14 SPI 机制:Dubbo的SPI比JDK的SPI好在哪里?
你好,我是何辉。今天我们来深入研究Dubbo源码的第三篇,SPI 机制。
SPI,英文全称是Service Provider Interface,按每个单词翻译就是:服务提供接口。很多开发底层框架经验比较少的人,可能压根就没听过这个SPI 机制,我们先简单了解一下。
这里的“服务”泛指任何一个可以提供服务的功能、模块、应用或系统,这些“服务”在设计接口或规范体系时,往往会预留一些比较关键的口子或者扩展点,让调用方按照既定的规范去自由发挥实现,而这些所谓的“比较关键的口子或者扩展点”,我们就叫“服务”提供的“接口”。
比较常见的SPI机制是JDK的SPI,你可能听过,其实Dubbo中也有这样的机制,在前面章节中,我们接触过利用Dubbo的SPI机制将过滤器的类路径配置到资源目录(resources)下,那为什么有了JDK的SPI后,还需要有Dubbo的SPI呢?究竟Dubbo的SPI比JDK的SPI好在哪里呢?
带着这个问题,我们开始今天的学习。
SPI是怎么来的
首先要明白SPI到底能用来做什么,我们还是结合具体的应用场景来思考:
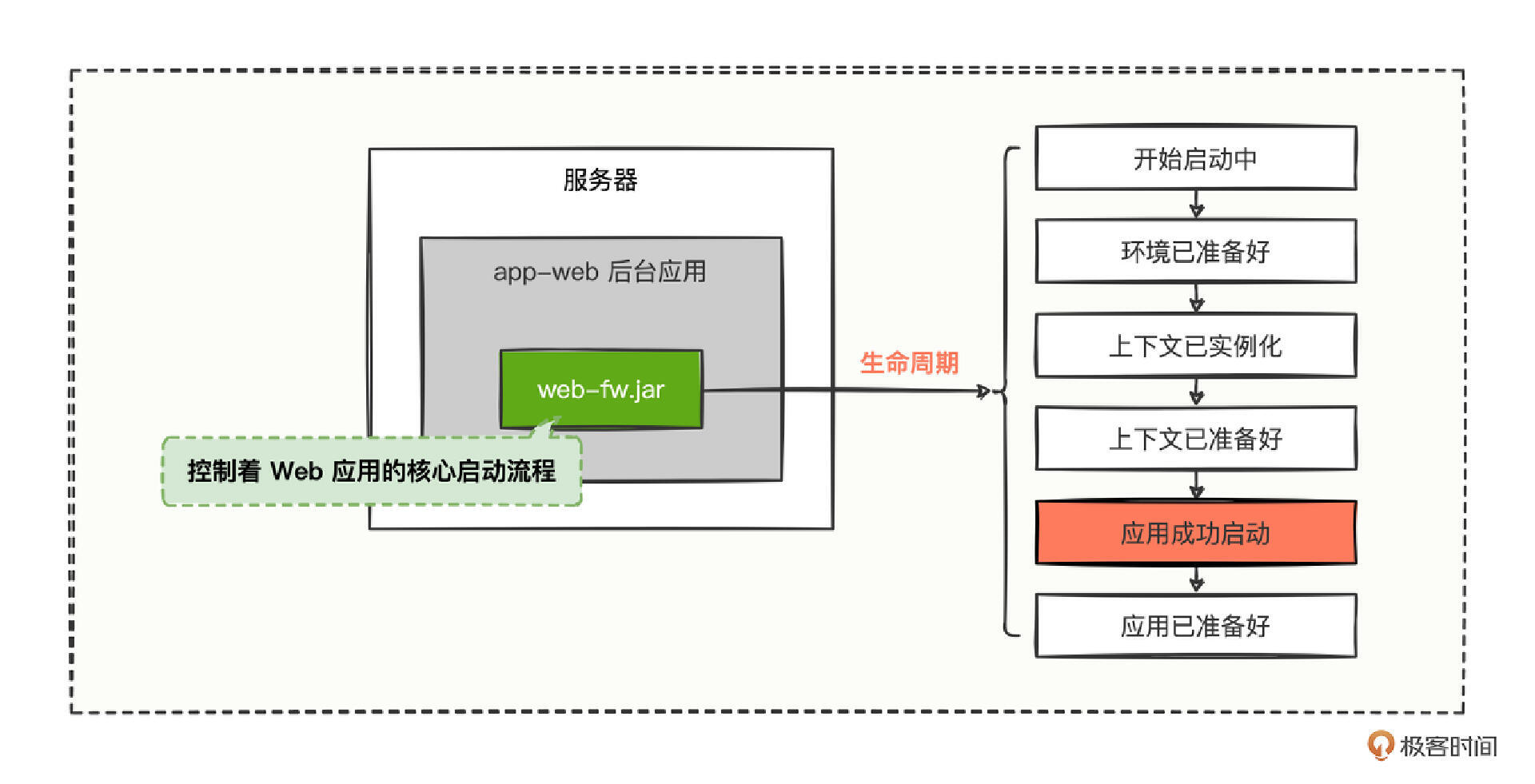
app-web 后台应用引用了一款开源的 web-fw.jar 插件,这个插件的作用就是辅助后台应用的启动,并且控制 Web 应用的核心启动流程,也就是说这个插件控制着 Web 应用启动的整个生命周期。
现在,有这样一个需求,在 Web 应用成功启动的时刻,我们需要预加载 Dubbo 框架的一些资源,你会怎么做呢?
你可能会说,这有什么难的。直接去插件翻代码,找到插件生命周期的“应用成功启动”时刻的代码,然后选个合适的位置,写上一段代码来预加载 Dubbo 框架的一些资源,应该可以解决问题了。
思维严谨些,我们看这个需求的背景,开源的第三方插件是一个 jar 包,是不能编辑的,就算在 IDE 编码工具中想办法编辑插件,也顶多只是编辑第三方插件的源码包(web-fw-source.jar),好像根本没啥用。
既然插件(web-fw.jar)不能为项目所用,如果替换插件呢?
可是短时间内,我们难以找到可替代的且对工程代码无侵入改造的插件,难不成要把插件(web-fw.jar)的源码下载下来进行二次开发改造么?就像这样:
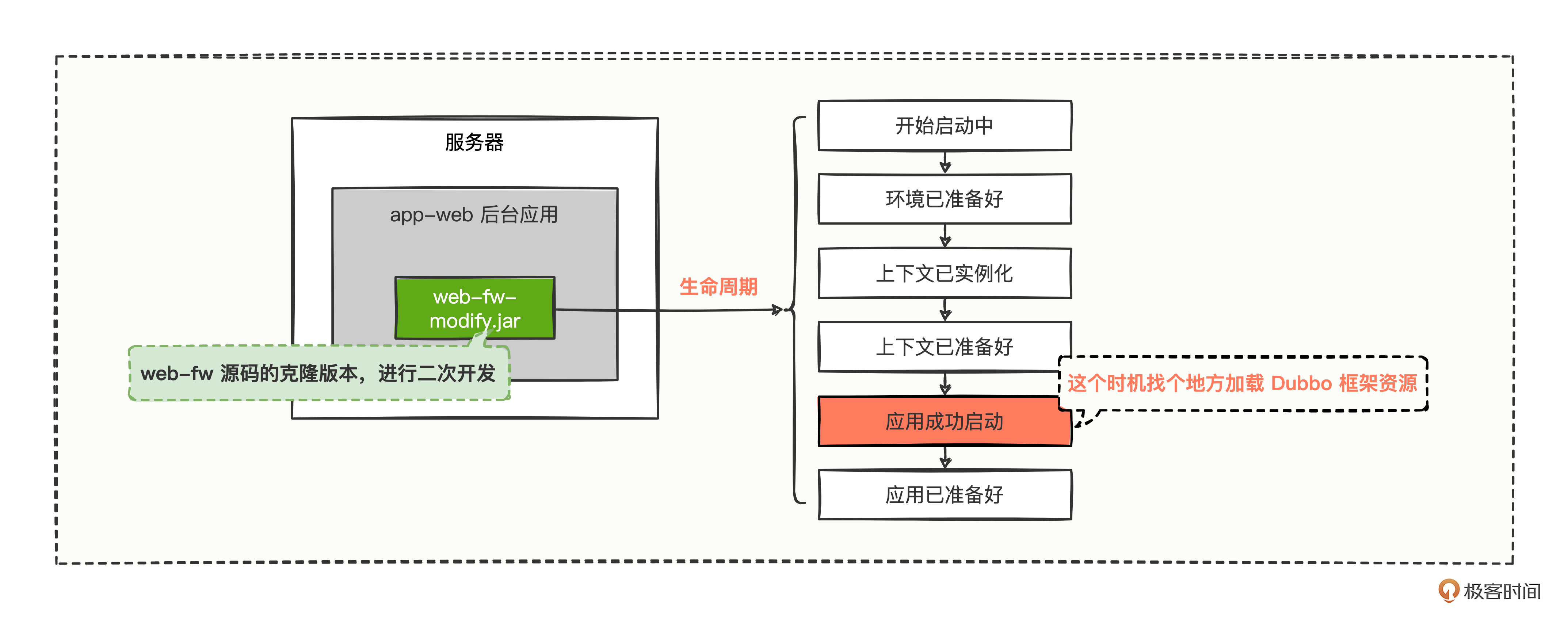
把原来的插件替换为了现在的二次开发插件(web-fw-modify.jar),然后在应用启动成功的地方加载 Dubbo 框架资源。
改造倒不会有什么大的阻碍,但是在工程中,凡是想二次改造开源,不但要考虑开发人员驾驭底层框架的抽象封装能力,还得考虑后续的维护和迭代成本。
比如,如果二次开发的插件(web-fw-modify.jar)发现了一些历史的重大漏洞问题或严重性能问题,总是需要有人维护的,这又得花费大量的人力和时间去研究源码插件。即使解决了插件的漏洞和性能问题,可是市场上的插件(web-fw.jar)却在不断更新增强,新特性越来越多,难道我们又要把新增的差异代码拷贝到二次开发的插件(web-fw-modify.jar)中?
所以,二次开发这个插件后,不但后续工作量没完没了,还跟不上市场上的迭代速度,徒增很多和业务无关的烦恼。 不可行。
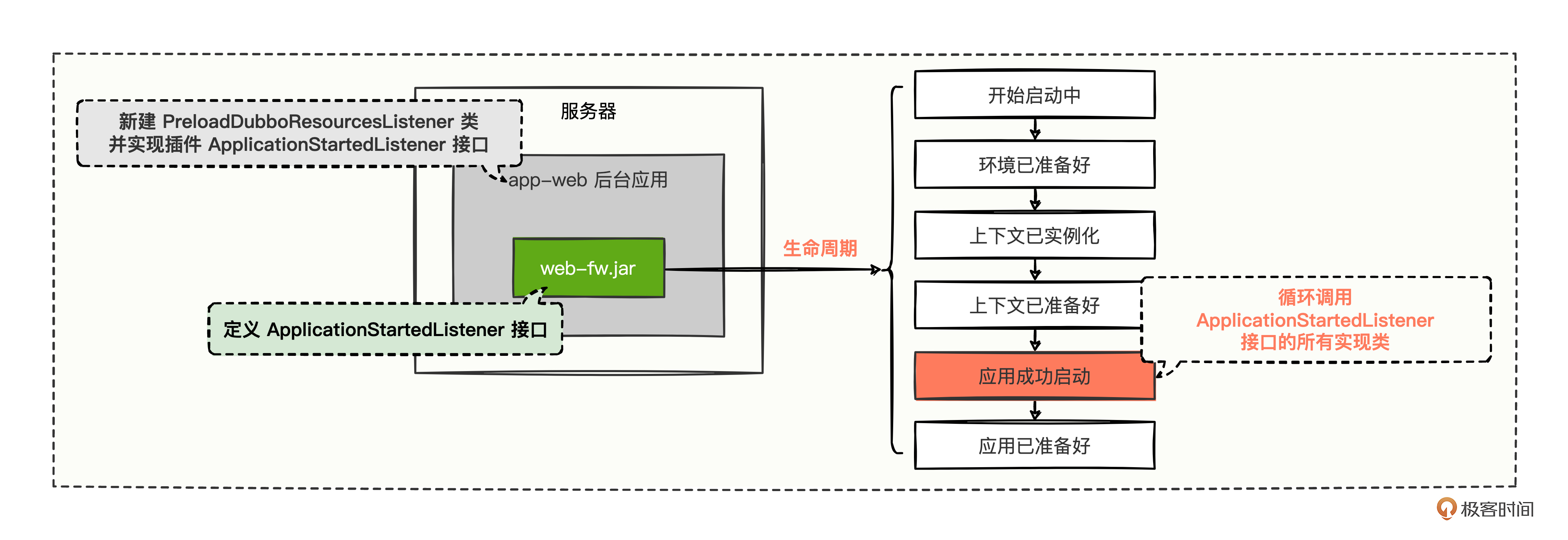
如果给开发该插件的开源团队提需求呢?好像有点不切实际,像这种企业定制化诉求,人家根本不会搭理。 即使搭理了,为了讲究通用性,开源团队也只会提供一个口子,定义一种规范约束,给上层开发人员实现该口子做一些定制化逻辑,一般会这样做:
然后配备代码:
///////////////////////////////////////////////////
// web-fw.jar 插件的启动类,在“应用成功启动”时刻提供一个扩展口子
///////////////////////////////////////////////////
public class WebFwBootApplication {
// web-fw.jar 插件的启动入口
public static void run(Class<?> primarySource, String... args) {
// 开始启动中,此处省略若干行代码...
// 环境已准备好,此处省略若干行代码...
// 上下文已实例化,此处省略若干行代码...
// 上下文已准备好,此处省略若干行代码...
// 应用成功启动
onCompleted();
// 应用已准备好,此处省略若干行代码...
}
// 应用成功启动时刻,提供一个扩展口子
private static void onCompleted() {
// 加载 ApplicationStartedListener 接口的所有实现类
ServiceLoader<ApplicationStartedListener> loader =
ServiceLoader.load(ApplicationStartedListener.class);
// 遍历 ApplicationStartedListener 接口的所有实现类,并调用里面的 onCompleted 方法
Iterator<ApplicationStartedListener> it = loader.iterator();
while (it.hasNext()){
// 获取其中的一个实例,并调用 onCompleted 方法
ApplicationStartedListener instance = it.next();
instance.onCompleted();
}
}
}
///////////////////////////////////////////////////
// web-fw.jar 插件的“应用启动成功的监听器接口”,定制一种接口规范
///////////////////////////////////////////////////
public interface ApplicationStartedListener {
// 触发完成的方法
void onCompleted();
}
///////////////////////////////////////////////////
// app-web 后台应用的启动类代码
///////////////////////////////////////////////////
public class Dubbo14JdkSpiApplication {
public static void main(String[] args) {
// 模拟 app-web 调用 web-fw 框架启动整个后台应用
WebFwBootApplication.run(Dubbo14JdkSpiApplication.class, args);
}
}
///////////////////////////////////////////////////
// app-web 后台应用的资源目录文件
// 路径为:/META-INF/services/com.hmilyylimh.cloud.jdk.spi.ApplicationStartedListener
///////////////////////////////////////////////////
com.hmilyylimh.cloud.jdk.spi.PreloadDubboResourcesListener
代码中定义了一个应用启动成功的监听器接口(ApplicationStartedListener),接着 app-web 自定义一个预加载Dubbo资源监听器(PreloadDubboResourcesListener)来实现该接口。
在插件应用成功启动的时刻,会寻找 ApplicationStartedListener 接口的所有实现类,并将所有实现类全部执行一遍,这样,插件既提供了一种口子的规范约束,又能满足业务诉求在应用成功启动时刻做一些事情。
其实插件在指定标准接口规范的这件事情上,就是 SPI 的思想体现,只不过是 JDK 通过 ServiceLoader 实现了这套思想,也就是我们耳熟能详的 JDK SPI 机制。
JDK SPI
好奇的你,一定想知道,这么神乎其神的 JDK SPI 底层到底是怎么实现的?为什么就能通过底层逻辑直接驱动上层按照规范进行编码呢?
我们可以到 ServiceLoader 里面看个究竟,同样的,我也总结了大致的核心代码流程逻辑:
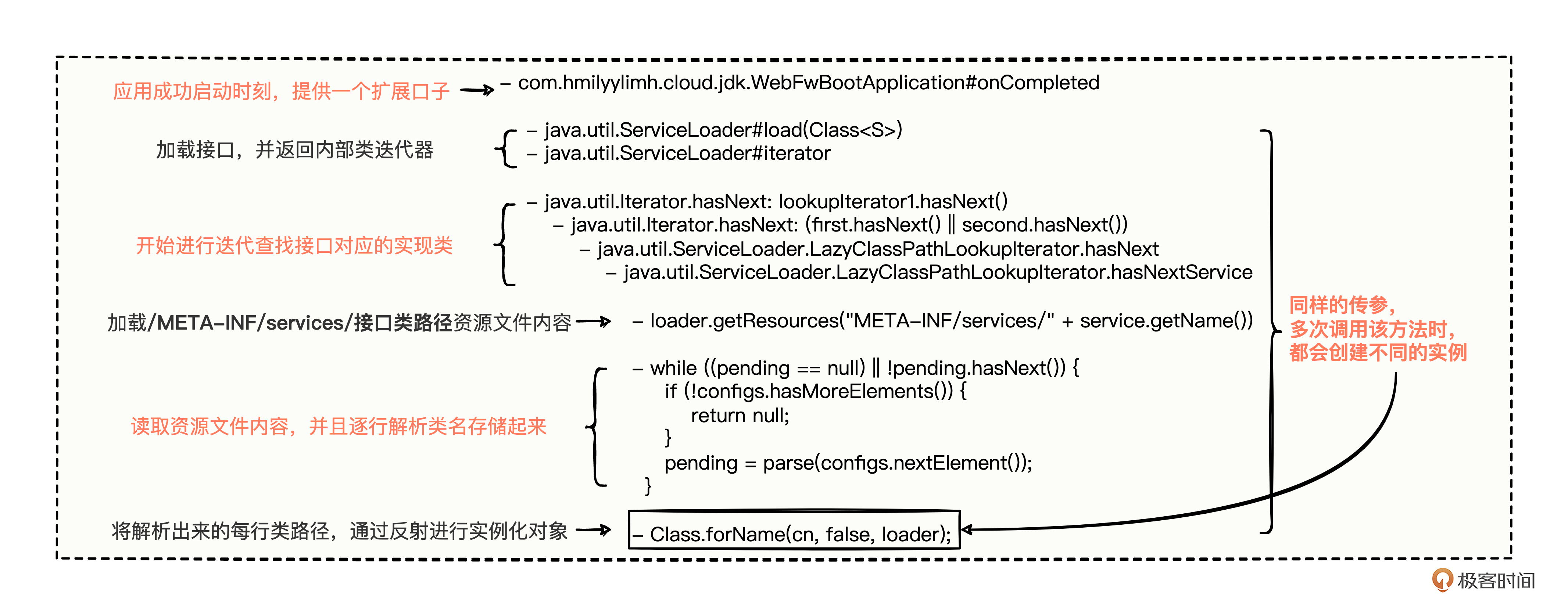
源码流程主要有三块。
- 第一块,将接口传入到 ServiceLoader.load 方法后,得到了一个内部类的迭代器。
- 第二块,通过调用迭代器的 hasNext 方法,去读取“/META-INF/services/接口类路径”这个资源文件内容,并逐行解析出所有实现类的类路径。
- 第三块,将所有实现类的类路径通过“Class.forName”反射方式进行实例化对象。
在跟踪源码的过程中,我还发现了一个问题,当我们使用 ServiceLoader 的 load 方法执行多次时,会不断创建新的实例对象。你可以这样编写代码验证:
public static void main(String[] args) {
// 模拟进行 3 次调用 load 方法并传入同一个接口
for (int i = 0; i < 3; i++) {
// 加载 ApplicationStartedListener 接口的所有实现类
ServiceLoader<ApplicationStartedListener> loader
= ServiceLoader.load(ApplicationStartedListener.class);
// 遍历 ApplicationStartedListener 接口的所有实现类,并调用里面的 onCompleted 方法
Iterator<ApplicationStartedListener> it = loader.iterator();
while (it.hasNext()){
// 获取其中的一个实例,并调用 onCompleted 方法
ApplicationStartedListener instance = it.next();
instance.onCompleted();
}
}
}
代码中,尝试调用 3 次 ServiceLoader 的 load 方法,并且每一次传入的都是同一个接口,运行编写好的代码,打印出如下信息:
预加载 Dubbo 框架的一些资源, com.hmilyylimh.cloud.jdk.spi.PreloadDubboResourcesListener@300ffa5d
预加载 Dubbo 框架的一些资源, com.hmilyylimh.cloud.jdk.spi.PreloadDubboResourcesListener@1f17ae12
预加载 Dubbo 框架的一些资源, com.hmilyylimh.cloud.jdk.spi.PreloadDubboResourcesListener@4d405ef7
打印出来的日志信息,验证了我们的猜想,每次调用 load 方法传入同一个接口的话,打印出来的引用地址都不一样,说明创建出了多个实例对象。
你可能会问,创建出多个实例对象,有什么问题呢?
如果同一个接口使用 load 方法的次数非常少,而且每次调用 load 方法创建出新的实例对象并不影响你的业务逻辑,其实问题也不大,顶多就是占用了一点内存,这点毛毛雨的内存占用可以忽略不计。
但是,如果调用 load 方法的频率比较高,那每调用一次其实就在做读取文件->解析文件->反射实例化这几步,不但会影响磁盘IO读取的效率,还会明显增加内存开销,我们并不想看到。
而且 load 方法,每次在调用时想拿到其中一个实现类,使用起来也非常不舒服,因为我们不知道想要的实现类,在迭代器的哪个位置,只有遍历完所有的实现类,才能找到想要的那个。假如项目中,有很多业务逻辑都需要获取指定的实现类,那将会充斥着各色各样针对 load 进行遍历的代码并比较,无形中,我们又悄悄产生了很多雷同代码。
JDK SPI 的问题
所以,JDK 的SPI 创建出多个实例对象,总结起来有两个问题。
- 问题一,使用 load 方法频率高,容易影响 IO 吞吐和内存消耗。
- 问题二,使用 load 方法想要获取指定实现类,需要自己进行遍历并编写各种比较代码。
我们看看如何解决。
针对问题一,引发的关键在于大量的磁盘 IO 操作以及大量的实例对象产生,那有什么办法可以降低一下磁盘的频繁操作和对象的大量产生呢?
在“缓存操作”那一讲中也有方法被大量调用,我们的尝试是看看是否可以缓存起来。有 N 次调用,如果第一次通过读取文件、解析文件、反射实例化拿到接口的所有实现类并缓存起来,后面 N - 1 次就可以直接从缓存读取,大大降低了各种耗时的操作,性能有质的提升。
针对问题二,每次需要遍历找到想要的实现类,说白了其实就是 O(n) 的时间复杂度,那有啥办法可以降低到 O(1) 的时间复杂度呢?
从 O(n) 降低到 O(1) ,如果你对算法有过一定了解,想必也想到了,可以以空间换时间,叠加哈希算法进行快速寻址查找,基本上就可以做到了。那回忆下,Java 基础知识中哪些常用的工具类,可以辅助我们做到 O(1) 检索复杂度呢?
没错,List 的 index 查找、Map 的 hash 查找,都可以做到 O(1) 检索复杂度,这两个集合工具类,我们平时经常用,但都没发现有这么神奇的效果。
那 List 和 Map 两个工具,这里该用哪个呢?
这个好区分,需要从一个接口的所有实现类中,查找某个实现类,既然要寻找,那肯定不知道要找的实现类在第几个位置,因此 List 不可行,剩下的就只有 Map 了,Map 支持通过不同的一个对象获取另外一个对象,类似通过别名获取另外一个对象,比较符合常规查找操作。
好,到这里,我们梳理下两个问题的结论。
- 结论一,增加缓存,来降低磁盘IO访问以及减少对象的生成。
- 结论二,使用Map的hash查找,来提升检索指定实现类的性能。
Dubbo SPI
于是,为了弥补我们分析的 JDK SPI 的不足,Dubbo 也定义出了自己的一套 SPI 机制逻辑,既要通过 O(1) 的时间复杂度来获取指定的实例对象,还要控制缓存创建出来的对象,做到按需加载获取指定实现类,并不会像JDK SPI那样一次性实例化所有实现类。
正因为有了这些改进,Dubbo 设计出了一个 ExtensionLoader 类,实现了 SPI 思想,也被称为 Dubbo SPI 机制。
在代码层面使用起来也很方便,你看这里的代码:
///////////////////////////////////////////////////
// Dubbo SPI 的测试启动类
///////////////////////////////////////////////////
public class Dubbo14DubboSpiApplication {
public static void main(String[] args) {
ApplicationModel applicationModel = ApplicationModel.defaultModel();
// 通过 Protocol 获取指定像 ServiceLoader 一样的加载器
ExtensionLoader<IDemoSpi> extensionLoader = applicationModel.getExtensionLoader(IDemoSpi.class);
// 通过指定的名称从加载器中获取指定的实现类
IDemoSpi customSpi = extensionLoader.getExtension("customSpi");
System.out.println(customSpi + ", " + customSpi.getDefaultPort());
// 再次通过指定的名称从加载器中获取指定的实现类,看看打印的引用是否创建了新对象
IDemoSpi customSpi2 = extensionLoader.getExtension("customSpi");
System.out.println(customSpi2 + ", " + customSpi2.getDefaultPort());
}
}
///////////////////////////////////////////////////
// 定义 IDemoSpi 接口并添加上了 @SPI 注解,
// 其实也是在定义一种 SPI 思想的规范
///////////////////////////////////////////////////
@SPI
public interface IDemoSpi {
int getDefaultPort();
}
///////////////////////////////////////////////////
// 自定义一个 CustomSpi 类来实现 IDemoSpi 接口
// 该 IDemoSpi 接口被添加上了 @SPI 注解,
// 其实也是在定义一种 SPI 思想的规范
///////////////////////////////////////////////////
public class CustomSpi implements IDemoSpi {
@Override
public int getDefaultPort() {
return 8888;
}
}
///////////////////////////////////////////////////
// 资源目录文件
// 路径为:/META-INF/dubbo/internal/com.hmilyylimh.cloud.dubbo.spi.IDemoSpi
///////////////////////////////////////////////////
customSpi=com.hmilyylimh.cloud.dubbo.spi.CustomSpi
看这里的使用,主要有三大步骤。
- 第一,定义一个 IDemoSpi 接口,并在该接口上添加 @SPI 注解。
- 第二,定义一个 CustomSpi 实现类来实现该接口,然后通过 ExtensionLoader 的 getExtension 方法传入指定别名来获取具体的实现类。
- 最后,在“/META-INF/services/com.hmilyylimh.cloud.dubbo.spi.IDemoSpi”这个资源文件中,添加实现类的类路径,并为类路径取一个别名(customSpi)。
然后运行这段简短的代码,打印出日志。
com.hmilyylimh.cloud.dubbo.spi.CustomSpi@143640d5, 8888
com.hmilyylimh.cloud.dubbo.spi.CustomSpi@143640d5, 8888
从日志中可以看到,再次通过别名去获取指定的实现类时,打印的实例对象的引用是同一个,说明 Dubbo 框架做了缓存处理。而且整个操作,我们只通过一个简单的别名,就能从 ExtensionLoader 中拿到指定实现类,确实简单方便。
当你了解了 SPI 的思想,也在代码层面感受了它的功效,至于如何应用,就非常清晰了,主要是通过定制底层规范接口,在不同的业务场景,封装底层逻辑不变性,提供扩展点给到上层应用做不同的自定义开发实现,既可以用来提供框架扩展,也可以用来替换组件。
总结
今天,我们从一个 Web 应用预加载 Dubbo 框架资源的案例开始,思考如何实现需求。
从修改源码插件,到让开源团队提供扩展口子,逐渐理解了 SPI 思想,并且通过使用 JDK 中的 ServiceLoader 关键类实现了 SPI 思想,也就是 JDK SPI 机制。
JDK SPI 的使用三部曲。
- 首先,定义一个接口。
- 然后,定义一些类来实现该接口,并将多个实现类的类路径添加到“/META-INF/services/接口类路径”文件中。
- 最后,使用 ServiceLoader 的 load 方法加载接口的所有实现类。
但 JDK SPI 在高频调用时,可能会出现磁盘 IO 吞吐下降、大量对象产生和查询指定实现类的 O(n) 复杂度等问题,采用缓存+Map的组合方式来解决,就是 Dubbo SPI 的核心思想。
Dubbo SPI 的使用步骤三部曲:
- 首先,同样也是定义一个接口,但是需要为该接口添加 @SPI 注解。
- 然后,定义一些类来实现该接口,并将多个实现类的类路径添加到“/META-INF/services/接口类路径”文件中,并在文件中为每个类路径取一个别名。
- 最后,使用 ExtensionLoader 的 getExtension 方法就能拿到指定的实现类使用。
思考题
了解了 JDK SPI 和 Dubbo SPI,还有 Spring SPI,留 2 个小作业给你。
- 研究下 Dubbo SPI 的底层加载逻辑是怎样的。
- 总结下 Spring SPI 的使用步骤是怎样的。
期待看到你的思考,如果觉得今天的内容对你有帮助,也欢迎分享给身边的朋友一起讨论。我们下一讲见。
13 思考题参考
上一期的问题是让你尝试研究下Spring与Mybatis是怎么有机结合起来使用的。
- 通过
org.springframework.context.annotation.ClassPathBeanDefinitionScanner,找到关于 mybatis 的实现类org.mybatis.spring.mapper.ClassPathMapperScanner。 - 在
org.mybatis.spring.mapper.ClassPathMapperScanner#doScan中通过调用 super.doScan,让Spring帮忙扫描出一堆的 BeanDefinition 集合,并且修改 BeanDefinition 集合。 - 通过
org.springframework.beans.factory.support.AbstractBeanDefinition#setBeanClass设置org.mybatis.spring.mapper.MapperFactoryBean类,目的是方便将来创建代理类。 - 在
org.mybatis.spring.mapper.MapperFactoryBean#getObject方法中创建核心代理类org.apache.ibatis.binding.MapperProxy。 - 最后在
org.apache.ibatis.binding.MapperProxy#invoke方法中,SqlSession 处理业务代码增删改查的 SQL 业务逻辑。
到这里,我们就从源码层面弄明白了Spring与Mybatis是怎么有机结合起来使用的。
- Lum 👍(1) 💬(2)
dubbo得spi加载还是要依赖java的spi的 在 loadLoadingStrategies策略中调用原生的ServiceLoador加载dubbo的load策略,记录一下,另外dubbo的spi还支持自适应扩展等,老师没有讲解一下
2023-03-01 - 小华 👍(0) 💬(0)
老师你好,有两个问题: 1、JDK SPI的示例代码中,我运行main函数没有得到打印,调试发现while(it.hasNext())没有进去,是因为我用了JDK17吗? 2、trpc-go的插件化设计也是通过实现框架预定义的标准接口,支持开发者自己实现,利用配置文件注入,和Dubbo SPI有什么区别吗
2023-12-28