03丨套接字和地址:像电话和电话号码一样理解它们
在网络编程中,我们经常会提到socket这个词,它的中文翻译为套接字,有的时候也叫做套接口。
socket这个英文单词的原意是“插口”“插槽”, 在网络编程中,它的寓意是可以通过插口接入的方式,快速完成网络连接和数据收发。你可以把它想象成现实世界的电源插口,或者是早期上网需要的网络插槽,所以socket也可以看做是对物理世界的直接映射。
其实计算机程序设计是一门和英文有着紧密联系的学科,很多专有名词使用英文原词比翻译成中文更容易让大家接受。为了方便,在专栏里我们一般会直接使用英文,如果需要翻译就一律用“套接字”这个翻译。
socket到底是什么?
在网络编程中,到底应该怎么理解socket呢?我在这里先呈上这么一张图,你可以先看看。
 这张图表达的其实是网络编程中,客户端和服务器工作的核心逻辑。
这张图表达的其实是网络编程中,客户端和服务器工作的核心逻辑。
我们先从右侧的服务器端开始看,因为在客户端发起连接请求之前,服务器端必须初始化好。右侧的图显示的是服务器端初始化的过程,首先初始化socket,之后服务器端需要执行bind函数,将自己的服务能力绑定在一个众所周知的地址和端口上,紧接着,服务器端执行listen操作,将原先的socket转化为服务端的socket,服务端最后阻塞在accept上等待客户端请求的到来。
此时,服务器端已经准备就绪。客户端需要先初始化socket,再执行connect向服务器端的地址和端口发起连接请求,这里的地址和端口必须是客户端预先知晓的。这个过程,就是著名的TCP三次握手(Three-way Handshake)。下一篇文章,我会详细讲到TCP三次握手的原理。
一旦三次握手完成,客户端和服务器端建立连接,就进入了数据传输过程。
具体来说,客户端进程向操作系统内核发起write字节流写操作,内核协议栈将字节流通过网络设备传输到服务器端,服务器端从内核得到信息,将字节流从内核读入到进程中,并开始业务逻辑的处理,完成之后,服务器端再将得到的结果以同样的方式写给客户端。可以看到,一旦连接建立,数据的传输就不再是单向的,而是双向的,这也是TCP的一个显著特性。
当客户端完成和服务器端的交互后,比如执行一次Telnet操作,或者一次HTTP请求,需要和服务器端断开连接时,就会执行close函数,操作系统内核此时会通过原先的连接链路向服务器端发送一个FIN包,服务器收到之后执行被动关闭,这时候整个链路处于半关闭状态,此后,服务器端也会执行close函数,整个链路才会真正关闭。半关闭的状态下,发起close请求的一方在没有收到对方FIN包之前都认为连接是正常的;而在全关闭的状态下,双方都感知连接已经关闭。
请你牢牢记住文章开头的那幅图,它是贯穿整个专栏的核心图之一。
讲这幅图的真正用意在于引入socket的概念,请注意,以上所有的操作,都是通过socket来完成的。无论是客户端的connect,还是服务端的accept,或者read/write操作等,socket是我们用来建立连接,传输数据的唯一途径。
更好地理解socket:一个更直观的解释
你可以把整个TCP的网络交互和数据传输想象成打电话,顺着这个思路想象,socket就好像是我们手里的电话机,connect就好比拿着电话机拨号,而服务器端的bind就好比是去电信公司开户,将电话号码和我们家里的电话机绑定,这样别人就可以用这个号码找到你,listen就好似人们在家里听到了响铃,accept就好比是被叫的一方拿起电话开始应答。至此,三次握手就完成了,连接建立完毕。
接下来,拨打电话的人开始说话:“你好。”这时就进入了write,接收电话的人听到的过程可以想象成read(听到并读出数据),并且开始应答,双方就进入了read/write的数据传输过程。
最后,拨打电话的人完成了此次交流,挂上电话,对应的操作可以理解为close,接听电话的人知道对方已挂机,也挂上电话,也是一次close。
在整个电话交流过程中,电话是我们可以和外面通信的设备,对应到网络编程的世界里,socket也是我们可以和外界进行网络通信的途径。
socket的发展历史
通过上面的讲解和这个打电话的类比,你现在清楚socket到底是什么了吧?那socket最开始是怎么被提出来的呢?接下来就很有必要一起来简单追溯一下它的历史了。
socket是加州大学伯克利分校的研究人员在20世纪80年代早期提出的,所以也被叫做伯克利套接字。伯克利的研究者们设想用socket的概念,屏蔽掉底层协议栈的差别。第一版实现socket的就是TCP/IP协议,最早是在BSD 4.2 Unix内核上实现了socket。很快大家就发现这么一个概念带来了网络编程的便利,于是有更多人也接触到了socket的概念。Linux作为Unix系统的一个开源实现,很早就从头开发实现了TCP/IP协议,伴随着socket的成功,Windows也引入了socket的概念。于是在今天的世界里,socket成为网络互联互通的标准。
套接字地址格式
在使用套接字时,首先要解决通信双方寻址的问题。我们需要套接字的地址建立连接,就像打电话时首先需要查找电话簿,找到你想要联系的那个人,你才可以建立连接,开始交流。接下来,我们重点讨论套接字的地址格式。
通用套接字地址格式
下面先看一下套接字的通用地址结构:
/* POSIX.1g 规范规定了地址族为2字节的值. */
typedef unsigned short int sa_family_t;
/* 描述通用套接字地址 */
struct sockaddr{
sa_family_t sa_family; /* 地址族. 16-bit*/
char sa_data[14]; /* 具体的地址值 112-bit */
};
在这个结构体里,第一个字段是地址族,它表示使用什么样的方式对地址进行解释和保存,好比电话簿里的手机格式,或者是固话格式,这两种格式的长度和含义都是不同的。地址族在glibc里的定义非常多,常用的有以下几种:
- AF_LOCAL:表示的是本地地址,对应的是Unix套接字,这种情况一般用于本地socket通信,很多情况下也可以写成AF_UNIX、AF_FILE;
- AF_INET:因特网使用的IPv4地址;
- AF_INET6:因特网使用的IPv6地址。
这里的AF_表示的含义是Address Family,但是很多情况下,我们也会看到以PF_表示的宏,比如PF_INET、PF_INET6等,实际上PF_的意思是Protocol Family,也就是协议族的意思。我们用AF_xxx这样的值来初始化socket地址,用PF_xxx这样的值来初始化socket。我们在<sys/socket.h>头文件中可以清晰地看到,这两个值本身就是一一对应的。
/* 各种地址族的宏定义 */
#define AF_UNSPEC PF_UNSPEC
#define AF_LOCAL PF_LOCAL
#define AF_UNIX PF_UNIX
#define AF_FILE PF_FILE
#define AF_INET PF_INET
#define AF_AX25 PF_AX25
#define AF_IPX PF_IPX
#define AF_APPLETALK PF_APPLETALK
#define AF_NETROM PF_NETROM
#define AF_BRIDGE PF_BRIDGE
#define AF_ATMPVC PF_ATMPVC
#define AF_X25 PF_X25
#define AF_INET6 PF_INET6
sockaddr是一个通用的地址结构,通用的意思是适用于多种地址族。为什么定义这么一个通用地址结构呢,这个放在后面讲。
IPv4套接字格式地址
接下来,看一下常用的IPv4地址族的结构:
/* IPV4套接字地址,32bit值. */
typedef uint32_t in_addr_t;
struct in_addr
{
in_addr_t s_addr;
};
/* 描述IPV4的套接字地址格式 */
struct sockaddr_in
{
sa_family_t sin_family; /* 16-bit */
in_port_t sin_port; /* 端口号 16-bit*/
struct in_addr sin_addr; /* Internet address. 32-bit */
/* 这里仅仅用作占位符,不做实际用处 */
unsigned char sin_zero[8];
};
我们对这个结构体稍作解读,首先可以发现和sockaddr一样,都有一个16-bit的sin_family字段,对于IPv4来说这个值就是AF_INET。
接下来是端口号,我们可以看到端口号最多是16-bit,也就是说最大支持2的16次方,这个数字是65536,所以我们应该知道支持寻址的端口号最多就是65535。关于端口,我在前面的章节也提到过,这里重点阐述一下保留端口。所谓保留端口就是大家约定俗成的,已经被对应服务广为使用的端口,比如ftp的21端口,ssh的22端口,http的80端口等。一般而言,大于5000的端口可以作为我们自己应用程序的端口使用。
下面是glibc定义的保留端口。
/* Standard well-known ports. */
enum
{
IPPORT_ECHO = 7, /* Echo service. */
IPPORT_DISCARD = 9, /* Discard transmissions service. */
IPPORT_SYSTAT = 11, /* System status service. */
IPPORT_DAYTIME = 13, /* Time of day service. */
IPPORT_NETSTAT = 15, /* Network status service. */
IPPORT_FTP = 21, /* File Transfer Protocol. */
IPPORT_TELNET = 23, /* Telnet protocol. */
IPPORT_SMTP = 25, /* Simple Mail Transfer Protocol. */
IPPORT_TIMESERVER = 37, /* Timeserver service. */
IPPORT_NAMESERVER = 42, /* Domain Name Service. */
IPPORT_WHOIS = 43, /* Internet Whois service. */
IPPORT_MTP = 57,
IPPORT_TFTP = 69, /* Trivial File Transfer Protocol. */
IPPORT_RJE = 77,
IPPORT_FINGER = 79, /* Finger service. */
IPPORT_TTYLINK = 87,
IPPORT_SUPDUP = 95, /* SUPDUP protocol. */
IPPORT_EXECSERVER = 512, /* execd service. */
IPPORT_LOGINSERVER = 513, /* rlogind service. */
IPPORT_CMDSERVER = 514,
IPPORT_EFSSERVER = 520,
/* UDP ports. */
IPPORT_BIFFUDP = 512,
IPPORT_WHOSERVER = 513,
IPPORT_ROUTESERVER = 520,
/* Ports less than this value are reserved for privileged processes. */
IPPORT_RESERVED = 1024,
/* Ports greater this value are reserved for (non-privileged) servers. */
IPPORT_USERRESERVED = 5000
实际的IPv4地址是一个32-bit的字段,可以想象最多支持的地址数就是2的32次方,大约是42亿,应该说这个数字在设计之初还是非常巨大的,无奈互联网蓬勃发展,全球接入的设备越来越多,这个数字渐渐显得不太够用了,于是大家所熟知的IPv6就隆重登场了。
IPv6套接字地址格式
我们再看看IPv6的地址结构:
struct sockaddr_in6
{
sa_family_t sin6_family; /* 16-bit */
in_port_t sin6_port; /* 传输端口号 # 16-bit */
uint32_t sin6_flowinfo; /* IPv6流控信息 32-bit*/
struct in6_addr sin6_addr; /* IPv6地址128-bit */
uint32_t sin6_scope_id; /* IPv6域ID 32-bit */
};
整个结构体长度是28个字节,其中流控信息和域ID先不用管,这两个字段,一个在glibc的官网上根本没出现,另一个是当前未使用的字段。这里的地址族显然应该是AF_INET6,端口同IPv4地址一样,关键的地址从32位升级到128位,这个数字就大到恐怖了,完全解决了寻址数字不够的问题。
请注意,以上无论IPv4还是IPv6的地址格式都是因特网套接字的格式,还有一种本地套接字格式,用来作为本地进程间的通信, 也就是前面提到的AF_LOCAL。
几种套接字地址格式比较
这几种地址的比较见下图,IPv4和IPv6套接字地址结构的长度是固定的,而本地地址结构的长度是可变的。
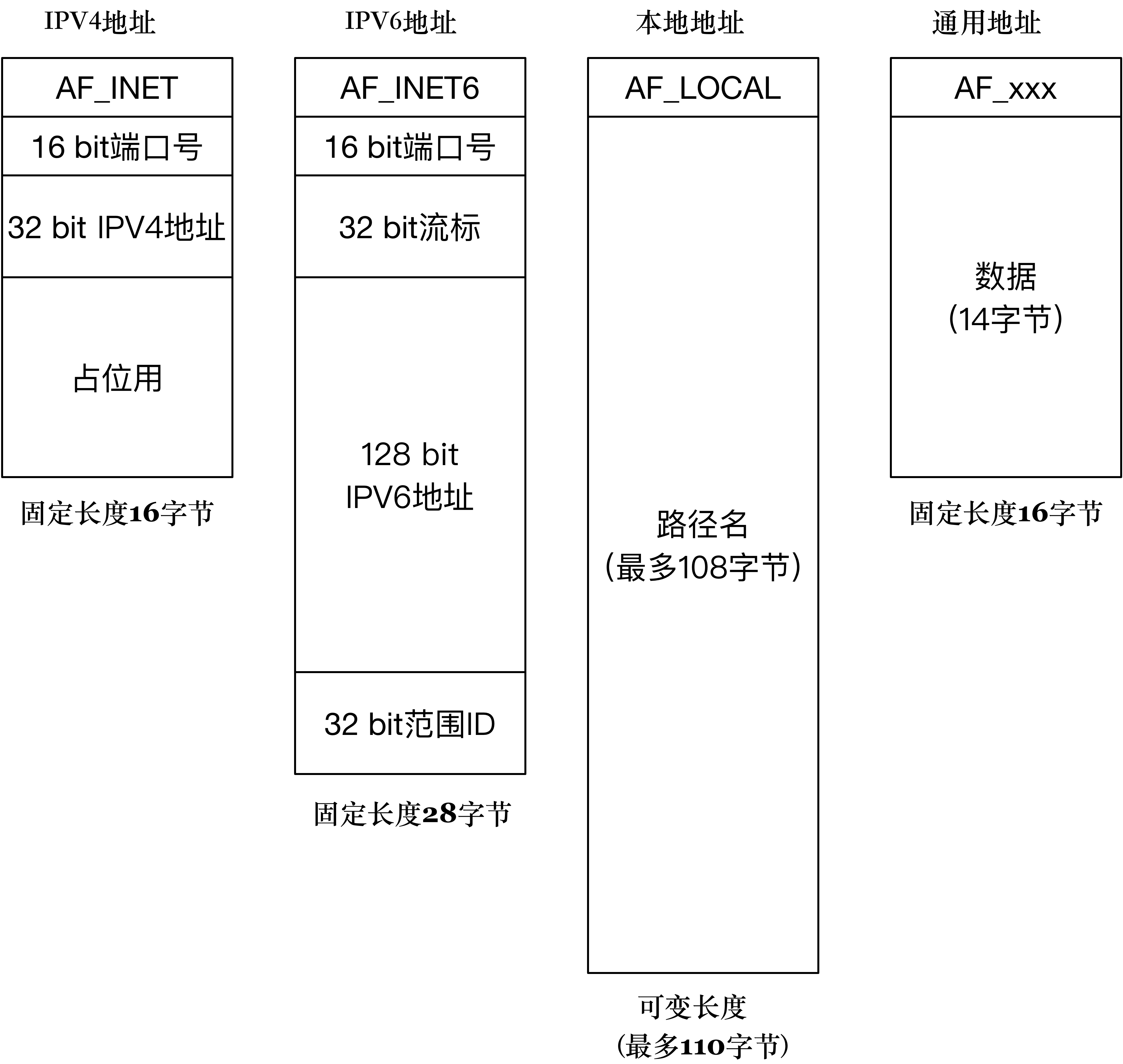
总结
这一讲我们重点讲述了什么是套接字,以及对应的套接字地址格式。套接字作为网络编程的基础,概念异常重要。套接字的设计为我们打开了网络编程的大门,实际上,正是因为BSD套接字如此成功,各大Unix厂商(包括开源的Linux)以及Windows平台才会很快照搬了过来。在下一讲中,我们将开始创建并使用套接字,建立连接,进一步开始我们的网络编程之旅。
思考题
最后给你留两道思考题吧,你可以想一想IPv4、IPv6、本地套接字格式以及通用地址套接字,它们有什么共性呢?如果你是BSD套接字的设计者,你为什么要这样设计呢?
第二道题是,为什么本地套接字格式不需要端口号,而IPv4和IPv6套接字格式却需要端口号呢?
我在评论区期待你的思考与见解,如果你觉得这篇文章对你有所帮助,欢迎点击“请朋友读”,把这篇文章分享给你朋友或同事。
- 业余爱好者 👍(226) 💬(9)
unix系统有一种一统天下的简洁之美:一切皆文件,socket也是文件。 1.像sock_addr的结构体里描述的那样,几种套接字都要有地址族和地址两个字段。这容易理解,你要与外部通信,肯定要至少告诉计算机对方的地址和使用的是哪一种地址。与远程计算机的通信还需要一个端口号。而本地socket的不同之处在于不需要端口号,那么就有了问题2; 2.本地socket本质上是在访问本地的文件系统,所以自然不需要端口。远程socket是直接将一段字节流发送到远程计算机的一个进程,而远程计算机可能同时有多个进程在监听,所以用端口号标定要发给哪一个进程。
2019-08-07 - 奔跑的码仔 👍(58) 💬(7)
个人感觉“Pv4、IPv6、本地套接字格式以及通用地址套接字”的思想类似于OOP中的继承和多态。通用套接子为抽象类,其他套接字实现该抽象类。这样,可以定义基于通用套接字这个抽象类各种通用接口,其他套接字,也就是具体类,可以完全复用这套接口,即,实现了socket编程的多态!
2019-08-10 - conanforever22 👍(42) 💬(2)
1. 我觉得这样设计的目的是为了给用户提供一个统一的接口, 不用每个地址族成员都增加个函数原型; 只用通过sockaddr.sa_family来确定具体是什么类型的地址, 有点工厂模式的意思; 如果是C++的话就可以用函数重载来实现了 2. socket主要还是为了进程间通信, 本地套接字主要用于本地IPC, 网络套接字用于跨机器通信; 如果把socket抽象成文件的话, 通信进程双方需要能够根据一个唯一的fd来找到彼此, 跨机器的话可以用端口, 本地的话直接用文件inode就可以了
2019-08-07 - nil 👍(30) 💬(3)
第一问,通用网络地址结构是所有具体地址结构的抽象,有了统一可以操作的地址结构,那么就可以涉及一套统一的接口,简化了接口设计。通用地址结构中第一个字段表明了地址的类型,后面的数据可以通过具体类型解析出来,一般只有将具体地址类型的指针强制转化成通用类型,这样操作才不会造成内存越界。 第二问,本地socket基于文件操作的,因此只需要根据文件路径便可区分,不需要使用端口的概念。
2019-08-07 - xcoder 👍(28) 💬(4)
老师能讲下关于WebSocket、Http和socket之间的联系吗?
2019-08-07 - Mark 👍(25) 💬(4)
AF_xxx 这样的值来初始化 socket 地址,用 PF_xxx 这样的值来初始化 socket。 请教老师,这一句具体怎么理解?
2019-09-12 - Sweety 👍(12) 💬(1)
打卡。感觉评论区的人都好厉害。
2019-08-07 - 衬衫的价格是19美元 👍(10) 💬(5)
通用地址格式sockaddr长度只有16字节,实际存放ip地址的只有14字节,怎么存的下ip6的地址的?这里还是不太明白
2019-09-30 - Linuxer 👍(9) 💬(2)
2字节表示地址族很富裕,知道地址族,基本确定地址结构,通用地址结构,能够很好区分这两部分,一个字符数组就能知道每一种地址结构的起始地址,高明
2019-08-07 - 钱 👍(6) 💬(6)
评论区都是高手,不过只输入不输出,脑袋是容不下的。所以,先不管对错,也记一下自己的思考。 感觉电脑一多,脑袋就乱,我来简化一下 如果世界上只有一台,那网络通信也就不需要了,不过单独的这台电脑上的文件,只要知道路径应该是能访问的,所以,不需要什么IP和端口 如果世界上只有两台电脑,并且每台电脑上可以运行多个进程,如果这两台电脑上的两个进程间想通信,那就需要端口号了,否则定位不了唯一的进程 如果世界上只有三台电脑,并且每台电脑上可以运行多个进程,其中有两台电脑上的进程之间想通信,那么就需要有IP和端口号了,IP用于定位电脑,端口号用于定位进程 世界上只有三台电脑,其实可以扯三根网线,此时长链接也是很容易理解的,实际上现在世界上有上亿级的电脑都在互联网上,如果两两互联都通过专有的网线,那这网线的数量就是个天文数字,也不现实。此时,这个长链接是怎么维护的,有些线路必然会公用的,我有些想不明白,分时公用?还是有个特殊标志?或者线路本身就是无时无刻都在公用的?
2019-11-19 - 陈致瀚 👍(4) 💬(1)
讲的太好了,越来越懂网络编程了
2019-08-07 - zhchnchn 👍(3) 💬(1)
请问老师,实际编程中一般使用sockaddr_in,sockaddr_in6,sockaddr_un结构,那么通用套接字地址结构sockaddr的作用是什么?一般在什么场景下使用?
2019-08-07 - нáпの゛ 👍(2) 💬(1)
1 通用地址的作用主要是为了充当通用的指针,使接口参数传入统一,具体使用时强制转换为实际地址类型来解析。 2 感觉端口就是文件路径索引的意思,设计者为了方便使用搞了端口的概念。我的理解是走文件系统(本地套接字)就不需要端口,如果走协议栈就需要端口,远端通信只能走协议栈,所以必须要端口号。
2020-08-14 - youngitachi 👍(2) 💬(1)
这个是上次的问题: 老师好,对于第二个问题我有个疑问。 假如知道远程服务器socket的路径,从理论上来讲,是否可以不需要端口号了呢? 接下来是第二次提问: 可能我没描述清楚,其实我的意思是这样的:我理解的是,指定了端口,就知道了和那个进程通信嘛,那么如果假设知道了远程主机的socket的路径了,是否可以不需要端口就能通信? 就假设我们要自己设计并实现个传输层协议,这个协议里我不指定端口,而是指定双方通信进程在主机上的路径,这样的协议是否可以满足通信呢?
2019-09-19 - 吴文敏 👍(2) 💬(1)
老师可以讲一下grpc和rest的区别有哪些吗?为什么都说grpc比rest好、性能更高?
2019-08-28