11 代码实现(中):怎样创建领域对象、实现领域逻辑?
你好,我是钟敬。今天咱们继续撸代码。
上节课我们解决了层间依赖的问题,今天我们讨论几个更深入的问题。
第一,在面向过程的程序里,领域逻辑一般是写在应用服务里的,那么,DDD有什么不同的思路呢?为了解决这个问题,我们需要掌握DDD的领域服务模式和表意接口模式。
第二,过去我们常常在应用服务里面直接 “New” 出领域对象,如果创建领域对象的逻辑比较复杂,那要怎么办呢?对于这个问题,我们需要了解DDD的工厂模式。
另外,尽管我们已经介绍了分层架构和模块模式,但实现的时候,你可能还会有一些困惑,我们也会在这节课里一并解决。后面代码比较多,建议你一边看文稿,一边听我说。
“表意接口”(Intention-Revealing Interfaces)模式
“添加组织”这个功能的领域逻辑主要体现在各种校验规则上,咱们先粗略地看看应用服务的代码的结构,暂时不需要细看每个校验的具体逻辑。
package chapter11.unjuanable.application.orgmng;
// imports...
@Service
public class OrgService {
private final UserRepository userRepository;
private final TenantRepository tenantRepository;
private final OrgTypeRepositoryJdbc orgTypeRepository;
private final OrgRepository orgRepository;
private final EmpRepository empRepository;
@Autowired
public OrgService(UserRepository userRepository
, TenantRepository tenantRepository
, OrgRepository orgRepository
, EmpRepository empRepository
, OrgTypeRepositoryJdbc orgTypeRepository) {
//为注入的 Repository 赋值...
}
// "添加组织"功能的入口
public OrgDto addOrg(OrgDto request, Long userId) {
validate(request);
Org org = buildOrg(request, userId);
org = orgRepository.save(org);
return buildOrgDto(org);
}
private OrgDto buildOrgDto(Org org) {
//将领域对象转成DTO...
}
private Org buildOrg(OrgDto request, Long userId) {
//将DTO转成领域对象...
}
//主要的领域逻辑在这个方法
private void validate(OrgDto request) {
final var tenant = request.getTenant();
// 租户必须有效
if (!tenantRepository.existsByIdAndStatus(tenant, TenantStatus.EFFECTIVE)) {
throw new BusinessException("id为'" + tenant
+ "'的租户不是有效租户!");
}
// 组织类别不能为空
if (isBlank(request.getOrgType())) {
throw new BusinessException("组织类别不能为空!");
}
// 企业是在创建租户的时候创建好的,因此不能单独创建企业
if ("ENTP".equals(request.getOrgType())) {
throw new BusinessException("企业是在创建租户的时候创建好的,因此不能单独创建企业!");
}
// 组织类别必须有效
if (!orgTypeRepository.existsByCodeAndStatus(tenant, request.getOrgType(), OrgTypeStatus.EFFECTIVE)) {
throw new BusinessException("'" + request.getOrgType()
+ "'不是有效的组织类别代码!");
}
// 上级组织应该是有效组织
Org superior = orgRepository.findByIdAndStatus(tenant
, request.getSuperior(), OrgStatus.EFFECTIVE)
.orElseThrow(() ->
new BusinessException("'" + request.getSuperior()
+ "' 不是有效的组织 id !"));
// 取上级组织的组织类别
OrgType superiorOrgType = orgTypeRepository.findByCodeAndStatus(tenant
, superior.getOrgType()
, OrgTypeStatus.EFFECTIVE)
.orElseThrow(() ->
new DirtyDataException("id 为 '"
+ request.getSuperior()
+ "' 的组织的组织类型代码 '"
+ superior.getOrgType() + "' 无效!"));
// 开发组的上级只能是开发中心
if ("DEVGRP".equals(request.getOrgType()) && !"DEVCENT".equals(superiorOrgType.getCode())) {
throw new BusinessException("开发组的上级(id = '"
+ request.getSuperior() + "')不是开发中心!");
}
// 开发中心和直属部门的上级只能是企业
if (("DEVCENT".equals(request.getOrgType()) || "DIRDEP".equals(request.getOrgType()))
&& !"ENTP".equals(superiorOrgType.getCode())) {
throw new BusinessException("开发中心或直属部门的上级(id = '"
+ request.getSuperior() + "')不是企业!");
}
// 组织负责人可以空缺,如果有的话,的必须是一个在职员工(含试用期)
if (request.getLeader() != null
&& !empRepository.existsByIdAndStatus(tenant, request.getLeader()
, EmpStatus.REGULAR, EmpStatus.PROBATION)) {
throw new BusinessException("组织负责人(id='"
+ request.getLeader() + "')不是在职员工!");
}
// 组织必须有名称
if (isBlank(request.getName())) {
throw new BusinessException("组织没有名称!");
}
// 同一个组织下的下级组织不能重名
if (orgRepository.existsBySuperiorAndName(tenant, request.getSuperior(), request.getName())) {
throw new BusinessException("同一上级下已经有名为'"
+ request.getName() + "'的组织存在!");
}
}
}
浏览了一下这个代码后,你会不会在直觉上已经觉得有什么不妥了呢?
先说说我的看法。首先,第39行开始的 validate() 这个用于校验的方法有80行,太长了。从“重构”角度,这是一种“坏味道”,叫做过长的函数。
“坏味道”(smell)是Martin Fowler在《重构》一书中提出的说法,指的是一眼就能看出来的,烂代码的征兆。当然,由于只是征兆,也说不定再多看几眼发现并没有问题。
一般来说,函数一旦太长,就会不容易维护和测试。那么多长合适呢?业界并没有统一的说法。我个人的建议是,一般不要超过十行,最多不超过二十行。
你可能还注意到,为了补救由于方法太长导致的不容易理解的问题,程序里特意加了注释,说明实现的是哪条业务规则。
其实,最好的代码应该是本身写得足够清晰,以至于不需要注释;中等的代码是不太清晰,但是有注释,也能看懂;最差的代码是不但不清晰,还没有注释。我们的程序属于中等。在《重构》中,注释也算是一种坏味道,暴露了可能存在的代码不清晰问题。
我们可以通过抽取函数这个重构手法,同时解决这两个坏味道。也就是说,把每一段校验逻辑抽成单独的方法。抽取之后是下面这样:
@Service
public class OrgService {
// 声明用到的 Repository...
@Autowired
public OrgService(UserRepository userRepository
, TenantRepository tenantRepository
, OrgRepository orgRepository
, EmpRepository empRepository
, OrgTypeRepositoryJdbc orgTypeRepository) {
//为注入的 Repository 赋值...
}
public OrgDto addOrg(OrgDto request, Long userId) {
validate(request);
Org org = buildOrg(request, userId);
org = orgRepository.save(org);
return buildOrgDto(org);
}
private OrgDto buildOrgDto(Org org) {
//将领域对象转成DTO...
}
private Org buildOrg(OrgDto request, Long userId) {
//将DTO转成领域对象...
}
//把各业务规则抽成了方法
private void validate(OrgDto request) {
final Long tenant = request.getTenant();
tenantShouldValid(tenant);
leaderShouldBeEffective(tenant, request.getLeader());
//为了避免这个方法太长,把一些规则进一步分了组
verifyOrgType(tenant, request.getOrgType());
validateSuperior(tenant, request.getSuperior(), request.getOrgType());
verifyOrgName(tenant, request.getName(), request.getSuperior());
}
// 租户必须有效
private void tenantShouldValid(Long tenant) {
//...
}
// 组织负责人可以空缺,如果有的话,的必须是一个在职员工(含试用期)
private void leaderShouldBeEffective(Long tenant, Long leader) {
//...
}
//校验组织类别的规则分组
private void verifyOrgType(Long tenant, String orgType) {
orgTypeShouldNotEmpty(orgType);
orgTypeShouldBeValid(tenant, orgType);
shouldNotCreateEntpAlone(orgType);
}
// 组织类别不能为空
private void orgTypeShouldNotEmpty(String orgType) {
//...
}
// 组织类别必须有效
private void orgTypeShouldBeValid(Long tenant, String orgType) {
//...
}
// 企业是在创建租户的时候创建好的,因此不能单独创建企业
private void shouldNotCreateEntpAlone(String orgType) {
//...
}
//校验上级组织的规则分组
private void validateSuperior(Long tenant, Long superior, String orgType) {
Org superiorOrg = superiorShouldEffective(tenant, superior);
OrgType superiorOrgType = findSuperiorOrgType(tenant, superior, superiorOrg);
superiorOfDevGroupMustDevCenter(superior, orgType
, superiorOrgType);
SuperiorOfDevCenterAndDirectDeptMustEntp(superior, orgType
, superiorOrgType);
}
// 上级组织应该是有效
private Org superiorShouldEffective(Long tenant, Long superior) {
//...
}
private OrgType findSuperiorOrgType(Long tenant, Long superior, Org superiorOrg) {
//...
}
// 开发中心和直属部门的上级只能是企业
private void SuperiorOfDevCenterAndDirectDeptMustEntp(Long superior, String orgType, OrgType superiorOrgType) {
//...
}
// 开发组的上级只能是开发中心
private void superiorOfDevGroupMustDevCenter(Long superior, String orgType, OrgType superiorOrgType) {
//...
}
// 校验组织名称的规则分组
private void verifyOrgName(Long tenant, String name, Long superior) {
orgNameShouldNotEmpty(name);
nameShouldNotDuplicatedInSameSuperior(tenant, superior, name);
}
// 组织必须有名称
private void orgNameShouldNotEmpty(String name) {
//...
}
// 同一个上级下的组织不能重名
private void nameShouldNotDuplicatedInSameSuperior(Long tenant, Long superior, String name) {
//...
}
}
你看,我们不但把每个规则都抽成了独立的方法,而且每个方法都按含义进行了命名。比如说“租户必须有效”这个规则的方法名就是 “tenantShouldValid”。DDD强调,每个类和方法的命名都应该尽量直观地反映领域知识,与统一语言保持一致。这种做法也是DDD的一个模式,叫做 “Intention-Revealing Interfaces”,可以译作表意接口。我们一定要意识到,初学者往往不重视命名,越是高手,越重视命名。
有了表意接口,如果是英语国家的程序员,就不需要加注释了。上面的程序里仍然有注释,是考虑到多数中国人读中文更快。这是实践中的妥协,不是命名不好造成的。
由于规则比较多,即使把每个规则都抽出来,validate方法还是有点长,所以我们又为其中一些规则分了组。
“领域服务”(Domain Service)模式
抽取了表意接口,我们再考虑下一个问题:实现校验规则的那些方法,放对地方了吗?
业务规则是领域知识,按照DDD的思路,应该放在领域层才对,而现在却在应用层。为了解决这个问题,我们创建一个叫OrgValidator的类,也就是组织校验器,把规则都放到这个类里面,通过一个统一的validate() 方法来调用。然后,把OrgValidator放到领域层。程序结构变成下面这样:
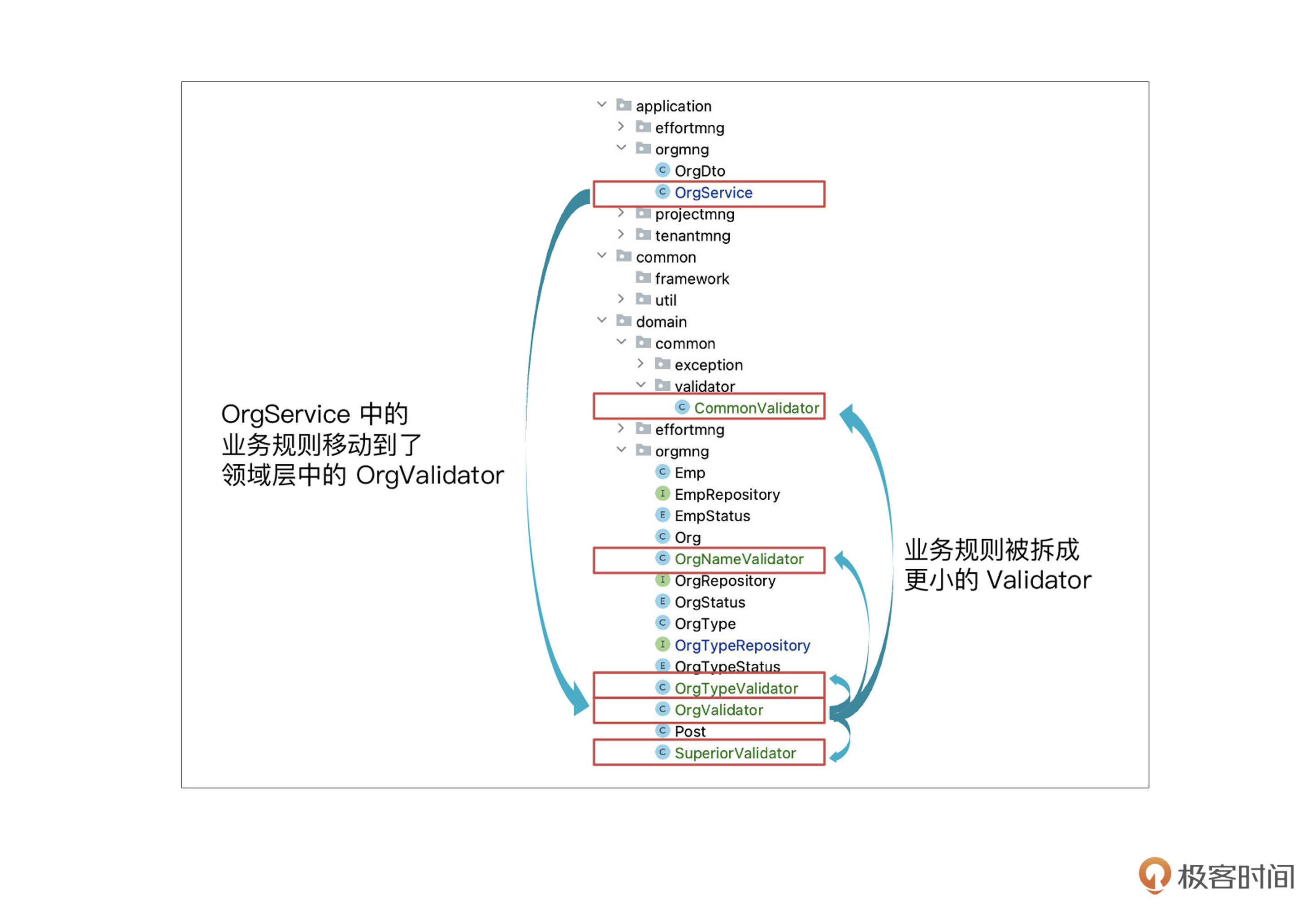
为了避免OrgValidator过于庞大,我们又进一步拆成几个小的 Validator,通过依赖注入,注入到 OrgValidator 中。现在,OrgService 变成下面的样子:
package chapter11.unjuanable.application.orgmng;
// imports...
@Service
public class OrgService {
private final OrgValidator validator; //代替了原来多个 Repository
private final OrgRepository orgRepository;
@Autowired
public OrgService(OrgValidator validator
, OrgRepository orgRepository) {
// 为依赖注入赋值...
}
public OrgDto addOrg(OrgDto request,Long userId) {
validator.validate(request); // 代替原来的 validate() 方法调用
Org org = buildOrg(request, userId);
org = orgRepository.save(org);
return buildOrgDto(org);
}
private OrgDto buildOrgDto(Org org) {
//将领域对象转成DTO...
}
private Org buildOrg(OrgDto request, Long userId) {
//将DTO转成领域对象...
}
现在整个类比原来小多了,依赖注入的组件数量也比原来少了三个。再看一下OrgValidator的样子:
package chapter11.unjuanable.domain.orgmng; //位于领域层
// imports...
@Component
public class OrgValidator {
//依赖更小的 Validator,也就是更小的规则分组
private final CommonValidator commonValidator;
private final OrgTypeValidator orgTypeValidator;
private final SuperiorValidator superiorValidator;
private final OrgNameValidator orgNameValidator;
private final OrgLeaderValidator orgLeaderValidator;
@Autowired
public OrgValidator(CommonValidator commonValidator
, OrgTypeValidator orgTypeValidator
, SuperiorValidator superiorValidator
, OrgNameValidator orgNameValidator
, OrgLeaderValidator) {
// 为依赖注入的组件赋值...
}
public void validate(OrgDto request) {
final Long tenant = request.getTenant();
commonValidator.tenantShouldValid(tenant);
orgLeaderValidator.verfy(tenant, request.getLeader;
orgTypeValidator.verify(tenant, request.getOrgType());
superiorValidator.verify(tenant, request.getSuperior()
, request.getOrgType());
orgNameValidator.verify(tenant, request.getName()
, request.getSuperior());
}
}
之所以要把业务规则移动到领域层,本质原因是业务规则属于“领域逻辑”,表达了领域知识。相应地,一般把应用层的逻辑称为“应用逻辑”。看到这儿,你可能会问,领域逻辑和应用逻辑的区别到底是什么呢?
首先要承认,这两者有时候确实有些模糊地带。不过还是有一个总的思路:如果一个逻辑需要和领域专家讨论才能确认的,就是领域逻辑;如果领域专家根本不感兴趣的,多半就是应用逻辑。
比如说,Validator中的各种校验规则,都是与领域专家澄清的,所以属于领域逻辑。而 OrgService里,怎么进行DTO和领域对象之间的转换,怎么把数据保存到数据库,都是领域专家不关心的,因此属于应用逻辑。
这里的各种 Validator也是DDD中的一个模式,叫做领域服务(domain service)。这个模式的思路是这样的:按照面向对象的做法,领域逻辑本来最好放到领域对象中去,不过有些逻辑又不适合放到领域对象,这时,干脆放到一些只有方法,没有状态的类里面。给这些类取个名字,就叫领域服务吧。
在我们现在的例子里,校验规则没有放到领域对象的原因有两个:
1.为了保持领域对象与数据库的解偶,我们希望领域对象不要访问数据库,而有些校验规则要访问数据库;
2.我们目前采用的还是偏过程的方式。
还有一点要提一下,我发现一些小伙伴喜欢统一用XxxDomainSerivce的方式给领域服务命名,这似乎有些拘泥了。我建议最好按照含义来命名,比如这里就用了XxxValidator的名字。
“工厂”(Factory)模式
处理完业务规则,我们再来聊一下DDD建议的创建领域对象的方法。
DDD认为,领域对象的创建逻辑也是领域层的一部分。如果创建领域对象的逻辑比较简单,可以直接用对象的构造器来实现。但是如果比较复杂,就应该把创建逻辑放到一个专门的机制里,来保证领域对象的简洁和聚焦。
这里说的专门机制可以是一个方法或者一个类,可以有很多种实现方式。不论具体方式是什么,在 DDD里统称为工厂(Factory)模式。准确地说,工厂其实是用来创建聚合的,由于我们在迭代二才会讲到聚合模式,所以这里先粗略地认为工厂是创建对象的。工厂和前面说的仓库这两个模式,其实是一种隐喻(metaphor):用工厂来创造产品,然后存到仓库。
所谓创建逻辑复杂,包括两方面:一是规则复杂,二是结构复杂。DDD认为用于校验的领域逻辑也属于创建过程的一部分,因此我们目前的例子主要是规则复杂。等到后面我们创建复杂聚合的时候,可能会遇到结构复杂的问题。
现在我们创建一个叫做OrgFactory的类,里面只有一个build() 方法,用来创建Org对象。代码是下面的样子:
package chapter11.unjuanable.domain.orgmng; //工厂在领域层
//imports...
@Component
public class OrgFactory {
private final OrgValidator validator;
@Autowired
public OrgFactory(OrgValidator validator) {
this.validator = validator;
}
public Org build(OrgDto request, Long userId) {
validator.validate(request);
return buildOrg(request, userId);
}
private Org buildOrg(OrgDto request, Long userId) {
//DTO转换成领域对象
}
}
相应的,OrgService修改成这个样子:
package chapter11.unjuanable.application.orgmng;
//imports...
@Service
public class OrgService {
//现在只需要注入工厂和仓库了
private final OrgFactory orgFactory;
private final OrgRepository orgRepository;
@Autowired
public OrgService(OrgFactory orgFactory
, OrgRepository orgRepository) {
//依赖注入赋值...
}
public OrgDto addOrg(OrgDto request, Long userId) {
//包含校验逻辑在内的创建逻辑都委托给了工厂
Org org = orgFactory.build(request, userId);
org = orgRepository.save(org);
return buildOrgDto(org);
}
private static OrgDto buildOrgDto(Org org) {
//领域对象转换成DTO...
}
//原来DTO转领域对象的逻辑也移到了工厂
}
到现在为止,好像还不错。不过你可能已经注意到,OrgFactory的build() 方法的参数类型是 OrgDto,而这个DTO是在应用层定义的,也就是领域层依赖了应用层,又一次破坏了层间依赖原则。
咱们来探讨几种可能的解决方案。
第一种方案是把OrgDto的定义直接从应用层移动到领域层。这虽然解决了依赖问题,但 OrgDto是领域对象的“门面”,应该留在应用层,所以这种方案不可取。
第二种方案是把DTO拆开,用基本类型来调用build() 方法。用于创建 Org 的基本类型参数其实一共有6个,所以可以像下面这样定义build()方法:
public Org build(Long tenant, Long superior, String orgType
, Long leader, private String name, Long userId)
不过,太长的参数列表本身就是一种坏味道,容易出错而且不好理解。所以我建议只在参数不大于三个的时候采用这种方式。
第三种方案是把上述6个参数再捏成一个DTO,在领域层中定义,专门作为工厂参数。这种方案没有大毛病,但显得有些繁琐。
第四种方案是我们所建议的,就是采用Builder模式。下面我们就来看看Builder模式是怎么实现的。
我们会编写OrgBuilder代替刚才的OrgFactory, 写出来是这个样子:
package chapter11.unjuanable.domain.orgmng;
// import...
public class OrgBuilder {
//用到的 validator
private final CommonValidator commonValidator;
private final OrgTypeValidator orgTypeValidator;
private final SuperiorValidator superiorValidator;
private final OrgNameValidator orgNameValidator;
private final OrgLeaderValidator orgLeaderValidator;
//用这些属性保存创建对象用到的参数
private Long tenantId;
private Long superiorId;
private String orgTypeCode;
private Long leaderId;
private String name;
private Long createdBy;
public OrgBuilder(CommonValidator commonValidator
, OrgTypeValidator orgTypeValidator
, SuperiorValidator superiorValidator
, OrgNameValidator orgNameValidator
, OrgLeaderValidator orgLeaderValidator) {
//注入各个 Validator...
}
// 为builder 的 tenant 属性赋值,然后返回自己,以便实现链式调用
public OrgBuilder tenantId(Long tenantId) {
this.tenantId = tenantId;
return this;
}
// 其他5个属性赋值与 tenantId 类似 ...
public Org build() {
validate();
Org org = new Org();
org.setOrgTypeCode(this.orgTypeCode);
org.setLeaderId(this.leaderIc);
org.setName(this.name);
org.setSuperiorId(this.superiorId);
org.setTenantId(this.tenantId);
org.setCreatedBy(this.createdBy);
org.setCreatedAt(LocalDateTime.now());
return org;
}
private void validate() {
commonValidator.tenantShouldValid(tenantId);
orgTypeValidator.verify(tenantId, orgTypeCode);
superiorValidator.verify(tenantId, superiorId, orgTypeCode);
orgLeaderValidator.verify(tenantId, leaderId);
orgNameValidator.verify(tenantId, name, superiorId);
}
}
Builder其实也是工厂模式的一种实现方式,所以放在领域层。Builder接收到各个需要的参数值,保存到自己的属性中。在创建Org前先进行校验,然后真正创建。由于Builder起到了将各组校验规则组织起来的作用,所以原来的OrgValidator就不需要了。
由于OrgBuilder有可变属性,因此不能按单例注入到OrgService,所以我又写了一个单例的 OrgBuilderFactory负责创建OrgBuilder。代码比较简单,是下面的样子:
package chapter11.unjuanable.domain.orgmng;
// imports...
@Component
public class OrgBuilderFactory {
private final CommonValidator commonValidator;
private final OrgTypeValidator orgTypeValidator;
private final SuperiorValidator superiorValidator;
private final OrgNameValidator orgNameValidator;
private final OrgLeaderValidator orgLeaderValidator;
@Autowired
public OrgBuilderFactory(CommonValidator commonValidator
, OrgTypeValidator orgTypeValidator
, SuperiorValidator superiorValidator
, OrgNameValidator orgNameValidator
, OrgLeaderValidator orgLeaderValidator) {
//注入各个 Validator...
}
//每次调用都创建一个新的 OrgBuilder
public OrgBuilder create() {
return new OrgBuilder(commonValidator
, orgTypeValidator
, superiorValidator
, orgNameValidator
, orgLeaderValidator);
}
}
当然你也可以用Spring中prototype的方式来注入OrgBuilder,这样就不用自己写OrgBuilderFactory了。
下面再看看OrgService里怎样使用OrgBuilder:
package chapter11.unjuanable.application.orgmng;
// imports...
@Service
public class OrgService {
private final OrgBuilderFactory orgBuilderFactory;
private final OrgRepository orgRepository;
@Autowired
public OrgService(OrgBuilderFactory orgBuilderFactory
, OrgRepository orgRepository) {
//为依赖注入的属性赋值...
}
public OrgDto addOrg(OrgDto request) {
OrgBuilder builder = orgBuilderFactory.create();
//修改的部分在这里
Org org = builder.tenantId(request.getTenantId())
.orgTypeCode(request.getOrgTypeCode())
.leaderId(request.getLeaderId())
.superiorId(request.getSuperiorId())
.name(request.getName())
.createdBy(userid)
.build();
org = orgRepository.save(org);
return buildOrgDto(org);
}
private static OrgDto buildOrgDto(Org org) {
// 领域对象转换为DTO...
}
}
我们可以看到,比起方案二里,为工厂的build() 方法传递多个参数的方式,Builder的好处是无论参数有多少,含义都很明确,而且传递参数的顺序是任意的,不会因为参数顺序而出错。
模块划分的“打横”与“打竖”
现在来看一看领域层变成什么样了:

经过咱们刚才一顿操作,组织管理(orgmng)这个模块下的类已经比较多了。尽管《重构》一书中没有明确说,但是一个包下有太多的类,也是一种常见的坏味道。那么多少算“多”呢,也没有明确的标准,不过根据心理学的认知负载理论,我建议,一个包里的类和子包的数量加在一起,最好不要超过9个。
那么怎么分子包呢?你可能注意到了这些类里,有些是实体,有些是仓库,有些是工厂,有些是领域服务,所以很多小伙伴会这么分:
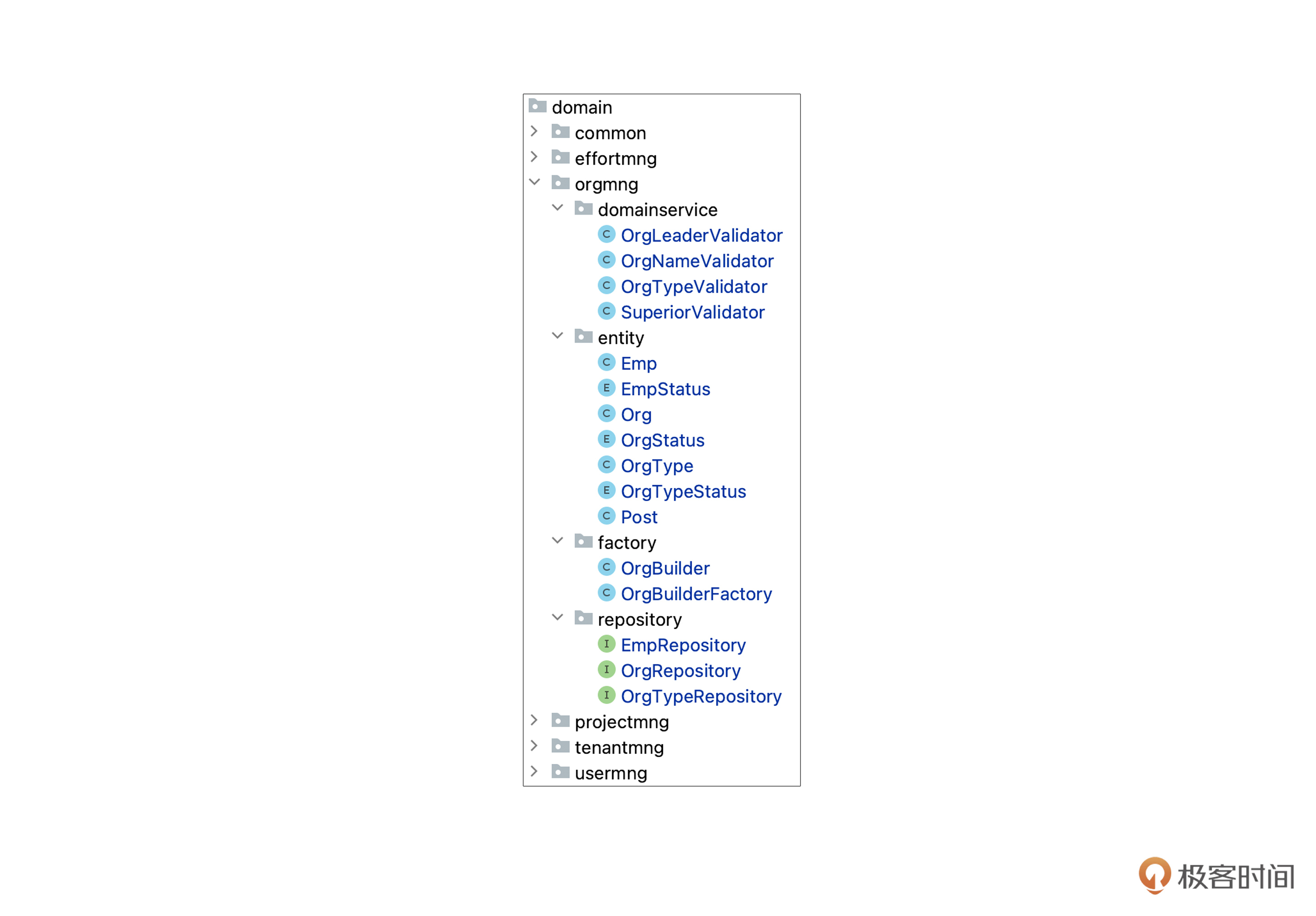
我们分了entity、repository、factory和domainservice几个子包,然后把各个类移进去。看起来也挺清晰的吧?这里,我们采用了搬移类这种重构手法。
那么,有没有其他选择呢?让我们看一种不同的分法:

这里,我在组织管理(orgmng)包为每个实体分了一个子包,然后把与每个实体相关的类移了进去。
咱们细品一下,这两种方法的区别在哪里?
第一种方法是按照类的“性质”来分的。OrgRepository和EmpRepository在性质上都属于 Repository,所以把它们放在同一个包,至于它们之间有没有调用关系,并不重要。
第二种是按照耦合关系来分。OrgRepository中方法的参数用到了Org类,说明这两个类型之间有耦合关系,所以把它们放在同一个包,尽管它们的性质不一样,一个是实体,一个是仓库。
这两种方式没有绝对的对错,需要进行权衡。比如说,分层架构其实就是按性质来分的。应用层的应用服务,之所以在同一个包里面,并不是因为他们之间有耦合关系,而是因为他们都是领域对象的“门面”。
事实上,一个应用服务和调用它的控制器以及被它调用的领域对象之间才具有耦合性。分层架构把本来耦合的几个对象拆到了不同的包。之所以我们在分层架构中采用按性质分包的方式,是因为,将领域逻辑与其非领域逻辑分离,以及将技术相关和无关两部分分离,这两个“关注点分离”的好处实在太大,大过了破坏“松耦合高内聚”原则的代价。
但是另一方面,在每个层次内部,我比较建议尽量按照耦合性分包。这是由于排除上述两个“关注点分离”以后,“松耦合高内聚”的好处就体现出来了。如果把按层次划分叫做“打横”分,把按耦合性划分叫做“打竖”分,咱们目前采取的是就是“先横后竖”的分法。
不过你可能又发现,上面org包下有9个类,似乎多了一点,不便理解,所以我们还可以再分一下。一种可行的办法是把validator单独分成一个包,像下面这样:

各个validator之间未必有什么耦合关系,所以这里又是“打横”分了。在实际项目中,你可以参考上面的思路,作出自己的权衡。
总结
好,今天的内容先讲到这里,我们来总结一下。
这节课,主要讲的是领域逻辑的实现和领域对象的创建,此外还进一步探讨了程序里模块的划分问题。
对于实现领域逻辑的方法,我们应该用能够表达领域知识的词汇进行命名,这就是DDD的表意接口(Intention-Revealing Interfaces)模式。违反了表意接口模式,常常会出现过长的函数和注释这两个坏味道,我们可以通过抽取函数这个重构手法进行了解决。
领域逻辑应该放在领域层,不属于领域逻辑的代码逻辑通常称为“应用逻辑”。“应用逻辑”和“领域逻辑”的本质区别在于是否蕴含着领域专家关心的领域知识。我们应该首先考虑把领域逻辑放在领域对象里。但那些不适合放到领域对象的逻辑,可以放在领域服务。
对于复杂领域对象的创建,可以采用DDD的工厂(Factory)模式。这个模式有多种实现方式,对于参数较少的情况,可以直接用参数调用工厂,参数较多时,则可以采用Builder模式。
最后,程序里模块的划分方式,有按性质分和按耦合分两种,通俗地说就是“打横”分和“打竖”分,我们建议采用“先横后竖”的方法。
思考题
1.如果实现某个业务规则的代码只有一行,还值得抽成单独的方法吗?
2.我们在实现Validator的时候,并没有用到Java中的“接口”,但为什么这个模式还叫表意接口呢?
好,今天的课程结束了,有什么问题欢迎在评论区留言,下节课,我们继续聊聊“封装”的问题,并从另一个角度理解一下应用服务和领域服务的区别。
- 赵晏龙 👍(19) 💬(1)
1你问我值不值?我当然说值!代码即文档 2表意接口的接口只是个概念,不是编程语言中的interface。
2023-01-02 - Michael 👍(8) 💬(1)
问题1.值得 从代码维护的角度说,抽方法可以用方法名来表意 从代码设计上说,方法也是一种抽象,应该依赖抽象而不是实现 问题2.这里的接口指的是抽象,不是编程语言里的语言特性,应该跟语言无关 关于隐喻,想请教老师,到底什么是隐喻呢?看徐老师的业务建模,他也提到为系统找到一个简洁的隐喻来解决问题之类的,不是很懂,老师可否再解释解释
2022-12-29 - 瀚海 👍(4) 💬(1)
感觉为了DTO类不破坏层间依赖关系,而引入builder、factory实在过于重了
2023-07-19 - 虚竹 👍(4) 💬(3)
builder模式用起来还是过于繁琐,因为实际业务参数可能很多,我们更可能选择将DTO对象定义下沉,通过内层包或者类名后缀知道它是用于应用层的
2022-12-29 - Ice 👍(2) 💬(1)
DTO是否可以放到common中作为支撑层被各层引用?
2023-02-03 - 老狗 👍(2) 💬(1)
最可怕的是有注释但是注释说的跟代码不是一回事
2023-01-10 - KOK体育手机APP苹果 👍(2) 💬(3)
老师,课程中涉及到的代码,会开源出来放在github上吗?
2022-12-29 - 6点无痛早起学习的和尚 👍(1) 💬(1)
一些问题: 3. 这里的校验规则是否又分的太多类了,是否直接用一个类里封装校验规则即可 4. 为什么不把校验规则放到相应的 Dto 实体类里去,而去单独去抽离一个“领域服务”模式 5. 用复杂的 Builder 模式去创建领域对象,有点太复杂了,实际项目中,应该不会采用这种方式,为了完全依赖关系去牺牲代码编码性,这个实际上需要权衡。
2023-01-16 - 张逃逃 👍(1) 💬(2)
有个疑问请教老师,为什么不把Validator的逻辑封装到Repository?
2023-01-08 - 曦 👍(1) 💬(3)
过去,单纯的以为领域服务就是XxxDomainService,然后在这个类中封闭很多方法。看了老师的解释,恍然大悟。但是,在实践的过程中,有一些业务规则,是需要通过不同的上下文或者聚合交互验证实现的,所以这些规则很难抽象到独立的、具体的某一个领域服务中,于是,一些原本属于领域层的知识在应用层进行了组合,这使得应用层又特别的臃肿且破坏了分层也只能边界,这种情况,老师要如何解决?或者类似的解决方案?
2022-12-30 - J.Smile 👍(0) 💬(1)
老师,咨询下,这里OrgBuilder和Org既然在同一个包下,为什么setName这个Org方法还需要使用public呢?包级权限是不是更合适?
2024-07-10 - Geek_ac7a29 👍(0) 💬(1)
老师,领域层OrgValidator引用应用层的orgDTO的是不是有问题?
2024-05-15 - 掂过碌蔗 👍(0) 💬(1)
写的太好了,很多问题都是写代码真实遇到的问题。之前一直以为只有我有这个困惑。
2024-04-02 - 雷欧 👍(0) 💬(1)
private final CommonValidator commonValidator; 为什么要用final修饰,然后再用@Autowired通过构造器注入 直接 @Autowired private final CommonValidator commonValidator不行么
2024-02-04 - 末日,成欢 👍(0) 💬(1)
老师,对领域服务也存在一些困惑, 看了下书,感觉有点迷惑 1.书里写的服务和本文中的领域服务是一个东西吗? 2.有些操作从本质上讲是一些活动或动作,而不是事物, 故这些操作从概念上讲不属于任何对象。 那么在本文中,添加组织中,校验组织的这个操作,从本质上不应该属于组织这个领域对象吗?还是因为它牵扯到了很多领域对象, 故将其放到领域服务中了? 如果强行将这个操作要放到领域对象中的话, 是不是组织对象必须存在租户和上级组织的引用是吗? 3.我的理解是领域服务和工厂模式甚至是可以互相取代的,领域模式如果已经把所有的校验逻辑都做完了, 就单单进行转化, 哪怕参数过多,一个一个赋值也可以不用工厂模式把? 那对于我的理解来说, 工厂模式创建领域对象, 业务规则复杂的时候, 我放到领域服务中,只有当结构复杂的时候,我在用工厂是不是也可行?
2023-09-17