18 其他重要标准库特性:还有哪些库变更值得关注?
你好,我是卢誉声。
在第二章的开头,我们曾提到过,通常意义上所讲的C++,其实是由核心语言特性和标准库(C++ Standard Library)共同构成的。
在学习了Ranges库和Formatting库之后,还有一些比较重要的标准库变更值得我们关注,包括jthread、source location、Sync stream和u8string。今天,我会带你了解它们的用法和注意事项。
好,话不多说,就让我们从jthread开始今天的学习之旅吧(课程配套代码可以从这里获取)。
jthread
长久以来,在C++中实现多线程都需要借助于操作系统API或者第三方库。好在这一情况在C++11中得以扭转,C++11为标准库带来了并发库,即标准的thread类。
但是,我们在工程中使用C++11的thread类,仍然存在一些问题。
首先是线程运行时默认行为不够灵活。thread的内部线程是进程的子线程,当thread还关联着一个活动线程时,C++运行时会调用terminate()中断整个程序的执行,这种行为对于很多没有认真管理线程资源的程序,不但非常危险,而且难以追踪。
另外,thread类还缺乏强制取消或通知取消线程的功能,在很多使用线程的场景中,这都是经常需要使用到的功能。还记得么?在第七讲至第十讲中讨论C++ coroutines的时候,我们就不得不自己实现了请求取消线程特性。
那时候我们的实现非常粗糙。比如说,没有考虑确保请求线程的线程安全,也无法告知请求方是否成功发送请求。如果要实现这些特性需要考虑很多边界条件,还真不容易。
由于这些问题的存在,我们在实际开发过程中使用C++11标准thread类时,就需要非常小心谨慎,说白了就是不但难用,而且容易出错。为此,C++20终于增加了jthread类来解决这些问题。
我们先结合后面这段示例代码,对jthread建立初步的认识。
#include <iostream>
#include <thread>
#include <chrono>
#include <cstdint>
#include <string>
void simpleSleep() {
using namespace std::literals::chrono_literals;
std::cout << "[SIMPLE] Before simple sleep" << std::endl;
std::this_thread::sleep_for(2000ms);
std::cout << "[SIMPLE] After simple sleep" << std::endl;
}
// jthread的工作函数可以通过第一个类型为stop_token的参数获取线程中断请求
void stopTokenSleep(std::stop_token stoken, std::string workerName) {
using namespace std::literals::chrono_literals;
std::cout << "Worker name: " << workerName << std::endl;
while (true) {
std::cout << "[STOP_TOKEN] Before sleep" << std::endl;
std::this_thread::sleep_for(100ms);
std::cout << "[STOP_TOKEN] After sleep" << std::endl;
// 调用stop_requested可以得知是否有其他线程请求中断本线程
if (stoken.stop_requested()) {
std::cout << "[STOP_TOKEN] Received stop request" << std::endl;
return;
}
}
}
int main() {
// ms等自定义文字量定义在std::literals::chrono_literals名称空间中
using namespace std::literals::chrono_literals;
std::cout << "[MAIN] Before create simple thread" << std::endl;
// 创建线程
std::jthread simpleWorker(simpleSleep);
std::cout << "[MAIN] After create simple thread" << std::endl;
std::cout << "[MAIN] Before create stop token thread" << std::endl;
// 创建线程
std::jthread stopTokenWorker(stopTokenSleep, "Worker1");
// 注册request_stop成功后的回调
std::stop_callback callback(stopTokenWorker.get_stop_token(), [] {
std::cout << "[MAIN] Called after thread stop requested" << std::endl;
});
std::cout << "[MAIN] After create stop token thread" << std::endl;
std::this_thread::sleep_for(500ms);
std::cout << "[MAIN] Request stop" << std::endl;
stopTokenWorker.request_stop();
std::cout << "[MAIN] Main function exited" << std::endl;
return 0;
}
在这段代码中,我们没有使用thread类,而是通过jthread类来创建线程。
代码中创建了两个子线程,从第39行到42行创建了第1个子线程对象simpleWorker,从第44到56行创建了第2个子线程对象stopTokenWorker。
这里我们并没有像thread类一样,调用join主动等待线程结束。但是,程序会自动等待所有线程停止后才会退出,这是如何实现的呢?
这一切的玄机,都在 jthread类的析构函数中!
在jthread对象析构时,如果jthread依然关联了活动线程(线程为joinable),会自动调用关联线程的request_stop,并调用join等待线程结束。线程结束后才会继续执行析构。
现在回到我们的代码,main函数在return前,会自动依次调用两个jthread对象的析构函数,销毁线程对象。这时主线程就会自动join这两个线程,确保线程对象销毁之前,子线程已经结束。这种默认行为可以确保主线程结束前,子线程必定都已经结束,不会引发不可预期的错误。
如果不希望jthread自动join,可以不在栈上直接创建jthread对象、或者直接调用detach解除线程与jthread对象的关联。从C++20开始支持的jthread,既保留了灵活性,又确保了默认行为的安全性,更符合一般使用线程的场景。
另外,stopTokenWorker演示了jthread的第二个重要特性—— stop_token。
每个jthread的工作函数的第一个参数,都可以定义为std::stop_token类型。这时,其他线程可以调用该jthread对象的request_stop成员函数,向jthread绑定的线程发送中断请求。
实际上request_stop并不会真的中断线程,而是将stop_token对象的stop_requested设置为true。jthread绑定的线程可以通过stop_requested获知是否有线程通知其中断,并自行决定是否结束线程。
按照标准规定,调用request_stop的过程是线程安全的——只有一个线程可以成功发送请求,一个线程发送请求成功后,其他线程调用request_token会失败,但不会引发异常。还有一个作用相同的类型是stop_source,如果你感兴趣,可以自己阅读相关文档了解如何使用。
代码的第48到50行还演示了 stop_callback 的用法,该类用于在一个jthread上注册一个成功调用request_stop后的回调函数——如果其他线程已经成功request_stop了一个jthread线程,那么,这个线程调用request_stop是不会触发本线程注册的回调函数的。
另外我们需要注意的是,一个线程可以注册多个stop_callback,标准只能保证所有的stop_callback会被同步依次调用,不能保证stop_callback的调用顺序(也就是并不一定按照注册顺序调用)。
综上所述,我们可以看到jthread提供了安全的默认行为,具备线程中断机制,可以根据实际情况调整具体行为,在确保安全的前提下支持灵活调用,在大多数场景中是更符合实际需求的设计。
source location
了解了jthread后,我们继续了解下一个相当重要的标准库变更——source location。
在C++中,如果我们希望获取当前行的源代码位置,一直都需要使用C预处理指令中预设的__FILE__和__LINE__两个宏。
但在C++中,这两个宏并不足以支持我们对程序跟踪调试的需求。
- __LINE__无法自动包含函数名等关键信息,需要采用#line指令手动控制输出的标记。
- __FILE__和__LINE__都会在预处理阶段被替换为特定的字符串。但是,对于C++中使用的模板函数来说,只有在编译阶段,才能获知当前行所在函数的参数实例化信息。因此,使用__LINE__也无法获取所在行的模板实例化情况。
C++20终于提出了source_location这个标准类,可以获取当前行更完整的源代码信息。我们结合这段示例代码来看看。
#include <iostream>
#include <source_location>
#include <string>
void logInnerLocation(const std::string& message);
void logLocation(
const std::string& message,
std::source_location location = std::source_location::current()
);
int main() {
logInnerLocation("Inner location message");
// 通过默认参数通过current获取source_location对象
// 这时source_location包含的信息就是在main内
logLocation("Location message");
return 0;
}
void logInnerLocation(const std::string& message) {
// 在logInnerLocation内部通过current获取source_location对象
// 这时source_location包含的信息就是在logInnerLocation内
std::source_location location = std::source_location::current();
std::cerr << message << std::endl <<
" [" <<
location.file_name() << "(" <<
location.line() << ":" <<
location.column() << ")@" <<
location.function_name() << "]" << std::endl;
}
void logLocation(
const std::string& message,
std::source_location location
) {
std::cerr << message << std::endl <<
" [" <<
location.file_name() << "(" <<
location.line() << ":" <<
location.column() << ")@" <<
location.function_name() << "]" << std::endl;
}
代码中通过source_location的静态成员函数current,获取了当前位置的源代码信息。其中,获取到的信息包含file_name、line、column和function_name这几个字段,每个字段的含义你可以参考下表。
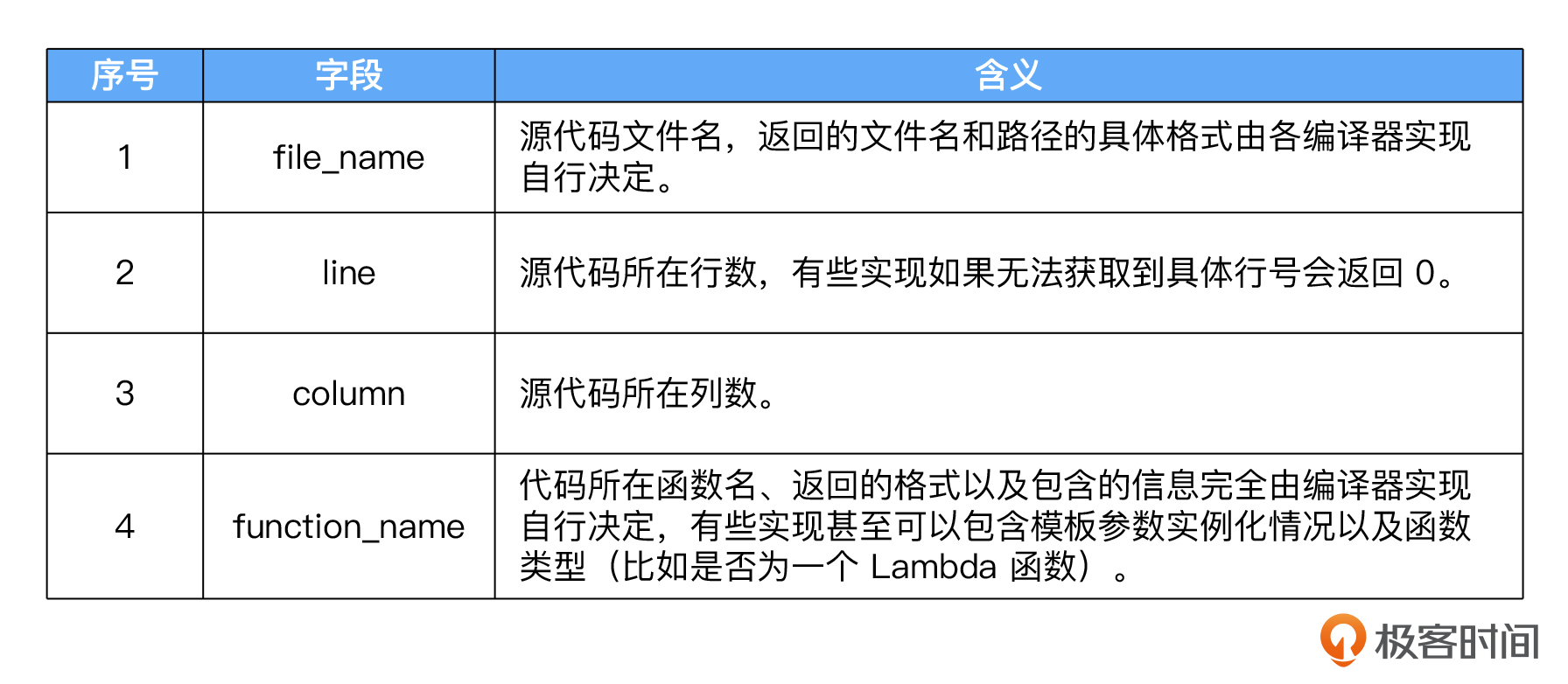
可以看到,source_location这一标准类,能为我们提供精确的编译时源代码信息,涵盖了普通函数调用和模板函数所有使用场景。这对于发布用于调试的程序极为有用。
sync stream
在多线程场景中,使用C++传统输出流接口会存在一个问题:多个线程直接向同一个输出流对象输出内容时,会得到无法预估的错乱输出。
因此,我们一般需要自己通过互斥锁等方式,实现输出的线程同步。这种方式虽然能够解决问题,但是编程效率低下,运行时也会有潜在的性能问题。
C++20提出的sync stream解决了这个问题。先来看一段代码。
#include <iostream>
#include <string>
#include <syncstream>
#include <thread>
#include <vector>
#include <cstdint>
namespace chrono = std::chrono;
// 普通stream版本
void coutPrinter(const std::string message1, const std::string message2);
// syncstream版本
void syncStreamPrinter(const std::string message1, const std::string message2);
int main() {
std::cout << "Cout workers:" << std::endl;
// 创建多个thread
std::vector<std::thread> coutWorkers;
for (int32_t workerIndex = 0; workerIndex < 10; ++workerIndex) {
std::thread coutWorker(coutPrinter,
"ABCDEFGHIJKLMNOPQRSTUVWXYZ",
"abcdefghijklmnopqrstuvwxyz"
);
coutWorkers.push_back(std::move(coutWorker));
}
// 普通thread需要手动join
for (auto& worker : coutWorkers) {
if (worker.joinable()) {
worker.join();
}
}
std::cout << "SyncStream workers:" << std::endl;
// 创建多个jthread,会在析构时自动join
std::vector<std::jthread> syncStreamWorkers;
for (int32_t workerIndex = 0; workerIndex < 10; ++workerIndex) {
std::jthread syncStreamWorker(
syncStreamPrinter,
"ABCDEFGHIJKLMNOPQRSTUVWXYZ",
"abcdefghijklmnopqrstuvwxyz"
);
syncStreamWorkers.push_back(std::move(syncStreamWorker));
}
return 0;
}
void coutPrinter(const std::string message1, const std::string message2) {
std::cout << message1 << " " << message2 << std::endl;
}
void syncStreamPrinter(const std::string message1, const std::string message2) {
// 使用std::osyncstream包装输出流对象即可
std::osyncstream(std::cout) << message1 << " " << message2 << std::endl;
}
我们在代码18到32行,创建了多个thread对象,并以coutPrinter为入口函数,创建线程后逐个调用join等待线程完成。coutPrinter中直接调用cout输出字符串,这样可以方便我们看到,同时调用相同的输出流对象输出时会发生什么。
在代码36到44行,创建了多个jthread对象,并以syncStreamPrinter为入口函数。由于jthread会在析构时自动join,因此,这里就不需要手动等待线程完成了。syncStreamPrinter中调用 std::osyncstream将cout包装成一个syncstream,然后将字符串输出到osyncstream对象中。
运行这段程序,你可能会看到下图这样的输出。
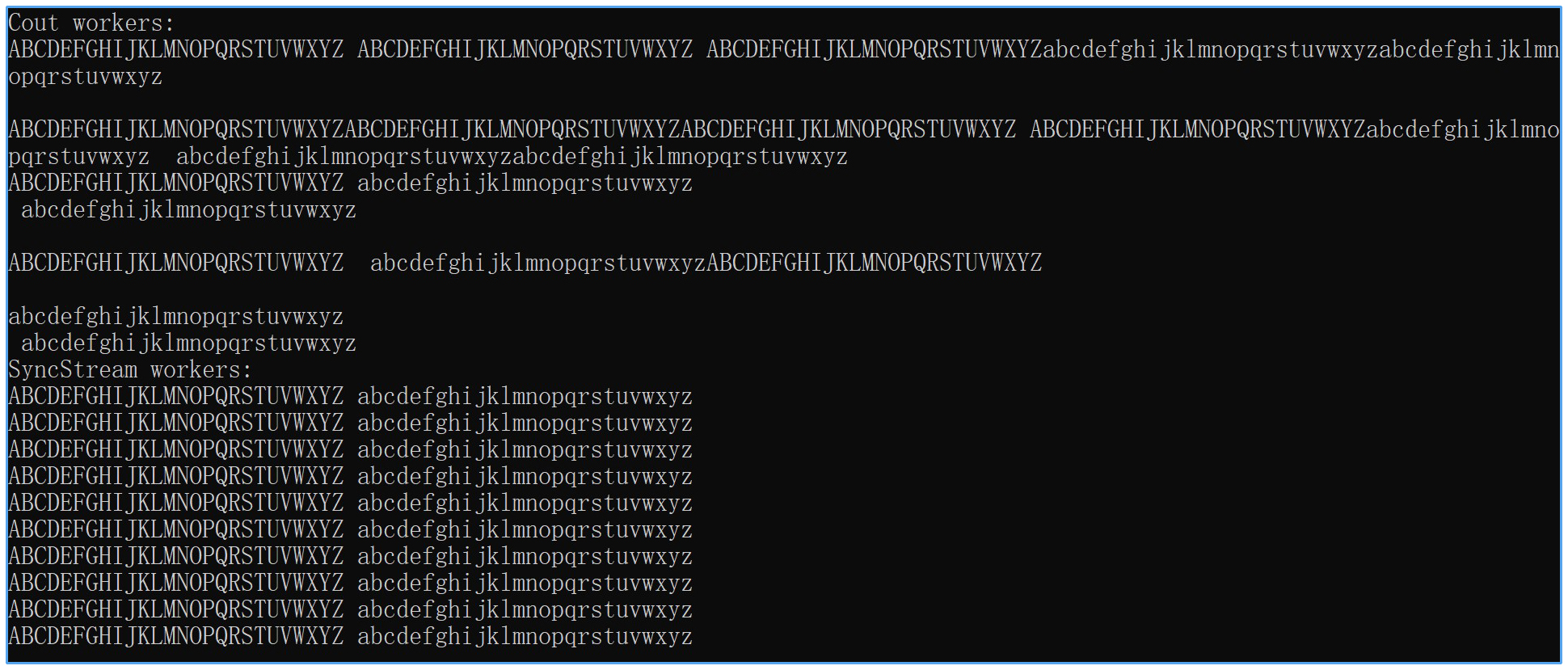
很明显,并发输出到cout时出现了无法预期的混乱输出。然而,输出到osyncstream时没有出现直接使用cout输出时的混乱。为什么会出现这样的情况呢?
这是因为osyncstream会包装输出流对象的内部缓冲区,确保通过osyncstream输出时每次输出都具备原子性,因此也就不会出现错乱的输出了。
u8string
在C++11中,引入了std::u16string和std::u32string,用于描述utf-16和utf-32的字符串。它们分别使用char16_t和char32_t两个新的字符类型,描述UTF-16与UTF-32代码点。但奇怪的是,标准始终没有提供对utf-8字符描述方式。
好在C++20中终于引入了u8string,用于描述UTF-8字符串。在引入u8string的同时,C++20还定义了一个新的字符类型char8_t,用于描述UTF-8的代码点。u8string就是类型为char8_t的序列。
但是这里有一个问题,为什么C++20要引入新的字符类型,而不是用char呢?
这是因为,C++标准定义的char存在两个比较大的坑。
首先,与其他整数类型不同,标准没有定义char是signed char还是unsigned char,有无符号具体由实现决定。
其次,标准只为char定义了最小长度为8位,实际长度也由实现决定(虽然事实标准的确是8位),这就导致我们无法严格采用char来描述UTF-8的代码点(UTF-8代码点固定为8位)。
因此,标准必须引入char8_t这个新类型。不过需要注意的是,char8_t和char是无法直接隐式转换的,而标准库的很多标准函数都是基于char这个类型定义的,如果需要转换,必须要强制类型转换。
后面这段代码演示了如何定义u8string,以及如何处理输出与转码。
#include <fstream>
#include <string>
#include <iostream>
#include <clocale>
#include <cuchar>
#include <cstdint>
int main() {
std::setlocale(LC_ALL, "en_US.utf8");
// 使用u8创建u8string字面量
std::u8string utf8String = u8"你好,这是UTF-8";
// 调用size()获取UTF-8代码点数量
std::cout << "Processing " << utf8String.size() << " bytes: [ " << std::showbase;
for (char8_t c : utf8String) {
std::cout << std::hex << +c << ' ';
}
std::cout << "]\n";
// 获取UTF-8代码点序列的起始位置与结束位置
const char* utf8Current = reinterpret_cast<char*>(&utf8String[0]);
const char* utf8End = reinterpret_cast<char*>(&utf8String[0] + utf8String.size());
char16_t c16;
std::mbstate_t convertState{};
// 定义UTF-16字符串
std::u16string utf16String;
// 调用mbrtoc16执行转码
while (std::size_t rc = std::mbrtoc16(&c16, utf8Current, utf8End - utf8Current + 1, &convertState)) {
std::cout << "Next UTF-16 char: " << std::hex
<< static_cast<int32_t>(c16) << " obtained from ";
if (rc == (std::size_t)-3)
std::cout << "earlier surrogate pair\n";
else if (rc == (std::size_t)-2)
break;
else if (rc == (std::size_t)-1)
break;
else {
std::cout << std::dec << rc << " bytes [ ";
for (std::size_t n = 0; n < rc; ++n)
std::cout << std::hex << +static_cast<unsigned char>(utf8Current[n]) << ' ';
std::cout << "]\n";
utf8Current += rc;
utf16String.push_back(c16);
}
}
// 输出UTF-8编码字符串
std::ofstream u8OutputFile("out.utf8.txt", std::ios::binary);
u8OutputFile.write(reinterpret_cast<char*>(utf8String.data()), utf8String.size() * sizeof(char8_t));
// 输出UTF-16编码字符串
std::cout << std::dec << utf16String.size() << std::endl;
std::ofstream u16OutputFile("out.utf16.txt", std::ios::binary);
u16OutputFile.write(reinterpret_cast<char*>(utf16String.data()), utf16String.size() * sizeof(char16_t));
return 0;
}
在代码第12行使用了u8创建u8string的字面量字符串。
在代码14到18行,首先输出了u8string的代码点数量,然后使用十六进制输出了u8string内的代码点数量。我们处理UTF-8字符串的时候,必须要知道UTF-8是变长编码,所以一个真正的字符可能包含不同数量的代码点,就像代码中字符串包含10个字符,但是包含20个代码点。
在代码第29到47行,我们演示如何调用mbrtoc16函数,完成UTF-8编码向UTF-16编码的转换。

由于UTF-8是变长编码集,因此我们需要多次调用mbrtoc16将UTF-8的字符逐个转换成UTF-16的代码点。
每次调用时,会将第二个参数(类型为const char*,这里相当于UTF-8字符串的开始位置)开始的特定数量代码点,转换成一个UTF-16中对应的代码点,写入到该函数的第一个参数中(类型为char16_t*)。
这里需要注意mbrtoc16的返回值rc,我画了一张表,帮你梳理了rc可能的返回值。

遗憾的是,这种标准库支持的编码转换方式依赖于C的locale。但是,C的locale实现支持完全取决于具体的C/C++运行时环境(也会进一步依赖于操作系统)。
因此,我们的代码虽然可以运行在主流系统与运行时环境中,但不能保证兼容性。
另外,C的locale还有C标准库经常遇到的多线程环境问题,因为setlocale是全局的,所以在一个线程中setlocale对其他线程中行为的影响是未知的。也就是说,setlocale并非线程隔离,也不是线程安全的,所以在多线程程序中使用C的locale,我们需要慎之又慎。
因此,在大部分场景下,我还是建议你使用iconv之类的第三方编码转换库执行编码转换。希望C++能在日后标准中,进一步脱离C的locale,然后彻底解决编码问题吧。
此外,与C++11加入的u16string一样,C++20的u8string也缺乏输入输出流的直接支持(根本原因是C++17废弃了codecvt的具体实现)。因此,在代码50到56行中,我们不得不使用二进制的方式将其输出到文件中。
不得不说,C++针对语言编码的支持,依然任重而道远!我们期待着在后续演进标准中逐步解决这些问题。
总结
我们在这一讲中,进一步补充了C++20标准中重要的库变更,包括它们的用法和注意事项。
jthread是自C++11之后对标准的并发编程的一次重要补充,它支持了安全的默认行为,具备线程中断机制,可以根据实际情况调整具体行为,在确保安全的前提下支持灵活的调整,在大多数场景中是更符合实际需求的设计。
source location对输出代码的准确位置提供了有力支撑,同时解决了模板函数中长久以来存在的问题——无法输出准确代码执行位置。这为调试复杂程序和输出信息提供了新工具。
另外,我们还讨论了u8string,以及C++针对语言编码支持的问题。标准库支持的编码转换方式仍然依赖于C的locale,我们期待着在后续演进标准中逐步解决这些问题。
思考题
请你结合char的宽度问题,思考一下u8string转换示例代码中可能还会出现什么兼容性问题。
欢迎说出你的看法,与大家一起分享。我们一同交流。下一讲见!
- peter 👍(0) 💬(1)
请教老师几个问题: Q1:pthread_create属于thread类吗? 我从网上搜到了一个安卓代码,有C++代码。线程部分,用的是pthread_create、pthread_join、pthread_exit等函数。能正常工作,但不太了解这套东西。这套东西属于C++类库中的thread类吗?还是类似于系统调用一类的API? Q2:stop_requested设置为true,但线程本身不退出,会发生什么? Q3:一个线程发送request_stop成功后,什么时候其他线程才能发送? 文中提到“一个线程发送请求成功后,其他线程调用 request_token 会失败,但不会引发异常”,发送成功后,按道理其他线程就可以发送了啊;不能发送的话,何时才能发送?
2023-03-04