10 代码实现(上):要“贫血”还是要“充血”?
你好,我是钟敬。
上节课我们根据DDD的分层架构,建立了程序的“骨架”,今天开始,我们来编写具体的逻辑,给骨架上“添肉”。其实仅仅从完成功能的角度来说,这些程序你也会写,但关键是怎么按照DDD的要求来写。
按照DDD的要求,我们首先要考虑的问题是,怎么使代码和模型保持一致?这还可以细化成几个子问题,比如怎么实现业务规则、怎么表示对象间的关联、怎么区分领域逻辑和应用逻辑等等。
其次,我们还要考虑一些通用的编程问题,比如说是采用贫血模型还是充血模型、怎么减少重复、怎样实现模块化,等等。
所以接下来三节课,咱们先选取几个比较简单的功能,用不太完善的方法把程序写出来,再一步一步地重构,达到我们希望的样子。在这个过程中,我们也会学到DDD在实现层面的几个模式。
今天,我们会首先讨论面向对象和面向过程间的权衡,然后在代码层面重点解决层间依赖问题。
开始之前要先说明一下,下面例子中的代码是用Java和Spring来写的,不过我们的重点是普遍原理而不是语言和框架的细节,所以对于其他语言来说,道理也是一样的。
“面向对象”还是“面向过程”?
提到编码,我们常常说起的一个问题就是:应该采用贫血模型还是充血模型?
一些人主张,DDD应该采用充血模型, 但是实践中,多数小伙伴,虽然也觉得充血模型更高大上一点,但用的还是贫血模型。今天咱们就先掰扯一下这个话题。
贫血模型,英文叫做Anemic Domain Model ,是Martin Fowler 在 2003 年提出的,恰好在《DDD》这本书写作的同一年。贫血模型指的是领域对象中只有数据,没有行为,由于过于单薄,就好像人贫血了一样,显得不太健康。这种风格违背了面向对象的原则。
所以,Martin Fowler 认为这是一种反模式,他主张的方式叫做 Rich Domain Model,可以译作“富领域模型”,也就是领域对象里既包含数据,也包含行为。
至于所谓充血模型则是后人提出的,这个人还把模型分成四种:失血模型、贫血模型、充血模型和胀血模型。问题在于他说的贫血模型和Matin Fowler说的又不一样,而“充血模型”和“富领域模型”也不是一回事,这就造成了今天业界术语的混乱。
所以,为了避免混淆,我不采用“充血模型”这个词。在后面的讨论中,我会把贫血模型称为面向过程或者过程式编程,把富领域模型称为面向对象或对象式编程,因为真正的面向对象本来就是包含丰富逻辑的。
那么问题来了,如果面向对象真的明显好于面向过程,为什么多数人还在用面向过程呢?除了咱们程序员自己学艺不精以外,有没有什么合理性呢?
其实,早期的面向对象编程,主要是用来开发桌面软件的,比如说开发一个Office、一个IDE 等等。这类软件的特点是基本上整个软件的数据都能装入内存,这样就可以通过对象之间自由的导航实现复杂的逻辑。对象在内存里形成一种网状结构,称为对象图(Object Graph)。
但是企业应用则有一个本质的不同,就是数据主要在数据库里,每次只能把一小部分远程拿到内存,所以不能在内存里对对象进行自由地导航。这个区别就造成,早期的面向对象编程很难直接用在企业应用,间接导致了贫血模型的普及。尽管用 JPA 之类的 ORM 框架可以减少这种痛苦,但底层原因并没有消除,所以ORM框架在解决一些问题的同时,又带来了另外一些的问题。
早年,很多像Martin Fowler这样的专家认为面向对象就是王道,我把他们称为面向对象的“原教旨主义者”。但是到了今天,包括Martin Fowler在内的很多人已经成长为编程范式的“中立主义者”,也就是并不局限于面向对象,而是将面向对象、面向过程、面向方面、函数式等等编程范式结合起来。这也是咱们的课程所遵循的思想。
实际上,面向对象和面向过程并不是非黑即白的关系,而是像下面这张图这样:

在纯粹的面向对象和纯粹的面向过程之间有一个广阔的“灰色地带”。这里面的变化非常多,难以穷尽。这两个极端都不是我们要追求的,我们要做的是找到其中的一个平衡点。
那这个平衡点怎么找呢?根据目前国内多数人的编程习惯,在这门课程里,我们采用这样的原则:在领域对象不直接或间接访问数据库的前提下,尽量面向对象。
为了理解这句话,咱们一会儿先按面向过程的方式写出程序,然后通过重构,逐渐向面向对象靠拢。在这个过程里,咱们可以体会不同编程范式的特点,以及思考它们怎样融合。
另外,由于不能在对象之间自由导航,所以相对传统的面向对象编程来说,我们的编程风格会偏过程一些。
我还是要提醒一句,在架构师的眼里往往没有唯一正确的方法,而是要在几种不同方法中作出权衡。
“开卡”和“验卡”
好,理论就讲这么多,回到开发过程。现在咱们俩都是资深程序员,另外,还有一个领域专家和我们配合,就叫他老王。
假设距离领域建模已经过去三四天了,今天我们开始真正编写“添加组织”这个功能。但是有两个问题:第一,尽管几天前已经澄清过需求,但会不会当时有什么遗漏呢?第二,就算当时没有遗漏,那么最近几天,会不会又有些新的变化没有通知到我们呢?
所以,有必要在真正动手编码之前,找老王再次确认一下。这实际上是敏捷中的一个常用实践,叫做“开卡”。相应地,在代码开发完毕,正式提交测试之前,也会把领域专家或测试人员叫过来大体看一下有没有方向上的错误,这一步叫“验卡”。这两个实践可以有效避免因为需求理解不一致而导致的返工。
经过和老王确认,我们果然又发现了几个新的业务规则。比如,同一个组织里,不能有两个同名的下级组织。也就是说,假如“金融开发中心”下面已经有“开发一组”了,那么新加的开发组,不能也叫“开发一组”。
下面这张表,是和老王澄清需求以后整理的和“添加组织”有关的业务规则。其中绿色部分是这次新加的:
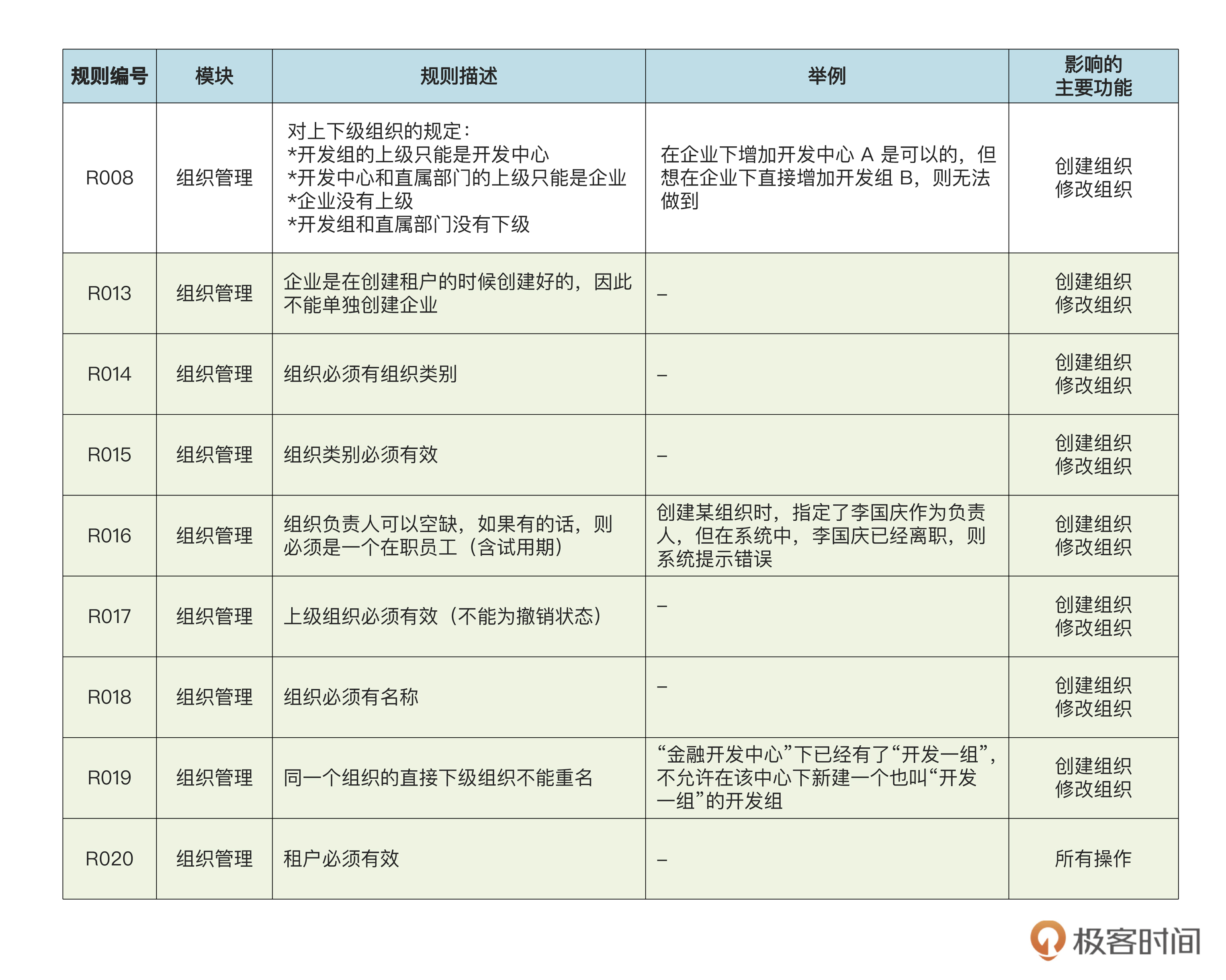
其实,和业务人员不断澄清需求,不断补充新的领域知识,正是DDD和敏捷软件开发的常态。
在这个表里我们发现,有一些“租户必须有效”“上级组织必须有效”这样的规则,说明在相应的实体里要增加状态属性来表达“有效”“终止”等状态。经过和老王的讨论,我们决定在租户、组织、组织类别、员工、客户、合同、项目等实体中都增加状态,并且在数据库里添加相应的字段。
DDD强调,在代码编写阶段,如果发现模型的问题,要及时修改模型,始终保持代码和模型的一致。
面向过程的代码
需求澄清以后,我们终于可以写代码了。假如我刚学了一点DDD的分层架构,但是只会面向过程的方法,那么写出来大概是下面这个样子。
我们先通过包结构,看一下总体的逻辑。
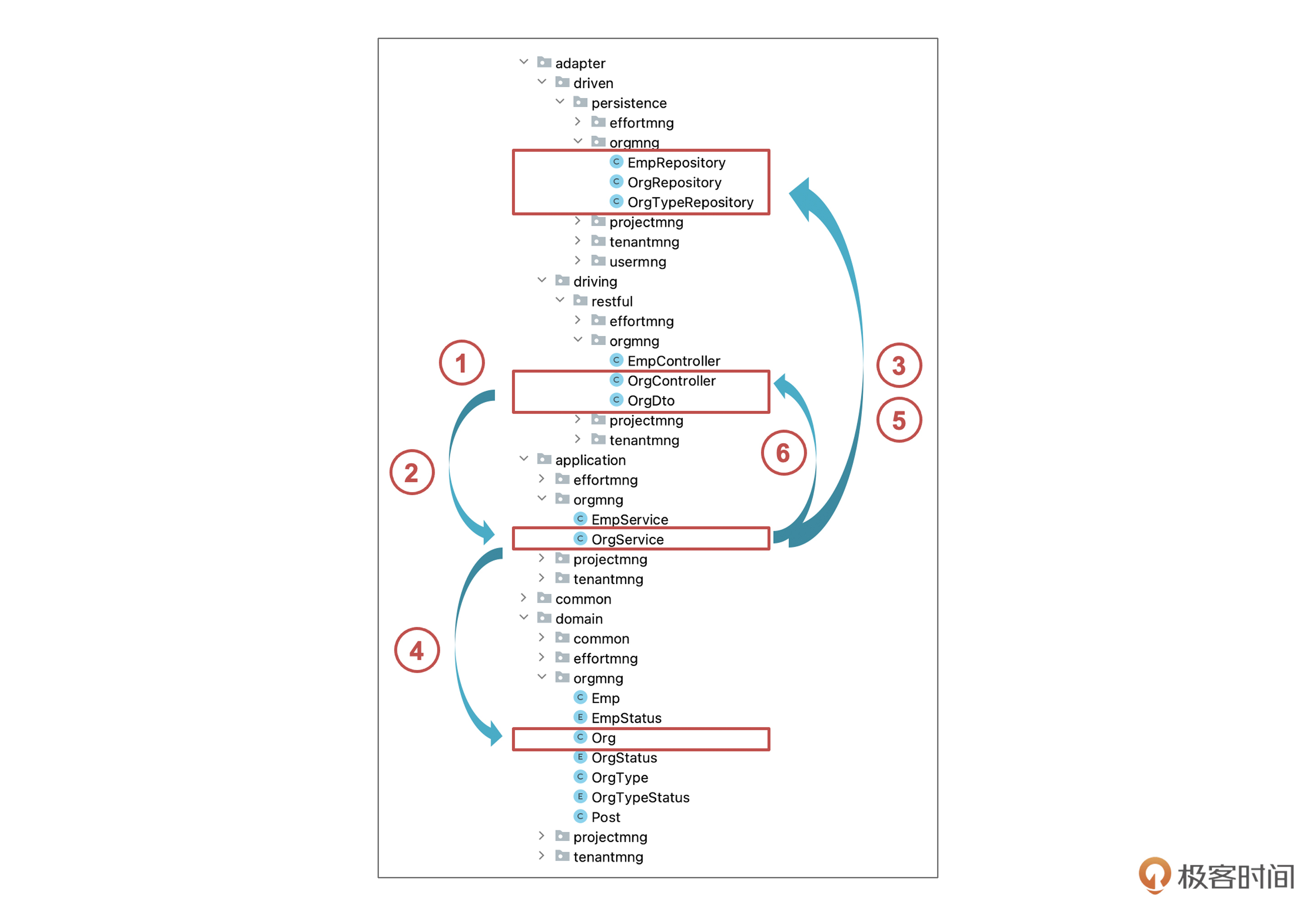
这里分成了六步,我们简单解释下。
- 第一步,适配器层里的OrgController 通过Restful API接收到添加组织的请求,请求数据封装在OrgDto里。
- 第二步,Controller以OrgDto为参数,调用应用层里的OrgService服务中的addOrg() 方法进行处理。
- 第三步,OrgService对参数进行校验,过程中会调用适配器层里的 Repository 来访问数据库。
- 第四步,OrgService创建领域层里的Org对象,也就是组织对象。
- 第五步,OrgService调用OrgRepository把组织对象存到数据库,并回填组织 id。
- 第六步,OrgService把组织对象装配成DTO,返回给控制器,控制器再返回给前端。
整个过程还是比较直白的,目前主要逻辑都集中在OrgService里,也就是第三步到第六步。
我们再看看两个主要的数据类。一个是领域对象类Org。
public class Org {
private Long id;
private Long tenantId;
private Long superiorId;
private String orgTypeCode;
private Long leaderId;
private String name;
private OrgStatus status; // 使用了枚举类型
private LocalDateTime createdAt;
private Long createdBy;
private LocalDateTime lastUpdatedAt;
private Long lastUpdatedBy;
public Org() {
status = OrgStatus.EFFECTIVE; //组织的初始状态默认为有效
}
//getters and setters ...
}
另一个是 OrgDto。
public class OrgDto {
private Long id;
private Long tenantId;
private Long superiorId;
private String orgTypeCode;
private Long leaderId;
private String name;
private String status;
private LocalDateTime createdAt;
private Long createdBy;
private LocalDateTime lastUpdatedAt;
private Long lastUpdatedBy;
// getters and setters ...
}
目前这两个类十分相似,而且都只有数据没有行为。唯一的不同是,Org的状态属性 Status是一个枚举类型,算是比OrgDto略微“面向对象”一点。
层间依赖原则和依赖倒置
现在我们从Controller开始逐层往下捋,下面是Controller的代码。
@RestController
public class OrgController {
private final OrgService orgService;
@Autowired
public OrgController(OrgService orgService) {
this.orgService = orgService;
}
@PostMapping("/api/organizations")
public OrgDto addOrg(@RequestBody OrgDto request) {
//从请求里解析出 userId ...
return orgService.addOrg(request, userId);
}
}
简单起见,我省略了身份认证、Http返回码等处理。所以addOrg方法中只有一句,就是调用Service。然而就是这一句,已经违反了我们上节课说的层间依赖原则。你能发现是哪里出了问题吗?
没错,由于OrgDto是应用服务中addOrg方法的入口参数类型,所以应用层是依赖OrgDto 的,而OrgDto又在适配器层。也就是说,应用层依赖了适配器层。而在上节课的分层架构中,应用层在适配器层的内层,而内层是不应该依赖外层的。这样,就违反了层间依赖原则。
改起来倒是简单,只要把OrgDto移动到应用层就可以了,修改后是后面这样。

这里还要注意一点,手工移动类是很麻烦的。现在像IDEA、Eclipse 这样的IDE,都有“重构”菜单,提供了丰富的自动化重构功能,我们应该学会尽量使用。后面课程的重构我们都是尽量依靠重构菜单完成的。
看完Controller,我们再重点看一下应用层的 OrgService,代码结构是后面这样。
@Service
public class OrgService {
private final UserRepository userRepository;
private final TenantRepository tenantRepository;
private final OrgTypeRepository orgTypeRepository;
private final OrgRepository orgRepository;
private final EmpRepository empRepository;
@Autowired
public OrgService(UserRepository userRepository
, TenantRepository tenantRepository
, OrgRepository orgRepository
, EmpRepository empRepository
, OrgTypeRepository orgTypeRepository) {
//为各个Repository赋值...
}
public OrgDto addOrg(OrgDto request, Long userId) {
validate(request, userId);
Org org = buildOrg(request, userId);
org = orgRepository.save(org);
return buildOrgDto(org);
}
private OrgDto buildOrgDto(Org org) {
// 将领域对象的值赋给DTO...
}
private Org buildOrg(OrgDto request, Long useId) {
// 将DTO的值赋给领域对象...
}
private void validate(OrgDto request) {
//进行各种业务规则的校验,会用到上面的各个Repository...
}
}
主控逻辑在addOrg方法里(19~24行),也很简单,先校验参数,再创建领域对象,然后保存到数据库,最后返回DTO。不过在这里,是不是又发现了一处违反层间依赖的地方呢?
可能你已经找到了,就是对仓库,也就是Repository的调用。根据上节课,仓库放在适配器层,而应用层调用了仓库,造成应用层对适配器层的依赖,这就再一次违反了层间依赖规则。
这时候我们该怎么办呢?像前面那样,把仓库移到应用层吗?可是仓库是适配器,就应该放在适配器层呀。这里就要用到一个技巧了,通过两步就可以解决.
- 第一步,从仓库抽出一个接口,原来的仓库成为了这个接口的实现类。
- 第二步,把这个接口移动到领域层。
修改后的结构是后面这样。
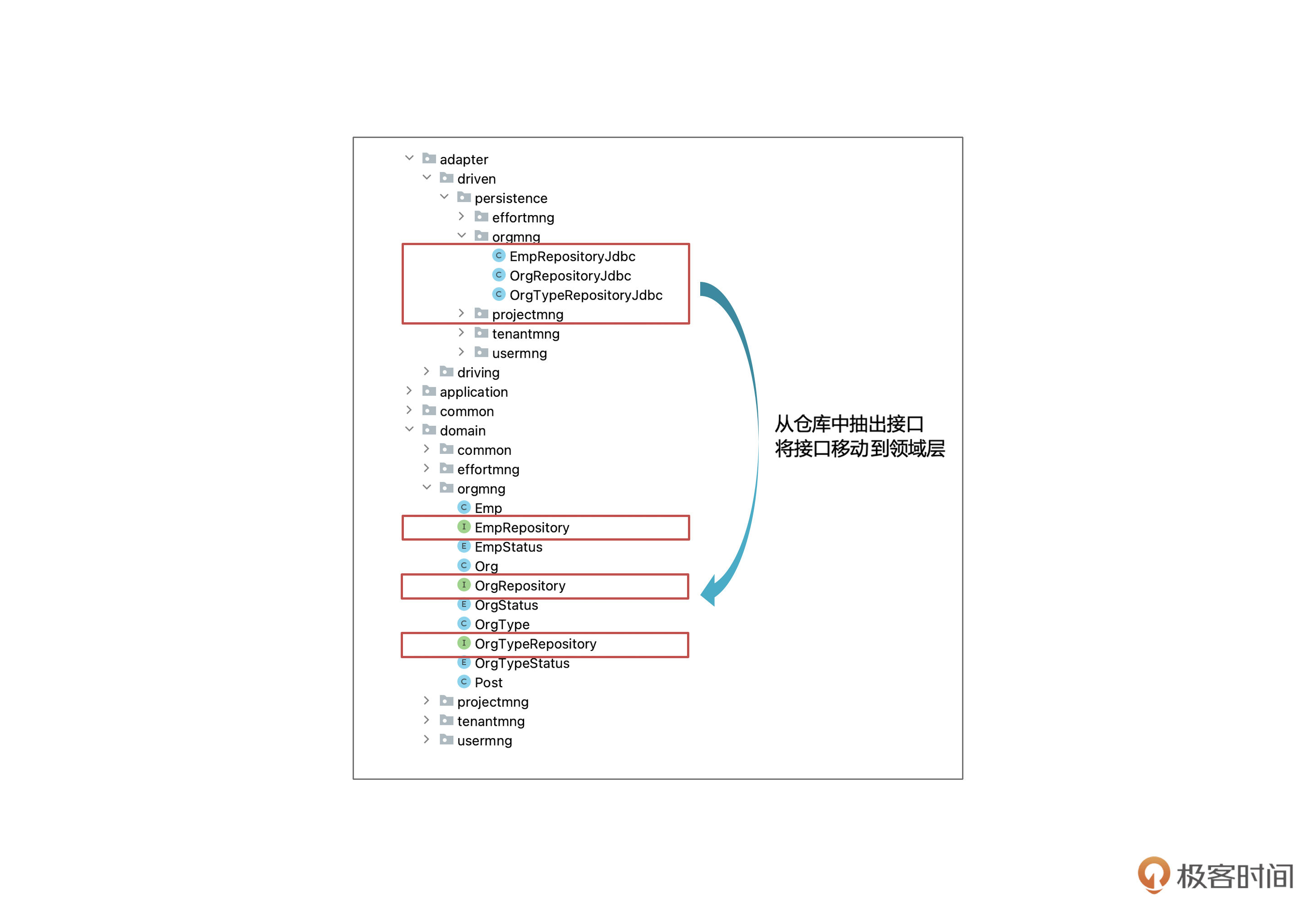
仓库接口都按照 XxxRepository 的形式命名。而仓库的实现是在接口名字的后面加上Jdbc ,这是因为在目前的例子里只是用了Jdbc来做持久化。OrgService中的代码,除了 import 语句要调整一下以外,其他都没有变化。Spring框架会“偷偷地”把实现类注入到相关属性。
以OrgRepository为例,接口代码是后面这样的。
package chapter10.unjuanable.domain.orgmng; //注意:仓库的接口在领域层
//import ...
public interface OrgRepository {
Optional<Org> findByIdAndStatus(long tenantId, Long id
, OrgStatus status);
int countBySuperiorAndName(long tenantId, Long superiorId
, String name);
boolean existsBySuperiorAndName(Long tenant, Long superior
, String name);
Org save(Org org);
}
而实现类仍然在适配器层,像后面这样。
//注意:Repository 的实现类在适配器层
package chapter10.unjuanable.adapter.driven.persistence.orgmng;
//import ...
@Repository
public class OrgRepositoryJdbc implements OrgRepository {
JdbcTemplate jdbc;
SimpleJdbcInsert insertOrg;
@Autowired
public OrgRepositoryJdbc(JdbcTemplate jdbc) {
//...
}
@Override
public Optional<Org> findByIdAndStatus(Long tenantId, Long id, OrgStatus status) {
//...
}
@Override
public int countBySuperiorAndName(Long tenantId, Long superiorId, String name) {
//...
}
@Override
public boolean existsBySuperiorAndName(Long tenant, Long superior, String name) {
//...
}
@Override
public Org save(Org org) {
//...
}
}
为什么这样做就解决了层间依赖呢?让我们画一个UML图来更直观地看一下。
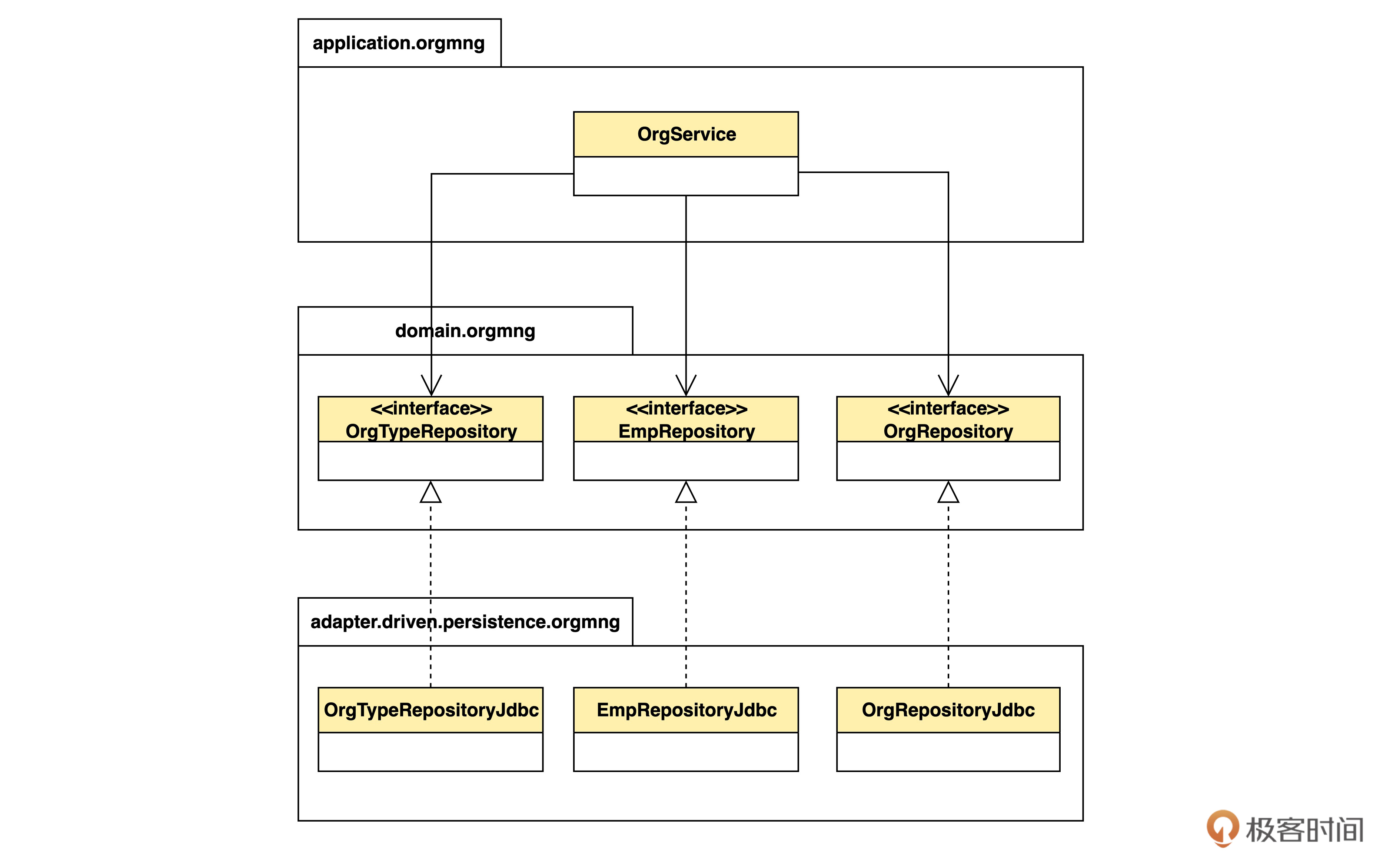
这是和程序结构等价的UML图。不过要注意,我们现在画的是设计模型的类图,和前面领域建模的类图会有一些区别。
首先,在设计图里用的是英文,而领域模型图里用了中文。这是因为用中文更容易和领域专家交流,而设计图是给程序员看的,用英文更贴近代码。中英文的转换则依照词汇表。
第二个区别是,这个图里画的都不是领域对象,而是用来实现程序的对象。当然,设计图里也可以画领域对象,只不过针对目前这个问题,我们把领域对象省略了。但是反过来,领域模型图中一定不能存在只有技术人员才懂的内容。
现在我们看一下从OrgService到领域层中仓库接口的三个箭头。它们实际上代表了 OrgService中用这三个接口定义的属性。这些箭头也是关联关系,只不过是技术意义上的。由于OrgService可以通过属性导航到仓库,而仓库中并没有属性能够导航到OrgService,所以关联是单向的。关联也是一种依赖关系,所以可以说OrgServie依赖仓库,说明应用层依赖领域层。
再看从仓库实现类指向接口的带虚线的空三角箭头。这个符号表示类对接口的实现关系,在领域模型中一般是不使用的。实现关系也是一种依赖,所以现在适配器层也依赖了领域层。
看见没有?原来应用层对适配器层的依赖神奇地消失了,取而代之的是应用层和适配器层两者对领域层的依赖。层间依赖的问题就解决了。
原来是别的层依赖适配器,现在通过抽取和移动接口,变成了适配器依赖别的层,依赖关系被“倒过来”了。所以这种技巧就称为依赖倒置(dependency inversion),是面向对象设计中常见的调整依赖关系的手段。
最后还有一个问题,为什么要把仓库接口移动到领域层而不是应用层呢?移到应用层不是也可以解决这个问题吗?
不错,就目前而言,移动到应用层也可以。但是后面我们会看到,领域层中的代码也有可能访问数据库。所以要移动到领域层,否则会出现新的层间依赖问题。
总结
好,今天的内容先讲到这里,我们来总结一下。
这节课我们开始编写代码,要实现两个要求:一个是保持代码和模型一致;另一个是符合通用的编程原则和最佳实践。
我们讨论了“贫血模型”“充血模型”“面向对象”和“面向过程”几个概念的关系。这里我们要清楚,在实践中,面向对象和面向过程往往不是非黑即白的,传统意义上纯粹的面向对象编程在企业应用中未必适合,应该把多种编程范式结合起来。
我们还讲了敏捷中“开卡”和“验卡”两个实践,补充了业务规则。这里我想再次强调,编写代码的时候如果发现模型的问题,要及时修改模型,始终保持代码和模型的一致。
在代码层面,今天的重点是解决层间依赖问题。我们做了两个改进:一是把DTO从适配器层移到了应用层;另一个是采用“依赖倒置”原则,使适配器层依赖于领域层。
在解释依赖倒置时,我们还用到了设计层面的UML图,希望你能借此理解领域模型和设计模型的区别。理解这种区别有两方面的好处,一个是在沟通过程中,知道哪些应该和业务人员讨论,哪些应该只在程序员内部讨论;另一个是区分不同的抽象层次,使我们思考问题的能够更加聚焦和高效。
思考题
1.在你的心目中,面向对象有哪些特征?假如用偏过程的方式,是否也能实现这些特征?
2.在今天的程序中,领域逻辑主要体现在哪段代码,它们放对地方了吗?
好,今天的课程结束了,有什么问题欢迎在评论区留言,下节课,我们继续优化程序,达到DDD的要求,并且更加“面向对象”一点。
- 子衿 👍(14) 💬(3)
老师这个地方有一个问题,我们通常为了方便微服务调用,会让Controller实现一个XxxApi接口,然后将XxxApi单独打包,这样下游可以将这XxxApi这个接口,通过maven引入到自己项目,然后直接通过XxxApi就可以完成远程调用,我们通常叫XxxApi所在的包为二方库,但如果将DTO放到了应用层,那么DTO和XxxApi就不在一层了,也就是XxxApi在适配器层,而DTO在应用层,如果强行将DTO也对外发布出去,会导致相关应用服务也被发布,这个应用服务对下游来说是没用的,这种有什么好的实践方式吗
2023-01-29 - Geek_1cb6f4 👍(8) 💬(4)
这里有个疑问,开发中发现dto的属性命名实际是要与外部调用者的命名一致的,比如页面请求或者第三方接口。于是就存在同一个dto的多个版本。那么dto不就应该属于适配器层么?搬至应用层后就感觉不那么合适了。
2022-12-29 - 奕 👍(5) 💬(1)
依赖倒置那个 有2个问题需要请教下老师: 1. 适配器层中 仓库的实现类,什么时候注入 到 Service 中,这里肯定不能在 Service 中初始化 否则还是会依赖 2. 适配层依赖 领域层,这里不是跨层依赖了吗?
2022-12-28 - Jxin 👍(4) 💬(3)
内容: 1.权衡问题,个人认为dto不该移动到应用层。就像要不要追加get set方法,原则上破坏封装性不要,实际上框架依赖只能要。java的rpc框架需要dto。如果你为交付负责,我觉得保守点,先追求框架红利,因为你算不准个中成本差异。 2.仓储的入参具象了(干没了加一层带来的扩展性),直接用聚合根实体就好。仓储是聚合的仓储。 课后题: 1.封装多态继承。可以,早期带团队面向对象落地难,用dci的思路带团队干过,效果能做出来,就是多了挺多概念,后期不好沟通。 2.add那块应用层里面。 说不上合不合理。核心逻辑是检验,检验我的观点是跟着领域对象走。但你说dto或则其他内部类加点检验可不可以,可以,不放内里面行不行,挺好,我就只抓领域层内部,其他的不放类里面指不定还是好事。(富客户端 api传递依赖 都是麻烦)(对象转换可以用框架,干净些)
2023-01-09 - 磐石 👍(4) 💬(2)
看高潮了,爽文,继续更新,不要停
2022-12-30 - gitqh 👍(3) 💬(3)
关于将dto移动到application层解决外层依赖内层的问题,我在项目中会用另外一种方式,dto依然在adapter层,adapter层在调用application层的方法时,将参数转换为domain层的对象,这种方式也没有破坏外层依赖内层的规则。 关于这两种方式的对比,想听听老师的观点
2022-12-31 - Faddei 👍(2) 💬(2)
老师请教下,repository 查出来的对象就是 domain对象了吗?还是需要再封装一个DO类,再将DO转换成domain
2023-08-30 - NoSuchMethodError 👍(1) 💬(1)
有个问题想问下,我看到有说法说app层只负责业务流程的编排,那业务流程是不是指的是业务用例或者系统用例?
2023-04-23 - Ramanujan 👍(1) 💬(1)
老师,你这个实现是贫血还是充血
2023-03-15 - 6点无痛早起学习的和尚 👍(1) 💬(2)
一些思考和问题 1. 如何保证模型永远是最新的,有时候只会改代码,不改模型,这里就是绝大部分程序员不能保证统一,很多时候文档迭代就会滞后。 2. 领域逻辑体现在应用层的OrgService里行为validate、buildOrgDto、buildOrg位置不对,应该把这些行为放到各自的领域对象里,比如validate、buildOrgDto放到OrgDto里,buildOrg放到Org里
2023-01-05 - 无问 👍(0) 💬(1)
repository的具体实现的位置跟我常见的ddd架构不太一样 没放在infra里 是出于什么原因?
2023-08-10 - LittleFatz 👍(0) 💬(1)
“非常近似的 OrgDto 和 Org 为什么不能合二为一?” 关于这个问题我的理解是,OrgDTO更多的是为了自身应用和其他应用的交互问题,而Org只是自身应用的数据库表的直接映射。因为很多时候对外返回一个OrgDTO中,可能会包含很多其他关联实体的数据
2023-07-25 - 末日,成欢 👍(0) 💬(2)
老师,还有一个疑问,适配层做数据库持久化我可以理解,但是逻辑角度, 应用层还是间接调用了持久层做数据存储,这不是层间关系混乱了吗
2023-06-13 - 末日,成欢 👍(0) 💬(1)
老师,有个疑问,repositry说的是直接调用数据库,如果我在对repositry这层再封装一层,直接用这一层是不是也可以能够达到隔离变化,而不必抽一个接口。 那么我这一层是不是也需要放到领域层?
2023-06-13 - 黄旗锋_APP小程序H5开发 👍(0) 💬(1)
老师,有一个问题请教一下,我感觉现在的写法好像还是贫血模型,因为领域对象基本上就是对属性的get和set,而不包含具体的业务逻辑,业务逻辑主要还是在Repository仓储类和领域层的Handler中,在application层中还是要调用Repository和Handler中的方法。充血模型在领域驱动里面是如何体现出来的呢?是不是把orgRepository.findById()和orgHandler.update(org)这些的逻辑写在Org这个领域对象的一个方法中供application调用,才是更加符合充血模型呢?
2023-04-18