20 安全:如何设计高吞吐和大流量分布式集群的限流方案?
你好,我是文强。
上节课讲了网络隔离、传输加密、认证、鉴权,今天我们继续讲消息队列系统安全的第二部分:数据自我保护和服务自我保护。
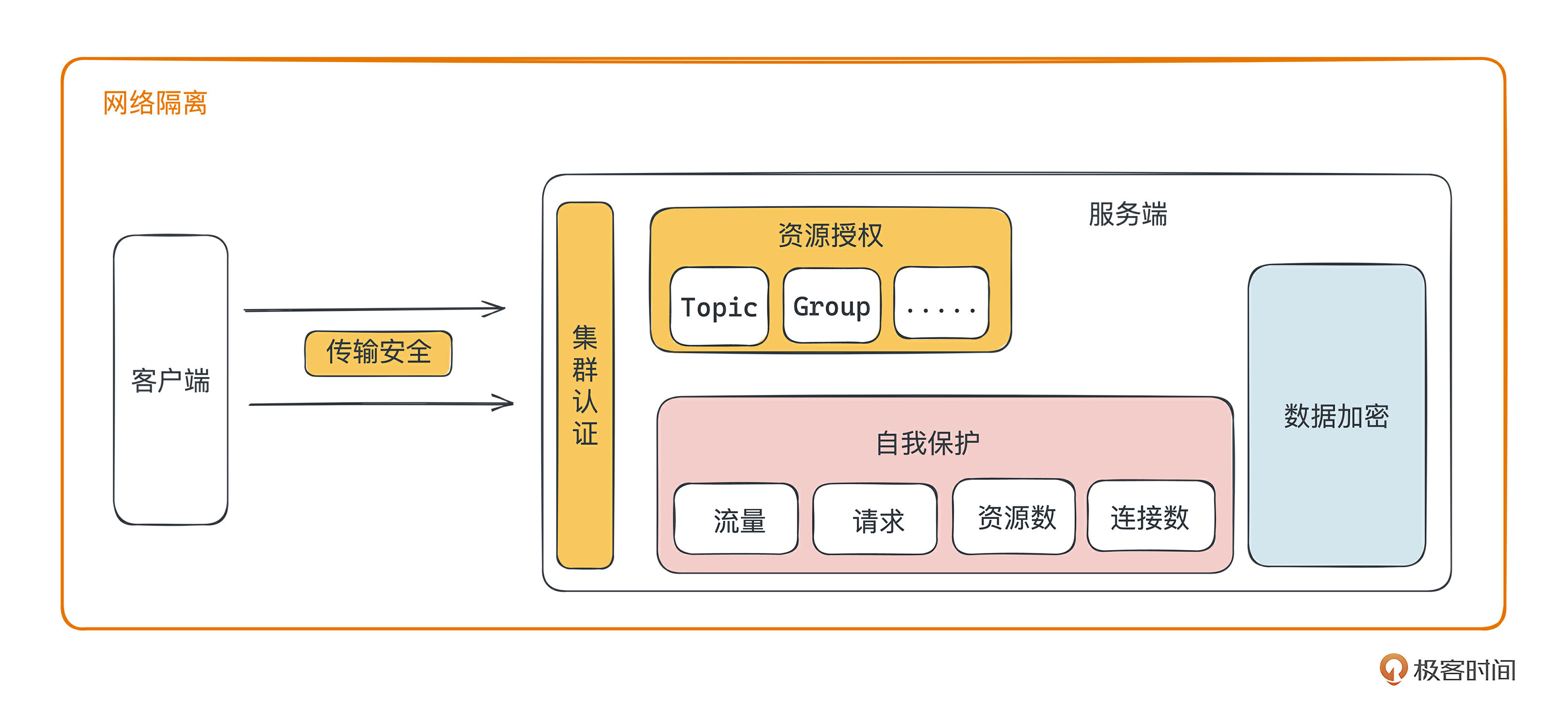
数据维度的自我保护主要指如何保证服务端数据的安全,不被窃取。服务维度的自我保护主要指集群的限流机制,通过限制客户端的流量、请求、连接等保护自身不被击垮。
我们先来看一下如何保证存储的数据不会被第三方窃取。
集群中的数据加密
如果你从事金融或证券领域,因为企业的数据比较重要,应该经常会问:发送到消息队列中的数据能不能加密后再存储?
这个问题希望达到的效果是:当客户端发送消息A(比如 hello world)到Broker,Broker保存到磁盘的数据是一串内容A加密后的字符串,当消费端消费数据时,Broker 将加密后的字符串解密成消息A返回给消费端。
在业务看来,数据加密配合传输加密、认证、鉴权等机制,在数据的安全性上是非常强的。
要实现这个效果一般有以下两种方案:
- 第一种就是上面说的,由服务端自动化做好加密解密。工作量全在服务端,客户端没有任何工作量。
- 第二种是客户端在生产的时候自助做好加密逻辑,在消费的时候自助做好解密操作。好处在于消息队列服务端没有任何工作量,坏处在于工作量全部在客户端,所有的客户端和消费端都需要感知加密的逻辑,在编码和协调各方的成本方面较高。
不过目前业界主流开源消息产品都是不支持消息加密的,我们无法用第一个方案,但一些闭源的商业化消息队列产品具备这个能力。在我看来,这是一个刚需能力,特别在银行、证券行业的服务部署到公有云的场景中。所以,我一般推荐你用第二种方案。
不过还是可以拓展说说,如果需要第一种方案,技术上要怎么实现呢?主要分为三步。
- 首先,把接收到的数据解析为生产端发送出来的原始消息格式。需要解析是因为客户端可能设置了批量发送、压缩等行为,导致服务端收到的格式和原始的消息不一致。
- 其次,对这些消息进行加密,并存储到磁盘。
- 最后,在客户端消费数据时,把加密的消息解密成为原始接收到的消息格式返回给客户端。
这里最需要关注的是第二步,加密算法的选择,核心依据是:可以解密获得原始数据、加解密速度快、安全性高。
加密算法分为可逆加密和不可逆加密。可逆加密意思就是经过加密后的数据,能够经过解密步骤还原出原始数据,主要算法有DES、AES等。不可逆加密就是指加密后的消息无法还原出原始数据,主要算法有MD5、SHS等。从需求来看,我们肯定需要选择可逆加密类的算法。
不过,可逆加密又分为对称加密和不对称加密。如何选择呢?
它们俩最大的区别在于加解密的速度和安全性。对称加密的优点是解密速度快,但保密性差,主要算法有DES、3DES、AES等。非对称加密的优点是加密算法保密性好,但是加解密速度要远远低于对称加密,主要算法有RSA、DSA、ECC等。
因为消息队列需要较高的性能,并且数据的加解密都是在服务端内核完成的,安全性较高。所以我们一般选择对称加密算法,比如 AES。
加解密的过程会消耗很多CPU资源,对程序的性能和吞吐影响较大。所以一般情况下,服务端需要配备一些加密算法硬件加速设备,以提高加解密的速度。比如英特尔的AES-NI,它是商品硬件中最常见的加密加速器。
好,到这里我们已经完成了集群数据维度的自我保护,那么如何保护好集群的服务不会因为外力原因而崩溃呢?在服务自我保护维度,主要包含两个方面:服务限流、服务降级。
消息队列限流机制思考
限流可以说是每个系统的标配,业界在限流方面的理论结构和开源组件也都非常丰富。限流主要包含两个部分,限流算法和实现机制。我们先了解一下不同机制的具体实现和优缺点,最后会针对具体案例,实战设计限流方案。
目前有四种常见的限流算法。
在业务系统中,这四种算法都比较常用。因为消息队列经常需要应对突发流量,需要尽量平滑的限流机制,所以从实现上来看会比较推荐令牌桶算法。
限流的实现机制主要分为两种:单机限流和全局限流。
单机限流就好理解了,限流配额发送到单机维度,在内存中完成计数、比对、限流决策。它的优点是在单机内存内完成限流逻辑的闭环,几乎不影响主流程的耗时。缺点是集群部署时,无法在多台节点之间共享集群信息,从而导致无法进行集群维度的限流。
全局限流,一般基于第三方的集中式服务来实现分布式的多机限流。在集中式服务中完成配额的记录、限流判断等行为,各个服务节点,通过对中心服务的上报和访问完成限流。在第三方组件的选择上,主要有Redis、Sentinel、ASAS、PolarisMesh等。优缺点跟单机限流刚好相反,能在多节点之间完成限流信息的共享,但是在限流操作上的耗时较高。
全局限流还是单机限流?
消息队列的核心产品特性是高吞吐、低延时。所以消息队列对限流方案的最核心的诉求就是,限流操作不能对性能产生影响。基于这个诉求,我们来讨论一下是全局限流还是单机限流。
如果为了满足高吞吐和低延时,肯定要限流操作不对性能产生影响,就只能用单机限流。但是,消息队列一般是分布式多机组成的集群形态部署的,为了多台节点共享限流数据,在集群维度实现限流,就只能用全局的限流方案。
这两种方案是从机制上是互斥的,如何选择呢?
当前主流消息队列产品,主要选择还是单机限流机制,比如Kafka、Pulsar。思路是:放弃集群维度的精准限流,将集群总的配额根据节点数据量均分到每个节点,在每个节点内部完成单机限流。
这种方案的好处就是限流的逻辑对耗时无影响,另外主流程不会依赖第三方服务,不会因为第三方服务的稳定性问题导致主流程不可用。
缺点是当写入、读取出现倾斜时,会出现单机维度达到限流值,集群维度却没有达到限流值的问题。这个问题,我们可以通过不断地动态调节单机限流配额的方式,尽量提高限流精度,但是这也无法根本解决毛刺、限流不精准等问题。
而全局限流的耗时问题,我们通过架构层面上的优化,可以将每次限流操作耗时消耗控制在1~5ms之间。这个级别的耗时,大部分情况下客户是可以接受的。所以全局限流的最大问题是在主流程引入第三方服务而带来的稳定性风险,此时就会强依赖第三方服务的稳定性。
所以,限流方案的选择,我会建议优先使用全局限流的机制,支持临时开启关闭限流能力、支持限流策略降级结合的机制,让某些延时敏感的客户或者限流Server异常的时候,支持关闭限流或者降级为单机限流。
业界消息队列在限流方面的工作做得没有特别精细,比如Pulsar和Kafka都是基于单机限流策略实现的,RabbitMQ和RocketMQ主要是消费端的一些限流机制,服务端限流做的工作较少。从实现程度来看都不够完整,都有各自的侧重点和优缺点。
有了限流机制,我们就可以看看具体要对哪些资源和维度进行限流。
对哪些资源和维度进行限流
从消息队列的特性上来看,主要对流量、连接数、请求数三类资源进行限流,有些消息队列还会对CPU和内存进行限制。限制的维度一般包括:集群、节点、租户/ Namespace、Topic、Partition、Group/Subscribe 六个维度。
流量限制指对生产、消费的流量限制,是消息队列的核心限流指标。因为很多问题都是流量波动引起的,限制好集群的流量,很大程度上能保证集群的稳定。所以你会在各款消息队列里看到对流量的限制。一般会对集群、节点、租户/ Namespace、Topic、Group/Subscribe这几个维度配置。
连接数限制指对客户端连接到服务端的TCP连接数量进行限制。因为TCP连接的建立和关闭需要消耗CPU、内存等资源,限制是为了保护服务端不会因为连接数太多,耗尽资源,导致服务不可用。虽然现在技术上的网络编程有异步IO、多路复用等技术,但是连接太多还是会出现问题。所以RabbitMQ在连接的基础上设计了Channel信道,避免TCP连接频繁建立关闭、TCP连接数太多。
连接数主要从三个层面进行限制。
- 服务端单机可承载的最大连接数限制。
- 客户端单个IP可建立的连接数。
- 单个集群可建立的总链接数。
连接数的限制一般在集群、节点、租户/ Namespace三个维度配置。
请求数限制指对单个接口的访问频次进行限制,来保护集群自身的可用性。比如消息队列中的获取元数据(Lookup、寻址)接口,这个接口一般需要返回所有Topic、分区、节点的数据,需要做很多获取、组合、聚合的操作,很消耗CPU。在客户端很多的情况下,如果客户端同时更新元数据,很容易把服务端的CPU耗完,导致集群生产消费异常。请求限流就能起很好的保护作用。连接数的限制一般在集群、租户/ Namespace两个维度配置。
发生限流后怎么处理
当限流发生后,会发生什么事情呢?按正常的逻辑,限流发生后,肯定是拒绝请求或者流量了。但注意,在消息队列里,我们是需要分情况来考虑的。
因为消息队列本身的功能是削峰填谷,在有突发流量的时候,流量很容易超过配额。此时,机器层面一般是有能力处理流量的,如果直接拒绝流量,就会导致消息投递失败,客户端请求异常。所以,在限流后,我们一般有两种处理形式。
- 返回超额错误,拒绝请求或流量。
- 延时回包,通过加大单次请求的耗时,整体上降低集群的吞吐。因为正常状态下,客户端和服务端的连接数是稳定的,如果提升单次处理请求的耗时,集群整体流量就会相应下降。
Kafka的主要处理机制是延时回包。延时回包的优点是可以承载突发流量,当有突发流量时,不会对客户端造成严重影响,缺点是无法精准限制流量。比如Kafka在Ack=0的时候或者客户端不断新建连接打入流量的时候,客户端的流量会突破服务端的限制,极端情况下会打爆集群。此时就需要配合返回超额错误拒绝流量的策略,以达到保护集群的目的。
返回超额错误的实现很简单,收到流量后,根据当前使用的限流算法来判断是否超过限流配额,是的话,就返回报错。
延时回包的实现比较复杂,收到流量后,需要根据当前的延时回包算法,计算一个延时回包的时长,然后把回包信息放入到延时回包队列(延时回包队列的实现一般是使用时间轮的方案),等过了延时回包的时间,再给客户端回包。
延时回包的算法设计起来比较复杂,我们看一个例子,Kafka 的延时回包算法代码。
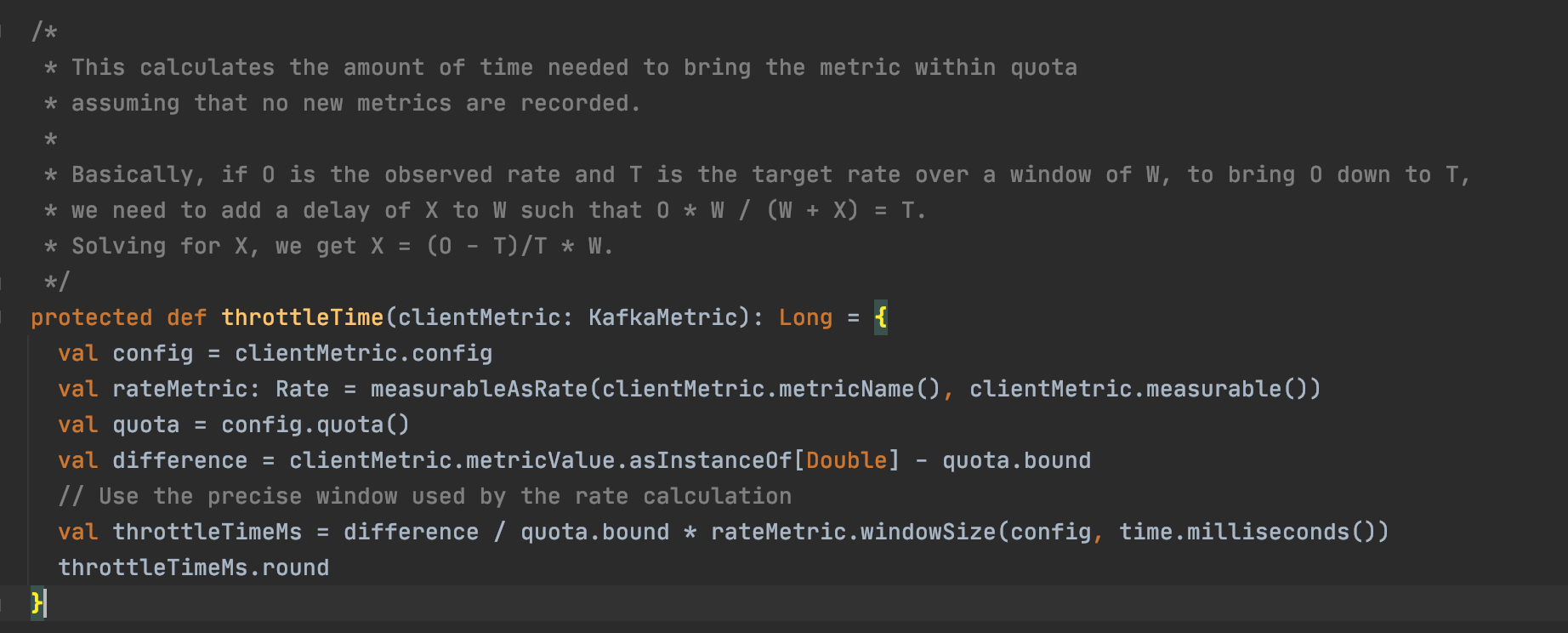
在算法的核心逻辑中,O是观测到的速率,T是W窗口内的目标速率,为了让O降到T,我们需要给W增加一个X的延迟,使得 O * W / (W + X) = T。求X,得到X = (O - T)/T * W。如果你自己实现延时回包,这个逻辑很值得参考。
消息队列全局限流设计
了解了各种机制的优缺点和具体实现思路,接下来我们来实操综合运用一下,如何为一个消息队列集群设计实现单机限流方案和全局限流方案。
单机限流方案
单机限流的方案思路比较简单,首先将集群总配额除以集群总的节点数,得到每个节点上可用的配额。在各个节点下发配额数据,然后在单机维度使用漏斗算法等算法,实现单机维度的限流。
具体实现分以下四步:
- 计算单节点的配额。
- 存储每个节点的配额信息,以免节点重启后配额信息丢失,比如Kafka和Pulsar都是存储在ZooKeeper上。
- 为每个节点下发变更配额信息,节点在重启的时候加载配额信息。
- 当生产消费的时候,在内存存储计算流量,并和配额数据进行比较,确认是否限流。
单机限流还有一个小优化,我们可以实时监控每台节点的限流情况,动态修改每台节点的配额。通过判断,给流量较高的节点分配较多的配额,给流量较少的节点分配较少的配额,从而在流量倾斜的时候,也能够做到较为精准的限流。
全局限流方案
从技术上看,全局限流方案思考的核心有三点。
- 对当前主流程不能影响或者影响极低。
- 限流的精度需要仔细权衡,需要考虑限流是否足够精准,是否会有倾斜。
- 需要设计好回退措施,即限流组件抖动时,不能影响主流程。
接下来我们来看看全局限流的方案思路,相对复杂,主要分为五步。
- 首先选择一个集中式的限流Server,你可以选择业界的全局限流的组件,比如Sentinel或PolarisMesh,也可以是消息队列内置实现的一个全局限流的组件,简单点也可以是MySQL或者Redis。
- 然后把组件中写入限流配额。
- 在生产和消费时,向限流Server记录配额信息,获取限流状态,判断是否进行限流。
- 同时根据单机限流的方案,在本地缓存一份均分的配额数据,当限流Server异常时,直接使用本地缓存的配额数据进行计算限流。
- 同时提供开关,在某些情况下可以关闭限流。
另外,在代码实现层面,我们还可以插件化地支持多种限流机制,通过配置可生效。从代码实现流程来看,如下图所示,具体实现可以分为五步。
- 往限流Server写入集群配额。
- 同时Broker会获取到均摊的配额信息,流程和单机限流方案一样。
- 生产消费的时候,会判断是否走本地限流逻辑,是的话,跟单机限流方案一样。
- 正常会走上报数据和获取限流状态的逻辑,进行限流判断。
- 同时支持开启关闭限流状态,Broker允许接收指令开启或关闭限流信息。
消息队列的服务降级
在实际的生产环境中,因为一些环境因素的影响,比如节点故障、机房故障或某些异常的攻击行为。可能导致一些限流策略无法生效,就会导致集群在一段时间内的负载很高或无法正常提供服务。此时我们需要进行服务降级,通过拒绝流量或者拒绝连接的方式,完成自我保护,以保证消息队列核心链路的功能正常使用。
消息队列中常见的降级策略一般有三种。
配置Broker的CPU或内存的使用率额度,当使用率到达配额时,通过拒绝生产或消费流量的形式来保证服务的部分正常。
通常会优先拒绝生产流量,因为大部分集群过载是生产流量过大引起的。此时禁止生产流量的写入,可以保证消费的正常,服务不至于崩溃,消费端可以及时消费掉积压的数据。RabbitMQ就内置了这个策略。
配置磁盘保护机制,可以保护消费不会有异常。当真实的磁盘使用率使用达到一定的程度时,就禁止流量写入。因为在消息队列中,磁盘较容易被打满,打满的话如果还允许写入服务程序就会有异常,从而影响消费。
判断异常自动重启Broker,通过自动判断服务的运行情况,决定是否重启Broker。比如当发现频繁发生Full GC的时候,就自动重启自身服务,以达到回收资源的目的。这种方式用得比较少,因为比较危险,可能会导致集群中的所有Broker频繁重启。一般需要依赖第三方组件的多维度判断,以降低误重启的风险。
总结
集群在运行过程中,需要保证存储的数据安全,不会被第三方窃取,也需要能够保护好自身的服务,不会因为外力的原因而崩溃。即使在服务异常的情况下,也尽量保证自身的服务部分可用。
数据保护的核心逻辑是通过加密保护数据。加密算法的选择需要兼顾安全性和加解密的速度。因为是在Broker内部完成加解密的,安全性较高,所以重点关注加解密的速度。我推荐对称加密算法,我们也可以通过专有的设备加快加解密的速度。
服务保护的核心是限流机制。限流方案的选择主要有全局限流和单机限流两种方案。我推荐的选择是复合方案,也就是在大部分场景下,启用全局限流方案,在全局限流不能正常工作时,启动单机限流方案。限流算法的选择上,建议使用令牌桶算法。
一些情况下,限流机制无法百分百保证服务的正常运行,我们还需要预备紧急状态下的降级机制。
思考题
全局限流Server选型的要点是什么?社区有哪些选择?
欢迎分享你的思考,如果觉得有收获,也欢迎你把这节课分享给感兴趣的朋友。我们下节课再见!
上节课思考闭环
从做一个Web后台管理系统的角度来看,传输加密、认证、鉴权分别对应系统中的什么呢?
传输加密对应的是Web页面的HTTPS访问。认证对应的是系统登录时的用户名和密码校验。鉴权对应的是后台系统中的权限分配,即A用户可以访问菜单1,B用户可以访问菜单2。
- Stark 👍(0) 💬(0)
如果是消息量超出了消费者的能力,那么消费者自己也要做限流,这种一般应该控制拉取的消息量即可,消费完再Pull。
2024-11-24 - 贝氏倭狐猴 👍(0) 💬(1)
老师您好,关于全局限流问个问题。如果均摊总限流数到各个broker,会导致发生限流时总流量低于总阈值,因为broker之间的流量可能是不均衡的。而且如果只是简单均摊的话,也不需要redis等中间存储介质了。
2023-08-05