24 微服务拆分(四):其他话题
你好,我是姚琪琳。
在前面三节课,我们分别讲解了如何拆分代码、数据库表和存储过程。可以说,掌握了这三个方向的拆分技巧,微服务拆分就不在话下了。不过除此之外,还有一些非常重要的点,如果不注意,会造成巨大的认知负载,影响拆分的进度。这些点包括:
- 微服务拆分和新业务需求如何兼顾?
- 如何避免其他团队的改动影响我们的改造?
- 一个API如果几个月还改不完怎么办?
- 数据所有权拆分完成后,如何做数据迁移?
- ……
这一讲,我们就来看看这些问题如何解决,权且看做是对前面三讲的查缺补漏吧。
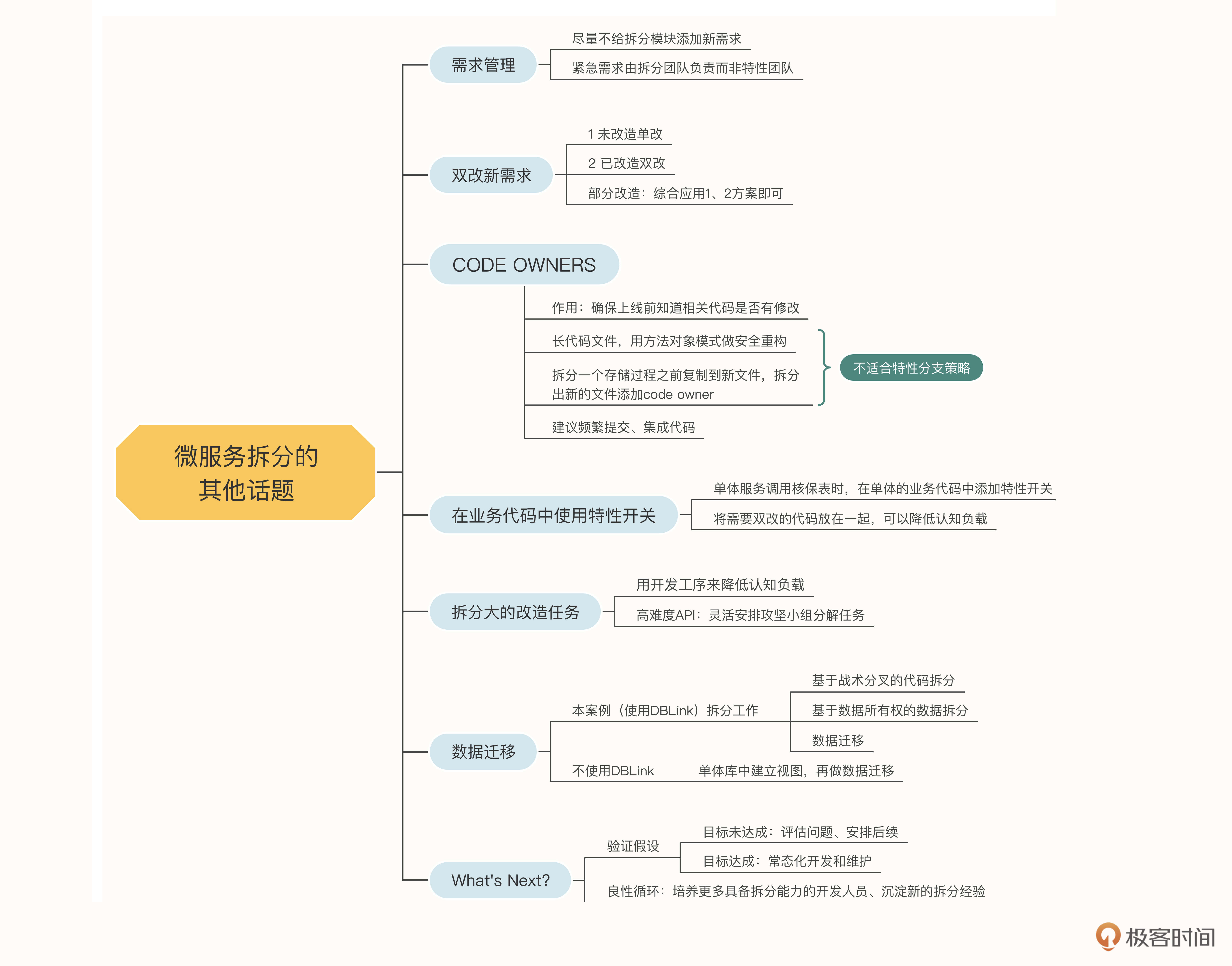
需求管理
我们知道,系统都是在不断向前发展的,即使遗留系统也不例外。那么当团队正在如火如荼地推进微服务拆分的时候,又有源源不断的新需求要上线,这时候应该怎么办呢?
我们在拆分初期最重要的一件事,就是要和业务方协商好,尽量不要给拆分的模块添加新的需求。比如我们要拆分核保服务,那么就尽量在拆分期间不要添加核保相关的新需求。否则,拆分工作就会变得相当麻烦。
如果新的需求交给拆分团队之外的特性团队去开发,由于他们并不熟悉拆分团队的工作内容和进展情况,会造成严重的代码冲突,团队之间沟通协作的成本也相当高。而如果新的需求交给拆分团队来做,又会减缓拆分团队的开发进度。
当然,尽量不添加新需求并不代表一定不能添加。当需求十分紧急,优先级高于微服务拆分的时候,还是要添加的。这时候,我的建议是由拆分团队负责这个新需求的开发,避免和其他团队的沟通协作,以降低认知负载。
双改新需求
那么,拆分团队应该如何开发这个高优先级的业务需求呢?如何兼顾业务开发和拆分任务呢?
不要慌,由于我们使用了战术分叉和细粒度开关,面对需求和改造冲突的时候,可以做到丝滑地切换。
我们首先要分析一下,这个需求需要改动哪部分代码。主要有以下三种情况:
1.需要改动的代码还没有在微服务中改造。这是最理想的情况,只需要在单体服务中开发需求即可,然后用单体中的新代码覆盖核保服务中的旧代码。
2.需要改动的代码已经在微服务中改造完毕。这时候稍微麻烦一些,需要同时修改单体服务和微服务两部分代码,来实现这个需求,也就是“双改”。这样可以保证在开关打开或关闭的情况下,需求都能被满足。
3.需要改动的代码部分已经改造,部分还没有改造。这也没有什么,综合应用上面两种方案,对已经改造的部分进行“双改”,没有改造的部分“单改”即可。
对于需要全部或部分“双改”的需求,测试人员需要记住的是,一定要同时测试和对比开关打开和关闭两种情况,只有行为一致且正确才能通过。
CODE OWNERS
除了新需求,还有一种潜在的风险值得引起注意,就是单体中的核保代码很有可能被其他团队修改。如果我们不能在上线之前知道代码被修改了,就会导致开关打开和关闭的行为会不一致,造成问题。
如何在上线之前知道这件事呢?我们前面的课程说过,在遗留系统现代化之前,要通知所有干系人我们即将开始的工作,一方面是向业务方展示我们的工作以及即将产生的价值,另一方面也是让其他开发团队知道我们正在做的事情,修改这部分代码时需要通知我们。
当然,人的记忆始终是不靠谱的,要想真正做到没有遗漏,需要一些自动化机制来确保万无一失。很多基于Git的源代码管理工具,都会提供Code Owner功能,这样的功能就能帮我们实现自动化机制。
当相关的代码被修改时,它会根据配置,自动将一些人加为Pull Request(PR)的评审人。比如下面这行配置,当核保目录下的代码发生修改时,我就会成为PR的评审人,绝不会漏掉任何一行修改。
不仅是我们在改造的核保代码,有时候我们也会修改与其他模块公用的代码,这些也要加上Code Owner。这时可以将前面的路径设置为文件名。
然而遗留系统的代码往往动辄几千行,这样的文件被修改了,我们被迫去review,结果看了半天发现与核保业务半毛钱关系都没有,这就让人很沮丧了。这时候有一个小技巧,可以帮助我们减少review的工作量。
对于很长的代码文件,我们可以先进行安全重构,应用方法对象模式(可以回顾第九节课),把要修改的代码提取成一个方法,再移动到一个类中。然后在新类中将方法复制一份,在其中一个方法上实现我们的改造,用于开关打开的时候调用;另一个方法保持原样,用于开关关闭的时候。然后对新的文件添加code owner。其他开发人员只有在修改我们提取出来的新文件时,才需要我们来review,这样就极大地降低了工作量。
不仅是代码,存储过程也可以采用同样的方式。在拆分一个存储过程之前,先把它复制到一个新的SQL文件中,并只对这个新文件添加code owner。
但你会发现,这种方法不适用于特性分支的分支策略。如果我们的拆分任务,都是在特性分支上开发的,完成之后才提PR合并代码,那么别人可能已经对你改造的API做了修改,而且这时合并代码不会引起任何冲突。而你的code owner配置也刚刚合并上去,别人的修改不会自动通知你。
因此要想很好地使用code owner技巧,以及更好地与其他团队合作,就必须频繁地提交代码,和其他团队的代码彼此频繁地集成。
在业务代码中使用特性开关
我在课程中曾经无数次提到过特性开关,像这个案例这样使用绞杀植物模式,通过反向代理中的开关来控制访问哪个API;或者在没有测试的保护下,使用扩张-收缩模式重构代码,通过代码内部的开关来实现A/B测试。
在微服务拆分的时候,我们有时也需要在代码内部使用开关,来控制使用新、旧哪部分代码。
我们要彻底将核保数据库拆分出去,就要让数据各归其主。前面课程里我们主要讲了原核保模块中的代码对非核保表的所有权的释放。除此之外,单体中的其他模块还有不少代码在访问核保的数据表,这部分数据的所有权同样需要处理,但处理后的代码仍然留在单体服务中,不需要拆分出去。
这时,我们仍然可以使用反向代理来控制新旧代码的分发。只不过在开关打开的时候,反向代理仍然会重定向到单体服务内部,一个我们复制出来的API中(这个API甚至很可能和原API位于同一个controller类),而不再是重定向到核保服务中。
而且,虽然我们在项目初期和业务方达成一致的是,尽量减少核保模块的业务变更,但这并不包括其他模块。因此单体中各个模块业务的需求变更可能会很频繁。
如果一个API的需求发生了变更,而我们又对它添加了API级别的开关,那么双改和code owner的工作量都会非常巨大。有没有办法减少这部分工作量呢?当然有。我们可以把开关的判断放在需要改造的地方,也就是业务代码中,让需要双改的代码紧紧挨着,这样一来认知负载就大大降低了。
比如单体服务中的理赔模块有一个提交二次核保的功能,它会直接向核保的表中插入数据。我们在改造这个API时,自然是希望将插入核保数据的代码替换成调用核保服务的某个API,但这个理赔API如何实现增量地交付呢?也就是说,一旦发现改造的代码出现了bug,应该如何做到及时回退呢?
// ClaimController.java - 理赔API
public void applyUnderwrite() {
// claim = 理赔
ClaimDao claimDao = new ClaimDao();
claimDao.updateClaim();
UnderwriteApplicationDao underwriteApplicationDao = new UnderwriteApplicationDao();
underwriteApplicationDao.insertUnderwriteApplication();
}
我们可以在需要改动的位置引入开关:
public void applyUnderwrite() {
ClaimDao claimDao = new ClaimDao();
claimDao.updateClaim();
if (CLAIM_APPLY_UNDERWRITE_TOGGLE_ON) {
// 当开关打开的时候,调用核保服务
UnderwriteServiceProvider underwriteServiceProvider = new UnderwriteServiceProvider();
underwriteServiceProvider.applyUnderwrite();
}
else {
// 当开关关闭的时候,仍然访问单体库中的核保表
UnderwriteApplicationDao underwriteApplicationDao = new UnderwriteApplicationDao();
underwriteApplicationDao.insertUnderwriteApplication();
}
}
这种方法也并不是十全十美的,因为当代码异常复杂的时候,一个方法的不同位置可能会引入很多开关判断。而且如果需要前后挪动代码,很有可能判断开关不同状态的代码会分散到不同的位置,这时就会显得有些失控了:
public void applyUnderwrite() {
ClaimDao claimDao = new ClaimDao();
claimDao.updateClaim();
if (CLAIM_APPLY_UNDERWRITE_TOGGLE_ON) {
UnderwriteServiceProvider underwriteServiceProvider = new UnderwriteServiceProvider();
underwriteServiceProvider.applyUnderwrite();
}
// 其他代码
// ...
// 判断开关关闭的代码与判断开关打开的代码距离很远
if (!CLAIM_APPLY_UNDERWRITE_TOGGLE_ON) {
UnderwriteApplicationDao underwriteApplicationDao = new UnderwriteApplicationDao();
underwriteApplicationDao.insertUnderwriteApplication();
}
}
面对这种情况,我们就需要在团队内部展开讨论,是灵活一点针对不同复杂度的API采用不同的开关策略(即复杂的API在反向代理中加入开关,简单的API在改动处加入开关)?还是保持一致的开关策略从而避免混乱?我们应该把这个决定权交给团队的成员,而团队成员的判断依据则应该是,对自己来说哪种方式的认知负载更低。
拆分大的改造任务
前面我们讲过用开发工序来降低认知负载,就是因为一个改造任务(比如改造一个API)要涉及很多方面,要梳理业务流程、确定改造重点、制定改造方案、实施改造方案、本地验证等等,把任务拆解成工序,可以帮助我们聚焦当前的小任务,降低认知负载。
在我们之前的设计中,一个API的改造任务是由一个开发人员完成的。但遗留系统中往往存在一些难度非常高的API,不但涉及大量的代码依赖,而且代码和存储过程的深处,还存在着大量的数据库表依赖。这样的API很可能一两个月都改造不完。
这时候我们要灵活安排,由若干开发人员组成一个攻坚小组,指定一个owner来负责这个API的交付。他将组织组内人员开展讨论、制定方案、拆分任务、分配工作,将一个大的改造任务,拆解成若干小的、可以在几天时间内完成的小任务。比如一个API可能包含10处需要解耦的地方,就可以拆分成10个小任务。等这些小任务都开发完毕,owner负责将代码集成,并进行内测。
这么做的目的除了降低认知负载,也是为了能够更快速地完成一些事情,得到一些正向反馈,避免一个人长时间地耗在一个大任务上,消耗着体力,也消磨了意志。
值得注意的是,这时拆分的小任务是无法作为增量独立交付的,需要整体大任务完全改造完毕后一起交付。其实也不是完全不能独立交付,只是代价比较大,需要引入很多更细粒度的开关,引入不必要的认知负载。
数据迁移
当所有的API都已经改造完毕,数据的所有权都各自就位后,在我们的案例中,还剩下一件事需要做,就是数据迁移,把当前位于单体数据库中的与核保业务相关的表,以及需要冗余到核保库中的表,都迁移到核保数据库中。
由于我们使用了DBLink,因此在拆分API时不需要考虑数据迁移,而只需要在单体数据库中先建立视图,再在核保数据库中建立同义词,指向单体库中的视图即可:
-- 在单体数据库中创建被保人视图
CREATE OR REPLACE VIEW V_UNDERWRITE_INSURED AS
SELECT NAME, GENDER, DATE_OF_BIRTH, SOCIAL_SECURITY_NO
FROM TBL_CUSTOMER C, TBL_UNDERWRITE_APPLICATION U
WHERE C.ID = U.INSURED_ID
-- 在核保数据库中创建同义词
CREATE SYNONYM V_UNDERWRITE_INSURED
FOR V_UNDERWRITE_INSURED@monolithLocation
这样我们就把整个拆分工作分成了三个部分:基于战术分叉的代码拆分、基于数据所有权的数据拆分以及数据迁移。其中代码拆分和数据迁移是可以在一个迭代中做完的,而数据拆分则是逐个API在多个迭代中增量交付的。
这时我们的数据在物理上仍然位于单体数据库中,当所有API改造完成后,就要在最后一个迭代中做数据迁移了。
迁移的脚本其实还是非常简单的,与建立视图的脚本十分类似,这里就不再赘述了。
如果你的数据库无法使用DBLink,在拆分数据所有权时,可以在单体库中建立这种视图,让核保服务的代码仍然访问单体数据库中的核保表和其他表的视图,然后再做数据迁移即可。
这是我们发现的认知负载最低的数据拆分和迁移方案。
What’s Next?
当迁移了数据之后,我们的微服务拆分就完成了。接下来该做些什么呢?
短期内,你需要根据上线后的数据,验证在项目初期所制定的假设:看看核保业务的响应力和吞吐量是否有了提升,是否达到了当初制定的目标。
如果没有达到目标,我们需要评估一下是哪里的问题,是否需要后续的工作。比如,我们虽然拆分出了微服务,但是秉承一次只做一件事的原则,并没有对代码做任何重构,代码的认知负载仍然很高,会成为影响需求响应力和吞吐量的罪魁祸首。那么后续就要继续对代码做重构,以及设计领域模型。
如果达到了目标,核保服务就可以进入常态化开发和维护的节奏了。可以让拆分团队留下一部分人维护这个服务,组成一个业务流团队。另一部分人因为有了拆分经验,可以组成一个赋能团队,去带领另外一个业务流团队,拆分下一个服务。
这样,每个精益切片做下来,整个项目组就会多出一些具备拆分能力的开发人员,总结出新的拆分经验。整个遗留系统就从一个架构越来越混乱、人员越来越挣扎的恶性循环,变成了架构越来越健康、人员能力越来越强的良性循环。
小结
又到了总结的时候,今天我们学习了在改造的过程中需要注意的一些事项,既包括需求管理相关的,也包括用技术手段来避免沟通协作时产生的纰漏,还包括将大任务拆小,以及最后逃不过的数据迁移。
你会发现,我们的大多数解决方案和技巧都是为了降低认知负载。比如由拆分团队来负责该模块高优先级需求的开发,表面上看拆分团队的工作量似乎变大了,但由于避免了跨团队的沟通协作,其实是降低了认知负载。再比如拆分出新的文件添加code owner、对于复杂任务继续拆分,以及通过DBLink和视图延迟数据迁移,都很好地贯彻了以降低认知负载为前提这个原则。
到目前为止,我们用四节课的内容学习了拆分微服务时的各种问题和解决方案。其实,每次增量演进时,都需要测试人员验证我们的改造是否正确,是否和改造之前完全一致。下节课我们就来聊聊这方面的内容。
思考题
感谢你学完了今天的课程,今天的思考题请你来聊聊你是否在项目中做过微服务拆分?你有没有什么经验和技巧想要分享呢?
期待你的分享,如果你觉得这节课对你有帮助,别忘了分享给你的同事和朋友,我们下节课见。
- aoe 👍(4) 💬(1)
老师专栏上架前不久,我就开始了改造送礼物的接口。直到今天还在写功能测试,在这期间植物绞杀、分离关注点帮了很大的忙,感谢老师!
2022-06-07 - 子夜枯灯 👍(2) 💬(1)
认真学习了每一节课,收获满满。感谢作者和编辑的分享。
2022-06-03 - chon 👍(0) 💬(1)
其中代码拆分和数据迁移是可以在一个迭代中做完的,而数据拆分则是逐个 API 在多个迭代中增量交付的。 而后面一段又说:这时我们的数据在物理上仍然位于单体数据库中,当所有 API 改造完成后,就要在最后一个迭代中做数据迁移了。 这两句话是不是有矛盾?按照第一句的说法,代码拆分也是要在最后一个迭代才做了?难道代码拆分不应该是一开始就要做了吗?
2022-06-03