10 从基础功能拆解RabbitMQ的架构设计与实现
你好,我是文强。
在基础篇开篇的时候,我们说过最基础的消息队列应该具备通信协议、网络模块、存储模块、生产者、消费者五个模块。在之前的课程中,我们详细分析了这五个模块的选型、设计和实现思路,接下来我们从消息和流的角度,用四节课的篇幅分别讲一下消息方向的消息队列RabbitMQ、RocketMQ,流方向的消息队列Kafka、Pulsar,在这五个模块的实现思路和设计思想。这节课我们先讲 RabbitMQ。

RabbitMQ 系统架构
在正式讲解之前,我们先来看一下RabbitMQ的系统架构。
如上图所示,RabbitMQ由Producer、Broker、Consumer三个大模块组成。生产者将数据发送到Broker,Broker 接收到数据后,将数据存储到对应的Queue里面,消费者从不同的Queue消费数据。
那么除了Producer、Broker、Queue、Consumer、ACK 这几个消息队列的基本概念外,它还有 Exchange、Bind、Route 这几个独有的概念。下面我来简单解释下。
Exchange 称为交换器,它是一个逻辑上的概念,用来做分发,本身不存储数据。流程上生产者先将消息发送到Exchange,而不是发送到数据的实际存储单元Queue里面。然后 Exchange 会根据一定的规则将数据分发到实际的Queue里面存储。这个分发过程就是Route(路由),设置路由规则的过程就是Bind(绑定)。即 Exchange 会接收客户端发送过来的 route_key,然后根据不同的路由规则,将数据发送到不同的Queue里面。
这里需要注意的是,在RabbitMQ中是没有Topic这个用来组织分区的逻辑概念的。RabbitMQ中的Topic是指Topic路由模式,是一种路由模式,和消息队列中的Topic意义是完全不同的。
那为什么RabbitMQ 会有Exchange、Bind、Route这些独有的概念呢?
在我看来,主要和当时业界的架构设计思想以及主导设计 AMQP 协议的公司背景有关。当时的设计思路是:希望发消息跟写信的流程一样,可以有一个集中的分发点(邮局),通过填写好地址信息,最终将信投递到目的地。这个集中分发点(邮局)就是Exchange,地址信息就是Route,填写地址信息的操作就是Bind,目的地是Queue。
讲清楚基本概念和架构,我们就围绕着前面提到的五个模块来分析一下RabbitMQ,先来看一下协议和网络模块。
协议和网络模块
在网络通信协议层面,RabbitMQ 数据流是基于四层TCP协议通信的,跑在TCP上的应用层协议是AMQP。如果开启 Management 插件,也可以支持HTTP协议的生产和消费。TCP + AMQP 是数据流的默认访问方式,也是官方推荐的使用方式,因为它性能会比 HTTP 高很多。
RabbitMQ在协议内容和连接管理方面,都是遵循AMQP规范。即RabbitMQ的模型架构和AMQP 的模型架构是一样的,交换器、交换器类型、队列、绑定、路由键等都是遵循AMQP 协议中相应的概念。
AMQP 是一个应用层的通信协议,可以看作一系列结构化命令的集合,用来填充TCP 层协议的body 部分。通过协议命令进行交互,可以完成各种消息队列的基本操作,如Connection.Start(建立连接)、Basic.Publish(发送消息)等等,详细的AMQP协议内容可以参考文档 AMQP Working Group 1.0 Final。
下面是一张生产消息流程的协议命令交互图,大概包含了建立连接、发送消息、关闭连接三个步骤。
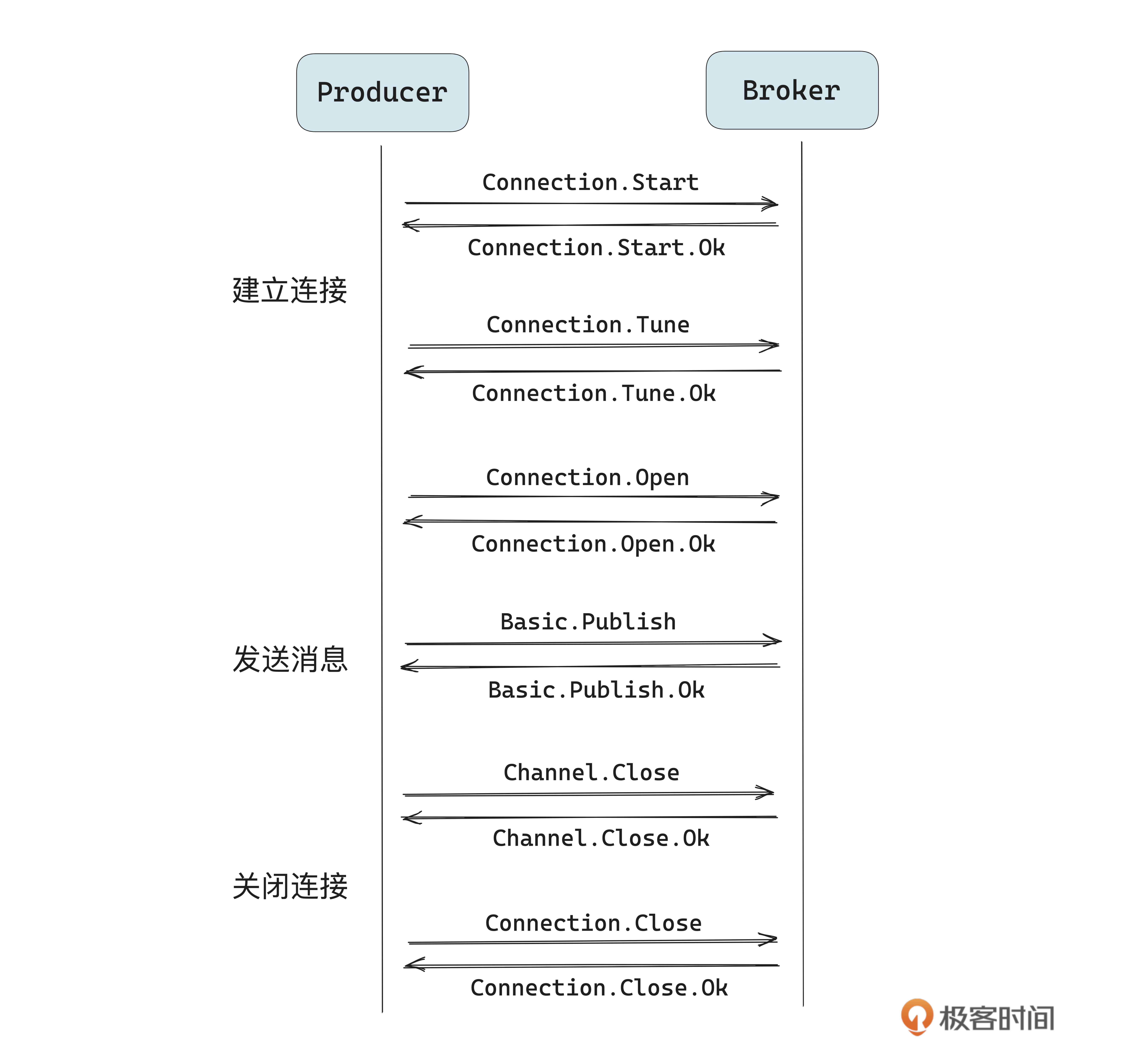
讲完了协议,我们来看看网络模块。
先来看下面这张图,在RabbitMQ的网络层有Connectoion和Channel 两个概念需要关注。
Connection 是指TCP连接,Channel 是Connection中的虚拟连接。两者的关系是:一个客户端和一个Broker之间只会建立一条TCP连接,就是指 Connection。Channel(虚拟连接)的概念在这个连接中定义,一个 Connection中可以创建多个Channel。
客户端和服务端的实际通信都是在Channel维度通信的。这个机制可以减少实际的TCP连接数量,从而降低网络模块的损耗。从设计角度看,也是基于IO复用、异步I/O的思路来设计的。
从编码实现的角度,RabbitMQ 的网络模块设计会比较简单。主要包含 tcp_listener、tcp_acceptor、rabbit_reader 三个进程。如下图所示,RabbitMQ 服务端通过 tcp_listener 监听端口,tcp_acceptor 接收请求,rabbit_reader 处理和返回请求。本质上来看是也是一个多线程的网络模型。
接下来我们看看 RabbitMQ 的存储模块。
数据存储
RabbitMQ 的存储模块也包含元数据存储与消息数据存储两部分。如下图所示,RabbitMQ 的两类数据都是存储在 Broker 节点上的,不会依赖第三方存储引擎。我们先来看一下元数据存储。
元数据存储
RabbitMQ的元数据都是存在于Erlang自带的分布式数据库Mnesia中的。即每台Broker都会起一个Mnesia进程,用来保存一份完整的元数据信息。因为 Mnesia 本身是一个分布式的数据库,自带了多节点的 Mnesia 数据库之间的同步机制。所以在元数据的存储模块,RabbitMQ 的Broker 只需要调用本地的 Mnesia 接口保存、变更数据即可。不同节点的元数据同步 Mnesia 会自动完成。
Mnesia对RabbitMQ的作用,相当于ZooKeeper对于Kafka、NameServer对于RocketMQ的作用。因为Mnesia是内置在Broker中,所以部署RabbitMQ集群时,你会发现只需要部署Broker,不需要部署其他的组件。这种部署结构就很简单清晰,从而也降低了后续的运维运营成本。
在一些异常的情况下,如果不同节点上的 Mnesia 之间的数据同步出现问题,就会导致不同的 Mnesia 数据库之间数据不一致,进而导致集群出现脑裂、无法启动等情况。此时就需要手动修复异常的Mnesia实例上的数据。
因为Mnesia 本身是一个数据库,所以它和数据库一样,可以进行增删改查的操作。需要了解Mnesia 的更多操作,你可以参考 ErLang Mnesia。
消息数据存储
如下图所示,RabbitMQ 消息数据的最小存储单元是Queue,即消息数据是按顺序写入存储到Queue里面的。在底层的数据存储方面,所有的Queue数据是存储在同一个“文件”里面的。这个“文件”是一个虚拟的概念,表示所有的Queue数据是存储在一起的意思。
这个“文件”由队列索引(rabbit_queue_index)和消息存储(rabbitmq_msg_store)两部分组成。即在节点维度,所有 Queue 数据都是存储在rabbit_msg_store里面的,每个节点上只有一个rabbit_msg_store,数据会依次顺序写入到rabbit_msg_store中。
rabbit_msg_store是一个逻辑概念,底层的实际存储单元分为两个,msg_store_persistent和msg_store_transient,分别负责持久化消息和非持久化消息的存储。
msg_store_persistent 和 msg_store_transient 在操作系统上是以文件夹的形式表示的,具体的数据存储是以不同的文件段的形式存储在目录中,所有消息都会以追加的形式写入到文件中。当一个文件的大小超过了配置的单个文件的最大值,就会关闭这个文件,然后再创建一个文件来存储数据。关于RabbitMQ底层的数据存储结构,如下图所示:
队列索引负责存储、维护队列中落盘消息的信息,包括消息的存储位置、是否交付、是否ACK等等信息。队列索引是Queue维度的,每个Queue都有一个对应的队列索引。
RabbitMQ 也提供了过期时间(TTL)机制,用来删除集群中没用的消息。它支持单条消息和队列两个维度来设置数据过期时间。如果在队列上设置TTL,那么队列中的所有消息都有相同的过期时间。我们也可以对单条消息单独设置TTL,每条消息的TTL可以不同。如果两种方案一起使用,那么消息的TTL 就会以两个值中最小的那个为准。如果不设置TTL,则表示此消息不会过期。
删除消息时,不会立即删除数据,只是从Erlang 中的ETS表删除指定消息的相关信息,同时更新消息对应的存储文件的相关信息。此时文件中的消息不会立即被删除,会被标记为已删除数据,直到一个文件中都是可以删除的数据时,再将这个文件删除,这个动作就是常说的延时删除。另外内核有检测机制,会检查前后两个文件中的数据是否可以合并,当符合合并规则时,会进行段文件的合并。
在了解了RabbitMQ的协议、网络模块和数据存储后,我们再来看一下RabbitMQ的生产者和消费者的实现。
生产者和消费者
当生产者和消费者连接到Broker进行生产消费的时候,是直接和Broker交互的,不需要客户端寻址。客户端连接Broker的方式,跟我们通过HTTP服务访问Server是一样的,都是直连的。部署架构如下图所示:
RabbitMQ集群部署后,为了提高容灾能力,就需要在集群前面挂一层负载均衡来进行灾备。客户端拿到负载均衡IP后,在生产或消费时使用这个IP和服务端直接建立连接。因为Queue是具体存储数据的单元,不同的Queue 有可能分布在不同的Broker上,就有可能出现生产或消费基于负载均衡IP请求到的Broker,并不是当前Queue所在的Broker,从而导致生产消费失败。
为了解决这个问题,在每个Broker上会设置有转发的功能。在实现上,每台Broker节点都会保存集群所有的元数据信息。当Broker收到请求后,根据本地缓存的元数据信息判断Queue是否在本机上,如果不在本机,就会将请求转发到Queue所在的目标节点。
从客户端的实现来看,因为各个语言的实现机制不太一样,基础模块的连接管理、心跳管理、序列化等部分遵循各编程语言的开发规范去实现。例如网络模块的实现,如果客户端是用Java语言写的,那么可以使用Java NIO库完成网络模块的开发。客户端和服务端传输协议的内容遵循AMQP协议,底层以二进制流的形式序列化数据。即根据 AMQP 协议的格式构建内容后,然后序列化为二进制的格式,传递给 Broker 进行处理。
生产端发送数据不是直接发送到Queue,而是直接发送到Exchange。即发送时需要指定Exchange和route_key,服务端会根据这两个信息,将消息数据分发到具体的Queue。因为Exchange和route_key都是一个逻辑概念,数据是直接发送到Broker的,然后在服务端根据路由绑定规则,将数据分发到不同的Queue中,所以在客户端是没有发送生产分区分配策略的逻辑。其实从某种程度来看,Exchagne和Route的功能就是生产分区分配的过程,只是将这个逻辑从客户端移动到了服务端而已。
在消费端,RabbitMQ 支持Push(推)和Pull(拉)两种模式,如果使用了Push模式,Broker会不断地推送消息给消费者。不需要客户端主动来拉,只要服务端有消息就会将数据推给客户端。当然推送消息的个数会受到 channel.basicQos 的限制,不能无限推送,在消费端会设置一个缓冲区来缓冲这些消息。拉模式是指客户端不断地去服务端拉取消息,RabbitMQ的拉模式只支持拉取单条消息。
在AMQP协议中,是没有定义Topic和消费分组的概念的,所以在消费端没有消费分区分配、消费分组 Rebalance 等操作,消费者是直接消费Queue数据的。
为了保证消费流程的可靠性,RabbitMQ也提供了消息确认机制。消费者在消费到数据的时候,会调用ACK接口来确认数据是否被成功消费。
底层提供了自动ACK和手动ACK两种机制。自动ACK表示当客户端消费到数据后,消费者会自动发送ACK,默认是自动ACK。手动ACK表示客户端消费到数据后,需要手动调用。ACK的时候,支持单条ACK和批量ACK两种动作,批量ACK可以用来提升ACK效率。另外,为了提升ACK动作的性能,有些客户端也支持异步的ACK。
在了解了上述的五个模块后,最后我们来看一下 RabbitMQ 对HTTP协议的支持和管控操作。
HTTP 协议支持和管控操作
RabbitMQ 内核本身不支持 HTTP 协议的生产、消费和集群管控等操作。如果需要支持,则需要先手动开启Management插件,通过插件的形式让内核支持这个功能。
大部分情况下,我都会建议你启用Management插件,否则集群使用就会不太方便。如下图所示,从实现上来看 Management 插件对 HTTP 协议的支持,就是在开启插件的时候,会启动一个新的 HTTP Server 来监听一个新的端口。客户端只需要访问这个端口提供的HTTP接口,就可以完成HTTP读写数据和一些集群管控的操作。如果你想了解更多细节,可以查看这个文档 Management Plugin。
开启插件后,就可以通过HTTP接口实现生产、消费、集群的配置、资源的创建、删除等操作。比如下面是一个查看 Vhost 列表的 curl 命令示例:
总结
RabbitMQ 主要有 Producer、Broker、Consumer、Exchange、Queue、Route、Bind、Connection、Channel、ACK 等概念。
总结 RabbitMQ,可以从以下七个方面入手:
- 协议层基于AMQP标准开发。
- 网络层核心数据流基于 TCP 协议通信,并通过Connection和Channel机制实现连接的复用,以减少创建的TCP连接数量。
- 存储层基于多个Queue数据统一到一个文件存储的思路设计,同时支持分段存储和基于时间的数据过期机制。
- 元数据存储是基于Erlang内置的数据库Mnesia来实现。
- 客户端的访问是直连的,没有客户端寻址机制。
- 生产端是通过Exchange和Route写入数据的,生产数据的分发是在服务端完成的,其他消息队列的分发一般都是在客户端。
- 消费端没有消费分组、消费分区分配等概念,直连Queue消费,同时也提供了手动和自动两种ACK机制。
思考题
请你按照基础篇的课程思路,完整描述一下RabbitMQ从生产到消费的全过程?
欢迎总结复习,如果觉得有收获,也欢迎你把这节课分享给身边的朋友。我们下节课再见!
上节课思考闭环
从代码的实现角度,如果让你负责开发某个消息队列客户端的消费模块,你会怎么思考?依次做哪些事情?
1. 做功能分析。分析消费端要实现哪些功能,比如消费、确认,然后分析是否需要提供顺序消费、广播消费、回溯消费等能力。
2. 根据功能需求,先看Broker侧是否支持这些能力,因为从消息队列的角度,客户端只是使用者,能否实现功能依赖服务端。
3. 了解服务端提供了哪些接口,调用方式是什么(TCP或HTTP),协议内容是怎样的。
4. 分析功能要如何实现,哪些功能需要和哪些接口交互,然后完成消费模型和分区消费模式的选择。
5. 完成网络模块、协议模块、序列化/反序列化等基础模块的开发。
6. 通过基础模块和服务端提供的接口,完成最基本的消费流程开发。
7. 完善消费组、消费确认等模块的开发。
8. 完善异常失败处理、日志记录、指标监控等工作。
- aoe 👍(1) 💬(1)
老师在文中用「邮局」举例非常好! 才发现「邮局」这个模式应用及其广泛:小到个人网购,大到国之重器「东风快递」 联想到「漂流瓶」可能是「邮局」的前身
2023-07-16 - cykuo 👍(0) 💬(4)
channel为何可以降低实际TCP的数量?
2023-07-12 - 奔腾ing 👍(3) 💬(1)
请问老师,针对Mnesia数据损坏的问题,有修复的方法吗?我们项目上经常遇到因服务器断电导致的rmq(目前是3.8.19版本,单机部署)启动不了的情况。目前处理方案都是备份然后删除Mnesia。研究了下rmq官方的文档以及git上issue上问题,没看到明确的修复方案,目前倾向于升级到3.11.20版本,来看看有没有解决此问题。
2023-08-11 - walle斌 👍(0) 💬(0)
开发某个消息队列客户端的消费模块,这部分补充一下 1)、是否支持多线程消费,尤其是会牵扯到ack,需要看这个mq的定位问题 2)、开了多线程,那么pull 得拉取 得流速限制,尤其是第一步开了多线程以后可能存在占用较多内存的问题 3)、考虑到异常消费,可以额外指定 过期时间、重复消费次数控制、堆积数据转移等option 功能
2024-12-11 - JooKS 👍(0) 💬(0)
客户端跟broker建连后就不会变了吗,如果某个broker的消费者阻塞了或者负载很高,其他broker的消费者负载很低,这种情况下是不是没办法解决这个broker的慢消费问题了。这时候选择扩容收益也比较低。
2024-05-30 - TKF 👍(0) 💬(0)
老师,既然rabbitmq的数据存储是顺序写到一个文件中的,那发送到queue的意义是不是仅仅构建一下相应的索引?
2023-08-16 - 贝氏倭狐猴 👍(0) 💬(0)
老师,有个问题:“在 AMQP 协议中,是没有定义 Topic 和消费分组的概念的,所以在消费端没有消费分区分配、消费分组 Rebalance 等操作,消费者是直接消费 Queue 数据的。”那消费模式是类似pulsar的shared么?
2023-07-12