你好,我是轩脉刃。
在专栏中,我们一起开发了一款名为Hade的Golang HTTP框架。Hade框架旨在为开发者提供一个高效、灵活且易于使用的开发工具,帮助他们更快速地构建高性能的Web应用。
在过去的两年间,我不断完善Hade框架,持续引入新的功能和特性。这些改进不仅提升了框架的性能和稳定性,还极大地扩展了其应用场景。
今天,我想借此机会,向你详细介绍一下Hade框架的改进,以及新增的主要特性和功能。
提供安全的 Go 封装
在业务代码开发过程中,我们经常使用goroutine关键字来创建一个协程执行一段业务,甚至开启多个goroutine并行执行多个业务逻辑。但是在实际开发过程中,很容易出现新启动的goroutine忘记捕获panic错误,而导致整个进程挂掉的情况。
所以,我为Hade框架增加了2个方法:goroutine.SafeGo和goroutine.SafeGoAndWait。
SafeGo
SafeGo这个函数是一个安全的goroutine启动函数,主要用于包装普通的goroutine,增加了错误恢复(panic recovery)和日志记录功能。它主要适用于业务中需要开启异步goroutine业务逻辑调用的场景。
// SafeGo 进行安全的goroutine调用
// 第一个参数是context接口,如果还实现了Container接口,且绑定了日志服务,则使用日志服务
// 第二个参数是匿名函数handler, 进行最终的业务逻辑
// SafeGo 函数并不会返回error,panic都会进入hade的日志服务
func SafeGo(ctx context.Context, handler func())
它的使用场景参考如下代码:
func TestSafeGo(t *testing.T) {
container := tests.InitBaseContainer()
container.Bind(&log.HadeTestingLogProvider{})
ctx, _ := gin.CreateTestContext(httptest.NewRecorder())
goroutine.SafeGo(ctx, func() {
time.Sleep(1 * time.Second)
return
})
t.Log("safe go main start")
time.Sleep(2 * time.Second)
t.Log("safe go main end")
goroutine.SafeGo(ctx, func() {
time.Sleep(1 * time.Second)
panic("safe go test panic")
})
t.Log("safe go2 main start")
time.Sleep(2 * time.Second)
t.Log("safe go2 main end")
}
SafeGoAndWait
SafeGoAndWait函数的名称暗示了它的主要功能:安全地执行多个goroutine并等待它们全部完成。
这个函数在需要并行处理多个任务,同时又需要等待所有任务完成并获取执行结果的场景下特别有用,它提供了一个安全、可靠的并发处理方案。
// SafeGoAndWait 进行并发安全并行调用
// 第一个参数是context接口,如果还实现了Container接口,且绑定了日志服务,则使用日志服务
// 第二个参数是匿名函数handlers数组, 进行最终的业务逻辑
// 返回handlers中任何一个错误(如果handlers中有业务逻辑返回错误)
func SafeGoAndWait(ctx context.Context, handlers ...func() error) error
它的使用方式如下:
func TestSafeGoAndWait(t *testing.T) {
container := tests.InitBaseContainer()
container.Bind(&log.HadeTestingLogProvider{})
errStr := "safe go test error"
t.Log("safe go and wait start", time.Now().String())
ctx, _ := gin.CreateTestContext(httptest.NewRecorder())
err := goroutine.SafeGoAndWait(ctx, func() error {
time.Sleep(1 * time.Second)
return errors.New(errStr)
}, func() error {
time.Sleep(2 * time.Second)
return nil
}, func() error {
time.Sleep(3 * time.Second)
return nil
})
t.Log("safe go and wait end", time.Now().String())
if err == nil {
t.Error("err not be nil")
} else if err.Error() != errStr {
t.Error("err content not same")
}
// panic error
err = goroutine.SafeGoAndWait(ctx, func() error {
time.Sleep(1 * time.Second)
return errors.New(errStr)
}, func() error {
time.Sleep(2 * time.Second)
panic("test2")
}, func() error {
time.Sleep(3 * time.Second)
return nil
})
if err == nil {
t.Error("err not be nil")
} else if err.Error() != errStr {
t.Error("err content not same")
}
}
通过这段代码,我们可以看到goroutine.SafeGoAndWait的使用方式:它接受多个并发任务函数,并在所有任务完成后返回第一个发生的错误。如果某个任务触发panic,也会被捕获并返回为错误。
数据库表自动生成 model 和 api 代码命令
在Web开发中,我们大多数时间都在与数据库进行交互。通常,我们会根据数据库表结构生成相应的模型代码和API代码。然而,我们发现大部分情况下,这些工作都是在重复生成类似的模型和API代码。实际上,这些模型和API代码是有一定模式和套路的。因此,如果有一个命令能够根据数据表自动生成模型代码和API代码,将会大大节省我们的时间。
这正是“model”系列命令的初衷。
命令展示
./hade model由3个命令组成:
- ./hade model api通过数据表自动生成api代码
- ./hade model gen通过数据表自动生成model代码
- ./hade model test测试某个数据库是否可以连接
下面我一一描述这些命令的作用。
首先是./hade model test。当你想测试某个配置好的数据库是否能连接上,都有哪些表的时候,这个命令能帮助你。
其次是./hade model gen,这个命令帮助你生成数据表对应的gorm的model。
> ./hade model gen
Error: required flag(s) "output" not set
Usage:
hade model gen [flags]
Flags:
-d, --database string 模型连接的数据库 (default "database.default")
-h, --help help for gen
-o, --output string 模型输出地址
其中接受两个参数:
- database这个参数可选,用来表示模型连接的数据库配置地址。默认是database.default,表示config目录下的{env}目录下的database.yaml中的default配置。
- output这个参数必填,用来表示模型文件的输出地址。如果填写相对路径,系统会在前面填充当前执行路径,将其补充为绝对路径。
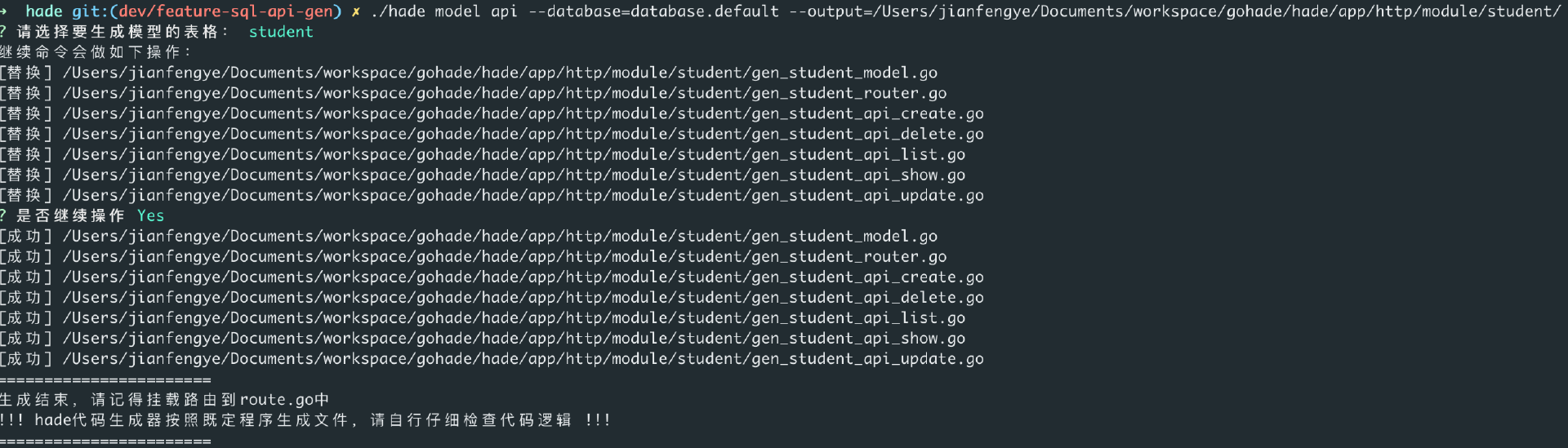
最后是./hade model api命令。
> ./hade model api
--database=database.default
--output=/Users/jianfengye/Documents/workspace/gohade/hade/app/http/module/student/
它的参数和./hade model gen类似,接受database和output参数,最终能生成包含增删改查的5个api接口(查分为查单个和查多个)。
原理说明
接下来,我们详细说一下最复杂的 model API 命令的具体实现原理,其他命令的实现你可以阅读Hade框架源码。
首先,我们明确一下目标:已知一个数据表,生成相应的 API 代码。就像将大象放进冰箱需要三步,我们实现这个目标也需要三步:
- 理解数据表,解析其中的每个字段,并将其存储在命令中的一个Go内存结构中。
- 使用这个内存结构生成一段Go代码。
- 将这个逻辑封装为一个命令。
下面,我们逐一详细说明。
怎么获取一个表的所有字段
我们可以用gorm获取一个表的所有字段到一个map[string]string中,具体使用的SQL语句是:SHOW COLUMNS FROM student。
然后,我们可以使用GORM的Raw方法和Scan方法,将SHOW COLUMNS FROM语句查询到的结果解析为一个map类型。具体的代码如下:
// 定义一个用于存储字段名和字段类型的结构体
type Column struct {
Field string `gorm:"column:Field"`
Type string `gorm:"column:Type"`
}
// 定义一个map类型,用于存储字段名和字段类型
columns := make(map[string]string)
// 执行原始的SQL语句
rows, err := db.Raw("SHOW COLUMNS FROM student").Rows()
if err != nil {
// 处理错误
}
// 逐行解析查询结果
for rows.Next() {
var column Column
if err := db.ScanRows(rows, &column); err != nil {
// 处理错误
}
columns[column.Field] = column.Type
}
// 输出结果
fmt.Println(columns)
在上述代码中,首先定义了一个结构体Column,用于存储每个字段的名称和类型。接着定义了一个map[string]string类型的变量columns,用于存储所有字段的名称和类型。
然后,使用Raw方法执行原始的SQL语句SHOW COLUMNS FROM student,并通过Rows方法获取查询结果的行数据。对于每一行数据,使用ScanRows方法将其解析为一个Column结构体,再将结构体中的Field字段作为columns的键,Type字段作为columns的值,存储到columns变量中。
最后,输出columns变量的内容,即可得到包含所有字段名称和类型的Map。注意,在使用完查询结果之后,需要及时关闭rows,避免资源泄露。我们可以在循环结束后,通过调用rows.Close()来关闭rows。
上述代码中的columns是一个map[string]string类型的变量,用于存储所有字段的名称和类型。它的输出结果类似下面这样:
输出结果中的map表示这是一个Map类型的变量,而id、name、age和class_id则是这个map中的键,它们的值分别是uint和string类型,表示对应字段的数据类型。注意,输出结果中各个键值对的顺序可能会因为内部实现原因而不同。
尝试了一下确实可行,但是在Hade中一切皆接口,于是我修改了之前orm的接口协议。
type TableColumn struct {
Field string `gorm:"column:Field"`
Type string `gorm:"column:Type"`
Null string `gorm:"column:Null"`
Key string `gorm:"column:key"`
Default string `gorm:"column:Default"`
Extra string `gorm:"column:Extra"`
}
// ORMService 表示传入的参数
type ORMService interface {
// GetDB 获取某个db
GetDB(option ...DBOption) (*gorm.DB, error)
// CanConnect 是否可以连接
CanConnect(ctx context.Context, db *gorm.DB) (bool, error)
// Table 相关
GetTables(ctx context.Context, db *gorm.DB) ([]string, error)
HasTable(ctx context.Context, db *gorm.DB, table string) (bool, error)
GetTableColumns(ctx context.Context, db *gorm.DB, table string) ([]TableColumn, error)
}
增加了如下命令:
- CanConnect:用ping方法测试数据库是否可连接
- GetTables:获取一个DB的所有表格
- HasTable:判断一个表名是否存在这个DB中
- GetTableColumns:获取一个表的所有字段
它们的实现原理其实很简单:
- CanConnect本质是使用ping命令。
- GetTables是使用SQL语句“SELECT TABLE_NAME FROM information_schema.tables”。
- HasTable就是在GetTables取回的所有表名中查找是否有目标表名。
- GetTableColumns是使用SQL语句“SHOW COLUMNS FROM TABLE”。
怎么用Go生成一段Go代码
一般来说,用Go生成Go代码有三种方式。
首先,可以使用text/template或html/template库。这两个库可以根据模板生成代码。模板中包含占位符,可以在运行时将占位符替换成具体的值,从而生成代码。使用模板生成代码比较方便,但需要学习模板语法。
其次,可以使用代码生成工具。Go中有一些代码生成工具,比如go generate、go tool yacc、go tool cgo等,这些工具可以根据特定的规则自动生成代码。这种方式比较高效,但需要熟悉工具的使用方法和规则。
最后,可以使用代码生成库。Go中有一些代码生成库,比如go/ast、github.com/dave/jennifer、github.com/gobuffalo/flect等,这些库可以根据Go语法树或其他方式生成代码。这种方式比较灵活,可以直接生成Go代码,不需要使用模板或手动拼接字符串。
之前Hade也使用过第一种方式,即通过模板生成代码,但后来发现这种方式并不优雅。因为这种方式不够灵活,比如在定义一个包含很多字段的Go数据结构时,只能通过拼接字符串来完成。
对于第二种方式,我经过调研后发现需要附带很多工具,更适合在编译期添加某些代码的场景。因此,我决定使用第三种方式来实现自动生成 API 的功能。
实际上,第三种方式也有很多库可供选择。我尝试了一下Go原生的ast库和jennifer库,发现它们都比较麻烦。即使是生成一段只有几行的Go代码,也需要写出类似下面这样复杂的代码:
jen.Id("logger").Op(":=").Id("c").Dot("MustMakeLog").Call(),
jen.Var().Id(table).Qual("", tableModel),
jen.If(
jen.Err().Op(":=").Id("c").Dot("BindJSON").Call(jen.Op("&").Id(table)),
jen.Err().Op("!=").Nil(),
).Block(
jen.Id("c").Dot("JSON").Call(jen.Lit(400), jen.Op("&").Qual("github.com/gohade/hade/framework/gin", "H").Values(jen.Dict{
jen.Lit("code"): jen.Lit("Invalid parameter"),
})),
jen.Return(),
),
jen.Var().Id("db").Op("*").Qual("gorm.io/gorm", "DB"),
jen.Var().Err().Error(),
因此,尽管之前进行了调研,但这个功能一直没有动手实现。直到最近GPT变得非常流行,我才想到,是否可以将一段代码交给GPT,让它使用某个库来实现这个功能。
于是,我先编写了一段接口代码,然后使用以下提示输入到GPT中:
请使用github.com/dave/jennifer 库来写一段代码,能产出下列文本代码:
func (api *StudentApi) Create(c *gin.Context) {
logger := c.MustMakeLog()
// 绑定JSON数据到student结构体中
var student StudentModel
if err := c.BindJSON(&student); err != nil {
c.JSON(400, gin.H{"error": "Invalid JSON"})
return
}
// 初始化一个orm.DB
gormService := c.MustMake(contract.ORMKey).(contract.ORMService)
db, err := gormService.GetDB(orm.WithConfigPath("database.default"))
if err != nil {
logger.Error(c, err.Error(), nil)
_ = c.AbortWithError(50001, err)
return
}
// 向数据库中添加新的学生模型
if err := db.Create(&student).Error; err != nil {
c.JSON(500, gin.H{"error": "Server error"})
return
}
// 返回新创建的学生模型
c.JSON(200, student)
}
这样,GPT就把最繁琐又重复的部分给我生成出来了。按照这个思路,我把delete/list/show/update/model/router都用这种方式实现。
其中每个接口具体的GPT的实现逻辑你都可以在Hade的GitHub项目中找到源码,如果你有兴趣可以点击过去看看。
当然,在这个过程中,GPT生成的代码并不是0 Bug的,也需要人工一个个语句确认,不过AI已经节省了我不少的工作量。
现在,最繁琐的工作在GPT的帮助下,就这样快乐地完成了。
命令编写
有了数据表的读取能力,也有了GO代码自动生成能力,后续写命令的逻辑其实就是粘合的工作了。为了易用性,整个命令还是设计为交互式。
第一步,自动检测配置的数据库是否有错误。如果没有错误,弹出数据库的所有表,让用户主动选择一个表。第二步,告知用户会做如下操作。这个操作列表要展示出来,是会新建一个文件还是替换原有的问题。第三步,就是真正去生成文件了。最终的效果如图所示:
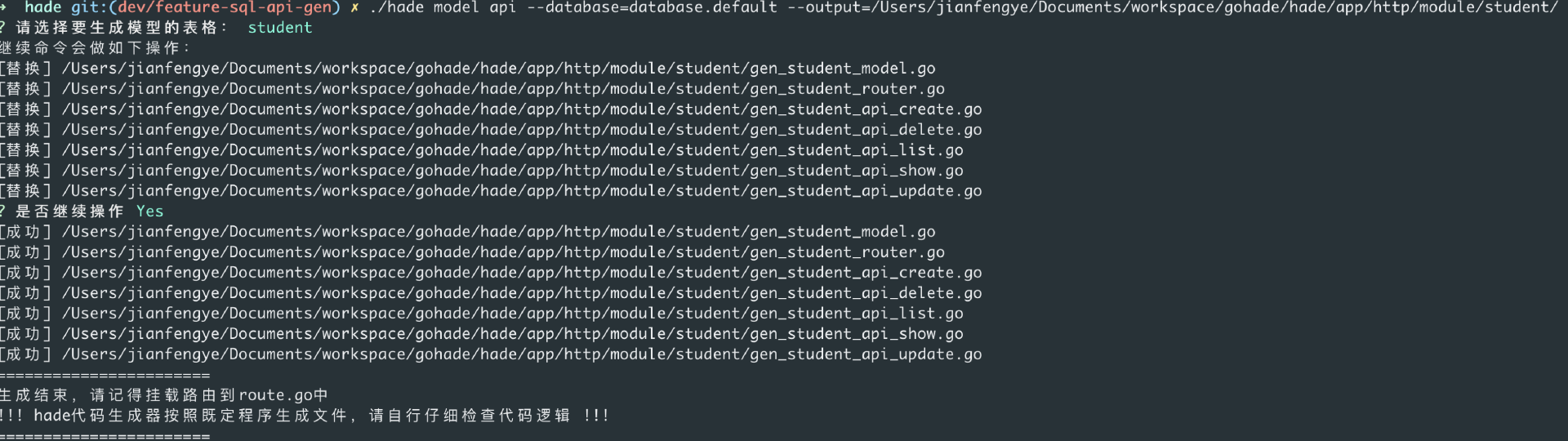
至此,我们就完成了model api的编写。
gRPC 的支持
除了上述功能,我们还在 Hade 框架中增加了对gRPC(Google Remote Procedure Call)的支持。gRPC是一个高性能且开源的远程过程调用(RPC)框架,广泛用于构建分布式系统和微服务架构。随着微服务架构的普及,服务间通信变得越来越重要。相比传统的 HTTP/REST 接口,gRPC 带来了许多令人兴奋的优势。
首先是其出色的性能表现。gRPC 采用了 Protocol Buffers 这种轻量级的数据序列化方式,比传统的 JSON 更加高效。再加上它基于 HTTP/2 协议,实现了多路复用和二进制传输,使得通信效率得到了显著提升。
其次,gRPC 在开发体验上也非常友好。通过编写 .proto 文件来定义服务接口,可以自动生成客户端和服务端的代码,避免了大量重复性的手工编码工作,从而大大提升了开发效率。
基于这些优势,我们在 Hade 框架中集成了 gRPC 功能,使开发者能够更轻松地构建高性能的微服务应用。
总的来说,Hade 框架依赖于 gRPC 的 Go 语言官方实现库 google.golang.org/grpc,并提供了以下命令行工具:
- hade grpc start是启动gRPC服务
- hade grpc stop是停止gRPC服务
- hade grpc restart是重启gRPC服务
- hade grpc state是查看gRPC服务状态
下面,我将结合一个例子,为你展示这些命令的使用。
命令展示
我们用Hade创建一个gRPC服务,步骤如下:
- 创建proto文件
- 生成Go文件
- 创建服务
- 注册服务
- 启动服务
下面,我们展开来讲。
首先,我们在项目的app/grpc/proto/目录下创建一个proto文件,例如:proto/helloworld.proto,内容如下:
syntax = "proto3";
option go_package = "examples/helloworld";
option java_multiple_files = true;
option java_package = "io.grpc.examples.helloworld";
option java_outer_classname = "HelloWorldProto";
package helloworld;
// The greeting service definition.
service Greeter {
// Sends a greeting
rpc SayHello (HelloRequest) returns (HelloReply) {}
}
// The request message containing the user's name.
message HelloRequest {
string name = 1;
}
// The response message containing the greetings
message HelloReply {
string message = 1;
}
这一个proto就是标准的proto3的gRPC语法。
然后,我们使用gRPC官网提供的proto工具生成对应的Go文件。关于proto工具的使用,网上有很多文章了,所以这里就简要列下Mac端的安装命令。
brew install protobuf
go install google.golang.org/protobuf/cmd/protoc-gen-go
go install google.golang.org/grpc/cmd/protoc-gen-go-grpc
生成Go文件的命令如下:
我们可以看到,在目录app/grpc/proto/下生成了文件:
接着,我们要实现proto文件中定义的这个服务:helloworld.GreeterServer。在app/grpc/service/目录下创建一个文件:app/grpc/service/helloworld/service.go,内容如下:
package helloworld
import (
"context"
"log"
pb "github.com/gohade/hade/app/grpc/proto/examples/helloworld"
)
// Server is used to implement helloworld.GreeterServer.
type Server struct {
pb.UnimplementedGreeterServer
}
// SayHello implements helloworld.GreeterServer
func (s *Server) SayHello(ctx context.Context, in *pb.HelloRequest) (*pb.HelloReply, error) {
log.Printf("Received: %v", in.GetName())
return &pb.HelloReply{Message: "Hello " + in.GetName()}, nil
}
下一步就是在app/grpc/kernel.go文件中注册服务:
package grpc
import (
helloworldgen "github.com/gohade/hade/app/grpc/proto/examples/helloworld"
"github.com/gohade/hade/app/grpc/service/helloworld"
"github.com/gohade/hade/framework"
pkggrpc "google.golang.org/grpc"
"google.golang.org/grpc/reflection"
)
// NewGrpcEngine 创建了一个绑定了路由的Web引擎
func NewGrpcEngine(container framework.Container) (*pkggrpc.Server, error) {
s := pkggrpc.NewServer()
// 这里进行服务注册
helloworldgen.RegisterGreeterServer(s, &helloworld.Server{})
reflection.Register(s)
return s, nil
}
这里我们不仅注册了服务,还注册了反射服务,这样就可以使用grpcurl工具来测试我们的gRPC服务了。
最后,我们编译自身项目hade build self,在项目根目录下执行命令:hade grpc start,启动gRPC服务。
➜ hade git:(dev/feature-grpc) ✗ ./hade grpc start
成功启动进程: hade grpc
进程pid: 96290
监听地址: grpc://localhost:8888
基础路径: /Users/jianfengye/Documents/workspace/gohade/hade/
日志路径: /Users/jianfengye/Documents/workspace/gohade/hade/storage/log
运行路径: /Users/jianfengye/Documents/workspace/gohade/hade/storage/runtime
配置路径: /Users/jianfengye/Documents/workspace/gohade/hade/config
你也可以通过命令hade grpc start -d启动服务,这样服务会在后台运行。默认端口是8888,你可以通过命令行参数 --address来指定端口。
hade git:(dev/feature-grpc) ✗ ./hade grpc start --address=:8777 -d
成功启动进程: hade grpc
进程pid: 97685
监听地址: grpc://localhost:8777
基础路径: /Users/jianfengye/Documents/workspace/gohade/hade/
日志路径: /Users/jianfengye/Documents/workspace/gohade/hade/storage/log
运行路径: /Users/jianfengye/Documents/workspace/gohade/hade/storage/runtime
配置路径: /Users/jianfengye/Documents/workspace/gohade/hade/config
如果你还想了解更多关于gRPC的操作,可以参考Hade的官网,这里就不继续展开了。
原理说明
我们知道,gRPC的底层协议主要基于HTTP/2和Protocol Buffers(Protobuf),和我们专栏中描述的实现HTTP协议服务的逻辑类似。
现在,我们要实现gRPC服务器,并不需要从TCP底层开始实现gRPC的解析,因为Google封装的google.golang.org/grpc已经实现了底层协议的封装。我们要做的就是将这个包融合进Hade框架。
首先,使用gRPC库来启动一个服务器,最核心的代码其实就下面两行:
以上代码主要是用来创建一个服务器对象,再启动服务器。而创建服务器对象的步骤,我们可以放到main函数中。
func main() {
// 初始化服务容器
container := framework.NewHadeContainer()
...
if engine, err := grpc.NewGrpcEngine(container); err == nil {
kernelProvider.GrpcEngine = engine
}
_ = container.Bind(kernelProvider)
...
}
对应的 NewGrpcEngine 的方法实现如下:
// NewGrpcEngine 创建了一个绑定了路由的Web引擎
func NewGrpcEngine(container framework.Container) (*pkggrpc.Server, error) {
s := pkggrpc.NewServer()
// 这里进行服务注册
helloworldgen.RegisterGreeterServer(s, &helloworld.Server{})
reflection.Register(s)
return s, nil
}
在main函数中,我们将gRPC生成的服务器对象称为GrpcEngine,并存储在kernelProvider这个服务提供者中。如果你不记得provider在Hade框架中的含义,可以回顾专栏第10节和第11节。
注意,和HTTP服务不同的是,在创建gRPC的服务对象时,我们要将我们的业务服务,即gRPC工具生成的Go代码注册进入,也就是helloworldgen.RegisterGreeterServer这行代码的含义。
那么接下来我们在哪里调用呢?代码如下:
然后,我们可以在./hade grpc start 的命令中真正启动服务。
我们定义了一个gRPC二级命令, 以及start、state、stop和restart这四个三级命令。具体的命令行实现还比较繁琐,我们这里也不追溯了,可以参考专栏第13节。
在这几个命令中,最重要的就是启动start命令,它最重要的是调用了如下函数:
// 启动AppServer, 这个函数会将当前goroutine阻塞
func startAppServe(ctx context.Context, server *grpc.Server, lis net.Listener, c framework.Container) error {
logger := c.MustMake(contract.LogKey).(contract.Log)
// 这个goroutine是启动服务的goroutine
goroutine.SafeGo(ctx, func() {
if err := server.Serve(lis); err != nil {
logger.Error(ctx, "grpc serve error", map[string]interface{}{
"error": err.Error(),
})
}
})
// 当前的goroutine等待信号量
quit := make(chan os.Signal)
// 监控信号:SIGINT, SIGTERM, SIGQUIT
signal.Notify(quit, syscall.SIGINT, syscall.SIGTERM, syscall.SIGQUIT)
// 这里会阻塞当前goroutine等待信号
<-quit
configService := c.MustMake(contract.ConfigKey).(contract.Config)
// 默认是grace stop
forceStop := false
// 调用Server.Shutdown graceful结束
if configService.IsExist("grpc.force_stop") {
forceStop = configService.GetBool("grpc.force_stop")
}
if forceStop {
server.Stop()
} else {
server.GracefulStop()
}
return nil
}
这里,我们使用上了最开始讲的goroutine.SafeGo封装函数,通过它在一个goroutine中调用 server.Serve(lis)。然后在主线程中使用signal.Notify来监听信号量,并且阻塞主线程。
当监听到结束的信号量时,我们在主线程中调用server.Stop() 或者 server.GracefulStop() 就能结束goroutine.SafeGo 中调用的gRPC服务了。
至此,Hade框架对于gRPC服务的融合就完成了。
总结
这一节我们详细介绍了Hade框架的三个重要进展。
首先是goroutine的安全管理机制,通过SafeGo封装函数优雅地处理了panic的情况,使得程序更加健壮和可靠。这种设计不仅提高了系统的稳定性,还为开发者提供了更好的错误追踪能力。
其次是根据数据表自动生成model代码和api接口代码,这个功能的使用和原理。这个功能极大地提高了开发效率,通过简单的命令,就能根据数据库表结构自动生成标准的model层代码和对应的 API 接口。
最后,我们详细阐述了如何将gRPC服务优雅地集成到Hade框架中。通过精心设计的服务启动和关闭机制,结合信号处理和优雅退出策略,确保了gRPC服务能够稳定可靠地运行在Had 框架之上。
这些进展充分展示了Hade框架在不断演进和完善的过程中,始终注重实用性、可靠性和开发体验。通过这些改进,Hade框架正在成为一个更加成熟和强大的Go语言开发框架。
好了,今天的内容就到这里,如果你觉得有收获,也欢迎你把它分享给身边的朋友,我们下一节见。