25 使用阻塞I O和进程模型:最传统的方式
你好,我是盛延敏,这里是网络编程实战第25讲,欢迎回来。
上一讲中,我们讲到了C10K问题,并引入了解决C10K问题的各种解法。其中,最简单也是最有效的一种解决方法就是为每个连接创建一个独立的进程去服务。那么,到底如何为每个连接客户创建一个进程来服务呢?在这其中,又需要特别注意什么呢?今天我们就围绕这部分内容展开,期望经过今天的学习,你对父子进程、僵尸进程、使用进程处理连接等有一个比较直观的理解。
父进程和子进程
我们知道,进程是程序执行的最小单位,一个进程有完整的地址空间、程序计数器等,如果想创建一个新的进程,使用函数fork就可以。
如果你是第一次使用这个函数,你会觉得难以理解的地方在于,虽然我们的程序调用fork一次,它却在父、子进程里各返回一次。在调用该函数的进程(即为父进程)中返回的是新派生的进程ID号,在子进程中返回的值为0。想要知道当前执行的进程到底是父进程,还是子进程,只能通过返回值来进行判断。
fork函数实现的时候,实际上会把当前父进程的所有相关值都克隆一份,包括地址空间、打开的文件描述符、程序计数器等,就连执行代码也会拷贝一份,新派生的进程的表现行为和父进程近乎一样,就好像是派生进程调用过fork函数一样。为了区别两个不同的进程,实现者可以通过改变fork函数的栈空间值来判断,对应到程序中就是返回值的不同。
这样就形成了编程范式:
当一个子进程退出时,系统内核还保留了该进程的若干信息,比如退出状态。这样的进程如果不回收,就会变成僵尸进程。在Linux下,这样的“僵尸”进程会被挂到进程号为1的init进程上。所以,由父进程派生出来的子进程,也必须由父进程负责回收,否则子进程就会变成僵尸进程。僵尸进程会占用不必要的内存空间,如果量多到了一定数量级,就会耗尽我们的系统资源。
有两种方式可以在子进程退出后回收资源,分别是调用wait和waitpid函数。
函数wait和waitpid都可以返回两个值,一个是函数返回值,表示已终止子进程的进程ID号,另一个则是通过statloc指针返回子进程终止的实际状态。这个状态可能的值为正常终止、被信号杀死、作业控制停止等。
如果没有已终止的子进程,而是有一个或多个子进程在正常运行,那么wait将阻塞,直到第一个子进程终止。
waitpid可以认为是wait函数的升级版,它的参数更多,提供的控制权也更多。pid参数允许我们指定任意想等待终止的进程ID,值-1表示等待第一个终止的子进程。options参数给了我们更多的控制选项。
处理子进程退出的方式一般是注册一个信号处理函数,捕捉信号SIGCHLD信号,然后再在信号处理函数里调用waitpid函数来完成子进程资源的回收。SIGCHLD是子进程退出或者中断时由内核向父进程发出的信号,默认这个信号是忽略的。所以,如果想在子进程退出时能回收它,需要像下面一样,注册一个SIGCHLD函数。
阻塞I/O的进程模型
为了说明使用阻塞I/O和进程模型,我们假设有两个客户端,服务器初始监听在套接字lisnted_fd上。当第一个客户端发起连接请求,连接建立后产生出连接套接字,此时,父进程派生出一个子进程,在子进程中,使用连接套接字和客户端通信,因此子进程不需要关心监听套接字,只需要关心连接套接字;父进程则相反,将客户服务交给子进程来处理,因此父进程不需要关心连接套接字,只需要关心监听套接字。
这张图描述了从连接请求到连接建立,父进程派生子进程为客户服务。
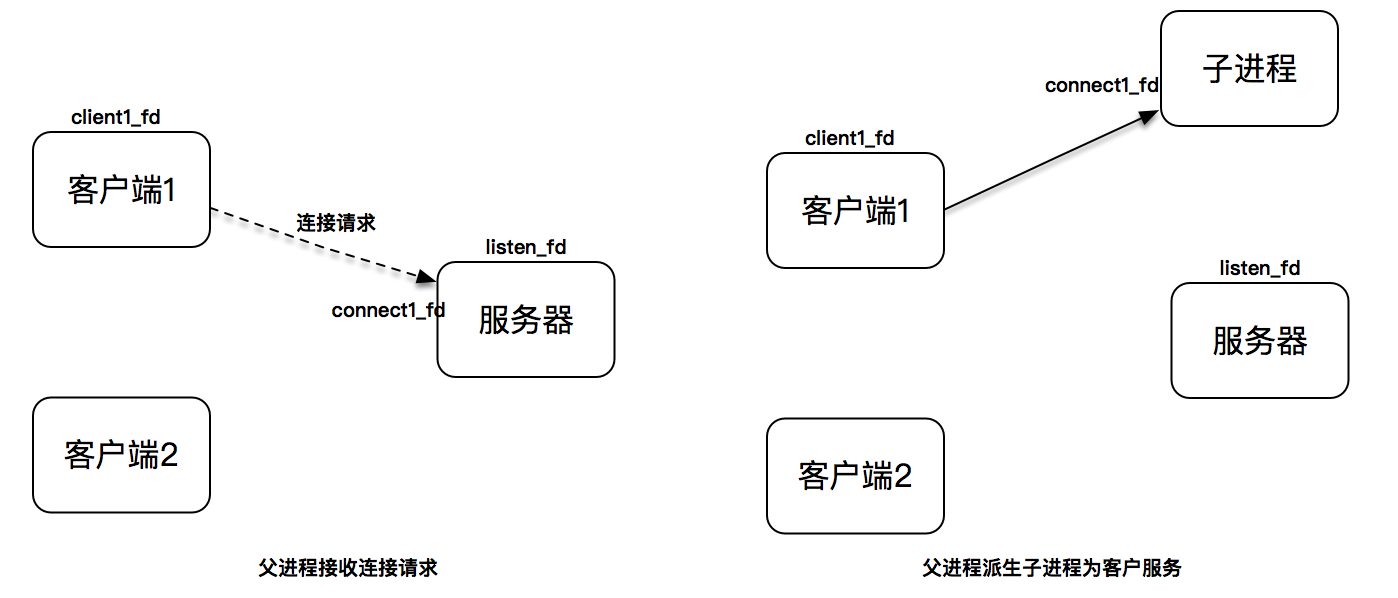 假设父进程之后又接收了新的连接请求,从accept调用返回新的已连接套接字,父进程又派生出另一个子进程,这个子进程用第二个已连接套接字为客户端服务。
假设父进程之后又接收了新的连接请求,从accept调用返回新的已连接套接字,父进程又派生出另一个子进程,这个子进程用第二个已连接套接字为客户端服务。
这张图同样描述了这个过程。
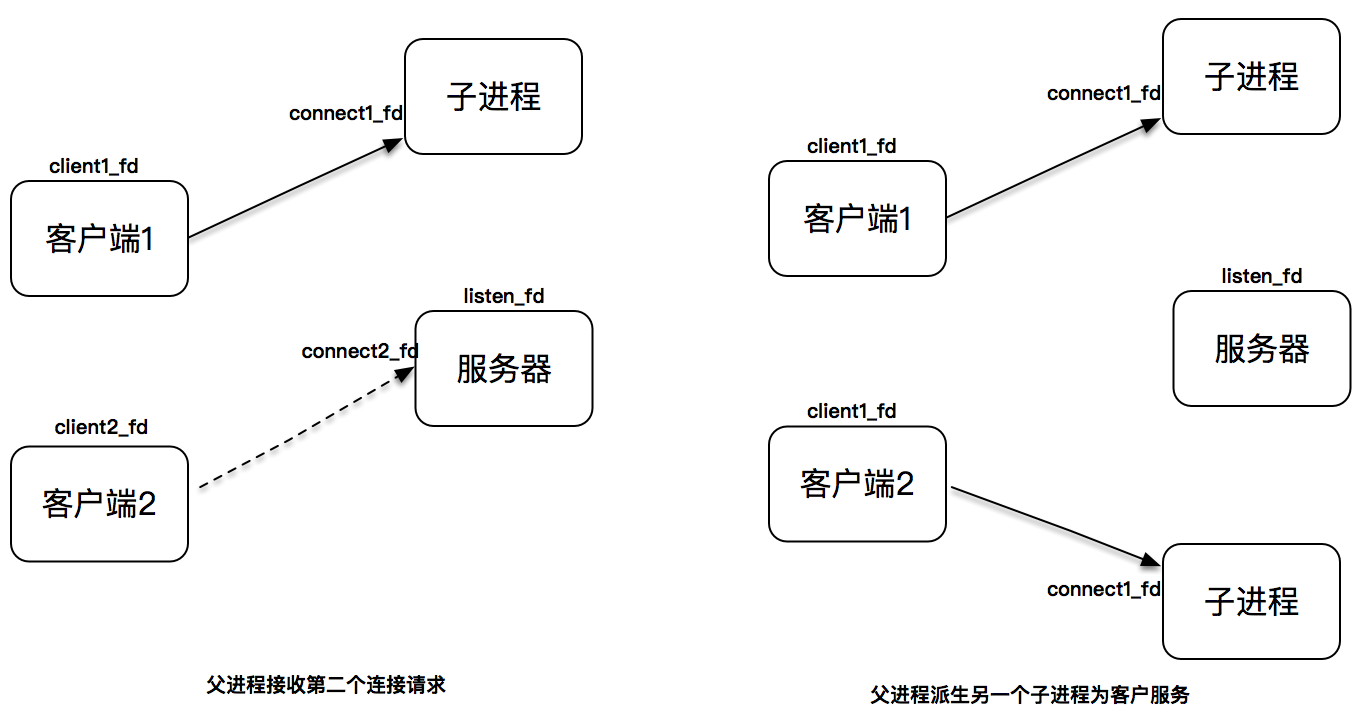 现在,服务器端的父进程继续监听在套接字上,等待新的客户连接到来;两个子进程分别使用两个不同的连接套接字为两个客户服务。
现在,服务器端的父进程继续监听在套接字上,等待新的客户连接到来;两个子进程分别使用两个不同的连接套接字为两个客户服务。
程序讲解
我们将前面的内容串联起来,就是下面完整的一个基于进程模型的服务器端程序。
#include "lib/common.h"
#define MAX_LINE 4096
char rot13_char(char c) {
if ((c >= 'a' && c <= 'm') || (c >= 'A' && c <= 'M'))
return c + 13;
else if ((c >= 'n' && c <= 'z') || (c >= 'N' && c <= 'Z'))
return c - 13;
else
return c;
}
void child_run(int fd) {
char outbuf[MAX_LINE + 1];
size_t outbuf_used = 0;
ssize_t result;
while (1) {
char ch;
result = recv(fd, &ch, 1, 0);
if (result == 0) {
break;
} else if (result == -1) {
perror("read");
break;
}
if (outbuf_used < sizeof(outbuf)) {
outbuf[outbuf_used++] = rot13_char(ch);
}
if (ch == '\n') {
send(fd, outbuf, outbuf_used, 0);
outbuf_used = 0;
continue;
}
}
}
void sigchld_handler(int sig) {
while (waitpid(-1, 0, WNOHANG) > 0);
return;
}
int main(int c, char **v) {
int listener_fd = tcp_server_listen(SERV_PORT);
signal(SIGCHLD, sigchld_handler);
while (1) {
struct sockaddr_storage ss;
socklen_t slen = sizeof(ss);
int fd = accept(listener_fd, (struct sockaddr *) &ss, &slen);
if (fd < 0) {
error(1, errno, "accept failed");
exit(1);
}
if (fork() == 0) {
close(listener_fd);
child_run(fd);
exit(0);
} else {
close(fd);
}
}
return 0;
}
程序的48行注册了一个信号处理函数,用来回收子进程资源。函数sigchld_handler,在一个循环体内调用了waitpid函数,以便回收所有已终止的子进程。这里选项WNOHANG用来告诉内核,即使还有未终止的子进程也不要阻塞在waitpid上。注意这里不可以使用wait,因为wait函数在有未终止子进程的情况下,没有办法不阻塞。
程序的58-62行,通过判断fork的返回值为0,进入子进程处理逻辑。按照前面的讲述,子进程不需要关心监听套接字,故而在这里关闭掉监听套接字listen_fd,之后调用child_run函数使用已连接套接字fd来进行数据读写。第63行,进入的是父进程处理逻辑,父进程不需要关心连接套接字,所以在这里关闭连接套接字。
还记得第11讲中讲到的close函数吗?我们知道,从父进程派生出的子进程,同时也会复制一份描述字,也就是说,连接套接字和监听套接字的引用计数都会被加1,而调用close函数则会对引用计数进行减1操作,这样在套接字引用计数到0时,才可以将套接字资源回收。所以,这里的close函数非常重要,缺少了它们,就会引起服务器端资源的泄露。
child_run函数中,通过一个while循环来不断和客户端进行交互,依次读出字符之后,进行了简单的转码,如果读到回车符,则将转码之后的结果通过连接套接字发送出去。这样的回显方式,显得比较有“交互感”。
实验
我们启动该服务器,监听在对应的端口43211上。
再启动两个telnet客户端,连接到43211端口,每次通过标准输入和服务器端传输一些数据,我们看到,服务器和客户端的交互正常。
$telnet 127.0.0.1 43211
Trying 127.0.0.1...
Connected to localhost.
Escape character is '^]'.
afasfa
nsnfsn
]
telnet> quit
Connection closed.
$telnet 127.0.0.1 43211
Trying 127.0.0.1...
Connected to localhost.
Escape character is '^]'.
agasgasg
ntnftnft
]
telnet> quit
Connection closed.
客户端退出,服务器端也在正常工作,此时如果再通过telnet建立新的连接,客户端和服务器端的数据传输也会正常进行。
至此,我们构建了一个完整的服务器端程序,可以并发处理多个不同的客户连接,互不干扰。
总结
使用阻塞I/O和进程模型,为每一个连接创建一个独立的子进程来进行服务,是一个非常简单有效的实现方式,这种方式可能很难满足高性能程序的需求,但好处在于实现简单。在实现这样的程序时,我们需要注意两点:
- 要注意对套接字的关闭梳理;
- 要注意对子进程进行回收,避免产生不必要的僵尸进程。
思考题
给你出两道思考题:
第一道,你可以查查资料,看看有没有比较著名的程序是使用这样的模式来构建的?
第二道,程序中处理SIGCHLD信号时,使用了一个循环来回收处理终止的子进程,为什么要这么做呢?如果不使用循环会有什么后果?
欢迎你在评论区写下你的思考,我会和你一起交流,也欢迎把这篇文章分享给你的朋友或者同事,一起交流一下。
- rrbbt 👍(18) 💬(4)
文章开头部分,应该是线程是程序执行的最小单位吧。进程是cpu分配资源的最小单位。还有,每个线程有一个程序计数器,不是每个进程。
2019-11-08 - Kepler 👍(14) 💬(3)
这种古老的多进程方式来处理io应该是apache服务器了吧,新型的redis, nginx都是事件驱动epoll来实现的; 采用while循环是为了回收所有已退出子进程的状态。
2019-10-11 - 刘丹 👍(13) 💬(1)
请问主进程结束的时候没有关闭listener_fd,子进程结束的时候没有关闭fd,是让操作系统在关闭进程时自动回收资源吗?
2019-10-04 - Simple life 👍(1) 💬(1)
这种阻塞进程模型与单进程accept+处理有什么区别?仅仅为了环境隔离?效率上并没有带来提升,还增加了上下文切换的操作,感觉有点得不偿失
2020-08-03 - 菜鸡 👍(0) 💬(2)
这个代码我运行了一下,当有一个客户端关闭时,服务端会出现accept failed: Interrupted system call (4),然后其它客户端就无法再进行交互了,直到被强制关闭
2022-05-05 - supermouse 👍(0) 💬(1)
请问老师,文稿中的代码child_run函数里面的recv是一次只接收一个字符吗?为什么不一次接收一个字符串呢?
2020-02-24 - 传说中的成大大 👍(43) 💬(0)
读书少的人只能直接回答第二问 第一问回答不了哈哈哈 是因为如果有多个子进程同时结束的话内核只会产生一次SIGCHLD信号至少信号处理函数只会唤醒一次,如果不循环就无法取得所有已终止的子进程数据
2019-10-10 - Geek_sky 👍(11) 💬(0)
一个发出而没有被接收的信号叫做待处理信号(pending signal)。在任何时刻,一种类型至多只会有一个待处理信号。如果一个进程有一个类型为k的待处理信号,那么任何接下来发送到这个进程的类型为k的信号都不会排队等待;它们只是被简单地丢弃。一个进程可以有选择性地阻塞接收某种信号。当一种信号被阻塞时,它仍可以被发送,但是产生的待处理信号不会被接收,直到进程取消对这种信号的阻塞。 一个待处理信号最多只能被接收一次。内核为每个进程在pending位向量中维护着待处理信号的集合,而在blocked位向量中维护着被阻塞的信号集合。只要传送了一个类型为k的信号,内核就会设置pending中的第k位,而只要接收了一个类型为k的信号,内核就会清除pending中的第k位。——深入理解计算机系统
2019-12-06 - 传说中的成大大 👍(5) 💬(0)
上面说错了 信号会产生多次 信号处理函数只会调用一次
2019-10-10 - yang 👍(4) 💬(0)
1. 按老师说的去搜了一下,也看到评论区其他同学的留言,发现redis的bgsave使用了fork创建子进程来保存数据。 2. 不使用while循环 在子进程退出时,会错过在子进程的资源回收叭
2019-10-08 - 钱 👍(2) 💬(0)
我理解的进程和线程 进程:OS的最小执行单位 线程:OS的最小调度单位 线程又称轻量级进程,他们的本质都是一段代码指令,被放到内存中等待执行,不过区别在于,进程间完全是隔离的互不影响,但是一个进程内的线程间是共享内存空间的,当然线程也有自己私有的一下资源,比如栈空间和PC寄存器等。 阻塞IO+多进程的实现已知有apache服务器
2019-11-24 - Hale 👍(1) 💬(1)
Nginx采用了进城池的模式来处理连接。使用循环是为了回收所有的子进程资源,一直到退出,否则接收完一个就直接退出了。
2019-10-08 - Geek_1696dd 👍(0) 💬(0)
这一讲在UNP第一卷第五章有非常详细的论述
2022-11-03 - Geek_842f07 👍(0) 💬(0)
如果在信号处理程序执行期间有其他两个SIGCHID信号来到,则信号处理程序只会再执行一次,少处理了一次
2021-09-09 - 忆水寒 👍(0) 💬(0)
第一题,redis和nginx底层都是基于epoll实现的。当然了,像nodejs 也是livevent实现的,底层也是epoll。 第二题,使用循环的目的是,第一次父进程创建的子进程。后面子进程还会创建子进程。需要回收全部子进程。
2020-09-05