02 消息队列在架构和功能层面都包含哪些概念?
你好,我是文强。
这节课我们来了解一下消息队列在架构和功能层面的基本概念,也是想有针对性地对齐一些通用基础概念,同时让你对消息队列有一个整体认识,从而让后面的学习过程更加顺利。
什么时候会用到消息队列?
首先我们从使用者的角度,来聊聊什么情况下我们会用到消息队列。
在系统架构中,消息队列的定位就是总线和管道,主要起到解耦上下游系统、数据缓存的作用。它不像数据库,会有很多计算、聚合、查询的逻辑,它的主要操作就是生产和消费。所以,我们在业务中不管是使用哪款消息队列,我们的核心操作永远是生产和消费数据。
一般情况下,我们会在需要解耦上下游系统、对数据有缓冲缓存需求或者需要用到消息队列的某些功能(比如延时消息、优先级消息)的时候选择使用消息队列,然后再根据实际需求选型。
下面我们就用经典的订单下单流程,来简要概括下对消息队列的使用情况。
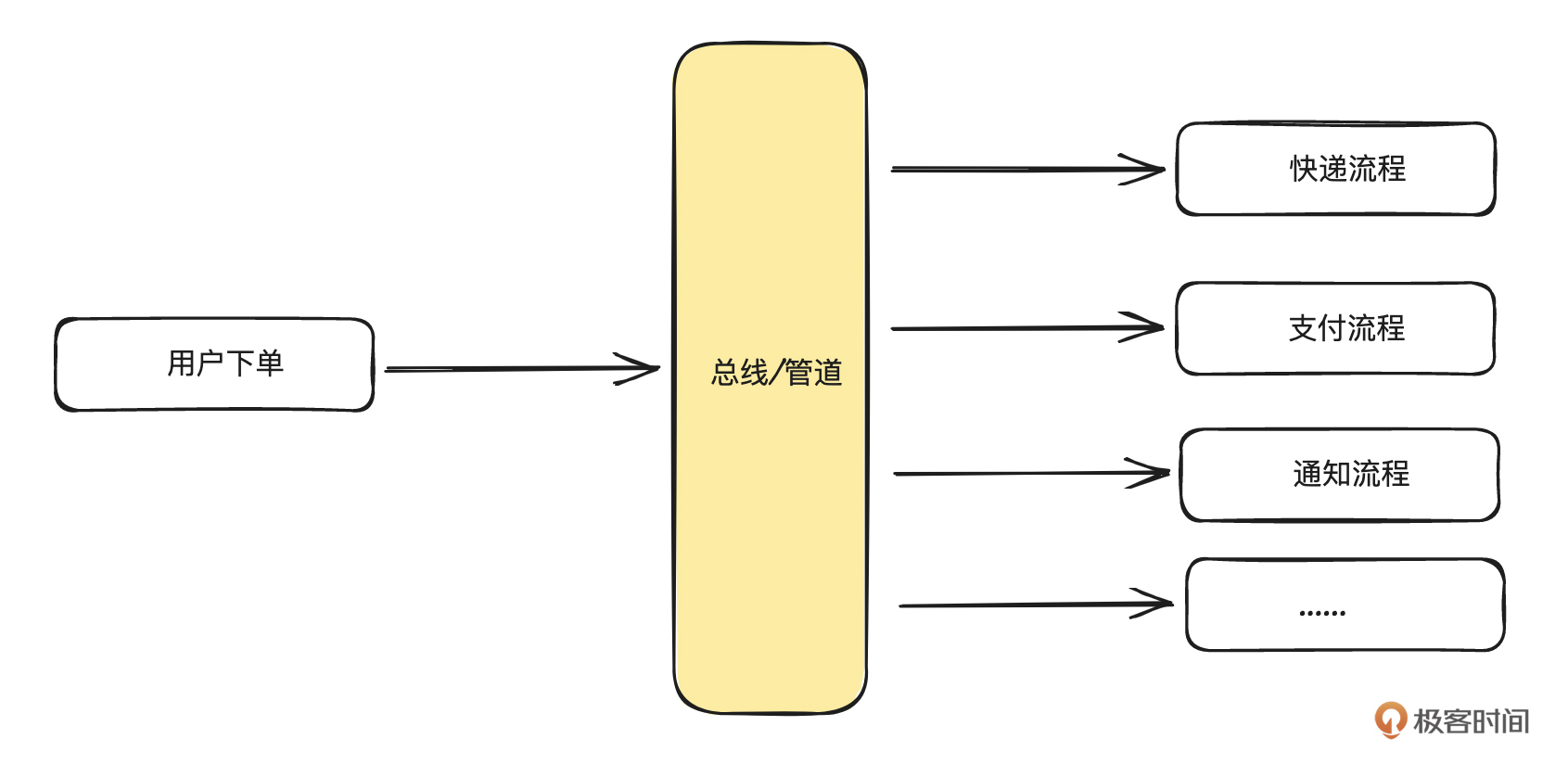
下单流程是一个典型的系统解耦、消息分发的场景,一份数据需要被多个下游系统处理。另外一个经典场景就是日志采集流程,一般日志数据都很大,直接发到下游,下游系统可能会扛不住崩溃,所以会把数据先缓存到消息队列中。所以消息队列的基本特性就是高性能、高吞吐、低延时。
架构层面的基本概念
接下来我们将通过一张图示,来了解一下消息队列架构层面常见的一些基本概念。
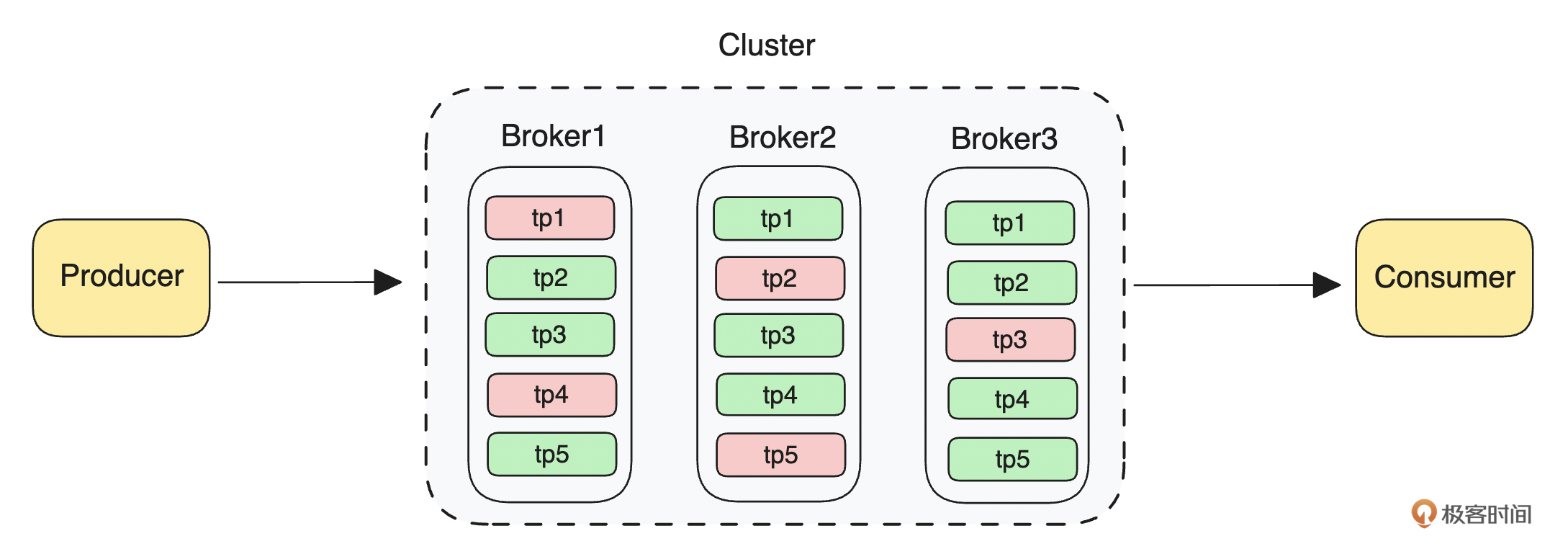
- Broker:Broker 本质上是一个进程,比如 RocketMQ 的 Broker 就是指RocketMQ Server 启动成功后的一个进程。在实际部署过程中,通常一个物理节点只会起一个进程,所以大部分情况下我们认为 Broker 就表示一个节点,但是在一些特殊场景下,一个物理节点中也可以起多个进程,就表示一台节点有多个Broker。
- Topic(主题):在大部分消息队列中,Topic 都是指用来组织分区关系的一个逻辑概念。通常情况下,一个 Topic 会包含多个分区。但是 RabbitMQ 是一个例外,Topic 是指具体某一种主题模式。
- Partition/Queue/MessageQueue(分区/分片):在消息队列中,分区、分片、Partiton、Queue、MessageQueue 是一个概念,后面统一用分区来称呼,都是用来表示数据存储的最小单位。一般可以直接将消息写入到一个分区中,也可以将消息写入到Topic,再分发到具体某个分区。一个Topic 通常会包含一个或多个分区。
- Producer(生产者): 生产者指消息的发送方,即发送消息的客户端,也叫生产端。
- Consumer(消费者):消费者指消息的接收方,即接收消息的客户端,也叫消费端。
- ConsumerGroup/Subscription(消费分组/订阅):一般情况下,消息队列中消费分组和订阅是同一个概念,后面统一用消费分组来称呼。它是用来组织消费者和分区关系的逻辑概念,也有保存消费进度的作用。
- Message(消息):指一条真实的业务数据,消息队列的每条数据一般都叫做一条消息。
- Offset/ConsumerOffset/Cursor(位点/消费位点/游标):指消费者消费分区的进度,即每个消费者都会去消费分区,为了避免重复消费进度,都会保存消费者消费分区的进度信息。
- ACK/OffsetCommit(确认/位点提交):确认和位点提交一般都是指提交消费进度的操作,即数据消费成功后,提交当前的消费位点,确保不重复消费。
- Leader/Follower(领导者/追随者,主副本/从副本):Leader 和 Follower一般是分区维度副本的概念,即集群中的分区一般会有多个副本。此时就会有主从副本的概念,一般是一个主副本配上一个或多个从副本。
- Segment(段/数据分段):段是指消息数据在底层具体存储时,分为多个文件存储时的文件,这个文件就叫做分区的数据段。即比如每超过 1G 的文件就新起一个文件来存储,这个文件就是Segment。基本所有的消息队列都有段的概念,比如Kakfa的Segment、Pulsar的Ledger等等。
- StartOffset/EndOffset(起始位点/结束位点):起始位点和结束位点是分区维度的概念。即数据是顺序写入到分区的,一般从0的位置开始往后写,此时起始位点就是0。因为数据有过期的概念,分区维度较早的数据会被清理。此时起始位点就会往后移,表示当前阶段最早那条有效消息的位点。结束位点是指最新的那条数据的写入位置。因为数据一直在写入分区,所以起始位点和结束位点是一直动态变化的。
- ACL(访问控制技术):ACL 全称是Access Control List,用来对集群中的资源进行权限控制,比如控制分区或Topic的读和写等。
功能层面的基本概念
讲完了架构层面的基本概念,我们来看看功能层面的基本概念。
相比于数据库的基本操作是增删改查,消息队列的基本操作就是生产和消费,即读和写。消息队列一般是不支持客户端修改和删除单条数据的。接下来我们就从功能的角度,来了解一些常见的基本概念。
- 顺序消息:是指从生产者和消费者的视角来看,生产者按顺序写入Topic的消息,在消费者这边能不能按生产者写入的顺序消费到消息,如果能就是顺序消息。
- 延时消息/定时消息:都是指生产者发送消息到 Broker 时,可以设置这条消息在多久后能被消费到,当时间到了后,消息就会被消费到。延时的意思就是指以 Broker 收到消息的时间为准,多久后消息能被消费者消费,比如消息发送成功后的30分钟才能被消费。定时是指可以指定消息在设置的时间才能被看到,比如设置明天的20:00才能被消费。从技术上来看,两者是一样的;从客户端的角度,功能上稍微有细微的差别;从内核的角度,一般两种消息是以同一个概念出现的。
- 事务消息:消息队列的事务因为在不同的消息队列中的实现方式不一样,所以定义也不太一样。正常情况下,事务表示多个操作的原子性,即一批操作要么一起成功,要么一起失败。在消息队列中,一般指发送一批消息,要么同时成功,要么同时失败。
- 消息重试:消息重试分为生产者重试和消费者重试。生产者重试是指当消息发送失败后,可以设置重试逻辑,比如重试几次、多久后重试、重试间隔多少。消费者重试是指当消费的消息处理失败后,会自动重试消费消息。
- 消息回溯:是指当允许消息被多次消费,即某条消息消费成功后,这条消息不会被删除,还能再重复到这条消息。
- 广播消费:广播听起来是一个主动的,即 Broker 将一条消息广播发送给多个消费者。但是在消息队列中,广播本质上是指一条消息能不能被很多个消费者消费到。只要能被多个消费者消费到,就能起到广播消费的效果,就可以叫做广播消费。
- 死信队列:死信队列是一个功能,不是一个像分区一样的实体概念。它是指当某条消息无法处理成功时,则把这条消息写入到死信队列,将这条消息保存起来,从而可以处理后续的消息的功能。大部分情况下,死信队列在消费端使用得比较多,即消费到的消息无法处理成功,则将数据先保存到死信队列,然后可以继续处理其他消息。当然,在生产的时候也会有死信队列的概念,即某条消息无法写入Topic,则可以先写入到死信队列。从功能上来看,死信队列的功能业务也可以自己去实现。消息队列中死信队列的意思是,消息队列的SDK已经集成了这部分功能,从而让业务使用起来就很简单。
- 优先级队列:优先级队列是指可以给在一个分区或队列中的消息设置权重,权重大的消息能够被优先消费到。大部分情况下,消息队列的消息处理是FIFO先进先出的规则。此时如果某些消息需要被优先处理,基于这个规则就无法实现。所以就有了优先级队列的概念,优先级是消息维度设置的。
- 消息过滤:是指可以给每条消息打上标签,在消费的时候可以根据标签信息去消费消息。可以理解为一个简单的查询消息的功能,即通过标签去查询过滤消息。消息过滤主要在消费端生效。
- 消息过期/删除(TTL):是指消息队列中的消息会在一定时间或者超过一定大小后会被删除。因为消息队列主要是缓冲作用,所以一般会要求消息在一定的策略后会自动被清理。
- 消息轨迹:是指记录一条消息从生产端发送、服务端保存、消费端消费的全生命周期的流程信息。用来追溯消息什么时候被发送、是否发送成功、什么时候发送成功、服务端是否保存成功、什么时候保存成功、被哪些消费者消费、是否消费成功、什么时候被消费等等信息。
- 消息查询:是指能够根据某些信息查询到消息队列中的信息。比如根据消息ID或根据消费位点来查询消息,可以理解为数据库里面的固定条件的select操作。
- 消息压缩:是指生产端发送消息的时候,是否支持将消息进行压缩,以节省物理资源(比如网卡、硬盘)。压缩可以在SDK完成,也可以在Broker完成,并没有严格限制。通常来看,压缩在客户端完成会比较合理。
- 多租户:是指同一个集群是否有逻辑隔离,比如一个物理集群能否创建两个名称都为test的主题。此时一般会有一个逻辑概念 Namespace(命名空间)和 Tenant(租户)来做隔离,一般有这两个概念的就是支持多租户。
- 消息持久化:是指消息发送到Broker后,会不会持久化存储,比如存储到硬盘。有些消息队列为了保证性能,只会把消息存储在内存,此时节点重启后数据就会丢失。
- 消息流控:是指能否对写入集群的消息进行限制。一般会支持Topic、分区、消费分组、集群等维度的限流。
总结
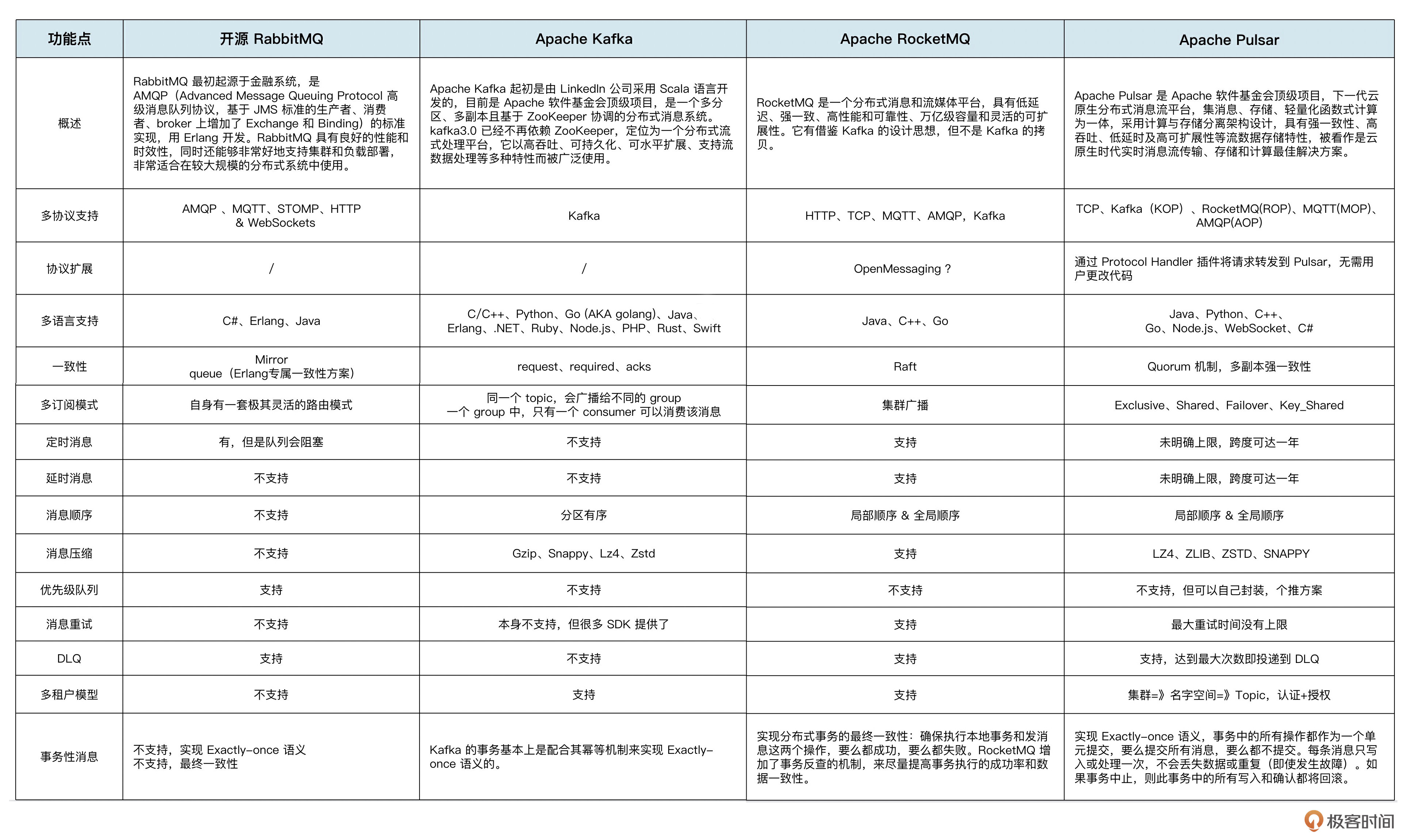
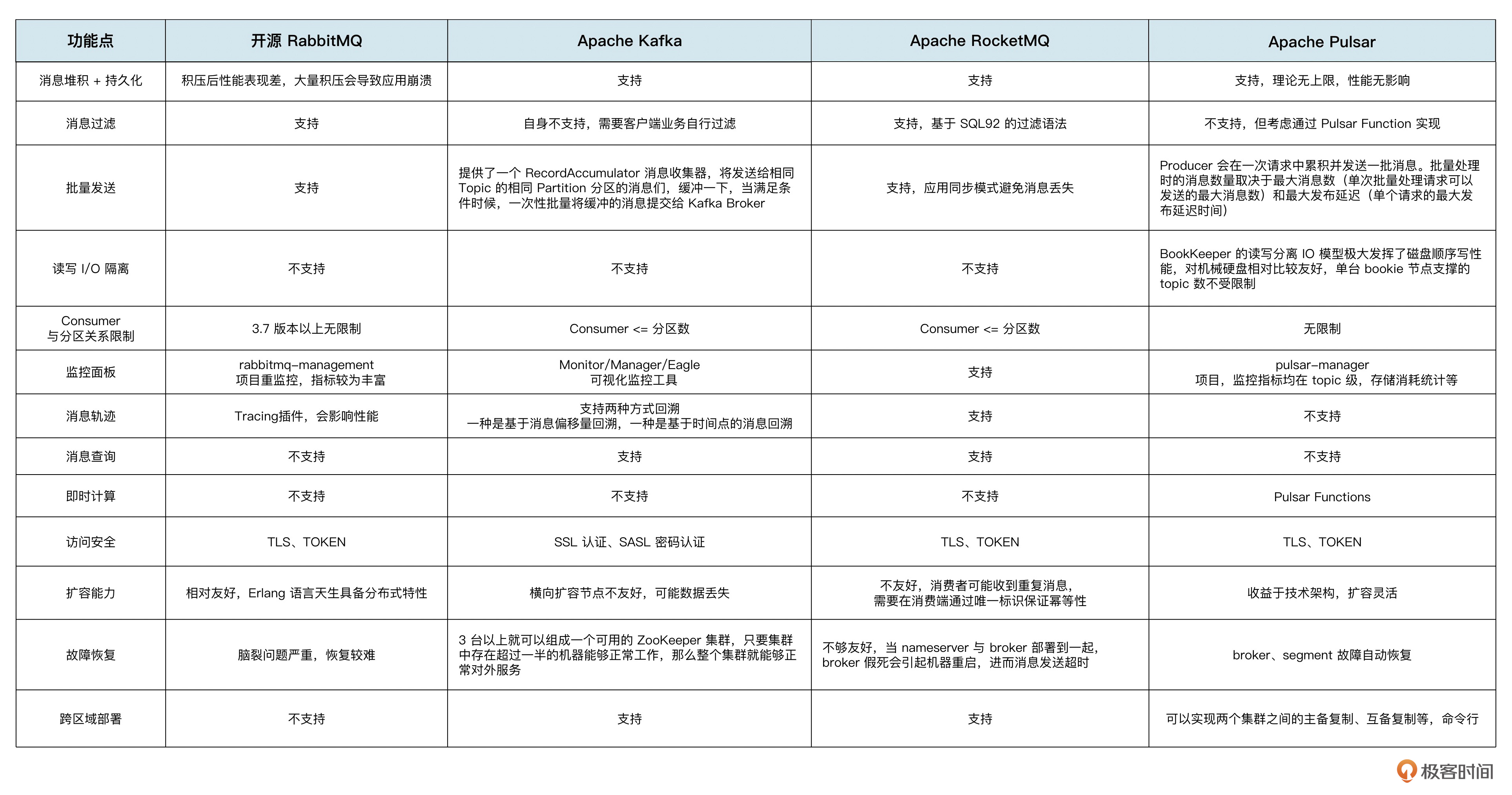
到这儿,我们预习篇的内容就结束了,这个起步是不是非常简单。概念就不过多总结了,最后我们来总结一下 4 款主流消息队列的区别以及选型建议,第01讲也提到过,它们分别是RabbitMQ、RocketMQ、Kafka、Pulsar。
- RabbitMQ和RocektMQ属于业务消息类的消息队列,它们的特点是功能丰富、低延时、数据高可靠性、消息可追踪等等,同时也支持延时消息、优先级队列、消息过滤等功能特性。RabbitMQ发展较早,RocketMQ则是新生的消息类的消息队列,从功能、集群化、稳定性、性能来看,RocketMQ 都是比 RabbitMQ 表现要好的。所以从某种意义上说,RocketMQ是可以替代RabbitMQ的,但是因为RabbitMQ发展悠久、内核稳定以及能满足大部分的业务消息场景,所以目前用户群体也很大。国内的业务消息类的选型一般以RocketMQ优先,然后才是RabbitMQ,而国外的业务消息类选型一般优先的是RabbitMQ。
- Kakfa 属于主打流场景的消息队列。它的特点是追求高吞吐、大流量,在功能上相对简单。不支持太多消息队列的功能,比如死信队列、延时消息、消息过滤等等。但它的核心竞争力就是非常稳定、吞吐性能非常高,能承担超大流量的业务场景。所以它是流场景下的消息管道的不二选择。
- Pulsar 从定位上是消息和流一体的。目标就是满足所有消息和流的场景,希望同时满足功能和性能两方面的需求。所以Pulsar的内核会支持很多功能,在性能和吞吐方面也经常拿来与Kakfa做比较。但是因为其发展时间较短,目前还不是那么稳定,正处于快速发展阶段。
从个人选择来看,我也给你一些建议。
- 业务消息类的场景,我会推荐你优先选择RocketMQ。主要原因是RocketMQ的性能高、社区活跃、集群化架构稳定、功能也非常丰富。而RabbitMQ当前架构存在缺点,单机存在瓶颈,在高QPS场景表现不是那么好,并且可能出现网络分区。所以从功能、性能、稳定性出发,我会优先推荐你使用RocketMQ。
- 流方向的场景,我会推荐你优先选择Kafka。主要原因是Kafka本身的性能和吞吐表现非常优越,延时和可靠性表现也不错。而Pulsar虽然主打的是替换Kafka,并且功能丰富,架构设计理念先进,但是因为发展周期较短,很多功能还不稳定,当前阶段的现网运营表现并不是那么好。所以虽然Kafka存在扩容、Rebalance方面的缺陷,但是从稳定性、性能出发,我还是会优先推荐你使用Kafka。
- 在日常使用中,我们也可能会根据业务需求同时运营多款消息队列,比如RocketMQ/RabbitMQ+Kafka。
更多细节总结如下,你可以再详细看看。
 }{:referrerpolicy="no-referrer"
}{:referrerpolicy="no-referrer"
今天的课程就到这里,预习篇非常简单,但相当重要。这节课我们就不留作业了,期待你能反复学习、牢牢记住。如果今天的课程让你有所收获,也欢迎你分享给有需要的朋友,我们下节课再见!
- 大胖子呀、 👍(5) 💬(2)
多语言支持那一栏,Kafka不支持Java语言的吗?
2023-06-28 - Geek_66158e 👍(4) 💬(1)
因为kafka第一开始的主要目标是日志处理,需要非常大的吞吐量,消息的延迟在最初的设计中没有很大优先级,所以一般是生产端批量发送,消费端一般是批量拉取,不支持push模式,而且kafka在支持消息协议,各种高级消息功能,延时消息等都兴趣不大。这方面就是rocket mq的优势。在一些中小公司,kafka的延迟和基本消息队列功能都非常够用,而且在各种开源connector,soure连接组件都很多,中小团队会优先考虑,后续加spark或者flink做分析难度不大。RocketMQ号称金融级别的可靠性和低延迟,消息队列低级高级应有尽有。
2023-07-02 - aoe 👍(4) 💬(1)
第一次遇到没有作业的一课,庆祝一下
2023-06-27 - 未设置 👍(2) 💬(1)
流方向是不是只追求大吞吐量的业务场景,比如kafka的批量发送特性,而rocketMQ一般不会设置批量发送特性,更注重消息的及时性呢?
2023-06-27 - liu 👍(0) 💬(1)
架构层面的基本概念及联系 能通过一张图画出来吗?
2023-07-23 - walle斌 👍(0) 💬(0)
consumer 与分区数 看不出rocketmq的优势来,应该说并发度,rocketmq max是读队列数(分区数)* 并发线程数
2023-08-09 - 花花大脸猫 👍(0) 💬(0)
所以是不是可以说,在选择消息队列时,如果能选择到RocketMQ,其实尽量就不需要在选择RabbitMQ来作为选项了?毕竟如果RocketMQ都涵盖RabbitMQ所有功能,并且在分布式架构上更能贴近现在的发展趋势,没有选择RabbitMQ的必要了。
2023-08-07 - Mr.J 👍(0) 💬(2)
还是没太懂什么是流方向
2023-06-27