你好,我是轩脉刃。
我们的日常 Web 业务开发大多数都属于 IO 密集型的业务,需要对业务数据进行存储、访问。在这个过程中,存储相关的组件(数据库和缓存)就是我们最经常打交道的平台服务了。
在专栏第 25-27 章中,我们将 MySQL 和 Redis 这两个最常用的数据库和缓存基础设施融合到了 Hade 框架中。可在评论和讨论群中,大家问得最多的却是如何设置这些配置项。确实,掌握框架用法之后,大家最想知道的就是如何最优设置这些配置项,让框架性能达到最优。
配置项的设置是一门经验艺术。
我也想简简单单给你一个配置项,让你闭眼就能设置到最优。但我想说,并不存在什么统一的最优配置,不同的服务器环境、不同的业务,就会有不同的配置项设置。我们需要掌握的是配置项的思考方法论,即面对一个配置,能够明确需要考虑哪些因素。这需要你在不同的业务中摸爬滚打,才能总结思考出来。所以我才说“配置项的设置是一门经验艺术”。
这一章,就让我们一起来讨论存储相关配置项的设置。
Redis
在 Hade 框架中,我们集成了 github.com/go-redis/redis 库作为 Redis 的调用,它的配置项如下:
// Options 用于设置 Redis 连接的配置。
type Options struct {
// 网络类型,可以是 tcp 或 unix。
// 默认是 tcp。
Network string
// 主机:端口 地址。
Addr string
// Dialer 创建新的网络连接,优先级高于 Network 和 Addr 选项。
Dialer func(ctx context.Context, network, addr string) (net.Conn, error)
// 当新连接建立时调用的钩子函数。
OnConnect func(ctx context.Context, cn *Conn) error
// 使用指定的用户名来认证当前连接,
// 适用于 Redis 6.0 或更高版本,使用 Redis ACL 系统时。
Username string
// 可选的密码。必须与服务器配置选项 requirepass 指定的密码匹配
// (如果连接到 Redis 5.0 或更低版本),
// 或者与使用 Redis ACL 系统时的用户密码匹配(如果连接到 Redis 6.0 或更高版本)。
Password string
// 连接到服务器后选择的数据库。
DB int
// 在放弃之前的最大重试次数。
// 默认是重试 3 次;-1(不是 0)表示禁用重试。
MaxRetries int
// 每次重试之间的最小退避时间。
// 默认是 8 毫秒;-1 表示禁用退避。
MinRetryBackoff time.Duration
// 每次重试之间的最大退避时间。
// 默认是 512 毫秒;-1 表示禁用退避。
MaxRetryBackoff time.Duration
// 建立新连接的拨号超时时间。
// 默认是 5 秒。
DialTimeout time.Duration
// 套接字读取的超时时间。如果达到此时间,命令将失败并返回超时错误,而不是阻塞。
// 使用 -1 表示没有超时,0 表示使用默认值。
// 默认是 3 秒。
ReadTimeout time.Duration
// 套接字写入的超时时间。如果达到此时间,命令将失败并返回超时错误。
// 默认是 ReadTimeout。
WriteTimeout time.Duration
// 连接池的类型。
// true 表示 FIFO(先进先出)池,false 表示 LIFO(后进先出)池。
// 注意,FIFO 比 LIFO 有更高的开销。
PoolFIFO bool
// 最大套接字连接数。
// 默认是每个可用 CPU 10 个连接(由 runtime.GOMAXPROCS 报告)。
PoolSize int
// 最小空闲连接数,当建立新连接较慢时很有用。
MinIdleConns int
// 客户端在连接达到此年龄时将其关闭。
// 默认是不关闭老化的连接。
MaxConnAge time.Duration
// 如果所有连接都忙,客户端等待连接的时间,然后返回错误。
// 默认是 ReadTimeout + 1 秒。
PoolTimeout time.Duration
// 客户端关闭空闲连接的时间。
// 应小于服务器的超时时间。
// 默认是 5 分钟。-1 表示禁用空闲超时检查。
IdleTimeout time.Duration
// 空闲连接检查的频率。
// 默认是 1 分钟。-1 表示禁用空闲连接检查,
// 但如果设置了 IdleTimeout,客户端仍会丢弃空闲连接。
IdleCheckFrequency time.Duration
// 启用在从节点上进行只读查询。
ReadOnly bool
// 使用的 TLS 配置。如果设置了,将进行 TLS 协商。
TLSConfig *tls.Config
// 用于实现断路器或限流器的接口。
Limiter Limiter
}
上面这些就是配置项的用途,我以注释的方式描述出来了。有的描述可能你一看就懂,但是有的不管怎么看也是一脸迷糊,为什么要有这个配置项?我该如何配置呢?下面,我就一一解答。
首先,我们将这里的配置项分为 4 个部分:
- 连接项相关
- 重试相关
- 超时相关
- 连接池相关
下面,我们一一来看。
连接项相关
连接项相关的配置有如下几种:
- Network
- Addr
- Dialer
- OnConnect
- Username
- Password
- DB
连接项相关的配置都是为了保证我们的 Golang 代码能准确连接上目标 Redis。其中, Network、Addr、Username、Password、DB 的配置项你应该都能理解,就是 Redis 连接所必须的。
但是,为什么有了 Addr 之后,还要有 Dialer 的的配置项呢?以及我是否需要填写 Dialer 的配置项呢?
Dialer 配置项让我们在和 Redis 建立连接时能自主定义连接方式。这该怎么理解呢?我举个例子你就明白了。
实际工作中,Redis 部署的网络状况各种各样。比如,我就遇到过在做政府私有化部署时,他们的数据存储和业务是两个网络,Redis 部署在数据存储网络,业务部署在局域网络,两个网络通过一个代理请求机进行请求代理。而我们的业务代码无法直连到数据存储网络,这时,我就用到了 Dialer 这个配置项,在其中自定义我们的代理服务器连接。
customDialer := func(ctx context.Context, network, addr string) (net.Conn, error) {
// 连接到代理机器
dialer := &proxy.Dialer{
ProxyAddress: "proxy:port",
Timeout: 5 * time.Second,
}
return dialer.Dial(network, addr)
}
这里还有一个 OnConnect 参数值得注意。在业务中,Redis 连接之后,我们一般都会使用 Ping 来测试这个连接是否可用。这非常重要,一旦一个连接池中有连接不可用,就代表着影响具体的业务使用了,所以我一般会使用 OnConnect 来做一次 Ping 请求。
func onConnect(ctx context.Context, cn *redis.Conn) error {
// 发送 PING 命令来验证连接
pong, err := cn.Ping(ctx).Result()
if err != nil {
return err
}
fmt.Println("PING response:", pong)
// 选择数据库
err = cn.Do(ctx, "SELECT", 1).Err()
if err != nil {
return err
}
return nil
}
func main() {
// 创建 Redis 客户端,并设置 OnConnect 回调函数
rdb := redis.NewClient(&redis.Options{
Addr: "localhost:6379",
Password: "", // 无密码
DB: 0, // 使用默认数据库
OnConnect: onConnect,
})
...
}
好了,这部分你重点关注我讲的配置项就可以了,其他就没有特别需要注意的了。
重试相关
重试相关的配置项有三个:
- MaxRetries // 表示在放弃之前的最大重试次数,默认为 3。
- MinRetryBackoff // 表示每次重试之间的最小退避时间,默认为 8ms。
- MaxRetryBackoff // 表示每次重试之间的最大退避时间,默认为 512ms。
一般我不设置这三个值,会使用系统默认的配置项。但是,恐怕很多人不知道,其实 go-redis 库会为你设置这三个值,并且在后台增加重试机制。
这里,我用一个图就能为你解释清楚这三个参数的逻辑:
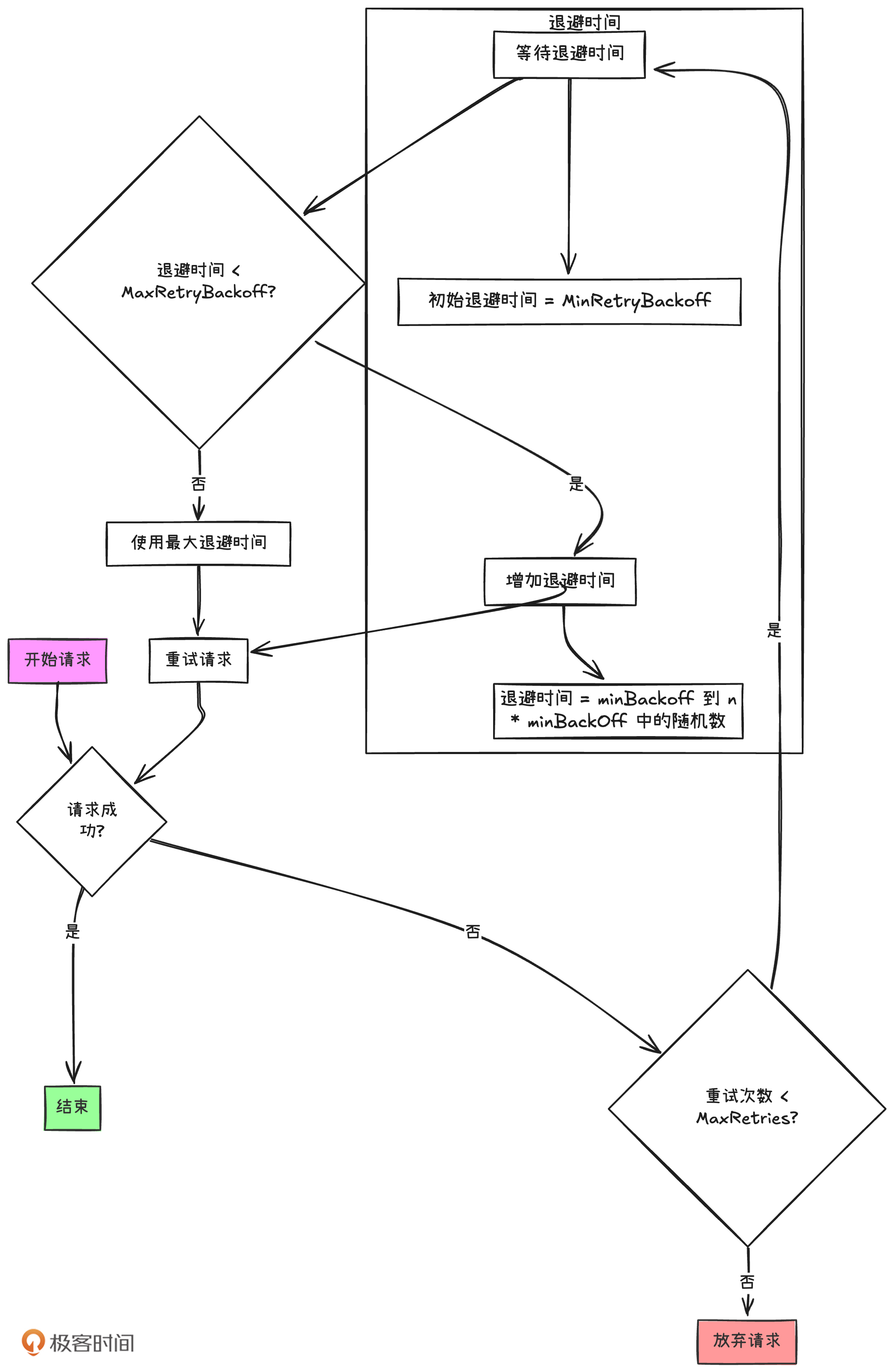
在业务服务器到 Redis 服务器的网络不好的情况下,发送一个请求到 Redis,是有可能由于网络原因而失败的。如果请求失败了,go-redis 就会进行 MaxRetries 次数的重试机制,初始退避时间(重试间隔时间)为 MinRetryBackOff,后面每次重试会以某种机制不断递增重试间隔时间,直到达到最大退避时间 MaxRetryBackoff。当所有重试失败的时候,这个 Redis 请求才算真正失败。
这也是我们使用 go-redis 库能增加业务可用性的机制之一。
超时相关
超时相关的配置项也有三个:
- DialTimeout // 默认 5s
- ReadTimeout // 默认 3s
- WriteTimeout // 默认和 ReadTimeout 值相同
这里的配置项我一般也不会修改,但有几种特殊情况:
- 如果业务必须要有容易超时的请求,我就适度加大 ReadTimeout,容易超时的请求包括但不限于 smember、keys、scan 等。
- 如果业务服务器到 Redis 的网络较差,我就不会更改 DialTimeout。如果一个 Redis 的连接时间超过 5s,我基本认为它不可用。但我也会适量设置 ReadTimeout,因为我们的读请求返回数据量大小和命令相关,也和网络相关,适度增加 ReadTimeout 有助于稳定 Redis 的大数据量返回命令。
这三个配置项我们一般不会往小了设置。因为在具体的分布式业务中,我们一般会使用带 Timeout 的 Context 来进行全链路超时控制。一个用户请求从入口服务进来,就会为 Context 设置一个超时时间。在全链路服务传递中,Context 的超时时间会不断递减,那当链路传递到我们业务的 Redis 请求时,我们也要将 Context 的超时时长传递进去。
所以,这个 Context 的超时时长必须小于 ReadTimeout 或者 WriteTimeout。一旦 Context 的超时设置大于这两个配置项,我们就会因为“过度限制请求耗时”而导致用户请求不可用。
这里你可以想想,为什么一般 WriteTimeout 和 ReadTimeout 会设置成一样的呢?
因为不考虑具体的命令耗时,读和写都是通过相同的网络传输,所以设置相同的超时时间,就可以确保在相同的网络状况下,读写都能有一致的表现。
连接池相关
连接池相关的配置项如下:
// 连接池的类型。
// true 表示 FIFO(先进先出)池,false 表示 LIFO(后进先出)池。
// 注意,FIFO 比 LIFO 有更高的开销。
PoolFIFO bool
// 最大套接字连接数。
// 默认是每个可用 CPU 10 个连接(由 runtime.GOMAXPROCS 报告)。
PoolSize int
// 最小空闲连接数,当建立新连接较慢时很有用。
MinIdleConns int
// 客户端在连接达到此年龄时将其关闭。
// 默认是不关闭老化的连接。
MaxConnAge time.Duration
// 如果所有连接都忙,客户端等待连接的时间,然后返回错误。
// 默认是 ReadTimeout + 1 秒。
PoolTimeout time.Duration
// 客户端关闭空闲连接的时间。
// 应小于服务器的超时时间。
// 默认是 5 分钟。-1 表示禁用空闲超时检查。
IdleTimeout time.Duration
// 空闲连接检查的频率。
// 默认是 1 分钟。-1 表示禁用空闲连接检查,
// 但如果设置了 IdleTimeout,客户端仍会丢弃空闲连接。
IdleCheckFrequency time.Duration
我个人最经常设置的配置项有两个:MinIdleConns 和 MaxConnAge。
MinIdleConns 是最小的空闲连接数,默认为 0,表示不保留空闲的连接,也就是在无请求发送时,连接池中的所有空闲连接都会被回收。在高并发情景下,这是不友好的。高并发请求经常伴随着变动波动较大的请求,如果设置为0,就会频繁创建和销毁连接池中的连接,会加大单个请求的连接耗时(因为创建连接的次数变多了)。
但是,MinIdleConns 也不是越大越好。想要搞清楚它具体要设置到多少,就要明白一个空闲连接会占用哪些资源,大致包括:连接结构本身的大小(大概是 1KB),每个连接使用的缓冲区大小(大概是 4KB),以及一个文件描述符(FD)。
也就是说,我们需要根据内存和文件描述符的大小来控制 MinIdleConns。如果没有具体的监控数据,可以参考以下经验值进行初始设置,然后根据实际情况进行调整。
- 对于小型应用或低并发场景,可以设置 MinIdleConns 为 1-5。
- 对于中型应用或中等并发场景,可以设置 MinIdleConns 为 5-20。
- 对于大型应用或高并发场景,可以设置 MinIdleConns 为 20-50 或更多。
一个连接一旦建立,永久占用不老化也是一个问题,MaxConnAge 就是为了解决这个问题而存在。如果连接占用久了,我们让它重新建立一次连接,这样可以有效避免网络不稳定,或者 Redis 重启更新导致的连接不可用情况。
当然如果 MaxConnAge 设置过短,也会导致频繁的连接重建,从而影响性能。
我们需要选择一个适中的存活时间。一般我默认我的业务服务器和 Redis 之间的连接是可信的,会设置 1 小时来保证存活的 Redis 连接可用。
至于其他的连接池相关设置,go-redis 的默认设置就比较合理的了。
MySQL
在专栏第 25-26 章中,我们集成了 Gorm 进入 Hade 框架,来进行数据库的连接,不知道你是否还记得文中的配置项结构 DBConfig。
我也将其分为三类:连接相关、超时相关和连接池相关。其中每个字段的含义我都用注释说明了,所以下面我们着重说说在高并发场景下,需要重点考虑修改的配置项。
连接相关
如下这些字段主要用于配置数据库连接的基本信息,如地址、端口、用户名、密码等。
- Port //:端口
- Protocol //:传输协议
- Dsn //:直接传递dsn,如果传递了,其他关于dsn的配置均无效
- Database //:数据库
- Username //:用户名
- Password //:密码
- Driver //:驱动
- Host //:数据库地址
- AllowNativePasswords //:是否允许nativePassword
- Charset //:字符集
- Collation //:字符序
- Loc //:时区
- ParseTime //:是否解析时间
前面几个配置项没什么复杂的逻辑,当我们在服务端设置好一个数据库的时候,就可以得到这些设置值。而后面的四个配置项我一般会像下面这么设置:
- charset=utf8mb4 设置字符集为 utf8mb4。
- parseTime=true 启用时间解析,将时间字段解析为 time.Time 类型。
- loc=Local 设置时区为本地时区。
- collation=utf8mb4_general_ci 设置字符序为 utf8mb4_general_ci。
将 charset 和 collation 设置为支持 utf8mb4 的字符集,可以保证我们能对特殊字符如 emoji 表情进行设置。parseTime 能将数据库中时间类型 DateTime 以 time.Time 的结构返回,否则你还需要手动从 string 解析。而将 loc 设置为 Local,有助于确保数据库中的时间数据与应用程序的本地时区一致。这对于处理时间数据非常重要,尤其是在涉及跨时区操作或需要精确时间戳的应用程序中。
超时相关
下面这些字段主要用于配置数据库连接和操作的超时时间。
- WriteTimeout //:写超时时间
- ReadTimeout //:读超时时间
- Timeout //:连接超时时间
MySQL 设置这三个超时时间的逻辑基本和 Redis 设置的相同,也要考虑网络情况、命令情况等,但是又有一些不一样。
MySQL 的读操作命令比写操作复杂。我们的 Web 业务一般是读多写少的场景,比如专栏最后实战演练的类论坛网站,一般网站读请求的 QPS 会多于写请求的 QPS。并且,读需要用各种 SQL 来请求,有的 SQL 会走索引请求,快速返回数据;有的 SQL 不会走索引请求,返回数据较慢。
所以,我们要设置的 ReadTimeout 就很艺术了。设置太小了,一旦遇到慢的请求,就会被直接拒绝,出现 “i/o timeout” 的错误;而设置太大了,一旦业务写了错误的 MySQL(比如全表查询,忘记使用 limit 了),就会长期占用这个连接不释放,高并发下就会造成连接池连接被占满,正常业务无法使用。
我的建议是:ReadTimeout设置为“用户可容忍时长”。如果你的业务定的目标为“用户最多可以容忍最慢 3s 的页面请求时长”,那么读超时时间就可以设置为 3s。这里的业务目标需要你诚实地给自己制定,同时也要确保每个上线业务带来的 SQL 请求都能符合这个要求。
当然,这里和前面提到的 Redis 连接超时设置一样。实际运行的时候,我们还是会结合业务全链路的 Context 带下来的超时时间,来决定最终的单个请求的超时。我们可以使用 Context 为 A 请求设置超时时间为 1s,为 B 请求设置超时时间为 1.5s,但是所有业务超时时长最好小于或等于我们设置的 ReadTimeout 。
连接池相关
以下这些字段主要用于配置数据库连接池的参数:
- ConnMaxIdle //:最大空闲连接数
- ConnMaxOpen //:最大连接数
- ConnMaxLifetime //:连接最大生命周期
- ConnMaxIdletime //:空闲最大生命周期
这里我用一张图帮助你直观地了解这四个配置项的关系。
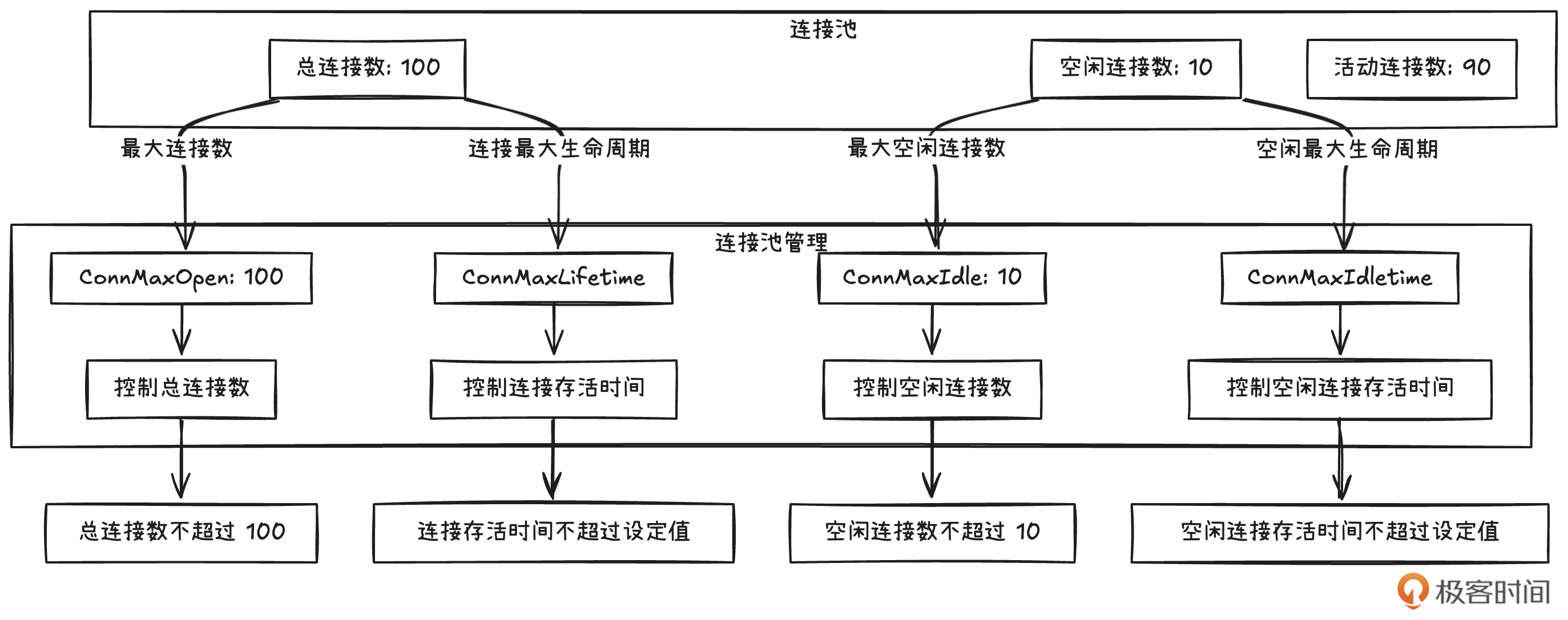
在 MySQL 的设置上我踩过不少的坑,接下来,我把我的经验一一分享给你。
首先,最大连接数 ConnMaxOpen 怎么设置呢?
我们要先计算 MySQL的总连接数,这要根据整体架构来计算。假如,我现在的业务集群机器为 20 个,这些机器要连接到一个 1 主 2 从的数据库集群,主库和从库单个 MySQL 最多可以支撑 1000 个连接。这种情况下,我们该如何计算 ConnMaxOpen 呢?
我们要先明白,对于我们的业务来说,写在主库,而读在从库。因为是写少读多的场景(基本上大部分 Web 业务都是这样),所以在计算 MySQL 总的最大连接数时,我们不应该计算写库。
那在这个例子中,MySQL 最多支持 2000 连接(2 个从库,每个从库支持 1000 个连接),所以这 20 个业务机器平均每个最多能支持 100 个连接。为了安全起见,我们还会预留一些安全水位,来支持一些脚本类操作,或者人工排查问题时的手动连接等操作。因此,我们为每个机器预留 10 个连接,那 ConnMaxOpen 就可以设置为 90。
然后,我们再来看看最大空闲连接数 ConnMaxIdle 怎么计算。
我们需要了解自己的机器,连接这个数据结构本身占用一定的内存大小,同时每个连接附带的缓冲区也会占一定的内存大小。按照个人经验,我一般预设每个连接的缓冲区占 4k 内存,自身数据结构占 1k 内存,那一个连接总共占 5k 内存,然后将自身机器内存数除以 5k。这样,我们就能计算出机器最大可支持多少空闲连接。但是,由于是空闲连接,不可能超过 MySQL 的最大连接承担能力,其数量一定要小于可以设置的最大连接 ConnMaxOpen。
此外,我们还要注意,ConnMaxIdle 设置太小对于高并发很不友好。
我就遇到过一次,当时我按照 ConnMaxOpen = 90,ConnMaxIdle = 10 进行业务上线前压测,发现压测一到一定时间就出现错误:connect: cannot assign requested address。遇到这个错误后,我们第一时间就怀疑是不是业务中有连接泄漏,也就是创建了连接却没有释放。但是,我按照这个方向排查后却一无所获。
最后才发现,原来是创建连接池的时候,我设置的 ConnMaxIdle 和 ConnMaxOpen 差距太大了。
在高并发场景下,请求浮动较大,连接数会不定期出现暴涨和暴跌现象。以办公软件业务为例,在上班高峰期大家都使用业务,于是连接数暴涨,但是在午饭时间,大家统一下线,于是连接数会出现暴跌现象。
在我们这个例子中,暴涨时最多创建了 90 个连接,暴跌时只保留了 10 个连接,也就代表着释放了 80 个连接。但是这些释放的连接所占用的 fd 端口却没有被立即释放。原因是客户端主动断开连接,在close后,基于 TCP 的四次挥手机制,释放端的 fd 会有 time_wait 等待时长,一般为 2 倍的 MSL(60s)。这就导致大量的端口被占用,最后产生报错:cannot assign requested address。
后续,我调大了 ConnMaxIdle 的值,目标压测 QPS 就能通过了。
当然,ConnMaxIdle 设置过大也有坏处。首先会导致数据库空闲情况下占用过多连接资源,这意味着业务的弹性伸缩受到限制,浪费了资源。
还拿刚才那个例子来说,数据库最多可以支持 2000 个连接。如果 2 台机器的空闲连接数已经占用了 1800 个,一旦我们业务机器先达到瓶颈的并不是连接数,而是 CPU 负载过高或者其他资源因素,为了缓解资源压力,我们就需要使用弹性扩容机制来增加机器数。这时每个机器的最大空闲连接数会随着机器数量增加而线性增加,就很容易超出数据库的最大连接数支持量,数据库就先支持不住了。
基于经验,我一般设置 ConnMaxIdle 为 ConnMaxOpen 的 30%-50%,比如这个例子中,我会设置 ConnMaxIdle 为 40 左右(90 * 40%)。
至于 ConnMaxLifetime 和 ConnMaxIdletime,就需要看你的网络情况了。如果你的网络非常不稳定,刚创建的连接可能 10 分钟后就不可用了,或者数据库的集群会经常变化,如删除某个从库或增加某个从库,那么我建议你尽量缩短这两个值的设置,按照分钟级别进行设置。
总之,将这两个值设置得较小的好处显而易见,能更好地维持连接池中连接的可用性。即尽量保证业务从连接池中获取的连接都是可用的,避免在发送具体的 SQL 命令时返回连接不可用的错误信息。
而在网络稳定,且数据库集群架构变化不是特别频繁的时候,这两个值设置小了就会非常浪费资源,频繁进行无效的断开、重连操作。
在网络稳定的情况下,我的经验是按照中等的连接周期(ConnMaxLifetime = 1 小时,ConnMaxIdletime = 30 分钟 )进行设置,但一定不会设置为永久(即为 0)。
总结
这一节,我们深入探讨了如何优化 Redis 和 MySQL 的配置项,以提升 Hade 框架在高并发场景下的性能。配置项可以分为四个部分:连接项相关、重试相关、超时相关和连接池相关,我们要掌握每个部分中的关键配置项及其背后的逻辑。
对于 Redis,我们可以通过自定义 Dialer 和 OnConnect 钩子函数来确保连接的稳定性,通过合理设置重试机制和超时时间来提高业务的可用性。此外,连接池相关的设置也很重要,尤其是 MinIdleConns 和 MaxConnAge。
对于 MySQL,我们同样分为连接相关、超时相关和连接池相关三部来讲解,详细介绍了通过 charset 参数设置 utf8mb4 字符集、通过 loc 参数设置 Asia/Shanghai 时区等连接相关的配置,以及通过 ReadTimeout 和 WriteTimeout 参数根据业务需求调整超时时间。特别是在连接池的设置上,我们分享了通过机器数量和单机最大连接数来计算 ConnMaxOpen,通过内存占用计算 ConnMaxIdle 的逻辑,并通过实际案例说明了设置不当可能带来的问题和解决方法。
总的来说,配置项的设置是一门经验艺术,没有一成不变的最佳配置。我们需要根据具体的业务场景、服务器环境和网络状况,灵活调整配置项,以达到最佳的性能和稳定性。希望通过这一章的内容,你能掌握配置项的思考方法论,在实际工作中不断总结和优化,提升系统的整体性能。
最后,感谢你的阅读!如果有任何问题或建议,欢迎在评论区留言讨论。