28 限界上下文(上):怎样为更大的需求建模?
你好,我是钟敬。
上节课我们概述了迭代三的主要内容和需求。这节课开始,我们将会学习DDD里的一个有代表性的模式“限界上下文”。
我相信你第一次听到这个名词的时候,肯定会觉得不知所云。这个词确实难以望文生义。不过别担心,我们可以暂且忘掉这个词本身,先回到我们的项目,我会一步一步地带你理解这个模式的概念和用法。
团队遇到的挑战
经过1年的苦心经营,“卷卷通”已经初步打开了局面。随着需求的增加,开发团队由原来的4个人发展到20个人。
假设你是开发团队的组长,我是技术骨干,我们都是这个项目的第一批成员,共同承担着架构师的职责。我比你先学了一点DDD。
这时候,作为这个产品的元老,我们发现了一些新的问题。
第一,沟通变困难了。之前人少的时候,什么事只要跑到那个同事旁边说一声,就解决了。现在需要不断开会。有时以为沟通已经到位了,等代码做出来,才发现还是没理解。
第二,系统的代码质量变差了。尽管我们已经用了 DDD 的分层架构,但还是难以避免代码的腐化。尤其是老员工离职,新人接手,特别容易出问题。
第三,系统的外在质量问题也跟着变多了。尤其是新需求稍微复杂一点,就很容易牵一发而动全身。改了一个地方,就要改很多其他地方,如果漏了,就会出错。
第四,由于目前用的是单体架构,造成了不同需求的互相等待。比如有两个需求同时在做,一个关于项目管理,一个关于人员管理。两者的逻辑互不相关。项目管理的功能做完了,本来可以上线,但人员管理的还没做完,所以必须等待。
最后,由于并发访问的人数越来越多,我们想通过横向扩展来提高性能。目前系统部署在两台服务器,我们想增加到五台,发现成本比较高。问题在于,不是每个功能都需要扩展。人员管理的并发要求没有报工时的要求高,其实只需要扩展报工时功能就可以了,但现在必须同时扩展所有功能。
当谈到这些问题的时候,我们都觉得,是时候把系统拆成几部分了。但是,该怎么科学地拆分呢?
我说:“可以考虑 DDD 里的限界上下文”。
你说:“我也听说过限界上下文,好像就是把系统按照业务边界拆开,也有人说就是拆成几个子系统。我们目前的模型已经按模块分了。那么按限界上下文拆分,和分模块、分子系统相比,有什么不同呢?”
我说:“我先介绍一下限界上下文的概念吧,然后我们通过拆分模型来实操一下。”
限界上下文的含义
限界上下文确实和划分模块、划分子系统一样,是一种分而治之的手段,可以起到分离关注点的作用。但限界上下文增加了一个要点,就是,它的目的还在于维护概念一致性。正是这一点,造成限界上下文和传统方法的本质不同。
早在六、七十年代,软件工程的早期,人们已经意识到,在大型系统中保持概念一致性非常困难。但人们潜意识中一直认为,总有办法达到全局的概念一致性,也为此想了很多办法,例如及时更新文档、增加开会沟通次数等等,但并没有达到预期效果。
而 DDD 认为,面对大规模的系统,全局概念一致性从根本上是不可能的。这是因为,人的认知能力是有限的。由于大型软件是团队协作开发的,因此这里其实是团队的认知能力。当系统规模增大时,团队规模也会相应增大,沟通难度会呈非线性增长。当系统达到一定规模,就超过了一个团队的认知能力,无法保证概念的一致性了。
这时候,就要把大系统分解成若干子系统,每个子系统对应一个领域模型。每个模型的规模都不超过一个开发小组的认知负载。在每个子系统的内部实现概念的严格一致性,而不同系统内部之间则没有必要一致。也就是说,不再追求全局一致性,而是退而求其次,只需追求局部的一致性,使概念不一致的问题得到合理管控,从而实现业务目标,这样就足够了。
概念的一致性是通过语义上的一致性来表达的,所以 Evans 引用了语言学上“上下文”(context)的术语,来表示一个子系统、子模型或者维护这个子系统的团队。
语言学认为,一个词汇或者语句,只有在一个上下文里才有确切的含义。
举个例子,比如我们都在银行信息部工作,现在随便抓一个搞 IT 的同事,说“我们聊聊账户吧”。这时候其实账户这个概念是不明确的。
如果这个同事是搞会计系统的,那么他理解的账户就是会计账户。如果他是做个人存款系统的,那么他理解的账户可能是个人银行账户。如果他是搞投资系统的,那么就是投资账户。而这些账户的概念是不一样的。只有我们明确了“咱们现在谈的是会计系统”的时候,账户这个概念才是明确的。这时候,“会计系统”就是我们谈话的上下文。
在日常谈话的时候,人们常常会随时切换上下文,不一定会影响沟通。但在计算机软件中,一个元素要么属于一个上下文,要么不属于,这个界限必须清清楚楚。为了强调这一边界(boundary)的重要性,因此称为“限界上下文”(bounded context)。
从这里也可以得出一个推论:课程的第一个迭代提过的统一语言是针对一个限界上下文而言的。也就是说,一个限界上下文对应一套统一语言。脱离上下文谈统一语言是没有意义的。
划分限界上下文
你说:“听你说了这么多,好像挺有道理的样子,可是咱们实际落地的时候,到底怎么做呢?”
我说:“咱们不妨先考虑一下拆分的粒度。也就是大概拆成3部分还是5部分的问题。由于概念不一致的症结在于团队的认知能力过载,所以粒度问题可以从团队的组织结构入手。我们先想一下,要维护一个模型的概念一致性,相应的开发组最多不能超过多少人。”
你说:“通常一个敏捷的团队的大小是 7 ± 2,也就是 5 ~ 9 个人。也有人说所谓 2 pizza team,也就是两个披萨够吃的规模,大概10个人上下。据说这个团队规模是有心理学的实验依据的。也就是超过这个规模,团队的协作就比较容易出问题了,就像我们现在这样。”
我说:“那我们就按这个数量级来考虑吧。咱们先盘一盘目前团队的情况。可以对着模型图来想一想。”
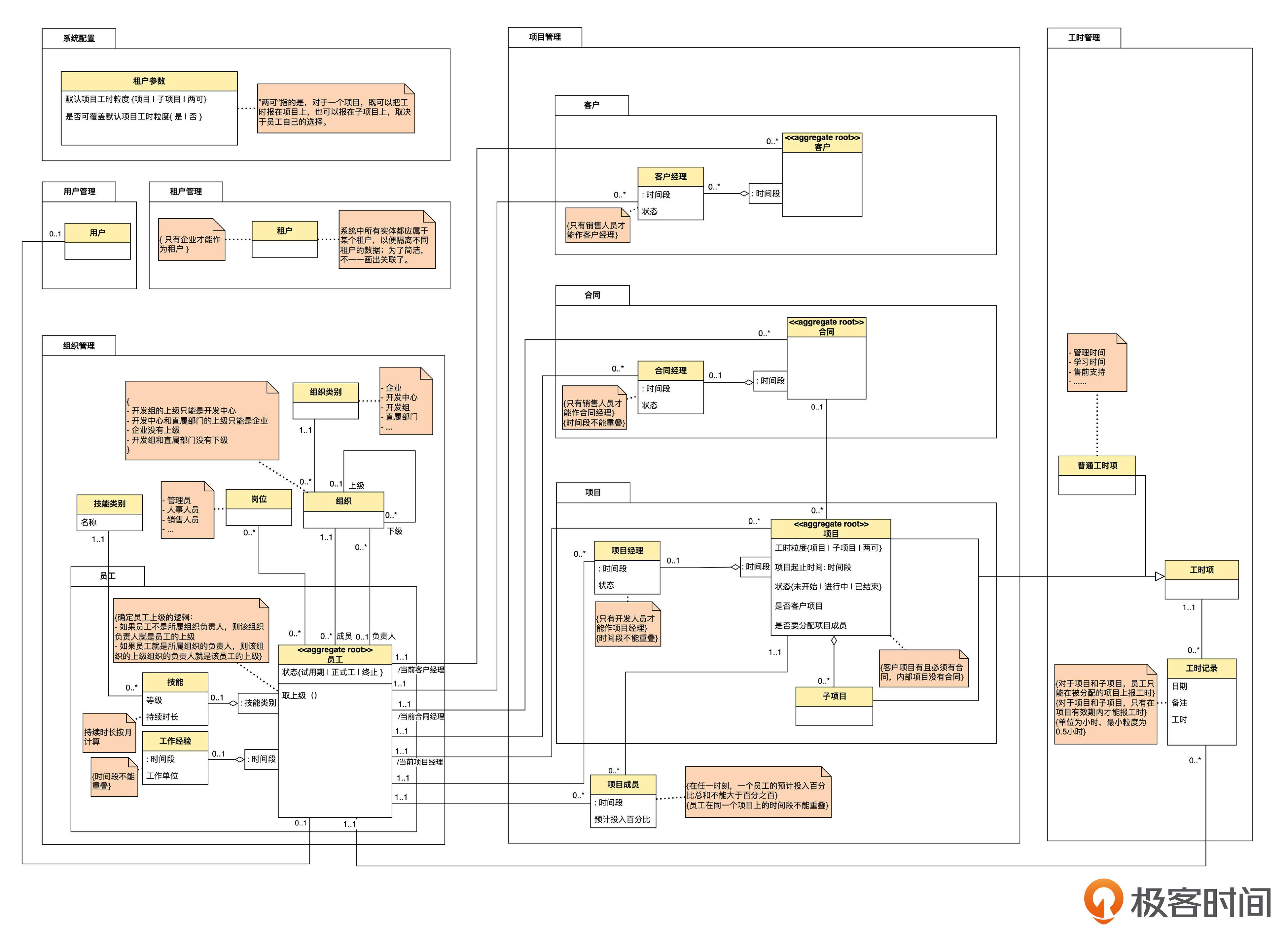
你说:“咱们团队目前总共20人,除去 1 名组长,2个产品经理, 3 个测试,还有 14 个开发人员。虽然分工不是太明确,不过仔细想一下,还是有点规律的。大概有 4 个人主要负责组织和人员管理,5个人负责项目管理,4个人负责工时管理。其他的,例如租户和用户管理部分,谁有空谁做,平均大概占 1 到 2 个人吧。这是这一年来自然形成的,也没有刻意安排。”
我说:“我在别的团队也观察到类似现象,就是做相关工作的同事,常常会自然聚在一起,这可以作为划分上下文的一个依据。”
你说:“这让我想到了敏捷软件开发里常常提到的‘康威定理’。也就是说,系统的架构总是与组织的沟通结构趋于一致。通俗地说,就是怎么划分子系统,相应就会怎么划分开发小组。”
我说:“那我们就按刚才说的人员自然形成的小组,划分成下面 4 部分?”
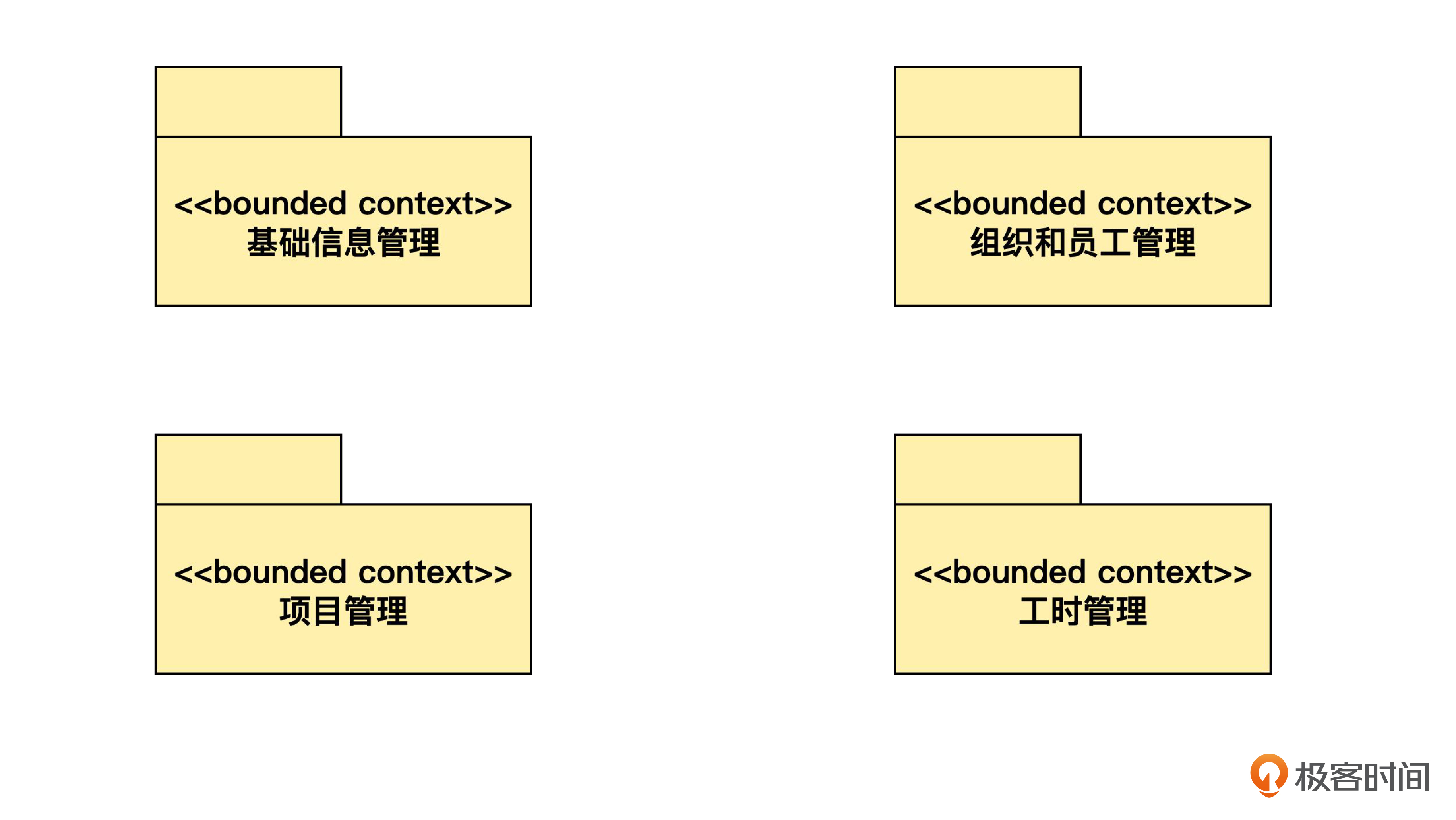
这里,我们用带有 <> 衍型的包来表示限界上下文。其中基础信息管理,就是前面说的1到2个人负责的,包括租户管理、用户管理和租户参数的部分。
你说:“基础信息管理只有一两个人,太单薄了,不如和‘组织和员工管理’合并。因为这两部分都是被其他部分所依赖的,都起到基础性的支撑作用。等到将来,这两部分如果发展得太大,再拆分也不迟。”
于是,你把图改成了下面的样子。
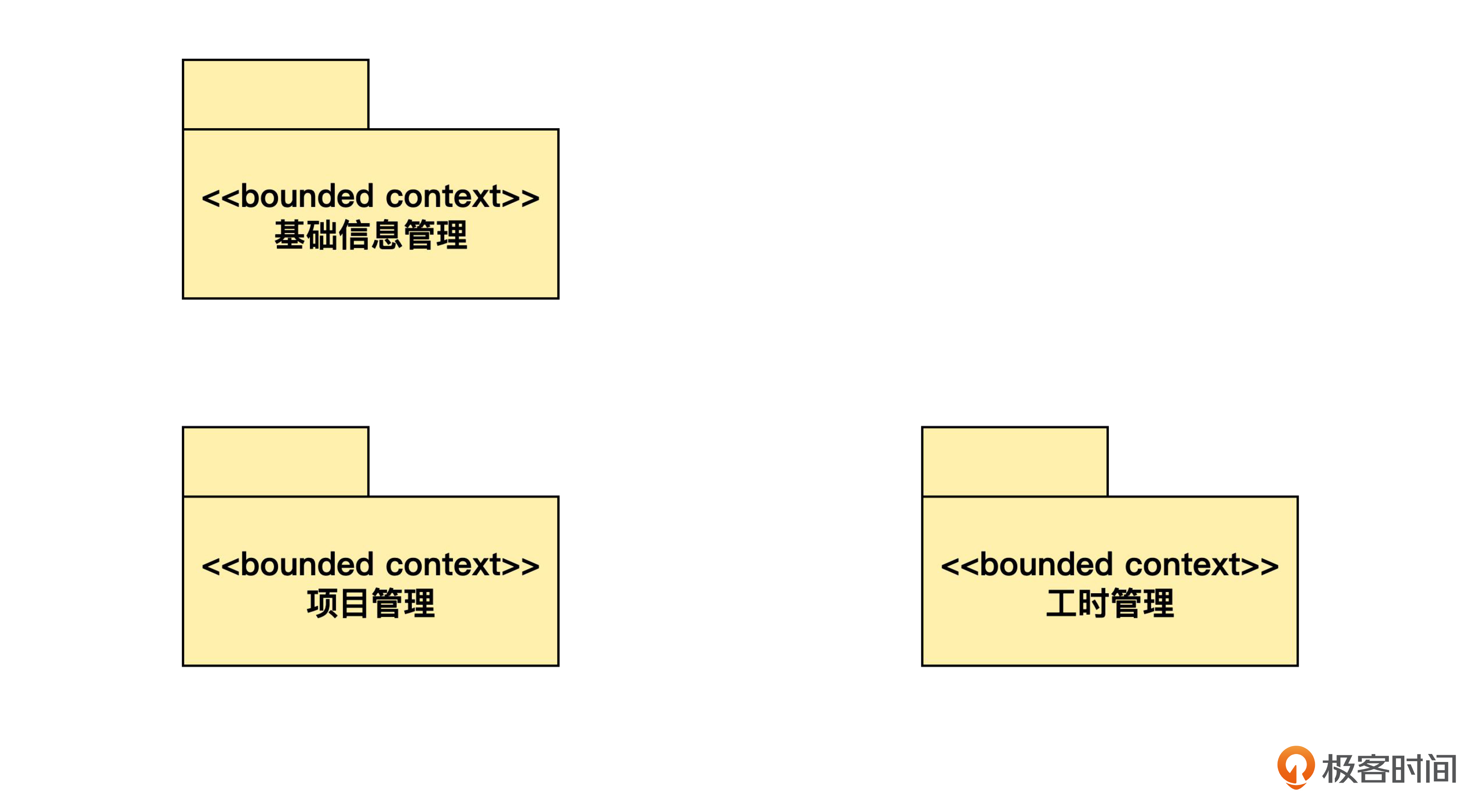
其中基础信息管理包含了租户管理和组织员工管理等部分。
我说:“根据新的需求,还要考虑接入企业自己的假期管理系统。这个系统是在我们控制范围之外的。DDD 通常的做法是把这种外部系统也识别为限界上下文。”
于是,你又把图改成了下面的样子。
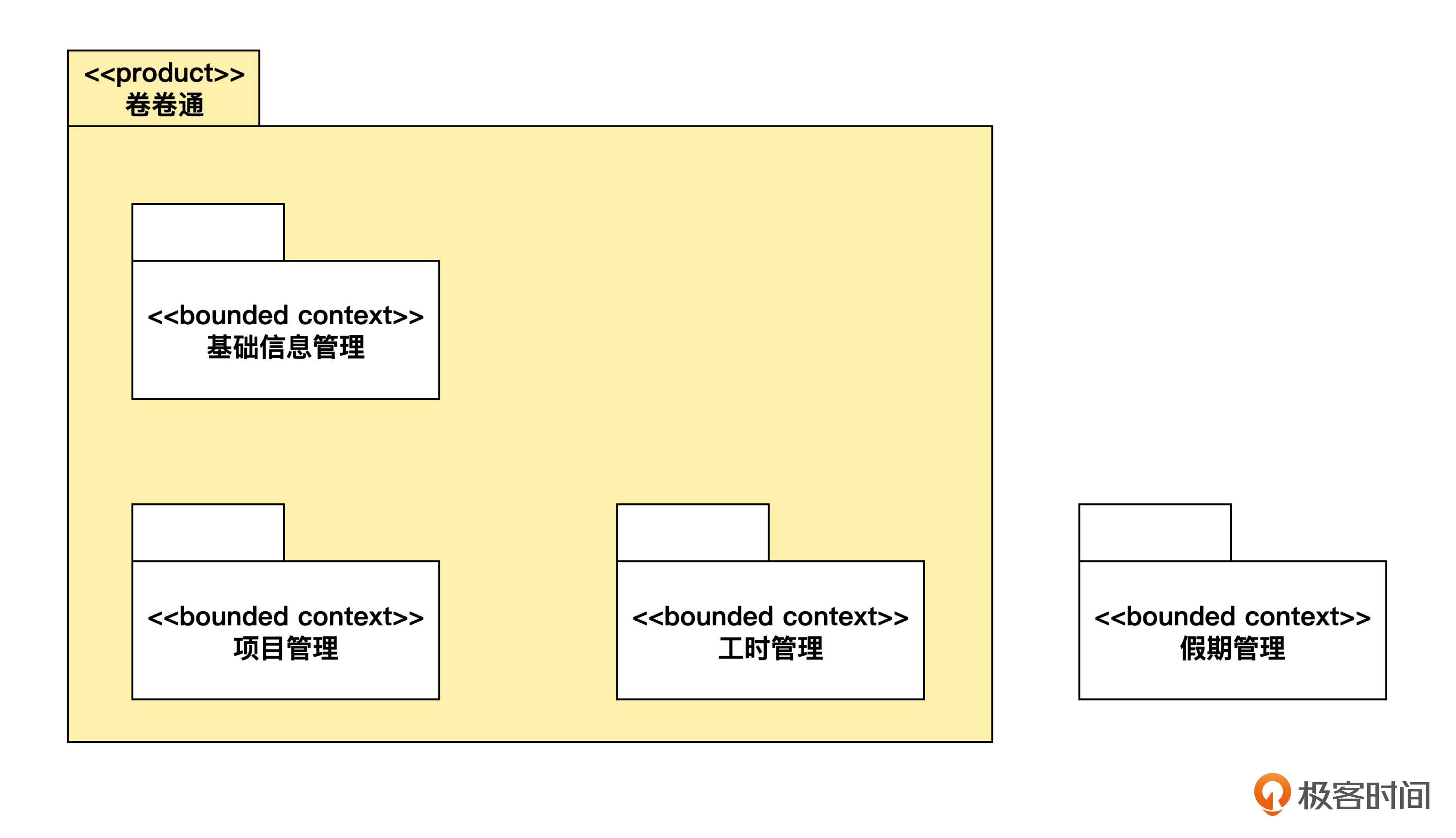
这里,你用带有 <> 衍型的包划定了我们产品的范围,并增加了假期管理这个外部的限界上下文。相应地,根据康威定律,我们可以把原来的开发团队分成 3 个小组。基础信息管理组 6 个人,项目管理组 5 个人,工时管理组 4 个人。
你跟着问道:“工时管理只有 4 个人,是不是可以考虑和项目管理合并,9 个人也不算太多”
我说:“9 个人介于两可之间吧。要不我们先看看每个部分内部的模型,分析一下概念的耦合性,再来决定。”
你说:“可以。不过现在还遗留了两个问题。第一个问题是,限界上下文内部的概念一致性容易理解,但是怎么理解不同上下文间的概念可以不一致呢?第二个问题是,怎么反映限界上下文之间的关系。”
我说:“咱们看看每个限界上下文内部的模型,应该就有答案了。”
上下文映射
当我们划分了限界上下文以后,实际上就是把一个大模型分成了若干小模型。一般来说,建议为每个模型单独画一张图。
于是,你先画出了基础信息管理上下文的模型图。
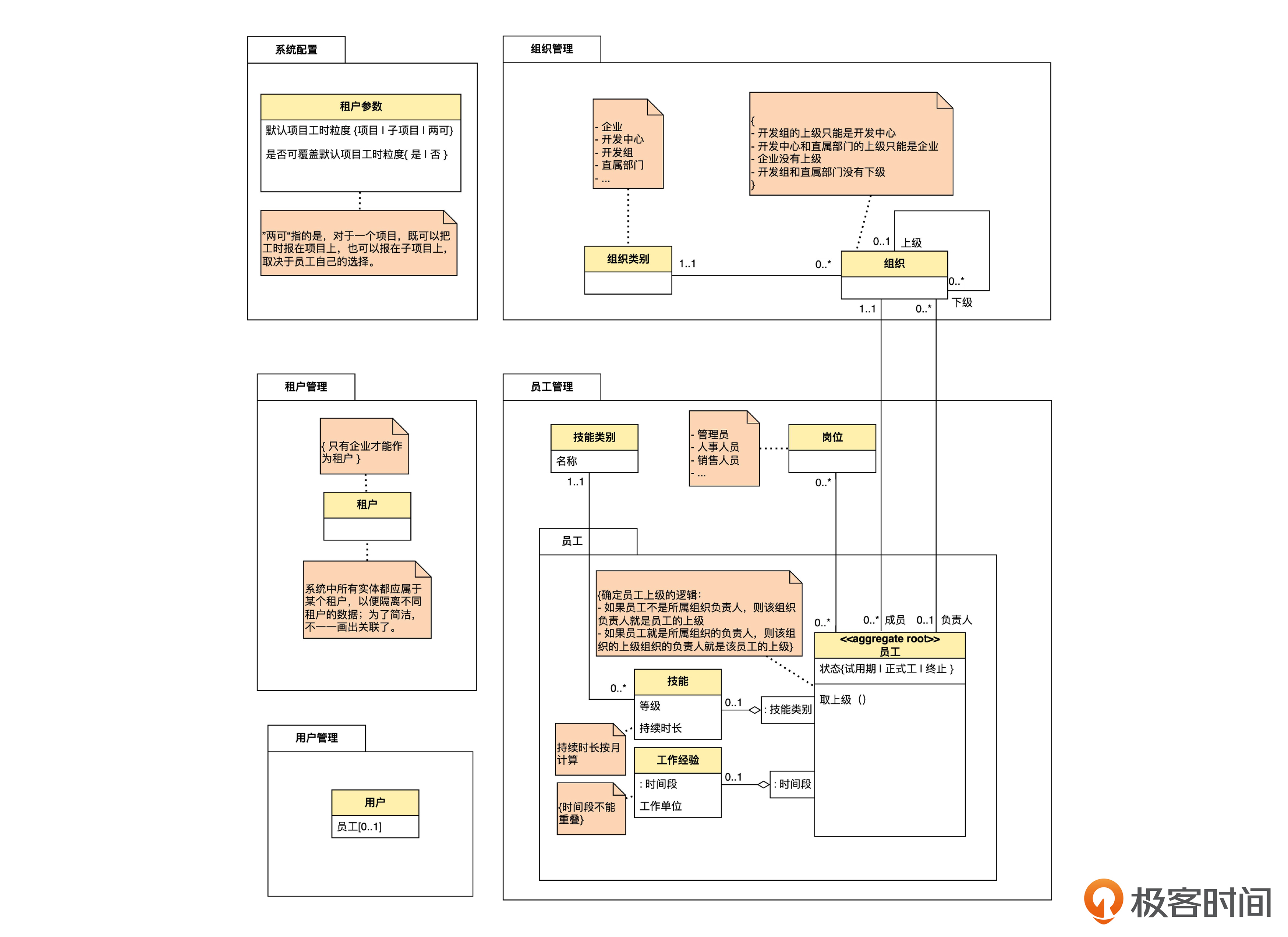
这个图其实就是从之前的大图里拆出来的,没有做实质性的改变。
接着,由我来画出项目管理上下文的模型图。
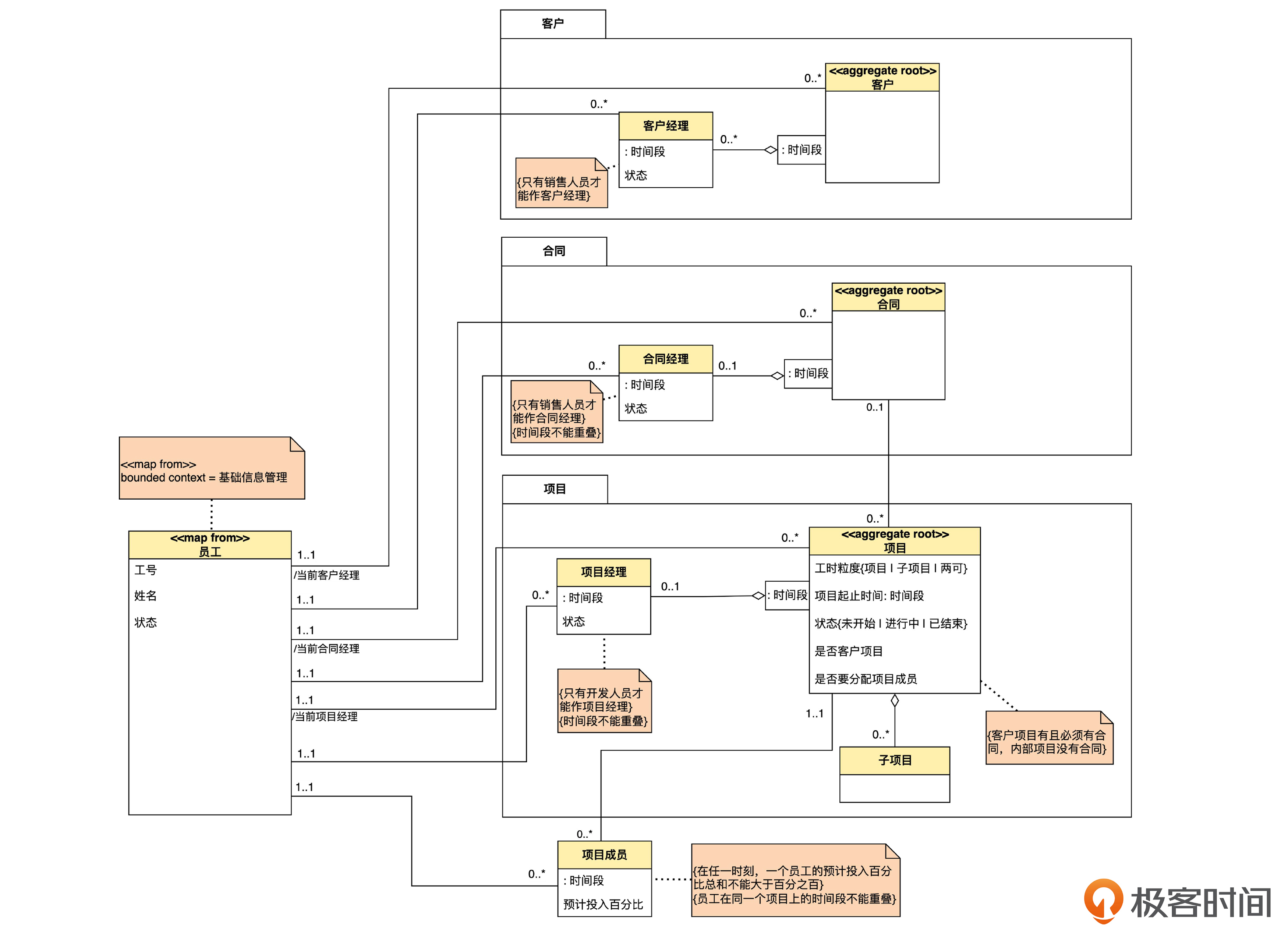
你看了一下这张图,提出了新的疑问:“这张图也是从原来的大图里拆出来的,看不出有太大的分别。唯一不明白的,是员工实体上面那个叫做 <> 的衍型,不知道是什么意思。”
我说:“这牵涉到 DDD 里的另一个模式,叫做‘上下文映射’,你听我慢慢说。”
员工这个实体,本来是“基础信息管理”上下文负责的。但是“项目管理”这个上下文要不要用到员工这个概念呢?也要用到。
所以,项目管理的模型图里面也要画出员工这个实体。但是,项目管理中的员工是从基础信息管理上下文里“映射”过来的。两个上下文之间的这种映射关系,就叫做上下文映射(context map)。
在《领域驱动设计》原书里,作者喜欢用非正式的方式表达上下文映射,因此并没有给出正规的表达方式。于是,我设计了一个叫做 <<map from>>(映射自……) 的衍型来表达这种关系。凡是有这个衍型的领域对象,就是从别的上下文里映射过来的。
那么是从哪个上下文映射过来的呢?我在员工上又加了一个带有<<map from>> 的注解。里面 “bounded context” 是 <<map from>> 的属性,“基础信息管理”是这个属性的值。合起来的意思就是说,员工这个实体是从基础信息管理上下文映射过来的。这种带有属性的衍型,是 UML 里标准的表达方法。
我们还要注意到,不同上下文的同一个名词,有可能概念已经不完全一致了。
比如说,在基础信息管理上下文中,员工是一个带有技能和工作经验的聚合,同时,员工实体可能还有更多属性。而在项目管理上下文里,则不关注员工的技能和工作经验,员工里只有工号、姓名和状态三个属性就足够了。所以,尽管两个上下文里都有员工,但他们的关联和属性不同,所以这两种员工在概念上已经不一致了。
这是关注点不同造成的不一致。而在上下文映射的过程中,发生这种概念不一致,是完全正常的。这是因为,限界上下文只要求内部的概念一致,这种发生在上下文边界上的不一致,恰恰反映了限界上下文的特点,希望你能体会一下。
既然概念不一致了,在实现层面,自然需要在代码的某个部分进行这种概念上的转换,这部分我们会在后面的课程再展开。
总结
好,这节课的主要内容就讲完了,下面来总结一下。
今天,我们主要学习了“限界上下文”以及“上下文映射”这两个模式。
我们首先谈了系统和团队规模变大后遇到的挑战,实际上,这些都是普遍性的问题。
解决的方法就是运用限界上下文。DDD 的限界上下文,是一种解决大系统或者大模型概念不一致的手段。我们把一个大模型分成几个小模型,保持每个小模型内部概念的一致性,而不同模型之间的概念不必一致,这种小模型就叫做限界上下文。
放弃对全局一致性不切实际的追求,退而求其次,代之以局部一致性,从而使概念一致性问题得到足够的管理,达到业务目标,这种思维就是限界上下文与传统划分模块或子系统思路的本质区别。
之所以限界上文不追求全局一致性,实际上是由于全局一致性已经超过了团队的认知负载。所以限界上下文的划分在理论上应该和团队的划分保持一致。这也印证了康威定律。
另外,统一语言只有在一个限界上下文中才有意义。或者说,一个限界上下文对应一套统一语言。
我们利用限界上下文的理论,对卷卷通的模型进行了划分。然后,发现了不同上下文中的概念存在映射关系,这就是“上下文映射”。我们还设计了一套 UML 的符号来表达上下文间的概念映射。
思考题
最后给你留两道思考题。
1.你能否举出自己经历过的项目中概念不一致的例子,这些不一致,造成了什么损害呢?
2.实现上下文映射时,需要在程序中对概念进行转换,你觉得应该在程序的哪个部分进行这种转换呢?
好,今天的课程结束了,有什么问题欢迎在评论区留言,下节课,我们继续深化上下文映射的使用,并且过渡到架构设计。
- 衷培坤 👍(11) 💬(1)
有个疑惑:我理解本文案例中项目管理和基础信息管理中的【员工】概念应该是一致的,否则就没必要用map from了吧?
2023-04-02 - 燃 👍(5) 💬(1)
2)第九课讲过,应该放在适配层,建立一个wrapper做防腐和模型转换,将DTO转为模型内部的DO。原文如下——在六边形架构里,把由外向内的适配器叫做 driven adapter,我把它译作被动适配器;而由内向外的适配器叫做 driving adapter,可以译作主动适配器。准确地说,主动适配器的作用不限于访问数据库,而是访问所有外部资源。这里请求是外部进来的,应该放被动适配器包下
2023-02-16 - 子衿 👍(5) 💬(1)
有一点没有特别弄清楚,是不是说,同一个服务下,也可以拆成多个界限上下文,而不一定非要每个界限上下文一个服务 如果是这样的话,我理解,如果界限上下文,在同一个服务中,那么转换逻辑应该放在应用服务,如果不在同一个服务中,转换逻辑应该放在适配器层,当成一个外部访问
2023-02-16 - humor 👍(1) 💬(1)
这是因为,人的认知能力是有限的。 老师,这里的认知能力是指什么啊?是说人不能学会很多概念吗?可是感觉不太对,人能学会的概念或者知识理论上应该是无限的,因为没有人达到过这个上限,那么这里的认知能力是指什么呢?
2024-04-11 - 黑夜看星星 👍(1) 💬(1)
请问老师通用域,核心域,支撑域与BC属于多对多关系?
2023-08-30 - aoe 👍(1) 💬(1)
原来当系统规模过大,超过人类认知能力的时候,混乱就自然到来
2023-02-28 - J.Smile 👍(0) 💬(1)
账单和支付域都有账单项的概念,但支付域的账单更包含了自己独有的概念,比如待支付金额、待退款金额,这些在账单域时不需要关注的。跟文章里基础信息管理的员工放在项目管理我理解是同一个问题
2024-07-17 - py 👍(0) 💬(1)
1. 沟通问题,说了半天对不上号。代码问题 同一类实体命名不一样,代码质量差 2. application层
2023-03-09 - 赵晏龙 👍(0) 💬(1)
1、竞争性考试的一个考生,在报名的时候、考试的时候、录用的时候都是不同的限界上下文。 2、这个转换我觉得我会在ApplicationService之间调用时以某种形式去做。
2023-02-28 - 邓西 👍(0) 💬(1)
2. 适配层
2023-02-27 - 6点无痛早起学习的和尚 👍(0) 💬(1)
问题 2: 限定上下文之后,上下文映射是在上下文互相之间访问,应该放在适配器层。属于被动适配器层吧
2023-02-27 - tt 👍(0) 💬(2)
我是这么想的,界限上下文既然是一个“边界”,跨边界必然要经过接口,所以转换就在接口上,不论接口是不是跨系统
2023-02-16 - 支离书 👍(0) 💬(2)
1)很多啊,比如复购率,不同的业务下的含义是不同的,导致的影响有大有小,小则浪费时间,大则给用户造成影响给公司带来损失; 2)个人觉得应该在应用服务层DTO那里转换好吧。
2023-02-16 - 霍霍 👍(0) 💬(1)
VO,DTO,概念不一致,应该在service层,vo转dto
2023-02-16