04 零拷贝:如何高效地传输文件?
你好,我是陶辉。
上一讲我们谈到,当索引的大小超过内存时,就会用磁盘存放索引。磁盘的读写速度远慢于内存,所以才针对磁盘设计了减少读写次数的B树索引。
磁盘是主机中最慢的硬件之一,常常是性能瓶颈,所以优化它能获得立竿见影的效果。
因此,针对磁盘的优化技术层出不穷,比如零拷贝、直接IO、异步IO等等。这些优化技术为了降低操作时延、提升系统的吞吐量,围绕着内核中的磁盘高速缓存(也叫PageCache),去减少CPU和磁盘设备的工作量。
这些磁盘优化技术和策略虽然很有效,但是理解它们并不容易。只有搞懂内核操作磁盘的流程,灵活正确地使用,才能有效地优化磁盘性能。
这一讲,我们就通过解决“如何高效地传输文件”这个问题,来分析下磁盘是如何工作的,并且通过优化传输文件的性能,带你学习现在热门的零拷贝、异步IO与直接IO这些磁盘优化技术。
你会如何实现文件传输?
服务器提供文件传输功能,需要将磁盘上的文件读取出来,通过网络协议发送到客户端。如果需要你自己编码实现这个文件传输功能,你会怎么实现呢?
通常,你会选择最直接的方法:从网络请求中找出文件在磁盘中的路径后,如果这个文件比较大,假设有320MB,可以在内存中分配32KB的缓冲区,再把文件分成一万份,每份只有32KB,这样,从文件的起始位置读入32KB到缓冲区,再通过网络API把这32KB发送到客户端。接着重复一万次,直到把完整的文件都发送完毕。如下图所示:
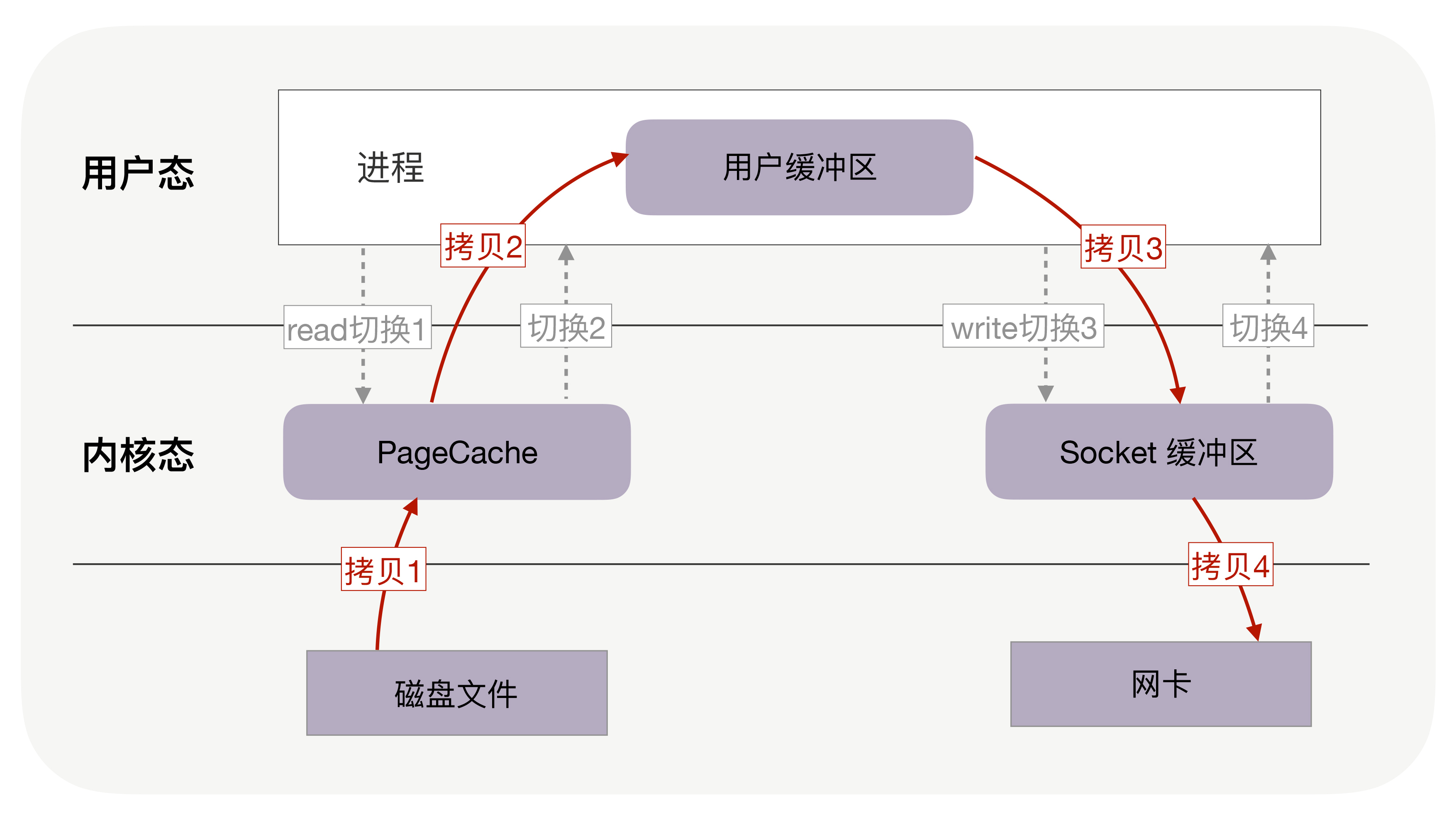
不过这个方案性能并不好,主要有两个原因。
首先,它至少经历了4万次用户态与内核态的上下文切换。因为每处理32KB的消息,就需要一次read调用和一次write调用,每次系统调用都得先从用户态切换到内核态,等内核完成任务后,再从内核态切换回用户态。可见,每处理32KB,就有4次上下文切换,重复1万次后就有4万次切换。
上下文切换的成本并不小,虽然一次切换仅消耗几十纳秒到几微秒,但高并发服务会放大这类时间的消耗。
其次,这个方案做了4万次内存拷贝,对320MB文件拷贝的字节数也翻了4倍,到了1280MB。很显然,过多的内存拷贝无谓地消耗了CPU资源,降低了系统的并发处理能力。
所以要想提升传输文件的性能,需要从降低上下文切换的频率和内存拷贝次数两个方向入手。
零拷贝如何提升文件传输性能?
首先,我们来看如何降低上下文切换的频率。
为什么读取磁盘文件时,一定要做上下文切换呢?这是因为,读取磁盘或者操作网卡都由操作系统内核完成。内核负责管理系统上的所有进程,它的权限最高,工作环境与用户进程完全不同。只要我们的代码执行read或者write这样的系统调用,一定会发生2次上下文切换:首先从用户态切换到内核态,当内核执行完任务后,再切换回用户态交由进程代码执行。
因此,如果想减少上下文切换次数,就一定要减少系统调用的次数。解决方案就是把read、write两次系统调用合并成一次,在内核中完成磁盘与网卡的数据交换。
其次,我们应该考虑如何减少内存拷贝次数。
每周期中的4次内存拷贝,其中与物理设备相关的2次拷贝是必不可少的,包括:把磁盘内容拷贝到内存,以及把内存拷贝到网卡。但另外2次与用户缓冲区相关的拷贝动作都不是必需的,因为在把磁盘文件发到网络的场景中,用户缓冲区没有必须存在的理由。
如果内核在读取文件后,直接把PageCache中的内容拷贝到Socket缓冲区,待到网卡发送完毕后,再通知进程,这样就只有2次上下文切换,和3次内存拷贝。
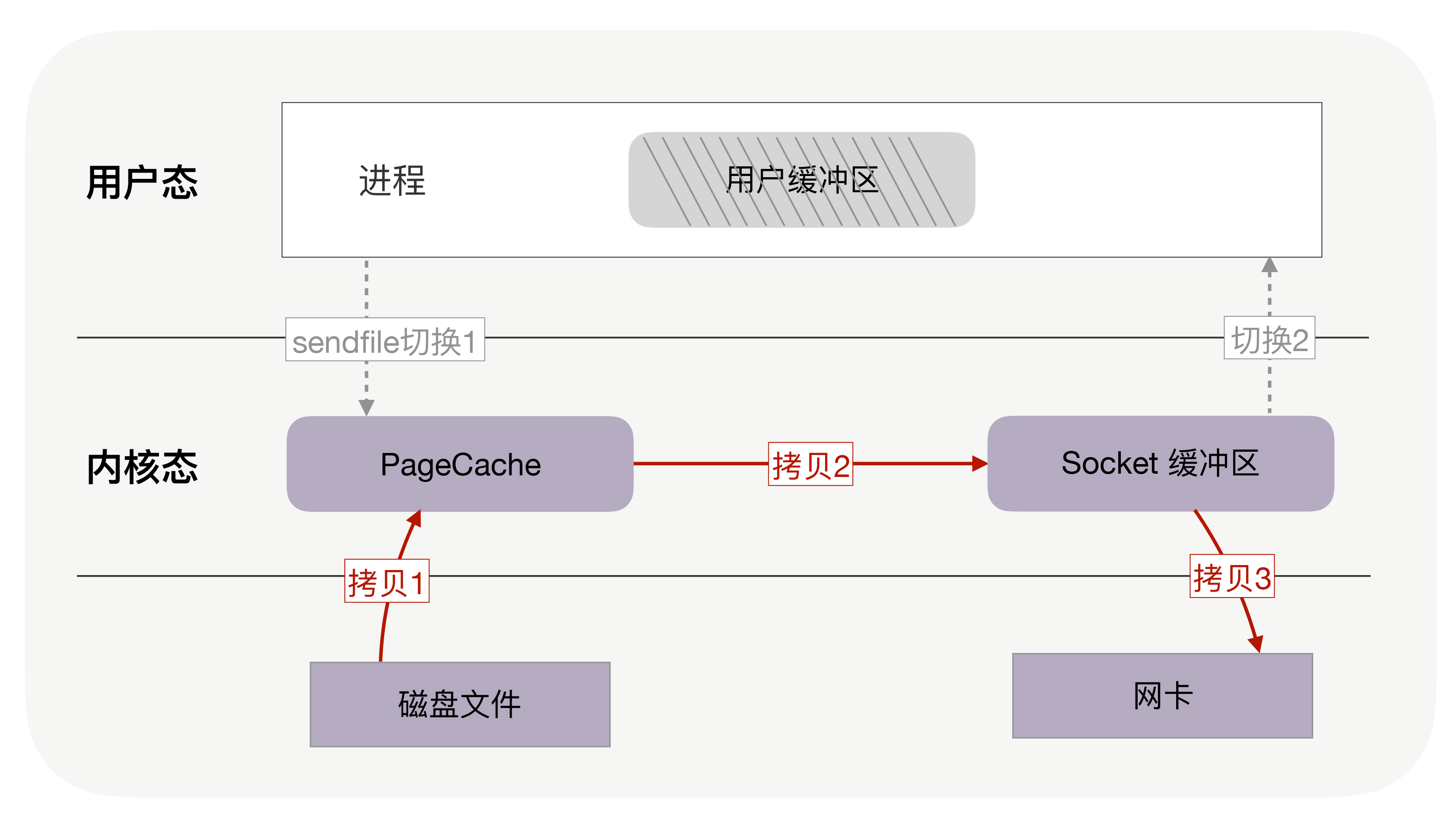
如果网卡支持SG-DMA(The Scatter-Gather Direct Memory Access)技术,还可以再去除Socket缓冲区的拷贝,这样一共只有2次内存拷贝。
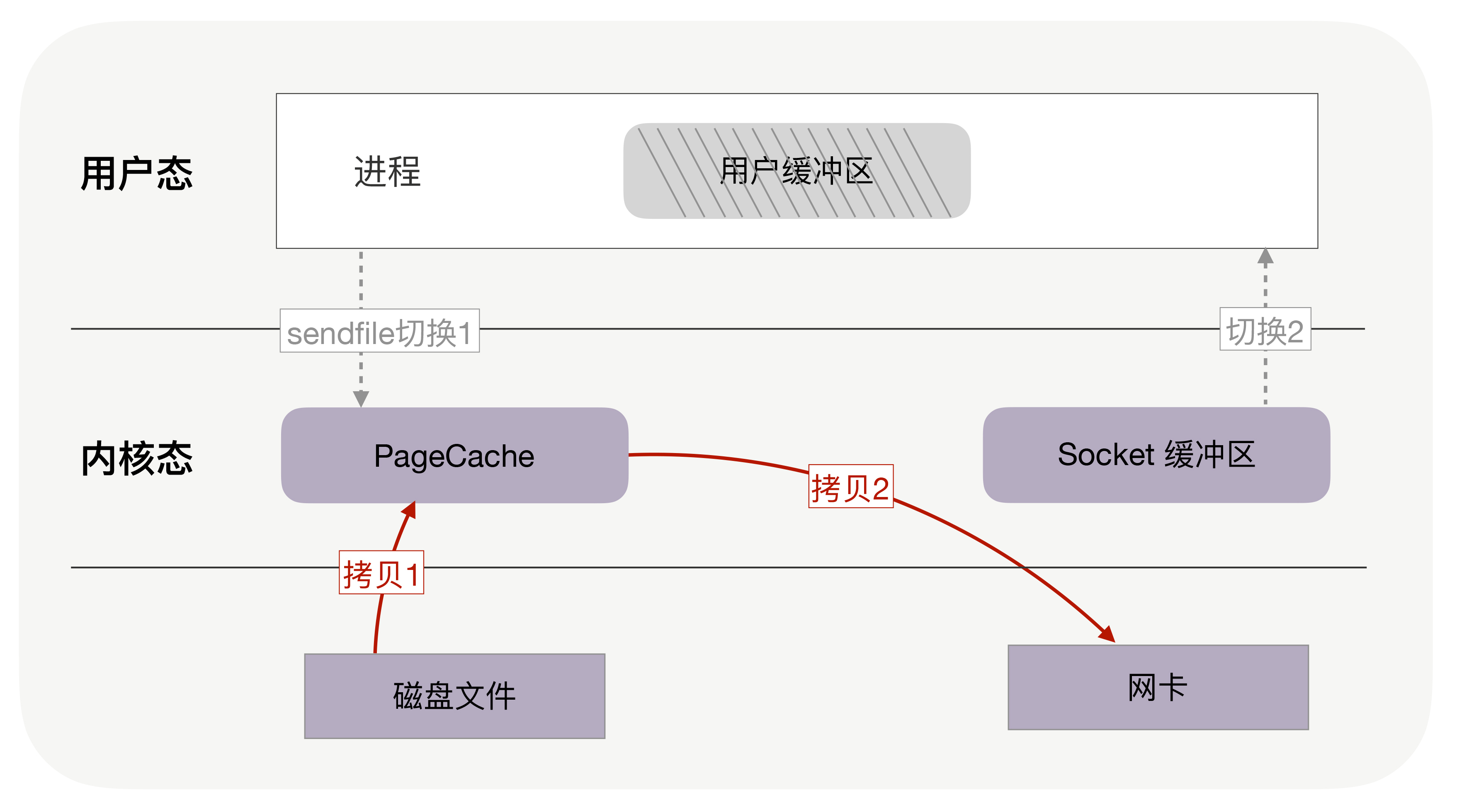
实际上,这就是零拷贝技术。
它是操作系统提供的新函数,同时接收文件描述符和TCP socket作为输入参数,这样执行时就可以完全在内核态完成内存拷贝,既减少了内存拷贝次数,也降低了上下文切换次数。
而且,零拷贝取消了用户缓冲区后,不只降低了用户内存的消耗,还通过最大化利用socket缓冲区中的内存,间接地再一次减少了系统调用的次数,从而带来了大幅减少上下文切换次数的机会!
你可以回忆下,没用零拷贝时,为了传输320MB的文件,在用户缓冲区分配了32KB的内存,把文件分成1万份传送,然而,这32KB是怎么来的?为什么不是32MB或者32字节呢?这是因为,在没有零拷贝的情况下,我们希望内存的利用率最高。如果用户缓冲区过大,它就无法一次性把消息全拷贝给socket缓冲区;如果用户缓冲区过小,则会导致过多的read/write系统调用。
那用户缓冲区为什么不与socket缓冲区大小一致呢?这是因为,socket缓冲区的可用空间是动态变化的,它既用于TCP滑动窗口,也用于应用缓冲区,还受到整个系统内存的影响(我在《Web协议详解与抓包实战》第5部分课程对此有详细介绍,这里不再赘述)。尤其在长肥网络中,它的变化范围特别大。
零拷贝使我们不必关心socket缓冲区的大小。比如,调用零拷贝发送方法时,尽可以把发送字节数设为文件的所有未发送字节数,例如320MB,也许此时socket缓冲区大小为1.4MB,那么一次性就会发送1.4MB到客户端,而不是只有32KB。这意味着对于1.4MB的1次零拷贝,仅带来2次上下文切换,而不使用零拷贝且用户缓冲区为32KB时,经历了176次(4 * 1.4MB/32KB)上下文切换。
综合上述各种优点,零拷贝可以把性能提升至少一倍以上!对文章开头提到的320MB文件的传输,当socket缓冲区在1.4MB左右时,只需要4百多次上下文切换,以及4百多次内存拷贝,拷贝的数据量也仅有640MB,这样,不只请求时延会降低,处理每个请求消耗的CPU资源也会更少,从而支持更多的并发请求。
此外,零拷贝还使用了PageCache技术,通过它,零拷贝可以进一步提升性能,我们接下来看看PageCache是如何做到这一点的。
PageCache,磁盘高速缓存
回顾上文中的几张图,你会发现,读取文件时,是先把磁盘文件拷贝到PageCache上,再拷贝到进程中。为什么这样做呢?有两个原因所致。
第一,由于磁盘比内存的速度慢许多,所以我们应该想办法把读写磁盘替换成读写内存,比如把磁盘中的数据复制到内存中,就可以用读内存替换读磁盘。但是,内存空间远比磁盘要小,内存中注定只能复制一小部分磁盘中的数据。
选择哪些数据复制到内存呢?通常,刚被访问的数据在短时间内再次被访问的概率很高(这也叫“时间局部性”原理),用PageCache缓存最近访问的数据,当空间不足时淘汰最久未被访问的缓存(即LRU算法)。读磁盘时优先到PageCache中找一找,如果数据存在便直接返回,这便大大提升了读磁盘的性能。
第二,读取磁盘数据时,需要先找到数据所在的位置,对于机械磁盘来说,就是旋转磁头到数据所在的扇区,再开始顺序读取数据。其中,旋转磁头耗时很长,为了降低它的影响,PageCache使用了预读功能。
也就是说,虽然read方法只读取了0-32KB的字节,但内核会把其后的32-64KB也读取到PageCache,这后32KB读取的成本很低。如果在32-64KB淘汰出PageCache前,进程读取到它了,收益就非常大。这一讲的传输文件场景中这是必然发生的。
从这两点可以看到PageCache的优点,它在90%以上场景下都会提升磁盘性能,但在某些情况下,PageCache会不起作用,甚至由于多做了一次内存拷贝,造成性能的降低。在这些场景中,使用了PageCache的零拷贝也会损失性能。
具体是什么场景呢?就是在传输大文件的时候。比如,你有很多GB级的文件需要传输,每当用户访问这些大文件时,内核就会把它们载入到PageCache中,这些大文件很快会把有限的PageCache占满。
然而,由于文件太大,文件中某一部分内容被再次访问到的概率其实非常低。这带来了2个问题:首先,由于PageCache长期被大文件占据,热点小文件就无法充分使用PageCache,它们读起来变慢了;其次,PageCache中的大文件没有享受到缓存的好处,但却耗费CPU(或者DMA)多拷贝到PageCache一次。
所以,高并发场景下,为了防止PageCache被大文件占满后不再对小文件产生作用,大文件不应使用PageCache,进而也不应使用零拷贝技术处理。
异步IO + 直接IO
高并发场景处理大文件时,应当使用异步IO和直接IO来替换零拷贝技术。
仍然回到本讲开头的例子,当调用read方法读取文件时,实际上read方法会在磁盘寻址过程中阻塞等待,导致进程无法并发地处理其他任务,如下图所示:
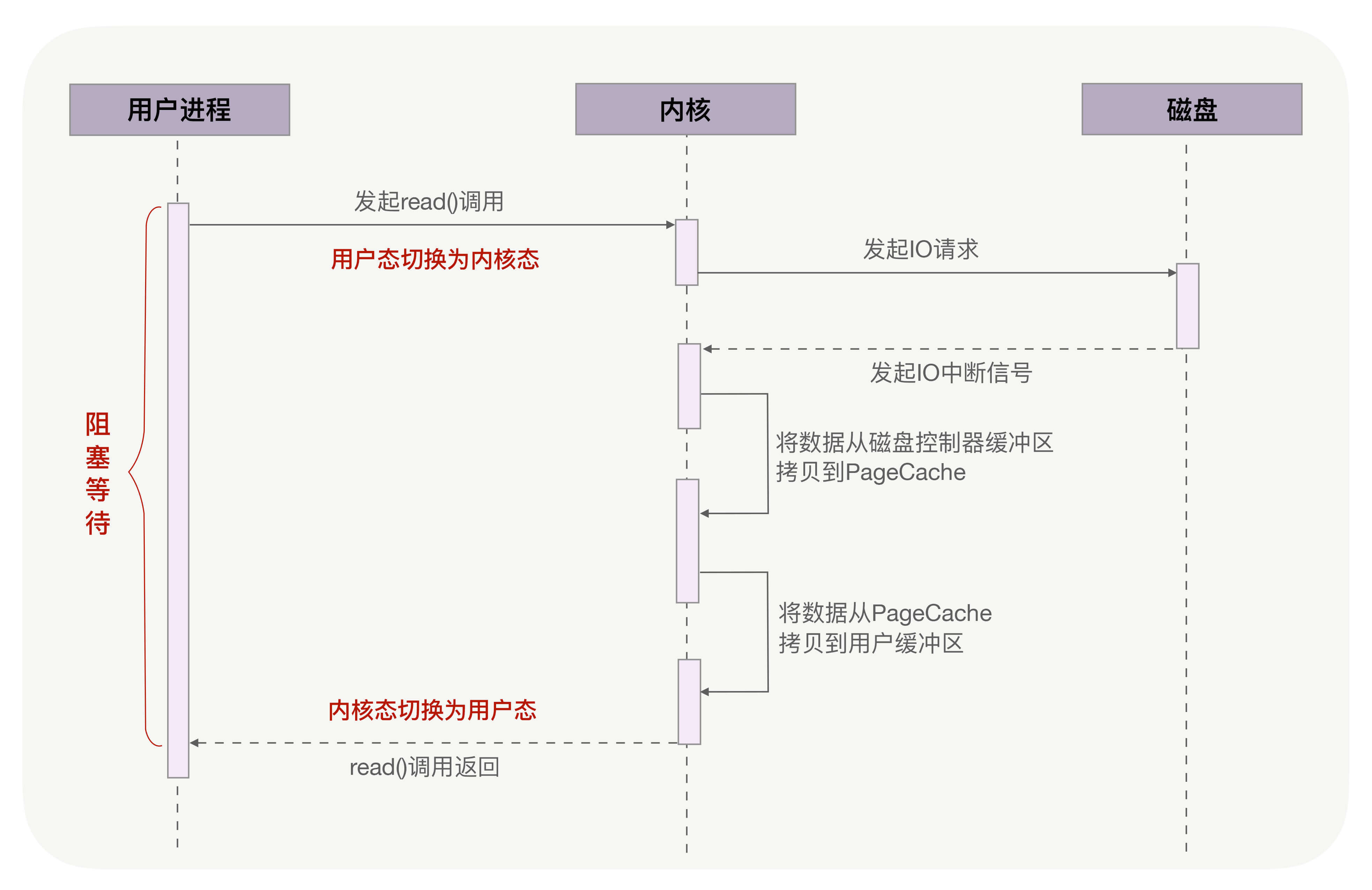
异步IO(异步IO既可以处理网络IO,也可以处理磁盘IO,这里我们只关注磁盘IO)可以解决阻塞问题。它把读操作分为两部分,前半部分向内核发起读请求,但不等待数据就位就立刻返回,此时进程可以并发地处理其他任务。当内核将磁盘中的数据拷贝到进程缓冲区后,进程将接收到内核的通知,再去处理数据,这是异步IO的后半部分。如下图所示:
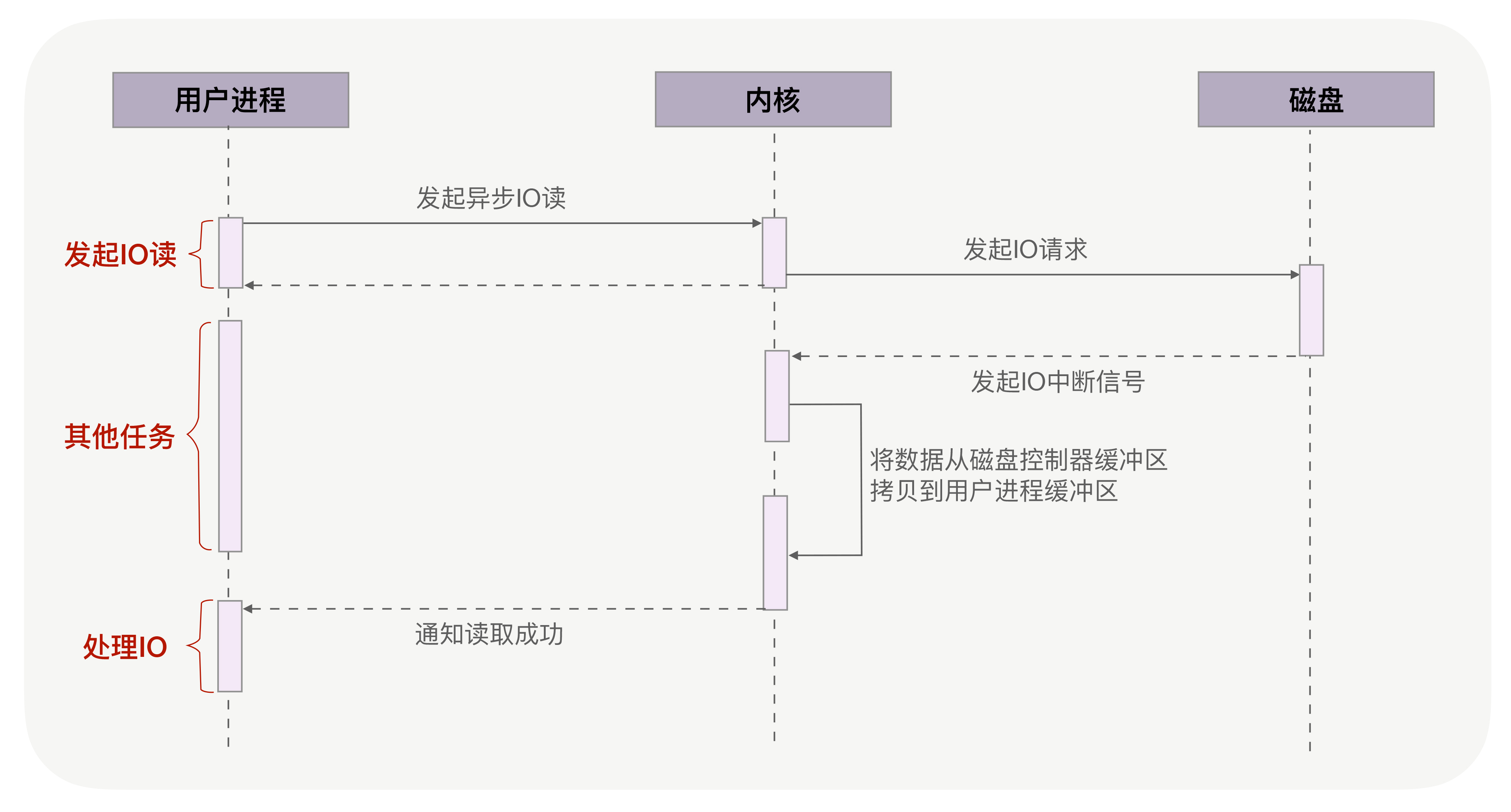
从图中可以看到,异步IO并没有拷贝到PageCache中,这其实是异步IO实现上的缺陷。经过PageCache的IO我们称为缓存IO,它与虚拟内存系统耦合太紧,导致异步IO从诞生起到现在都不支持缓存IO。
绕过PageCache的IO是个新物种,我们把它称为直接IO。对于磁盘,异步IO只支持直接IO。
直接IO的应用场景并不多,主要有两种:第一,应用程序已经实现了磁盘文件的缓存,不需要PageCache再次缓存,引发额外的性能消耗。比如MySQL等数据库就使用直接IO;第二,高并发下传输大文件,我们上文提到过,大文件难以命中PageCache缓存,又带来额外的内存拷贝,同时还挤占了小文件使用PageCache时需要的内存,因此,这时应该使用直接IO。
当然,直接IO也有一定的缺点。除了缓存外,内核(IO调度算法)会试图缓存尽量多的连续IO在PageCache中,最后合并成一个更大的IO再发给磁盘,这样可以减少磁盘的寻址操作;另外,内核也会预读后续的IO放在PageCache中,减少磁盘操作。直接IO绕过了PageCache,所以无法享受这些性能提升。
有了直接IO后,异步IO就可以无阻塞地读取文件了。现在,大文件由异步IO和直接IO处理,小文件则交由零拷贝处理,至于判断文件大小的阈值可以灵活配置(参见Nginx的directio指令)。
小结
基于用户缓冲区传输文件时,过多的内存拷贝与上下文切换次数会降低性能。零拷贝技术在内核中完成内存拷贝,天然降低了内存拷贝次数。它通过一次系统调用合并了磁盘读取与网络发送两个操作,降低了上下文切换次数。尤其是,由于拷贝在内核中完成,它可以最大化使用socket缓冲区的可用空间,从而提高了一次系统调用中处理的数据量,进一步降低了上下文切换次数。
零拷贝技术基于PageCache,而PageCache缓存了最近访问过的数据,提升了访问缓存数据的性能,同时,为了解决机械磁盘寻址慢的问题,它还协助IO调度算法实现了IO合并与预读(这也是顺序读比随机读性能好的原因),这进一步提升了零拷贝的性能。几乎所有操作系统都支持零拷贝,如果应用场景就是把文件发送到网络中,那么我们应当选择使用了零拷贝的解决方案。
不过,零拷贝有一个缺点,就是不允许进程对文件内容作一些加工再发送,比如数据压缩后再发送。另外,当PageCache引发负作用时,也不能使用零拷贝,此时可以用异步IO+直接IO替换。我们通常会设定一个文件大小阈值,针对大文件使用异步IO和直接IO,而对小文件使用零拷贝。
事实上PageCache对写操作也有很大的性能提升,因为write方法在写入内存中的PageCache后就会返回,速度非常快,由内核负责异步地把PageCache刷新到磁盘中,这里不再展开。
这一讲我们从零拷贝出发,看到了文件传输场景中内核在幕后所做的工作。这里面的性能优化技术,要么减少了磁盘的工作量(比如PageCache缓存),要么减少了CPU的工作量(比如直接IO),要么提高了内存的利用率(比如零拷贝)。你在学习其他磁盘IO优化技术时,可以延着这三个优化方向前进,看看究竟如何降低时延、提高并发能力。
思考题
最后,留给你一个思考题,异步IO一定不会阻塞进程吗?如果阻塞了进程,该如何解决呢?欢迎你在留言区与大家一起探讨。
感谢阅读,如果你觉得这节课对你有一些启发,也欢迎把它分享给你的朋友。
- Bitstream 👍(11) 💬(1)
到现在一共更了5讲,除了开篇,每讲都是干货。不是因为不知道老师讲的知识点,而是您讲的很系统,以场景带理论,学习起来很高效。
2020-05-06 - Ken 👍(8) 💬(1)
长肥网络定义 一个具有大带宽时延乘积的网络也被称之为长胖网络(long fat network,简写为LFN,经常发音为“elephen”)。根据RFC 1072中的定义,如果一个网络的带宽时延乘积显著大于105比特(12500字节),该网络被认为是长肥网络。
2020-05-08 - helloworld 👍(7) 💬(2)
第二,读取磁盘数据时,需要先找到数据所在的位置,对于机械磁盘来说,就是旋转磁头到数据所在的扇区,再开始顺序读取数据。其中,旋转磁头耗时很长,为了降低它的影响,PageCache 使用了预读功能 那是不是使用SSD这类固态硬盘(不用旋转磁头),PageCache就没有很大的影响?
2020-05-13 - benny 👍(5) 💬(2)
mmap的系统调用,可以直接将磁盘和内存映射,省去了从内核态copy到用户态,看起来要比直接IO更加高效
2020-06-14 - 亦知码蚁 👍(3) 💬(6)
从图中可以看到,异步 IO 并没有拷贝到 PageCache 中,这其实是异步 IO 实现上的缺陷。经过 PageCache 的 IO 我们称为缓存 IO,它与虚拟内存系统耦合太紧,导致异步 IO 从诞生起到现在都不支持缓存 IO。 陶老师 我在异步IO图中,看到的是把磁盘数据拷贝到PageCache,是图错了嘛,如果是直接IO的话,是直接拷贝到用户进程缓存区嘛,这个过程就是绕过了内核态嘛
2020-05-06 - C家族铁粉 👍(2) 💬(1)
看到陶辉老师在部落里说,最开始文章有6000字,后来不停删删删,变成了现在的版本,太可惜了,删减掉的部分可以考虑放到其他地方供读者阅读啊。
2020-05-08 - 烟雨登 👍(1) 💬(1)
“由于文件太大,文件中某一部分内容被再次访问到的概率其实非常低“ 这个不能理解,我理解大文件也是能享受到pagecache带来的优势吧,毕竟是预读了一部分,即使是大文件预读的那部分,下次还是会读到吧。这里真正的影响是把pagecache沾满,影响其他文件把?
2020-11-09 - 余松 👍(1) 💬(2)
MySQL在写redo log和bin log的时候都使用了PageCache。请问老师说的MySQL使用直接IO绕过PageCache是指MySQL的哪一部分逻辑?
2020-07-31 - 不能用真名字 👍(0) 💬(1)
老师,感觉课后题大家答的都不对啊,能给一下答案么?
2021-04-20 - 陌上桑 👍(0) 💬(1)
Lilux 有实现异步IO吗好多书上都是讲没有实现异步IO.只是在我们获取IO状态的时候可以非阻塞或者使用IO多路复用这样的技术。但是这些都是同步的,最终需要用户进程发送Read或者write这样的系统调用写到 内核缓冲区
2020-11-23 - Gavin 👍(0) 💬(1)
然而,由于文件太大,文件中某一部分内容被再次访问到的概率其实非常低。这带来了 2 个问题:首先,由于 PageCache 长期被大文件占据,热点小文件就无法充分使用 PageCache,它们读起来变慢了;其次,PageCache 中的大文件没有享受到缓存的好处,但却耗费 CPU 多拷贝到 PageCache 一次。 老师,将文件内容从磁盘拷贝到pagecache是dma,不是cpu吧?
2020-08-16 - wangkx 👍(0) 💬(1)
陶老师,Kafka读取patition中的日志消息算是读取大文件吗? 如果是的话, 我之前了解到Kafka用到了零拷贝。既然读取大文件零拷贝没有优势,为什么Kafka里用到了零拷贝呢?
2020-08-03 - J.Smile 👍(0) 💬(1)
老师问个问题:服务器如果有多块磁盘,那么对那些分区比较少的Topic来说,是不是会导致磁盘空间分布不均衡呢?还有选择服务器的磁盘时,选择多块磁盘和单块磁盘有什么区别呢?
2020-07-03 - 妥协 👍(0) 💬(2)
有个疑问,老师总结的pagecache有三个好处,预读功能,再次访问缓存功能和合并IO功能,这些好处小文件都可以充分利用。而大文件被再次访问的概率低,那就是无法利用再次访问缓存功能吧,其他两个好处还是可以利用的吧??如果存在大文件短时间再次访问的场景,三个好处,大文件都能利用吧?
2020-06-21 - 贝氏倭狐猴 👍(0) 💬(2)
请问Kafka Server利用了pagecache,所以Kafka Server就是同步io,那如何保证Kafka server的效率呢?
2020-06-07