08 动态链接(下):延迟绑定与动态链接器是什么?
你好,我是海纳。
在上节课里,我们学习了动态链接过程的基本原理。动态链接通过GOT表加一层间接跳转的方式,解决了代码中call指令对绝对地址的依赖,从而实现了PIC的能力。我们同时也讲到了GOT表中的地址是由加载器在加载时填充的。
不过,细心的你也发现了,动态链接带来的代价是性能的牺牲。这里性能的牺牲主要来自于两个方面:
- 每次对全局符号的访问都要转换为对GOT表的访问,然后进行间接寻址,这必然要比直接的地址访问速度慢很多;
- 动态链接和静态链接的区别是将链接中重定位的过程推迟到程序加载时进行。因此在程序启动的时候,动态链接器需要对整个进程中依赖的so进行加载和链接,也就是对进程中所有GOT表中的符号进行解析重定位。这样就导致了程序在启动过程中速度的减慢。
我们这节课来看看,如何通过延迟绑定技术,来解决性能下降的问题。延迟绑定不仅仅是用在动态链接中,还被广泛地应用在Hotspot,V8等带有即时编译功能的虚拟机中。另外,在游戏行业,修复服务器的错误的同时保证用户不掉线是硬需求,这种不停机进行代码修复的技术被称为热更新技术。学习完这节课后,你不仅能理解动态链接的基本原理,而且也能对热更新的基本原理有所感悟。
其实,不管是加载时重定位,还是延迟绑定技术,真正发挥作用的是动态链接器。所以这节课我也会给你简单介绍一下动态链接器的基本原理。
首先,我们从延迟绑定的最简单的形式,也就是Hotspot虚拟机中的运行时重定位技术patch code讲起。
patch code技术
我们知道,在Java语言中,类是按需加载的。也就是对于一个class文件,只有当hotspot第一次使用它的时候,它才会被加载进来。假如我们在即时编译A方法的时候要调用B方法,但这时B方法还没有被加载进来,该怎么办呢?
虚拟机会采用一种叫做patch code的技术,在运行时再进行加载。简单地说,就是在生成call指令时候,它的目标地址填成一个虚拟机内部的用于解析符号的方法。在CPU执行这条call语句的时候,就会调用符号解析函数。此时虚拟机就会加载B方法所在的类,然后就能确定B方法的地址了,这时再把B方法的地址写回到call指令里。这个过程如下图所示:
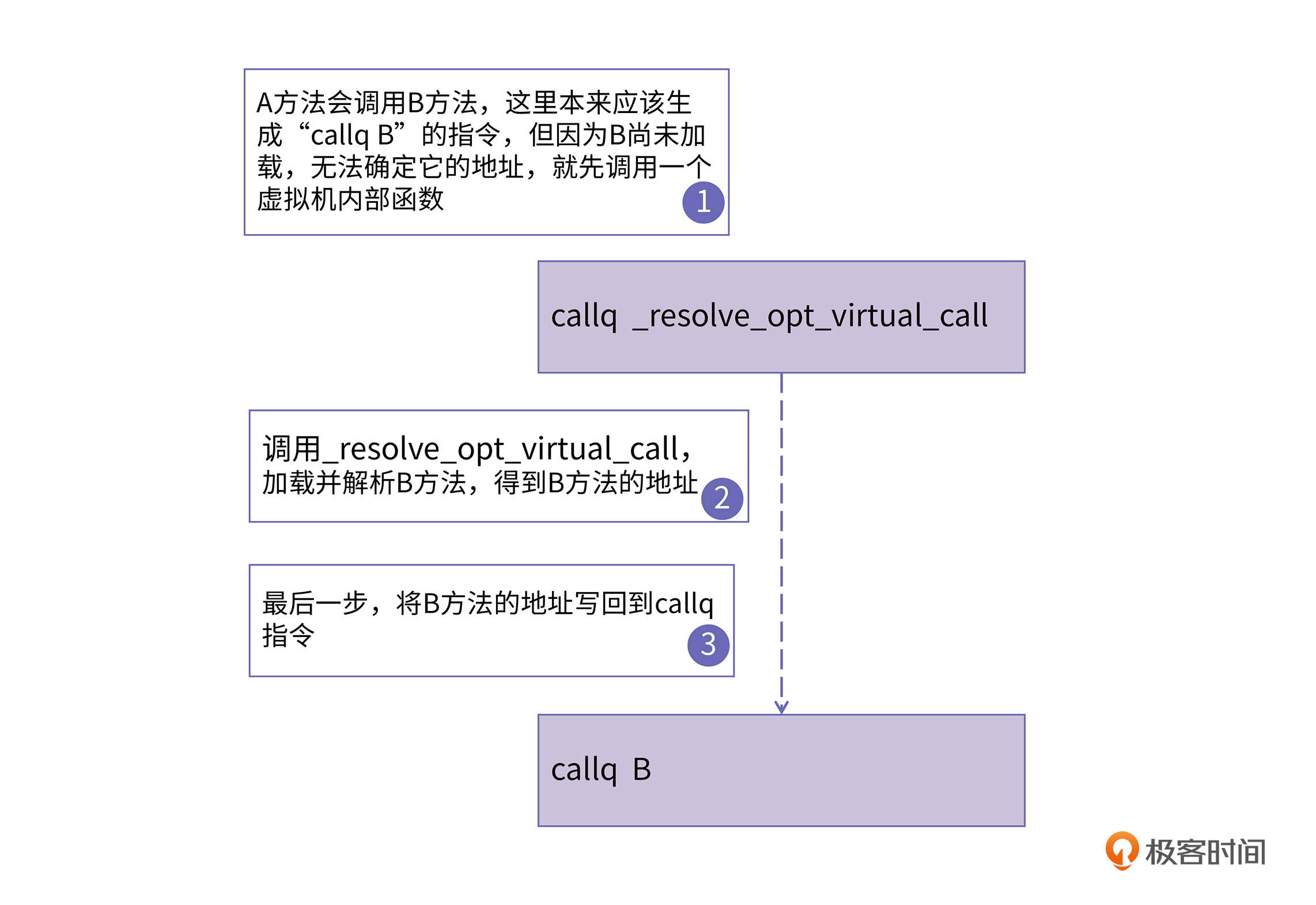
这个过程很像是在给原始的代码打补丁,所以人们就把这种方式称为patch code技术。这就像是在原来的代码安装了一个机关,当CPU执行到这个机关时,就会触发一次符号的重定位,然后这个机关就被替换掉了。下一次CPU再执行到这个call指令的时候,就可以正常地调用到B方法了。
上节课,加载器在加载动态库时就把它的GOT中的所有符号都解析了,这种方法却把解析符号的过程又往后推到了执行代码时解析。
在Hotspot里的patch code技术,会直接修改指令参数。不过,运行时修改指令总是一件很危险的事情。所以,动态库真正使用的运行时解析符号技术是延迟绑定技术,它的关键步骤和patch code很相似,但却比patch code的安全性更好一些,我们一起来看一下。
延迟绑定技术
为了避免在加载时就把GOT表中的符号全部解析并重定位,就需要采用计算机领域非常重要的一个思想:Lazy。也就是说,把要做的事情推迟到必须做的时刻。
对于我们当前的问题来说,将函数地址的重定位工作一直推迟到第一次访问的时候再进行,这就是延迟绑定(Lazy binding)的技术。这样的话,对于整个程序运行过程中没有访问到的全局函数,可以完全避免对这类符号的重定位工作,也就提高了程序的性能。
patch code显然也是一种延迟绑定的技术,但是它要在运行时修改指令参数,这会带来风险。所以动态库的延迟绑定选择了继续使用GOT表来进行间接调用,然后patch的对象就不再是指令了,而是GOT中的一项。
理想情况下,我们把GOT中的待解析符号的地方都填成动态符号解析的函数就可以了,当CPU执行到这个函数的时候,就会跳转进去解析符号,然后把GOT表的这一项填成符号的真正的地址。如下图所示:

但是动态解析符号的函数_dl_runtime_resolve依赖两个参数,一个是当前动态库的ID,另一个是要解析的符号在GOT表中的序号。动态库的ID存储在GOT的0x8偏移的位置,而要解析的符号序号却不容易得到。
为了解决传递参数的问题,动态链接又引入了过程链接表(Procedure Linkage Table, PLT),将动态解析符号的过程做成了三级跳。如下图所示:
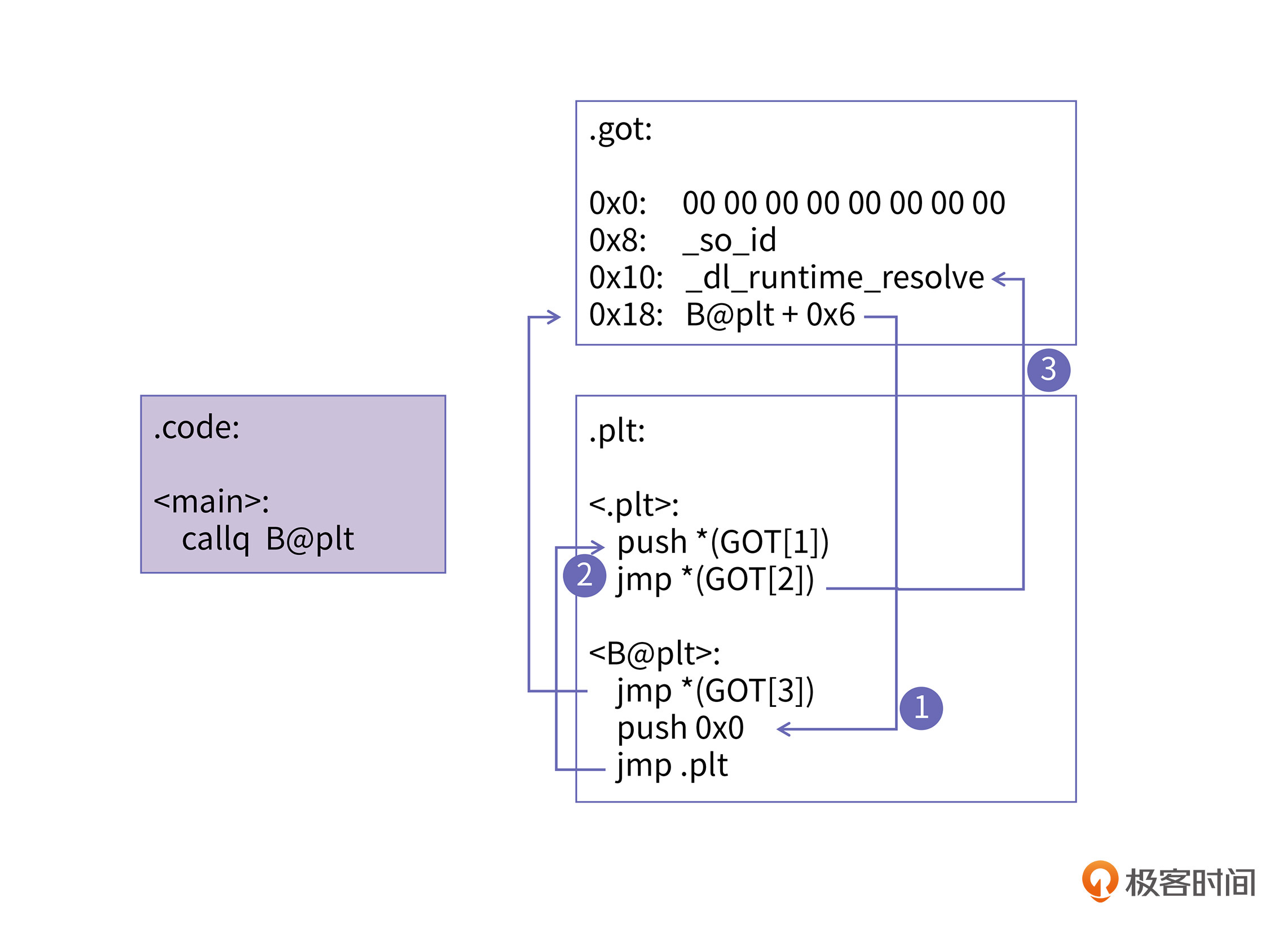
在图中,我用序号①、②、③和它们旁边的箭头分别给你标注出了三级跳的路径。如果你仔细观察的话,你还会发现这张图与上一张图的主要变化就是引入了.plt段,在代码段里,main函数对B函数的调用转成了对"B@plt"的调用,"B@plt"函数只有三条指令。
它的第一条指令jmp *(GOT[3])是一个间接跳转,跳转的目标是GOT表偏移为0x18的位置,正常情况下,这个位置应该放的是B函数的真实地址。但现在填入的是指向了B@plt + 0x6的位置,这是为了传递参数给_dl_runtime_resolve函数。B@plt+0x6的位置其实就是B@plt函数的第二条指令,它的作用是将函数参数入栈,然后执行第三条指令jmp .plt再准备第二个参数。
我们再回到图中看看,在序号①箭头的位置,也就是第一级跳转,它的目的是把参数0入栈。由于GOT表的0x0,0x8,0x10的位置都被占用了,所以参数0代表的就是0x18位置,这就是B函数的真实地址应该存放的地方。
然后在序号②箭头的位置,发生了第二级跳转,这一次是为了把动态库的ID号压栈传参。
最后在序号③箭头的位置,继续进行第三级跳转,这一次跳转才真正地调用到了_dl_runtime_resolve。调用完这个方法以后,B函数的真实地址就会被填入GOT表中了。
上述过程由于传参的需要而变成了多级跳转,但如果抛开因为传参而产生的两级跳转,你会发现它的基本结构与patch code技术如出一辙。
这样的跳转虽然麻烦,但有一个非常重要的优点,就是运行期间不会修改代码段的指令,所有的修改只涉及了GOT这个位于数据段的表里。我们在第3节课就已经介绍过,.code和.plt会被加载到内存的代码段(code segment),它的权限是可读可执行,但不可写;上节课也讲了.got会被加载进数据段,它的权限是可读可写。我们现在介绍的多级跳转的延迟绑定技术的整个重定位过程最终只会修改GOT的0x18这一个位置,其他位置都不必发生变化。
当执行完了重定位过程以后,CPU再一次运行到main里的call指令时,就能通过一次跳转就调用到真正的B函数了,这时的GOT已经与上节课所讲的加载时重定位后的GOT一模一样了。如图所示:
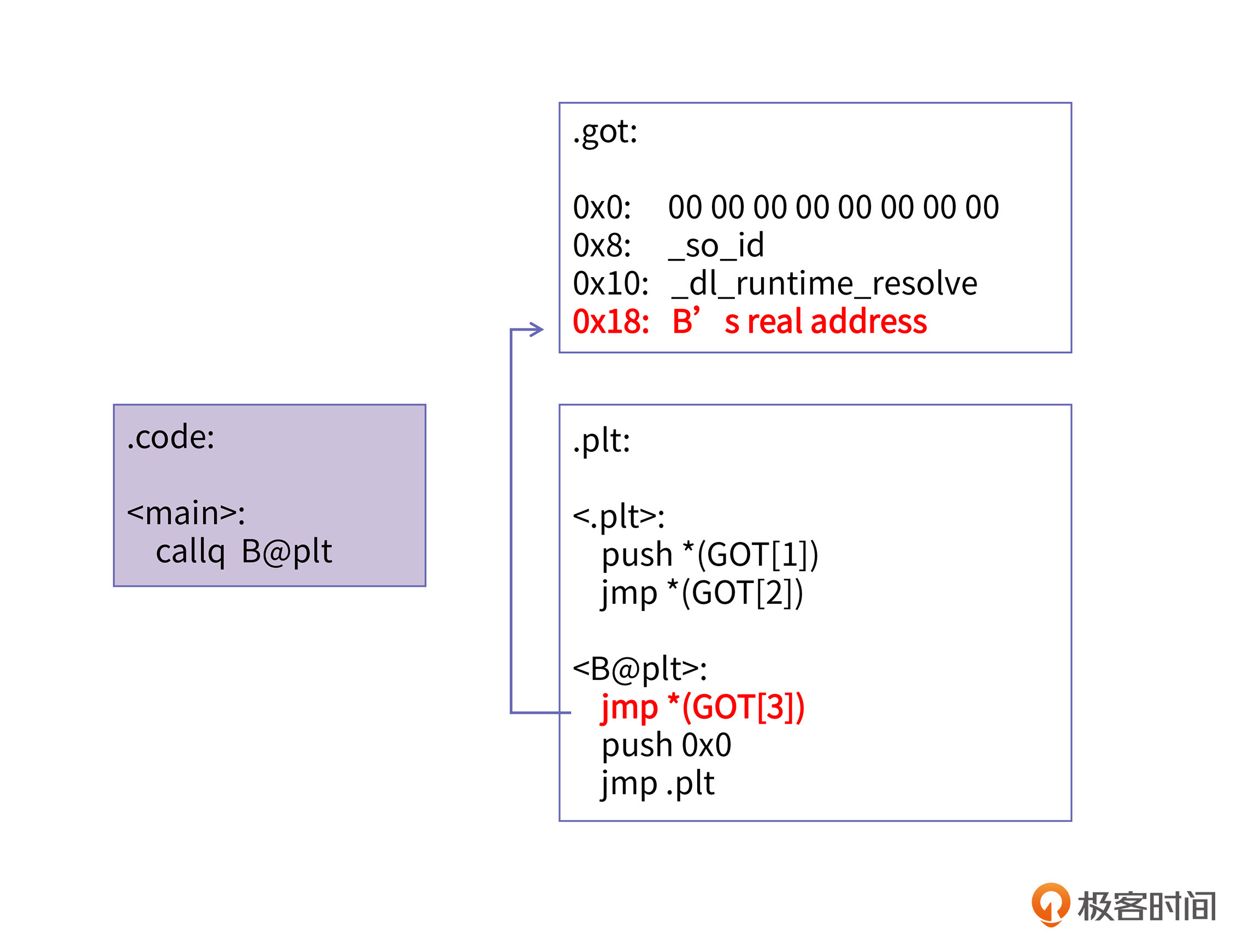
在这个图里,重定位完以后,只有红色字体的代码和数据是起作用的,.plt段里的其他代码就被“短路”掉了。这时,GOT表的结构就与上节课所讲的加载时重定位的情况完全一样了。只有用到的符号才会被重定位,这就是延迟绑定技术。未被用到的符号在加载时被重定位,这是一种浪费,而延迟绑定技术避免了这种浪费。为了加深理解,我结合一个具体例子向你展示延迟绑定是怎么实现的。
延迟绑定技术的具体实现
下面我们还是根据上节课的例子来看一下延迟绑定技术的具体实现。
// foo.c
static int static_var;
int global_var;
extern int extern_var;
extern int extern_func();
static int static_func() {
return 10;
}
int global_func() {
return 20;
}
int demo() {
static_var = 1;
global_var = 2;
extern_var = 3;
int ret_var = static_var + global_var + extern_var;
ret_var += static_func();
ret_var += global_func();
ret_var += extern_func();
return ret_var;
}
我们将这个例子编译成 libfoo.so ,编译命令是:
这里跟上节课编译的区别是,去掉了-fno-plt的编译选项,这样可以打开PLT表的生成。上一节课里,我们只需要关注PIC技术的实现,因此需要通过 -fno-plt 的选项来关闭PLT表的生成。
我们先通过反汇编先来看一下 demo 函数的汇编指令:
00000000000006a0 <demo>:
...
6fd: e8 7e fe ff ff callq 580 <global_func@plt>
702: 01 45 fc add %eax,-0x4(%rbp)
705: b8 00 00 00 00 mov $0x0,%eax
70a: e8 81 fe ff ff callq 590 <extern_func@plt>
70f: 01 45 fc add %eax,-0x4(%rbp)
712: 8b 45 fc mov -0x4(%rbp),%eax
715: c9 leaveq
716: c3 retq
从汇编中你可以看到,对函数global_func和extern_func的调用都变成了对global_func@plt和extern_func@plt的调用。继续查看这两个带@plt后缀的函数,其对应的VMA分别是0x580和0x590,所以接着看这两个位置的汇编代码。
Disassembly of section .plt:
0000000000000570 <.plt>:
570: ff 35 92 0a 20 00 pushq 0x200a92(%rip) # 201008 <_GLOBAL_OFFSET_TABLE_+0x8>
576: ff 25 94 0a 20 00 jmpq *0x200a94(%rip) # 201010 <_GLOBAL_OFFSET_TABLE_+0x10>
57c: 0f 1f 40 00 nopl 0x0(%rax)
0000000000000580 <global_func@plt>:
580: ff 25 92 0a 20 00 jmpq *0x200a92(%rip) # 201018 <global_func+0x200983>
586: 68 00 00 00 00 pushq $0x0
58b: e9 e0 ff ff ff jmpq 570 <.plt>
0000000000000590 <extern_func@plt>:
590: ff 25 8a 0a 20 00 jmpq *0x200a8a(%rip) # 201020 <extern_func>
596: 68 01 00 00 00 pushq $0x1
59b: e9 d0 ff ff ff jmpq 570 <.plt>
这段汇编是对libfoo.so中.plt段的反汇编。从这里我们可以看出来,PLT表的每一项其实都是一段相似的stub代码构成,这个stub共三条指令,这三条指令和我们上面的图中所画的是完全一样的。
从反汇编的结果来看,global_func@plt的第一行是一个间接跳转,跳转的目标地址存储在0x201018这个位置,通过objdump我们可以找到这个位置位于.got.plt段里。这个命令我们已经很熟悉了,你可以自己动手试一下。从名字中可以看出,.got.plt段跟.got段是一样的,存放的是GOT表,只不过.got.plt里边的GOT表是为PLT表准备的。
在这里 0x201018的位置存放的值是 0x586。这就跳回到global_func@plt里继续执行了,这是我们上面所分析的一级跳,是为了传递参数给符号解析函数的。最终经过传参,跳转,控制流才终于进入到dl_runtime_resolve中解析符号并做重定位。
最后,我们再总结一下GOT表中的各个表项的含义。
- GOT.PLT[0]位置被加载器保留,它里面存放的是.dynamic段的地址,这里我们不用关心。
- GOT.PLT[1]位置存放的是当前so的ID,这个ID是加载器在加载当前动态库文件的时候分配的。
- GOT.PLT[2]位置存放的是动态链接函数的入口地址,一般是动态链接器中的_dl_runtime_resovle函数。这个函数的作用是找到需要查找的符号地址,并最终回填到GOT.PLT表的对应位置。
然后再回顾一下延迟绑定的整个过程。
- 当 demo 函数想要调用 global_func 的时候,程序调用先进入 global_func@plt 中;
- 在 global_func@plt 中,会先执行 jmpq *GOT.PLT[3] ,此时 GOT.PLT[3] 里存放的是 global_func@plt 项中的第二条指令,因此控制流继续返回到 global_func@plt 中进行执行;
- 接下会把数值0x0进行压栈,这个数值代表了 global_func 的ID。然后jmp到 PLT[0] 的表项中进行执行;
- 在 PLT[0] 中,继续将 GOT.PLT[1] 的值也就是库文件的ID进行压栈,然后通过 GOT.PLT[2] 跳转到 _dl_runtime_resolve 函数中;
- _dl_runtime_resolve 则根据存在栈上的函数ID和so的ID进行全局搜索,找到对应的函数地址之后就可以将其重新填充到 GOT.PLT[3] 中,这个时候延迟加载的整个过程就完成了;
- 当下一次调用 global_func 的时候,CPU就可以通过 global_func@plt 中第一条指令 jmpq *GOT.PLT[3] 直接跳转到 global_func 的真实地址中。
到这里,我们对动态链接中PIC技术和延迟加载技术进行了深入的分析。这个过程中我们几次提到动态链接器,但一直没有展开说,接下来我们就来揭开动态链接器的神秘面纱。
Loader的加载机制
虽然我们已经搞清楚了链接的全部流程。不过还缺了最后一环,就是可执行文件和共享库文件是如何被加载的?
在Linux下,编译一个最简单的可执行程序,通过 ldd a.out 命令你会发现有一个特殊的共享库文件:ld-linux-x86-64.so。从名字上可以看出,这个ld-linux.so跟链接器ld应该是存在某种联系的。
动态链接会把不同模块之间,符号重定位的操作,推迟到程序运行的时候,而ld-linux.so就负责这个工作。所以我们经常称ld.so为动态链接器,又因为它还负责加载动态库文件,所以我们有时也叫它loader,或者加载器。
我们知道,一个完全静态链接的可执行文件则不需要动态链接器的辅助,所以内核加载完之后可以直接跳转到用户代码的入口中进行执行。内核加载的过程主要是打开文件,初始化进程空间,读磁盘加载文件数据等等,这部分工作不是我们关心的重点,所以就不再分析了。
而对于一个需要动态链接的可执行文件a.out,当我们在Linux的shell终端里边敲了./a.out的命令后,内核会先准备好可执行文件需要的环境,然后依次把a.out和ld-linux.so加载到内存中,下一步就是跳转到 ld-linux.so的入口函数中。
进入ld-linux.so以后,与上文所讲的内核的文件加载过程就有区别了。它已经不是内核态执行,而是用户态执行了。ld-linux.so的源码实际上是在glibc里边,主要实现都是在glibc的elf文件夹下。
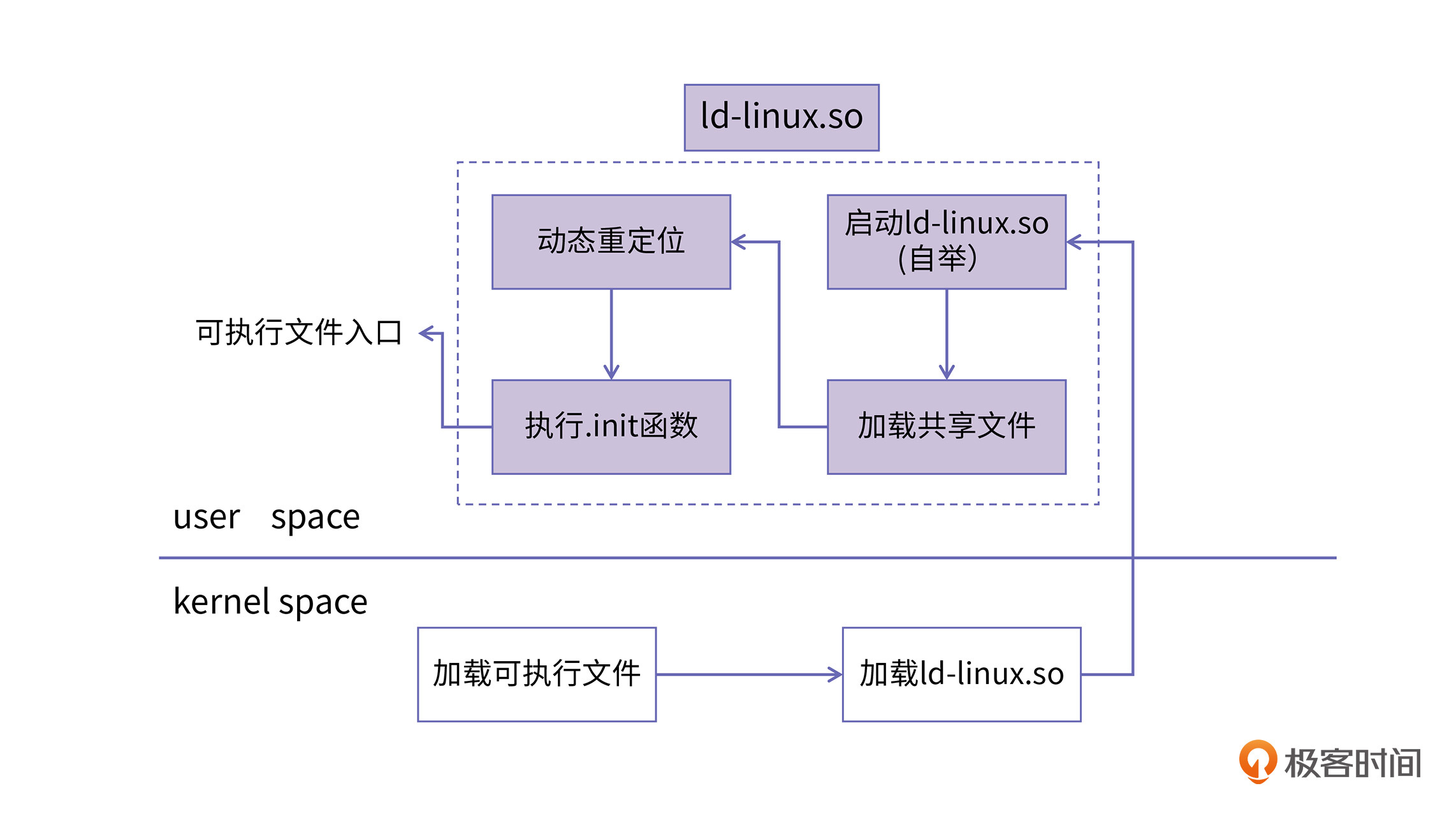
ld-linux.so做的事情主要有这么几件:第一是启动动态链接器;第二是根据可执行文件的动态链接信息,寻找并加载可执行文件依赖的.so文件;第三步是跟静态链接器一样,对所有的符号进行解析和重定位;最后会根据so的情况来依次执行各个so的init函数。
- 启动动态链接器
在第一点中,你可能会问,加载跟启动动态链接器的事情不是已经在内核里边做过了么?这里启动动态链接器是在做什么呢?
我们知道,动态链接器的作用是用来对可执行文件中需要动态链接的这些全局符号进行重定位解析,填写GOT表等,这时候你会发现,ld-linux.so本身也是一个共享文件,那它自己的动态链接的过程是谁来进行呢?
答案就是自己。ld-linux.so在启动之后,首先需要完成自己的符号解析和重定位的过程,这个过程叫做动态链接器的自举(Bootstrap)。ld-linux.so中的整个自举过程的代码是需要非常小心翼翼的,因为此时ld-linux.so本身的GOT/PLT信息都未完成,所以在自举过程中的代码不能使用全局符号和外部符号,稍有不慎就会导致整个程序崩溃。你可以到elf/rtld.c中看一下这块代码,主要逻辑在_dl_start函数里。
- 加载依赖共享文件
完成自举后,ld-linux.so就可以放心的使用各种全局符号和外部符号了。接下来第二步是根据可执行文件的.dynamic段信息依次加载程序依赖的共享库文件。程序的共享库依赖关系往往是一个图的关系,所以这里在加载共享库的过程也相当于是图遍历的过程,这里往往采用的是广度优先搜索的算法来遍历。
在第6节课,我们讲过静态链接,在链接的过程中需要维护一个全局的符号表,遍历.o文件的时候不断收集文件中的符号并且合并到全局符号表中。
同样的,ld-linux.so在加载共享文件的过程中也会维护一个全局符号表,每次加载新的共享文件后,将共享文件中的符号信息合并到全局符号表中。这个时候,问题来了:如果两个不同的so,如libfoo1.so与libfoo2.so都定义了一个foo函数,那ld-linux.so加载这两个so的时候会发生什么?
在静态链接的过程中,如果不同的.o里边定义了相同的符号,这时链接器会报出redefine的错误。而ld-linux.so的执行策略则是不同的,ld-linux.so在碰到相同的符号时,只会将第一次碰到的符号添加到全局符号表中,而后续碰到重名的符号就被自动忽略。
这样导致的结果是,不同so的同名函数,在运行时能看到的只有加载顺序在前的函数定义。所以对于上面的问题而言,如果libfoo1.so依赖在前,那么最终运行时只能看到libfoo1.so的foo函数,即使是libfoo2.so里的函数调用foo,调用的也是libfoo1.so里的foo,而不是自己so的foo。由此我们在开发过程中一定需要注意不同so中符号重名的问题,否则就会碰到意想不到的问题。
- 符号重定位与解析
在完成了共享文件的加载之后,全局符号表的信息就收集完成了,这时ld-linux.so就可以根据全局符号表和重定位表的信息依次对各个so和可执行文件进行重定位修正了。这个过程跟静态链接中重定位的过程类似,你可以自己去分析一下。
- init函数调用
最后,有的so文件还会有.init段,进行一些初始化函数的调用,例如so中全局变量的对象构造函数,或者用户自己生成在.init段的初始化函数等。这些都会由ld-linux.so在最后的阶段进行一次调用。当这些完成之后,ld-linux.so就会结束自己的使命,最终将程序的控制流转到可执行文件的入口函数中进行。
整个Loader加载动态链接的可执行文件流程如下图所示:
总结
我们通过三节课的学习,弄明白了“将符号转成地址”这个工作是由谁、在何时、如何完成的。
编译器在把源代码翻译成汇编指令的过程中,由于不知道其他编译单元的符号的真实地址,在引用这些符号的时候只能使用占位符(通常是0)来代替。这些占位符由链接器填充。当链接器把所有的符号的位置都确定好以后,再把真实地址回填到占位符里,这个过程就是重定位。
重定位的时机有三个,分别是编译期重定位(第6节课),加载期(第7节课)和这节课介绍的运行时重定位。
这节课我们先介绍了patch code技术,它被采用了即时编译的语言虚拟机广泛地使用。它可以做到运行时解析符号。它的主要原理是把call指令的目标地址填成用于解析符号的函数地址,当CPU执行到这个call指令时就会转去解析函数,然后把call指令的目标地址替换成符号的真实地址。
patch code技术有一个缺点,那就是在运行期要修改代码段的数据,这为系统带来了风险。动态链接库则引入了.plt和.got段,通过间接调用来解决这个问题。在运行时,符号解析函数只需要修改GOT的内容就可以了,代码段是不会发生任何变化的。
当然,因为要向符号解析函数传递参数,所以动态库的.plt设计成了三级跳转的结构,看上去虽然很复杂,但我们只需要牢牢记住.plt最终的目标还是调用到符号解析函数,然后重写GOT表的内容即可。
我们这两节课的内容都是动态链接,而真正负责动态链接的是ld-linux.so,它被称为动态链接器,但因为它还负责加载文件工作,所以也被人称为加载器或者loader。它的工作流程主要有启动,加载,重定位和init四个步骤。
链接与加载还有很多细节,但我已经带你建立起了基本的知识框架。如果对链接和加载还有更浓厚的兴趣,你可以参考《程序员的自我修养 》,《链接器和加载器 》等书,以便了解更多的相关结构和算法。
思考题
相信你已经完全理解了动态链接器的时机和原理了,那么请你思考一下:在生成一个动态库文件的时候,我们一定要加shared选项,但-fPIC选项是必然要加的吗?有没有不需要用这个选项的情况呢?如果没有,为什么?如果有的话,又是什么情况呢?欢迎你在留言区分享你的想法和收获,我在留言区等你。

好啦,这节课到这就结束啦。欢迎你把这节课分享给更多对计算机内存感兴趣的朋友。我是海纳,我们下节课再见!
- keepgoing 👍(11) 💬(5)
三节课的编译链接内容感觉收获不小,尝试把知识串连一下加深印象: 编译器:生成每个编译单元的机器码,生成重定位表,符号地址0占位 链接器:合并目标文件,静态符号分配地址,重定位表寻找静态符号填址 加载器(加载过程):重定位表找动态符号,根据符号所在动态库,把符号偏移定位在各个动态库的GOT表中。对于各个动态库中的符号,进行地址分配,填回GOT表中。 - 对于动态库本身,编译时会将需要重定位类型的符号也放到GOT表中,等到与可执行文件共同被装载的时候分配虚拟内存空间。 加载器(运行时加载):重定位表找动态符号,把符号引向PLT表,真正运行的时候找到对应动态库加载,将虚拟地址填到动态库GOT表中,保存下一次直接访问。 - 所以编译动态库的时候如果用了plt,跟上面的区别就是会把需要重定位的符号引向自身的plt表中,来间接访问GOT表。 不知道有没有理解错误的地方。 另外还想向老师请教几个问题: 1、plt可以理解为一段不会变更的跳转规则封装吗,目的就是为了避免直接修改执行指令,是不是也能理解不是绝对安全的,如果能直接修改GOT已经存好的符号地址(只不过难度比较大)? 2、上节课的提问老师帮忙解释了进程不会有GOT,只会存在动态库中,所以我上面在总结时猜测的多个动态库加载的情况,对于可执行文件中对动态库符号的访问,是不是就得访问多个动态库的GOT表,因为动态库本身编译的segement位置是固定的,如果合并GOT,自身依赖其他动态库符号就没法统一偏移了。 3、延迟绑定技术的设计是进程和各个动态库都会有一份自己的plt吗,因为看文中说的使用延迟绑定技术只有一个参数 -fno-plt 控制,是不是可以理解加载时链接和运行时链接这两种动态链接方式只能存在一种。 4、老师在最后举了一个A、B动态库符号相同的例子。如果情况编程可执行文件有方法foo,动态库A的方法foo2依赖动态库B的方法foo,如果在可执行文件里调用foo2方法,最终被调用的结果是不是也有不同的情况? 老师这三节课的确讲的太好了,所以疑问产生也比较多,感谢老师赐教。
2021-11-11 - kylin 👍(9) 💬(3)
-fPIC 选项有时候是不需要的。 在动态链接库不需要依赖其它动态库的时候,就不需要位置无关代码,所以我认为在这种特殊场景下是不需要打开-fPIC的。
2021-11-10 - thomas 👍(5) 💬(1)
在 Hotspot 里的 patch code 技术,会直接修改指令参数。不过,运行时修改指令总是一件很危险的事情. ---------------------------------------------------------> 老师,代码段不是可读的吗,怎么能够修改指令?
2021-12-30 - shenglin 👍(2) 💬(2)
Disassembly of section .got.plt: 0000000000201000 <_GLOBAL_OFFSET_TABLE_>: 201000: 08 0e or %cl,(%rsi) 201002: 20 00 and %al,(%rax) ... 201018: 46 06 rex.RX (bad) 20101a: 00 00 add %al,(%rax) 20101c: 00 00 add %al,(%rax) 20101e: 00 00 add %al,(%rax) 201020: 56 push %rsi 201021: 06 (bad) 201022: 00 00 add %al,(%rax) 201024: 00 00 add %al,(%rax) 0000000000000630 <extern_func@plt-0x10>: 630: ff 35 d2 09 20 00 pushq 0x2009d2(%rip) # 201008 <_GLOBAL_OFFSET_TABLE_+0x8> 636: ff 25 d4 09 20 00 jmpq *0x2009d4(%rip) # 201010 <_GLOBAL_OFFSET_TABLE_+0x10> 63c: 0f 1f 40 00 nopl 0x0(%rax) 0000000000000640 <extern_func@plt>: 640: ff 25 d2 09 20 00 jmpq *0x2009d2(%rip) # 201018 <_GLOBAL_OFFSET_TABLE_+0x18> 646: 68 00 00 00 00 pushq $0x0 64b: e9 e0 ff ff ff jmpq 630 <_init+0x28> 0000000000000650 <global_func@plt>: 650: ff 25 ca 09 20 00 jmpq *0x2009ca(%rip) # 201020 <_GLOBAL_OFFSET_TABLE_+0x20> 656: 68 01 00 00 00 pushq $0x1 65b: e9 d0 ff ff ff jmpq 630 <_init+0x28> 老师请问一下,从地址650处跳转到GOT表里执行之后,按照上面说的流程,GOT表里应该立即执行一条跳转指令,回到地址656处执行参数压栈,但是GOT表里的指令好像没有执行这个,是哪里有问题吗
2021-11-18 - 小时候可鲜啦 👍(0) 💬(2)
gdb调试的过程中发现 在main函数内调用动态库定义的函数之前其plt表内对应的地址项已经被重写了,这是怎么回事?貌似动态链接器在装载期就完成了动态库符号的重定位。
2021-12-09 - 我是内存 👍(0) 💬(1)
你好,文中描述plt的时候说:我们再回到图中看看,在序号①箭头的位置,也就是第一级跳转,它的目的是把参数 0 入栈。由于 GOT 表的 0x0,0x8,0x10 的位置都被占用了,所以参数 0 代表的就是 0x18 位置,这就是 B 函数的真实地址应该存放的地方。 ------------------- 这里没有懂。为什么got表里的0x0,0x08,0x10被占用了,参数0就代表0x18呢?如果0x18也被占用了,那参数0就代表0x20吗? 这里的“参数0”是指数值0吗?还是第0个参数?
2021-11-20 - kylin 👍(0) 💬(2)
海纳老师,您好,我有一个疑问,加载时动态链接的话,每个.so文件(动态链接库)是不是都有一个自己的GOT表?
2021-11-10 - 凯文小猪 👍(3) 💬(1)
动态链接延迟绑定在北美西北大学的课程网站上也有描述,文章也详述了GOT表前三项的表示含义: 截取GOT[1]的内容可做印证: GOT[1] is the pointer to a data structure that the dynamic linker manages. This data structure is a linked list of nodes corresponding to the symbol tables for each shared library linked with the program. When a symbol is to be resolved by the linker, this list is traversed to find the appropriate symbol. Using the LD_PRELOAD environment variable basically ensures that your preload library will be the first node on this list. reloc_index参数的意义: The next instruction pushes some info on the stack (the PLT offset) and jumps to the very first entry into the PLT, which calls into the dynamic linker's resolution function (_dl_runtime_resolve for ld.so). 原文链接:http://users.eecs.northwestern.edu/~kch479/docs/notes/linking.html
2023-02-21 - 凯文小猪 👍(3) 💬(2)
简单回应下这一节的PIC内容 其实解析PIC无关函数地址,目前linux上是使用_dl_runtime_resolve(link_map_obj, reloc_index)函数 该函数是一段汇编代码 源码解析可以在网上找到 建议只看英文 link_map_obj:要求传的是link_map,也就是维护.dynstr、.dynsym、.rela.plt等的双向链表 reloc_index:是.rela.plt表的索引项 老师给的图实际上是有歧义的,因为根据Sysytem V ABI Intel i386定义,GOT表前三项是保留字段 GOT[0] 是.dynamic地址 GOT[1] 是link_map地址 GOT[2] 是_dl_runtime_resolve地址 所以B.plt 的push 0x0 不能说是因为GOT前三项是被占用,所以压入0自然就是B函数,而是因为B函数在重定向表.rela.plt的索引是0,所以才压入0 要想明白动态链接流程,还是应该从汇编角度理解_dl_runtime_resolve在X86上调用流程 最后函数调用完,确实是回填GOT表,因为GOT表在数据段是可读可写的,下次就不用再解析一次了
2023-02-21 - 一个工匠 👍(0) 💬(0)
老师是大王,赞
2022-11-01 - Linuxer 👍(0) 💬(0)
有如下问题想请教下海纳老师 readelf -d bin/mysqld Dynamic section at offset 0x1e9fa60 contains 35 entries: Tag Type Name/Value 0x0000000000000001 (NEEDED) Shared library: [librt.so.1] ... 0x000000000000000f (RPATH) Library rpath: [$ORIGIN/../lib] 0x000000000000001d (RUNPATH) Library runpath: [$ORIGIN/../lib] 有RPATH和RUNPATH为什么不去lib目录下查找库libltdl.so.7呢? ldd bin/mysqld /lib64/ld-linux-x86-64.so.2 (0x00007f955fea3000) libltdl.so.7 => not found 另一种情况有RPATH,能正常找到lib下的libltdl.so.7库 Dynamic section at offset 0x219fc60 contains 35 entries: Tag Type Name/Value 0x0000000000000001 (NEEDED) Shared library: [librt.so.1] .. 0x000000000000000f (RPATH) Library rpath: [$ORIGIN/../lib] 0x000000000000000c (INIT) 0x7403f0 ldd bin/mysqld libltdl.so.7 => /opt/mariadb34/lib/libltdl.so.7 (0x00007f605a1c3000)
2022-08-03