31 死信队列和优先级队列:如何实现死信队列和优先级队列?
你好,我是文强。
在日常业务的消费数据过程中,如果遇到数据无法被正确处理,就需要先手动把消息保存下来然后ACK消息,这样才能顺利消费下一条数据。此时如果消息队列拥有死信队列的功能,就不需要这么繁琐的操作,直接开启死信队列就可以实现同样的效果。另外,当我们需要在业务中对消息设置优先级,让优先级高的消息能被优先消费,此时就需要用到消息队列中优先级队列的特性。
为了让你了解死信队列和优先级队列这两个功能特性的底层实现,这节课我们会详细分析它们的技术方案,学完之后,想必你对这两个功能的认识会更加深刻。
什么是死信队列
从本质上来看,死信队列不是一个队列,而是一个功能。为什么这么说呢?
参考图示,在实际业务场景中,死信队列一般有以下三种形态:
- 在生产端,如果数据写入某个Topic一直失败,则生产端可以将数据临时写入到另外一个Topic,这样可以避免后续数据写入阻塞。
- 在Broker端,如果存储在Topic的数据到过期后还没被消费,则可以将这些数据写入到另外一个Topic中,这样可以避免数据丢失。
- 在消费端,如果消费者消费到某条数据后本地处理一直失败,消费就会阻塞,此时可以将这条数据投递到另外一个Topic中,这样可以避免消费阻塞。
在上面这三种情况中,当数据写入失败、数据过期、消费处理失败后,自动将有问题的数据投递到另一个存储的功能就叫做死信队列。在实际业务中,用得最频繁的就是生产失败和消费失败时的死信队列。
接下来我们从技术上看一下死信队列是如何实现的。
死信队列实现的技术方案
从技术上看,生产和消费的死信队列的效果,业务端都能自定义实现。如下图所示:
在生产端,业务一直写入失败时,业务逻辑可以自行将数据写入到其他的Topic中,然后标记数据写入成功,从而保证业务的正常进行。再来看下面这张图:
可以看到,消息队列死信队列存在的意义是:将业务自定义处理这部分复杂重复的工作包装在消息队列内部完成, 从而降低业务的使用成本。
这里不知道你会不会有疑问,在这两张图中,死信队列配置的Topic就一定是Topic吗?可以是其他的存储引擎(比如MySQL)吗?如果是Topic的话,是同一个集群中的Topic,还是不同集群中的Topic呢?接下来我们就找找答案吧!
死信队列的存储目标
在日常的叫法中,因为大部分情况下,我们会将数据投递到消息队列集群中的另外一个Topic,所以我们会将死信队列数据投递的目标Topic叫做死信队列。但是严格意义上说,这样称呼是不对的。
从功能上来看,死信队列的目标一般是同一个集群或另一个集群中的 Topic。但是从技术上来看,死信队列的目标引擎也可以是其他的存储,比如说ES、MySQL等。
那什么时候是集群内/跨集群的Topic,什么时候是其他存储呢?这个问题没有固定答案,一般可以从业务自定义实现的死信队列和社区消息队列SDK实现的死信队列两个角度来看。
如果是业务自定义实现的死信队列,那么一般可以灵活选择其他存储引擎或其他集群的 Topic。因为在一些企业内部,为了满足业务侧的需求,会二次扩展社区的SDK功能。比如在业务稳定性的要求下,为了保证生产操作数据流的稳定,会要求在当前集群异常的时候,将数据临时存储在另外一个引擎或另一个消息队列的集群中,以保证数据流的稳定、不中断。
如果是消息队列内核SDK实现的死信队列,一般只支持同一个集群内的另外一个Topic作为目标存储,最多支持跨集群Topic的投递。这是因为如果客户端SDK集成其他的引擎,客户端就需要耦合其他引擎的写入逻辑,这会让消息队列的SDK变得很臃肿,不够单一,长期来看维护成本很高,所以社区的SDK一般不会支持跨存储引擎的投递。
接下来,我们来看一下消息队列内核SDK是如何实现死信队列功能的,其设计方案也比较有代表性。
死信队列的方案设计
从功能上看,我们可以分为生产死信队列、消费死信队列、Broker 死信队列三种场景。
先来回顾一下生产数据的全流程:
- 客户端初始化生产者。
- 客户端将数据发送到目标Topic,如果成功,流程结束,继续下一次发送。
- 如果失败,则判断客户端有没有配置重试机制,如果没有,流程结束,给业务报错。
- 如果有,则进行重试,当重试次数用完后,给业务侧报错。
从正常流程来看,上面的逻辑是没问题的,客户端可以感知到异常并进行处理,但是业务侧的需求是:底层基础组件需要尽量保证集群可用。而当集群不可用时,能不能把数据先存到其他地方,等集群可用时再继续投递,把逻辑闭环在底层,以免上层业务逻辑感知到更复杂的处理逻辑。
此时如下图所示:
流程就变成了:
- 如果有,则进行重试,当重试次数用完后,判断是否启用死信队列,如果没有启用,给业务端报错。
- 如果启用,那么则将数据投递到死信队列,上层业务正常处理返回,从而保证上层应用的正常运行。
从代码实现上来看并不复杂,只需要两步:
- 在启动生产者的时候配置好死信队列的配置信息。
- 在生产失败的最后一步,代码判断是否启用死信队列,就将数据写入目标队列即可。
以下为死信队列的伪代码示例:
// init producer && deadLetterProducer
try{
producer.send(message)
}catch(Exception e){
if(enableDeadLetter){
deadLetterProducer.send(message)
}
throw e
}
我们再来看一下消费数据的全流程:
- 客户端初始化消费者。
- 消费者正常消费数据,处理数据,如果数据处理成功,则提交消费进度,流程结束。
- 如果数据处理失败,则进行重试,重试到一定次数还失败的话,就直接报错。
跟上面类似,引入死信队列后,此时如下图所示:
流程就变成了:
- 如果数据处理失败,则进行重试,重试到一定次数还失败的话,就直接报错。如果没有配置死信队列,则直接报错,且不提交消费进度。
- 如果配置了死信队列,则将消息投递到死信队列,然后正常提交消费进度,开始消费下一条消息。
从代码实现上来看,我们通过一段伪代码来看一下消费的流程。
//消费的代码
message = consumer.poll()
try{
//todo process
}catch(Exception e){
consumer.markFail()
}
consumer.commit()
用户正常消费处理数据,当处理失败后,就记录本批次数据处理的失败次数。当失败次数达到配置的次数后,就将本次消费到的数据写入到死信队列,并且自动提交 Offset。
讲到这里,你会发现:生产和消费的死信队列的功能都是在客户端完成的,基本不需要服务端参与。
Broker 的死信队列的实现逻辑跟延时消息很像,所以技术实现方面你可以直接参考第29讲。简单来说,就是当消息过期或在删除的逻辑上加上死信队列的判断逻辑时,则根据配置的死信队列信息,将数据投递到某个目标队列。
讲完了死信队列的设计方案,接下来我们来看一下业界主流消息队列都支持什么形态的死信队列。
主流消息队列的死信功能
目前来看,只有RocketMQ、RabbitMQ支持死信队列。
其中,RocketMQ 实现的是消费死信队列。即当一条消息消费失败,RocketMQ 会自动进行重试。达到最大重试次数后,若消费依然失败,则表明消费者在正常情况下无法正确地消费该消息。此时如果开启了死信队列,则不会立刻将消息丢弃,而是将其发送到该消费者对应的特殊队列中。
这种正常情况下无法被消费的消息我们称之为死信消息(Dead-Letter-Message),存储死信消息的特殊队列我们称之为死信队列(Dead-Letter Queue)。在具体实现中,RocketMQ 会自动创建内部Topic,然后将消息投递到这个内部Topic中。
RabbitMQ 实现的是生产和Broker内的死信队列。RabbitMQ 的死信队列我们称之为死信交换机(Dead-Letter-Exchange,DLX)。在功能上,当消息变成死信消息后,它会被重新发送到另一个交换机中,这个交换机就是DLX ,绑定DLX的队列就称之为死信队列。
当出现这三种情况,消息就会被变为死信消息,投递到死信交换机中:
- 消息被拒绝
- 消息过期
- 队列达到最大长度
从实现上看,RocketMQ和RabbitMQ 的投递目标都是本集群内的资源,比如 Topic、Exchange、Queue。
讲完了死信队列,下面我们再来看一下优先级队列。
什么是优先级队列
我们先来看一个示例。在很多业务场景中,我们会对客户进行分级,比如头部客户、中腰部客户、尾部客户等。此时有个需求是,在给这些客户发通知时,希望头部客户先收到通知,然后是腰部客户,最后是尾部客户。
在这个场景中,我们就可以利用优先级队列的特性。如下图所示,只要我们发送通知的时候在每条消息上附带这个客户的优先级信息,比如头部客户的优先级是10、中腰部是5、尾部是1,此时不管生产端发送数据的顺序是怎样的,消费端一定是先拿到优先级高的信息,然后进行推送。
而如果没有优先级队列,此时就需要在生产端严格控制发送顺序,业务侧的工作量就会放大很多倍。有了优先级队列后,生产端和消费端就可以像普通消息一样生产和消费消息即可。
所以总结来说,优先级队列的定义就是:客户端在发送消息的时候会给每条消息加上优先级信息,不管客户端发送消息的顺序是怎样,Broker都会保证消费端一定会先消费到优先级高的消息。
接下来我们从技术上来看一下内核是怎样支持优先级队列的。
如何设计实现优先级队列
从业界来看,实现优先级队列有两条路径:
- 当消息队列内核不支持时,业务自定义实现优先级队列的效果。
- 在消息队列内核支持优先级队列。
我们分别来说一下这两种实现的主要思路。
业务实现优先级队列的效果
在实际业务中,大部分情况下优先级的设置会有一个数量范围,比如总共分为10等优先级,从1~10。另外在前面的课程我们讲过,消息队列是Topic分区模型。
所以我们可以基于Topic和分区模型来实现优先级队列的效果。
我们的核心思路是:为每个优先级分配一个分区,写入时将不同的优先级数据写入到不同的分区。消费时指定分区消费,优先消费优先级高的分区。
进一步说,为了保证性能和横向扩容的能力,我们可以为每个优先级级别分一个独立的Topic来存储数据。比如优先级1的数据存储在Topic1中,优先级2的数据存储在Topic2中,以此类推。
这种方案从功能上勉强可以满足优先级队列的需求,但是缺陷比较明显。主要缺点是没法支持灵活的优先级设置,在优先级级别很多的情况下,会额外冗余很多的分区和Topic。另外在生产端和消费端都需要感知到分区 / Topic 和优先级的关系,控制写入和消费,这会导致客户端的逻辑很复杂。
所以从技术合理性来看,还是在消息队列内核实现优先级队列更加合理。
内核支持优先级队列
那么要在 Broker 内核实现优先级队列,从技术上看主要分为两步。
- 协议层面:客户端发送消息时需要给消息加上优先级信息,所以请求协议就需要支持添加优先级信息的字段。
- 内核层面:Broker 接收到数据后,需要经过某种机制保证消费者优先消费到高优先级的消息。
其中协议层面的改动较为简单,只需要添加一个表示优先级信息的字段即可,比如在消息体里面加上 priority 字段用来表示这个消息的优先级是什么。我们来回顾一下第03讲讲到的Kafka的协议体,如下图所示,如果要在Kafka中加上优先级队列的特性,则在data字段里面加上 priotity 字段即可。
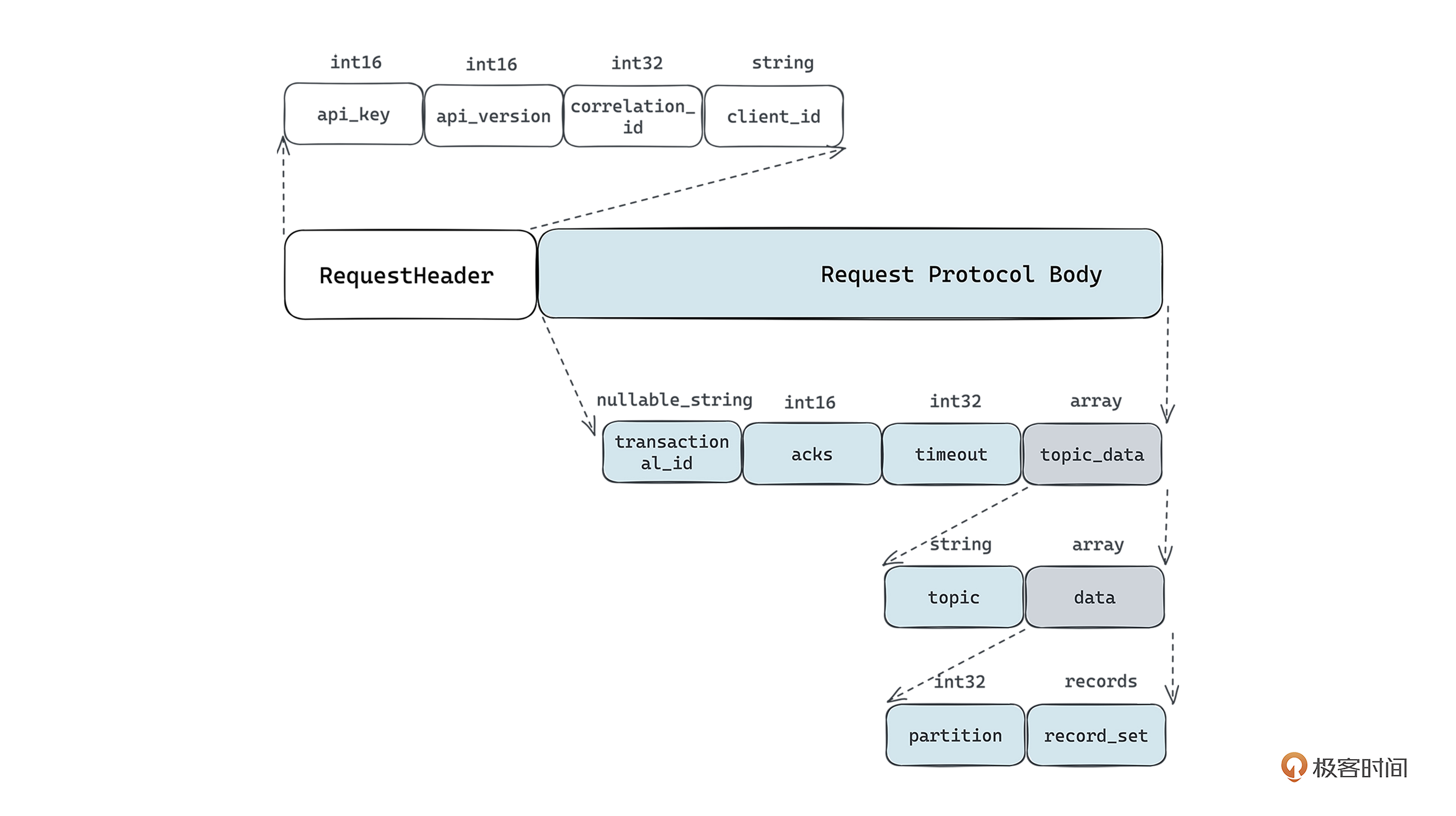
这里我们主要看看内核层面如何支持,从技术上来看,主要有以下几个思路:
- 正常写入数据,同时维护一个按照优先级排序后的消息索引,消费的时候根据索引的顺序去定位读取数据。
- 数据写入时对存量的消息数据进行全量重排序,然后按正常逻辑进行消费。
- 用空间换时间,只支持固定维度的优先级,比如总共100个优先级。在底层对于开启优先级队列的数据,进行分文件顺序存储。在写入的时候根据优先级顺序写入不同文件段,消费的时候优先消费优先级高的数据。
从实际实现的角度来看,第二和第三种方案用得比较少,因为需要对消息队列的顺序存储模型做较大改动。比如第二种方案需要频繁把数据全部取出来,排序后再重新写入,对资源的消耗太大。第三种方案需要修改底层数据的存储模型,改动也较大。
所以方案一是比较常用的方案,它的主要思路是:在内核中维护一个按优先级信息排序的索引结构,索引指向消息数据的实际存储位置。当数据写入时,会先把数据按照原先的流程写入到分区里面,然后根据消息的优先级信息去更新优先级索引。消费的时候会先读取优先级队列中的数据,判断应该读取哪些数据,定位到具体消息数据返回给客户端。
所以,可以知道方案一主要的工作量是优先级索引的实现。它的实现从技术上看,存在两个问题,必须要搞明白。
- 选择哪种数据结构来存储?以保证插入和获取的时间复杂度较低。
- 如何实现索引数据的持久化存储和快速重建?
从功能上来看,因为只有排序没有搜索的需求,所以我们可以基于排序链表来构建优先级索引。接下来我们需要选择合适的排序算法,排序算法主要关注的是时间复杂度和空间占用。
我们不妨先来对比一下8个主流排序算法的时间复杂度和稳定性。
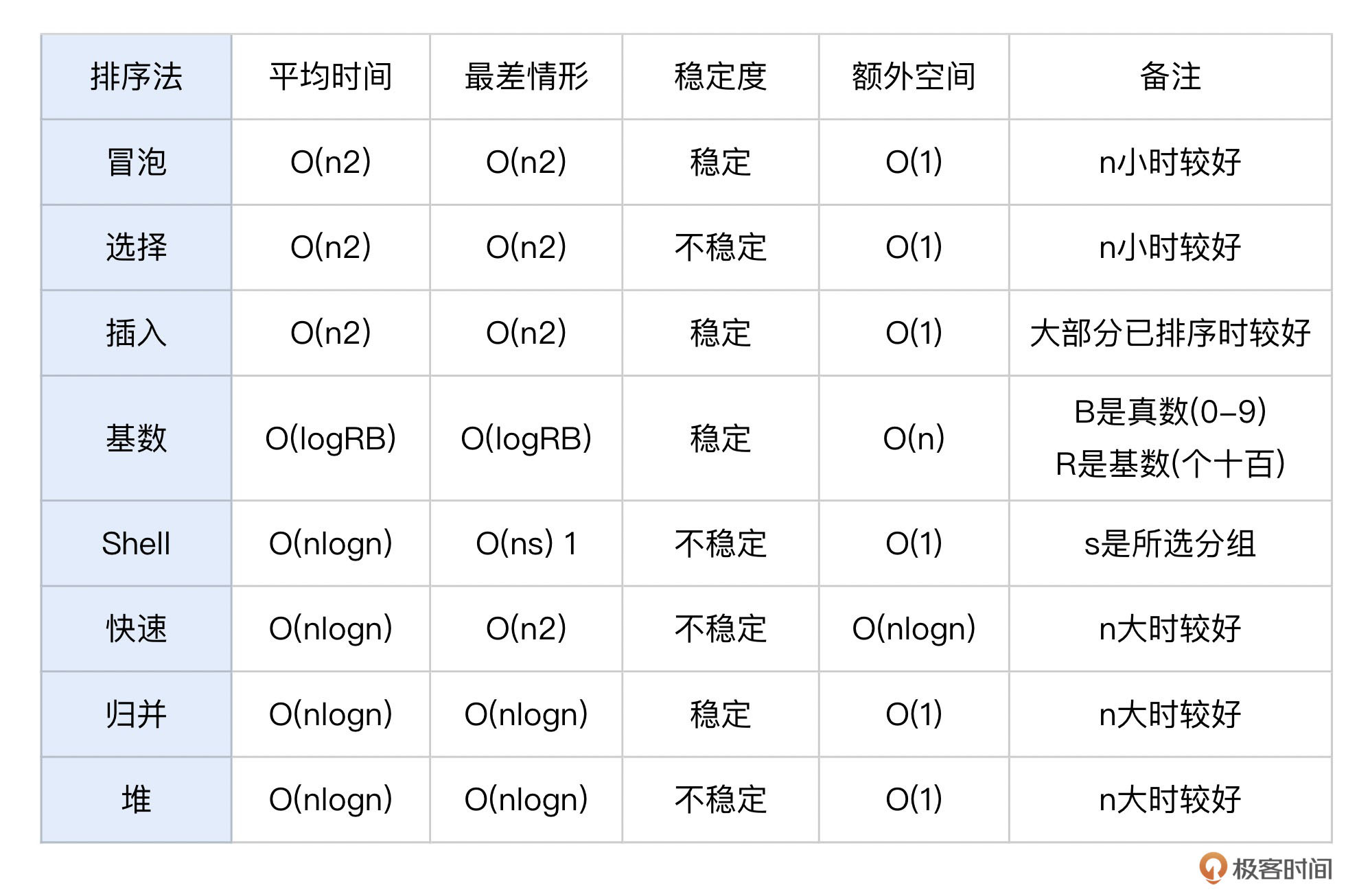
因为消息队列堆积的数据可能会很大,所以我们需要选择数据量大时性能仍然优秀且稳定的算法。从具体业务使用场景分析,消息队列优先级一般是相对固定的、有阶梯的,比如固定的5个、10个优先级这样子。基于这两个信息,结合上面的表格,我会建议你选择归并排序。
第一个问题解决了,那么下一个问题:如何实现索引数据的持久化存储和快速重建?
从实现来看,为了性能考虑,索引数据一般需要缓存在内存中。所以我们还需要评估对内存的占用情况。
这里我给你一个基本的评估算法吧。
- 假设链表的每个元素存储分区号、消息位点、优先级三个数据,都是int型数据,则每个节点占用的空间是12个字节。
- 假设我们支持最大容量为100w的优先级索引,则占用的空间是1000000*12/1024/1024~=11MB。
- 假设一个节点可以支持100个优先级队列的话,占用1.1G的内存。
从数值上来看,空间占用并不大。所以可以优先考虑存储在内存中。但是当需要支持容量更大的优先级队列时,则要考虑是否需要文件排序。
那么是否要对索引数据持久化存储呢?
我个人的建议是不用的,因为源数据都存储在分区中。我建议当索引数据丢失时,直接通过读取分区来读取源数据,然后重建优先级索引即可。这样的话,在Leader切换的时候,可以复用这部分的能力,直接在新的Leader重建优先级索引即可。
目前主流消息队列对优先级队列支持的较少,只有 RabititMQ 支持。接下来我们就来看一下 RabbitMQ 中优先级队列的实现方式。
RabbitMQ 中优先级队列的实现
先来看一下 RabbitMQ 中优先级队列的使用,主要分为以下3步:
- 创建队列时,通过设置 x-max-priority 属性来设定队列的最大优先级。
- 发送消息时,可以使用消息的 priority 属性来设置消息的优先级。
- 消费端无需进行任何更改,可以像普通队列一样消费消息。
下面来看一个代码示例:
// 创建了名为 priority_queue 的优先级队列,其最大优先级为 10。
channel.queue_declare(queue='priority_queue', arguments={'x-max-priority': 10})
// 向优先级队列 priority_queue 发送了一个带有优先级为 5 的消息
channel.basic_publish(exchange='', routing_key='priority_queue', body='Hello World!', properties=pika.BasicProperties(priority=5))
从RabbitMQ 内核底层实现来看,核心是优先级排序。即在 RabbitMQ 中优先级队列通过优先级堆(Priority Heap)的数据结构进行消息优先级的排序。对于具有不同优先级的消息,会被放入不同的子队列,每个子队列对应一个优先级。当有消息进入优先级队列时,RabbitMQ 会将其放入相应优先级的子队列。
当消费者从优先级队列消费消息时,RabbitMQ 会先检查优先级最高的子队列,如果有消息,则从中取出一个消息并发送给消费者;如果优先级最高的子队列为空,则检查次高优先级的子队列,以此类推。当所有子队列都为空时,说明优先级队列中没有消息。
另外还需要注意,大量使用优先级队列可能会导致性能下降。实际应用中应该根据需求和资源情况决定是否使用优先级队列。
总结
严格来讲,死信队列是一个功能,不是一个队列。它实现的是,当数据处理失败后,将数据缓存起来,继续处理后面的数据,以避免影响业务的流程。
死信队列的功能主要分为生产死信队列、Broker死信队列、消费死信队列三种形态。即当数据生产失败、数据过期、消费失败时,将数据先存到另外一个地方,然后继续主流程。从功能上看,这个存储数据的目的地可以是第三方存储,也可以是集群内或跨集群的Topic。默认情况下都是集群内的另外一个Topic。
生产和消费的死信队列的主要逻辑都是在消息队列SDK实现的,逻辑并不复杂。一般的流程是在数据处理失败的最后一个环节,判断是否开启死信队列,是的话就将数据写入到死信队列中。
目前主流消息队列RocketMQ、RabbitMQ支持死信队列的功能。
优先级队列是指不管生产端消息的顺序是什么,消费端肯定会先拿到优先级高的消息。即客户端在发送消息的时候给每条消息加上优先级信息,不管客户端发送消息的顺序是怎样的,Broker都会保证消费端一定会先消费到优先级高的消息。
业务可以将不同优先级的消息写入到不同的分区或Topic中,消费端优先去读取优先级较高的分区或Topic,从而实现类优先级队列的效果,但是这种方案业务的使用成本会较高。
标准的方案是在消息队列内核支持优先级队列。从技术上来看,一般会通过在内存中维护优先级索引来实现优先级队列。即写入时将消息树正常写入到分区,但是会根据优先级数据维护一个优先级索引。消费的时候先去优先级索引获取优先级高的数据,然后再去定位读取具体的消息数据。
目前主流消息队列对优先级队列支持得较少,只有RabititMQ支持优先级队列。
思考题
在你当前的业务中,有哪些场景需要用到死信队列和优先级队列?
期待你的分享,如果觉得有收获,也欢迎你把这节课分享给身边的朋友。我们下节课再见!
上节课思考闭环
为什么消息队列的事务不选择三阶段事务或者TCC呢?
三阶段事务(3PC)相对两阶段事务(2PC)多了一步,就是询问阶段,即询问是否有资源。但是在消息队列的场景中,消息生产、消费进度提交是不需要询问是否有资源的,只需要保证操作本身成功,此时3PC的这一步询问在消息队列的场景中就没有意义。
TCC 是用在业务场景中的,客户端需要去实现资源的锁定、提交和回滚操作,完全客户端自定义实现,不适合消息队列这种基础组件的场景。
- TKF 👍(0) 💬(0)
老师,pulsar也有消费端的死信队列。
2024-08-19 - | ~浑蛋~ 👍(0) 💬(1)
文中说的优先级索引的方案怎么管理消费位点呢
2024-01-15