08 缓存操作:如何为接口优雅地提供缓存功能?
你好,我是何辉。今天我们探索Dubbo框架的第七道特色风味,缓存操作。
移动端App你应该不陌生了,不过最近有个项目引发了用户吐槽:
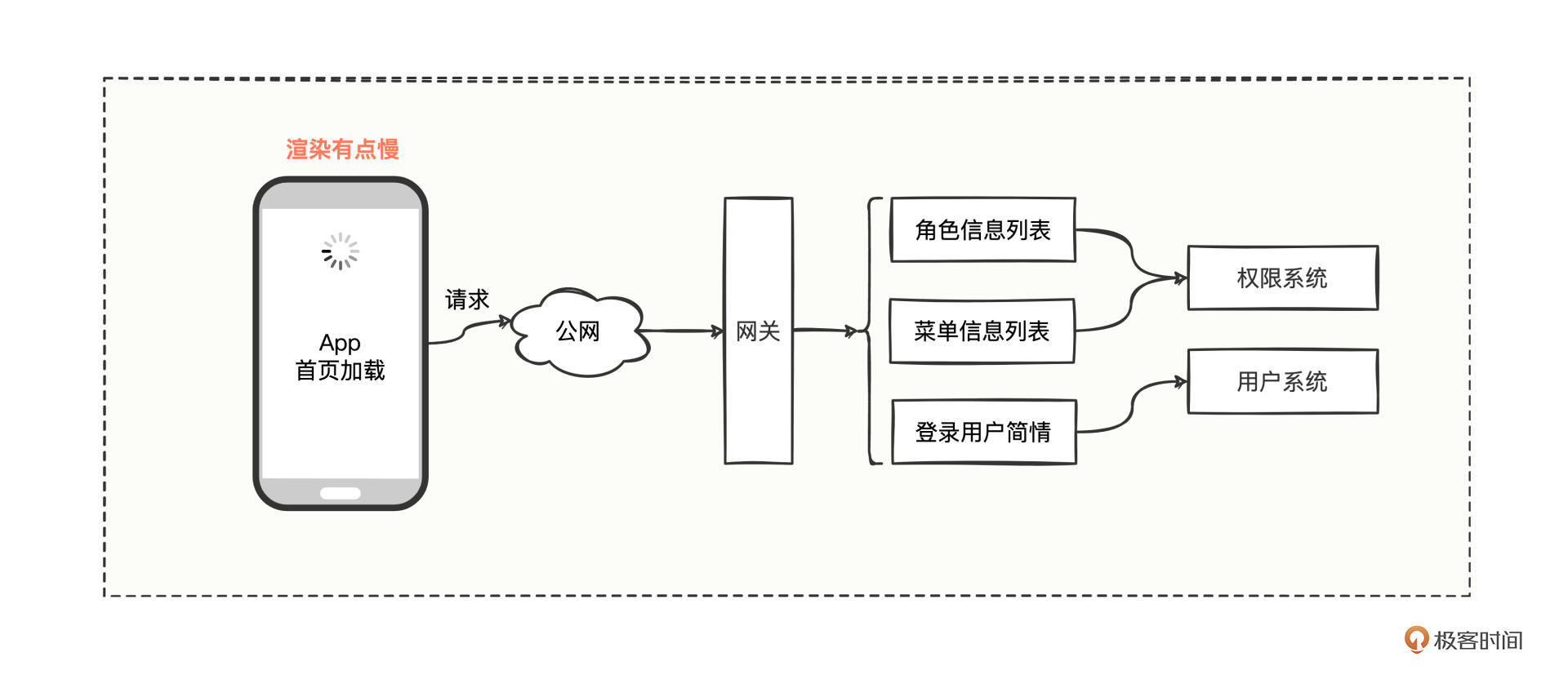
图中的App,在首页进行页面渲染加载时会向网关发起请求,网关会从权限系统拿到角色信息列表和菜单信息列表,从用户系统拿到当前登录用户的简单信息,然后把三块信息一并返回给到App。
然而,就是这样一个看似简单的功能,每当上下班的时候因为App被打开的频率非常高,首页加载的请求流量在短时间内居高不下,打开很卡顿,渲染很慢。
经过排查后,发现该App只有数十万用户,但意外的是在访问高峰期,权限系统的响应时间比以往增长了近10倍,权限系统集群中单机查询数据库的QPS高达500多,导致数据库的查询压力特别大,从而导致查询请求响应特别慢。
由于目前用户体量尚且不大,架构团队商讨后,为了稳住用户体验,最快的办法就是在网关增加缓存功能,把首页加载请求的结果缓存起来,以提升首页快速渲染页面的时效。
对于这个加缓存的需求,你会如何优雅地处理呢?
缓存疑惑
在正式思考处理思路前,不知道你对架构团队的结论有没有疑惑,为什么增加一个简单的缓存功能,就能提升接口响应时效呢?
我以前也有过这样的疑惑,直到有一天研究volatile原理时,看到了一张关于系统存储媒介的延时量化图(你可以搜索 “Latency numbers every programmer should know” 关键字),才恍然大悟:
// 这里我就列举出,我们需要关注的数据
L1 cache reference ........................... 1 ns
L2 cache reference ........................... 4 ns
Main memory reference ...................... 100 ns
Send packet CA->Netherlands->CA .... 150,000,000 ns = 150 ms
还记得你之前学过的计算机组成原理吗,我们看这里不同存储媒介的延时关系,L1和L2读取时间为纳秒级,Memory读取时间为纳秒级,发送数据包的时间为毫秒级。
那么,发送数据包的时间(150ms)除以Memory读取时间(100ns)等于 1500000,也就是说网络间的传输比内存传输慢了150万倍,差异一下就体现出来了。现在我想你应该理解了,缓存的增加,对接口响应时间的减少有着质的飞越。
解开了为什么增加缓存的疑惑后,我们进入正题看看怎么在网关这边增加缓存功能。
1.简单处理
你可能会说这不是小菜一碟,可以在网关向权限系统发起调用之前,增加一层缓存模块,系统之间的调用这么设计:
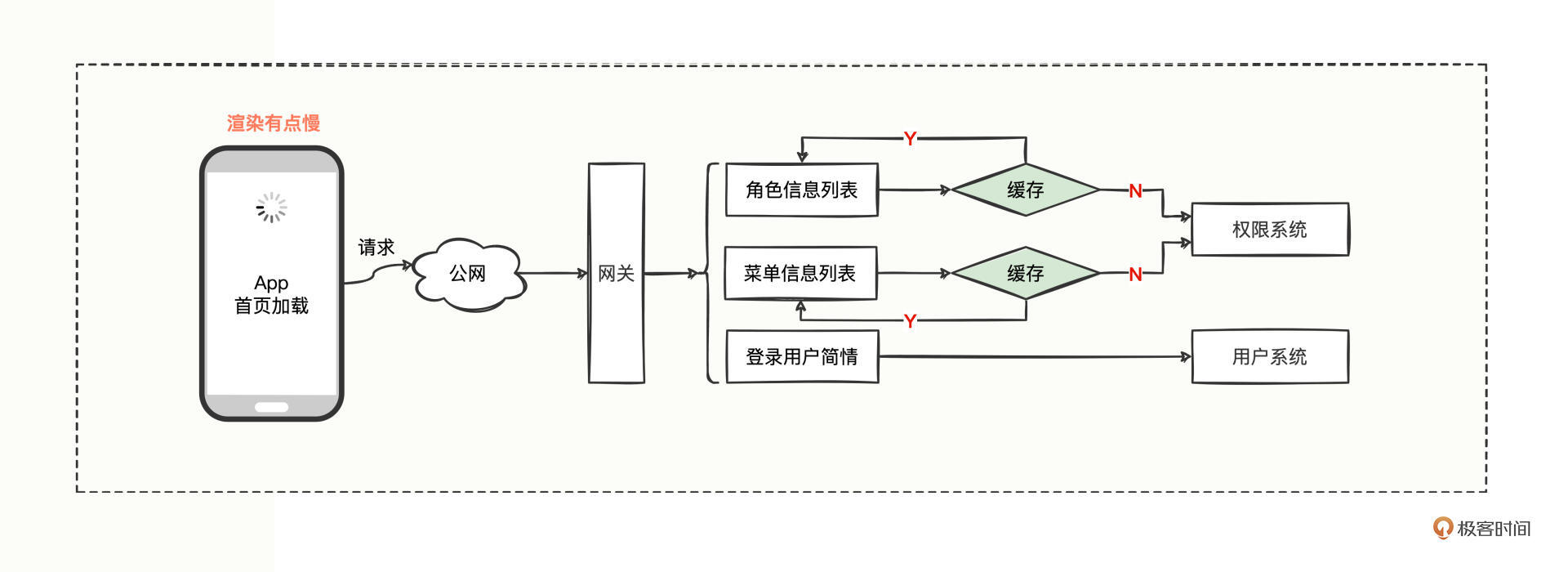
网关先查询缓存,有数据则直接使用,没有数据再发起远程调用,拿到远程调用的结果后再放到缓存中。大大减少了远程调用的次数,这样一来,权限系统查询数据库的频次就降低了,权限系统查询数据库的性能自然就回归正常了。牺牲空间来换取时效的提升,达到了曲线救国的目的。
代码可以这样改造:
public class InvokeCacheFacade {
// 引用下游查询角色信息列表的接口
@DubboReference
private RoleQueryFacade roleQueryFacade;
// 引用下游查询菜单信息列表的接口
@DubboReference
private MenuQueryFacade menuQueryFacade;
// 引用下游查询菜单信息列表的接口
@DubboReference
private UserQueryFacade userQueryFacade;
public void invokeCache(){
// 循环 3 次,模拟网关被 App 请求调用了 3 次
for (int i = 1; i <= 3; i++) {
// 查询角色信息列表
String roleRespMsg = null;
// 检查有没有缓存角色信息列表的数据
if (hasCachedQueryRoleList("Geek")) {
// 有缓存则直接使用
roleRespMsg = queryCachedQueryRoleList("Geek");
} else {
// 没缓存则继续调用远程
roleRespMsg = roleQueryFacade.queryRoleList("Geek");
if (roleRespMsg != null) {
// 拿到远程结果后再存储到缓存中
cacheQueryRoleListResult(roleRespMsg);
}
}
// 查询菜单信息列表
String menuRespMsg = null;
// 检查有没有缓存菜单信息列表的数据
if (hasCachedQueryAuthorizedMenuList("Geek")) {
// 有缓存则直接使用
menuRespMsg = queryCachedQueryAuthorizedMenuList("Geek");
} else {
// 没缓存则继续调用远程
menuRespMsg = menuQueryFacade.queryAuthorizedMenuList("Geek");
if (menuRespMsg != null) {
// 拿到远程结果后再存储到缓存中
cacheQueryAuthorizedMenuListResult(roleRespMsg);
}
}
// 查询登录用户简情
String userRespMsg = userQueryFacade.queryUser("Geek");
// 打印远程调用的结果,看看是走缓存还是走远程
String idx = new DecimalFormat("00").format(i);
System.out.println("第 "+ idx + " 次调用【角色信息列表】结果为: " + roleRespMsg);
System.out.println("第 "+ idx + " 次调用【菜单信息列表】结果为: " + menuRespMsg);
System.out.println("第 "+ idx + " 次调用【登录用户简情】结果为: " + userRespMsg);
System.out.println();
}
}
}
主要做了 2 点改造:
- 找到查询角色信息列表、查询菜单信息列表两段代码的切入点,进行缓存改造。
- 调用远程之前先查缓存,有就直接使用,没有则继续调用远程,待拿到远程的结果后再次保存到缓存中。
总体就是按照惯性思维,哪里要用到,我们就在哪里缓存一下,代码改完后,你有没有发现这个改法有点似曾相似?没错,和上一讲“参数验证”有着同样的配方,同样的坏代码味道。
那么这里我们也学习“参数验证”的统一处理方式,看看是不是可以提炼一下,调用A接口的时候有缓存的诉求,如果调用B、C接口也有缓存的诉求,只要稍微配置一下,就可以缓存调用结果了。
2.套用源码
好,我们顺着“参数验证”的统一处理思路整理一下:
- 首先,得定义一个过滤器,目的是拦截所有调用出去的接口做点缓存的逻辑。
- 其次,通过过滤器的 invocation 对象,寻找构建缓存 key 的规则标准。
- 最后,实现一套通过 key 查找缓存数据的逻辑。
下面要开始编写代码了。
不过别急,还记得上一讲学过的小技巧吗,像过滤器这种具有拦截所有请求机制功能的类,一定要先看看你所在系统的相关底层能力支撑,如果类似的功能存在,我们就能物尽其用。
按照小技巧来看 org.apache.dubbo.rpc.Filter 接口的实现类,寻找有没有缓存英文单词的类名,你会发现还真有一个叫 CacheFilter 名字的类,看起来像是缓存过滤器,咱们直接进入源码探个究竟。
看源码,你要养成先看类注释的习惯:
CacheFilter is a core component of dubbo.Enabling cache key of service,method,consumer or provider dubbo will cache method return value. Along with cache key we need to configure cache type. Dubbo default implemented cache types are:
lru
threadlocal
jcache
expiring
可以得知 3 个有用的信息:
- CacheFilter 是 Dubbo 的一个核心组件。
- 启用缓存键属性,将会缓存 method 的返回值。
- 需要为缓存键属性配置缓存类型,类型有 lru、threadlocal、jcache、expiring 四种。
看完这样的注释信息后,我们心里有底了,通过简短的3点貌似能满足缓存调用结果的诉求,然而,该怎么简单配置呢?
我们继续看注释,还有一部分注释是教我们如何使用缓存的:
e.g. 1)<dubbo:service cache="lru" />
2)<dubbo:service /> <dubbo:method name="method2" cache="threadlocal" /> <dubbo:service/>
3)<dubbo:provider cache="expiring" />
4)<dubbo:consumer cache="jcache" />
注释中告诉我们有 4 种方式启用缓存,分别是 <dubbo:service/>、<dubbo:method/>、<dubbo:provider/>、<dubbo:consumer/> 四种标签,而且从标签中可以更为直观地看到,我们在提供方、消费方都可以对方法的结果进行缓存。
还是 Dubbo 框架的设计者想的周到!我们原本只想着在消费方调用时将结果缓存一下,从源码中得知 Dubbo 在提供方同样可以缓存方法结果,缓存功能的通用性设计非常完善。
这里聊点题外话,为什么我们能如此快速地找到所需的实现类呢?优秀的源码主要有 2 点我们可以重点学习:
- 功能对应类的单词命名尽量简单易懂,使用与功能含义贴近且大众熟知的单词。
- 类的注释信息要有 3 块,第 1 块重点说明该类的用途,第 2 块详细告诉别人怎么使用,第 3 块简单列出与此功能关联非常紧密的相关类的指引。
这 2 点对源码阅读者来说非常关键。将心比心,当你阅读别人代码的时候,如果类名命名很随意,而且毫无注释信息,即便是再牛逼的框架也没有了阅读下去的欲望。所以,不管是写业务代码还是写插件,我们都需要尽量遵守见名知意、注释完整清晰的自我约束。
好了,回到正题,接下来我们可以根据源码提示的解决方案去改造代码了。改造如下:
@Component
public class InvokeCacheFacade {
// 引用下游查询角色信息列表的接口,添加 cache = lru 属性
@DubboReference(cache = "lru")
private RoleQueryFacade roleQueryFacade;
// 引用下游查询菜单信息列表的接口,添加 cache = lru 属性
@DubboReference(cache = "lru")
private MenuQueryFacade menuQueryFacade;
// 引用下游查询菜单信息列表的接口,没有添加缓存属性
@DubboReference
private UserQueryFacade userQueryFacade;
public void invokeCache(){
// 循环 3 次,模拟网关被 App 请求调用了 3 次
for (int i = 1; i <= 3; i++) {
// 查询角色信息列表
String roleRespMsg = roleQueryFacade.queryRoleList("Geek");
// 查询菜单信息列表
String menuRespMsg = menuQueryFacade.queryAuthorizedMenuList("Geek");
// 查询登录用户简情
String userRespMsg = userQueryFacade.queryUser("Geek");
// 打印远程调用的结果,看看是走缓存还是走远程
String idx = new DecimalFormat("00").format(i);
System.out.println("第 "+ idx + " 次调用【角色信息列表】结果为: " + roleRespMsg);
System.out.println("第 "+ idx + " 次调用【菜单信息列表】结果为: " + menuRespMsg);
System.out.println("第 "+ idx + " 次调用【登录用户简情】结果为: " + userRespMsg);
System.out.println();
}
}
}
主要是在定义 RoleQueryFacade 和 MenuQueryFacade 的字段 @DubboReference 注解中,添加了 cache = "lru" 的属性,改造非常简单。
信心满满的你,运行了 invokeCache 方法想看看改造效果,打印如下:
第 01 次调用【角色信息列表】结果为: 2022-11-18_22:52:00.402: Hello Geek, 已查询该用户【角色列表信息】
第 01 次调用【菜单信息列表】结果为: 2022-11-18_22:52:00.407: Hello Geek, 已查询该用户已授权的【菜单列表信息】
第 01 次调用【登录用户简情】结果为: 2022-11-18_22:52:00.411: Hello Geek, 已查询【用户简单信息】
第 02 次调用【角色信息列表】结果为: 2022-11-18_22:52:00.415: Hello Geek, 已查询该用户【角色列表信息】
第 02 次调用【菜单信息列表】结果为: 2022-11-18_22:52:00.419: Hello Geek, 已查询该用户已授权的【菜单列表信息】
第 02 次调用【登录用户简情】结果为: 2022-11-18_22:52:00.422: Hello Geek, 已查询【用户简单信息】
第 03 次调用【角色信息列表】结果为: 2022-11-18_22:52:00.415: Hello Geek, 已查询该用户【角色列表信息】
第 03 次调用【菜单信息列表】结果为: 2022-11-18_22:52:00.419: Hello Geek, 已查询该用户已授权的【菜单列表信息】
第 03 次调用【登录用户简情】结果为: 2022-11-18_22:52:00.426: Hello Geek, 已查询【用户简单信息】
“角色信息列表”在第2次和第3次的时间戳信息是一样的 415 结尾,“菜单信息列表”在第2次和第3次的时间戳信息也是一样的,而“登录用户简情”的时间戳每次都是不一样。
日志信息很有力地说明缓存功能生效了。嗯,参照源码提供的解决方案,确实改造的很好。
改造思考
不过完成后,我们仍然得思考下改造的一些影响。毕竟每引入一个组件,势必会导致复杂度的上升,需要做好利弊权衡。
缓存,虽然提升了快速响应的时效,但同时也带来了一些问题,我们需要从内存容量、缓存数据如何完成刷新和过期剔除、流量峰值可能引发的缓存雪崩、穿透、击穿等方面考虑,当然这些都是比较基本,当项目复杂时还要考虑有更多复杂因素。我们先一个个看。
1.改造方案的数据是存储在 JVM 内存中,那会不会撑爆内存呢?
我们盘算一下,假设角色信息列表和菜单信息列表占用内存总和约为 1024 字节,预估有 50 万用户体量,那么最终总共占用 50W * 1024字节 ≈ 488.28 兆,目前网关的老年代大小约为 1200 兆,是不会撑爆内存的。这个问题解决。
2.如果某些用户的权限发生了变更,从变更完成到能使用最新数据的容忍时间间隔是多少,如何完成内存数据的刷新操作呢?
目前改造方案使用的是 cache = "lru" 缓存策略,虽然我们对底层的实现细节一概不知,但也没有什么好胆怯的,开启 debug 模式去 CacheFilter 中调试一番:
// 过滤器被触发调用的入口
org.apache.dubbo.cache.filter.CacheFilter#invoke
↓
// 根据 invoker.getUrl() 获取缓存容器
org.apache.dubbo.cache.support.AbstractCacheFactory#getCache
↓
// 若缓存容器没有的话,则会自动创建一个缓存容器
org.apache.dubbo.cache.support.lru.LruCacheFactory#createCache
↓
// 最终创建的是一个 LruCache 对象,该对象的内部使用的 LRU2Cache 存储数据
org.apache.dubbo.cache.support.lru.LruCache#LruCache
// 存储调用结果的对象
private final Map<Object, Object> store;
public LruCache(URL url) {
final int max = url.getParameter("cache.size", 1000);
this.store = new LRU2Cache<>(max);
}
↓
// LRU2Cache 的带参构造方法,在 LruCache 构造方法中,默认传入的大小是 1000
org.apache.dubbo.common.utils.LRU2Cache#LRU2Cache(int)
public LRU2Cache(int maxCapacity) {
super(16, DEFAULT_LOAD_FACTOR, true);
this.maxCapacity = maxCapacity;
this.preCache = new PreCache<>(maxCapacity);
}
// 若继续放数据时,若发现现有数据个数大于 maxCapacity 最大容量的话
// 则会考虑抛弃掉最古老的一个,也就是会抛弃最早进入缓存的那个对象
@Override
protected boolean removeEldestEntry(java.util.Map.Entry<K, V> eldest) {
return size() > maxCapacity;
}
↓
// JDK 中的 LinkedHashMap 源码在发生节点插入后
// 给了子类一个扩展删除最旧数据的机制
java.util.LinkedHashMap#afterNodeInsertion
void afterNodeInsertion(boolean evict) { // possibly remove eldest
LinkedHashMap.Entry<K,V> first;
if (evict && (first = head) != null && removeEldestEntry(first)) {
K key = first.key;
removeNode(hash(key), key, null, false, true);
}
}
一路跟踪源码,最终发现了底层存储数据的是一个继承了 LinkedHashMap 的类,即 LRU2Cache,它重写了父类 LinkedHashMap 中的 removeEldestEntry 方法,当 LRU2Cache 存储的数据个数大于设置的容量后,会删除最先存储的数据,让最新的数据能够保存进来。
所以容忍的时间间隔其实是不确定的,因为请求流量的不确定性,LRU2Cache 的容量不知道多久才能打满,而刷新操作也是依赖于容量被打满后剔除最旧数据的机制,所以容忍的时间间隔和刷新的时效都存在不确定性。
3.每秒的请求流量峰值是多少呢,会引发缓存雪崩、穿透、击穿三大效应么?
从权限系统的单机查询数据库高达500多的QPS可以大概得知,目前网关接收首页加载的请求在500多QPS左右。
如果用户都在早上的上班时刻打开App,因为每个用户第一次请求在网关是没有缓存数据的,第二次发起的请求就可以使用上缓存数据了,也就是说,只要撑过第一次请求,后面的第二次乃至第N次请求就会改善很多。可以反推出,LruCache 的构造方法中cache.size 参数设置至关重要。
当然问题还有很多,比如网关系统只有这个首页加载的请求需要缓存么,是否还有其他的功能也用了缓存占用了 JVM 内存?
这么问下去,我们简单地用个 lru 策略已经招架不住了,该继续想其他法子了。
深挖源码
刚刚只是用了 lru 策略,我们还有另外 threadlocal、jcache、expiring 三个策略可以替换,先到这三个策略对应的缓存工厂类中去看看类注释信息:
- threadlocal,使用的是 ThreadLocalCacheFactory 工厂类,类名中 ThreadLocal 是本地线程的意思,而 ThreadLocal 最终还是使用的是 JVM 内存。
- jcache,使用的是 JCacheFactory 工厂类,是提供 javax-spi 缓存实例的工厂类,既然是一种 spi 机制,可以接入很多自制的开源框架。
- expiring,使用的是 ExpiringCacheFactory 工厂类,内部的 ExpiringCache 中还是使用的 Map 数据结构来存储数据,仍然使用的是 JVM 内存。
从这三种策略来看,threadlocal 和 expiring 两种策略使用的还是 JVM 内存来存储数据,和 lru 策略有着本质的共同性,由于 JVM 内存的有限性,无法支撑更多的接口具有缓存特性,如果稍不留神,很可能导致网关内存溢出或权限系统的数据库被打爆。那把 cache = "lru" 换成 cache = "jcache" 试试,这样好歹可以使用一些开源框架来进行缓存了。
接下来,我们将根据报错信息开启一段源码探索之旅,跳转比较多,为了方便理解,我特地录制了一段视频,你可以配合文字一起学习:
改完代码后我们继续运行,不巧的是启动就报错了:
Caused by: java.lang.NoClassDefFoundError: javax/cache/Caching
at org.apache.dubbo.cache.support.jcache.JCache.<init>(JCache.java:54)
at org.apache.dubbo.cache.support.jcache.JCacheFactory.createCache(JCacheFactory.java:45)
at org.apache.dubbo.cache.support.AbstractCacheFactory.getCache(AbstractCacheFactory.java:74)
at org.apache.dubbo.cache.CacheFactory$Adaptive.getCache(CacheFactory$Adaptive.java)
at org.apache.dubbo.cache.filter.CacheFilter.invoke(CacheFilter.java:95)
at org.apache.dubbo.rpc.cluster.filter.FilterChainBuilder$CopyOfFilterChainNode.invoke(FilterChainBuilder.java:321)
at org.apache.dubbo.rpc.cluster.filter.FilterChainBuilder$CallbackRegistrationInvoker.invoke(FilterChainBuilder.java:193)
at org.apache.dubbo.rpc.cluster.support.AbstractClusterInvoker.invokeWithContext(AbstractClusterInvoker.java:378)
at org.apache.dubbo.rpc.cluster.support.FailoverClusterInvoker.doInvoke(FailoverClusterInvoker.java:80)
... 25 more
从报错信息中,发现了 NoClassDefFoundError 异常信息,而该错误是发生在 JVM 运行时,根据工程代码中的类名,在 classpath 进行类加载时找不到这个类,就出现了这个错误。
既然报错这么明显,直接把 javax/cache/Caching 放到百度中搜索一下,就可以得出答案如下:
接下来把 cache-api 这个 maven 坐标添加到工程中,我们再次运行 invokeCache 方法,结果又报错了:
Caused by: javax.cache.CacheException: No CachingProviders have been configured
at javax.cache.Caching$CachingProviderRegistry.getCachingProvider(Caching.java:391)
at javax.cache.Caching$CachingProviderRegistry.getCachingProvider(Caching.java:361)
at javax.cache.Caching.getCachingProvider(Caching.java:151)
at org.apache.dubbo.cache.support.jcache.JCache.<init>(JCache.java:54)
at org.apache.dubbo.cache.support.jcache.JCacheFactory.createCache(JCacheFactory.java:45)
at org.apache.dubbo.cache.support.AbstractCacheFactory.getCache(AbstractCacheFactory.java:74)
at org.apache.dubbo.cache.CacheFactory$Adaptive.getCache(CacheFactory$Adaptive.java)
at org.apache.dubbo.cache.filter.CacheFilter.invoke(CacheFilter.java:95)
at org.apache.dubbo.rpc.cluster.filter.FilterChainBuilder$CopyOfFilterChainNode.invoke(FilterChainBuilder.java:321)
at org.apache.dubbo.rpc.cluster.filter.FilterChainBuilder$CallbackRegistrationInvoker.invoke(FilterChainBuilder.java:193)
at org.apache.dubbo.rpc.cluster.support.AbstractClusterInvoker.invokeWithContext(AbstractClusterInvoker.java:378)
at org.apache.dubbo.rpc.cluster.support.FailoverClusterInvoker.doInvoke(FailoverClusterInvoker.java:80)
... 25 more
报错信息出现了一个从来没见过的 CacheException 缓存异常的类,而且还提示 No CachingProviders have been configured 没有配置缓存提供者,这是什么缘故呢,有点不知所措了。
作为过来人也给你一个小小锦囊,遇到这种未知的错误,不要有任何心里阴影,直接去 Caching.java 的第 391 行,尝试分析源码,说不定有意外发现:
/**
* Obtains the only {@link CachingProvider} defined by the specified
* {@link ClassLoader}.
* <p>
* Should zero or more than one {@link CachingProvider}s be available, a
* CacheException is thrown.
* </p>
* @param classLoader the {@link ClassLoader} to use for loading the
* {@link CachingProvider}
* @return the {@link CachingProvider}
* @throws CacheException should zero or more than one
* {@link CachingProvider} be available
* or a {@link CachingProvider} could not be loaded
* @see #getCachingProviders(ClassLoader)
*/
// javax.cache.Caching.CachingProviderRegistry#getCachingProvider(java.lang.ClassLoader)
public CachingProvider getCachingProvider(ClassLoader classLoader) {
// 获取所有 CachingProvider 接口的所有实现类
// 如果配置了 javax.cache.spi.cachingprovider 系统属性,那就用 loadClass 方法加载实现类
// 否则通过 ServiceLoader.load JDK 的 SPI 机制进行加载所有的 CachingProvider 实现类
Iterator<CachingProvider> iterator = getCachingProviders(classLoader).iterator();
// 迭代开始循环所有的实现类
if (iterator.hasNext()) {
// 取出第一个实现类
CachingProvider provider = iterator.next();
// 然后再尝试看看是否还有第二个实现类
if (iterator.hasNext()) {
// 如果有第二个实现类,则直接抛出多个缓存提供者的异常
throw new CacheException("Multiple CachingProviders have been configured when only a single CachingProvider is expected");
} else {
// 如果没有第二个实现类,那么就直接使用第一个实现类
// 也就意味着,当前系统在运行时只允许有一个实现类去实现 CachingProvider 接口
return provider;
}
} else {
// 抛出了 CacheException 异常类
// 抛出的提示信息,不正是报错中的看到的那段没有配置提供者的原文么
throw new CacheException("No CachingProviders have been configured");
}
}
一番分析后,原来是因为没有 CachingProvider 的实现类才导致的报错,而实现类是可以通过 JDK SPI 机制加载的,更加证实了 JCacheFactory 类注释的说法。
那接下来,我们就寻找哪些开源框架实现了 CachingProvider 接口,而且数据还不是存储在网关的 JVM 内存里面的。
提到比较火热的开源缓存框架,而且还是分布式缓存框架,想必,我想你心中已经有了答案了,那就是 Redis 缓存框架,那具体叫什么名字呢?要想得到权威答案,还得去官网 Redis 的官网寻找答案。
果不其然,在 Redis 用 Java 写的客户端中,我们找到了 Redisson 框架,该框架在 Github 上有解释具备的特性,其中就提到实现了 JCache API (JSR-107) 规范,而且从 Redisson 框架中也找到了实现 CachingProvider 接口的类, 这就是我们要找的 Redis 缓存框架了。
通过 Github 的快速开始,我们找到 Redisson 的 maven 坐标:
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson</artifactId>
<version>3.18.0</version>
</dependency>
然后把坐标继续添加到工程中,再次启动运行 invokeCache 方法。但,仍然报错了:
Caused by: java.lang.IllegalStateException: Default configuration hasn't been specified!
at org.redisson.jcache.JCacheManager.createCache(JCacheManager.java:118)
at org.apache.dubbo.cache.support.jcache.JCache.<init>(JCache.java:67)
at org.apache.dubbo.cache.support.jcache.JCacheFactory.createCache(JCacheFactory.java:45)
at org.apache.dubbo.cache.support.AbstractCacheFactory.getCache(AbstractCacheFactory.java:74)
at org.apache.dubbo.cache.CacheFactory$Adaptive.getCache(CacheFactory$Adaptive.java)
at org.apache.dubbo.cache.filter.CacheFilter.invoke(CacheFilter.java:95)
at org.apache.dubbo.rpc.cluster.filter.FilterChainBuilder$CopyOfFilterChainNode.invoke(FilterChainBuilder.java:321)
at org.apache.dubbo.rpc.cluster.filter.FilterChainBuilder$CallbackRegistrationInvoker.invoke(FilterChainBuilder.java:193)
at org.apache.dubbo.rpc.cluster.support.AbstractClusterInvoker.invokeWithContext(AbstractClusterInvoker.java:378)
at org.apache.dubbo.rpc.cluster.support.FailoverClusterInvoker.doInvoke(FailoverClusterInvoker.java:80)
... 25 more
看这个非法状态的异常 Default configuration hasn't been specified!,表示没有指定的默认配置文件,不过想想也是的,Redis 是第三方缓存服务,当然需要对应的配置文件,不然应用程序怎么知道要连接哪个 Redis 服务呢?
老规矩,我们找到底层源码看看需要配置哪些要素。继续调试源码,在 JCacheManager 的第 118 行报错的地方打个断点看看:
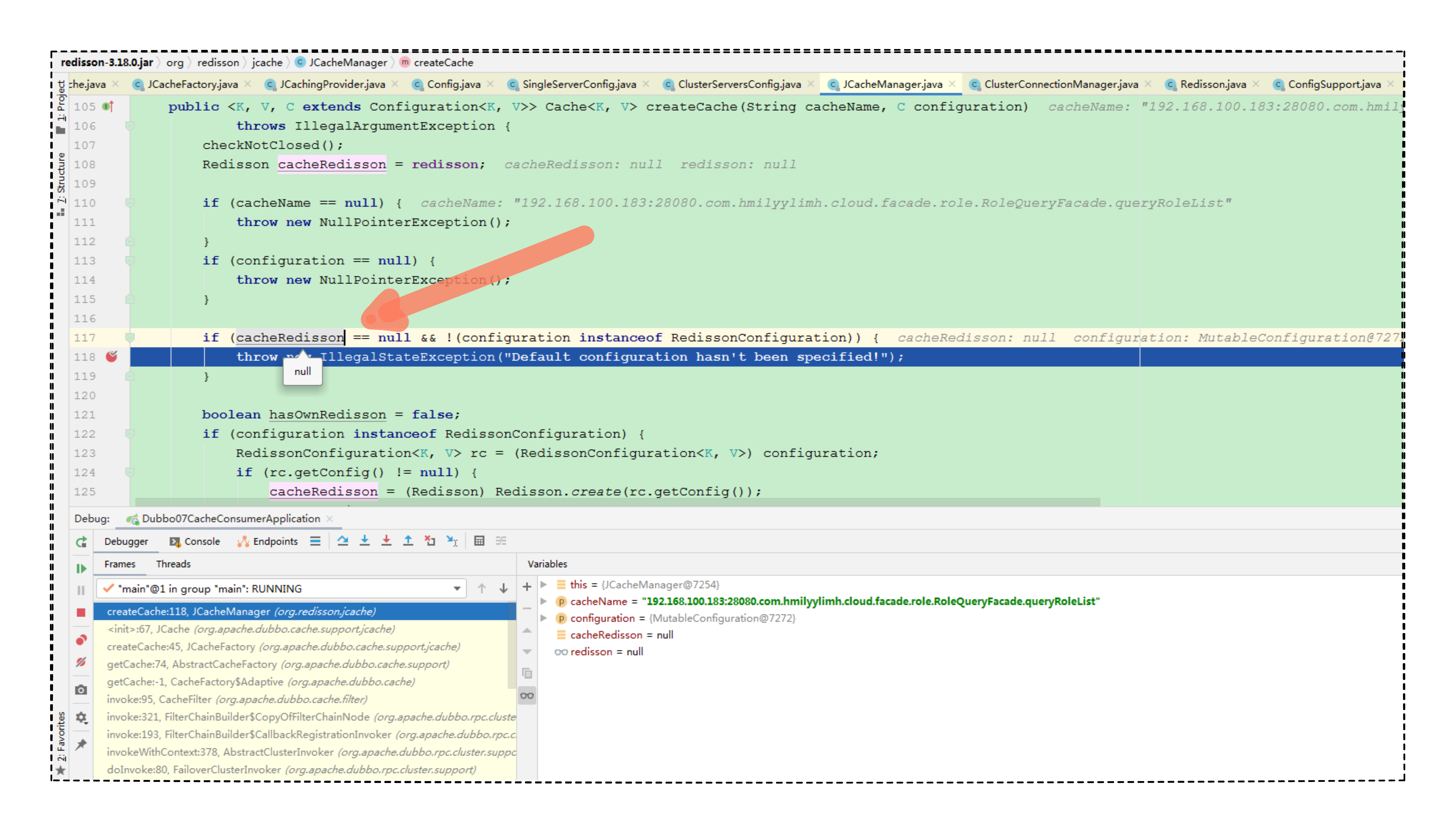
从断点处,我们发现 cacheRedisson 为空,而且 cacheRedisson 是由 redisson 对象赋值过来,因此我们得在当前 JCacheManager 类中寻找,到底是谁又给 redisson 进行赋值了。
因为redisson是私有变量,那我们检索一下当前类,结果找到了 JCacheManager 的构造方法:
// org.redisson.jcache.JCacheManager#JCacheManager
public JCacheManager(Redisson redisson, ClassLoader classLoader, CachingProvider cacheProvider, Properties properties, URI uri) {
super();
this.classLoader = classLoader;
this.cacheProvider = cacheProvider;
this.properties = properties;
this.uri = uri;
this.redisson = redisson;
}
在方法中,我们发现 redisson 对象是通过构造方法传进来的。 那么,到底谁调用了这个构造方法呢?我们继续在 JCacheManager 的这个构造方法里面打个断点,然后 debug 运行一下 invokeCache 方法:
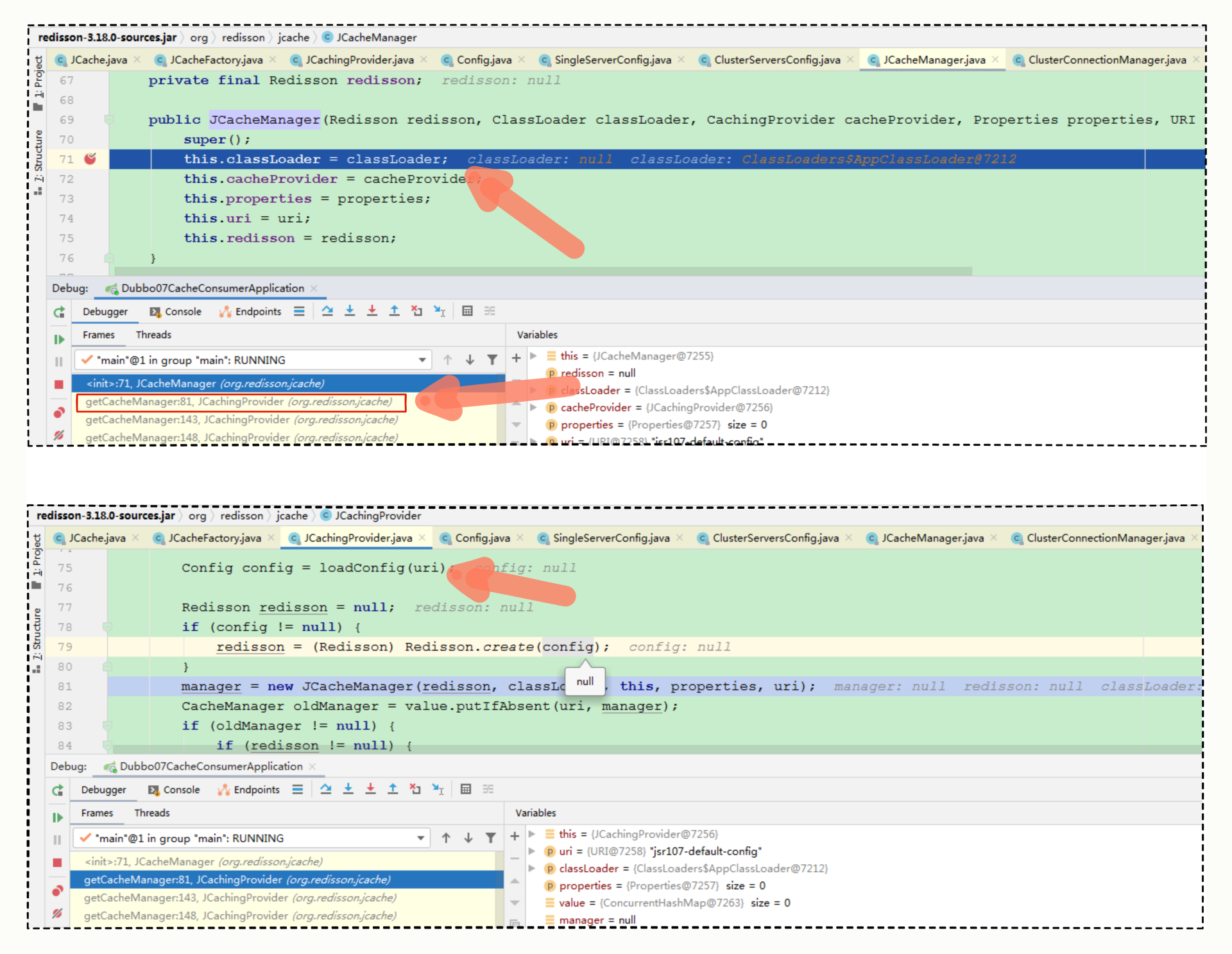
想知道谁调用了JCacheManager,首先要关注线程调用堆栈,然后从调用堆栈中去寻找“调用方”,也就是第一张图片红框的指示部分;找到后,点击“调用方”,可以看到第二张图中,我们继续看这里的详细逻辑。
在这里,终于找到了导致创建 redisson 为空的源头:loadConfig 方法的返回值为空,导致了跳过了 Redisson.create 创建 redisson 的时机。
那么 loadConfig 返回为空的真实原因是什么呢?
到这里相信你也很有把握了,进入 loadConfig 方法看看,每个关键逻辑我都写了注释:
// org.redisson.jcache.JCachingProvider#loadConfig
private Config loadConfig(URI uri) {
Config config = null;
try {
URL yamlUrl = null;
// 尝试加载 /redisson-jcache.yaml 配置文件
if ("jsr107-default-config".equals(uri.getPath())) {
yamlUrl = JCachingProvider.class.getResource("/redisson-jcache.yaml");
} else {
yamlUrl = uri.toURL();
}
// 最终转成 org.redisson.config.Config 对象
if (yamlUrl != null) {
config = Config.fromYAML(yamlUrl);
} else {
// 若没有 /redisson-jcache.yaml 配置文件则抛出文件不存在的异常
throw new FileNotFoundException("/redisson-jcache.yaml");
}
} catch (JsonProcessingException e) {
throw new CacheException(e);
} catch (IOException e) {
try {
URL jsonUrl = null;
// 尝试加载 /redisson-jcache.json 配置文件
if ("jsr107-default-config".equals(uri.getPath())) {
jsonUrl = JCachingProvider.class.getResource("/redisson-jcache.json");
} else {
jsonUrl = uri.toURL();
}
// 最终还是转成 org.redisson.config.Config 对象
if (jsonUrl != null) {
config = Config.fromJSON(jsonUrl);
}
} catch (IOException ex) {
// skip
}
}
return config;
}
进入 loadConfig 方法后,才发现原来缺少可以转成 Config 对象的两种配置文件。 那接下来,我们就老老实实按照源码的要求去编写配置文件。拿创建 redisson-jcache.json 文件举例,方便演示我们就先配置一个单机 redis 服务节点,如果要上到生产,记得采用 clusterServersConfig 集群服务配置:
.json配置文件中,我们只是配置了单机Redis服务的节点。现在启动Redis服务,再去触发调用一下运行 invokeCache 方法看看效果。
终于成功了,打印信息如下:
第 01 次调用【角色信息列表】结果为: 2022-11-19_01:44:43.482: Hello Geek, 已查询该用户【角色列表信息】
第 01 次调用【菜单信息列表】结果为: 2022-11-19_01:44:43.504: Hello Geek, 已查询该用户已授权的【菜单列表信息】
第 01 次调用【登录用户简情】结果为: 2022-11-19_01:44:43.512: Hello Geek, 已查询【用户简单信息】
第 02 次调用【角色信息列表】结果为: 2022-11-19_01:44:43.482: Hello Geek, 已查询该用户【角色列表信息】
第 02 次调用【菜单信息列表】结果为: 2022-11-19_01:44:43.504: Hello Geek, 已查询该用户已授权的【菜单列表信息】
第 02 次调用【登录用户简情】结果为: 2022-11-19_01:44:43.959: Hello Geek, 已查询【用户简单信息】
第 03 次调用【角色信息列表】结果为: 2022-11-19_01:44:43.482: Hello Geek, 已查询该用户【角色列表信息】
第 03 次调用【菜单信息列表】结果为: 2022-11-19_01:44:43.504: Hello Geek, 已查询该用户已授权的【菜单列表信息】
第 03 次调用【登录用户简情】结果为: 2022-11-19_01:44:43.975: Hello Geek, 已查询【用户简单信息】
“角色信息列表”3次调用的时间戳信息完全是一样的,“菜单信息列表”3次调用的时间戳信息也是一样的,我们接入 Redis 缓存框架生效了!
缓存操作的应用
在经过一番改造后,采用Redis分布式缓存的确可以缓解短时间内首页加载的压力。
但是也不是任何情况遇到问题了就用缓存处理,缓存也是有一些缺点的,比如大对象与用户进行笛卡尔积的容量很容易撑爆内存,服务器掉电或宕机容易丢失数据,在分布式环境中缓存的一致性问题不但增加了系统的实现复杂度,而且还容易引发各种数据不一致的业务问题。
那哪些日常开发的应用场景可以考虑呢?
- 第一,数据库缓存,对于从数据库查询出来的数据,如果多次查询变化差异较小的话,可以按照一定的维度缓存起来,减少访问数据库的次数,为数据库减压。
- 第二,业务层缓存,对于一些聚合的业务逻辑,执行时间过长或调用次数太多,而又可以容忍一段时间内数据的差异性,也可以考虑采取一定的维度缓存起来。
总结
从一个简单的App首页加载渲染缓慢例子开始,我们思考了简单处理、套用源码两种方式,但因为都是通过 JVM 内存来缓存数据的,横向扩展性差,容易导致内存溢出,我们不得不继续深挖源码一路探索,最终集成了 Redisson 缓存框架得以解决。
- 简单处理,这种方式虽然简单,但是代码复用性太差,扩展性太弱。
- 套用源码,借鉴了参数验证的统一拦截思想,充分利用了源码已有的支撑能力,但是同样忽略了可能导致 JMV 内存不足的致命风险。
- 深挖源码,探索未知的可能解决方案,在一路报错中分析问题并各个击破。
从源码中我们发现Dubbo缓存设置的主要有两步:
- 第一步,找到 <dubbo:service/>、<dubbo:method/>、<dubbo:provider/>、<dubbo:consumer/>、@DubboReference、@DubboService 这些可以设置缓存的标签或注解。
- 第二步,添加 cache 属性,并填充属性值,属性值有 lru、threadlocal、jcache、expiring 四种缓存策略。
回看我们今天的源码探索过程,虽然不是那么顺畅,经常被一些不认识的异常挡住了去路,但想在技术这条路上有较大的提升,关键就是要克服自身对于未知异常的恐惧,沉下心来仔细阅读错误信息,一步一步追根溯源,你一定会找到破解之道。
思考题
你已经掌握了如何在Dubbo框架中优雅提供缓存功能了,但是方案仍然有些美中不足。
假设调用下游某接口的入参有 id、name、sex 三个参数,目前的做法将入参的所有值拼接在一起构成缓存的Key,其实有时候只需要把 id 作为缓存Key就行了,其他多余的参数只会使得存储数据倍增。
所以这里留个小作业给你,尝试把 CacheFilter 稍微改造一下,既能支持所有参数值拼接作为缓存Key,也能挑选某些参数值拼接作为缓存Key,你会怎么改造呢?
欢迎写下你的思路和代码,参与讨论。如果今天的学习你有所收获,也欢迎分享给身边的朋友,说不定就帮他解决了一个问题。我们下一讲见。
07思考题参考
上一期的问题是在Spring的切面中完成对参数的统一验证。
我们可以套用参数校验的通用三部曲:
- 首先,寻找具有拦截机制的接口,不过在Spring这里会有点复杂,可以参照 Spring 官网的切面实现流程步骤来编码。
- 其次,寻找一套注解来定义校验的标准规则,Dubbo 框架中的 hibernate-validator 插件引用了一个 validation-api 插件,里面富含我们所需的各种注解来提供不同的校验规则。
- 最后,寻找一套校验逻辑来根据注解的标准规则来校验字段值,Dubbo 框架中的 hibernate-validator 插件已经提供通用的校验能力。
接下来,我们按部就班编写代码:
@Order(Integer.MIN_VALUE)
@Aspect
@Component
public class ParamsValidatorAspect {
/** <h2>定义参数校验器接口</h2> **/
private static Validator validator;
static {
// 通过工厂创建参数校验器
ValidatorFactory factory =
(Validation.byProvider(org.hibernate.validator.HibernateValidator.class).configure())
.failFast(true)
.messageInterpolator(new ResourceBundleMessageInterpolator(
new AggregateResourceBundleLocator(Arrays.asList("validationMessage"))))
.buildValidatorFactory();
validator = factory.getValidator();
}
// 切面拦截符合该正则表达式格式的业务类
@Pointcut("execution (* com.hmilyylimh.cloud.biz..*FacadeImpl.* (..))")
private void executeService() {
}
// 环绕通知,可以理解为进业务逻辑包裹起来了
@Around("executeService()")
public Object doAround(ProceedingJoinPoint pjp) throws Throwable {
try {
// 参数校验,如果校验不通过的话,会直接抛异常
validateParams(pjp.getArgs());
// pjp.proceed() 这行代码才是真正核心业务逻辑
// 比如:ValidationFacadeImpl.validateUser 就在这里被执行的
Object result = pjp.proceed();
// 正常响应
return buildNormalResp(result);
} catch (Throwable e) {
// 异常响应,可以考虑怎么统一包装异常响应的统一数据格式
return buildExceptionResp(e);
}
}
// 参数校验
private static void validateParams(Object[] args) {
// 循环所有参数,调用参数校验器的核心校验方法
for (Object obj : args) {
String errorMsg = validate(obj);
if (StringUtils.isNotBlank(errorMsg)) {
throw new RuntimeException("参数校验不通过: " + errorMsg);
}
}
}
// 校验入参对象,核心逻辑都是调用 hibernate-validator 插件里面的方法
private static String validate(Object obj) {
// 对象为空则提前返回
if (null == obj) {
return "校验对象不能为空";
}
StringBuilder message = new StringBuilder();
// 这里的 validator.validate 方法才是参数校验器的最核心API逻辑
Set<ConstraintViolation<Object>> constraintViolations
= validator.validate(obj);
int size = constraintViolations.size();
if (size == 0) {
return "";
}
// 最终将校验不同的描述信息拼接返回
int idx = 0;
for (ConstraintViolation<Object> v : constraintViolations) {
message.append(v.getPropertyPath()).append(" ").append(v.getMessage());
idx += 1;
if (idx < size) {
message.append("; ");
}
}
return message.toString();
}
}
- RocketMQ 👍(1) 💬(1)
为什么lru的方式下第二次和第三次调用结果相同,也就是第二次相同的调用才会缓存下来?但jcache方式下三次都是一样的
2023-03-17 - 飞飞 👍(0) 💬(2)
实际开发真的会真么用吗?一般不都是服务提供者直接在自己的业务逻辑里面使用redis等直接缓存结果吗?不需要配置这么多东西呀?
2023-05-30 - Lum 👍(0) 💬(1)
这个dubbo中的cache支持过期时间等定制化功能吗 看cache的接口只有两个方法
2023-03-05 - 杨老师 👍(0) 💬(2)
在平时工作中,可能不会通过@DubboReference(cache = "jcache")来引入redis。 而是就直接使用redis了。 这俩方案没啥区别吧?而且第一种好像更麻烦些了
2023-02-22 - 星期八 👍(0) 💬(1)
服务端提供缓存功能是为了缓存方法调用后的结果的,在下一次客户端调用过来,服务端只需要取缓存的吗?
2023-01-15 - 孙升 👍(0) 💬(1)
if (iterator.hasNext()) { CachingProvider provider = iterator.next(); if (iterator.hasNext()) { throw new CacheException("Multiple CachingProviders have been configured when only a single CachingProvider is expected"); } else { return provider; } } else { throw new CacheException("No CachingProviders have been configured"); } 自问自答了,这里会校验是否有多个实现类
2023-01-06 - 孙升 👍(0) 💬(0)
如果同时引入除redisson支持Jcache规范的其他maven包会怎么样?如何判断要使用哪个包的Cache呢?是通过spi配置吗
2023-01-06