13 从基础功能拆解Pulsar的架构设计与实现
你好,我是文强。
上节课我们分析了 Kafka 在协议、网络、存储、生产者、消费者这五个模块的设计实现。这节课我们用同样的思路来分析一下 Pulsar。
近几年,作为消息队列后起之秀的Pulsar,因为其存算分离、多租户、多协议、丰富的产品特性、支持百万Topic等特点,逐渐为大家所熟知。从定位来看,Pulsar 希望同时满足消息和流的场景。从技术上来看,它当前主要对标的是Kafka,解决 Kafka 在流场景中的一些技术缺陷,比如计算层弹性、超大分区支持等等。
接下来我们就围绕着基础篇的知识点来拆解一下 Pulsar。
Pulsar 系统架构
我们先来看一下Pulsar的架构图。
如上图所示,Pulsar的架构就复杂很多了,它和其他消息队列最大的区别在于 Pulsar 是基于计算存储分离的思想设计的架构,所以 Pulsar 整体架构要分为计算层和存储层两层。我们通常说的 Pulsar 是指计算层的 Broker 集群和存储层的 BookKeeper 集群两部分。
计算层包含 Producer、Broker、ZooKeeper、Consumer 四个组件,用来完成MQ相关的功能。存储层是独立的一个组件BookKeeper,是一个专门用来存储日志数据的开源项目,它由Bookies(Node)和ZooKeeper组成。
BookKeeper 本质上就是一个远程存储。比如Kafka的计算层是Broker,存储层是本地的硬盘空间,Broker收到数据后,通过本地文件的写入调用,如FileChannel,将数据写入到本地文件。Pulsar的计算层是Broker,存储层是远程的BookKeeper集群,Broker收到数据后,通过BookKeeper的客户端SDK将数据写入到BookKeeper集群中。
从部署上来看,计算层和存储层其实是独立的。先部署一套存储的BookKeeper集群,然后一套或多套Pulsar集群可以将数据写入到同一套BookKeeper集群中。
在Pulsar中,你还可以看到一套或者多套ZooKeeper。因为Pulsar 和 BookKeeper都是使用ZooKeeper来存储元数据的。在实际部署当中,为了节省资源的开销,通常Pulsar Broker集群和BookKeeper会共用一套ZooKeeper集群。
当你把 BookKeeper 当做一个存储来看,你会发现Pulsar计算层的架构和Kafka是一样的。Pulsar也有Topic、分区、订阅(消费分组)等概念,客户端也需要经过寻址操作发现Topic对应的Broker节点。Broker收到生产者的数据后,会将数据写入到BookKeeper存储。消费端会通过订阅(Subscription)来消费数据。
Pulsar会有一些自己的概念,比如Bundle、Bookie、Ledger、Entry等。这些概念都是和它的架构有关的,比如Bundle是为了满足计算层弹性提出的概念,Bookie、Ledger、Entry是存储层BookKeeper的概念。这些在后面讲存算分离架构的时候会仔细讲。
接下来我们继续围绕基础篇的五个模块来分析一下Pulsar。这节课我们主要分析Pulsar Broker的协议和网络模块,至于BookKeeper的协议和网络模块,你有兴趣的话可以自己去研究下,或者有需要的话,可以在课程后面评论,我们再补充讲解。
协议和网络层
和Kafka一样,Pulsar Broker的协议也是自定义的私有协议。协议的格式是以行格式解析,即自定义的编解码格式。
如下图所示,Pulsar 的整体协议是行格式的自定义编解码,但是协议中的命令(Command)和部分元数据是用 Protobuf 组织来表示的,比如下图黄色的部分。
从协议的结构来看,协议也是分为协议头和协议体两部分。TotalSize+CommandSize+Commnad就是协议头,Other就是协议体,协议体中包含很多请求维度需要的字段。
从协议的内容上看,Pulsar 协议分为了 SimpleCommands 和 MessageCommands 两种格式。
Simple Commands 指不需要携带消息内容的简单命令,即指在交互过程中不需要携带消息内容的交互请求,如建立连接,心跳检测等等。消息结构如下所示,可以看到简单协议只携带了TotalSize、CommandSize、Command三个字段,不携带消息体。

Message Commands 指需要携带消息内容的复杂命令,比如生产消息操作就需要携带消息内容、生产者信息、批量消息等等相关数据。此时就需要使用 Message Commands来进行交互,它的结构如下:
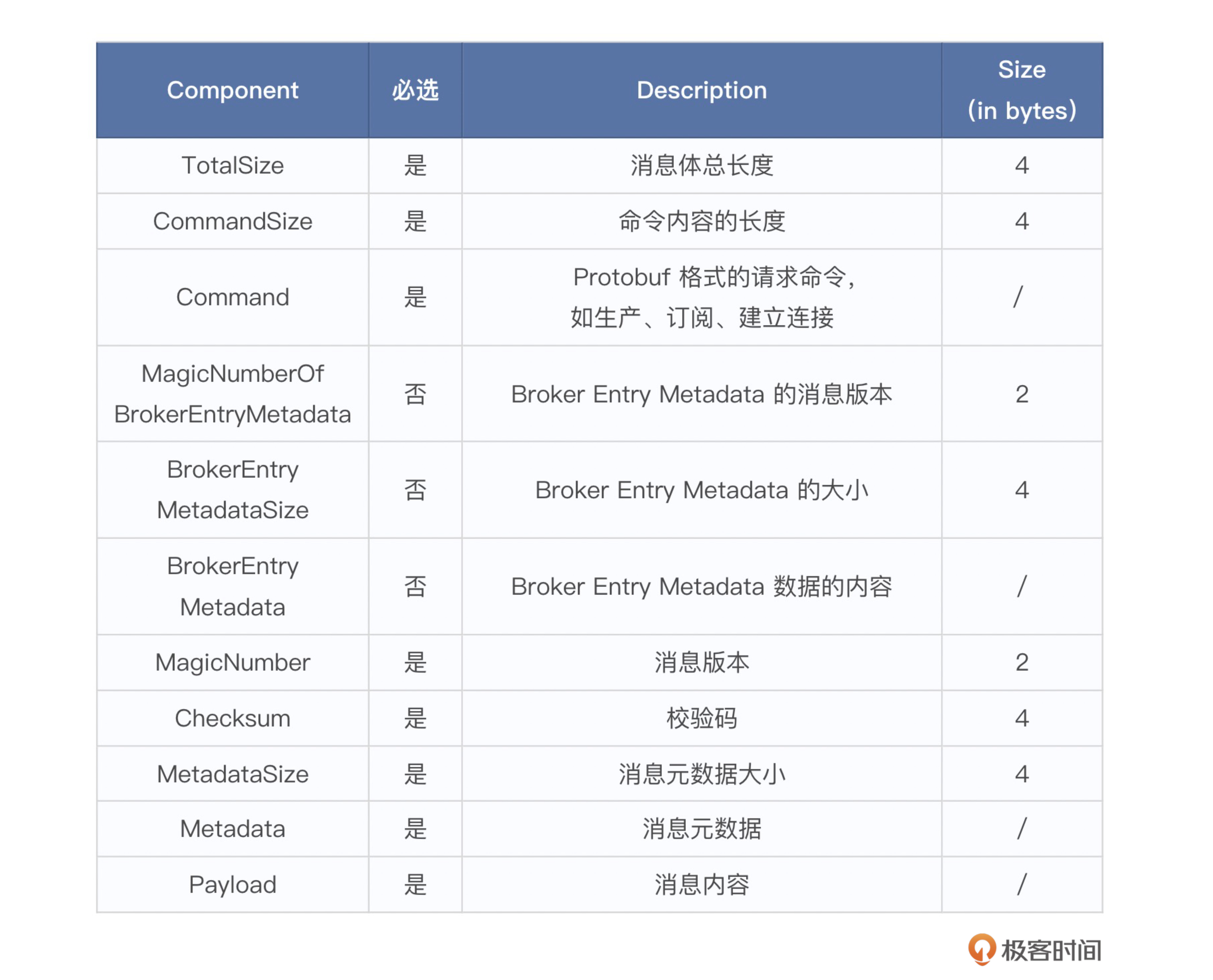
从结构上来看,Message Commands和Simple Commands是一样的,它也包含了TotalSize、CommandSize、Command三个字段,只是在Simple Commands的基础上,多了很多个跟请求相关的字段,如 Broker Entry Metadata、Message Metadata 等等。
在编解码的过程中,协议是以行格式解析的。以 Simple Commands 举例,服务端拿到请求后,先用4个字节拿到消息总长度,然后根据之后4个字节拿到命令的长度,再根据命令的长度拿到命令的内容,然后再根据 Protobuf 格式解析出命令的具体内容。Message Commands 解析以此类推。
Pulsar Broker 的网络层是基于 Netty 框架开发实现的,属于业界比较常用的实现方案。如果想了解更多,建议你直接学习 Netty 的网络模型和开发指南,这里就不展开了。当然,你也可以参考我们的第03讲或第04讲。
数据存储
现在我们来看一下Pulsar的存储层。在数据存储方面,Pulsar 也同样分为元数据存储和消息数据存储两部分。
元数据存储
当前 Pulsar 元数据存储的核心是ZooKeeper。最新版本的内核支持可插拔的元数据存储框架,即支持将元数据存储到多种第三方存储引擎,比如etcd、本地内存、RocksDB等,架构如下图所示:
因为架构要求,Pulsar 需要存储更多元数据,所以Pulsar对ZooKeeper造成的压力会更大。也正因为如此,Pulsar才会支持可插拔的元数据存储框架,希望通过其他的存储引擎来缓解ZooKeeper的瓶颈。
和 Kafka 一样,因为都使用 ZooKeeper 来存储元数据,那么Kafka遇到的问题,Pulsar 也都会遇到,如集群的规模、可承载的分区数等等。从代码技术实现上来看,Pulsar 对 ZooKeeper的使用和Kafka是类似的,所以就不展开细讲了。
消息数据
接下来我们看一下Pulsar的消息存储。在计算层,Pulsar 不负责消息存储。流程上就是调用BookKeeper的SDK,往BookKeeper写入数据。在BookKeeper看来,Pulsar Broker 就是BookKeeper集群的一个普通的客户端。
在Pulsar Broker,消息数据的存储是以分区维度组织的,即一个分区一份文件。在实际的存储中,分区的数据是以一段一段Ledger的形式组织的,不同的Ledger会存储到不同的Bookie上。每段Ledger包含一批Entry,一个Entry可以理解为一条消息。存储结构如下图所示:
通过图示,我们可以看到,在Broker中,消息会先以Entry的形式追加写入到Ledger中,一个分区同一时刻只有一个Ledger处于可写状态。当写入一条新数据时,会先找到当前可用的Ledger,然后写入消息。当Ledger的长度或Entry个数超过阈值时,新消息会存储到新的Ledger中。一个 Ledger会根据 Broker 指定的QW数量,存储到多个不同的Bookie中。一个Bookie可以存放多个不连续的Ledger。
这种分段存储结构的好处就是,当一台Bookie(节点)的负载高了或者容量满了后,就可以通过禁用该台节点的写入,将负载快速转移到其他节点上,从而实现存储的弹性。讲到这里,你会发现,在Pulsar 看来,消息数据本质上就是分段存储的。
在写入性能方面,Broker不太关注实际的写入性能的提升,性能主要依赖BookKeeper的性能优化。BookKeeper在底层会通过WAL机制、批量写、写缓存的形式来提高写入的性能。底层的具体实现机制我们就不展开讲了,你有兴趣的话可以查阅相关资料
同时,Pulsar 提供了 TTL和 Retention 机制来支持消息删除。
TTL策略指消息在指定时间内没有被用户ACK掉时,会被 Broker 主动 ACK 掉。此处需注意,这个ACK操作不涉及数据删除,因为 TTL 不涉及与删除相关的操作。
Retention 策略指消息被 ACK之后(消费者ACK或者TTL ACK)继续在 Bookie 侧保留的时间,消息被 ACK 之后就归属于 Retention 策略,即在 BookKeeper 保留一定时间。Retention以 Ledger 为最小操作单元,删除即是删除整个 Ledger。
所以说,TTL 仅用于 ACK 掉在 TTL 范围内应被 ACK的消息,不执行删除操作。真正删除的操作是依靠 Retention 策略来执行的。下面我们再来看一下客户端,看看 Pulsar 的生产者和消费者的实现。
生产者和消费者
因为 Pulsar 也是 Topic、分区模型,所以 Pulsar 客户端在进行生产消费之前,也需要先进行客户端寻址操作。通过寻址找到Topic 分区所在的Leader节点,然后连接上节点进行生产消费。Pulsar 支持通过 Pulsar 协议和 HTTP 协议两种形式来完成寻址操作。
先来看看 Pulsar 的生产端。
生产端
Pulsar 生产端支持访问模式的概念。访问模式指的是一个分区在同一时间支持怎样的生产者以何种方式写入。比如一个分区同一时间是所有生产者都可以写,还是只有一个生产者可以写,还是多个生产者灾备写。在其他消息队列中,一般都是默认所有的生产者可以写。
Pulsar 提供了Shared(共享)、Exclusive(独占)、WaitForExclusive(灾备)三种访问模式。
Shared 指允许多个生产者将消息写入到同一个Topic。Exclusive指只有一个生产者可以将消息写入到 Topic,当其他生产者尝试写入消息到这个Topic 时,会发生错误。WaitForExclusive 指只有一个生产者可以将消息发送到 Topic,其他生产者连接会被挂起而不会产生错误,类似ZooKeeper的观察者模式。
因为分区模型的存在,Pulsar 在生产端提供了 RoundRobinPartition(轮询)、SinglePartition(随机选择分区)、CustomPartition(自定义)三种路由模式,用来决定数据会发送到哪个分区里面。
- RoundRobinPartition,指当消息没有指定 Key 时,生产者以轮询方式将消息写入到所有分区。
- SinglePartition,指当消息没有指定 Key,生产者会随机选择一个分区,并将所有消息写到这个分区。针对上述这两种策略,如果消息指定了 Key,分区生产者会优先根据Key的Hash值将该消息分配到对应的分区。
- CustomPartition,用户可以创建自定义路由模式,通过实现 MessageRouter 接口来自定义路由规则。
因为 Pulsar 的协议支持Batch语义,所以在生产端是支持批量发送的。启用批量处理后,生产者会在客户端累积并发送一批消息。批量处理时的消息数量,取决于最大可发送消息数和最大发布延迟。
在客户端写入模式上,Pulsar 生产端也支持同步写入、异步写入两种方式。
消费端
在消费端,Pulsar 主要支持 Pull 消费模型,即由客户端主动从服务端Pull数据来支持消费。同样的,Pulsar 在消费端也支持订阅的概念,订阅对Pulsar的作用相当于 Kafka 的消费分组。
Pulsar的订阅支持消息和分区两个维度,即可以将整个分区绑定给某个消费者,也可以将分区中的消息投递给不同的消费者。
所以在实现上,Pulsar 支持独占、灾备、共享、Key_Shared 四种订阅类型。
- 独占,指一个订阅只可以与一个消费者关联,只有这个消费者能接收到Topic的全部消息,如果这个消费者故障了就会停止消费。
- 灾备,指一个订阅可以与多个消费者关联,但只有一个消费者会消费到数据,当该消费者故障时,由另一个消费者来继续消费。
- 共享,指一个订阅可以与多个消费者关联,消息会通过轮询机制发送给不同的消费者。
- Key共享,指一个订阅可以与多个消费者关联,消息根据给定的映射规则,相同Key的消息由同一个消费者消费。
Pulsar 支持持久化和非持久化两种订阅模式。这两种模式的核心区别在于,游标是否是持久化存储。如果是持久化的存储,当Broker重启后还可以保留游标进度,否则游标就会丢失。RocketMQ和Kafka的消费分组都是持久化的订阅。
当客户端消费成功后,为了确认消费完成,也需要进行消费确认。消费确认就是提交当前消费的进度,Pulsar指的是提交游标的进度。它提供了累积确认和单条确认两种模式,累积确认指消费者只需要确认收到的最后一条消息,在此之前的消息,都不会被再次发送给消费者;单条确认指消费者需要确认每条消息并发送 ACK 给 Broker。
如果希望保存消费进度,那么就需要选择持久化订阅。如果是为了提高ACK性能,就需要选择累积确认。
在实际运行过程中,Puslar的单条ACK机制给Broker带来了蛮大的挑战。因为允许客户端一条一条ACK数据,就会造成某些数据一直不被ACK,从而造成消息空洞的现象。
同时Pulsar 也提供了取消确认的功能。即当某些消息已经被确认,已经消费不到数据了,此时如果还想消费到数据,就要通过客户端发送取消确认的命令,使其可以再消费到这条数据。取消确认操作支持单条和批量,不过这两种操作方式在不同订阅类型中的支持情况是不一样的,这一点需要注意一下。
最后我们还是来看一下 Pulsar 对HTTP协议和管控操作的支持。
HTTP协议支持和管控操作
在访问层面,Pulsar的管控操作和生产消费数据流操作是分开支持的。即数据流走的是自定义协议通信,管控走的是HTTP 协议形式的访问。从访问上就隔离了管控和数据流操作,在后续的权限管理、客户端访问等方面提供了很多便利。
如上图所示,HTTP协议的端口和私有协议的端口是独立的,内核中启动了一个单独的HTTP Server 来提供服务。我们在代码上可以通过HTTP Rest的API 直接进行管控操作。命令行CLI的底层也是通过HTTP Client发起访问的,用HTTP的好处就是,不需要单独在二进制协议、服务端接口、客户端SDK方面单独进行管控的支持。
在上面的 HTTP Rest 接口中,同时提供了简单的生产接口和消费接口,即可以通过HTTP协议进行数据的写入和消费,但这个功能不建议用在现网的大流量的业务中。如果需要支持HTTP协议的生产和消费,有些商业化的产品是可以支持的,底层技术层面走的还是 Proxy 的方案。
总结
这节课我们讲了 Pulsar 的五个部分。和其他MQ不一样的是,因为Pulsar的社区当前发展很快,随着时间的推移,这节课的内容可能会和最新版本的实现对不上。如果有疑问,欢迎各位同学抛出来讨论。
从产品定位上来看,Pulsar 把自己定位为Kafka的升级版。所以它是在Kafka的基础上,对概念进行了升级和细化,以满足更多的场景,同时也解决了Kafka自身的一些架构缺陷和功能不足问题。如果你从这个角度去理解Pulsar,就会比较好懂了,比如Pulsar比Kafka会有更多的Topic类型、更多的订阅模式以及更弹性的计算层和存储层等等。
这节课我们用一张表格,针对基础篇的知识点,从4个主流消息队列出发,做一下原理概览性的总结。建议你收藏!
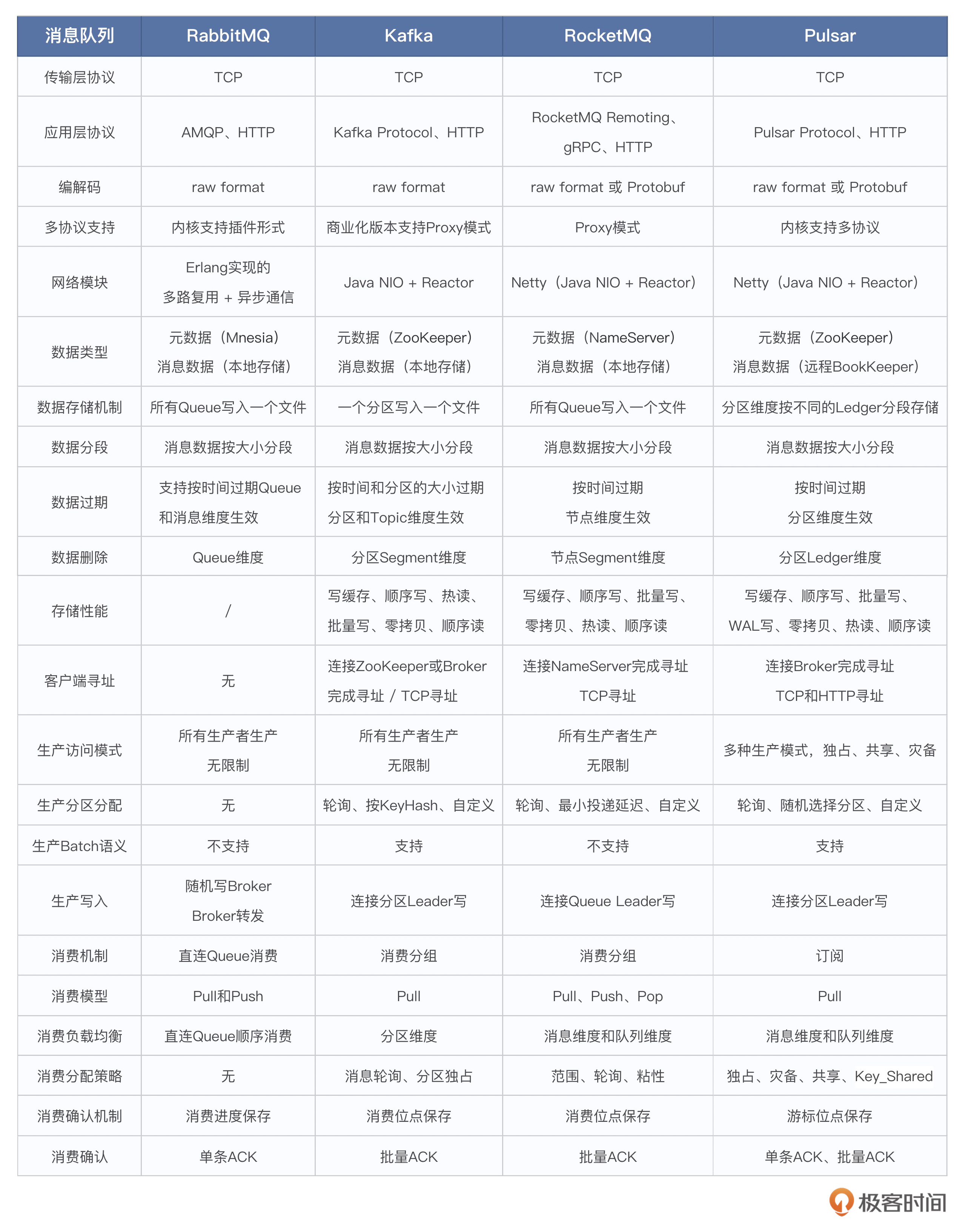
思考题
Pulsar为什么会对ZooKeeper造成很大的压力?
欢迎分享你的思考,如果觉得有收获,也欢迎你把这节课分享给身边的朋友。我们下节课再见!
上节课思考闭环
请你按照基础篇的思路,描述一下Kafka从生产到消费的全过程?
Kafka的生产到消费总共经过生产者、Broker、消费者三个模块。大致的流程如下:
1. 在生产端,客户端会先和Broker建立TCP连接,然后通过Kafka协议访问Broker的Metadata接口获取到集群的元数据信息。接着生产者会向Topic或分区发送数据,如果是发送到Topic,那么在客户端会有消息分区分配的过程。因为Kafka协议具有批量发送语义,所以客户端会先在客户端缓存数据,然后根据一定的策略,通过异步线程将数据发送到Broker。
2. Broker接收到数据后,会根据Kafka协议解析出请求内容,做好数据校验,然后重整数据结构,将数据按照分区的维度写入到底层不同的文件中。如果分区配置了副本,则消息数据会被同步到不同的Broker中进行保存。
3. 在消费端,Kafka提供了消费分组消费和指定分区消费两种模式。消费端也会先经过寻址拿到完整的元数据信息,然后连接上不同的Broker。如果是消费分组模式消费,则需要经过重平衡、消费分区分配流程,然后连接上对应的分区的Leader,接着调用Broker的Fetch接口进行消费。最后一步也是需要提交消费进度来保存消费信息。
- 虚竹 👍(1) 💬(3)
老师好,作为新一代的mq,为何pulsar会在明知zk会成为瓶颈的情况下,依然选择zk呢?另外,pulsar的明显优势是哪些呢?
2023-10-10 - 张申傲 👍(1) 💬(2)
请教下强哥:像Pulsar这类存算分离架构,存储性能不会存在瓶颈吗?像RocketMQ、Kafka消息都是存本地文件,最多就是一次磁盘IO,而Pulsar要存远程BookKeeper,相当于是网络IO+磁盘IO,虽然会有PageCache、WAL顺序写等优化机制,但是理论上性能还是不如本地存储吧? 还是说存算分离架构就是要牺牲存储性能来换取架构的弹性?
2023-07-19 - 陈 👍(0) 💬(1)
Pulsar底层也是一个分区数据一个文件存放的,为什么能支持百万topic?不会产生随机IO带来的性能影响吗?
2023-07-31 - Geek_ec80d2 👍(0) 💬(0)
",TTL 仅用于 ACK 掉在 TTL 范围内应被 ACK 的消息,不执行删除操作。真正删除的操作是依靠 Retention 策略来执行的" 这个帮忙代码上确定一下,看日志,5分钟周期ack消息后,马上把满足条件的ledger删除,而不是走retention的删除周期,多谢。
2023-07-20