04 事件风暴(下):事件风暴还有哪些诀窍?
你好,我是钟敬。
上节课我们完成了事件风暴的第一步,识别领域事件。
领域事件表示的是每个业务步骤的结果。那么我们再往深想一步,到底是什么人,执行了什么操作才会造成这种结果的呢?另外,识别行为需求以后,又该怎么进一步导出领域模型呢?
为了解决这些问题,这节课里,我们来一起完成事件风暴的另外两步,识别命令和识别领域名词。
把事件风暴的三步都搞清楚后,我们再来归纳一下事件风暴的作用以及实操时候的一些常见的问题。
事件风暴第二步:识别命令
现在,我们开始进行第二步,识别命令。
所谓命令(command),就是引发领域事件的操作,我们可以通过分析领域事件得到。除了识别出命令本身以外,我们通常还要识别出谁执行的命令,以及为了执行命令我们要查询出什么数据。
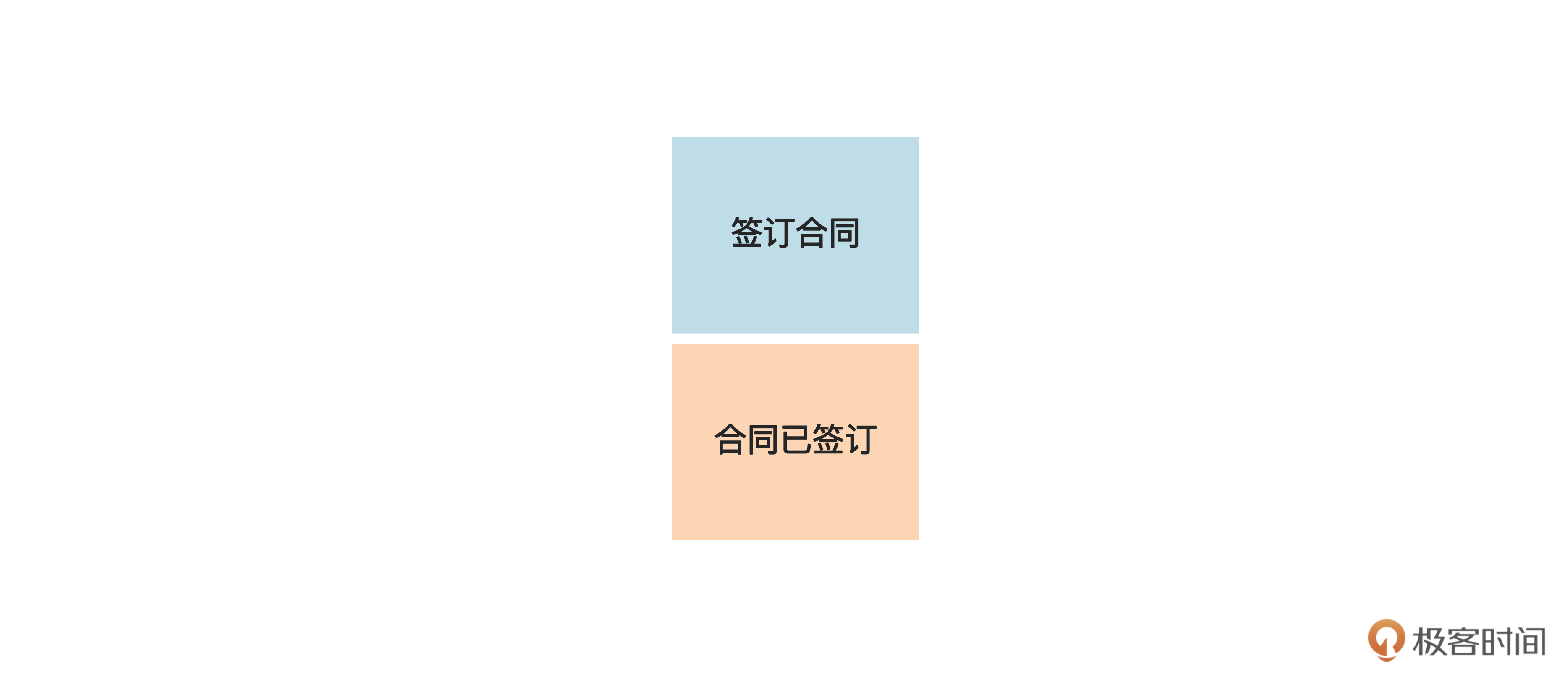
比如说,对于“合同已签订”这个事件,对应的命令就是“签订合同”。这里,我们在水蓝色的便利贴上写出命令,然后贴在对应的领域事件上方。如下图:
那么“签订合同”这个操作是什么人执行的呢?需求里说是“销售人员”。这里的销售人员术语上叫做“执行者”,英文是actor。我们把执行者写在小一点的粉色便利贴上,贴在命令上方,如下图:
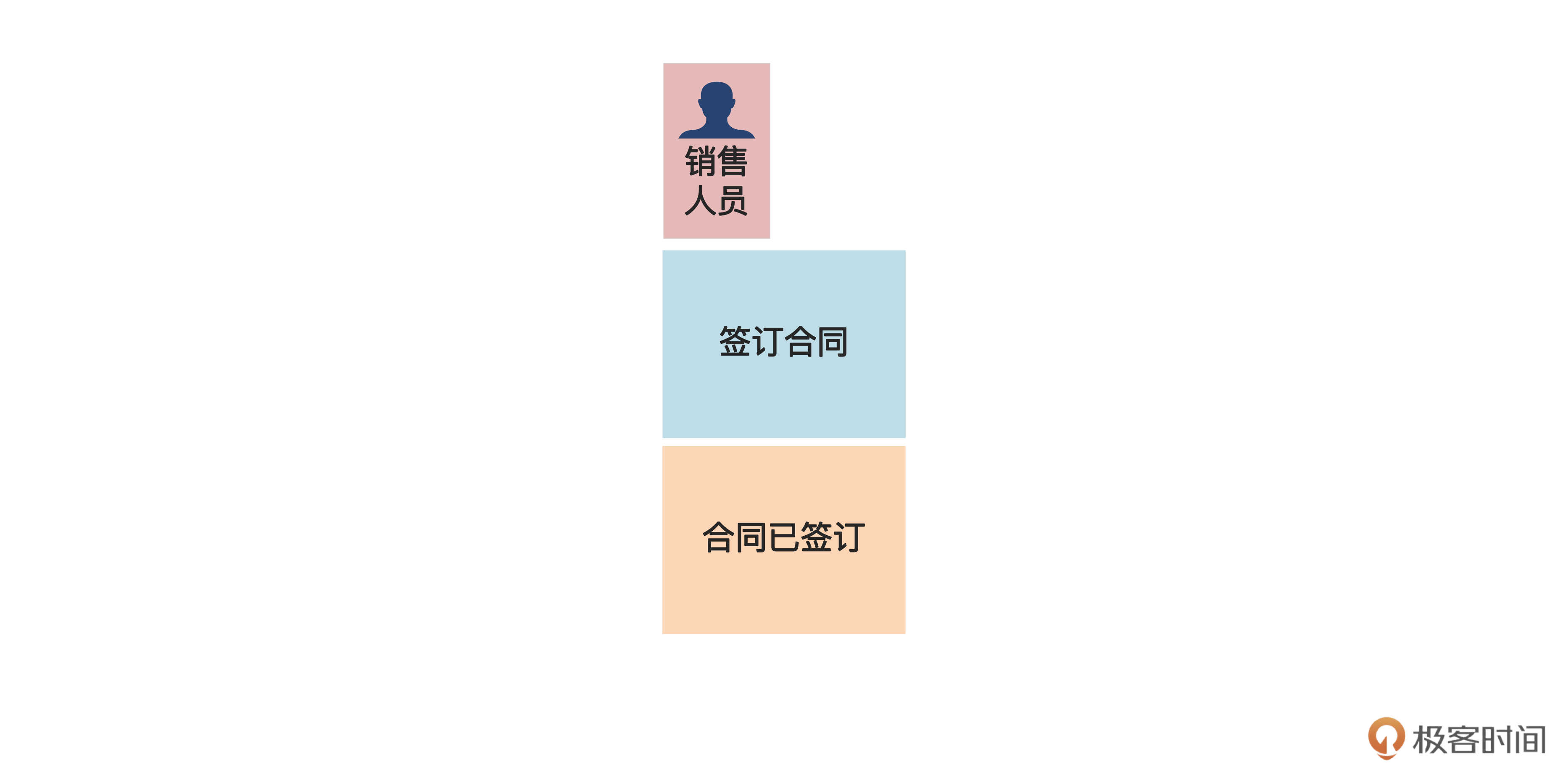
为了表示执行者是人,这里还在便利贴上画了一个小人儿。之所以这样,是因为有时执行者还可以是系统,可以在便利贴上画一个屏幕的图像表示系统执行者。像下图这样:

这里还有一个问题,在执行“签订合同”操作时,执行者要先从系统里查出客户信息,才能和这个客户签订合同。这里,“客户”是一种“查询数据”。我们把查询数据写在小一点的绿色便利贴上,也贴在命令上方,如下图:
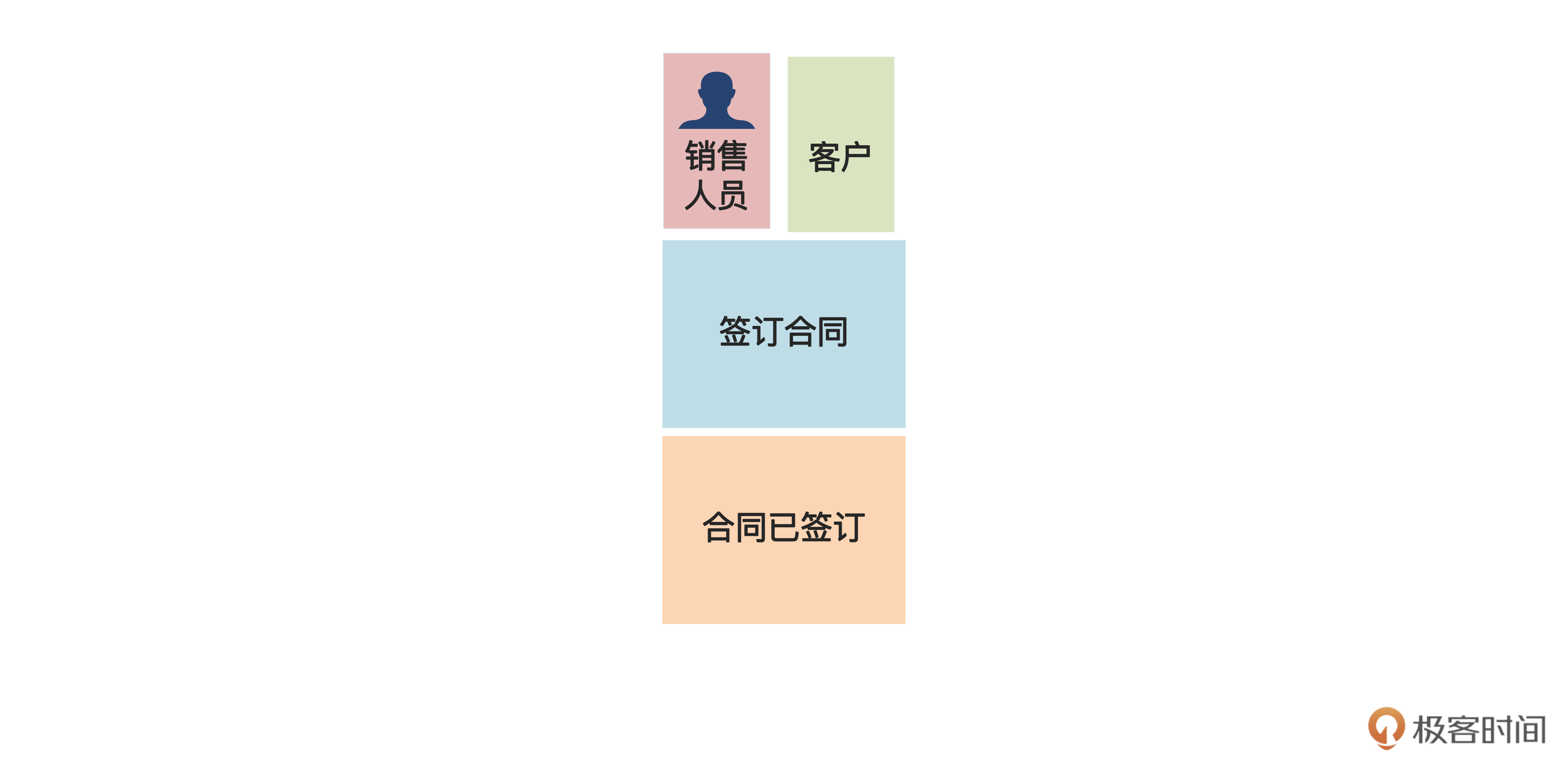
这样,一个命令的所有信息就识别完了。现在,假设我们按照前面的方法一边讨论,一边识别出所有的命令,结果就是后面这个样子。
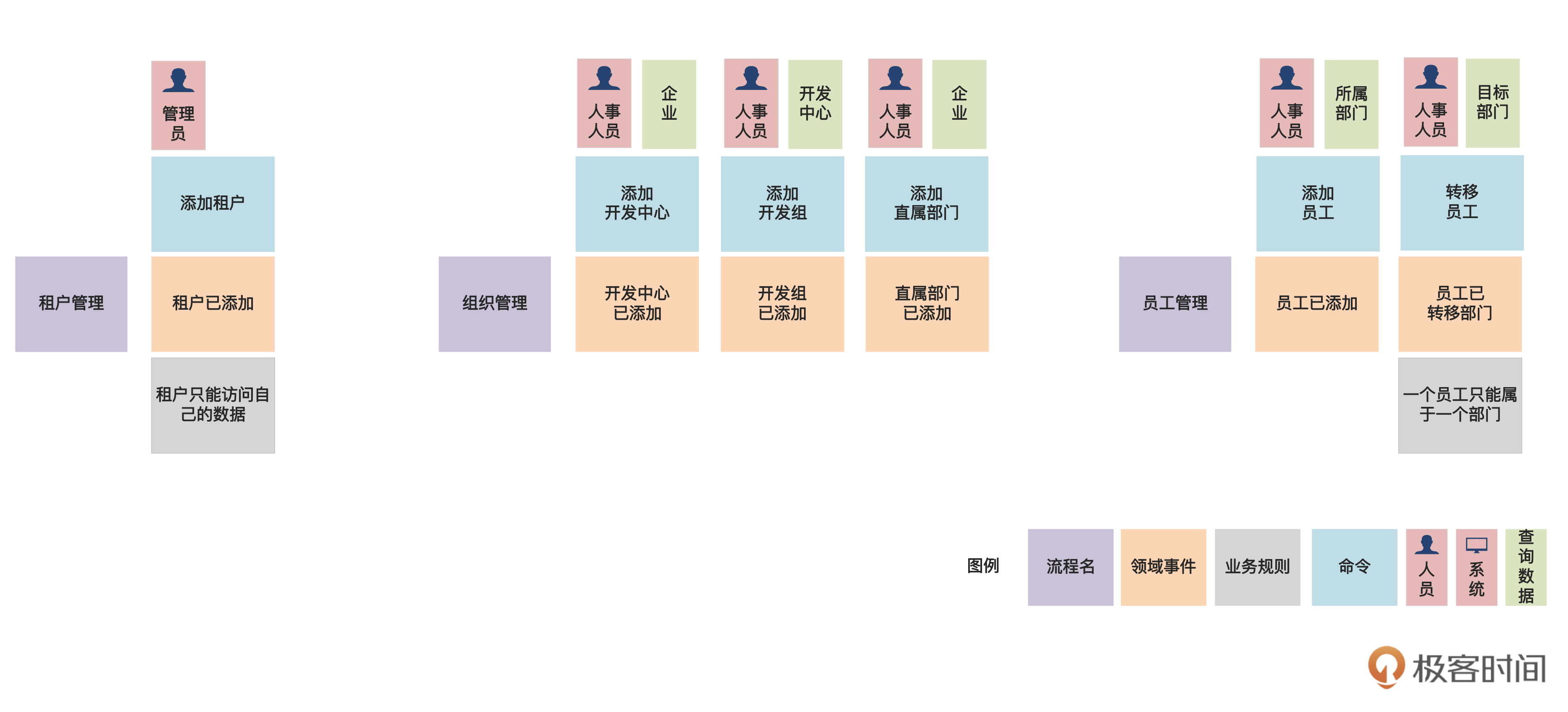
关于这个图,我们还要再补充说明几点。
首先,有些命令可能没有查询数据。比如添加客户,从需求来看,添加客户时不需要查询出什么其他信息,如下图:
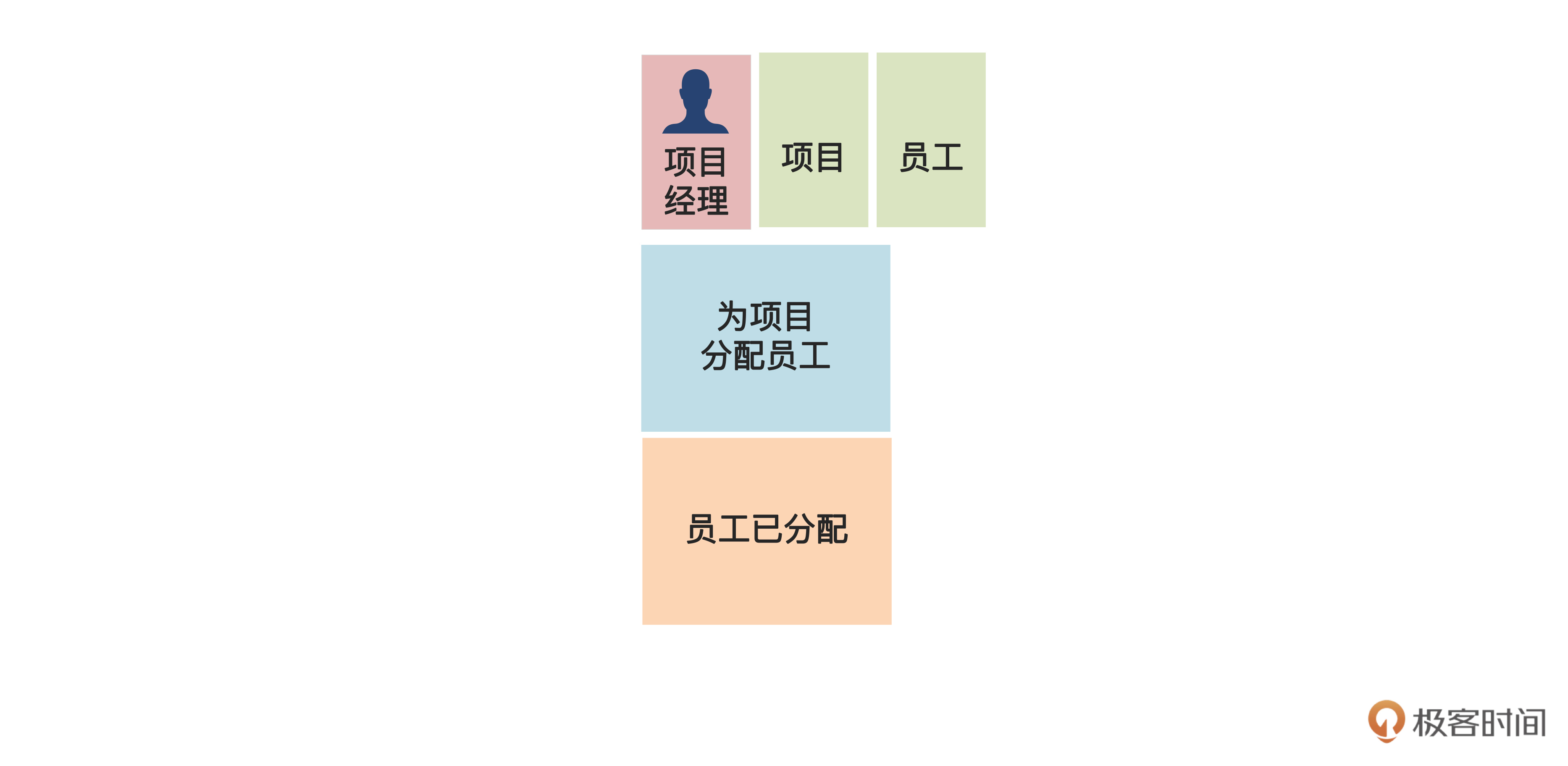
其次,还有的命令会有多个查询数据。比如说为项目分配员工,要查出项目和员工两个信息,如下图:
另外,还有的命令会有多个执行者。例如更换客户经理,既可以由客户经理把自己的客户转给另一个客户经理,也可以由客户经理的上级来操作,这时就可以有不止一个执行者了,如下图:
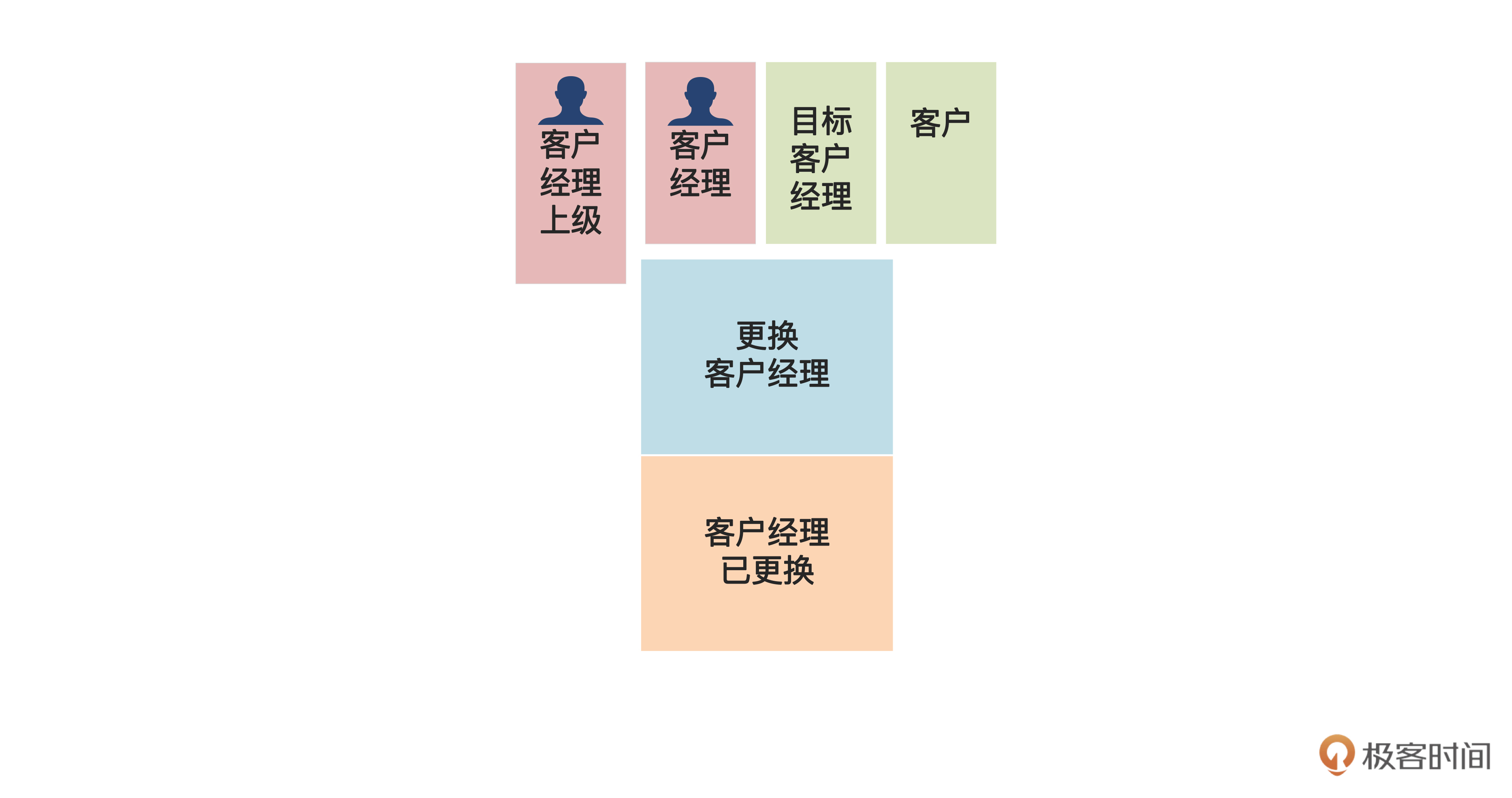
看到这里,你可能会提出疑问:“客户经理上级”这个执行者含义好像有些模糊呀?比如说,客户经理的上级还是客户经理吗?对于这个问题,我表示一时也没想清楚,可以先这么写,留到进一步做领域建模时再澄清。
还有最后一点你要注意,执行者是某个角色,而不是具体的人。例如“张大文”是一个客户经理,这时在便利贴上写的是“客户经理”这个角色,而不能是张大文这个具体的人。
事件风暴第三步:识别领域名词
识别完命令,我们来做第三步,识别领域名词。
这里说的领域名词,是从命令、领域事件、执行者、查询数据里找到的名词性概念。例如,对于签订合同这个命令而言,受到影响的名词性概念是“合同”;类似地,对于合同已签订这个领域事件,是由于“合同”这个名词性概念的状态变化所导致的。
识别领域名词的操作步骤可以分成两小步。
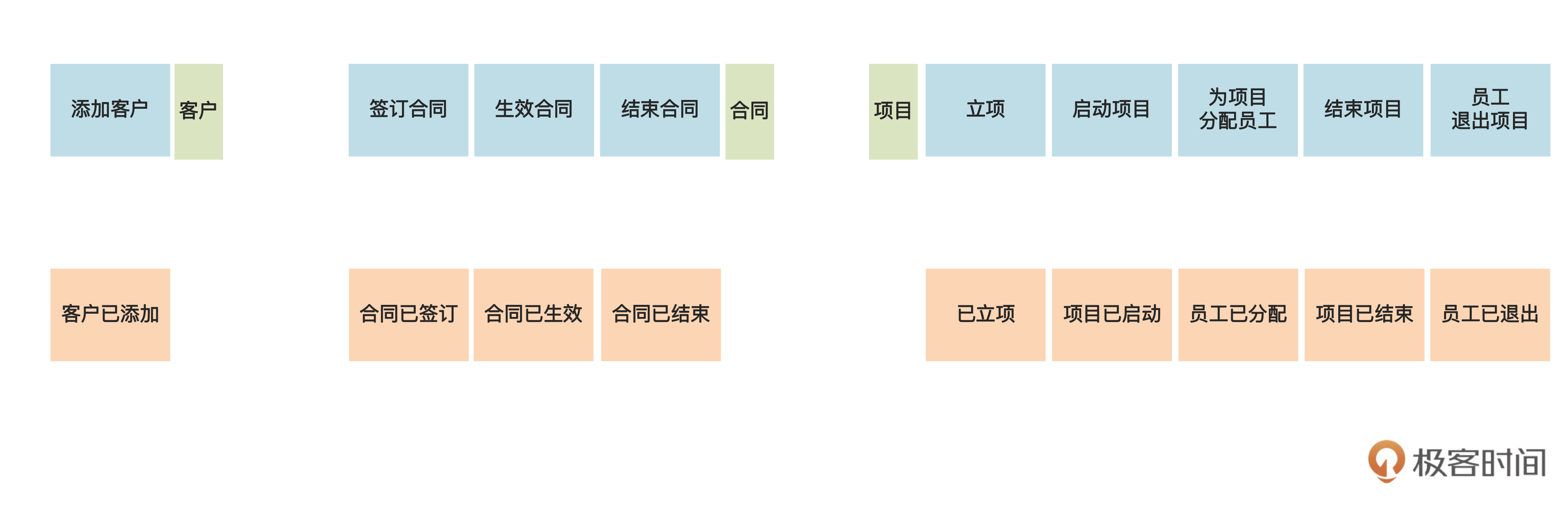
第一步,我们要挪动上一步的便利贴,把围绕同一个名词的命令、事件、执行者、查询数据摆在一起,分成好几“堆”,贴在墙上。下图是其中一部分:
第二步,把领域名词写在大一点的黄色便利贴上,贴在每堆便利贴的中间,如下图:
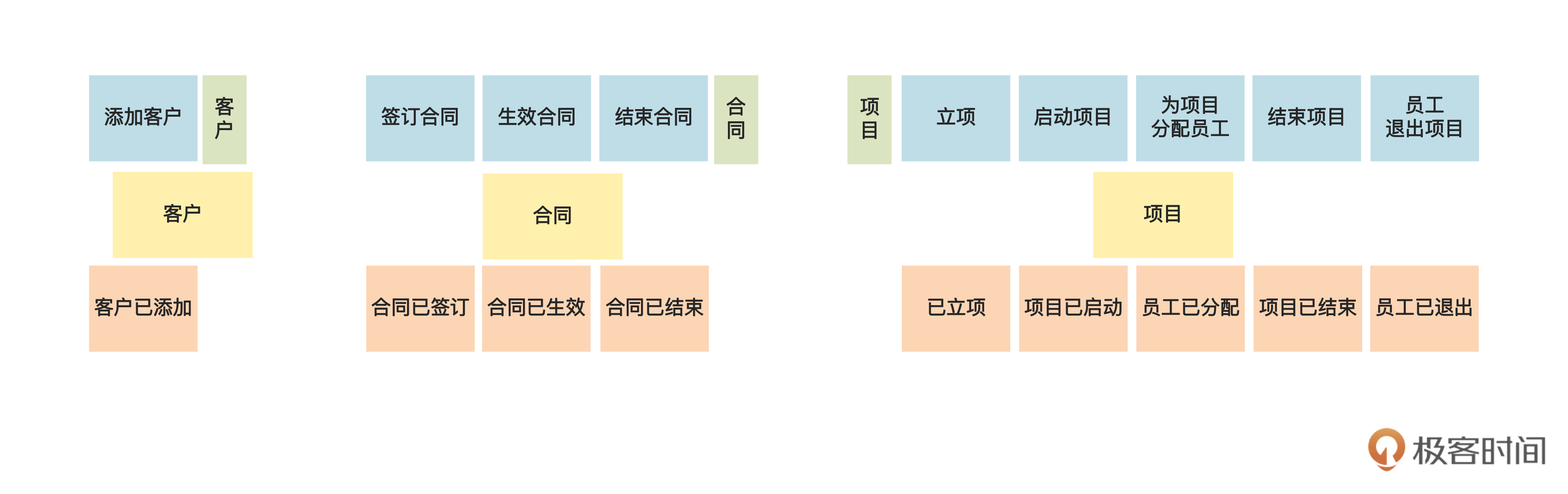 所有领域名词都识别出来后,就是下面这个样子:
所有领域名词都识别出来后,就是下面这个样子:
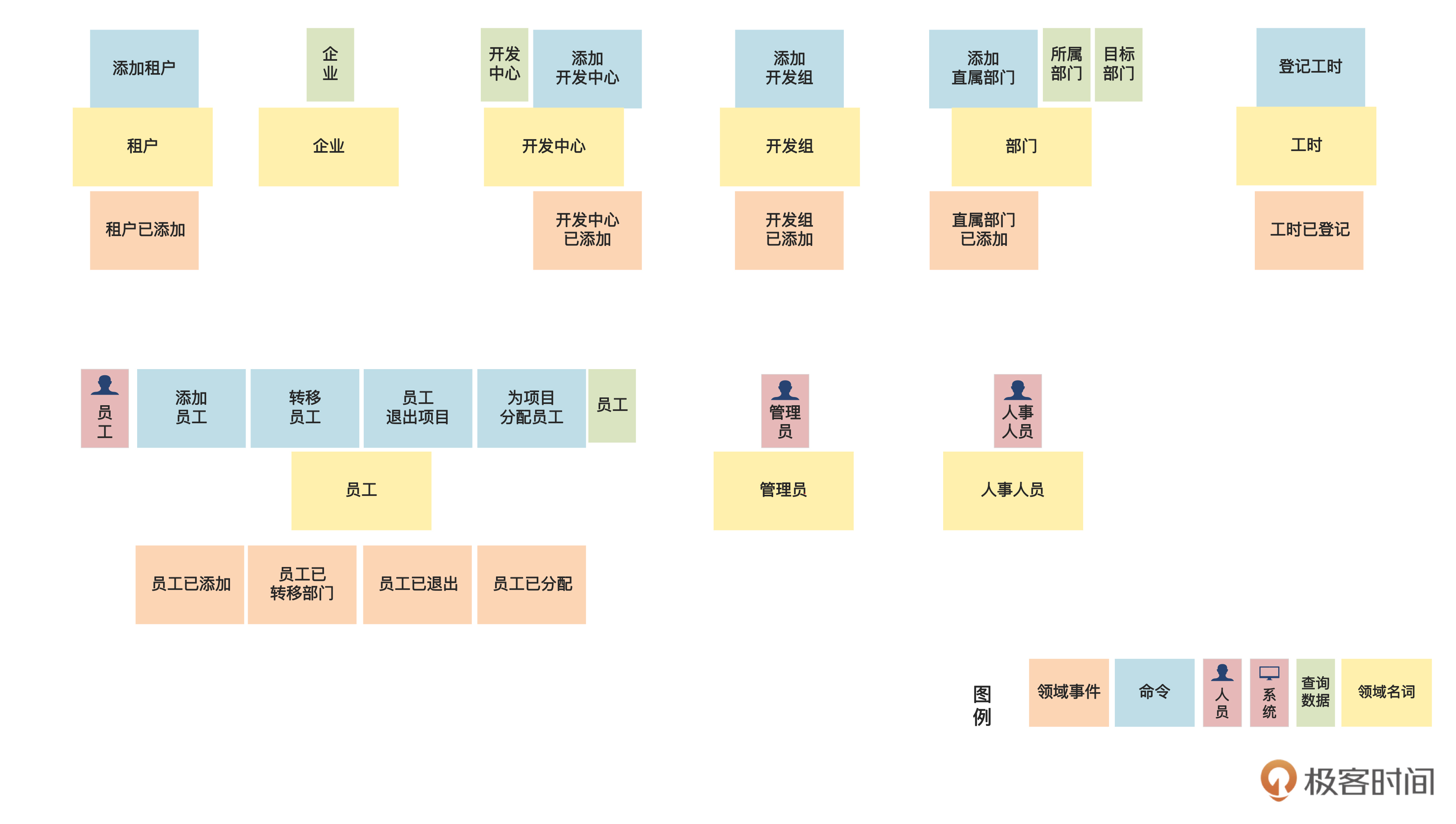
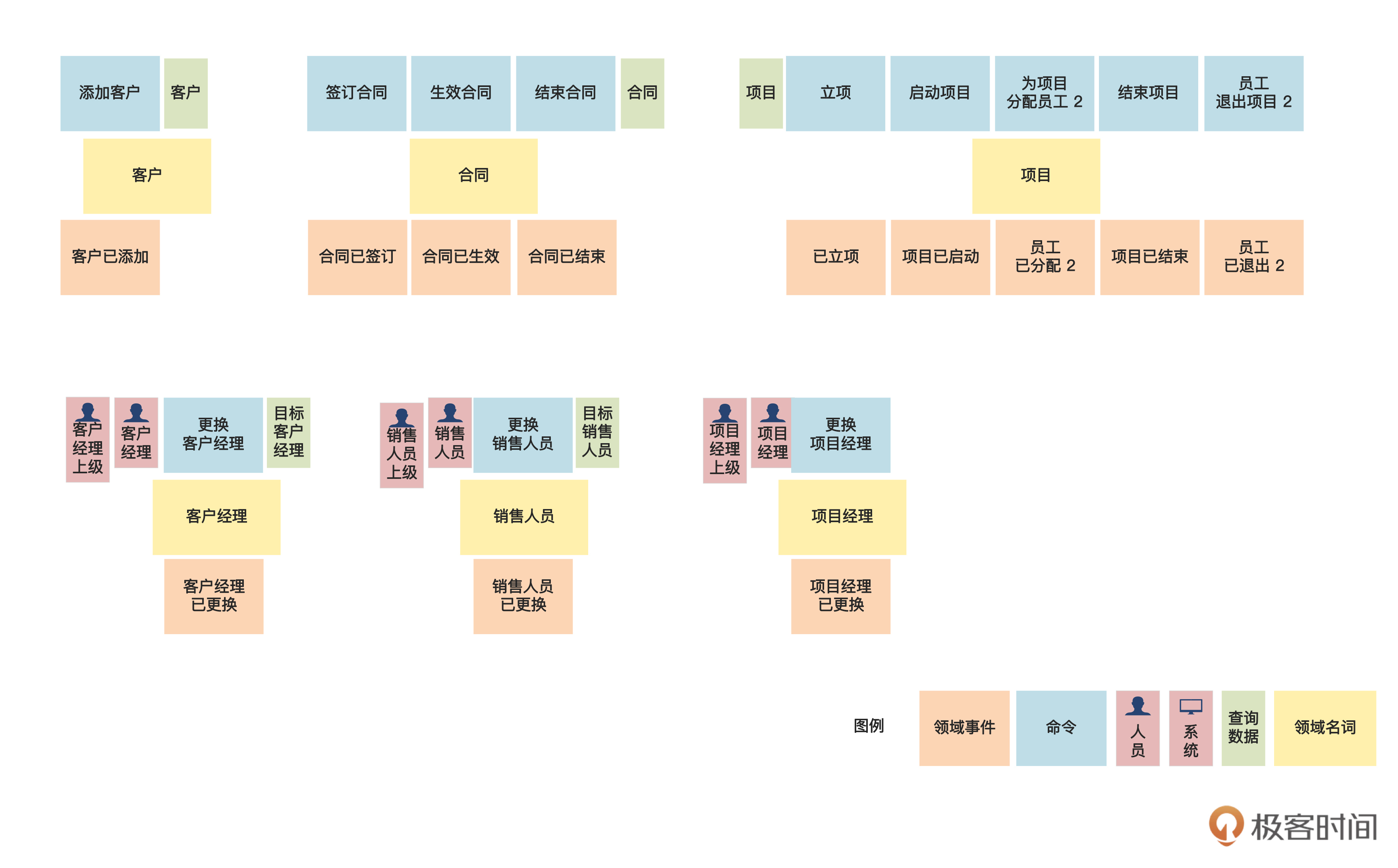 }{:referrerpolicy="no-referrer"
}{:referrerpolicy="no-referrer"
让咱们再仔细看看这张图。
首先我们发现,“为项目分配员工”和“员工已分配”出现了两次,一次是关于“员工”的,另一次是关于“项目”的。
因为这对命令和事件是关于两个名词的,所以我们抄写了两遍。其中你可以看到,关于项目的那次,我在命令和事件后面加了一个 “2” ,就是同一个概念在图中出现了第二次的意思,这是我们画图时的一个常用技巧,其他有 “2” 的命令和事件也是同理。
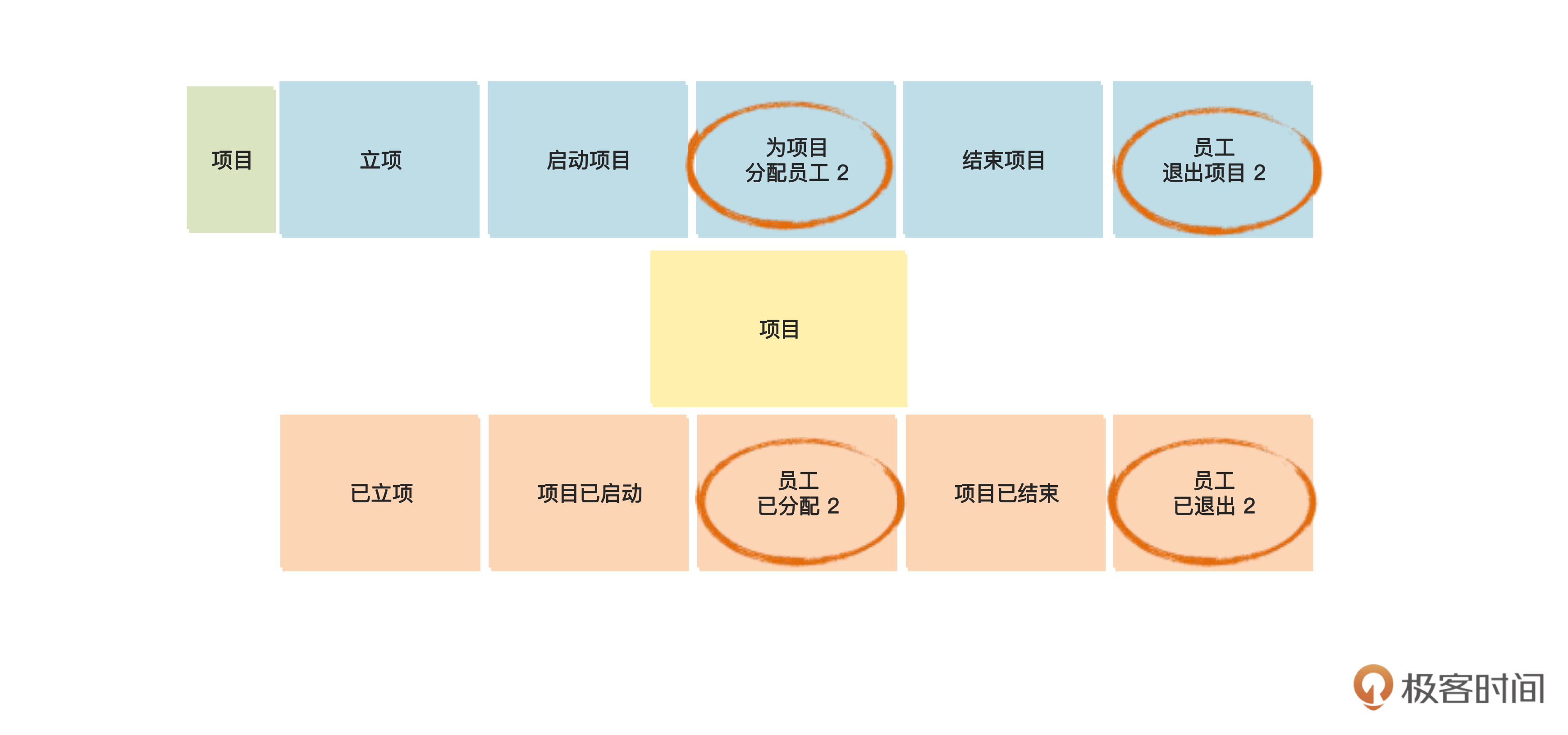
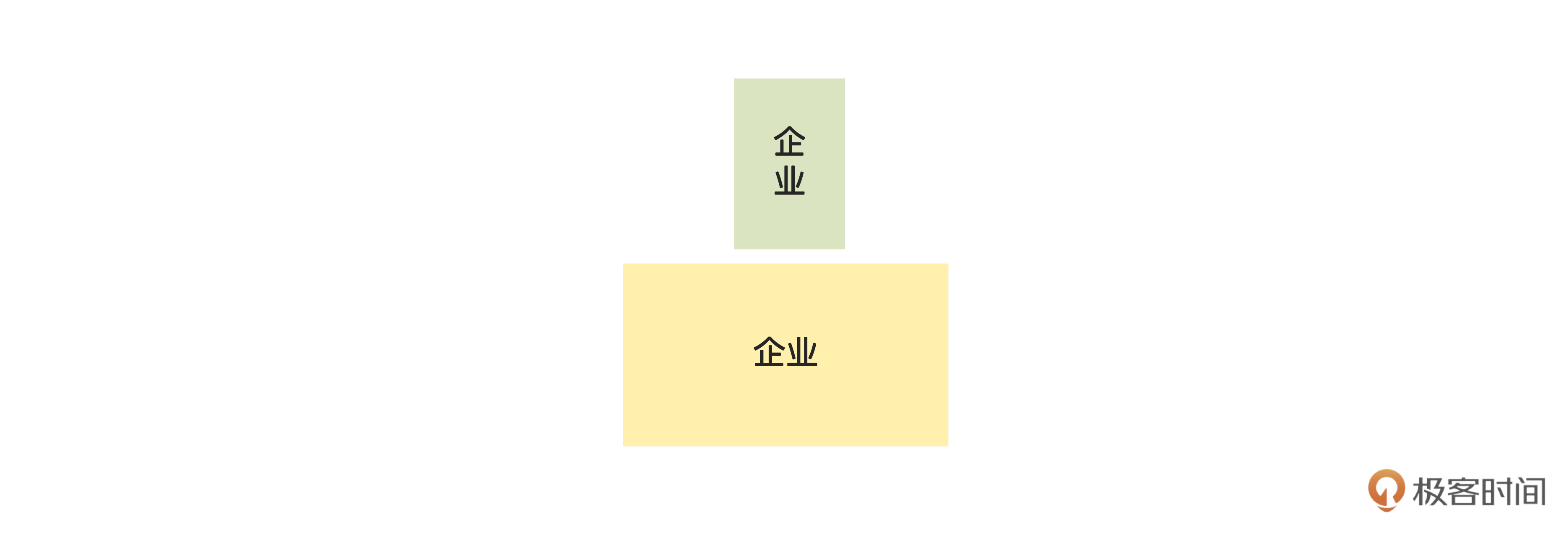
另外,我们还看到,“企业”这个名词只和“企业”这个查询数据有关,但是没有“添加企业”之类的命令。
咱们俩讨论了一下,认为租户和企业是一回事,添加了租户,自然就添加了企业,所以目前这样好像没毛病。那就先这样吧,如果还有问题的话,等到领域建模的时候再澄清。
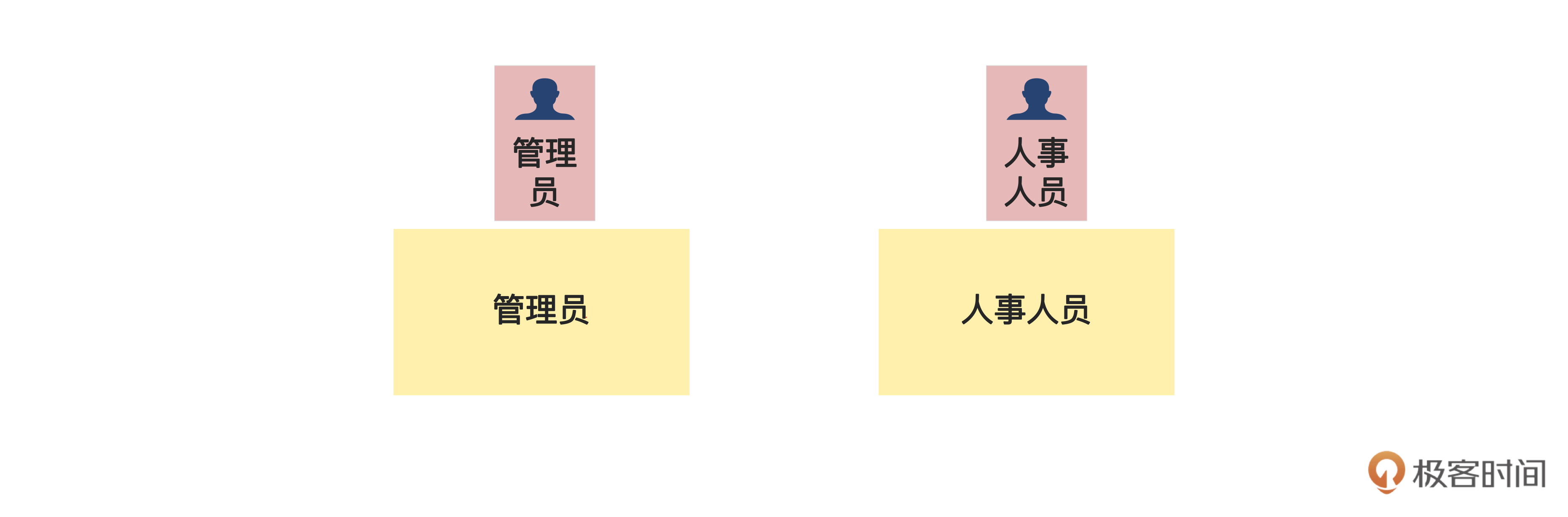
类似地,管理人员和人事人员也只和执行者相关,而没有相应的命令。这些我们都可以留到领域建模的时候再进一步想清楚。
现在,我们就完成了事件风暴的所有步骤,后面就可以用这个为基础进行领域建模了。
再谈事件风暴的作用
在进行后续的工作之前,咱们还是来归纳一下事件风暴的作用,进一步加深理解。
上一节课我们已经说过,事件风暴是业务人员和技术人员一起协作,捕获行为需求、消化领域知识、形成统一语言的一种方法。这是就整体来说的。
现在我们已经一起做了一场事件风暴了,咱们可以结合这两节课的学习,再体会一下每个要素在建模和实现层面更具体的用处。
首先我们看看领域事件的作用。从代码实现的角度来看,领域事件一般会对应一段代码逻辑,这段逻辑可能会最终改变数据库中的数据。另外,在事件驱动的架构中,一个领域事件可能会表现为一个向外部发送的异步消息。
那命令的作用体现在哪儿呢?领域建模时,我们可以通过对命令的走查(walkthrough),细化和验证领域模型。在实现层面,一个命令可能对应前端的一个操作,例如按下按钮;对于后端而言,一个命令可能对应一个API。
再来说命令的执行者。在领域建模时,执行者可能本身就是一个领域对象,也可能是领域对象充当的角色,或者是权限管理中的一个角色。
至于查询数据,我们上一讲说过,查询功能不产生领域事件,因此也不会有相应的命令。那么怎样保证查询功能不被遗漏呢?
实际上,每个查询数据,就对应着一个查询功能。不过,这里的查询数据是为了某个命令服务的。系统中可能还有一些单纯的查询功能,并不与某个特定的命令绑定。这些查询功能不会通过事件风暴识别出来,需要单独进行分析。
最后,我们再看看领域名词的作用。其实识别领域名词的最终目的是要找到领域模型中的对象。那么为什么我们不把这一步直接叫做识别领域对象呢?
这是因为,在这一步里识别出的名词,虽然很可能就是领域对象,但也未必。一个名词有可能只是一个对象充当的角色,或者对象的属性,还有些名词需要经过合并或拆解后,才是合理的领域对象,而这些需要等到领域建模时才能真正搞清楚。
事件风暴本身并不是进行这种深入分析的合适工具,所以,我们在这一步只需要识别出领域名词就可以了,这些名词将成为领域建模的“素材”。
事件风暴的常见问题
好,聊完事件风暴的作用,我们再谈谈实践中常常遇到的一些问题。
第一个问题是,在事件风暴里是否要列出所有的领域事件和命令?
你可能已经发现,在我们现在做的事件风暴里,其实只列出了部分领域事件和命令。例如,有签订合同这个命令,但没有修改合同和删除合同,但修改和删除功能应该也是系统中必要的呀。
其实,列出所有领域事件和命令并没有原则上的错误,但这样做会让结果变得繁琐,反而让人抓不住重点。
所以我的建议是:在事件风暴里只列出主要的、足以用于表达和交流领域知识的步骤,例如签订合同、生效合同等等。而像修改合同和删除合同这样的步骤是显而易见的,在讨论过程中可以提一下,但不必真的列出来,这样是为了保持简洁。
那么不列出来,怎么保证这些功能不被遗漏呢?我们可以结合用户故事或者传统的功能列表等方法保存系统功能的全集,这样就能解决了。
第二个问题是,各个领域事件需要体现严格的时间顺序吗?
在上一讲我们说过,只需要按照大致的顺序,贴出领域事件就可以了。这是因为,如果要体现严格的时间顺序,需要用到更复杂的符号,例如条件判断,还有要画更多的连线,这会使事件风暴变得非常繁琐。
因此,我们应该关注点分离。如果要体现严格的时间顺序,我们可以用流程图、用顺序图等方法,但事件风暴不必关注这一点。
第三个问题是,每个步骤的颗粒度应该有多大?
这里说的步骤,指的是一对领域事件和命令。
比如说,“签订合同”这个命令,在具体操作的时候,可能分成录入合同基本信息、录入合同明细、上传附件等等更小的步骤。那么,我们需要为每一个小步骤都识别出领域事件和命令吗?
这就要考虑从业务的角度,我们是把每个小步骤都当作独立的一个事务来看待,还是把它们合起来作为同一个事务。
另外,可以设想,如果每个小步骤都向外界发出一个领域事件,对系统后续的功能是不是有意义。那么在目前的需求里,合同作为一个整体来提交就可以了,分成小的领域事件,并没有意义,所以不再分成更小的步骤了。
在实践里,有时仍然会有模棱两可的情况,这时,原则上宜粗不宜细。可以先采用比较大的颗粒度。后面必要的时候,再拆细,就可以了。
第四个问题是,事件风暴适用于所有项目吗?
这个问题可以从两个层面回答。第一个层面,事件风暴主要应用在需求不清晰,或者理解不统一的情况下,通过协作的方式理清业务、达成一致,所以通常对于新项目比较适用。
至于遗留系统改造的情况,如果这个系统的知识已经流失得很严重,那么事件风暴仍然是有意义的。但如果大家对这个系统的业务知识很清楚,只是要进行架构改造,那么事件风暴的意义就不大了。
第二个层面,即便在适用的场合,事件风暴也不是唯一的方法,我们还可以用用例分析、用户故事等方法实现类似的目的。只要抓住协作、统一语言等等要点,这些方法都可以用在DDD的项目里。
所以,如果你的项目里还没有正规的、令人满意的捕获行为需求方法,那就可以使用事件风暴。如果已经有了成熟的方法,你可以借鉴事件风暴的思路,在原来的方法里加入协作、统一语言、识别领域名词的实践,也能达到同样的效果。
第五个问题是,怎么保存和维护事件风暴的结果?
到现在为止,事件风暴的结果都是贴在便利贴上的,显然不容易长期保存。一般来说,我们可以在事件风暴的过程中专门安排一个记录员,由他使用PPT之类的画图工具,把贴在纸上的内容重新画一遍,就可以实现电子化的保存了。
还有一个更深入的问题是,事件风暴是不是需要长期维护和更新?还是说我们只是把事件风暴当作一次性的步骤,不必长期维护?
通常,如果事件风暴的内容最终会反映到用户故事、用例、功能列表等产出物中,而这些产出物会进行维护,那我们就不必专门更新事件风暴的产出物了,只在需要的时候作为一种沟通工具,将电子化的结果作为一种中间产物保存就可以了。
但是,如果你的团队并没有用户故事和用例等保存行为需求的方式,那么我建议你对事件风暴进行维护和更新。
除了绘图之外,事件风暴也可以用表格的形式来保存,你可以参考一下后面的表格。
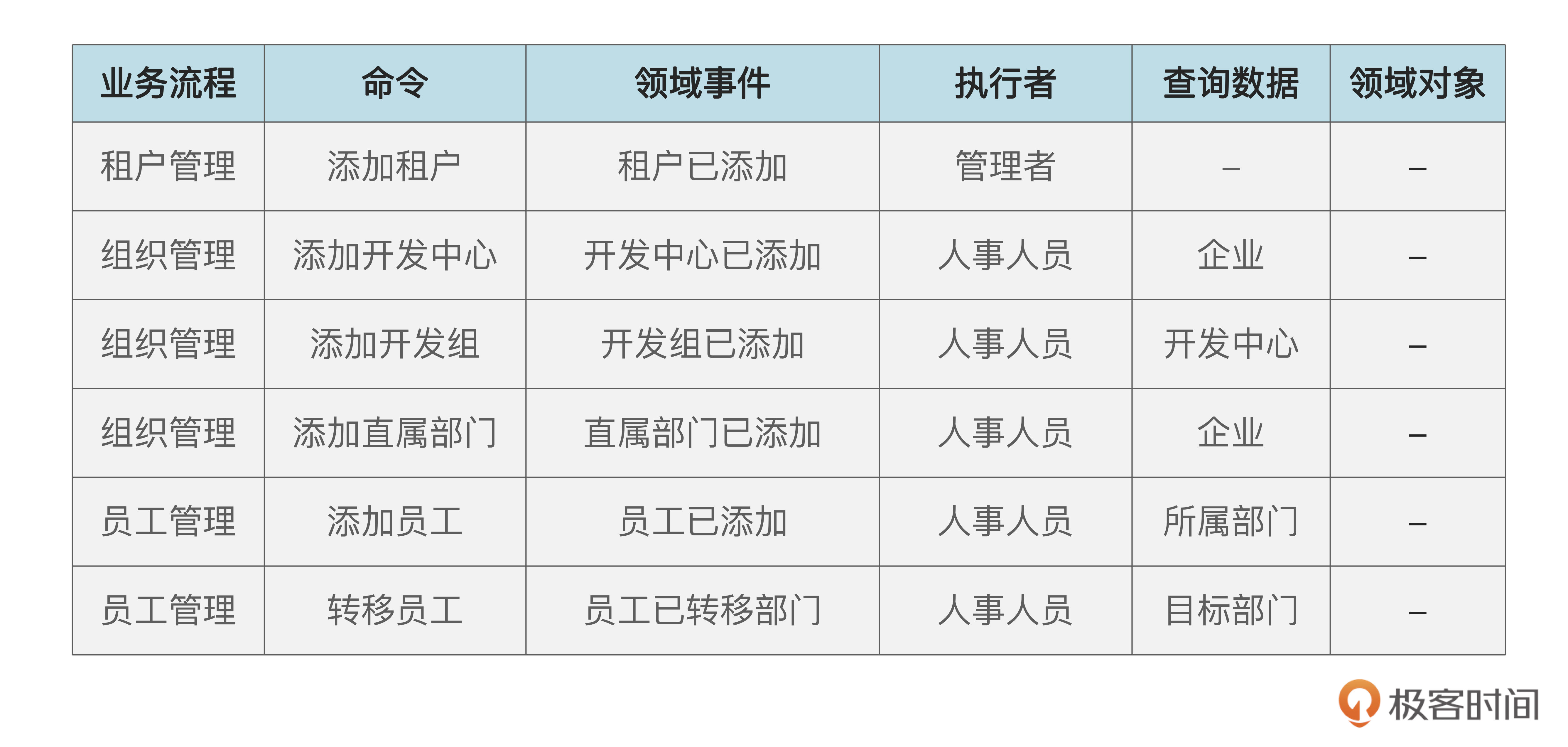 不过,这个表里的领域对象需要在领域建模阶段才能分析清楚,这里先空着,到时再回填。
不过,这个表里的领域对象需要在领域建模阶段才能分析清楚,这里先空着,到时再回填。
最后一个问题是,怎么保存领域规则?
领域规则是重要的领域知识,必须妥善保存。在事件风暴的过程里我们已经识别出了一些领域规则,在后续的领域建模阶段,可能还会识别出更多。如果只是写在便利贴上,或者画在图上,时间长了,就很难维护了。
所以,我们要编一个领域规则表,把所有的领域规则都汇总在里面,然后再把领域规则表和领域模型放在一起,作为领域知识的重要组成部分,后面就是一个例子。
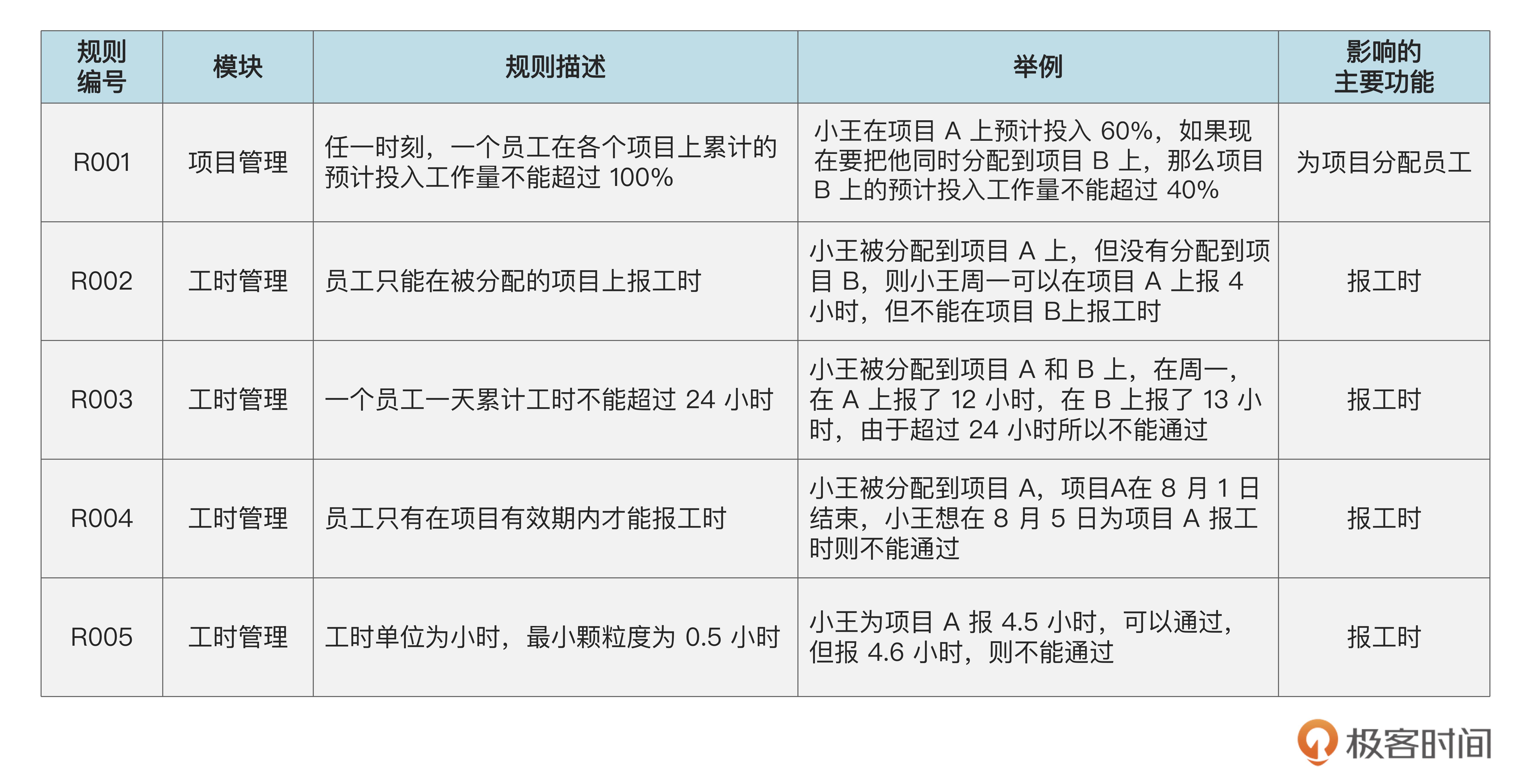 在这张表里,你还看到了一个“模块”列,这个概念我们会在以后的课程再讲。
在这张表里,你还看到了一个“模块”列,这个概念我们会在以后的课程再讲。
总结
现在,我们对这两节关于事件风暴的课程做一个总结。
事件风暴是一种通过协作的方式捕获行为需求的方法,在这个过程里,业务人员和技术人员一起消化领域知识、形成统一语言、并为领域建模奠定基础。
事件风暴分为识别领域事件、识别命令、识别领域名词三个步骤。这一节课讲的是后面两个步骤。
“命令”是引发领域事件的操作,可以从领域事件“反推”出来。此外,还可以识别命令的两个附加信息,一个是发出命令的“执行者”,另一个是为了完成命令要查询出的数据。
“领域名词”是隐含在命令和领域事件中的名词性概念。这些名词是领域建模的素材,而对于这些素材的深入分析可以留到领域建模进行。
在这三个步骤中我们还看到,有一些遗留问题还没得到很好地处理。这是因为事件风暴的能力还不足以分析一些更加深入细致的问题,这些可以等到领域建模的时候再解决。也就是说,领域建模具有“兜底”的作用。
此外,我们在这一讲还讨论了事件风暴中各个要素的作用,也分析了几个实践中常见的问题,你可以再着重看一看。
思考题
最后,给你留两道思考题。
1.如果你以前学习过用例分析、用户故事等方法,那么比较一下,看它们和事件风暴各自有什么优缺点?
2.如果你自己的项目中,已经有捕获行为需求的方法,那么怎样借鉴事件风暴的思路,为现有的方法添加协作和统一语言的实践?
好,今天的课就结束了,有什么问题欢迎在评论区留言,下节课,我们一起实践DDD的核心部分——领域建模。
- escray 👍(5) 💬(2)
这里是四色建模法么? 识别领域事件:场景已创建、策略已创建、任务已创建、装备已选择、目标已标定、玩家已选定(红蓝白) 识别命令:创建场景、创建任务、选择目标、设置毁伤、创建装备、创建想定、创建兵力 识别领域名词:场景、任务、装备、模型、目标 对于思考题: 之前接触过用户故事,感觉用户故事可以把系统的功能串联在一起,更加场景化一些;而事件风暴感觉有点类似于头脑风暴的过程,相对发散一些。比较好的方法可能是先采用事件风暴发散,找到足够多的领域事件,然后使用用例分析或者用户故事将领域时间串联在一起。 如果借鉴事件风暴的思路,那么可能首先需要和业务人员同步一下对于业务中各个概念的定义,形成一个团队内部的术语表。曾经在业务讨论中,出现过多次业务术语不一致的情况。从这个角度来说,事件风暴其实也是一次很好的统一语言的方式。
2022-12-20 - 超斌hello 👍(42) 💬(4)
https://www.processon.com/view/link/639920d07d9c0866853d9d91 试验了一下,技术和业务都听得懂了
2022-12-14 - Jxin 👍(38) 💬(1)
1.用例和用户故事更独立细致,是垂直视角对需求的提炼。产物更详细,耗时更长; 事件风暴则比较像水平视角对需求的提炼,重心在快速了解核心业务,识别核心领域名词,粒度更粗,但广度更广,耗时相对短很多。主要也是为后续沟通的开展建立基础。 如果领域名词比较多,且关系复杂,就很有必要在项目前期做一轮事件风暴,拉齐基础认知。 2.事件风暴会去识别规则吗? 我一般不做,规则在后续,通过用户故事来补齐。主要是事件风暴时间线在前期,对规则容易陷入细节,不好把握会议节奏。所以更多的是仅串主流程,识别核心领域名词。 3.事件风暴仅罗列“主流程”吗?我一般不限制,因为在开事件风暴的时候,我脑子里的“主流程”大概率只是一厢情愿。我们都知道有隐式概念,隐式,表达的是知识归宿的特殊性。可能只有圈内人懂,可能只有那么几个人甚至一个人脑子里才有。隐式概念的显式化靠的是业务专家几年几十年的积累,而不是一场事件风暴。而一厢情愿的“主流程”容易漏掉这些关键概念,所以我一般是简单引导 + 不断追问是否有补充,尽量收集信息。后续自己过滤一遍,然后与专家再碰,达成一致。 4.记录事件风暴时,带命令和执行者吗? 我不带,一方面时间不够(时间问题可以通过工作坊形式的调整来满足),另一方面给自己做后续分析时埋思考的机会。只要事后补执行者和命令,就一定会有模糊的点,这些都是展开思考和后续沟通对齐的点。
2022-12-26 - Jaising 👍(5) 💬(3)
这样看来事件风暴抓准了企业软件开发中协作困难这个痛点,以事件为核心允许不同背景的利益相关方展开对话,并超越各自的专业背景界限,借助白板便利贴重视头脑风暴的可视化,尽可能让所有参与者充分咀嚼领域知识,从而深刻高效地挖掘与传递业务知识,形成业务全景图,减少信息孤岛等偏差存在,有效降低复杂软件的需求分析与传递成本。 做了个2000字小笔记,对事件风暴的粗浅认知:https://juejin.cn/post/7182111319967924282
2022-12-28 - 奇小易 👍(4) 💬(1)
2w2h笔记 why what 事件风暴步骤回顾 识别领域事件。 识别命令和角色以及相关查询数据。 识别领域名词。(从命令、角色、事件中提取对事件有影响的名词) 命令是什么? 产生业务结果的动作,可以从领域事件中倒推出来。 签订合同(命令)-> 合同已签订(领域事件) 角色是什么? 发起动作的对象就是所谓的角色。 例如:客户(角色) -> 签订合同(命令)-> 合同已签订(领域事件) 查询数据是什么? 要使角色完成动作所需要的最少必要数据。 例如:上述示例需要客户和合同信息才能完成。 事件风暴中不同元素在建模和实现层面都有什么作用? TODO 常见问题 第一个问题是,在事件风暴里是否要列出所有的领域事件和命令? 否,列出当前最为关注的内容。这一步关注的是全面,较为粗粒度的结果。 细化的部分放到后面进行。 第二个问题是,各个领域事件需要体现严格的时间顺序吗? 细节放在其它环节 第三个问题是,每个步骤的颗粒度应该有多大? 宜粗不宜细,保证每个步骤都在一个层次的粗粒度。 第四个问题是,事件风暴适用于所有项目吗? 它要解决的问题是需求与业务的一致等问题,只要需要解决这个问题,就可以用。 第五个问题是,怎么保存和维护事件风暴的结果? 1、如果需求管理有其它手段代替的话(用户故事、用例等),则可以把它当做临时结果。 2、如果没有的话,就持续维护它。 how Q: 识别命令和角色以及相关查询数据? A: 理解相关概念,然后用不同的便利贴来体现。 Q: 如何进行识别领域名词? 1、识别出角色、命令、查询数据、领域事件中的名词性概念。 2、把围绕同一名词的角色、命令、查询数据、领域事件放在一堆。 3、此时该名词已是领域名词。只需将其做个特殊标识,便于区分。 Q: 一个名词在事件和命令中都出现如何标识? 该名词后给个出现次数的数字即可。 how good --- 思考题: 1、如果你以前学习过用例分析、用户故事等方法,那么比较一下,看它们和事件风暴各自有什么优缺点? 两者实践不多,直观感受是事件风暴的文字量极少,图形展示比较直观。其它两种可能就对文字描述更为依赖。 2、如果你自己的项目中,已经有捕获行为需求的方法,那么怎样借鉴事件风暴的思路,为现有的方法添加协作和统一语言的实践? 统一语言的话,需求梳理过程中强调命名的统一,加个术语表。 协助过程优化TODO。
2023-02-08 - 郭嵩阳 👍(4) 💬(1)
事件风暴这些产物要体现在设计文档上吗?应该体现在哪部分?大部分场景下我们拿到的需求都是prd,这部分有些已经很明确了,还需要事件风暴吗
2022-12-18 - leesper 👍(3) 💬(2)
抓个虫,最后一幅图中 R001的“举例“和R005的举例重复了,应该体现不同项目之间分配投入时间比例不超过100% 我认为事件风暴建模法比传统方法更敏捷高效,强调协作,三下五除二就把主要业务流程建模出来了,不用一上来就陷入不必要细节,而且和领域驱动设计是天生一对
2022-12-13 - Dowen Liu 👍(2) 💬(1)
看了05、06领域建模又回来看这两讲事件风暴,重新理解了下,感觉事件风暴就是两个核心作用:对齐理解、统一语言。事件风暴对建模的帮助像是这两核心功能顺带的,而建模不必依赖事件风暴。
2023-11-02 - 夏 👍(2) 💬(1)
基本上一个领域事件只对应一个命令,写了命令就相当于写了事件,把事件和命令都写出来,不是很啰嗦吗?
2023-07-09 - aoe 👍(0) 💬(1)
DDD 寻找「领域名词」的过程 ====== 1. 通过头脑风暴,找出「领域事件」 2. 由「领域事件」推导出「命令」 3. 从「领域事件」、「命令」、「查询数据」里找到共同的名词,这些名词就是「领域名词」 名词解释 ====== 领域事件:业务中已经发生的重要事件,是业务方必须关心的,对业务流程有重大影响,发生后会改变系统数据。例如用户已注册、商品已下单。领域事件应该具备原子性,方便解耦、异步处理、追踪审计。查询功能不算领域事件。 命令:引发领域事件的操作,我们可以通过分析领域事件得到。除了识别出命令本身以外,我们通常还要识别出谁执行的命令,以及为了执行命令我们要查询出什么数据。例如用户注册、用户下单(需要查询出商品信息)。命令是对领域事件的描述,是对领域事件的触发。 第三次学习
2024-04-12 - Spoon 👍(0) 💬(1)
1.用例分析感觉颗粒度比较大,并不能很好的提取出领域事件、领域模型,会比较粗粒度的从用户交互出发;用户故事这个没有用过 2.统一语言应该是业务、产品、开发对齐一致的结果,从需求梳理到最后一致的表达,刻画在模型上
2024-02-05 - 傲慢与偏见 👍(0) 💬(1)
老师,比如 认证流 流程中,有三种类型 公司+法人,公司+代理人,个人。 这三种类型后续认证动作不一样。(比如法人只需要短信,代理人需要授权书、回款金额,个人只需要提交资料即可) 我们可以按流程类型分组排列命令吗?
2023-12-28 - 黑夜看星星 👍(0) 💬(2)
老师,比如有个情况 帧号计算,执行者系统,查询数据包括GPS时间,TOD时间,涉及操作硬件psync和pll ,那么这些都算上?
2023-11-19 - 末日,成欢 👍(0) 💬(1)
老师,想要咨询一个问题, 对查询数据/业务规则这里还有点困惑 对于命令来说,可能就是对应的一个API,拿购买商品命令举例 对于查询数据这里, 可能这个领域逻辑需要很多种类的数据,比如【商品信息,活动信息,优惠券信息】 如果还要根据查询出来的商品数据里的一些数据,比如说商品SKU等其他信息, 还要做其他数据的查询, 图里【查询数据】这里就会表示的很多, 或者是业务规则很多的话, 如果一一识别的话, 就感觉过了一遍详细用例,但是感觉不过的话,就怕会遗漏一些场景, 对领域知识理解的不够。 现在的困惑就是我有一个业务流程 业务规则很多, 依赖的数据种类也很多, 有点无从下手。 这是我画的事件风暴,老师可以看下说下问题所在https://www.processon.com/view/link/64ef4046db6e4c759267f88f
2023-08-30 - aoe 👍(0) 💬(1)
第二次学习「事件风暴」,关于「识别领域名词」,按自己的理解整理了一下: 第一步:把围绕同一个名词(相同/相关名词)的「领域事件」放在一起,按「名词」分组 第二步:将「领域事件」对应的「命令」、「查询数据」加入分组 第三步:将「领域名词」加入分组 详见 https://wyyl1.com/post/23/07/
2023-07-25