AIGC应用 魔改GPT,快速打造一个私人助手
你好,我是徐长龙。
相信最近你一定听到了不少ChatGPT的讨论,甚至自己也体验过了。
不知道你感觉如何?对于ChatGPT,我印象最深刻的就是它仅仅通过多次对话,就可以按我们期望不断优化输出内容的能力。原本令人头大的文本整理工作,现在我们只需要给ChatGPT下达类似编程指令一样的 Promopt 就可以轻松搞定,这帮助我们节约了不少时间和精力。
不过,现在的ChatGPT还是有局限性的,它收集的资料截止到2021年,并没有最新的内容。另外,token字数上的限制也不太方便,在梳理大量文本或者做总结的场景里使用起来很麻烦。
这节课,我就带你一起基于GPT做点“魔改”,做一个更方便我们使用的私人小助手,这是一个嵌入了Faiss 私有数据库的小助手,它能帮你实现知识库、资料整理(突破默认token字数限制)、内容总结和文章润色等功能。
想实现这个小助手,我们需要用到 Python 3.10、LangChain 0.0.145还有OpenAI 0.27.0(由于这几个开发依赖包比较新还在持续迭代,未来可能会因为依赖包升级导致无法使用情况,届时我会再同步更新)。
基础知识及对话接口
想要魔改,先得熟悉一下GPT的基础调用方法,所以我们先热热身,看看如何实现基础的对话。
对接 ChatGPT 的基础对话功能很简单,接口文档地址是 https://platform.openai.com/docs/api-reference/chat/create 。
我们使用这个接口,就可以直接跟 OpenAI 通讯,官方提供的 API curl 示范是后面这样。
curl https://api.openai.com/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-d '{
"model": "gpt-3.5-turbo",
"messages": [{"role": "user", "content": "Hello!"}]
}'
我们运行前面的代码,调用OpenAI以后,就得到了后面的返回内容。
{
'id': 'chatcmpl-6p9XYPYSTTRi0xEviKjjilqrWU2Ve',
'object': 'chat.completion',
'created': 1677649420,
'model': 'gpt-3.5-turbo',
'usage': {'prompt_tokens': 56, 'completion_tokens': 31, 'total_tokens': 87},
'choices': [
{
'message': {
'role': 'assistant',
'content': 'The 2020 World Series was played in Arlington, Texas at the Globe Life Field, which was the new home stadium for the Texas Rangers.'},
'finish_reason': 'stop',
'index': 0
}
]
}
前面的代码很好理解,这里要提示你一下, OPENAI_API_KEY 我们需要去 https://platform.openai.com/account/api-keys 获取。另外要注意,目前OPEN AI对免费普通用户做了限速,20 秒只能请求一次。
可以看到,聊天接口需要的参数并不是很多,基本上就是用哪个模型以及输入的内容是什么。
目前OpenAI提供的模型主要是后面图里这些,还有更多其他选型你可以查看官方文档。

可以看到,这个列表中还有其他模型可以选,那为什么我们还是选择了GPT3.5这个模型作为后续演示的基础呢?
这是因为成本问题、虽然 GPT-4 更智能,但是价格比 3.5 版本贵上 15~20 倍,并且只有很少一部分人拥有试用的权限。
选好模型之后,我们继续看看对话里面的结构。其实这个结构是一个数组,它可以放多条对话内容,如果我们和 ChatGPT 多次互动的话,那么最近的历史会话都要在这里传递,也就是说上下文都在这里传递。因此,这个部分很重要,如果我们想做本地私有知识问答、总结以及大量文本生成等服务,都需要在对话的数组这里做文章。
我们再看看官方示范代码。
curl https://api.openai.com/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-d '{
"model": "gpt-3.5-turbo",
"messages": [{"role": "user", "content": "Hello!"}]
}'
代码里的message我要单独说明一下,其实它就是我们跟人工智能的对话历史和新提交的内容。其中每句对话都会有个 role 属性,这个属性代表了这句话的用途和来源。
我们再来看看role后面这几个具体属性都是什么意思。
- system:拥有这个属性的message可以用于系统功能定义。它对返回结果的表达方式有一定影响,但影响有限。有的时候这里的定义不会立即生效,需要在后续user再次提及才会生效。
- assistant:拥有这个属性的message代表是这句话是ChatGPT的回复内容,每次请求带上这个历史,可以帮助人工智能了解之前对话内容的上下文。
- user:拥有这个属性的message,都是用户提交的对话内容
对话功能我们分析得差不多了,你会发现整体看起来很简单。为了让你聚焦重点,我省略了不太重要的参数,你想了解的话,可以去看一下 API 文档的介绍。
模型的长度限制
前面我们提到了GPT 3.5的token限制,具体就是模型里限制了message内容不能超过4096个 token,超过了请求就会被拒绝。这里的token是OpenAI 里面的计量单位。你可以通过这个链接测试一个文本占用多少token,不过需要注意,这个测试工具不支持中文,对于中文测试不准。
代码上我们可以使用 tiktoken包 来统计 token 。一般来说,常见的中文utf8一个汉字就是一个token,使用 cl100k_base 编码 encode 后直接计算数组元素个数就能统计(官方推荐把一些无用回车和空格替换成单个空格,这样可以节省token)。
但是如果内容超过了4096这个长度,我们应该如何做呢?
这就不得不提到 LangChain 这个开源库了,它能轻松将多个LLM和各种辅助功能拼装在一起,能帮我们方便地实现模型的各种组合。长文本处理方面,你可以参考后面的链接做更多了解。
基于 LangChain的支持,有三种常用方式供我们选择,我们分别看看它们的思路和适用场景。
1.FIFO 先进先出方式:当长度超出规定长度时触发,会自动删除掉老对话内容,适合闲聊或者上下文关联不强的数据分析。
2.对话历史汇总:也就是 ChatGPT 对旧的对话历史做一次文本汇总,借此减少文本长度。这个方式能让我们的长内容对话不会丢失太多上下文,可以用来做文本的内容总结。
3.本地向量近似度数据库:这个方式适合大规模文本生成,比如长篇小说、大规模代码开发、自定义助理。实现思路等到后面“Embedding与向量库”的部分,我再具体讲解。
其实这几个功能是可以相互组合的。不过组合的场景有些复杂,我们还是循序渐进地学习,这样效果更好。接下来,我们就结合一些细分场景来继续讨论怎么魔改。
最新信息如何注入
我们再说说ChatGPT数据信息的事儿,前面说过GPT 3.5、4.0 内的数据到 2021 年 9 月就不再更新了。那么我们如何给 ChatGPT “投喂”最新信息,扩展它的能力呢?
我给你介绍三种价格低廉,而且比较典型的方法。
- 搜索引擎:从搜索引擎API检索内容获取最新信息,再把整理后的结果提供给ChatGPT。
- 本地知识库:依赖本地的大量资料提供知识检索或问答服务。这个思路就是通过向量数据库对提问内容做近似度检索,筛选出高匹配度的资料提供给ChatGPT。
- 本地服务:通过Agent方式在本地实现数据接口或功能的服务,需要在每次问答前面声明一下,告诉 ChatGPT它能做什么,在需要时如何调用 Agent。这样需要这个功能时,人工智能会按你规定返回内容。
另外,我们还可以使用 Fine-Tuning来扩展模型的行为和能力,但是这种方式太贵了,用的人也很少,如果有兴趣的话你可以课后自行了解。
为了更好理解这里的知识,我单独拿出本地向量知识库的实现给你做进一步讲解。
Embedding与向量库
比较典型的案例通常使用OpenAI 的 Embedding API 和 Faiss 向量库来实现私有库问答服务,使用它是因为用起来比较简单。当然,除了Faiss也有其他的向量库可供选择,你可以参考这里的链接,我个人推荐生产环境使用Qdrant或Redis。
Faiss 是 Facebook AI Similarity Search 缩写,是 Facebook AI 团队开源的针对聚类和相似性搜索库,能够提供稠密向量相似度搜索和聚类,支持十亿级别向量的搜索,是目前较成熟的近似近邻搜索库。
那么问题来了,Embedding API 和向量库是怎么配合工作的呢?
我们对本地的数据有一个加工的过程。通俗地讲就是先将我们本地的文本切块,一块文本长度是 500 token(可以根据自己资料情况决定长度,一般 500~1000)。然后,将切块后文本内容输入给 Embedding API,由它负责加工文本内容。最终,Emebdding API会对每一段输入文字生成 1536 个向量。
关于Embedding API调用你可以再结合官方提供的例子琢磨一下这个过程。
curl https://api.openai.com/v1/embeddings \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-d '{
"input": "Your text string goes here",
"model": "text-embedding-ada-002"
}'
返回内容是后面这样。
{
"data": [
{
"embedding": [
-0.006929283495992422,
-0.005336422007530928,
...
-4.547132266452536e-05,
-0.024047505110502243
],
"index": 0,
"object": "embedding"
}
],
"model": "text-embedding-ada-002",
"object": "list",
"usage": {
"prompt_tokens": 5,
"total_tokens": 5
}
}
通过这个接口我们就完成了文字段的向量生成,这个向量可以用来检测两段文字的近似度。下一步我们要做的就是把文本内容和向量保存在本地向量库里。
保存好文字段向量生成和文字内容以后,我们再聊聊用户进行私有库资料查找的过程会发生什么。

当我们用户提问或需要数据时,可以先通过 Embedding API 处理用户提问,得到问题的 1536 个向量。然后,用向量结果到本地向量库进行 Cosine算法查找(匹配度建议在 0.8 以上),找出近似度超过相关的文字段,提供给ChatGPT参考使用。
常规的模糊搜索引擎是通过关键字反向索引来做匹配的,而这个方式的近似度查找有些不同,它能够搜索内容的近似度。这一点和搜索引擎的关键词匹配是不一样的,你可以留意一下。
拿到近似度相近的文本内容后,使用私有库知识做问答加工的下一步就是将拿到的文本和用户的提问组装在 ChatGPT 接口的 message 内,并发送请求给ChatGPT。
除了使用本地知识库的知识做问答加工,还可以实现智能客服、文章模糊知识检索、近似文章查找等等类似功能,过程和前面讲的大同小异。
具体的实现代码我会在后面的小工具中提供,你有兴趣的话可以本地调试一下看看效果。
超过token上限如何处理
除了私有知识库提供各种最新知识功能外,ChatGPT 的文本总结改写能力也十分强大。利用这个功能,我们能让它实现文字润色、改写、知识点总结、关键字提取以及内容归类等多种功能。
这类场景可以概括成大文本处理,我们这就来聊聊想做这类功能要如何实现。既然是大文本,自然有个很重要的问题要解决,就是突破 4096 token 限制,实现更多文本汇总的。
常见的实现方式很简单,就是实现类似Map Reduce的分段汇总方式去对数据加工,具体就是把文本按长度切成多段,每段加上提问的问题后,再请求ChatGPT做分段汇总。当我们拿到每一段文本的汇总结果后,将结果再次加上问题做最终汇总。可以看到,这个功能实现很简单,为了帮助你理解,我简单画了个树形汇总实现数据的流向。
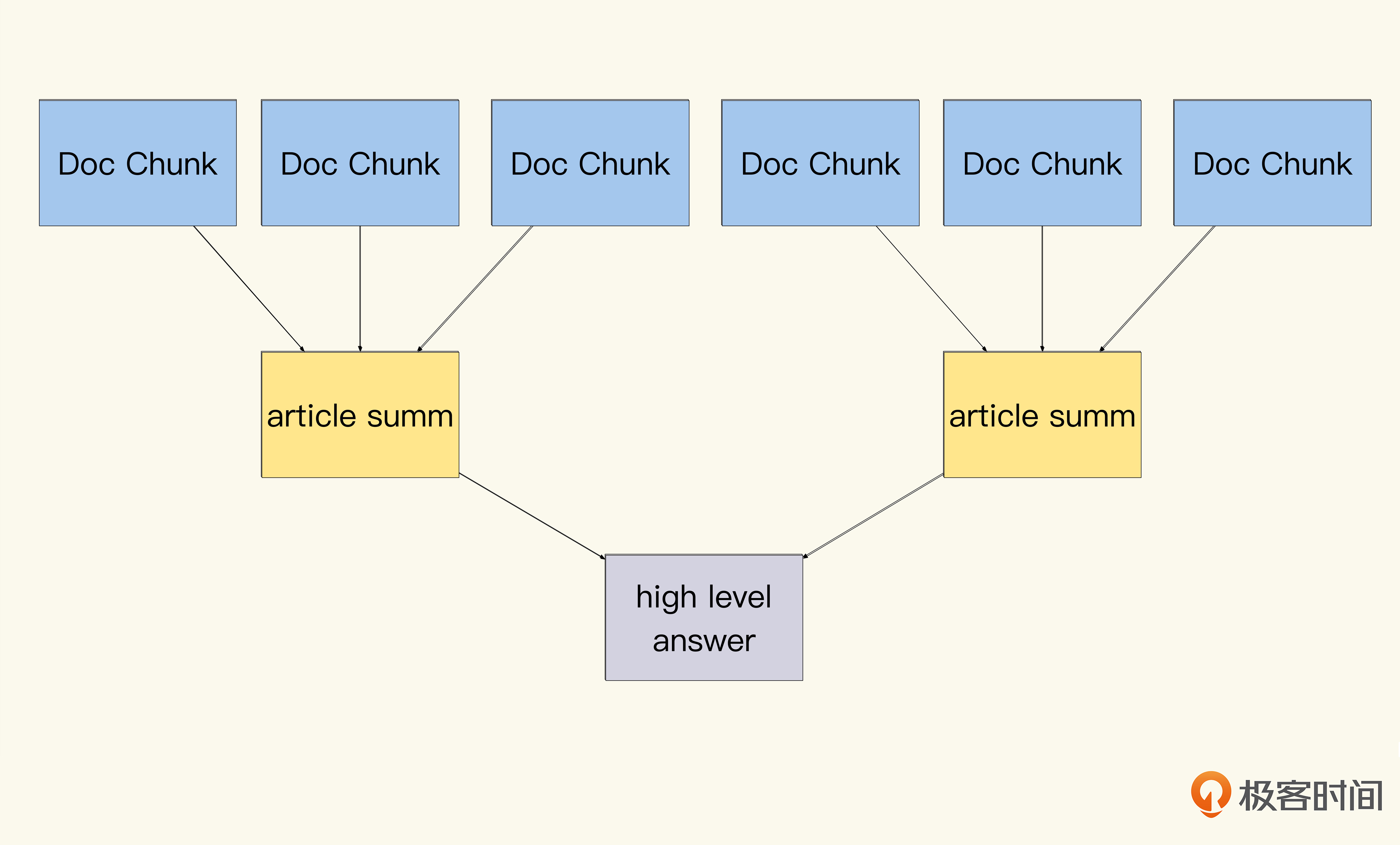
这个功能在LangChain内已经实现了,我们只需要在调用chain的时候,指定使用什么type的chain即可。其他类型的chain如何工作你可以参考这里的链接 ,后面的代码中也有类似的实现。
智能小助手源码
前面我们讲解了如何和ChatGPT通讯,如何整理资料并支持相似度资料搜索,给GPT填喂最新资料,以及如何汇总总结超过4096 token的资料。
万事俱备,相信你已经迫不及待尝试一下了。接下来就到了激动人心的代码实现环节。
首先,我们需要安装依赖,创建一个 requirement.txt 文件,内容如下。
aiodns==3.0.0
aiohttp==3.8.4
aiohttp-retry==2.8.3
aiosignal==1.3.1
alabaster==0.7.13
async-timeout==4.0.2
attrs==23.1.0
cffi==1.15.1
charset-normalizer==3.1.0
frozenlist==1.3.3
idna==3.4
multidict==6.0.4
pycares==4.3.0
pycparser==2.21
yarl==1.8.2
langchain==0.0.145
openai==0.27.0
tiktoken==0.1.2
然后是第二步,安装相关依赖。
具体实现代码如下,你可以将它复制到hey.py文件中,就可以直接试用。
import os
from typing import List, Optional
import typer
from langchain import PromptTemplate
from langchain.chains import RetrievalQA
from langchain.chains.summarize import load_summarize_chain
from langchain.chat_models import ChatOpenAI
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores import FAISS
# cmd init
app = typer.Typer(add_completion=False)
api_key = "sk-" # 这里获取你的 token https://platform.openai.com/account/api-keys
# db path 向量数据库 文件保存地址
vectorStore = os.path.expanduser('~/' + 'hey')
# 初始化向量数据库,会在~/hey 目录下生成一个数据库,用于保存你输入的数据
# 这个库主要用于近似搜索功能,当我们搜索的内容和和我们的资料有近似的时候,这个内容会自动填给 openai 参考
@app.command()
def init():
# 向量接口,会将输入文本向量化后录入到 faiss 向量库内
embeddings = OpenAIEmbeddings(openai_api_key=api_key)
text = ["init document"]
db = FAISS.from_texts(text, embeddings)
print("create index")
db.save_local(vectorStore)
# test
print("test index")
# 测试检索 Faiss 库看看是否能找到
doc = db.similarity_search_with_score("init")
print(doc, flush=True)
# 倒入私人知识文本到向量数据库,支持多个文件
# 会把文件切成 800 token 作为一个块录入进去
@app.command()
def embed(file: Optional[List[str]] = typer.Option(None,
help="""File paths.
E.g. --file inputs/1.md --file inputs/2.md"""),
):
print("import text:")
print(file)
# 支持输入多个文件,如果一个文件没有,那么报错
if len(file) == 0:
print("you must special the txt with --file")
return
# 使用 openai 的 Emebedding 功能,计算文本讲述内容
embeddings = OpenAIEmbeddings(openai_api_key=api_key)
db = FAISS.load_local(vectorStore, embeddings)
text_splitter = CharacterTextSplitter.from_tiktoken_encoder(
chunk_size=800, # 一段 800 token,要知道 GPT3.5 输入和回答总计 4096
chunk_overlap=0,
)
# 遍历路径,挨个切块,转换成 800 token 一个的小文字块,记录在 Faiss 向量库
for fpath in file:
with open(fpath) as fa:
doc = fa.read()
# 附加记录 meta 信息
metadatas = [{"path": fpath}]
docs = text_splitter.create_documents([doc], metadatas=metadatas)
print("split text file:" + fpath + " len:" + str(len(doc)) + " split count:" + str(len(docs)))
# 添加入库
db.add_documents(docs, path=fpath)
print("save to local")
# 向量库落地
db.save_local(vectorStore)
# print("test search")
# doc = db.similarity_search_with_score("历史记录")
# print(doc)
# 向量库数据检索私有知识库
# 可以检索近似事物
# 可以做近似推荐、近似知识事务查找、近似文章段落检测
@app.command()
def search(query: Optional[str] = typer.Option(None, help="""query text""")):
print("import query:")
print(query)
if len(query) == 0:
print("you must special query text")
return
embeddings = OpenAIEmbeddings(openai_api_key=api_key)
db = FAISS.load_local(vectorStore, embeddings)
# 近似查询
doc = db.similarity_search_with_score(query)
print(doc, flush=True)
# 先查询私有库内容,找出近似内容
# 使用私有库内容附带提供给 chatGPT 提问
@app.command()
def ask(question: Optional[str] = typer.Option(None, help="""question text""")):
# embedding 模型使用 openai 的 embedding
embeddings = OpenAIEmbeddings(openai_api_key=api_key)
# 检索使用 Faiss
docsearch = FAISS.load_local(vectorStore, embeddings)
# llm 使用 openai
llm = ChatOpenAI(openai_api_key=api_key)
# 使用 RetrievalQA chain,自动的将多个内容挨个聚合,这个 800 token 改为 3000 也可以
qa = RetrievalQA.from_chain_type(llm=llm, chain_type="map_reduce", retriever=docsearch.as_retriever(k=3),
return_source_documents=True)
# map reduce 多个搜索出来的私有库答案后,对答案进行汇总,返回结果
result = qa({"query": question})
print(result, flush=True)
# 对输入的文本切分成多个段,挨个进行汇总,最终将所有结果汇总在一起再次总结,返回结果
@app.command()
def summary(sum: Optional[str] = typer.Option(None, help="""summary text"""),
file: Optional[str] = typer.Option(None, help="""File paths to use.
E.g. --file inputs/1.md"""),
):
print("summary file:")
print(file)
if file is None:
print("you must special the txt with --file")
return
# 总结建议如果没有输入、那么不写只是总结
if sum is None:
sum = ""
# 对输入文字进行切分、2800 token 一段进行总结
text_splitter = CharacterTextSplitter.from_tiktoken_encoder(
chunk_size=2800,
chunk_overlap=0,
)
# 读取单个文件
with open(file) as fa:
doc = fa.read()
# 切分文件
docs = text_splitter.create_documents([doc])
print("split text file:" + file + " len:" + str(len(doc)) + " split count:" + str(len(docs)))
# 每次总结所用的 prompt 模板
prompt_template = """你是一个技术作家,请写出以下内容的主要讲解内容关键知识和技巧进行总结:
{text}
""" + sum
# 创建模板,替换变量
PROMPT = PromptTemplate(template=prompt_template, input_variables=["text"])
# 使用 openai
llm = ChatOpenAI(openai_api_key=api_key)
# 使用 summary chain 进行文字总结
chain = load_summarize_chain(llm, chain_type="map_reduce", map_prompt=PROMPT, combine_prompt=PROMPT,
return_intermediate_steps=False)
# 执行 chain
result = chain({"input_documents": docs}, return_only_outputs=True)
print(result, flush=True)
if __name__ == "__main__":
app()
使用这个工具我们能做什么样有趣的功能呢?可以运行一下后面的代码,跑起来看看。
python3 hey.py init #初始化本地知识向量库,数据会在~/hey 目录
python3 hey.py embed --file xxx.txt # 导入私有知识文本到向量库
python3 hey.py ask --question "如何预防流量穿透,并且并发好" # 提问 chatGPT,并且自动匹配私有库知识提供给ChatGPT参考
python3 hey.py summary --file xxx.txt --sum "你是一个新闻播报员,将这些内容改写成新闻稿" #将指定文本文件做各种汇总、总结、改写,别超过18000token
这样我们就实现了简单有趣的私有知识库助手,这个代码简单改改也可以快速在生产上使用,有网络条件并且会用CoLab的同学,可以通过这个链接测试前面的代码。
当然LangChian提供的功能不仅仅是这些,你可以对这个包继续迭代来扩充功能。
这里我还想推荐你关注一下最近正火的AutoGPT,它被看成是能独立思考的机器人。具体可以参考 LangChain 的实现,你可以通过后面这个链接来了解。
另外,我要友情提示一下安全问题。虽然LangChain提供了很多有趣的封装,但是不推荐你直接让它接收用户信息对外服务,因为这个包还在不断地迭代(最多的时候一星期更新10个小版本),并且包内是有类似eval的能够直接执行提交的代码,这很可能导致你的系统被入侵。
如果生产上有对安全和性能比较高的场景,建议你还是自行实现比较安全。
思考题
你觉得文章翻译使用map reduce方式比较好,还是切成块之后一块块处理更好呢?
期待你在留言区和我交流互动。如果觉得加餐内容还不错,也推荐你把这节课分享给更多朋友,和他一起学习进步。
- 希波莱 👍(0) 💬(1)
老师如果想做推荐系统和电商,但引入整套llm 的rag工作流,是不是可以淘汰掉传统的mysql,只用elasticsearch + mongdb + redis就足够了
2024-01-13 - AI悦创 👍(0) 💬(1)
老师向量数据库有没有什么好的教程?
2023-08-26 - AI悦创 👍(0) 💬(1)
文章的示例代码,向量数据库能否提供一下测试?
2023-08-13 - AI悦创 👍(0) 💬(1)
1. 就是结合 CHatGPT 和公司或个人数据库或向量数据库其他的,实现智能客服之类的; 2. 老师的文章中还提及了:多种实现方法和技术,我想系统跟着老师的课程学学,开发开放; 3. 公司目前需要这方面的研发客服啥的,市面上没有这类结合私有数据库开发的[流泪]
2023-08-02 - AI悦创 👍(0) 💬(5)
这个有后续吗?快速打造一个私人助手
2023-07-29