09 所有权:一个值可以有多个所有者么?
你好,我是陈天。
之前介绍的单一所有权规则,能满足我们大部分场景中分配和使用内存的需求,而且在编译时,通过 Rust 借用检查器就能完成静态检查,不会影响运行时效率。
但是,规则总会有例外,在日常工作中有些特殊情况该怎么处理呢?
- 一个有向无环图(DAG)中,某个节点可能有两个以上的节点指向它,这个按照所有权模型怎么表述?
- 多个线程要访问同一块共享内存,怎么办?
我们知道,这些问题在程序运行过程中才会遇到,在编译期,所有权的静态检查无法处理它们,所以为了更好的灵活性,Rust 提供了运行时的动态检查,来满足特殊场景下的需求。
这也是 Rust 处理很多问题的思路:编译时,处理大部分使用场景,保证安全性和效率;运行时,处理无法在编译时处理的场景,会牺牲一部分效率,提高灵活性。后续讲到静态分发和动态分发也会有体现,这个思路很值得我们借鉴。
那具体如何在运行时做动态检查呢?运行时的动态检查又如何与编译时的静态检查自洽呢?
Rust 的答案是使用引用计数的智能指针:Rc(Reference counter) 和 Arc(Atomic reference counter)。这里要特别说明一下,Arc 和 ObjC/Swift 里的 ARC(Automatic Reference Counting)不是一个意思,不过它们解决问题的手段类似,都是通过引用计数完成的。
Rc
我们先看 Rc。对某个数据结构 T,我们可以创建引用计数 Rc,使其有多个所有者。Rc 会把对应的数据结构创建在堆上,我们在第二讲谈到过,堆是唯一可以让动态创建的数据被到处使用的内存。
之后,如果想对数据创建更多的所有者,我们可以通过 clone() 来完成。
对一个 Rc 结构进行 clone(),不会将其内部的数据复制,只会增加引用计数。而当一个 Rc 结构离开作用域被 drop() 时,也只会减少其引用计数,直到引用计数为零,才会真正清除对应的内存。
上面的代码我们创建了三个 Rc,分别是 a、b 和 c。它们共同指向堆上相同的数据,也就是说,堆上的数据有了三个共享的所有者。在这段代码结束时,c 先 drop,引用计数变成 2,然后 b drop、a drop,引用计数归零,堆上内存被释放。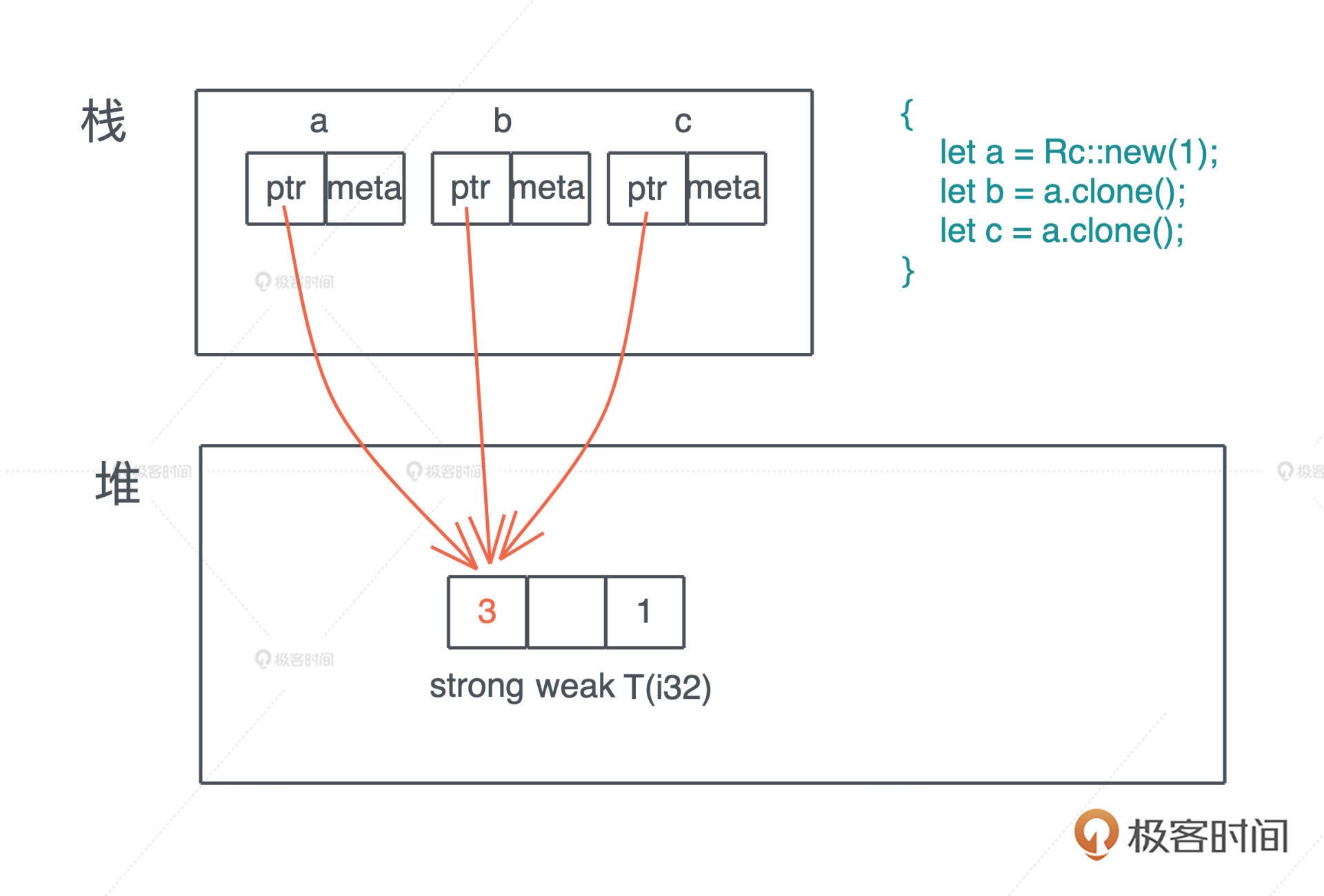
你也许会有疑问:为什么我们生成了对同一块内存的多个所有者,但是,编译器不抱怨所有权冲突呢?
仔细看这段代码:首先 a 是 Rc::new(1) 的所有者,这毋庸置疑;然后 b 和 c 都调用了 a.clone(),分别得到了一个新的 Rc,所以从编译器的角度,abc 都各自拥有一个 Rc。如果文字你觉得稍微有点绕,看看 Rc 的 clone() 函数的实现,就很清楚了(源代码):
fn clone(&self) -> Rc<T> {
// 增加引用计数
self.inner().inc_strong();
// 通过 self.ptr 生成一个新的 Rc 结构
Self::from_inner(self.ptr)
}
所以,Rc 的 clone() 正如我们刚才说的,不复制实际的数据,只是一个引用计数的增加。
你可能继续会疑惑:Rc 是怎么产生在堆上的?并且为什么这段堆内存不受栈内存生命周期的控制呢?
Box::leak()机制
上一讲我们讲到,在所有权模型下,堆内存的生命周期,和创建它的栈内存的生命周期保持一致。所以 Rc 的实现似乎与此格格不入。的确,如果完全按照上一讲的单一所有权模型,Rust 是无法处理 Rc 这样的引用计数的。
Rust必须提供一种机制,让代码可以像 C/C++ 那样,创建不受栈内存控制的堆内存,从而绕过编译时的所有权规则。Rust 提供的方式是 Box::leak()。
Box 是 Rust 下的智能指针,它可以强制把任何数据结构创建在堆上,然后在栈上放一个指针指向这个数据结构,但此时堆内存的生命周期仍然是受控的,跟栈上的指针一致。我们后续讲到智能指针时会详细介绍 Box。
Box::leak(),顾名思义,它创建的对象,从堆内存上泄漏出去,不受栈内存控制,是一个自由的、生命周期可以大到和整个进程的生命周期一致的对象。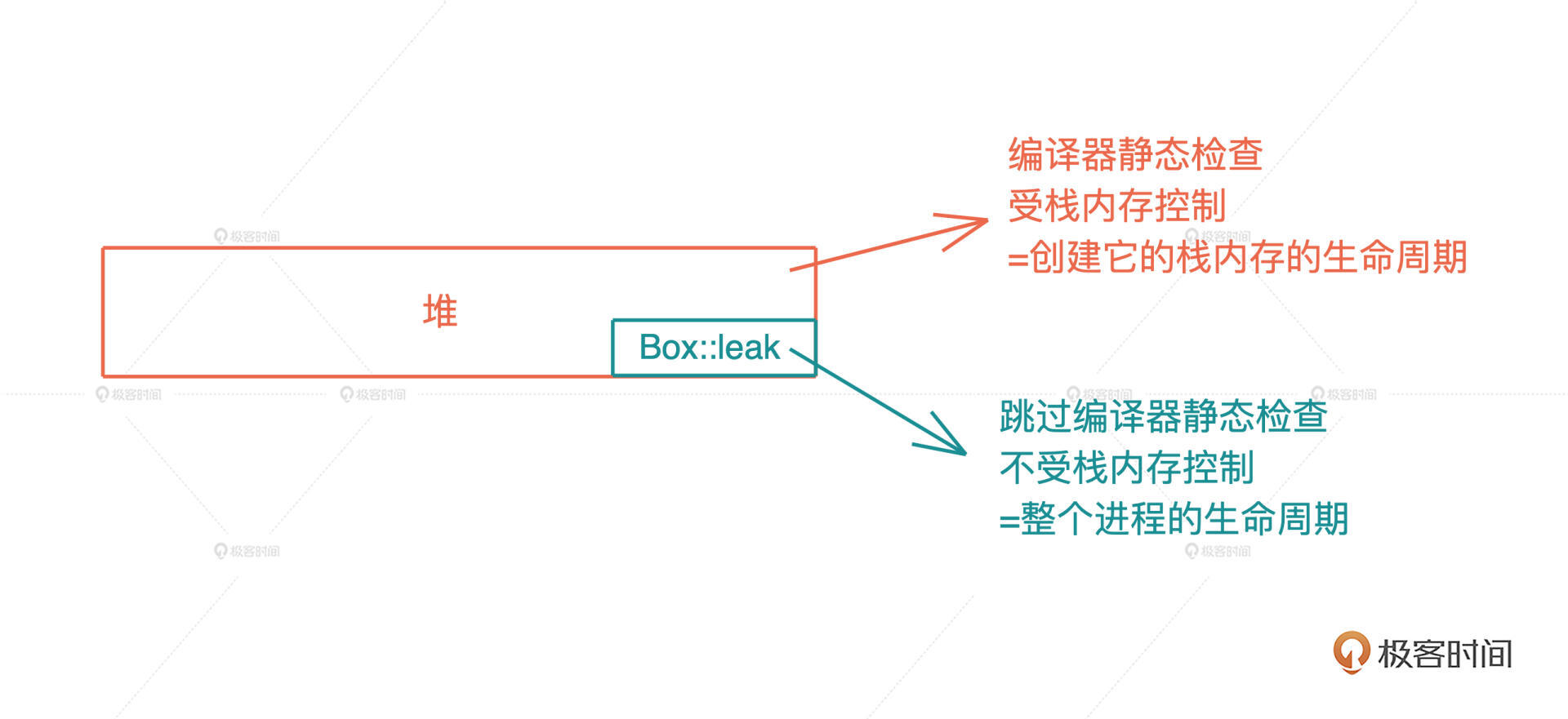
所以我们相当于主动撕开了一个口子,允许内存泄漏。注意,在 C/C++ 下,其实你通过 malloc 分配的每一片堆内存,都类似 Rust 下的 Box::leak()。我很喜欢 Rust 这样的设计,它符合最小权限原则(Principle of least privilege),最大程度帮助开发者撰写安全的代码。
有了 Box::leak(),我们就可以跳出 Rust 编译器的静态检查,保证 Rc 指向的堆内存,有最大的生命周期,然后我们再通过引用计数,在合适的时机,结束这段内存的生命周期。如果你对此感兴趣,可以看 Rc::new() 的源码。
插一句,在学习语言的过程中,不要因为觉得自己是个初学者,就不敢翻阅标准库的源码,相反,遇到不懂的地方,如果你去看对应的源码,得到的是第一手的知识,一旦搞明白,就会学得非常扎实,受益无穷。
搞明白了 Rc,我们就进一步理解 Rust 是如何进行所有权的静态检查和动态检查了:
- 静态检查,靠编译器保证代码符合所有权规则;
- 动态检查,通过 Box::leak 让堆内存拥有不受限的生命周期,然后在运行过程中,通过对引用计数的检查,保证这样的堆内存最终会得到释放。
实现 DAG
现在我们用 Rc 来实现之前无法实现的 DAG。
假设 Node 就只包含 id 和指向下游(downstream)的指针,因为 DAG 中的一个节点可能被多个其它节点指向,所以我们使用 Rc<Node> 来表述它;一个节点可能没有下游节点,所以我们用 Option<Rc<Node>> 来表述它。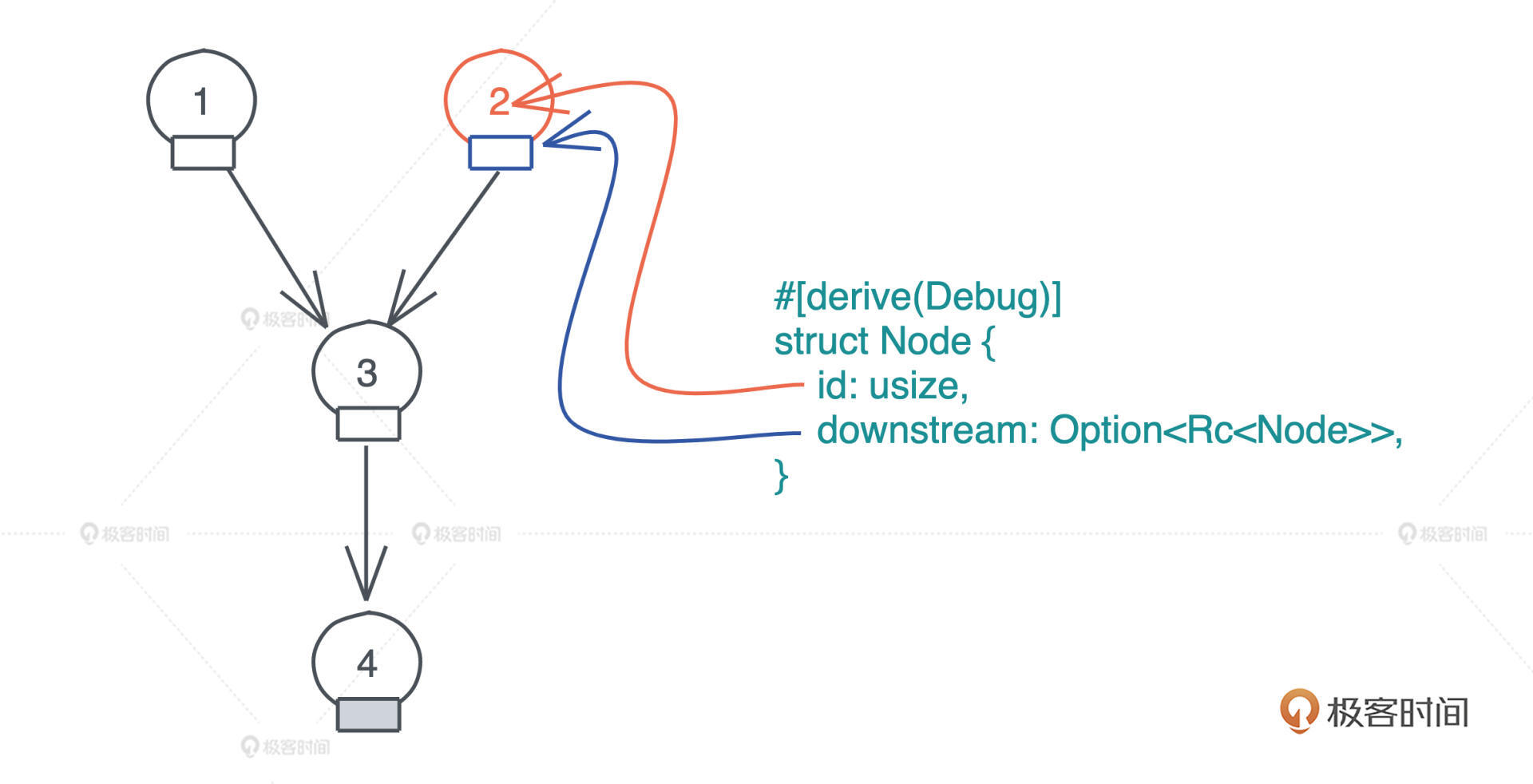
要建立这样一个 DAG,我们需要为 Node 提供以下方法:
- new():建立一个新的 Node。
- update_downstream():设置 Node 的 downstream。
- get_downstream():clone 一份 Node 里的 downstream。
有了这些方法,我们就可以创建出拥有上图关系的 DAG 了(代码1):
use std::rc::Rc;
#[derive(Debug)]
struct Node {
id: usize,
downstream: Option<Rc<Node>>,
}
impl Node {
pub fn new(id: usize) -> Self {
Self {
id,
downstream: None,
}
}
pub fn update_downstream(&mut self, downstream: Rc<Node>) {
self.downstream = Some(downstream);
}
pub fn get_downstream(&self) -> Option<Rc<Node>> {
self.downstream.as_ref().map(|v| v.clone())
}
}
fn main() {
let mut node1 = Node::new(1);
let mut node2 = Node::new(2);
let mut node3 = Node::new(3);
let node4 = Node::new(4);
node3.update_downstream(Rc::new(node4));
node1.update_downstream(Rc::new(node3));
node2.update_downstream(node1.get_downstream().unwrap());
println!("node1: {:?}, node2: {:?}", node1, node2);
}
RefCell
在运行上述代码时,细心的你也许会疑惑:整个 DAG 在创建完成后还能修改么?
按最简单的写法,我们可以在上面的代码1的 main() 函数后,加入这段代码(代码2),来修改 Node3 使其指向一个新的节点 Node5:
let node5 = Node::new(5);
let node3 = node1.get_downstream().unwrap();
node3.update_downstream(Rc::new(node5));
println!("node1: {:?}, node2: {:?}", node1, node2);
然而,它无法编译通过,编译器会告诉你“node3 cannot borrow as mutable”。
这是因为Rc 是一个只读的引用计数器,你无法拿到 Rc 结构内部数据的可变引用,来修改这个数据。这可怎么办?
这里,我们需要使用 RefCell。
和 Rc 类似,RefCell 也绕过了 Rust 编译器的静态检查,允许我们在运行时,对某个只读数据进行可变借用。这就涉及 Rust 另一个比较独特且有点难懂的概念:内部可变性(interior mutability)。
内部可变性
有内部可变性,自然能联想到外部可变性,所以我们先看这个更简单的定义,对比着学。
当我们用 let mut 显式地声明一个可变的值,或者,用 &mut 声明一个可变引用时,编译器可以在编译时进行严格地检查,保证只有可变的值或者可变的引用,才能修改值内部的数据,这被称作外部可变性(exterior mutability),外部可变性通过 mut 关键字声明。
然而,这样不够灵活,有时候我们希望能够绕开这个编译时的检查,对并未声明成 mut 的值或者引用,也想进行修改。也就是说,在编译器的眼里,值是只读的,但是在运行时,这个值可以得到可变借用,从而修改内部的数据,这就是 RefCell 的用武之地。
我们看一个简单的例子(代码2):
use std::cell::RefCell;
fn main() {
let data = RefCell::new(1);
{
// 获得 RefCell 内部数据的可变借用
let mut v = data.borrow_mut();
*v += 1;
}
println!("data: {:?}", data.borrow());
}
在这个例子里,data 是一个 RefCell,其初始值为 1。可以看到,我们并未将 data 声明为可变变量。之后我们可以通过使用 RefCell 的 borrow_mut() 方法,来获得一个可变的内部引用,然后对它做加 1 的操作。最后,我们可以通过 RefCell 的 borrow() 方法,获得一个不可变的内部引用,因为加了 1,此时它的值为 2。
你也许奇怪,这里为什么要把获取和操作可变借用的两句代码,用花括号分装到一个作用域下?
因为根据所有权规则,在同一个作用域下,我们不能同时有活跃的可变借用和不可变借用。通过这对花括号,我们明确地缩小了可变借用的生命周期,不至于和后续的不可变借用冲突。
这里再想一步,如果没有这对花括号,这段代码是无法编译通过?还是运行时会出错(代码3)?
use std::cell::RefCell;
fn main() {
let data = RefCell::new(1);
let mut v = data.borrow_mut();
*v += 1;
println!("data: {:?}", data.borrow());
}
如果你运行代码3,编译没有任何问题,但在运行到第 9 行时,会得到:“already mutably borrowed: BorrowError” 这样的错误。可以看到,所有权的借用规则在此依旧有效,只不过它在运行时检测。
这就是外部可变性和内部可变性的重要区别,我们用下表来总结一下: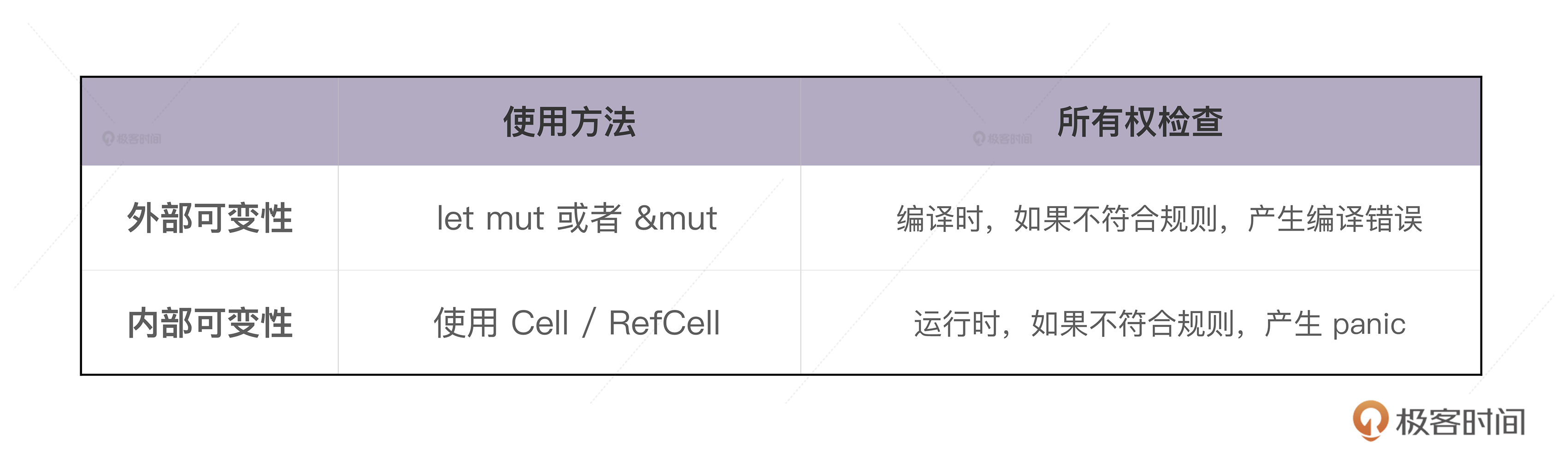
实现可修改DAG
好,现在我们对 RefCell 有一个直观的印象,看看如何使用它和 Rc 来让之前的 DAG 变得可修改。
首先数据结构的 downstream 需要 Rc 内部嵌套一个 RefCell,这样,就可以利用 RefCell 的内部可变性,来获得数据的可变借用了,同时 Rc 还允许值有多个所有者。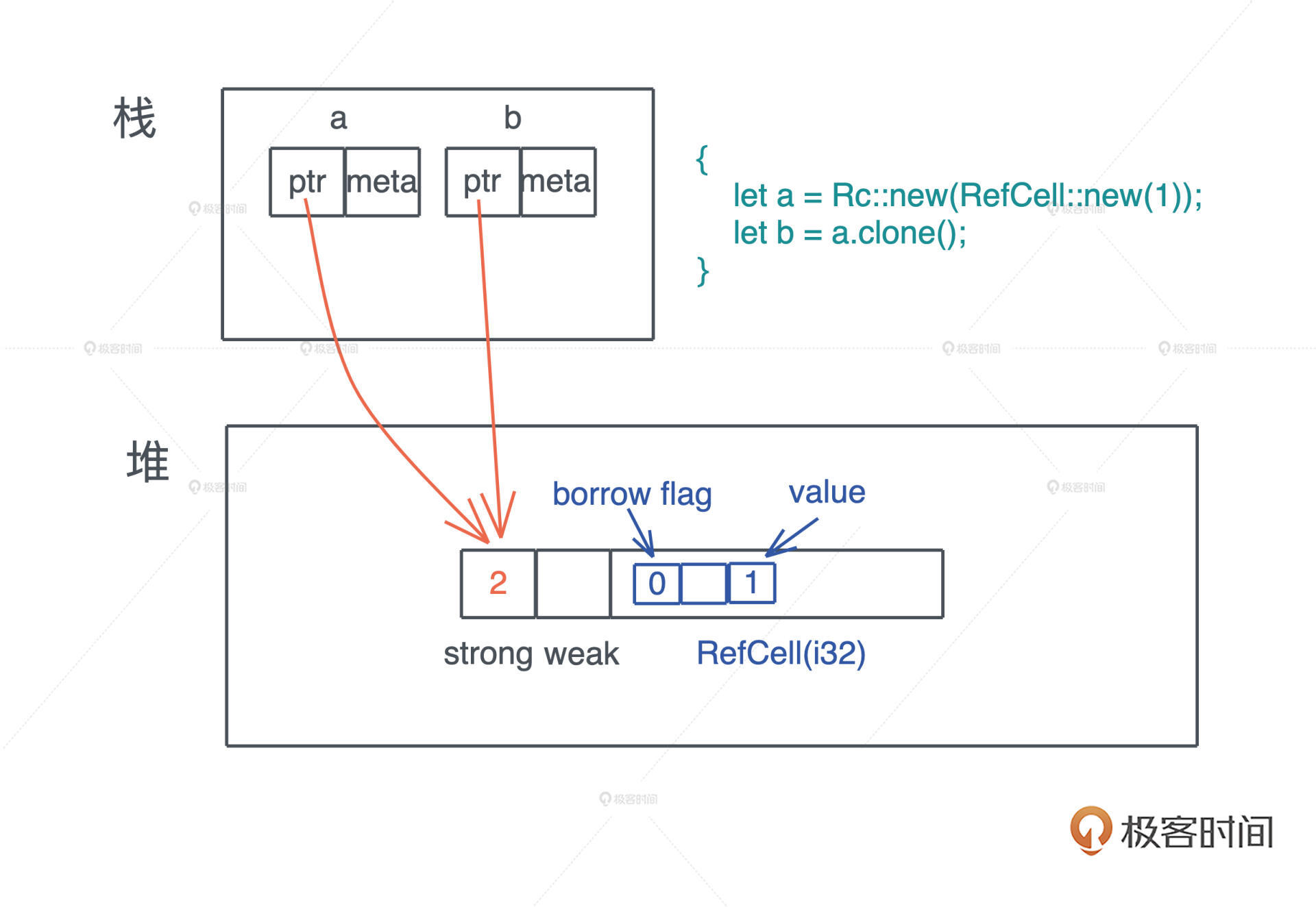
完整的代码我放到这里了(代码4):
use std::cell::RefCell;
use std::rc::Rc;
#[derive(Debug)]
struct Node {
id: usize,
// 使用 Rc<RefCell<T>> 让节点可以被修改
downstream: Option<Rc<RefCell<Node>>>,
}
impl Node {
pub fn new(id: usize) -> Self {
Self {
id,
downstream: None,
}
}
pub fn update_downstream(&mut self, downstream: Rc<RefCell<Node>>) {
self.downstream = Some(downstream);
}
pub fn get_downstream(&self) -> Option<Rc<RefCell<Node>>> {
self.downstream.as_ref().map(|v| v.clone())
}
}
fn main() {
let mut node1 = Node::new(1);
let mut node2 = Node::new(2);
let mut node3 = Node::new(3);
let node4 = Node::new(4);
node3.update_downstream(Rc::new(RefCell::new(node4)));
node1.update_downstream(Rc::new(RefCell::new(node3)));
node2.update_downstream(node1.get_downstream().unwrap());
println!("node1: {:?}, node2: {:?}", node1, node2);
let node5 = Node::new(5);
let node3 = node1.get_downstream().unwrap();
// 获得可变引用,来修改 downstream
node3.borrow_mut().downstream = Some(Rc::new(RefCell::new(node5)));
println!("node1: {:?}, node2: {:?}", node1, node2);
}
可以看到,通过使用 Rc<RefCell<T>> 这样的嵌套结构,我们的 DAG 也可以正常修改了。
Arc 和 Mutex/RwLock
我们用 Rc 和 RefCell 解决了 DAG 的问题,那么,开头提到的多个线程访问同一块内存的问题,是否也可以使用 Rc 来处理呢?
不行。因为 Rc 为了性能,使用的不是线程安全的引用计数器。因此,我们需要另一个引用计数的智能指针:Arc,它实现了线程安全的引用计数器。
Arc 内部的引用计数使用了 Atomic Usize ,而非普通的 usize。从名称上也可以感觉出来,Atomic Usize 是 usize 的原子类型,它使用了 CPU 的特殊指令,来保证多线程下的安全。如果你对原子类型感兴趣,可以看 std::sync::atomic 的文档。
Rust 实现两套不同的引用计数数据结构,完全是为了性能考虑,从这里我们也可以感受到 Rust 对性能的极致渴求。如果不用跨线程访问,可以用效率非常高的 Rc;如果要跨线程访问,那么必须用 Arc。
同样的,RefCell 也不是线程安全的,如果我们要在多线程中,使用内部可变性,Rust 提供了 Mutex 和 RwLock。
这两个数据结构你应该都不陌生,Mutex是互斥量,获得互斥量的线程对数据独占访问,RwLock是读写锁,获得写锁的线程对数据独占访问,但当没有写锁的时候,允许有多个读锁。读写锁的规则和 Rust 的借用规则非常类似,我们可以类比着学。
Mutex 和 RwLock 都用在多线程环境下,对共享数据访问的保护上。刚才中我们构建的 DAG 如果要用在多线程环境下,需要把 Rc<RefCell<T>> 替换为 Arc<Mutex<T>> 或者 Arc<RwLock<T>>。更多有关 Arc/Mutex/RwLock 的知识,我们会在并发篇详细介绍。
小结
我们对所有权有了更深入的了解,掌握了 Rc / Arc、RefCell / Mutex / RwLock 这些数据结构的用法。
如果想绕过“一个值只有一个所有者”的限制,我们可以使用 Rc / Arc 这样带引用计数的智能指针。其中,Rc 效率很高,但只能使用在单线程环境下;Arc 使用了原子结构,效率略低,但可以安全使用在多线程环境下。
然而,Rc / Arc 是不可变的,如果想要修改内部的数据,需要引入内部可变性,在单线程环境下,可以在 Rc 内部使用 RefCell;在多线程环境下,可以使用 Arc 嵌套 Mutex 或者 RwLock 的方法。
你可以看这张表快速回顾: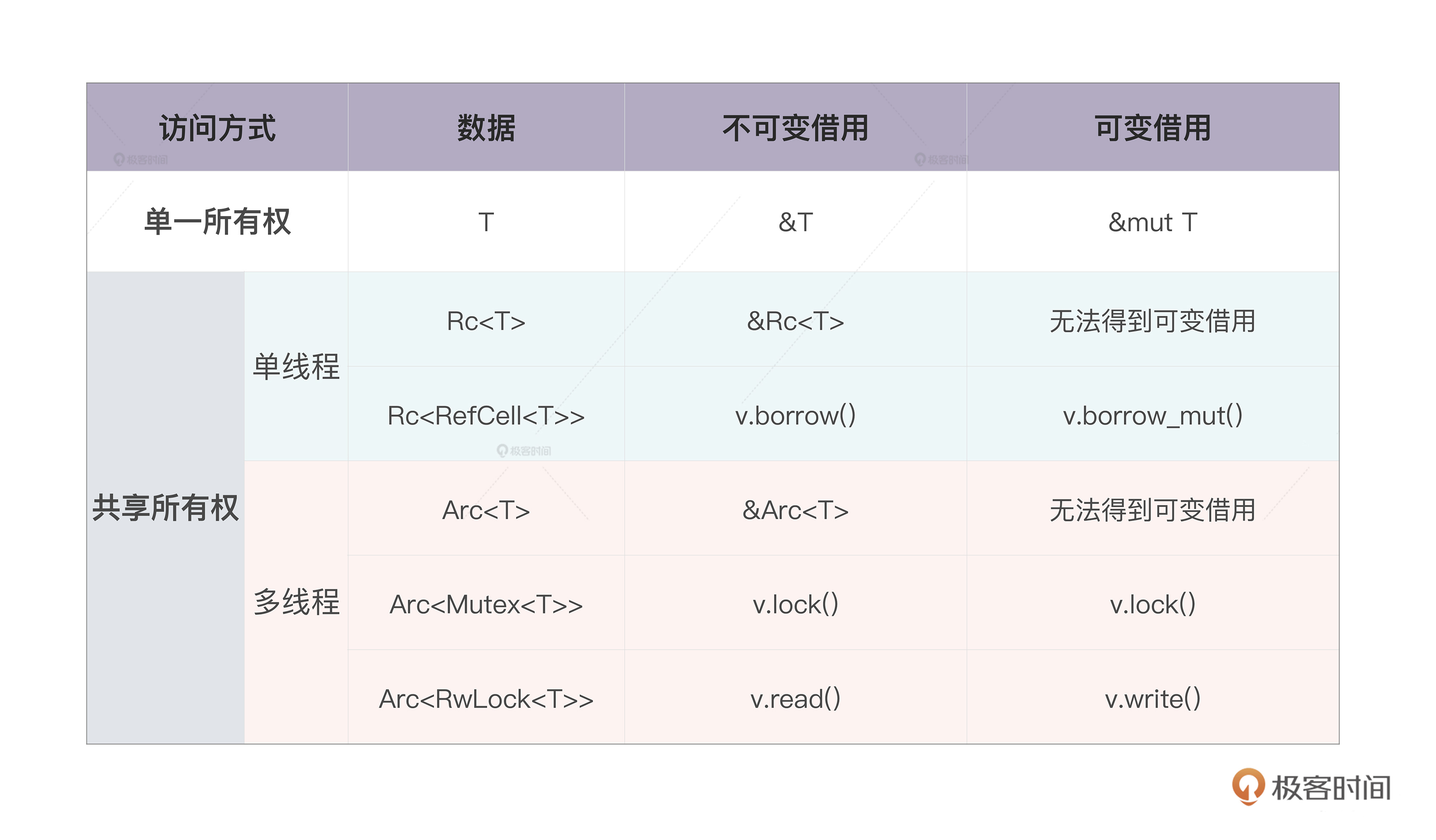
思考题
- 运行下面的代码,查看错误,并阅读 std::thread::spawn 的文档,找到问题的原因后,修改代码使其编译通过。
- 你可以写一段代码,在 main() 函数里生成一个字符串,然后通过
std::thread::spawn创建一个线程,让 main() 函数所在的主线程和新的线程共享这个字符串么?提示:使用 std::sync::Arc。 - 我们看到了 Rc 的 clone() 方法的实现:
fn clone(&self) -> Rc<T> {
// 增加引用计数
self.inner().inc_strong();
// 通过 self.ptr 生成一个新的 Rc 结构
Self::from_inner(self.ptr)
}
你有没有注意到,这个方法传入的参数是 &self ,是个不可变引用,然而它调用了 self.inner().inc_strong() ,光看函数名字,它用来增加 self 的引用计数,可是,为什么这里对 self 的不可变引用可以改变 self 的内部数据呢?
欢迎在留言区分享你的思考。恭喜你完成了 Rust 学习的第九次打卡,如果你觉得有收获,也欢迎分享给你身边的朋友,邀TA一起讨论。
参考资料
- clone() 函数的实现源码
- 最小权限原则
- Rc::new() 的源码
- Arc 内部的引用计数使用了 Atomic Usize
- Atomic Usize 是 usize 的原子类型: std::sync::atomic 的文档
- 内部可变性:除了 RefCell 之外,Rust 还提供了 Cell。如果你想对 RefCell 和 Cell 进一步了解,可以看 Rust 标准库里cell 的文档。
- 清风徐来 👍(14) 💬(6)
老师问一个额外的问题 以anyhow、clap库为例,通篇看rust技术文档有一种很蒙蔽的感觉,感觉文档只是把技术点拆的很零碎进行说明(如:有哪些struct、trait等),外加一个没有实质性帮助的为例文档代码,感觉和其他语言的技术文档很不一样;一句话来说明:文档描述拆的很零碎,并没有一个清晰地整体的统一使用说明,致使无从下手;这个问题如何解决???
2022-03-18 - 有铭 👍(69) 💬(7)
今天这章我看完以后感觉有一股非常遗憾的情绪: 我原本以为rust真的用编译时检查解决了当年C++面临的那些问题。结果最后还是妥协撕开了一道口子开了后门,而且这个后门开的很复杂,我的感觉,这个特性,将来要么就是没什么人用,要么就是被人滥用。这个东西对人的自控要求太高了
2021-09-11 - lisiur 👍(39) 💬(3)
老师您好,在代码3里,把内部作用域去掉会导致运行时错误,但是如果使用普通的借用方式像这样:
却不需要使用多余的作用域。 我的理解是普通的借用方式走的是编译期检查,编译器标记借用的生命期的粒度比作用域要小,比如上述代码的 mut 借用,正常的生命期应该是到main函数结束,但是编译器应该是把它缩小到了 println 代码之前的位置,所以 println 的不可变借用并不和上面的可变借用冲突。但是运行时的"生命期检查"应该就是作用域粒度的,所以需要使用额外的作用域来达到手动 drop 可变借用的效果。 我的想法是,既然编译期能够做到尽可能小的缩小借用的生命周期,那编译器能不能自动对这种特殊的内部可变性的借用在合适的位置插入drop代码,使得不使用额外的作用域也能满足运行时检查呢?2021-09-10 - 千回百转无劫山 👍(37) 💬(3)
1. 错误为线程借用的arr生命周期可能会长于main函数中的arr,简单处理的话把main中arr的所有权move到线程里即可,编译器对此有详尽的提示:
2. 这个问题其实是第1个问题的延续,如果将main中变量的所有权move到线程中,那么在main中将无法访问,所以使用Arc这个智能指针即可实现共享所有权: 3. 不太确定,查文档看调用链是inner方法返回了RcBox,RcBox调用的inc_strong是RcInnerPtr这个trait的方法,它会通过调用该trait的strong_ref方法返回cell,而cell是一个可变的共享容器,即最终通过cell共享内存来改变内部数据。 看完这一小节产生一个疑问,本小节介绍的智能指针都是为了突破rust编译期的所有权规则限制。那为什么要先做限制再提供突破限制的方法呢?这样做的意义是否可以理解为就像unsafe或者最小权限原则一样,大部分情况下,遵循所有权规则,仅在必要的时候使用智能指针来突破限制?如果用户滥用了智能指针,那么是否就像滥用了unsafe一样,rust内存安全等特性就无法保证了?2021-09-10 - dotfiles 👍(17) 💬(1)
1. rust由于所有权以及默认不可变等限制,导致最常见的数据结构---链表的实现变得相当复杂,常见的实现使用了3层结构体. Option<>提供空和非空,相关: Some/None Rc<T>提供引用计数,相关: New/clone; 如果为了避免循环引用,还要考虑downgrade/upgrade; 这块和cpp的shared_ptr/weak_ptr类似. RefCell<T>提供内部可变性,基于unsafe机制,提供运行时检查. 相关: borrow/borrow_mut 2. 内部可变性 Rc的引用计数器和RefCell中的数据可变,都是基于unsafe实现的. 我们以Rc引用计数器的更新为例:
如上可以看到,即使replace的参数self是不可变的,也可以通过unsafe去改变其中的值.也就是说rust通过unsafe具有完全的c/c++类似的能力. 同理,可以看到Refcell获取可变引用,也是通过unsafe将指针直接转成可变引用.可以想象的是,在RefCell中,还需要通过额外的代码来处理可读不可写,可写不可读的类似读写锁的问题. 在rust的设计中,明显推崇将问题尽量在静态编译期解决.实在搞不定的,就是通过unsafe和额外的处理推迟到运行期解决.2021-10-12 - noisyes 👍(10) 💬(1)
fn main() { /*let data = RefCell::new(1); let mut v = data.borrow_mut(); *v += 1; println!("data: {:?}", data.borrow()); */ let mut v = vec![1, 2, 3]; let data1 = &mut v[1]; *data1 = 2; let data2 = &v[1]; println!("{}", data2); } 老师这段代码注释的部分,运行时不能通过,可变借用和不可变借用并没有冲突呀(v并没在borrow之后使用,同一时刻并没有同时有可变借用和不可变借用),我自己写的这部分就是可以编译运行的。
2021-09-10 - Marvichov 👍(6) 💬(3)
为啥要week == 0的时候才deallocate所有内存呢? 这样是不是不太高效?
use std::thread; fn main() { let arr = vec![1]; let handler = thread::spawn(move || { println!("{:?}", arr); }); handler.join().unwrap(); } use std::thread; use std::sync::Arc; fn main() { let five = Arc::new("hello Tyr"); { let give_me_five = five.clone(); let handler = thread::spawn(move || { println!("thread greeting: {:?}", give_me_five); }); handler.join().unwrap(); } println!("main greeting: {:?}", five); } #[doc(hidden)] trait RcInnerPtr { fn weak_ref(&self) -> &Cell<usize>; fn strong_ref(&self) -> &Cell<usize>; #[inline] fn strong(&self) -> usize { self.strong_ref().get() } #[inline] fn inc_strong(&self) { let strong = self.strong(); // We want to abort on overflow instead of dropping the value. // The reference count will never be zero when this is called; // nevertheless, we insert an abort here to hint LLVM at // an otherwise missed optimization. if strong == 0 || strong == usize::MAX { abort(); } self.strong_ref().set(strong + 1); } ... }fn drop(&mut self) { unsafe { self.inner().dec_strong(); if self.inner().strong() == 0 { // destroy the contained object ptr::drop_in_place(Self::get_mut_unchecked(self)); // remove the implicit "strong weak" pointer now that we've // destroyed the contents. self.inner().dec_weak(); if self.inner().weak() == 0 { Global.deallocate(self.ptr.cast(), Layout::for_value(self.ptr.as_ref())); } } } } ```</p>2021-09-12</li><br/><li><span>枸杞红茶</span> 👍(5) 💬(2)<p>1. 线程的运行时间可能会比当前函数还要长,而闭包中又借用了arr,使用move将当前函数的arr所有权转移给线程。花括号中的两种写法,一种不通过,报错error[E0382]: borrow of moved value: `v`;一种又可以通过,是为什么呢?使用一个花括号增加了一个作用域以后,对于作用域内使用的外部变量的所有权到底产生了怎样的影响呢?2021-09-11增加计数器```self.inner().inc_strong();```调用的```inc_strong```函数修改的是```strong_ref()```,属于Cell类型,Shareable mutable containers,可共享可修改的容器。</p>2021-10-10</li><br/><li><span>Kerry</span> 👍(4) 💬(2)<p>课后思考题: 1. 生命周期问题,主线程可能比派生线程更早结束,导致派生线程引用了过期的值。 你也许会想到加上join强制派生线程先于主线程结束,以此解决编译问题。然而这是行不通的。这里的问题是语法层面的,而不是语义层面的。 解决方法有两种:一是move,二是用ARC。方法一的代码如下: fn main() { let arr = vec![1]; std::thread::spawn(move || { println!("{:?}", arr); }).join().unwrap(); } 方法二参考思考题2即可。 2. 如下所示,用ARC包一下要共享的资源: use std::sync::{Arc, RwLock}; use std::rc::Rc; fn main() { let s = Arc::new(RwLock::new("Hello")); let r = s.clone(); std::thread::spawn(move || { println!("{:?}", r.as_ref().read().unwrap()); }).join().unwrap(); println!("{:?}", s.as_ref().read().unwrap()); } 3. 是时候步入unsafe的世界了~编译器终究只是帮我们干活,规则再严格,那都是死的。为了提供一定灵活性,会像RefCell这样提供一些机制给我们做一些不安全的操作。通过阅读self.inner().inc_strong()的源码,可以知道底层是通过unsafe实现不可变转可变引用的: unsafe { &mut *self.value.get() } </p>2021-09-12</li><br/><li><span>Arthur</span> 👍(4) 💬(1)<p>老师好,关于使用花括号提前结束生命周期这点有一点不明白 ```rust fn main() { let mut v = vec![1, 2, 3]; { v // 编译不通过 v.push(3); //编译通过 }; v.push(4); } - 夏洛克Moriaty 👍(4) 💬(2)
终于理解了Rc的本质了,以前只是知道实现二叉树这种数据结构必须用Rc,因为他允许有多个所有者。但是不理解或者说不知道为什么要有内部可变性和运行时检查这个东西,今天看了Box::leak() 机制的解释终于明白了。
2021-09-10 - noisyes 👍(2) 💬(1)
思考题: 1. fn main() { let arr = vec![1]; let handler = std::thread::spawn(move || { println!("{:?}", arr); }); handler.join().unwrap(); } 2. fn main() { let ss = Arc::new(String::from("hello world")); let ss1 = ss.clone(); let handler = std::thread::spawn(move || { println!("{}", ss1); }); println!("{}", ss); handler.join().unwrap(); } 3. 还没看源码 应该就是内部可变性吧
2021-09-10 - 葡萄 👍(2) 💬(1)
3. Rc类创建 Box::leak(box RcBox { strong: Cell::new(1), weak: Cell::new(1), value }) self.inner().inc_strong() 获得了Rc里 strong, 也就是Cell对象,Cell是内部可变的,使用set方法进行修改。 fn inc_strong(&self) { let strong = self.strong(); self.strong_ref().set(strong + 1); }
2021-09-10 - chyuwei 👍(1) 💬(1)
个人感觉就是 所有权导致不能出现多个可变引用, 借鉴了多线程里面的mutex,所以有了这个所谓的内部可变性。 对于mutex,操作系统可以保证独占性, 对于refcell应该就是库代码去保证。 至于有些同学说撕口子这个事, safe rust可以写绝大多数程序了。 当你不得不去撕口子,写unsafe时,其实和c++就没什么区别了
2022-01-13 - dch666 👍(1) 💬(1)
在代码1中,我把 self.downstream.as_ref().map(|v| v.clone()) 改成了 self.downstream.clone() 看到 print 输出结果是一样的,想问下这两种写法有区别吗?
2021-11-27