+
| emp_no | emp_name | emp_intro |
+--------+----------+------------------------------------------------------+
| 10001 | 张三 | 一生二,二生三,三生万物。 |
| 10002 | 李某 | 引用一句名言:"天行健
君子以自强不息" |
| 10003 | 陈某 | D:\Pictures\myself.png |
+--------+----------+------------------------------------------------------+
3 rows in set (0.00 sec)
刚才的例子中,CSV文件中字段数量和顺序跟表里面的字段数量和顺序完全一致。如果文件和表里面字段数量或顺序不一致,应该怎么处理呢?
我们使用一个具体的例子来说明如何处理这种情况。
create table emp4(
emp_name varchar(64),
emp_no int,
emp_intro varchar(100),
grade int,
primary key(emp_no)
) engine=InnoDB;
emp4这个表和刚才的emp2.csv文件的字段顺序不一样,字段数量也不一样。
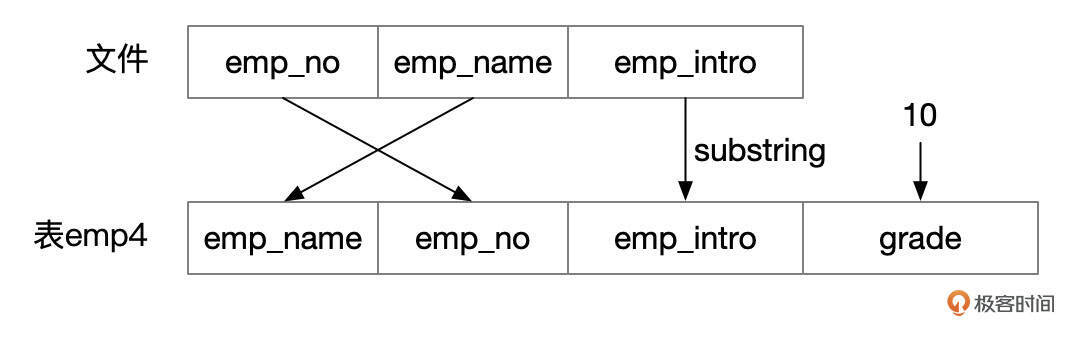
导入数据时,以CSV文件中字段顺序为准,指定字段列表。我们的例子中,第一列对应到emp_no字段,第二列对应到emp_name字段,第三列对应到变量@emp_intro。然后再使用SET,将表的grade字段设置成固定值10,将emp_intro字段设置为文件中emp_intro列的前缀。
mysql -vvv -uuser_01 -h172.16.121.234 -pabc123 -psomepass --local-infile employees <<EOF
load data local infile '/data/backup/emp2.csv'
replace into table emp4
character set utf8mb4
fields terminated by ','
optionally enclosed by '"'
escaped by '\\\\'
lines terminated by '\n'
(emp_no, emp_name, @emp_intro)
set grade = 10, emp_intro = substring(@emp_intro, 1, 5)
EOF
我们来看一下导入的数据是不是符合预期。
mysql> select * from emp4;
+----------+--------+-----------------+-------+
| emp_name | emp_no | emp_intro | grade |
+----------+--------+-----------------+-------+
| 张三 | 10001 | 一生二,二 | 10 |
| 李某 | 10002 | 引用一句名 | 10 |
| 陈某 | 10003 | D:\Pi | 10 |
+----------+--------+-----------------+-------+
MySQL Shell 并行导入
使用Load Data命令导入一个文件时,数据库内部使用了单线程处理。服务端接收到LOAD DATA LOCAL INFILE命令后,向客户端访问文件内容。客户端依次读取文件的内容,通过网络发送到服务端,服务端将网络中读取到的数据解析成一行一行的记录,再调用存储引擎接口写入数据。
MySQL Shell的import_table工具提供了并行导入数据的功能,如果你的MySQL服务器配置比较高,CPU和IO性能都很好,使用并行导入可能能提高大表的导入速度。
MySQL Shell Dump导出的文件,也可以用import_table来导入。有一点需要注意,import_table可以直接导入zstd压缩过的文件,但是对于单个压缩文件是无法使用并行导入的。
下面这个例子中,我们先解压文件,再使用import_table来导入。我们将bytesPerChunk设置为1M,也就是每执行一次LOAD DATA命令,就发送1M的文件内容。threads设置为8。
# zstd -d employees@salaries@@0.tsv.zst
# mysqlsh -u user_01 -h172.16.121.234 -psomepass --py --mysql
MySQL Py > util.import_table(
"/data/backup/employees_dump/employees@salaries@@0.tsv",
{
"schema": "employees",
"table": "salaries_backup",
"bytesPerChunk": "1M",
"threads":8
})
到目标服务器上执行show processlist,可以看到有8个会话都在执行LOAD DATA命令。
*************************** 10. row ***************************
Id: 60
User: user_01
Host: mysql02:45028
db: employees
Command: Query
Time: 36
State: executing
Info: LOAD DATA LOCAL INFILE '/data/backup/employees_dump/employees@salaries@@0.tsv' INTO TABLE `employees
*************************** 11. row ***************************
Id: 61
User: user_01
Host: mysql02:45026
db: employees
Command: Query
Time: 36
State: executing
Info: LOAD DATA LOCAL INFILE '/data/backup/employees_dump/employees@salaries@@0.tsv' INTO TABLE `employees
......
*************************** 17. row ***************************
Id: 67
User: user_01
Host: mysql02:45040
db: employees
Command: Query
Time: 36
State: executing
Info: LOAD DATA LOCAL INFILE '/data/backup/employees_dump/employees@salaries@@0.tsv' INTO TABLE `employees
指定相应的参数后,import_table也能用来导入CSV格式的文件,可以看出,这些参数和LOAD DATA命令可以一一对应起来。
util.import_table(
"/data/backup/emp2.csv",
{
"schema": "employees",
"table": "emp4",
"linesTerminatedBy": "\n",
"fieldsTerminatedBy": ",",
"fieldsEnclosedBy": '"',
"fieldsOptionallyEnclosed": True,
"fieldsEscapedBy": "\\",
"replaceDuplicates": True,
"columns": ["emp_no", "emp_name", 1 ],
"decodeColumns": {
"grade":11,
"emp_intro":"substring(@1, 1, 10)",
}
})
mysql> select * from emp4;
+----------+--------+----------------------------+-------+
| emp_name | emp_no | emp_intro | grade |
+----------+--------+----------------------------+-------+
| 张三 | 10001 | 一生二,二生三,三生 | 11 |
| 李某 | 10002 | 引用一句名言:"天行 | 11 |
| 陈某 | 10003 | D:\Picture | 11 |
+----------+--------+----------------------------+-------+
import_table选项
我整理了import_table支持的部分选项,供你参考。完整的选项请参考官方文档。

总结
这一讲我们探讨了MySQL数据导入导出的一些工具和方法,这都是官方提供的工具。mysqldump使用起来非常方便,但由于是单线程的,如果你的数据库特别大,导入数据可能会需要很长的时间。你需要注意,导出数据时是否会锁表,尤其是导出生产环境的数据库时,不要影响正常的业务访问。
MySQL Shell的Dump和Load工具能以多线程的方式运行,在导出和导入大量数据时有优势。当然,如果你需要复制整个数据库实例,使用物理备份的方式可能性能更好,后续的课程中,我们会分别介绍使用xtrabackup和clone插件来复制整个库的方法。
如果你需要将大量数据从别的数据库迁移到MySQL,一种可行的方法是先将源库的数据导出成CSV文件,然后再使用LOAD DATA或MySQL Shell的import_table导入数据。数据导出和导入时,还需要注意文本数据的字符集,导入数据后要检查是否有乱码产生。同时也要检查导入前后的数据量是否一样。
思考题
由于公司的策略,需要将一个核心业务系统的Oracle数据库迁移到MySQL。这个Oracle数据库大概有1T数据,迁移过程中,要尽可能缩短业务停机的时间,业务方能接受的最大停机时间在1~2小时之内。请你设计一个方案,将数据平滑地迁移到MySQL。你需要考虑全量数据如何迁移,业务运行期间新产生的数据如何迁移。
期待你的思考,欢迎在留言区中与我交流。如果今天的课程让你有所收获,也欢迎转发给有需要的朋友。我们下节课再见!
- 123 👍(2) 💬(1)
思考题: 可以通过Oracle工具多线程导出整个数据库实例,设置开启事务,短暂的获取全局锁后进行快照导出,将数据导出到指定目录中,并且每个库表的ddl和数据都是分开存放,方便后面的并行导入; 导入过程中使用import_table,指定线程数,具体的线程数据还是要根据目标数据库的并发写性能来确定,尽可能的缩短时间; 对于导出导入过程中的增量数据,可以在导出开始的时候记录binlog位置或GTID的全局事务id,导入增量数据的时候可以通过binlog位置和GTID来恢复增量数据,且导出数据的过程尽量在用户量少的时间操作,确保增量的数据尽可能少,同时来减少导入增量数据时业务库的停机时间;
2024-09-09 - ls 👍(0) 💬(1)
也可以看数据变化程度,如果历史数据几乎不会改变,可以直接oracle 并发导出csv ,然后mysql 并发导入csv,最后检查数据
2024-09-10 - ls 👍(0) 💬(1)
借用ogg 先实时同步 Oracle和MySQL的数据,切换窗口时间用来检测数据同步是否正确。
2024-09-10 - Geek_0126 👍(0) 💬(1)
异构数据源之间的同步问题,就要借助同步工具了,例如DataX、cloudcanal等,可以先进行全量迁移,然后再开启增量同步。不过其中需要注意的细节太多了,比如数据类型及各种数据库对象之间的转换。
2024-09-09