26 从集群角度拆解Pulsar的架构设计与实现
你好,我是文强。
上节课我们讲完了 Kafka ,这节课我们再来看一下消息队列领域最新的成员 Pulsar。在开始学习本节课之前,你可以先复习一下第13讲,这样的话你对本节内容吸收得会更好。
我们在基础篇讲过,从设计定位上来看,Pulsar 是作为 Kafka 的升级替代品出现的,它主要解决了 Kafka 在集群层面的弹性和规模限制问题。那么现在我们就从集群的角度来拆解一下 Pulsar 的架构设计和实现,先来看一下集群构建。
集群构建
在当前版本,Pulsar 集群构建和元数据存储的核心依旧是 ZooKeeper,同时社区也支持了弱ZooKeeper化改造。如下图所示,Pulsar Broker 集群的构建思路和 Kafka 是一致的,都是通过 ZooKeeper 来完成节点发现和集群的元数据管理。
从实现角度来看,Broker 启动时会在 ZooKeeper 上的对应目录创建名称为 BrokerIP + Port 的子节点,并在这个子节点上存储Broker相关信息,从而完成节点注册。Pulsar Broker 的节点信息是存储在 ZooKeeper 上的 /loadbalance/brokers 节点上,目录结构如下所示:
[zk: 9.164.54.17:2181(CONNECTED) 67] ls /loadbalance/brokers
[30.13.4.1:8080, 30.13.8.2:8080, 30.13.4.3:8080]
还是从实现的角度,Pulsar 的全部元数据都持久化存储在 ZooKeeper 中,同时 Broker 也会缓存一部分数据。Pulsar 在 ZooKeeper 中主要存储了包括集群管控,存储层的Bookie、Ledgers,计算层LoadBalance、Bundle,周边功能Schema、Stream、Function等信息。ZooKeeper中的节点结构如下所示:
[admin, bookies, counters, ledgers, loadbalance, managed-ledgers,
namespace, pulsar, schemas, stream, zookeeper]
在集群管理方面,每个 Pulsar 集群都有一个主节点(Master Node)。
主节点
主节点对 Pulsar 的作用,就相当于 Kakfa 中的 Controller。主节点负责管理集群的元数据和状态信息,例如主题、订阅、消费者等。主节点还负责协调集群中的各个节点,例如选举副本、分配分区等。
那么主节点是怎么产生的呢?
当一个节点启动时,它会向ZooKeeper注册自己,并尝试成为主节点。如果当前没有主节点,或者当前的主节点失效了,那么该节点就会成为新的主节点。如果多个节点同时尝试成为主节点,那么它们会通过ZooKeeper的选举机制来进行竞争,最终只有一个节点会成为主节点。
从节点机制上看,和 Kafka 的Controller选举机制的实现是一样的。从代码的角度,也是依赖ZooKeeper的存储和Watch来实现分布式协调。所以可以看出,ZooKeeper 作为分布式协调服务,用处非常广泛。
我们之前提到过 Zookeeper 集群本身存在性能和容量限制。从技术上分析,是因为ZooKeeper在底层的存储数据结构是分层树结构。分层树结构在读取时需要多层检索,从而导致数据如果存储在硬盘,读取性能会很低。因此 ZooKeeper 只有将所有数据加载到内存中,才能提供较好的性能。
此时单个节点可承载的容量上限,就是集群所能承载的容量上限。而 Pulsar 存算分离架构和计算层弹性需要存储很多元数据,所以ZooKeeper就成为了瓶颈。为了解决这个问题,Pulsar 走的技术路径是弱ZooKeeper,而不是去ZooKeeper。
弱 ZooKeeper 实现
弱 ZooKeeper 就是允许将 ZooKeeper 替换为其他的单机或分布式协调服务。目前支持ZooKeeper、etcd、RocksDB、内存四种方案。
如上图所示,基于etcd的方案是当前集群化部署的推荐方案。etcd底层存储是B树的结构,在硬盘层面的读取性能较高,不一定要把数据加载到内存中,所以存储容量不受单机的限制。
基于 RocksDB 的方案和 RabbitMQ 的 Mnesia 大致上是一个思路,都是基于节点层面的存储引擎来完成元数据的存储。RocksDB的方案主要用在单机模式上,主要原因是 RocksDB 是一个单机数据库。
基于内存的方案主要用在集成测试的场景中。
从实现角度,这种可插拔的方案都是先定义好接口,比如获取资源、获取子节点、增加或删除内容等等。然后具体的元数据引擎实现会继承这个接口,去实现不同的逻辑。如下代码是Pulsar 可插拔的元数据服务所定义的接口MetadataStore。
public interface MetadataStore extends AutoCloseable {
CompletableFuture<Optional<GetResult>> get(String path);
CompletableFuture<List<String>> getChildren(String path);
CompletableFuture<Boolean> exists(String path);
CompletableFuture<Stat> put(String path, byte[] value,
Optional<Long> expectedVersion);
CompletableFuture<Void> delete(String path,
Optional<Long> expectedVersion);
}
讲到这里,你应该会发现,不同的消息队列(RabbitMQ、RocketMQ、Kafka、Pulsar)在元数据存储、节点发现的具体实现都是不一样的。不过从原理上来看,你应该也会觉得这 4 个消息队列在集群构建模块上都很相似。更多细节,你可以回顾第15讲和第16讲。
接下来我们来看看Pulsar数据的可靠性。
数据可靠性
我们知道,Pulsar 是计算存储分离的架构,数据是通过 Ledger 和 Entry 的形式写入BookKeeper的。所以跟其他消息队列不一样的是,Pulsar 的 Topic 没有副本概念,消息数据的可靠性是通过 Ledger 多副本来实现的。
我们在第17讲讲过,Pulsar 通过在 Broker 中设置 Qw 和 Qa 来设置 Ledger 的总副本数和写入成功的副本数。所以从一致性来看,Pulsar 既可以是强一致,也可以是最终一致。
接下来我们来看一张图,你应该在第13讲中看到过。
如上图所示,每条消息是一个 Entry ,一批 Entry 组成一个 Ledger ,一批 Ledger 组成一个分区。 所以当数据不断写入分区时,Broker 会根据条件来不停地创建分区维度的 Ledger。这个条件通常是 Ledger 的固定长度,另外当 Ledger 写入流断开时,也会创建新的 Ledger。
所以,在 Ledger 创建时就会根据设置的 Qw 数量,在 多个 Bookie 中创建 Ledger。这个过程就需要控制Ledger 分布在哪些 BookKeeper 节点,怎么实现的呢?
BookKeeper 可以通过配置机架感知(RackawareEnsemblePlacementPolicy)、区域感知(RegionAwareEnsemblePlacementPolicy)、可用区感知(ZoneawareEnsemblePlacementPolicy)3 种集成放置策略,来控制 Ledger 在 BookKeeper 多节点中的分布,从而实现多副本数据的高可靠和跨机架、跨可用区、跨区域容灾。
当一个 Bookie 节点挂了后,BookKeeper 会自动检测到该节点的失效,并将该节点上的Ledger 副本切换到其他节点上。具体来说,BookKeeper 会使用 Quorum 机制来进行副本切换,确保新的副本和原有的副本具有相同的数据内容和顺序。在副本切换过程中,BookKeeper会使用一些机制来保证数据的一致性和完整性,例如写前确认、写后确认等等。
接下来我们来看一下 Pulsar 在安全控制方面的实现。
安全控制
Pulsar 提供了传输加密、身份认证、资源鉴权、端到端加密四种手段。
传输加密
默认情况下,Pulsar 客户端是通过明文方式与 Broker 通信的,也不需要经过身份认证和授权。
为了保证数据在传输过程中的安全,Pulsar 支持通过 TLS 对数据进行加密传输。从使用角度,需要先申请或者创建证书,然后在 Broker 中配置启用 TLS,再在客户端配置证书信息来完成访问。
从代码实现的角度,Pulsar 是使用 netty-tcnative 库在 Broker 中实现支持 TLS 的。在部署层面,Pulsar 支持在 Pulsar Broker 和 Pulsar Proxy 组件开启TLS。即如果要支持 TLS 传输,既可以通过配置 Proxy 来支持,也可以通过 Broker 来支持。Pulsar Proxy 是 Pulsar 内核自带的一个代理模块,可以理解是一个负载均衡。
端到端加密
除了支持 TLS 传输加密,Pulsar 还支持数据端到端加密。即在生产者端加密消息,然后在消费者端解密消息,从而保证数据在 Broker 保存的是经过加密后的数据,这能有效避免存储在 Broker 中的数据被泄露。
从实现的角度,Pulsar 会使用动态生成的对称会话密钥来加密数据。来看下图,这是 Pulsar 在生产者端加密消息,然后在消费者端解密消息的流程图。

如上图所示:
- 生产者会定期(每 4 小时或在发布一定数量的消息后)生成一个会话密钥,然后使用对称算法(例如 AES)对消息进行加密,并每 4 小时获取一次非对称公钥。
- 生产者使用消费者提供的公钥,然后使用非对称算法(例如 RSA)加密会话密钥,并在消息头中携带加密后的会话秘钥信息。
- 消费者读取消息头,并使用其私钥解密会话密钥。
- 消费者使用解密的会话密钥来解密消息。
端到端加密在一些对数据安全要求较高的场景中用得很多,比如金融、快递等等。其他消息队列很少有支持端到端加密功能的,Pulsar 的这项功能极大地降低了用户的使用成本。
身份认证
Pulsar 当前支持 mTLS、JSON Web Token 令牌、Athenz、Kerberos、OAuth 2.0、OpenID Connect、HTTP 基本身份验证等7种认证方式。
从代码实现的角度,都是标准的 Java Server 的集成实现,即Java Server + mTLS、Java Server + Athenz等等。
为了更好地支持多种身份认证方式,Pulsar 在内核提供了一个可插拔的身份认证框架。即可以通过实现接口,自定义实现身份认证机制。自定义实现插件分为客户端和服务端两部分。
- 自定义实现客户端身份验证插件org.apache.pulsar.client.api.AuthenticationDataProvider 为Broker/Proxy 提供身份验证数据。
- 自定义实现 Broker/Proxy 身份验证插件org.apache.pulsar.broker.authentication.AuthenticationProvider 用来对客户端的身份验证数据进行身份验证。
同时 Pulsar 也支持链式的身份认证,即支持同时配置多种身份认证方式。比如你希望将集群的认证方式从 JWT 升级为 OAuth2.0 ,此时可以同时配置两种认证方式,如下所示:
authenticationProviders=org.apache.pulsar.broker.authentication.AuthenticationProviderToken,org.apache.pulsar.broker.authentication.AuthenticationProviderOAuth2
在上面的配置中,Broker 收到请求后会先进行 JWT 认证。如果无法通过 JWT 认证,则使用 OAuth2.0 认证。这点和 RabbitMQ 鉴权的实现思路是一样的。
资源鉴权
同样的,Pulsar 也提供了插件化的鉴权机制。默认情况下,如果不配置鉴权,认证通过后就可以访问集群中的所有资源。
Broker 当前提供了 AuthorizationProvider 和 MultiRolesTokenAuthorizationProvider 两种鉴权实现,其中 MultiRolesTokenAuthorizationProvider 只支持配合 JWT 认证使用。可以在 Broker 配置文件中配置启用哪种鉴权插件。
authorizationProvider=org.apache.pulsar.broker.authorization.AuthenticationProviderToken
或
authorizationProvider=org.apache.pulsar.broker.authorization.MultiRolesTokenAuthorizationProvider
和其他消息队列直接通过用户名或者客户端信息来完成鉴权不一样的是,Pulsar 是通过 Role Token(角色令牌)来完成鉴权的。Role Token本质就是一个字符串,是一个逻辑的概念,用来在后续授权中标识客户端身份用的。
从实现上看,认证组件完成认证后会将客户端和角色(Role)关联,即客户端不管使用的是 Auth2.0、JWT 或 Kerberos 认证方式,当通过认证后都会关联一个Role。然后再根据这个 Role 携带的权限信息来进行鉴权。
Pulsar 的 Role 分为超级用户和普通用户。超级用户有集群的所有权限,如创建、删除租户,并且对所有租户具有访问权限,超级用户需要在Broker的配置文件中进行配置。
另外 Tenant(租户)有 Tenant Admin(租户管理员)概念。在创建租户时,可以指定租户的Admin Role,这个 Role 拥有这个 Tenant 的全部权限。
Pulsar 支持对 Broker、Tenant、Namespace、Topics 四个维度鉴权。其中 Broker、Tenant 主要是管控级别的操作,比如创建、删除资源等。Namespace 和 Topic 级别的主要是生产和消费相关的权限管控,其中 Namespace 还有 Function 相关的权限控制。
接下来,我们从指标和消息轨迹两个方面讲一下 Pulsar 的可观测性。
可观测性
Pulsar 定位云原生消息队列,所以它的指标模块主要围绕 Prometheus 和 Grafana 体系来搭建的。
在指标定义记录方面,Pulsar 使用 Prometheus 指标库来完成指标记录。从代码上看,是通过引入 Java 的 io.prometheus 库来实现的,具体实现可以参考官方文档。在记录指标时,支持Counter、Gauge、Histogram、Summary 四种指标类型,用来完成瞬时值、统计值、分布值的统计。
Pulsar 的架构相对复杂,组件较多,Pulsar 为所有组件都提供了丰富的指标。主要包含了Broker、BookKeeper、ZooKeeper、Proxy、Function、IO 等等,详细的指标请你参考 Pulsar 指标。
在指标暴露方面,Pulsar 通过在组件上支持 HTTP 接口 /metrics 来支持Prometheus的采集。接口的数据格式是标准 Prometheus 格式,直接配置Prometheus采集 + Grafana展示或告警即可,使用成本较低。跟RocketMQ的支持Prometheus方案是一样的。
Pulsar的指标模块采用的是当前业界最常用的方案。如果你在自定义的组件中需要实现指标,建议可以直接参考。
当前社区版本的 Pulsar 是不支持消息轨迹的,但是一些商业化的版本是支持的。从技术实现的角度来看,和之前讲过的其他消息队列实现思路一样,这里不再赘述。
总结
其实 Pulsar 的总结是最不好写的,因为Pulsar社区发展非常快,可能没几天内容就会过期、失效或总结错误。所以如果需要了解最新的信息,建议你去看源码或官方的最新文档。
但是万变不离其宗,当我们掌握了原理,无论如何变化,对我们来讲都不过是变化而已。
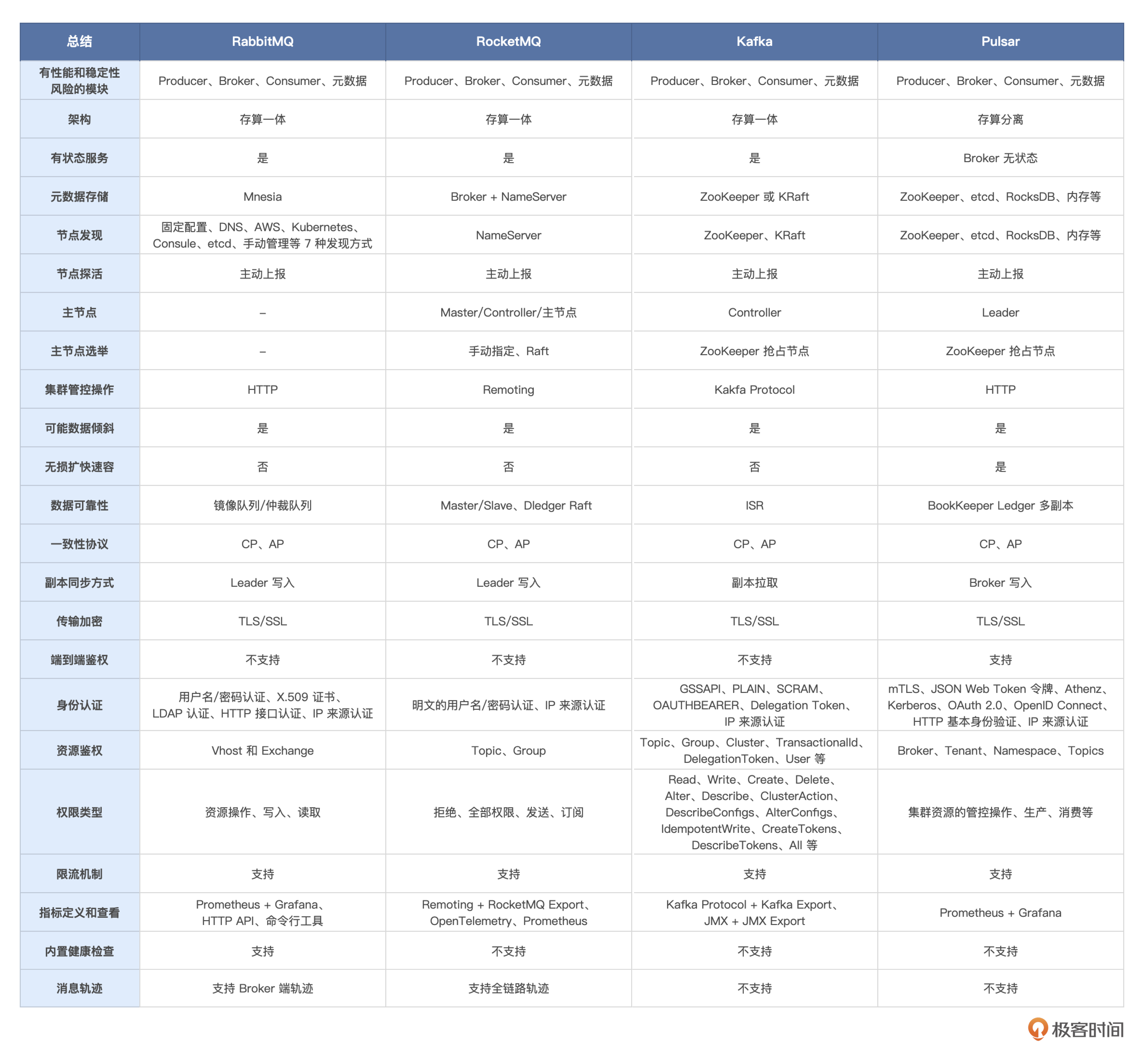
接下来我们用一张表格,针对进阶篇的所有知识点,从四个主流消息队列的角度来做一个原理概览性的总结。建议收藏!
思考题
为什么在去ZooKeeper的路上选择了可插拔的元数据存储框架,而不是去掉第三方存储引擎?
欢迎分享你的思考,如果觉得有收获,也欢迎你把这节课分享给身边的朋友。我们下节课再见!
上节课思考闭环
为保证副本一致性,在 Leader 收到数据主动分发给副本的实现中,当某个节点出问题时,如何设计退避方案,以避免出现一些频繁的无效的调用?
一般来讲,在Leader主动分发的场景中,当Leader收到数据后,会同时给多个副本分发数据,以提高分发性能。
此时在Leader端,为了避免异常副本的影响,一般会提供请求降级机制。即如果某个副本有性能问题或者宕机,Leader 连续分发数据就会超时或者失败。Leader 就可以根据一定的策略记录失败信息,比如连续3次失败则进行降级,在接下来的30s不给这个副本分发数据。以此类推进行降级,直至剔除这个副本。
同时也需要对副本进行定时探测,以保证副本恢复后,可以再给副本分发数据。
- Johar 👍(0) 💬(0)
为什么在去 ZooKeeper 的路上选择了可插拔的元数据存储框架,而不是去掉第三方存储引擎? 1.优秀分布式存储实现不易,需要技术积累,和成本 2.目前技术日新月异,每个中间件都自己的优点缺点,
2023-08-19