38 Serverless:如何基于Serverless架构实现流式数据处理?
你好,我是文强。
从这节课开始,我们将用两节课的内容来梳理一下 Serverless 、Event(事件)、消息队列三者之间的关系和应用价值。这节课我们就聚焦如何基于 Serverless 架构实现流式处理,下节课会详细分析如何基于消息队列和 Serverless 设计事件驱动架构。
为什么要搞明白上述问题?我们从一张架构图讲起。
这是一张消息队列上下游生态的架构图,分为数据源、总线管道、数据目标三部分。可以看到消息队列在架构中处于缓存层,起到的是削峰填谷的缓冲作用。
从技术上看,构建以消息队列为中心的数据流架构,有很多现成的技术方案和开源框架。比如分布式流计算框架 Spark/Flink,开源体系内自带的Kafka Stream、SeaTunnel/DataX 等数据集成产品,或者ELK体系下的采集和数据处理的组件Logstash,都具有处理数据的能力。
然而在上面的架构中,存在一个问题:每种技术方案所适用的场景不一样,业务一般需要同时使用多种方案,而使用和运维多种方案的成本很高。
为了解决使用和运维成本问题,接下来我们来学习一种非常实用的方案,那就是基于 Serverless Funciton 实现流式的数据处理。而为了让你对数据流场景有一个更深刻的理解,我们先来看几个业务中常见且典型的数据流场景。
典型的数据流场景
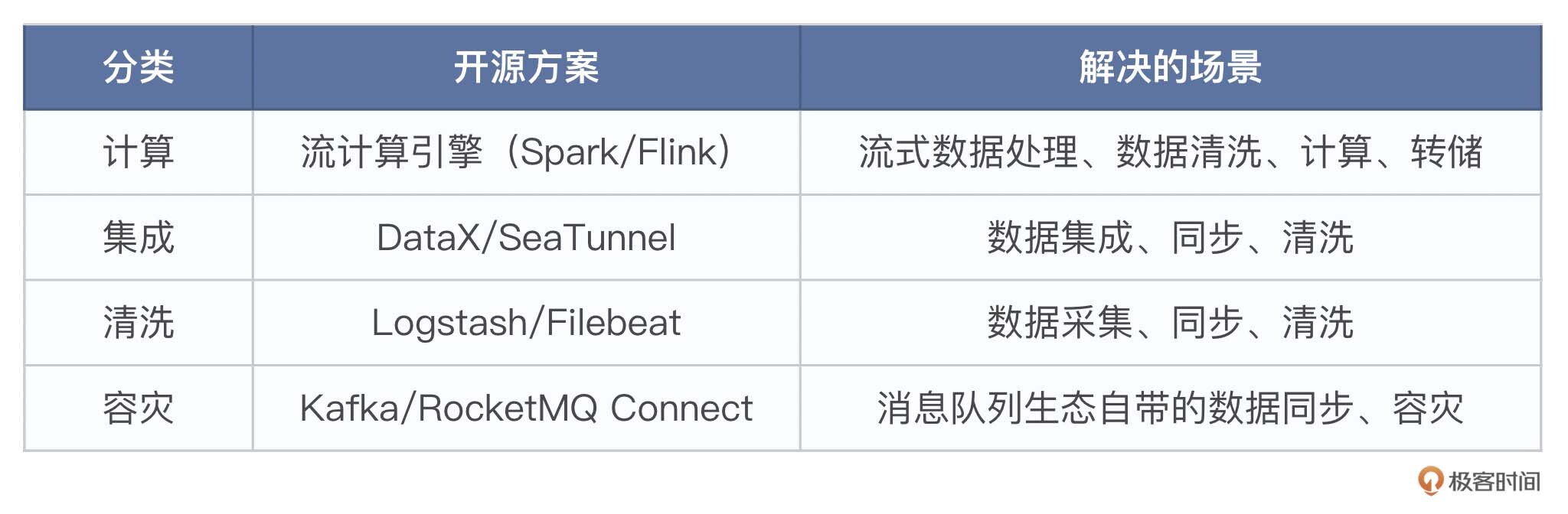
从业务形态上看,数据流场景主要可以分为计算、集成、清洗、容灾 4 个方向。
- 计算:主要解决流式数据处理计算、分析、清洗、聚合、转储等需求。Spark/Flink是计算方向中的主流解决方案,其优点是功能和性能都很强大,几乎可以满足所有流式计算的需求。缺点是学习和运维成本较高,在很大一部分简单的数据处理场景(如ETL)下的投入产出比不高。
- 集成:是指将数据从数据源同步到数据目标的过程。链路构成通常为:数据源、数据集成套件、数据目标。其代表组件为 Flink CDC、Apache SeaTunnel、DataX 等等。这些组件的优势是具备开箱即用的能力。缺点是无法满足复杂的计算场景,遇到一些复杂的计算场景,需要引入Spark/Flink。另外,一般集成组件底层引擎是Spark或Flink,在引擎上层做了应用封装,所以在运维成本上也相对较高。
- 清洗:严格来说清洗场景是计算或集成场景下的一个子集,具备计算、集成的套件都具备ETL能力。这里的处理指简单的数据清洗,即将数据简单清洗格式化(不需要计算聚合)后分发到下游。主要代表组件是Logstash、MQ Connector。它们通过简单的语法完成数据的格式化、清洗、分发。优点是使用简单、运维简单。缺点是功能场景相对局限、单一。
- 容灾:指消息队列集群之间的容灾,即集群间的数据同步,包括元数据、业务数据。主要解决方案是采用各个消息队列自带的容灾组件,比如Kafka/RocketMQ Connector、Pulsar IO、RabbitMQ Federation/Shovel 等等。
最后我们通过一个表格来总结一下这 4 个方向。
接下来我们看一下基于 Serverless 架构是如何同时满足上面这四种场景的。
什么是 Serverless
首先我们得搞明白什么是 Serverless。
Serverless 的定义
Serverless 从语义上来讲是“无服务器”。从技术架构和底层技术运行的角度看,服务运行不可能没有服务器。实际上,无服务器是从客户的角度来理解的,指的是客户不需要关心服务器。某种意义上看,不关心相当于没有,因此是 Serverless 平台来负责服务器资源管理及运行。
举个例子来说明一下。现在我们使用Kubernetes和容器,研发或运维需要负责服务器的部署、运行、扩容、故障处理,但是如果使用 Serverless 的 Kubernetes 集群,我们就不需要关心这些细节,只要负责使用即可。集群的安装、部署、运行、调度、扩缩容都会由平台帮忙实现。
目前业界 Serverless 的理念已经融入到各个领域,比如 Serverless 数据库、Serverless 消息队列等等。目前 Serverless 主要的产品形态是 Serverless Funtion。
我们这节课的核心思路就是基于 Serverless Function 来实现简单、轻量的数据流动。所以接下来我们还得了解一下什么是 Serverless Function。
Serverless Function
Serverless Function 是指运行在 Serverless 平台中的函数段。这里的函数和任何一个开发语言中函数的概念是同一个。比如下面是一个 Python 函数,同时也是一个可以运行在 Serverless 平台的函数段。
import logging
logger = logging.getLogger()
logger.setLevel(logging.INFO)
def main_handler(event, context):
logger.info('got event{}'.format(event))
print("got event{}".format(event))
return 'Hello World!'
上面的函数段可以直接提交到 Serverless 平台上运行,平台会执行整个函数代码流程,并输出结果。我们可以通过 Serverless Function 的生命周期来加深一下理解。
参考图示可以知道,函数的生命周期主要包含6个阶段:
- 编写代码段,即写一个函数。
- 定义一个事件,即定义在什么情况下触发这个函数,比如定义用户上传了一个图片后就需要触发某个函数执行,这就是一个事件。
- 触发事件,上传图片成功后,触发一个事件,这个事件就会触发函数去运行。
- 部署函数,即在函数运行之前,首先要部署它。部署函数本质上就是把这个函数放在一个容器里,做成一个非常小的镜像,然后把这个镜像写到 Kubernetes 里去运行。
- 输出结果,运行之后,它会返回一个结果。
- 销毁资源,函数运行完成之后,会将容器销毁。
从使用的角度看,Serverless Funciton 和 Spark 很像。比如我们用 Spark 之前需要去学习 Spark 的语法,编写代码逻辑,然后打包,最后将包发布到 Spark 集群去运行。而 Serverless Funciton 是用熟悉的语言、熟悉的语法去编写函数,然后提交到 Serverless Function 平台去运行。而从学习、使用、运维成本的角度看,Serverless Function 会低很多。
好,这节课最重要的几个概念搞明白了,接下来我们就来讲一下基于 Serverless Function 实现数据流转的处理流程,及其底层运行原理。
如何基于 Serverless 实现数据处理
我们从基于 Serverless Function 的数据处理流程开始。
数据处理流程
先来看下面这张图:
这张图和最开始那张,最大的区别在于:把中间这两个处理层替换为了 Serverless Function平台,用它来替代流入和流出过程中的多款开源组件。
接下来我们用经典的数据清洗和转储场景来说明一下它的运行流程。
在这个场景中,我们可以写一个函数代码段来消费数据,并做一些处理,然后写入下游。代码逻辑是对数据进行处理后,返回一个新的数据。代码示例如下:
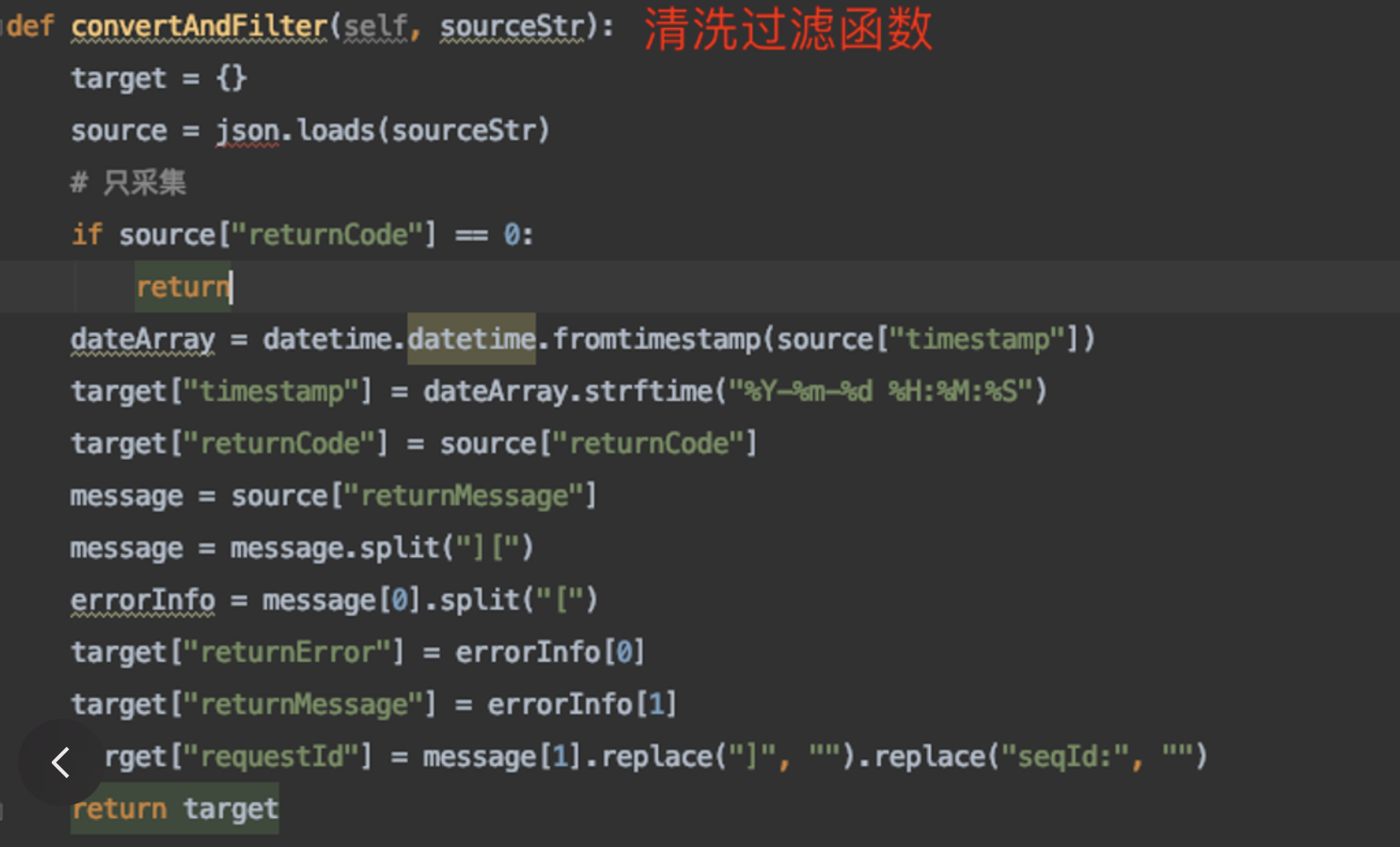
这个代码段在业务量很小时,只需写个 Cron 定时运行或者单进程运行即可。当数据量大时再把它放到 Serverless Function 平台去运行。唯一的区别在于,运行的地方平台不一样,对研发来讲没有重复的开发成本。
了解完数据处理流程,我们接下来讲一下这个流程的底层架构和技术原理。
底层架构和技术原理
先来看一张架构图。
在这张图中,从左到右依次是输入源、Serverless 调度运行平台、数据目标三部分。这里面需要重点关注两个部分,一个是数据源事件的触发方式,另一个是Serverless Function 平台的底层运行原理。
数据源事件的触发方式,是指当数据源有数据后,如何触发下游的函数执行。从技术上看,主要有事件触发、定时触发、流式拉取 3 种形式。
- 事件触发是指数据源接收到某个数据后,主动触发下游的函数段执行。
- 定时触发是指设定时间后触发某个事件,比如设置为0点定时触发平台去运行某个函数代码段。
- 流式拉取是指实时不间断地流式拉取数据源的数据,拉取到数据就触发函数逻辑进行处理。
从业界使用来看, 3 种形态都有其适用场景,属于相互补充的关系。
Serverless 运行调度平台是指运行函数的平台,该平台底层的运行核心基本都是 Kubernetes 和容器。运行的原理是:先把函数代码段封装在镜像中;启动时,调度 Kubernetes 去运行带有代码段的镜像,并启动 Pod(Pod为Kubernetes中的最小调度对象);镜像的核心逻辑都运行在这个调度平台里,因此系统会自动运行函数、扩容和缩容,以及上传运行结果等。
Serverless 平台的核心竞争力是通过灵活的调度能力来提高资源的利用率,从而降低成本。技术上的核心是中间的这层运行调度平台。调度平台能达到优化成本效果的理论依据是:下沉和规模效应。因为业务都有波峰波谷效应,多个业务使用同一个平台的话,就可以通过资源调度,达到资源复用的效果,从而提高利用率,节省成本。
所以从实际落地来看,虽然有一些开源的 Serverless 平台项目,比如Knative。 但是我还是会建议你使用公有云的Serverless产品,比如腾讯云、AWS等等。因为基于规模效应,从成本结构来看,会比自建更有优势。
那是不是基于 Serverless 的方案就是完美的呢?带着这个问题,我们接着来看一下基于开源方案和基于 Serverless Function 方案的优劣势对比。
两种方案的优劣势对比
这里我整理了一个表格。
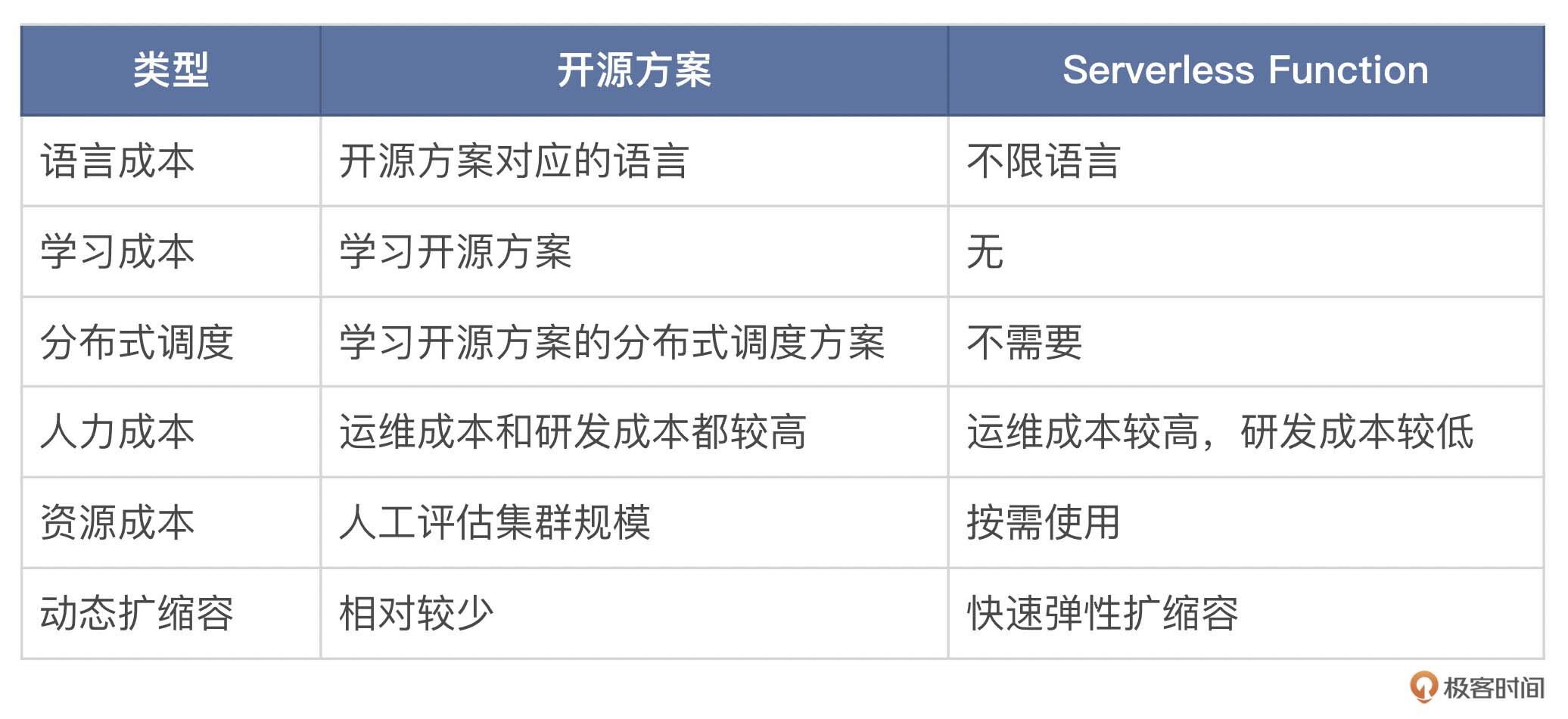
从技术的角度上讲,当前Serverless还处于快速发展阶段,技术架构和稳定性等都处于快速完善期,因此会不太稳定,其本身的运维成本是比较高的。所以,它并不能完全替代其他的方案,而是提供一种可能的选择,在某些场景下它的表现更优,比如图片处理、小流量的流式数据处理、事件型流处理等。那么随着云原生架构的成熟,Serverless 方案也会越来越成熟。
接下我们通过日志清洗(ETL)和事件流处理两个场景,来看一下这个方案实际落地场景及其效果。
业务案例和场景分析
先来看一下日志清洗的案例。
日志清洗场景
场景描述:合作方业务运行时,每天都要产生大量的日志。因为业务限制,不能实时传到我们的流式处理平台。只能先打包成文件,然后上传到我们的文件系统,然后再对日志进行提取、转换,并存储到下游,以进行相关的分析工作。
它有3个特点:
- 数据量特别大
- 业务有明显的波峰/波谷曲线
- 成本非常敏感
在老的架构中,我们先后使用过 HDFS + Logstash + Spark 进行日志解压和处理。日常准备了峰值机器,在低峰时资源存在严重浪费。不仅资源成本高,运维成本也很高。
为了解决这个问题,我们引入了 Serverless Function 来处理数据。方案架构图如下:
首先合作方会把日志上传到我们业务的 HDFS。这里要经过跨网络传输、压缩等,才能存储到统一的 HDFS。接下来用户需要对 HDFS 的数据进行处理,业务上有两条链路:
- 先用 Funtion 解压文件,并进行数据清洗格式化,再存为 HDFS 作为持久化存储,最后再进行流式的处理。
- 业务要实时消费这些日志。
在架构中,解压用的是事件模型,直接触发函数去运行解压。其他的处理函数是使用 Python 函数段实现的,逻辑非常简单。基于 Serverless Function,在运行过程中,因为不用关注下游的数据量,平台会进行调度、扩缩容,平台能够根据流量的曲线调度机器,节省接近40%的成本。
下面再来看一个事件流处理的案例。
事件流处理
场景描述:在我们的场景中,系统中的视频数据、评论数据、帖子数据等会实时更新,中台审核系统需要非常实时地对这些数据进行相应处理,例如图片审核、文本审核、商品打标、统一类目、死链监测、视频解压分析、图片转存等。
这些业务数据的特点是,需要非常及时的自动化处理。举个例子,我有个网站,用户发了一个帖子,但里面有违规词语需要被禁,如果没有采用事件模型,那么在拉取审核的窗口时就会被直接暴露到外网,产生不好的影响,这就是事件触发的用途。
来看一下基于 Serverless Function 的解决方案。
如上图所示,我们的消息首先接入RabbitMQ,通过事件触发的模型主动触发函数。它是推模式(Push),因此实时性很强。
在之前的课程中,我们讲过推模型的一个缺点,那就是在业务高峰的时候,如果下游的处理系统有瓶颈,就会处理不过来,导致数据反压,影响服务端推的性能。而这种场景正是Serverless 平台能发挥优势的地方,容量近乎无限(依赖平台储备),弹性扩缩容,按量付费。整体算下来,更省成本,也更及时。
总结
和当前的开源方案相比,Serverless 在架构理念和设计上是有极大的优势,在未来也具有很大的想象空间和收益空间。但是 Serverless 也有一些缺点,业务使用时需要根据当前的需求进行合理的选型。
从技术上看,Serverless 也会涉及到一些冷启动问题。比如当运行容器数缩减到了0,如果有事件触发,如何才能快速地拉起函数运行呢?虽然还有很多需要不断迭代和完善的地方,但从整个架构来讲,它已经能够给我们带来一定的价值了。
长期来看,基于 Serverles 的流处理方案有几点可以改善。
- 支持持久化的函数运行态。函数当前阶段主要是以函数形态短时间运行的,为了更好地支持稳定的流式处理场景,需要函数支持持久化运行能力。
- 更多的事件源。事件触发模型肯定会比现在的拉模型更及时、更有效,更多的事件源也意味着有更完整的生态,更多的应用场景。
- 丰富的扩缩容因子。目前从场景来看,业务的扩缩容因子相对会很复杂,比如Kafka主要是根据消息的堆积数量,图片转换场景则是根据仓库中堆积的图片数量来判断是否需要更多的处理能力。那就需要平台支持更多维度的指标,比如CPU、Kafka堆积消息、仓库图片数量等来作为扩缩容因子。
- 高阶算子的封装。函数编写因为有算子能够使用,所以不需要很复杂的学习成本,开箱即用。后面可以持续探索算子能力,比如添加一些高阶的算子,它会带来更多的便利。
思考题
在你当前的业务中,还有哪些场景能够基于 Serverless 架构实现数据的流式处理?
欢迎分享你的思考,如果觉得有收获,也欢迎你把这节课分享给感兴趣的朋友。我们下节课再见!
上节课思考闭环
为什么 RocketMQ 使用准实时的方式将数据上传到远端存储引擎呢?
官方解释如下:
1. 均摊成本。RocketMQ 多级存储需要将全局 CommitLog 转换为 Topic 维度,并重新构建消息索引,一次性处理整个 CommitLog 文件会带来性能毛刺。
2. 对小规格实例更友好。小规格实例往往配置较小的内存,这意味着热数据会更快换出成为冷数据,等待 CommitLog 写满再上传,本身就有冷读风险。采取准实时上传的方式既能规避消息上传时的冷读风险,又能尽快使冷数据可以从多级存储读取。
在我看来,主要原因是 RocketMQ Broker 底层所有 Topic 的消息数据都存储在同一个 CommitLog 文件中。从业务的角度看,不是每个 Topic 都需要开启分层,因此分层特性一般是在 Topic 维度开启的。
此时如果要把某个 Topic 的冷数据存储到远程,就需要从单个 CommitLog 里面把某个Topic的数据提取出来,重新构建成为独立的文件存储到远程。在重构文件存储结构的过程中,就会有上面提到的毛刺和冷读风险。所以 RocketMQ 选择了准实时的方式上传数据到远端存储。