25 泛化的实现(上):怎样为泛化设计数据库?
你好,我是钟敬。
前面几节课,我们学习了泛化的建模,今天开始我们继续学习泛化的实现。这节课我们先探讨怎样为泛化进行数据库设计,下节课再讨论怎样为泛化编写代码。
回忆一下第 8 节课讲过的数据库设计方法,如果只有实体和关联,那么数据库的设计还是比较直白的。但是泛化就会有些难度了。这是因为,同样的泛化模型,可以有不同的数据库设计方式,需要我们根据情况进行权衡。
这里又包含两个维度的变化,一个是怎样设计表,一个是怎样确定主键。
设计表的策略
我们先来讨论设计表的方法。为了说明问题,我们结合一个商家向不同客户售卖商品的例子来讲。
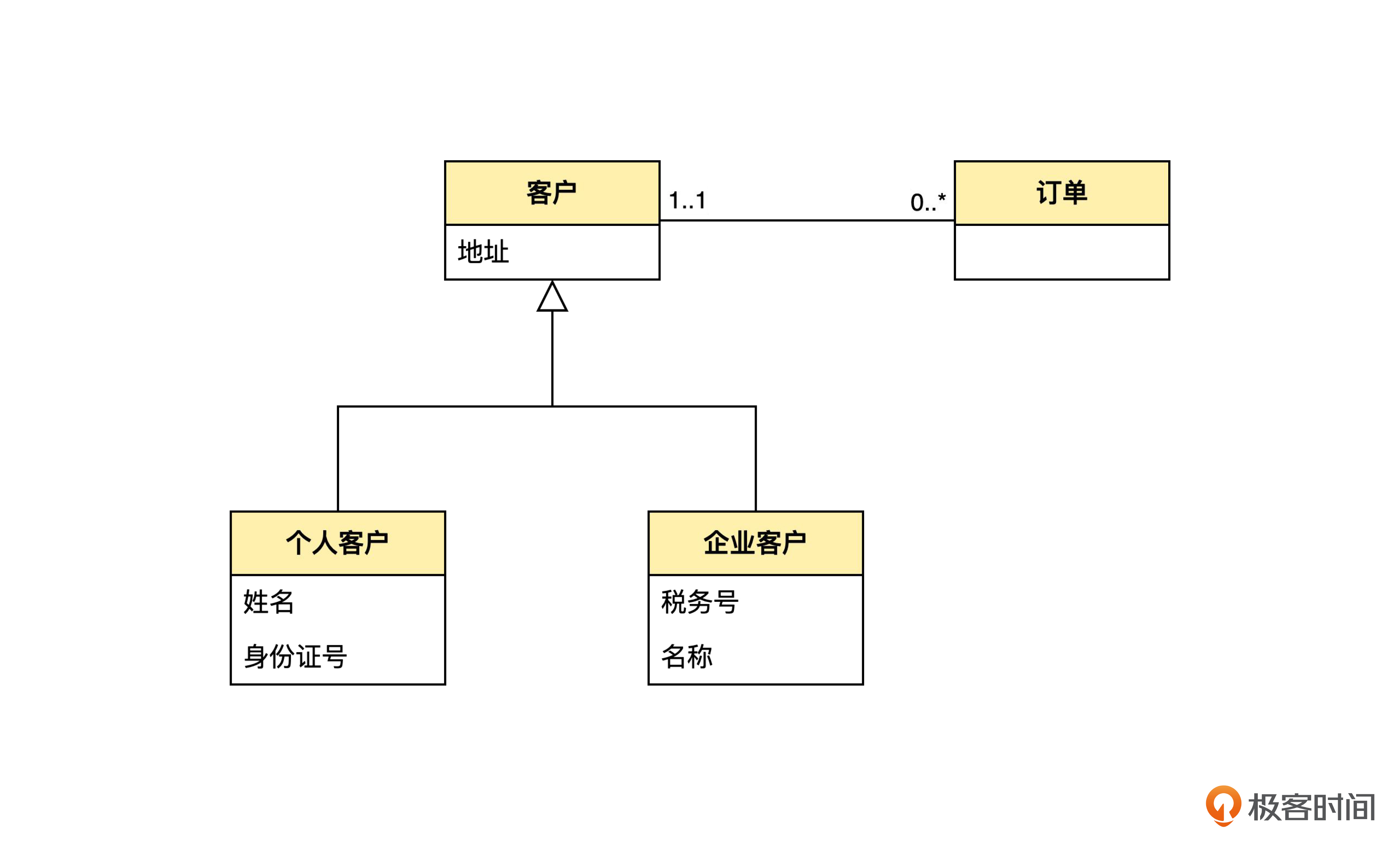
这个领域模型,说的是一个商家可以把商品卖给个人或者企业。也就是说,个人客户和企业客户都是客户。所以可以抽取出泛化关系。客户实体里的送货地址属性,以及客户和订单之间的一对多关联,都体现了个人客户和企业客户的共性。而个人客户里的姓名、企业客户里的税务号等属性,体现了个人客户和企业客户的区别。
为泛化体系设计表,有 3 种基本策略。
- 每个类一个表。
- 每个子类一个表。
- 整个泛化体系一个表。
这三条策略读起来可能有些拗口,没关系,我们一个一个解释。
每个类一个表
第一种策略是“每个类一个表”,也就是说不管父类还是子类,都各建一个表。对于上面这个关于客户的例子,实际上就要建 3 个表。就是下面这个图的样子。
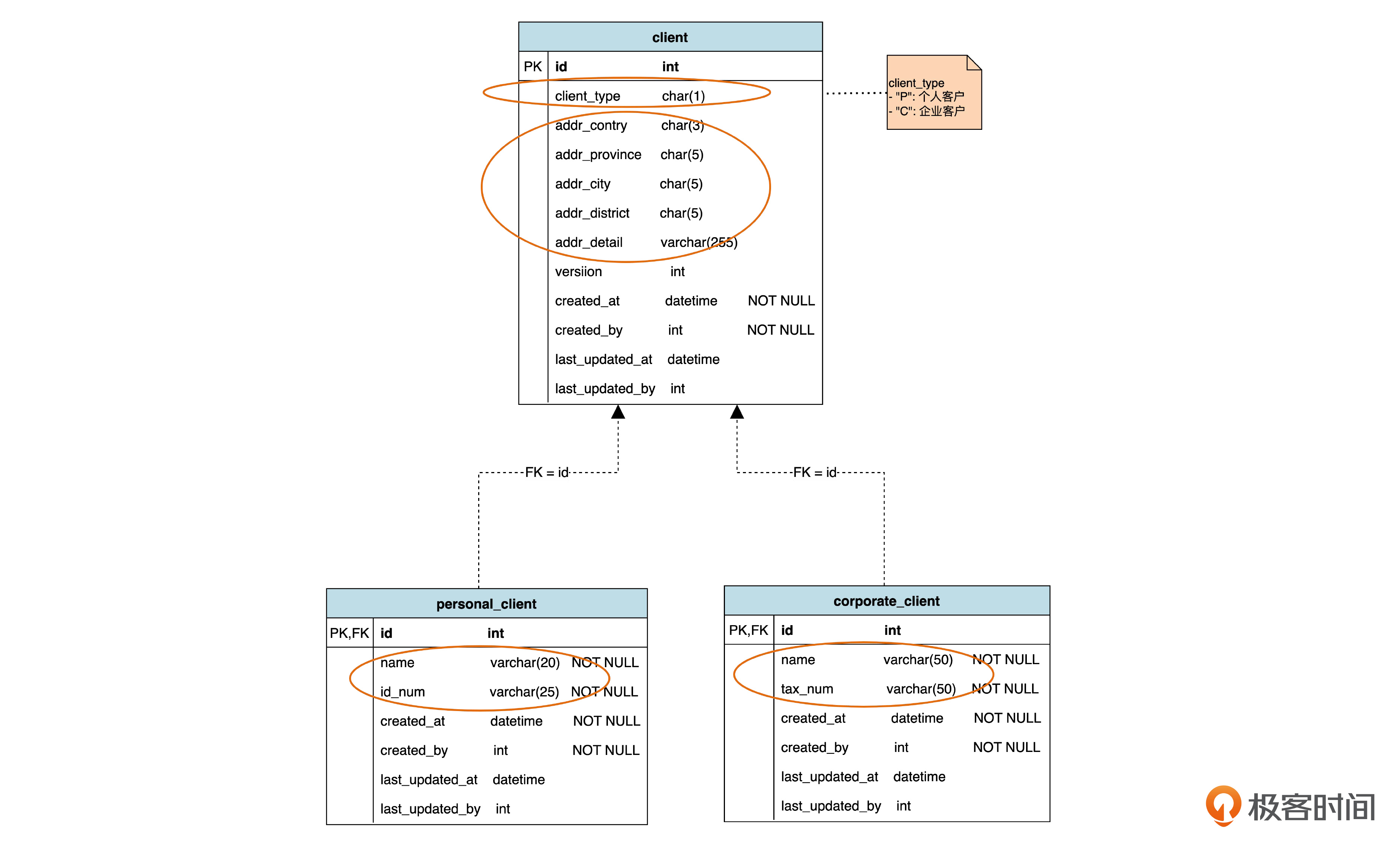
在这个表结构里,表示父类的 client(客户)表中存放公共的属性。从 addr_contry(地址里的国家) 一直到 addr_detail(地址详细描述)5 个字段表示地址,这就是个人客户和公司客户公共的属性。而且,这里是用嵌入式的方式存储的。另外,还有一个 client_type(客户类型)属性,用于区分是个人还是团体客户,主要是为了实现一些逻辑时更加方便。
两个子类对应的表,各自存放自己的属性。注意,个人客户和团体客户表里都有 name 属性,但一个是个人的姓名,一个是公司名称,所以它们的英文虽然碰巧一样,实际上不是同一种属性。
当新建一个个人客户的时候,会在 client 表和 presonal_client 表里各插一条记录;类似地,当新建一个公司客户的时候,会在 client 表和 corporate_client 表里各插一条记录。从而,父表的记录数量,就是两个子表记录数量的总和。而子表里的每条记录,在父表里都能找到对应的记录。
最后,对于个人客户表,假设业务需求是必须填写姓名和身份证号,那么我们就可以在name 和 id_num 两个字段加上非空(NOT NULL)约束。企业客户表里的非空约束是同样的道理 。
每个子类一个表
第二种建表策略,是“每个子类一个表”,也就是说,只为子类建表,父类不单独建表,而是把公共属性分别放在子类。
对于上面的例子,可以像后面这样建立两个表。
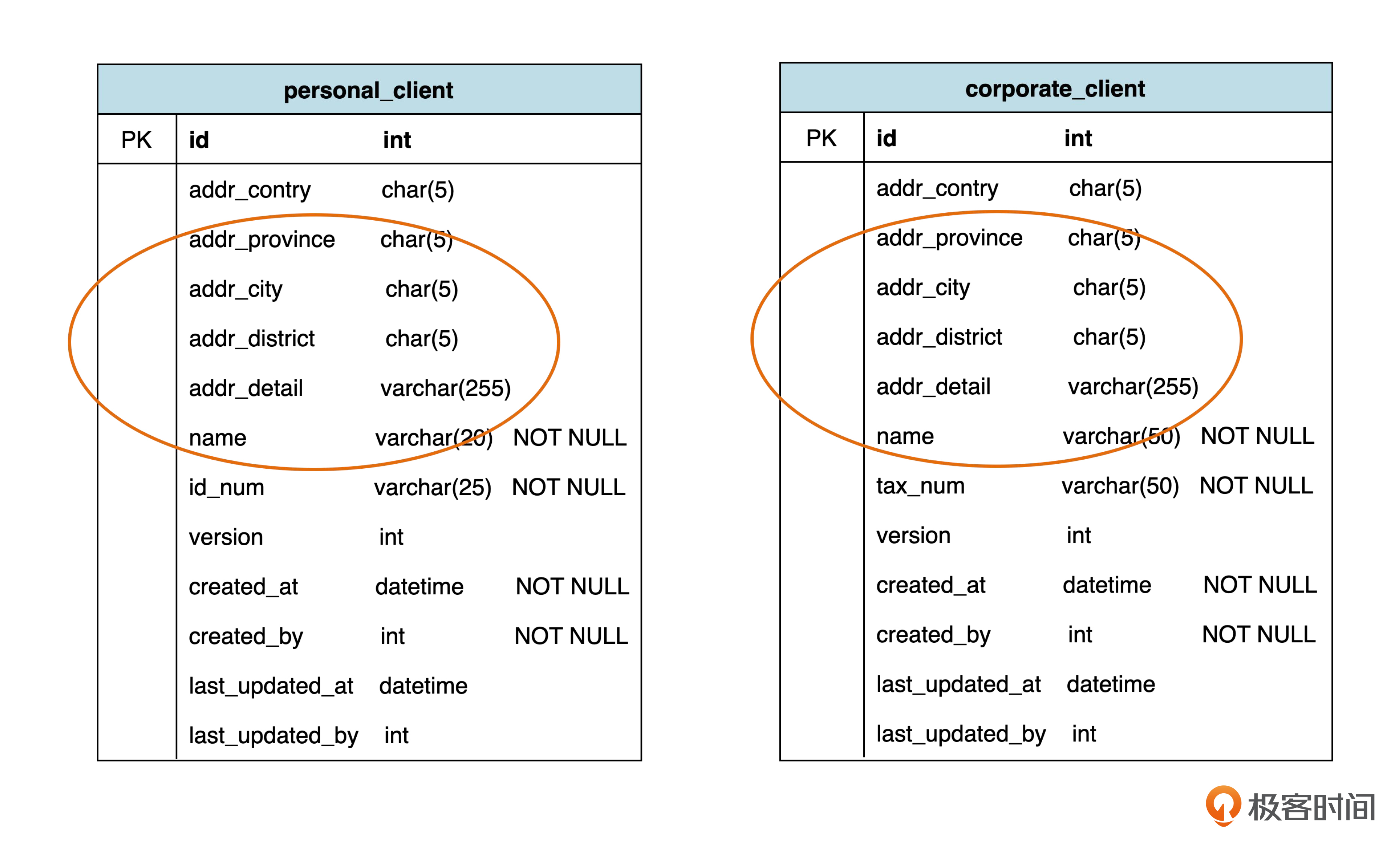
可以看到,在这种方案里,公共属性,也就是有关地址的属性,分别放在两个表里了。因此不再需要单独为父类建表,原来父表中的 client_type(客户类型) 也不需要了。
整个泛化体系一个表
第三种,是整个泛化体系一个表。在这种方式下,我们只建立一个表,把 3 个类的属性都放到这个表里。
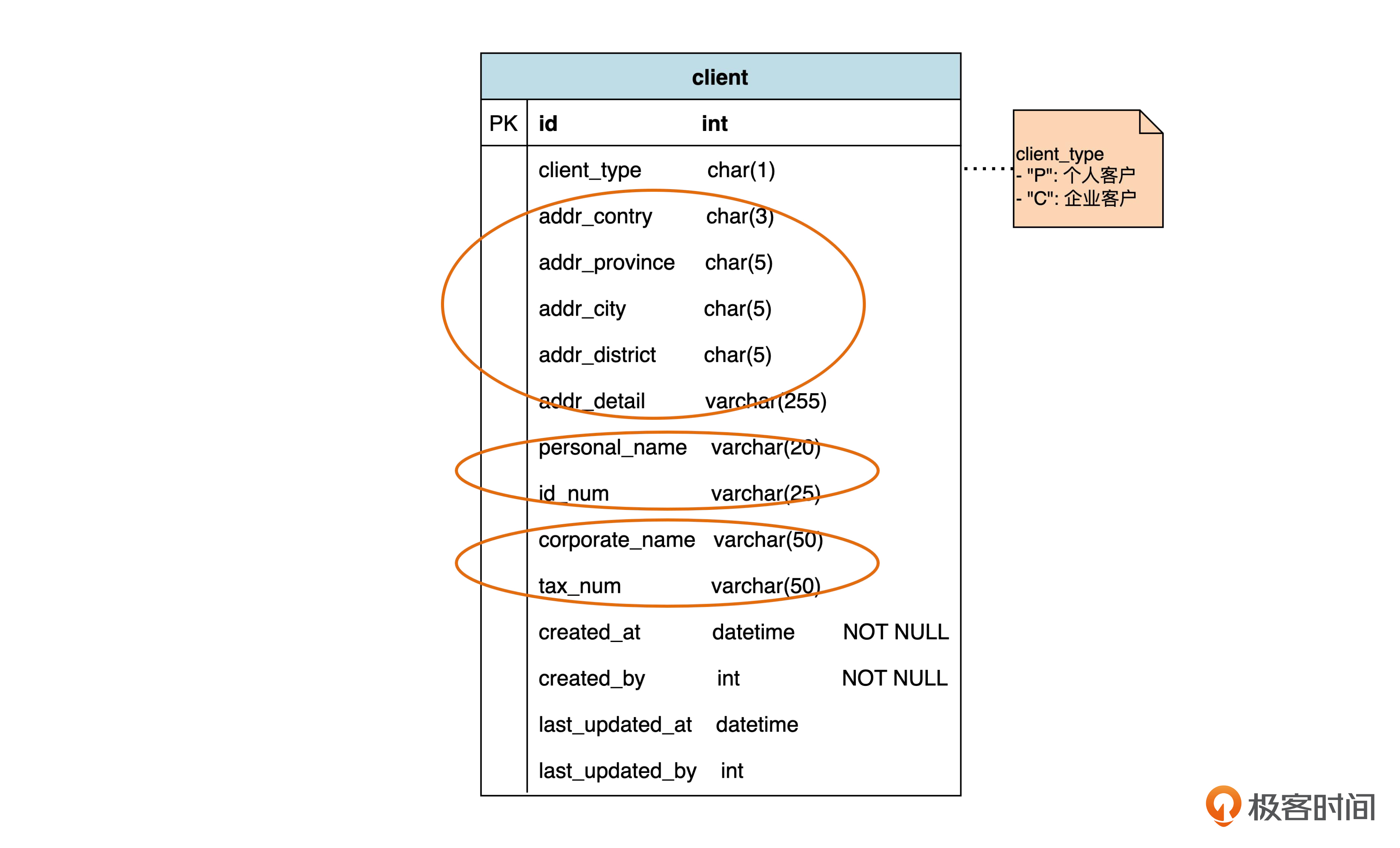
我们看到,这个表里包括公共属性,也就是地址相关的属性;个人客户独有的属性,也就是姓名和身份证号,以及企业客户独有的属性,包括企业名称和税务号。由于个人客户姓名和企业客户名称都在同一个表里,所以不能都命名为“name”了,要用 personal_name 和 corporate_name 区分开。另外,client_type(客户类型)也是需要的。
当 client_type 为 “P”,也就是当前数据是个人客户的时候,企业客户独有的字段都为空。当client_type 为 “C”,也就是企业客户的时候,个人客户独有的字段就为空。
在前两种方式中,我们可以分别对个人和企业客户的必填属性进行非空约束,而现在这种策略就不能进行非空约束了。
建表策略的权衡
既然有这 3 种设计表的策略,我们在实践中应该怎么选择呢?这需要考虑若干个维度,没有唯一的答案。
首先,我们可以从空间效率的角度考虑。如果两个子类的属性种类差别很大,比如说,子类A有10个不同的属性,子类B有20个不同的属性,而公共的属性只有一两个。
这种情况下,如果采用“整个泛化体系一个表”的策略,表里就会有大量空字段,空间的浪费就会比较大,对索引性能也有不良影响。反之,如果子类大部分属性都相同,只有一两个属性不同,那么建一个表可能就是比较好的选择。
其次,从时间效率的角度考虑。比如说,如果要查父类下的所有记录,那么“整个泛化体系一个表”的策略不需要连表查询,而且只需要查一次,从这一点来说,性能是最高的。而“每个子类一个表”,也就是两个表的策略,就至少要查两次。
对于“每个类一个表”,也就是三个表的策略,有时候只查父表就够了,这时性能不比一个表的策略差。但如果需要查出父表和子表两者的属性,就需要连表查询了。到底哪种策略的查询性能高,取决于具体的查询需求。
然后,还可以从系统的可维护性角度考虑。
如果采用一个表的策略,一旦控制得不严,难免有人会误用字段。比如说本来应该是子类 A 的属性,但是却“借用”了子类 B 的字段,反正子类 B 的字段也是空的。虽然暂时可以实现正确的功能,但时间久了,必然造成理解上的混乱,使系统腐化,难以维护。
不过,如果本来父类和子类加起来字段就不多,意义非常明确,不容易混淆的话,那么这种做法也可以接受。
最后,我们前面还说过,“一个表”的策略,无法进行必要的非空约束,也算是这种策略的一个不足之处。
我画了一张表,帮你总结了三种策略的优缺点。
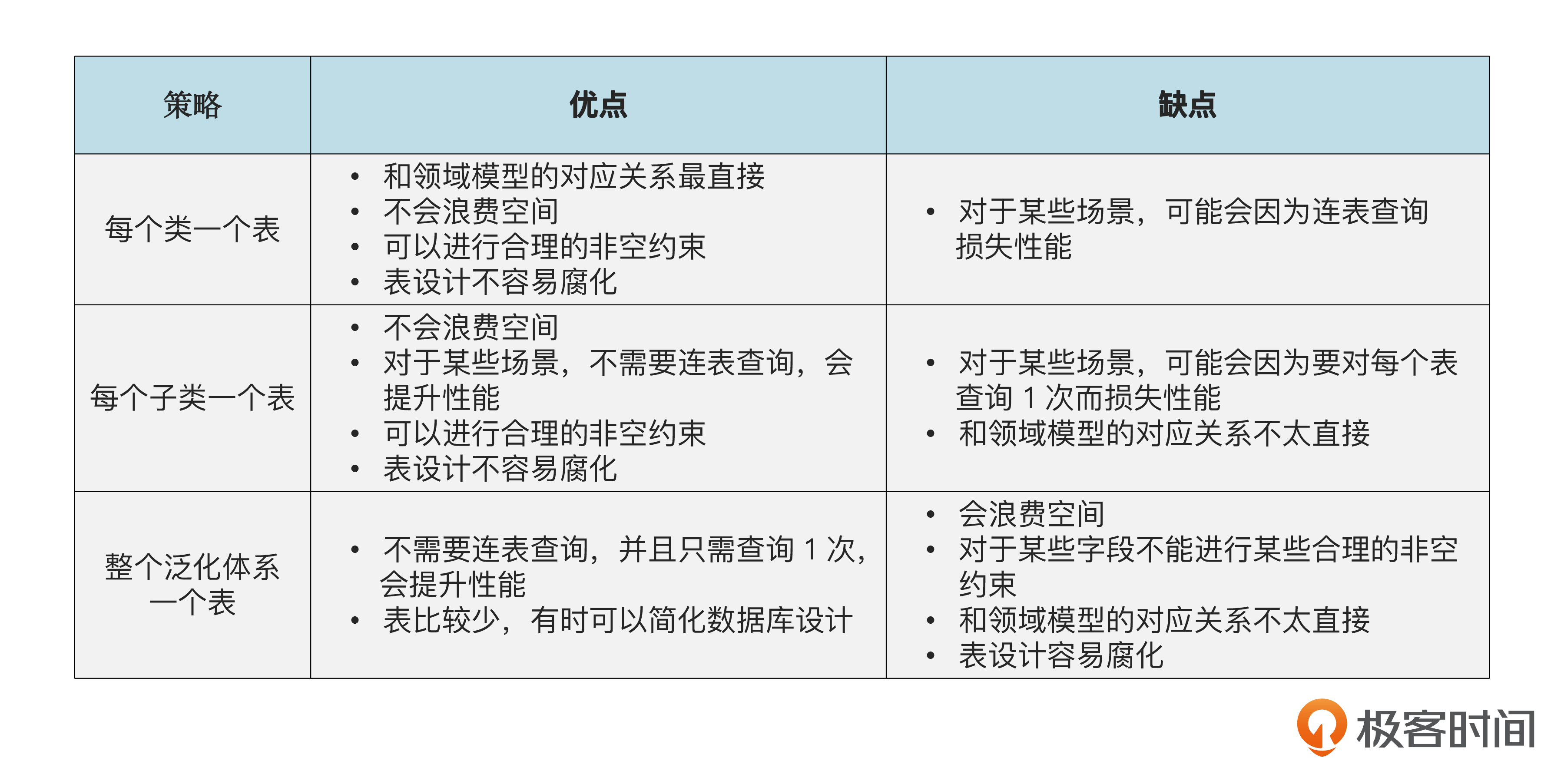
总之,对建表策略的选择,需要综合考虑几方面的因素做出权衡,这正是对泛化建表的微妙之处。
设计主键的策略
说完 3 种建表策略,我们再讨论一下设计主键的策略。共有两种选择:“共享主键”和“不共享主键”。
共享主键策略
什么是共享主键策略呢?我们再回顾一下前面说的“每个类一个表”的数据库设计。
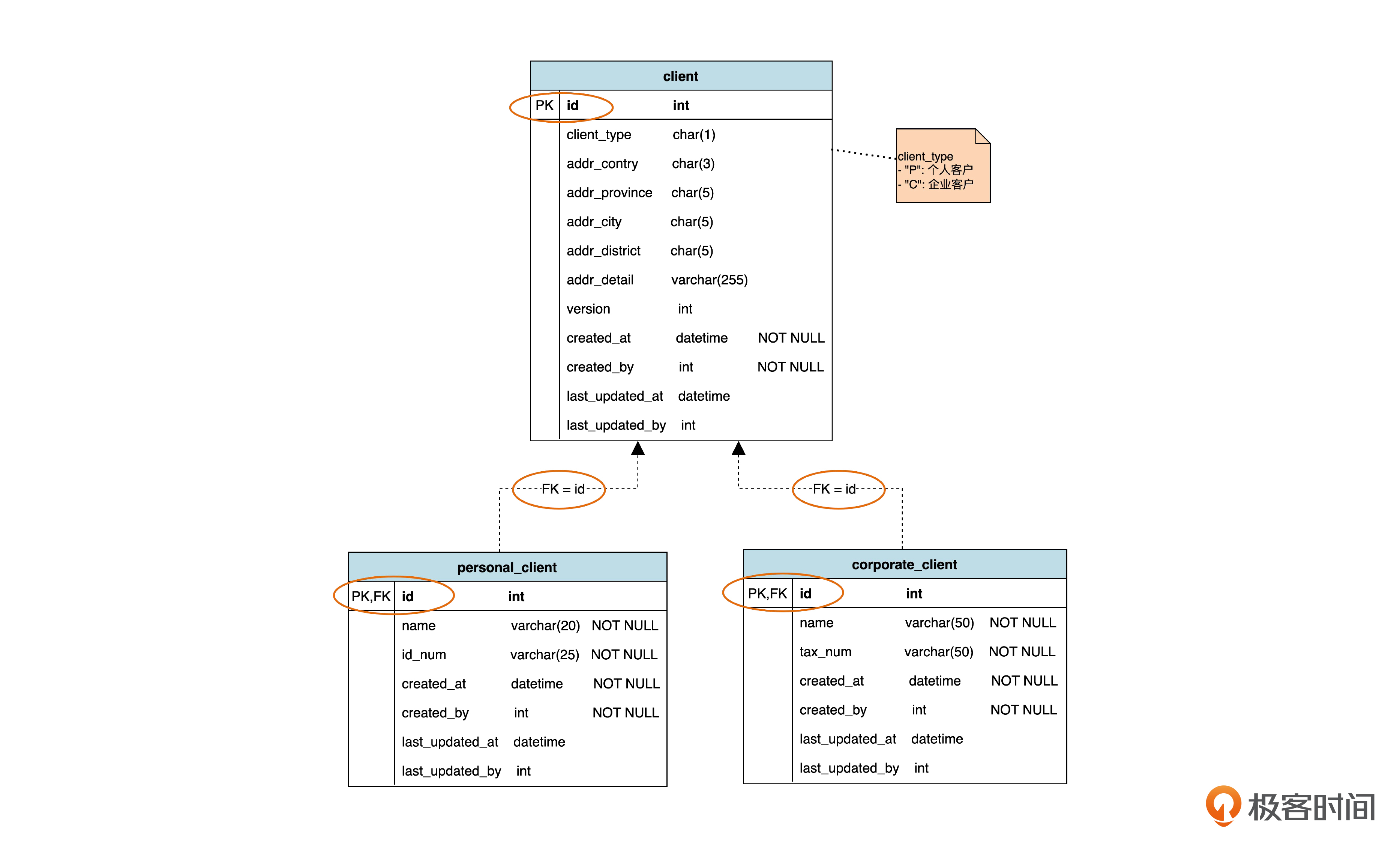
可以看到,子表和父表之间有逻辑上的外键关系。个人客户表和企业客户表的主键,同时也充当指向父表的外键。也就是说,子表和父表,共用了同一套主键。我们把这种策略叫做“共享主键”。
对于“整个泛化体系一个表”的情况,显然也是共享主键的。至于“每个子类一个表”的情况,虽然是分开的 2 个表,我们也可以让这两个表在逻辑上共享同一套主键。
不共享主键策略
那么,假如“每个类一个表”的数据库设计采用“不共享主键”的策略,就会是后面这样。
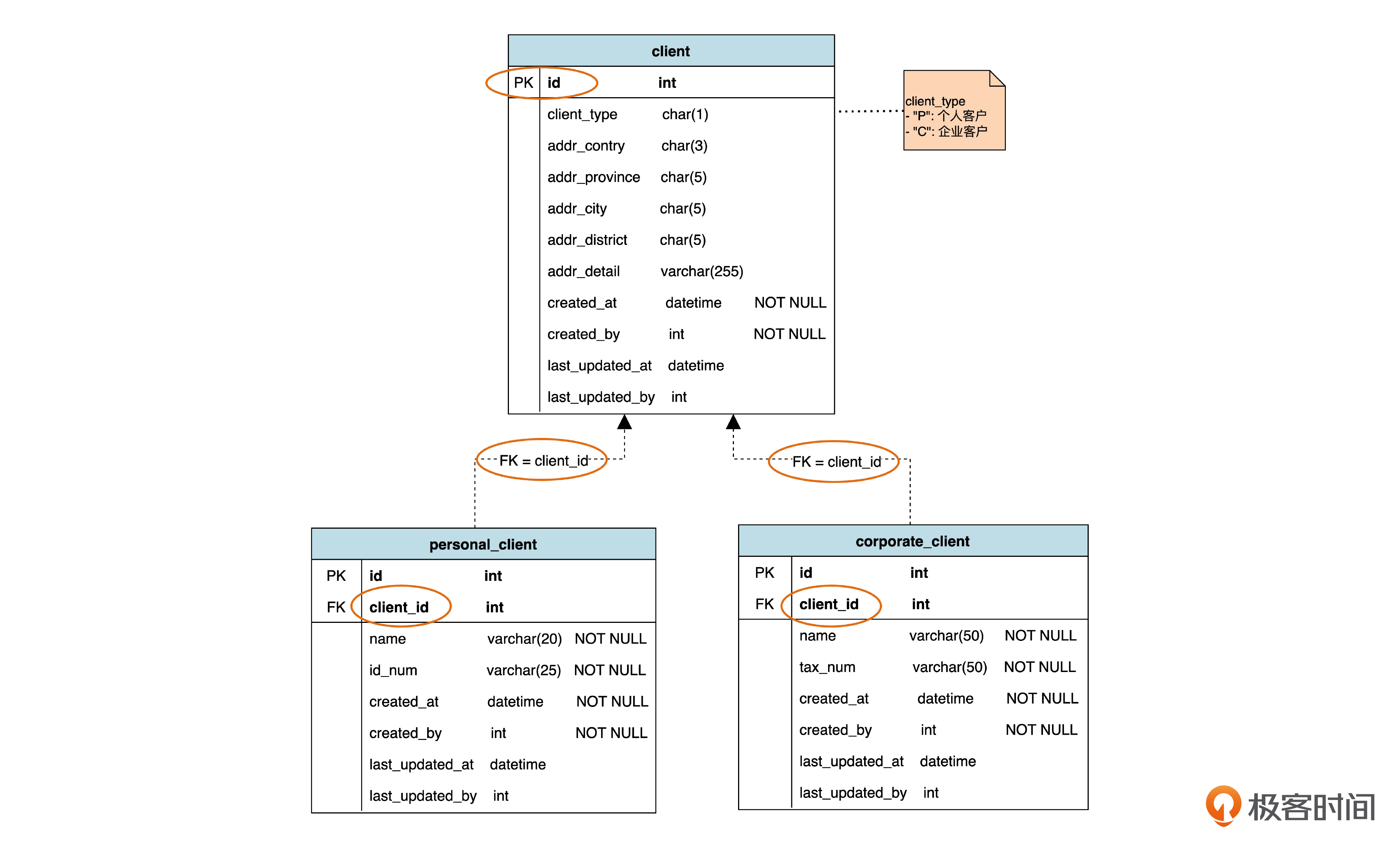
个人客户表和公司客户表自己有各自的主键,另外还有一个 client_id。这个 client_id 才是对应于父表中主键的外键。这时候,在子表里面,主键和外键是两个不同的字段,所以我们把这种策略称作“不共享主键”。
就目前的例子来说,共享主键是一个自然的选择。尽管从技术的角度来说可以不共享主键,但是似乎看不到不共享主键的必要性。不要急,让我们回到工时项的案例,马上就可以看到这种场景的例子了。
工时项案例的数据库设计
下面我们就运用前面学到的知识,看看在工时项的例子里应该怎么设计数据库。
我们先回顾一下领域模型图。
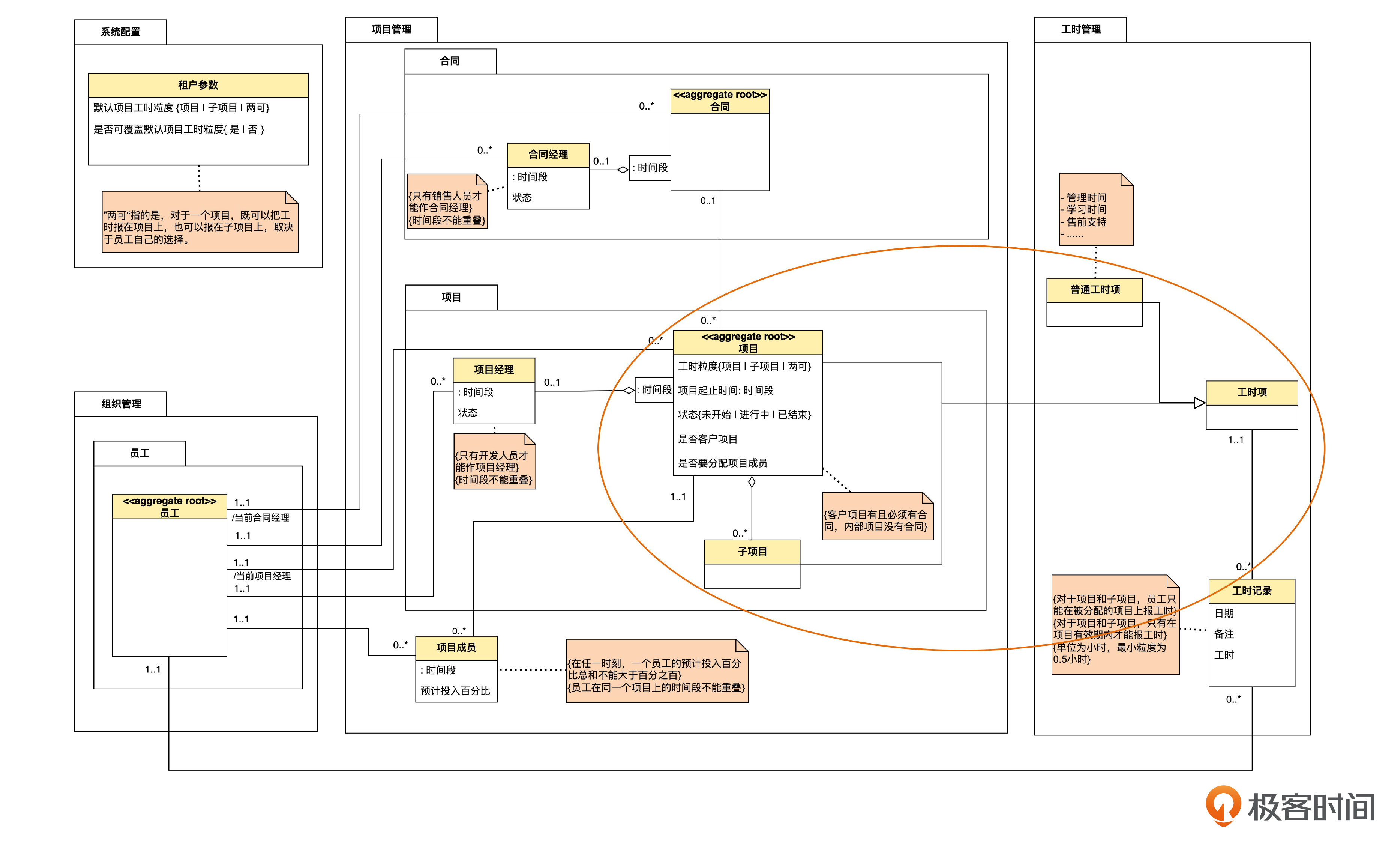
我们先思考一下到底应该采用哪种建表策略。
首先,项目、子项目、普通工时项这几个实体,各自有不同的关注点,而且还处在不同的模块。混在一个表,显然是不合理的,所以“整个泛化体系一个表”的策略显然是不合理的。
然后,再考虑一下是否要采用“每个类一个表”的策略。关键是要不要为工时项这个父类单独建一个表,我们一起分析一下。
假如为父类建表的话,共享的属性只有“工时项ID”和“工时项名称”两个。而项目、子项目等,自身有名称,重用这些名称就可以了,所以,共享的属性就只剩下“工时项ID”了。
为这样一个属性建表,最可能的作用就是提高某些场合的查询性能。根据我们的需求,最重要的查询就是在报工时的时候,要给员工列出那些可以报工时的项目。
而这个功能需要 3 个 SQL 查询。第一个是对项目和项目成员表进行一个连表查询,找到分配给这个成员的项目;第二个是再查项目表,找到不需要分配成员的那些项目;第三个是查“普通工时项”里的所有记录。然后把这三个查询的结果拼起来。对于这样的查询,建立工时项这个父类的表,其实是没有帮助的。所以,不需要为父类建表。
顺便说一下,这种查询方法虽然是一个可行的方案,但未必是最优的。等到第三个迭代,讲到限界上下文和 CQRS 的时候,我们还会进一步优化。
最终的结论就是,采用每个子类一个表的策略。表结构是下面这样。
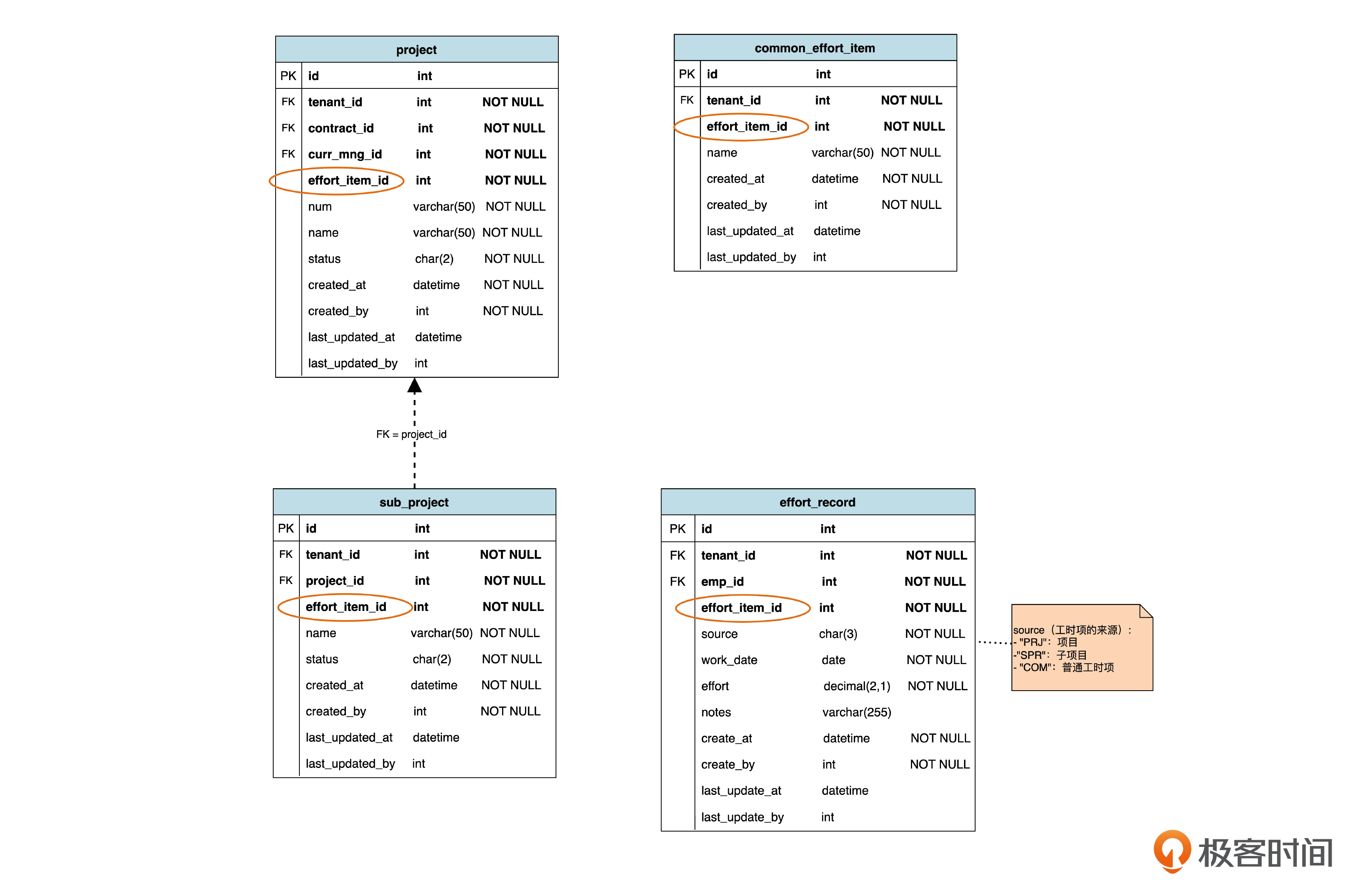
我们只列出几个关键的表。
可以看到,在项目(project)、子项目(sub_project)和普通工时项(common_effort_item)里都有一个工时项 ID(effor_item_id)。想象一下,假如我们为工时项这个父类建了一个表的话,那么工时项 ID就是这个表的主键,而在几个子表里是外键。
但由于现在我们决定不建工时项表,所以从技术的角度看,工时项 ID 并不是某个表的主键。但从逻辑上,我们仍然应该认为工时项 ID 其实就是工时项这个泛化体系的主键。虽然它们在三个不同的表里,但应该用同一套主键生成机制来生成,这样才能保证在三个表之间,工时项 ID 都是不重复的。
再看一下工时项记录(effort_record)表。回忆一下,在第一个迭代,这个表里有一个项目 ID(project_id),作为虚拟外键,指向项目表。
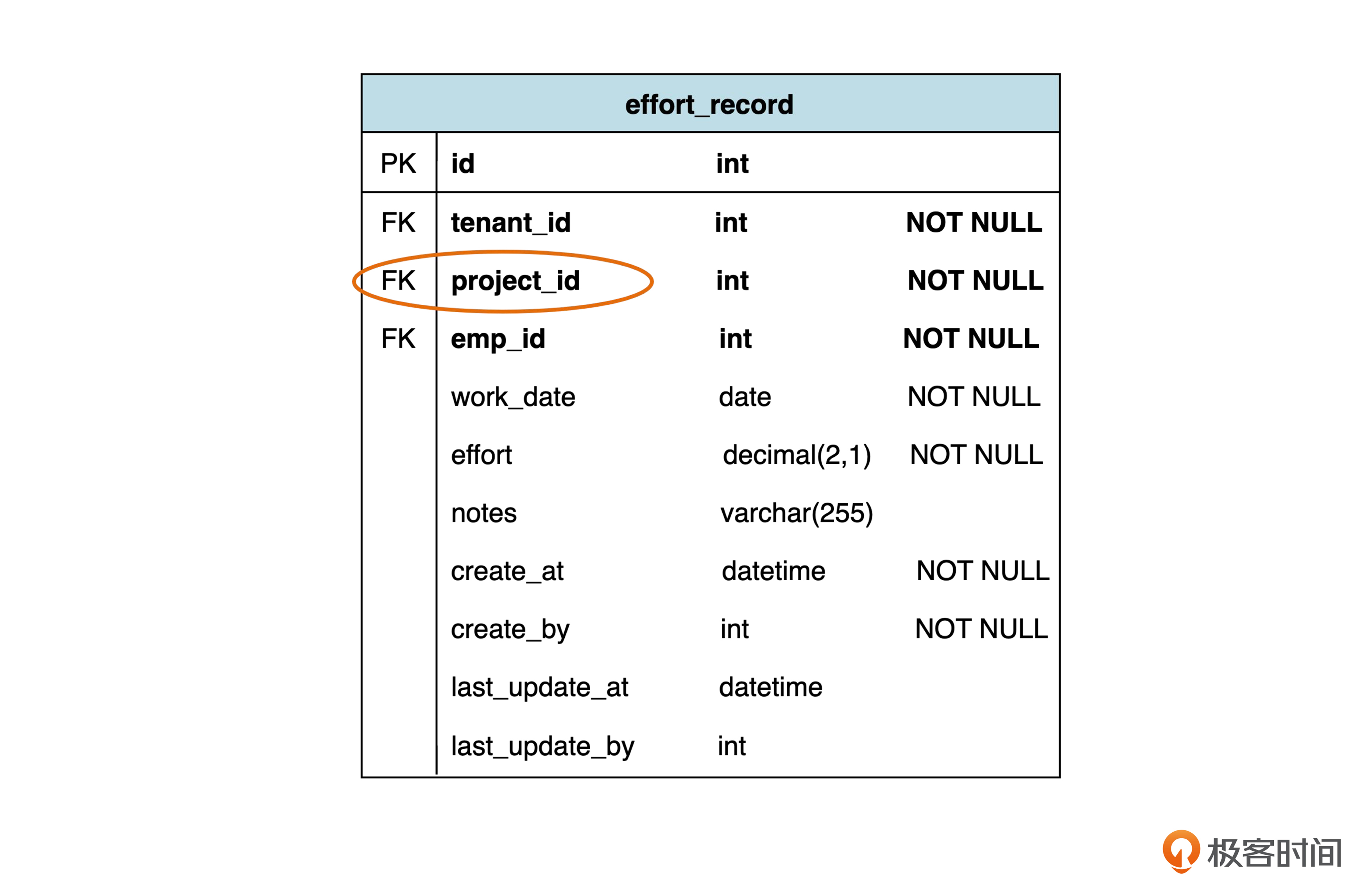
现在,我们把项目 ID 替换成了工时项 ID,以便指向逻辑上的各个工时项。由于这些工时项可能是项目、子项目或普通工时项,为了某些功能下查询的方便,我们用工时项记录表里的 source 字段表示工时项的来源,以便区分这三种情况。
建立好表以后,我们再考虑一下主键策略。由于项目、子项目、普通工时项是三个性质不同的实体,所以有各自的主键。而为了表达泛化体系,又增加了工时项 ID,作为泛化体系在逻辑上的主键。这其实就是“不共享主键”的策略了。你可以和前面“共享主键”的策略再比较一下,体会一下两者的不同使用场景。
总结
好,这节课的主要内容就讲到这,我们来总结一下。
今天,我们学习了怎样为泛化关系进行数据库设计。主要考虑两个问题:一个是建几张表;另一个是怎样确定主键。
对于建表来说,有 3 种基本策略:每个类一个表、每个子类一个表、以及整个泛化体系一个表。具体的选择,要根据空间效率、时间效率、可维护性、非空约束等不同的因素综合考虑,做出权衡。假如你实在举棋不定的话,那么可以先用“每个类一个表”的策略。
设计主键有两种策略:共享主键和不共享主键。如果父类和各个子类在业务概念上,本质上就是一类事物,只是在某些方面有所差别,那么共享主键是比较合理的。反之,如果在业务概念上不是同一类事物,只是由于某些个别方面有共性才造成的泛化关系,那么不共享主键比较合理。
说到这里,我们可以再想一想。或许和今天这样类似的数据库设计,你之前也能做出来。但是,DDD 方法的特点在于,我们是从领域知识的梳理、到利用领域建模对泛化进行识别、然后再权衡不同的建表策略,这样一步一步地推导出设计结果,而不是仅凭直觉和经验。这样的设计,不仅更有说服力,而且反映了业务的本质,因此设计的可扩展性和可维护性也会更好。
思考题
下面给你留了两道思考题。
1.今天我们讨论的时候提到,在报工时的时候,查询一个员工可以对哪些项目报工时的逻辑不是最优的。如果换做你来设计,会怎么做呢?
2.关于泛化表的设计,我们用客户这个“一父两子”的例子,说了 3 种建表策略。如果一父多子,或者不止两层泛化,那么还可以有什么变化呢?
好,今天的课程结束了,有什么问题欢迎在评论区留言,下节课,我们讨论泛化的代码实现,敬请期待。
- Michael 👍(5) 💬(2)
我明白泛化建表的三种策略的考量,但是不太明白“共享主键”在设计里起到的作用,或者说为什么还要考虑共享主键这件事情?老师能不能再展开说说?
2023-02-10 - KelperOvO 👍(2) 💬(2)
我感觉建出来出来的模型是有问题,项目和子项目不应该有工时项id,工时项id不是项目的信息
2023-05-28 - 子衿 👍(2) 💬(1)
1. 可以考虑新增一个表表示所有员工都可以填报的工事项有哪些,当新增不需要分配员工的项目,或普通工时项时,都冗余插入该表一份,这样原来查询3次就优化为查询两次,本质还是CQRS,从查询角度考虑如何设计,但导致写加重,读减轻 2. 感觉本质考虑的还是一样的,多个表更灵活更贴合领域模型,但需要关联的场景就会性能下降
2023-02-07 - 麦耀锋 👍(1) 💬(1)
在“每个类一个表”的例子里,在personal_client和corporate_client表都分别有name字段,理由是client表中如果放name,不能区分是个人姓名还是公司名称。对于此,我有不同的看法。首先,如果从业务角度(一般来看),应该能够有一个比较好的共识,就是对于name,如果用于个人,那么就是姓名,如果用于公司,那么就是公司名称,我觉得这是大部分业务逻辑都能接受的“共识”;其次,如果这种区分是必要的,那么对于“地址”呢,是否也得分“个人家庭住址”和“公司办公地址”? 这样拆分的话,其实更加重了对模型的理解负担(对于本质上大家都认同的共识做不必要的拆分)从而造成不必要的复杂性。 即使到了实现阶段,假如采用继承,一般而言这个name也会放在基类。
2024-11-11 - Geek_682837 👍(1) 💬(1)
在不共享主键的方案中,不一定需要逻辑主键吧,工时项可以用关联表的主键加source作为关联外键,这样也不会重复
2024-04-25 - 掂过碌蔗 👍(1) 💬(1)
工时项id,主要还是看有没有使用全局所有类型工时项的需求吧。比方说,根据工时项id对某个工时项进行一些操作。 如果所有操作都是基于项目、子项目、普通工时项单一维度进行操作的,工时项id就看上去没什么必要了。
2024-04-05 - 6点无痛早起学习的和尚 👍(0) 💬(1)
学着学着,逐渐吃力起来,前面的好多业务知识都忘了
2023-02-21