33 Schema:如何设计实现Schema模块?
你好,我是文强。
这节课我们来看看消息队列中的 Schema 模块。看到 Schema 这个词,你可能会有点陌生,从而产生一些疑问。比如Schema是什么?它有什么用?什么时候可以用到它?这节课我们就重点解决这三个问题。
Schema 是什么
Schema 翻译过来是“模式”的意思。它表示的是数据结构定义,即定义数据是什么格式的。
如下图所示,默认情况下消息数据在生产者、Broker、Consumer 的全流程中,代码层面没有对消息内容格式进行限制或校验。
因此存在的问题是:消费者和生产者需要线下对齐数据格式,然后消费者根据约定的消息格式编写相应的处理逻辑。当生产端的数据格式或者某个字段的数据类型发生变化时,如果没有及时通知下游消费者,消费者就会无法解析数据,导致数据消费异常。
Schema就是用来解决全流程中的数据格式的规范定义问题,即保证上下游数据在传递过程中,消息可以根据指定的格式和定义进行传递。
举个例子,在订单场景中,一般通过消息管道传递订单数据,实现系统解耦。因此每个订单数据必须包含订单ID(OrderID)字段,否则下游就无法处理。此时就可以启用Schema,在生产端规范数据传递,在Broker端进行数据校验,在消费端根据指定的格式进行数据解析。
那 Schema 具体是一个什么形式呢?其本质就是一个字符串,用来定义数据是什么样子的。然后客户端和服务端会根据定义的这个格式,组装、校验、解析消息数据,从而规范数据的传递。
你可以通过 MySQL 中表的 Schema,来理解消息队列中的 Schema。它们都是表达这批数据有几个字段、这个字段是什么类型、长度是多长这些信息。
看一段代码示例,比如我们需要接收包含名字和地域两个字段的数据,此时通过MySQL Schema和消息队列 Schema分别如下表示:
MySQL 表的Schema:
CREATE TABLE IF person(
id INT NOT NULL AUTO_INCREMENT,
name VARCHAR(100) NOT NULL,
region VARCHAR(40) NOT NULL
);
消息队列数据的Schema:
[
{
"name":"name",
"type":"string",
"maxLength":100
},
{
"name":"region",
"type":"string",
"maxLength":40
}
]
那如何在消息队列的架构中支持Schema特性呢?我们继续来看一下。
Schema 技术方案设计
先来分析一下需求,我们知道整体的需求是:需要规范生产到消费的数据的格式化传递。所以拆解需求后,可以分为以下五点:
- Scehma 信息是如何存储的?
- 客户端、Broker如何获取到Schema信息?
- Schema 是在什么维度生效的?比如Topic维度、集群维度、命名空间维度、消息维度等等。
- Schema 信息可以变更吗?变更后生产者、Broker、消费者如何处理?
- 生产者、Broker、消费者如何使用Schema?
带着这五个问题,我们来看一张架构图。
从图中可以看到,在当前消息队列架构的基础上,我们引入了一个新的组件:Schema Register,即 Schema 注册中心。SchemaRegister 的作用是持久化保存具体的 Schema 信息,并提供接口给客户端增删改查 Scheme 信息。
在消息全生命周期中,Scheme 的使用可以拆解为五个步骤。
- 生产者或消费者可以自动调用SchemaRegister创建Schema信息,也可以通过运营端增加 Schema 的信息。
- 一旦开启了Schema,生产者、消费者初始化时需要配置SchemaRegister的访问地址。启动的时候,从 SchemaRegister 获取所需的 Schema 信息,并缓存起来。
- 生产者启动时会配置好本次需要发送的数据的Schema。此时SDK 会根据客户端配置的Schema 信息判断这个Schema是否存在。如果存在就正常发送,如果不存在则判断集群是否允许自动注册Schema。如果允许自动注册,则调用SchemaRegister提供的CreateSchema接口进行注册。SchemaRegister会为每个Schema分配唯一的ID,生产者会将这个ID写入到消息的属性中。
- Broker 启动时会从 Schema 注册中心获取全量的 Schema 信息,缓存到本地。当接收到消息数据后,拿出消息中的SchemaID,获取到具体的Schema信息,然后使用这个Schema信息对数据进行校验。
- 消费端启动时也会加载Schema信息,获取到数据后,根据消息ID及其对应的Schema去解析、处理数据。如果不符合格式的数据,就丢弃或者报错。
讲完了整体的运行过程,接下来我们来详细看一下Schema Register的实现。
Schema Register
Schema Register 也称为 Schema 注册中心。它的功能是存储数据,并提供增、删、改、查的功能接口来管理Schema信息。
所以,Schema Register 本质上是一个Server,由计算逻辑层和存储层两部分组成。计算逻辑层负责提供增删改查的接口支持对Schema 信息的操作,持久层负责分布式、持久化存储Schema信息。
从技术上看,Schema Register 有独立部署和Broker内核集成两种实现形态。
独立部署是指 Schema Register 独立成一个Server进行部署,比如它可以是一个 HTTP Server,通过 MySQL 存储Schema信息,暴露 Restful 接口提供服务。
这种方案是目前主流消息队列用得最多的方案,业界Kafka、RocketMQ、Pulsar 用的都是这种方案。它最大的好处是:独立部署的Schema服务可以给多套消息队列集群使用。比如一个公司只需要部署一套Schema Register即可,毕竟一套消息队列集群独立部署一个Schema Register 太浪费了。
从代码实现上来看,独立的Schema Register 开发复杂度不高。一般基于Spring Boot + MySQL 就可以实现。 但是这里有一个点,引入MySQL 当作存储的话,相当于需要多部署一个MySQL,会增加系统部署运维的复杂度。所以我们一般会把数据存储在消息队列的Topic,因为Topic也是分布式的可靠存储,从而避免引入MySQL。
但是在某些私有部署场景,独立部署的Schema Register就会增加部署运维的复杂度。那有没有可能把Schema Register 集成在Broker内核中呢?
Broker 内核集成是指在 Broker 内核实现Schema Register。如下图所示,即在Broker 上提供四层或七层的接口来满足 Schema 信息的增删改查等操作,同时集群内部创建一个内部Topic来保存Schema信息。
所以这种方案的技术实现思路大致如下:
- 创建一个内部的 Topic(比如__schema)来存储Schema信息。
- 在 Broker 中实现 Schema CRUD 接口,来支持增删改查等操作。接口是四层TCP还是七层HTTP,区别不大,主要是根据架构的实际情况来决定。
- 接口的逻辑就主要是对__schema中的内容进行操作。
这种方案的好处跟第一种刚好是相反的,是通过增加内核的复杂度来降低部署的复杂度。这种方案的最大缺点是,Schema Register 修改都需要更新内核版本,成本太高了。因为Schema Register 本质上是一个独立的服务,单独部署维护的技术合理性更高。这也是业界主流消息队列都使用第一种方案的原因。
接下来我们来看一下 Scehma 的格式是什么样子的。
Schema 格式设计
前面讲到,Schema 格式可以简单理解为MySQL 的表的结构。我们还是基于上面的例子进行扩展说明。
因为 Schema 是和具体的消息队列集群绑定的,所以Schema信息应该包含集群信息。进一步,如果有租户的概念,那么 Schema 信息也需要包含租户的信息。从技术上看,Schema 都是和Topic进行绑定的,即表示当前这个 Topic 允许接收什么格式的数据。所以,Schema 信息也需要包含Topic信息。
除了这些基础信息,最关键的是要标识这个消息数据的格式,即需要表达出以下两个信息:
- 包含name、region两个字段。
- name的类型是字符串,最大的长度是100;region的类型也是字符串,最大的长度是40。
基于上面的需求,我们可以用 JSON 格式来表示Schema,具体如下所示:
{
"id":"kjdsjfudfd",
"version":1,
"cluster":"cluster1",
"tenant":"tenant1",
"topic":"topic1",
"name": "schema1",
"properties": [
{
"name":"name",
"type":"string",
"maxLength":100
},
{
"name":"region",
"type":"string",
"maxLength":40
}
]
}
在上面的Schema中:
id是这个Schema的唯一标识,后续的变更、查询、删除都是根据这个唯一ID来的。version表示这个id对应的版本。因为每个Schema会经过多次修改,所以一个唯一ID会存在多个版本的Schema。严格来说,id + version才能唯一标识一个Schema。cluster、tenant、topic、name分别表示集群、租户、Topic和Schema的名称。properties是 Schema 的重点内容,表示这个消息的数据的格式。它是一个JSON数组,里面有多个元素,用来表示这个Schema应该包含哪些字段以及每个字段的信息。比如上面的name是字符串型,最大长度是100,region也是 string 型,最大长度是40。
所以如下图所示,一个Schema的具体结构可以是这样的。
当然这个Schema 格式只是一个基础,实际场景中还需要更多的字段来表达更多信息。所以在实现上,还需要进行一定的扩展。
刚刚说到,Schema一般是跟Topic绑定的,所以拉长时间周期来看,Topic 的 Schema 肯定变更。可能是从一个Schema 换成了另外一个Schema,或者在当前的基础上添加、删除字段,修改字段类型等等。
所以如下图所示,Topic 中肯定会存在前后数据的Schema 不一样的情况。
那么当生产者发送消息时,每条消息就需要携带所属的SchemaID和Version标记。此时:
- 当Broker收到数据,会根据SchemaID和Version去找到对应的Schema详情,进行数据校验。
- 当消费端收到数据时,会根据SchemaID和Version去找到对应的Schema详情,进行数据解析处理。
所以,在消息的协议结构中,就需要增加SchemaID和SchemaVersion两个字段。
下面我们来看一下 Broker 端是如何集成 Schema 的。
服务端集成 Schema
先来回顾一下上面的那张架构图。
从 Broker 的角度来看,它对Schema的支持主要分为以下四个部分:
- 添加Schema Register相关配置,比如Schema Register的地址。
- 启动时从Schema Register加载本集群的Schema信息,缓存在本地。
- 判断是否开启Schema,或者在什么维度(比如集群维度、租户维度、Topic维度)开启Schema。
- 接收到数据时,从消息中解析出SchemaID,根据 ID 找到对应的 Schema 对数据进行校验。
所以整体来看,Broker 端集成Schema的工作量并不大。接下来我们再看看客户端是如何集成 Schema 的。
客户端集成 Schema
先来看一段 Pulsar 生产端和消费端使用Schema特性的代码示例。
static class SchemaDemo { //定义一个Schema
public String name;
public int age;
}
Producer<SchemaDemo> producer = pulsarClient
.newProducer(Schema.JSON(SchemaDemo.class)) //生产使用Schema
.topic("my-topic")
.create();
Consumer<SchemaDemo> consumer = pulsarClient
.newConsumer(Schema.JSON(SchemaDemo.class)) // 消费使用Schema
.topic("my-topic")
.subscriptionName("my-sub")
.subscribe();
// 生产
SchemaDemo schemaDemo = new SchemaDemo();
schemaDemo.name = "puslar";
schemaDemo.age = 20;
producer.newMessage().value(schemaDemo).send();
// 消费
Message<SchemaDemo> message = consumer.receive(5, TimeUnit.SECONDS);
上面的核心流程是,定义了一个数据结构SchemaDemo,然后在生产端使用这个数据结构发送数据,在消费端使用这个数据结构来解析数据。在生产端,集成 Schema 后的主要流程如下:
- 生产端加上Schema Register相关配置。
- 生产端启动时,从Schema Register 加载相关的 Schema 信息,比如本次发送的集群、Topic等。
- 定义好要发送的数据格式,并构建数据。
- 在发送服务端之前,SDK 会根据客户端配置的 Schema 信息判断这个Schema是否存在。如果存在就正常发送,如果不存在则判断集群是否允许自动注册Schema。如果允许自动注册,则调用SchemaRegister提供的CreateSchema接口进行注册。SchemaRegister会为每个Schema分配唯一的ID,生产者会将这个ID写入到消息的属性中。
消费端集成Schema的流程和生产端基本类似,具体如下:
- 消费端加上Schema Register相关配置。
- 消费端启动时,从Schema Register 加载相关的 Schema 信息,比如本次消费的集群、Topic等。
- 同时也会把消费端设置的Schema和Topic与实际的Schema进行比对,然后判断是否使用还是自动注册这个Schema,流程和生产的第四步是一样的。
- 拿到数据,先判断是否携带SchemaID,然后判断是否是有效的Schema,再解析处理。
不过,此时有个问题是,消息内容数据是以什么格式发送的呢?
序列化和反序列化
这个问题想问的是,比如我们需要发送name和region两个信息,那这个消息内容是以什么格式序列化和反序列化后发送呢?这里一定要约定好使用的格式,否则下游就不知道如何解析数据了。
目前业界主要支持Avro、JSON、Protobuf、Thrift 等多种数据格式。即消息发送时,数据是以 Avro、JSON、Protobuf 等格式来编码的。
在消息队列中,编解码一般是在生产端和消费端配置的,比如Kakfa的配置如下:
// 生产使用avro格式来编码
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,
KafkaAvroSerializer.class.getName());
// 消费avroJson格式来编码
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,
"org.apache.kafka.common.serialization.ByteArraySerializer");
目前主流消息队列Kafka、RocketMQ、Pulsar在内核都支持了Schema。从技术的角度来看,RocketMQ、Kakfa、Pulsar 在Schema上的技术方案基本一致。一方面是因为场景和需求都是一样的,另一方面也是相互借鉴参考导致的。
接下来我们就主要分析一下 RocketMQ Schema 的详细实现。
RocketMQ Schema 的实现
来看下面这张架构图:

如图所示,可以看到RocketMQ 在原先架构中引入了Schema Registry 用于保存Schema信息,也可以看到 Schema Registry 和 Broker 是分开部署的。
Schema Registry 通过 SpingBoot 开发了 HTTP 服务,提供了 Restful 接口支持创建、更新、删除、绑定等操作。当前支持使用内置的 Compact Topic 来存储Schema 信息,未来规划引入 MySQL 等DB型存储。
RocketMQ的 Schema 格式如下:
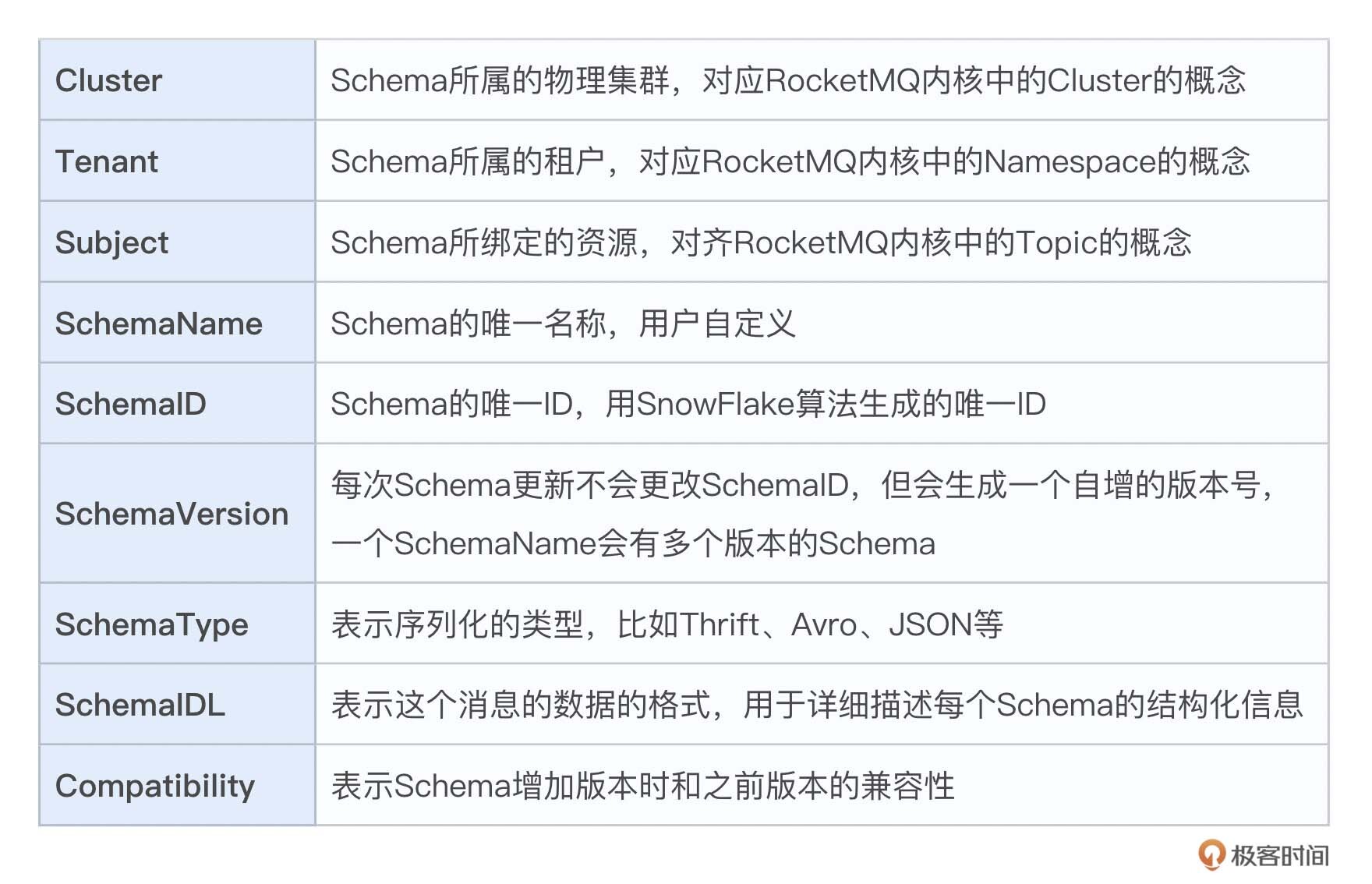
下面我们来看一下SchemaIDL的内容示例,可以看到,它包含 name 和 id 两个字段,name 和 id 都是字符串类型,id 的默认值为0。
{
"type": "record",
"name": "SchemaName",
"namespace": "rocketmq.schema.example",
"fields": [
{
"name": "name",
"type": "string"
},
{
"name": "id",
"type": "string",
"default": "0"
}
]
}
如果生产者和消费者每一次收发消息都要与 Registy 交互,name就会非常影响性能和稳定性。因此RocketMQ在客户端缓存了Schema信息,从而让 Schema 更新频率比较低。
下面我们再来看一个RocketMQ 客户端使用Schema的实例,先来看一下底层的客户端和服务端是如何集成Schema的。
先来看生产者示例:

可以看到,在生产者启动时,配置了SchemaRegister的访问地址,并配置了序列化方式为Avro。然后可以看到发送的数据是结构体Payment,而不是普通的字符串。此时会解析Schema并检查其是否符合Topic Schema兼容性要求。如果通过,生产者将序列化数据,并为其添加 SchemaID 等信息;如果验证失败,发送请求将被拒绝。
在Broker端,Broker 通过 RocksDB 做了一层 Schema 的缓存,避免频繁对Schema Register 的访问。当接收到数据后,再从消息里面解析出SchemaID,对数据进行校验。
再来看看消费者示例:

消费端创建时,同样需要指定 Registry URL 和序列化类型,然后通过 getMessage 方法直接获取泛型或实际对象。此时如果消费到的数据类型不是我们需要的类型,就会报错。
总结
Schema 是数据结构定义的意思,即定义数据是什么格式的。消息队列中的Schema用来保证上下游数据在传递过程中,消息根据指定的格式和定义进行传递,从而解决上游的数据变更所导致的下游消费失败问题。
消息队列Schema的核心是:客户端按照指定的数据格式发送数据,Broker 按照配置的数据格式进行校验,消费者根据指定的格式解析数据。
Schema Register,即 Schema 注册中心,它是Schema 特性的核心模块。它一般是一个独立的服务,用来保存Schema信息,并提供管理 Schema 的增删改查接口。大部分情况下,都会将Schema 信息存储在消息队列中的Topic,以避免引入其他存储组件,增加复杂度。
因为Schema Register一般会给多个物理集群使用,所以存储时需要明确Schema属于哪个集群、哪个租户、哪个Topic。因此 Schema 存储时会携带集群、租户、Topic等信息。每个Schema 会有一个唯一ID来标识,因为一个Schema可能有多个版本,所以一般也会有一个Version字段。
Schema 最重要的是数据的DDL的定义,即这个数据包含哪些字段、字段的类型是什么样子的。
Broker和客户端在启动时都需要配置Schema Register的地址,然后存储Schema信息。生产端发送时会对发送的数据进行校验,Broker也会对收到的数据进行校验,消费者消费到数据时也会进行比对,从而保证链路的数据是符合规范的。
思考题
这节课的作业我们包含两个任务,一个是做思考题,一个是学习任务。
- 既然Schema Register都是独立部署的,业界的RocketMQ、Kafka、Pulsar 都分别实现了独立的Schema Register,那么实现一个统一通用的Schema Register有意义吗?有什么好处或者难点?
- Pulsar 的社区版本也支持Schema特性,Kakfa 的商业化公司Confluent的商业化版本Kafka也支持了Schema,请你去官网学习一下它们的实现,然后对比一下这节课的所学。
欢迎分享你的思考,如果觉得有收获,也欢迎你把这节课分享给身边的朋友。我们下节课再见!
上节课思考闭环
在消息轨迹的场景中,我们是把轨迹信息存在Topic中的。此时结合我们这节课说到的查询能力,请你思考一下,在内核中我们是如何实现消息轨迹的存储和查询的?大致流程是怎样的?
1. 客户端将客户端的轨迹数据上报到内置Topic存储。 2. Broker将服务端的轨迹数据页写入到内置Topic中。 3. 因为轨迹数据一般需要一个唯一标识来串联,在前面的课程讲过,这个标识一般是消息ID。 4. 因此我们可以基于消息ID来查找到存储在Topic中的多条轨迹信息。 5. 最后读取轨迹信息,返回给查询方。
- Geek_ec80d2 👍(2) 💬(0)
pulsar并没有使用独立的注册中心
2023-09-13 - 贝氏倭狐猴 👍(1) 💬(1)
已个人经验,schema,尤其是强制schema验证还是会让使用方不太适应。一方面,用户不习惯于这种强制校验方式,经常忘记,出错才发现并让管理员关闭;另一方面,shema属于业务接口范畴,是否需要绑定在中间件里面,这个有点跨层,举例:schema应和具体消息中间件选型无关,但存储schema则难以迁移。
2023-09-04