19 值对象(中):值对象有什么好处?
你好,我是钟敬。
上节课我们讲了值对象的基本概念和编程方法。实体和值对象的差别大体可以总结成这句话:实体是一个“东西”,而值对象是一个“值”,往往用来描述一个实体的属性。
学完前面的内容,不知道你会不会有这样的疑问:我们花了这么大的功夫来区分实体和值对象,那么识别值对象有什么好处呢?今天我们就来聊这个问题。
值对象的优点,主要体现在内存和数据库布局的灵活性上。有了这种灵活性,就可以根据性能、编程方便性等因素,决定值对象的不同实现方式。其次,值对象的不变性也会带来更高的程序质量。这些优点,都是实体所不具备的。
那么,这里说的“布局”指什么呢?我们慢慢讲。先提示一下,后面有不少图片和代码,你可以边看文稿,边听我说。
对象的内存布局
先说内存里的布局,也就是程序运行的时候,对象在内存里是怎么存储的。为了说明这个问题,我们可以利用UML的对象图(Object Diagram)来分析。
假如有一个员工,名字叫“张三”,出生日期是“1990年1月1日”,员工号是“1001”。他有两个技能:一个是Go语言,做过3年,达到中等水平;另一个是Java语言,做过10年,达到高级水平。他还有两段工作经历:从“2017年1月1日”到“2022年1月1日”在“ABC Inc”公司工作;从“2014年1月1日”到“2016年12月31日”在“123 Inc”工作。
那么,表示这个员工的对象图,可以画成下面这样。
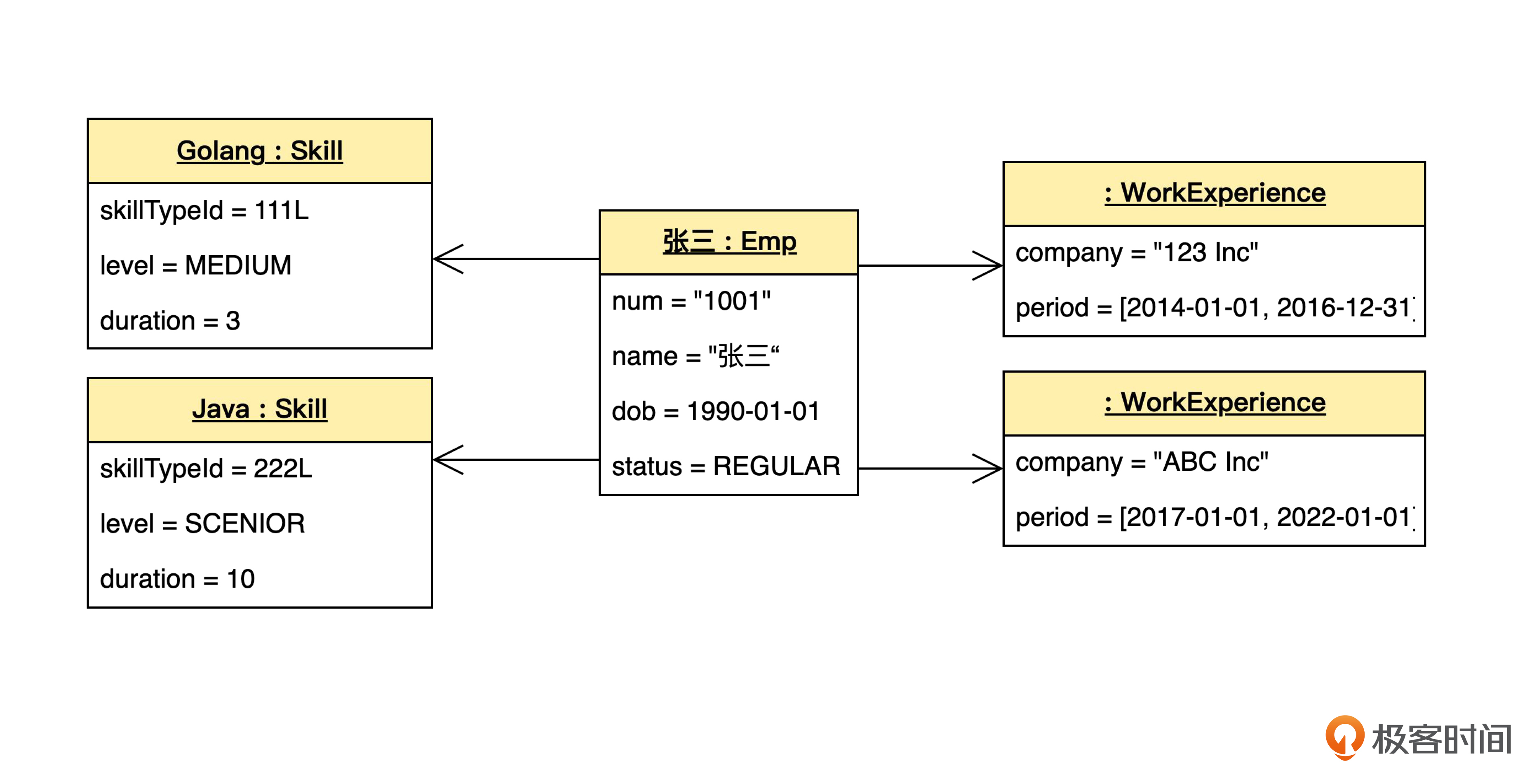
这个图看起来有点像领域模型图,但其实不是。领域模型的图是“类图”,每个方框代表一个类。但是对象图的每个方框代表一个对象。每个框的名字都有一个下划线,例如 张三 : Emp。在UML里,这种名字有下划线的框就表示一个对象,也就是一个类的实例。
对象名里有一个冒号,冒号前面是对象的名字,以便于描述;冒号后面是这个对象的类型。例如 张三 : Emp 这个对象,对象名是“张三”,对象的类型是 Emp 型。不过,对象的名字常常被省略掉。
箭头表示对象之间的引用,从技术的角度来说,代表了被引用对象的地址。
一个对象有很多属性,在对象图里可以用等号写出属性值。对象图和类图的一个区别就是对象图的属性有值,而类图没有。这是因为,只有具体到一个对象的时候,我们才会知道对象的属性值;而类只是对象的模版,所以只知道属性的类型,不知道值。
有了对象图,就可以表示对象在内存里的布局了。每个对象都占有一片内存空间,通过引用来互相关联。
你可能会发现,有些属性自身也是对象,例如 : Emp 对象的 num(员工号)属性是字符串(String)型,它本身也是个对象。如果我们把所有对象都展开的话,对象图就成了下面的样子。
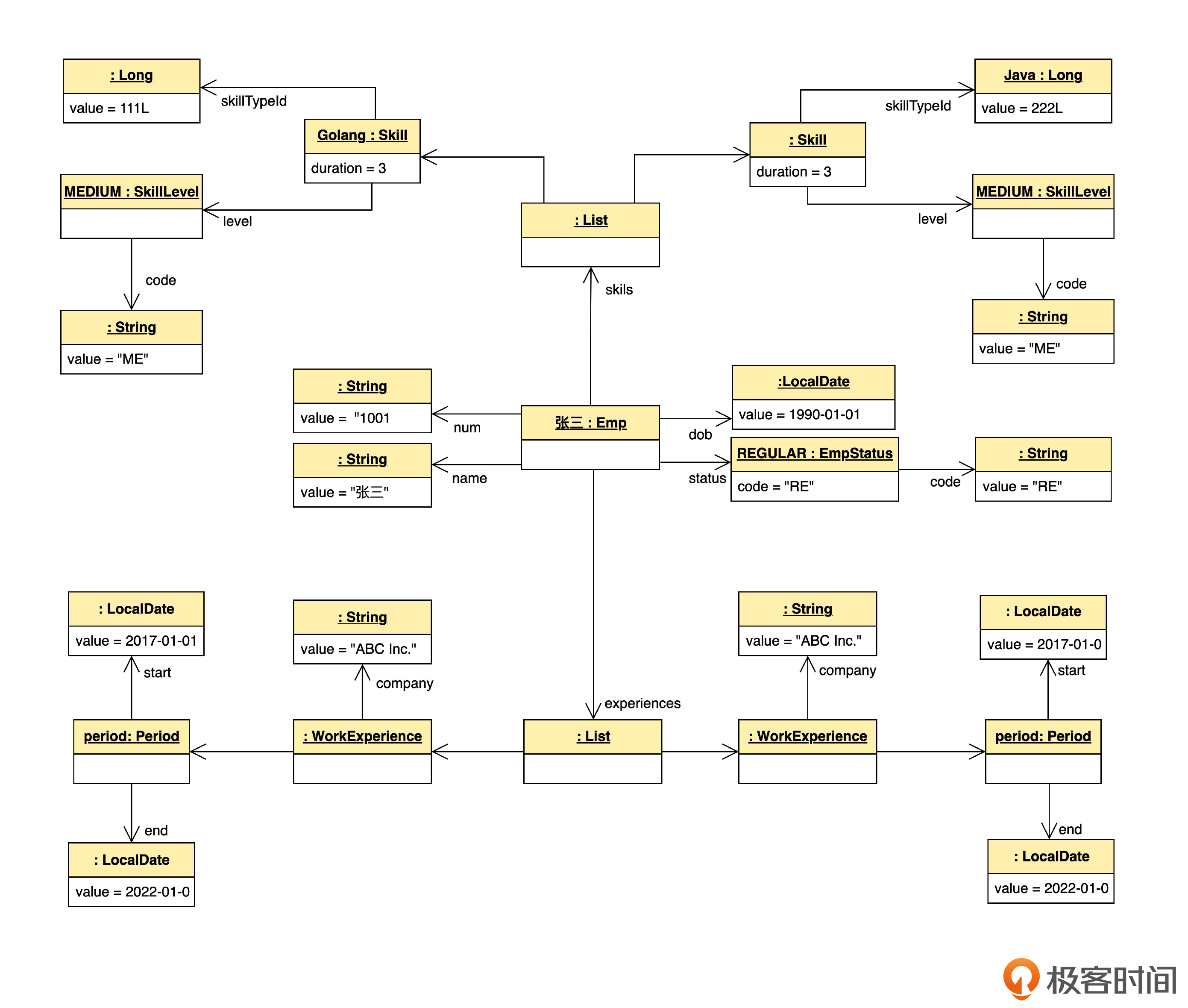
这个图更接近内存里真实的情况。像类图一样,对象图里也可以用“角色”表示属性名。另外,再看一看 Golang : Skill对象,里面的duration属性是整型(int),是一种基本数据类型,所以写在对象框的内部,说明duration所占的内存包含在 :Skill对象内部。而其他几个属性本身是对象,自己占有一块专门的内存,不过, :Skill保存它们的引用也是要花费内存的。
上面两个图要表达的含义基本是等价的。前一种比较简洁,也比较常用。后一种是为了更细致地理解原理。到底采用哪种形式,取决于我们想强调什么。
现在我们头脑中是不是已经可以想象出来,一个对象和它关联的对象一起,在内存中组成了一个“图”(graph)。有了这个工具,我们就可以比较实体和值对象在内存布局上的不同了。
实体的内存布局
对于实体而言,关键是把握一个原则:在同一个线程里,一个实体对象在内存空间里只能出现一次。也就是说,如果同一个实体在内存里被多个对象引用,那么这个实体必须被多个对象共享。
为了说明这个问题,咱们考虑一下员工和组织的关系。我们假设员工用对象导航的方式指向组织。张三和李四都是IT部的员工,那么对象图就是下面这样。
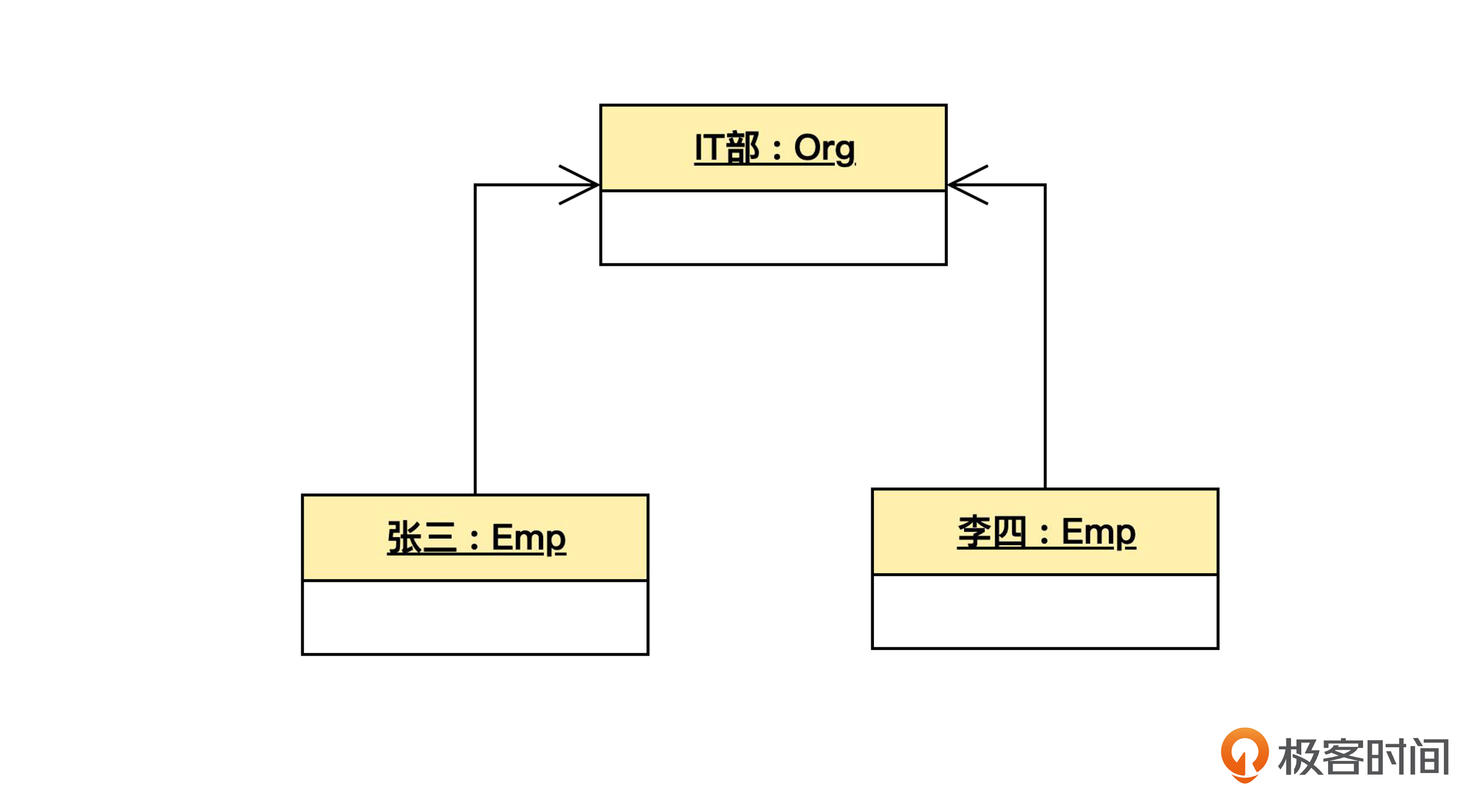
简单起见,我们忽略了这几个对象的其他属性。
目前这种内存布局是正确的。但是,有时候编程不小心,可能会导致下面这样的布局。
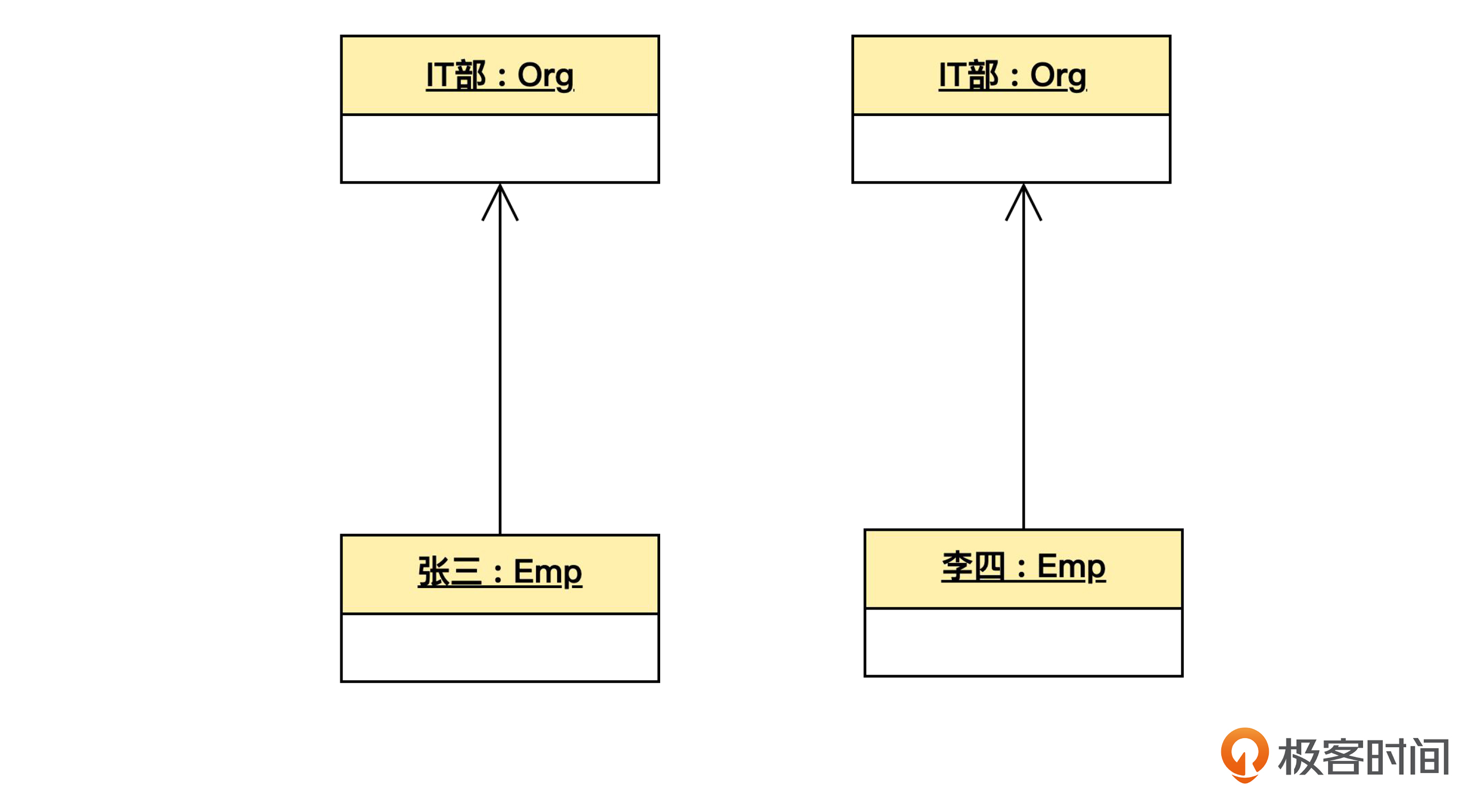
也就是说,同一时刻,在内存里有两个对象,表示同一个“IT部”,这就违反了我们前面说的原则。
这样会有什么害处呢?假如我们改了其中一个组织对象的某个属性值,而另一个没有改,那么,在同一时刻,表示同一个部门的对象,就会存在不同的属性值,这在概念上是矛盾的,很可能会导致隐含的逻辑错误。
值对象的内存布局
说完了实体的内存布局,我们看看值对象有什么不同。
假设员工张三只有一段工作经验,是在2014年1月1日到2016年12月31日,在“123 Inc”公司工作。我同样画了图,来表示内存布局。
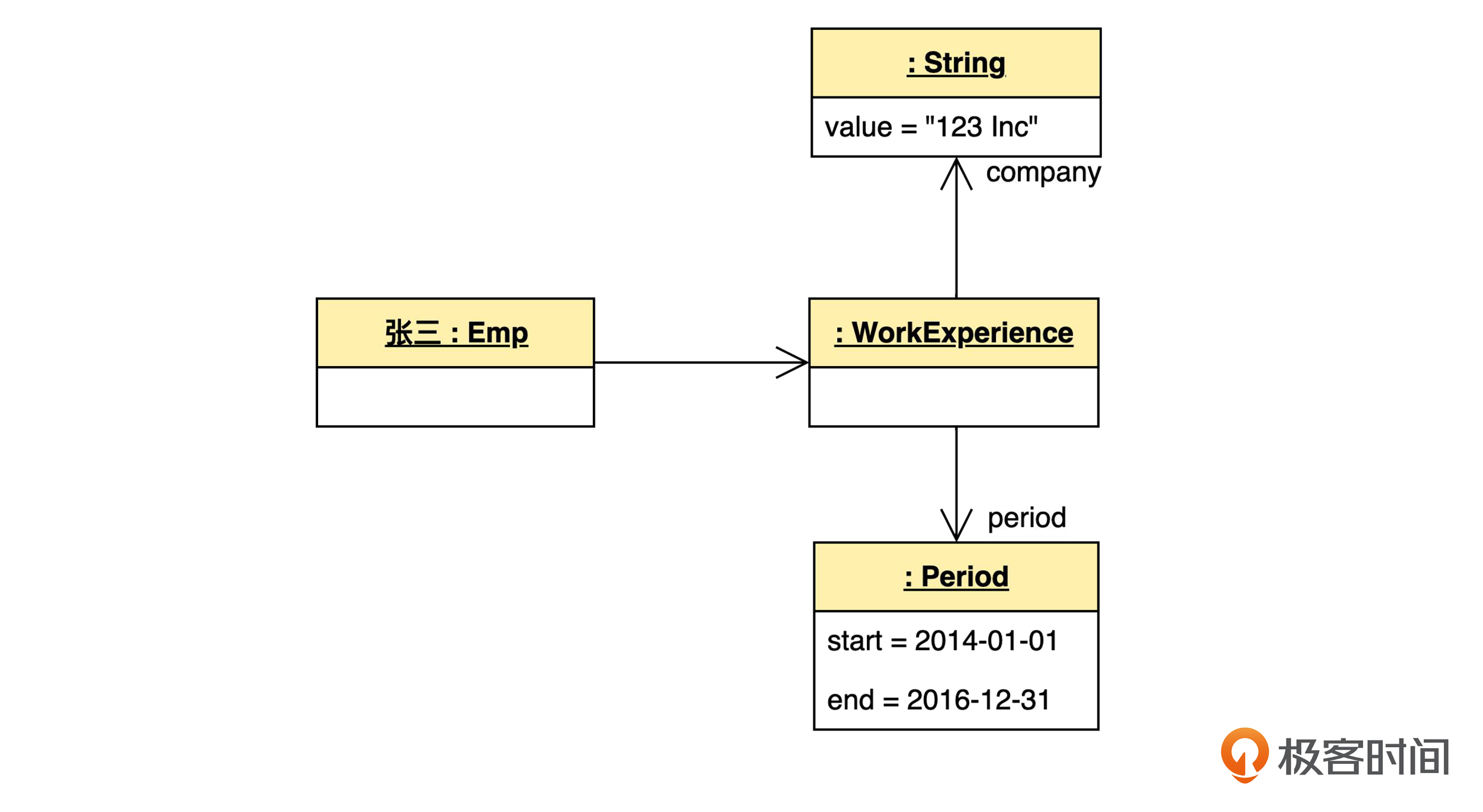
为了简化一点,我们省略了员工的其他属性,时间段里的日期也没有进一步展开。在上面的图里,String(字符串)和Period(时间段)都是值对象,各自占有一片内存空间。现在还没什么问题。
但假如还有另一个员工李四,他也在2014年1月1日到2016年12月31日,在“123 Inc”公司工作。那么,当张三和李四同时装入内存的时候,内存布局可以有两种:一种是共享值对象,另一种不共享。共享的情况可以看看下面这张图。

我们看到,字符串和时间段都在两个工作经验之间共享。
不共享的情况,则是下面这样。
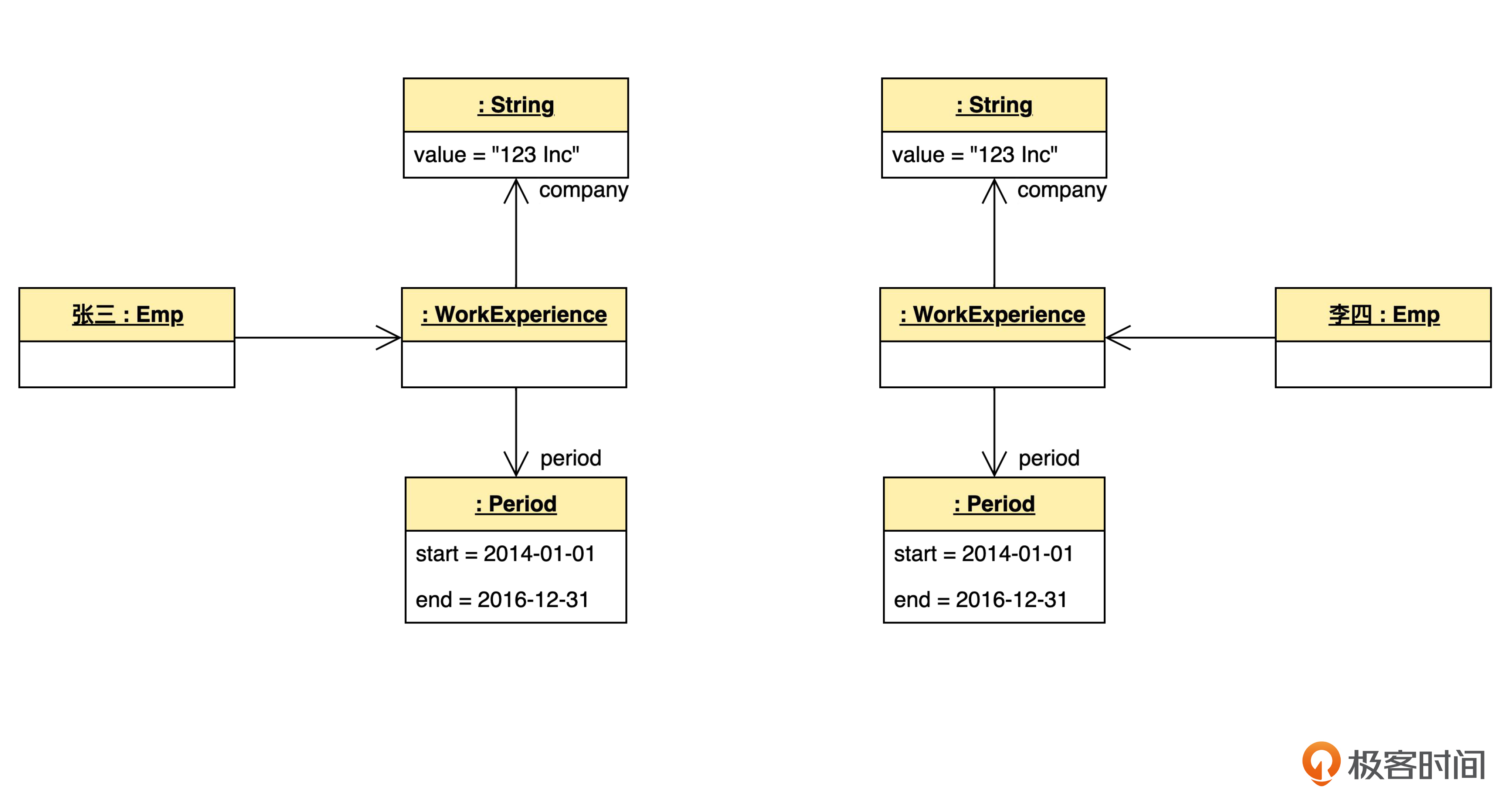
哪怕两个字符串的值是相同的,在内存里,也是重复出现的,内存空间多占了一倍。
那么,哪种是对的呢?答案是:两个都对!
这就奇怪了。对于实体来说,共享是对的,不共享就不对了;而对于值对象来说,共享和不共享,都对。这是为什么呢?
这是因为,值对象是不可修改的。所以,即使在内存里重复出现了,也不会像实体那样,由于修改而导致错误。
那么既然两者都可以,我们应该怎么选择呢?
要实现对象的共享,其实需要更复杂的编程,所以,值对象在内存里多数是不共享的。比如Java语言里,默认情况下,字符串(String)、整数(Integer)等等都是不共享的。但有时候,JVM会“偷偷地”把相同的字符串共享,以便节省内存空间。不过,这对程序员是不可见的,我们总是应该假定字符串没有共享。
那么,什么时候应该共享值对象呢?当值对象的体积比较大,数量比较多,共享值对象可以节省大量内存的时候,就可以采用共享的方式。这种用法实际上是一种设计模式,叫做“享元”,也就是共享的单元,英文是 Flytweight。有兴趣的话,你可以看看设计模式方面的书来进一步了解。
要注意一点:不论共享还是不共享,都只是一种实现上的选择,在概念层面,一个值对象总是唯一的。
现在可以看到,在内存里,我们既可以为了编程的方便,不共享值对象,也可以为了节省内存而共享,这种灵活性是实体所不具备的。这正是值对象的主要优点之一。
实体的数据库布局
说完了内存布局,我们再看看数据库布局。值对象在数据库的存储方式上也有更多的灵活性。
还是先考虑实体。我们继续用“张三和李四都在IT部”这个例子。和内存布局类似,在数据库表里,一个实体也只能有一条记录,不应该重复。例如,下面的存储方式是正确的。
员工(emp)表的数据:
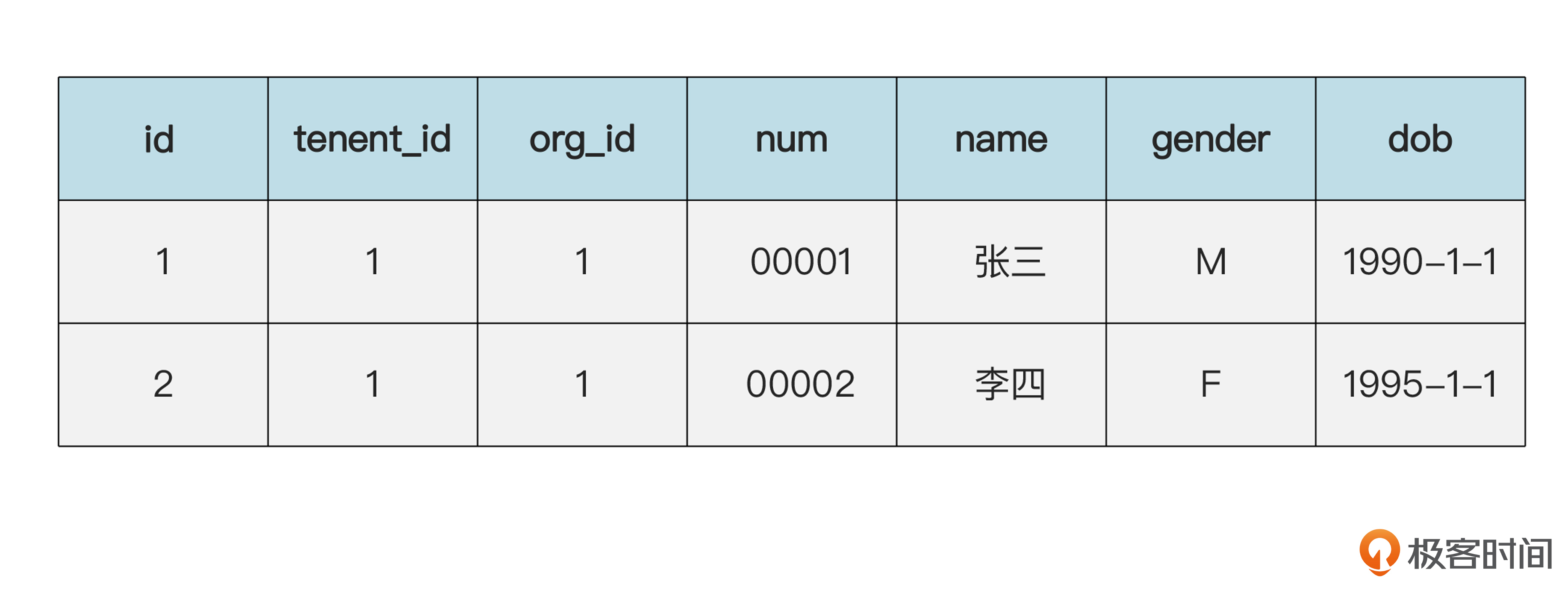
组织(org)表的数据:

为了突出重点,我们省略了一些字段。在上面的员工表里面,张三和李四都通过 org_id 指向组织表里的同一条表示IT部的记录。
如果不小心弄成了下面这样,就错了。你可以把后面的数据和前面正确的做个对比。
员工(emp)表的数据:
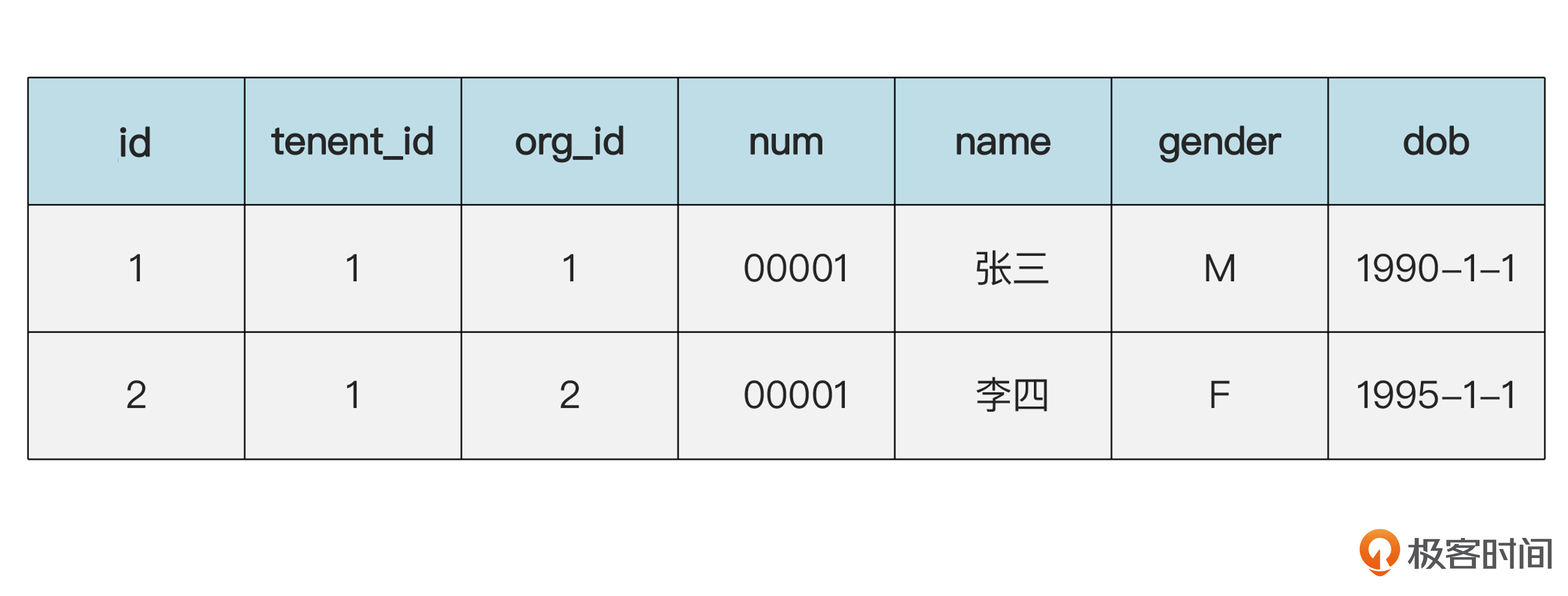
组织(org)表的数据:

在组织表里,表示IT部的记录存了两次。这样,如果改了其中一条,另一条没有改,就会造成数据不一致,成了脏数据。
值对象的数据库布局
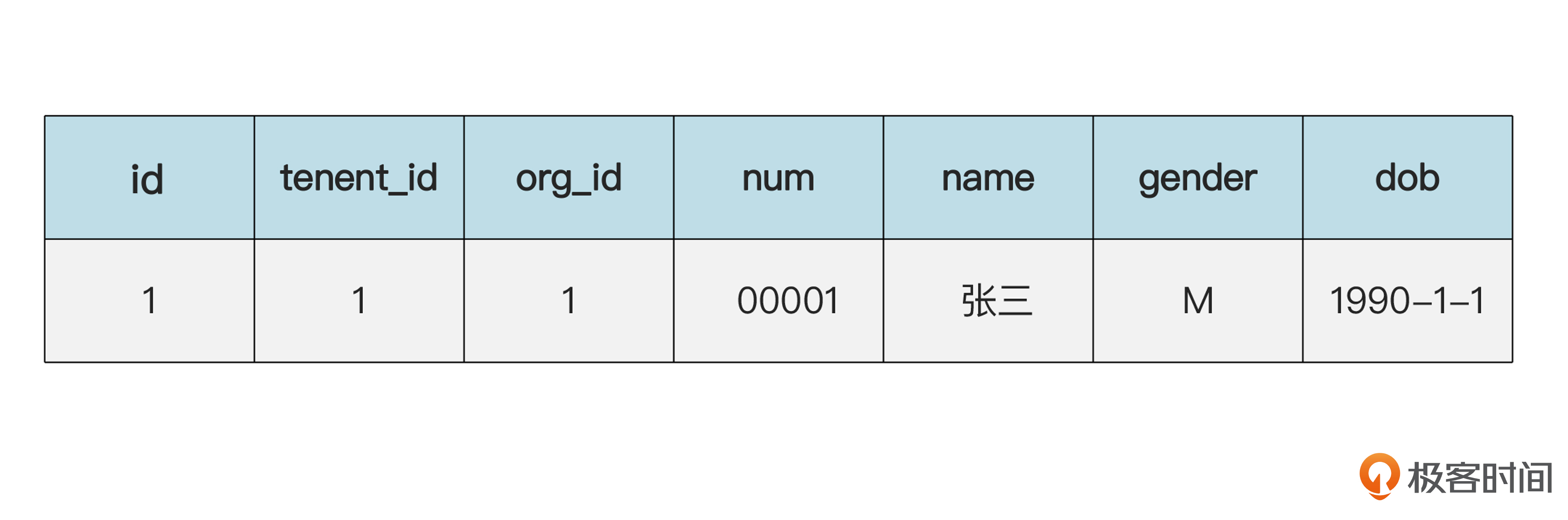
现在再来看看值对象。我们继续用“张三和李四都有相同工作经验”的例子。员工表和工作经验表的内容是下面的样子,重点看工作经验表。
员工(emp)表的数据:
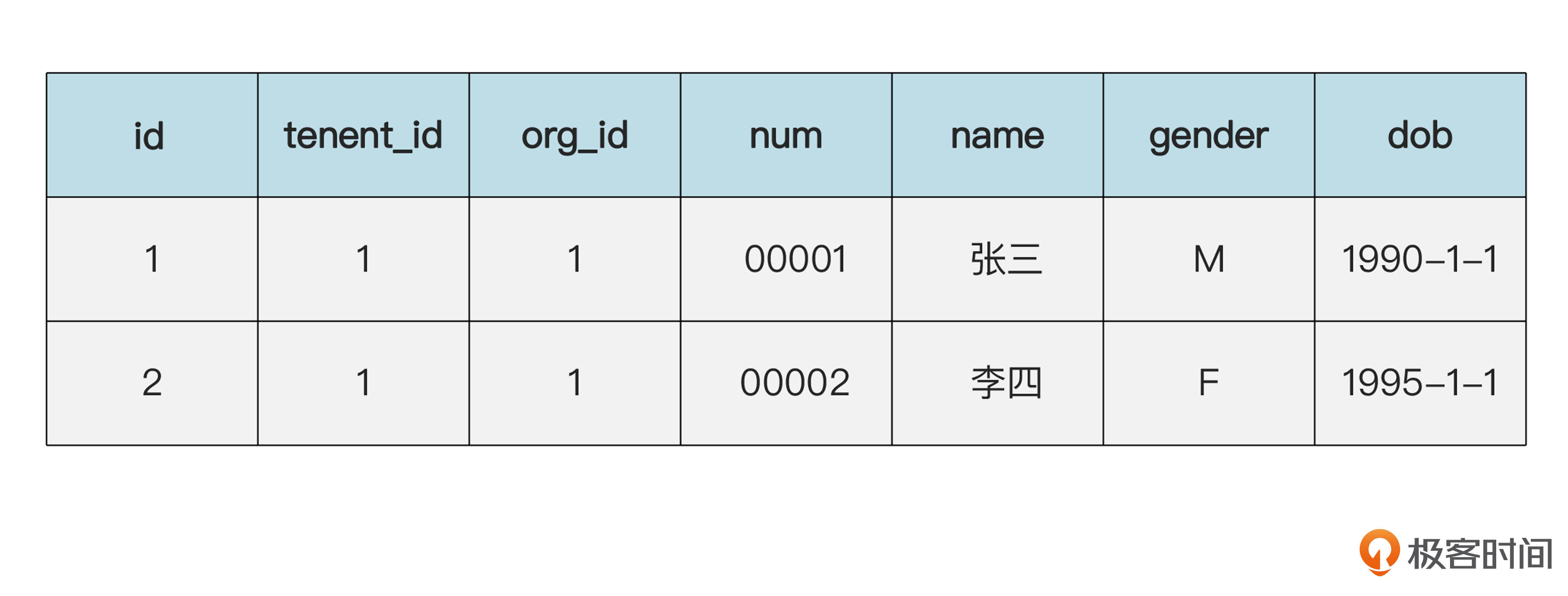
工作经验(work_experience)表的数据:
首先要说一下,在内存布局里面,时间段对象占有自己的内存空间,但在数据库里,并没有单独的“时间段表”。
相反,时间段的属性,也就是开始日期和结束日期,成了工作经验表里的两个字段。也就是说,时间段这个值对象被“嵌入”到工作经验表里了。这种“嵌入”到所属实体表的方式,正是值对象最常见的存储方式。
在数据库里是同一个表,在内存里却是不同的对象,这种数据库和内存的差异,称为阻抗不匹配。阻抗不匹配有多种形式,对象的嵌入式存储只是其中一种。在程序里进行数据存取的时候,就要进行转换,来消除这种不匹配。这种转换工作,是在仓库,也就是 Repository 中完成的。其实,消除这种阻抗不匹配,正是像Hibernate这样的ORM框架的主要目的之一。
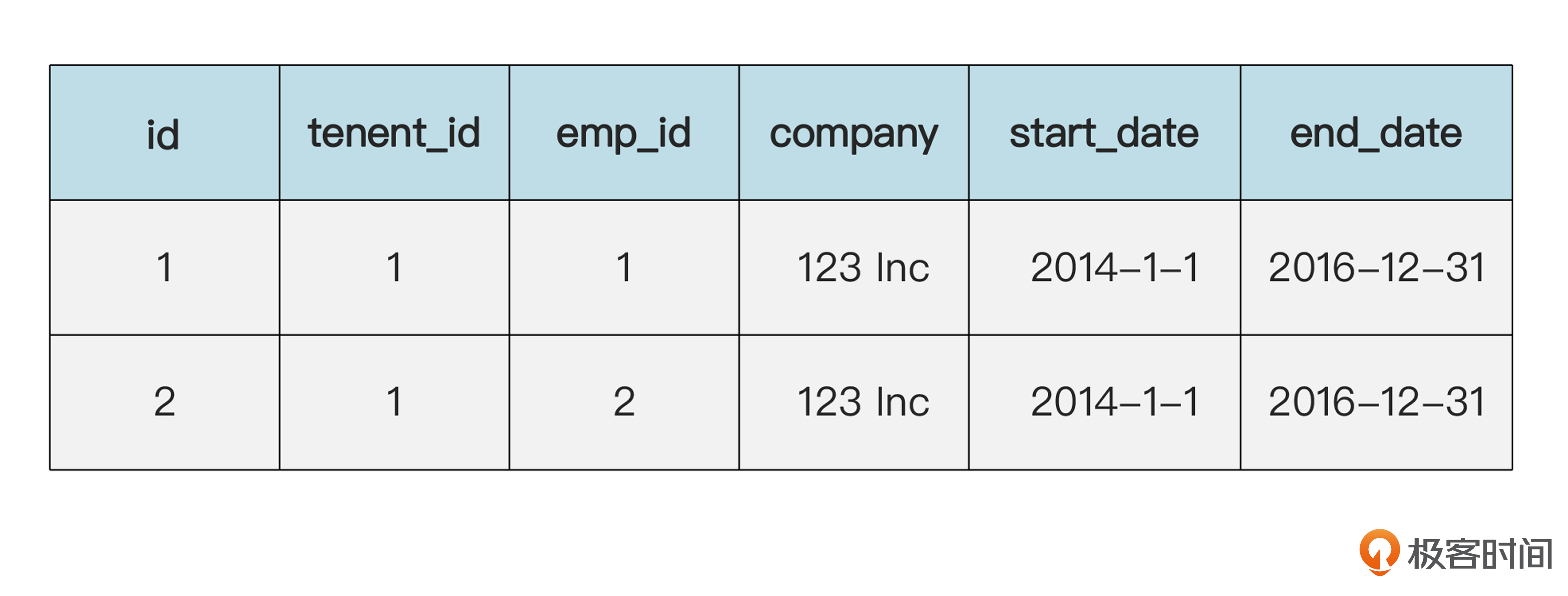
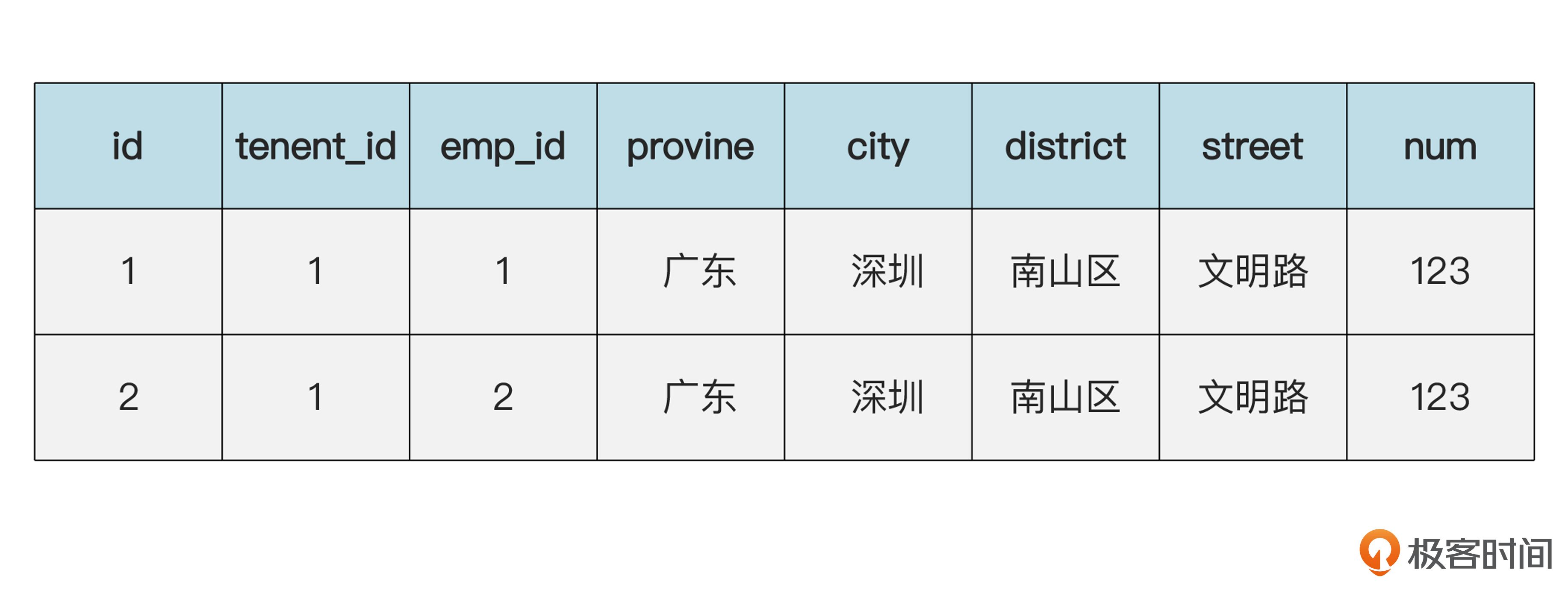
像时间段这种比较小的值对象,一般都是嵌入式存储的。下面咱们再看一个不嵌入的例子。假设我们还要在系统里维护员工的地址。我们上节课说过,地址一般也是值对象。地址占的空间比较大,可以不用嵌入的方式,而是单独建立一个地址表。下面是张三在数据库里的数据。
员工(emp)表的数据:
地址(addr)表的数据:
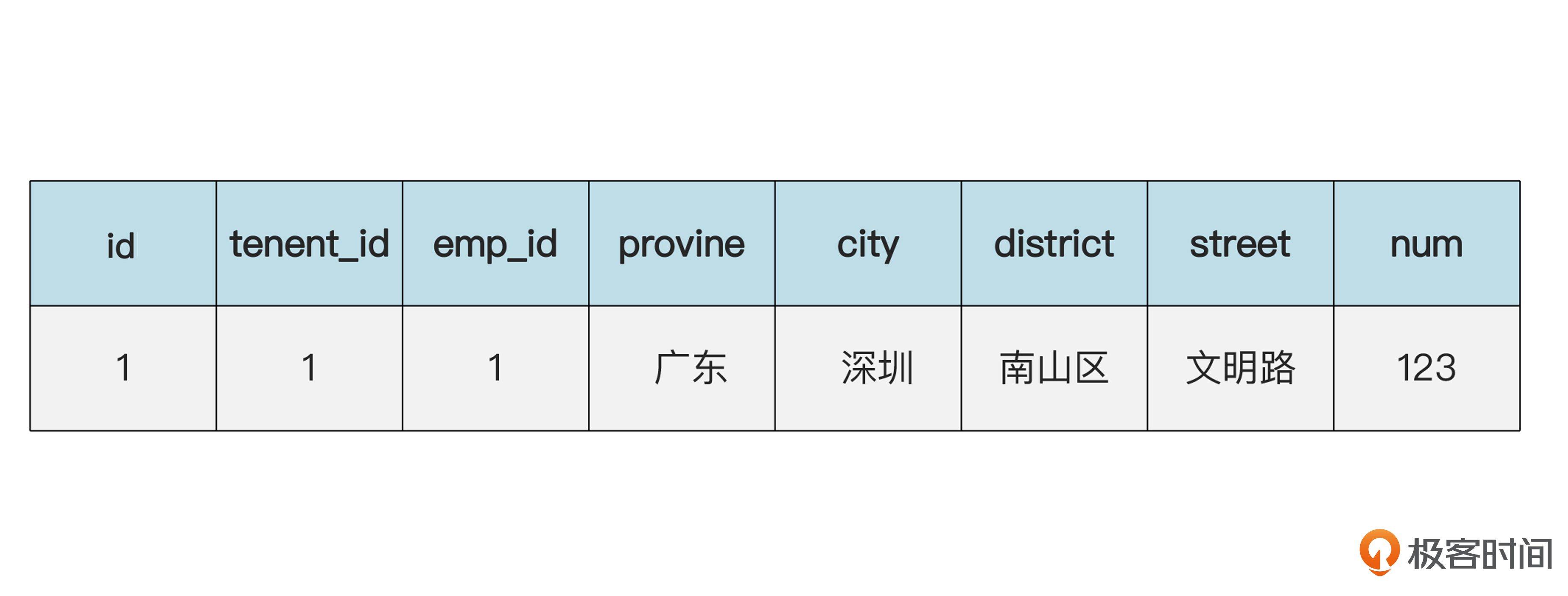
现在假设,李四和张三是合租的房子,两个人的地址一样。换句话说,在概念上,两个人共享同一个地址。那么数据库里可以是下面的样子。
员工(emp)表的数据:
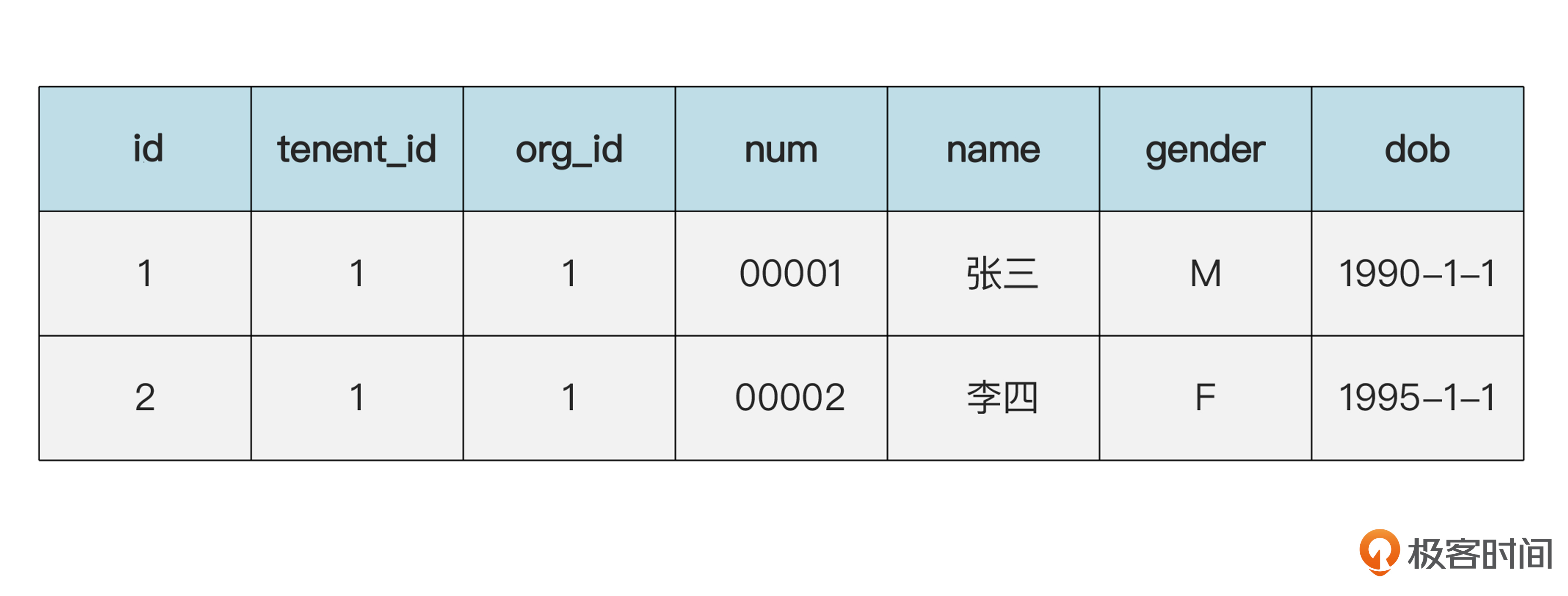
地址(addr)表的数据:
这时候,同一个地址信息存了两遍。这种情况对于实体是不对的,但对于值对象就没有问题,这同样是因为值对象的不变性。这种不变性在数据库操作的体现是:假如李四搬走了,换了地址,那么应该把和他相关的地址记录删除,再插入一条新地址,而不是改变地址表里原来的记录。
那么地址是否也可以按照共享的方式存储呢?也是可以的。就是下面这样。
员工(emp)表的数据:
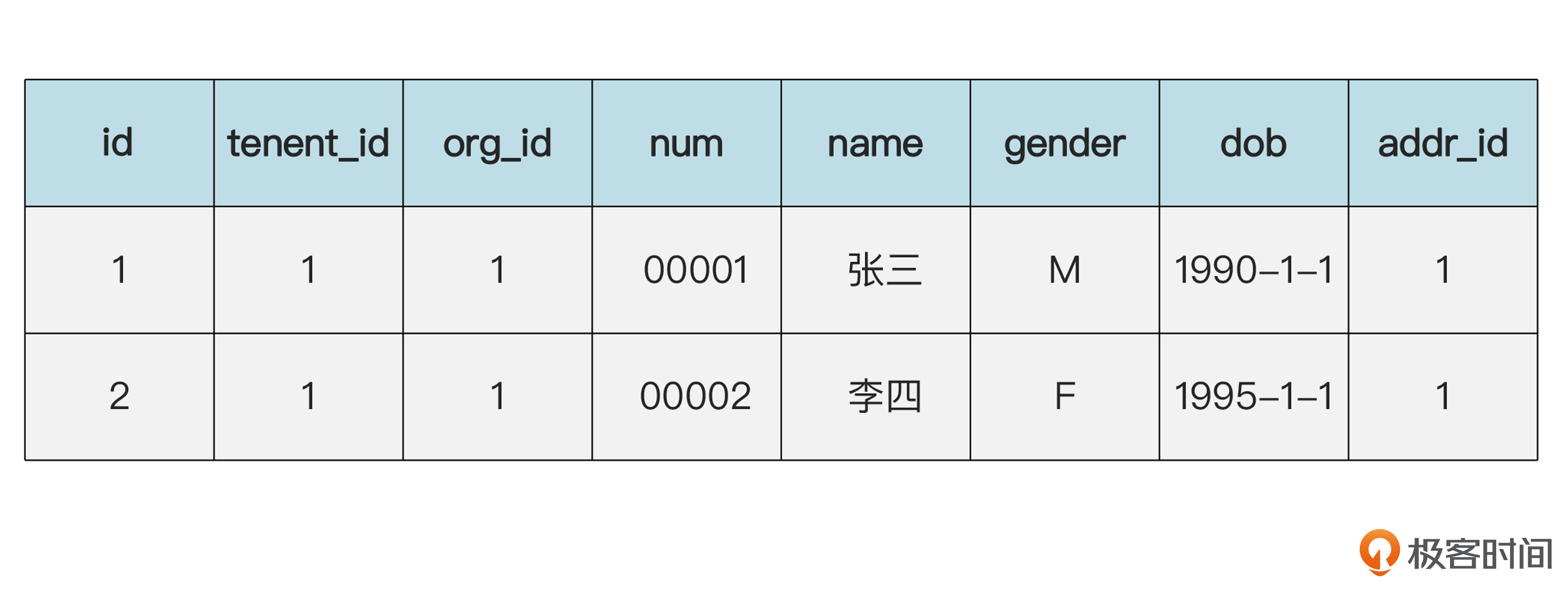
地址(addr)表的数据:
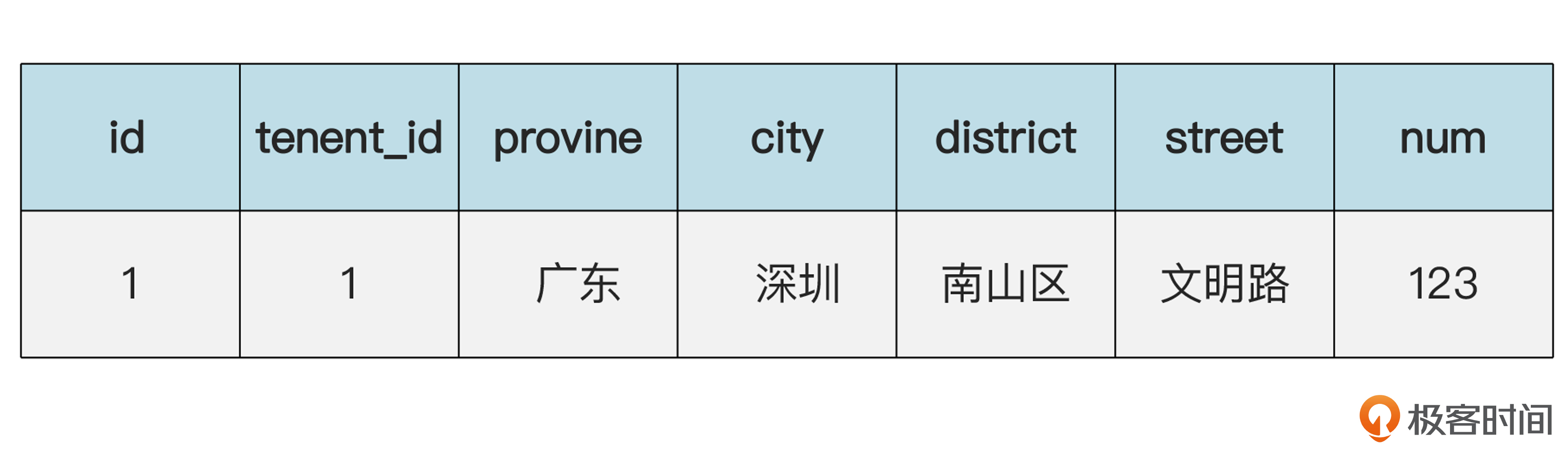
注意,现在两个表的依赖关系反过来了。地址表里不再有员工的ID(emp_id),反之,员工表里有一个地址ID(add_id),指向地址表。这样,就实现了地址的共享。这也是一种可行的做法。
让我们比较一下这两种做法。共享值对象的第一个好处,是节省存储空间。第二个好处,是很容易通过数据库查询找到住在同一个地址的人。
代价是,删除员工的时候不能随便删他的地址,因为可能别人还在用。而如果不删的话,如果所有使用这个地址的人都被删除了,就会留下垃圾数据。所以需要有清理垃圾数据的机制。由于现在硬盘都比较便宜了,所以,不共享的方式反而比较常用。
现在我们看到,和内存布局类似,值对象在数据库里也是既可以共享,也可以不共享,比实体更灵活。
值对象的其他优点
除了前面所说的灵活性以外,值对象还有一些其他的优点。这几点比较容易理解,我们简单说一下。
首先,很多程序的错误,是由于修改对象时不小心引起的。由于值对象是不可变的,所以采用值对象就可以减少出错的几率。
其次,在并发编程里,主要的错误来源也是可变性,使用值对象,也可以减少并发错误。
最后,函数式编程总是假定被操作的对象是不变的,因此,使用值对象也更容易进行函数式编程。
总结
好,今天就讲到这儿,下面来总结一下。
为了说明值对象的优点,这节课,我们首先介绍了“对象图”这个工具。其实对象图不仅能表达内存布局,也能在概念层面说明对象的关系,可以在领域建模的时候,作为类图的补充。
值对象的主要优点是,不论在内存还是数据库里,都可以选择共享和不共享的方式。这种灵活性,可以使我们在实现的时候,基于性能等原因进行优化。而这些优点,都是值对象的不变性带来的。
而实体不具备这样的优点,它们一般应该是共享的,所以需要更复杂的程序逻辑来保证。在特殊情况下,如果选择不共享,就要特别小心,避免错误。
此外,值对象还具有减少编程错误、利于并发以及利于函数式编程等好处。
思考题
1.我们说,值对象在数据库里常常用“内嵌”的方式存储在实体表里。那么,实体是否也可以采用内嵌的方式呢?如果可以,什么情况下可以内嵌呢?
2.我们说,维护值对象的共享需要更复杂的编程。你可以尝试一下,用共享和不共享两种方式实现员工和地址,看看复杂在哪里。
好,今天的课程结束了,有什么问题欢迎在评论区留言,下节课,我们继续讨论值对象在领域模型里的表达方式,以及值对象的本质。
- 南山 👍(12) 💬(4)
个人理解嵌入的前提是实体与实体之间一对一关联的时候,要不要嵌入还要再做考虑,比如是否归属同一聚合内,是否经常一起变更等。
2023-01-18 - 6点无痛早起学习的和尚 👍(3) 💬(1)
这里有个问题请教一下: 1. 国内还是用 mybatis及mybatis plus 多一些,会根据数据库自动生成单表的 xxMapper 和 xxEntity,所以一般都在仓库的实现层做 xxEntity 和领域对象的转换是吧?不管是 save 、update、select 还是 delete
2023-02-15 - py 👍(2) 💬(4)
享元模式是Flyweight,不是lightweight
2023-02-22 - H·H 👍(2) 💬(1)
值对象也可以以json形式内嵌 我理解实体不能内嵌,如果内嵌就成了另一个实体的值对象了
2023-02-01 - tt 👍(2) 💬(1)
实体不可以采用内嵌的方式吧,因为实体有自己的标识,那么被内嵌到的实体数据如何保存唯一的标识呢?
2023-01-17 - Geek1560 👍(0) 💬(1)
技能和工作经验也可以定位成不可变的,当需要变化时,重建一个即可吧
2023-10-25 - Faddei 👍(0) 💬(1)
请问老师 工作经验和技能 这两个是实体吗?如果是实体的话,这两个又没有唯一的标识符;如果是值对象的话,工作经验和技能又都是可变的。有点搞不懂这两个
2023-09-10 - 风揽明月 👍(0) 💬(1)
个人理解,数据库存储共享“地址”,这时候已经把“地址”作为实体看待了,而又在内存层面看成是值对象,中间做的转换感觉是一个伪工作。所以我理解值对象只有非共享模式。
2023-05-30 - Sam.张朝 👍(0) 💬(1)
用mongoDB json 存储的话,属于自身的,都可以内嵌,如果没有外部关联查询
2023-04-19 - Michael 👍(0) 💬(1)
不共享对象特别是地址这种数据,也是我们正在用的方式,这种方式还有一个不好的地方,就是duplicate太多数据在数据库,导致查询性能降低。所以又渐渐开始共享数据,确实会增加编程复杂性,那么请问老师对于不共享数据造成的查询性能下降有什么解决办法么?
2023-03-07 - escray 👍(0) 💬(1)
对象图,以前也知道 UML 里面有对象图,但是却不知道怎么用,也没有注意到对象图和类图的差异。 对象的内存布局 实体的内存布局 值对象的内存布局 实体的数据库布局 值对象的数据库布局 享元 lightweight,共享的单元 阻抗不匹配:数据库里是同一个表,在内存中是不同对象;在仓库 Repository 中消除阻抗不匹配 → ORM 框架 值对象在内存和数据库中都可以采用共享或者不共享的方式,但是一般情况,不共享的方式比较常见。除非是为了优化存储性能或其他原因,可以考虑共享方式。(现在存储比较便宜,包括内存,所以更多采用不共享方式?) 实体一般是共享的,需要复杂逻辑保证;如果不共享,就更容易出错。 思考题: 1. 实体也可以采用内嵌的方式,感觉主要是为了节省计算资源,而采取的冗余存储。比如在历史变更表里面有人员的信息,可以使用人员表中的实体,也可以直接把实体信息复制到历史变更表中。 2. 地址的不共享方式维护,相对比较简单;如果采用共享方式,那么每次更新或者删除的时候,都需要遍历,看看是否有共享的情况,并且做出相应的处理。 其实,在大部分情况下,可以考虑实体共享,值对象不共享。
2023-01-31 - aoe 👍(5) 💬(0)
用 UML 画的内存布局通俗易懂,原来 UML 还可以这么玩! 因为值对象是不可变的,所以继承了值不可变对象的优缺点 关于不可变对象的优缺点,来自 perplexity.ai 的回答 优点: 当对象被不可信的库调用时,不可变形式是安全的; 不可变对象被多个线程调用时,不存在竞态条件问题; 不可变对象复制对象时,通过复制引用而不是整个对象来复制它,从而减少内存使用和提高执行速度 缺点: 需要为每个不同的值创建单独的对象; 当需要更改对象状态时,使用起来会比可变对象困难得多; 使用者体验差,因为实例化时需要初始化所有值
2023-01-18 - 月饼 👍(1) 💬(2)
国内开发大部分使用mybatis及mybatis plus框架,单表有直接的API可用,增加值对象后导致单表API无法使用,回到原始编写大量xml情况。我在使用的时候一般只带枚举类,其它值对象没有提取成类,并将值对象的逻辑放在实体中。当存在大宽表的时候会拆出值对象写sql配置文件。
2023-01-18