23 从集群角度拆解RabbitMQ的架构设计与实现
你好,我是文强。
到了这节课,我们就讲完了进阶篇所有的知识点了。在进阶篇,我们首先分析了消息队列集群中哪些地方可能存在性能瓶颈和可靠性风险,然后依次讲解了集群构建、数据一致性、数据安全、集群可观测性四大模块的设计和选型思路。同时也分享了一些Java在开发存储系统过程中的编码技巧。
接下来,我们围绕着进阶篇的内容,用四节课分别讲一下消息方向的RabbitMQ 、RocketMQ 以及流方向的Kafka、Pulsar 在这几个方面的实现。另外,你也可以先复习下第10~13讲,有助于你更好、更完整地理解内容。
那么这节课我们就先来讲一下RabbitMQ,从集群构建的设计思路开始。
集群构建
我们前面讲过,集群构建由节点发现和元数据存储两部分组成。RabbitMQ 也是一样的实现思路。
在节点发现方面,RabbitMQ 通过插件化的方式支持了多种发现方式,用来满足不同场景下的集群构建需求。如下图所示,主要分为固定配置发现、类广播机制发现、第三方组件发现、手动管理等4种类型,以及固定配置、DNS、AWS(EC2)、Kubernetes、Consule、etcd、手动管理等7种发现方式。
- 固定配置发现:是指通过在RabbitMQ的配置文件中配置集群中所有节点的信息,从而发现集群所有节点的方式。和ZooKeeper的节点发现机制是一个思路。
- 类广播机制发现:是指通过DNS本身的机制解析出所有可用IP列表,从而发现集群中的所有节点。和 Elasticsearch 通过多播来动态发现集群节点是类似的思路。
- 第三方组件发现:是指通过多种第三方组件发现集群中的所有节点信息,比如 AWS(EC2)、Kubernetes、Consul、etcd 等。和Kafka、Pulsar依赖ZooKeeper,RocketMQ依赖NameServer是一个思路。
- 手动管理:是RabbitMQ比较特殊的实现方式,是指通过命令 rabbitmqctlctl 工具往集群中手动添加或移除节点。即依赖人工来管理集群,这种方式使用起来不太方便,其他消息队列很少采用这个方案。
再来看一下元数据存储,我们之前说到过,RabbitMQ的元数据是通过内置数据库Mnesia来存储的。这里需要重点注意的是,Mnesia 是一个分布式的数据库,可以简单理解为它是Erlang语言自带的内置的分布式数据库(详细参考Mnesia Wiki)。这点非常重要,因为Mnesia已经是分布式存储了,所以在进程启动就具备了元数据存储能力。
RabbitMQ 基于Erlang开发的一个好处就是,相当于天生自带了一个Kafka KRaft构建的元数据存储服务。基于这个前提,再去思考整个集群的构建过程,就会比较容易理解RabbitMQ的集群构建思路。
接下来,我们来看看 RabbitMQ 集群维度的数据可靠性。
数据可靠性
RabbitMQ 集群维度数据可靠性的核心是副本和数据一致性协议。在之前的课程中,我们知道RabbitMQ没有Topic,只有Queue的概念。所以是通过在 Queue 维度创建副本来实现数据的高可靠。
比较特殊的是,RabbitMQ 在创建 Queue 时没有副本概念,即创建出来的Queue都是单副本的。如果要支持多副本,在 3.8.0 之前需要通过配置镜像队列来实现,在 3.8.0 后可以使用Quorum Queue(仲裁队列)来实现。
所以从集群维度看,RabbitMQ 的数据可靠性是由镜像队列和仲裁队列来保证的。因为在RabbitMQ 3.8.0之前,这是数据可靠的唯一手段。
镜像队列
在RabbitMQ中,镜像队列是一个独立的功能。它通过为Queue创建副本、完成主从副本之间数据同步、维护主从副本之间数据的一致性等3个手段来保证数据的可靠性。
队列的副本数量是通过All、Exactly、Nodes 3 种策略来设置的。
- All 是指集群中所有节点上都要有这个Queue的副本。
- Exactly 是指Queue的副本分布在几个节点上,可以理解成Queue的副本数。
- Nodes 是指这个Queue的副本具体分布在哪几个节点上。
通过指定这三个策略,用户可以控制副本数量和副本的分布。在其他队列的实现中,一般会在创建队列时指定副本数,然后内核根据当前的分区和副本信息,以节点之间的负载均衡为目标,自动算出副本的分布,然后创建副本。而 RabbitMQ 把这个过程,通过策略的形式让用户来选择,更加灵活的同时,用户的使用成本也会更高。
RabbitMQ 的镜像队列是通过内核中的GM模块将数据分发到从副本,从而完成主从副本之间的数据同步。GM模块能保证组播数据的原子性,即保证数据要么能发送到所有模块上,要么不能。
副本间数据一致性策略,使用的是强一致的策略。从性能上来看,这个强一致的策略也是影响性能的一个重要原因。
总结来说,镜像队列在实现上有同步和性能上的缺陷,主要体现在以下三点:
- 强一致的同步策略很影响性能,导致集群的性能不高。
- 当节点挂掉后,节点上的队列数据数据都会被清空,需要重新从其他节点同步数据。
- 队列同步数据时会阻塞整个队列,导致队列不可用。如果数据量很大,同步时间长会导致队列长时间不可用。
所以,3.8.0以后,RabbitMQ 用仲裁队列替代了镜像队列来解决这些问题。
仲裁队列
从实现的角度看,仲裁队列是基于 Raft 算法来设计的,依赖 Raft 共识协议来确保数据的一致性和可靠性。
如上图所示,仲裁队列是主从模型,至少得有三个副本。通过主副本和多个从副本之间的数据同步,来实现数据的高可靠。队列会选举出主副本来实现数据的读写,当主副本不可用,会根据算法从副本中选举出新的主副本。
和镜像队列不同的是:当副本挂掉重新启动时,只需要从主节点同步增量数据,并且不会影响主副本的可用性,从而避免了镜像队列的缺点。
在数据一致性方面,仲裁队列通过 Raft 协议来完成副本间的数据同步和一致性。
使用的是多数原则,即多数副本写入成功后,就算数据写入成功。因为一个集群需要超过一半的节点可以工作,所以一个集群至少需要3个节点。当有3~4个节点时,只能允许一个节点损坏;当有5个节点时,允许两个节点损坏,以此类推。对于大于5个节点的仲裁队列,性能会下降很多,原因就是需要超过3个节点拿到数据才算写入成功。
整体来看,RabbitMQ的仲裁队列和ZooKeeper的Zab协议、Pulsar的一致性协议是一样的,通过遵循多数原则来保证一致性。更多的仲裁队列细节,有兴趣的话,你可以参考官方文档 quorum-queues。
接下来,我们来看看RabbitMQ的安全机制。
安全控制
在安全篇我们讲到,消息队列的安全的核心分为传输加密、认证、鉴权 3 个方面。我们也从这 3 个方面来分析一下RabbitMQ。
传输加密
在传输加密方面,RabbitMQ 内置了对TLS的支持,通过TLS来实现数据的加密传输。
从内核实现的角度来看,内核对TLS的支持是根据TLS的官方标准实现的。TLS 是通用的加密通信标准,消息队列对于TLS来说只是一个使用者。代码实现的方式对于所有消息队列或者所有组件都是一样的,内核直接通过官网标准文档集成这部分能力即可。比如Java写的服务端需要支持TLS,可以参考 Implementing TLS in Java。
从使用的角度来看,需要先创建证书,然后在服务端配置 TLS 相关信息来启用传输加密。客户需要配置公钥等信息来和服务端创建加密的连接。
在RabbitMQ中支持TLS,如下图所示,主要有以下两种形式:
- 直接配置RabbitMQ支持TLS。
- 在代理或者负载均衡(如HAProxy)上配置支持TLS。
从安全的角度来看,两种选择并没有太明显的优劣势。在RabbitMQ Broker中,当启动TLS后,服务端需要指定一个新的端口来支持TLS。即支持TLS和不支持TLS的服务端口是不一样的。
身份认证
当客户端连接到RabbitMQ Broker时,必须先进行身份认证,才能进行后续的操作。
当前版本的RabbitMQ主要支持用户名/密码认证和X.509证书两种认证形式。同时通过插件化机制,支持了LDAP认证、HTTP 接口认证、IP来源认证等认证方式。
从具体实现的角度,RabbitMQ 基于SASL认证框架,实现支持了 PLAIN、AMQPPLAIN、EXTERNAL 三种机制。
- PLAIN 和 AMQPPLAIN 就是用户名/密码这种明文形式的认证。
- EXTERNAL 是指插件化支持多种认证形式,比如LADP、X.509、IP范围认证就是以这种方式实现的。如果你想了解这些认证方式的使用方式,可以参考官方文档 RabbitMQ 权限控制。
在认证配置上,RabbitMQ 支持链式认证。即同时支持多种认证方式,比如在某些高安全要求的场景,需要完成多重身份认证才算认证成功,就可以用到链式认证。
如上图所示,需要同时完成IP来源认证、LDAP认证、用户名密码认证三重认证才算认证通过。这种链式的认证方式的好处是,可以满足多种场景,一般主流消息队列同时只能支持其中的一种认证方式,所以在认证配置的实现上,RabbitMQ做得蛮好的。
接下来,我们来看看资源鉴权。
资源鉴权
RabbitMQ的鉴权分为管理页面和数据流两个方面。
管理页面指启用Management 插件后的 Manager 页面。这个页面可以执行查看监控、创建资源、删除资源等操作,权限很大。所以为了保证集群的安全,需要对这个页面的访问进行权限控制。管理页面的UI如下所示:
Manager 页面权限控制的方式是,在创建用户时通过指定不同用户的访问角色类型,从而控制不同用户在管理页面上的操作权限。Manager 页面支持 management、policymaker、monitoring、administrator 四种角色类型,分别表示不同的权限粒度,算是一个比较常规的管控页面的权限控制实现方式。
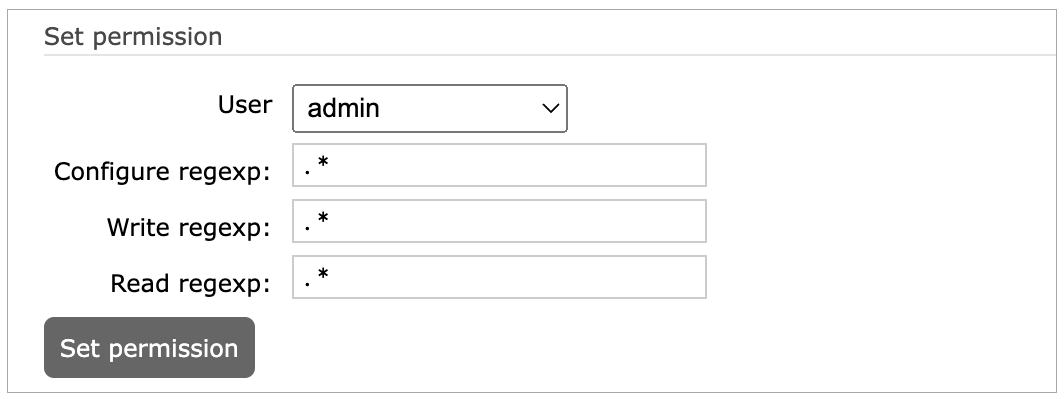
数据流的权限控制,主要包括资源操作(如创建、创建等)、写入、读取三种类型,分别对应Configure、Write、Read 三种权限。主要支持对 Vhost 和 Exchange 两种资源进行鉴权。资源配置页面如下所示:
接下来,我们来看看RabbitMQ的可观测性。
可观测性
RabbitMQ 的可观测性主要由监控、健康检查、日志和消息轨迹四个部分组成,先来看看监控指标。
整体来看,RabbitMQ 的监控指标非常丰富且立体,如下图所示,主要可以分为集群、节点、队列、应用程序四个维度。
- 集群维度:主要包含集群的监控指标,比如Exchange数、Queue数、Channel数、生产者数、消费者数等等。
- 应用程序维度:主要包含进程级的监控信息,比如Socket 连接打开率、Channel打开率等等。
- 队列维度:主要包含队列的监控指标,比如队列上的消息总数、未确认的消息总数等等。
- 节点维度:主要包含节点的信息,比如硬件层面的CPU、内存、硬盘,操作系统层面的Socket连接数、文件描述符数量,Erlang虚拟机层面的Erlang线程数、GC情况等等。
从现网运营经验来看,只要熟悉了这些指标的含义,基本就可以解决现网各种常见故障。如果你想了解完整的指标信息,可以参考 RabbitMQ Metrics。
在指标暴露方面,RabbitMQ提供了Prometheus + Grafana、HTTP API、命令行工具等多种方式。默认情况下,官方推荐使用Prometheus + Grafana的方式,所以在现网的使用中,大部分也是使用Prometheus + Grafana来完成监控指标的采集。
在某些和内部监控系统或者运营系统集成的场景中,通过HTTP API获取监控指标也是常用的方式。在现网排查问题时,直接使用命令行工具rabbitmq-diagnostics或rabbitmq-top来查看负载,也是非常常用的。下图就是通过rabbitmq-top命令行来查看进程监控的结果,非常齐全。

同时,RabbitMQ 因为其历史悠久、应用广泛,很多商业化或者开源的监控组件都天然支持和它集成,比如Zabbix、DataDog、AWS CloudWatch等。所以,从指标的暴露方式来看,RabbitMQ做得非常好、非常完整,能满足各个环境下的部署和监控运维需求。
值得一提的是,RabbitMQ 内核自带了健康检查机制。即支持通过命令行工具(rabbitmq-diagnostics)或HTTP API的方式对集群发起健康检查。检查集群的创建Exchange、创建Queue、生产消费消息全流程是否正常。
这个拨测机制是非常有用的,因为在现网集群运行中,监控指标只是二级信息,不能直接表达出集群是否有异常。有可能监控指标异常,但集群运行正常,相反集群运行异常,监控指标可能正常。所以,通过模仿客户端的实际行为,比如先创建资源、生产数据、消费数据的全流程,可以更加精准地发现集群是否有问题。在具体使用上,如果想了解更多的健康检查信息,你还可以看 RabbitMQ Health Chcek。
RabbitMQ 的日志模块跟其他组件的日志模块差不多,它支持多种类型、多种级别的日志记录。也支持将不同类型的日志打印到不同的文件,比如Connection、Channel、Upgrade、Queue等等。同时也支持按时间、大小保留滚动文件。如果需要了解更多日志配置的细节,你可以参考 RabbitMQ Logging。
RabbitMQ 对消息轨迹的支持,我们在第22讲已经讲过,这里就不展开说了,可以去回顾下。
总结
在集群构建方面,RabbitMQ 通过Erlang自带的分布式数据库Mnesia来实现元数据信息的存储。通过插件的形式支持多种节点发现机制,主要包括固定配置发现、类广播机制发现、第三方组件发现、手动管理四种类型。
集群构建完成后,RabbitMQ 通过副本机制、镜像队列或仲裁队列来实现数据的一致性和可靠存储。镜像队列因为本身的一些架构缺陷,会逐步被仲裁队列替换。仲裁队列是基于Raft 算法来实现的,写入的可靠性遵循多数原则,即只要多数节点写入成功就可以。
在安全管控方面,RabbitMQ 通过传输加密、身份认证、资源鉴权三个维度来保证数据安全。传输加密主要支持TLS,同时支持多种身份认证机制,比如用户名/密码、LDAP等。资源鉴权支持对Vhost、Exchange两种资源进行鉴权,权限分为配置、写入、读取三种。
在可观测方面,RabbitMQ内核提供了丰富的多维度的监控指标,并提供了多种指标采集方式。官方推荐Prometheus + Grafana 来实现集群监控。RabbitMQ在内核支持了健康检查机制,健康检查是及时发现集群问题的一个非常好用的方法。
RabbitMQ 原生不支持消息轨迹的功能,但是我们可以基于 Firehose 插件来扩展支持消息轨迹的功能。
思考题
为什么 RabbitMQ 支持多种节点发现机制,其他的消息队列却不支持?为什么 RabbitMQ 支持手动通过命令行来完成节点发现?
欢迎分享你的思考,如果觉得有收获,也欢迎你把这节课分享给身边的朋友。我们下节课再见!
上节课思考闭环
在RabbitMQ的消息轨迹方案设计中,如果调整1和5的条件,数据量变为非常大,而成本需要尽量控制,你会如何设计方案呢?
1. 首先,我会先拉起讨论,看消息查询的功能是否可以简化,比如是否可以简化为只根据消息ID查询。根据消息ID查询有一个前提,因为RabbitMQ的消息ID不是必传的,如果要根据消息ID查询,就需要在客户端封装的时候,默认生成一个唯一ID。
2. 如果不能改变查询条件的话,存储引擎的选择基本只能用ES了。如果可以只根据ID查询,在存储引擎的选择上就可以有很多选择,比如MongoDB、HBase。
3. 接下来就需要尽量精简轨迹内容,极端情况下,只保留消息ID、类型(Produce、Consume)、记录时间三个字段,就可以满足排障功能了。
4. 如果需要进一步压缩成本,可以把轨迹存在本地硬盘,利用本来空闲的空间,使用grep实现查询检索的功能。
- 小手冰凉*^O^* 👍(0) 💬(0)
RabbitMQ 没有 Topic,只有 Queue 的概念?这个怎么理解呢。RabbitMQ不是有六种工作模式,其中一种不就是Topic模式吗?
2024-05-20