高可用篇 课后题答疑
你好,我是俊达。我们继续看最后一章的课后题。
第34讲
问题:MySQL主备数据复制默认是异步的。如果主库执行成功,但binlog还没来得及发送给备库,可能会存在备库的事务比主库少的情况。反过来,有没有可能出现备库事务比主库多的情况呢(不考虑业务在备库上写入数据的情况)?
@叶明 在评论区提供了这个问题的解答。
如果sync_binlog没有设置成1,那么就有可能出现备库事务比主库多的情况。
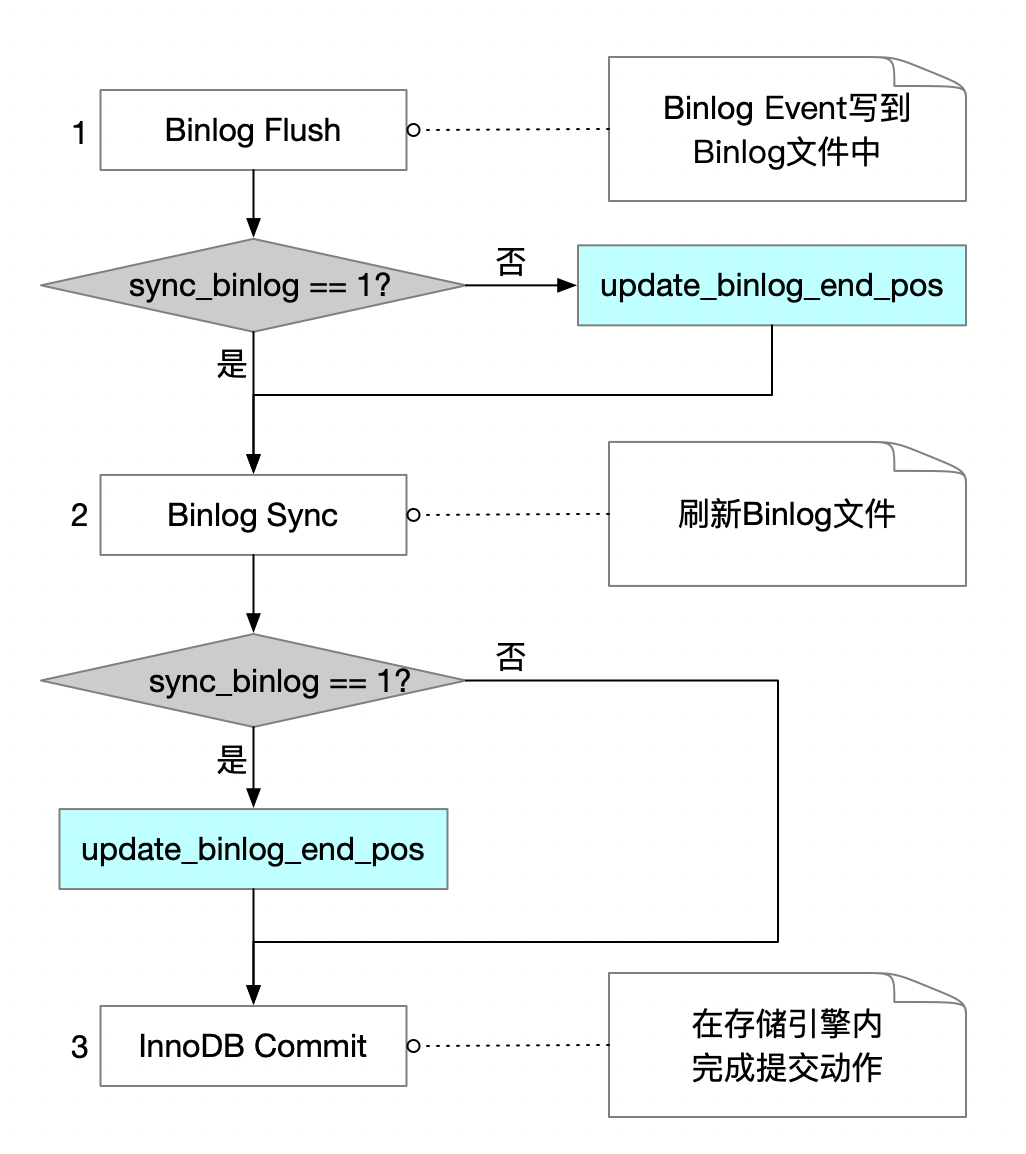 看一下上面这个简化了的事务提交的流程图,事务提交时,会经过三个关键的步骤。
看一下上面这个简化了的事务提交的流程图,事务提交时,会经过三个关键的步骤。
- Binlog Flush:将Binlog Event从Binog Cache写到Binlog文件中。注意,这个步骤只是将Event写到了Binlog文件中,而Binlog文件本身还有文件系统Cache,如果操作系统异常重启,这时Binlog文件的内容可能会丢失。
如果sync_binlog没有设置为1,那么Binlog Flush后,就会调用update_binlog_end_pos函数,唤醒Binlog Dump线程。Binlog Dump线程这时就能将最新的Event发送给备库了。如果Dump线程已经将Event发送给了备库,但是主库所在的服务器异常崩溃了,事务在主库上还没有完成提交,就出现了备库事务比主库多的情况。
- Binlog Sync:这个步骤会刷新(fsync)Binlog文件。具体是否执行fsync操作,和sync_binlog参数的设置有关。如果执行了fsync,那么binlog文件就完成了持久化,即使操作系统异常重启,也不会丢Binlog。
如果sync_binlog设置为1,会在Binlog文件完成fsync之后,再调用update_binlog_end_pos函数,唤醒Binlog Dump线程发送Event。此时由于Binlog文件已经完成了持久化,就不会出现备库binlog比主库多的情况了。
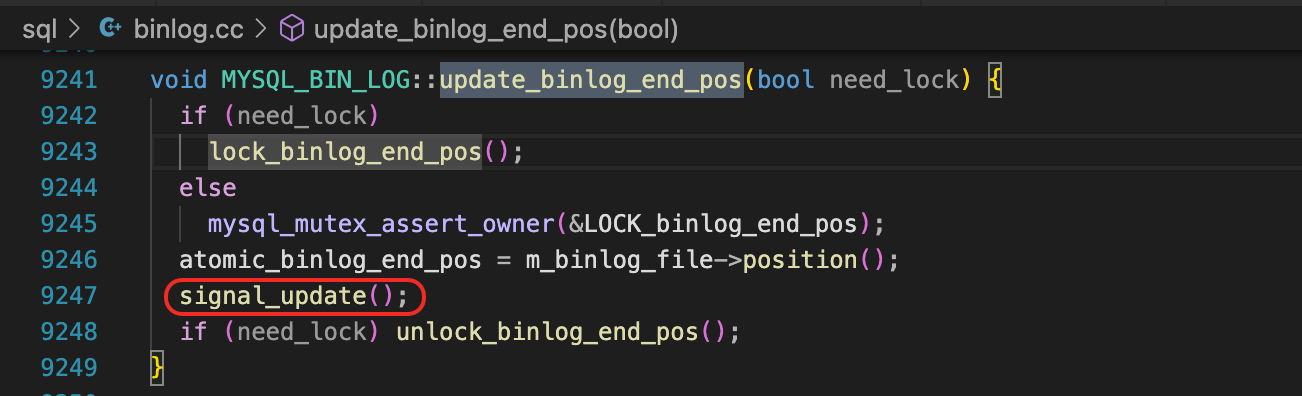
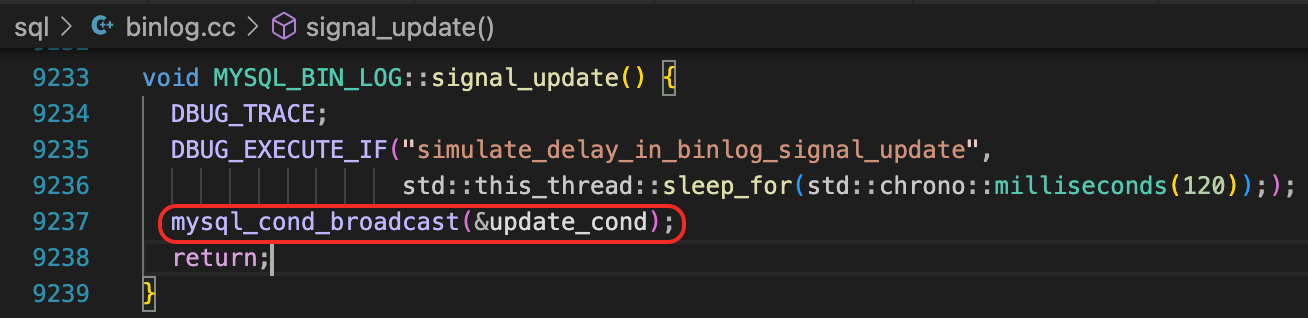
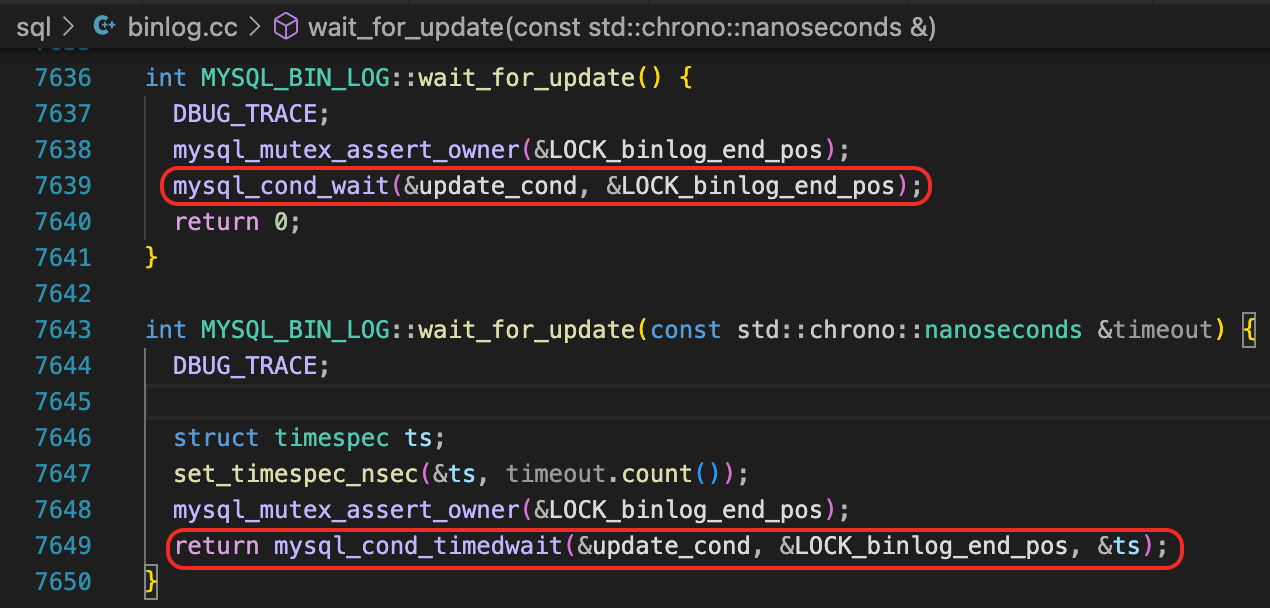
我们来看一下update_binlog_end_pos函数,里面做个一个mysql_cond_broadcast的操作。
对应的,Dump线程在正常情况下,执行get_binlog_end_pos,等待新的binlog Event生成。
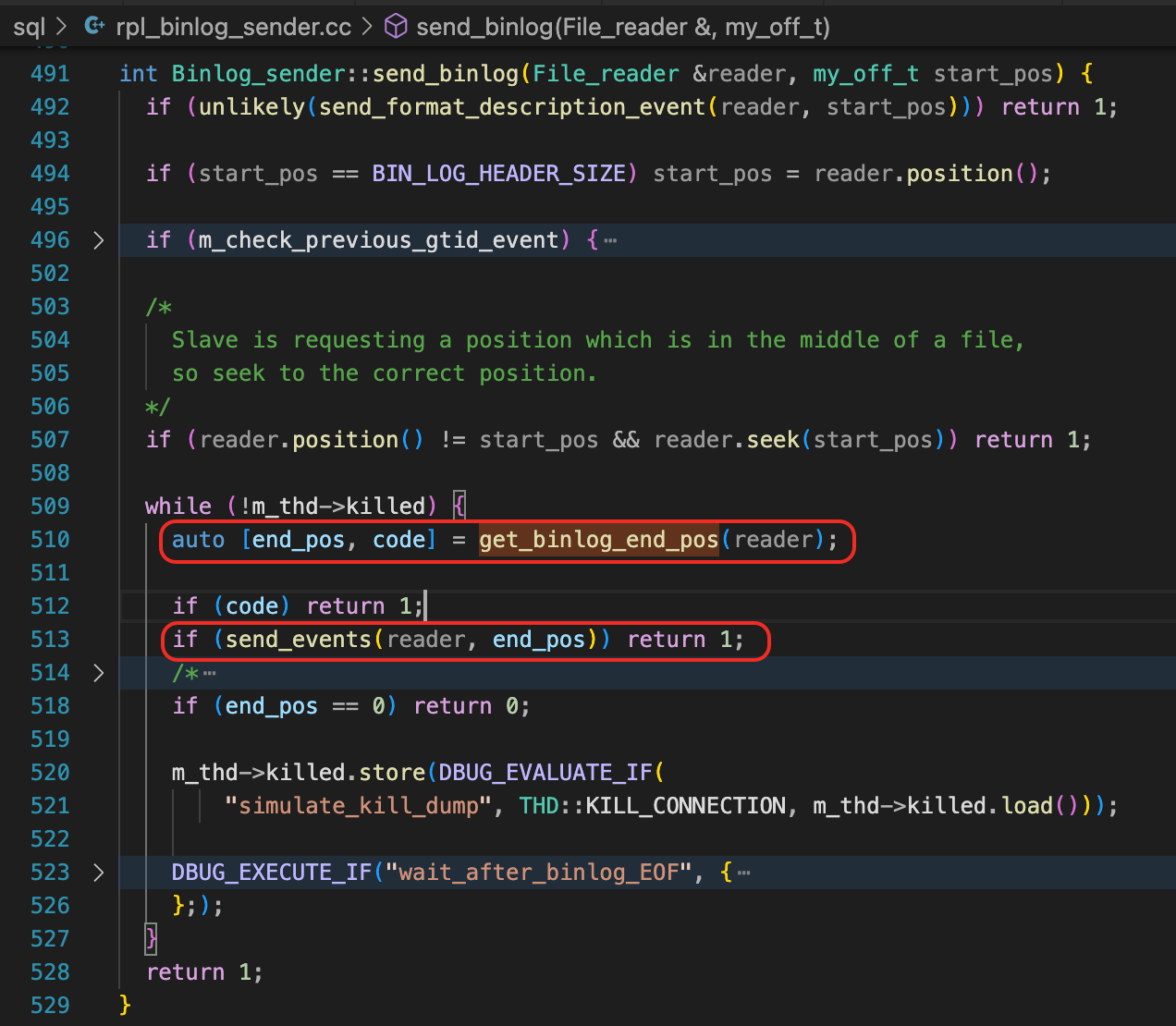
最终,Dump线程会在mysql_cond_wait(或mysql_cond_timedwait)中,等待update_cond这个条件变量。
第35讲
问题:主备库数据的一致性非常重要。如果数据不一致了,会带来很多问题,备库的复制可能会中断,业务切换到备库后,会取到错误的数据,影响业务。而且一般我们会在备库上备份,避免备份时影响主库性能,但如果备库的数据有问题,那么我们的备份也都是有问题的。
那么怎么检查主备库之间的数据是不是一致的呢?
@叶明 在评论区提供了一种方法,使用 pt-table-checksum来检查主备数据的一致性。
是不是可以根据seconds_behind_source来判断主备数据一致呢?这其实是不行的。比如设置了参数replica_skip_errors,跳过了复制异常,那么即使数据不一致了,seconds_behind_source也可能是0。或者最近没有操作不一致的数据,seconds_behind_source也可能是0。
是不是可以对比主备库的GTID_EXECUTED来判断数据是否一致呢?这也是不行的。因为有时候我们可能会设置gtid_next变量,注入空事务。而且还可以设置GTID_PURGED变量,来间接地修改GTID_EXECUTED变量。
怎么才能确认主备库数据是一致的呢?最直接的方法就是分别把主备库的数据查询出来,一条记录一条记录对比。当然这里可能会存在一些问题,如果数据量特别大,这么对比可能会消耗比较多的资源。还有一个问题是,主库的记录在不停的变化,备库应用Binlog可能会存在一定的延迟,因此发现数据不一致时,可能是真的不一致,也可能是Binlog应用有一些延迟。一个简单的策略是,在备库延迟比较小的情况下,如果发现数据不一致,可以等待一段时间(比如几秒),重新对比不一致的记录。只要这条记录不是在被持续地更新,使用这种简单的策略就能对比出真正不一致的数据。
第36讲
问题:备库在运行过程中,会实时更新一些位点信息,包括主库Binlog的读取位点、SQL线程解析Relaylog的位点,以及worker线程执行事务的情况。如果备库异常崩溃,下次启动时,还能恢复这些位点信息吗?有没有可能出现位点信息没有及时更新的情况?如果这些位点有一些延迟,对备库复制会有影响吗?
这个问题在37讲中有比较详细的解释。
首先是备库读取主库Binlog的位点。如果这个位点不准,就可能会重复读取Binlog。如果将参数sync_master_info设置为1,每读取一个事件就保存一下位点,可以最大程度避免重复读取Binlog,但是有性能开销。如果使用了GTID AutoPosition,这个位点就不重要了,因为备库重连到主库时,可以根据gtid_executed自动计算出哪些Binlog需要同步。
另外一个是备库执行Binlog的位点。对于单线程复制,如果relay_log_info_repository设置为Table,事务提交时,会在同一个事务中更新slave_relay_log_info表,因此提交事务的位点总是一致的。
如果使用了多线程复制,那么slave_relay_log_info表中记录的是Gaq Checkpoint事务的位点。数据库启动时,要根据slave_worker_info表中记录的位点和bitmap信息,以及Relay Log,来判断哪些事务已经提交。如果Relay Log有丢失,那么就可能无法准确判断哪些事务已经提交。但如果使用了Gtid AutoPosition,那么gtid_executed中已经准确地记录了哪些事务已经提交,因此不依赖Relay Log中的信息,也能正常恢复数据复制。
第37讲
问题:MySQL 8.0默认就开启了GTID,5.7版本中,默认还没有开启GTID。如果没有开启GTID,但是又使用了多线程复制,存在的风险是什么?怎么解决?
这个问题其实和前面一个问题比较类似。如果没有开启GTID,有使用了多线程复制,那么如果备库异常崩溃后,在启动时,不知道slave_relay_log_info中记录的位点之后的那些事务,哪些已经提交,哪些还没有提交。需要进行一个称为MTS恢复的操作,根据slave_worker_info表里的记录,以及Relay Log,来判断哪些事务已经提交,解决可能存在的事务Gap,然后才能恢复数据复制。能进行MTS恢复的一个前提,是Relay Log没有问题,因此要将sync_relay_log设置为1,但是这会带来很大的性能开销。
因此,如果要使用多线程复制,建议开启GTID,并使用Gtid AutoPosition。
第38讲
问题:如果你管理了大量的数据库实例,为了提高运维效率,需要设计一个备份调度管理系统。你会怎么来设计这个系统呢?
我可能会需要几个核心的功能。
- 管理备份策略
备份系统要能支持设置备份策略。
- 设置每个数据库备份的方式,是使用物理备份还是逻辑备份,是全量备份还是增量备份。
- 设置备份的开始时间,备份的频率。
- 设置备份文件的存储空间,比如存储到Nas,或者对象存储。
- 设置备份的保留周期,包括Binlog的保存时间,本地Binlog的保留时间。
- 管理备份任务
备份系统要能调度备份任务。还要把每次备份的情况记录下来,比如备份开始时间、结束时间、备份是否成功、备份集的大小、备份是否上传到了备份存储空间中。
对于MySQL,在备库上备份时,要先检查备库延迟时间不能太长。
基于这些信息,可以每天检查备份情况,该备份的数据库是否都在合理的时间内完成备份了,备份存储空间是否充足。
- 恢复演练
如果备份系统能支持恢复演练,就更好了。大部分备份文件,平时都不会用到。这些备份文件,是否能顺利地用来恢复数据,恢复数据需要多少时间,可以通过定期的恢复演练来进行验证。
第39讲
问题:如果数据库中有几个表被错误地Truncate了,如何在最短的时间内,将这几个表的数据恢复到执行truncate命令前的时间点?
这里的操作是Truncate Table,因此Binlog中只记录了Truncate table的命令,没有记录被Truncate的数据,无法通过Binlog回滚的方式来恢复。
首先要找到Truncate Table的时间。解析Binlog,搜索Truncate关键字,就能找到Truncate 发生的确切时间。
然后找到一个在Truncate时间点之前就已经完成备份的全量备份集。如果数据库很大,可以使用InnoDB的单表恢复,来提升恢复效率。如果全量备份中的数据已经能满足要求了,那么只要把相关的表import到正式数据库中,就完成恢复了。
很多情况下,我们需要将数据恢复到误操作的时间点之前。
先将全量备份恢复到一个临时的环境中。为了加快恢复速度,可以只恢复被Truncate的表。
然后应用Binlog。找到从全备完成到误操作发生时,期间所有的binlog,启动一个Binlog实例。临时恢复实例从这个Binlog实例读取Binlog,应用Binlog。如果只恢复部分表,还要通过replicate-do-table或replicate-do-db指定需要恢复的库表。
恢复到指定时间点之后,再将数据导入到正式环境。可以使用第9讲、第10讲介绍过的数据导出和导入方法。
第40讲
问题:你需要将一个Clone出来的数据库,作为备库,加入到原先的复制架构中。如果使用GTID Auto Positon,那么Clone的数据库启动时,会根据mysql.gtid_executed表的记录,正确地设置gtid_executed变量,因此可以直接建立复制关系。但如果使用了基于位点的复制,你应该从哪个Binlog位点开启复制呢?这个Binlog位点信息是存储在哪个地方的?
评论区中 @范特西 提供了这个问题的答案。使用Clone备份的数据文件启动数据库后,查询performance_schema.clone_status表,就可以看到主库完成Clone操作时的Binlog位点,如果开启了GTID,这个表还记录了GTID_EXECUTED。
mysql> select * from performance_schema.clone_status\G
*************************** 1. row ***************************
ID: 1
PID: 0
STATE: Completed
BEGIN_TIME: 2024-12-17 10:04:39.490
END_TIME: 2024-12-17 10:47:50.303
SOURCE: LOCAL INSTANCE
DESTINATION: LOCAL INSTANCE
ERROR_NO: 0
ERROR_MESSAGE:
BINLOG_FILE: mysql-binlog.000011
BINLOG_POSITION: 668
GTID_EXECUTED: 4bb30f4e-a618-11ef-9dc0-fab81f64ee00:1-10,
7caa9a48-b325-11ed-8541-fab81f64ee00:1-91
但是clone_status是一个PERFORMANCE_SCHEMA表,这个表的数据是怎么来的呢?
mysql> show create table performance_schema.clone_status\G
*************************** 1. row ***************************
Table: clone_status
Create Table: CREATE TABLE `clone_status` (
`ID` int DEFAULT NULL,
`PID` int DEFAULT NULL,
`STATE` char(16) DEFAULT NULL,
`BEGIN_TIME` timestamp(3) NULL DEFAULT NULL,
`END_TIME` timestamp(3) NULL DEFAULT NULL,
`SOURCE` varchar(512) DEFAULT NULL,
`DESTINATION` varchar(512) DEFAULT NULL,
`ERROR_NO` int DEFAULT NULL,
`ERROR_MESSAGE` varchar(512) DEFAULT NULL,
`BINLOG_FILE` varchar(512) DEFAULT NULL,
`BINLOG_POSITION` bigint DEFAULT NULL,
`GTID_EXECUTED` varchar(4096) DEFAULT NULL
) ENGINE=PERFORMANCE_SCHEMA
在数据目录下的#clone目录中,有一个#view_status文件,这个文件中记录了binlog位点、gtid_executed。
# cat data/#clone/#view_status
2 1
1734401079490061 1734403670303391
LOCAL INSTANCE
0
/data/mysql3306/binlog/mysql-binlog.000011
668
4bb30f4e-a618-11ef-9dc0-fab81f64ee00:1-10,
7caa9a48-b325-11ed-8541-fab81f64ee00:1-91
如果在Clone完成时,查看这个文件,会发现这里面并没有记录binlog位点。
$ ls /data/clone/mysql01_backup/#clone/
#replace_files #status_fix #view_progress #view_status
$ cat /data/clone/mysql01_backup/#clone/#view_status
2 1
1734401079490061 1734401465529274
LOCAL INSTANCE
0
0
使用Clone备份出来的数据文件启动数据库,可以看到#clone目录下会生成一个#status_recovery文件,这里面有binlog位点信息。
$ ls data/#clone/
#replace_files #status_recovery #view_progress #view_status
$ cat data/#clone/#status_recovery
1734403668231753
1734403670303391
/data/mysql3306/binlog/mysql-binlog.000011
668
4bb30f4e-a618-11ef-9dc0-fab81f64ee00:1-10,
7caa9a48-b325-11ed-8541-fab81f64ee00:1-91
这时候查询一下 performance_schema.clone_status 表后,可以看到#status_recovery文件不见了,binlog位点信息写到了#view_status文件中。
$ ls data/#clone/
#view_progress #view_status
$ cat data/#clone/#view_status
2 1
1734401079490061 1734403670303391
LOCAL INSTANCE
0
/data/mysql3306/binlog/mysql-binlog.000011
668
4bb30f4e-a618-11ef-9dc0-fab81f64ee00:1-10,
7caa9a48-b325-11ed-8541-fab81f64ee00:1-91
那么#status_recovery这个文件中的数据是从哪里来的呢?Clone完成时并没有这个文件,而是在第一次启动时生成了这个文件。
在代码中搜索“status_recovery”,可以看到几个变量名,CLONE_INNODB_RECOVERY_FILE和CLONE_RECOVERY_FILE。
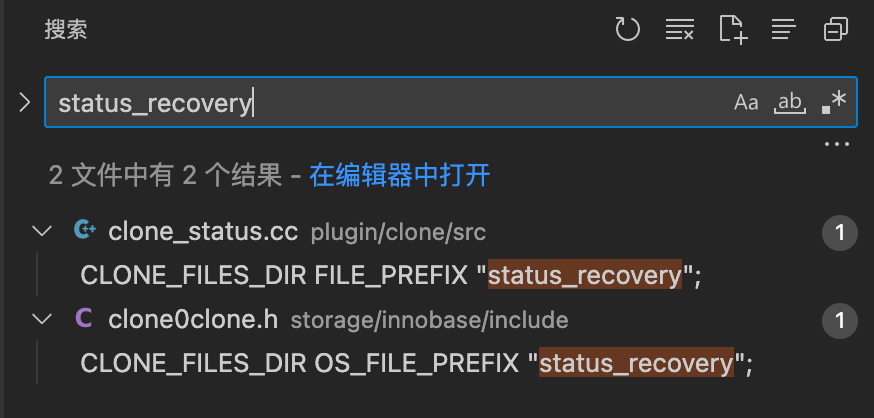
/** Clone recovery status. */
const char CLONE_INNODB_RECOVERY_FILE[] =
CLONE_FILES_DIR OS_FILE_PREFIX "status_recovery";
const char CLONE_RECOVERY_FILE[] =
CLONE_FILES_DIR FILE_PREFIX "status_recovery";
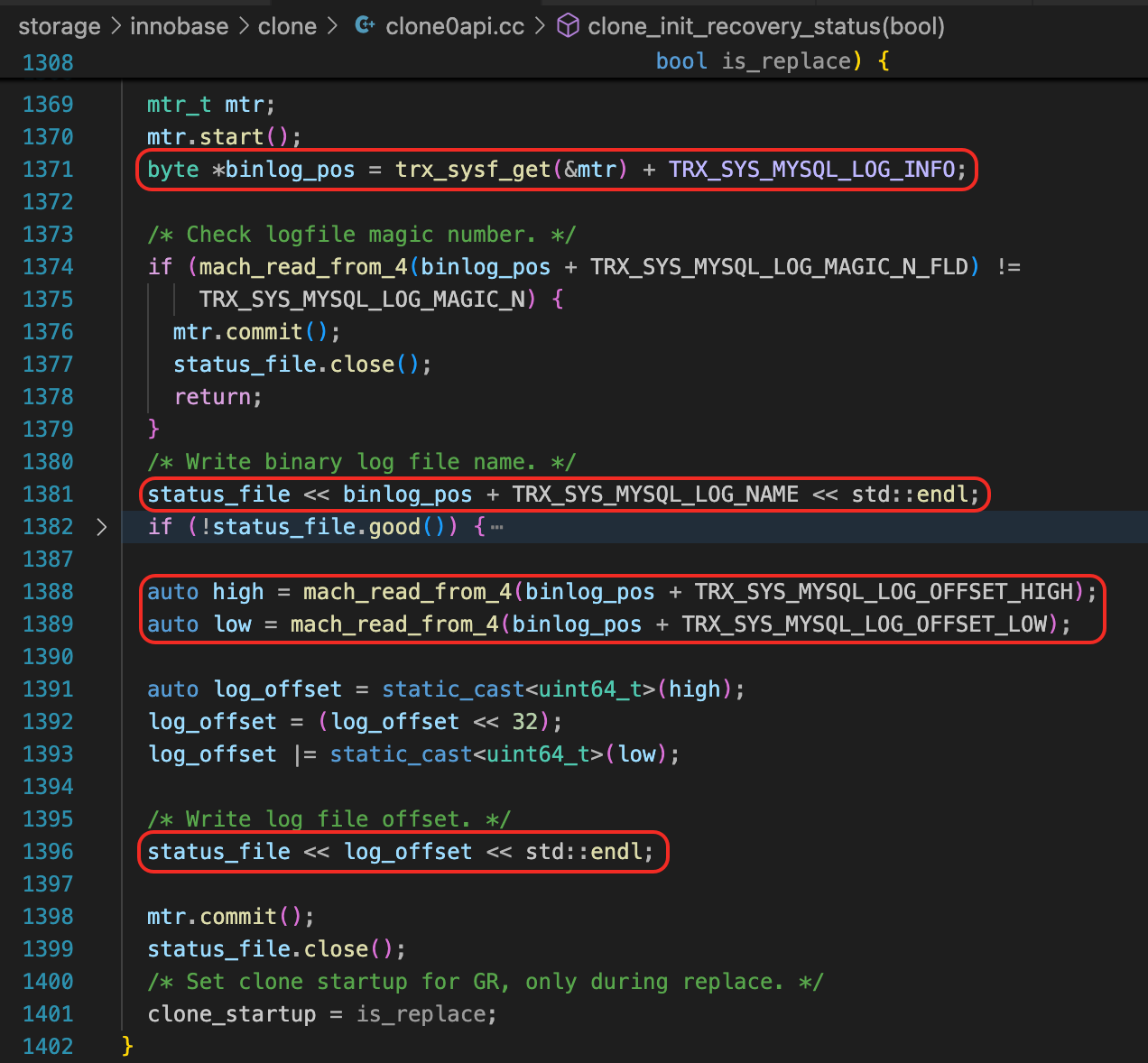
然后再搜索CLONE_INNODB_RECOVERY_FILE,会发现Binlog位点是从InnoDB的系统表空间中获取的。
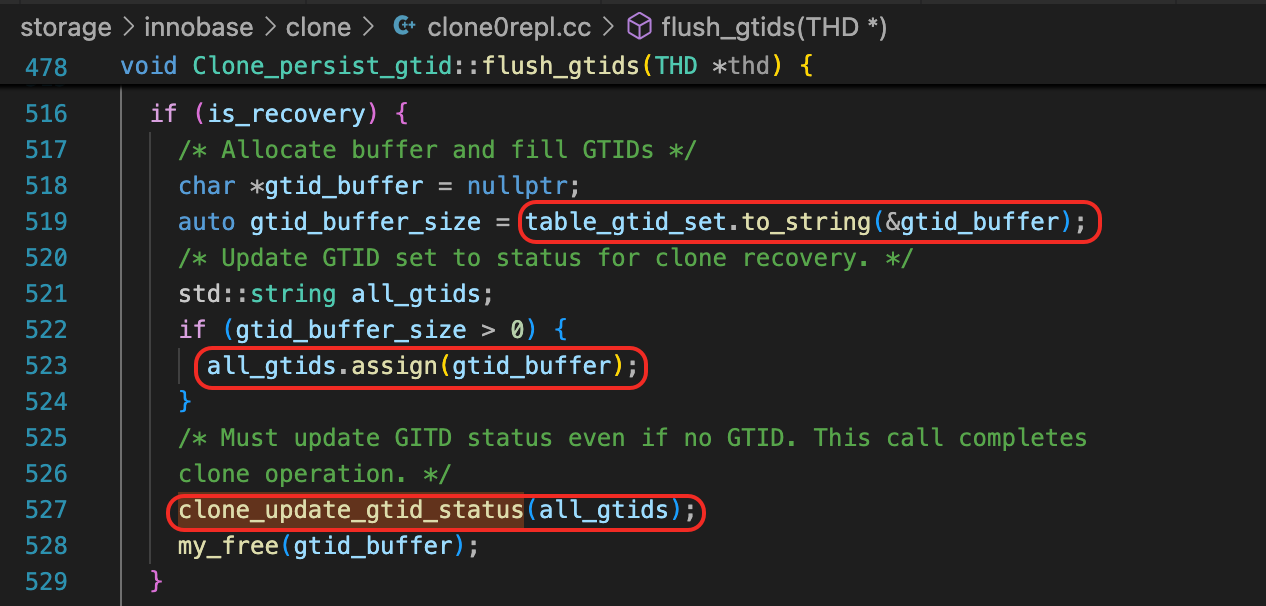
而GTID_EXECUTED,则应该是从mysql.gtid_executed表查询得到的。
mysql> select * from mysql.gtid_executed;
+--------------------------------------+----------------+--------------+
| source_uuid | interval_start | interval_end |
+--------------------------------------+----------------+--------------+
| 4bb30f4e-a618-11ef-9dc0-fab81f64ee00 | 1 | 10 |
| 7caa9a48-b325-11ed-8541-fab81f64ee00 | 1 | 91 |
+--------------------------------------+----------------+--------------+
至于InnoDB系统表空间中的Binlog信息,则是在Clone操作快完成的时候写进去的,这里会保证Binlog位点和提交的事务是一致的。
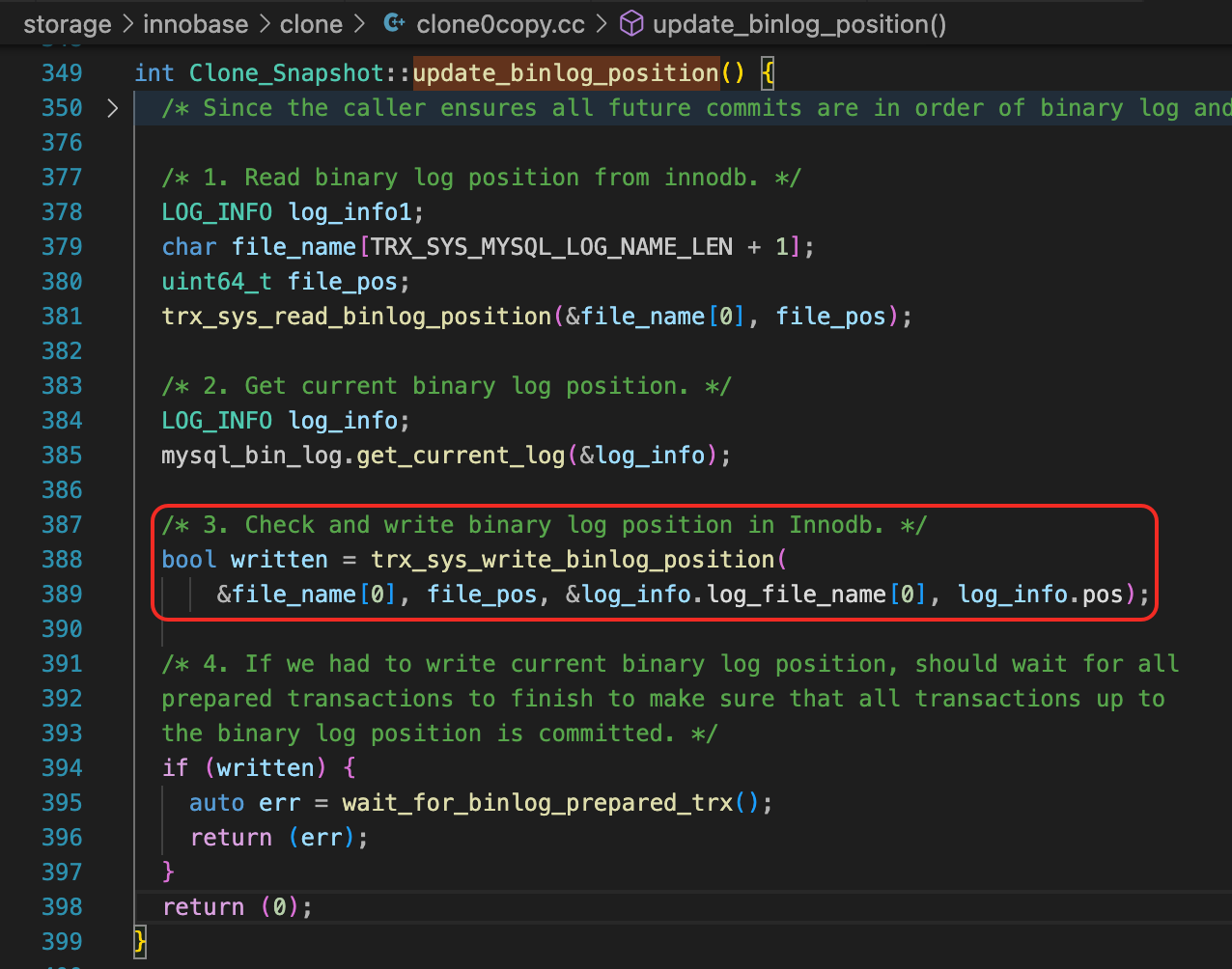
第41讲
问题:我们说组复制能保证集群中各个节点的数据完全一致。但是在默认的设置下,只能说主库提交的事务,Binlog一定已经复制到了集群中的大多数节点上,但是其他节点在应用Binlog时,还是可能会存在延迟的。因此,应用程序连接到不同的节点读取数据时,有可能会读取到不一致的数据。对这个问题,可以怎么来解决呢?
这个问题在第42讲 的“MGR 集群数据一致性”这里有一些介绍。MGR默认使用了最终一致性,最终一致性的意思,是说如果主节点停止写入,那么经过一定的时间,所有节点的数据都会变成一只。但是主节点数据一直写入时,备节点上可能会读取到数据老的版本。
MGR提供了参数group_replication_consistency,如果写入数据的会话将这个参数设置为AFTER,那么要等所有节点都应用完Binlog后,数据写入才算成功,这样其他会话从任何节点读取的数据,都是一致的。当然这样对写入性能会有很大的影响。
如果在备库上读取数据的会话,将参数group_replication_consistency设置为BEFORE,那么在开始读取数据前,需要先将其他节点在这个时间点之前提交的事务的Binlog执行完,才能读取到数据,以此来避免在备库上读取到老的数据。
第42讲
问题:使用异步复制时,需要监控好备库的延迟。使用了组复制后,也要监控好备节点上事务应用的延迟时间。那么组复制下,事务的延迟怎么监控呢?
使用异步复制时,IO线程接收Binlog,SQL线程和Worker线程应用Binlog。使用MGR时,通过Paxos协议发送Binlog事件,然后由Applier模块应用Binlog。
MGR各个节点接收Binlog和应用Binlog的延迟,可以从几个方面来监控。
- 查询replication_applier_status_by_coordinator和replication_applier_status_by_worker表
使用下面这两个SQL,分别获取协调线程处理事件的延迟,以及Worker线程应用事务的延迟。
select CHANNEL_NAME, service_state,
LAST_PROCESSED_TRANSACTION_END_BUFFER_TIMESTAMP - LAST_PROCESSED_TRANSACTION_ORIGINAL_COMMIT_TIMESTAMP as last_process_delay,
PROCESSING_TRANSACTION_START_BUFFER_TIMESTAMP - PROCESSING_TRANSACTION_ORIGINAL_COMMIT_TIMESTAMP as current_process_delay
from replication_applier_status_by_coordinator;
select
CHANNEL_NAME, service_state,
worker_id,
LAST_APPLIED_TRANSACTION_END_APPLY_TIMESTAMP - LAST_APPLIED_TRANSACTION_ORIGINAL_COMMIT_TIMESTAMP as last_apply_delay,
APPLYING_TRANSACTION_START_APPLY_TIMESTAMP - APPLYING_TRANSACTION_ORIGINAL_COMMIT_TIMESTAMP as current_apply_delay
from replication_applier_status_by_worker;
- 查询replication_group_member_stats表
select member_id, COUNT_TRANSACTIONS_IN_QUEUE, COUNT_TRANSACTIONS_REMOTE_IN_APPLIER_QUEUE
from replication_group_member_stats;
指标COUNT_TRANSACTIONS_IN_QUEUE是队列中等待冲突检测的事务数。指标COUNT_TRANSACTIONS_REMOTE_IN_APPLIER_QUEUE是applier队列中等待应用的事务数。如果applier队列中有积压的任务,说明节点上应用有延迟。
MGR也可以使用类似pt-heartbeat的方式,更新一个心跳表,检查不同节点上数据的时间差。
第43讲
问题:如果自己实现一个MySQL的自动切换程序,要考虑哪些方面的问题?
自己实现一个MySQL的自动切换程序,最基本的要考虑下面这些问题。
- 异常检测机制
切换程序要检查主库和备库是否健康。一般可以通过连接主库、执行一个简单的DML语句,来检查主库是否健康。要设置合理的超时时间,还要设置一个合理的重复检测机制,避免短暂的一个抖动就触发主备切换。
还要检测备库的健康度,以及备库的数据复制延迟。
- 切换触发机制
切换的触发机制,可分为手动出发和自动触发。比如有的操作要重启数据库,可以考虑先重启备库,再正常切换,然后再重启老的主库。或者有时候主库发生严重故障,但是备库可能存在数据不一致,不满足自动切换条件,但是为了尽快恢复业务,需要强制切换。
另外一种就是自动切换。主库发生异常,备库满足切换条件时,自动切换主备。
这里还可以考虑控制一下切换的频率,比如控制短时间内允许切换的次数。
- 切换的步骤
正常切换时,为了保证数据的一致性,先在主库将read_only或super_read_only设置为ON。等备库应用完所有的Binlog后,再将业务流量切换到备库。
如果主库异常,无法连接,那么要判断备库是否满足切换条件。最基本的条件是备库上要应用完所有已经接收到的Binlog。但如果有Binlog还没有发送到备库,或者Binlog还在传输中,那么切换可能会引起数据丢失。使用Semi-sync能减少这种情况的发生。
- 记录切换日志
记录切换过程中的详细日志,包括异常检测的结果,触发切换的原因,发生切换时主备库Binlog的位点信息,每个步骤的耗时等信息,便于事后分析。
对数据库主备切换,也可以设置监控告警,及时通知出来。
第44讲
问题:系统出了问题,我们希望监控系统能及时告警出来,但是如果监控系统自身出问题了,我们有哪些方法能及时发现问题呢?
这里可能遇到几个方面的问题。
- 数据采集异常
由于各种原因,一些指标数据没有采集到。而很多监控项依赖监控数据来触发,如果没有数据,就触发不了告警。有的监控系统支持“无数据告警”,可以充分利用起来。
- 监控项缺失
比如新的系统上线,没有添加监控。或者监控项配置不全,或者在变更时关闭了告警,后续又忘了把告警开起来。
为了避免出现这些情况,可以考虑定期检查下监控项配置。
- 告警通道失效
一般会通过各种通道来发送告警消息,比如各类IM软件、短信、电话语音通知。有些紧急问题,会使用电话语音通知。但如果某个告警通道有问题,就会导致相关人员无法及时接收到告警。对于这里问题,也可以考虑在一定的周期内强制触发一些告警,验证告警能正常发送。
- 监控系统本身故障
如果监控系统本身由于各种原因发生故障了,那么所有的告警都失效了。首先监控系统本身要有一定的容错能力,保证监控系统本身的高可用。另一方面,可以常规对监控系统进行巡检。
对于运维,除了监控,也需要按一定的周期,对系统运行状况进行巡检,确认系统运行的各个方面都是正常的。
第45讲
问题:MySQL是一个多线程的服务器,代码运行到一个断点时,所有线程都会暂停运行。有些情况下,我们可能只想调试其中一个线程,调试过程中,其他线程要保持运行状态。使用GDB,怎么实现这一点呢?
比如有这个一个场景,我想知道在事务提交的过程中,执行到哪一行代码时,事务的修改对其他会话可见。可以在事务提交的一些关键节点上设置断点,然后跟踪事务提交的代码执行过程。同时,还要在另外一个会话中,随时查询数据,检查事务中的修改是否能查到。
可以用gdb的non-stop模式来实现这个需求。
先设置non-stop,然后再attach到mysqld进程上。
# gdb /usr/local/mysql/bin/mysqld
(gdb) set pagination off
(gdb) set non-stop on
(gdb) attach <pid of mysqld>
先设置一些断点,然后使用continue -a命令,让mysqld恢复运行状态。
(gdb) break ordered_commit
(gdb) break trx_commit
(gdb) break trx_commit_in_memory
(gdb) break trx_release_impl_and_expl_locks
(gdb) break trx_erase_from_serialisation_list_low
(gdb) continue -a
下面是用来测试的数据。
mysql> select * from t1;
+-----+------+------+
| id | b | c |
+-----+------+------+
| 100 | 100 | 100 |
+-----+------+------+
在另外一个会话中执行一个update语句,会先停在ordered_commit上的断点处。切换到这个线程。
Thread 47 "connection" hit Breakpoint 1, MYSQL_BIN_LOG::ordered_commit (this=0x86e6e80 <mysql_bin_log>, thd=0x7f2bcc007130, all=false, skip_commit=false) at /root/mysql/mysql-8.0.32/sql/binlog.cc:8821
8821 DBUG_TRACE;
(gdb) thread 47
[Switching to thread 47 (Thread 0x7f2bc856b700 (LWP 28863))]
另外一个线程中,查询数据。你会发现select的执行过程中,也会遇到一些断点。
Thread 48 "connection" hit Breakpoint 2, trx_commit (trx=0x7f2c2d2f2798) at /root/mysql/mysql-8.0.32/storage/innobase/trx/trx0trx.cc:2201
2201 mtr_t local_mtr;
可以重新设置一下断点,这里我们只想调试Thread 47,设置断点时可以指定对哪些线程生效。
(gdb) info b
Num Type Disp Enb Address What
1 breakpoint keep y 0x00000000045df732 in MYSQL_BIN_LOG::ordered_commit(THD*, bool, bool) at /root/mysql/mysql-8.0.32/sql/binlog.cc:8821
breakpoint already hit 1 time
2 breakpoint keep y 0x0000000004f01957 in trx_commit(trx_t*) at /root/mysql/mysql-8.0.32/storage/innobase/trx/trx0trx.cc:2201
breakpoint already hit 2 times
3 breakpoint keep y 0x0000000004f00e32 in trx_commit_in_memory(trx_t*, mtr_t const*, bool) at /root/mysql/mysql-8.0.32/storage/innobase/trx/trx0trx.cc:1913
breakpoint already hit 1 time
4 breakpoint keep y 0x0000000004f00b59 in trx_release_impl_and_expl_locks(trx_t*, bool) at /root/mysql/mysql-8.0.32/storage/innobase/trx/trx0trx.cc:1799
5 breakpoint keep y 0x0000000004eff9bf in trx_erase_from_serialisation_list_low(trx_t*) at /root/mysql/mysql-8.0.32/storage/innobase/trx/trx0trx.cc:1438
(gdb) delete 1 2 3 4 5
(gdb) break ordered_commit thread 47
(gdb) break trx_commit thread 47
(gdb) break trx_commit_in_memory thread 47
(gdb) break trx_release_impl_and_expl_locks thread 47
(gdb) break trx_erase_from_serialisation_list_low thread 47
然后切换到Thread 47,继续调试。
(gdb) thread 47
[Switching to thread 47 (Thread 0x7f2bc856b700 (LWP 28863))]
#0 trx_commit (trx=0x7f2c2d2f23a8) at /root/mysql/mysql-8.0.32/storage/innobase/trx/trx0trx.cc:2201
2201 mtr_t local_mtr;
(gdb) c
Continuing.
Thread 47 "connection" hit Breakpoint 8, trx_commit_in_memory (trx=0x7f2c2d2f23a8, mtr=0x7f2bc85663a0, serialised=true) at /root/mysql/mysql-8.0.32/storage/innobase/trx/trx0trx.cc:1913
1913 ut_ad(trx_can_be_handled_by_current_thread_or_is_hp_victim(trx));
(gdb) c
Continuing.
Thread 47 "connection" hit Breakpoint 9, trx_release_impl_and_expl_locks (trx=0x7f2c2d2f23a8, serialised=true) at /root/mysql/mysql-8.0.32/storage/innobase/trx/trx0trx.cc:1799
1799 check_trx_state(trx);
(gdb) c
Continuing.
Thread 47 "connection" hit Breakpoint 10, trx_erase_from_serialisation_list_low (trx=0x7f2c2d2f23a8) at /root/mysql/mysql-8.0.32/storage/innobase/trx/trx0trx.cc:1438
1438 ut_ad(trx_sys_serialisation_mutex_own());
每执行到一个断点,就到另外一个会话检查一下数据。发现到达trx_release_impl_and_expl_locks的断点时,数据还查不到,但是到达trx_erase_from_serialisation_list_low这个断点时,数据就可以查到了。
接下来可以重新调试,在函数trx_release_impl_and_expl_locks内单步执行。先把当前的update语句执行完,再重新发起一个update语句。
mysql> update t1 set b=b*10, c=c*11 where id = 100;
Query OK, 1 row affected (10 min 49.13 sec)
Rows matched: 1 Changed: 1 Warnings: 0
mysql> update t1 set b=b*10, c=c*11 where id = 100;
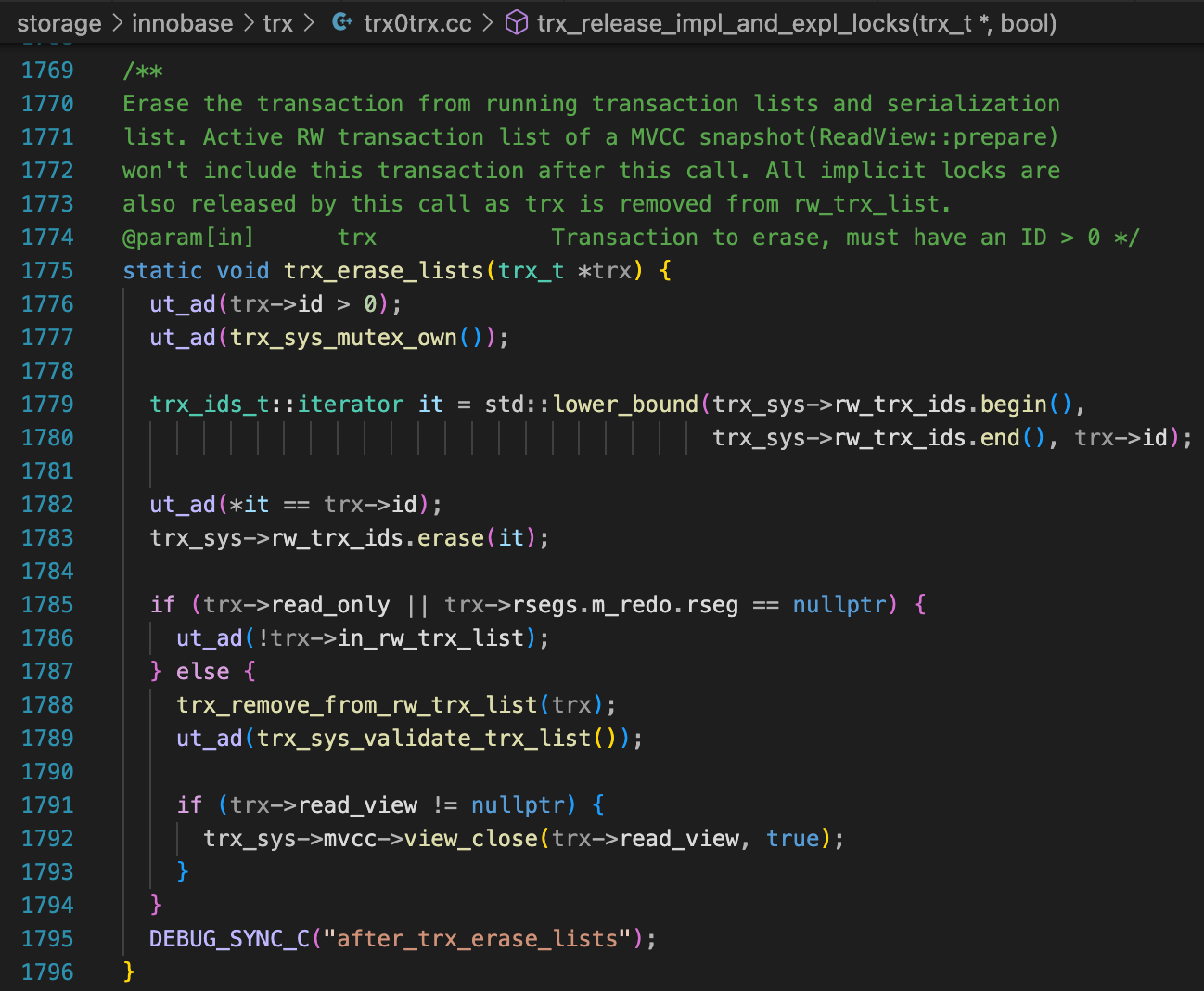
经过一些尝试,可以发现,当执行完trx_erase_list,并且执行trx_sys_mutex_exit后,就可以看到事务中的修改了。
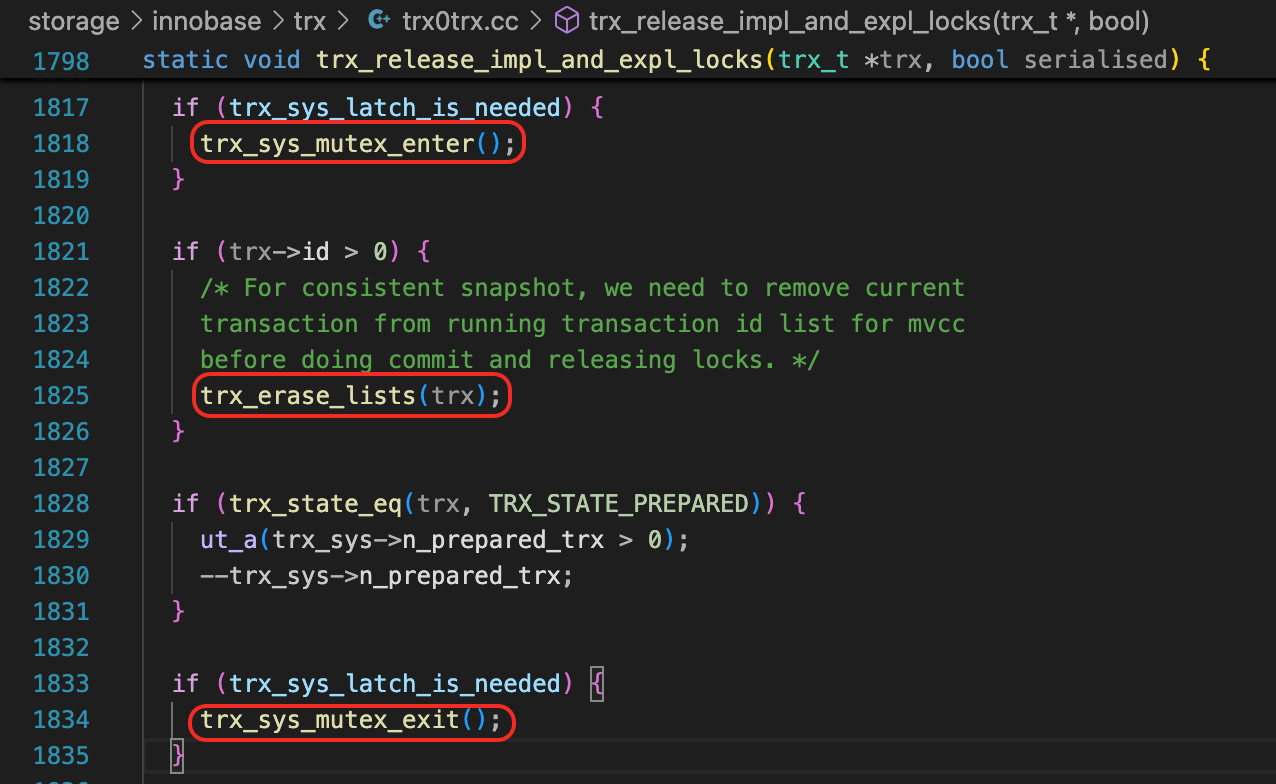
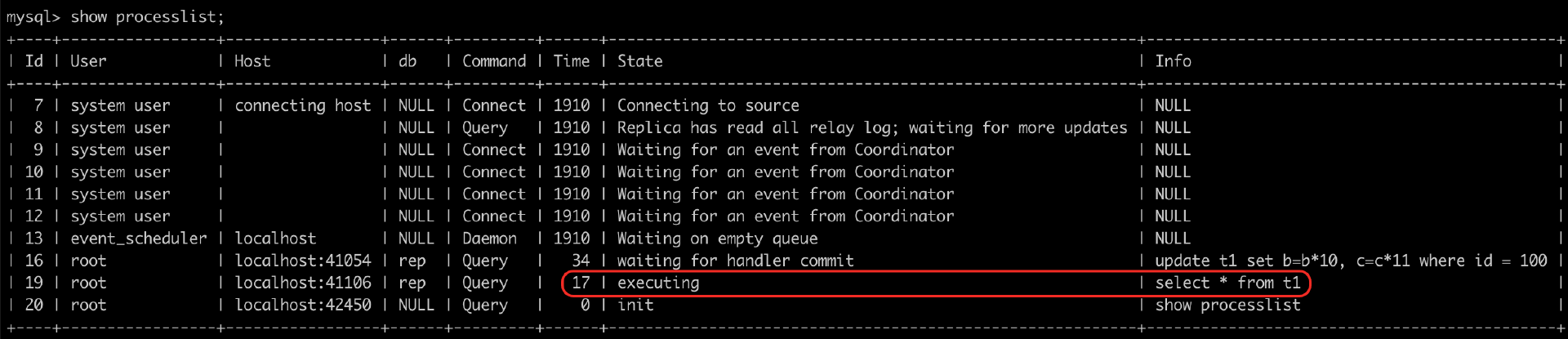
在执行trx_sys_mutex_exit之前,select语句会被阻塞,可以再另外一个会话中,执行show processlist,查看这几个线程的状态。
当然,你还可以继续分析下trx_erase_list函数,为什么执行完这个函数后,事务的修改就对其它会话可见了。
好了,到这里所有的课后题全部解答完毕,如果你有别的疑问,欢迎在对应的课程下面留言,我会定期查看,为你解答。