03 通信协议:如何设计一个好的通信协议?
你好,我是文强。
今天我们正式进入基础篇的学习,我会带你构建最基础的消息队列。
从功能上来看,一个最基础的消息队列应该具备生产、存储、消费的能力,也就是能完成“生产者把数据发送到Broker,Broker收到数据后,持久化存储数据,最后消费者从Broker消费数据”的整个流程。
我们从这个流程来拆解技术架构,如下图所示,最基础的消息队列应该具备五个模块。
- 通信协议:用来完成客户端(生产者和消费者)和Broker之间的通信,比如生产或消费。
- 网络模块:客户端用来发送数据,服务端用来接收数据。
- 存储模块:服务端用来完成持久化数据存储。
- 生产者:完成生产相关的功能。
- 消费者:完成消费相关的功能。
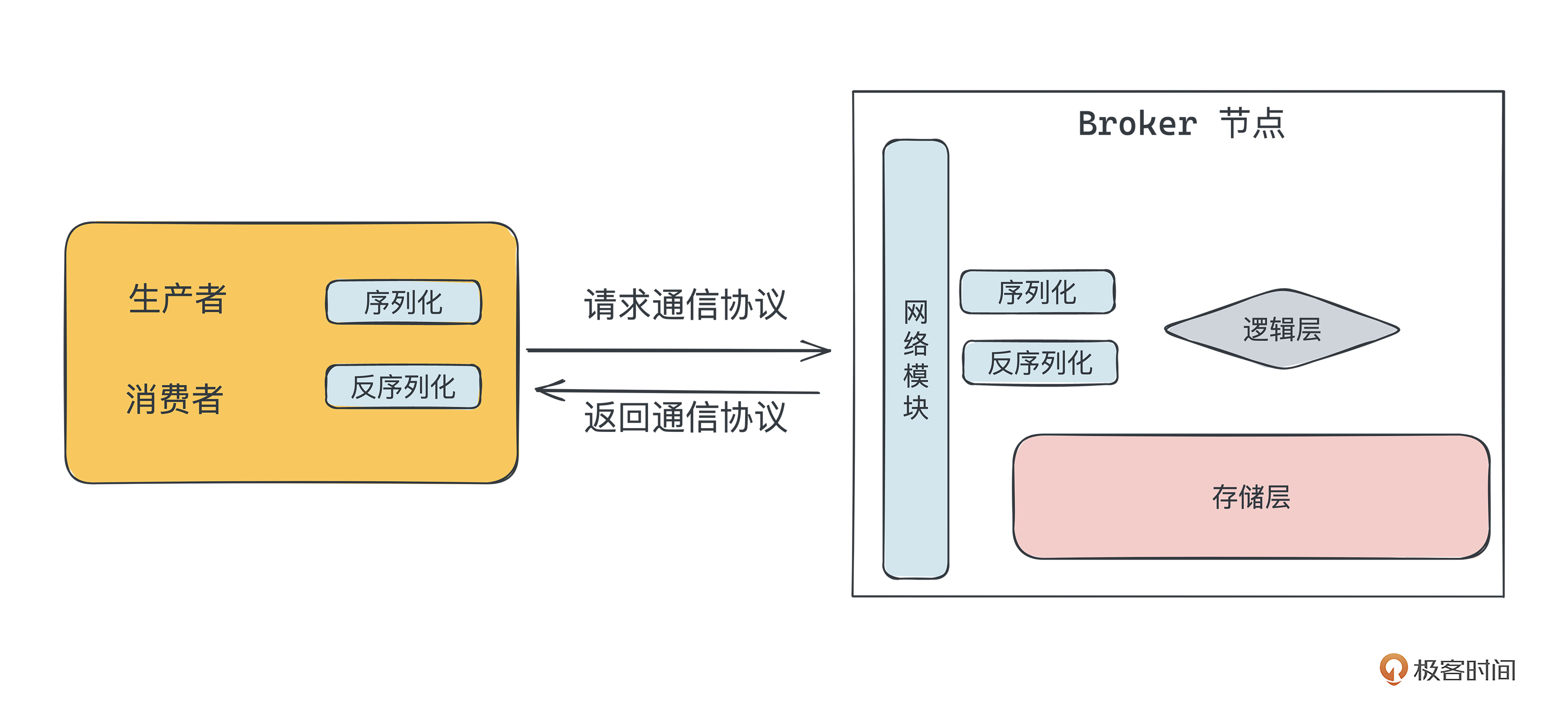
我们知道,消息队列本质上讲是个CS模型,通过客户端和服务端之间的交互完成生产、消费等行为。不知道你在日常的开发过程中,是否会好奇客户端和服务端之间的通信流程是怎么实现的呢?
那今天我们就开始学习基础篇的第一讲——通信协议。为了完成交互,我们第一步就需要确定服务端和客户端是如何通信的。而通信的第一步就是确定使用哪种通信协议进行通信。
说到协议,我们开发者最熟悉的可能就是HTTP协议了,HTTP作为一个标准协议,有很多优点。那能否用HTTP协议作为消息队列的通信协议呢?带着你的思考,我们开始学习。
通信协议基础
所有协议的选择和设计都是根据需求来的,我们知道消息队列的核心特性是高吞吐、低延时、高可靠,所以在协议上至少需要满足:
- 协议可靠性要高,不能丢数据。
- 协议的性能要高,通信的延时要低。
- 协议的内容要精简,带宽的利用率要高。
- 协议需要具备可扩展能力,方便功能的增减。
那有没有现成的满足这四个要求的协议呢?
目前业界的通信协议可以分为公有协议和私有协议两种。公有协议指公开的受到认可的具有规范的协议,比如JMS、HTTP、STOMP等。私有协议是指根据自身的功能和需求设计的协议,一般不具备通用性,比如Kafka、RocketMQ、Puslar的协议都是私有协议。
其实消息队列领域是存在公有的、可直接使用的标准协议的,比如AMQP、MQTT、OpenMessaging,它们设计的初衷就是为了解决因各个消息队列的协议不一样导致的组件互通、用户使用成本高、重复设计、重复开发成本等问题。但是,公有的标准协议讨论制定需要较长时间,往往无法及时赶上需求的变化,灵活性不足。
因此大多数消息队列为了自身的功能支持、迭代速度、灵活性考虑,在核心通信协议的选择上不会选择公有协议,都会选择自定义私有协议。
那私有协议要怎么设计实现呢?
从技术上来看,私有协议设计一般需要包含三个步骤。
- 网络通信协议选型,指计算机七层网络模型中的协议选择。比如传输层的TCP/UDP、应用层的HTTP/WebSocket等。
- 应用通信协议设计,指如何约定客户端和服务端之间的通信规则。比如如何识别请求内容、如何确定请求字段信息等。
- 编解码(序列化/反序列化)实现,用于将二进制的消息内容解析为程序可识别的数据格式。
每一步具体如何选择和实现呢?我们先看网络通信协议。
网络通信协议选型
从功能需求出发,为了保证性能和可靠性,几乎所有主流消息队列在核心生产、消费链路的协议选择上,都是基于可靠性高、长连接的TCP协议。
下面是一张当前业界主要的协议类型图:
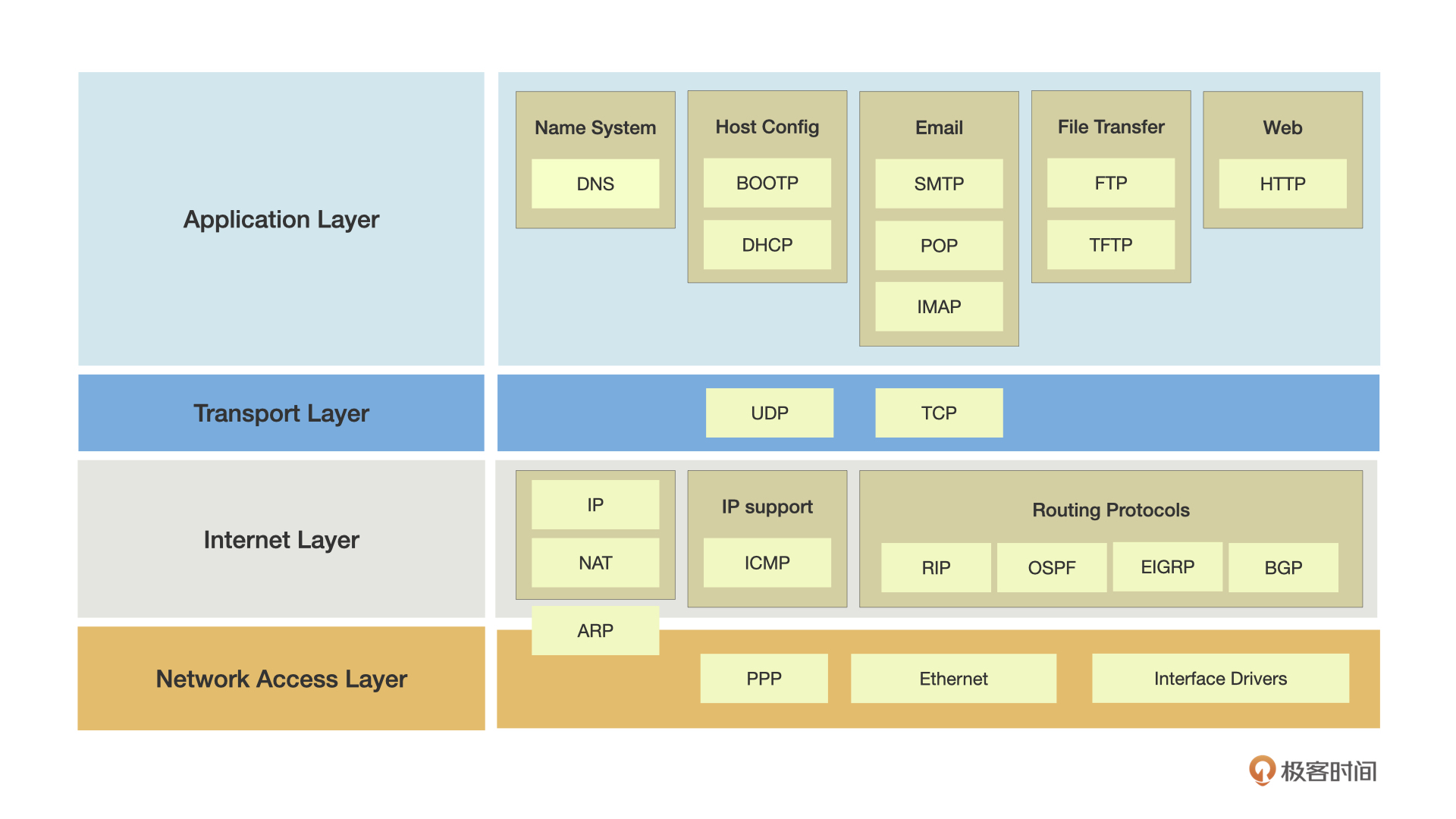 四层的UDP虽然也是长连接,性能更高,但是因为其不可靠传输的特性,业界几乎没有消息队列用它通信。
四层的UDP虽然也是长连接,性能更高,但是因为其不可靠传输的特性,业界几乎没有消息队列用它通信。
七层的HTTP协议每次通信都需要经历三次握手、四次关闭等步骤,并且协议结构也不够精简。从而在性能(比如耗时)上的表现较差,不适合高吞吐、大流量、低延时的场景。所以主流协议在核心链路上很少使用HTTP。
但是,很少并不代表没有,HTTP协议的优点是客户端库非常丰富,协议成熟,非常容易和第三方集成,用户使用起来成本非常低。
所以一些主打轻量、简单的消息队列,比如AWS SQS、Tencent CMQ,它们主链路的协议就是用的HTTP协议。核心考虑是满足多场景的需求,即支持多种接入方式并降低接入门槛。七层协议虽然在性能上有一些降低,但是在一些特殊场景或者某些对耗时不敏感的业务中,降低接入成本是收益很高的事情。
接下来看应用通信协议的设计,如何构成?设计的时候我们应该关注什么呢?
应用通信协议设计
从应用通信协议构成的角度,协议一般会包含协议头和协议体两部分。
- 协议头包含一些通用信息和数据源信息,比如协议版本、请求标识、请求的ID、客户端ID等等。
- 协议体主要包含本次通信的业务数据,比如一串字符串、一段JSON格式的数据或者原始二进制数据等等。
从编解码协议的设计角度来看,需要分别针对“请求”和“返回”设计协议,请求协议结构和返回协议结构一般长这样。
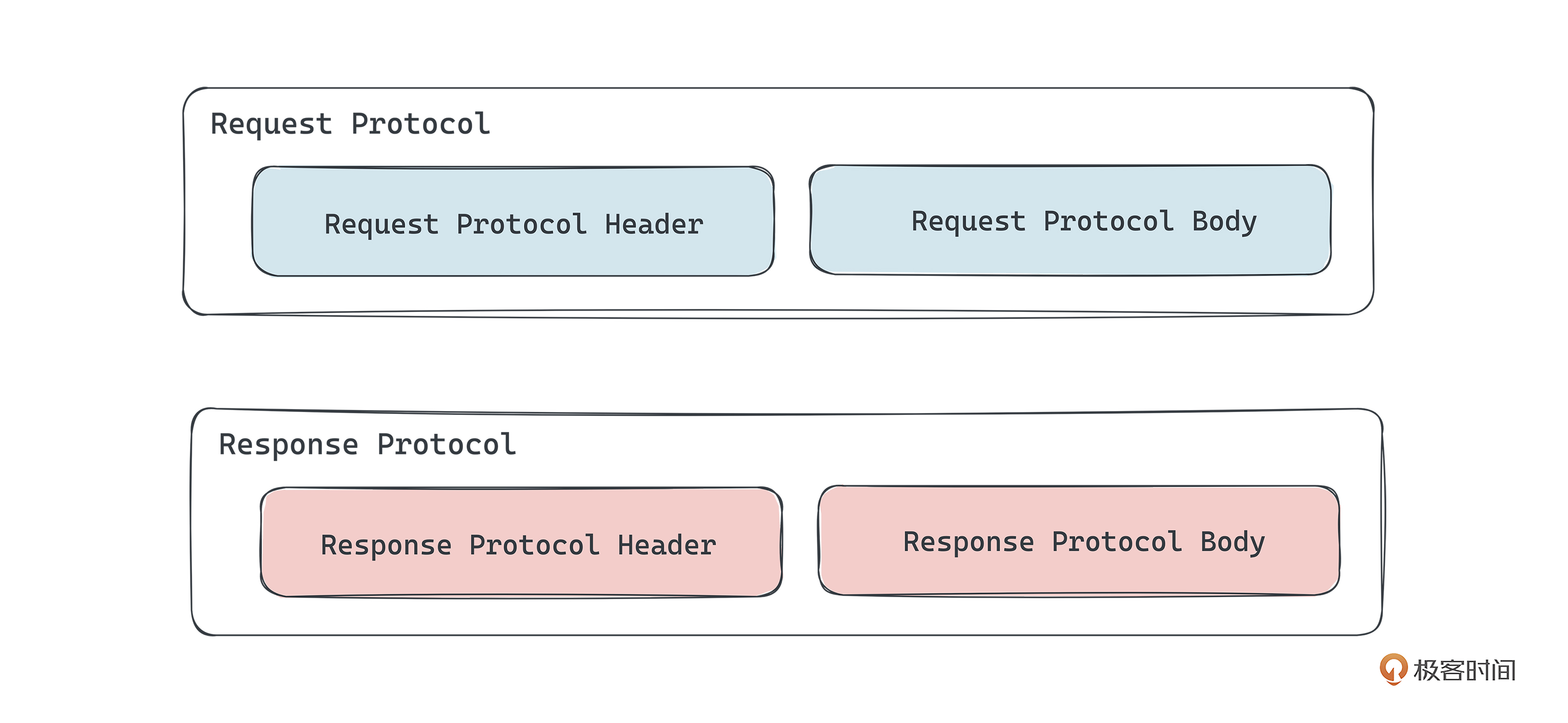
设计的原则是:请求维度的通用信息放在协议头,消息维度的信息就放在协议体。那具体怎么设计呢?我们结合Kafka协议来分析。
协议头的设计
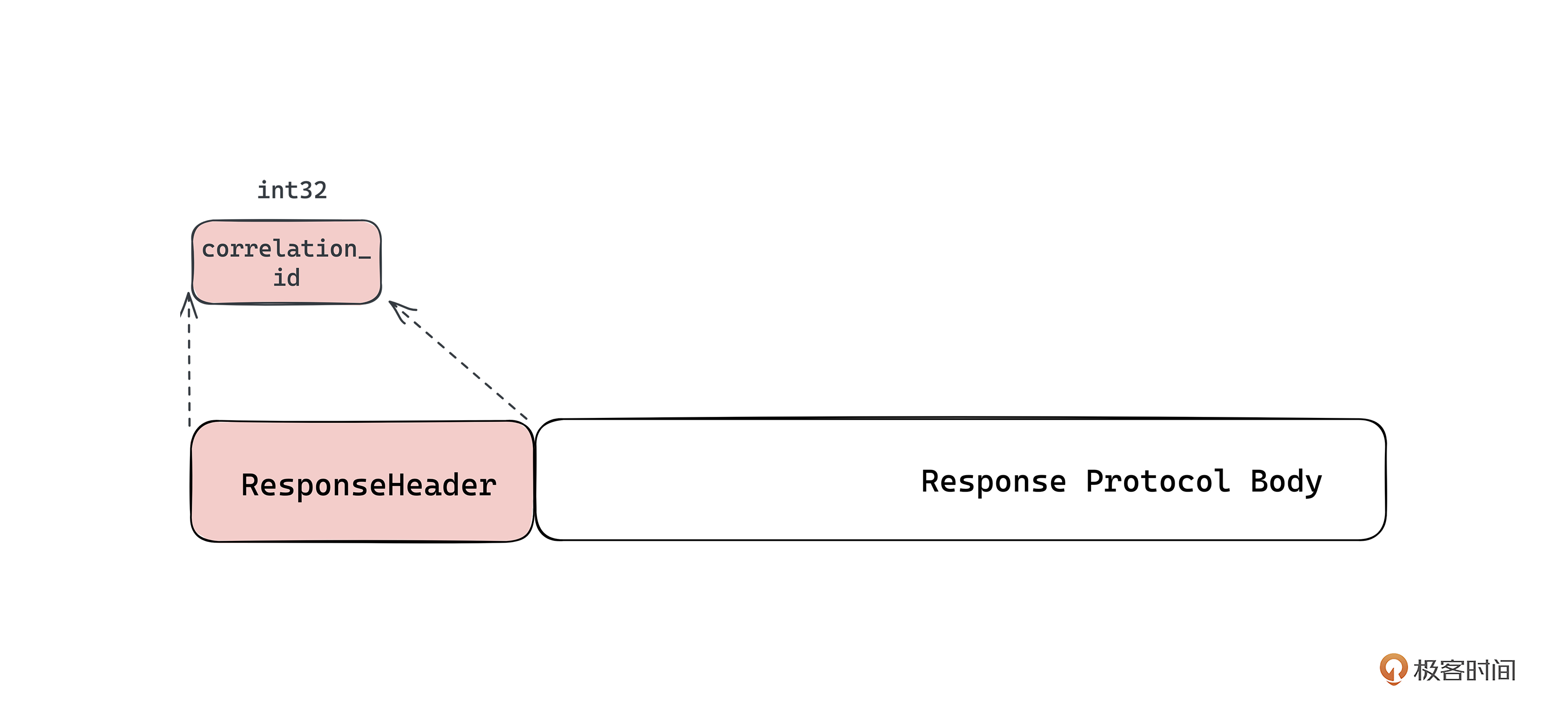
协议头的设计,首先要确认协议中需要携带哪些通用的信息。一般情况下,请求头要携带本次请求以及源端的一些信息,返回头要携带请求唯一标识来表示对应哪个请求,这样就可以了。
所以,请求头一般需要携带协议版本、请求标识、请求的ID、客户端ID等信息。而返回头,一般只需要携带本次请求的ID、本次请求的处理结果(成功或失败)等几个信息。
接下来,我们分析一下Kafka协议的请求头和返回头的内容,让你对协议头的设计有个更直观认识。如下图所示,Kafka V2 协议的请求头中携带了四个信息。

- 用来标识请求类型的api_key,如生产、消费、获取元数据。
- 用来标识请求协议版本的api_version,如V0、V1、V2。
- 用来唯一标识该请求correlation_id,可以理解为请求ID。
- 用来标识客户端的client_id。
Kafka V0协议的返回头中只携带了一个信息,即该请求的correlation_id,用来标识这个返回是哪个请求的。
这里有个细节你可能注意到了,请求协议头是V2版本,返回协议头是V0版本,会不会有点问题呢?
其实是没有的。因为从协议的角度,一般业务需求的变化(增加或删除)都会涉及请求内容的修改,所以请求的协议变化是比较频繁的,而返回头只要能标识本次对应的请求即可,所以协议的变化比较少。所以,请求头和返回头的协议版本制定,是建议分开定义的,这样在后期的维护升级中会更加灵活。
协议体的设计
协议体的设计就和业务功能密切相关了。因为协议体是携带本次请求/返回的具体内容的,不同接口是不一样的,比如生产、消费、确认,每个接口的功能不一样,结构基本千差万别。
不过设计上还是有共性的,注意三个点:极简、向后兼容、协议版本管理。如何理解呢?
协议在实现上首先需要具备向后兼容的能力,后续的变更(如增加或删除)不会影响新老客户端的使用;然后协议内容上要尽量精简(比如字段和数据类型),这样可以降低编解码和传输过程中的带宽的开销,以及其他物理资源的开销;最后需要协议版本管理,方便后续的变更。
同样为了让你直观感受协议体的设计,我们看Kafka生产请求和返回的协议内容,你可以先自己分析一下。
Kafka 生产请求协议体如下:
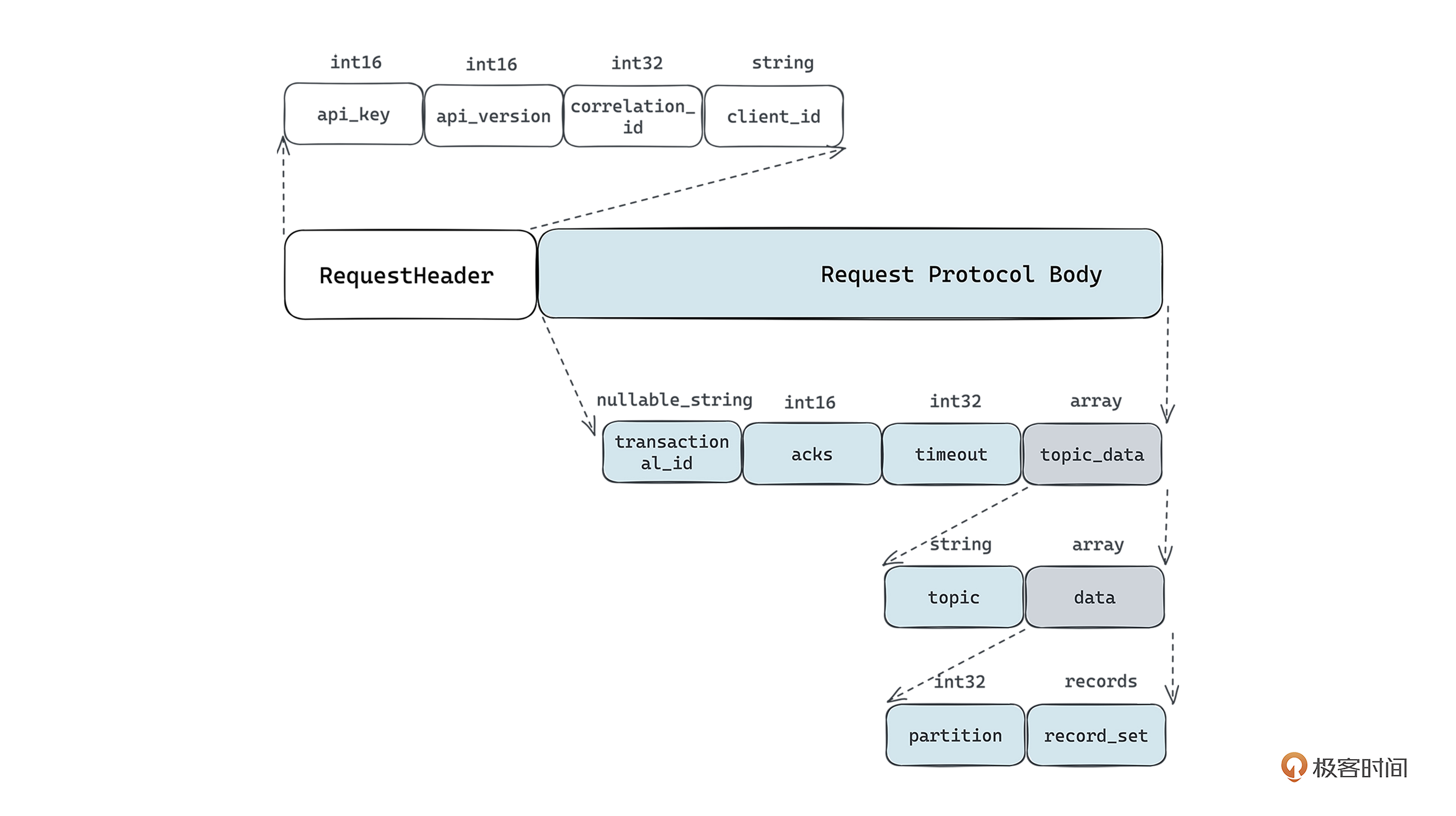
Kafka 生产返回协议体如下:
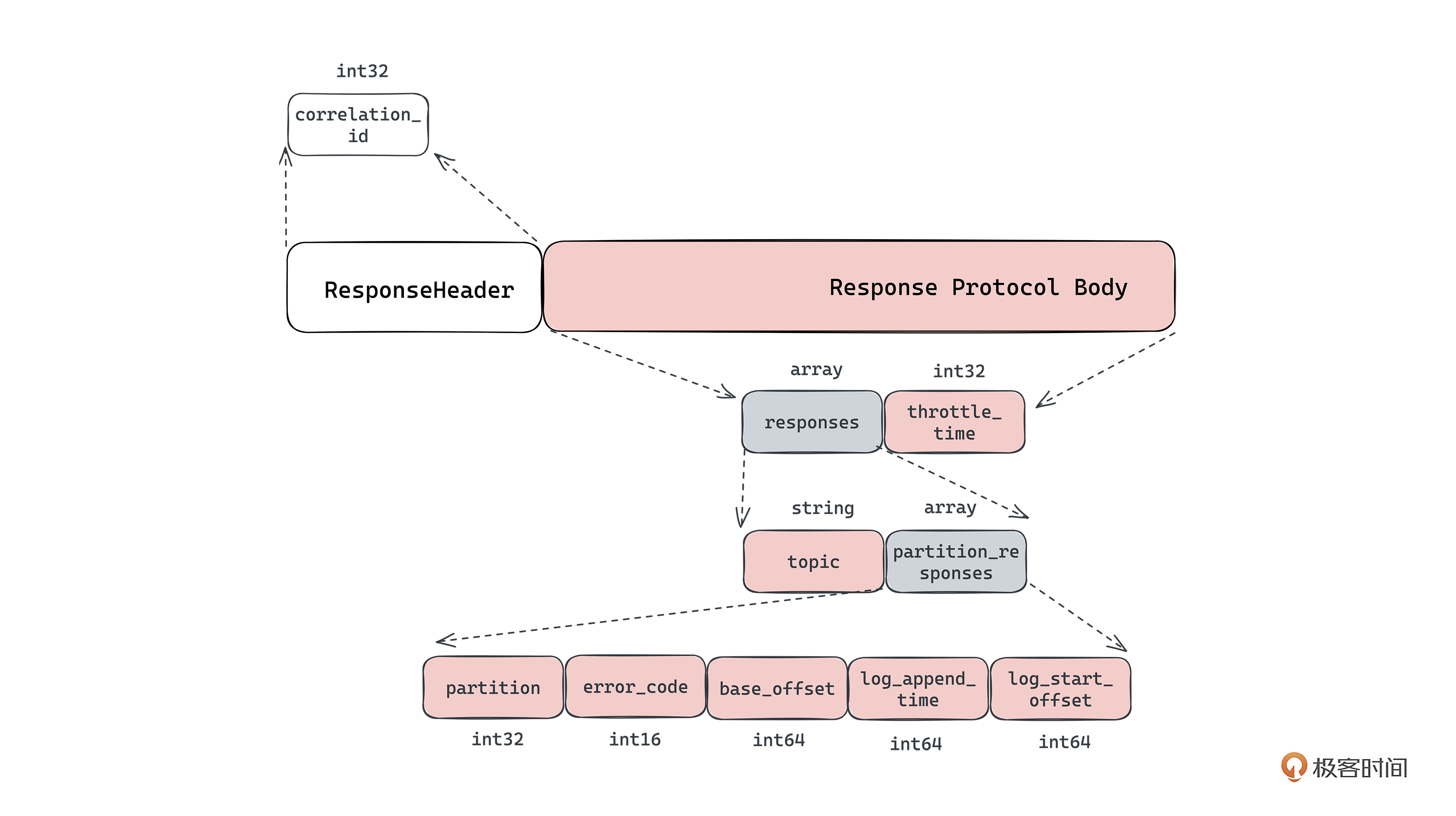
Kafka 生产请求的协议体包含了事务ID、acks信息、请求超时时间、Topic相关的数据,都是和生产操作相关的。生产返回的协议体包含了限流信息、分区维度的范围信息等。这些字段中的每个字段都是经过多轮迭代、重复设计定下来的,每个字段都有用处。
所以在协议体的设计上,最核心的就是要遵循“极简”原则,在满足业务要求的基础上,尽量压缩协议的大小。
接下来我想讨论一下数据类型,在协议设计里,我们很容易忽略的一个事就是数据类型,比如上面 throttle_time_ms 是 INT32,error_code 是 INT16。
数据类型很简单,用来标识每个字段的类型,不过为什么会有这个东西呢,不能直接用int、string、char 等基础类型吗?这里有两个原因。
- 消息队列是多语言通信的。不同语言对于同一类型的定义和实现是不一样的,如果使用同一种基础类型在不同的语言进行解析,可能会出现解析错乱等错误。
- 需要尽量精简消息的长度。比如只需要1个byte就可以表示的内容,如果用4个byte来表示,就会导致消息的内容更长,消耗更多的物理带宽。
所以一般在协议设计的时候,我们也需要设计相关的基础数据类型(如何设计你可以参考 Kafka 的协议数据类型或者 Protobuf 的数据类型)。
接下来我们看看编解码的实现吧。
编解码实现
编解码也称为序列化和反序列,就是数据发送的时候编码,收到数据的时候解码。
为什么要编解码呢? 如下图所示,因为数据在网络中传输时是二进制的形式,所以在客户端发送数据的时候就要将原始的格式数据编码为二进制数据,以便在TCP协议中传输,这一步就是序列化。然后在服务端将收到的二进制数据根据约定好的规范解析成为原始的格式数据,这就是反序列化。
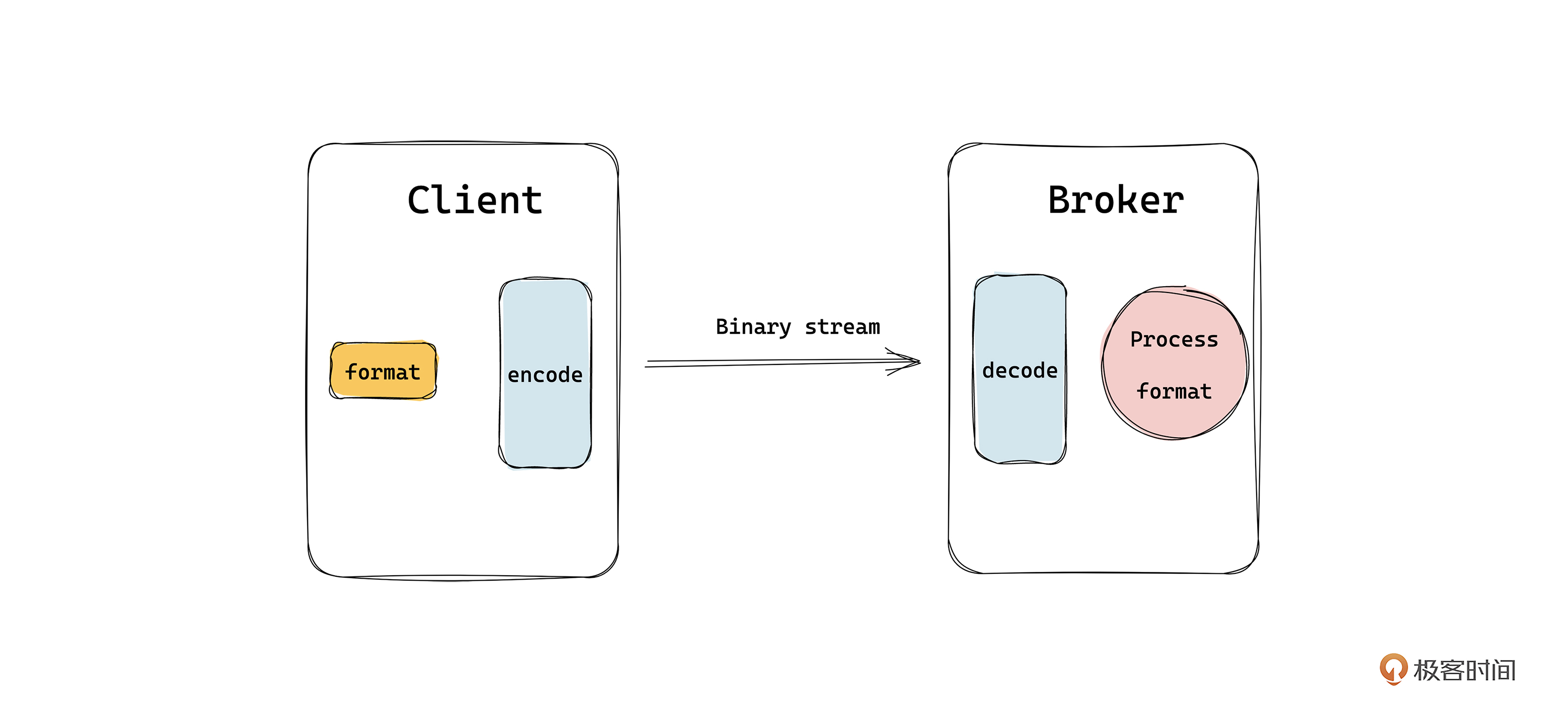
在序列化和反序列化中,最重要的就是TCP的粘包和拆包。我们知道TCP是一个“流”协议,是一串数据,没有明显的界限,TCP层面不知道这段流数据的意义,只负责传输。所以应用层就要根据某个规则从流数据中拆出完整的包,解析出有意义的数据,这就是粘包和拆包的作用。
粘包/拆包的几个思路就是:
- 消息定长。
- 在包尾增加回车换行符进行分割,例如FTP协议。
- 将消息分为消息头和消息体,消息头中包含消息总长度,然后根据长度从流中解析出数据。
- 更加复杂的应用层协议,比如HTTP、WebSocket等。
早期,消息队列的协议设计几乎都是自定义实现编解码,如RabbitMQ、RocektMQ 4.0、Kafka等。
但从0实现编解码器比较复杂,随着业界主流编解码框架和编解码协议的成熟,一些消息队列(如Pulsar和RocketMQ 5.0)开始使用业界成熟的编解码框架,如Google的Protobuf。
Protobuf是一个灵活、高效、结构化的编解码框架,业界非常流行,很多商业产品都会用,它支持多语言,编解码性能较高,可扩展性强,产品成熟度高。这些优点,都是我们在设计协议的时候需要重点考虑和实现的,并且我们自定义实现编解码的效果不一定有Protobuf好。所以新的消息队列产品或者新架构可以考虑选择Protobuf作为编解码框架。
为了加深你对“自定义实现编解码”和“使用现成的编解码框架”两个路径的选择判断,我们来结合RocketMQ的通信协议分析一下。
从RocketMQ看编解码的实现
RocketMQ是业界唯一一个既支持自定义编解码,又支持成熟编解码框架的消息队列产品。RocketMQ 5.0之前支持的Remoting协议是自定义编解码,5.0之后支持的gRPC协议是基于Protobuf 编解码框架。
用Protobuf的主要原因是它选择gRPC框架作为通信框架。而gRPC框架中默认编解码器为Protobuf,编解码操作已经在gRPC的库中正确地定义和实现了,不需要单独开发。所以RocketMQ可以把重点放在Rocket消息队列本身的逻辑上,不需要在协议方面上花费太多精力。
接下来,我们看一下RocketMQ的“生产请求”在Remoting协议和gRPC协议中的协议结构。
如下图所示,自定义的Remoting协议的整体结构,包括协议头(消息头)和协议体(消息体)两部分。消息头包含请求操作码、版本、标记、扩展信息等通用信息。消息体包含的就是各个请求的具体内容,比如生产请求就是包含生产请求的请求数据,是一个复合的结构。
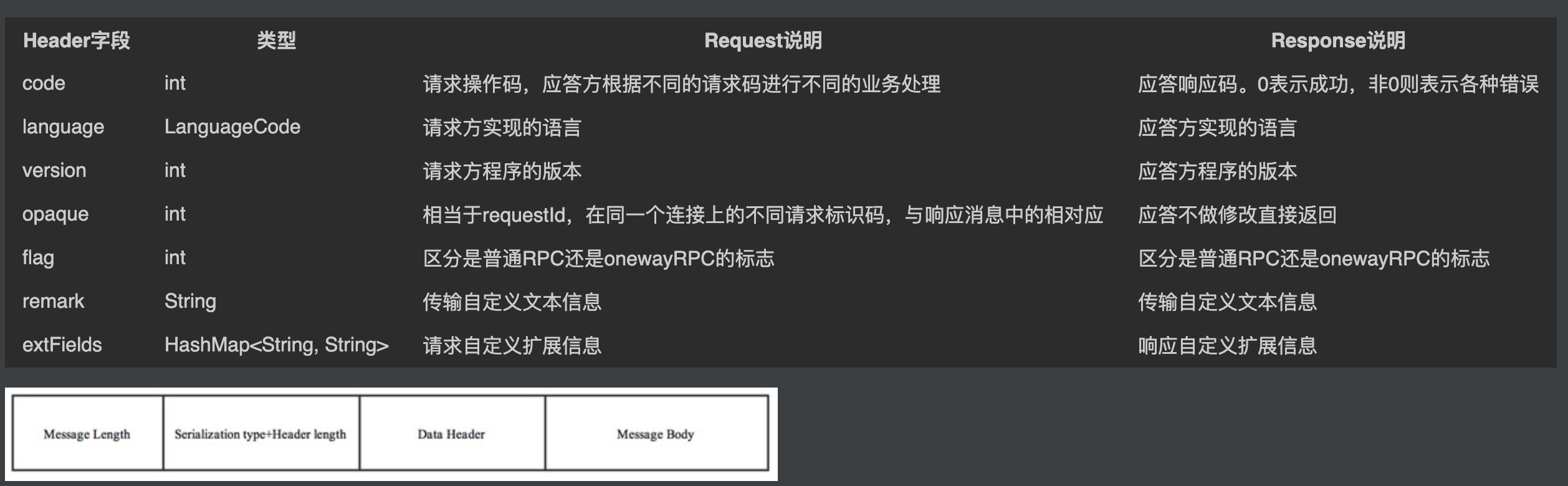
生产请求接口的消息体中的具体内容,包含生产组、Topic、标记等生产请求需要携带的信息,服务端需要根据这些信息完成对应操作。
public class SendMessageRequestHeader......{
private String producerGroup;
private String topic;
private String defaultTopic;
private Integer defaultTopicQueueNums;
private Integer queueId;
private Integer sysFlag;
private Long bornTimestamp;
private Integer flag;
private String properties;
private Integer reconsumeTimes;
private boolean unitMode = false;
private boolean batch = false;
private Integer maxReconsumeTimes;
......
private transient byte[] body;
}
gRPC的生产消息的请求结构,内容简单,只需要定义生产请求需要携带的相关信息,比如Topic、用户属性、系统属性等。
message Message {
Resource topic = 1;
map<string, string> user_properties = 2;
SystemProperties system_properties = 3;
bytes body = 4;
}
message SendMessageRequest {
repeated Message messages = 1;
}
service MessagingService {
rpc SendMessage(SendMessageRequest) returns (SendMessageResponse) {}
}
对比上面两段代码,我们可以很直观地看到区别,gRPC的协议结构比Remoting的协议结构简单很多,比如不需要定义消息头,定义方式也更加简单。
有这样的区别主要有以下两点原因:
- Remoting需要先设计协议的整体结构,协议头和协议体,而gRPC只需要关注协议体。因为gRPC已经完成了整体结构和协议体的设计。
- Remoting需要在各个语言自定义实现相关代码,而gRPC基于Protobuf编解码框架,只要根据Protobuf语法定义好协议体的内容,就可以使用工具生成各语言的代码。
这也佐证了我们的看法,使用现成的编解码框架比自定义编解码更加方便和高效。
总结
到这里,今天的主要内容——消息队列的通信协议设计我们就学完了。
从功能支持、迭代速度、灵活性上考虑,大多数消息队列的核心通信协议都会优先考虑自定义的私有协议。
私有协议的设计主要考虑网络通信协议选择、应用通信协议设计、编解码实现三个方面。
- 网络通信协议选型,基于可靠、低延时的需求,大部分情况下应该选择TCP。
- 应用通信协议设计,分为请求协议和返回协议两方面。协议应该包含协议头和协议体两部分。协议头主要包含一些通用的信息,协议体包含请求维度的信息。
- 编解码,也叫序列化和反序列化。在实现上分为自定义实现和使用现成的编解码框架两个路径。
其中最重要的是应用通信协议部分的设计选型,这部分需要设计协议头和协议体。重要的是要思考协议头和协议体里面分别要放什么,放多了浪费带宽影响传输性能,放少了无法满足业务需求,需要频繁修改协议内容。另外,每个字段的类型也有讲究,需要尽量降低每次通信的数据大小。
所以应用通信协议的内容设计是非常考验技术功底或者经验的。有一个技巧是,如果需要实现自定义的协议,可以去参考一下业界主流的协议实现,看看都包含哪些元素,各自踩过什么坑。总结分析后,这样一般能设计出一个相对较好的消息队列。
另外,我们不可能一下子设计出完美的协议,所以核心是保证协议的向前兼容和向后兼容的能力,以便后续的升级和改造。
因为历史发展原因,业界大部分的消息队列的编解码都是自己实现的,只有近年兴起的Pulsar和RocketMQ的新版本选择了Protobuf作为编解码框架。从编解码框架的选择来看,如果是一个全新的项目或架构,使用现成的编解码框架比如Protobuf,是比较好的选择。
思考题
为什么业界的消息队列有多种标准的协议呢?
期待你的分享。今天我们没有展开讲各个消息队列的协议细节,如果你感兴趣也可以留言讨论。欢迎你把这节课分享给身边的朋友一起学习。我们下节课再见!
- 张申傲 👍(7) 💬(2)
请问老师,如果一款新的消息队列直接采用了gRPC,那么是不是相当于同时具备了网络通信协议(gRPC底层是HTTP2.0)、应用通信协议(Protobuf的IDL定义)和编解码(Protobuf)三种功能,这样实现成本就更低了?
2023-06-27 - 青鸟飞鱼 👍(4) 💬(2)
用QUIC协议会不会好一点呢??
2023-07-09 - 二夕 👍(3) 💬(1)
读了本节的内容之后,对于后面的部分愈发感觉到期待。起初读前面的章节还有点比较普通内容有点水的感觉,从这部分来看内容逐渐硬核起来,催更催更!!
2023-07-06 - aoe 👍(3) 💬(1)
我觉得「请求头和返回头的协议版本制定,是建议分开定义的」有以下优点: 1. 分离关注点,可降低复杂度 2. 符合单一原则,功能更内聚,设计上对测试友好,有利于编写单元测试 所以这样在后期的维护升级中会更加灵活
2023-06-28 - 木几丶 👍(3) 💬(1)
回答问题:为什么业界的消息队列有多种标准的协议呢? 我觉得是因为每种消息队列功能不同,特点不同,定位不同,都会根据自身的功能特性量身定制一种协议以达到性能、扩展性的最大化,同时也能根据自己的节奏控制版本迭代
2023-06-28 - kai 👍(1) 💬(1)
通信协议,主要负责客户端和服务端之间的通信。 通信协议的设计要求: 1 可靠性高 2 性能好 3 节省带宽 4 扩展性好 通信协议的设计主要包括三部分: 网络协议的设计:一般选择可靠的 TCP 协议 应用协议的设计:应用协议主要分为两部分,请求和响应。每部分又分为协议头和协议体。 设计原则要求向前和向后兼容,极简以节省带宽,以及注意版本管理。 可以选择使用私有协议,好处是自己控制,可以按需开发,也可以使用通用协议,好处是工作量降低,比如使用 gRPC。 编解码设计:也就是序列化和反序列化。 可以自己实现,也可以选择成熟框架,比如使用 gRPC。
2023-07-04 - 翡翠虎 👍(1) 💬(1)
看了前面几篇,能猜到后面的内容也很精彩。重点关注分布式协议和实践那部分,加油⛽️跟着老师进步
2023-06-27 - takumi 👍(0) 💬(4)
如果在UDP上实现可靠性会不会好一点?
2023-07-06 - Satroler 👍(0) 💬(1)
棒,文强哥请速更
2023-06-27 - 文敦复 👍(2) 💬(0)
3个字,棒棒棒。再来2个字,催更。
2023-06-29 - 张洋 👍(1) 💬(0)
不同的消息队列再各个层面都有一些自己定制的需求。 1.网络通信协议不同的消息队列对都用各自的需求,例如Kafka、Pulsar、RocketMQ在网络通信中都选择了TCP,但是老师的文章中举的一些例子中也有使用HTTP协议的,所以针对于不同的应用场景不同的消息队列会有不同的网络协议。还有就是如果未来QUIC得到一些开源产品的验证那么相信使用QUIC的消息队列也会出现,所以很难统一。 2.应用层就拿Kafka来说,有有批量消息、还有自己实现的幂等、事务消息等这样消息头和消息体肯定会有自己的一些特殊的设计。 3.编解码的话,如果自己实现只是为了解决粘包 / 拆包的问题,个人觉得统一使用Protobuf不失为一个好的选择,但是看完老师的评论Protobuf的一些缺点,确实如果从自己实现转战一个开源的组件存在一下几个问题:1.很难对底层做一些定制的优化。2.如果出现一些bug,可能修复的不会特别及时。 总体来说就是不灵活受制于人。所以根据不同的定位还是会选择不同的方式去处理编解码处理。
2023-07-14 - superyins 👍(1) 💬(0)
其实消息队列领域是存在公有的、可直接使用的标准协议的,比如 AMQP、MQTT、OpenMessaging,它们设计的初衷就是为了解决因各个消息队列的协议不一样导致的组件互通、用户使用成本高、重复设计、重复开发成本等问题。但是,公有的标准协议讨论制定需要较长时间,往往无法及时赶上需求的变化,灵活性不足。因此大多数消息队列为了自身的功能支持、迭代速度、灵活性考虑,在核心通信协议的选择上不会选择公有协议,都会选择自定义私有协议。
2023-06-28 - 咖啡☕️ 👍(0) 💬(2)
三次握手不是TCP 的特性吗,为什么说是HTTP的特性呢
2024-09-11 - Geek_d8b559 👍(0) 💬(0)
老师我想要问一下,为什么大部分私有协议在做到TCP这一层就终止了,不适配更加底层and高性能的比如IB,RoCE?
2024-02-04 - Lee 👍(0) 💬(0)
老师,想问一下,应用通信协议的协议头和协议体,是作为整体去编码的吗
2023-09-24