08 程序访问数据库内存溢出怎么解决?
你好,我是俊达。
不知道你平时使用各种语言编写程序访问数据库的时候,有没有遇到过内存方面的问题,确切地讲,是应用程序访问数据库时,消耗了大量的内存,甚至导致整个服务器的内存都耗尽了。
作为一名数据库的用户,我原先也写过一些简单的程序,用来同步数据。代码的核心逻辑很简单,就是到源库执行SELECT语句查询数据,每次读取一行数据,然后到目标库执行INSERT写入数据,就像下面这段简单的Python代码所展示的。
import MySQLdb
def copy_table(src_conn, dest_conn):
sql_select = 'select * from src_tab'
sql_insert = "insert into dest_tab values(%s,%s,%s)"
cur = src_conn.cursor()
cur.execute(sql_select)
row = cur.fetchone()
while row:
insert_row(dest_conn, sql_insert, row)
row = cur.fetchone()
def insert_row(dbconn, sql, data):
cur = dbconn.cursor()
cur.execute(sql, data)
dbconn.commit()
if __name__ == '__main__':
src_conn = MySQLdb.connect(host='src_host', port=3306, user='user_01', passwd='somepass', db='src_db');
dest_conn = MySQLdb.connect(host='dest_host', port=3306, user='user_01', passwd='somepass', db='dest_db');
copy_table(src_conn,dest_conn )
上面这段代码没有做异常处理,也没有采用批量写入来提高性能,但是在不出异常的情况下,是可以执行的。直到后来发现了一个严重的问题。如果源表数据量很大,那么执行这段代码时,程序会消耗大量的内存,使用top命令可以观察到进程使用的内存持续上涨,但是在目标表中却查不到任何新插入的数据。
为什么会这样呢?这一讲我们就来好好地分析一下这个问题。
内存分析
在上面这个例子中,代码非常简单,因此我们比较容易想到内存使用量高可能跟源表数据量多有关系。但是在实际场景中,代码可能会很复杂,你首先需要搞清楚内存到底消耗在哪里了。接下来我以一个真实的Java程序为例,演示如何进行内存分析。之所以选用Java,主要是因为Java在企业级应用中运用很广泛,而且相关的配套工具也比较完善。
我们可以使用Heapdump来分析Java程序的内存使用情况,从Heapdump中可以分析出程序的很多信息,包括:
- 各种类型对象的数量、占用的空间
- 对象之间的引用关系
- 对象属性的值
- 线程的调用栈
我们使用MAT(Memory Analyzer Tool)来分析Java的Heapdump文件。首先需要获取Java程序的Heapdump,我们可以使用jmap等工具来生成Heapdump,具体的方法这里就不展开了。获取到Dump文件后,使用MAT打开。如果生成的Dump文件比较大,打开可能需要比较多的时间。
总览页
打开Dump文件后,从总览页面可以看到内存消耗最高的那些对象。在我们这个Dump文件中,内存占用最高的是JDBC42ResultSet,从名字我们猜测这应该是从数据库取回的结果集。
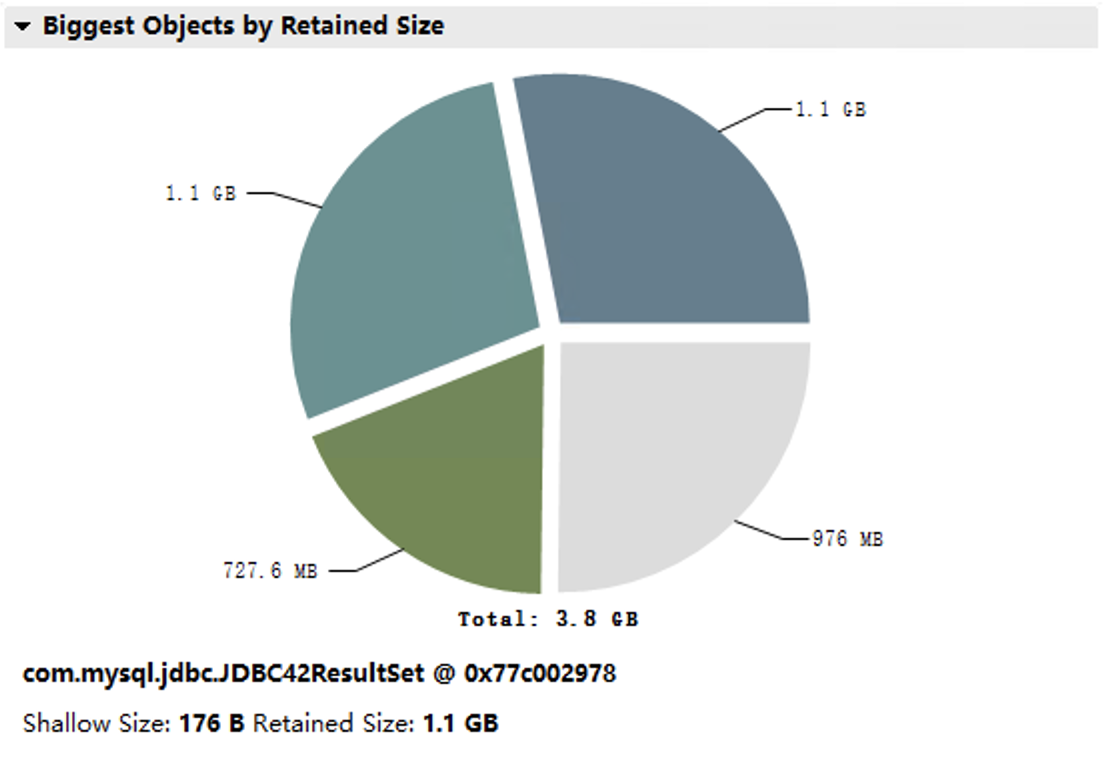
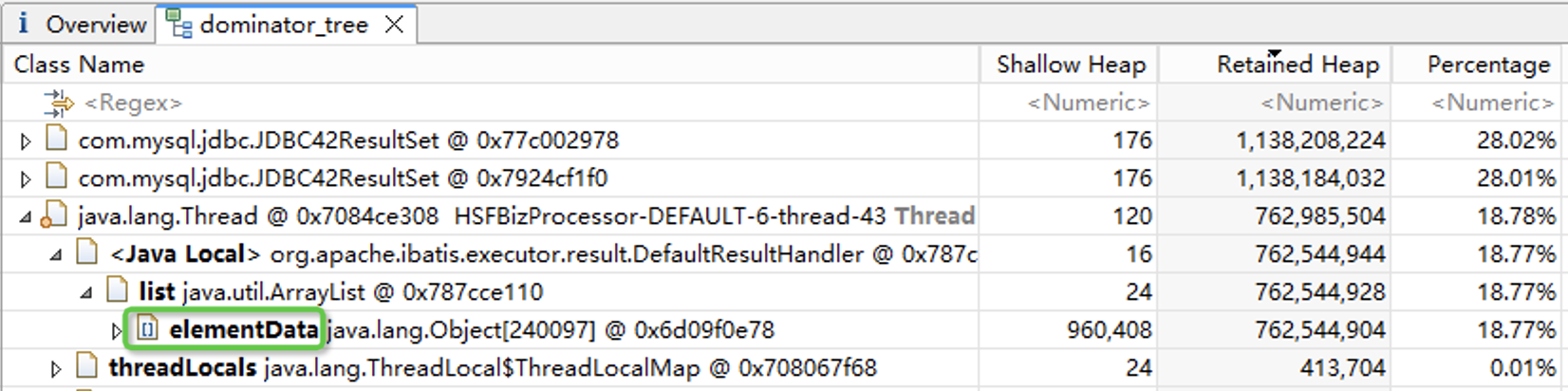
Dominator Tree
进入Dominator Tree模块,查看内存占用最高的对象。这里我们主要关注的是Retained Heap这一列,也就是对象本身加上该对象引用的其他对象占用的内存总和。我们的Dump文件中,主要是JDBC42ResultSet和Thread对象,总共占用了超过90%的内存。
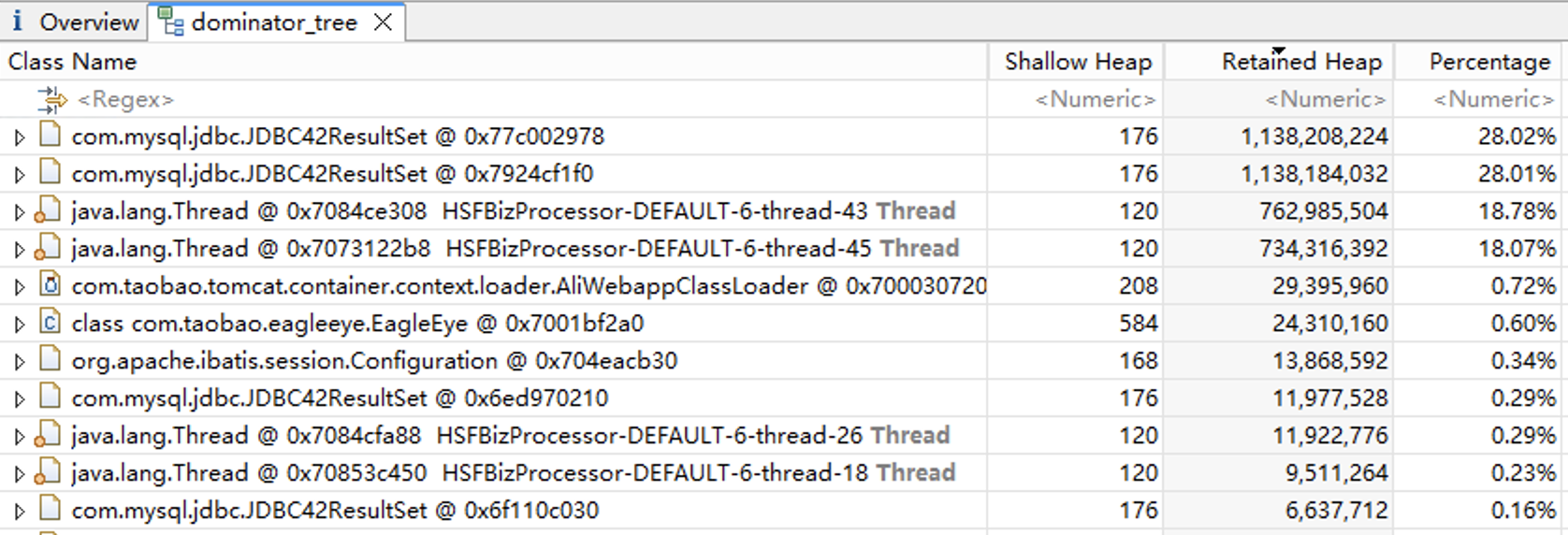
对象属性
展开对象,我们发现JDBC42ResultSet内存使用这么高的原因是里面有一个elementData数组,这个数组里有80多万个对象,我们猜测这些对象对应数据库返回的记录。
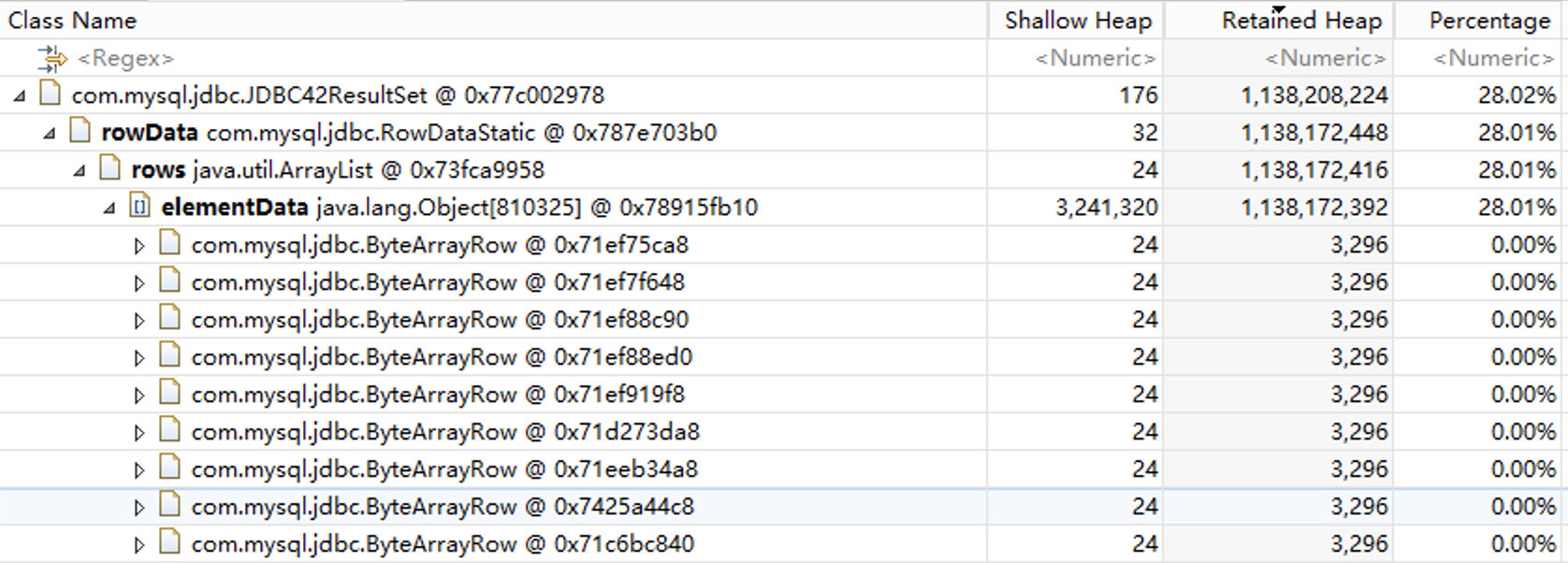
查看对象引用
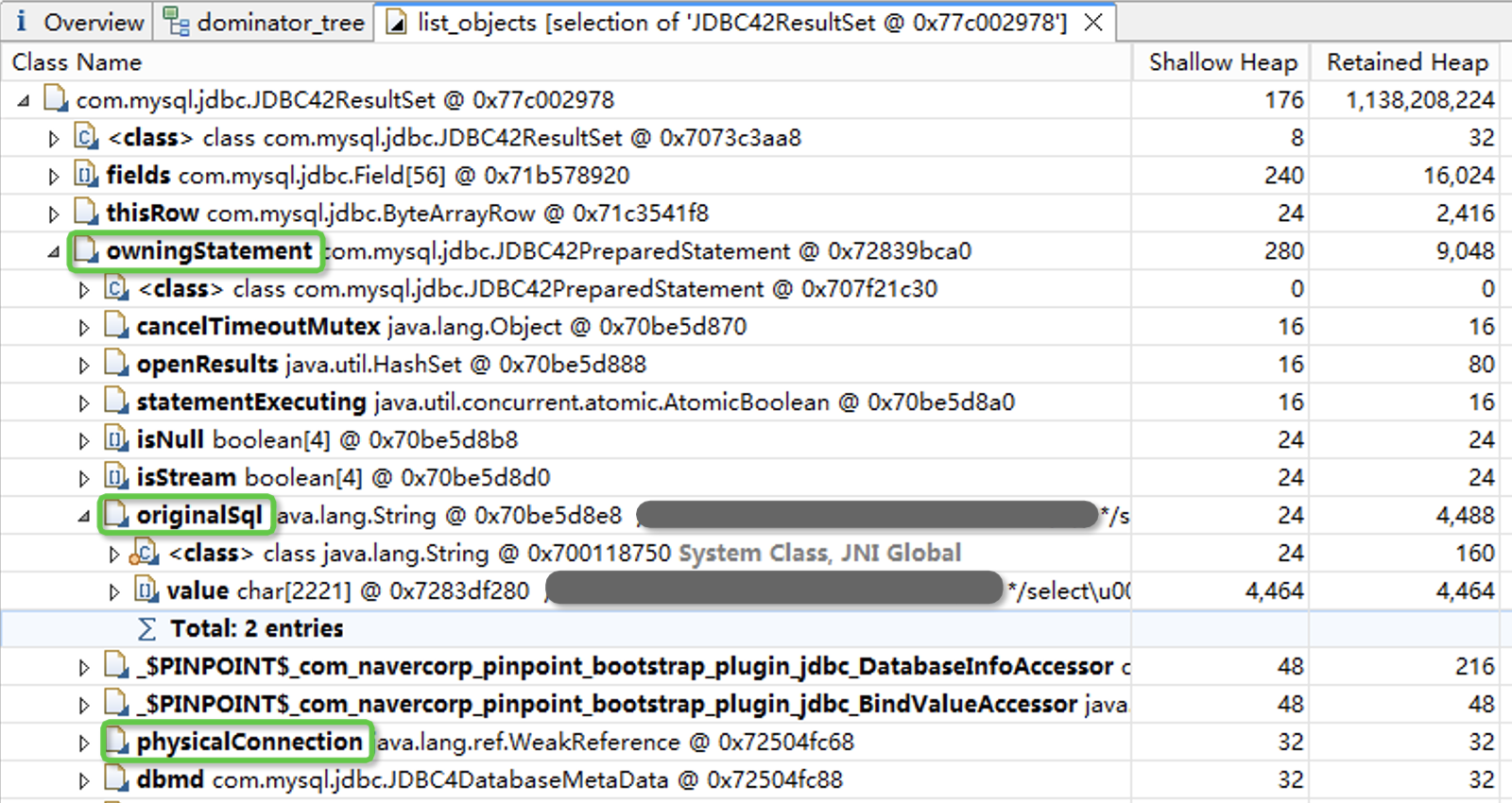
接下来我们希望能找到这是哪个SQL查询得到的数据。点击鼠标右键,打开“List objects”下的“with outgoing references”菜单页。
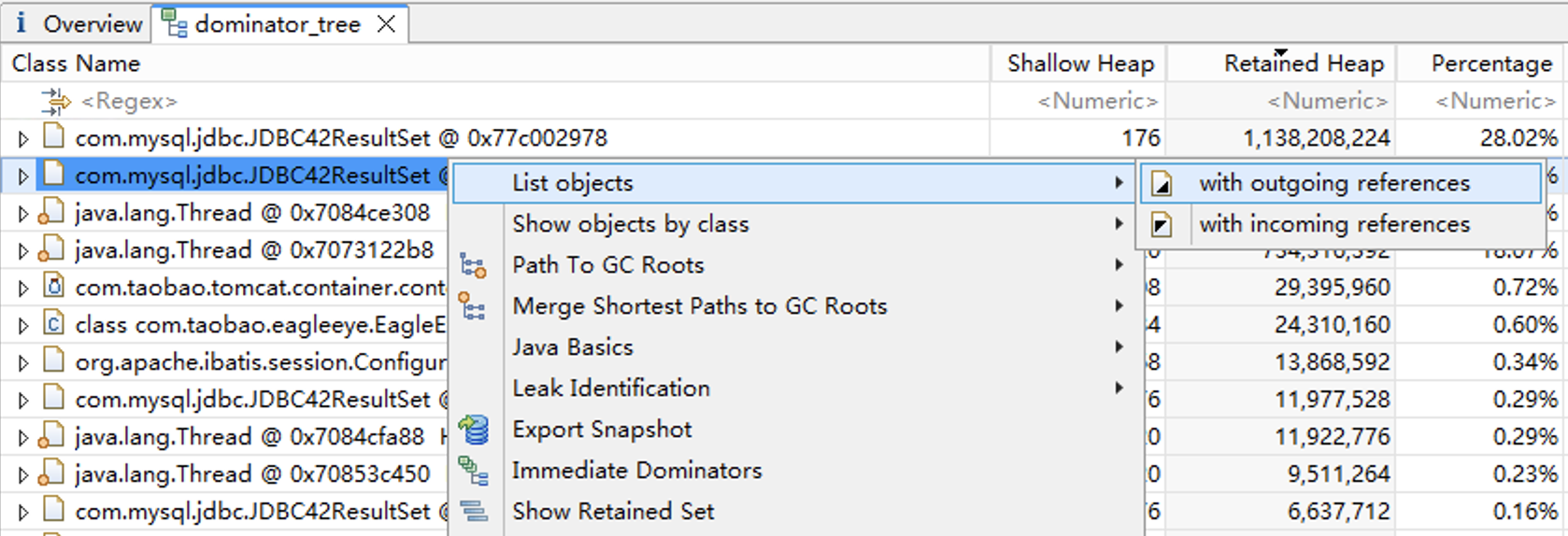
进入list_objects菜单页,我们发现在owningStatement属性中,可以找到原始的SQL语句文本。从physicalConnection属性中,我们还能看到数据库连接的相关属性。到这里我们就已经定位到了具体的SQL语句。
分析调用栈
Thread对象也占用了比较多的内存,展开后可以看到其中也有一个长度为20多万的elementData数组,elementData里面存的是业务的对象,跟数据库中的记录相对应。
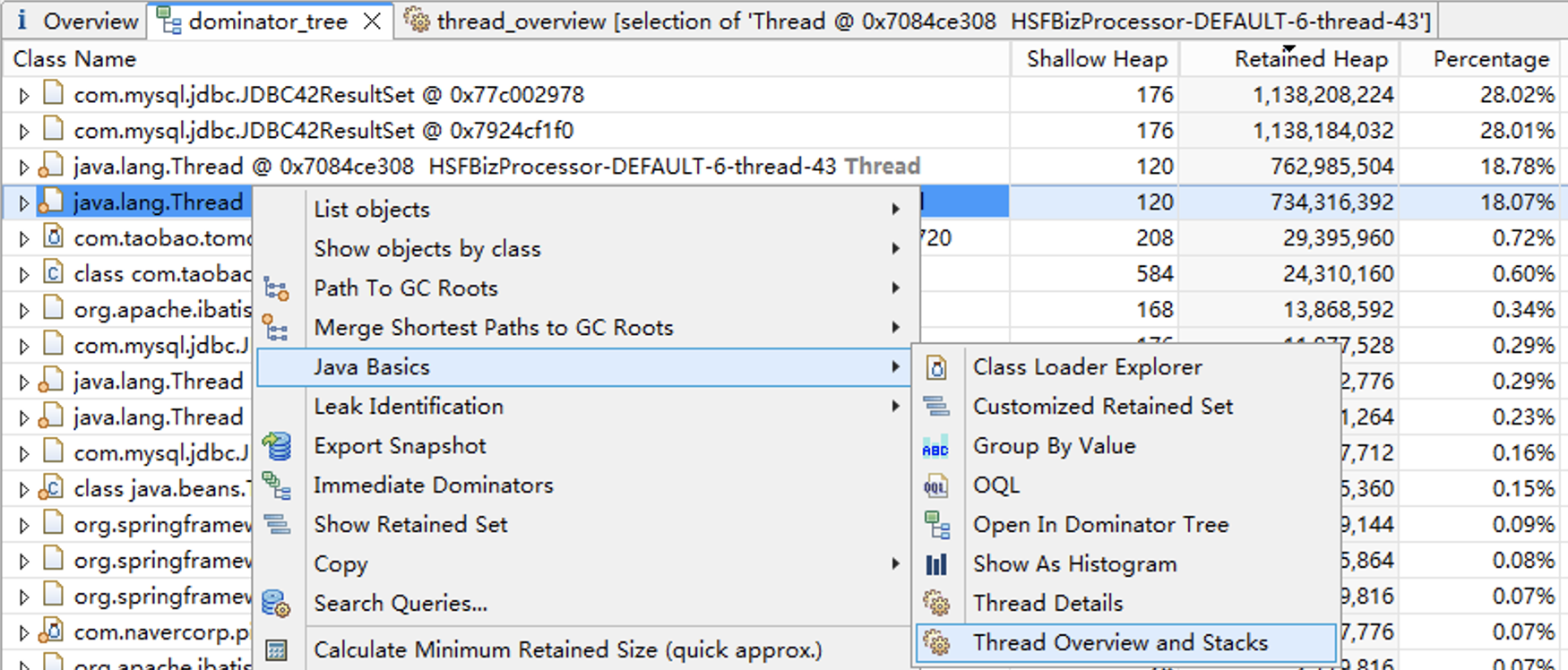
为了分析这些对象是哪个SQL查询得到的,我们需要分析线程的调用栈,打开“Java Basics”下的“Thread Overview and Stacks”菜单。
在thread_overview菜单页中,我们可以看到线程的调用栈。内存主要由handleResultSet的局部变量占用,而SQL语句可能是在SimpleExecutor.doQuery方法中发起的。
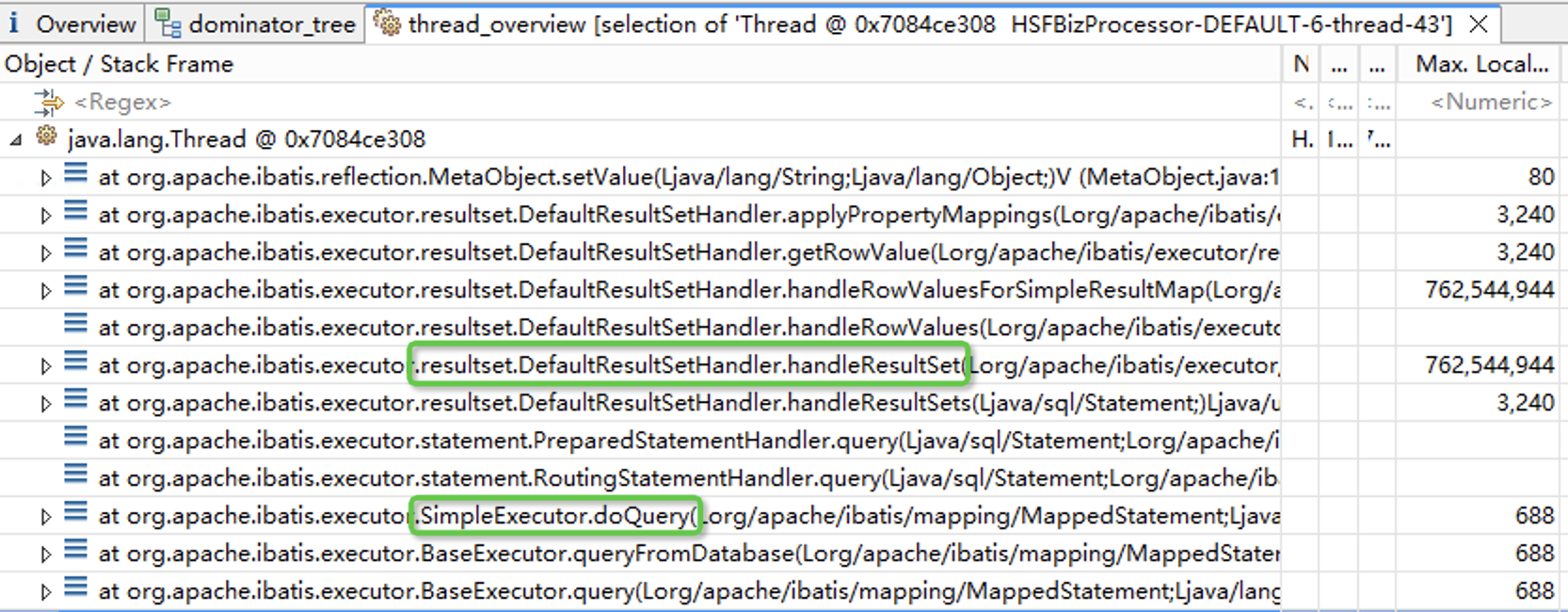
点开doQuery,我们找到了代码中执行的SQL语句。点开statement还可以看到传给SQL的具体参数。
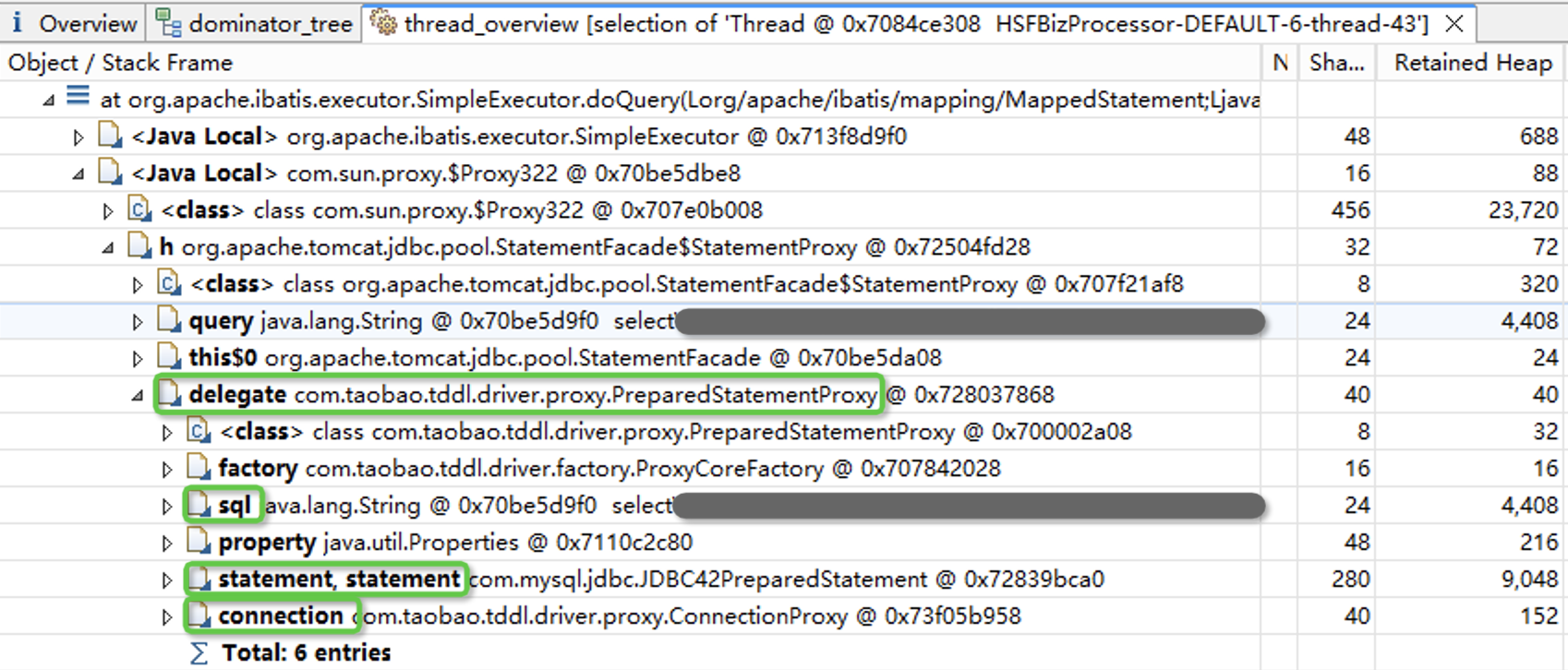
我们演示了从Heapdump文件中定位SQL语句的一些方法。一条SQL的执行结果,在程序中可能会存储两次,一次以JDBCResultSet的方式存储,一次以应用程序对象的方式存储。找到SQL语句后,就可以从业务的角度进行分析,SQL语句是否合理、是否可以优化。
接下来我们来回答这一讲开头提出的那个问题:为什么从代码逻辑上看,每次只处理了一行记录,但是程序却占用了大量内存,就好像将所有返回的记录都缓存到了内存中?
为此我们先来分析一个普通的SELECT语句完整的执行流程。
SELECT语句是怎么执行的?
我们以最简单的一条SQL为例,来说明SQL的执行步骤。我们假定src_tab使用InnoDB存储引擎。
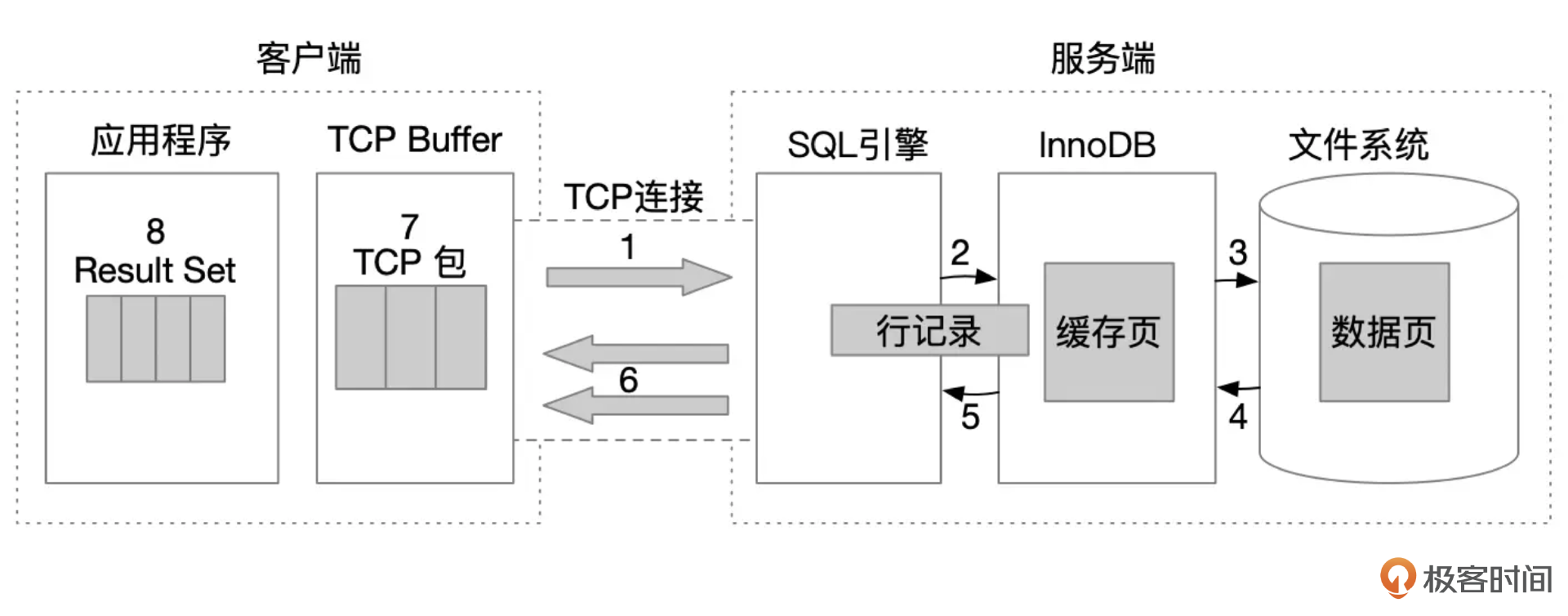
SELECT语句的完整执行流程大致上可以分为下面这几个步骤:
- 客户端提交SQL语句。客户端驱动程序将SQL语句打包,发送给服务器。
- 数据库服务端接收到客户端发起请求,解析SQL文本,生成执行计划,并开始执行SQL语句。执行时,需要到存储引擎获取数据。
- InnoDB存储引擎中,数据存放在数据页面中,数据页缓存到Buffer Pool中。
- 如果数据页还没有缓存到Buffer Pool中,就需要发起IO操作,从文件系统中读取整个页面进行缓存。
- 最终InnoDB存储引擎将一行数据返回给SQL引擎。
- SQL引擎将一行记录打包,发送给客户端。
- 数据包通过TCP协议传输到客户端。
- 客户端读取网络包,解析出一行记录。
这里需要注意的是,SQL开始执行后,SQL引擎会持续从存储引擎中获取数据,每读取到一行记录,就把记录通过网络发送给客户端,直到所有的数据都查询完成。所有数据都发送完成后,服务端还要发送一个结束标记,告诉客户端这个SQL的所有结果都已经发送了。
MySQL客户端服务端交互协议
MySQL客户端和服务端之间的交互遵循一定的协议,协议的基本格式如下图所示:
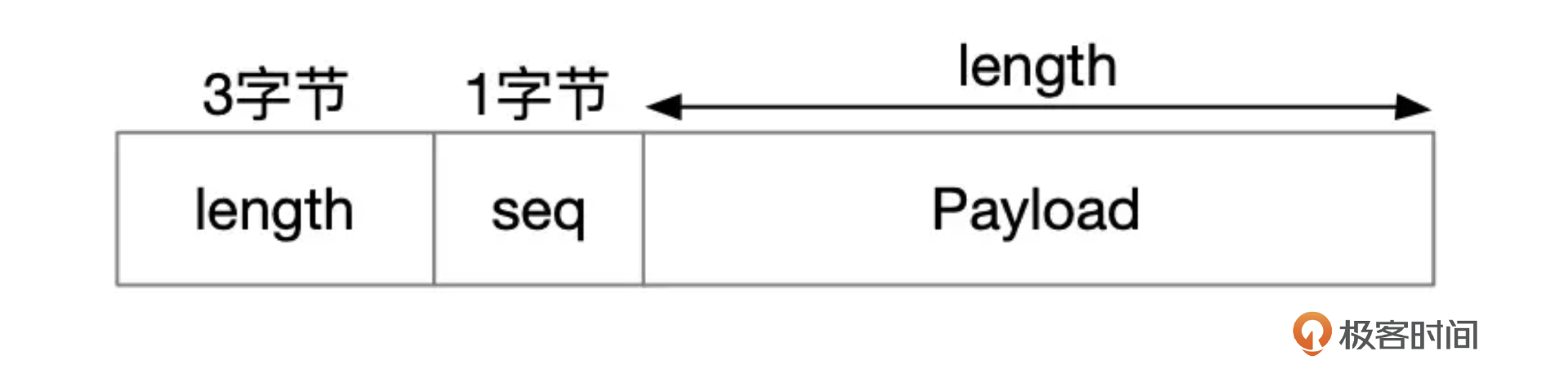
length为3个字节,标识包的长度,一个包最大长度为16M。超过16M的部分需要拆成多个包,seq是包的序号,payload是具体的协议数据。对于一个SELECT查询语句,客户端发送的请求包格式大致上就是下面图片中展示的这样。其中command是命令的类型,目前MySQL中总共定义了几十种类型,对于查询语句,command是COM_QUERY。

服务端返回的包大致可以分为三种类型。
- 结果集
结果集数据包由元数据、行记录、结束标记这几部分组成。元数据实际上是一个字段列表,告诉你返回的数据由哪几个字段组成。行记录从数据库中查询得到,结果集中可能包含0行或多行记录,每行记录由多个字段组成。

- OK_Packet
OK_Packet标志着一个语句的结束,包里面也包含了一些额外的信息,比如SQL影响了多少行数据,SQL执行是否有Warning。

- Err_Packet
如果SQL执行过程中出错了,服务端会返回一个Err_Packet,包括错误编号和错误消息。

SQL引擎的核心逻辑
MySQL优化器生成的执行计划,交给SQL引擎执行。SQL引擎的核心是一个大的循环,根据执行计划中的步骤,从表或索引中获取数据。在最简单的情况下,查询只涉及一个表,SQL引擎调用存储引擎接口,如果正常地获取到了记录,就把记录打包,发送给客户端,然后再继续调用存储引擎接口,获取下一行记录。处理完所有记录后,发送OK_Packet,告诉客户端所有数据都已经发送完成。
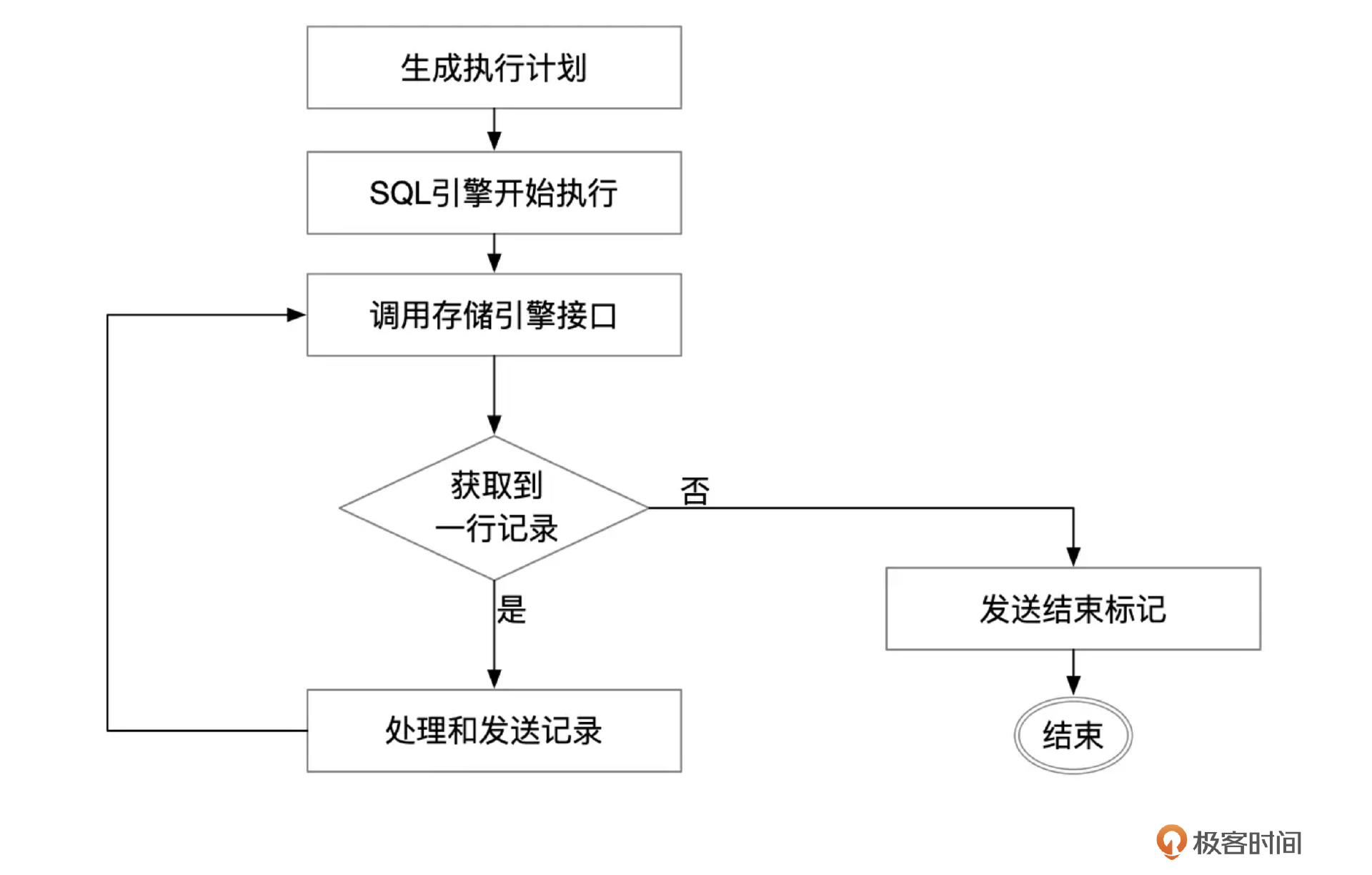
存储引擎接口
SQL引擎调用存储引擎接口时,每次调用最多只获取一行记录,SQL引擎会提供一段临时内存用来存放这一行记录。存储引擎获取到记录后,进行必要的格式转换后,将记录写到SQL引擎提供的临时内存中。
客户端获取数据
MySQL的客户端驱动获取数据时,有两种不同的方式。一种方式是将所有的记录都缓存在本地内存中,然后再将结果集交给应用程序处理。MySQL C API中,mysql_store_result就是这样处理SQL返回的数据的。
这一讲开头的例子中,cur.execute()这一行代码执行完成后,服务端发送过来的所有数据就已经全部存放在客户端的内存中了。后续再执行cur.fetchone()时,实际上只是从本地缓存的结果集中取数据。所以当源表的数据量很大时,程序会消耗大量的内存,甚至引起内存溢出。
def copy_table(src_conn, dest_conn):
sql_select = 'select * from src_tab'
sql_insert = "insert into dest_tab values(%s,%s,%s)"
cur = src_conn.cursor()
cur.execute(sql_select)
row = cur.fetchone()
while row:
insert_row(dest_conn, sql_insert, row)
row = cur.fetchone()
客户端还有另外一种处理方式,如果你不想一次性缓存服务端返回的所有记录,可以调用C API mysql_use_result,调用这个函数并不会真正从网络读取记录,只是初始化了一些数据结构。你需要调用mysql_fetch_row,每调用一次就获取一行记录,这就是流式处理。我们以下面这段Python代码为例来演示流式处理。注意代码中使用了MySQLdb.cursors.SSCursor,这样当执行cur.execute()时,不会从网络中读取记录,只有后续执行cur.fetchone()的时候,才从网络中读取一行记录。
>>> import MySQLdb
>>> import MySQLdb.cursors
>>> import time
>>> conn = MySQLdb.connect(host='172.16.121.234',port=3306,user='user_01', passwd='somepass',db='src_db')
>>> cur = conn.cursor(cursorclass=MySQLdb.cursors.SSCursor)
>>> cur.execute('select * from tab3')
18446744073709551615L
>>> row = cur.fetchone()
如果我们使用tcpdump对MySQL进行抓包分析,会发现执行cur.execute()这一行代码后,服务端向客户端发送了一些数据后就停止发送了,这个时候客户端的TCP接收窗口为0。
如果客户端在net_write_timeout设置的时间内都没有读取数据,服务端的网络写操作会超时,这个时候客户端如果再次获取数据,会发现连接已经被断开了。
>>> time.sleep(60)
>>> row = cur.fetchone()
>>> while row:
... row = cur.fetchone()
...
Exception _mysql_exceptions.OperationalError: (2013, 'Lost connection to MySQL server during query')
使用流式处理还有一个副作用,就是执行一个SQL后,必须先处理完当前SQL返回的结果集中所有的记录,才能执行下一个SQL,否则会报错“Commands out of sync”。
>>> cur = conn.cursor(cursorclass=MySQLdb.cursors.SSCursor)
>>> cur.execute('select * from tab3')
18446744073709551615L
>>> cur.execute('select 1')
_mysql_exceptions.ProgrammingError: (2014, "Commands out of sync; you can't run this command now")
如果你使用了JDBC,默认的结果集处理方式和mysql_store_result一样,会将服务端发送的所有数据都放到内存中,这也是我们从前面Heapdump中看到的那样。如果结果集太大,你不想将所有记录都放到内存中,可以采用流式处理,需要在createStatement时传入几个参数,具体使用方法你可以参考官方文档。
Statement stmt = conn.createStatement(java.sql.ResultSet.TYPE_FORWARD_ONLY,
java.sql.ResultSet.CONCUR_READ_ONLY);
stmt.setFetchSize(Integer.MIN_VALUE);
使用这种方式执行完一个SQL的时候,需要将当前的stmt关闭后,才能创建下一个Statement,否则会抛出下面这样的异常。
java.sql.SQLException: Streaming result set com.mysql.cj.protocol.a.result.ResultsetRowsStreaming@1e1a0406 is still active. No statements may be issued when any streaming result sets are open and in use on a given connection. Ensure that you have called .close() on any active streaming result sets before attempting more queries.
我们看到,不管是C API还是Java API,在处理结果集的时候,默认行为都是将数据全部加载到内存中。当返回的记录数不多时,这种处理方式是比较合理的,因为这样可以尽快地获取所有数据,这样在服务端,SQL也能及时完成。但如果结果集太大,这样做就可能会导致客户端内存溢出,这时你可以使用流式处理,一次只读取一行记录。有一点需要注意,读取记录后要尽快完成业务处理,并及时读取下一行记录。
服务端通过TCP协议发送数据,这些数据会先进入到客户端所在机器的TCP Buffer中。如果客户端没有及时将数据从TCP Buffer中取走,TCP Buffer很快就会用完,这时客户端就会告诉服务端,我这边TCP Buffer已经满了,你先不要发送数据过来了。这实际上是通过TCP协议中的Window Size来实现的。
客户端TCP接收窗口大小为0时,服务端发送数据时就会被阻塞。MySQL通过参数net_write_timeout来设置网络发送超时时间,该参数默认为60秒。如果服务端发送数据时阻塞时间超过了这个设置,就会将连接断开。
总结时刻
这一讲中,我们一起学习了MySQL客户端和服务端的交互过程,分析了MySQL处理结果集的两种方式,以及查询大表为什么会引起客户端内存溢出。
对于Java程序,我们可以使用Heapdump分析,找到返回大量数据的那些SQL。如果业务中有SQL返回了太多的数据,一般我建议先从业务上进行分析,业务是否真的需要查询这么多数据?是不是可以将SQL改写成分页的方式,一次只查询一部分数据?
如果你的应用场景就是需要查询大量的数据,也不方便使用分页SQL,比如你可能在写一个类似mysqldump的数据导出工具,可以采用流式处理。不过采用流式处理时,需要尽快将数据从TCP Buffer中取出,否则会导致服务端发送数据被阻塞,如果阻塞时间超过net_write_timeout,还会导致连接中断。即使连接没有中断,也会导致服务端发送数据的效率降低,增加SQL的执行时间,如果SQL还持有锁,这会引起更大的性能问题。
思考题
源库中有一个大表,表结构定义如下:
create table big_table(
col1 varchar(32) not null,
col2 varchar(32) not null,
col3 varchar(32) not null,
col4 varchar(256),
col5 varchar(256),
....
col10 varchar(512),
primary key(col1, col2, col3)
) engine=innodb;
这个表总共有3000万行数据,平均行长度大约为2K。现在需要将这个表复制到目标库。源库和目标库都是MySQL。有一台4核8G的中转机器供你使用。请问你会怎么解决这个需求?如果要你写一段程序来完成这个任务,需要注意什么?如何提高数据复制的速度?
期待你的思考,欢迎在留言区中与我交流。如果今天的课程让你有所收获,也欢迎转发给有需要的朋友。我们下节课再见!
- TheOne 👍(2) 💬(1)
老师,mysql 的客户端和服务端之间也是 tcp 连接的吧,存储引擎拿到一行后,给到 service 层,service 应该会先暂存起来,达到一个阈值之后,一起发给客户端吧 应该不是存储引擎返回一行,就给客户端发一行吧
2024-09-20 - 鬼吹der 👍(0) 💬(1)
为啥调用引擎接口时,最多只能查询出一行数据呀?一次查询出多个数据显然效率更好呀
2024-09-29 - dream 👍(0) 💬(1)
文章中的抓包命令 `tcpdump -i any port 3306 -t -nnnntcpdump -i any port 3306 -t -nnnn` 应该粘贴了两次... 实际上的抓包命令应该是: tcpdump -i any port 3306 -t -nnnn
2024-09-06 - dream 👍(0) 💬(1)
思考题: 比如用一个 java 程序来处理。 一个线程从源表读取数据(使用 jdbc 流式读取),读取出来的数据保存到本地的一个线程安全的队列中,8G 的机器,大概可以拿出 3g 来存储,也就是 3g/2k,大概可以存储 1500 条数据,也就是保证队列长度最大不要超过 1500。 另外启动三个线程,从本地队列中消费数据,任意一个线程消费满 1000 条,就往目标数据库进行批量写操作。 在读线程完成后,用一个变量标识一下,写线程从本地队列中消费不到数据就直接写数据库。 *** 如果上面的分析中,批量写比读的速度更快,可以考虑用两个线程来读,两个线程来写。 具体操作还是和上面一致,但是读取的时候尝试把 sql 中的条件按照主键分成尽量相等的两部分,一个线程读取一部分
2024-09-06 - 一本书 👍(0) 💬(1)
https://dev.mysql.com/doc/dev/mysql-server/latest/page_protocol_basic_ok_packet.html中有As of MySQL 5.7.5, OK packets are also used to indicate EOF, and EOF packets are deprecated.,https://dev.mysql.com/doc/dev/mysql-server/latest/page_protocol_basic_eof_packet.html中有Due to changes in MySQL 5.7 in the OK_Packet packets (such as session state tracking), and to avoid repeating the changes in the EOF_Packet packet, the OK_Packet is deprecated as of MySQL 5.7.5.,到底哪个被废弃了呢?(极客时间不能删除留言重新编辑,没完全想好再问,有点打扰老师了不好意思)
2024-09-06 - 123 👍(0) 💬(1)
思考题: 3000 万行数据,平均行长度大约为2K => 2k*3000w ≈ 57G,所以肯定是需要进行分批获取存储的 如果使用流式获取,在客户端不会有太大的压力,但是数据量过大,服务端需要承载这些内存使用,况且当前连接不能断开,又因为数据量大,可能造成超时,需要配置下对应的连接时间; 使用默认配置,就需要掌握好数据量,每次获取多少条,不能将内存打满。通过多线程并设置好偏移量的方式来保证数据不会被重复插入,例如批量一次插入50000条,多线程并行插入。但是批量插入的值不能设置的太小,不然就没有意义,还是要承担网络、事务提交、索引更新等开销。最终还是要根据目标库的写能力来决定,可以测试下目标库对应的写入性能,在决定并发插入多少条合适。
2024-09-05