4个示例,带你理解Golang代码最佳实践
你好,我是轩脉刃。
很多同学都有这样的困惑:为什么我用了框架,还是写不好业务代码?
其实,框架只是搭建了一个架构,它只能解决一项业务至多 20% 的问题,剩下 80% 的内容需要你在业务中填充业务代码,以此来实现各种各样的功能。而每个人又都有自己的编码风格和开发思路,所以就会有“写得好”和“写得不好”的区别了。
那么是否存在一种最佳实践,可以让所有人统一 Golang 代码的编写风格和思路呢?其实是有的,过去 2 年,我就一直在做这项工作。我不仅为部门制定了一套 Golang 代码最佳实践,还参与了公司级别的代码最佳实践的编写工作。我发现,代码最佳实践并不只是一项项的代码规范,用来教我们怎么写代码。更重要的是,它告诉了我们如何避免编写错误的代码,即在我们的脑海中建立起对错误代码清晰的认知。
所以今天,我不想重复列出 Golang 代码最佳实践的所有规范,而是会为你展示错误代码示例,它们都是 Golang 编码中最容易犯的,并且在演示完代码后,我会为你详细讲解代码中不符合最佳实践的地方,帮助你彻底掌握。
因此,希望你在看到错误代码时,先别急着下拉,而是能多留一些思考的时间,看看自己是否能发现这些问题。
示例一:获取单个用户数据
下面是第一个错误代码示例:
func (s *LayoutService) ListLayout() (layouts []*db.Layout, total int64, err error) {
// 初始化返回值
layouts = make([]*db.Layout, 0)
// 获取 layout 列表
whereClause := fmt.Sprintf("uid = %v and corp_id = %v", s.uid, s.corpId)
if err := s.orm.Model(&db.Layout{}).Where(whereClause).Order("updated_at desc").Find(&layouts).Error; err != nil {
return nil, 0, err
}
// 获取 layout 总数
if err := s.orm.Model(&db.Layout{}).Where(whereClause).
Count(&total).Error; err != nil {
return nil, 0, err
}
return layouts, total, nil
}
这段代码逻辑非常简单,我们要去数据库中进行 db.Layout 的查询,查询出对象数据 Layouts 并且返回总共有多少条数据。函数代码仅有短短 18 行,却有 5 处不符合最佳实践的 Golang 代码错误,你能看出来吗?
第一处,也是最明显的问题:函数最核心的数据库查询操作是使用字符串拼接的方式,而不是使用数据库预处理方式来调用。
这种拼接 SQL 的方式会带来以下问题:
- SQL 注入攻击风险,攻击者可以通过构造特殊的输入值(如 1 OR 1=1)绕过 WHERE 条件限制。
- 性能问题,无法利用数据库的查询计划缓存,在高并发场景下会显著增加数据库负载。
- 维护性问题,代码更容易出现 Bug。
因此,正确做法是使用预处理方式来做 SQL 查询:
// 使用参数化查询
if err := s.orm.Model(&db.Layout{}).
Where("uid = ? and corp_id = ?", s.uid, s.corpId).
Order("updated_at desc").
Find(&layouts).Error; err != nil {
return nil, 0, err
}
第二处, err 未包装直接返回。在 Golang 中直接返回底层函数的原始错误而不进行包装会带来以下问题:
- 错误信息的上下文丢失。比如,我们调用这个函数的外层代码,就无法知道是由于列表查询失败,还是获取总数的查询失败而导致这个函数失败。
- 错误处理不灵活。由于上下文信息丢失,因此我们调用这个函数的外层代码,是无法仅对获取总数查询失败进行降级处理的。
- 存在安全风险,会将底层错误,特别是数据库类型错误暴露出去,让敏感信息泄露到错误消息中,继而让攻击者有机可乘。
正确做法是使用 fmt.Errorf 或者 github.com/pkg/errors 库(这个库在我们的专栏第 34 章也提到过)进行错误封装。
import github.com/pkg/errors
...
if err := s.orm.Model(&db.Layout{}).Where("uid = ? and corp_id = ?", s.uid, s.corpId).Order("updated_at desc").Find(&layouts).Error; err != nil {
return nil, 0, errors.Wrap(err, "list layout failed")
}
...
第三处的问题就比较隐蔽了,没有使用Context 进行统一的超时限制。
Golang 官方推荐每个函数的第一个参数都是 Context,这不仅仅是为了能从上游传递 trace 等信息,更重要的是为全链路超时提供可能。
在实际生产项目中,我们目前使用的基本都是微服务架构,这个架构对用户请求的超时必须是链路级别的控制。我们结合下图一起来理解。用户请求进入服务 A,服务 A 承诺用户 1s 超时处理,那么不仅仅是服务 A,服务 A 的调用下游也必须遵循这个超时承诺,并且随着调用链路,下游服务的超时设置会比上一级递减。假设,A 自身处理了 200ms,那么 B 服务的超时时间为 1s - 200ms = 800ms, B 自身处理需要 500ms,那么留给 B 的下游 C 服务的超时时间为 800ms - 500ms = 300ms,Golang 是通过 Context 来传递全链路逐级递减的超时信息的。
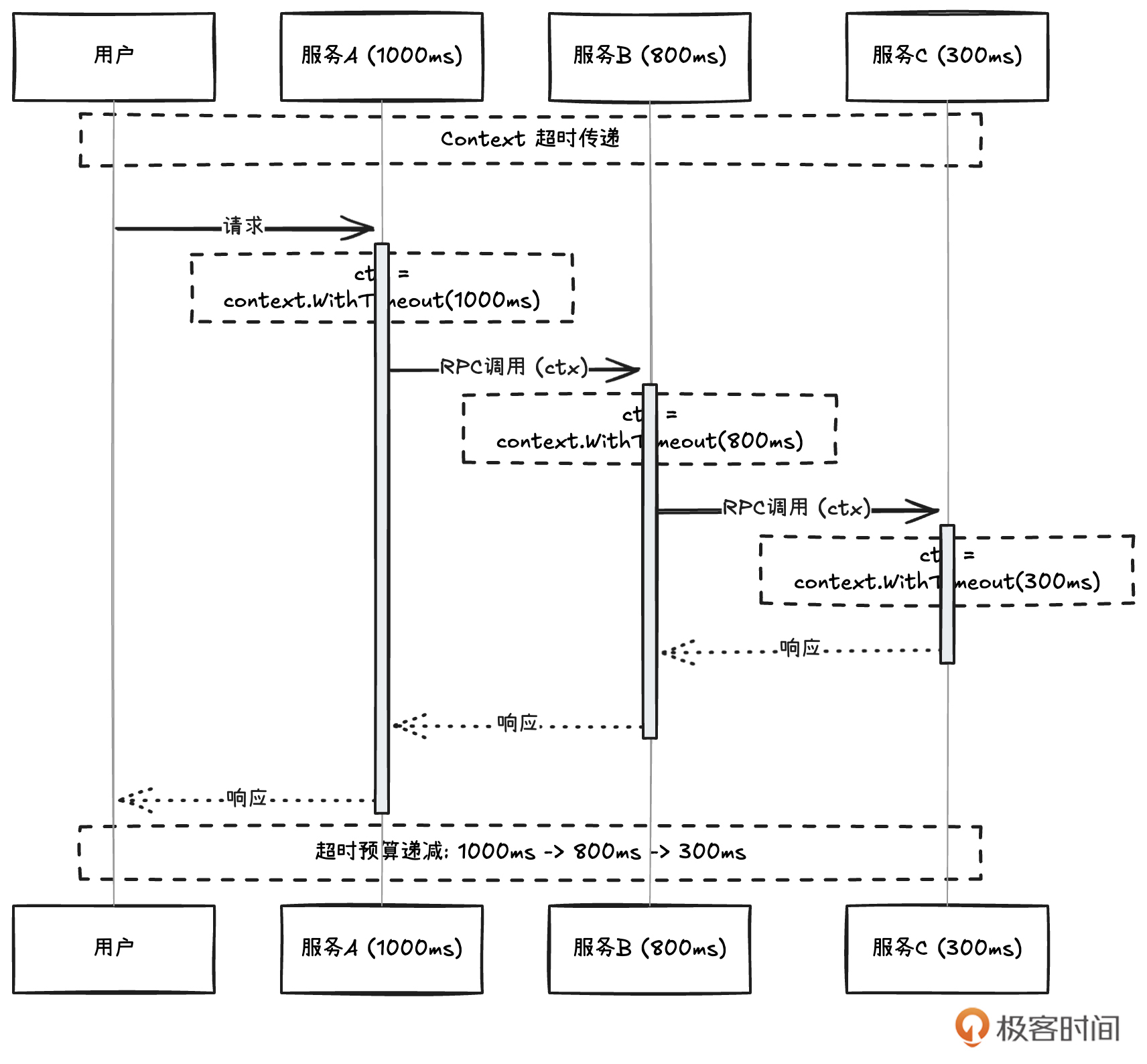
对于数据库操作来说,更是如此。如果没有传递 Context 给数据库操作,那这次数据库请求就是无超时控制的,有可能出现无限等待(当然这里依赖数据库侧的配置)。这也就意味着 goroutine 资源未及时释放,会出现占用资源的情况。在高并发场景下,这就代表着连接数占用,最终可能导致服务不可用。
因此,Golang 代码的最佳实践必须遵从以下规则:
- 所有函数第一个参数都是 Context
- 所有下层调用都必须传递 Context
那么,示例代码需要按下面这样去纠正:
func (s *LayoutService) ListLayout(ctx context.Context) (layouts []*db.Layout, total int64, err error) {
...
// 获取 layout 列表
whereClause := fmt.Sprintf("uid = %v and corp_id = %v", s.uid, s.corpId)
if err := s.orm.WithContext(ctx).Model(&db.Layout{}).Where(whereClause).Order("updated_at desc").Find(&layouts).Error; err != nil {
return nil, 0, err
}
...
第四处的问题更隐蔽,SQL查询没有进行分页设计。
我们在获取 Layout 结构列表时,是直接将满足 uid 和 corp_id 的 Layout 数据全部返回。那么随着业务发展,会不会出现某个 uid 和 corp_id 的 Layout 数据非常多呢?多到这个请求必然出现超时情况?
这并不是臆想,也不是过度设计。我们在实际开发中,由于这种原因导致的开发返工的例子很多。比如,开发同学第一版本开发时,以数据不多、无需分页查询为由进行全量查询,随着业务发展,全量查询出现了超时问题,某个重要用户反馈超时错误,进而加班加点返工修复。
这都是设计的缺陷,在开发最初我们就必须要考虑到如何避免全量查询。
func (s *LayoutService) ListLayout(ctx context.Context, offset, limit int64) (layouts []*db.Layout,
total int64, err error) {
// 查询数据
...
if err := s.orm.WithContext(ctx).Model(&db.Layout{}).Where("uid = ? and corp_id = ?", s.uid, s.corpId).
Offset(int(offset)).Limit(int(limit)).Order("updated_at desc").Find(&layouts).Error; err != nil {
return nil, 0, errors.Wrap(err, "list layout failed")
}
最后一处,当 total 为 0 的时候,可以减少一次列表的 SQL 请求。
这你不一定能想到,但却是非常有效的优化手段。如果业务中大多数人没有创建 Layout 这个数据,但是在某个高并发的查询页面,我们却需要调用这个 ListLayout 函数,那不妨先查询下要查询的总数,如果为 0 的话,我们就不必进行列表查询了。这无疑节省了不少的 SQL 请求,从而提升了接口性能。
func (s *LayoutService) ListLayout(ctx context.Context, offset, limit int64) (layouts []*db.Layout,
total int64, err error) {
...
// 查询总数
if err := s.gdb.WithContext(ctx).Model(&db.Layout{}).Where("uid = ? and corp_id = ?", s.uid, s.corpId).
Count(&total).Error; err != nil {
return nil, 0, errors.Wrap(err, "list layout failed")
}
// 如果 total 为 0,就不进行列表查询
if total == 0 {
return nil, 0, nil
}
// 查询数据
if err := s.gdb.WithContext(ctx).Model(&db.Layout{}).Where("uid = ? and corp_id = ?", s.uid, s.corpId).
Offset(int(offset)).Limit(int(limit)).Order("updated_at desc").Find(&layouts).Error; err != nil {
return nil, 0, errors.Wrap(err, "list layout failed")
}
return layouts, total, nil
}
怎么样,是不是大大超出你的预期?仅仅一个只有 18 行代码的函数,竟然存在 5 处可以依据最佳实践进行优化的地方。最后,我们再针对这些优化要点做下总结:
- 数据库查询尽量使用预处理机制。
- 下层 error 要封装后再返回给上层。
- 全链路必须传递 Context 保证超时。
- 数据库列表页查询必须设计分页机制。
- 尽量优化设计,避免不必要的 SQL 或者 RPC 查询。
示例二:批量获取用户信息
func getBatchUser(ctx context.Context, userKeys []*UserKey) (users []*User, error) {
userList := make([]*User, len(userKeys))
for i, u := range userKeys {
user, err := redis.GetGuest(ctx, u.Id)
if err != nil {
log.WarnContextf(ctx, "no found guest user: %v", u)
continue
}
userList[i] = user
}
return userList, nil
}
这段代码至少有 3 处错误。
第一处,是在 for 循环中进行了远程调用。
在 for 循环中进行远程调用(如 HTTP、RPC、数据库、Redis 等)是一种常见的反模式,但会带来以下严重问题:
- 性能问题:每次循环都需要等待网络往返时间,请求串行执行,总耗时随数据量线性增长。
- 资源浪费:如果底层的 Redis 没有使用连接池复用技术,就可能出现频繁创建和销毁连接,造成服务器连接池占满。
- 超时风险:循环网络往返时间,累积的延迟可能超出上游超时限制。
那在我们这个代码示例中,在 userKeys 的 for 循环中使用了 redis.GetGuest 函数,随着userKeys 的数量增加,会导致整个函数的性能降低,服务器资源造成浪费。
这种情况下,我们应该怎么修改呢?修改的方案要具体看情况。
首先,尽量让下游给出批量接口。
如果下游无法给出批量接口,就需要使用并发来调用 redis.GetGuest 函数,从而提升接口速度。具体怎么写并发,我们会在示例 3 中讨论。
第二处错误,函数的防御逻辑不足。
我们的参数是一个指针数组:[]*UserKey。指针数组就需要考虑两个边界情况:
- 整个指针数组为 nil
- 指针数组中某个元素为 nil
比如在这个示例中,如果传入的数组中有某个元素为 nil,那么 for 循环中的 u 就是 nil,而 u.Id 就会出现 panic 错误,导致程序异常退出。
所以我们需要在 for 循环中对每个元素进行防御逻辑判断,判断它是否为 nil,如果为 nil,则进行 continue操作。
func getBatchUser(ctx context.Context, userKeys []*UserKey) (users []*User, error) {
...
for i, u := range userKeys {
if u == nil {
continue
}
user, err := redis.GetGuest(ctx, u.Id)
...
}
...
}
第三处,指针数组返回了空元素。
这个点比较隐蔽,在我们的 for 循环中存在 continue 行为。这就意味着,我们可能会跳过某个 i 下标。那么,最后返回的指针数组 []*User 的结构可能如下:
- 0 下标,*User 指向一个对象。
- 1 下标,*User 为 nil。
- 2 下标,*User指向一个对象。
一旦这种结构暴露到上游,上游就有可能犯第二处的错误,也就是没有进行完善的防御逻辑,从而导致 panic 错误。
通过代码示例二,我们得到 3 个最佳实践的建议:
- 不要在 for 循环中进行远程调用。
- 每个函数都要进行充足的防御逻辑。
- 指针数组不要返回空元素。
示例三:并发获取用户信息
假设,有的同学思考了示例二的问题,然后使用 Go 关键字做了如下改造:
func getBatchUser(ctx context.Context, userKeys []*UserKey) (users []*User, error) {
userList := make([]*User, 0)
var wg sync.WaitGroup
for i, u := range userKeys {
if u == nil {
continue
}
wg.Add(1)
// 使用 goroutine 并发加速接口
go func() {
defer wg.Done()
user, err := redis.GetGuest(ctx, u.Id)
if err != nil {
log.WarnContextf(ctx, "no found guest user: %v", u)
continue
}
userList = append(userList, user)
}()
}
return userList, nil
}
上面这个代码仅仅改动了 10 行不到的逻辑,反而又引入了至少 4 处不符合最佳实践的地方,你看出来了吗?
第一处,在 for 循环中使用 goroutine 要注意“range 循环的指针副本问题”。这是我们非常容易犯的错误,所以要重点讲讲。
即在 for 循环中,这里的 u 变量其实是一个指针副本,Go 的 range 循环会复用这个指针副本,每次迭代都会更新同一个变量的值,所以这里的所有 goroutine 实际上都持有同一个 u 的地址,进入GetGuest 的 u.Id 实际上是一样的值。
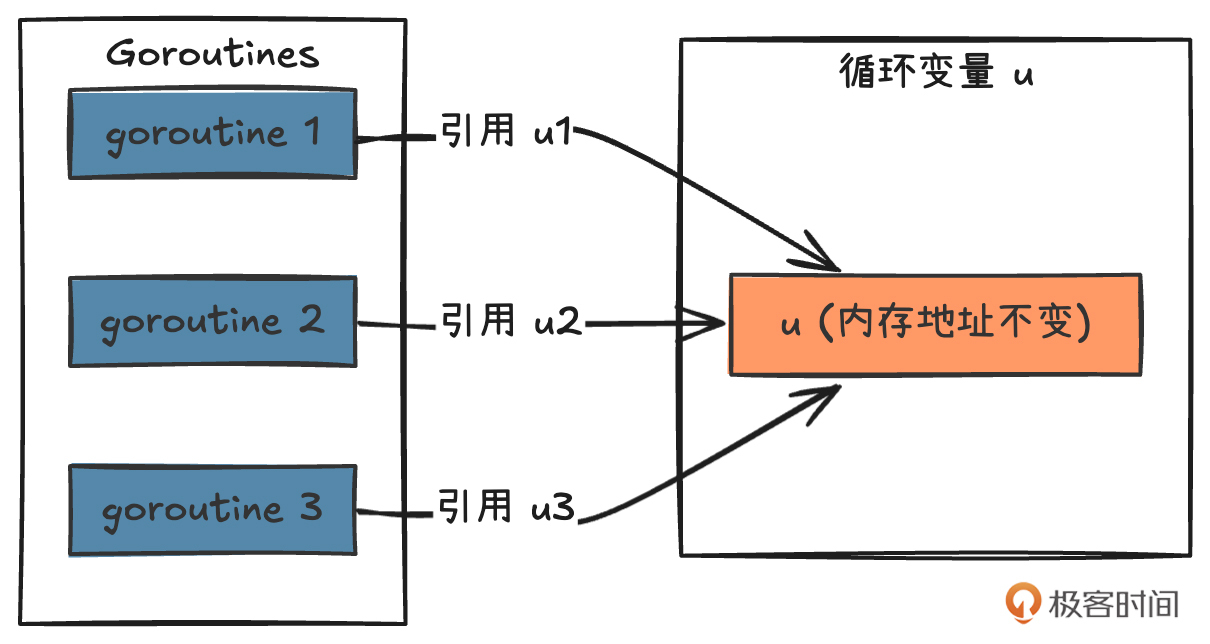
针对这个问题,有几种解决办法,我们一起来看下。
方法 1,创建局部变量副本:
for , u := range userKeys {
...
wg.Add(1)
ut := u // 创建局部变量副本
go func() {
defer wg.Done()
user, err := redis.GetGuest(ctx, ut.Id) // 使用局部副本
...
}()
...
}
这里的 ut := u 代表创建一个局部变量 ut,它拥有新的内存地址。然后在创建 goroutine 的时候,传递进入的实际上是 ut 这个新的内存地址,所以 goroutine 就持有新的 ut 数值。
方法 2,通过函数参数传递:
for _, u := range userKeys {
if u == nil {
continue
}
wg.Add(1)
go func(u UserKey) { // 通过参数传递
defer wg.Done()
user, err := redis.GetGuest(ctx, u.Id)
// ...
}(u)
}
每个 goroutine 获得自己的参数副本,参数传递发生在 goroutine 创建时,即使循环变量后续改变,也不会影响已创建的 goroutine。
方法 3,使用索引访问。这也是我最常用的方式,因为修改最小,只需要将 u 替换为 userKeys[i] 就行了。代码如下:
for i,u := range userKeys {
if userKeys[i] == nil {
continue
}
wg.Add(1)
go func() {
defer wg.Done()
user, err := redis.GetGuest(ctx, userKeys[i].Id)
// ...
}()
}
第二处问题,Go 开启的协程,没有 recover panic。
千万不要觉得我对下游有把握,认为不会 panic,就不需要 recover panic。要知道,所谓的“下游绝不会 panic”这种想法不可能永远成立。如果你对下游函数的认知存在错误,或未来某个时刻,下游函数出现了错误而引发 panic,而你作为调用方没有 recover 这个 panic,那你面对的就是进程挂了、服务停止的惨痛代价。
所以,针对 Go 开启的协程,一定记得先用 defer 关键字来 recover panic。
for i, u := range userKeys {
if userKeys[i] == nil {
continue
}
wg.Add(1)
go func(i int) {
defer wg.Done()
defer func() {
if r := recover(); r != nil {
// 处理 panic
fmt.Printf("Recovered from panic: %v\n", r)
}
}()
user, err := redis.GetGuest(ctx, userKeys[i].Id)
if err != nil {
// 处理错误
fmt.Printf("Error getting guest: %v\n", err)
return
}
// 处理 user
}(i)
}
第三处,slice 的操作并不是线程安全的。
我们在 goroutine 中对 userList 进行 append 操作时,是有可能出现线程同时处理一个内存地址,从而导致 panic 的。
为了确保在并发环境下对 userList 的访问是线程安全的,我们需要在对 userList 进行操作时加锁。我们可以使用 sync.Mutex 来实现这一点,如下是修改后的代码:
func getBatchUser(ctx context.Context, userKeys []*UserKey) ([]*User, error) {
userList := make([]*User, 0)
var wg sync.WaitGroup
var mu sync.Mutex
for i, u := range userKeys {
...
wg.Add(1)
// 使用 goroutine 并发加速接口
go func(u *UserKey) {
...
.
mu.Lock()
userList = append(userList, user)
mu.Unlock()
}(u)
}
wg.Wait() // 等待所有 goroutine 完成
return userList, nil
}
第四处,没有对 goroutine 数进行控制。
这一点其实也比较隐晦。Golang 确实提供了 Go 关键字以方便并发处理业务逻辑,但一旦被滥用,就很容易造成进程中 goroutine 数增加,而每个 goroutine 也占用系统资源,因此这可能会让我们的系统资源不足,进而影响业务。
这里说的 goroutine 滥用的场景之一,就是在 for 循环中无限制地使用 goroutine。设想一下,如果 userKeys 有 1w 个,一个请求我们就会启动 1w 个 goroutine,这确实是一件很恐怖的事情。
使用 goroutine 池可以有效地控制并发的数量,避免创建过多的 goroutine 导致系统资源耗尽。具体来说,我们可以使用第三方库如 ants 来实现 goroutine 池,以下是使用 ants 库优化后的代码:
import (
"context"
"log"
"sync"
"github.com/panjf2000/ants/v2"
)
func getBatchUser(ctx context.Context, userKeys []*UserKey) ([]*User, error) {
userList := make([]*User, 0)
var wg sync.WaitGroup
var mu sync.Mutex
pool, _ := ants.NewPoolWithFunc(10, func(i interface{}) {
defer wg.Done()
u := i.(*UserKey)
user, err := redis.GetGuest(ctx, u.Id)
if err != nil {
log.WarnContextf(ctx, "no found guest user: %v", u)
return
}
mu.Lock()
userList = append(userList, user)
mu.Unlock()
})
defer pool.Release()
for _, u := range userKeys {
if u == nil {
continue
}
wg.Add(1)
_ = pool.Invoke(u)
}
wg.Wait() // 等待所有 goroutine 完成
return userList, nil
}
我们做了以下修改:
- 使用 ants.NewPoolWithFunc 创建一个带有函数的 goroutine 池,池的大小为 10(你可以根据需要调整池的大小)。
- 在循环中,使用 pool.Invoke(u) 将任务提交到 goroutine 池中执行。
- 在 pool.Invoke 中传递 *UserKey 类型的参数,并在池的函数中进行处理。
- 使用 wg.Wait() 等待所有 goroutine 完成。
这样可以有效地控制并发的数量。
总结的来说,从代码示例三中,我们获取了四个最佳实践:
- 在 for 循环中使用 goroutine 要注意“range 循环的指针副本问题”。
- Go 开启的协程,一定记得先用defer关键字来 recover panic。
- slice 的操作并不是线程安全的,需要用锁来保证线程安全。
- 使用 pool 对 goroutine 数进行控制。
示例四:初始化配置信息
var config Config
func main() {
loadConfig("../config.yaml")
StartProcess()
}
// 读取配置文件
func loadConfig(configFile string) error {
file, err := os.Open(configFile)
defer file.Close()
if err != nil {
return errors.Wrap("load config err", err)
}
// 解析配置
err = json.Unmarshal(data, &config)
if err != nil {
// 记录错误日志
fmt.Printf("Failed to parse config file: %v\n", err)
return errors.Wrap("parse config err", err)
}
// 返回解析后的配置
return nil
}
这段代码中也有 3 处不合理的地方。
第一处,IO操作需要先处理操作错误,再定义 defer 关闭行为。
在 loadConfig 函数中,当我们打开一个配置文件时,没有先判断 error,而是先用 defer 调用了 file.Close。这样就有一个隐患:当 os.Open 返回的 file 是 nil 时,这里的 file.Close 由于预先被 defer 定义了,也会被执行,就会出现 panic 错误。
修改起来很简单,把 file.Close() 放到 err 处理的后边就行。
第二处,配置初始化出现错误就直接panic,阻止程序继续启动。
在 main 函数中的所有配置加载错误,我们都必须使用最严格的 panic 来处理,阻止程序继续启动。因为对于这种配置性错误,我们无法预估后续的错误影响,这种错误属于不可恢复性错误,需要最严格的处理。
在代码示例中,对于 localConfig 中的两个错误:读取配置失败和解析配置失败,我们只是打了日志,这远远不够。如果我们继续让业务运行,这里的 config 在业务中会出现不可预期的错误。
所以我们应该在启动函数 main 中进行错误 panic:
var config Config
func main() {
err := loadConfig("../config.yaml")
if err != nil {
panic(err) // 进程直接退出
}
StartProcess()
}
第三处,函数调用都要处理error,不处理的没有明确标识。
在我们的代码中,loadConfig 是有返回 error 的,但是在 main 函数中,我们并没有在外层处理这个 error。这是很多开发同学会犯的错误,可能是由于懒或者自信,觉得下游不会出现 error,所以在调用的地方,就不对 error 进行处理。
当一个业务上线的时候,会有很多预想不到的错误出现,所以我们不应当预期任何一个下游函数都不会出现 error 错误。实际上,一旦出现了 error,调用方对错误的处理是能监控并处理问题的唯一机制了。否则遇到线上异常,你就会像无头苍蝇一样,一直在纠结问题出在哪里。
因此,每个函数都要处理 error。当然,有的时候,比如业务上允许下游出现 error,且不影响主要的业务时,你可以不处理 error,但也要使用下划线来明确告诉别人,这里的 error 我并不需要处理。
最后,我们从代码示例三中获取了三条最佳实践:
- IO操作需要先处理操作错误,再定义 defer 关闭行为。
- 配置初始化加载错误就直接 panic,将报错提前。
- 函数调用都要处理 error,不处理的要明确标识。
总结
今天我通过四个代码示例,为你展示了 15 条最佳实践。这些最佳实践也是我们平时业务代码开发过程中最容易忽视的。通过今天的课程,相信你也可以体会到,编写优质的 Golang 代码并不仅仅是让程序能够运行起来那么简单。一段看似简单的代码背后,往往蕴含着诸多需要注意的细节。我将今天讲到的最佳实践做个汇总:
- 数据库查询尽量使用预处理机制。
- 下层 error 要封装后再返回给上层。
- 全链路必须传递 context 保证超时。
- 数据库列表页查询必须设计分页机制。
- 尽量优化设计避免不必要的 SQL 或者 RPC 查询。
- 不要在 for 循环中进行远程调用。
- 每个函数都要进行充足的防御逻辑。
- 指针数组不要返回空元素。
- 在 for 循环中使用 goroutine 要注意“range 循环的指针副本问题”。
- Go 开启的协程,一定记得先用defer关键字来 recover panic。
- slice 的操作并不是线程安全的,需要用锁来保证线程安全。
- 使用 pool 对 goroutine 数进行控制。
- IO操作需要先处理操作错误,再定义 defer 关闭行为。
- 配置初始化出现错误就直接panic,阻止程序继续启动。
- 函数调用都要处理error,不处理的要明确标识。
当然,除此之外还有很多其他的最佳实践,如果你还想了解,我推荐你阅读如下两本书,它们都在 Golang 编码方面给出了一些很好的建议:
最后,我还想说,写好 Golang 代码就像盖房子,不仅要让房子能住人,更要确保它经得起风雨的考验。这就要求我们在日常编码中始终保持警惕,将这些最佳实践融入到编码习惯中。优秀的代码不是一蹴而就的,而是在不断实践和改进中逐步完善的。通过持续学习和总结这些最佳实践,相信我们都能写出更加优质可靠的 Golang 代码。