24 泛化建模(下):怎样权衡是否采用泛化?
你好,我是钟敬。
前两节课,我们重点结合报工时的需求来讨论了关于泛化的问题。在第22课,我们为工时项建模的时候使用了泛化;而第23课,在为客户项目和内部项目建模时,尽管可以泛化,最终却没有采用泛化。
你可能会有个困惑:前两节课的例子里,是否采用泛化,似乎完全是凭经验和直觉,有没有更多规律可循呢?
事实上,要学会一项技术,不仅要知道什么时候用它,更要知道什么时候不用。泛化虽然很有用,但也是一种容易被过度使用的技术。
是否要采用泛化,有时并没有唯一正确的答案,而是个权衡问题。站在业务的角度,泛化可以让我们通过抽象思维而得到更深刻的领域知识,并且运用得当的话可以使模型更简洁。但另一方面,也正是由于有些抽象,所以有时反而让模型变得费解。而站在开发人员的视角,还需要考虑技术上是否容易实现,是否容易保证代码和模型一致性的问题。
既然是“权衡”,那么必然有一些“艺术”的成分在里面。不过,我们今天还是尽量找出一些规律性的东西,以便你能尽快形成“感觉”。先提示一下,后面有不少示意图,你可以边看文稿边听我说。
识别泛化的两个方向
首先,我们在建模的时候识别泛化的过程,其实有两个不同的方向。
一个方向是先识别出了子类,然后从子类中归纳出共性,形成父类。比如在第22课,我们先识别出项目和子项目,然后发现这两者都能报工时,也就是说具有能够报工时这个共性,于是识别出了工时项这个表示共性的父类。
另一种是先识别出父类,然后发现这个类中的不同对象有一些显著的差异,需要再分成两个子类。例如第23课,我们先识别出项目,然后发现“客户项目有合同,内部项目没有合同”这一差异,于是可以识别出客户项目和内部项目两个子类。
我们可以借用逻辑学上的术语,把第一种自底向上的方法称为“归纳法”,把第二种自顶向下的方法称为“演绎法”。
表示“分类”的两种方式
下面我们再聊一下表示分类的两种方式。上节课说过,泛化表达的含义是“分类”。其实,分类是人们认识世界时采用的最基本的思维方式之一。通过分类,我们就可以理解不同事物的共性和个性。对于有共性的事物可以从整体上理解它们的规律,而不必一个一个地去辨认,从而提高了思维的效率。
泛化可以表示分类,但分类不一定要用泛化。事实上,领域模型里除了用泛化表示分类,还有一种做法就是通过不同的特性值来表示。
还记得我们在第20课讲值对象的时候提到的“属性和关联的等价性原理”吗?其实,属性(attribute)和关联(association)统称为特性(property)。所以,后文凡是讲到这两者统称的时候,我就直接说特性了。
在上节课的例子里把客户项目和内部项目作为项目的两个子类的做法就是泛化;而在项目中增加一个“是否客户项目”属性的做法就是基于特性值的。
再举一个简单的例子。假如我们把马按颜色分成白马、黑马、红马、棕马。那么下面三种画法,仅从表达的含义来说,是相同的。
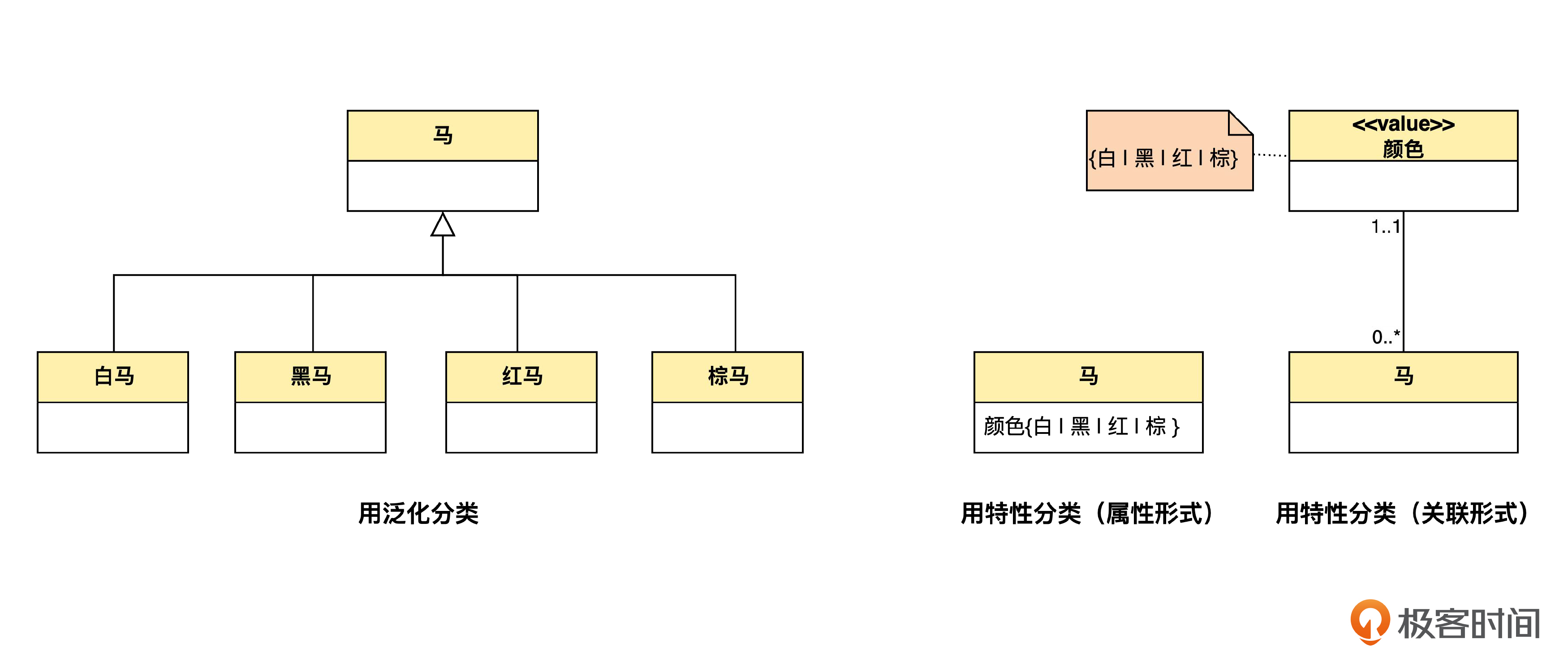
左边的图就是用泛化表示分类,右边的两个图就是用特性表示分类,一个是用属性的形式,另一个是用关联的形式。
分类的这两种表示方式,表达能力是不一样的。用特性值来表示分类的场合,一定可以用泛化来表示;但用泛化表示的分类,未必能用特性值表示。比如说下面这种情况。
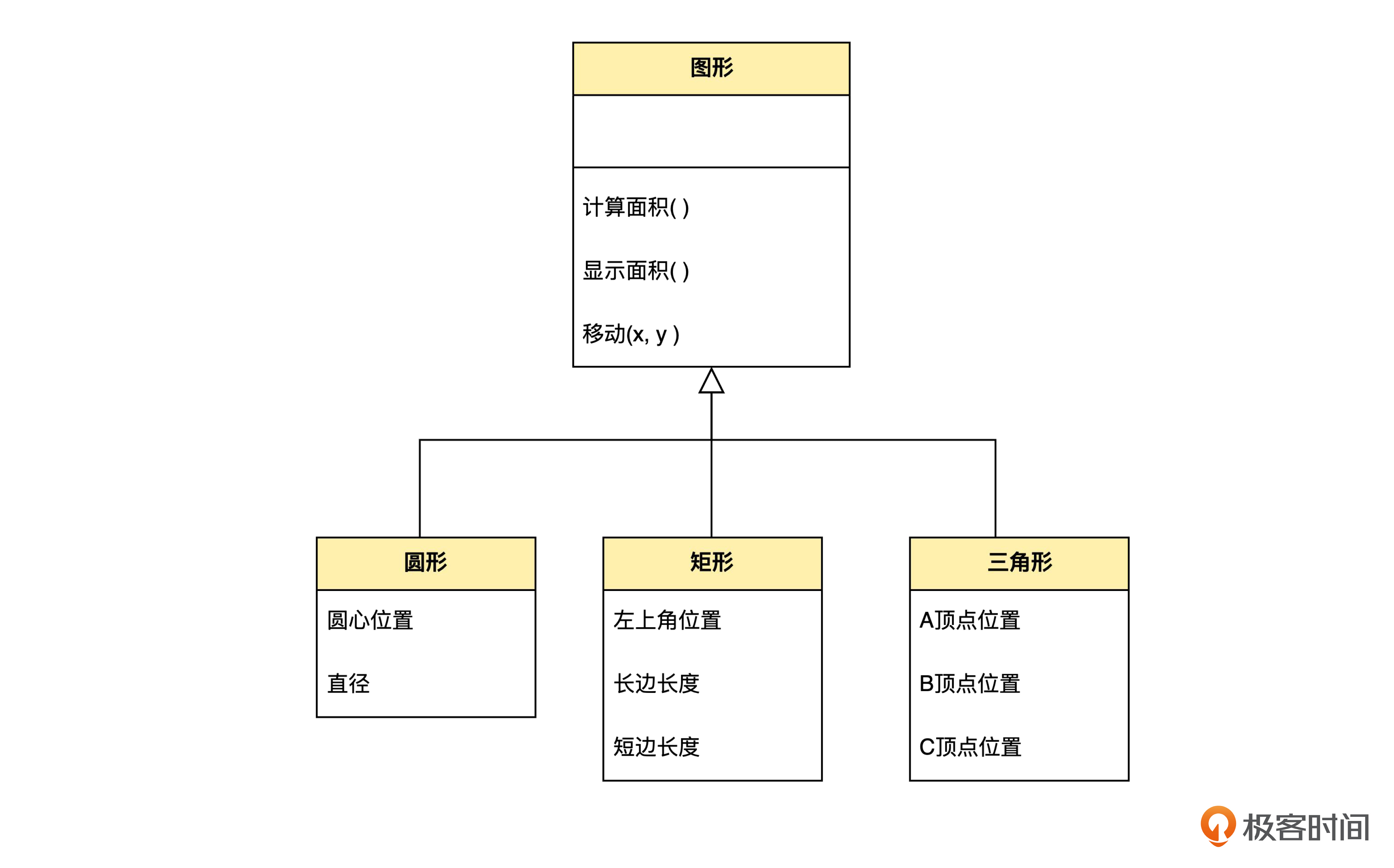
圆形、矩形和三角形都是图形,都可以计算面积和移动。但各自的特性种类不同,所以只能用特性的不同种类来区分而不能用同一种特性的不同值来区分了。而之所以前面的“马”可以合并成一个类,是因为不同颜色的马都只有颜色特性。
注意一下我们这里说“特性种类”和“特性值”时的区别。圆形有“直径”而矩形没有,反之,矩形有“长边长度”,而圆形没有,所以我们说圆形和矩形的“特性种类”不同。而不同颜色的马,都有颜色这个特性,所以特性种类是相同的,只是特性的值不同。
分类的“共性”和“个性”
讨论完领域模型中分类的两种表示方式,我们再来聊聊分类的“共性”和“个性”。我们知道,只有若干的事物之间既有共性又有个性的时候,才有所谓分类。那么,这些所谓共性和个性,在领域模型中的具体体现是什么呢?我们再来归纳一下。
在特性种类、特性值、业务规则、操作接口、操作实现等方面,不同的类既有共性又有个性的时候,才有所谓分类,也才可以进行泛化。
我们刚才已经讨论过了特性种类和特性的值,现在再看看业务规则的共性。比如说,把项目作为一个父类,下面有若干子类,如客户项目、内部项目等。那么基于目前的需求,“所有项目都要有项目经理”就是父类中一个共性的业务规则。
我们再来理解一下具有“共性”的操作接口。尽管领域模型里识别操作不多,但有时候也有。尤其是做桌面应用的时候。比如前面举过的关于图形的例子。
圆形、矩形和三角形都是图形。它们有共同的操作接口,例如“计算面积()”“移动()”等。不过,具体的逻辑是在子类里多态地实现的。
理解了操作接口的共性,我们再看看操作实现的共性。假定图形类里的显示面积()方法的功能只是在控制台打印出面积,那么这个方法就不必多态,直接在图形类里实现就可以了。这时,这个操作就是这些子类的共性。
权衡泛化的两个视角
接下来,再讨论一下权衡泛化的两个视角:业务视角和技术视角。
业务视角,实际上是业务人员和技术人员都理解的视角。站在这个视角,我们要考虑:引入泛化后,有没有在模型里增加新的知识,有没有使模型更加简洁,更容易理解?
而站在技术视角,就要考虑这个模型是否能自然、直接地映射到设计模型和代码。我们沿用上面关于马的例子来说明。先看一看下面这张图。
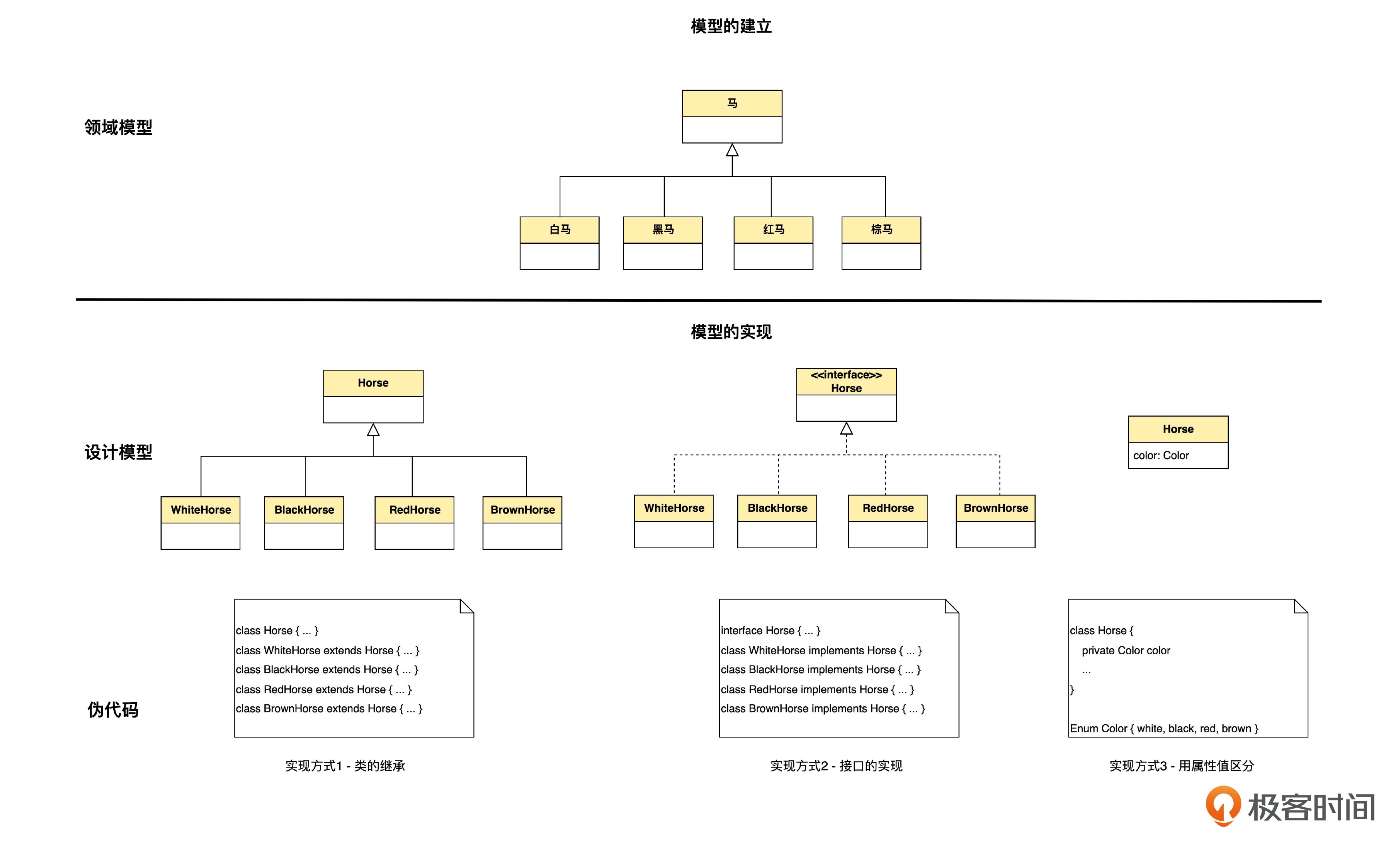
这个图说明,领域模型中的泛化在设计和编码的时候可以有三种基本方式。
第一种,是使用类的继承。领域模型中的父类、子类,和实现中的父类、子类直接对应。
这里有一个微妙的地方,要注意区分。在领域模型里,表示泛化的空三角符号就是分类的意思。而在设计模型里,这个空三角符号表示的则是面向的对象设计和编程中的“继承”。而继承,只是实现泛化的方式中的一种。它的特点在于,必须有不同种类的特性或者不同的操作。如果仅仅是某个属性值不同造成的泛化,那么用继承就不合适了。
第二种,是接口的实现。如果各个子类在属性和操作实现方面没有共性,但有相同的操作接口,就使用这种方式。
第三种,是用特性的值来区分,这时候在实现层面,就没有父类和子类之分了。
显然,领域模型中的泛化,转化成类的继承和接口的实现这两种方式,图的形式很接近,是比较直接的;而转化成特性值区分的方式,就没这么直接了。
当架构师看到,领域模型中的某部分可以用泛化和特性值两种方式建模的时候,就可以“偷偷地”想一下,考虑到简洁性、可理解性、可维护性等方面,在实现层面采用哪种方式更合适呢?
就这个例子而言,假定除了颜色不同,各种马的特性种类、操作等都是相同的,那么,用特性值区分的实现方式就是合理的,而继承是不合理的。那么架构师就可以建议,在领域模型中,也采用特性值区分的方式,以便保证领域模型和实现的一致性。也就是下面的方式。
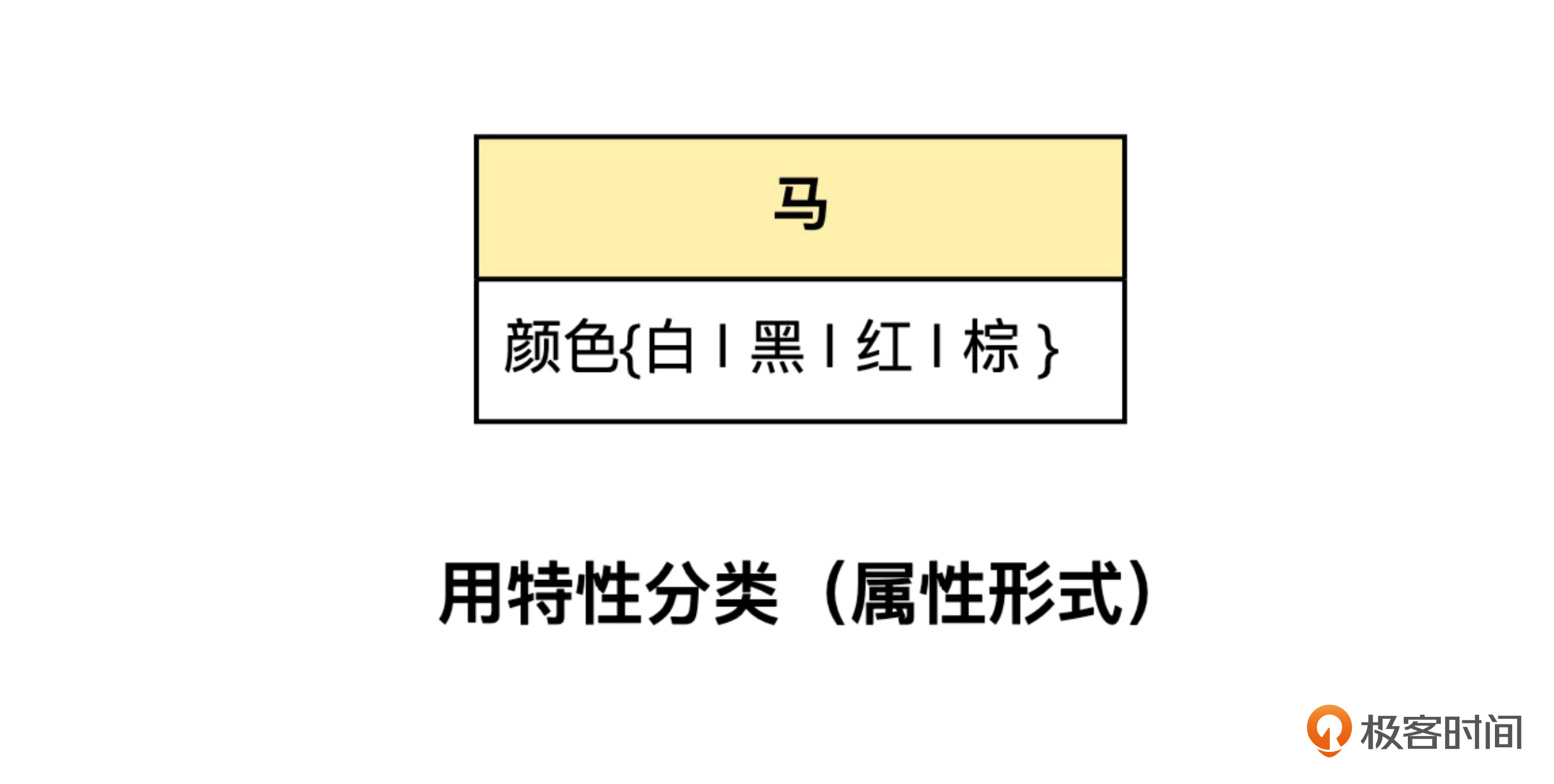
那么领域专家再从业务视角考虑,发现在简洁性、领域知识的准确性等方面也没有问题,那么就可以确定这个方案了。
注意,尽管获得这个模型的过程中加入了技术视角,但最终呈现出的结果,仍然只有业务概念。你可以好好体会一下这个辩证关系。
再重申一下,可以泛化,不代表必然要泛化。那么怎么选择呢?我为你梳理了后面三条经验。
第一,假如只有特性值不同,那么用特性值为对象分类就可以了,不必使用泛化。
第二,如果特性种类不同,那么很可能要采用泛化。
第三,如果在业务规则、操作接口或操作实现方面有共性和个性,首先考虑在实现上是否可以使用策略模式,如果可以,那么在领域模型中就不必泛化,否则考虑泛化。如果你还不太了解策略模式,可以参考《领域驱动设计》原书第12.1节,或其他关于设计模式的书。
案例中的泛化问题
现在我们运用前面的思考方式,再回味一下前两节课提到的案例中的泛化问题。
工时项要泛化吗?
在第22课里进行了工时项的泛化,我们把那节课的最终模型图拷贝到下面,你可以回忆一下。
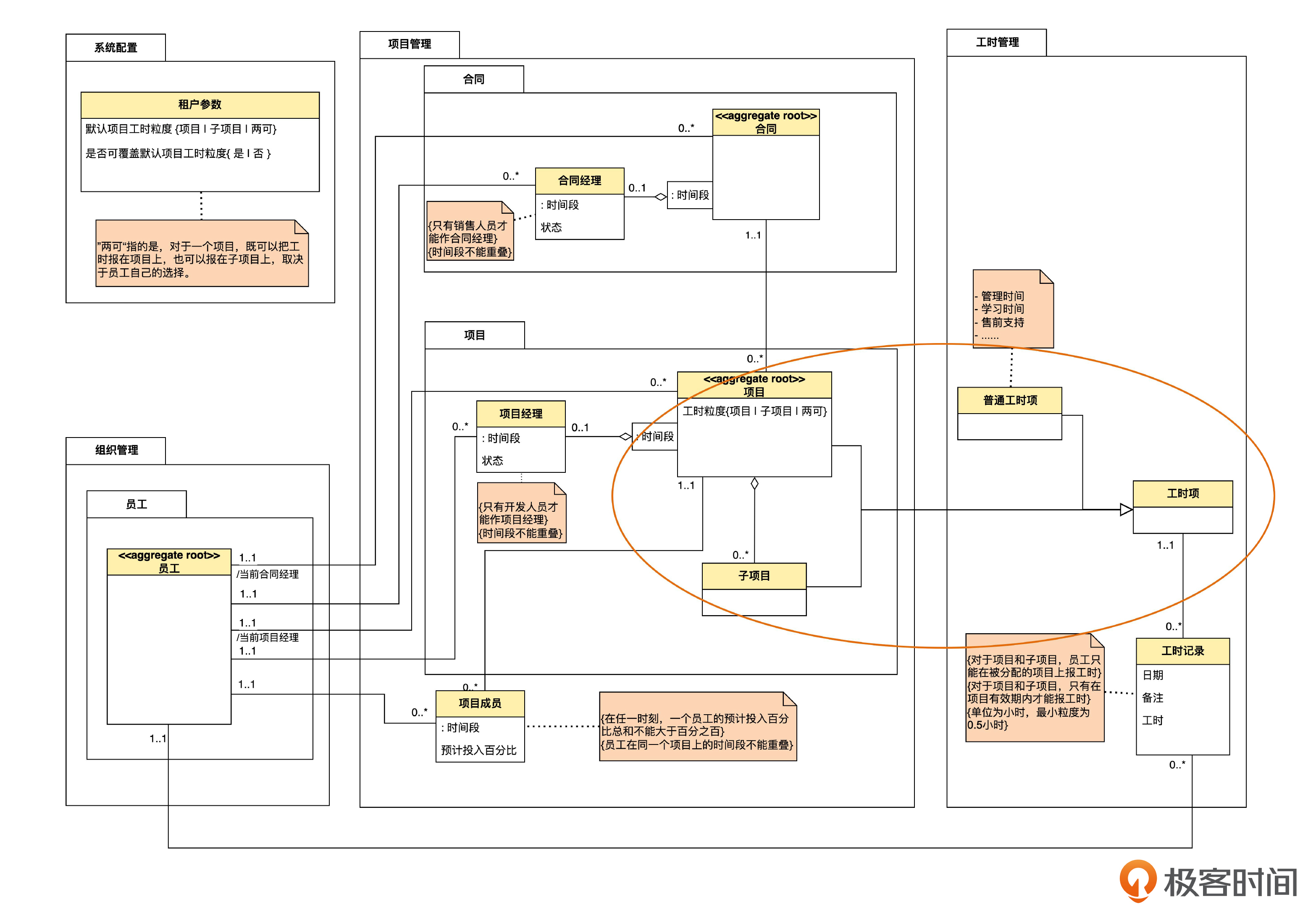
假如不泛化,那么模型图可能是下面的样子。
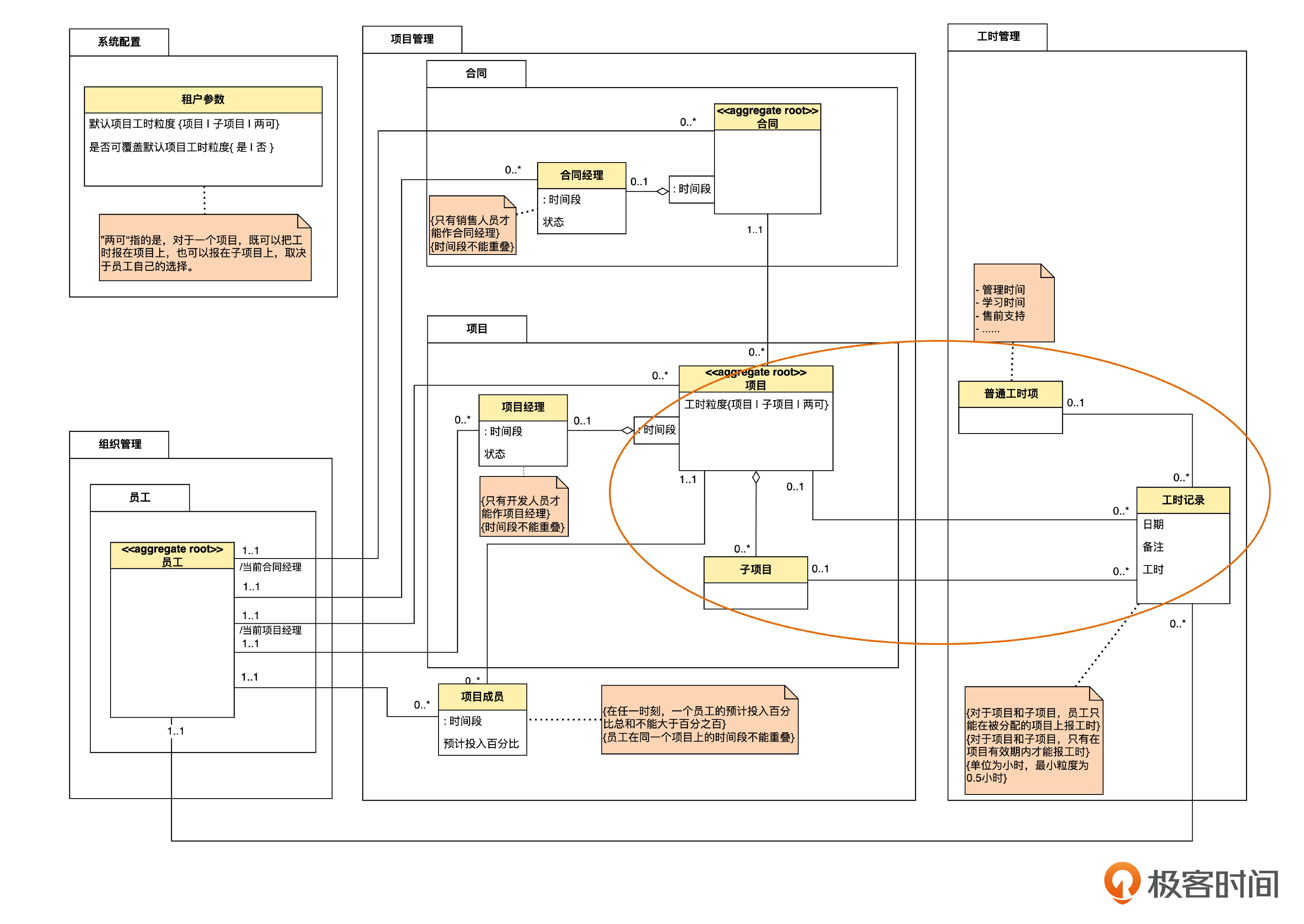
那么,为什么我们在上节课,像第一张图那样采用了泛化,而不是像第二张图那样不采用泛化呢?下面咱们就来分析一下。
工时项的泛化,一开始是从项目和子项目中“归纳”出来的。在归纳前,项目、子项目都有各自不同种类的特性,因此用特性值来表示分类是不行的。所以,这里的问题不是用什么方式表示分类,而是要不要表示分类。如果要表示出分类,那么就必然要用泛化了。
先从业务视角考虑,当我们抽象出泛化以后,实际上就在模型中增加了三条领域知识:第一,项目、子项目、普通工时项有一个共性,就是都能报工时,这个共性抽象成了“工时项”这个概念;第二,凡是工时项,必然和工时记录具有一对多的关系;第三,每条工时记录,必然与且仅与一条工时项关联。
你可能会问,即使不用泛化,图里面不是也表达出了上面的第一和第二条领域知识了吗?
这里的区别在于,不用泛化的话,这些知识是隐式表达的,需要看模型图的人在头脑中再抽象一下,而且人们也不知道这种共性到底是偶然的,还是必然的;而用了泛化,这种共性的必然性就显式地表达在模型里了。
另外,这个泛化也在一定程度上起到了简化模型的作用,因为原来项目、子项目、普通工时项各自和工时记录相关联,一共 3 条关联。现在,抽象并简化成了工时项和工时记录之间的 1 条关联。
再从技术视角看,我们使用泛化的话,可以把工时项直接映射成程序中的父类,在这个父类中处理和工时记录的关系,而不必在三个子类中分别处理,提高了可复用性,而且,将来如果再增加一种不同的工时项,只需增加一个子类就可以了,也符合程序的可扩展性。
所以,综合业务和技术的视角,我们决定采用泛化。
客户项目和内部项目要泛化吗?
我们再回味一下上节课有关客户项目和内部项目是否要采用泛化的问题。
如果要用泛化,并且和是否要分配项目成员这个选项区分开来的话,那么模型图应该是下面这样。
不采用泛化的话,是下面这样。
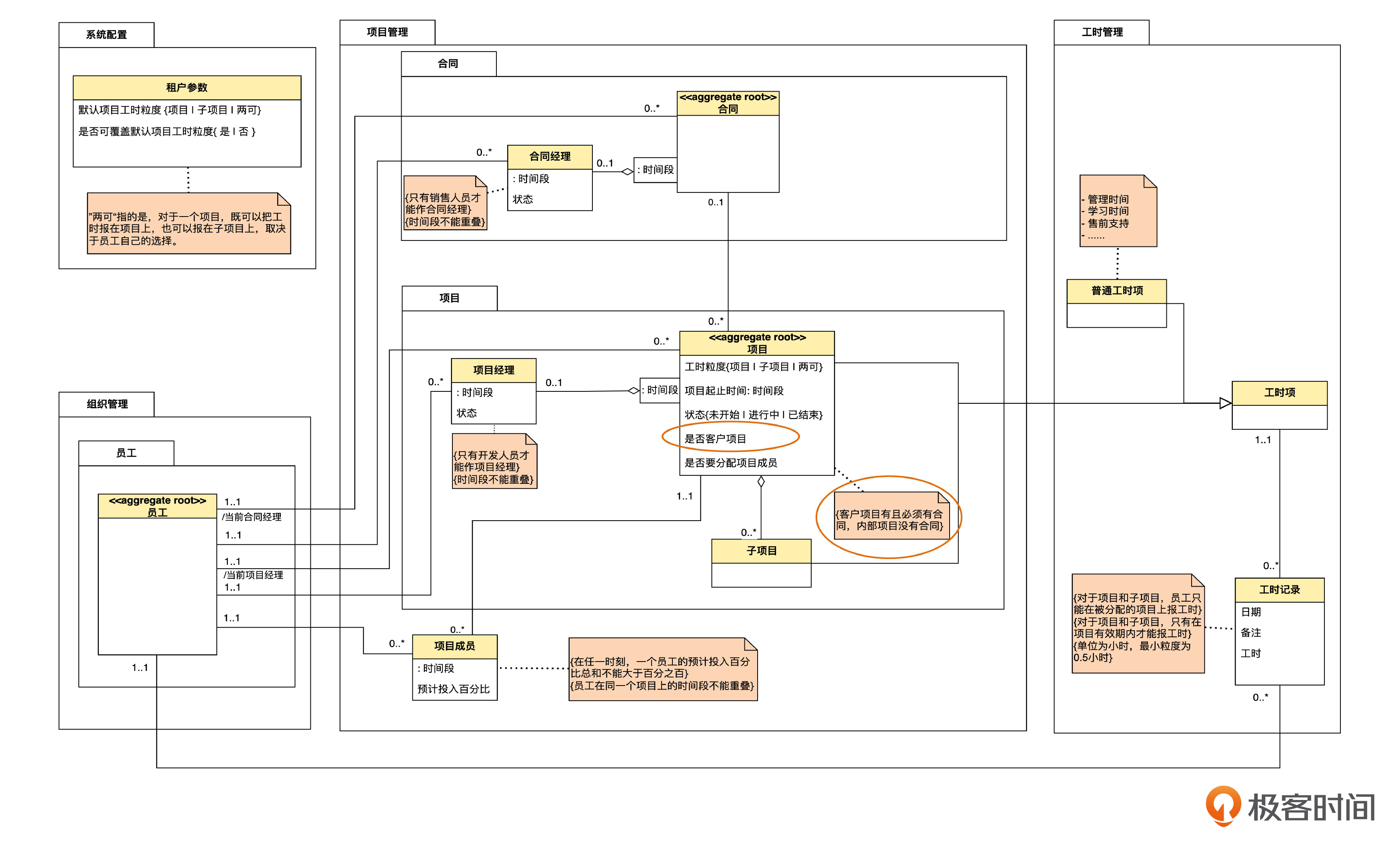
在这个例子中,识别泛化的方向,是先识别项目,再“演绎”出客户项目和内部项目的。客户项目和内部项目的相似性非常高。
站在业务视角,首先我们要承认,泛化以后,确实把“客户项目才有合同,内部项目没有合同”这条领域知识显式地表达了出来,但代价是模型变得复杂了。
站在技术视角,仅仅为了有没有合同这一个区别就采用继承,建立一个父类和两个子类,显得过于复杂了。另一方面,不采用继承的话,只需要在项目中有一个合同ID,通过判断这个ID是否有值,就可以区分了。
所以综合考虑业务和技术、成本和收益,最终决定不用泛化。
普通工时项要泛化吗?
上节课遗留的另一个问题是,学习时间和管理时间也可以统称为普通工时项,那么这三者要采用泛化吗?
如果不用泛化,那么就是我们现在的样子。
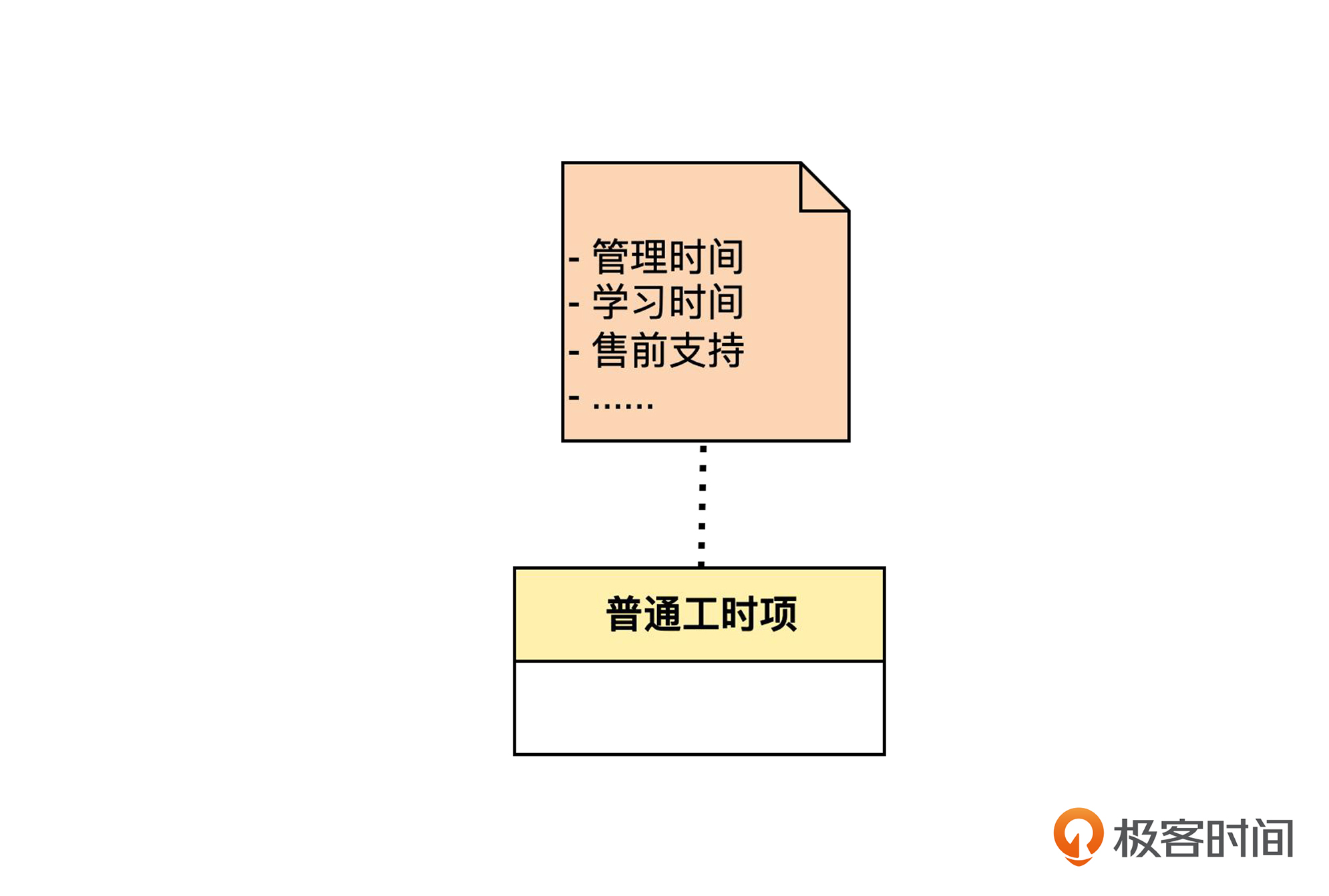
如果要用泛化,就是下面的样子。
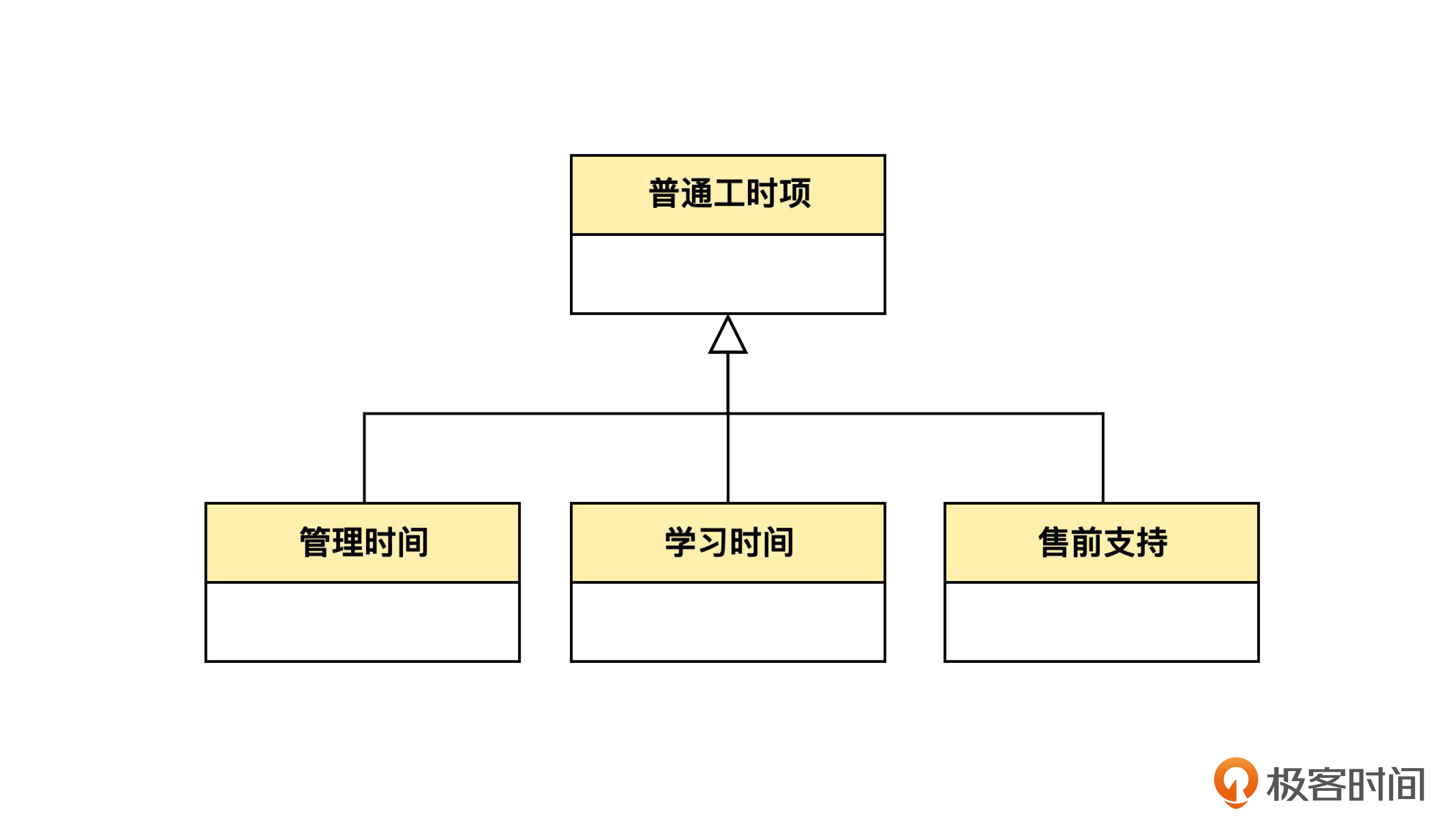
其实,泛化是类和类之间的关系。我们的思路是首先要不要进行“分类”,如果要分类的话,再考虑是不是要泛化。
比如说,如果学习时间还要再细分为“学习开发技术的时间”“学习需求分析的时间”“学习管理的时间”等等,并且要在这些细项上报工时,那么就可以考虑把学习时间作为一“类”事物,这时候才考虑是否要泛化。
但是我们现在没有这个需求,学习时间和管理时间都是不需要再细分的。这时候,普通工时项就是一个类,而学习时间和管理时间只是这个类的实例,所以就无所谓泛化了。
领域模型中的几种关系
学习完泛化,我们就可以来归纳一下领域模型中的几种关系了。
第一,是实例和实例之间的关系。也可以说是对象和对象之间的关系。当我们谈关联和聚合的时候,说的就是实例之间的关系。比如说组织和员工之间具有一对多关联,实际上是说一个组织实例可以有多个员工实例。
第二,是类和类之间的关系。泛化其实就是类和类之间的关系,而不是实例和实例之间的关系。当我们说圆形是图形的子类的时候,实际上是说,圆形这一类事物,是图形这一类事物的子集。
第三,是类和实例之间的关系。比如圆形这个类和某个具体的圆之间的关系。或者前面说的普通工时项和学习时间之间的关系。
上面三条看起来可能很简单,但我们常常会混淆。如果能把它们搞得清清楚楚,那说明你已经具有一定的建模能力了。
总结
好,这节课的主要内容就讲到这,我们来总结一下。
今天,为了帮助你权衡是否采用泛化,我们一起总结了泛化的一些规律。
在模型中识别泛化的过程可以有两种,一种是归纳法,也就是先识别出了一些类,然后发现它们之间有共性,于是抽象出父类。另一种是演绎法,也就是先识别出了一个类,然后发现这个类又可以分成几种不同的情况,于是识别出不同的子类。
理论上,所有的分类都可以用泛化来表示。但泛化并不是表示分类的唯一的方式,当几类事物只有特性值不同的时候,可以通过特性值来表示分类。
权衡泛化要通过业务和技术两个视角来考虑。尽管从技术视角可以帮助选出更合适的模型,但最终的建模结果仍然只包含业务概念。
泛化是对共性和个性的抽象。共性和个性在模型中具体体现在特性种类、特性值、业务规则、操作接口、操作实现等方面。
最后,领域建模中,我们要分清实例之间、类之间以及类和实例之间这三种关系。其中泛化是类和类之间的关系,而关联是实例和实例之间的关系。
思考题
下面我给你留了两道思考题。
1.在目前的需求中,学习时间、管理时间没有再细分。那么,如果要细分的话,你认为需要使用泛化吗?
2.可否在你的实际项目中再找一些泛化的例子,说明父类和子类的共性和个性表现在哪些方面?
好,今天的课程结束了,有什么问题欢迎在评论区留言,下节课,我们讨论泛化的实现。
- 南山 👍(8) 💬(1)
钟老师,请教个问题:像这种采用了泛化的,如何识别聚合根,比如工时管理的聚合根还是工时管理吗?项目管理的还是项目,是这样的吗?
2023-02-06 - ╭(╯ε╰)╮ 👍(5) 💬(2)
工作中经常遇到的问题: 1 技术上的泛化跟业务上的泛化不能很好的共存, 最常见的案例就是有个AbstractXXX的基(提取公共方法,封装技术实现比如把一类操作消息中间件的代码抽到父类里而产生的),另外有一个业务上归纳出来的父类。 因为不能多继承我的代码要么放弃技术上的抽象选择业务上的父类来继承,导致技术实现相关的代码到处复制粘贴。要么放弃业务上的父类,后果就是领域建模不能落地。 2 业务上的泛化使用技术不好实现(语言不支持多继承,接口不能有属性) 我是做游戏开发的,游戏设计各种天马行空,策划随便给过来一个技能,很可能就把之前版本的代码结构破坏掉,几十层的继承关系并不稀罕,各种散弹式修改和发散式修改。 身边不乏工作十几年的老程序员,但上面两个问题大家好像没有什么好的办法(或者他们习以为常不觉得这是问题),甚至很多屎山就是公司大牛的杰作。
2023-02-06 - 子衿 👍(5) 💬(1)
这章其实感觉读起来有点绕,我能不能这样理解一下,就是说泛化是领域模型图中的一个标识而已,要不要使用这个标识,其实只取决一一点,就是是否使用特性值的方式进行实现,如果使用特性值方式进行实现,那么因为没有父子类的概念,就会导致模型和代码不一致,因此就不应该用泛化,而文章其实整体讨论的不是应不应该使用泛化,而是讨论用具体哪种实现方式来实现分类 1. 有不同种类的特性或者不同的操作:使用继承 2. 子类在属性和操作实现方面没有共性,但有相同的操作接口:使用接口实现 3. 仅特性值不同:使用新增属性值的方式
2023-02-05 - 或许 👍(0) 💬(1)
“第三,如果在业务规则、操作接口或操作实现方面有共性和个性,首先考虑在实现上是否可以使用策略模式,如果可以,那么在领域模型中就不必泛化,否则考虑泛化。” 老师您好,上面这句话我没有太理解,希望老师可以抽空解答一下我的疑问: 策略模式定义了一个抽象的算法,以及一组具体的实现。我理解抽象的算法和这组具体的实现,也可以用来表示分类关系,为什么可以用策略实现,就不建议使用泛型呢?
2024-07-01 - 才华 👍(0) 💬(1)
钟老师。请教一个问题,比如广告投放系统中,对于投放资源位,营销目标,推广标的等来说,不同的值决定了后续的业务逻辑判断和属性填充,这种的建议使用泛化还是特性值呢。
2023-06-20 - icode 👍(0) 💬(1)
领域模型的第三个关系,是不是可以理解成类和子类的关系啊?
2023-02-21 - 6点无痛早起学习的和尚 👍(0) 💬(3)
思考题 2:2 个例子,但是感觉第一个例子不应该用泛化,第二个可以用泛化 第一: - 父类:账户项 - 子类:现金账户、备付金账户、待清算账户、待结算账户等等 共性:都有可用余额、冻结余额、挂靠会计科目等特性值 个性:业务规则不一样,子类的余额方向和交易方向对应出来的余额增减结果是不一样的,但是规则都是同增异减 第二:可以用泛化,但是最后用了策略 - 父类:正向交易 - 子类:支付、充值、提现 共性:业务规则流程相同,先校验参数、再校验是否原单和状态、组装请求外部参数、处理请求外部结果。 个性:每个子类的具体业务规则实现是不一样的。
2023-02-20 - 赵晏龙 👍(0) 💬(1)
1、没有进一步的需求,我觉得,不需要,用属性标识也够了。 2、 极客时间专栏、Java专栏/.Net专栏/Go专栏,这一类就不需要泛化,只有共性,没有特性 极客时间用户、企业用户/个人用户,这一类可能就需要泛化,如果企业用户和个人用户某些操作不同的话。 我感觉老师的帮我把知识梳理到底了,更清晰了。
2023-02-17