11 如何修改TCP缓冲区才能兼顾并发数量与传输速度?
你好,我是陶辉。
我们在[第8课] 中讲了如何从C10K进一步到C10M,不过,这也意味着TCP占用的内存翻了一千倍,服务器的内存资源会非常紧张。
如果你在Linux系统中用free命令查看内存占用情况,会发现一栏叫做buff/cache,它是系统内存,似乎与应用进程无关。但每当进程新建一个TCP连接,buff/cache中的内存都会上升4K左右。而且,当连接传输数据时,就远不止增加4K内存了。这样,几十万并发连接,就在进程内存外又增加了GB级别的系统内存消耗。
这是因为TCP连接是由内核维护的,内核为每个连接建立的内存缓冲区,既要为网络传输服务,也要充当进程与网络间的缓冲桥梁。如果连接的内存配置过小,就无法充分使用网络带宽,TCP传输速度就会很慢;如果连接的内存配置过大,那么服务器内存会很快用尽,新连接就无法建立成功。因此,只有深入理解Linux下TCP内存的用途,才能正确地配置内存大小。
这一讲,我们就来看看,Linux下的TCP缓冲区该如何修改,才能在高并发下维持TCP的高速传输。
滑动窗口是怎样影响传输速度的?
我们知道,TCP必须保证每一个报文都能够到达对方,它采用的机制就是:报文发出后,必须收到接收方返回的ACK确认报文(Acknowledge确认的意思)。如果在一段时间内(称为RTO,retransmission timeout)没有收到,这个报文还得重新发送,直到收到ACK为止。
可见,TCP报文发出去后,并不能立刻从内存中删除,因为重发时还需要用到它。由于TCP是由内核实现的,所以报文存放在内核缓冲区中,这也是高并发下buff/cache内存增加很多的原因。
事实上,确认报文被收到的机制非常复杂,它受制于很多因素。我们先来看第一个因素,速度。
如果我们发送一个报文,收到ACK确认后,再发送下一个报文,会有什么问题?显然,发送每个报文都需要经历一个RTT时延(RTT的值可以用ping命令得到)。要知道,因为网络设备限制了报文的字节数,所以每个报文的体积有限。
比如,以太网报文最大只有1500字节,而发送主机到接收主机间,要经历多个广域网、局域网,其中最小的设备决定了网络报文的最大字节数,在TCP中,这个值叫做MSS(Maximum Segment Size),它通常在1KB左右。如果RTT时延是10ms,那么它们的传送速度最多只有1KB/10ms=100KB/s!可见,这种确认报文方式太影响传输速度了。
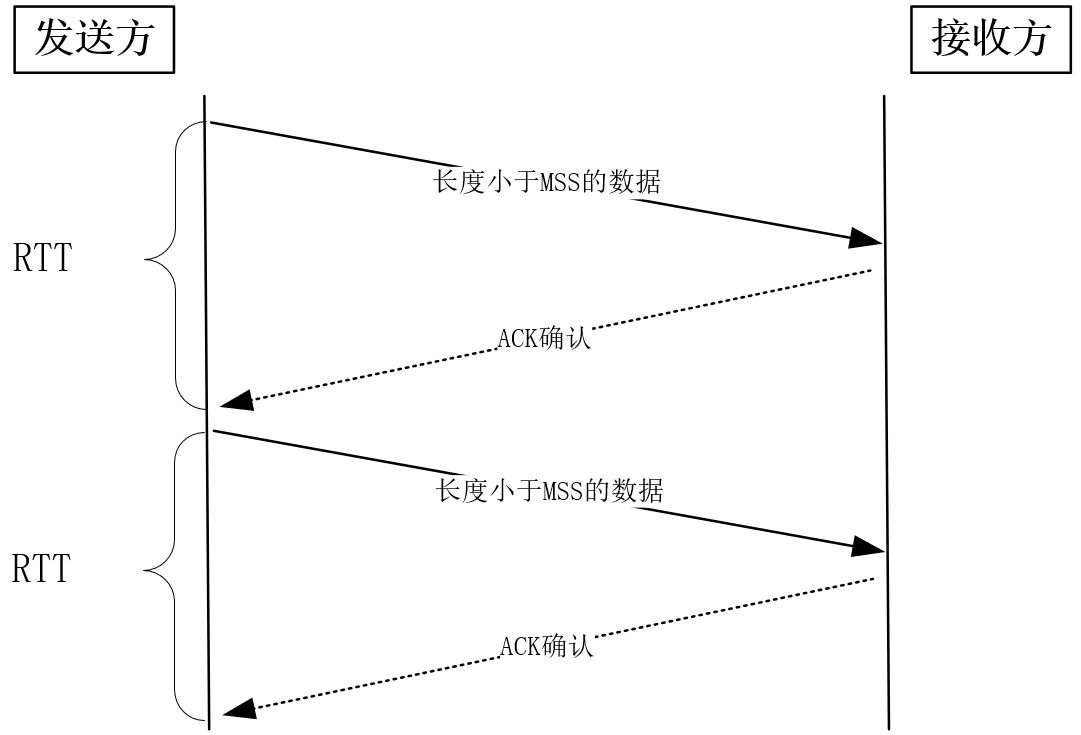
提速的方式很简单,并行地批量发送报文,再批量确认报文即可。比如,发送一个100MB的文件,如果MSS值为1KB,那么需要发送约10万个报文。发送方大可以同时发送这10万个报文,再等待它们的ACK确认。这样,发送速度瞬间就达到100MB/10ms=10GB/s。
然而,这引出了另一个问题,接收方有那么强的处理能力吗?接收方的处理能力,这是影响确认机制的第二个因素(网络也没有这么强的处理能力,下一讲会介绍应对网络瓶颈的拥塞控制技术)。
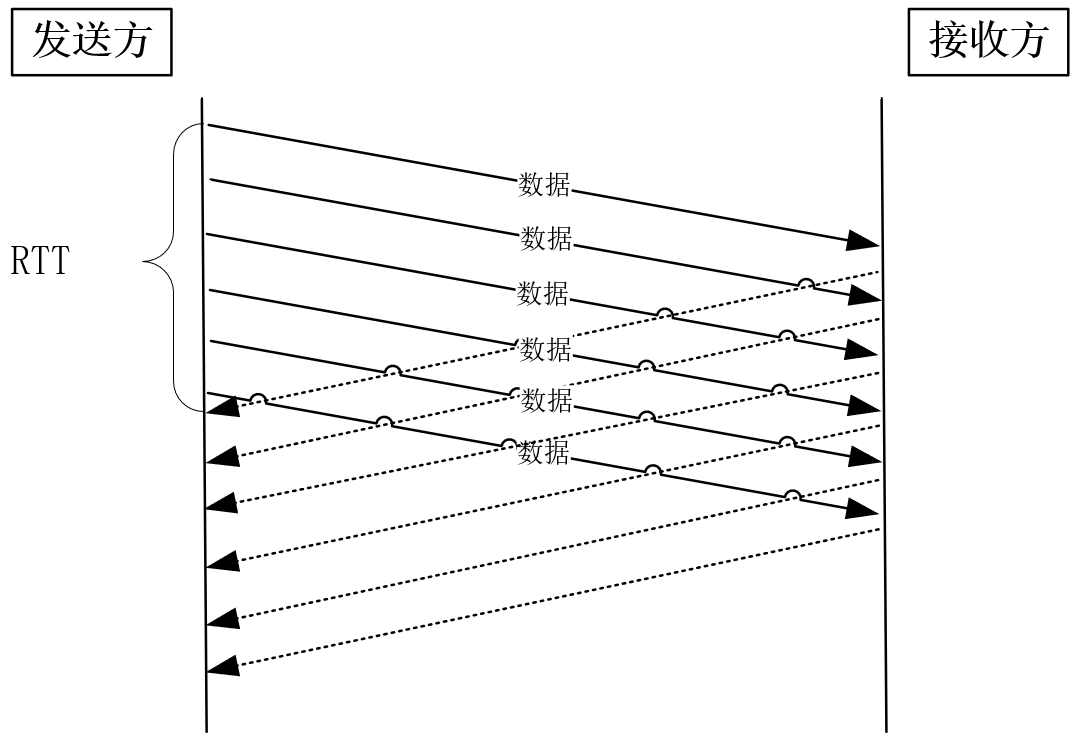
当接收方硬件不如发送方,或者系统繁忙、资源紧张时,是无法瞬间处理这么多报文的。于是,这些报文只能被丢掉,网络效率非常低。怎么限制发送方的速度呢?
接收方把它的处理能力告诉发送方,使其限制发送速度即可,这就是滑动窗口的由来。接收方根据它的缓冲区,可以计算出后续能够接收多少字节的报文,这个数字叫做接收窗口。当内核接收到报文时,必须用缓冲区存放它们,这样剩余缓冲区空间变小,接收窗口也就变小了;当进程调用read函数后,数据被读入了用户空间,内核缓冲区就被清空,这意味着主机可以接收更多的报文,接收窗口就会变大。
因此,接收窗口并不是恒定不变的,那么怎么把时刻变化的窗口通知给发送方呢?TCP报文头部中的窗口字段,就可以起到通知的作用。
当发送方从报文中得到接收方的窗口大小时,就明白了最多能发送多少字节的报文,这个数字被称为发送方的发送窗口。如果不考虑下一讲将要介绍的拥塞控制,发送方的发送窗口就是接收方的接收窗口(由于报文有传输时延,t1时刻的接收窗口在t2时刻才能到达发送端,因此这两个窗口并不完全等价)。
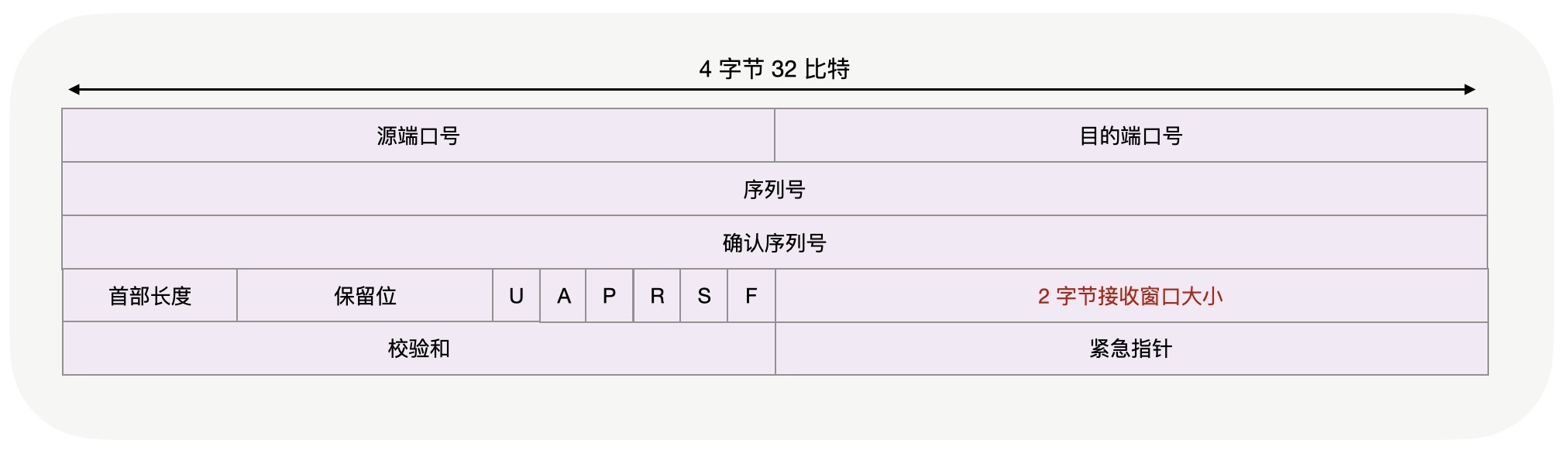
从上图中可以看到,窗口字段只有2个字节,因此它最多能表达216 即65535字节大小的窗口(之所以不是65536,是因为窗口可以为0,此时叫做窗口关闭,上一讲提到的关闭连接时让FIN报文发不出去,以致于服务器的连接都处于FIN_WAIT1状态,就是通过窗口关闭技术实现的),这在RTT为10ms的网络中也只能到达6MB/s的最大速度,在当今的高速网络中显然并不够用。
RFC1323 定义了扩充窗口的方法,但Linux中打开这一功能,需要把tcp_window_scaling配置设为1,此时窗口的最大值可以达到1GB(230)。
这样看来,只要进程能及时地调用read函数读取数据,并且接收缓冲区配置得足够大,那么接收窗口就可以无限地放大,发送方也就无限地提升发送速度。很显然,这是不可能的,因为网络的传输能力是有限的,当发送方依据发送窗口,发送超过网络处理能力的报文时,路由器会直接丢弃这些报文。因此,缓冲区的内存并不是越大越好。
带宽时延积如何确定最大传输速度?
缓冲区到底该设置为多大呢?我们知道,TCP的传输速度,受制于发送窗口与接收窗口,以及网络传输能力。其中,两个窗口由缓冲区大小决定(进程调用read函数是否及时也会影响它)。如果缓冲区大小与网络传输能力匹配,那么缓冲区的利用率就达到了最大值。
怎样计算出网络传输能力呢?带宽描述了网络传输能力,但它不能直接使用,因为它与窗口或者说缓冲区的计量单位不同。带宽是单位时间内的流量 ,它表达的是速度,比如你家里的宽带100MB/s,而窗口和缓冲区的单位是字节。当网络速度乘以时间才能得到字节数,差的这个时间,这就是网络时延。
当最大带宽是100MB/s、网络时延是10ms时,这意味着客户端到服务器间的网络一共可以存放100MB/s * 0.01s = 1MB的字节。这个1MB是带宽与时延的乘积,所以它就叫做带宽时延积(缩写为BDP,Bandwidth Delay Product)。这1MB字节存在于飞行中的TCP报文,它们就在网络线路、路由器等网络设备上。如果飞行报文超过了1MB,就一定会让网络过载,最终导致丢包。
由于发送缓冲区决定了发送窗口的上限,而发送窗口又决定了已发送但未确认的飞行报文的上限,因此,发送缓冲区不能超过带宽时延积,因为超出的部分没有办法用于有效的网络传输,且飞行字节大于带宽时延积还会导致丢包;而且,缓冲区也不能小于带宽时延积,否则无法发挥出高速网络的价值。
怎样调整缓冲区去适配滑动窗口?
这么看来,我们只要把缓冲区设置为带宽时延积不就行了吗?比如,当我们做socket网络编程时,通过设置socket的SO_SNDBUF属性,就可以设定缓冲区的大小。
然而,这并不是个好主意,因为不是每一个请求都能够达到最大传输速度,比如请求的体积太小时,在慢启动(下一讲会谈到)的影响下,未达到最大速度时请求就处理完了。再比如网络本身也会有波动,未必可以一直保持最大速度。
因此,时刻让缓冲区保持最大,太过浪费内存了。
到底该如何设置缓冲区呢?
我们可以使用Linux的缓冲区动态调节功能解决上述问题。其中,缓冲区的调节范围是可以设置的。先来看发送缓冲区,它的范围通过tcp_wmem配置:
其中,第1个数值是动态范围的下限,第3个数值是动态范围的上限。而中间第2个数值,则是初始默认值。
发送缓冲区完全根据需求自行调整。比如,一旦发送出的数据被确认,而且没有新的数据要发送,就可以把发送缓冲区的内存释放掉。而接收缓冲区的调整就要复杂一些,先来看设置接收缓冲区范围的tcp_rmem:
它的数值与tcp_wmem类似,第1、3个值是范围的下限和上限,第2个值是初始默认值。发送缓冲区自动调节的依据是待发送的数据,接收缓冲区由于只能被动地等待接收数据,它该如何自动调整呢?
可以依据空闲系统内存的数量来调节接收窗口。如果系统的空闲内存很多,就可以把缓冲区增大一些,这样传给对方的接收窗口也会变大,因而对方的发送速度就会通过增加飞行报文来提升。反之,内存紧张时就会缩小缓冲区,这虽然会减慢速度,但可以保证更多的并发连接正常工作。
发送缓冲区的调节功能是自动开启的,而接收缓冲区则需要配置tcp_moderate_rcvbuf为1来开启调节功能:
接收缓冲区调节时,怎么判断空闲内存的多少呢?这是通过tcp_mem配置完成的:
tcp_mem的3个值,是Linux判断系统内存是否紧张的依据。当TCP内存小于第1个值时,不需要进行自动调节;在第1和第2个值之间时,内核开始调节接收缓冲区的大小;大于第3个值时,内核不再为TCP分配新内存,此时新连接是无法建立的。
在高并发服务器中,为了兼顾网速与大量的并发连接,我们应当保证缓冲区的动态调整上限达到带宽时延积,而下限保持默认的4K不变即可。而对于内存紧张的服务而言,调低默认值是提高并发的有效手段。
同时,如果这是网络IO型服务器,那么,调大tcp_mem的上限可以让TCP连接使用更多的系统内存,这有利于提升并发能力。需要注意的是,tcp_wmem和tcp_rmem的单位是字节,而tcp_mem的单位是页面大小。而且,千万不要在socket上直接设置SO_SNDBUF或者SO_RCVBUF,这样会关闭缓冲区的动态调整功能。
小结
我们对这一讲的内容做个小结。
实现高并发服务时,由于必须把大部分内存用在网络传输上,所以除了关注应用内存的使用,还必须关注TCP内核缓冲区的内存使用情况。
TCP使用ACK确认报文实现了可靠性,又依赖滑动窗口既提升了发送速度也兼顾了接收方的处理能力。然而,默认的滑动窗口最大只能到65KB,要想提升发送速度必须提升滑动窗口的上限,在Linux下是通过设置tcp_window_scaling为1做到的。
滑动窗口定义了飞行报文的最大字节数,当它超过带宽时延积时,就会发生丢包。而当它小于带宽时延积时,就无法让TCP的传输速度达到网络允许的最大值。因此,滑动窗口的设计,必须参考带宽时延积。
内核缓冲区决定了滑动窗口的上限,但我们不能通过socket的SO_SNFBUF等选项直接把缓冲区大小设置为带宽时延积,因为TCP不会一直维持在最高速上,过大的缓冲区会减少并发连接数。Linux带来的缓冲区自动调节功能非常有效,我们应当把缓冲区的上限设置为带宽时延积。其中,发送缓冲区的调节功能是自动打开的,而接收缓冲区需要把tcp_moderate_rcvbuf设置为1来开启,其中调节的依据根据tcp_mem而定。
这样高效地配置内存后,既能够最大程度地保持并发性,也能让资源充裕时连接传输速度达到最大值。这一讲我们谈了内核缓冲区对传输速度的影响,下一讲我们再来看如何调节发送速度以匹配不同的网络能力。
思考题
最后,请你观察下Linux系统下,连接建立时、发送接收数据时,buff/cache内存的变动情况。用我们这一讲介绍的原理,解释系统内存的变化现象。欢迎你在留言区与我沟通互动。
感谢阅读,如果你觉得这节课对你有一些启发,也欢迎把它分享给你的朋友。
- J.Smile 👍(18) 💬(1)
总结: ----------缓冲区动态调节功能----------- ①发送缓冲区自动调整(自动开启): net.ipv4.tcp_wmem = 4096(动态范围下限) 16384(初始默认值) 4194304(动态范围上限) 一旦发送出的数据被确认,而且没有新的数据要发送,就可以把发送缓冲区的内存释放掉 ②接收缓冲区自动调整(通过设置net.ipv4.tcp_moderate_rcvbuf = 1开启): net.ipv4.tcp_rmem = 4096(动态范围下限) 87380(初始默认值) 6291456(动态范围上限) 可以依据空闲系统内存的数量来调节接收窗口。如果系统的空闲内存很多,就可以把缓冲区增大一些,这样传给对方的接收窗口也会变大,因而对方的发送速度就会通过增加飞行报文来提升。反之,内存紧张时就会缩小缓冲区,这虽然会减慢速度,但可以保证更多的并发连接正常工作。 ③接收缓冲区判断内存空闲的方式: net.ipv4.tcp_mem = 88560 118080 177120 当 TCP 内存小于第 1 个值时,不需要进行自动调节; 在第 1 和第 2 个值之间时,内核开始调节接收缓冲区的大小; 大于第 3 个值时,内核不再为 TCP 分配新内存,此时新连接是无法建立的。 ④带宽时延积的衡量方式:对网络时延多次取样计算平均值,再乘以带宽。
2020-07-16 - 锋 👍(9) 💬(3)
老师好,我有一个疑问想请教老师,在使用tcp来传输大数据包时,比如2M。这样的数据包在业务中很频繁出现,这样的数据包我们需要在我们的业务代码层面来实现拆包后发送,还是将拆包的工作交给网络设备来处理?为什么?谢谢
2020-06-13 - 代后建 👍(6) 💬(2)
老师,你好,我项目上用了nginx做代理,但偶尔会出现请求响应特别忙慢的情况(20s左右),目前系统暂未上线,不存在并发影响性能的问题。我也用命令看了请求已到达网卡,却不知道nginx为何不响应,日志问题看不到什么问题,请教下排查问题的思路,谢谢!
2020-06-23 - Thinking 👍(4) 💬(1)
请问一条TCP连接的带宽时延积中的带宽大小内核如何计算出来的?
2020-09-09 - kimileonis 👍(3) 💬(1)
老师,当 net.ipv4.tcp_rmem 的当前值超过 net.ipv4.tcp_mem 的第三个值,就不会接受发送端新的TCP请求,直到 net.ipv4.tcp_rmem 的当前值小于 net.ipv4.tcp_mem 的第三个值后,才会接收新的连接请求,请问这么理解对吗?
2020-10-27 - 张华中-Blackc 👍(3) 💬(1)
比如,发送一个 100MB 的文件,如果 MSS 值为 1KB,那么需要发送约 10 万个报文。发送方大可以同时发送这 10 万个报文,再等待它们的 ACK 确认。这样,发送速度瞬间就达到 100MB/10ms=10GB/s。 这里发送方同时发送10万个报文是需要应用层做,还是说操作系统默认就是这么做的?
2020-07-31 - 橙子橙 👍(2) 💬(2)
老师 目前请求1000qps, client每次发送2MB数据, 服务器返回20MB数据, 要求每个请求client端rtt 50ms内, 不知道有没有可能? 还有老师对dpdk是什么看法, 针对这个场景有没有可能使用dpdk优化?
2020-12-09 - Only now 👍(2) 💬(1)
这里设置的带宽时延积是从哪里来的? 我有一私有网络PriNet, 其内部带宽1G bit/s,但是出口带宽5M/s,那么网络内的服务器调整参数是,带宽时延积计算,这个带宽和时延分别取哪一段???
2020-11-18 - Trident 👍(1) 💬(1)
带宽时延积如何衡量呢,网络时延不是固定的,是要多次取样计算平均网络时延?然后估算出这个时延积
2020-05-27 - kimileonis 👍(0) 💬(1)
老师,当 net.ipv4.tcp_rmem 的当前值超过 net.ipv4.tcp_mem 的第三个值,就不会接受发送端新的TCP请求,直到 net.ipv4.tcp_rmem 的当前值小于 net.ipv4.tcp_mem 的第三个值后,才会接收新的连接请求,请问这么理解对吗?
2020-10-27 - 分清云淡 👍(25) 💬(7)
TCP性能和发送接收窗口、Buffer的关系, 定量分析和图形展示, 正好看看wireshark分析这类问题的魅力: https://plantegg.github.io/2019/09/28/%E5%B0%B1%E6%98%AF%E8%A6%81%E4%BD%A0%E6%87%82TCP--%E6%80%A7%E8%83%BD%E5%92%8C%E5%8F%91%E9%80%81%E6%8E%A5%E6%94%B6Buffer%E7%9A%84%E5%85%B3%E7%B3%BB/
2020-05-22 - 安排 👍(6) 💬(1)
tcp的缓冲区占用的buffer/cache不算在进程的内存中吗?那如果系统开了swap,这些缓冲区是否会在内存紧张时被回收呢?
2020-05-22 - Bourne 👍(2) 💬(1)
老师您好,我有两个疑问: 1、一个TCP连接在客户端和服务端是都会有两个内存缓冲区吗,一个接收缓冲区,一个发送缓冲区?还是说各只有一个缓冲区,接收和发送共用? 2、文章说的带宽时延积是用带宽乘以时延,这里的带宽是指客户端的还是服务端的?因为客户端和服务端的带宽不可能都一样,所以算出来的时延积是不同的。
2020-06-23 - stackWarn 👍(2) 💬(0)
相关的内存配置在nginx调优中使用过,这次终于从前到后理解了意义
2020-06-12 - leslie 👍(1) 💬(0)
建立和释放以及为了连接数而滑动合适设置值,这个只能通过不断的观察去调整适应主要时间段的业务;均衡的设计考虑确实不易。
2020-05-22