大咖助阵 存储过程的拆分锦囊
你好,我是姚琪琳。我在课程第二十三节课讲到了一些存储过程拆分的通用方法。你读后一定意犹未尽吧。那些方法、技巧可能与你的系统接近,但就是差那么一点儿无法解决实际的问题。比如存储过程过于复杂,根本不可能替换成API调用。那今天我就邀请我的同事黄炳洪,为你分享一下存储过程拆分的高阶技巧,希望对你有所帮助。
你好,我是黄炳洪(如果你愿意,可以叫我大饼)。
作为 Thoughtworks 中国区的一名技术顾问,我近年来专注于敏捷软件开发、团队赋能、遗留系统现代化等领域。很高兴受邀和你分享我和团队的一些经验。
在我们帮助客户对遗留系统做微服务化改造的过程中,存储过程是大伙儿最为头疼的一个问题。
这是因为在一些遗留系统里,存储过程是其重要的组成部分,大量的业务逻辑写在存储过程中。而存储过程的拆分,跟上层代码的拆分有着诸多不同,难度甚至高好几个等级。
为什么说它难以拆分呢?原因有以下四个方面:
1.存储过程中的 SQL 直接读写多个业务的表,表与表之间耦合紧密,不易拆分。
2.存储过程的业务逻辑分布在 SQL 语句的 select、join、where 部分中,分析工作量大。
3.主流 IDE 对存储过程的重构、调试、自动化测试的支持非常有限,因此开发工作大量依赖手工修改,出错风险大。
4.熟悉存储过程的开发人员数量比熟悉高级开发语言的少,导致人手不足、开发进度缓慢。
因此,开发团队对此望而生畏、谈虎色变。在没有高效解决方案的情况下,面对风险和成本,技术决策者甚至无法下定决心开始遗留系统的拆分改造。
今天,我会为你分享几个存储过程复杂的拆分场景,以及对应的拆分手法,希望这些手法能够成为你的锦囊妙计,让你从容应对存储过程剥离过程中的大部分挑战。
实战模拟
我们还是借用姚琪琳老师《遗留系统现代化实战》里,车险遗留系统的案例。
核保业务作为微服务化改造的试点业务,你所在的团队不仅要把上层业务代码拆分到独立的代码仓库中,还需要把核保业务相关的数据库对象也拆分到独立的 Oracle 数据库新实例中。作为团队的核心骨干,你负责最有挑战的一部分,把数据库存储过程这部分剥离出来。
锦囊一:新增历史表
接到任务后,我们首先要对系统的存储过程做个梳理,分成两大类:核保的存储过程与非核保的存储过程。这两类存储过程里,都有访问对方表的情况。
对于非核保的存储过程访问核保表的情况,你发现大部分都是读的场景,并且绝大部分读的 SQL 语句里,都加上了核保完成的限定条件,这是为什么呢?
业务间的交互常常是有严格的时序的。例如投保业务申请核保后,投保内部流程会暂停操作,甚至可能会通过添加乐观锁的方式,来避免其他业务影响投保的业务数据。直到核保完成后,投保才会拿着核保的处理结果,接着继续投保的操作(如下图)。在这种场景下,新增历史表就派上用场了。
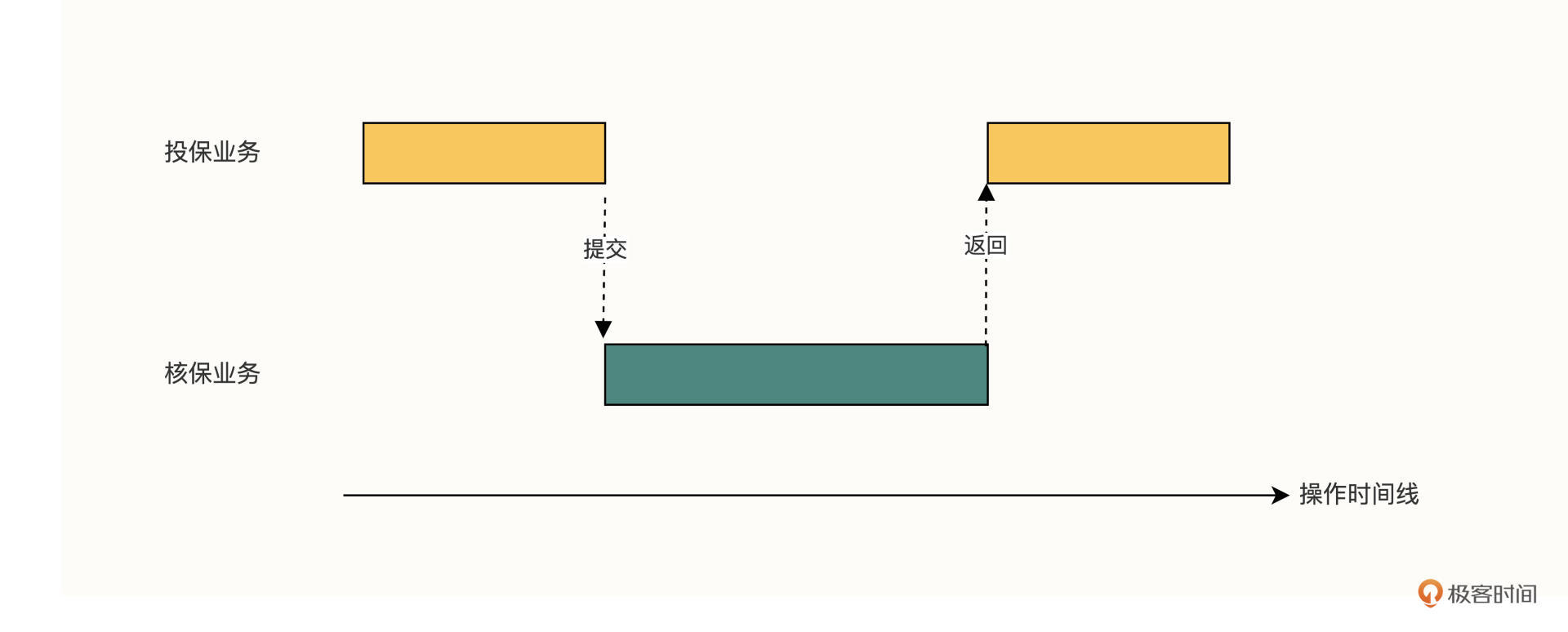
在剥离之前,投保的很多存储过程读取了核保的表,其所在位置离 Java 端调用点非常深,因此用 Java 重写整个调用链的代价很高。
这样的问题怎么解决呢?其实在很多情况下,投保只关心核保的处理结果数据,对核保的处理过程数据是不关心的(核保也不希望把自己的业务过程数据暴露给其他服务——“我自己内部的事情,凭啥要让别人看得一清二楚?!”)。这样的存储过程通常是在核保完成后才会被调用,也就是在上图右侧的黄色方框区域。
应对这种场景,我们可以引入一个历史表,通过这四步来实现从投保的存储过程里移除对核保表的直接访问。
- 第一步,创建历史表:在原来的单体数据库中新增一个核保的历史表,包含投保等业务需要的字段;
- 第二步,新增核保历史:投保模块在申请核保时,往核保历史表中新增一条历史记录,记录此次申请核保的基本信息;
- 第三步,更新核保历史:核保处理完毕时,将核保产生的、且投保关心的字段更新到对应的历史记录上;
- 第四步,读取核保历史:在投保存储过程读取原核保表的地方,改为读取核保历史表。
这个历史表有两个作用,记录投保申请了多少次核保,以及记录核保对投保每次申请的处理结果。
为什么要这样设计呢?我带你分析分析,对于投保来说,记录投保申请了多少次核保,通常可以帮我们做重复提交校验。
因为这样的校验需求只关心是否申请过核保,并不关心核保的处理结果,这时候只需要查历史表即可。至于记录处理结果就是常见的需求了,投保只关心核保的处理结果,并不关心核保的处理过程。
因此如果我们发现存储过程的意图是重复校验、或者查询处理结果,那就可以考虑把对核保表的读取改为对核保历史表的读取。
我想再次强调的是,我们需要根据拆分前已有 SQL 涉及到的核保表和字段,来决定创建哪些历史表及其字段,历史表有可能不止一个;历史表里的字段名和类型,要与原核保表的字段保持一致。这样在修改存储过程的 SQL 时,只需替换核保表的名字为历史表的名字即可,不需要修改 select、where、order by 的字段,改动的成本非常低。
举个例子,下面这段 SQL 是在投保的存储过程中,查询某一次核保申请的核保结论:
SELECT B.CONCLUSION -- 核保结论
INTO V_UW_CONCLUSION -- 存储过程中定义的临时变量
FROM TBL_POLICY A, TBL_UNDERWRITE_APPLICATION B -- A 是投保单表,B 是核保申请表
WHERE A.POLICY_ID = B.POLICY_ID -- 投保号
AND B.SOURCE = 'NEW_ORDER' -- 为投保单而申请的核保
AND B.STATUS = 'FINISHED'; -- 核保状态是“已处理完成”
引入核保历史表后,我们只需把核保表 TBL_UNDERWRITE_APPLICATION 换成核保历史表 TBL_UNDERWRITE_HISTORY 即可:
SELECT B.CONCLUSION
INTO V_UW_CONCLUSION
FROM TBL_POLICY A, TBL_UNDERWRITE_HISTORY B -- 重点是这里,换成了核保历史表
WHERE A.POLICY_ID = B.POLICY_ID
AND B.SOURCE = 'NEW_ORDER'
AND B.STATUS = 'FINISHED';
历史表和第二十二节课中的冗余数据类似,都可以看成是同一个领域概念在不同上下文中的映射。
不同的是,核保库中冗余的保单、客户等数据,是在核保过程中不会发生改变的快照数据,核保的业务只关心这种类型快照数据;而单体中冗余的核保历史,是在核保完成后不会发生改变的数据,单体中的投保等业务只关心这种类型的快照数据。
你也许会担心它冗余了数据,或者引入了额外的表操作。但如果考虑到对模型解耦和存储过程剥离带来的价值,我觉得还是值得一试的。
锦囊二:套壳法
虽然大多数情况下,我们可以通过读取历史表的方式,让其他业务不再直接读取核保的表,但总会有个别存储过程不符合历史表的适用场景。
比如说保费计算的存储过程用到了核保的表,核保在其处理过程中也会调用这个功能,此时核保业务流程还没有处理完毕,数据都还在核保的表里,尚未更新到历史表。
这时,我们可以让保费计算的 Java 端在调用其存储过程前,先调用核保的 HTTP 接口,实时获取所需的数据,然后通过给存储过程增加入参的方式,将核保的数据传进去,用这个方法来代替对核保表的直接访问。
这就是姚琪琳老师讲过的“引入对象类型来进行参数传递”手法(你可以回顾专栏第二十三节课)。这里有个需要注意的细节是,为了确保代码能回退,我们需要把存储过程复制一份。
不过代码复制也有隐患:如果在剥离过程中,被复制代码对应的需求发生了变化,那么代码需要修改两份,这样会增大我们的维护成本。
为了降低维护成本,我们可以对存储过程稍作调整,以便让剥离前后的调用点,尽可能多地访问同一块代码,只让少部分代码有所不同。在这种情况下,只有少部分代码的需求发生变化,才需要双改。具体步骤如下:
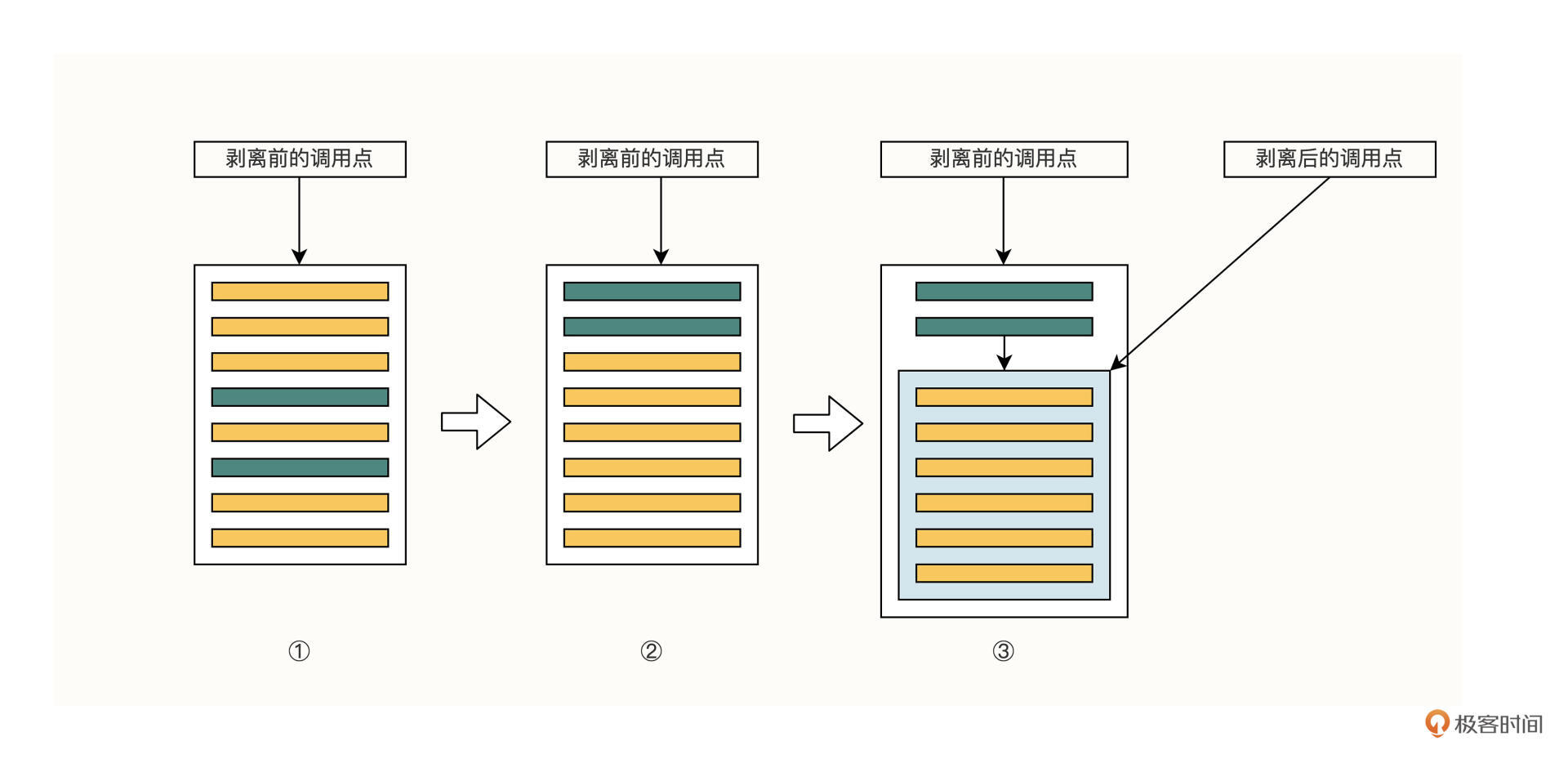
1.确定哪些表的操作是要从存储过程剥离的,如上图第一步对应的绿色部分。
2.将待剥离的操作挪到存储过程的前部,如上图第二步。
3.将不剥离的操作封装到一个新的存储过程中,已剥离部分的数据,通过入参的方式传入到新的存储过程中,如上图第三步。
4.剥离后的调用点,先通过 HTTP API 获取绿色部分的数据,传入并调用新的存储过程;而剥离前的调用点,依旧调用之前的存储过程。
我们把这个手法称作“套壳法”。我们新建了一个存储过程,当作一个壳,把保费计算的操作封装在一起,放在壳里,壳里的内容对应着图片第三步的黄色区域;然后我们把非保费计算的操作挪到壳外,也就是图片第三步的绿色部分。
等剥离验证阶段结束后,确认剥离后的调用点提供的功能没问题了,我们就可以把剥离前的调用点、剥离前的存储过程、以及操作核保表的代码删除掉,完成对原有存储过程的剥离。
前面讲到的新增历史表跟套壳法,这两种手法适合用在读数据的场景。接下来我们再来看看,应对写数据的场景有哪些好用的手法。
锦囊三:用异步任务代替修改操作
有一些存储过程会对核保的表执行修改操作,比如修改状态、设置标志位之类。
如果是 Java 直接调用的存储过程,那我们可以考虑把修改操作移到 Java 端处理。但如果修改操作与 Java 端之间隔着好几层存储过程,这样挪到 Java 端需要修改的存储过程就很多了,甚至调用这些存储过程的不同 Java 端也要跟着修改,我们要付出很高的修改成本。
这时,我们可以考虑把这些存储过程里同步的修改操作改为异步操作。不同业务之间,并不一定处处要求强一致性,弱一致性有时候也是可以接受的。换句话说,在处理完本业务的操作后,通知一下其他业务可以开始处理它们的修改操作了,然后本业务这边就可以继续自己的操作,其他业务那边可以稍晚些时候开始处理。
具体改造步骤如下:
1.新建一个异步任务表。
2.引入一个定时任务框架(如 QuartZ),能调用 Java 程序即可。
3.将存储过程中的修改操作,替换为往异步任务表里新增一条任务记录。
4.定时任务轮询异步任务表,调用 Java 程序,由 Java 程序通知对应的业务系统执行修改操作。
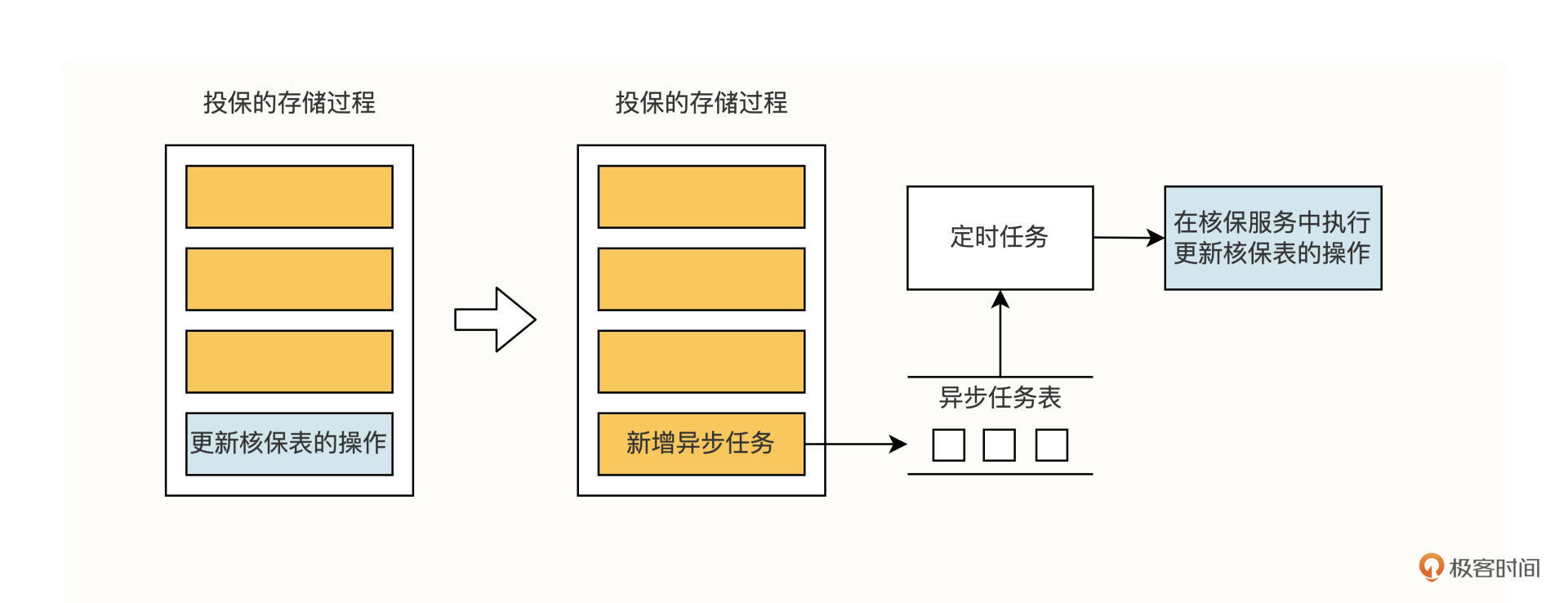
这样我们就通过异步任务,剥离了存储过程中对其他业务表的直接修改操作。
看到这儿,是不是觉得这个改造步骤有点眼熟?没错,在琪琳老师的专栏第二十三节课里,分享了“将同步API调用改为异步事件”的方法。二者都是用异步的方式,把隶属于不同业务的操作拆开。
不同的是,由 Java 端将同步 API 调用改为异步事件,是为了优化性能和简化重试;对于存储过程来说,它的职责是执行数据库操作,如果让它直接调用 HTTP API 或者直接触发事件,着实是勉为其难。
因此,我们通过插入异步任务的方式,让 Java 端帮助存储过程触发其他业务的操作。相当于是引入了一个中间层(数据库),中转了一下。
锦囊四:用临时表简化创建操作
还有一类写数据的场景十分常见,那就是数据的创建操作。数据的创建过程,常常包含着复杂的逻辑。例如申请核保时,需要从 m 张其他业务的表中读取数据,经过复杂的业务逻辑后,生成 n 张核保表的数据。
如果这个数据读取、数据组装、数据创建的过程,之前是在存储过程中实现的,那么我们通常的做法是在单体系统中用 Java 重写数据读取、数据组装的逻辑,然后通过 HTTP API 或者 MQ 把数据发给核保服务去进行数据创建。当要重写的逻辑十分复杂时,开发、验证的工作量就十分可观了。
可是我们真的需要冒着巨大的风险重写逻辑吗?未必。如果我们的 Java 程序能直接拿到存储过程里最终要写入到核保表里的数据,那 Java 程序就不用操心数据如何读取和组装了,岂不快哉!
这时候,就需要“临时表”出场了。拿核保申请表为例,我们可以这样操作:
第一步,创建一个事务级临时表 TBL_UNDERWRITE_APPLICATION_TMP,其表结构与 TBL_UNDERWRITE_APPLICATION 一模一样。
CREATE GLOBAL TEMPORARY TABLE TBL_UNDERWRITE_APPLICATION_TMP (
ID NUMBER(20) NOT NULL,
SOURCE NUMBER(2) NOT NULL,
POLICY_ID NUMBER(20) NOT NULL
-- 其他字段省略
)
接下来是第二步,我们要替换表名,将存储过程中对 TBL_UNDERWRITE_APPLICATION 表的 INSERT、UPDATE、SELECT 操作,改为对临时表 TBL_UNDERWRITE_APPLICATION_TMP 的操作。
修改前的代码如下:
INSERT INTO TBL_UNDERWRITE_APPLICATION (
ID, SOURCE, POLICY_ID -- 其他字段省略
)
SELECT V_UNDERWRITE_ID, V_SOURCE, POLICY_ID
FROM TBL_POLICY WHERE POLICY_ID = I_POLICY_ID -- I_POLICY_ID 是本次提交核保的保单 ID
修改后的代码将是这样的:
INSERT INTO TBL_UNDERWRITE_APPLICATION_TMP ( -- 这换成了往临时表插入数据
ID, SOURCE, POLICY_ID
)
SELECT V_UNDERWRITE_ID, V_SOURCE, POLICY_ID
FROM TBL_POLICY WHERE POLICY_ID = I_POLICY_ID
然后进入第三步,在临时表的 INSERT 操作后面,我们需要新增一段逻辑,将临时表里的数据写入到原来的 TBL_UNDERWRITE_APPLICATION 中。
这么做是因为临时表只是数据的暂存地,最终还是需要把数据从临时表中取出来,持久化到真正的物理表中。
INSERT INTO TBL_UNDERWRITE_APPLICATION (
ID, SOURCE, POLICY_ID
)
SELECT ID, SOURCE, POLICY_ID
FROM TBL_UNDERWRITE_APPLICATION_TMP WHERE ID = V_UNDERWRITE_ID
之后是第四步,我们让Java 代码调用这段存储过程后,查询临时表 TBL_UNDERWRITE_APPLICATION_TMP 取出其数据,通过 HTTP API 或 MQ 发送给核保服务。
最后一步,我们创建一个开关,用来切换核保数据真正的创建操作,是由第三步还是由第四步来执行。因为如果是用 Java 来执行,那么就不需要存储过程去创建数据了;如果不是用 Java 来执行,那依旧需要存储过程去创建数据。
临时表的创建步骤就是这样,我在后面画了一张流程图,帮助你理解引入临时表后,将要对代码做哪些改动。
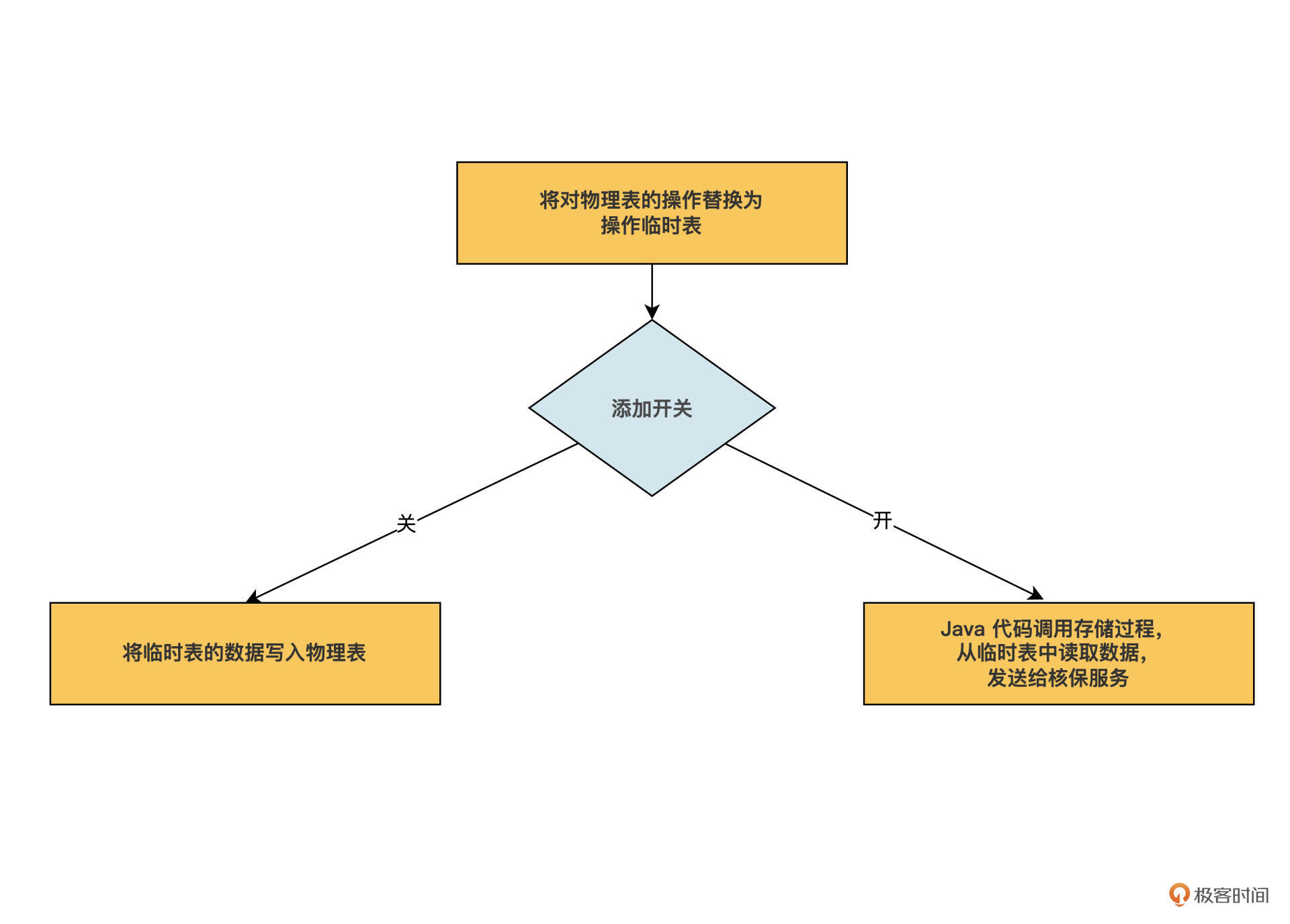
当临时表中的数据由存储过程写入到物理表,或者由 Java 发送给核保服务后,它们的使命就完成了。我们也不需要手动删除临时表中的数据,因为我们使用的是事务级临时表,当事务结束后,数据库会自动删除临时表中的数据,这还是挺省心的。
这里有个细节需要注意:如果需要在一个事务里提交多个核保申请的话,需要在读临时表的 SQL 语句里都加上核保申请 ID 的过滤条件,避免把临时表中其他的核保申请数据也读出来了。
这样一来,数据读取和组装操作还是由原存储过程实现,而 Java 端却能“坐享其成”,轻松拿到要创建的最终数据。对存储过程的改动,仅仅需要关注表名的替换是否完整、开关书写和配置是否正确即可。开发工作量很有可能从几十人天,骤降到几人天,收效十分显著。
小结
针对存储过程拆分,我今天给你分享了四个“锦囊”,分别是新增历史表、套壳法、用异步任务代替修改操作,以及用临时表简化创建操作。
为了方便你回顾、记忆,我特意准备了一张表格。你可以按照自己的需求,选择适合你项目的手法。
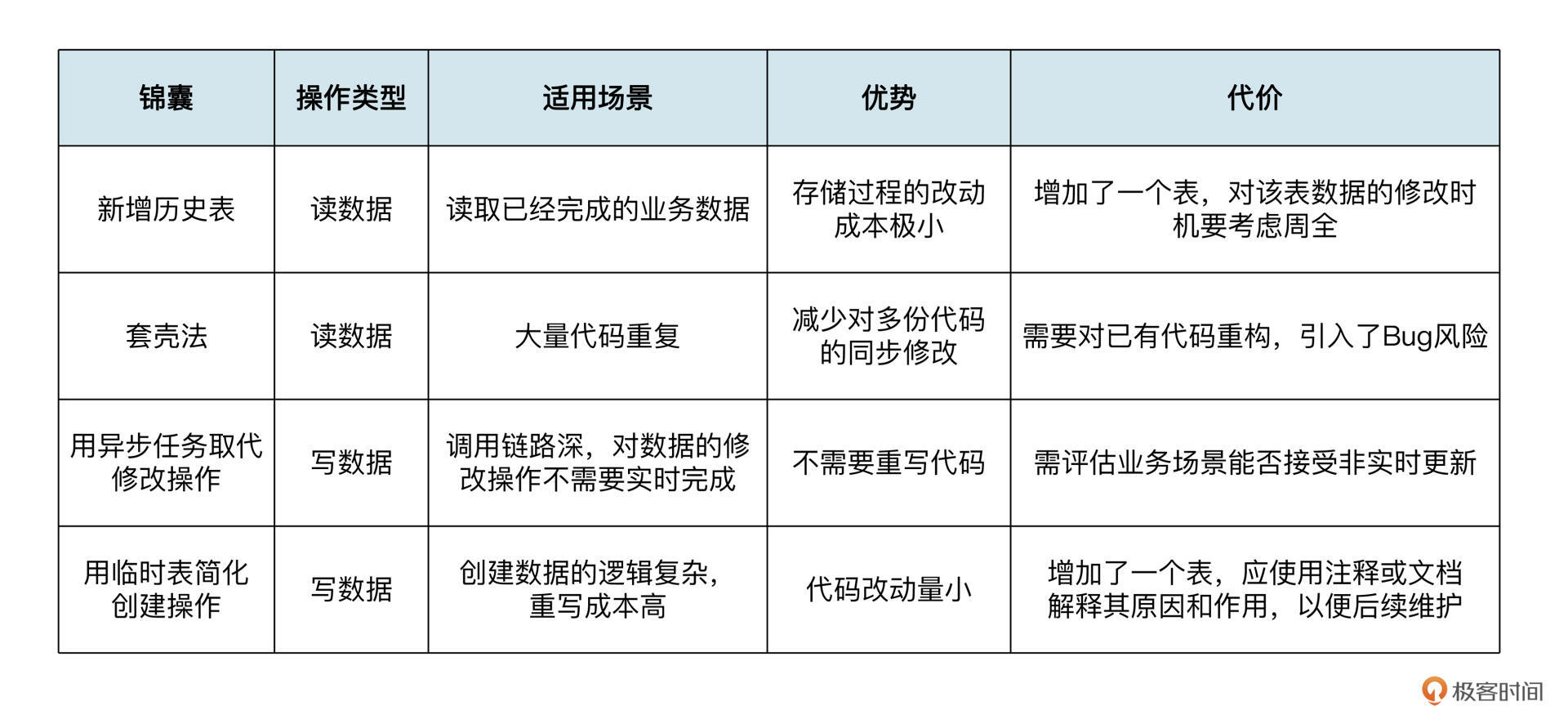
当我们掌握了这些手法,并能融会贯通之后,你再应对存储过程的拆分问题时,就能事半功倍。从我的经验来看,把存储过程里的疑难杂症分类梳理之后,“二八定律”会再次出现。大部分问题都有比较快捷方便的解决方案,只有少数特别复杂的场景需要大动干戈,投入“精英战队”专门攻坚。
即使上面这些手法不能完全实现你的目标,用好了这些也能简化你的问题。有了这些锦囊的加持,原先无法逾越的鸿沟,也能找到建桥铺路的方向,胜利的曙光就在眼前。
讨论题
我们使用套壳法,可以让 Java 端把存储过程中所需的数据通过参数传进来。但如果存储过程的调用链路很深,则需要给调用链路上的所有存储过程添加入参,把数据一层层传下去。这么一来,可能要修改很多存储过程,工作量和风险一下子就上来了。如果是你,会如何解决这个问题呢?
如果你觉得今天的内容对你有启发,欢迎你转发给更多同事、朋友,共同学习进步。
- aoe 👍(3) 💬(0)
还好,面试的时候不问存储过程,工作中大家也不写存储过程。庆幸没遇到有很多存储过程的系统
2022-06-23