35 从高级功能拆解4款主流MQ的架构设计与实现
你好,我是文强。
到了本节课,我们就讲完了功能篇的所有知识点了。下面我根据本阶段的课程内容,整理了一下4款主流消息队列所支持的功能清单。
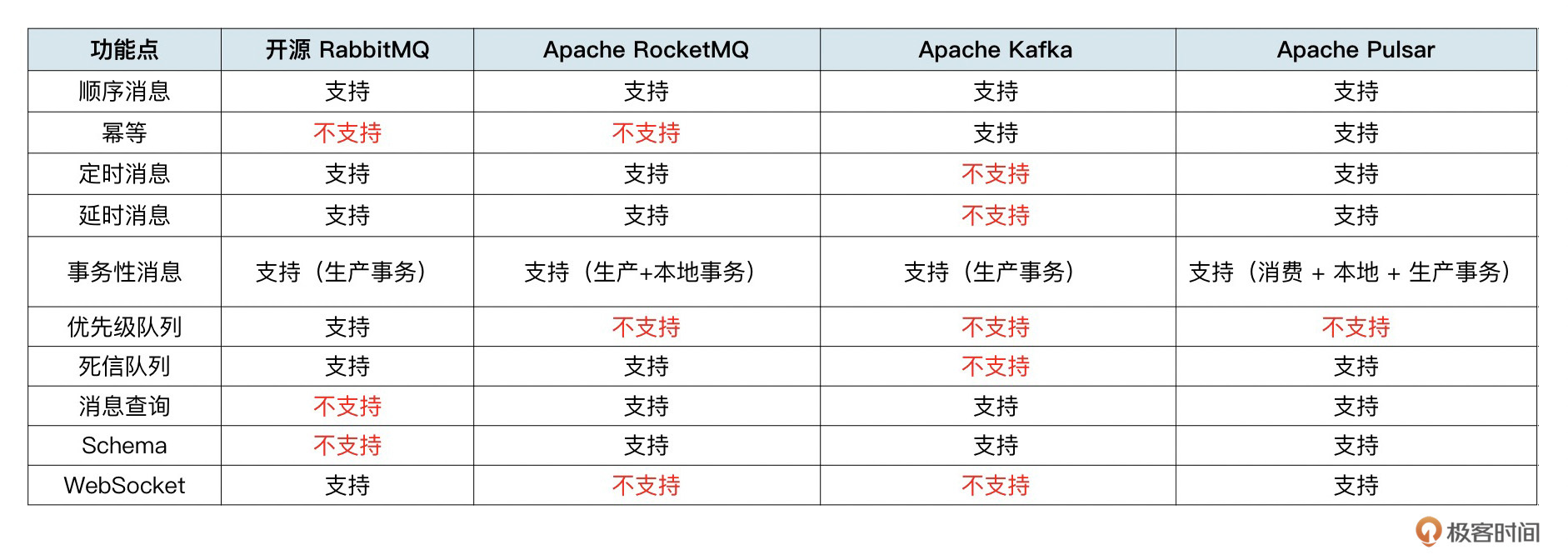
在上面的表格中,你会发现一个现象,Pulsar 支持的功能最多,RabbitMQ 和 RocketMQ 其次,Kafka支持的功能最少。原因我们在第01讲中说过,和它们自身的定位和发展历史有关。
接下来我们从功能出发,来分析一下这4款主流消息队列的原理和使用方式。先来个说明,这节课中的每个部分都是独立的,你可以挑感兴趣的内容进行学习。
RabbitMQ
RabbitMQ 支持顺序消息、定时和延时消息、事务消息、优先级队列、死信队列、WebSocket 等功能,但是不支持消息查询、幂等消息和Schema。
顺序消息
如下图所示,RabbitMQ 顺序消息的核心是底层 Queue 维度的顺序存储模型。图中将 RouteKey=A 绑定给 Queue1,把RouteKey=B绑定给Queue2。发送数据时只要给需要顺序的消息设置相同的RouteKey,就能保证这些消息是有序的。
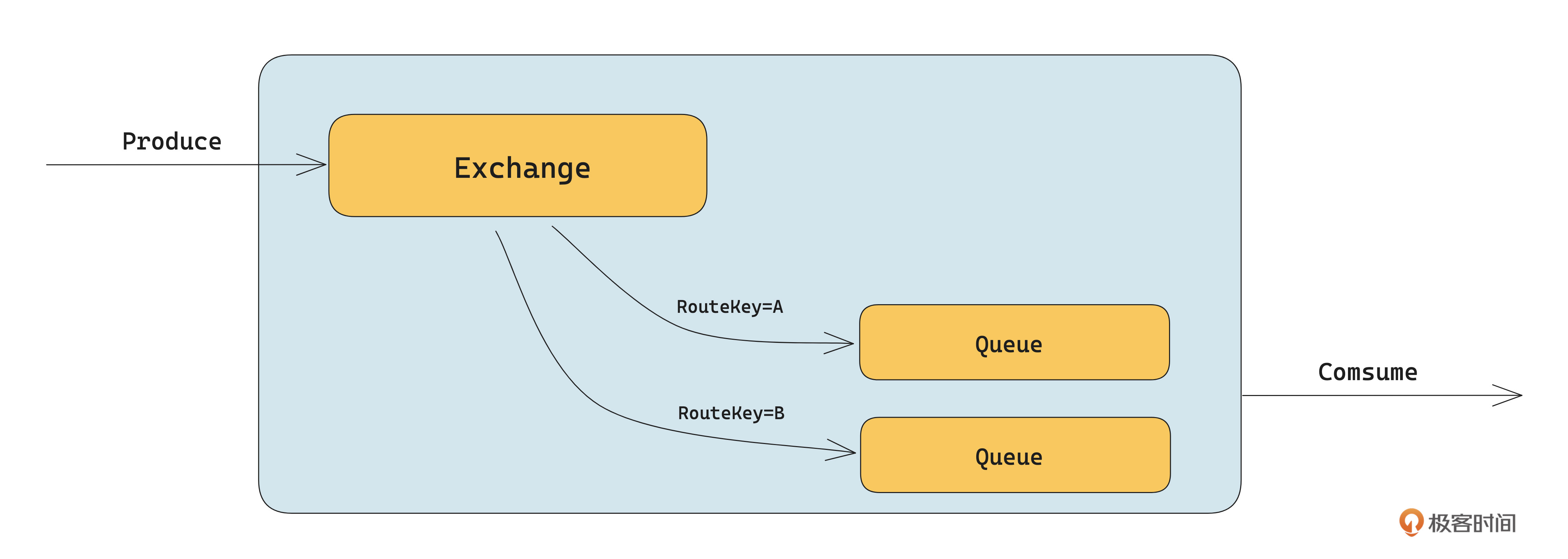
需要注意的是,这个路由关系是在定义 Exchange 时绑定的,代码示例如下:
# 创建 queue
channel.queue_declare(queue='route_queue1',
exclusive=True, durable=True)
# 绑定 queue到交换机,并指定 routing key
channel.queue_bind(exchange='direct_exchange',
queue="route_queue1", routing_key=routingKey)
绑定完成 Exchange 和 Queue 的关系后,就可以将消息投递到Queue中。下面的示例表示,RouteKey 为 A 的数据都会保存到名为 route_queue1 的 Queue 中。
channel.basic_publish(exchange='direct_exchange',
routing_key='A',
body=('hello world').encode(),
properties=pika.BasicProperties(delivery_mode=2))
定时和延时消息
RabbitMQ 的定时和延时消息,有基于死信队列和集成延迟插件两种方案,这部分已经在第29讲中详细讲了,就不展开了。
事务消息
RabbitMQ 的事务是指生产的事务,是在 Channel 维度生效的。底层是两阶段事务的实现,包含开启事务、提交事务、回滚事务三个阶段。
在 Channel 维度开启事务后,在这条 Channel 中生产的消息不会立即被投递到目标Exchange,而是会先在一个临时的 Exchange 中保存数据。当提交事务后,再把数据投递到实际的 Exchagne 中。如果事务回滚,则将临时数据丢弃。
下面是 RabbitMQ 使用事务的示例,代码中最重要的就是开启事务(txSelect)、提交事务(txCommit)、回滚事务(txRollback)三个函数的使用。
Connection connection=null;
Channel channel=null;
try {
connection = factory.newConnection(); //连接工厂创建连接
channel = connection.createChannel(); //创建信道
channel.txSelect(); //开启事务
channel.queueDeclare(QUEUE_NAME, false,
false, false, null); //绑定队列
channel.basicPublish("", QUEUE_NAME,
null, "Hello World!".getBytes(StandardCharsets.UTF_8));
channel.txCommit(); //提交事务
System.out.println(" [x] Sent '" + message + "'");
} catch (Exception e){
e.printStackTrace();
channel.txRollback(); //回滚事务
}
优先级队列
RabbitMQ 的优先级队列在第31讲有详细说明,它的效果是保证优先级高的消息能有先被消费者消费到。它的底层是通过优先级堆(Priority Heap)的数据结构进行消息优先级的排序,然后在消费的时候优先返回给客户优先级高的消息。
下面是使用优先级的代码示例,核心点是创建优先级队列时指定最大优先级,然后发送消息时给每个消息设置优先级。每个消息的优先级不能超过队列的最大优先级。在消费的时候,优先级高的消息会被优先消费。
// 创建了名为 priority_queue 的优先级队列,其最大优先级为 10。
channel.queue_declare(queue='priority_queue', arguments={'x-max-priority': 10})
// 向优先级队列 priority_queue 发送了一个带有优先级为 5 的消息
channel.basic_publish(exchange='', routing_key='priority_queue', body='Hello World!', properties=pika.BasicProperties(priority=5))
死信队列
RabbitMQ 支持死信队列的功能。它的作用是,如果遇到客户端发送消息被拒绝、消息过期没被消费、队列达到最大长度三种场景,消息会被投递到死信队列中。
和其他常见的实现方案不同的是,RabbitMQ 的死信队列是在 Broker 中闭环完成的,客户端不需要感知到死信队列的逻辑。
从使用上看,RabbitMQ 的死信队列的使用分为三步。
- 创建死信交换机,定义一个名为 dlx_direct 的 Exchange。
- 创建死信队列,并绑定到死信交换机。创建一个名为 dead_queue 的 Queue,并将这个 Queue 绑定到名为 dlx_direct 的 Exchange 中。
# 定义死信交换机
channel.queue_declare(queue='dead_queue')
# 死信队列绑定到第一步创建的死信
channel.queue_bind(
queue='dead_queue', exchange='dlx_direct', routing_key='dead_queue')
- 创建正常队列时,设置死信属性。创建一个名为 dxl_queue 的正常队列,并给它设置死信队列的属性,设置死信队列为 dlx_direct,路由 Key 为 dead_queue。
channel.queue_declare(
queue="dlx_queue",
arguments={
'x-dead-letter-exchange': 'dlx_direct',
'x-dead-letter-routing-key': 'dead_queue'
})
当完成这三步后,在生产端就生产消费消息即可,当遇到上面说的三种场景,数据就会自动变为死信消息,从而进入死信队列。
如果要消费到死信队列中的消息,则直接按照普通的消费逻辑去消费死信队列对应的 Queue 里面的消息即可。
WebSocket
我们在第34讲中讲到,WebSocket 协议的支持分为协议的设计、内核 WebSocket Server 的支持两部分。RabbitMQ 支持 WebSocket ,在协议设计层面是以 STOMP over WebSockets 和 MQTT over WebSockets 的形式实现的。即没有单独设计协议,而是直接使用 STOMP 和 MQTT 协议以 WebSocket 的形式通信。
从使用上,需要先启用对应的插件,开启 STOMP over WebSockets 和 MQTT over WebSockets 的插件。具体如下所示:
// 启用基于Stomp协议的websocket插件:
rabbitmq-plugins enable rabbitmq_web_stomp
// 启用基于MQTT协议的websocket 插件
rabbitmq-plugins enable rabbitmq_web_mqtt
启用插件后,直接使用对应的协议编解码,然后通过 WebSocket 协议和 RabbitMQ Broker 交互即可。代码示例如下:
上面的示例,客户端通过 URL ws://127.0.0.1:15674/ws 和 Broker 建立通信,然后通过STOMP 协议进行通信。如果需要了解更多细节,可以参考官方文档 STOMP over WebSockets 和 MQTT over WebSockets。
RocketMQ
RabbitMQ 支持顺序消息、定时和延时消息、事务消息、死信队列、消息查询、Schema等功能,不支持幂等、优先级队列、WebSocket功能。
顺序消息
RocketMQ 的顺序消息是一个独立的功能,它是通过消息组(MessageGroup)来实现顺序消息的功能。发送顺序消息时,需要为每条消息设置归属的消息组,相同消息组的多条消息能保证顺序。
如下图所示,携带MessageGroup1、MessageGroup2、MessageGroup3、MessageGroup4的消息,会被哈希发送到不同的Queue,同一个消息组的消息会被发送到同一个Queue。

下面是一个发送顺序消息的代码示例,代码的核心是 setMessageGroup 函数,给这条消息设置一个消息组 fifoGroup001,同一个消息组的消息会发送到同一个 Queue。
//顺序消息发送。
MessageBuilder messageBuilder = new MessageBuilderImpl();;
Message message = messageBuilder.setTopic("topic")
//设置消息索引键,可根据关键字精确查找某条消息。
.setKeys("messageKey")
//设置消息Tag,用于消费端根据指定Tag过滤消息。
.setTag("messageTag")
//设置顺序消息的排序分组,该分组尽量保持离散,避免热点排序分组。
.setMessageGroup("fifoGroup001")
//消息体。
.setBody("messageBody".getBytes())
.build();
try {
//发送消息,需要关注发送结果,并捕获失败等异常
SendReceipt sendReceipt = producer.send(message);
System.out.println(sendReceipt.getMessageId());
} catch (ClientException e) {
e.printStackTrace();
}
定时和延时消息
我们在第29讲讲了 RocketMQ 定时和延时消息的底层原理,这里我们补充几点使用注意事项。
- 定时时间指的是消息到期的时间,延时时间需要转换成消息的到期时间,即当前系统时间后的某一个时间戳,而不是一段延时时长。
- 定时时间的格式是毫秒级的Unix时间戳,即需要将要设置的时刻转换成时间戳形式。
- 定时时长最大值默认为24小时,不支持自定义修改。
- 定时时间必须设置在定时时长范围内,超过范围则定时不生效,服务端会立即投递消息。
下面来看一个定时消息的示例,代码中最需要注意的是 setDeliveryTimestamp,它设置了这条消息在10分钟后可以被消费者消费到。
//定时/延时消息发送
MessageBuilder messageBuilder = new MessageBuilderImpl();;
//以下示例表示:延迟时间为10分钟之后的Unix时间戳。
Long deliverTimeStamp = System.currentTimeMillis() + 10L * 60 * 1000;
Message message = messageBuilder.setTopic("topic")
//设置消息索引键,可根据关键字精确查找某条消息。
.setKeys("messageKey")
//设置消息Tag,用于消费端根据指定Tag过滤消息。
.setTag("messageTag")
.setDeliveryTimestamp(deliverTimeStamp)
//消息体
.setBody("messageBody".getBytes())
.build();
try {
//发送消息,需要关注发送结果,并捕获失败等异常。
SendReceipt sendReceipt = producer.send(message);
System.out.println(sendReceipt.getMessageId());
} catch (ClientException e) {
e.printStackTrace();
}
事务消息
我们在第30讲讲了 RocketMQ 事务的原理。它是一种基于生产 + 本地事务的两阶段事务实现。
从使用上来看,需要分为创建消息类型为TRANSACTION的Topic和发送事务消息两步。
- 创建 Topic,并设置 Topic 的 message.type 的属性为 TRANSACTION,示例如下:
./bin/mqadmin updatetopic -n localhost:9876 -t TestTopic -c DefaultCluster -a +message.type=TRANSACTION
- 在生产端发送事务消息。下面是官网提供的事务Demo,可以看到的步骤是:先在构建生产者的时候初始化一个本地事务,然后开启生产的事务,再根据本地事务的执行情况,判断是否提交事务。如果本地事务执行成功,就提交事务,否则就回滚事务。代码里面有详细的注释说明,可以看一下。
//演示demo,模拟订单表查询服务,用来确认订单事务是否提交成功。
private static boolean checkOrderById(String orderId) {
return true;
}
//演示demo,模拟本地事务的执行结果。
private static boolean doLocalTransaction() {
return true;
}
public static void main(String[] args) throws ClientException {
ClientServiceProvider provider = new ClientServiceProvider();
MessageBuilder messageBuilder = new MessageBuilderImpl();
//构造事务生产者:事务消息需要生产者构建一个事务检查器,用于检查确认异常半事务的中间状态。
Producer producer = provider.newProducerBuilder()
.setTransactionChecker(messageView -> {
/**
* 事务检查器一般是根据业务的ID去检查本地事务是否正确提交还是回滚,此处以订单ID属性为例。
* 在订单表找到了这个订单,说明本地事务插入订单的操作已经正确提交;如果订单表没有订单,说明本地事务已经回滚。
*/
final String orderId = messageView.getProperties().get("OrderId");
if (Strings.isNullOrEmpty(orderId)) {
// 错误的消息,直接返回Rollback。
return TransactionResolution.ROLLBACK;
}
return checkOrderById(orderId) ? TransactionResolution.COMMIT : TransactionResolution.ROLLBACK;
})
.build();
//开启事务分支。
final Transaction transaction;
try {
transaction = producer.beginTransaction();
} catch (ClientException e) {
e.printStackTrace();
//事务分支开启失败,直接退出。
return;
}
Message message = messageBuilder.setTopic("topic")
//设置消息索引键,可根据关键字精确查找某条消息。
.setKeys("messageKey")
//设置消息Tag,用于消费端根据指定Tag过滤消息。
.setTag("messageTag")
//一般事务消息都会设置一个本地事务关联的唯一ID,用来做本地事务回查的校验。
.addProperty("OrderId", "xxx")
//消息体。
.setBody("messageBody".getBytes())
.build();
//发送半事务消息
final SendReceipt sendReceipt;
try {
sendReceipt = producer.send(message, transaction);
} catch (ClientException e) {
//半事务消息发送失败,事务可以直接退出并回滚。
return;
}
/**
* 执行本地事务,并确定本地事务结果。
* 1. 如果本地事务提交成功,则提交消息事务。
* 2. 如果本地事务提交失败,则回滚消息事务。
* 3. 如果本地事务未知异常,则不处理,等待事务消息回查。
*
*/
boolean localTransactionOk = doLocalTransaction();
if (localTransactionOk) {
try {
transaction.commit();
} catch (ClientException e) {
// 业务可以自身对实时性的要求选择是否重试,如果放弃重试,可以依赖事务消息回查机制进行事务状态的提交。
e.printStackTrace();
}
} else {
try {
transaction.rollback();
} catch (ClientException e) {
// 建议记录异常信息,回滚异常时可以无需重试,依赖事务消息回查机制进行事务状态的提交。
e.printStackTrace();
}
}
}
死信队列
跟 RabbitMQ 不同的是,RocketMQ 的事务是消费的事务。即当一条消息初次消费失败,消息队列会自动进行消息重试。达到最大重试次数后,若消费依然失败,则表明消费者在正常情况下无法正确地消费该消息,此时,消息队列不会立刻将消息丢弃,而是将其发送到该消费者对应的特殊队列中。
消费端使用死信队列代码示例如下,核心就是在消费的时候设置死信队列名称和消费者组名称。设置了这两个参数,当消费消息失败,则消息会被投递到设置好的死信队列中。
// 1. 创建DefaultMQPushConsumer实例
DefaultMQPushConsumer consumer = new DefaultMQPushConsumer("DLQ_CONSUMER");
// 2. 设置NameServer地址
consumer.setNamesrvAddr("127.0.0.1:9876");
// 3. 设置死信队列名
consumer.setDLQName("DLQ_NAME");
// 4. 设置处理死信队列消息的消费者组
consumer.setDLQConsumerGroup("DLQ_CONSUMER_GROUP");
// 5. 启动消费者实例,连接NameServer
consumer.start();
}
消息查询
RocketMQ 支持丰富的查询功能,它提供了根据根据 Offset、根据时间戳、消息 ID 三种类型的消息查询。
从技术上来看,都是通过构建二级索引的方式来提高数据查询的速度。详细的技术实现,可以回顾一下第32讲。
根据 Offset 查询消息的代码示例如下。即消费者通过调用 Consumer 的 Pull 方法来获取指定队列(MessageQueue)的指定偏移量位置(offset)的消息,同时可以设置拉取的数量。下面的示例表示在获取 queue1 中,偏移量是从 10 开始的往后 32 条消息。
// 设置偏移量
long offset = 10;
while (true) {
// 拉取消息
PullResult pullResult =consumer.pull("queue1", "*", offset, 32);
System.out.println(pullResult);
// 更新偏移量
offset = pullResult.getNextBeginOffset();
// 消费消息并设置延迟,模拟业务处理
Thread.sleep(1000);
}
根据时间戳查询消息的示例如下,可以使用 consumer.searchOffset 方法获取与指定时间戳最近的消息偏移量(Offset),然后再根据 Offset 去获取到对应的消息。
// 设置查询消息的时间戳(毫秒)
long timestamp = System.currentTimeMillis() - (1000 * 60 * 60);
// 获取与时间戳最近的消息偏移量
long offset = consumer.searchOffset(mq, timestamp);
while (true) {
// 拉取消息
PullResult pullResult = consumer.pull(mq, "*", offset, 32);
System.out.println(pullResult);
// 更新偏移量
offset = pullResult.getNextBeginOffset();
// 消费消息并设置延迟,模拟业务处理
Thread.sleep(1000);
}
据消息 ID 查询消息示例如下, 它需要使用到 MQAdmin 来查询消息。下面代码表示查询消息 ID 为 k1 的消息的内容。
// 创建 DefaultMQAdminExt 对象
DefaultMQAdminExt mqAdmin = new DefaultMQAdminExt();
// 设置 NameServer 地址
mqAdmin.setNamesrvAddr("localhost:9876");
// 启动
mqAdmin.start();
// 查询消息 ID
String msgId = "k1";
// 根据消息 ID 查询消息
MessageExt message = mqAdmin.viewMessage("TopicTest", msgId);
// 输出消息内容
if (message != null) {
System.out.println("Message: " + message);
} else {
System.out.println("Message not found.");
}
Schema
当前 RocketMQ 消息体的数据格式没有限制。当上游数据类型变更后,如果下游没有及时修改代码。就有可能解析失败,从而导致链路异常。为了解决这个问题,RocektMQ 近期引入了 RocketMQ Schema 来规范上下游数据的传递。
我们在第33讲详细讲解了它的实现,如果需要了解更多,可以去 GitHub 仓库 Apache Rocektme Schema 查看更多信息。
Kafka
Kafka 支持顺序消息、幂等、事务消息、消息查询、Schema等功能,不支持定时和延时消息、优先级队列、死信队列、WebSocket 等功能。
顺序消息
Kafka 实现的顺序消息是单个生产者维度的顺序消息,即多个生产者之间的数据是无法保证有序的。
单个生产者实现顺序消息也有以下两个限制:
- 如果 Topic 只有一个分区,那么消息会根据服务端收到的数据顺序存储,则数据就是分区有序的。
- 如果 Topic 有多个分区,可以在生产端指定这一类消息的 Key,这类消息都用相同的 Key 进行消息发送,Kafka 会根据 Key 哈希取模选取其中一个分区进行存储,由于一个分区只能由一个消费者进行监听消费,此时消息就具有消息消费的顺序性了。
另外需要注意客户端参数 linger.ms 的设置。如果设置了 linger.ms 大于 0,则消息重传可能会导致消息无法保证有序。因此就需要把 linger.ms 设置为0,即表示数据立即发送。
linger.ms 表示消息延迟发送的时间,它的用处是可以等待更多的消息组成 batch 发送。默认为 0 表示立即发送。当待发送的消息达到 batch.size 设置的大小时,不管是否达到 linger.ms 设置的时间,请求也会立即发送。
下面代码示例是表示,通过在生产端设置 linger.ms 和消息 ID 为 key1,来保证消息是有序的。
Properties props = new Properties();
props.put(ProducerConfig.LINGER_MS_CONFIG, "1000");
KafkaProducer<String, String> producer = new KafkaProducer<>(props);
producer.send(new ProducerRecord<>(topic,
"key1",""code:1,message:" + Time.SYSTEM.nanoseconds()));
幂等
我们在第28讲讲过,Kafka 支持生产的幂等,即通过为每个生产者分配唯一的 ProducerID 和为这个生产者发送的消息分配一个自增的序号 SeqNum 来唯一标识这条消息。Broker 会根据 ProducerID 和 SeqNum 来实现消息的重复判断,从而保证消息不重复。
下面是生产者开启幂等的代码示例。如下所示,核心代码是设置 enable.idempotence 为 true,只要设置了这个参数,就相当于开启幂等了,使用起来非常简单。
Properties props = new Properties();
props.put("bootstrap.servers", bootstrap);
props.put("retries", 2); // 重试次数
props.put("batch.size", 100); // 批量发送大小
props.put("buffer.memory", 33554432); // 缓存大小,根据本机内存大小配置
props.put("linger.ms", 1000); // 发送频率,满足任务一个条件发送
props.put("client.id", clientId); // 发送端id,便于统计 "token#sfdiewrnxkcvvulsdfsdfdsijuiewrewr"
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("enable.idempotence", true); // 设置幂等性
KafkaProducer<String, String> producer = new KafkaProducer<>(props);
Long startTime = Time.SYSTEM.milliseconds();
Integer count = 0;
while (true) {
try {
// 开启事务
// 发送消息到producer-syn
producer.send(new ProducerRecord<>(topic, "msg1");
} catch (Exception e) {
e.printStackTrace();
}
}
事务消息
Kafka 的事务是两阶段事务的实现,主要保证的是生产的事务。它可以保证对多个分区写入操作的原子性,操作的原子性是指多个操作要么全部成功,要么全部失败,不存在部分成功、部分失败的可能。
为了使用事务,需要在客户端显式设置唯一的 transactional.id 参数并开启幂等特性。因此通过将 transactional.id 参数设置为非空从而开启事务特性的同时,需要将 enable.idempotence 设置为 true。如果用户将 enable.idempotence 设置为 false,则会报错。
下面是Kafka 生产事务的使用示例。核心代码就是 transactional.id 和 enable.idempotence 参数的配置,以及 beginTransaction、commitTransaction、abortTransaction 三个步骤。
Properties props = new Properties();
props.put("bootstrap.servers", bootstrap);
props.put("retries", 2); // 重试次数
props.put("batch.size", 100); // 批量发送大小
props.put("buffer.memory", 33554432); // 缓存大小,根据本机内存大小配置
props.put("linger.ms", 1000); // 发送频率,满足任务一个条件发送
props.put("client.id", "producer-txn-test"); // 发送端id,便于统计
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("transactional.id", txnId); // 每台机器唯一
props.put("enable.idempotence", true); // 设置幂等性
KafkaProducer<String, String> producer = new KafkaProducer<>(props);
producer.initTransactions();
Long startTime = Time.SYSTEM.milliseconds();
Integer count = 0;
while (true) {
try {
// 开启事务
producer.beginTransaction();
// 发送消息到producer-syn
producer.send(new ProducerRecord<>(topic, "message"));
} catch (Exception e) {
e.printStackTrace();
// 终止事务
producer.abortTransaction();
}
}
消息查询
从功能上来看,Kafka 支持按照 Offset 和时间戳查询消息。从内核的实现来看,技术原理跟第32讲讲的是一致的,通过构建 Offset 和时间戳的二级索引来加快数据查询的速度。二级索引底层在底层的数据结构如下所示:
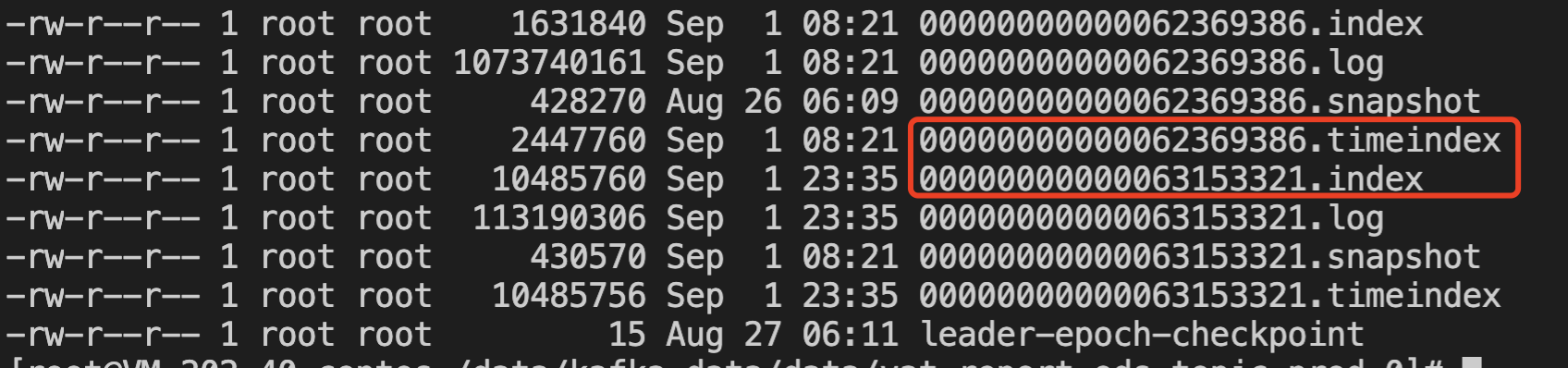
.timeindex 索引的内容如下所示:
timestamp: 1693001346933 offset: 62369391
timestamp: 1693001346957 offset: 62369395
timestamp: 1693001347033 offset: 62369397
timestamp: 1693001420165 offset: 62369402
timestamp: 1693001420203 offset: 62369408
.index 索引的内容如下所示:
offset: 62369391 position: 4462
offset: 62369395 position: 9664
offset: 62369397 position: 13986
offset: 62369402 position: 18309
offset: 62369408 position: 23699
offset: 62369414 position: 29882
offset: 62369418 position: 35910
所以从原理上看,根据 Offset 查询数据,就是通过 Offset 找到数据在文件中的具体位置。根据时间查询数据,就是通过时间找到 Offset,然后再根据 Offset 找到对应的数据。具体的实现原理可以回顾一下第32讲。
Schema
Kafka 社区版本支持的 Schema 不是一个完整的功能。完整的 Schema 只有在 Kafka 的商业化公司 Confluent 提供的商业化版本的 Kafka 才支持。比如 Kafka Schema Registry 这个项目是在 Confluent 公司的仓库中的,并没有贡献给Apache。
不过我们可以来看一下 Kafka Schema 的架构图。

参考图示,你会发现架构的核心是Schema Register,它用来存储 Schema 相关信息,每个Schema ID也有唯一的ID。Producer 和 Consumer 都会从 Schema Register 获取缓存相关的 Schema 信息来实现数据的编码、解码、校验。
Kafka Schema 整体的架构思路和第33讲基本一致,如果需要可以去回顾一下。另外,想了解更多关于 Kafka Schema 的信息,可以参考Confluent 官方文档 Kafka Schema Register。
Pulsar
Pulsar 支持顺序消息、幂等、定时和延时消息、事务消息、死信队列、消息查询、Schema、WebSocket 等功能,不支持优先级队列。
因为 Pulsar 的发展很快,功能点的代码和设计思路都有持续的迭代和演化。当前的总结可能很快就会过期,所以我们把 Pulsar 的实现和设计放在思考题。你可以先根据官网资料学习一下最新的设计和实现。
总结
总结下来,你会发现不同消息队列在功能方面的支持是很不一样的,侧重点各有不同。但是同一个功能的底层实现原理,大家的思路基本是一致的。
从用户的角度来看,功能是选型的核心。所以在业务消息类的场景,我会优先推荐你使用RabbitMQ 或 RocketMQ。在流方向的场景,我会推荐你使用Kafka。详细选型建议回顾一下第02讲。
要了解完整的 RabbitMQ 官方支持的功能,可以直接查看这个官方文档,这里面有详细的说明。
最后我想说明的是,虽然 Pulsar 支持的功能是最多的,但并不代表 Pulsar 是最优解。选型除了功能外,稳定性也是重要的考虑点。Pulsar 因为迭代较快,目前还处于快速发展阶段,一些功能还在开发中,在使用时需要判断是否适合生产场景。
思考题
因为Pulsar 是一个定位消息和流一体、发展速度很快的消息队列,所以我们并未在正文中进行总结。不过我们在表格中总结了 Pulsar 在功能层面的支持点,现在请你根据表格中的各个功能去学习一下 Pulsar 在这些功能上的使用和实现。
提示: 这些内容在 Pulsar 官网文档都可以找到相关资料。
欢迎分享你的想法,如果觉得有收获,也欢迎你把这节课分享给感兴趣的朋友。我们下节课再见!
上节课思考闭环
为什么在讲生产消费协议时我们说“简单理解成 WebSocket 是基于HTTP的”,请你从 WebSocket 建立连接、数据交互的角度来尝试回答一下这个问题。
WebSocket 建立连接的过程主要包括以下几个步骤:
1. 客户端发起HTTP请求:客户端(通常是浏览器)首先向服务器发送一个HTTP请求,这个请求是一个标准的HTTP请求,但是包含一些特殊的头信息,比如 “Upgrade: websocket” 和“Connection: Upgrade”,这些信息告诉服务器,客户端希望建立一个WebSocket连接。
2. 服务器响应:如果服务器支持WebSocket,并且同意建立连接,那么服务器会返回一个HTTP 101 Switching Protocols 的响应,这个响应也包含一些特殊的头信息,比如 “Upgrade: websocket” 和 “Connection: Upgrade”,这些信息告诉客户端,服务器已经切换到了WebSocket协议。
3. 握手完成,建立连接:一旦服务器返回了101响应,那么握手过程就完成了,WebSocket连接就建立了。此时,客户端和服务器就可以通过这个连接进行全双工、实时的数据传输。
这个过程被称为 WebSocket 握手。值得注意的是,虽然握手过程使用的是HTTP协议,但是一旦连接建立,数据传输就不再使用HTTP协议,而是使用WebSocket协议。
所以说,WebSocket协议可以简单理解成是基于HTTP 协议的。
- 快手阿修 👍(0) 💬(0)
【勘误】RocketMQ开头的RabbitMQ => RocketMQ
2024-06-15