20 订阅流程:消费方是怎么知道提供方地址信息的?
你好,我是何辉。今天我们深入研究Dubbo源码的第九篇,订阅流程。
上一讲,我们通过一个简单的 @DubboService 注解,挖出了服务发布的内幕,找到了 ServiceBean 的 Bean 定义、ServiceConfig 的导出关键节点,发现了本地导出和远程导出,在远程导出的过程中还顺便进行了服务注册。可以说,发布流程为提供方做足了提供服务的准备。
但是,消费方,向提供方发起调用时,并没有设置需要调用提供方的哪个地址,却能神不知鬼不觉地调通提供方,并拿到结果。是不是很神奇。那消费方到底是怎么知道提供方的地址呢?
在“温故知新”中,我们学过消费方如何发起调用,可以用 <dubbo:reference/> 标签引用提供方服务来发起调用,或者换成 @DubboReference 注解也可以。不管使用标签,还是注解,我们都是在想办法拿到调用提供方的一个引用句柄而已。
所以,我们也可以逆向排查 @DubboReference 注解,来进一步探索今天的问题。
对比复习
提到通过 @DubboReference,早在之前的“泛化调用”中,我们就逆向查找 @DubboReference 注解,找到了 ReferenceConfig 这个核心类,通过调用 ReferenceConfig 的 get 方法,拿到可以向下游发起调用的泛化对象。
参考上一讲,我们可以尝试着将 @DubboReference、@DubboService 两个注解延伸出来的知识点比对总结一下。
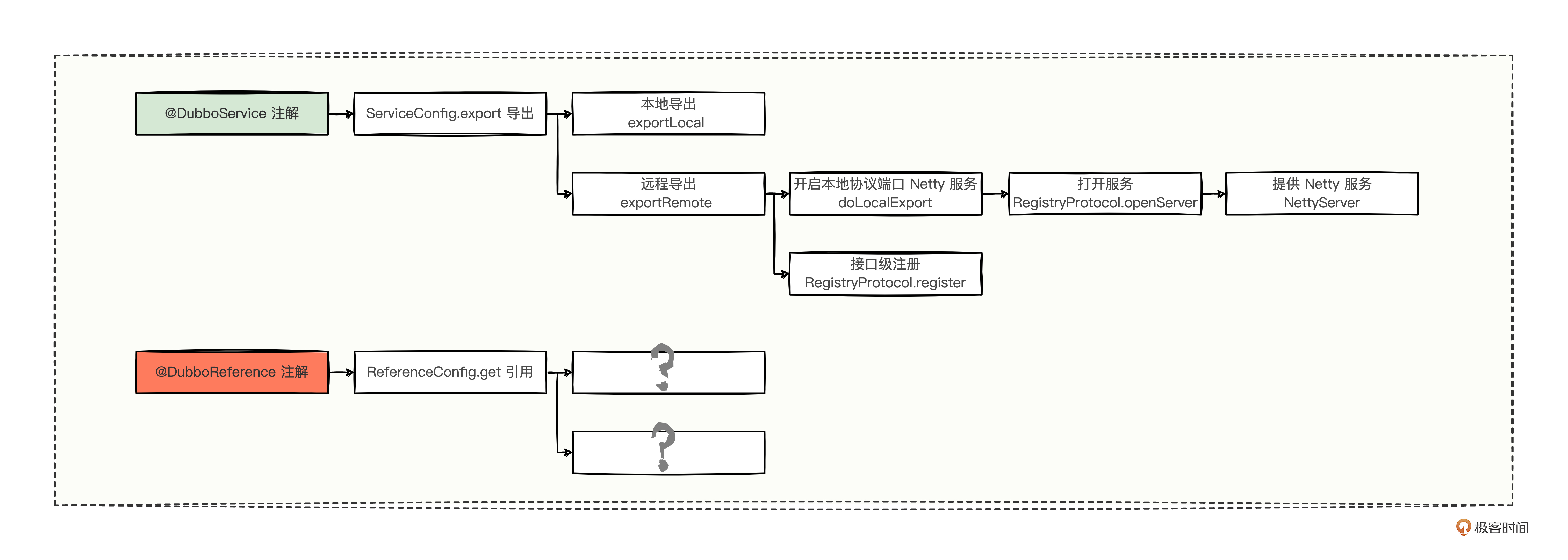
大体形式已经很清晰了,重点看三方面的对比。
- 作用域,@DubboService 是作用于提供方的,而 @DubboReference 是作用于消费方的;
- 类的名称,@DubboService 会落到 ServiceConfig 中进行导出,而 @DubboReference 会落到 ReferenceConfig 中进行引用;
- 辐射功能,ServiceConfig 中涵盖了本地导出和远程导出两个重要的分支逻辑,但是 ReferenceConfig 还暂时不清楚。
有没有发现,这些小知识点你都学过。学知识,越比较,越能发现问题,然后在逐步解答问题的过程中,你会发现各个知识点已经融入了你的知识体系中。
说回来,这里通过简单的对比,想必你心中有了继续深挖的方向了。没错,就是 ReferenceConfig 的 get 方法,我们深入看看会不会像 ServiceConfig 一样发现新大陆。
///////////////////////////////////////////////////
// org.apache.dubbo.config.ReferenceConfig#get
// 引用提供方的核心方法
///////////////////////////////////////////////////
@Override
public T get() {
// 省略其他部分代码...
if (ref == null) {
// ensure start module, compatible with old api usage
getScopeModel().getDeployer().start();
synchronized (this) {
// !!!!!!!!!!!!!!!!!!!!!!!!!!!!
// 重点关注这里
// 如果 ref 对象为空,这就初始化一个
// 说明引用提供方的每个接口都有着与之对应的一个 ref 对象
if (ref == null) {
// 初始化 ref 对象
init();
}
}
}
return ref;
}
↓
///////////////////////////////////////////////////
// org.apache.dubbo.config.ReferenceConfig#init
// 初始化的逻辑很多,这里就直接挑选最重要的核心逻辑,创建代理对象方法来跟踪
///////////////////////////////////////////////////
protected synchronized void init() {
// 省略其他部分代码...
// 这里省略了一大堆的引用提供方所设置的一些参数
// 就是那些设置在 @DubboReference 注解中的配置,最终会在综合为一个 Map 对象
// 而这个所谓的 Map 对象其实就是 referenceParameters 这个引用参数对象
// 根据引用参数创建代理对象
ref = createProxy(referenceParameters);
// 省略其他部分代码...
}
↓
///////////////////////////////////////////////////
// org.apache.dubbo.config.ReferenceConfig#createProxy
// 创建代理对象的核心逻辑:injvm引用 + 远程引用 + 生成代理对象
///////////////////////////////////////////////////
private T createProxy(Map<String, String> referenceParameters) {
// 判断是不是按照 injvm 协议进行引用
if (shouldJvmRefer(referenceParameters)) {
createInvokerForLocal(referenceParameters);
}
// 能来到这里,说明不是 injvm 协议,那就按照正常的协议进行引用
else {
urls.clear();
// url 不为空,说明有单独进行点点直连的诉求
if (StringUtils.isNotEmpty(url)) {
// user specified URL, could be peer-to-peer address, or register center's address.
// 将填写的 url 字符串内容解析为 URL 对象,并添加到 urls 集合中去
// 这里有个小细节就是,若解析的过程中发现是注册中心地址的话
// 那么就会将服务引用的 referenceParameters 整体信息归到注册中心地址的 "refer" 属性上
// 就像服务导出时一样,将服务接口的整体信息归到注册中心地址的 "export" 属性上
parseUrl(referenceParameters);
} else {
// if protocols not in jvm checkRegistry
// 如果协议不是 injvm 的话,那么这里还会再次获取最新的注册中心地址
// 如果最后发现 urls 中的集合为空的话,那么就会抛出异常
// 目的就是检查一定得有 urls 内容,否则根本不用走后续的引用逻辑了
if (!"injvm".equalsIgnoreCase(getProtocol())) {
aggregateUrlFromRegistry(referenceParameters);
}
}
// 为远程引用创建 invoker 对象
createInvokerForRemote();
}
// 省略其他部分代码...
// 创建刚刚创建出来的 invoker 对象通过调用 proxyFactory.getProxy 方法包装成代理对象
return (T) proxyFactory.getProxy(invoker, ProtocolUtils.isGeneric(generic));
}
果然从 ReferenceConfig 的 get 方法中,发现了一些非常重要的逻辑。
ReferenceConfig 的 get 方法中,以线程安全的方式来创建 ref 引用对象;ReferenceConfig 的 init 方法中,除了构建引用服务所需的参数,还有个创建代理(createProxy)的方法,并且将创建代理方法的返回值赋值给了 ref 对象。
创建代理的内部逻辑中,有条件地进行了本地引用(createInvokerForLocal)和远程引用(createInvokerForRemote),并将引用之后的结果 invoker 对象再次包装为代理对象,以供消费方调用远程使用。
通过对比翻阅代码,确实是一种不错的方式,我们可以稍微完善一下对比图了。
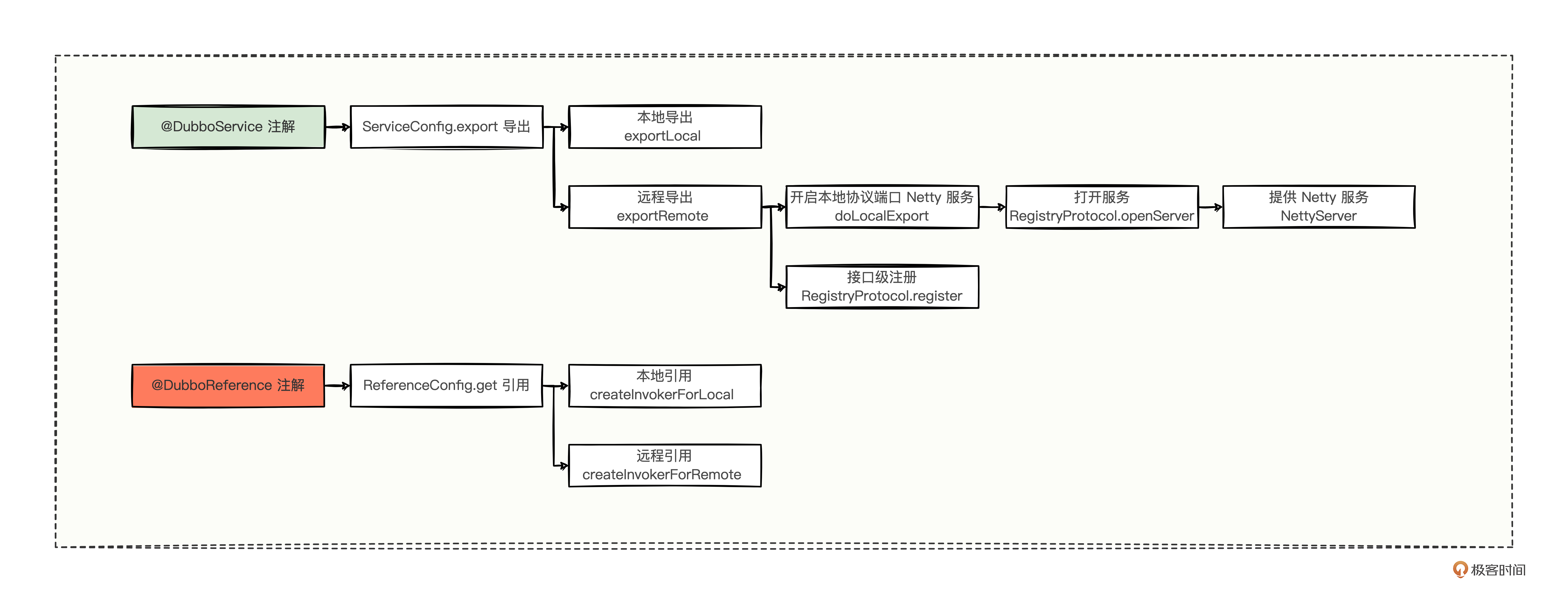
既然有了本地引用和远程引用这两个重大发现,想必你已经迫不及待了,那么接下来我们就挨个分析。
1. createInvokerForLocal 本地引用
先看本地引用的方法:
///////////////////////////////////////////////////
// org.apache.dubbo.config.ReferenceConfig#createInvokerForLocal
// 为本地引用创建 invoker 对象
///////////////////////////////////////////////////
private void createInvokerForLocal(Map<String, String> referenceParameters) {
// 将引用服务的参数对象 referenceParameters、injvm 重新再次封装为一个新对象
URL url = new ServiceConfigURL("injvm", "127.0.0.1", 0, interfaceClass.getName(), referenceParameters);
url = url.setScopeModel(getScopeModel());
url = url.setServiceModel(consumerModel);
// url:injvm://127.0.0.1/com.hmilyylimh.cloud.facade.demo.DemoFacade?application=dubbo-20-subscribe-consumer&background=false&dubbo=2.0.2&interface=com.hmilyylimh.cloud.facade.demo.DemoFacade&methods=sayHello,say&pid=8632&qos.enable=false®ister.ip=192.168.100.183&release=3.0.7&side=consumer&sticky=false×tamp=1670774005173
// 服务引用,返回的 invoker 对象这里也做了比较友好的命名说明
// withFilter 其实就是想表达,即使是本地引用也有过滤器拦截那一堆的特性
Invoker<?> withFilter = protocolSPI.refer(interfaceClass, url);
// Local Invoke ( Support Cluster Filter / Filter )
// 将 invoker 对象最终聚合为一个集群 invoker 对象
// 从另外一个角度看的话,也就意味着 Cluster 里面是有多个 invoker 对象的
List<Invoker<?>> invokers = new ArrayList<>();
invokers.add(withFilter);
invoker = Cluster.getCluster(url.getScopeModel(), "failover").join(new StaticDirectory(url, invokers), true);
}
整体流程非常简单,一上来创建一个 injvm 协议的 url 对象,紧接着调用了 protocolSPI 的 refer 方法,返回了一个含有过滤器拦截特性的 invoker 对象,最后被集群扩展器再次聚合成了单个 invoker 对象。
然而细心的你可能已经发现了,protocolSPI 这个变量在上一讲“发布流程”的导出中也见过,难道 refer 和 export 方法有内在联系?
为了验证这个问题,你再次进入 Protocol 接口。
///////////////////////////////////////////////////
// Protocol 接口,export 与 refer 是成对存在的
///////////////////////////////////////////////////
@SPI(value = "dubbo", scope = ExtensionScope.FRAMEWORK)
public interface Protocol {
// 省略其他部分代码...
/**
* Export service for remote invocation: <br>
* 1. Protocol should record request source address after receive a request:
* RpcContext.getServerAttachment().setRemoteAddress();<br>
* 2. export() must be idempotent, that is, there's no difference between invoking once and invoking twice when
* export the same URL<br>
* 3. Invoker instance is passed in by the framework, protocol needs not to care <br>
*
* @param <T> Service type
* @param invoker Service invoker
* @return exporter reference for exported service, useful for unexport the service later
* @throws RpcException thrown when error occurs during export the service, for example: port is occupied
*/
@Adaptive
<T> Exporter<T> export(Invoker<T> invoker) throws RpcException;
/**
* Refer a remote service: <br>
* 1. When user calls `invoke()` method of `Invoker` object which's returned from `refer()` call, the protocol
* needs to correspondingly execute `invoke()` method of `Invoker` object <br>
* 2. It's protocol's responsibility to implement `Invoker` which's returned from `refer()`. Generally speaking,
* protocol sends remote request in the `Invoker` implementation. <br>
* 3. When there's check=false set in URL, the implementation must not throw exception but try to recover when
* connection fails.
*
* @param <T> Service type
* @param type Service class
* @param url URL address for the remote service
* @return invoker service's local proxy
* @throws RpcException when there's any error while connecting to the service provider
*/
@Adaptive
<T> Invoker<T> refer(Class<T> type, URL url) throws RpcException;
// 省略其他部分代码...
}
可以看到,原来 export 和 refer 是成对存在的。
有了 export 的分析经验,再分析 refer 就是小菜一碟了。refer 方法上也是有 @Adaptive 注解的,那可以借鉴上一讲分析对象会经历哪些调用流程的经验,画出这样的调用链。
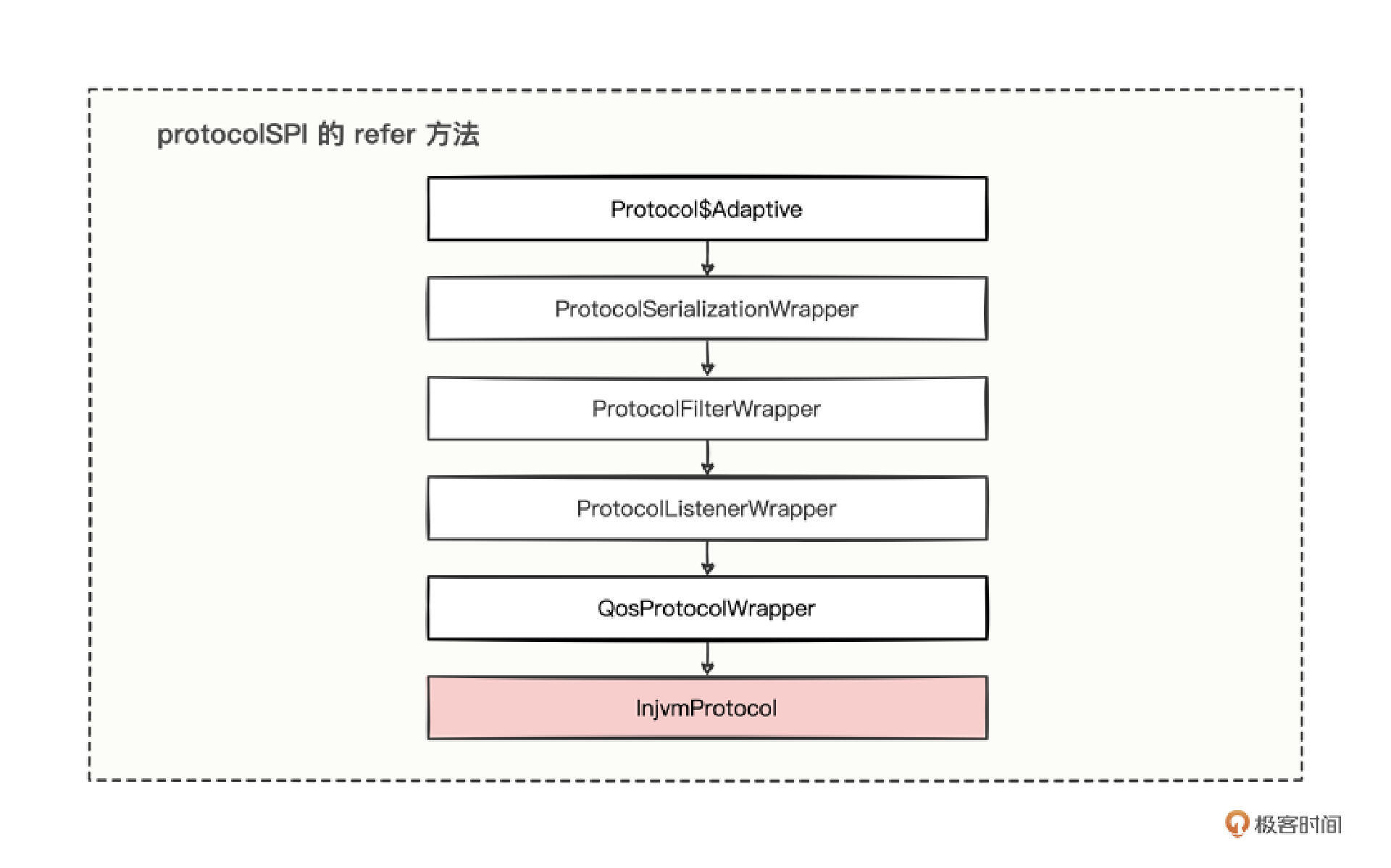
先经过了一系列的包装类,然后进入到 InjvmProtocol 实现类中。和导出时通过 injvm 走的流程,其实是一样的,再次证明了 export 和 refer 是成对存在的。
既然是成对存在的,injvm 的导出,是将创建出来的 invoker 对象放进 InjvmProtocol 中的,难道 refer 会返回一个 invoker 么?这也只是推测,我们不妨进入 InjvmProtocol 中验证看看。
///////////////////////////////////////////////////
// org.apache.dubbo.rpc.protocol.AbstractProtocol#refer
// 抽象类中有 refer 方法,但是 refer 中又调用了 protocolBindingRefer 抽象方法
///////////////////////////////////////////////////
@Override
public <T> Invoker<T> refer(Class<T> type, URL url) throws RpcException {
return protocolBindingRefer(type, url);
}
↓
///////////////////////////////////////////////////
// org.apache.dubbo.rpc.protocol.injvm.InjvmProtocol#protocolBindingRefer
// 重写父类中的 protocolBindingRefer 方法,其实间接执行了 refer 的逻辑
// 发现没,这里就直接创建了一个 InjvmInvoker 类的的对象
///////////////////////////////////////////////////
@Override
public <T> Invoker<T> protocolBindingRefer(Class<T> serviceType, URL url) throws RpcException {
return new InjvmInvoker<T>(serviceType, url, url.getServiceKey(), exporterMap);
}
通过深入 InjvmProtocol 的源码可以得知,推测是正确的,所谓的本地引用,就是直接在本地创建了一个 InjvmInvoker 对象而已,并且源码再次向我们证明了 export 和 refer 是成对存在的。
2. createInvokerForRemote 远程引用
分析了本地引用,我们继续看远程引用。一定要注意,成对存在的概念,对比很重要,大概率就能推测出底层的核心逻辑。所以我们先结合提供方的操作,对比猜测一下消费方会做哪些处理。
提供方在远程导出时,利用 Netty 绑定了协议端口来提供服务,对应绑定端口的核心类是 NettyServer,那消费方引用时,会不会尝试连接 Netty 服务呢?连接 Netty 服务的类会不会是 NettyClient 呢?
提供方最后在远程导出时,顺便将服务接口信息写到了注册中心,那么在消费方的远程引用时,会不会也往注册中心写数据呢?又或者会不会从注册中心获取数据呢?
带着推测,我们继续深入远程引用的代码中去看看。
///////////////////////////////////////////////////
// org.apache.dubbo.config.ReferenceConfig#createInvokerForRemote
// 为远程引用创建 invoker 对象
///////////////////////////////////////////////////
private void createInvokerForRemote() {
// 若 urls 集合只有 1 个元素的话,则直接调用 refer 进行远程引用
if (urls.size() == 1) {
URL curUrl = urls.get(0);
// 远程引用的核心代码
invoker = protocolSPI.refer(interfaceClass, curUrl);
if (!UrlUtils.isRegistry(curUrl)) {
// 如果这个 curUrl 不是注册协议的话,
// 那么就用集群扩展器包装起来
List<Invoker<?>> invokers = new ArrayList<>();
invokers.add(invoker);
invoker = Cluster.getCluster(scopeModel, Cluster.DEFAULT).join(new StaticDirectory(curUrl, invokers), true);
}
}
// 能来到这里,说明 urls 有多个地址,
// 可能有注册中心地址,也可能有服务接口引用地址
// 反正有混合的可能性
else {
List<Invoker<?>> invokers = new ArrayList<>();
URL registryUrl = null;
// 既然 urls 有多个元素的话,那就干脆直接循环进行挨个挨个远程引用
for (URL url : urls) {
// For multi-registry scenarios, it is not checked whether each referInvoker is available.
// Because this invoker may become available later.
// 循环体中单独针对针对一个 url 进行远程引用
invokers.add(protocolSPI.refer(interfaceClass, url));
if (UrlUtils.isRegistry(url)) {
// use last registry url
registryUrl = url;
}
}
// 如果循环完了之后,发现含有注册中心地址的话,
// 那就继续用集群扩展器包装起来
if (registryUrl != null) {
// registry url is available
// for multi-subscription scenario, use 'zone-aware' policy by default
String cluster = registryUrl.getParameter(CLUSTER_KEY, ZoneAwareCluster.NAME);
// The invoker wrap sequence would be: ZoneAwareClusterInvoker(StaticDirectory) -> FailoverClusterInvoker
// (RegistryDirectory, routing happens here) -> Invoker
// 集群扩展器包装 invokers 列表
invoker = Cluster.getCluster(registryUrl.getScopeModel(), cluster, false).join(new StaticDirectory(registryUrl, invokers), false);
}
// 循环完了后若发现没有注册中心地址,
// 那很有可能就是点点直连方式进行点对点连接
// 于是,还是一样采用集群扩展器包装起来
else {
// not a registry url, must be direct invoke.
if (CollectionUtils.isEmpty(invokers)) {
throw new IllegalArgumentException("invokers == null");
}
URL curUrl = invokers.get(0).getUrl();
String cluster = curUrl.getParameter(CLUSTER_KEY, Cluster.DEFAULT);
// 集群扩展器包装 invokers 列表
invoker = Cluster.getCluster(scopeModel, cluster).join(new StaticDirectory(curUrl, invokers), true);
}
}
}
↓
///////////////////////////////////////////////////
// org.apache.dubbo.registry.integration.RegistryProtocol#refer
// 注册协议的引用方法,该类中还有一个 export 导出的方法,他们俩是成对存在的
///////////////////////////////////////////////////
public <T> Invoker<T> refer(Class<T> type, URL url) throws RpcException {
// 首先一进入方法,你可以先看下入参url是个大概的什么内容
// 入参url:registry://127.0.0.1:2181/org.apache.dubbo.registry.RegistryService?REGISTRY_CLUSTER=registryConfig&application=dubbo-20-subscribe-consumer&dubbo=2.0.2&pid=7032&qos.enable=false®istry=ZooKeeper&release=3.0.7×tamp=1670774973194
url = getRegistryUrl(url);
// 然后经过 getRegistryUrl 方法后,又变成了什么样子
// 结果发现协议被替换了,由 registry 协议替换成了 zookeeper 协议
// getRegistryUrl 后的 url:zookeeper://127.0.0.1:2181/org.apache.dubbo.registry.RegistryService?REGISTRY_CLUSTER=registryConfig&application=dubbo-20-subscribe-consumer&dubbo=2.0.2&pid=7032&qos.enable=false&release=3.0.7×tamp=1670774973194
Registry registry = getRegistry(url);
if (RegistryService.class.equals(type)) {
return proxyFactory.getInvoker((T) registry, type, url);
}
// group="a,b" or group="*"
// 这里涉及一个一个分组的概念,不过常常会和 merger 聚合参数一起使用
Map<String, String> qs = (Map<String, String>) url.getAttribute(REFER_KEY);
String group = qs.get(GROUP_KEY);
if (StringUtils.isNotEmpty(group)) {
if ((COMMA_SPLIT_PATTERN.split(group)).length > 1 || "*".equals(group)) {
// 执行核心的 doRefer 方法
return doRefer(Cluster.getCluster(url.getScopeModel(), MergeableCluster.NAME), registry, type, url, qs);
}
}
// 能来到这个还是,发现最终还是调用核心的 doRefer 方法
// 因此不管是分组聚合情况,还是普通的情况,最终重心都落到了 doRefer 方法
Cluster cluster = Cluster.getCluster(url.getScopeModel(), qs.get(CLUSTER_KEY));
return doRefer(cluster, registry, type, url, qs);
}
可以总结出 3 点。
- 远程引用的 urls 集合,既可以是注册中心地址,也可以多个提供方的点对点地址。
- 不管 urls 集合的数量是一个还是多个,最终都是循环调用 refer 方法,然后累加 refer 的所有结果,最终被集群扩展器包装成了一个 invoker。
- refer 的方法体中将注册器、集群扩展器、接口等信息全部封装到了一个 doRefer 方法中。
第三点,所有抽象的对象都传入了 doRefer 方法中,由此可见,这个方法应该就是我们研究的重中之重。我也给你总结了代码的调用流程图。
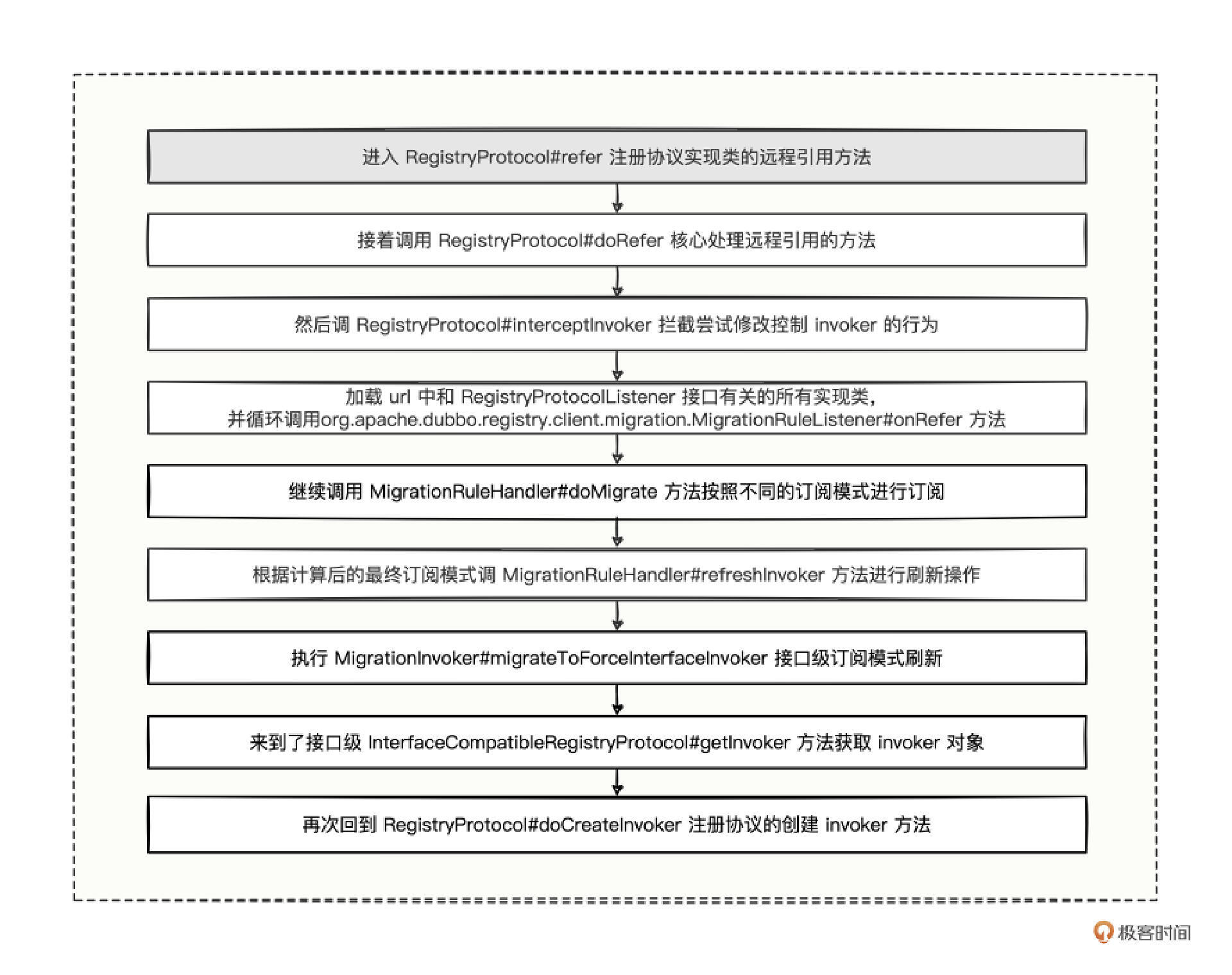
我们得出了一个非常重要的结论,从 RegistryProtocol 的 doRefer 一路跟踪,最终又回到了 RegistryProtocol 的 doCreateInvoker 方法,而且从方法名也能看出是创建 invoker 对象的核心逻辑,因此远程引用的核心逻辑就落到了 doCreateInvoker 方法中。
快要见到曙光了,我们看 doCreateInvoker 方法。
///////////////////////////////////////////////////
// RegistryProtocol#doCreateInvoker
// 兜兜转转又回到了注册协议实现类的创建 invoker 方法来了
///////////////////////////////////////////////////
protected <T> ClusterInvoker<T> doCreateInvoker(DynamicDirectory<T> directory, Cluster cluster, Registry registry, Class<T> type) {
directory.setRegistry(registry);
directory.setProtocol(protocol);
// all attributes of REFER_KEY
// 这里构建了一个需要写到注册中心的地址信息
// 之前在导出的方法中我们也看到了提供者会把服务接口的地址信息写到注册中心上
// 结果这里同样写到注册中心上,说明只要是 dubbo 服务,不管是提供者还是消费者,
// 最终都会把自己的提供的服务接口信息,或需要订阅的服务接口信息,都会写到注册中心去
Map<String, String> parameters = new HashMap<>(directory.getConsumerUrl().getParameters());
URL urlToRegistry = new ServiceConfigURL(
parameters.get(PROTOCOL_KEY) == null ? CONSUMER : parameters.get(PROTOCOL_KEY),
parameters.remove(REGISTER_IP_KEY),
0,
getPath(parameters, type),
parameters
);
urlToRegistry = urlToRegistry.setScopeModel(directory.getConsumerUrl().getScopeModel());
urlToRegistry = urlToRegistry.setServiceModel(directory.getConsumerUrl().getServiceModel());
if (directory.isShouldRegister()) {
// 将构建好的的 urlToRegistry 字符串内容写到注册中心去
directory.setRegisteredConsumerUrl(urlToRegistry);
registry.register(directory.getRegisteredConsumerUrl());
}
// 设置路由规则
directory.buildRouterChain(urlToRegistry);
// 构建订阅的地址 subscribeUrl 然后发起订阅,然后会监听注册中心的目录
directory.subscribe(toSubscribeUrl(urlToRegistry));
return (ClusterInvoker<T>) cluster.join(directory, true);
}
果然还是熟悉的套路,在 doCreateInvoker 方法中主要做了两件事情:向注册中心注册了消费接口的信息、向注册中心发起了订阅及监听。
我们又可以完善这张对比图,找到了远程引用做的两件重要事情。
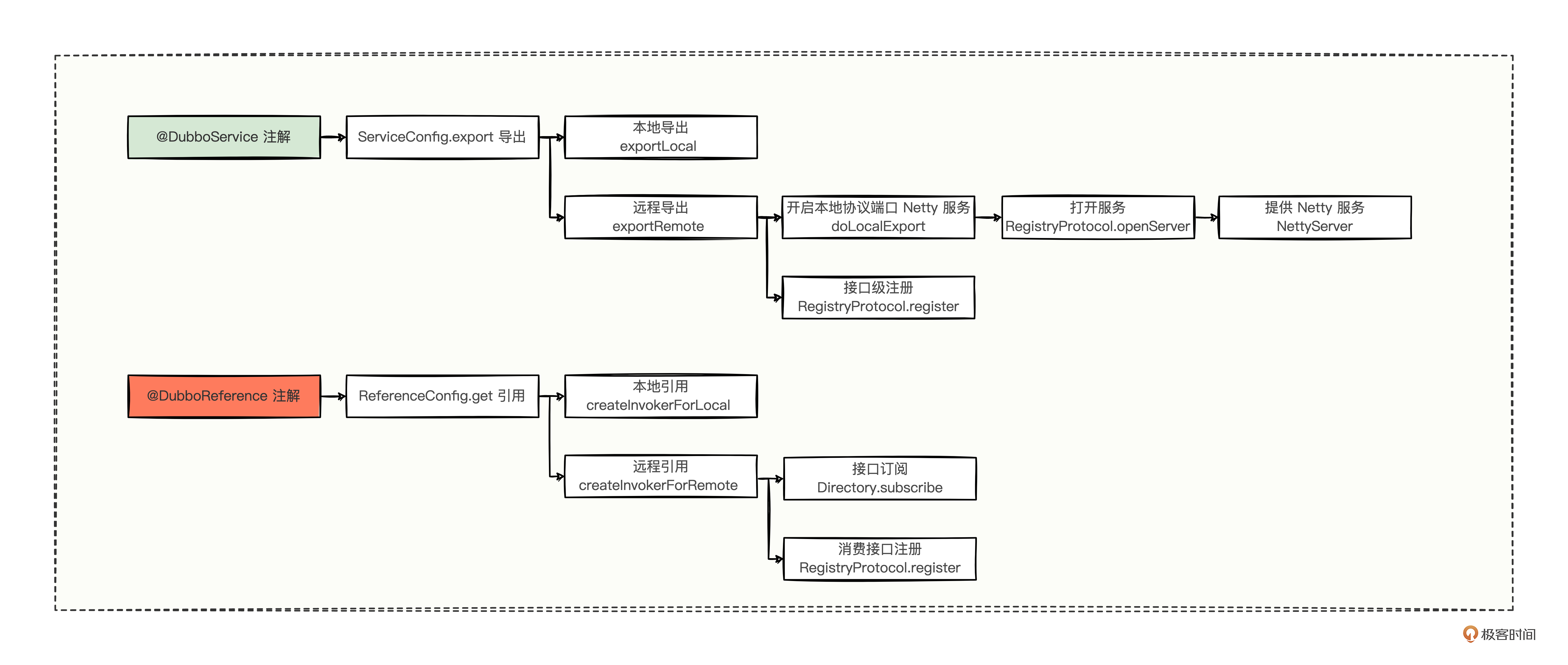
到此,我们回过头来看看之前的推测。
推测一: 提供方在远程导出时,利用 Netty 绑定了协议端口来提供服务,对应绑定端口的核心类是 NettyServer,那消费方引用时,会不会尝试连接 Netty 服务呢?连接 Netty 服务的类会不会是 NettyClient 呢? 推测二: 提供方最后在远程导出时,顺便将服务接口信息写到了注册中心,那么在消费方的远程引用时,会不会也往注册中心写数据呢?又或者会不会从注册中心获取数据呢?
我们发现只有推测二被证明了,消费者在远程引用时,确实会把自己需要消费哪个接口也写到注册中心,这样一来可以反向说明,通过提供方的一个接口,可以从注册中心找到有哪些提供方服务节点,还能找到有哪些消费方来使用这个接口。
推测一呢?别着急,我们还有一个 subscribe 没看,这个订阅方法看起来只有一行简短的代码,里面的逻辑深度却不亚于 doRefer 方法。
但是也别担心,这里我教你一个以终为始的反向验证小技巧,既然我们推测 NettyClient 会是最终结果,不如将计就计,找找有没有类名中含有 Netty 关键字且是操作 Netty 的客户端类。
- 如果找到了,看有没有尝试连接服务端的方法,打个断点。
- 如果没有,就看父类有没有连接服务端的方法。
- 如果都没有,就直接进入 Netty 的 Bootstrap 类继续找连接服务端的方法。
总之,我们的目的就是要找到通信的出口,落实到代码中,就是要找到关于 Netty 发出连接服务端请求的相关 API。
按照小技巧,我们输入了 Netty 关键字,看看有没有操作 Netty 的客户端类,又或者去 Netty 的 Bootstrap 类中看看有没有 connect 连接之类的方法,检索的结果展示如下:

两种检索方式都找到了对应的结果,因为不管是哪种方式最后都会证明推测一是正确的,因此,我这里就使用 NettyClient 这个类,找个连接的方法。
结果发现 NettyClient 中有个 doConnect 方法,见名知意,这大概率就是连接服务端的核心方法,于是我们就在消费方 NettyClient 这里打个断点,先启动提供方,再 Debug 启动消费方,静静等候断点的到来:

这就是我们当前断点到来时呈现的调用堆栈,从下往上看。
- 首先是熟悉的方法名,为远程引用创建 invoker 的方法入口 createInvokerForRemote。
- RegistryProtocol 中创建 invoker 的核心方法 doCreateInvoker。
- 还未来得及进入源码一探究竟的 subscribe 接口订阅方法。
- 接口订阅之后来了一堆的 notify 的通知方法,并且又再次走了一遍 refer 方法,很是奇怪。
- 最后是NettyClient 的 doConnect 方法。
到这里,我们通过 NettyServer 推测出了 NettyClient 是成立的,推测一完全正确。
订阅
你可能会说,还没完,我们刚刚的调用堆栈图中不是还有两个问号么?
这个好说,毕竟断点停在这里,我们可以直接找到第一个 notify 方法被调用的地方,也就是 doSubscribe 方法中调用了 notify 方法,进入源码看看。
///////////////////////////////////////////////////
// org.apache.dubbo.registry.zookeeper.ZookeeperRegistry#doSubscribe
// 订阅的核心逻辑,读取 zk 目录下的数据,然后通知刷新内存中的数据
///////////////////////////////////////////////////
@Override
public void doSubscribe(final URL url, final NotifyListener listener) {
try {
checkDestroyed();
// 因为这里用 * 号匹配,我们在真实的线上环境也不可能将服务接口配置为 * 号
// 因此这里的 * 号逻辑暂且跳过,直接看后面的具体接口的逻辑
if ("*".equals(url.getServiceInterface())) {
// 省略其他部分代码...
}
// 能来到这里,说明 ServiceInterface 不是 * 号
// url.getServiceInterface() = com.hmilyylimh.cloud.facade.demo.DemoFacade
else {
CountDownLatch latch = new CountDownLatch(1);
try {
List<URL> urls = new ArrayList<>();
// toCategoriesPath(url) 得出来的集合有以下几种:
// 1、/dubbo/com.hmilyylimh.cloud.facade.demo.DemoFacade/providers
// 2、/dubbo/com.hmilyylimh.cloud.facade.demo.DemoFacade/configurators
// 3、/dubbo/com.hmilyylimh.cloud.facade.demo.DemoFacade/routers
for (String path : toCategoriesPath(url)) {
ConcurrentMap<NotifyListener, ChildListener> listeners = zkListeners.computeIfAbsent(url, k -> new ConcurrentHashMap<>());
ChildListener zkListener = listeners.computeIfAbsent(listener, k -> new RegistryChildListenerImpl(url, path, k, latch));
if (zkListener instanceof RegistryChildListenerImpl) {
((RegistryChildListenerImpl) zkListener).setLatch(latch);
}
// 向 zk 创建持久化目录,一种容错方式,担心目录被谁意外的干掉了
zkClient.create(path, false);
// !!!!!!!!!!!!!!!!
// 这段逻辑很重要了,添加对 path 目录的监听,
// 添加监听完成后,还能拿到 path 路径下所有的信息
// 那就意味着监听一旦添加完成,那么就能立马获取到该 DemoFacade 接口到底有多少个提供方节点
List<String> children = zkClient.addChildListener(path, zkListener);
// 将返回的信息全部添加到 urls 集合中
if (children != null) {
urls.addAll(toUrlsWithEmpty(url, path, children));
}
}
// 从 zk 拿到了所有的信息后,然后调用 notify 方法
// url.get(0) = dubbo://192.168.100.183:28200/com.hmilyylimh.cloud.facade.demo.DemoFacade?anyhost=true&application=dubbo-20-subscribe-consumer&background=false&check=false&deprecated=false&dubbo=2.0.2&dynamic=true&generic=false&interface=com.hmilyylimh.cloud.facade.demo.DemoFacade&methods=sayHello,say®ister-mode=interface&release=3.0.7&side=provider
// url.get(1) = empty://192.168.100.183/com.hmilyylimh.cloud.facade.demo.DemoFacade?application=dubbo-20-subscribe-consumer&background=false&category=configurators&dubbo=2.0.2&interface=com.hmilyylimh.cloud.facade.demo.DemoFacade&methods=sayHello,say&pid=11560&qos.enable=false&release=3.0.7&side=consumer&sticky=false×tamp=1670846788876
// url.get(2) = empty://192.168.100.183/com.hmilyylimh.cloud.facade.demo.DemoFacade?application=dubbo-20-subscribe-consumer&background=false&category=routers&dubbo=2.0.2&interface=com.hmilyylimh.cloud.facade.demo.DemoFacade&methods=sayHello,say&pid=11560&qos.enable=false&release=3.0.7&side=consumer&sticky=false×tamp=1670846788876
notify(url, listener, urls);
} finally {
// tells the listener to run only after the sync notification of main thread finishes.
latch.countDown();
}
}
} catch (Throwable e) {
throw new RpcException("Failed to subscribe " + url + " to zookeeper " + getUrl() + ", cause: " + e.getMessage(), e);
}
}
订阅的核心逻辑,总结下来就是 3 点。
- 第一点,根据订阅的 url 信息,解析出 category 类别集合,类别除了有看到的 providers、configurators、routers,还有一个 consumers,但是因为我们目前是消费方进行订阅,解析出来的类别集合没有 consumers 也是合乎情理的。
- 第二点,循环为刚刚解析出来的 category 类别路径添加监听,并同时获取到类别目录下所有的信息,也就是说这里与注册中心有了通信层面的交互,拿到了注册中心关于订阅接口的所有信息。
- 第三点,将获取到的所有信息组装成为 urls 集合,统一调用 notify 方法刷新。
根据这 3 点结论,似乎解答了我们开篇的问题,为什么消费方能感知到提供方的地址呢?其实就是在这个环节,当消费方向注册中心发起接口订阅的时候,就已经拿到了该接口在注册中心的提供方信息、配置信息、路由信息。
拿到该接口的所有信息后,我们再细看 notify 后面调用的方法名。

结果看到了一个 toInvokers 的方法,将刚刚所有的 urls 转成对应 invoker 对象。
既然转成 invoker 对象后,就自然变成了当初进入 refer 的逻辑了,因为 refer 的目的就是根据 url 得到 invoker 对象,现在整个逻辑就理顺了,我们再补充一下图。
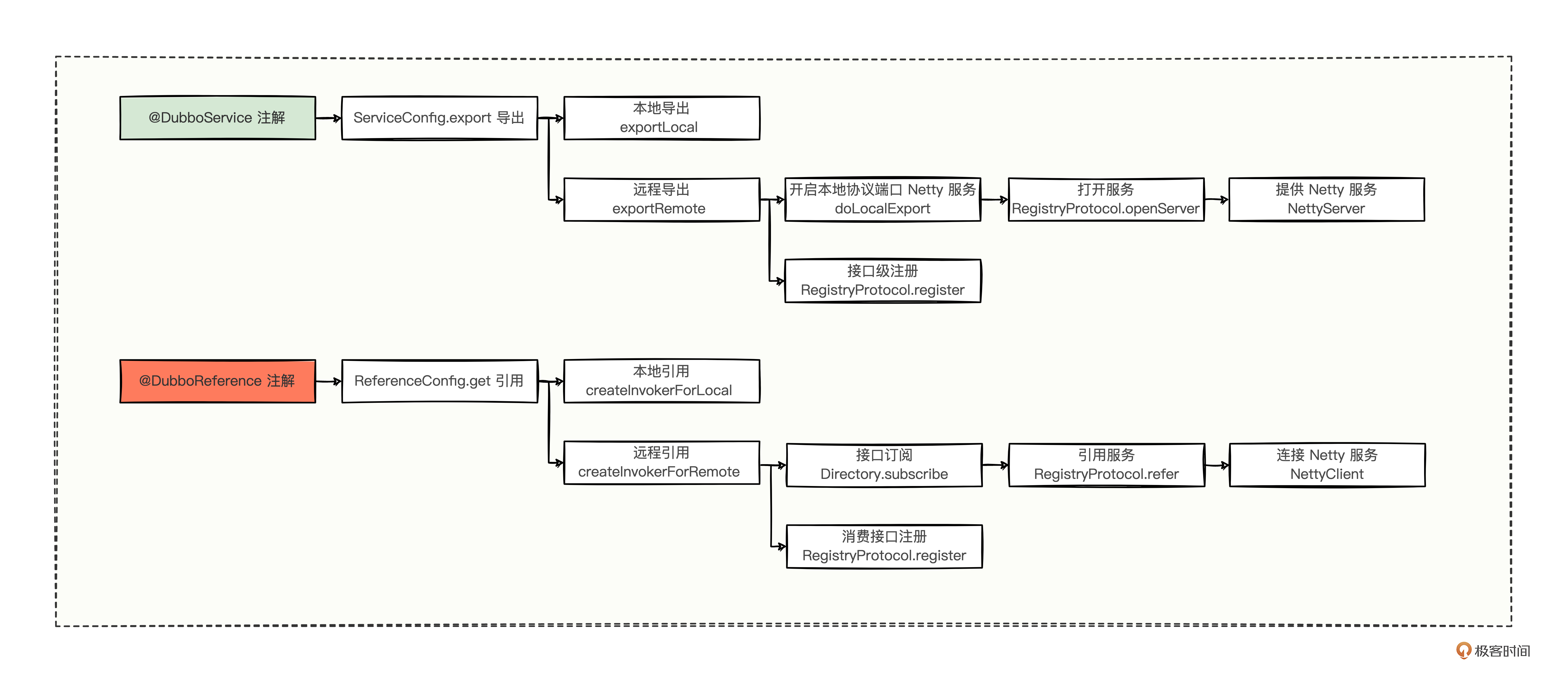
订阅流程的推拉案例
在今天的订阅流程中,消费方第一次启动时,会主动去注册中心拉取最新的信息,这也是我们常见的推拉模型中的 pull 模型,其实还有另外一种 push 模型,推拉模型在我们日常开发中还是挺常见的,那日常有哪些常用的框架有着这样的发布订阅或推拉模式呢?
- Redis 的发布订阅,生产者将消息发布到某个频道,订阅这个频道的消费方都会收到消息。
- Kafka 的消费轮询,生产者将消息发送到 Broker 中后,消费方会采取长轮询的 pull 拉取模式来自主控制消费速率。
- ZooKeeper 的事件通知,消费方会订阅监听 ZooKeeper 服务的文件目录,一旦有变更,ZooKeeper 服务会基于长连接的方式,通知监听该目录的消费方,而通知的内容甚少,若消费方需要知道更多信息的话,那由消费方自主控制去 ZooKeeper 服务端拉取最新信息。
不同的框架采用不同的方式,也有自己的利弊权衡。
push 模式的优点是实时性强,客户端只要简单的被动接收即可。但是也容易导致消息积压,同时也加大了服务端的逻辑复杂度。
pull 模式的优点是主动权掌握在客户端自己手中,消费多少就取多少,长轮询的操作也顶多就是耗费消费方一些线程资源和网络带宽,但是,轮询间隔也得在实时性能容忍的情况下,且不会对服务端造成太大请求压力冲击。这样,客户端的逻辑就会更加复杂,反而会使得服务端简单干脆。
总结
今天,我们抛出消费方是怎么知道提供方地址的问题,对比订阅流程与发布流程、 @DubboService 与 @DubboReference、ServiceConfig 与 ReferenceConfig、本地导出与本地引用、远程导出与远程引用。通过比对,分析未知的流程,是一件很值得推敲和验证的事情。
这里我用 4 个步骤总结下今天学的订阅流程。
- 首先,通过 @DubboReference 注解跟踪源码的使用地方,找到了平常进行远程调用的核心类 ReferenceConfig。
- 紧接着,在ReferenceConfig 的 get 方法中见识到了本地引用与远程引用的主干流程。
- 然后,深入远程引用的分支逻辑,找到了最核心的创建远程 invoker 的核心逻辑 doCreateInvoker。
- 最后,在这段 doCreateInvoker 逻辑中,发现了消费者注册和接口订阅逻辑,在接口订阅中见识到了感知提供方的地址原来如此简单。
订阅流程的推拉案例,有Redis 的发布订阅、Kafka 的消费轮询、ZooKeeper 的事件通知。
思考题
留个作业给你,在接口订阅的逻辑中,我们挖出消费方是如何一次性获取提供方的所有地址列表的,但消费方在接口订阅方法中只是添加了对 ZooKeeper 目录的监听,那对应接收 ZooKeeper 服务端事件变更,在代码哪个位置呢?
期待看到你的回答,如果觉得今天的内容对你有帮助,也欢迎分享给身边的朋友一起讨论。我们下一讲见。
19 思考题参考
上一期留了个作业,研究下 ProtocolFilterWrapper 协议过滤器包装类,对 export 方法的拦截做了哪些事情。
想要解答这个问题,其实也不是很难,我们直接进入到该类去看看。
///////////////////////////////////////////////////
// 协议过滤器包装类
///////////////////////////////////////////////////
@Activate(order = 100)
public class ProtocolFilterWrapper implements Protocol {
private final Protocol protocol;
// 构造方法的入参是 SPI 接口,典型的包装类写法
public ProtocolFilterWrapper(Protocol protocol) {
if (protocol == null) {
throw new IllegalArgumentException("protocol == null");
}
this.protocol = protocol;
}
@Override
public int getDefaultPort() {
return protocol.getDefaultPort();
}
@Override
public <T> Exporter<T> export(Invoker<T> invoker) throws RpcException {
// 如果 url.getProtocol() 的值为:
// registry
// 或 service-discovery-registry
// 或是 -registry-protocol 结尾的话,
// 都会认为是注册协议,则走注册协议的道路分支
if (UrlUtils.isRegistry(invoker.getUrl())) {
return protocol.export(invoker);
}
// 如果不是注册协议的话,那么就会走组装过滤器的分支逻辑
FilterChainBuilder builder = getFilterChainBuilder(invoker.getUrl());
// 将 invoker 经过过滤器层层包装之后的对象传入到 protocol.export 方法中
return protocol.export(builder.buildInvokerChain(invoker, SERVICE_FILTER_KEY, CommonConstants.PROVIDER));
}
private <T> FilterChainBuilder getFilterChainBuilder(URL url) {
return ScopeModelUtil.getExtensionLoader(FilterChainBuilder.class, url.getScopeModel()).getDefaultExtension();
}
// 省略其他部分逻辑...
}
↓
///////////////////////////////////////////////////
// 构建过滤器的核心逻辑
///////////////////////////////////////////////////
@Override
public <T> Invoker<T> buildInvokerChain(final Invoker<T> originalInvoker, String key, String group) {
Invoker<T> last = originalInvoker;
URL url = originalInvoker.getUrl();
List<ModuleModel> moduleModels = getModuleModelsFromUrl(url);
List<Filter> filters;
// 这里省略了 filters 是如何获取的逻辑,反正最终要获取到 filters 过滤器集合...
if (!CollectionUtils.isEmpty(filters)) {
// 从最后一个过滤开始循环,并且将入参的 originalInvoker 赋值给到 last 变量
// 第一次循环时,将 last 赋值给 next,然后将 next 给到新创建的对象,最后把新创建的对象再赋值给 last 变量
// 就这样,第一次循环过后,last 变量其实是一个新的引用对象,并且引用里面持有 originalInvoker 对象
// ...
// 以此类推,你感受一下这个循环过程,是不是有点像层层套娃的概念
for (int i = filters.size() - 1; i >= 0; i--) {
final Filter filter = filters.get(i);
final Invoker<T> next = last;
last = new CopyOfFilterChainNode<>(originalInvoker, next, filter);
}
return new CallbackRegistrationInvoker<>(last, filters);
}
return last;
}
进入 export 方法中,发现主要有两个分支逻辑。
- 分支一:如果是注册协议的话,那么就中规中矩走注册协议的逻辑。
- 分支二:如果不是注册协议的话,那么就将 invoker 用过滤器层层包装起来,将包装后的对象再次传入 protocol.export 方法中。
分之一的逻辑,想必你已经非常清楚了,就是上一讲详细学习的。
分支二的逻辑,为什么会有这么多的过滤器,是干什么用的呢?还记得在“缓存操作”“参数验证”“流量控制”几讲中提过的 Filter 过滤器么,其实就是在分支二这个环节加载进去的,不信的话,我们就挑“流量控制”的代码,断点查看一下 buildInvokerChain 的返参数据就知道了。
启动“流量控制”提供方代码,断点查看。

看完图中的构建过滤器的结果,恍然大悟,原来过滤器的组装早就在导出的环节就已经准备就绪了,后续触发过滤器的调用,也只不过是按部就班地从对象的最外层一直执行到最内层而已。
- Lum 👍(0) 💬(1)
这么多Invoker 感觉好乱,风中凌乱了,希望老师可以总结一下这些Invoker的各个功能
2023-03-02 - 手冢治熊 👍(0) 💬(1)
跟着源码过来,没2小时弄不完这些流程
2023-02-08 - Nights 👍(0) 💬(1)
老师,Netty不熟悉,需要补课嘛?
2023-02-01 - Jack 👍(0) 💬(1)
老师,有没有课程群?我订阅的其他课程有建微信群,老师可否也建一个群?
2023-02-01